aesop change data propagation
TRANSCRIPT

Aesop Change Data Propagation : Bridging SQL and NoSQL Systems
Regunath B, Principal Architect, Flipkart
github.com/regunathb twitter.com/RegunathB

What data store?
• In interviews: I need to scale and therefore will use a NoSQL database • Avoids the overheads of RDBMS!?
• XX product brochure: • Y million ops/sec (Lies, Damn Lies, and Benchmarks) • In-memory, Flash optimised
• In architecture reviews: • Durability of data, disk-to-memory ratios • How many nodes in a single cluster?
• CAP tradeoffs: Consistency vs. Availability 2

SCALING AN E-COMMERCE WEBSITE
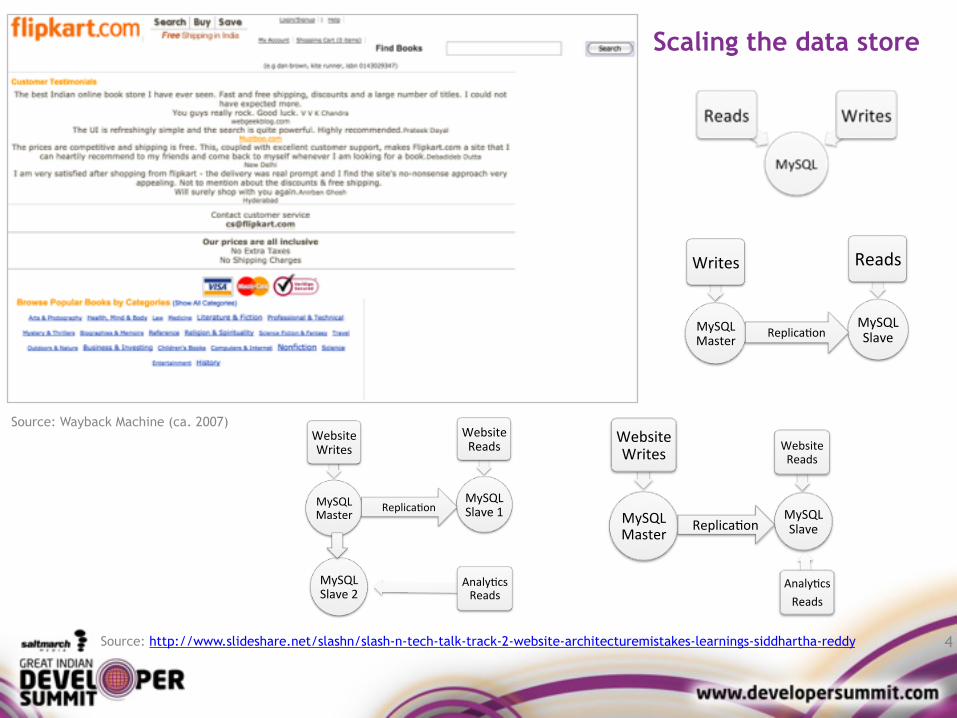
4
Source: Wayback Machine (ca. 2007)
Scaling the data store
Source: http://www.slideshare.net/slashn/slash-n-tech-talk-track-2-website-architecturemistakes-learnings-siddhartha-reddy
MySQL&Master&
Website&Writes&
MySQL&Slave&
Website&Reads&
Analy5cs&Reads&
Replica5on&
MySQL&Master&
Website&Writes&
MySQL&Slave&1&
Website&Reads&
Replica6on&
MySQL&Slave&2&
Analy6cs&Reads&
Replica6on&
MySQL&Master&
Writes&
MySQL&Slave&
Reads&
Replica4on&
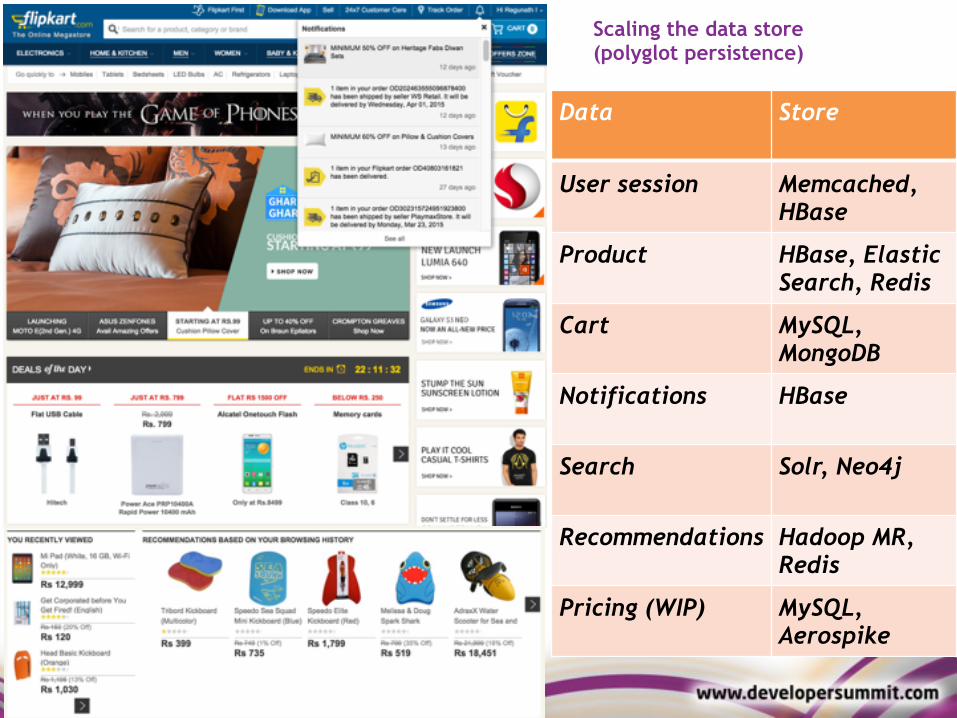
5
Data Store
User session Memcached, HBase
Product HBase, Elastic Search, Redis
Cart MySQL, MongoDB
Notifications HBase
Search Solr, Neo4j
Recommendations Hadoop MR, Redis
Pricing (WIP) MySQL, Aerospike
Scaling the data store (polyglot persistence)

