agile, dynamic provisioning of multitier internet applications bhuvan urgaonkar, prashant shenoy,...
TRANSCRIPT

1
AGILE, DYNAMIC PROVISIONING OF MULTITIERINTERNET APPLICATIONSBhuvan Urgaonkar, Prashant Shenoy, Abhishek Chandray, and Pawan Goyal
ACM Transactions on Autonomous Adaptive Systems, 3(1), 2008

2
Agenda
Introduction System Overview Provisioning Algorithm
How much When
Server Switching Evaluation Conclusion Comments

3
Introduction (1/4)
Internet applications employ a multi-tier architecture, with each tier providing a certain functionality Such applications tend to see dynamically
varying workloads that contain long-term variations such as time-of-day effects short-term fluctuations due to flash crowds
Predicting the peak workload of an Internet application and capacity provisioning based on these worst case estimates is notoriously difficult

4
Introduction (2/4)
Since many single-tier provisioning mechanisms have already been proposed a straightforward extension is to employ such
an approach at each tier of the application But….
Use single-tier provisioning mechanisms Bottleneck Shifting
Model all tiers as a black box and allocate servers whenever the observed response time exceed a threshold
Hard to determine how much servers and where the server should be allocated

5
Introduction (3/4)

6
Introduction (4/4)
Research Contributions Predictive and Reactive Provisioning Analytical modeling and incorporating tails
of workload distributions Virtual Machine based provisioning Handling session-based workloads
7
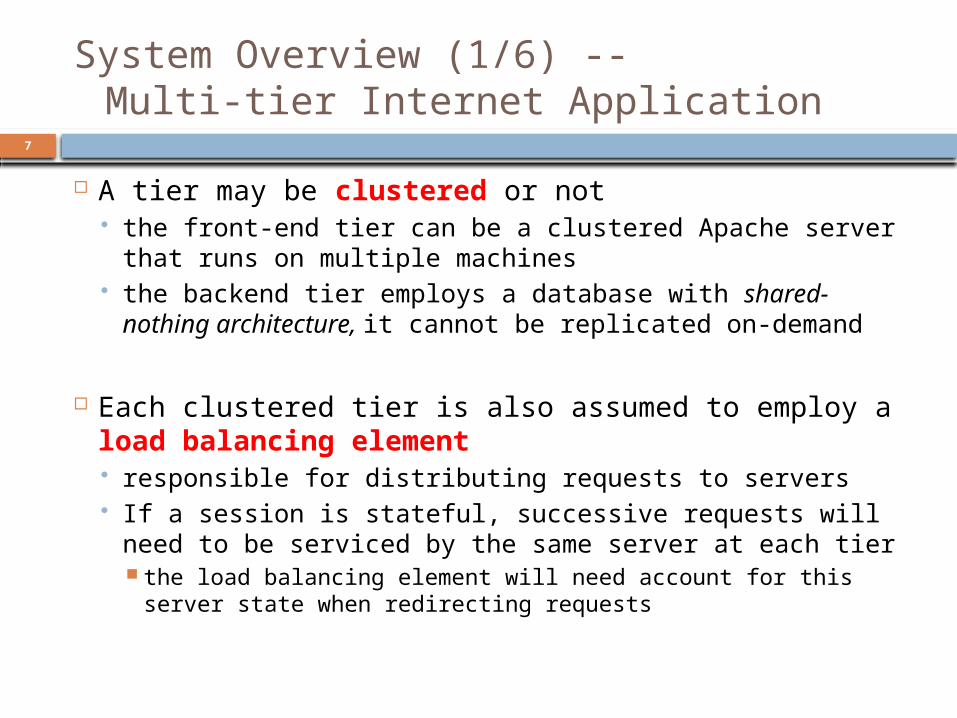
System Overview (1/6) --Multi-tier Internet Application
A tier may be clustered or not the front-end tier can be a clustered Apache server that
runs on multiple machines the backend tier employs a database with shared-
nothing architecture, it cannot be replicated on-demand
Each clustered tier is also assumed to employ a load balancing element responsible for distributing requests to servers If a session is stateful, successive requests will need to
be serviced by the same server at each tier the load balancing element will need account for this server
state when redirecting requests

