advanced operating systems #1 - pflab
TRANSCRIPT

Advanced Operating Systems
#3
Shinpei Kato
Associate Professor
Department of Computer Science
Graduate School of Information Science and Technology
The University of Tokyo
<Slides download>http://www.pf.is.s.u-tokyo.ac.jp/class.html

Course Plan
• Multi-core Resource Management
• Many-core Resource Management
• GPU Resource Management
• Virtual Machines
• Distributed File Systems
• High-performance Networking
• Memory Management
• Network on a Chip
• Embedded Real-time OS
• Device Drivers
• Linux Kernel
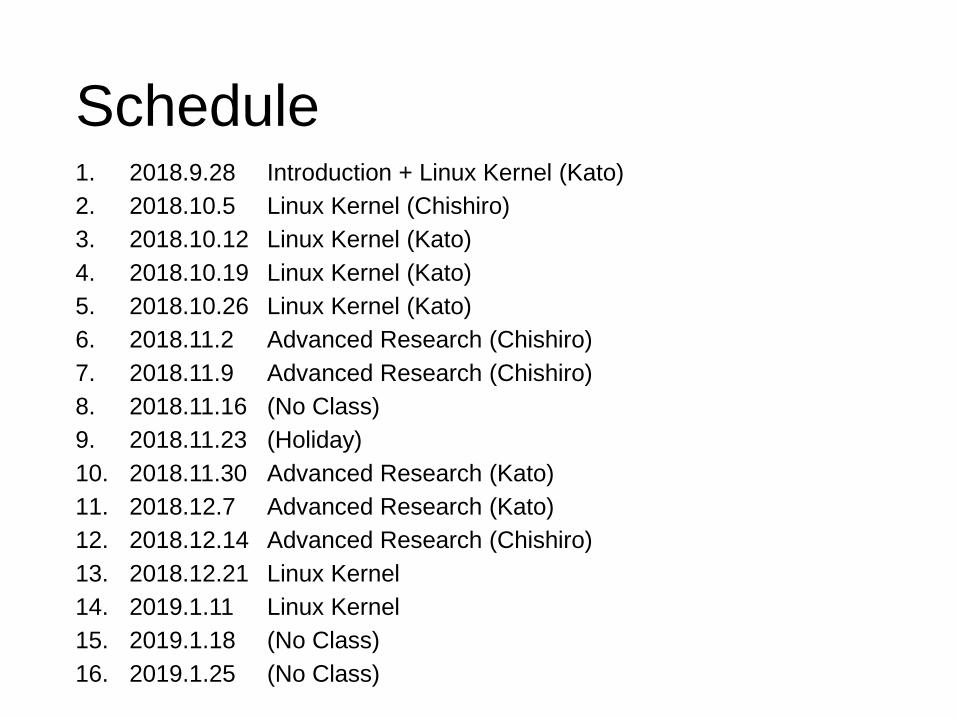
Schedule1. 2018.9.28 Introduction + Linux Kernel (Kato)
2. 2018.10.5 Linux Kernel (Chishiro)
3. 2018.10.12 Linux Kernel (Kato)
4. 2018.10.19 Linux Kernel (Kato)
5. 2018.10.26 Linux Kernel (Kato)
6. 2018.11.2 Advanced Research (Chishiro)
7. 2018.11.9 Advanced Research (Chishiro)
8. 2018.11.16 (No Class)
9. 2018.11.23 (Holiday)
10. 2018.11.30 Advanced Research (Kato)
11. 2018.12.7 Advanced Research (Kato)
12. 2018.12.14 Advanced Research (Chishiro)
13. 2018.12.21 Linux Kernel
14. 2019.1.11 Linux Kernel
15. 2019.1.18 (No Class)
16. 2019.1.25 (No Class)

Memory Management
Abstracting Memory Resources
/* The case for Linux */
Acknowledgement:Prof. Pierre Olivier, ECE 4984, Linux Kernel Programming, Virginia Tech

Outline
1 Pages and zones
2 Low-level memory allocator
3 k m a l l o c ( ) andv m a l l o c ( )
4 Slab layer
5 Stack, high memory and per-cpu allocation

Outline
1 Pages and zones
2 Low-level memory allocator
3 k m a l l o c ( ) andv m a l l o c ( )
4 Slab layer
5 Stack, high memory and per-cpu allocation

Pages and zonesPages
� Memory allocation in the kernel is different from user space.., How to handle memory allocation failures?.., In some situations the kernel cannot sleep.., Etc.
� The page is the basic unit for memory management by the MMU, and thus the kernel
.., Page size is machine dependent.., Typical values for x86 are 4K, 2M, and 1G.., Get the page size on your machine:
1 G e t c o n f PAGESIZE

Pages and zonesPages: s t r u c t page
� Each physical page is represented by a s t r u c t page
.., Most of the pages are used for (1) kernel/userspace memory
(anonymous mapping) or (2) file mapping
� Simplified version:
1
23
4
56
7
89
10
s t r u c t page {
uns igned l ong f l a g s ;
uns igned c o u n t e r s ;
a t o m i c _ t _mapcoun t ;
uns igned l ong p r i v a t e ;s t r u c t a d d r e s s _ s p a c e *mapping;
p g o f f _ t i n d e x ;
s t r u c t l i s t _ h e a d l r u ;
v o i d * v i r t u a l ;
}
� f l a g s : page status
(permission, dirty, etc.)
� c o u n t e r s : usage count
� p r i v a t e : private mapping
� mapping : file mapping
� i ndex : offset within mapping
� v i r t u a l : virtual address
� More info on s t r u c t page : [1]

Pages and zonesPages (2)
� The kernel uses s t r u c t page to keep track of the owner of the page
.., User-space process, kernel statically/dynamically allocated data,
page cache, etc.
� There is one s t r u c t page object per physical memory page
.., s i z e o f ( s t r u c t p a g e ) with regular kernel compilation options:
64 bytes.., Assuming 8GB of RAM and 4K-sized pages: 128MB reserved for
s t r u c t p ag e objects (∼1.5%)

Pages and zonesZones
� Because of hardware limitations, only certain physical pages can be used in certain contexts
.., Example: on x86 some DMA-enabled
devices can only access the lowest 16M
part of physical memory.., On x86 32 the kernel address space area
sometimes cannot map all physical RAM
(1/3 model)
� Physical memory is divided into zones:.., ZONE DMA: pages with which DMA can be used.., ZONE DMA32: memory for other DMA limited devices.., ZONE NORMAL: page always mapped in the address space.., ZONE HIGHMEM: pages only mapped temporary
� Zones layout is completely architecture dependent

Pages and zonesZones (2)
� x86 32 zones layout:
� x86 64 zones layout:
� Some memory allocation requests must be served in specific
zones� While the kernel tries to avoid it, general allocations requests
can be served from any zone if needed

