adversarial searchcse.iitrpr.ac.in/ckn/courses/s2016/csl452/w5.pdfjohn von neumann min-max theorem...
TRANSCRIPT


Adversarial Search

John Von Neumann
Min-max theorem
John McCarthyAlpha-Beta Pruning
Claude ShannonMin-max depth
cutoff
D. G. Prinz, Alan TuringChess Program
Donald KnuthAlpha-Beta
Analysis
IBM Deep Blue
Adversarial Search 3

Types of Games
Deterministic Stochastic
Perfect Information chess, checkers, go backgammon, monopoly
Imperfect Information
blind tictactoe, battleships
bridge, poker, scrabble, nuclear war
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 4

Deterministic Single Player Game?qDeterministic Single Player, Perfect InformationoKnow the rulesoKnow the set of actionsoKnow when you winoEg: Freecell, Rubik’s cube, n-puzzle
q… it’s just Search!
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 5

Adversarial Searchq“Unpredictable” Opponent -solution is a strategyoSpecifying a move for every possible opponent move
qAI- Games – Zero Sum GamesoDeterministic – Two playeroTurn takingoFully Observable
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 6

Deterministic GamesqFormalizationo𝑆" - initial state specifies initial setup of the gameo𝑃𝑙𝑎𝑦𝑒𝑟(𝑠): Defines which player has the move in a
stateo𝐴𝑐𝑡𝑖𝑜𝑛𝑠(𝑠): Returns the set of legal moves in a stateo𝑅𝑒𝑠𝑢𝑙𝑡(𝑠, 𝑎): Transition model, that defines the
outcome of a move in a stateo𝑇𝑒𝑟𝑚𝑖𝑛𝑎𝑙 − 𝑇𝑒𝑠𝑡(𝑠): A terminal test, which is true if
the game is over and false otherwise. States where the game has ended are called terminal states.
o𝑈𝑡𝑖𝑙𝑖𝑡𝑦(𝑝, 𝑠): A utility/objective/payoff function that determines the final numeric value for a game that ends in the terminal state 𝑠 for player 𝑝.
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 7
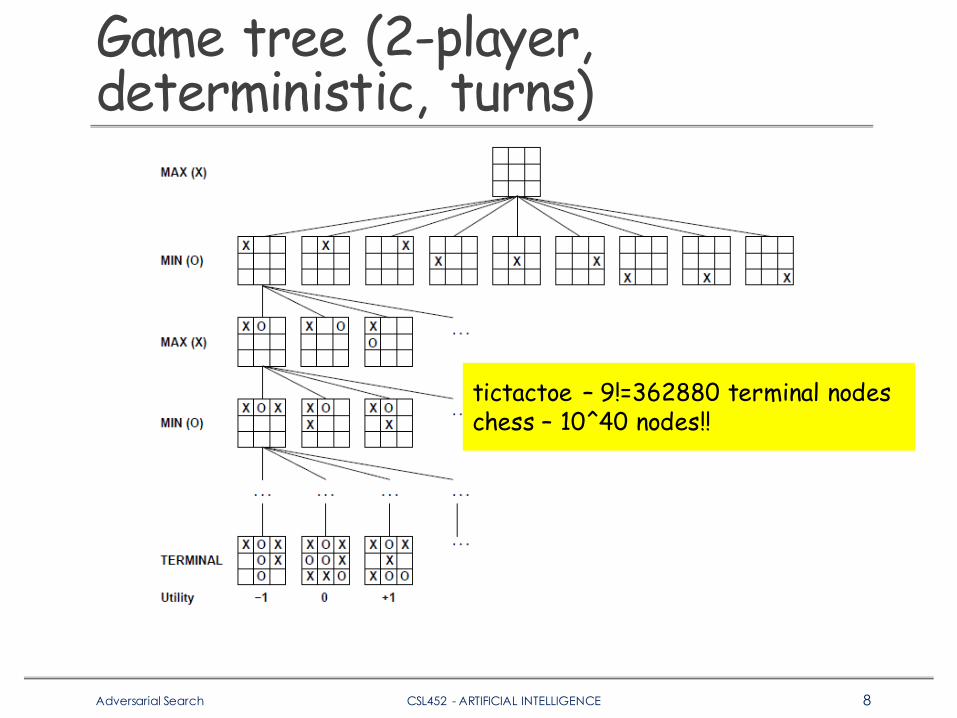
Game tree (2-player, deterministic, turns)
tictactoe – 9!=362880 terminal nodeschess – 10^40 nodes!!
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 8
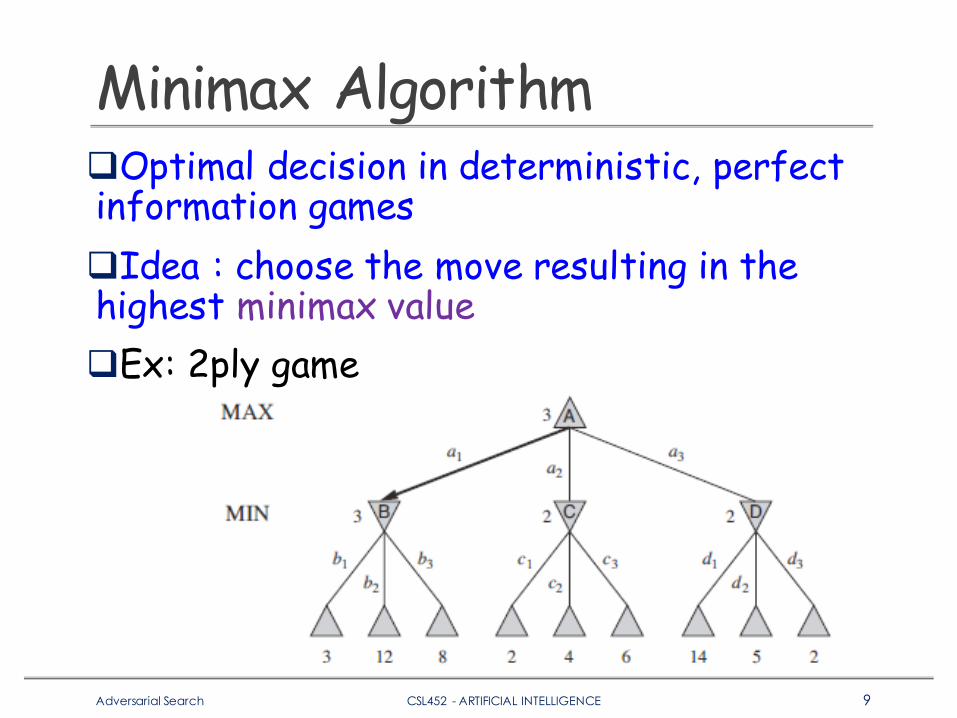
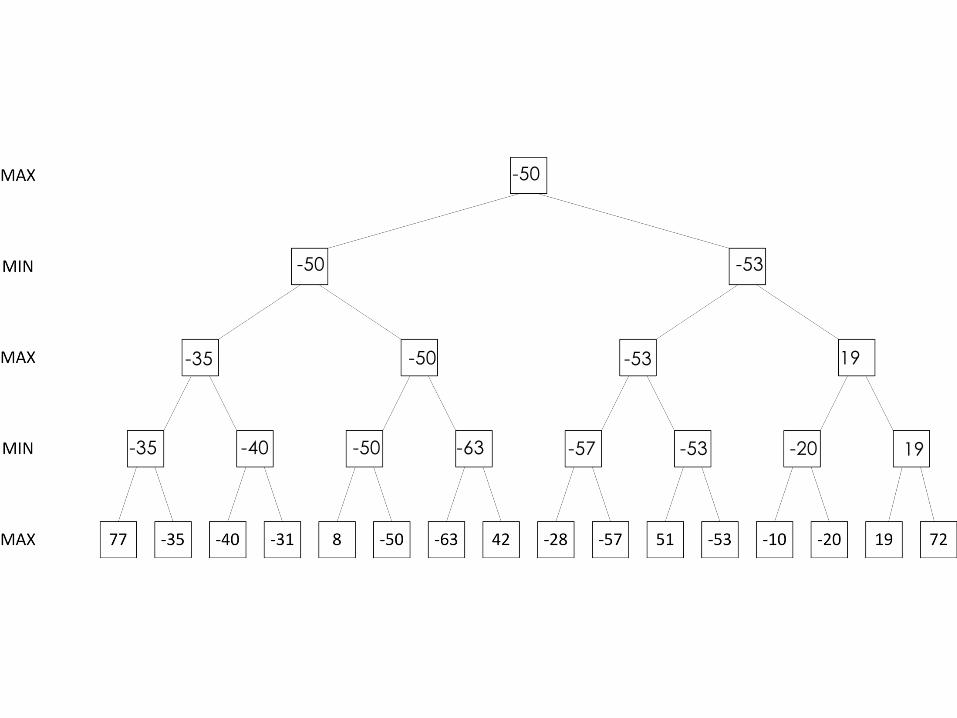
Minimax AlgorithmqOptimal decision in deterministic, perfect information gamesqIdea : choose the move resulting in the highest minimax valueqEx: 2ply game
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 9