DATA CONSISTENCY IN POLYGLOT PERSISTENCE

Caching/Serving Layer challenges
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
7
• Cache TTLs, High Request concurrency, Lazy caching • Thundering herds • Availability of primary data store
• Cache size, distribution, no. of replicas • Feasibility of write-through
• Serving layer is Eventually Consistent, at best

Eventual Consistency
• Replicas converge over time • Pros
• Scale reads through multiple replicas • Higher overall data availability
• Cons • Reads return live data before convergence
• Need to implement Strong Eventual Consistency when timeline-consistent view of data is needed
• Achieving Eventual Consistency is not easy • Trivially requires Atleast-Once delivery guarantee of
updates to all replicas8

AESOP - CHANGE DATA CAPTURE, PROPAGATION

Introduction
10
• A keen observer of changes that can also relay change events reliably to interested parties. Provides useful infrastructure for building Eventually Consistent data sources and systems.
• Open Source : https://github.com/Flipkart/aesop • Support : [email protected] • Production Deployments at Flipkart :
• Payments : Multi-tiered datastore spanning MySQL, HBase • ETL : Move changes on User accounts to data analysis platform/
warehouse • Data Serving : Capture Wishlist data updates on MySQL and index
in Elastic Search • WIP : Accounting, Pricing, Order management etc.
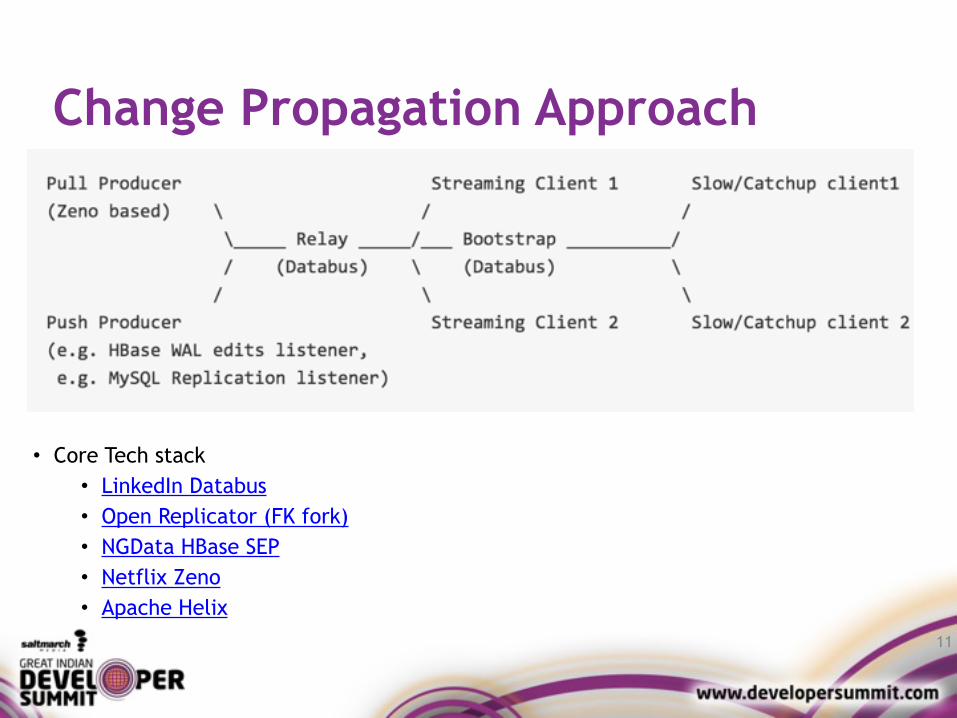
Change Propagation Approach
11
• Core Tech stack • LinkedIn Databus • Open Replicator (FK fork) • NGData HBase SEP • Netflix Zeno • Apache Helix