Pages and zonesZones (3)
� Each zone is represented by a s t r u c t zone object.., Defined in i n c l u d e / l i n u x / m m z o n e . h.., Simplified version with notable fields:
1
23
4
56
7
s t r u c t zone {
uns igned long watermark[NR_WMARK];
c o n s t char *name;
s p i n l o c k _ t l o c k ;
s t r u c t f r e e _ a r e a free_area[MAX_ORDER];/ * . . . * /
}
� wate rmark minimum, low and high watermarks used for per-area
memory allocation
� l ock : protects against concurrent access
� f r e e _ a r e a : list of free pages to serve memory allocation
requests

Outline
1 Pages and zones
2 Low-level memory allocator
3 k m a l l o c ( ) andv m a l l o c ( )
4 Slab layer
5 Stack, high memory and per-cpu allocation

Low-level memory allocatorMemory allocation: general overview

Low-level memory allocatorMemory allocation: general overview

Low-level memory allocatorGetting pages
� Low-level mechanisms allocating memory with page-sized
granularity
� Interface in i n c l u d e / l i n u x / g f p . h # g f p : G e t F r e e P a g e
.., Core function:
1 s t r u c t page * a l l o c _ p a g e s ( g f p _ t gfp_ mask , uns igned i n t o r d e r ) ;
.., Allocates 2order contiguous pages (1 < < order )
.., Returns the address of the first allocated s t r u c t page
.., To actually use the allocated memory, need to convert to virtual
address:
1 vo id * p a g e _ a d d r e s s ( s t r u c t page * p a g e ) ;
.., To allocate and get the virtual address directly:
1 uns igned l o ng g e t _ f r e e _ p a g e s ( g f p _ t gfp_ mask , uns igned i n t o r d e r ) ;

Low-level memory allocatorGetting pages (2)
� To get a single page:
1
2
s t r u c t page * a l l o c _ p a g e ( g f p _ t gfp _ ma s k ) ;
uns igned l ong g e t _ f r e e _ p a g e ( g f p _ t gfp _ ma s k ) ;
� To get a page filled with zeros:
1 uns igned l ong g e t _ z e r o e d _ p a g e ( g f p _ t gfp _ ma s k ) ;
.., Needed for pages given to user space.., A page containing user space data (process A) that is freed can be
later given to another process (process B).., We don’t want process B to read information from process A

Low-level memory allocatorFreeing pages
� Freeing pages - low level API:
1
23
4
v o i d f r e e _ p a g e s ( s t r u c t page * p a ge , uns igned i n t o r d e r ) ;
vo id f r e e _ p a ge s ( u n s i g n e d l ong a d d r , uns igned i n t o r d e r ) ;
vo id f r e e _ p a g e ( s t r u c t page * p a g e ) ;vo id f r e e _ p a ge ( u n s i g n e d l ong a d d r ) ;
.., Free only the pages you allocate!
.., Otherwise: corruption

Low-level memory allocatorBuddy system

Low-level memory allocatorUsage example
1 # i n c l u d e < l i n u x / mo d u l e . h >
2 # i n c l u d e < l i n u x / k e r n e l . h >
3 # i n c l u d e < l i n u x / i n i t . h >
4 # i n c l u d e < l i n u x / g f p . h >
56 # d e f i n e PRINT_PREF "[LOWLEVEL]: "
7 # d e f i n e PAGES_ORDER_REQUESTED 3
8 # d e f i n e INTS_IN_PAGE ( P AGE_ S I Z E/ s i ze o f ( i n t ) )
910 uns igned l ong v i r t _ a d d r ;
1112 s t a t i c i n t i n i t my_ mod_ in i t ( v o i d )
13 {
1 4 i n t * i n t _ a r r a y ;
1 5 i n t i ;
16
17 printk(PRINT_PREF " E n t e r i n g m o d u l e . ¥ n " ) ;
18
1 9 v i r t _ a d d r = get_free_pages(GFP_KERNEL,
PAGES_ORDER_REQUESTED);2 0 i f ( ! v i r t _ a d d r ) {
21 printk(PRINT_PREF " E r r o r i n
a l l o c a t i o n ¥ n " ) ;2 2 re turn - 1 ;
23 }
242 5 i n t _ a r r a y = ( i n t * ) v i r t _ a d d r ;
2 6 f o r ( i = 0 ; i<INTS_IN_PAGE; i + + )
2 7 i n t _ a r r a y [ i ] = i ;
282 9 f o r ( i = 0 ; i<INTS_IN_PAGE; i + + )
30 printk(PRINT_PREF " a r r a y[ % d ] = %d ¥ n " ,
i , i n t _ a r r a y [ i ] ) ;3132 re turn 0 ;
33 }
3435 s t a t i c vo id e x i t my_mod_ex i t (void )
36 {
3 7 f r e e _ p a g e s ( v i r t _ a d d r ,
PAGES_ORDER_REQUESTED);
38 printk(PRINT_PREF " E x i t i n g m o d u l e . ¥ n " ) ;
39 }
4041 module_i n i t ( m y _mod_i n i t ) ;
4 2 modu le_ex i t (my_ mo d_e x i t ) ;

Outline
1 Pages and zones
2 Low-level memory allocator
3 k m a l l o c ( ) andv m a l l o c ( )
4 Slab layer
5 Stack, high memory and per-cpu allocation

k m a l l o c ( ) and v m a l l o c ( )k m a l l o c ( ) usage andk f r e e ( )
� k m a l l o c ( ) allocates byte-sized chunks of memory
� Allocated memory is physically contiguous
� Usage similar to userspace m a l l o c ( ).., Returns a pointer to the first allocated byte on success.., Returns NULL onerror
� Declared in i n c l u d e s / l i n u x / s l a b . h :
1 vo id * k m a l l o c ( s i z e _ t s i z e , g f p _ t f l a g s ) ;
� Usage example:
1
23
4
56
s t r u c t m y_ s t r u c t * p t r ;
p t r = k m a l l o c ( s i z e o f ( s t r u c t m y _ s t r u c t ) , GFP_KERNEL);
i f ( ! p t r ) {/ * handle e r ro r * /
}