Minimax Algorithm
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 10

Minimax Algorithm: AnalysisqCompleteness: Yes if the tree is finiteqOptimality: Yes, against an optimal opponent. Otherwise??qTime Complexity: 𝑂(𝑏<)qSpace Complexity: 𝑂(𝑏𝑚) – depth first explorationqFor chess - 𝑏 ≈ 35,𝑚 ≈ 100, for ‘reasonable’ gamesoExact solution is infeasible
qBut do we need to explore every path?
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 11
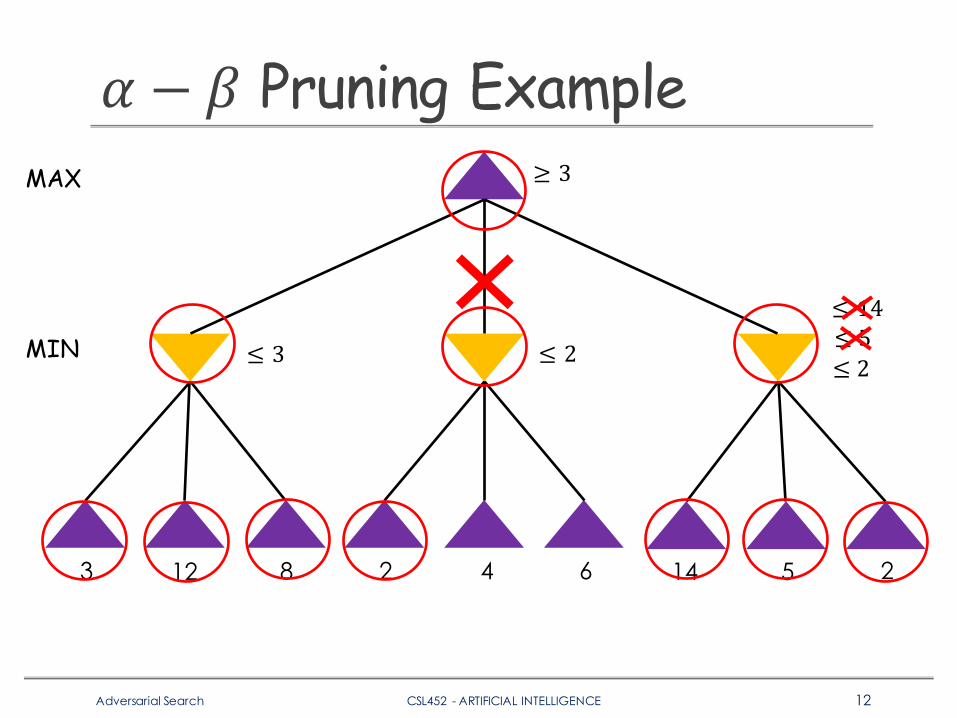
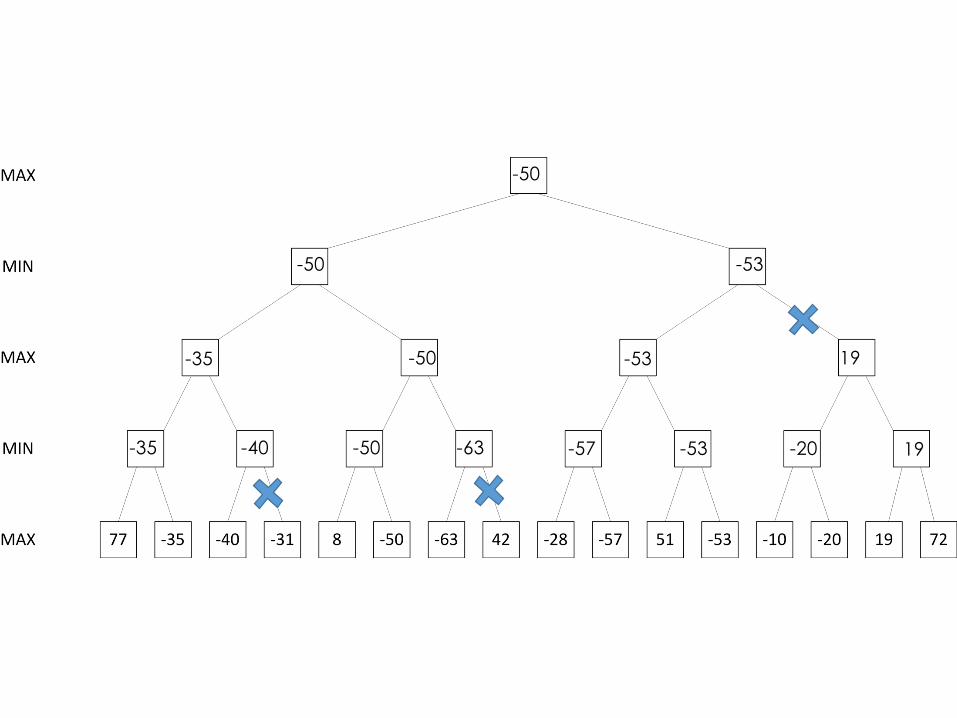
𝛼 − 𝛽 Pruning Example
3 12 8 2 4 6 5 214
MAX
MIN ≤ 3
≥ 3
≤ 2
≤ 14≤ 5≤ 2
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 12
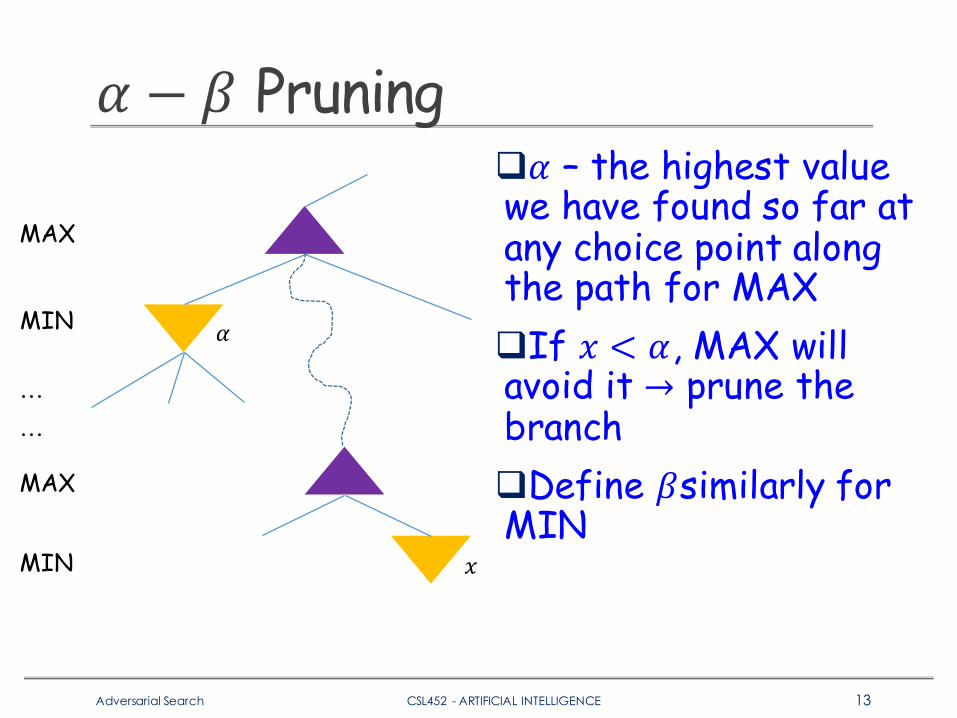
𝛼 − 𝛽 Pruningq𝛼 – the highest value we have found so far at any choice point along the path for MAXqIf 𝑥 < 𝛼, MAX will avoid it → prune the branch qDefine 𝛽similarly for MIN
MAX
MIN
……
MAX
MIN
𝛼
𝑥
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 13