8
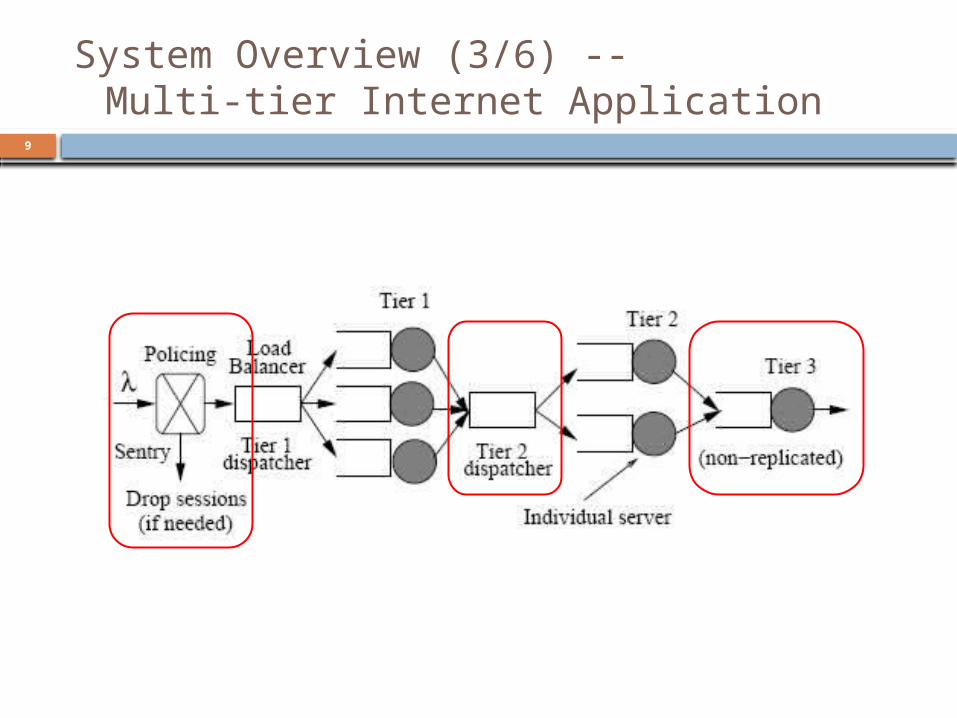
System Overview (2/6) --Multi-tier Internet Application
Every application also runs a special component called a sentry polices incoming sessions to an application’s
server pool unlike systems that use per-tier admission control
makes a one-time admission decision when a session arrives
avoids resource wastage resulting from partially serviced requests that may be dropped at later tiers
Once a session has been admitted, none of its requests can be dropped at any intermediate tier
9
System Overview (3/6) --Multi-tier Internet Application