k m a l l o c ( ) andv m a l l o c ( )Kmalloc flags
� g f p t type (unsigned int in i n c l u d e / l i n u x / t y p e s . h )
.., get free page [2]
� Specify options for the allocated memory
1
2
3
Action modifiers.., How should the memory be allocated? (for example, can the kernel
sleep during allocation?)
Zone modifiers
.., From which zone should the allocated memory come
Type flags
.., Combination of action and zone modifiers
.., Generally preferred compared to direct use of action/zone
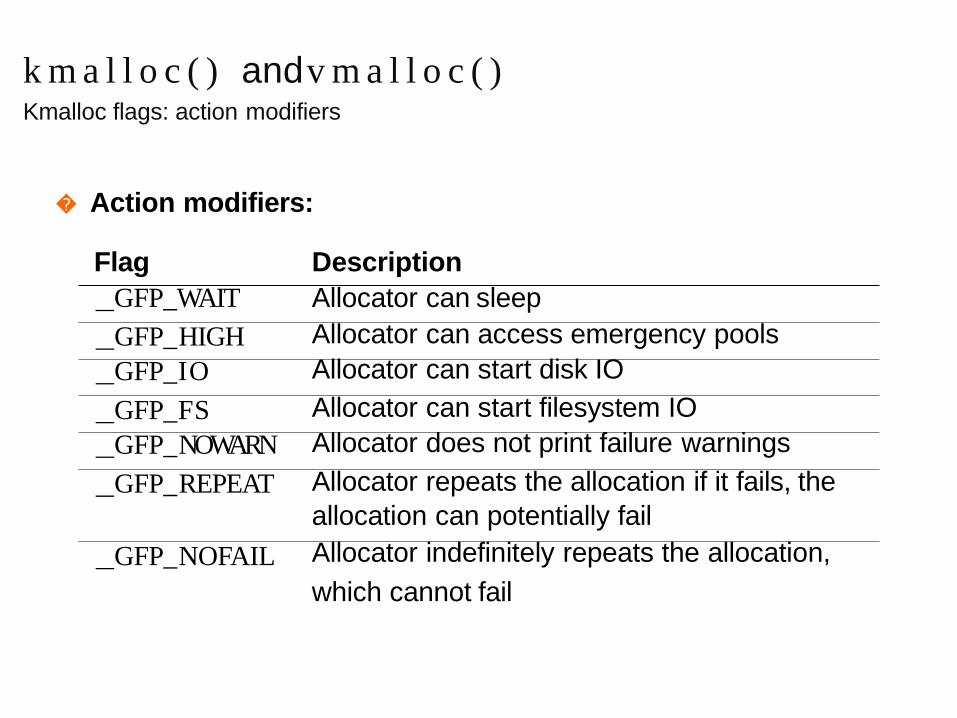
k m a l l o c ( ) andv m a l l o c ( )Kmalloc flags: action modifiers
� Action modifiers:
Flag
GFP_WAIT
Description
Allocator can sleep
GFP_HIGH
GFP_IO
Allocator can access emergency pools
Allocator can start disk IO
GFP_FS
GFP_NOWARN
Allocator can start filesystem IO
Allocator does not print failure warnings
GFP_REPEAT
GFP_NOFAIL
Allocator repeats the allocation if it fails, the
allocation can potentially fail
Allocator indefinitely repeats the allocation,
which cannot fail

k m a l l o c ( ) andv m a l l o c ( )Kmalloc flags: action modifiers (2)
Flag
GFP_NORETRY
Description
Allocator does not retry if the allocation fails
GFP_NOMEMALLOC
GFP_HARDWALL
Allocation does not fall back on reserves
Allocator enforces ”hardwall” cpuset
boundaries
Allocator marks the pages reclaimableGFP_RECLAIMABLE
GFP_COMP Allocator adds compound page metadata
(used by h u g e t l b code)
� Several action modifiers can be specified together:
1 p t r = k m a l l o c ( s i z e , GFP_WAIT | GFP_FS | GFP_IO);
.., Generally, type modifiers are used instead

k m a l l o c ( ) andv m a l l o c ( )Kmalloc flags: zone modifiers
� Zone modifiers:
Flag
GFP_DMA
Description
Allocates only from ZONE_DMA
GFP_DMA32 Allocates only from ZONE_DMA32
GFP_HIGHMEM Allocated from ZONE_HIGHMEM or ZONE_NORMAL
� _GFP_HIGHMEM: OK to use high memory, normal workstoo
� No flag specified?
.., Kernel allocates from ZONE_NORMAL or ZONE_DMA with a strong
preference for ZONE NORMAL
� Cannot specify _GFP_HIGHMEM to k m a l l o c ( ) or
g e t _ f r e e _p a g e s ( )
.., These function return a virtual address
.., Addresses in ZONE _HIGHMEM might not be mapped yet

k m a l l o c ( ) andv m a l l o c ( )Kmalloc flags: type flags
� GFP _ATOMIC: high priority allocation that cannot sleep.., Use in interrupt context, while holding locks, etc..., Modifier flags: ( GFP_HIGH)
� GFP_NOWAIT: same as GFP_ATOMIC but does not fall back on emergency memory pools
.., More likely to fail
.., Modifier flags: ( 0 )
� GFP_NOIO: can block but does not initiate disk IO.., Used in block layer code to avoid recursion.., Modifier flags: ( GFP_WAIT)
� GFP_NOFS: can block and perform disk IO, but does not initiate filesystem operations
.., Used in filesystem code
.., Modifier flags: ( GFP WAIT | GFP_ I O )

k m a l l o c ( ) andv m a l l o c ( )Kmalloc flags: type flags (2)
� GFP_KERNEL: default choice, can sleep and perform IO
.., Modifier flags: ( GFP_WAIT | GFP_IO | GFP_FS)
� GFP_USER: normal allocation, might block, for user-space memory
.., Modifier flags: ( GFP_WAIT | GFP_IO | GFP_FS)
� GFP_HIGHUSER: allocation for user-space memory, from
ZONE_HIGHMEM
.., Modifier flags: ( GFP_WAIT | GFP_IO | GFP_FS |
GFP_HIGHMEM)
� GFP_DMA: served from ZONE_DMA
.., Modifier flags: ( GFP_DMA)

k m a l l o c ( ) andv m a l l o c ( )Kmalloc flags: which flag to use?
Context Solution
Process context, can sleep
Process context, cannot sleep
GFP_KERNEL
GFP_ATOMIC or allocate ata
different time
GFP_ATOMICInterrupt handler
Softirq GFP_ATOMIC
GFP_ATOMICTasklet
Need to handle DMA, (GFP_DMA | GFP_KERNEL)
can sleep
Need DMA, (GFP_DMA | GFP_ATOMIC)
cannot sleep
� Other types and modifier are declared and documented in
i n c l u d e / l i n u x / g f p . h

k m a l l o c ( ) andv m a l l o c ( )k f r e e
� Memory allocated with k m a l l o c ( ) needs to be freed with
k f r e e ( )
� i n c l u d e / l i n u x / s l a b . h :
1 vo id k f r e e ( c o n s t v o i d * p t r ) ;
� Example:
1
23
4
56
7
89
10
s t r u c t m y_ s t r u c t p t r ;
p t r = k m a l l o c ( s i z e o f ( s t r u c t m y _ s t r u c t ) ) ;
i f ( ! p t r ) {/ * handle e r ro r * /
}
/ * work w i th p t r * /
k f r e e ( p t r ) ;
� Do not free memory that has already been freed
.., Leads to corruption