𝛼 − 𝛽 Pruning - AnalysisqPruning does not affect the final result.qDoes ordering effect the pruning process?
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 14
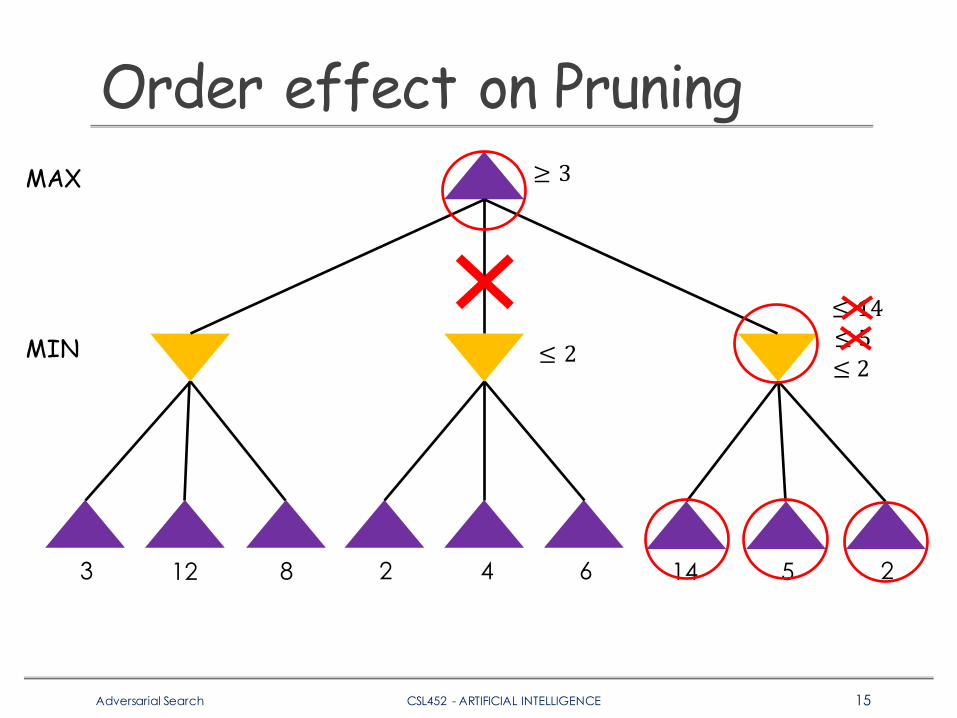
Order effect on Pruning
3 12 8 2 4 6 5 214
MAX
MIN
≥ 3
≤ 2
≤ 14≤ 5≤ 2
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 15
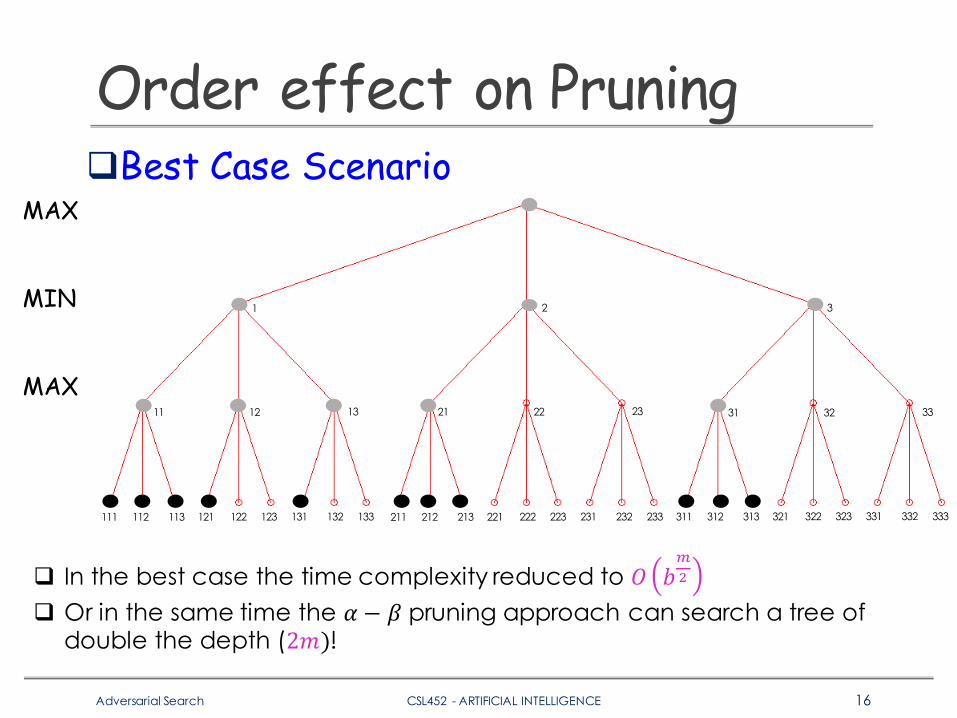
Order effect on PruningqBest Case Scenario
MAX
MIN
MAX
111 112 113 121 122 123 131 132 133 211 212 213 221 222 223 231 232 233 311 312 313 321 322 323 331 332 333
11 12 13 21 22 23 31 32 33
1 2 3
q In the best case the time complexity reduced to 𝑂 𝑏KL
q Or in the same time the 𝛼 − 𝛽 pruning approach can search a tree of double the depth (2𝑚)!
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 16

