aleksander zaigrajew analiza regresji i analiza …alzaig/araw.pdf · 2014-01-15 ·...
TRANSCRIPT

Projekt pn. „Wzmocnienie potencjału dydaktycznego UMK w Toruniu w dziedzinach matematyczno-przyrodniczych”
realizowany w ramach Poddziałania 4.1.1 Programu Operacyjnego Kapitał Ludzki
Aleksander Zaigrajew
ANALIZA REGRESJI I
ANALIZA WARIANCJI
UMK Toruń 2012
Projekt współfinansowany przez Unię Europejską w ramach Europejskiego Funduszu Społecznego


Przygotowane materiały dydaktyczne będą służyć pomocą studentom jakouzupełnienie wykładu do wyboru Analiza regresji i analiza wariancji, który prowa-dzę na studiach II stopnia kierunku Matematyka.Analiza regresji zajmuje się badaniem zależności pomiędzy interesującymi nas
wielkościami (zmiennymi), określeniem jej charakteru oraz siły, a także konstruk-cją modelu, który dobrze odzwierciedla tą zależność. Łatwo sobie wyobrazić nieo-mal dowolną liczbę przykładów z dziedziny nauk technicznych, przyrodniczych,ekonomicznych, socjologicznych i innych, w których chodzi o ustalenie podobnejzależności.W skrypcie najwięcej miejsca poświęcono klasycznemu obszaru analizy regresji,
mianowicie analizie regresji liniowej. Dokładnie omówiono zagadnienia estymacjiparametrów modelu oraz testowania hipotez statystycznych o parametrach mode-lu. W przypadku prostej regresji liniowej rozważono w sposób bardziej szczegółowyzagadnienie weryfikacji modelu na podstawie analizy wartości resztowych. Rozwa-żone też zostały nieklasyczne modele regresji liniowej, tzn. takie, w których pod-stawowe założenia modelu klasycznego nie są spełnione. Szczególny przypadekregresji liniowej - regresja wielomianowa - jest omówiony osobno. Krótko zostałaprzedstawiona też regresja nieliniowa z wyodrębnieniem regresji logistycznej, któ-ra w pewnych przypadkach może też być zaliczana do modeli linearyzowalnych.Regresja logistyczna jest często stosowana w naukach medycznych czy też socjolo-gicznych. Dla regresji nieliniowej zostały zaprezentowane ogólne metody szacowa-nia parametrów modelu.Dziedziną blisko związaną z analizą regresji jest analiza wariancji. Tutaj rozwa-
żamy zagadnienia, w których zmienne niezależne (czynniki) przyjmują tylko nie-wiele wartości (występują na kilku poziomach) oraz podstawowym pytaniem, naktóre chcielibysmy dostać odpowiedź, jest: czy zmiana poziomu czynnika/czynni-ków ma wpływ na średnią wartość zmiennej zależnej? Dość specyficzne metody,które są stosowane w analizie wariancji i które zapewniły jej nazwę, pozwalająwyodrębnić ją z szeregu dziedzin, w których są stosowane metody statystykimatematycznej. Rozważone zostały proste modele jednoczynnikowe i dwuczynni-kowe.Dla dobrego zrozumienia zaprezentowanych zagadnień i rozumowań potrzebne
są pewne fakty ze Statystyki matematycznej, Teorii macierzy, Teorii optymalizacji;większość z nich została podana w tekście. Tam, gdzie jest w tym potrzeba, sąprzytoczone przykłady ilustrujące prowadzone rozumowania. Pewna liczba dośćprostych zagadnień, których wyprowadzenie nie jest skomplikowane, są zostawioneCzytelnikowi jako zadania domowe.
Od autora


3
1. Wprowadzenie do analizy regresji
Przedmiot analizy regresji należy do zastosowań matematyki, związanych z rozwią-zaniem pewnych zagadnień statystyki matematycznej przy pomocy metod proba-bilistycznych. Podstawowym celem tej dziedziny jest określenie zależności pomię-dzy interesującymi nas wielkościami (zmiennymi), jej charakteru oraz siły, atakże konstrukcja modelu, który dobrze opisuje tą zależność. Najczęściej jedynąmożliwością badania takich zależności jest przeprowadzenie doświadczeń i tylko wnielicznych przypadkach mogą one być uzyskane teoretycznie. Przykłady takichzależności to: zależność wydajności ziemi od różnych nawozów mineralnych; zależ-ność poziomu zysku banku od ilości klientów, wysokości inwestycji, ilości wydanychkredytów itd.
Warto zaznaczyć, że słowo regresja w tłumaczeniu z łaciny oznacza cofanie.Stosowanie w nazwie tej dziedziny, jak też w nazwie kilku innych pojęć, słowaregresja jest historyczne i raczej niefortunne. Nazwa ta została, prawdopodobnie,po raz pierwszy użyta w 1885 r. przez angielskiego naukowca Sir F. Galtona(ucznia Darwina) pod czas badania zależności wzrostu potomstwa od wzrosturodziców. Wykazał on bowiem, że niezwykle wysocy rodzice (znacznie wyżsipowyżej przeciętności), mają dzieci niższego wzrostu, natomiast rodzice o wzrościeznacznie niższym, niż przeciętny, mają dzieci wyższe od nich. Galton nazwał tozjawisko cofaniem w kierunku przeciętności. Ale w istocie dziedzina zajmującasię poszukiwaniem zależności na podstawie prowadzenia doświadczeń jest o wielestarsza: tak na przykład matematycy francuscy (szczególnie Laplace) w XVIIIwieku przeprowadzały analizy, które nazwalibyśmy regresją.
Niech więc interesujące nas wielkości (dalej nazywamy je zmiennymi) to Y, X(1),. . . , X(m), m 1. Zmienna Y jest nazywana zmienną zależną, zaś zmienneX(1), . . . ,X(m) zmiennymi niezależnymi. Pytanie, na które chcielibyśmy dostać odpowiedź,to: czy jest zależność pomiędzy Y a X(1), . . . , X(m) (innymi słowy, czy zmienneX(1), . . . , X(m) wpływają na Y )? I jeżeli zależność jest, to chcielibyśmy wyrazićją za pomocą pewnego modelu (równania).
Załóżmy, że możemy przeprowadzić n eksperymentów, n pomiarów wielkoś-ci zmiennej Y w zależności od pewnych wielkości zmiennych X(1), . . . , X(m).Wartości powyzszych zmiennych, uzyskane w trakcie doświadczeń, będziemy ozna-czać odpowiednimi malymi literami. Więc punktem wyjścia w naszych rozu-mowaniach będą obserwacje (x
(1)i , . . . , x
(m)i , yi), i = 1, . . . , n.
Warto zaznaczyć, iż zmienne mogą być powiązane między sobą zależnościąfunkcyjną lub zależnością statystyczną. Związek funkcyjny odznacza się tym, żekażdemu naborowi wartości zmiennych niezależnych odpowiada tylko jedna, jedno-znacznie określona wartość zmiennej zależnej (na przykład pole kwadratu jestfunkcją jego boku). Bardzo rzadko jednak mamy do czynienia z danymi, któredokładnie opisują się podobną zależnością. Częściej mamy do czynienia z tzw.zależnością statystyczną. Związek statystyczny polega na tym, że określonym

4
wartościom zmiennych niezależnych odpowiadają ściśle określone średnie wartościzmiennej zależnej. Zależność taka może być opisaną za pomocą funkcjiE(Y | X(1) = x(1), . . . , X(m) = x(m)).Otóż dalej zakładamy, że wartości zmiennej zależnej są losowe (wartości zaś
zmiennych niezależnych wygodnie będzie nam rozważać jako nielosowe). Czyliobserwowane wartości {yi} zawierają pewne składniki losowe, często nazywanelub interpretowane jako błędy pomiarów. Tak naprawdę, źródła tych czynnikówlosowych mogą być bardzo różne: od błędów spowodowanych nieprecyzyjnościąurządzeń pomiarowych do błędów spowodowanych nieuwzględnieniem wszystkichczynników, wpływających na zmienną zależną.
Jako ilustracja pojęcia zależności statystycznej rozważmy następujący przyk-ład, zaczerpnięty z [1, s. 260-261].
Przykład.Rozpatrzmy rezultaty kolokwium (skala od 0 do 25 punktów) i egzami-nu koncowego (skala od 0 do 50 punktów) ze statystyki matematycznej. W kolok-wium i egzaminie brało udział 19 studentów pewnej szkoły technicznej. Wynikikolokwium i egzaminu są podane w tabelce:
Numer stud. 1 2 3 4 5 6 7 8 9 10 11 12 13Kolokwium 7 11 12 14 17 15 21 22 19 13 5 12 16Egzamin 20 24 25 30 35 30 43 42 41 24 14 27 35
Numer stud. 14 15 16 17 18 19Kolokwium 14 21 20 17 10 17Egzamin 28 42 40 34 23 40
Zależność pomiędzy wynikiem egzaminu końcowego (zmienna zależna) a kolok-wium (zmienna niezależna) przedstawiono na Rysunku 1. Rysunek taki nazywasię wykresem rozrzutu i jest użytecznym graficznym przedstawieniem zależnościmiędzy zmiennymi. Tworzy się on za pomocą par punktów (xi, yi), i = 1, . . . , 19.Zaznaczmy, że w przypadku gdy mamy do czynienia z jedną zmienną niezależną,zagadnienie konstrukcji modelu należy zawsze zaczynać od sporządzenia wykresurozrzutu. Widzimy, że istotnie mamy tutaj do czynienia z zależnością statystyczna,a nie funkcyjną, bowiem mamy studentów, których wynik kolokwium jest takisam, ale wynik egzaminu różni się (na przykład studenci o numerach 5, 17 i19 mają ten sam wynik kolokwium - 17 punktów, lecz różny wynik egzaminu -odpowiednio 35, 34 i 40 punktów).
Ogólnie proces konstrukcji modelu przebiega następujące etapy.Etap 1. Specyfikacja modelu. Na tym etapie dokonujemy wybór postaci modelu(liniowy, kwadratowy, nieliniowy itd), który będziemy rozważać. Wyboru tegodokonujemy na podstawie wykresu rozrzutu, bądź jakiejś wiedzy o możliwymcharakterze zależności. Możemy też sugerować się poszukiwaniem rozwiązaniajak najprostszego, czyli wybierając model liniowy. W tym skrypcie będziemyprzez znaczną większość czasu zajmować się właśnie modelami liniowymi. I na

5
1510
40
5
30
kolokwium
0
25
20
20
35
15
Rysunek 1: Wykres rozrzutu.
ogół, ograniczymy się tylko do rozważenia tzw. modeli parametrycznych, czylitakich, które są określone z dokładnością do pewnych nieznanych parametrów. Wtym przypadku zagadnienie znalezienia odpowiedniego modelu sprowadza się dozagadnienia znalezienia (oszacowania) parametrów, co znacznie upraszcza postę-powanie.Etap 2. Wnioskowanie statystyczne o parametrach modelu. Na tym etapie stosującodpowiednie metody statystyczne i w oparciu o dane, które posiadamy, dokonuje-my oszacowania parametrów modelu i ewentualnie testowania hipotez o tychparametrach.Etap 3. Weryfikacja modelu.Dalej należy sprawdzić, czy skonstruowany na poprze-dnim etapie przy pewnych założeniach model rzeczywiście spełnia te założeniai czy dobrze pasuje do posiadanych danych. Tutaj też, wykorzystując metodystatystyczne, szacujemy istotność otrzymanych parametrów. Jeśli model nie speł-nia stawianych mu wymagań, formułujemy nowy model i wracamy do poprzednie-go etapu.Etap 4. Używanie modelu. Jeżeli stworzony model uznajemy za poprawny, tomożemy wykorzystać go dalej, na przykład dla prognozowania wartości zmiennejzależnej w przypadku innych, aniżeli uzyskane dotychczas, wartości zmiennychniezależnych, lub do sterowania - czyli wyznaczenia wartości zmiennych niezależ-nych dla uzyskania odpowiedniej wartości zmiennej zależnej.Tak więc zgodnie z etapem 1 (etapem wyboru modelu), zawężamy krąg rozwa-
żanych funkcji, opisujących zależność, do pewnej parametrycznej klasy funkcji H ,tzn. zakładamy, że model opisuje się funkcją z klasy H, przy czym
H = {h(x, θ), θ ∈ Θ ⊂ Rk, x = (x(1), . . . , x(m)) ∈ R
m},

6
gdzie h : Rm × R
k → R jest zadaną funkcją ciągłą. Funkcja h jest nazywanafunkcją regresji. Warto podkreślić różną rolę argumentów x i θ funkcji regresji.Wartości x odpowiadają za warunki przeprowadzenia doświadczeń i często mogąbyć wybrane przed doświadczeniami. Natomiast θ jest argumentem (parametrem)nieznanym, na który wpływu nie mamy. Podkreślimy jeszcze raz, że w tej sytuacjiproblem poszukiwania dobrego modelu opisującego zależność sprowadza się doposzukiwania (szacowania) θ.Jeśli funkcja h jest liniowa względem θ, to regresja (i odpowiedni model)
nazywa się liniową, w przeciwnym przypadku – nieliniową. Ogólna postać funkcjiregresji liniowej, to:
h(x, θ) =k∑
j=1
θjfj(x),
gdzie fj : Rm → R są zadanymi funkcjami ciągłymi, j = 1, . . . , k.
Przykłady. Podamy tutaj kilka często spotykanych modeli liniowych (pierwszychtrzy przykłady), przykład modelu nieliniowego (ostatni) oraz przykład modelulinearyzowalnego (przedostatni), czyli takiego, który można sprowadzić do modeluliniowego za pomocą prostych przekształceń.
1. Prosta regresja liniowa: m = 1, k = 2, h(x, θ) = θ0 + θ1x.
2. Liniowa regresja wielokrotna (wieloraka):k = m+ 1, h(x, θ) = θ0 + θ1x
(1) + . . .+ θmx(m).
3. Regresja wielomianowa stopnia p > 1:m = 1, k = p+ 1, h(x, θ) = θ0 + θ1x+ . . .+ θpx
p.
4. Regresja potęgowa: m = 1, k = 2, h(x, θ) = θ0xθ1 .
W tym przypadku za pomocą logarytmowania sprowadzamy funkcję regresji dopostaci liniowej: h′(x′, θ′) = θ′0+θ
′
1x′, gdzie h′ = lnh, θ′0 = ln θ0, θ
′
1 = θ1, x′ = ln x.
5. Regresja nieliniowa: m = 1, k = 3, h(x, θ) = θ0 + θ1e−θ2x.
W tej sytuacji żadne przekształcenie nie sprowadzi funkcji regresji do liniowejfunkcji parametrów.

7
2. Klasyczny model regresji liniowej
2.1. Estymacja parametrów
Rozważmy model regresji liniowej. W tej sytuacji zakładamy, że mamy obserwacjepostaci
yi =k∑
j=1
θjfj(xi) + εi, i = 1, . . . , n, (2.1)
gdzie θ = (θ1, . . . , θk)T ∈ R
k jest wektorem nieznanych parametrów (współczynni-ków funkcji regresji), {fj} są znanymi funkcjami, {xi} są zadanymi wektorami,{εi} są zmiennymi losowymi (błędami pomiarów). Co do tych zmiennych losowych,to dość często zakładamy, że
Eεi = 0, Eεiεj =
{σ2, i = j0, i 6= j,
gdzie σ > 0 jest nieznaną stałą. To oznacza, że macierz kowariancji Cov ε =E(ε−Eε)(ε−Eε)T wektora ε = (ε1, . . . , εn)T ma postać Cov ε = σ2In, gdzie Inoznacza macierz jednostkową wymiaru n× n. Oznaczmy: y = (y1, . . . , yn)T ,
F =
f1(x1) . . . . . . fk(x1)...
......
f1(xn) . . . . . . fk(xn)
- prostokątna macierz wymiaru n×k, która często jest nazywana macierzą planu.Będziemy dalej rozważać przypadek, gdy n k i macierz F ma pełny rząd, tzn.rząd macierzy F jest równy k. Dwa warunki podkreślone definiują tzw. modelklasyczny regresji liniowej.Korzystając z wprowadzonych oznaczeń, równania (2.1) można zapisać w
postaci: y = Fθ+ε, przy czym Ey = Fθ, Covy = σ2In. Tak więc model klasycznyregresji liniowej zwykle zapisuje się za pomocą trójki (y, Fθ, σ2In), gdzie y jestwektorem obserwacji, Fθ jest jego wartością oczekiwaną, σ2In jest jego macierząkowariancji.Jak wiemy, następnym problemem po wyborze typu funkcji regresji h jest
znalezienie takiej wartości wektora parametrów θ (problem estymacji), dla którejfunkcja regresji będzie jak najlepiej opisywać otrzymane dane. Tutaj będziemypotrzebowali kilku pojęć ze Statystyki matematycznej.
Definicja 2.1.Każde odwzorowanie mierzalne ze zbioru wartości wektora obserwa-cji y do przestrzeni euklidesowej, niezależne od nieznanych parametrów, nazywamystatystyką.
Definicja 2.2.Każdą statystykę θ(y) o wartościach w Rk, której wartości traktuje-
my jako przybliżenie dla θ, nazywamy estymatorem wektora parametrów θ.

8
Definicja 2.3. Estymator θ(y) nazywamy liniowym, jeśli funkcja θ(y) jest liniowa
względem y, i nieobciążonym, jeśli Eθ(y) = θ ∀θ.Definicja 2.4. Estymator θ(y) nazywamy najlepszym liniowym nieobciążonym
estymatorem (NLNE), jeśli jest on liniowym i nieobciążonym oraz Cov θ(y) ¬Cov θ∗(y) dla każdego innego estymatora liniowego nieobciążonego θ∗(y).
Uwaga. Nierówność A ¬ B pomiędzy dwoma kwadratowymi k × k macierzamiA i B tutaj i dalej rozumiemy w tym sensie, że macierz B − A jest nieujemnieokreślona.
Definicja 2.5.Macierz A wymiaru k×k nazywamy nieujemnie określoną (piszemyA 0), jeśli ∀z ∈ R
k zTAz 0. Macierz A wymiaru k× k nazywamy dodatniookreśloną (piszemy A > 0), jeśli ∀z ∈ R
k, z 6= 0, zTAz > 0.Uwaga. Relacja Cov θ(y) ¬ Cov θ∗(y) jest równoważna relacji: ∀z ∈ R
k
Var zT θ(y) ¬ Var zT θ∗(y). Istotnie,
Cov θ(y) ¬ Cov θ∗(y) ⇐⇒ ∀z ∈ Rk zTE(θ−θ)(θ−θ)T z ¬ zTE(θ∗−θ)(θ∗−θ)T z
⇐⇒ ∀z ∈ Rk E(zT (θ−θ))2 ¬ E(zT (θ∗−θ))2 ⇐⇒ ∀z ∈ R
k Var zT θ ¬ Var zT θ∗.Dla rozwiązania problemu estymacji wektora parametrów θ zastosujmy tzw.
metodę najmniejszych kwadratów (MNK), wprowadzoną jeszcze na początku XIXwieku przez Legandre’a i Gaussa. Polega ona na tym, że mając obserwacje {(xi, yi)}wybieramy estymator θ w taki sposób, że
θ = Arg minθ(y − Fθ)T (y − Fθ) = Arg min
θ
n∑
i=1
(yi −
k∑
j=1
θjfj(xi))2.
Jaki jest sens w tej metodzie? Otóż wybieramy w rodzinie H = {∑kj=1 θjfj(x),θ ∈ R
k, x ∈ Rm} taką funkcję, dla której suma kwadratów różnic pomiędzy
obserwacjami {yi} a wartościami funkcji regresji w punktach {xi} jest najmniejsza(czyli błąd średniokwadratowy jest najmniejszy). Na Rysunku 2 zostaly zaprezento-wane te różnicy w przypadku k = 2.
Uwaga. Oznaczmy ~fj = (fj(x1), . . . , fj(xn))T ∈ R
n, j = 1, . . . , k. Wektory tesą liniowo niezależne, ponieważ macierz F ma rząd równy k. Niech F będziek-wymiarową podprzestrzenią R
n rozpiętą nad wektorami {~f1, . . . , ~fk}. Wówczaswektor
k∑
j=1
θjfj(xi) =k∑
j=1
θj ~fj gdzie θ = (θ1, . . . , θk)T ∈ R
k,
jest wektorem z F , a ‖y−∑kj=1 θj ~fj‖ jest odległością w przestrzeni Rn pomiędzynim a wektorem y.MNK polega na wyborze takiego wektora
∑kj=1 θj
~fj ∈ F , któryminimalizuje tę odległość. Z kursu Algebry liniowej wiadomo, że
∑kj=1 θj
~fj = PFy– rzut (ortogonalny) wektora y na F .