k m a l l o c ( ) andv m a l l o c ( )vmalloc()
� v m a l l o c ( ) allocates virtually contiguous pages that are not guarantee to map to physically contiguous ones
.., Page table is modified → no problems from the programmer
usability standpoint
� Buffers related to communication with the hardware generally need to be physically contiguous
.., But most of the rest do not, for example user-space buffers
� However, most of the kernel uses k m a l l o c ( ) for performance reasons
.., Pages allocated with k m a l l o c ( ) are directly mapped
.., Less overhead in virtual to physical mapping setup and translation
� v m a l l o c ( ) is still needed to allocate large portions of memory
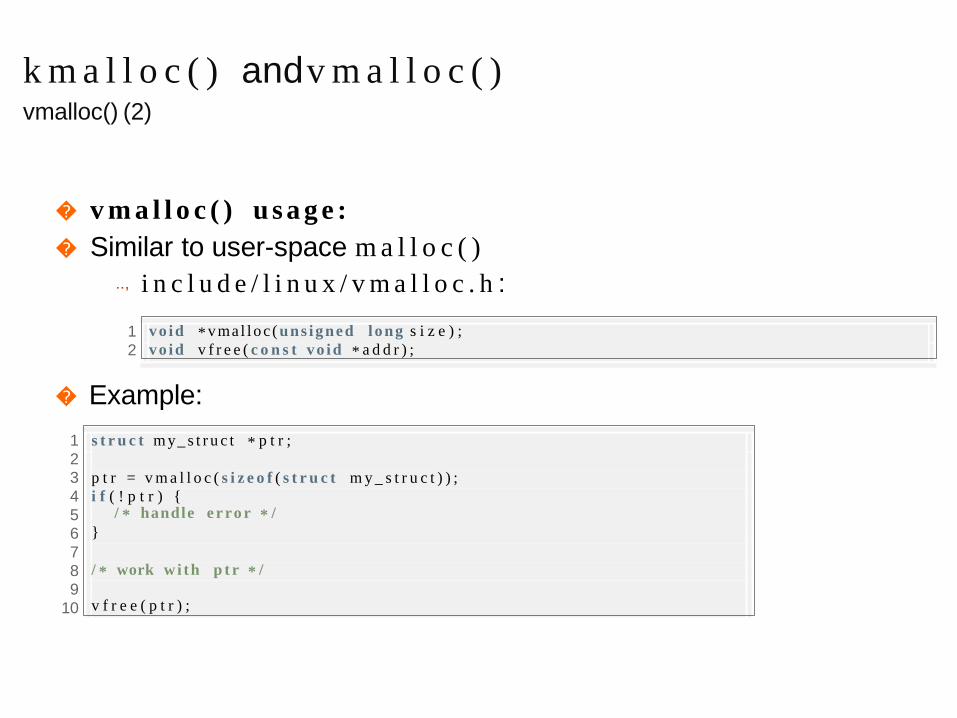
k m a l l o c ( ) andv m a l l o c ( )vmalloc() (2)
� v m a l l o c ( ) u s a g e :
� Similar to user-space m a l l o c ( )
.., i n c l u d e / l i n u x / v m a l l o c . h :
1
2
vo id * vmal loc ( uns igned l ong s i z e ) ;
vo id v f r e e ( c o n s t v o i d * a d d r ) ;
� Example:
1
23
4
56
7
89
10
s t r u c t m y_ s t r u c t * p t r ;
p t r = v m a l l o c ( s i z e o f ( s t r u c t m y _ s t r u c t ) ) ;
i f ( ! p t r ) {/ * handle e r ro r * /
}
/ * work w i th p t r * /
v f r e e ( p t r ) ;

k m a l l o c ( ) andv m a l l o c ( )vmalloc(): k m a l l o c ( ) allocated size limitation
1
23
4
56
7
89
10
1112
13
1415
16
1718
19
2021
22
2324
25
# i n c l u d e < l i n u x / mo d u l e . h >
# i n c l u d e < l i n u x / k e r n e l . h >
# i n c l u d e < l i n u x / i n i t . h >
# i n c l u d e < l i n u x / s l a b . h >
# d e f i n e PRINT_PREF "[KMALLOC_TEST]: "
s t a t i c i n t i n i t my_mod _ in i t ( v o i d )
{
uns igned l ong i ;
v o i d * p t r ;
printk(PRINT_PREF " E n t e r i n g m o d u l e . ¥ n " ) ;
f o r ( i = 1 ; ; i * = 2 ) {
p t r = k m a l l o c ( i , GFP_KERNEL);
i f ( ! p t r ) {
printk(PRINT_PREF " c o u l d n o t
a l l o c a t e %lu b y t e s ¥ n " , i ) ;
break ;}
k f r e e ( p t r ) ;
}
re turn 0 ;
}
26
2728
29
3031
32
3334
s t a t i c vo id e x i t my_mod_exi t (void )
{
printk(KERN_INFO " E x i t i n g m o d u l e . ¥ n " ) ;
}
mo d u l e _ i n i t ( my_ m o d _ i n i t ) ;
modu le_ex i t (my_ mo d_e x i t ) ;
MODULE_LICENSE("GPL");

k m a l l o c ( ) andv m a l l o c ( )vmalloc(): k m a l l o c ( ) allocated size limitation (2)
� Max size: 8MB

Outline
1 Pages and zones
2 Low-level memory allocator
3 k m a l l o c ( ) andv m a l l o c ( )
4 Slab layer
5 Stack, high memory and per-cpu allocation
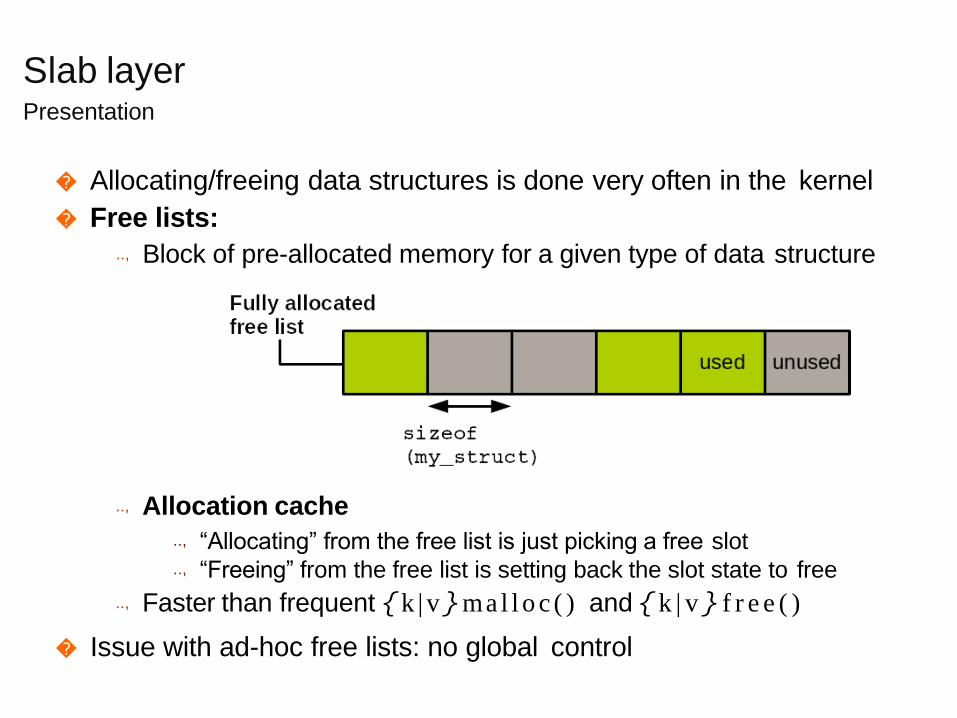
Slab layerPresentation
� Allocating/freeing data structures is done very often in the kernel
� Free lists:
.., Block of pre-allocated memory for a given type of data structure
.., Allocation cache
.., “Allocating” from the free list is just picking a free slot
.., “Freeing” from the free list is setting back the slot state to free
.., Faster than frequent {k | v}mal l o c ( ) and { k | v } f r e e ( )
� Issue with ad-hoc free lists: no global control