10
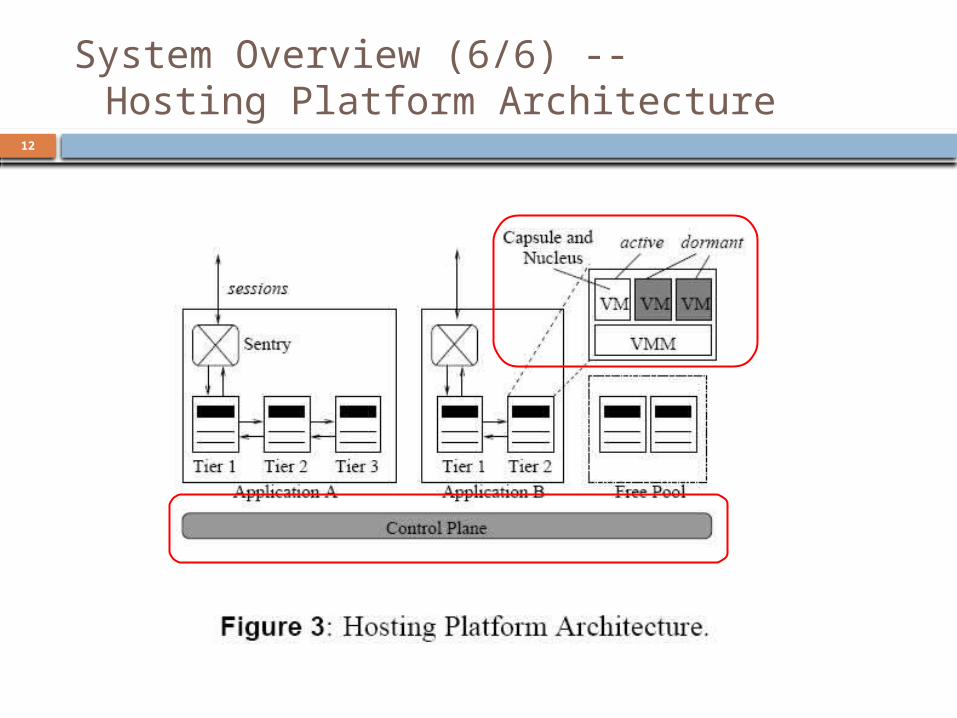
System Overview (4/6) --Hosting Platform Architecture
The hosting platform is a data center that consists of a cluster of commodity servers interconnected by gigabit Ethernet
Servers Hosting Application Components each application runs on a subset of the servers
and a server is allocated to at most one application at any given time
The component of an application that runs on a server is referred to as a capsule If the capsule is replicable – the server is called Elf If the capsule is non-replicable – the server is called
Ent

11
System Overview (5/6) --Hosting Platform Architecture
Nucleus a software component that performs online
measurements of the capsule workload, performance and resource usage
these statistics are periodically conveyed to the control plane
Control Plane responsible for dynamic provisioning of
servers to individual applications
12
System Overview (6/6) --Hosting Platform Architecture

13
Provisioning Algorithm --How much (1/3)
Model each server as a G/G/1 queuing model
Request arrival rate to tier i λi : the request arrival rate to tier i di : the mean response time for tier i si : the average service time for a request : the variance of inter-arrival time : the variance of service time

14
=>
=>
=>
=>
=>
Wq : the waiting time in queue
X : the (random) service time

15
Provisioning Algorithm --How much (2/3)
Observe that di is known the per-tier service time si the variance of inter-arrival and service
times and can be monitored online in the system. By substituting these values, a lower bound
on request rate λi that can serviced by a single server can be obtained.

16
Provisioning Algorithm --How much (3/3)
ηi : The number of servers needed at tier i (output) Z : average session think-time : the rate that a session issues requests λ : the session arrival rate : the average session duration βi: the requests that triggered by a single
incoming request at tier i