𝛼 − 𝛽 Pruning - AnalysisqPruning does not affect the final result.qDoes ordering effect the pruning process?oBest case 𝑂(𝑏
KL )
oRandom (instead of best first search) - 𝑂(𝑏MKN )
qIterative deepeningoChange the ordering while doing the search
qUsing information from past explorationsoTransposition tables
q35O" is still a very large search space
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 17

Imperfect Real-Time DecisionsqClaude Shannon: programming a computer to play chessoUse EVAL (evaluation function) instead of UTILITYoUse CUTOFF-TEST instead of TERMINAL-TEST
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 18

Evaluation FunctionsqEstimate of the expected utility of the game from a given positionqPerformance depends strongly on the quality of the functionqEVAL should order the terminal states in the same way as the utility functionqComputation must not take too longqFor non-terminal states, EVAL should strongly correlate to the actual chances of winning
𝐸𝑉𝐴𝐿 𝑠 = U𝑤W𝑓W 𝑠Y
WZ[
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 19

Cutting Off SearchqDeeper is better but why?
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 20

Deeper is BetterqPossible reasonsoPropagation of evaluation values through mins and maxs improves the collective accuracy?oGoing deeper makes the agent look for “traps”, thus improving the evaluation function?
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 21

Cutting Off SearchqDeeper is better but why?qAt what depth to cutoff search?oA move is selected within the allocated timeoIterative deepening?
qUniform DepthoQuiescence search – go deeper when the game state is in a flux
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 22

Quiescence Search
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 23
Section 5.4. Imperfect Real-Time Decisions 173
(b) White to move(a) White to move
Figure 5.8 Two chess positions that differ only in the position of the rook at lower right.In (a), Black has an advantage of a knight and two pawns, which should be enough to winthe game. In (b), White will capture the queen, giving it an advantage that should be strongenough to win.
For this reason, current programs for chess and other games also use nonlinear combinationsof features. For example, a pair of bishops might be worth slightly more than twice the valueof a single bishop, and a bishop is worth more in the endgame (that is, when the move numberfeature is high or the number of remaining pieces feature is low).
The astute reader will have noticed that the features and weights are not part of the rulesof chess! They come from centuries of human chess-playing experience. In games where thiskind of experience is not available, the weights of the evaluation function can be estimatedby the machine learning techniques of Chapter 18. Reassuringly, applying these techniquesto chess has confirmed that a bishop is indeed worth about three pawns.
5.4.2 Cutting off search
The next step is to modify ALPHA-BETA-SEARCH so that it will call the heuristic EVAL
function when it is appropriate to cut off the search. We replace the two lines in Figure 5.7that mention TERMINAL-TEST with the following line:
if CUTOFF-TEST(state , depth) then return EVAL(state)
We also must arrange for some bookkeeping so that the current depth is incremented on eachrecursive call. The most straightforward approach to controlling the amount of search is to seta fixed depth limit so that CUTOFF-TEST(state , depth) returns true for all depth greater thansome fixed depth d. (It must also return true for all terminal states, just as TERMINAL-TEST
did.) The depth d is chosen so that a move is selected within the allocated time. A morerobust approach is to apply iterative deepening. (See Chapter 3.) When time runs out, theprogram returns the move selected by the deepest completed search. As a bonus, iterativedeepening also helps with move ordering.
Section 5.4. Imperfect Real-Time Decisions 173
(b) White to move(a) White to move
Figure 5.8 Two chess positions that differ only in the position of the rook at lower right.In (a), Black has an advantage of a knight and two pawns, which should be enough to winthe game. In (b), White will capture the queen, giving it an advantage that should be strongenough to win.
For this reason, current programs for chess and other games also use nonlinear combinationsof features. For example, a pair of bishops might be worth slightly more than twice the valueof a single bishop, and a bishop is worth more in the endgame (that is, when the move numberfeature is high or the number of remaining pieces feature is low).
The astute reader will have noticed that the features and weights are not part of the rulesof chess! They come from centuries of human chess-playing experience. In games where thiskind of experience is not available, the weights of the evaluation function can be estimatedby the machine learning techniques of Chapter 18. Reassuringly, applying these techniquesto chess has confirmed that a bishop is indeed worth about three pawns.
5.4.2 Cutting off search
The next step is to modify ALPHA-BETA-SEARCH so that it will call the heuristic EVAL
function when it is appropriate to cut off the search. We replace the two lines in Figure 5.7that mention TERMINAL-TEST with the following line:
if CUTOFF-TEST(state , depth) then return EVAL(state)
We also must arrange for some bookkeeping so that the current depth is incremented on eachrecursive call. The most straightforward approach to controlling the amount of search is to seta fixed depth limit so that CUTOFF-TEST(state , depth) returns true for all depth greater thansome fixed depth d. (It must also return true for all terminal states, just as TERMINAL-TEST
did.) The depth d is chosen so that a move is selected within the allocated time. A morerobust approach is to apply iterative deepening. (See Chapter 3.) When time runs out, theprogram returns the move selected by the deepest completed search. As a bonus, iterativedeepening also helps with move ordering.