9
x
y
10
5
8
4
3
6
2
142
Rysunek 2: Metoda najmniejszych kwadratów.
Twierdzenie Gaussa-Markowa. W ramach klasycznego modelu regresji linio-wej (y, Fθ, σ2In) estymator MNK wektora parametrów θ wyznacza się w sposóbjednoznaczny i ma postać θ = (F TF )−1F Ty. Jest to estymator liniowy i nieobcią-żony oraz najlepszy (czyli NLNE), a jego macierz kowariancji wynosi Cov θ =σ2(F TF )−1.
Dowód. 1. Oznaczmy Q(θ) = (y−Fθ)T (y−Fθ).Dla znalezienia punktu minimumfunkcji Q policzmy pochodne cząstkowe:
∂Q
∂θl=∂
∂θl
n∑
i=1
(yi −
k∑
j=1
θjfj(xi))2 =
2n∑
i=1
(yi −
k∑
j=1
θjfj(xi))∂
∂θl
(yi −
k∑
j=1
θjfj(xi))=
−2n∑
i=1
(yi −
k∑
j=1
θjfj(xi))fl(xi) = 2
( n∑
i=1
k∑
j=1
θjfj(xi)fl(xi)−n∑
i=1
yifl(xi))
=⇒(∂Q
∂θ1, . . . ,
∂Q
∂θk
)T= 2
(F TFθ − F Ty
).
Przyrównując wszystkie pochodne cząstkowe do zera, otrzymamy równanie F TFθ= F Ty nazywane równaniem normalnym (lub układem równań normalnych).Przy naszych założeniach macierz F TF jest odwracalna, co jest skutkiem tego,że zawsze F TF 0, a jeśli ponadto rząd k × k macierzy F TF wynosi k, tomacierz F TF jest dodatnio określona. (Jeśli rząd n× k macierzy F wynosi k, to

10
rząd macierzy F TF też wynosi k - zadanie domowe). Tak więc, układ równańnormalnych posiada tylko jedno rozwiązanie. Ma ono postać θ = (F TF )−1F Tyi jest punktem minimum funkcji Q(θ) = (y − Fθ)T (y − Fθ), ponieważ macierzdrugich pochodnych spełnia warunek ∂
2Q∂θ2= 2F TF > 0.
2. Mamy dla wszystkich θ
Eθ = E((F TF )−1F Ty
)= E
((F TF )−1F TFθ + (F TF )−1F Tε
)= θ,
Cov θ = E(θ − θ)(θ − θ)T = E((F TF )−1F T ε
) ((F TF )−1F Tε
)T=
(F TF )−1F TCov εF (F TF )−1 = σ2(F TF )−1F TF (F TF )−1 = σ2(F TF )−1.
3. Niech θ∗(y) będzie dowolnym innym estymatorem liniowym nieobciążonymdla θ, czyli istnieje k × n macierz L oraz wektor c ∈ R
k takie, że θ∗ = Ly + c.Ponieważ estymator θ∗ jest z definicji nieobciążonym, dostajemy: Eθ∗ = LFθ +c = θ ∀θ =⇒ LF = Ik, c = 0 – warunki nieobciążoności estymatora θ
∗.Pokażemy, że Cov θ∗ Cov θ = σ2(F TF )−1.W tym celu rozważmy k×n macierzA = (F TF )−1F T − L. Mamy AF = Ik − Ik = 0 (z warunków nieobciążoności).Ostatecznie,
Cov θ∗ = E(Ly − θ)(Ly − θ)T = E(Lε)(Lε)T = LCov εLT = σ2LLT =
σ2((F TF )−1F T − A
) ((F TF )−1F T − A
)T=
σ2((F TF )−1 − (F TF )−1F TAT −AF (F TF )−1 + AAT
)=
Cov θ + σ2AAT Cov θ,ponieważ zawsze σ2AAT 0. �Uwaga.Macierz PF rzutu ortogonalnego na k-wymiarową podprzestrzeń F prze-strzeni R
n z liniowo niezależną bazą {~fj}kj=1 ma postać PF = F (F TF )−1F T(przypomnijmy: F = (~f1, ~f2, . . . , ~fk)). Sprawdźmy to.(i) Mamy sprawdzić, że PFz = z dla z ∈ F . Istotnie, jeśli z ∈ F , to istniejea = (a1, . . . , ak)
T ∈ Rk takie, że z =
∑kj=1 aj
~fj = Fa. Wtedy F (FTF )−1F T z =
F (F TF )−1F TFa = Fa = z.
(ii) Mamy też sprawdzić, że PFz = 0 dla z⊥F . Istotnie, jeśli z⊥F , to ~fTj z = 0dla wszystkich j = 1, . . . , k, czyli F T z = 0 =⇒ PFz = F (F TF )−1F Tz = 0.Zatem PFy = F θ.
Wniosek 2.1. Niech z ∈ Rk będzie zadanym wektorem. W ramach klasycznego
modelu regresji liniowej NLNE parametru zT θ ma postać zT θ.W szczególności
∑kj=1 θjfj(x) jest NLNE wartości funkcji regresji
∑kj=1 θjfj(x) w
zadanym punkcie x różnym od punktów {xj}.Aby udowodnić wniosek najpierw pokazujemy, że estymator zT θ = zT (F TF )−1F Typarametru zT θ jest liniowy i nieobciążony. To, że posiada on najmniejszą wariancję

11
w klasie estymatorów liniowych i nieobciążonych, dowodzimy podobnie, jak ostat-nią część dowodu Twierdzenia Gaussa-Markowa (zadanie domowe).
Z dowodu Twierdzenia Gaussa-Markowa wynika też następująca bardzo poży-teczna równość, która zachodzi dla wszystkich θ:
(y − Fθ)T (y − Fθ) = (y − F θ)T (y − F θ) + (θ − θ)TF TF (θ − θ). (2.2)
Istotnie,
(y − Fθ)T (y − Fθ) = (y − F θ + F (θ − θ))T (y − F θ + F (θ − θ)) =
(y−F θ)T (y−F θ)+(y−F θ)TF (θ−θ)+(θ−θ)TF T (y−F θ)+(θ−θ)TF TF (θ−θ) =(y − F θ)T (y − F θ) + (θ − θ)TF TF (θ − θ).
Równość (2.2) jeszcze raz potwierdza, iż θ jest jedynym punktem minimum dlafunkcji Q.
Przykład 2.1. Niech y1, . . . , yn będą niezależnymi zmiennymi losowymi o tejsamej nieznanej wartości oczekiwanej θ i tej samej nieznanej wariancji σ2. Znaleźćestymator MNK parametru θ.Przedstawmy y1, . . . , yn w postaci:
yi = θ + εi, i = 1, . . . , n,
gdzie zmienna losowa εi reprezentuje „odchylenie” i-tej wyjściowej zmiennej loso-wej od wartości θ. Możemy teraz zapisać:
y1...yn
=
1...1
θ +
ε1...εn
, czyli y = Fθ + ε,
gdzie k = 1, a macierz F jest tak naprawdę n-wymiarowym wektorem złożonymz jedynek. Zgodnie z Twierdzeniem Gaussa-Markowa, NLNE parametru θ mapostać:
θ = (F TF )−1F Ty =1
n
n∑
i=1
yi.
Przykład 2.2. Dopasować prostą do punktów (xi, yi) = (0, 0), (1/2, 1/4), (1, 1)za pomocą MNK.Mamy h(x, θ) = θ0 + θ1x (m = 1, k = 2), n = 3. Wówczas
F =
1 01 1/21 1
, y =
01/41
=⇒

12
F TF =
(1 1 10 1/2 1
)1 01 1/21 1
=
(3 3/23/2 5/4
), det F TF = 3/2,
(F TF )−1 =
(5/6 −1−1 2
), F Ty =
(1 1 10 1/2 1
)01/41
=
(5/49/8
),
θ = (F TF )−1F Ty =
(5/6 −1−1 2
)(5/49/8
)=
(−1/121
)=⇒
najlepszą dopasowaną zgodnie z MNK prostą jest y = −1/12 + x.Przykład 2.3. Rozważmy to samo zadanie w przypadku n 2 punktów
obserwacji przy założeniu, że nie wszystkie punkty {xi} są jednakowe. Wówczas
F =
1 x1......
1 xn
, F TF =
(1 . . . 1x1 . . . xn
)
1 x1......
1 xn
=
(n
∑ni=1 xi∑n
i=1 xi∑ni=1 x
2i
),
det F TF = nn∑
i=1
x2i − (n∑
i=1
xi)2,
(F TF )−1 = (det F TF )−1( ∑n
i=1 x2i −∑ni=1 xi
−∑ni=1 xi n
),
F Ty =
(1 . . . 1x1 . . . xn
)
y1...yn
=
( ∑ni=1 yi∑ni=1 xiyi
),
θ = (F TF )−1F Ty = (det F TF )−1( ∑n
i=1 x2i −∑ni=1 xi
−∑ni=1 xi n
)( ∑ni=1 yi∑ni=1 xiyi
)=
(det F TF )−1( ∑n
i=1 yi∑ni=1 x
2i −
∑ni=1 xiyi
∑ni=1 xi
n∑ni=1 xiyi −
∑ni=1 yi
∑ni=1 xi
)=⇒
θ0 =
∑ni=1 yi
∑ni=1 x
2i −
∑ni=1 xiyi
∑ni=1 xi
n∑ni=1 x
2i − (
∑ni=1 xi)
2, θ1 =
n∑ni=1 xiyi −
∑ni=1 yi
∑ni=1 xi
n∑ni=1 x
2i − (
∑ni=1 xi)
2.
Równoważnie możemy zapisać:
θ1 =1n
∑ni=1(xi − x)(yi − y)1n
∑ni=1(xi − x)2
, θ0 = y − θ1x,
gdzie x = 1n
∑ni=1 xi, y =
1n
∑ni=1 yi.
Jeśli punkty {xi} spełniają równość x = 0, to powyższe wzory się uproszczą iotrzymamy
θ0 = y, θ1 =
∑ni=1 xiyi∑ni=1 x
2i
.

13
Rozważmy teraz zagadnienie estymacji parametru σ2 w klasycznym modeluregresji liniowej. Oznaczmy: y = F θ,
e = y − y = y − F (F TF )−1F Ty = y − PFy = (In − PF)y = PF⊥y (2.3)
(F⊥ jest podprzestrzenią w Rn ortogonalną do podprzestrzeni F). Wektor e
nazywamy wektorem reszt. Jest to wektor różnic pomiędzy zaobserwowanymiwartościami zmiennej zależnej a oszacowaniem wartości funkcji regresji w punk-tach pomiarów {xi}.Wartość
∑ni=1 e
2i = e
T e jest nazywana resztową sumą kwadra-tów, w skrócie RSS (ang. residual sum of squares).
Uwaga. Jak łatwo zrozumieć, w przypadku n = k mamy e = 0. Oznacza todokładne dopasowanie modelu do danych. Na przykład jeśli h(x, θ) = θ0 + θ1x(m = 1, k = 2) i mamy tylko dwie obserwacje, to możemy poprowadzić prostąprzez te dwa punkty, tzn. dopasować model bezbłędnie. Ale nie oznacza to wcale,że wykonaliśmy zadanie znalezienia nieznanej zależności perfekcyjnie. Przecieżgdyby mielibyśmy jeszcze obserwacje, nie musiałyby one pasować do otrzymanejprostej. Więc oznacza to tylko tyle, że raczej mamy za mało obserwacji. Ponadto,jak zobaczymy dalej, nie potrafilibyśmy w tym przypadku oszacować σ2.Otóż aby oszacowac σ2, dalej zakładamy, że n > k.
Lemat 2.1. Estymator s2 = 1n−keT e parametru σ2 jest nieobciążony.
Dowód. Mamye = (In − PF)(Fθ + ε) = (In − PF)ε.
Macierz G = In − PF jest macierzą rzutu ortogonalnego na podprzestrzeń F⊥ ispełnia warunki: G = GT , G2 = G, czyli jest symetryczną macierzą idempotentną.Więc,
eT e = εTGTGε = εTGε (2.4)
oraz
En∑
i=1
e2i =n∑
i=1
n∑
j=1
(Eεiεj)Gij = σ2n∑
i=1
Gii = σ2n∑
i=1
(In − PF)ii = σ2(n− k),
ponieważ (patrz Lemat 2.3 niżej) suma elementów stojących na przekątnej symet-rycznej macierzy idempotentnej jest równa rządowi tej macierzy (rząd macierzyPF wynosi k). �
Przykład 2.1 (kontynuacja) Niech w warunkach Przykładu 2.1 należy oszacowaćnieznany parametr σ2. Mamy e = y−F θ = y− y. Zatem zgodnie z Lematem 2.1,
s2 =1
n− 1n∑
i=1
(yi − y)2.
Tak więc klasyczne estymatory wartości oczekiwanej i wariancji rozkładu, czyliodpowiednio średnia z próby i nieobciążona wersja wariancji z próby, mogą byćteż uzyskane za pomocą MNK.

14
Definicja 2.6. Niech y = (y1, . . . , yn)T będą wartościami zaobserwowanymi i
łączny rozkład wektora y ma gęstość pθ(u1, . . . , un), gdzie θ jest wektorem niezna-nych parametrów. Wówczas funkcję
L(y, θ) = pθ(y1, . . . , yn)
nazywamy funkcją wiarygodności. Estymator θ(y) wektora parametrów θ określo-ny jako
θ(y) = Arg maxθL(y, θ)
nazywamy estymatorem największej wiarygodności (ENW) dla θ.
Uwaga. Często łatwiej jest szukać nie maxθL(y, θ), lecz max
θlnL(y, θ).
Taką metodę poszukiwania estymatorów nieznanych parametrów nazywamymetodą najwiekszej wiarygodności (MNW).
Lemat 2.2. Jeżeli w klasycznym modelu regresji liniowej (y, Fθ, σ2In) wektorlosowy y ma rozkład normalny, to estymator MNK θ jest też ENW wektoraparametrów θ, natomiast ENW parametru σ2 ma postać n−k
ns2 = 1
neT e.
Dowód. Wektor y ma rozkład normalny Nn(Fθ, σ2In). Więc,
L(y, θ, σ2) =1
(2πσ2)n/2exp
(− 12σ2(y − Fθ)T (y − Fθ)
).
Szukamy teraz maksimum funkcji lnL poprzez wyliczanie pochodnych cząstko-wych i przyrównanie ich do zera. Otrzymujemy:
∂ lnL
∂θ=1
σ2F T (y − Fθ) = 0
∂ lnL
∂σ2= − n2σ2+1
2σ4(y − Fθ)T (y − Fθ) = 0
=⇒
θ = θ
σ2 =1
neT e. �
Uwaga. ENW parametru σ2 jest obciążony, ponieważ Eσ2 = n−knσ2. Ale jest on
asymptotycznie nieobciążony, bowiem Eσ2 → σ2 gdy n→∞.Przykład 2.1 (ciąg dalszy) W warunkach Przykladu 2.1 ENW parametru θ jestśrednia z proby, bowiem θ = θ = y, natomiast ENW parametru σ2 wynosi
σ2 =1
neT e =
1
n
n∑
i=1
(yi − y)2 ,
czyli jest obciążoną wersją wariancji z próby.

15
2.2. Testowanie hipotez
Niech w klasycznym modelu regresji liniowej (y, Fθ, σ2In) wektor losowy y marozkład normalny (zapisujemy y ∼ Nn(Fθ, σ2In)), co jest równoważne ze stwierdze-niem, że ε ∼ Nn(0, σ2In).Wtedy z elementarnych własności rozkładu normalnegowynika, że: θ ∼ Nk(θ, σ2(F TF )−1), θi ∼ N
(θi, σ
2((F TF )−1)ii).Nadal zakładamy,
że n > k.Roważmy zagadnienie testowania hipotezy dotyczącej wartości i-go współczyn-
nika funkcji regresji postaci H0 : θi = c przeciwko hipotezie H1 : θi 6= c (liczbac ∈ R jest zadana). (Przypadki, gdy hipoteza alternatywna ma postać H1 : θi <c lub H1 : θi > c nie będą rozważane; testowanie hipotez bowiem odbywasię w bardzo podobny sposób z jedną zasadniczą różnicą: obszar krytyczny wodróżnieniu od rozważanego przypadku jest jednostronny – lewostronny lub prawo-stronny).Zauważmy, że najczęściej spotykamy przypadek, gdy c = 0; jest to bowiem
tzw. testowanie istotności i-go współczynnika funkcji regresji. Jeśli na chwilęzałożymy, że testujemy właśnie taką hipotezę H0 i się okaże, że nie mamy podstawdo jej odrzucenia, oznacza to, że tak naprawdę w równaniu (2.1) brak jest i-goskładnika, co na przykład w przypadku liniowej regresji wielokrotnej oznacza, żedo równania regresji nie ma sensu włączać odpowiednią zmienną niezależną. Tenostatni wynik często jest dość ważny, bowiem im mniej zmiennych niezależnychskutecznie mogą być użyte do przewidywania zmiennej zależnej, tym lepiej.Wróćmy jednak do sytuacji ogólnej. Jeśli hipoteza H0 : θi = c jest prawdziwa,
to θi ∼ N(c, σ2((F TF )−1)ii
).
Gdyby parametr σ2 był znany, to przy prawdziwości H0 statystyka
t =θi − c
σ√((F TF )−1)ii
∼ N (0, 1) (2.5)
mogła być wybrana jako testowa. Wowczas mielibyśmy następującą procedurętestowania hipotezy H0 przeciwko alternatywie H1:
• zadajemy (wybieramy) poziom istotności α testu (α jest prawdopodobieńst-wem odrzucenia hipotezy H0, gdy jest ona prawdziwa), standardowo α =0.05;
• z tablic rozkładu normalnego wyliczamy tα takie, że P (|ξ| < tα) = 1 − α,ξ ∼ N (0, 1);
• na podstawie posiadanych danych wyliczamy wartość t ze wzoru (2.5);
• jeśli t ∈ (−tα, tα), to nie mamy podstaw do odrzucenia hipotezy H0; wprzeciwnym przypadku hipotezę H0 należy odrzucić.