Aesop Components
• Producer : Uses Log Mining (Old wine in new bottle?) • "Durability is typically implemented via logging and
recovery.” Architecture of a Database System • "The contents of the DB are a cache of the latest records in
the log. The truth is the log. The database is a cache of a subset of the log.” - Jay Kreps (creator of Kafka)
• WAL (write ahead log) ensures: • Each modification is flushed to disk • Log records are in order
12

Aesop Components
• Databus Relay : Ring-Buffer holding Avro serialised change events • Memory mapped • Similar to a Broker in a pub-sub system • Enhanced in Aesop for configurability, metrics
collection and admin console • Databus Consumer(s) : Sinks for change events • Enhanced in Aesop for bootstrapping,
configurability, data transformation13

Aesop Architecture
14

Event Consumption
• Data transformation • Data Layer : Multiple
destinations • MySQL • Elastic Search • HBase
15

Client Clustering : HA & Load Balancing
16
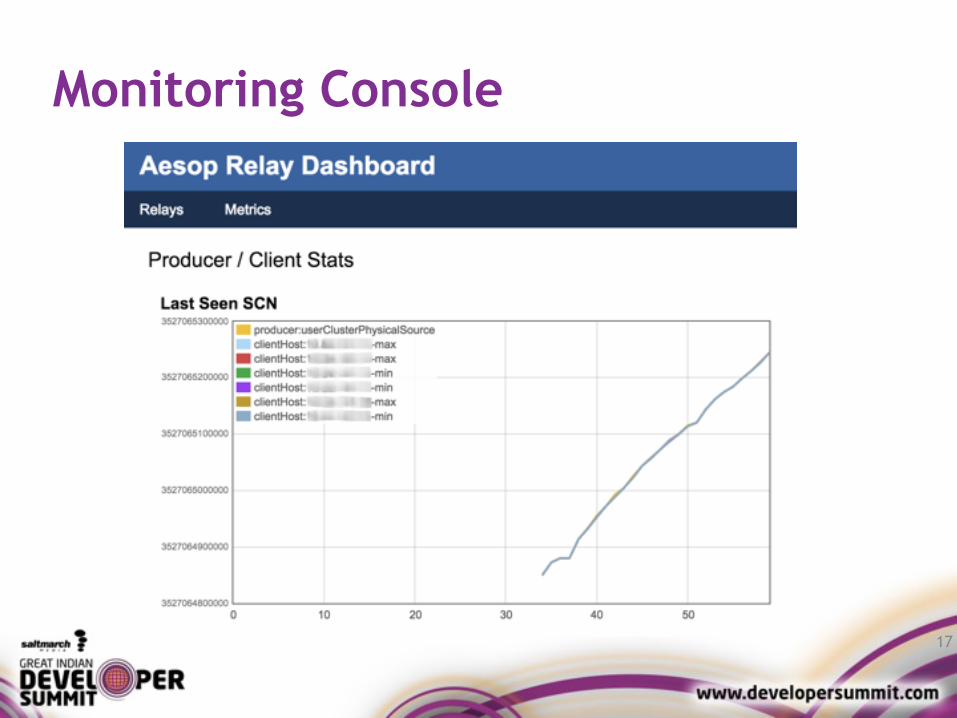
Monitoring Console
17
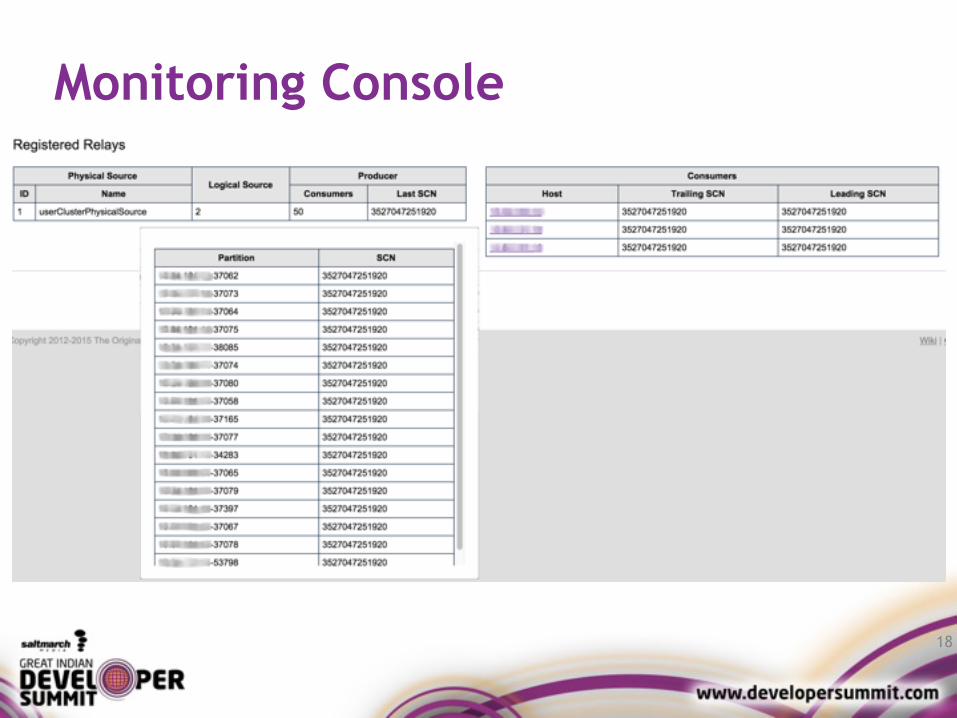