Cutting Off SearchqDeeper is better but why?qAt what depth to cutoff search?oA move is selected within the allocated timeoIterative deepening?
qUniform DepthoQuiescence search – go deeper when the game state is in a flux
qHorizon EffectoSerious damage that is temporarily avoided by delaying tactics
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 24
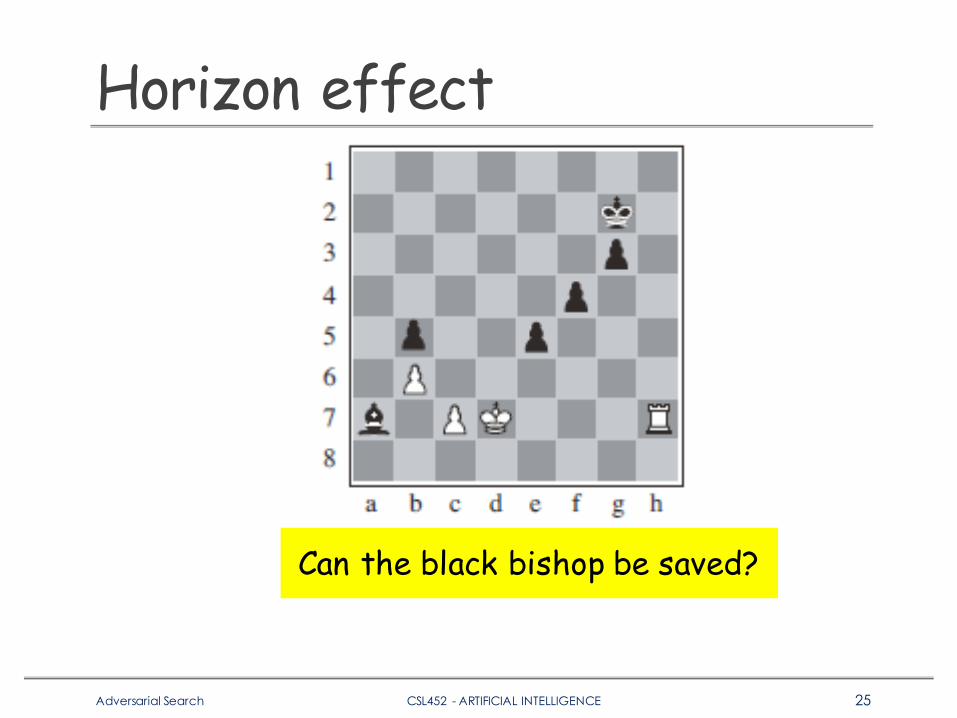
Horizon effect
Can the black bishop be saved?
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 25

Imperfect Real-Time DecisionsqClaude Shannon: programming a computer to play chessoUse EVAL (evaluation function) instead of UTILITYoUse CUTOFF-TEST instead of TERMINAL-TEST
qForward PruningoBeam search at each plyoProbabilistic Cut Algorithm
Fun Trivia• 4ply ~ human novice chess player• 8ply ~ typical PC, average human chess
player• 12ply ~ Deep Blue, Grand Masters
Adversarial Search CSL452 - ARTIFICIAL INTELLIGENCE 26