16
Gdy parametr σ2 jest nieznany, z czym mamy do czynienia w naszej sytuacji,to zamiast σ2 we wzorze (2.5) używamy s2 = eT e/(n − k). Zatem bierzemystatystykę
t′ =θi − c
s√((F TF )−1)ii
jako testową. Znajdźmy jej rozkład.
Lemat 2.3. Każda macierz idempotentna posiada wartości własne 0 lub 1, przyczym rząd macierzy idempotentnej jest równy ilości tych jedynek (krotności warto-ści własnej równej 1).
Dowód. Niech {λi} oraz {xi} będą odpowiednio wartościami własnymi orazodpowiadającymi tym wartościom wektorami własnymi pewnej macierzy idempo-tentnej A. Otrzymujemy
A2xi = AAxi = Aλixi = λiAxi = λ2ixi.
Z drugiej strony, ponieważ A2 = A, mamy
A2xi = Axi = λixi,
więc λ2i = λi. Druga teza wynika z tezy pierwszej (zadanie domowe). �
Fakt 2.1. Jeśli ξ1, . . . , ξn są niezależnymi zmiennymi losowymi o tym samymrozkładzie N (0, 1), to zmienna losowa ∑ni=1 ξ2i posiada rozkład o gęstości
f(u) =1
2n/2Γ(n2)un/2−1e−u/2, u > 0,
nazywany rozkładem χ2n – chi-kwadrat z n stopniami swobody.
Lemat 2.4. Niech ξ ∼ Nn(0, In) oraz niech A będzie n×n symetryczną macierząidempotentną, której rząd wynosi k ¬ n. Wtedy zmienna losowa ξTAξ ma rozkładχ2k.
Dowód. Wykorzystajmy tzw. spektralną dekompozycję symetrycznej macierzyA w postaci A = CΛCT , gdzie C – macierz ortogonalna, której kolumnami sąwektory własne macierzy A, natomiast Λ – macierz diagonalna z wartościamiwłasnymi {λi}macierzy A na przekątnej, przy czym można założyć, że λ1 . . . λn. Zgodnie z Lematem 2.3, k największych wartości wśród {λi} są jedynkami, apozostale (n− k) zerami. Zatem
ξTAξ = ξTCΛCT ξ = ζTΛζ =k∑
i=1
ζ2i ,
gdzie ζ = CT ξ. Stosowanie Faktu 2.1 kończy dowód, bo ζ ∼ Nn(0, In). �

17
Wniosek 2.2. Jeśli w klasycznym modelu regresji liniowej (y, Fθ, σ2In) wektorlosowy y ma rozkład normalny, to eT e/σ2 = (y − F θ)T (y − F θ)/σ2 ma rozkładχ2n−k.
Dowód wniosku opiera się na równości (2.4) oraz Lemacie 2.4.
Lemat 2.5. Jeśli w klasycznym modelu regresji liniowej (y, Fθ, σ2In) wektorlosowy y ma rozkład normalny, to estymator MNK θ wektora parametrów θ orazRSS eT e są niezależne.
Dowód. Przypomnijmy, że
θ = (F TF )−1F Ty = θ + Aε, eT e = εTGε,
gdzie ε ∼ Nn (0, σ2In) , A = (F TF )−1F T , G = In − F (F TF )−1F T . Wystarczywięc wykazać, że Aε i εTGε są niezależne.Jak łatwo sprawdzić, zachodzi AG = 0. Wykorzystamy teraz spektralną de-
kompozycję (patrz dowód Lematu 2.4) G = CΛCT . Oznaczmy: ζ = CT ε, B =AC. Wówczas ζ ∼ Nn (0, σ2In) oraz
Aε = Bζ, εTGε = ζTΛζ =n−k∑
i=1
ζ2i (Lemat 2.3),
przy czym BΛCT = 0 =⇒ BΛ = 0. Stąd wynika, że pierwszych (n− k) kolumnmacierzy B wymiaru k × n są zerami i
(Bζ)i =n∑
j=n−k+1
Bijζj,
a więc wektor losowy Aε = Bζ zależy tylko od ζn−k+1, . . . , ζn, natomiast εTGε =
ζTΛζ tylko od ζ1, . . . , ζn−k. Stąd wynika teza. �
Fakt 2.2. Jeśli ξ ∼ N (0, 1), η ∼ χ2n, oraz ξ i η są niezależne, to zmienna losowa√nξ/√η posiada rozkład o gęstości
f(u) =Γ(n+1
2)√
nπΓ(n2)
(1 +u2
n
)−(n+1)/2, u ∈ R,
nazywany rozkładem tn - Studenta o n stopniach swobody.
Z Wniosku 2.2, Lematu 2.5 i Faktu 2.2 otrzymujemy następujący wynik.
Lemat 2.6. Jeśli w klasycznym modelu regresji liniowej (y, Fθ, σ2In) wektorlosowy y ma rozkład normalny, to przy założeniu prawdziwości hipotezy H0 :θi = c statystyka
t′ =θi − c
s√((F TF )−1)ii
ma rozkład Studenta tn−k.

18
Dowód. Mamy
θi − cσ√((F TF )−1)ii
∼ N (0, 1), eT e
σ2=(n− k)s2σ2
∼ χ2n−k =⇒
√n− k
θi−c
σ√((FTF )−1)ii√(n−k)s2
σ2
∼ tn−k =⇒ θi − cs√((F TF )−1)ii
∼ tn−k. �
Zadanie domowe. Napisać procedurę testowania hipotezyH0 przeciwko alterna-tywie H1 w przypadku, gdy parametr σ
2 jest nieznany.
Rozważmy teraz bardziej ogólny przypadek testowania hipotezy o współczyn-nikach funkcji regresji liniowej. Załóżmy, że chcemy przetestować hipotezę postaciH0 : Aθ = c przeciwko hipotezie H1 : Aθ 6= c, gdzie A jest zadaną p×k macierzą,1 ¬ p ¬ k, której rząd wynosi p, a c ∈ R
p jest zadanym wektorem.
Od razu zaznaczmy, że bardzo ważnym szczególnym przypadkiem takiej hipote-zy jest H0 : θi1 = . . . = θip = 0, gdzie 1 ¬ i1 < . . . < ip ¬ k (tutaj oczywiściec jest wektorem zerowym, a j-ty wiersz macierzy A jest wektorem mającymjedynkę na miejscu ij i zera na pozostałych miejscach). Bowiem jest to hipoteza,w przypadku nieodrzucenia której dochodzimy do wniosku, że w równaniu (2.1)pominąć można p składników, co na przykład w przypadku liniowej regresjiwielokrotnej oznacza, że do równania regresji nie ma sensu włączać p odpowiednichzmiennych niezależnych (przypadek p = k w tej sytuacji oznacza nieistotnośćwszystkich zmiennych niezależnych, czyli nieistotność samego modelu).
Jeśli hipoteza H0 : Aθ = c jest prawdziwa, to Aθ ∼ Np(c, σ2A(F TF )−1AT ).Przytoczymy następujący znany wynik, z którego będziemy korzystać.
Lemat 2.7. Jeśli ξ ∼ Np (µ, V ) i macierz V jest dodatnio określona, to (ξ −µ)TV −1(ξ − µ) ∼ χ2p.Dowód lematu jest dość oczywisty: wystarczy rozważyć wektor losowy V −1/2(ξ−µ), znaleźć jego rozkład, korzystając z elementarnych własności rozkładu normal-nego, i skorzystać z definicji rozkładu chi-kwadrat. Macierz V −1/2 określamyjako V −1/2 = (V 1/2)−1, gdzie V 1/2 jest dodatnio określoną symetryczną macierząspełniającą warunek V 1/2V 1/2 = V.
Na mocy Lematu 2.7, jeśli hipoteza H0 jest prawdziwa, to
f =1
σ2(Aθ − c)T (A(F TF )−1AT )−1(Aθ − c) ∼ χ2p.
Zatem gdyby parametr σ2 był znany, to statystykę f można było wziąć za testową.
W przypadku nieznanej wartości σ2 postępujemy inaczej. Przypomnijmy naj-pierw następujący fakt.

19
Fakt 2.3. Jeśli ξ jest zmienną losową o rozkładzie χ2p, a η zmienną losową o roz-kładzie χ2m i niezależną od ξ, to zmienna losowa (mξ)/(pη) ma rozkład o gęstości
f(u) =Γ(n+m2
) (nm
)n/2
Γ(n2
)Γ(m2
) u(n−2)/2(1 +nu
m
)−(n+m)/2, u > 0,
nazywany rozkładem Fishera (Fishera-Snedecora) F (p,m) o (p,m) stopniach swo-body.
Jak wynika z Lematu 2.5, wektor losowy Aθ i zmienna losowa eT e są niezależne,przy czym zmienna losowa eT e/σ2 ma rozkład χ2n−k (patrz Wniosek 2.2). Zatemna mocy Faktu 2.3 uzyskujemy statystykę testową do testowania hipotezy H0:
f ′ =1
pσ2(Aθ − c)T (A(F TF )−1AT )−1(Aθ − c)/ eT e
(n− k)σ2 ,
która w przypadku prawdziwości H0 ma rozkład F (p, n− k), czyli
f ′ =(Aθ − c)T (A(F TF )−1AT )−1(Aθ − c)
ps2∼ F (p, n− k). (2.6)
Mamy następującą procedurę testowania hipotezy H0 przeciwko alternatywieH1:
• zadajemy (wybieramy) poziom istotności α testu;
• z tablic rozkładu Fishera wyliczamy fα takie, że P (ζ fα) = α,ζ ∼ F (p, n− k);
• na podstawie posiadanych danych wyliczamy wartość f ′ ze wzoru (2.6);
• jeśli f ′ ∈ (0, fα), to nie mamy podstaw do odrzucenia hipotezy H0; wprzeciwnym przypadku hipotezę H0 odrzucamy.
Uwaga. W przypadku p = 1 mamy hipotezę H0 : aT θ = c, gdzie wektor a ∈ R
k
oraz liczba c ∈ R są zadane. Jeśli a jest wektorem, którego i-ta współrzędnajest jedynką, a pozostałe współrzędne są zerami, to mamy sytuację rozważoną napoczątku tego podrozdziału. Zauważmy też, że rozkład F (1, n−k) jest rozkłademzmiennej losowej ξ2, gdzie ξ ∼ tn−k (zadanie domowe).Okazuje się, że statystykę f ′ można zapisać w nieco innej, ale bardzo pożytecz-
nej postaci. W tym celu rozważmy najpierw problem poszukiwania estymatoraMNK θH0 wektora parametrów θ w sytuacji, gdy prawdziwa jest hipoteza H0.
Lemat 2.8. W warunkach klasycznego modelu regresji liniowej estymator MNKθH0 wektora parametrów θ w sytuacji, gdy prawdziwa jest hipoteza H0, ma postać:
θH0 = θ + (FTF )−1AT (A(F TF )−1AT )−1(c− Aθ).

20
Dowód. Rozwiązujemy problem poszukiwania minimum funkcji Q(θ) = (y −Fθ)T (y−Fθ) przy warunku Aθ = c za pomocą tzw.metody mnożników Lagrange’a.W tym celu rozważamy funkcję
Q′(θ, λ) = (y − Fθ)T (y − Fθ) + λT (Aθ − c),
gdzie λ = (λ1, . . . , λp)T , i szukamy jej punkt minimum wyliczając pochodne
cząstkowe i przyrównując je do zera:
∂Q′
∂θ= 0
∂Q′
∂λ= 0
=⇒{2F TFθ − 2F Ty + ATλ = 0
Aθ = c=⇒
θ = (F TF )−1F Ty − (F TF )−1AT 1
2λ
Aθ = c=⇒
θ = θ − (F TF )−1AT 12λ
Aθ −A(F TF )−1AT 12λ = c.
Z ostatniego równania otrzymujemy
1
2λ = (A(F TF )−1AT )−1(Aθ − c),
co po podstawieniu do pierwszego równania układu daje tezę. �
Teza Lematu 2.8 daje możliwość zapisać: (Aθ−c)T (A(F TF )−1AT )−1(Aθ−c) =(θ − θH0)TF TF (θ − θH0). Natomiast podstawiając θ = θH0 do równości (2.2),ostatnie wyrażenie da się zinterpretować jako RSSH0 − RSS, gdzie RSSH0 =(y−F θH0)T (y−F θH0). Ostatecznie, statystyka f ′ może być też zapisana w postaci
f ′ =n− kp· RSSH0 − RSS
RSS∼ F (p, n− k). (2.7)
Przykład 2.4. W celu testowania istotności modelu regresji liniowej, rozważmyhipotezę H0 : θ1 = . . . = θk = 0 przeciwko hipotezie H1, że przynajmniej jedenwspółczynnik funkcji regresji jest odmienny od zera. Tutaj p = k, A = Ik, c = 0.Otrzymujemy: θH0 = 0,
f ′=θTF TF θ
ks2=n− kk· yT y
(y − y)T (y − y) =n− kk·yTy − (y − y)T (y − y)(y − y)T (y − y) ∼F (k, n−k).
Przykład 2.5. W sytuacji, gdy w modelu regresji liniowej obecny jest wyrazwolny, powiedźmy θ1 (czyli f1(x) ≡ 1), dla testowania istotności modelu wystarczyprzetestować hipotezę H0 : θ2 = . . . = θk = 0 przeciwko hipotezie H1, żeprzynajmniej jedna z tych wartości jest odmienna od zera. Tutaj k 2, p =

21
k − 1, c = 0, macierz A jest wymiaru (k − 1) × k i wygląda jako macierzIk−1 uzupełniona na początku kolumną skladającą się wyłącznie z zer. Mamy:θH0 = (y, 0, . . . , 0)
T ,
f ′ =θTAT (A(F TF )−1AT )−1Aθ
(k − 1)s2 =n− kk − 1 ·
∑ni=1(yi − y)2 − (y − y)T (y − y)
(y − y)T (y − y)∼ F (k − 1, n− k).
Przykład 2.6. Niech y′1, . . . , y′n1 będą niezależnymi zmiennymi losowymi o jedna-
kowym rozkładzieN (θ′, σ2), a y′′1 , . . . , y′′n2 będą niezależnymi zmiennymi losowymio jednakowym rozkładzie N (θ′′, σ2), przy czym zmienne losowe z pierwszegonaboru są niezależne w stosunku do zmiennych losowych z drugiego naboru.Przetestować hipotezę H0 : θ
′ = θ′′ przeciwko hipotezie H1 : θ′ 6= θ′′ przy
założeniu, że n1 + n2 > 2.Przypominając postępowanie z Przykładu 2.1, zapiszemy model regresji linio-
wej y = Fθ + ε, gdzie y = (y′1, . . . , y′
n1, y′′
1 , . . . , y′′
n2)T , n = n1 + n2, θ = (θ
′, θ′′)T ,k = 2, ε ∼ (0, σ2In), a macierz F ma dwie kolumny: w pierwszej stoi n1 jedynek,a dalej n2 zer, a w drugiej n1 zer, a potem n2 jedynek. Hipotezę H0, którą należyprzetestować, da się teraz zapisać w postaci H0 : Aθ = c, gdzie A = (1 −1)jest wektorem dwuwymiarowym, p = 1, c = 0. W tej sytuacji estymatory MNKparametrów θ′ i θ′′ mają, odpowiednio, postaci (zadanie domowe) θ′ = y′, θ′′ =y′′, a RSS ma postać:
RSS =n1∑
i=1
(y′i − y′)2 +n2∑
i=1
(y′′i − y′′)2.
Ponieważ
(Aθ − c)T (A(F TF )−1AT )−1(Aθ − c) =(1
n1+1
n2
)−1(y′ − y′′)2,
statystyka testowa f ′ wygląda jako
f ′ =(n1 + n2 − 2)(y′ − y′′)2
( 1n1+ 1n2)(∑n1i=1(y
′i − y′)2 +
∑n2i=1(y
′′i − y′′)2)
i w przypadku prawdziwości hipotezy H0 ma ona rozkład F (1, n1+n2− 2). Przyuwzględnieniu faktu, zamieszczonego w uwadze na s. 19 i dotyczącego powiązaniapomiędzy rozkładami Studenta i Fishera, wnioskujemy, że uzyskany wynik pokry-wa się z klasycznym.
2.3. O współczynniku determinacji
Jak zaznaczaliśmy wyżej w Rozdziale 1, kolejnym po estymacji parametrów mode-lu i weryfikacji hipotez o tych parametrach, etapem analizy regresji jest ocena

22
jakości dopasowania modelu do danych. Dokładniej zajmiemy sie tym tematemdalej rozważając prostą regresję liniową (patrz Rozdział 5). Tutaj natomiastopowiemy o dość uniwersalnym i powszechnie stosowanym narzędziu służącymdo odpowiedzi na pytanie: na ile dobrze zmienna zależna jest „odtwarzana” przezzmienne niezależne za pomocą zaproponowanej funkcji regresji. Mowa o tzw.współczynniku determinacji R2, który określa się wzorem
R2 =
∑ni=1(yi − y)2∑ni=1(yi − y)2
.
Właściwe używanie tego współczynnika zakłada, iż spełniony jest warunek:f1(x) ≡ 1, czyli że funkcja regresji ma wyraz wolny θ1. Dalej w tym podrozdzialezakładamy, że warunek ten jest spełniony (oznaczmy go przez (∗)).Jaki jest sens współczynnika R2? Odpowiedź na to pytanie po części daje
prosta tożsamość
n∑
i=1
(yi − y)2 =n∑
i=1
(yi − y)2 +n∑
i=1
(yi − yi)2, (2.8)
którą interpretujemy następująco: całkowita zmienność wartości zmiennej zależnejda się przedstawić w postaci sumy dwóch składników: pierwszy to zmiennośćwyjaśniona przez model, drugi zaś jest resztową sumą kwadratów RSS (zmiennośćnie wyjaśniona przez model).Dowód tożsamości (2.8) jest elementarny. Mamy
n∑
i=1
(yi−y)2 =n∑
i=1
(yi−yi+yi−y)2 =n∑
i=1
(yi−yi)2+n∑
i=1
(yi−y)2+2n∑
i=1
(yi−yi)(yi−y).
Tożsamość będzie udowodniona, jeśli wykażemy, że ostatni składnik jest zerowy.Istotnie,
n∑
i=1
(yi − yi)(yi − y) =n∑
i=1
(yi − yi)yi = 0. (2.9)
Pierwsza równość w (2.9) jest konsekwencją tego, że przy spełnieniu warunku (∗)zachodzi
∑ni=1(yi − yi) =
∑ni=1 ei = 0 (zauważmy, że stąd też wynika pożyteczna
równość y = ¯y), co można udowodnić na dwa sposoby: (i) wynika to wprostze spełnienia dla wektora θ pierwszego równania z układu równań normalnych(patrz dowód Twierdzenia Gaussa-Markowa); (ii) z uwag zamieszczonych na s.
9-10, wynika, że wektorem ~f1 jest wektor złożony z jedynek; wektor reszt e zaśjest rzutem ortogonalnym y na przestrzeń F⊥, ortogonalną do F (patrz (2.3)),czyli należy do F⊥, i dlatego ~fT1 e = 0. Druga równość w (2.9) wynika z tego, żen∑
i=1
(yi−yi)yi = (F θ)T (y−F θ) = θTF T (In−F (F TF )−1F T )y = θT (F T−F T )y = 0,

23
co zachodzi w niezależności od spełnienia warunku (∗).Zatem współczynnik determinacji R2 pokazuje, jaka część zmienności wartości
zmiennej zależnej została wyjaśniona przez model. Wartości tego współczynnikależą w przedziale [0, 1]; im większe R2, tym lepiej. Symbol R2 wziął się z tego,że w modelu regresji liniowej współczynnik determinacji jest równy kwadratowiwspółczynnika korelacji pomiędzy y a y. Istotnie, oznaczmy
r0 =
∑ni=1(yi − y)(yi − y)√∑n
i=1(yi − y)2∑ni=1(yi − y)2
i pokażemy, że r20 = R2. Mamy
n∑
i=1
(yi − y)(yi − y) =n∑
i=1
(yi − yi + yi − y)(yi − y) =n∑
i=1
(yi − y)2
(ostatnia równość tutaj wynika z (2.9)). Podstawiając do wzoru na r0 i podnoszącdo kwadratu, dostajemy R2.
Uwaga. Zdarzają się jednak sytuacje, w których R2 nie daje zbyt wiarygodnegowyniku. Na przykład, jeśli n jest niewiele większe od k, to R2 daje trochę „zawyżo-ne” wyniki (bowiem dla n = k zawsze mamy R2 = 1, ponieważ reszty zerują się,o czym już mówiliśmy w uwadzę na s. 13). Dlatego w podobnych sytuacjachspecjalnie trochę „obniżają” wartość R2 stosując tzw. poprawiony R2:
R2 = R2 − k − 1n− k (1− R
2).