Slab layerPresentation (2)
� Slab layer/slab allocator: Linux’s generic allocation caching
interface
� Basic principles:.., Frequently used data structures are allocated and freed often →
needs to be cached.., Frequent allocation/free generates memory fragmentation
.., Caching allocation/free operations in large chunks of contiguous
memory reduces fragmentation
.., An allocator aware of data structure size, page size, and total cache
size is more efficient.., Part of the cache can be made per-cpu to operate without a lock.., Allocator should be NUMA-aware and implement cache-coloring

Slab layerPresentation (3)
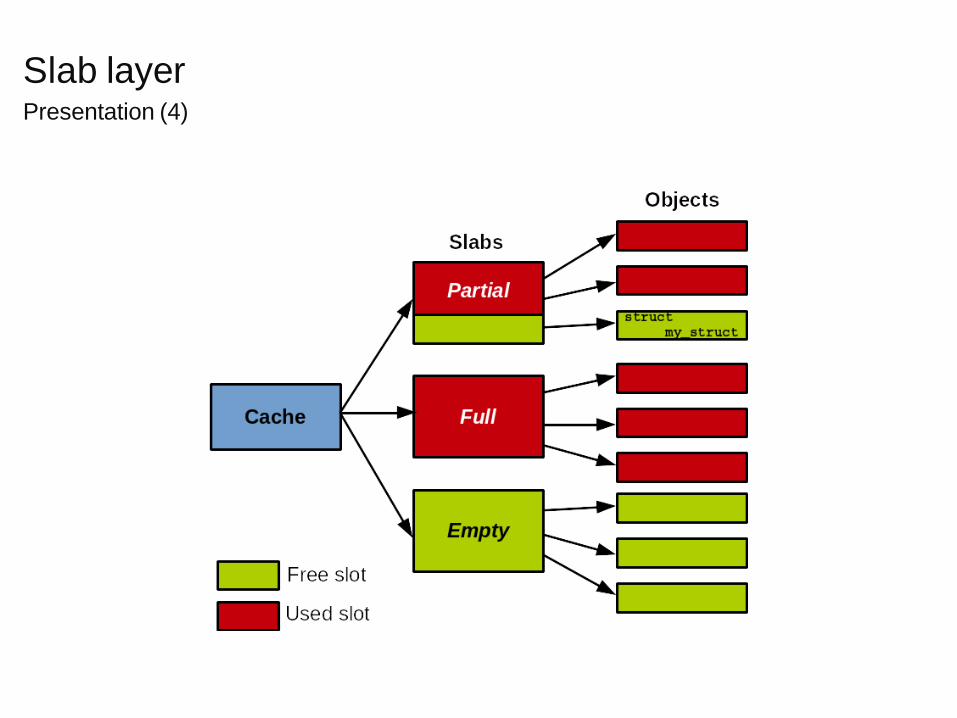
� The slab layer introduces defines the concept of caches.., One cache per type of data structure supported
.., Example: one cache for s t r u c t t a s k s t r u c t , one cache for
s t r u c t inode , etc.
� Each cache contains one or several slabs.., One or several physically contiguous pages
� Slabs contain objects.., The actual data structure slots
� A slab can be in one of three states:.., Full: all slots used.., Partial: some, not all slots used.., Empty: all slots free
� Allocation requests are served from partial slabs if present, or empty slabs → reduces fragmentation
.., A new empty slab is actually allocated in case the cache is full
Slab layerPresentation (4)

Slab layerUsage
� A new cache is created using:
1
23
4
5
s t r u c t kmem_cache * kmem_cache _c rea t e ( co ns t char *name,
s i z e _ t s i z e ,
s i z e _ t a l i g n ,uns igned l ong f l a g s ,
vo id ( * c t o r ) ( v o i d * ) ) ;
� name: cache name
� s i z e : data structure size
� a l i g n : offset of the first element
within the page (can put 0)
� c t o r : constructor called when a new data structure is allocated
.., Rarely used, can put NULL
� f l a g s : settings controlling
the cache behavior

Slab layerUsage: flags
� SLAB HW CACHEALIGN.., Each object in a slab is aligned to a cache line
.., Prevent false sharing:

Slab layerUsage: flags
� SLAB HW CACHEALIGN.., Each object in a slab is aligned to a cache line
.., Prevent false sharing:
� Increased memory footprint

Slab layerUsage: flags (2)
� SLAB POISON
.., Fill the slab with know values (a5a5a5a5) to detect accesses to
uninitialized memory
� SLAB RED ZONE
.., Extra padding around objects to detect buffer overflows
� SLAB PANIC
.., Slab layer panics if the allocation fails
� SLAB CACHE DMA
.., Allocation made from DMA-enabled memory

Slab layerUsage: allocating from the cache, cache destruction
� Allocating from the cache:
1 vo id * kmem_cache _a l l oc ( s t r uc t kmem_cache * c a c h e p , g f p _ t f l a g s ) ;
� To free an object:
1 vo id kmem_cache_ f ree ( s t ru c t kmem_cache * c a c h e p , v o i d * o b j p ) ;
� To destroy a cache:
1 i n t kmem_cache _d es t ro y ( s t r uc t kmem_cache * c a c h e p ) ;
� kmem c a c h e d e s t r o y ( ) should only be called when:
.., All slabs in the cache are empty
.., Nobody is accessing the cache during the execution ofkmem c a c h e d e s t r o y ( )
.., Implement synchronization