17
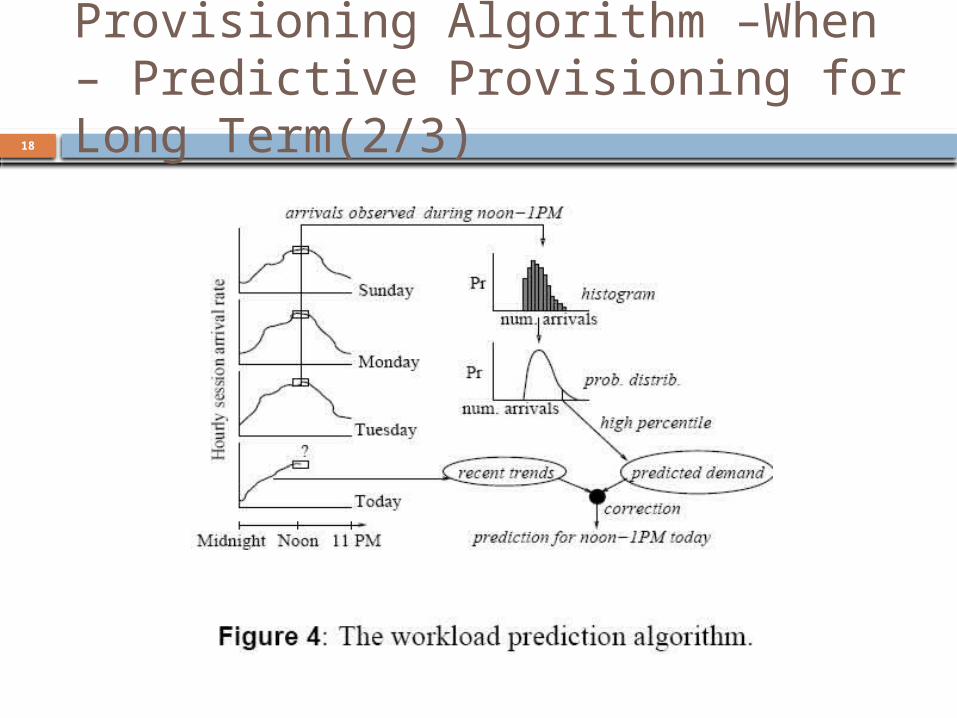
Provisioning Algorithm –When – Predictive Provisioning for Long Term(1/3) Predictive provisioning is motivated by long-
term variations such as time-of-day or seasonal effects exhibited by Internet workloads the workload seen by an Internet application
typically peaks around noon every day and is minimum in the middle of the night
The predictor uses past observations of the workload to predict peak demand that will be seen over a period of T hours For simplicity of exposition, assume that T = 1 hour
18
Provisioning Algorithm –When – Predictive Provisioning for Long Term(2/3)

19
Provisioning Algorithm –When – Predictive Provisioning for Long Term(3/3) λpred(t): the predicted arrival rate during a
particular hour denoted by t λobs(t): the actual arrival rate seen during
this hour λobs(t) - λpred(t): the prediction error h : the mean prediction error over the
past h hours

20
Provisioning Algorithm –When – Reactive Provisioning for Short Term(1/3) sudden load spikes or flash crowds are
inherently unpredictable phenomena Reactive provisioning is used to swiftly
react to such unforeseen events operates on short time scales—on the order of
minutes—checking for workload anomalies

21
Provisioning Algorithm –When – Reactive Provisioning for Short Term(2/3) Reactive provisioning is invoked once every
few minutes It can also be invoked on-demand by the
application sentry
Two approaches Recompute a new allocation of server for the
various tiers Increase the allocation of all tiers that are at or
near saturation by a constant amount

22
Provisioning Algorithm –When – Reactive Provisioning for Short Term(3/3) If the free pool is empty or has
insufficient servers need to be borrowed from other
underloaded applications running on the hosting platform
An application is said to be underloaded if its observed workload is significantly lower than its provisioned capacity

23
Server Switching (1/2)
assume that each Elf server runs multiple virtual machines and capsules of different applications within it Only one capsule and its virtual machine is
active at any time Other virtual machines are dormant—they
are allocated minimal server resources If the server belongs to the free pool, all of
its resident VMs are dormant

24
Server Switching (2/2)
switching an Elf server from one application to another implies deactivating a VM by reducing its resource allocation to ε ε is a small value such that the VM consumes
negligible resources But, if the server retains state of existing
sessions Fixed rate ramp down
Some long-lived residual session will be forced to terminate
Measurement-based ramp down The server switching time is long

25
Evaluation –Environment (1/3)
a prototype data center a cluster of 40 Pentium servers
An application capsule (2.8GHz, 512MB RAM) Load balancer Control plane (dual-processor 450MHz, 1GB RAM) Sentry (dual-processor 1GHz, 1GB RAM) Workload Generator
connected via a 1Gbps ethernet switch running Linux 2.4.20
Three tiers Apache Web server (2.0.48) Tomcat servlets container (4.1.29) Non-replicable Mysql database server (4.0.18)