24
3. Przypadek niespełnienia założeń klasycznego
modelu regresji liniowej
W tym rozdziale zostaną rozważone przypadki odstępstwa od założeń klasycznegomodelu regresji liniowej. Główny nacisk będzie położony na zagadnienia estymacjiparametrów modelu.
3.1. Niespełnienie założenia dotyczącego macierzy Cov y
W klasycznym modelu regresji liniowej zakładaliśmy, iż macierz kowariancji Cov ywektora obserwacji y ma postać Cov y = σ2In. Zrezygnujmy teraz z tego ogranicze-nia i załóżmy, że Cov y = σ2W, gdzieW jest zadaną macierzą dodatnio określoną.Zatem mówimy, że mamy do czynienia z modelem (y, Fθ, σ2W ) .Łatwo jednak sprowadzić ten model do klasycznego. Istotnie, określimy syme-
tryczną dodatnio określoną macierz W−1/2 (patrz s. 18) i wprowadźmy oznacze-nia: y = W−1/2y, F = W−1/2F. Wtedy model (y, Fθ, σ2W ) jest równoważny
modelowi klasycznemu postaci(y, F θ, σ2In
). Estymator MNK wektora paramet-
rów θ w przypadku tego ostatniego modelu ma postać (zgodnie z TwierdzeniemGaussa-Markowa):
θ∗ = (F T F )−1F T y = (F TW−1F )−1F TW−1y.
Estymator θ∗ minimalizuje względem θ funkcję
Q(θ) = (y − F θ)T (y − F θ) = (y − Fθ)TW−1(y − Fθ).
Układ równań normalnych w tym przypadku ma postać F TW−1Fθ = F TW−1y.Jak łatwo obliczyć, estymator θ∗ jest nieobciążony, a jego macierz kowariancji
wynosiCov θ∗ = σ2(F T F )−1 = σ2(F TW−1F )−1.
Estymator ten nazywamy uogólnionym estymatorem MNK (dla odróżnienia odzwykłego estymatora MNK).
Uwaga.W tymmodelu możemy też rozważyć tzw. zwykły nieobciążony estymatorMNK, który otrzymujemy minimalizując funkcję Q, i który wynosi, jak wiemy,θ = (F TF )−1F Ty. Ale w tym przypadku
Cov θ = σ2(F TF )−1F TWF (F TF )−1.
Zgodnie z Twierdzeniem Gaussa-Markowa zastosowanego do modelu(y, F θ, σ2In
),
estymator θ∗ wektora parametrów jest NLNE. A zatem, w szczególności, Cov θ∗ ¬Cov θ.
Niech e będzie wektorem reszt dla modelu (y, Fθ, σ2W ) , czyli e = y − Fθ∗,natomiast e będzie wektorem reszt dla modelu
(y, F θ, σ2In
), czyli e = y− F θ∗ =

25
W−1/2(y − Fθ∗) =W−1/2e. Jak łatwo zrozumieć, teraz estymator s2 = eT e/(n−k) = eTW−1e/(n− k) jest nieobciążonym dla σ2. Estymator θ∗ jest także ENWwektora parametrów θ, natomiast estymator (n−k)s2/n jest ENW parametru σ2.W przypadku testowania hipotez o współczynnikach regresji liniowej w tym
modelu (parametr σ2 nie jest znany, H0 : θi = c lub H0 : Aθ = c) bazujemyprocedurę odpowiednio na następujących statystykach testowych:
t′ =θ∗i − c
s√((F TW−1F )−1)ii
=
√n− k(θ∗i − c)√
eTW−1e((F TW−1F )−1)ii∼ tn−k,
f ′ =n− kp· (Aθ
∗ − c)T (A(F TW−1F )−1AT )−1(Aθ∗ − c)eTW−1e
∼ F (p, n− k),
które w przypadku prawdziwości hipotezy H0 mają podane wyżej rozkłady.
3.2. Niespełnienie obu założeń
Będziemy mówić tutaj o przypadku, gdy w modelu regresji liniowej (y, Fθ, σ2W )rząd macierzy F wynosi p < k. Dla takich modeli, stosując MNK ponowniedostajemy układ równań normalnych F TW−1Fθ = F TW−1y, lecz rozwiązanietego układu już nie jest jednoznaczne, ponieważ z k równań przy rozwiązywaniuukładu tak naprawdę zostaje nam tylko p równań, a niewiadomych wciąż mamyk > p.
Lemat 3.1. Niech θ(1) i θ(2) będą dwoma rozwiązaniami układu równań normal-nych (dwoma uogólnionymi estymatorami MNK). Wówczas F θ(1) = F θ(2).
Dowód. Macierz F wymiaru n × k ma tylko p liniowo niezależnych kolumnspośród k. Rozważmy najpierw przypadek, gdy p pierwszych kolumn są liniowoniezależne. Wtedy możemy zapisać
F =(F1 F2
)=(F1 F1L
)
dla pewnej p × (k − p)-macierzy L, gdzie macierzy F1 i F2 mają odpowiedniowymiary n× p i n× (k − p). Mamy układ równań normalnych:
F TW−1Fθ = F TW−1y ⇐⇒(F T1LTF T1
)W−1
(F1 F1L
)θ =
(F T1LTF T1
)W−1y
⇐⇒(F T1 W
−1F1 F T1 W−1F1L
LTF T1 W−1F1 L
TF T1 W−1F1L
)(θ(1)θ(2)
)=
(F T1 W
−1yLTF T1 W
−1y
),
gdzie wektor θ(1) składa się z p pierwszych współrzędnych wektora θ, a θ(2) zpozostałych k − p współrzędnych. Z powyższego układu zostaje nam tylko prównań:
F T1 W−1F1θ(1) + F
T1 W
−1F1Lθ(2) = FT1 W
−1y

26
⇐⇒ θ(1) = (FT1 W
−1F1)−1F T1 W
−1y − Lθ(2).Współrzędne wektora θ(2) możemy wybierać dowolnie; wówczas jednoznacznie
odnajdujemy współrzędne wektora θ(1). Zatem dowolne rozwiązanie θ układurównań normalnych ma postać
θ =
((F T1 W
−1F1)−1F T1 W
−1y − Lzz
)=
(θ∗(1) − Lzz
), z ∈ Rk−p,
gdzie θ∗(1) = (FT1 W
−1F1)−1F T1 W
−1y możemy traktować jako uogólniony estymator
MNK wektora parametrów θ(1) w modelu (y, F1θ(1), σ2W ). Czyli uzyskujemy nie-
skończenie wiele uogólnionych estymatorów MNK. Oczywiście,
F θ =(F1 F1L
)( θ(1)θ(2)
)= F1θ(1)+F1Lθ(2) = F1(F
T1 W
−1F1)−1F T1 W
−1y = F1θ∗
(1),
a więc F θ nie zależy od z, tzn. nie zależy od wyboru uogólnionego estymatoraMNK.Jeśli pierwszych p kolumn macierzy F nie są liniowo niezależne, to dokonamy
takiego przestawienia kolumn macierzy F , by pierwszych p kolumn były liniowoniezależne. Oczywiście, przestawienie kolumn macierzy F wymaga też odpowied-niego przestawienia współrzędnych wektora θ i estymatora θ. �
Uwaga. Jak łatwo policzyć,
Eθ =
(θ(1) + L(θ(2) − z)
z
), Cov θ = σ2
((F T1 W
−1F1)−1 0
0 0
).
Czyli, estymator θ jest obciążony, natomiast jego macierz kowariancji nie zależyod wyboru estymatora uogólnionego MNK.W sytuacji rozważonej w tym podrozdziale w ogóle nie istnieje estymatora
liniowego nieobciążonego wektora parametrów θ. Istotnie, gdyby dla pewnej macie-rzy A wymiaru k×n estymator θ = Ay był nieobciążony, to musiałaby zachodzićrówność Eθ = AFθ = θ ∀θ ⇐⇒ AF = Ik. Ale taka równość nie może zachodzićdla żadnej macierzy A, bowiem rząd macierzy AF jest mniejszy od k.Tym nie mniej, istnieją funkcje liniowe nieznanych parametrów postaci Tθ,
gdzie macierz T jest wymiaru q × k (zazwyczaj zakładamy, że 1 ¬ q < k i rządmacierzy T wynosi q), dla których nieobciążone liniowe estymatory postaci Byistnieją (tutaj macierz B jest wymiaru q × n).Definicja 3.1. Mówimy, że wektor parametrów Tθ jest estymowalny, jeśli dlaniego istnieje estymator liniowy nieobciążony By.
Konieczny i dostateczny warunek estymowalności Tθ: istnieje taka macierz B,że EBy = Tθ ∀θ ⇐⇒ BF = T. W tej sytuacji, rząd macierzy T nie może byćwiększy niż p (czyli musi być spełniona nierówność q ¬ p).

27
Twierdzenie 3.1.Wmodelu regresji liniowej (y, Fθ, σ2W ) , w którym rząd macie-rzy F wynosi p < k, niech θ będzie dowolnym rozwiązaniem układu równań nor-malnych. Wtedy jeśli wektor parametrów Tθ jest estymowalny, to estymator T θjest NLNE wektora parametrów Tθ i nie zależy od wyboru θ.
Dowód. Niech wektor parametrów Tθ będzie estymowalny. Wówczas istniejemacierz B taka, że BF = T. Więc, T θ = BF θ i na mocy Lematu 3.1 T θ niezależy od wyboru θ.Bez straty ogólności załóżmy, że to p pierwszych kolumn macierzy F są liniowo
niezależne. Wtedy z tegoż Lematu 3.1 mamy:
T θ = BF θ = BF1(FT1 W
−1F1)−1F T1 W
−1y =⇒
ET θ = BF1(FT1 W
−1F1)−1F T1 W
−1Fθ = BFθ = Tθ (nieobciążoność),
Cov T θ = TCov θT T = σ2BF
((F T1 W
−1F1)−1 0
0 0
)F TBT =
σ2BF1(FT1 W
−1F1)−1F T1 B
T = σ2T1(FT1 W
−1F1)−1T T1 ,
gdzie T1 to macierz stojąca w pierwszych p kolumnach macierzy T.Niech Cy będzie dowolnym innym estymatorem liniowym nieobciążonym wek-
tora parametrów Tθ, czyli macierz C spełnia warunek CF = T. Udowodnijmy,że
Cov T θ ¬ Cov Cy = CCov yCT = σ2CWCT .Oznaczmy: A = BF1(F
T1 W
−1F1)−1F T1 W
−1−C. Z warunku nieobciążoności uzys-kujemy AF = 0. Wówczas
σ2CWCT =
σ2(BF1(F
T1 W
−1F1)−1F T1 W
−1 −A)W(W−1F1(F
T1 W
−1F1)−1F T1 B
T − AT)=
σ2BF1(FT1 W
−1F1)−1F T1 B
T − σ2BF1(F T1 W−1F1)−1F T1 AT−σ2AF1(F
T1 W
−1F1)−1F T1 B
T +σ2AWAT = σ2BF1(FT1 W
−1F1)−1F T1 B
T +σ2AWAT
Cov T θ. �
Co do estymacji σ2, to estymatorem nieobciążonym jest s2 = eTW−1e/(n −p), gdzie e = y − F θ jest wektorem reszt niezależnym od wyboru estymatorauogólnionego MNK.W przypadku testowania hipotez o współczynnikach regresji liniowej w tym
modelu (parametr σ2 nie jest znany, H0 : θi = eTi θ = c, gdzie ei ∈ R
k jestwektorem, i-ta współrzędna którego jest jedynka, a pozostałe zerami, oraz para-metr θi jest estymowalny, lub H0 : Aθ = c, gdzie macierz A jest wymiaru q × k,

28
1 ¬ q ¬ p, której rząd wynosi q, oraz wektor parametrów Aθ jest estymowalny)bazujemy procedurę odpowiednio na następujących statystykach testowych:
t′ =
√n− p(θi − c)√
eTW−1e((F T1 W−1F1)−1)ii
∼ tn−p,
f ′ =n− pq· (Aθ − c)
T (A1(FT1 W
−1F1)−1AT1 )
−1(Aθ − c)eTW−1e
∼ F (q, n− p),
które w przypadku prawdziwości hipotezy H0 mają podane wyżej rozkłady; tutajA1 to macierz wymiaru q × p stojąca w pierwszych p kolumnach macierzy A.

29
4. Regresja wielomianowa
W tym rozdziale zostanie rozważony szczególny, lecz bardzo ważny przypadekregresji liniowej, mianowicie regresja wielomianowa. Przypomnijmy, że w tej sytu-acji funkcja regresji jest wielomianem (niech wielomian ten ma stopień p):
h(x, θ) = θ0 + θ1x+ . . .+ θpxp. (4.1)
Tak więc zakładamy, że mamy obserwacje postaci
yi = θ0 +p∑
j=1
θjxji + εi, i = 1, . . . , n,
czyli y = Fθ+ε, gdzie y = (y1, . . . , yn)T , θ = (θ0, . . . , θp)
T , ε = (ε1, . . . , εn)T , n
p+ 1,
F =
1 x1 . . . . . . xp1
......
......
1 xn . . . . . . xpn
.
Na pierwszy rzut oka, dokonuąc odpowiednich założeń co do wektora ε (Eε =0, Cov ε = σ2In) oraz rzędu macierzy F (liczba różnych punktów wśród {xi} jestnie mniejsza niż p+ 1 =⇒ rząd macierzy F wynosi p+ 1) możemy postępowaćjak w Rozdziale 2. Problem jednak polega na tym, że nawet przy niewielkichwartościach p macierz F TF w praktyce może okazać się bliskiej do macierzyosobliwej, co utrudnia obliczenie (F TF )−1.Aby nie walczyć z tym problemem, sprytnie omijamy go. Zamiast zwykłej
postaci wielomianu stopnia p, jak w (4.1), zapisujemy go inaczej – za pomocątzw. wielomianów ortogonalnych:
h(x, θ) = β0φ0(x) + β1φ1(x) + . . .+ βpφp(x). (4.2)
Tutaj funkcja φj jest wielomianem stopnia j, j = 0, 1, . . . , p, przy czym, jaksię okazuję, dla odpowiednio wybranych {φj} każdy wielomian stopnia p postaci(4.1) da się w sposob jednoznaczny przedstawić w postaci (4.2). Ortogonalnośćwielomianów oznacza, iż spełniony jest warunek:
n∑
i=1
φj(xi)φs(xi) = 0 ∀j 6= s (4.3)
(w zasadzie, (4.3) zawiera (p+1)p2warunków). Warto podkreślić, że postać wielomia-
nów {φj} zależy od punktów {xi} (jak wybrać takie wielomiany pokażemy niżej).Możemy teraz zapisać model w postaci y = Φβ + ε, lub w postaci trójki
(y,Φβ, σ2In), gdzie β = (β0, . . . , βp)T ,
Φ =
φ0(x1) φ1(x1) . . . . . . φp(x1)...
......
...φ0(xn) φ1(xn) . . . . . . φp(xn)
,

30
przy czym, na mocy warunku (4.3),
ΦTΦ =
∑ni=1 φ
20(xi) 0 . . . . . . 00
∑ni=1 φ
21(xi) . . . . . . 0
......
......
0 0 . . . . . .∑ni=1 φ
2p(xi)
.
W tej sytuacji, zgodnie z Twierdzeniem Gaussa-Markowa, estymator MNK wekto-ra parametrów β ma postać
β = (ΦTΦ)−1ΦTy =
(∑ni=1 φ0(xi)yi∑ni=1 φ
20(xi)
,
∑ni=1 φ1(xi)yi∑ni=1 φ
21(xi)
, . . . ,
∑ni=1 φp(xi)yi∑ni=1 φ
2p(xi)
)T.
Ważną własnością estymatora βj parametru βj (j ¬ p) jest to, że wyznacza sięon wyłącznie za pomocą wielomianu φj stopnia j, bowiem
βj =
∑ni=1 φj(xi)yi∑ni=1 φ
2j(xi)
, j = 0, 1, . . . , p. (4.4)
Uwaga. Ponieważ φ0 jest wielomianem stopnia 0, czyli stałą, przyjmijmy bezstraty ogólności, że φ0(x) ≡ 1. Wówczas β0 = y.Wektor reszt ma postać:
e = y − Φβ =
y1...yn
−
1 φ1(x1) . . . . . . φp(x1)...
......
...1 φ1(xn) . . . . . . φp(xn)
y...
βp
,
więc
ei = yi − y −p∑
j=1
φj(xi)βj .
Zatem RSS zapisuje się w postaci
n∑
i=1
e2i =n∑
i=1
(yi − y)2 +n∑
i=1
p∑
j=1
φj(xi)βj
2
− 2n∑
i=1
(yi − y)p∑
j=1
φj(xi)βj . (4.5)
Jeśli przyjmiemy, że n > p+1, to estymatorem nieobciążonym parametru σ2, jakwiemy, jest
σ2 =1
n− p− 1n∑
i=1
e2i .
Resztową sumę kwadratów (4.5), ze względu na warunek (4.3), można zapisaćtrochę inaczej (dalej będziemy ją oznaczać przez RSSp; indeks p wskazuje naregresję wielomianową stopnia p):
RSSp =n∑
i=1
(yi − y)2 +n∑
i=1
p∑
j=1
p∑
s=1
φj(xi)φs(xi)βjβs − 2n∑
i=1
yi
p∑
j=1
φj(xi)βj+

31
2yn∑
i=1
p∑
j=1
φj(xi)βj =n∑
i=1
(yi−y)2+p∑
j=1
(n∑
i=1
φ2j(xi)
)β2j−2
n∑
i=1
yi
p∑
j=1
φj(xi)
∑ns=1 φj(xs)ys∑ns=1 φ
2j(xs)
=n∑
i=1
(yi − y)2 +p∑
j=1
(n∑
i=1
φ2j(xi)
)β2j − 2
p∑
j=1
(∑ns=1 φj(xs)ys)
2
∑ns=1 φ
2j(xs)
=n∑
i=1
(yi − y)2 +p∑
j=1
(n∑
i=1
φ2j(xi)
)β2j − 2
p∑
j=1
(n∑
s=1
φ2j(xs)
)β2j
=n∑
i=1
(yi − y)2 −p∑
j=1
(n∑
i=1
φ2j(xi)
)β2j .
Ponieważ dla regresji wielomianowej stopnia p−1 (bez φp) uzyskujemy analogicznie
RSSp−1 =n∑
i=1
(yi − y)2 −p−1∑
j=1
(n∑
i=1
φ2j(xi)
)β2j ,
mamy
RSSp−1 = RSSp +
(n∑
i=1
φ2p(xi)
)β2p .
Załóżmy teraz, że chcemy przetestować hipotezę H0 : βp = 0 (hipoteza tajest równoważna do hipotezy H0 : θp = 0 w przypadku zapisu funkcji regresjiw postaci (4.1)) przeciwko hipotezie H1 : βp 6= 0. Testowanie takiej hipotezyjest ważne z praktycznego punktu widzenia, bowiem nieodrzucenie hipotezy H0pociąga za sobą możliwość stosowania wielomianu stopnia o jeden mniejszego niżp. Z wyników Podrozdziału 2.2 uzyskujemy, że testowanie takiej hipotezy odbywasię za pomocą statystyki testowej
t′ =√n− p− 1 βp√
RSSp√((ΦTΦ)−1)pp
,
która przy prawdziwości hipotezy H0 ma rozkład tn−p−1, lub statystyki testowej
(t′)2 = (n− p− 1) β2pRSSp((ΦTΦ)pp)−1
=RSSp−1 − RSSpRSSp/(n− p− 1)
,
która przy prawdziwości hipotezy H0 ma rozkład F (1, n− p− 1).Przejdźmy teraz do zagadnienia związanego z wyborem wielomianów {φj}
spełniających warunek (4.3). W zastosowaniach podstawą do takiego wyborunajczęściej służą tzw. wielomiany ortogonalne Czebyszewa. Najpierw punkty po-miarów {x1, . . . , xn} przekształcamy na punkty pomocnicze {z1, . . . , zn} ⊂ [−1, 1]za pomocą wzoru:
zi =2(xi −minj xj)maxj xj −minj xj
− 1 = 2xi −minj xj −maxj xjmaxj xj −minj xj