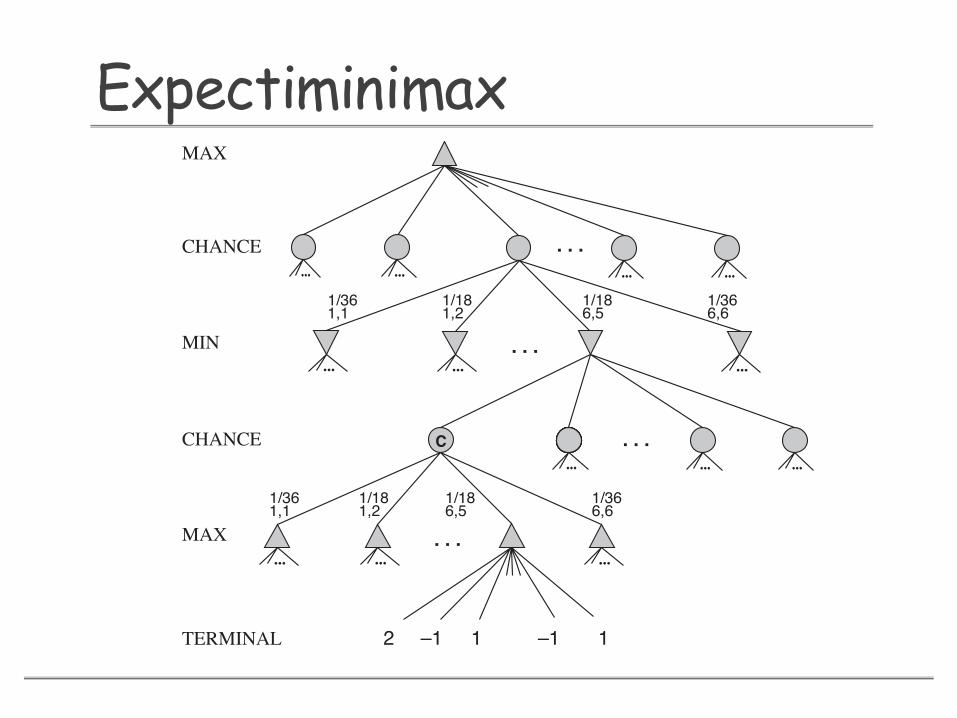
Stochastic GamesqGames that include an element of randomnessoThrow of diceoEg. Backgammon
qGame tree includes chance nodesoEdges out of chance nodes indicate the possibilities with their probability of occurrences
Expectiminimax178 Chapter 5. Adversarial Search
CHANCE
MIN
MAX
CHANCE
MAX
. . .
. . .
B
1
. . .
1,11/36
1,21/18
TERMINAL
1,21/18
......
.........
......
1,11/36
...
...... ......
...
C
. . .
1/186,5 6,6
1/36
1/186,5 6,6
1/36
2 –11–1
Figure 5.11 Schematic game tree for a backgammon position.
The next step is to understand how to make correct decisions. Obviously, we still wantto pick the move that leads to the best position. However, positions do not have definiteminimax values. Instead, we can only calculate the expected value of a position: the averageEXPECTED VALUE
over all possible outcomes of the chance nodes.This leads us to generalize the minimax value for deterministic games to an expecti-
minimax value for games with chance nodes. Terminal nodes and MAX and MIN nodes (forEXPECTIMINIMAX
VALUE
which the dice roll is known) work exactly the same way as before. For chance nodes wecompute the expected value, which is the sum of the value over all outcomes, weighted bythe probability of each chance action:
EXPECTIMINIMAX(s) =⎧⎪⎪⎨
⎪⎪⎩
UTILITY(s) if TERMINAL-TEST(s)
maxa EXPECTIMINIMAX(RESULT(s, a)) if PLAYER(s)= MAX
mina EXPECTIMINIMAX(RESULT(s, a)) if PLAYER(s)= MIN∑r P (r)EXPECTIMINIMAX(RESULT(s, r)) if PLAYER(s)= CHANCE
where r represents a possible dice roll (or other chance event) and RESULT(s, r) is the samestate as s, with the additional fact that the result of the dice roll is r.
5.5.1 Evaluation functions for games of chance
As with minimax, the obvious approximation to make with expectiminimax is to cut thesearch off at some point and apply an evaluation function to each leaf. One might think thatevaluation functions for games such as backgammon should be just like evaluation functions
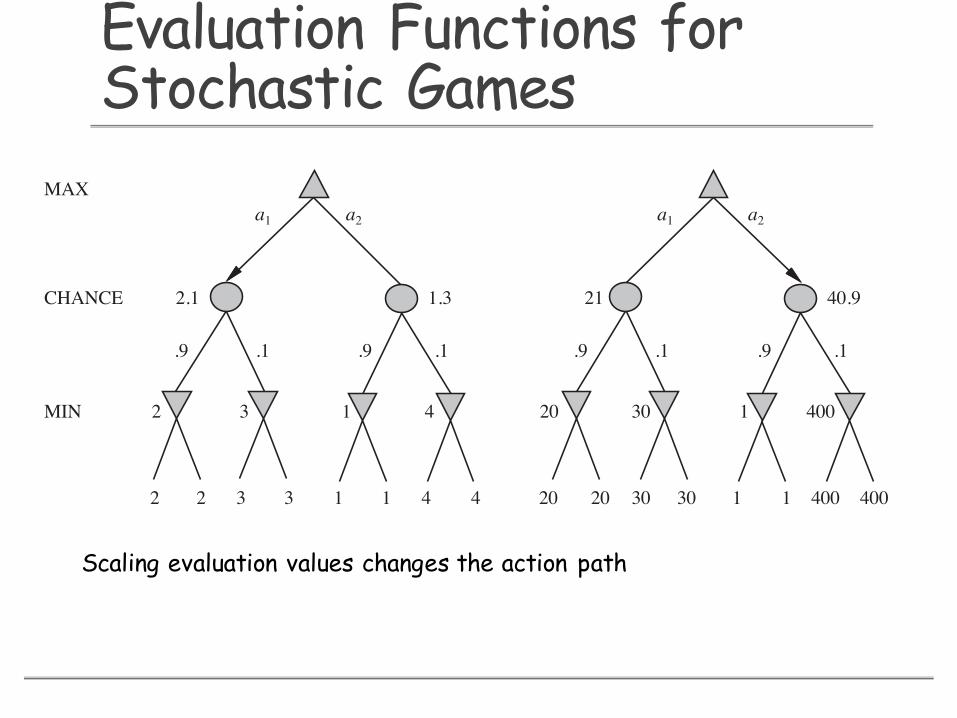
Evaluation Functions for Stochastic Games
Section 5.5. Stochastic Games 179
for chess—they just need to give higher scores to better positions. But in fact, the presence ofchance nodes means that one has to be more careful about what the evaluation values mean.Figure 5.12 shows what happens: with an evaluation function that assigns the values [1, 2,3, 4] to the leaves, move a1 is best; with values [1, 20, 30, 400], move a2 is best. Hence,the program behaves totally differently if we make a change in the scale of some evaluationvalues! It turns out that to avoid this sensitivity, the evaluation function must be a positivelinear transformation of the probability of winning from a position (or, more generally, of theexpected utility of the position). This is an important and general property of situations inwhich uncertainty is involved, and we discuss it further in Chapter 16.
CHANCE
MIN
MAX
2 2 3 3 1 1 4 4
2 3 1 4
.9 .1 .9 .1
2.1 1.3
20 20 30 30 1 1 400 400
20 30 1 400
.9 .1 .9 .1
21 40.9
a1 a2 a1 a2
Figure 5.12 An order-preserving transformation on leaf values changes the best move.
If the program knew in advance all the dice rolls that would occur for the rest of thegame, solving a game with dice would be just like solving a game without dice, which mini-max does in O(bm) time, where b is the branching factor and m is the maximum depth of thegame tree. Because expectiminimax is also considering all the possible dice-roll sequences,it will take O(bm
nm), where n is the number of distinct rolls.
Even if the search depth is limited to some small depth d, the extra cost compared withthat of minimax makes it unrealistic to consider looking ahead very far in most games ofchance. In backgammon n is 21 and b is usually around 20, but in some situations can be ashigh as 4000 for dice rolls that are doubles. Three plies is probably all we could manage.
Another way to think about the problem is this: the advantage of alpha–beta is thatit ignores future developments that just are not going to happen, given best play. Thus, itconcentrates on likely occurrences. In games with dice, there are no likely sequences ofmoves, because for those moves to take place, the dice would first have to come out the rightway to make them legal. This is a general problem whenever uncertainty enters the picture:the possibilities are multiplied enormously, and forming detailed plans of action becomespointless because the world probably will not play along.
It may have occurred to you that something like alpha–beta pruning could be applied
Scaling evaluation values changes the action path