26
Evaluation –Environment (2/3)
Virtual Machine Monitor Xen 1.2 …..
Nucleus online measurements of resource usages and request performance real-time processing of logs provided by the application software
components offline measurements to determine various quantities needed by the
control plane Sentry and Load balancer
Use Kernel TCP Virtual Server (ktcpvs) version 0.0.14 for sentry and Apache layer
mod_jk: an Apache module that implement a varient of round robin request distribution for Tomcat layer
Control Plane A daemon running in a dedicated machine Implements the predictive and reactive provisioning

27
Evaluation –Environment (3/3)
two open-source multi-tier applications Rubis
An eBay like auction site Three type of user sessions : selling, browsing, bidding 9 tables in the database 26 interactions that can be accessed from the clients’ Web
browsers Rubbos
A bulletin-board application Two different levels of access : regular user and moderator provides 24 Web interactions
SLA: the 95th percentile of the response time is no greater than 2 seconds

28
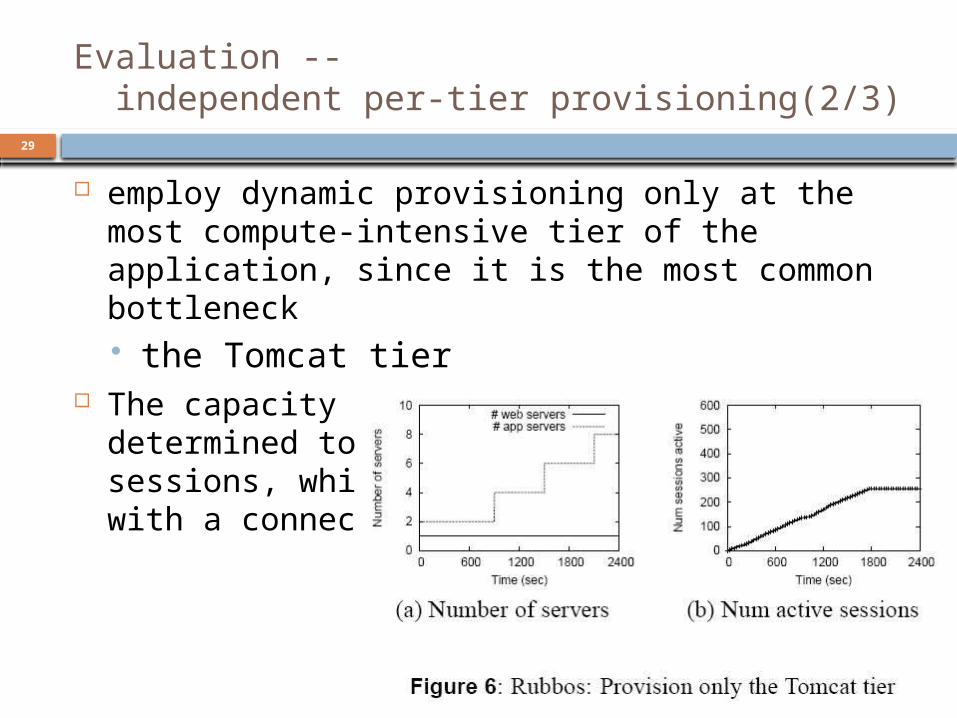
Evaluation -- independent per-tier provisioning(1/3)
Use Rubbos application Workload increase every 10 minutes
29
Evaluation -- independent per-tier provisioning(2/3)
employ dynamic provisioning only at the most compute-intensive tier of the application, since it is the most common bottleneck the Tomcat tier
The capacity of a Tomcat server was determined to be 40 simultaneous sessions, while Apache was configured with a connection limit of 256 sessions

30
Evaluation -- independent per-tier provisioning(3/3)
Use multi-tier provisioning technique

31
Evaluation -- the black box approach(1/2)
Use Rubis assume that two Tomcat servers and one
Apache server are added to the application every time a capacity increase is signaled
But database is not replicable