32
(jest to przekształcenie liniowe punktów odcinka [minj xj ,maxj xj ] w punktyodcinka [−1, 1]). Dalej do wyznaczenia wielomianów {φj} stosujemy następującywzór rekurencyjny:
φ0(z) ≡ 1, φ1(z) = 2(z − z), φj+1(z) = 2(z − aj+1)φj(z)− bjφj−1(z), j 1,
gdzie liczby {bj , aj+1} określone są jako
bj =
∑ni=1 φ
2j(zi)∑n
i=1 φ2j−1(zi)
, aj+1 =
∑ni=1 ziφ
2j(zi)∑n
i=1 φ2j(zi)
, j 1.
Można sprawdzić, że tak określone wielomiany {φj} spełniają warunek ortogonal-ności (4.3) dla naboru punktów {zi}.Uwaga. Oczywiście, wielomiany {φj} nie spełniają warunku ortogonalności (4.3)dla wyjściowego naboru punktów {xi}. Ale nie sprawia to nam żadnych kłopotów,ponieważ przy zamianie z powrotem punktów {zi} punktami {xi} jakość dopasowa-nia nie ulega zmianie!
Przykład 4.1. Zakładając spełnienie założeń klasycznego modelu regresji liniowej,dopasować wielomian drugiego stopnia do danych: (2009, y1), (2010, y2), (2011, y3),(2012, y4). Przymując y1 = 1, y2 = 3, y3 = 8, y4 = 18, przetestować hipotezęH0 : β2 = 0 przeciwko hipotezie H1 : β2 6= 0.Mamy n = 4, p = 2. Najpierw przechodzimy do punktów pomocniczych:
z1 =2 · 2009− 2009− 20122012− 2009 = −1, z2 =
2 · 2010− 2009− 20122012− 2009 = −1
3,
z3 =2 · 2011− 2009− 20122012− 2009 =
1
3, z4 =
2 · 2012− 2009− 20122012− 2009 = 1.
Zatem φ0(z) ≡ 1, φ1(z) = 2(z− z) = 2z, φ2(z) = 2(z− a2) · 2z− b1.Wyliczamy:
b1 =φ21(z1) + φ
21(z2) + φ
21(z3) + φ
21(z4)
4=20
9,
a2 =z1φ21(z1) + z2φ
21(z2) + z3φ
21(z3) + z4φ
21(z4)
φ21(z1) + φ21(z2) + φ
21(z3) + φ
21(z4)
= 0,
więc φ2(z) = 4z2 − 20
9= 49(9z2 − 5).
Uwaga. Mnożenie wielomianu φj, j = 1, . . . , p, przez dowolną stałą, w zasadzie,nie zmienia poprawności rozumowania (nie zmienia warunku (4.3)!). Dlatego wpraktyce każdy wielomian φj , j = 1, . . . , p, mnożymy przez pewną stałą, abyułatwić obliczenia.
A więc możemy przyjąć, że φ0(z) ≡ 1, φ1(z) = z, φ2(z) = 9z2−5. Korzystającz (4.4), otrzymujemy estymatory MNK współczynników regresji:
β0 = y, β1 =φ1(z1)y1 + φ1(z2)y2 + φ1(z3)y3 + φ1(z4)y4φ21(z1) + φ
21(z2) + φ
21(z3) + φ
21(z4)
=−9y1 − 3y2 + 3y3 + 9y4
20,

33
β2 =φ2(z1)y1 + φ2(z2)y2 + φ2(z3)y3 + φ2(z4)y4φ22(z1) + φ
22(z2) + φ
22(z3) + φ
22(z4)
=y1 − y2 − y3 + y4
16.
A zatem wielomian drugiego stopnia, który według MNK najlepiej pasuje dopunktów (zi, yi), i = 1, 2, 3, 4, to
β0+β1φ1(z)+β2φ2(z) = y+−9y1 − 3y2 + 3y3 + 9y4
20z+y1 − y2 − y3 + y4
16(9z2−5).
Czyli wielomian drugiego stopnia, który według MNK najlepiej pasuje do wyjścio-wych punktów, to
y+−9y1 − 3y2 + 3y3 + 9y4
20·2x− 40213
+y1 − y2 − y3 + y4
16
(9(2x− 40213
)2− 5
).
Oczywiście, o ile jest to potrzebne, wielomian ten możemy zapisać w postaci (4.1).Zauważmy, że przy podanych wartościach {yi}mamy: β0 = 7.5, β1 = 8.4, β2 =
0.5 oraz dopasowany wielomian drugiego stopnia to 2x2 − 8036.4x+ 8072966.7.Wyliczamy teraz wartość statystyki testowej (t′)2 służącej do testowania hipo-
tezy H0 :
RSS2 =4∑
i=1
(yi− y)2−(4∑
i=1
φ21(zi)
)β21 −
(4∑
i=1
φ22(zi)
)β22 = 173− 156.8− 16 = 0.2,
RSS1 =4∑
i=1
(yi − y)2 −(4∑
i=1
φ21(zi)
)β21 = 173− 156.8 = 16.2,
(t′)2 =RSS1 − RSS2RSS2
=16.2− 0.20.2
= 80.
Przy założeniu prawdziwości hipotezy H0, statystyka (t′)2 ma rozkład F (1, 1).
Przyjmijmy α = 0.05.Wówczas z tablic rozkładu F (1, 1) znajdujemy fα = 161.4.Ponieważ (t′)2 ∈ (0, fα), nasza decyzja brzmi: nie mamy podstaw do odrzuceniahipotezy H0. W praktyce to oznacza, iż możemy przyjąć β2 = 0 i próbowaćdopasowywać wielomian pierwszego stopnia do danych.
Uwaga.Mimo że Rysunek 3 sugeruje, iż wielomian drugiego stopnia w tym przy-kładzie byłby bardziej wskazany (lepiej pasuje do danych), testowanie hipotezyH0 doprowadziło nas do decyzji nieodrzucenia tej hipotezy. Oczywiście, stało sięto wskutek tego, że mamy zbyt mało danych (n = 4).Warto podkreślić jeszcze jedną wygodę rozważanego w regresji wielomianowej
podejścia. Otóż jeśli zdecydujemy się przejść do rozważania wielomianu stopnia ojeden mniejszego niż p, to postaci wielomianów ortogonalnych {φj} oraz estyma-torów {βj} przy j < p będą takie same! Wyliczenia, które były zrobione przytestowaniu hipotezy H0 : βp = 0, można teraz wykorzystać przy testowaniuhipotezy o zerowaniu współczynnika przy największej potędze dopasowywanegowielomianu w nowym modelu.
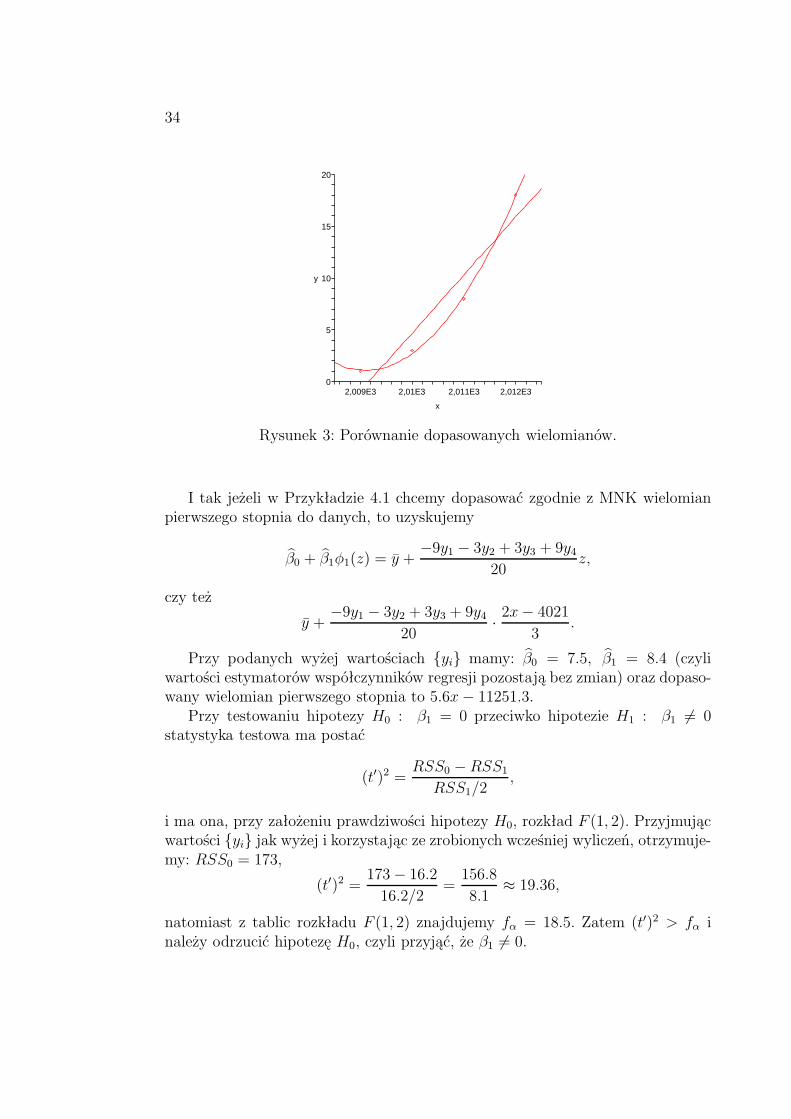
34
y
x
20
2,012E3
15
10
2,011E3
5
02,01E32,009E3
Rysunek 3: Porównanie dopasowanych wielomianów.
I tak jeżeli w Przykładzie 4.1 chcemy dopasować zgodnie z MNK wielomianpierwszego stopnia do danych, to uzyskujemy
β0 + β1φ1(z) = y +−9y1 − 3y2 + 3y3 + 9y4
20z,
czy też
y +−9y1 − 3y2 + 3y3 + 9y4
20· 2x− 4021
3.
Przy podanych wyżej wartościach {yi} mamy: β0 = 7.5, β1 = 8.4 (czyliwartości estymatorów współczynników regresji pozostają bez zmian) oraz dopaso-wany wielomian pierwszego stopnia to 5.6x− 11251.3.Przy testowaniu hipotezy H0 : β1 = 0 przeciwko hipotezie H1 : β1 6= 0
statystyka testowa ma postać
(t′)2 =RSS0 −RSS1RSS1/2
,
i ma ona, przy założeniu prawdziwości hipotezy H0, rozkład F (1, 2). Przyjmującwartości {yi} jak wyżej i korzystając ze zrobionych wcześniej wyliczeń, otrzymuje-my: RSS0 = 173,
(t′)2 =173− 16.216.2/2
=156.8
8.1≈ 19.36,
natomiast z tablic rozkładu F (1, 2) znajdujemy fα = 18.5. Zatem (t′)2 > fα i
należy odrzucić hipotezę H0, czyli przyjąć, że β1 6= 0.

35
5. Prosta regresja liniowa
W tym rozdziale zostanie rozważony w sposób bardziej szczegółowy najprostszyklasyczny model regresji liniowej, czyli prosta regresja liniowa. Więcej uwagibędzie przydzielone nie rozważanym wcześniej problemom prognozy oraz weryfi-kacji modelu za pomocą wartości resztowych.Niech mamy do czynienia z jedną zmienną niezależną i dysponujemy n parami
obserwacji zmiennej niezależnej i zmiennej zależnej: (xi, yi), i = 1, . . . , n. Zakłada-my, że obserwacje te spełniają równanie:
yi = θ0 + θ1xi + εi, i = 1, . . . , n, (5.1)
czy też y = Fθ + ε, gdzie Eε = 0, Covε = σ2In, oraz wśród n punktów {xi} sąprzynajmniej dwa różne (n 2). Oznacza to, że założenia klasycznego modeluregresji liniowej są spełnione.
5.1. Estymacja parametrów i testowanie hipotez o nich
Zgodnie z Twierdzeniem Gaussa-Markowa (patrz Przykład 2.3), estymatory współ-czynników regresji mają postać:
θ0 = y − θ1x, θ1 =
∑ni=1(xi − x)(yi − y)∑ni=1(xi − x)2
=
∑ni=1(xi − x)yi∑ni=1(xi − x)2
,
gdzie x = 1n
∑ni=1 xi, y =
1n
∑ni=1 yi.Wartość θ1 jest współczynnikiem kierunkowym
dopasowanej do danych prostej, zaś θ0 wyrazem wolnym. Inny często stosowanyzapis współczynnika kierunkowego prostej regresji liniowej to
θ1 = rsysx, gdzie s2x =
1
n
n∑
i=1
(xi − x)2, s2y =1
n
n∑
i=1
(yi − y)2,
natomiast
r =
∑ni=1(xi − x)(yi − y)√∑n
i=1(xi − x)2∑ni=1(yi − y)2
jest współczynnikiem korelacji pomiędzy x a y.Niech ei=yi − yi=yi − θ0 − θ1xi będzie i-tą wartością resztową, i=1, . . . , n.
Wypiszmy teraz kilka pożytecznych tożsamości, z których będziemy dalej korzys-tać. Przypadek, gdy w równaniu regresji jest obecny wyraz wolny, był już rozważa-ny w Podrozdziale 2.3 (warunek (∗)). Tam zostały udowodnione następujące dwierówności (patrz tożsamość (2.9) i rozumowania na temat jej dowodu), z którychwynika też równość trzecia:
n∑
i=1
ei = 0,n∑
i=1
eiyi = 0 =⇒n∑
i=1
eixi = 0. (5.2)

36
Oprócz tego, dla współczynnika detrminacji R2 zachodzi równość:
R2 =
∑ni=1(yi − y)2∑ni=1(yi − y)2
=
∑ni=1(θ1xi + θ0 − y)2∑ni=1(yi − y)2
=
∑ni=1(θ1xi − θ1x)2∑ni=1(yi − y)2
= θ21s2xs2y= r2.
Pokażemy teraz, że
Cov(y, θ1) = E(y − Ey)(θ1 − Eθ1) = 0. (5.3)
Istotnie, ponieważ
θ1 = θ1
∑ni=1(xi − x)xi∑ni=1(xi − x)2
+
∑ni=1(xi − x)εi∑ni=1(xi − x)2
= θ1 +
∑ni=1(xi − x)εi∑ni=1(xi − x)2
,
mamy
Cov(y, θ1) = Eε
∑ni=1(xi − x)εi∑ni=1(xi − x)2
=1
nE
∑nj=1
∑ni=1(xi − x)εiεj∑ni=1(xi − x)2
=σ2
n
∑ni=1(xi − x)∑ni=1(xi − x)2
= 0.
Jak wiemy, Eθ = θ, Cov θ = σ2(F TF )−1. Czyli Eθ0 = θ0, Eθ1 = θ1 oraz, jakwynika z Przykładu 2.3,
σ2(F TF )−1 =σ2
ns2x
(1n
∑ni=1 x
2i −x
−x 1
)=⇒
Var θ0 =σ2
ns2x· 1n
n∑
i=1
x2i =σ2
n
(1 +x2
s2x
), Var θ1 =
σ2
ns2x.
Zauważmy, że w powyższe wzory wchodzi nieznany parametr σ2. Jego nieobciążo-nym estymatorem przy założeniu n > 2, jak wiemy, jest
σ2 = s2 =1
n− 2n∑
i=1
(yi − yi)2.
Błędem standardowym estymatorów θ0, θ1 nazywamy odpowiednio
SE(θ0) =s√n
√√√√1 +x2
s2x, SE(θ1) =
s√nsx.
Dla testowania hipotez o współczynnikach regresji, jak pamiętamy, zakładaliś-my normalność rozkładu wektora losowego y oraz n > 2. Na przykład hipotezęH0 : θ1 = 0 (jest to, w zasadzie, hipoteza o istotności modelu, bowiem nieodrzuce-nie jej oznacza brak wpływu zmiennej niezależnej na zmienną zależną) przeciwkohipotezie H1 : θ1 6= 0 testujemy za pomocą statystyki t′ = θ1/SE(θ1) =θ1√nsx/s, która przy założeniu prawdziwości H0 ma rozkład tn−2, lub statystyki
(t′)2 =θ21
SE2(θ1)=θ21ns
2x
s2=r2ns2ys2=R2ns2ys2= (n− 2)
∑ni=1(yi − y)2∑ni=1(yi − yi)2
,
która przy założeniu prawdziwości H0 ma rozkład F (1, n− 2).

37
5.2. Problem prognozy
Nadal zakładamy, że n > 2. Jeśli dopasowanie modelu do danych uznajemy zazadowalające, to możemy użyć go do zagadnień prognozy. Na przykład możemystarać się przewidzieć, jaka będzie średnia wartość zmiennej zależnej, gdy zmiennaniezależna przyjmie wartość x0, różną od {xi} (jest to prognoza wartości funkcjiregresji w punkcie x0: Ey(x0) = h(x0, θ) = θ0 + θ1x0). Lub przewidzieć, jakąbędzie przyszła wartość zmiennej zależnej, gdy zmienna niezależna przyjmie war-tość x0, różną od {xi} (jest to prognoza wartości y(x0) = θ0 + θ1x0 + ε0, gdziezmienna losowa ε0 o rozkładzie N (0, σ2) jest niezależna w stosunku do zmiennychlosowych {εi}).Problem pierwszy. Oczywistym oszacowaniem dla wartości h(x0, θ) służy y(x0)= θ0 + θ1x0. Estymator y(x0) jest nieobciążonym dla h(x0, θ). Jakość prognozynaturalnie określamy za pomocą błędu średniokwadratowego estymatora y(x0),który w tej sytuacji dorównuje jego wariancji: E(y(x0)− h(x0, θ))2 = Var y(x0).Wariancja ta wynosi:
Var y(x0) = Var (θ0 + θ1x0) = Var (y + θ1(x0 − x)) = Var y + (x0 − x)2Var θ1
=σ2
n
(1 +(x0 − x)2s2x
). (5.4)
Tutaj skorzystaliśmy z równości (5.3). Błąd standardowy tego estymatora wynosi
SE(y(x0)) =s√n
√√√√1 +(x0 − x)2s2x
.
Wartość ta będzie najmniejsza (równa s/√n), gdy x0 = x, i rośnie wraz ze
wzrostem odległości punktu x0 od średniej x.Problem drugi. Oszacowaniem dla wartości y(x0) ponownie służy y(x0).W tymprzypadku mamy trudniejsze zadanie, bowiem szacujemy wartość losową. MamyEy(x0) = Ey(x0) = θ0 + θ1x0, zatem jakość prognozy określamy za pomocąE(y(x0)− y(x0))2 = Var (y(x0)− y(x0)). Otrzymujemy:
Var (y(x0)−y(x0)) = Var((θ0−θ0)+(θ1−θ1)x0−ε0
)= E
((θ0−θ0)+(θ1−θ1)x0−ε0
)2
=E((θ0−θ0)+(θ1−θ1)x0
)2+σ2=
σ2
n
(1 +(x0 − x)2s2x
)+σ2=σ2
(1 +1
n+(x0 − x)2ns2x
).
Tutaj skorzystaliśmy z równości (5.4) oraz niezależności ε0 i {εi}.Ostatnia wielkośćjest definitywnie większa od (5.4), bowiem szacowaliśmy wartość losową, co powięk-sza niepewność prognozy. Oprócz tego ponownie można zauważyć, że jakośćprognozy jest tym gorsza, im większa jest odległość punktu x0 od średniej x.Mamy
SE(y(x0)− y(x0)) = s√√√√1 +
1
n+(x0 − x)2ns2x
.