Expectiminimax - AnalysisqInclude n- chance nodeso𝑂(𝑏<𝑛<) – assuming uniform branching
qExtra cost associated with chance nodes makes it unrealistic for looking ahead very far.qCan alpha-beta pruning be applied?oYes – one way to do it is make bounds on the values of the utility functionoAlternative – Monte-Carlo Simulation to evaluate a position (explore later)
-35 -40
-35
-50
-50
-63
-50
-50
-57 -53
-53
-20 19
19
-53
-35 -40
-35
-50
-50
-63
-50
-50
-57 -53
-53
-20 19
19
-53
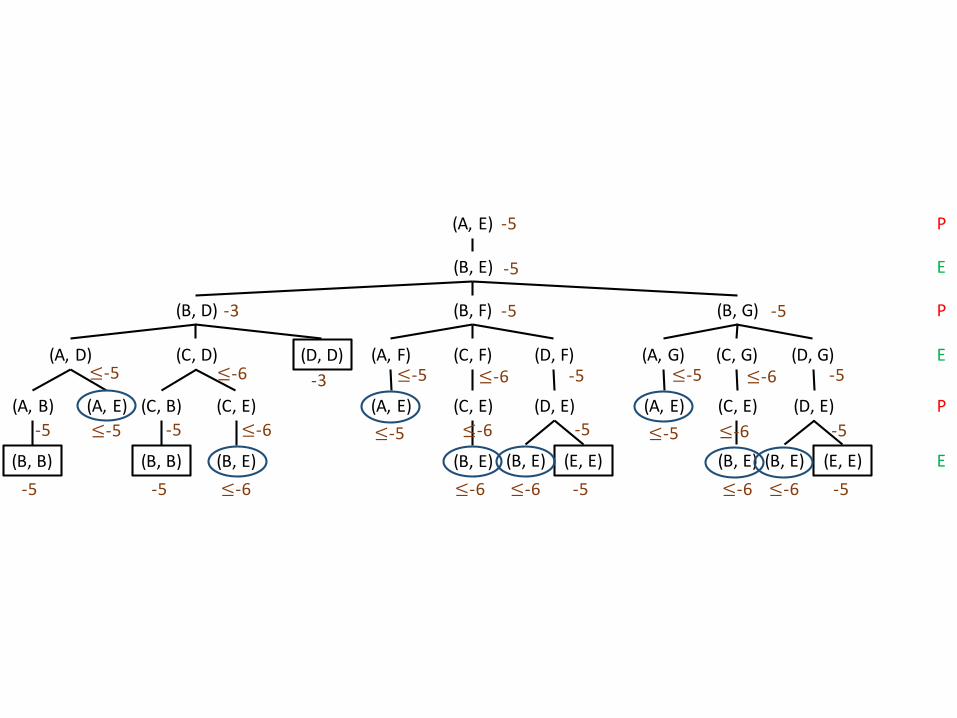
(A,E)
(B,E)
(B,D) (B,F) (B,G)
(A,D) (C,D) (D,D) (A,F) (C,F) (D,F) (A,G) (C,G) (D,G)
(A,E)(A,B) (C,E)(C,B) (A,E) (C,E) (D,E) (A,E) (C,E) (D,E)
(B,B) (B,B) (B,E) (B,E) (B,E) (E,E) (B,E) (E,E)(B,E)
P
E
P
E
P
E-5 -5 -5-5 ≤-6 ≤-6 ≤-6 ≤-6 ≤-6
-5 ≤-5 -5 -5≤-5 ≤-6≤-6 ≤-5 -5≤-6
≤-5 ≤-6 -3 ≤-5 ≤-6 -5 ≤-5 ≤-6 -5
-3 -5 -5
-5
-5