32

33
Evaluation -- the black box approach(2/2)
Use multi-tier provisioning technique

34
Evaluation -- Predictive and Reactive Provisioning(1/4)
Use Rubis Workload
1998 Soccer World Cup Site 8 day period
Compressing the original 24-hr long trace to 1hr Picking every 24th minutes and discarding the
rest Day 6(typical day) Day 7(moderate overload) Day 8(extreme overload)

35
Evaluation -- Predictive and Reactive Provisioning(2/4)
Day 6 Only predictive provisioning

36
Evaluation -- Predictive and Reactive Provisioning(3/4)
Day 7 Predicted with/without recent trand Prediction failed during interval 2 Reactive must trigger after the SLA is
violated
37
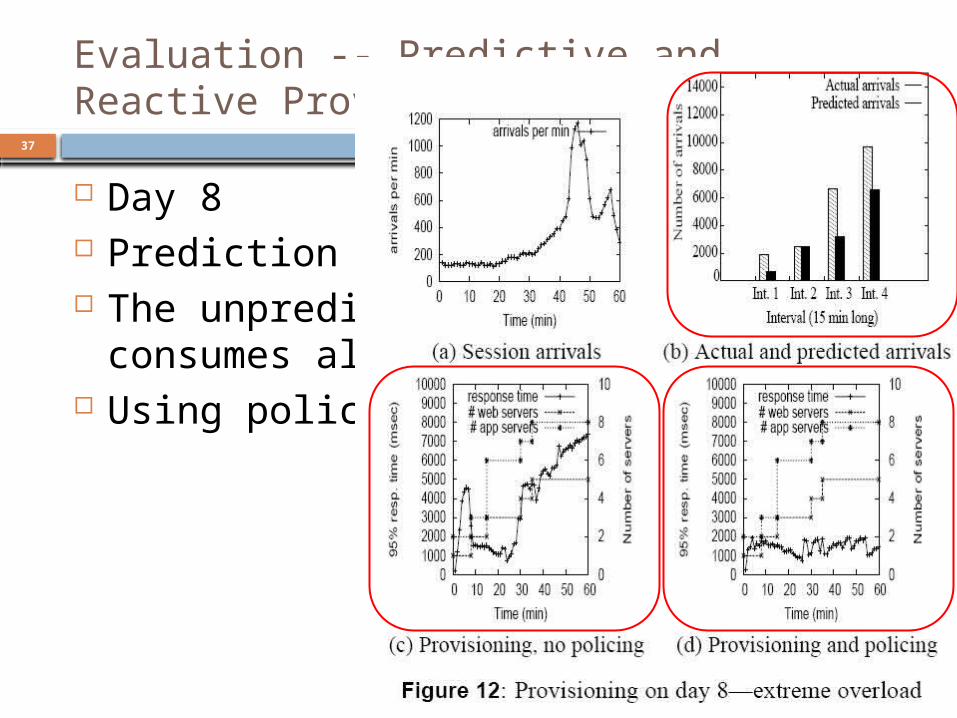
Evaluation -- Predictive and Reactive Provisioning(4/4)
Day 8 Prediction is failed The unpredictable workload consumes
all the server Using policing to drop sessions

38
Evaluation –Switching of server resources
Scenario 1: New server taken from free pool; the application must be start
Scenario 2: as 1, but application is already running
Scenario 3: taken from another application, waiting for all residual sessions to finish
Scenario 4: as 3, let two VMs share the CPU equally until the session finish
Scenario 5: as 3, using “fixed rate ramp down”

39
Conclusion
a flexible queuing model to determine how much resources to allocate to each tier of the application
a combination of predictive and reactive methods that determine when to provision these resources, both at large and small time scales

40
Comments(1/2)
A different thinking about resource provisioning Which service should be allocated resource ?
SLA must be violated first How many resources and when to allocate to
services ? The accuracy of prediction is key point
Can the two ways combine together? The evaluation result in the paper seems not so
good The prediction interval and reactive interval is too
long (15 min and few minutes) But frequently checking will make more loading

41
Comments(2/2)
Unpredictable workload is really unpredictable ? Cooperate with news But its not automatic
Queuing theory…………

42
Thanks The End