38
5.3. Analiza wartości resztowych
Gdy model regresji liniowej jest poprawny, czyli zachodzi (5.1) oraz zmiennelosowe εi = yi − θ0 − θ1xi, i = 1, . . . , n, n > 2, są niezależne o tym samymrozkładzie N (0, σ2), to ciąg wartości resztowych ei = yi − θ0 − θ1xi, i = 1, . . . , npowinien zachowywać się w przybliżeniu tak, jak ciąg {εi}. W szczególności,wykres wartości resztowych (na osi y) względem odpowiednich numerów porządko-wych lub względem odpowiednich wartości przewidywanych zmiennej zależnej{yi} (na osi x) powinien przedstawiać chmurę punktów skupioną dookoła osix i nie mającą żadnej wyraźnej struktury czy tendencji. Pewną trudność możepowodować fakt, iż wartości resztowe nie są całkowicie niezależne (spełniająbowiem równości (5.2)) i mimo że wartość oczekiwana ich wynosi 0, nie mająjednakowej wariancji, co pokazują następujące wyliczenia:
Var ei = Var (yi − yi) = Var yi +Var yi − 2Cov(yi, yi) =
σ2 + σ2(1
n+(xi − x)2ns2x
)− 2Cov(yi, y + θ1(xi − x)) =
σ2 + σ2(1
n+(xi − x)2ns2x
)− 2σ2
(1
n+(xi − x)2ns2x
).
Ostatnia równość jest prawdziwa na mocy tego, że
Cov(yi, y + θ1(xi − x)) = Cov(yi, y) + (xi − x)Cov(yi, θ1) =
Cov(εi,1
n
n∑
j=1
εj) +(xi − x)
∑nj=1(xj − x)Cov(yi, yj)ns2x
=σ2
n+σ2(xi − x)2ns2x
.
Ostatecznie,
Var ei = σ2
(1−
(1
n+(xi − x)2ns2x
))= σ2(1− hi),
gdzie wartość hi =1n+ (xi−x)
2
ns2xbędziemy nazywać dźwignią obserwacji o numerze
i, i = 1, . . . , n. Odpowiedni błąd standardowy dla ei wynosi
SE(ei) = s√1− hi.
W przypadku dużej liczebności próby wartość Var ei niewiele różni się od σ2
(wartość hi jest mała), ale dla małych n ta różnica może być znacząca. Wartościei/SE(ei) nazywamy resztami standaryzowanymi.Spróbujmy teraz odpowiedzieć na pytanie: jak można stwierdzić, że któreś z
podstawowych założeń modelu nie jest spełnione? Można to zrobić albo używającpewnych wykresów, albo też, co jest bardziej wiarygodne, pewnych testów. Tutaj

39
skupimy się tylko na wykresach. Przede wszystkim trzeba powiedzieć, że każdeodstępstwo od założeń modelu odbija się na resztach {ei}. Rozpatrzmy kilkatypowych odstępstw od założeń modelu, które najczęściej spotykamy w praktyce.
Rozważmy najpierw przypadek, gdy równość (5.1) zachodzi, ale rozkład wekto-ra y znacznie różni się od normalnego. Sytuację taką można wykryć, rysująchistogram bądź wykres kwantylowy reszt (lub standaryzowanych reszt). Przypo-mnijmy, że gdy reszty mają w przybliżeniu rozkład normalny, punkty na wykresiekwantylowym powinny skupiać się wokół pewnej prostej.
Innym odstępstwem od założeń modelu jest właściwie zły wybór modelu, czylifunkcji regresji. Odstępstwo tego typu można wykryć, rysując wykres wartościresztowych (na osi y) względem odpowiednich wartości przewidywanych zmiennejzależnej (na osi x). Jak już zaznaczaliśmy wyżej, chmura punktów skupionadookoła osi x i nie mająca żadnej wyraźnej struktury świadczy o trafnym wyborzemodelu. W przeciwnym przypadku model jest wybrany niewłaściwie.
Jeszcze jednym przypadkiem odstępstwa od założeń modelu jest zwiększeniezmienności wartości {εi} wraz ze zwiększeniem wartości zmiennej niezależnej, cooznacza, że wartości Var εi są różne. Takie odstępstwo ponownie możemy wykryćna powyższym wykresie: zobaczymy na nim, że zmienność reszt rośnie wraz zewzrostem przewidywanych wartości zmiennej zależnej. W takiej sytuacji należyzastosować zamiast zwykłego estymatora MNK - uogólniony estymator MNK(patrz Podrozdział 3.1).
5.4. Klasyfikacja obserwacji nietypowych
Poprawne wnioskowanie i poprawna diagnoza dopasowanego modelu jest niemoż-liwa bez wykrycia i analizy wpływu na model tzw. obserwacji nietypowych.Obserwacje takie mogą, choć nie muszą, wywierać istotny wpływ na wyniki.Wśród takich obserwacji będziemy wyróżniać: punkty wysokiej dźwigni, punktyodstające (oddalone), punkty wpływowe.
Zacznijmy od punktów wysokiej dźwigni. Na poprzedniej stronie już wprowa-dziliśmy pojęcie dźwigni dla obserwacji o numerze i, i = 1, . . . , n:
hi =1
n+(xi − x)2ns2x
=1
n+(xi − x)2∑nj=1(xj − x)2
.
Jak pamiętamy, dźwignia określa wariancję i-tej reszty (większa dźwignia powodu-je mniejszą wariancję). Zwróćmy uwagę, że większą dźwignię mają obserwacje,które znajdują się na skraju zakresu zmiany zmiennej niezależnej, natomiastwartość zmiennej zależnej zupełnie nie wpływa na wielkość dźwigni. Najmniejsządźwignię (równą 1/n) ma obserwacja, której wartość xi pokrywa się z wartosciąśrednią x. Kres górny dla wartości dźwigni jest równy jedności. Jak łatwo obliczyć,∑ni=1 hi = 2, więc średnia wartość dźwigni wynosi 2/n.

40
czas
16141210
40
35
8
30
25
6
20
15
4
10
2
Rysunek 4: Wykres rozrzutu wraz z prostą regresji.
Definicja 5.1. Obserwację o numerze i, i = 1, . . . , n, nazywamy punktem wyso-kiej dźwigni, jeśli jej dźwignia przekracza wartość 4/n. (W przypadku regresjiwielokrotnej, gdy mamy m > 1 zmiennych niezależnych, dźwignią i-tej obserwacjinazywamy hi = (F (F
TF )−1F T )ii oraz punkt wysokiej dźwigni określamy jako taki,dla którego hi > 2(m+ 1)/n).
Przykład 5.1. Rozpatrzmy dane dotyczące odległości (w kilometrach) przebytejprzez zawodników i czas biegu każdego zawodnika (w godzinach):
Numer zaw. 1 2 3 4 5 6 7 8 9 10Czas 2 14 3 4 4 5 6 7 6 15Odległość 10 20 12 13 14 15 20 18 18 35
W następnej tabelce podane są wartości dźwigni (zaokrąglone do dwóch znakowpo przecinku) dla każdej obserwacji:
Numer zaw. 1 2 3 4 5 6 7 8 9 10Dźwignia 0.22 0.41 0.17 0.14 0.14 0.11 0.10 0.10 0.10 0.50
Stwierdzamy, że dwie obserwacje (o numerach 2 i 10) są punktami wysokiejdźwigni.
Przejdźmy teraz do charakteryzacji punktów odstających. Są to punkty, którenajbardziej nie pasują do modelu, a dokładniej mają duże bezwzględne wartościstandaryzowanych reszt. Dopasowana za pomocą MNK prosta w rozważanymprzykładzie ma postać: y = 1.378x + 8.408 (patrz Rysunek 4). Współczynnikdeterminacji wynosi R2 = 0.753.

41
Definicja 5.2.Obserwację o numerze i, i = 1, . . . , n, nazywamy punktem odstają-cym (oddalonym), jeśli
|ei|SE(ei)
=|ei|
s√1− hi
> 2.
Reszty oraz reszty standaryzowane (zaokrąglone do dwóch znakow po przecin-ku) dla każdej obserwacji w Przykładzie 5.1 są podane w następnej tabelce:
Numer zaw. 1 2 3 4 5 6 7Reszta −1.16 −7.69 −0.54 −0.92 0.08 −0.30 3.33Reszta st. −0.36 −2.71 −0.16 −0.27 0.02 −0.08 0.95Numer zaw. 8 9 10Reszta −0.05 1.33 5.93Reszta st. −0.01 0.38 2.26
Z tabeli wynika, że te same obserwacje o numerach 2 i 10, które są punktamiwysokiej dźwigni, są też punktami odstającymi. Ale nie zawsze tak musi być.Punkt może być punktem wysokiej dżwigni, lecz nie być punktem odstającym, ina odwrót (patrz niżej).
Czy rozważone obserwacje nietypowe mają istotny wpływ na dopasowanymodel? Aby odpowiedzieć na to pytanie, omówimy pojęcie obserwacji wpływowej.Obserwacja jest wpływowa, jeśli model istotnie zmienia się w zależności od obecno-ści lub nieobecności tej obserwacji w zbiorze danych. Punkt odstający może, alenie musi być wpływowy. Podobnie punkt wysokiej dźwigni może, ale nie musi byćwpływowy. Zwykle obserwacje wpływowe łączą cechy dużej wartości reszty i dużejwartości dźwigni. Istnieje możliwość, że obserwacja nie będzie rozpoznana jakopunkt odstający ani jako punkt wysokiej dźwigni, ale będzie wpływowa, ponieważbędzie łączyć w sobie obie te cechy.
Definicja 5.3. Odległością Cooka dla obserwacji o numerze i, i = 1, . . . , n,nazywamy
Di =e2ihi
2s2(1− hi)2
(w przypadku regresji wielokrotnej, gdy mamy m > 1 zmiennych niezależnych,zamiast 2 w mianowniku używamy czynnikm+1). Obserwację nazywamy wpływo-wą, jeśli dla niej Di > 1.
Odległości Cooka (zaokrąglone do dwóch znakow po przecinku) dla każdejobserwacji w Przykładzie 5.1 są podane w następnej tabelce:
Numer zaw. 1 2 3 4 5 6 7 8 9 10Di 0.02 2.55 0.00 0.01 0.00 0.00 0.05 0.00 0.01 2.56
Zatem stwierdzamy, że obserwacje o numerach 2 i 10 są wpływowe, co nie dziwi,

42
czas
16141210
40
35
8
30
25
6
20
15
4
10
2
Rysunek 5: Proste regresji po usunięciu obserwacji 10 (ciągła) lub 2 (przerywana).
ponieważ te obserwacje są punktami odstającymi i jednocześnie punktami wyso-kiej dźwigni.Na Rysunku 5 podane zostały dwie proste regresji: w przypadku usunięcia
ze zbioru danych obserwacji o numerze 10 oraz w przypadku usunięcia ze zbiorudanych obserwacji o numerze 2. W obu przypadkach model istotnie się zmienia.Dopasowana za pomocą MNK prosta w sytuacji, gdy usunięta została obserwa-
cja o numerze 10, ma postać y = 0.813x + 10.949, natomiast dopasowana zapomocą MNK prosta w sytuacji, gdy usunięta została obserwacja o numerze2, ma postać y = 1.925x + 6.100. Współczynniki determinacji dla tych modeliwynoszą odpowiednio R2 = 0.621 i R2 = 0.979, czyli dopasowanie w przypadkupierwszym pogorszyło się, zaś w przypadku drugim bardzo się polepszyło i jestprawie idealnym.Analizując pod kątem nietypowości punktów dwa zbiory danych składające
się z 9 obserwacji każdy - pierwszy po usunięciu obserwacji o numerze 10, drugipo usunięciu obserwacji o numerze 2 - można stwierdzić, że: w pierwszym zbiorzeobserwacja 2 nadal jest jednocześnie punktem wysokiej dźwigni, punktem odstają-cym oraz punktem wpływowym; natomiast w przypadku zbioru drugiego punktemwysokiej dźwigni jest obserwacja o numerze 10, punktem odstającym zaś jestobserwacja o numerze 7, a punktów wpływowych niema. Na Rysunku 5 wyraźniewidać, że obserwacja o numerze 10 teraz już nie jest ani punktem odstającym, anipunktem wpływowym. Natomiast obserwacja o numerze 7 jest przykładem tego,że obserwacja może być punktem odstającym, ale nie być ani punktem wysokiejdźwigni, ani punktem wpływowym.

43
5.5. O liniowej regresji wielokrotnej
Opowiemy tutaj krótko o pewnych nowych problemach, z którymi należy sięliczyć, gdy stykamy się z liniową regresją wielokrotną. Tutaj mamy do czynieniaz m > 1 zmiennymi niezależnymi i zakładamy, że obserwacje spełniają równanie:
yi = θ0 +m∑
j=1
θjx(j)i + εi, i = 1, . . . , n,
czy też y = Fθ + ε, gdzie Eε = 0, Covε = σ2In, oraz wśród punktów {xi} sąprzynajmniej m + 1 różnych (n m + 1). Zatem założenia klasycznego modeluregresji liniowej są spełnione.W zasadzie wiele z tego, co było powiedziano wyżej w tym rozdziale, z pewnymi
modyfikacjami można powtórzyć i dla tego przypadku. A zatem podobnie rozwią-zujemy zagadnienia i kwestie estymacji parametrów, testowania hipotez, prognozy,analizy wartości resztowych, czy też klasyfikacji obserwacji nietypowych. Nowymiproblemami, które mogą wyniknąć w tym modelu, są problemy współliniowości idoboru zmiennych niezależnych do modelu.Problem współliniowości nierzadko występuje w przypadku dużej liczby zmien-
nych niezależnych. Jak mówi sama nazwa, współliniowość to istnienie związkówliniowych (lub bliskich do liniowych) pomiędzy dwoma lub więcej zmiennyminiezależnymi. Fakt ten negatywnie wpływa na wyliczenie estymatorów MNK,jak już było powiedziano na początku Rozdziału 4, ponieważ macierz F TF jestosobliwa (lub bliska do osobliwej), co oznacza niemożność oszacowania wszystkichparametrów modelu w sposób nieobciążony (lub kłopoty z wyliczeniem (F TF )−1 iniestabilność estymatorów). W celu wykrycia współliniowości można stosować naprzykład następujące podejście: wyliczamy wartość współczynnika determinacjiR2j dla modelu regresji wielokrotnej, w którym rolę zmiennej zależnej odgrywa j-tazmienna niezależna, zaś pozostałe zmienne niezależne pozostają wśród niezależ-nych, j = 1, . . . , m. Jeśli jakaś wartość R2j jest bliska 1, wskazuje to na współlinio-wość j-tej zmiennej niezależnej i pozostałych zmiennych niezależnych. Wykrywa-jąc współliniowość, można spróbować wyrzucić j-tą zmienną niezależną z modelui powtórzyć konstrukcję właściwego modelu.Temu problemowi można też zaradzić poprzez dobór właściwych zmiennych
niezależnych do modelu. Ponieważ przy dużej ilości zmiennych niezależnych zreguły mamy wśród nich jak zmienne istotnie wpływające na zmienną zależną,tak i te nieistotne, często na samym początku tworzenia modelu stawiamy zadaniewyboru „najlepszego” podzbioru zmiennych niezależnych, czyli takiego, który wmiarę dobrze wyjaśnia zmienność zmiennej zależnej, a pozostałe zmienne już niewnoszą istotnych zmian w polepszenie modelu.Dla szukania tego „najlepszego” podzbioru istnieje bardzo dużo różnych metod:
od nowoczesnych, korzystających na przykład z sieci neuronowych, do bardziejklasycznych metod sekwencyjnych (krokowych). Przedstawimy krótko istotę dwóch

44
metod sekwencyjnych: metody eliminacji i metody dołączania. Metoda eliminacjipolega na tym, że na pierwszym kroku tworzymy model ze wszystkimi zmiennyminiezależnymi. Następnie testujemy istotność każdego parametru w modelu (H0 :θj = 0 przeciwko H1 : θj 6= 0, j = 1, . . . , m) i usuwamy najmniej istotną zmienną(tzn. taką, dla której wartość bezwzględna odpowiedniej statystyki testowej jestnajmniejsza i zarazem nie przekracza pewnego ustawionego przez nas progu;taką zmienną uważamy za nieistotną). Procedurę powtarzamy z coraz mniejszympodzbiorem zmiennych niezależnych w modelu dopóty, dopóki w modelu niepozostaną tylko zmienne istotne. Metoda dołączania na odwrót startuje od modeluzawierającego tylko stałą (krok 1). Następne wybieramy wśród wszystkich zmien-nych niezależnych taką, która jest najbardziej istotna. Powtarzając procedurękrok po kroku zwiększamy podzbiór istotnych zmiennych niezależnych dopóty,dopóki wszystkie pozostałe poza modelem zmienne już będą nieistotne.Metody sekwencyjne, pomimo powszechnego ich stosowania, mają jednak
kilka wad. Wpierw zaznaczmy, że pechowy wybór zmiennej dokonany na pewnymetapie selekcji nie może być już później skorygowany. Tak może się zdarzyć,ponieważ różnego rodzaju powiązania pomiędzy zmiennymi niezależnymi mogąspowodować, że wprowadzono do modelu zmienną, która później, po wprowadza-niu kilku innych zmiennych, przestaje być istotną. Tej wady nie ma tzw. metodaselekcji krokowej, która łączy w sobie cechy obu wyżej opisanych metod. Zgodnie ztą metodą na każdym kroku po dołączeniu nowej zmiennej do modelu odbywa siętestowanie wszystkich zmiennych w modelu pod kątem ich istotności, i jeśli jakaśzmienna przestała być istotną, to będzie wyrzucona z modelu. Innym problememmetod selekcji jest wybór progu, tzn. wartości statystyki testowej, która odróżniazmienne istotne od nieistotnych. Nie możemy wybrać tę wartość zbyt dużą lubzbyt małą, ponieważ wówczas będziemy mieć albo zbyt mało zmiennych istotnych,albo zbyt dużo. No i wreszcie wadą metod sekwencyjnych jest to, że różne metodymogą doprowadzać do różnych modeli, wybrać z których odpowiedni nie jest łatwobez dodatkowej informacji o badanej zależności.Więcej o liniowej regresji wielokrotnej można poczytać w [1] lub w [2].

45
6. O regresji nieliniowej
W tym rozdziale skrótowo rozważymy zagadnienie regresji nieliniowej i przedstawi-my kilka metod szacowania parametrów modelu. Na początek jednak trochędokładniej przyjrzyjmy się dość specyficznemu modelu regresji logistycznej, któryw pewnych przypadkach może też być zaliczany do modeli linearyzowalnych.
6.1. Regresja logistyczna
Jest ona szczególnie przydatna wtedy, gdy zmienna zależna jest zmienną jakościo-wą. Tutaj ograniczymy się do rozważenia przypadku, gdy przyjmuje ona tylkodwie wartości: 1 i 0 (przykład: 1 – wydarzenie nastąpi, 0 – wydarzenie nie nastąpi).W takiej sytuacji stosowanie regresji liniowej jest nieprzydatne i może nawet byćpozbawione interpretacyjnego sensu.
Rozważmy następujący przykład, zaczerpnięty z [2, s. 164].
Przykład 6.1. Rozpatrzmy dane dotyczące badania zależności obecności (1) lubnieobecności (0) pewnej choroby (zmienna zależna) od wieku pacjenta (zmiennaniezależna):
Numer pac. 1 2 3 4 5 6 7 8 9 10 11 12 13Wiek 25 29 30 31 32 41 41 42 44 49 50 59 60Choroba 0 0 0 0 0 0 0 0 1 1 0 1 0
Numer pac. 14 15 16 17 18 19 20Wiek 62 68 72 79 80 81 84Choroba 0 1 0 1 0 1 1
Na Rysunku 6 przedstawiono wykres rozrzutu wraz z najlepszą prostą uzyskanąza pomocą MNK (y = 0.013x − 0.334, R2 = 0.265) oraz najlepszą krzywą dlamodelu logistycznego. Jak łatwo widać, krzywa znacznie lepiej obrazuje zależnośćobecności lub nieobecności choroby od wieku. Co więcej, stosowanie regresji linio-wej może doprowadzić do zupełnie bezsensownych wyników (dla pierwszego pacjen-ta mającego 25 lat uzyskujemy y1 < 0).
Skąd się wzięła taka krzywa? Przypomnijmy, że funkcja regresji przedstawiawartość E(Y | X = x), czyli warunkową wartość oczekiwaną zmiennej zależnej Ypod warunkiem, że zmienna niezależna X przyjmuje wartość x. Funkcja regresjilogistycznej zastosowana w Przykładzie 6.1 ma postać:
h(x, θ) =eθ0+θ1x
1 + eθ0+θ1x=
1
1 + e−θ0−θ1x, (6.1)
gdzie θ = (θ0, θ1)T jest wektorem nieznanych parametrów, które należy oszacować.
Jak łatwo zrozumieć, 0 < h(x, θ) < 1, a więc wartości funkcji regresji możnainterpretować jako prawdopodobieństwo. A dokładniej, jako prawdopodobieństwo

46
6040
0,2
20
1
0,8
100800
0,4
wiek
0,6
Rysunek 6: Linie regresji logistycznej (ciągła) oraz prostej (przerywana).
występowania choroby, gdy X = x (bowiem dla zero-jedynkowej zmiennej losowejY zachodzi E(Y | X = x) = P (Y = 1 | X = x)).Historia stosowania modelu logistycznego jest dość bogata i sięga końca XIX
wieku, a ogólna postać funkcji regresji logistycznej w rozważanej sytuacji to
h(x, θ) =eθ0+θ1f1(x)+...+θkfk(x)
1 + eθ0+θ1f1(x)+...+θkfk(x)=
1
1 + e−(θ0+θ1f1(x)+...+θkfk(x)).
(Czasami rozważają jeszcze bardziej ogólną postać funkcji regresji logistycznej:
h(x, θ) =θk+1
1 + θk+2e−(θ0+θ1f1(x)+...+θkfk(x)),
która juz jest przykładem funkcji regresji istotnie nieliniowej; ale tym przypadkiemnie będziemy się zajmowali.) Regresja logistyczna oparta jest na funkcji logistycz-nej postaci g(z) = (1 + ez)−1ez = (1 + e−z)−1, wykres której jest podobny dokrzywej przedstawionej na Rysunku 6. Ważną cechą tej funkcji, wyjaśniającą takąjej popularność, oprócz przyjmowania wartości w przedziale [0, 1], jest jej kształtw postaci rozciągniętej litery S : najpierw wartości tej funkcji znajdują się bliskozera i zmiany ich są minimalne; w pewny moment następuje gwałtowny wzrostwartości funkcji prawie do jedynki; później wartości funkcji są bliskie jedynkii zmiany ich znowu są minimalne. Te własności bardzo dobrze odpowiadająpowyższej interpretacji funkcji regresji logistycznej jako prawdopodobieństwa wa-runkowego w sytuacji, gdy zmienna zależna przyjmuje tylko wartości 0 lub 1.