Slab layerUsage example
1
23
4
56
7
89
10
1112
13
1415
16
1718
19
2021
22
23
24
# i n c l u d e < l i n u x / mo d u l e . h >
# i n c l u d e < l i n u x / k e r n e l . h >
# i n c l u d e < l i n u x / i n i t . h >
# i n c l u d e < l i n u x / s l a b . h >
# d e f i n e PRINT_PREF "[SLAB_TEST] "
s t r u c t m y_ s t r u c t {
i n t i n t _ p a r a m ;
l ong l ong_pa ra m;} ;
s t a t i c i n t i n i t my_mod _ in i t ( v o i d )
{
i n t r e t = 0 ;
s t r u c t m y_ s t r u c t * p t r 1 , * p t r 2 ;
s t r u c t kmem_cache *my_cache;
printk(PRINT_PREF " E n t e r i n g m o d u l e . ¥ n " ) ;
my_cache = k m e m _ c a c h e _ c r e a t e ( " p i e r r e -
c a c h e " , s i z e o f ( s t r u c t m y _ s t r u c t ) ,
0 , 0 , NULL);i f ( ! m y_ c a c h e )
re turn - 1 ;
25
26
27
2829
30
31
3233
34
3536
37
3839
40
p t r 1 = kmem_cache_al loc(my_cache ,
GFP_KERNEL);i f ( ! p t r 1 ) {
r e t = -ENOMEM;
go to d e s t r o y _ c a c h e ;
}
p t r 2 = kmem_cache_al loc(my_cache ,
GFP_KERNEL);i f ( ! p t r 2 ) {
r e t = -ENOMEM;
go to f r e e p t r 1 ;
}
p t r 1 - > i n t _ p a r a m = 4 2 ;
p t r 1 - > l o n g_ p a r a m = 4 2 ;
p t r 2 - > i n t _ p a r a m = 4 3 ;
p t r 2 - > l o n g_ p a r a m = 4 3 ;

Slab layerUsage example (2)
41
4243
44
4546
47
4849
50
5152
53
5455
56
5758
59
6061
62
63
printk(PRINT_PREF " p t r 1 = {%d, %ld} ; p t r 2 = {%d, % l d } ¥ n " , p t r 1 - > i n t _ p a r a m ,
p t r 1 - > l o n g _ p a r a m , p t r 2 - > i n t _ p a r a m , p t r 2 - > l o n g _ p a r a m ) ;
kmem_cache_free(my_cache , p t r 2 ) ;
f r e e p t r 1 :
kmem_cache_free(my_cache , p t r 1 ) ;
d e s t r o y _ c a c h e :
kmem_cache_des t roy(my_cache) ;
re turn r e t ;
}
s t a t i c vo id e x i t my_mod_exi t (void )
{
printk(KERN_INFO " E x i t i n g m o d u l e . ¥ n " ) ;
}
mo d u l e _ i n i t ( my_ m o d _ i n i t ) ;
modu le_ex i t (my_ mo d_e x i t ) ;
MODULE_LICENSE("GPL");

Slab layerSlab allocator variants and additional info
� Slab allocator variants:
.., SLOB (Simple List Of Blocks):
.., Used in early Linux version (from 1991)
.., Low memory footprint → used in embedded systems
.., SLAB:
.., Integrated in 1999
.., Cache-friendly
.., SLUB:
.., Integrated in 2008
.., Scalability improvements (amongst other things) over SLAB on
many-cores
� More info: [5, 3, 4]

Outline
1 Pages and zones
2 Low-level memory allocator
3 k m a l l o c ( ) andv m a l l o c ( )
4 Slab layer
5 Stack, high memory and per-cpu allocation

Stack, high memory and per-cpu allocationAllocating on the stack
� Each process has:
.., A user-space stack for execution in user space
.., A kernel stack for execution in the kernel
� User-space stack is large and grows dynamically
� Kernel stack is small and has a fixed-size
.., Generally 8KB on 32-bit architectures and 16KB on 64-bit
� What about interrupt handlers?.., Historically using the kernel stack of the interrupted process.., Now using a per-cpu stack (1 single page) dedicated to interrupt
handlers.., Same thing for softirqs
� Reduce kernel stack usage to a minimum
.., Local variables & function parameters

Stack, high memory and per-cpu allocationHigh memory allocation
� On x86_32, physical memory above 896MB is not permanently mapped within the kernel address space
.., Because of the limited size of the address space and the 1G/3G
kernel/user-space physical memory split
� Before usage, pages from highmem must be mapped after allocation
.., Recall that allocation is done through a l l o c _ p a g e s ( ) withthe
GFP_HIGHMEMflag
� Permanent mapping ( inc lude/ l inux/highmem.h ) :
1 vo id * kmap( s t r uc t page * p a g e ) ;
.., Works on low and high memory
.., Maps (update the page table) and return the given
.., May sleep, use only in process context
.., Number of permanent mappings is limited, unmap when done:
1 vo id kunmap( s t r uc t page * p a g e ) ;

Stack, high memory and per-cpu allocationHigh memory allocation: usage example
1
23
4
56
7
8
910
11
1213
14
1516
17
1819
20
2122
23
# i n c l u d e < l i n u x / mo d u l e . h >
# i n c l u d e < l i n u x / k e r n e l . h >
# i n c l u d e < l i n u x / i n i t . h >
# i n c l u d e < l i n u x / g f p . h >
# i n c l u d e <l inux /h ighme m.h >
# d e f i n e PRINT_PREF "[HIGHMEM]: "
# d e f i n e INTS_IN_PAGE (PAGE_SIZE/ s i zeof (
i n t ) )
s t a t i c i n t i n i t my_mod _ in i t ( v o i d )
{
s t r u c t page *my_page;
v o i d * my_p t r ;
i n t i , * i n t _ a r r a y ;
printk(PRINT_PREF " E n t e r i n g m o d u l e . ¥ n " ) ;
my_page = alloc_page(GFP_HIGHUSER);
i f ( !my_page)
re turn - 1 ;
my_ptr = kmap(my_page);
i n t _ a r r a y = ( i n t * ) m y_ p t r ;
24
2526
27
28
2930
31
3233
34
3536
37
3839
40
41
f o r ( i = 0 ; i<INTS_IN_PAGE; i + + ) {
i n t _ a r r a y [ i ] = i ;
printk(PRINT_PREF " a r r a y[ % d ] = %d ¥ n " , i ,
i n t _ a r r a y [ i ] ) ;}
kunmap(my_page);
f r e e _ p a ge s ( m y_ p a g e , 0 ) ;
re turn 0 ;
}
s t a t i c vo id e x i t my_mod_exi t (void )
{
printk(PRINT_PREF " E x i t i n g m o d u l e . ¥ n " ) ;
}
mo d u l e _ i n i t ( my_ m o d _ i n i t ) ;
modu le_ex i t (my_ mo d_e x i t ) ;