Monitoring Console
18
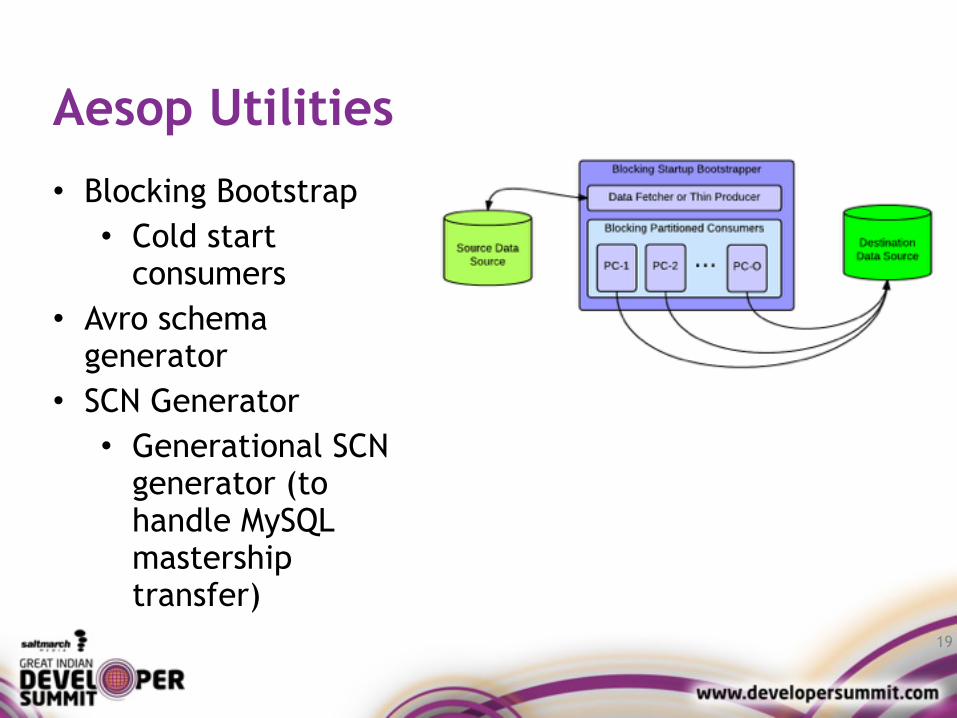
Aesop Utilities• Blocking Bootstrap • Cold start
consumers • Avro schema
generator • SCN Generator • Generational SCN
generator (to handle MySQL mastership transfer)
19

Performance (Lies, Damn Lies, and Benchmarks)
• MySQL —> HBase • Relay : 1 XL VM (8 core, 32GB) • Consumers : 4 XL, 200 partitions • Throughput : 30K Inserts per sec. • Data size : 800 GB • Time : 60 hrs
• Observations: • Busy Relay - 95% CPU (serving data to 200 partitions) • High producer throughput - Log read operates at disk transfer
rate • High consumer throughput - Append-only writes of HBase
• Better scale possible with larger machine for Relay • Partitioning Relay might be tricky - to preserve WAL edits ordering
20

Future Work
• Enhance, Implement: • Producers
• HBase, MongoDB, etc. • Data Layers
• Redis, Aerospike, etc. • Document Operational best practices
• e.g. MySQL mastership transfer • Infra component for building tiered data stores
• Sharded, Secondary indices, Low Latency, HW optimized (high Disk-Memory ratios)
21