47
Uwaga. Funkcja odwrotna do logistycznej, czyli g−1(z), jest postaci g−1(z) =ln(z/(1− z)), 0 < z < 1, i nazywana jest funkcją logitową.Przejdźmy teraz do zagadnienia estymacji nieznanych parametrów modelu.
Jeśli obserwacje (xi, yi), i = 1, . . . , n, które posiadamy, zapiszemy, jak zwykle torobiliśmy, w postaci równań
yi = h(xi, θ) + εi, i = 1, . . . , n; n k,
to zmienne losowe {εi} można scharakteryzować następująco: dla każdego i
P(εi = 1− h(xi, θ)
)= P (Y = 1 | X = xi) = h(xi, θ),
P(εi = −h(xi, θ)
)= P (Y = 0 | X = xi) = 1− h(xi, θ) =⇒
Eεi =(1− h(xi, θ)
)h(xi, θ)− h(xi, θ)
(1− h(xi, θ)
)= 0,
Var εi =(1− h(xi, θ)
)2h(xi, θ) + h
2(xi, θ)(1− h(xi, θ)
)= h(xi, θ)
(1− h(xi, θ)
).
Te proste rozumowania pokazują, że wariancje zmiennych losowych {εi} nie sąjednakowe, a ponadto są one zależne od wektora nieznanych parametrów θ orazod wartości zmiennych niezależnych. W takiej sytuacji częściej stosują nie MNK,lecz MNW. Funkcja wiarygodności ma postać:
L(y, θ) =n∏
i=1
P (Y = yi | X = xi) =n∏
i=1
[h(xi, θ)]yi [1− h(xi, θ)]1−yi =⇒
lnL(y, θ) =n∑
i=1
yi ln(h(xi, θ)) +n∑
i=1
(1− yi) ln(1− h(xi, θ)).
Estymatory NW parametrów {θj} można znaleźć, różniczkując ostatnią funkcjęwzględem każdego parametru i przyrównując otrzymane wyrażenia do zera, uzys-kując układ równań. Niestety, w przeciwieństwie do regresji liniowej, nie istniejąanalityczne wzory dla rozwiązań takiego układu równań. W celu poszukiwaniarozwiązań należy stosować różnorąkie metody numeryczne.Niech θ0, . . . , θk będą tymi rozwiązaniami, czyli będą estymatorami NW (pomi-
jamy kwestię jednoznaczności wyznaczania tych estymatorów). Wowczas, podob-nie jak w przypadku regresji liniowej, wartości
h(x, θ) =eθ0+θ1f1(x)+...+θkfk(x)
1 + eθ0+θ1f1(x)+...+θkfk(x)
można traktować jako prognozę średniej wartości zmiennej zależnej, gdy X = x,czyli w tej sytuacji jako estymator dla P (Y = 1 | X = x). Analogicznie, 1−h(x, θ)jest estymatorem dla P (Y = 0 | X = x).

48
Tak w Przykładzie 6.1 w sposob numeryczny (lub stosując pakiet programówstatystycznych) można uzyskać następujące wartości estymatorów NW: θ0 =−4.372, θ1 = 0.06696, natomiast prawdopodobieństwo tego, że pacjent w wiekux lat jest chory, szacujemy jako
h(x, θ) =eθ0+θ1x
1 + eθ0+θ1x=e−4.372+0.06696x
1 + e−4.372+0.06696x.
Na przykład dla pacjenta w wieku x = 50 lat ta wartość wynosi h(50, θ) ≈ 0.26,a w wieku x = 72 lat wynosi h(72, θ) ≈ 0.61.Jeśli chcemy przetestować hipotezę H0 : θ1 = 0 przeciwko hipotezie H1 :
θ1 6= 0, to w sytuacji, gdy liczba n jest wystarczająco duża, korzystamy z faktu,że estymatory NW przy dość szerokich założeniach są asymptotycznie normalnei asymptotycznie nieobciążone. Wówczas możemy użyć jako statystykę testową(patrz s. 36) t′ = θ1/SE(θ1), która przy założeniu prawdziwości hipotezy H0 maw przybliżeniu rozkład normalny standardowy N (0, 1).Zakończymy ten podrozdział rozumowaniami dotyczącymi interpretacji warto-
ści estymatorów współczynników regresji logistycznej dla najprostszego przypad-ku, gdy funkcja regresji h(x, θ) ma postać (6.1).Przypominając definicję funkcji logitowej g−1, mamy
g−1(h(x, θ)) = lnh(x, θ)
1− h(x, θ) = θ0 + θ1x. (6.2)
Zatem współczynnik kierunkowy θ1 jest równy przyrostowi funkcji (6.2), gdy war-tość zmiennej niezależnej wzrasta o 1, czyli
θ1 = g−1(h(x+ 1, θ))− g−1(h(x, θ)).
Wprowadźmy pojęcie szansy. Szansę definiujemy jako iloraz prawdopodobień-stwa, że wydarzenie nastąpi (Y = 1), przez prawdopodobieństwo, że wydarzenienie nastąpi (Y = 0). Szansa określa, w jakim stopniu jest bardziej prawdopodobne,że wydarzenie nastąpi, w porównaniu z tym, że ono nie nastąpi. Tak w warunkachPrzykładu 6.1, szansę zachorowania dla pacjenta w wieku 50 lat szacujemy na0.26/(1− 0.26) ≈ 0.35, natomiast szansę zachorowania dla pacjenta w wieku 72lat szacujemy na 0.61/(1 − 0.61) ≈ 1.56. Oczywiście, jeśli wartość szansy jestwiększa od 1, to jest bardziej prawdopodobne, że wydarzenie nastąpi, a jeśli jestmniejsza niż 1, to jest bardziej prawdopodobne, że wydarzenie nie nastąpi.W sytuacji, gdy zmienna niezależna też przyjmuje tylko dwie wartości: 0, 1,
szacowanie szansy, że wydarzenie nastąpi dla obserwacji z wartością x = 1, moznaobliczyć jako
h(1, θ)
1− h(1, θ)= eθ0+θ1 ,

49
a oszacowana szansa, że wydarzenie nastąpi dla obserwacji z wartością x = 0,wynosi
h(0, θ)
1− h(0, θ)= eθ0 .
Iloraz oszacowań tych szans, czyli
h(1, θ)(1− h(0, θ))h(0, θ)(1− h(1, θ))
=eθ0+θ1
eθ0= eθ1
jest całkowicie określony przez estymator współczynnika kierunkowego i jest po-wszechnie używany jako ważna charakterystyka w badaniach związanych ze stoso-waniem regresji logistycznej.
6.2. O metodach szacowania parametrów regresji nieliniowej
Załóżmy, że mamy obserwacje postaci
yi = h(xi, θ) + εi, i = 1, . . . , n; n k, (6.3)
gdzie nadal θ = (θ1, . . . , θk)T jest wektorem nieznanych parametrów, h jest pewną
wybraną (zadaną) funkcją nieliniową względem parametrów, {xi} są wektoramipomiarów, {εi} są niezależnymi zmiennymi losowymi o właśnościach Eεi = 0,Var εi = σ
2, i = 1, . . . , n.Określmy funkcję
Q(θ) =n∑
i=1
(yi − h(xi, θ)
)2
i zajmijmy się poszukiwaniem θ ∈ Arg minθQ(θ) (MNK). Biorąc pochodnę cząst-
kowe i przyrównując je do zera, otrzymamy układ równań normalnych postaci:
∂Q(θ)
∂θj= −2
n∑
i=1
(yi − h(xi, θ)
)∂h(xi, θ)
∂θj= 0, j = 1, . . . , k. (6.4)
Dla rozwiązania tego układu równań stosują różnego rodzaju metody numeryczne.Jednak wygodniej jest stosować metody numeryczne dla poszukiwania minimumfunkcji Q wprost, czyli bez korzystania z układu równań (6.4).Rozważmy bardziej dokładnie metodę linearyzacji (Gaussa-Newtona) poszuki-
wania minimum funkcji Q. Niech θ(0) = (θ01, . . . , θ0k)T będzie początkowym
estymatorem wektora parametrów θ.W otoczeniu punktu θ(0) rozwijamy funkcjęh w szereg Taylora zaniechając resztą:
h(xi, θ) ≈ h(xi, θ(0)) +k∑
j=1
∂h(xi, θ(0))
∂θj(θj − θ0j).

50
Oznaczmy:
h(xi, θ(0)) = h0i , βj = θj − θ0j , F 0ij =
∂h(xi, θ(0))
∂θj, i = 1, . . . , n; j = 1, . . . , k.
Wówczas równania (6.3) można zapisać w postaci:
yi − h0i =k∑
j=1
βjF0ij + εi, i = 1, . . . , n.
Przy spełnieniu założeń klasycznego modelu regresji liniowej, estymację wektoraparametrów β = (β1, . . . , βk)
T można dokonać za pomocą MNK. Z TwierdzeniaGaussa-Markowa uzyskujemy:
β = (F T0 F0)−1F T0 (y − h0),
gdzie
F0 =
F 011 . . . F0ik
.........
F 0n1 . . . F0nk
, h
0 = (h01, . . . , h0n)T .
Estymator ten minimalizuje względem β funkcję:
n∑
i=1
(yi − h(xi, θ(0))−
k∑
j=1
βjF0ij
)2.
Ponieważ β = θ − θ(0), przyjmijmy
θ(1) = θ(0) + β = θ(0) + (FT0 F0)
−1F T0 (y − h0).
Jest to następna iteracja dla estymatora wektora parametrów θ. Teraz postępuje-my podobnie jak wyżej, zastępując θ(0) przez θ(1), i uzyskujemy θ(2) itd. Na (s+1)-ym kroku otrzymujemy:
θ(s+1) = θ(s) + (FTs Fs)
−1F Ts (y − hs).
Ten proces iteracyjny kontynuujemy, dopóki nie będzie spełniony warunek:
∣∣∣∣∣θ(s+1)j − θsjθsj
∣∣∣∣∣ < δ, j = 1, . . . , k, (6.5)
gdzie δ > 0 jest wybraną dostatecznie małą liczbą. Proces iteracyjny poszukiwaniaprzybliżenia dla punktu minimum funkcji Q, na ogół, ma następujące wady:iteracje {θ(s)} mogą dość wolno zbiegać się do punktu minimum funkcji Q; mogą

51
też zbiegać się do minimum lokalnego, a nie globalnego; w niektórych „złośliwych”przypadkach mogą nawet nie zbiegać się wcale.Oprócz metody Gaussa-Newtona w poszukiwaniu punktu minimum funkcji
Q stosują też metodę najszybszego spadku. Polega ona na tym, że startując zpoczątkowego punktu θ(0), obliczamy gradient funkcji Q w tym punkcie. Jakwiadomo z Teorii optymalizacji, wektor
−∇Q(θ(0)) = −(∂Q(θ(0))
∂θ1, . . . ,
∂Q(θ(0))
∂θk
)T
określa kierunek najszybszego spadku funkcjiQ.Uwzględniając (6.4) oraz wprowa-dzone wyżej oznaczenia, przyjmujemy jako następny punkt iteracyjny
θ(1) = θ(0) −1
2λ0∇Q(θ(0)) = θ(0) + λ0F T0 (y − h0),
gdzie liczba λ0 wyznacza się jako
λ0 ∈ Argminλ>0Q(θ(0) + λF
T0 (y − h0))
(czyli idziemy z punktu θ(0) jaknajdalej w kierunku najszybszego spadku). Takrobimy na każdym kroku iteracyjnym, uzyskując kolejne iteracje:
θ(s+1) = θ(s) + λsFTs (y − hs),
gdzieλs ∈ Argmin
λ>0Q(θ(s) + λF
Ts (y − hs)).
Warunek stopu zazwyczaj znowu ma postać (6.5). Wady tego podejścia są zbliżonedo omówionych wyżej.Wreszcie, metoda Levenberga-Marquardta polega na tym, że na (s + 1)-ym
kroku punkt iteracyjny ma postać:
θ(s+1) = θ(s) + (FTs Fs + λsdiag(F
Ts Fs))
−1F Ts (y − hs),gdzie diag(F Ts Fs) jest macierzą diagonalną z diagonalnymi elementami macierzyF Ts Fs na przekątnej, natomiast λs jest pewnym parametrem równym λs−1/c, jeśliQ(θ(s)) < Q(θ(s−1)), oraz równym cλs−1, jeśli Q(θ(s)) > Q(θ(s−1)). Tutaj parametrc > 1 (nazywany współczynnikiem skalowania) oraz parametr λ0 > 0 wybieranisą na wstępie procedury (zauważmy, że przy λ0 = 0 mamy metodę Gaussa-Newtona). Warunek stopu nadal może mieć postać (6.5). Ta ostatnia metodajest bardziej skomplikowana od poprzednich, lecz na ogół efektywniejsza i nie maewentualnych klopotów z odwracaniem macierzy F Ts Fs.Jeśli iteracja θ(s+1) została przyjęta jako estymator wektora parametrów θ, to
estymatorem parametru σ2 w przypadku n > k będzie
σ2 =Q(θ(s+1))
n− k .

52
7. Analiza wariancji
Analiza regresji, jak wiemy, ma na celu ustalenie przybliżonej zależności wiążącejwartości zmiennej zależnej z wartościami zmiennych niezależnych poprzez wykona-nie pewnej liczby doświadczeń. Nierzadko zdarzają się jednak sytuacje, gdy warto-ści zmiennej zależnej możemy poznać dla niewielkiej tylko liczby różnych wartościjednej lub wielu zmiennych niezależnych. Takie właśnie sytuacje są typowe dlaanalizy wariancji. W tej dziedzinie zmienna zależna nazywana jest zmienną odpo-wiedzi, a zmienne niezależne – czynnikami. Na dodatek do założenia, że czynnikiprzyjmują tylko niewiele różnych wartości (mówimy: występują na niewielu pozio-mach), warto powiedzieć, iż dokładna postać zależności między zmienną odpowie-dzi a czynnikami nas nie interesuje. Wystarczy nam odpowiedź na pytanie: czyzmiana poziomu danego czynnika (lub poziomów wybranych czynników) ma wpływna średnią wartość zmiennej odpowiedzi?
Nic zatem dziwnego, że obok analizy regresji istnieje metoda szczególnie dobrzedostosowana do badania podobnych problemów. Metoda ta, blisko zresztą związa-na z analizą regresji, jest znana jako analiza wariancji (sens tej nazwy zrozumiemyw następnym podrozdziale). Jest to metoda tym popularniejsza i tym ważniejsza,że doskonale nadaje się do stosowania w przypadku występowania czynników,które są zmiennymi jakościowymi.
W pierwszym podrozdziale rozważymy analizę jednoczynnikową, gdy mamytylko jeden czynnik; w drugim zaś analizę dwuczynnikową, gdy czynników jestdwa. Zagadnienia te są różne, bowiem w drugim przypadku poza niezależnymi odsiebie wpływami każdego z czynników oddzielnie na zmienną odpowiedzi, możewystępować ich interakcja, czyli łączne oddzialywanie na zmienną odpowiedzi.Znając rozwiązanie zagadnienia analizy dwuczynnikowej, łatwo już sobie uzmysło-wić, jak powinno wyglądać jego uogólnienie na przypadek wielu czynników, które-go omówienie pomijamy.
W ostatnim dodatkowym podrozdziale podajemy krótki zarys zagadnieniazwiązanego z planowaniem doświadczeń czynnikowych. Modele, które tutaj rozwa-żamy, są bliższe tym z analizy regresji, natomiast pojęcia stosowane są podobnedo tych z analizy wariancji. Głównym celem w tej dziedzinie jest znalezienietakich kombinacji wartości zmiennych niezależnych (poziomów czynników), dlaktórych oszacowanie parametrów modelu będzie jak najlepsze i odbywa się jaknajmniejszym kosztem.
7.1. Analiza jednoczynnikowa
Załóżmy, że mamy jeden czynnik X, który może mieć wpływ na interesującąnas zmienną odpowiedzi Y. Niech ów czynnik może występować na k poziomach,k 2. Podstawowe zadanie jednoczynnikowej analizy wariancji polega na teściehipotezy o równości wartości średnich zmiennej odpowiedzi dla wszystkich k

53
poziomów czynnika: H0 : θ1 = . . . = θk, gdzie {θj} to są średnie wartościzmiennej odpowiedzi dla poszczególnych poziomów czynnika, przy alternatywieH1, że przynajmniej dwie wartości spośród {θj} są różne. Nieodrzucenie hipotezyH0 będzie oznaczać, że zmiana poziomów czynnika nie wpływa na średnią wartośćzmiennej odpowiedzi.
W analizie wariancji zakładamy, że dla każdego poziomu czynnika możemywykonać, na ogół, więcej niż jedno doświadczenie. Dokładniej mówiąc, niech dlaj-go poziomu czynnika wykonujemy nj niezależnych doświadczeń, j = 1, . . . , k;∑kj=1 nj = n > k. Zatem możemy mówić o wariancji wartości zmiennej odpowiedzidla tego poziomu czynnika; wariancję dla j-go poziomu będziemy oznaczać przezσ2j , j = 1, . . . , k. Wszystkie dalsze rozważania będziemy prowadzić przyjmując,że jest spełnione podstawowe założenie analizy wariancji: dla każdego poziomuczynnika rozkład wartości zmiennej odpowiedzi jest normalny z taką samą warian-cją σ2, czyli σ21 = . . . = σ
2k = σ
2.
Nasz problem można też sformułować następująco. Mając n1 obserwacji zpopulacji o rozkładzieN (θ1, σ2), n2 obserwacji z populacji o rozkładzieN (θ2, σ2),. . . , nk obserwacji z populacji o rozkładzieN (θk, σ2), chcemy przetestować hipote-zę H0 : θ1 = . . . = θk wobec alternatywy H1.
W Przykładzie 2.6 z Podrozdziału 2.2 już pokazaliśmy, jak ogólną teorięregresji można zastosować do porównywania średnich dwóch normalnych populacji.Teraz uogólnimy to zagadnienie na k normalnych populacji.
Obserwacje wartości zmiennej odpowiedzi możemy zapisać następująco:
yji = θj + εji, i = 1, . . . , nj ; j = 1, . . . , k, (7.1)
gdzie yji oznacza i-tą obserwację na j-tym poziomie czynnika, {εji} są niezależnymizmiennymi losowymi o jednakowym rozkładzie normalnymN (0, σ2). Innymi słowy,(yj1, . . . , yjnj) to niezależne próby z populacji o rozkładzieN (θj, σ2), j = 1, . . . , k.Wprowadźmy oznaczenia: y = (y11, . . . , y1n1, . . . , yk1, . . . , yknk)
T , θ = (θ1, . . . , θk)T ,
ε = (ε11, . . . , ε1n1, . . . , εk1, . . . , εknk)T ,
F =
1 0 0 . . . . . . 0.........
......
1 0 0 . . . . . . 00 1 0 . . . . . . 0.........
......
0 1 0 . . . . . . 0.........
......
0 0 0 . . . . . . 1.........
......
0 0 0 . . . . . . 1