Stack, high memory and per-cpu allocationHigh memory allocation: temporary mappings
� Temporary mappings
.., Also called atomic mappings as they can be used from interrupt
context.., Uses a per-cpu pre-reserved slot
1 vo id * kmap_a tomic ( s t r uc t page * p a g e ) ;
.., Disables kernel preemption
.., Unmap with:
1 vo id kunmap_atomic( void * a d d r ) ;
� Do not sleep while holding a temporary mapping
� After kunmap_a t o m i c ( ) , the next temporary mapping will
overwrite the slot

Stack, high memory and per-cpu allocationHigh memory allocation: temporary mappings usageexample
1
23
4
56
7
8
910
11
1213
14
1516
17
1819
20
2122
23
# i n c l u d e < l i n u x / mo d u l e . h >
# i n c l u d e < l i n u x / k e r n e l . h >
# i n c l u d e < l i n u x / i n i t . h >
# i n c l u d e < l i n u x / g f p . h >
# i n c l u d e <l inux /h ighme m.h >
# d e f i n e PRINT_PREF "[HIGHMEM_ATOMIC]: "
# d e f i n e INTS_IN_PAGE (PAGE_SIZE/ s i zeof (
i n t ) )
s t a t i c i n t i n i t my_mod _ in i t ( v o i d )
{
s t r u c t page *my_page;
v o i d * my_p t r ;
i n t i , * i n t _ a r r a y ;
printk(PRINT_PREF " E n t e r i n g m o d u l e . ¥ n " ) ;
my_page = alloc_page(GFP_HIGHUSER);
i f ( !my_page)
re turn - 1 ;
my_ptr = kmap_atomic(my_page) ;
i n t _ a r r a y = ( i n t * ) m y_ p t r ;
24
2526
27
28
2930
31
3233
34
3536
37
3839
40
41
f o r ( i = 0 ; i<INTS_IN_PAGE; i + + ) {
i n t _ a r r a y [ i ] = i ;
printk(PRINT_PREF " a r r a y[ % d ] = %d ¥ n " , i ,
i n t _ a r r a y [ i ] ) ;}
kunmap_a tomic ( my_ p t r ) ;
f r e e _ p a ge s ( m y_ p a g e , 0 ) ;
re turn 0 ;
}
s t a t i c vo id e x i t my_mod_exi t (void )
{
printk(PRINT_PREF " E x i t i n g m o d u l e . ¥ n " ) ;
}
mo d u l e _ i n i t ( my_ m o d _ i n i t ) ;
modu le_ex i t (my_ mo d_e x i t ) ;

Stack, high memory and per-cpu allocationPer-CPU allocation
� Per-cpu data: data that is unique to each CPU (i.e. each core).., No locking required.., Implemented through arrays in which each index corresponds to a
CPU:
1 uns igned l o ng my_percpu[NR_CPUS]; / * NR_CPUS c o n t a i n s t h e number o f c o re s * /
1
23
4
5
i n t c p u ;
cpu = g e t _ c p u ( ) ; / * g e t current CPU, d i s a b l e k e r n e l preemption * /
my_pe rc pu [cpu ] ++ ; / * a c c e s s t h e da ta * /
p u t _ c p u ( ) ; / * re - e n a b l e k e r n e l preemption * /
� Disabling kernel preemption ( g e t c p u ( ) / p u t c p u ( ) ) while accessing per-cpu data is necessary:
.., Preemption then reschedule on another core → cpu not valid
anymore.., Another task preempting the current one might access the
per-cpu data → race condition

Stack, high memory and per-cpu allocationPer-CPU allocation: the percpu API
� Linux provides an API to manipulate per-cpu data: percpu
.., In i n c l u d e / l i n u x / p e r c p u . h
� Compile-time per-cpu data structure usage:
.., Creation:
1 DEFINE_PER_CPU(type, name) ;
.., To refer to a per-cpu data structure declared elsewhere:
1 DECLARE_PER_CPU(name, t y p e ) ;
.., Data manipulation:
1
2
ge t_cpu_va r (na me )+ + ; / * increment ’name’ on t h i s CPU * /
p u t _ c p u _ v a r ( n a me ) ; / * Done, d i s a b l e k e r n e l preemption * /
.., Access another CPU data:
1 pe r_cpu (name , c p u ) + + ; / * increment name on t h e g i v e n CPU * /
Need to use locking!..,

Stack, high memory and per-cpu allocationPer-CPU allocation (2)
� Per-cpu data at runtime:
.., Allocation:
1
2
3
4
s t r u c t m y_ s t r u c t *my_var = a l l o c _ p e r c p u ( s t r u c t m y _ s t r u c t ) ;
i f ( ! m y _ v a r ) {/ * a l l o c a t i o n e r ro r * /
}
.., Manipulation:
1
2ge t_cpu_va r ( my_ va r ) + + ;
p u t _ c p u _ v a r ( m y_ v a r ) ;
.., Deallocation:
1 f r e e _ p e r c p u ( m y_ v a r ) ;
� Benefits of per-cpu data:.., Removes/minimizes the need for locking.., Reduces cache thrashing
.., Processor access local data so there is less cache coherency
overhead (invalidation) in multicore systems

Stack, high memory and per-cpu allocationPer-CPU allocation: usage example (static)
1 # i n c l u d e < l i n u x / mo d u l e . h >
2 # i n c l u d e < l i n u x / k e r n e l . h >
3 # i n c l u d e < l i n u x / i n i t . h >
4 # i n c l u d e < l i n u x / p e r c p u . h >
5 # i n c l u d e < l i n u x / k t h r e a d . h >
6 # i n c l u d e < l i n u x / s c h e d . h >
7 # i n c l u d e < l i n u x / d e l a y . h >8 # i n c l u d e < l i n u x / s mp . h >
91 0 # d e f i n e PRINT_PREF "[PERCPU] "
1 1 s t r u c t t a s k _ s t r u c t * t h r e a d 1 , * t h r e a d 2 , *t h r e a d 3 ;
12 DEFINE_PER_CPU(int, my_va r ) ;
1314 s t a t i c i n t t h r e a d _ f u n c t i o n ( v o i d * d a t a )
15 {1 6 w h i l e ( ! k t h r e a d _ s h o u l d _ s t o p (
) ) {
1 7 i n t c p u ;
1 8 ge t_cpu_va r ( my_ va r ) + + ;
19 cpu = s m p _ p r o c e s s o r _ i d ( ) ;
2 0 p r i n t k ( " c p u [ % d ] = %d ¥n " ,
c p u , ge t _ c p u _ v a r ( m y_ v a r ) ) ;2 1 p u t _ c p u _ v a r ( m y_ v a r ) ;
2 2 m s l e e p ( 5 0 0 ) ;
23 }
24 d o _ e x i t ( 0 ) ;25 }
25
2627
28
2930
31
3233
34
3536
37
38
39
4041
s t a t i c i n t i n i t my_ mo d _ i n i t (v o i d )
{
i n t c p u ;
printk(PRINT_PREF " E n t e r i n g m o d u l e . ¥ n " ) ;
f o r ( c p u = 0 ; cpu<NR_CPUS; cpu++)
per_cpu (my_va r , c p u ) = 0 ;
wmb();
t h r e a d 1 = k t h r e a d _ r u n ( t h r e a d _ f u n c t i o n ,
NULL, " p e r c p u - t h r e a d 1 " ) ;t h r e a d 2 = k t h r e a d _ r u n ( t h r e a d _ f u n c t i o n ,
NULL, " p e r c p u - t h r e a d 2 " ) ;
t h r e a d 3 = k t h r e a d _ r u n ( t h r e a d _ f u n c t i o n ,
NULL, " p e r c p u - t h r e a d 3 " ) ;
re turn 0 ;
}

Stack, high memory and per-cpu allocationPer-CPU allocation: usage example (static) (2)
40
4142
43
4445
46
4748
49
5051
s t a t i c vo id e x i t my_mod_exi t (void )
{
k t h r e a d _ s t o p ( t h r e a d 1 ) ;
k t h r e a d _ s t o p ( t h r e a d 2 ) ;
k t h r e a d _ s t o p ( t h r e a d 3 ) ;
printk(KERN_INFO " E x i t i n g m o d u l e . ¥ n " ) ;}
mo d u l e _ i n i t ( my_ m o d _ i n i t ) ;
modu le_ex i t (my_ mo d_e x i t ) ;
MODULE_LICENSE("GPL");

Stack, high memory and per-cpu allocationPer-CPU allocation: usage example (dynamic)
1 # i n c l u d e < l i n u x / mo d u l e . h >
2 # i n c l u d e < l i n u x / k e r n e l . h >
3 # i n c l u d e < l i n u x / i n i t . h >
4 # i n c l u d e < l i n u x / p e r c p u . h >
5 # i n c l u d e < l i n u x / k t h r e a d . h >
6 # i n c l u d e < l i n u x / s c h e d . h >
7 # i n c l u d e < l i n u x / d e l a y . h >
8 # i n c l u d e < l i n u x / s mp . h >
91 0 # d e f i n e PRINT_PREF "[PERCPU] "
1 1 s t r u c t t a s k _ s t r u c t * t h r e a d 1 ,
* t h r e a d 2 , * t h r e a d 3 ;*12 vo id my_var2 ;
1314 s t a t i c i n t t h r e a d _ f u n c t i o n ( v o i d * d a t a )
15 {
1 6 w h i l e ( ! k t h r e a d _ s h o u l d _ s t o p ( ) ) {
1 7 i n t * l o c a l _ p t r , c p u ;
1 8 l o c a l _ p t r = ge t _ c p u _ p t r ( m y_ v a r 2 ) ;
19 cpu = s m p _ p r o c e s s o r _ i d ( ) ;
2 0 ( * l o c a l _ p t r ) + + ;
2 1 p r i n t k ( " c p u [ % d ] = %d ¥ n " , c p u , * l o c a l _ p t r ) ;
2 2 p u t _ c p u _ p t r ( m y_ v a r 2 ) ;
2 3 m s l e e p ( 5 0 0 ) ;
24 }
25 d o _ e x i t ( 0 ) ;
26 }
27 s t a t i c i n t i n i t my_ mod _ in i t ( v o i d )
28 {
2 9 i n t * l o c a l _ p t r ;
3 0 i n t c p u ;
31 printk(PRINT_PREF " E n t e r i n g m o d u l e . ¥ n " ) ;
3233 my_var2 = a l l o c _ p e r c p u ( i n t ) ;
3 4 i f ( ! m y _ v a r 2 )
3 5 re turn - 1 ;
363 7 f o r ( c p u = 0 ; cpu<NR_CPUS; cpu++) {
3 8 l o c a l _ p t r = p e r _ c p u _ p t r ( m y_ v a r 2 , c p u ) ;
3 9 * l o c a l _ p t r = 0 ;
4 0 p u t _ c p u ( ) ;
41 }
4243 wmb();
44
4 5 t h r e a d 1 =
k t h r e a d _ r u n ( t h r e a d _ f u n c t i o n , NULL,
" p e r c p u - t h r e a d 1 " ) ;4 6 t h r e a d 2 =
k t h r e a d _ r u n ( t h r e a d _ f u n c t i o n ,
NULL, " p e r c p u - t h r e a d 2 " ) ;
4 7 t h r e a d 3 =
k t h r e a d _ r u n ( t h r e a d _ f u n c t i o n , NULL,
" p e r c p u - t h r e a d 3 " ) ;48
49 re turn 0 ;
50 }

Stack, high memory and per-cpu allocationPer-CPU allocation: usage example (dynamic) (2)
49
5051
52
5354
55
5657
58
5960
61
6263
s t a t i c vo id e x i t my_mod_exi t (void )
{
k t h r e a d _ s t o p ( t h r e a d 1 ) ;
k t h r e a d _ s t o p ( t h r e a d 2 ) ;
k t h r e a d _ s t o p ( t h r e a d 3 ) ;
f r e e _ p e r c p u ( m y_ v a r 2 ) ;
printk(KERN_INFO " E x i t i n g m o d u l e . ¥ n " ) ;
}
mo d u l e _ i n i t ( my_ m o d _ i n i t ) ;
modu le_ex i t (my_ mo d_e x i t ) ;
MODULE_LICENSE("GPL");

Stack, high memory and per-cpu allocationChoosing the right allocation method
� Need physically contiguous memory?.., k m a l l o c ( ) or low-level allocator, with flags:
.., GFP_KERNEL if sleeping is allowed.., GFP_ATOMICotherwise
� Need large amount of memory, not physically contiguous:
.., v m a l l o c ( )
� Frequently creating/destroying large amount of the same data structure:
.., Use the slab layer
� Need to allocate from high memory?
.., Use a l l o c p a g e ( ) then kmap() or kmap a t o m i c ( )

Bibliography I
1 Cramming more into struct page. h t t p s : / / l w n . n e t / A r t i c l e s / 5 6 5 0 9 7 / .
Accessed: 2017-03-12.
2 Gfp kernel or slab kernel? h t t p s : / / l w n . n e t / A r t i c l e s / 2 3 0 4 2 / .
Accessed: 2017-03-18.
3 The slub allocator. h t t p s : / / l w n . n e t / A r t i c l e s / 2 2 9 9 8 4 / .
Accessed: 2017-03-18.
4 BONWICK, J., ET AL.
The slab allocator: An object-caching kernel memory allocator. In USENIX summer (1994), vol. 16, Boston, MA, USA.
5 LAMETER, C.
Slab allocators in the linux kernel: Slab, slob, slub. LinuxCon/Dsseldorf 2014,h t t p : / / e v e n t s . l i n u x f o u n d a t i o n . o r g / s i t e s / e v e n t s / f i l e s / s l i d e s / s l a b a l l o c a t o r s . p d f .
Accessed: 2017-03-18.