54
– macierz wymiaru n × k, której rząd wynosi k. Tym samym mamy klasycznymodel regresji liniowej (y, Fθ, σ2In). Estymator MNK wektora parametrów θ,zgodnie z Twierdzeniem Gaussa-Markowa, ma postać: θ = (F TF )−1F Ty, skądotrzymujemy, że θj =
1nj
∑nji=1 yji = yj – średnia z wartości obserwacji dla j-go
poziomu czynnika, j = 1, . . . , k.Zauważmy, że hipotezę H0 : θ1 = . . . = θk można zapisać jako H0 : Aθ = 0 z
macierzą A wymiaru (k − 1)× k postaci:
A =
1 0 . . . . . . 0 −10 1 . . . . . . 0 −1......
.........
0 0 . . . . . . 1 −1
.
Korzystając z wyników Podrozdziału 2.2 stwierdzamy, że statystyką testowądla testowania hipotezy H0 służy (patrz wzór (2.7)):
f ′ =n− kk − 1 ·
RSSH0 − RSSRSS
. (7.2)
W przypadku prawdziwości hipotezy H0 ma ona rozkład F (k − 1, n− k).Resztową sumę kwadratów RSSH0 przy prawdziwości hipotezy H0 otrzymuje-
my z wyników Przykładu 2.1 (Podrozdział 2.1):
RSSH0 =k∑
j=1
nj∑
i=1
(yji − y)2, gdzie y =1
n
k∑
j=1
nj∑
i=1
yji =1
n
k∑
j=1
nj yj ,
natomiast RSS ma postać:
RSS =k∑
j=1
nj∑
i=1
(yji − yj)2.
Zauważmy, że
RSSH0 − RSS =k∑
j=1
nj∑
i=1
[(yji − y)2 − (yji − yj)2
]=k∑
j=1
nj∑
i=1
(yj − y)(2yji − yj − y)
=k∑
j=1
(yj − y)(2nj yj − nj yj − nj y) =k∑
j=1
nj(yj − y)2.
Wartość RSSH0 można interpretować jako całkowity rozrzut wartości obserwacjiwokół wspólnej sredniej, natomiast RSS jako sumaryczny rozrzut wartości obserwa-cji wewnątrz każdej populacji. Zatem widzimy, że całkowitą wariancję RSSH0 wmodelu można zapisać w postaci sumy dwóch składników: RSS – suma wariancji

55
wewnątrz każdej populacji oraz (RSSH0−RSS) – suma wariancji między popula-cjami. Nazwa analiza wariancji bierze się z tego, że wnioskowanie statystyczneoparte jest na przedstawieniu całkowitej wariancji wartości zmiennej odpowie-dzi w postaci sumy skladników oraz używaniu ilorazu wariancji dla testowaniapodstawowej hipotezy (wzór (7.2)). Nietrudno zauważyć, że przedstawienie całko-witej zmienności wartości zmiennej odpowiedzi w postaci sumy dwóch składnikówjest bardzo podobne do wzoru (2.8) na całkowitą zmienność wartości zmiennejzależnej w analizie regresji.Co prawda w analizie wariancji używamy nieco innego zapisu modelu niż
(7.1). Oznaczmy przez α0 = n−1∑k
j=1 njθj wspólną średnią wszystkich obserwacji.Wartość αj = θj − α0 nazywamy efektem (lub efektem głównym) j-go poziomuczynnika, j = 1, . . . , k. Zauważmy, że
k∑
j=1
njαj = 0. (7.3)
Uwaga. Z Wniosku 2.1 po Twierdzeniu Gaussa-Markowa wynika, że NLNEparametru α0 wynosi
α0 =1
n
k∑
j=1
nj θj =1
n
k∑
j=1
nj yj = y.
Analogicznie, αj = θj − α0 = yj − y, j = 1, . . . , k.Równania (7.1) możemy zapisać w postaci
yji = α0 + αj + εji, i = 1, . . . , nj; j = 1, . . . , k. (7.4)
W tym przypadku mamy model regresji liniowej (y, Fθ, σ2In), gdzie
θ = (α0, α1, . . . , αk)T , F =
1 1 0 0 . . . . . . 0............
......
1 1 0 0 . . . . . . 01 0 1 0 . . . . . . 0............
......
1 0 1 0 . . . . . . 0............
......
1 0 0 0 . . . . . . 1............
......
1 0 0 0 . . . . . . 1
– macierz wymiaru n× (k + 1), której rząd wynosi k. Więc, formalnie mamy doczynienia z sytuacją opisaną w Podrozdziale 3.2, ale w rzeczywistości nieznanychparametrów jest o jeden mniej z powodu warunku (7.3).

56
Zauważmy, że hipoteza H0 : θ1 = . . . = θk dla modelu (7.1) jest równoważnahipotezie H0 : α1 = . . . = αk = 0 dla modelu (7.4), ponieważ jeśli θ1 = . . . =θk = c, to α0 = c oraz α1 = . . . = αk = 0. Całkowitą wariancję RSSH0 w modeluoraz jej składowe tutaj można zapisać w postaci (zadanie domowe):
RSSH0 =k∑
j=1
nj∑
i=1
(yji − α0)2, RSS =k∑
j=1
nj∑
i=1
(yji − α0 − αj)2,
RSSH0 −RSS =k∑
j=1
njα2j .
Wzory trochę uproszczą się, jeśli nj = n = const. W tej sytuacji na przykładstatystyka testowa ma postać
f ′ =k(n− 1)k − 1 ·
RSSH0 − RSSRSS
,
a jej rozkład, w przypadku prawdziwości hipotezy H0, to F (k − 1, k(n− 1)).Jeśli zrezygnować z warunku (7.3), to już nie możemy wszystkie parametry
oszacować w sposób jednoznaczny i nieobciążony (patrz Podrozdział 3.2). Przypo-mnijmy, że w przypadku modeli rozważonych w Podrozdziale 3.2 ważnym byłopojęcie estymowalności funkcji liniowej od parametrów. Dla wektora t ∈ R
k+1
funkcja postaci tT θ jest estymowalna wtedy i tylko wtedy, gdy t = F T b dlapewnego wektora b = (b11, . . . , b1n1 , . . . , bk1, . . . , bknk)
T . W obecnej sytuacji ozna-cza to, że estymowalne są tylko funkcje liniowe postaci
tT θ = bTFθ =k∑
j=1
nj∑
i=1
bjiEyji =k∑
j=1
nj∑
i=1
bji(α0 + αj) =k∑
j=1
cj(α0 + αj)
= c1α1 + . . .+ ckαk + α0k∑
j=1
cj,
gdzie cj =∑nji=1 bji. Stąd wynika, że na przykład parametr
∑kj=1 cjαj jest estymo-
walny wtedy i tylko wtedy, gdy {cj} spełniają warunek∑kj=1 cj = 0, a parametr
αi − αj dla wszystkich i 6= j jest estymowalny.Jak już mówiliśmy, odrzucenie hipotezy H0 oznacza, że zmiana poziomów
czynnika wpływa na średnią wartość zmiennej odpowiedzi. Ale średnie te mogąróżnić się między sobą na wiele sposobów. Po stwierdzeniu, że przynajmniej dwieśrednie różnią się między sobą, naturalnym wydaje się znalezienie odpowiedzina pytanie: które średnie różnią się między sobą, a które nie? Prowadzi to dorozważenia całej serii testów (tylu, ile jest różnych par średnich), które są nazywa-ne porównaniami wielokrotnymi. Nie będziemy rozważać dokładnie tego zagadnie-nia, tylko zasygnalizujemy pewne uwagi do poprawnego stosowania takiej procedu-ry.

57
W przypadku porównywania dwóch średnich, oczywiście, możemy zastosowaćpodejście z Przykładu 2.6 (Podrozdział 2.2). Ale my chcemy porównaniem objąćwięcej niż jedną parę średnich. Ten aspekt wymaga szczególnej uwagi, bowiemjednoczesne wykonanie całej serii testów wymusza zastanowienie się nad proble-mem wyboru poziomu istotności α tych testów. Należy rozróżnić pojęcia poziomuistotności pojedynczego testu i poziomu istotności całej procedury. Poziom istotno-ści pojedynczego testu, jak pamiętamy, mówi o prawdopodobieństwie błędnegoodrzucenia hipotezy o równości tej konkretnej pary średnich, której test dotyczy.Natomiast poziom istotności całej procedury określa prawdopodobieństwo błędne-go odrzucenia którejkolwiek z hipotez z tej serii. Chcąc by poziom istotności całejprocedury, składającej się z testowania, powiedźmyK testów, wynosił co najwyżejα (tzw. podejście Bonferroniego), poziom istotności każdego indywidualnego testupowinien wynosić α/K.
7.2. Analiza dwuczynnikowa
Teraz będziemy badać możliwy wpływ dwóch czynników na wartość zmiennejodpowiedzi. Niech mamy dwa czynniki: pierwszy ma k poziomów, drugi zaśm poziomów. Niech θij będzie oznaczać średnią wartość zmiennej odpowiedzidla i-go poziomu pierwszego czynnika i j-go poziomu drugiego czynnika, i =1, . . . , k; j = 1, . . . , m. Dla każdego poziomu i pierwszego czynnika i każdegopoziomu j drugiego czynnika niech mamy nij obserwacji (yij1, . . . , yijnij) z populacjio rozkładzie N (θij, σ2). Zatem możemy zapisać:
yijl = θij + ξijl, l = 1, . . . , nij ; i = 1, . . . , k; j = 1, . . . , m, (7.5)
gdzie {ξijl} są niezależnymi zmiennymi losowymi o jednakowym rozkładzieN (0, σ2).Tak jak w analizie jednoczynnikowej, raczej używamy innego zapisu tegoż
modelu. Oznaczmy: θ(1)i =
∑mj=1 nijθij/
∑ms=1 nis – średnia wartość obserwacji dla
i-go poziomu pierwszego czynnika, i = 1, . . . , k; θ(2)j =
∑ki=1 nijθij/
∑kl=1 nlj –
średnia wartość obserwacji dla j-go poziomu drugiego czynnika, j = 1, . . . , m; orazwspólna średnia obserwacji α0 =
∑ki=1
∑mj=1 nijθij/
∑kl=1
∑ms=1 nls. Zdefiniujmy
efekt i-go poziomu pierwszego czynnika jako αi = θ(1)i − α0, i = 1, . . . , k; efekt
j-go poziomu drugiego czynnika jako βj = θ(2)j −α0, j = 1, . . . , m. Jak nietrudno
sprawdzić (zadanie domowe), zachodzą równości:
k∑
i=1
m∑
j=1
nijαi = 0,k∑
i=1
m∑
j=1
nijβj = 0. (7.6)
Parametr
γij = θij − θ(1)i − θ(2)j + α0 = θij − αi − βj − α0 (7.7)

58
nazywamy interakcjej lub współdziałaniem i-go poziomu pierwszego czynnika i j-go poziomu drugiego czynnika, i = 1, . . . , k; j = 1, . . . , m. Z (7.6) i (7.7) wynika,że
k∑
i=1
m∑
j=1
nijγij = 0. (7.8)
Na mocy (7.7) mamy θij = α0 + αi + βj + γij. Zatem zamiast (7.5) zapisujemymodel w postaci:
yijl = α0 + αi + βj + γij + ξijl, l = 1, . . . , nij ; i = 1, . . . , k; j = 1, . . . , m,
gdzie {ξijl} są niezależnymi zmiennymi losowymi o jednakowym rozkładzieN (0, σ2).Dalej w celu uproszczenia zapisu i rozumowań bedziemy rozważać przypadek,
gdy nij = n = const. W tej sytuacji równości (7.6) i (7.8) mają postać:
k∑
i=1
αi = 0,m∑
j=1
βj = 0,k∑
i=1
m∑
j=1
γij = 0.
Oprócz tego,
k∑
i=1
γij = 0 ∀1 ¬ j ¬ m;m∑
j=1
γij = 0 ∀1 ¬ i ¬ k.
Analogicznie jak w analizie jednoczynnikowej, zakładając, że n > 1, z Twier-dzenia Gaussa-Markowa i Wniosku 2.1 uzyskujemy estymatory MNK poszczegól-nych parametrów:
θij =1
n
n∑
l=1
yijl = yij ∀1 ¬ i ¬ k ∀1 ¬ j ¬ m,
α0 =1
km
k∑
i=1
k∑
=1
θij =1
kmn
k∑
i=1
m∑
j=1
n∑
l=1
yijl = y,
αi =1
m
m∑
j=1
θij −1
km
k∑
i=1
m∑
j=1
θij =1
mn
m∑
j=1
n∑
l=1
yijl −1
kmn
k∑
i=1
m∑
j=1
n∑
l=1
yijl = y(1)i − y,
βj =1
k
k∑
i=1
θij −1
km
k∑
i=1
m∑
j=1
θij =1
kn
k∑
i=1
n∑
l=1
yijl −1
kmn
k∑
i=1
m∑
j=1
n∑
l=1
yijl = y(2)j − y,
γij = θij −1
m
m∑
j=1
θij −1
k
k∑
i=1
θij −1
km
k∑
i=1
m∑
j=1
θij
=1
n
n∑
l=1
yijl −1
mn
m∑
j=1
n∑
l=1
yijl −1
kn
k∑
i=1
n∑
l=1
yijl +1
kmn
k∑
i=1
m∑
j=1
n∑
l=1
yijl

59
= yij − y(1)i − y(2)j + y.Załóżmy, że chcemy przetestować hipotezę H0 : α1 = . . . = αk = 0 przeciwko
hipotezie H1 polegającej na tym, że przynajmniej jeden z efektów pierwszegoczynnika jest odmienny od zera. Analogicznie jak w przypadku analizy jednoczyn-nikowej, można ustalić, że
RSS =k∑
i=1
m∑
j=1
n∑
l=1
(yijl − α0 − αi − βj − γij
)2=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − yij)2
jest sumarycznym rozrzutem wariancji wewnątrz każdej populacji,
RSSH0=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − α0 − βj − γij
)2=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − yij)2+mnk∑
i=1
(y(1)i − y
)2
jest sumarycznym rozrzutem wariancji między populacjami spowodowanym pierw-szym czynnikiem,
RSSH0 − RSS = mnk∑
i=1
α2i = mnk∑
i=1
(y(1)i − y
)2.
Teraz statystyka testowa dla testowania hipotezyH0 ma postać (patrz wzór (7.2)):
f ′ =km(n− 1)k − 1 · RSSH0 − RSS
RSS.
Przy prawdziwości hipotezy H0 ma ona rozkład F (k − 1, km(n− 1)).Analogicznie można wypisać wzory na statystykę testową dla testowania hipote-
zy H ′0 : β1 = . . . = βm = 0 lub hipotezy H′′
0 : γij = 0, i = 1, . . . , k, j =1, . . . , m. Tak testujemy hipotezę H ′0 przeciwko hipotezie H
′
1 polegającej na tym,że przynajmniej jeden z efektów drugiego czynnika jest odmienny od zera, zapomocą statystyki testowej
f ′ =km(n− 1)m− 1 · RSSH
′
0− RSSRSS
,
która przy prawdziwości H ′0 ma rozkład F (m− 1, km(n− 1)). Tutaj
RSSH′0=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − α0 − αi − γij)2=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − yij)2+knm∑
j=1
(y(2)j − y
)2
jest sumarycznym rozrzutem wariancji między populacjami spowodowanym dru-gim czynnikiem,
RSSH′0 −RSS = knm∑
j=1
β2j = knm∑
j=1
(y(2)j − y
)2.

60
Wreszcie testujemy hipotezę H ′′0 przeciwko hipotezie H′′
1 polegającej na tym, żeprzynajmniej jedno ze współdziałań pierwszego i drugiego czynnika jest odmienneod zera, za pomocą statystyki testowej
f ′ =km(n− 1)(k − 1)(m− 1) ·
RSSH′′0−RSS
RSS,
która przy prawdziwości H ′′0 ma rozkład F ((k−1)(m−1), km(n−1)), przy czym
RSSH′′0=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − α0 − αi − βj
)2
=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − yij)2 + nk∑
i=1
m∑
j=1
(yij − y(1)i − y(2)j + y
)2
jest sumarycznym rozrzutem wariancji między populacjami spowodowanym intera-kcjami,
RSSH′′0 − RSS = nk∑
i=1
m∑
j=1
γ2ij = nk∑
i=1
m∑
j=1
(yij − y(1)i − y(2)j + y
)2.
Całkowity rozrzut wartości obserwacji wokół wspólnej sredniej można zapisać wpostaci sumy czterech składników:
k∑
i=1
m∑
j=1
n∑
l=1
(yijl− y)2 = RSS+(RSSH0−RSS)+(RSSH′0−RSS)+(RSSH′′0 −RSS)
=k∑
i=1
m∑
j=1
n∑
l=1
(yijl − yij)2 +mnk∑
i=1
(y(1)i − y
)2+ kn
m∑
j=1
(y(2)j − y
)2
+nk∑
i=1
m∑
j=1
(yij − y(1)i − y(2)j + y
)2.
7.3.∗ O planowaniu doświadczeń czynnikowych
Ten podrozdział jest poświęcony prostym praktycznym zagadnieniom często wyni-kającym w ramach modeli rozważanych w analizie regresji i analizie wariancji.Rozważmy następujący problem. Niech mamy do czynienia z k czynnikami
X1, X2, . . . , Xk, przy czym czynnik Xj może występować na sj 2 poziomach,j = 1, . . . , k (wartości poziomów czynników będziemy dalej oznaczać odpowiedni-mi małymi literami). Załóżmy, że poziomy czynników, dla których przeprowadza-my doświadczenia, możemy wybierać przed doświadczeniami. Naszym podstawo-wym celem, jak pamiętamy, jest badanie wpływu czynników na zmienną odpowie-dzi. Dlatego chcielibyśmy zaplanować doświadczenia w taki sposób, by uzyskaćjak najlepsze wyniki jak najmniejszym kosztem.

61
Zakładamy, że wpływ czynników na zmienną odpowiedzi da się opisać zapomocą jednej z następujących funkcji regresji:
h(x, θ) = θ0 +k∑
j=1
θjxj − regresja liniowa,
h(x, θ) = θ0 +k∑
j=1
θjxj +∑
i<j
θijxixj − regresja niepełna kwadratowa,
h(x, θ)=θ0+k∑
j=1
θjxj+∑
i<j
θijxixj+∑
i<j<m
θijmxixjxm−regresja niepełna sześćścienna.
Tutaj parametr θ0 nazywamy wspólną średnią, parametry {θj} – efektami (główny-mi) czynników, parametry {θij}, i < j, – efektami współdziałań (interakcji) czynni-ków (podwójnymi), parametry {θijm}, i < j < m, – efektami współdziałań (intera-kcji) czynników (potrójnymi) itd (porównaj z oznaczeniami poprzedniego podroz-działu).Planem czynnikowym nazywamy kombinacje poziomów czynników, dla których
należy przeprowadzić doświadczenia. Plan czynnikowy nazywamy pełnym, jeślizgodnie z tym planem przeprowadzamy doświadczenia dla wszystkich możliwychkombinacji poziomów czynników. Odpowiednie doświadczenia nazywamy też peł-nymi. Pełny plan czynnikowy wymaga przeprowadzenia s1s2...sk doświadczeń(mówimy, że plan ten jest typu s1s2...sk). Jeśli s1 = . . . = sk = s, to pełnyplan czynnikowy oznaczamy jako sk. Plan czynnikowy nazywamy ułamkowym,jeśli zgodnie z nim należy przeprowadzić mniej niż s1s2...sk doświadczeń (tzn.przeprowadzamy doświadczenia nie dla wszystkich możliwych kombinacji pozio-mów czynników). Plany ułamkowe mają większe praktyczne zastosowanie, ponie-waż wymagają przeprowadzenia mniejszej liczby doświadczeń.
Przykład 7.1. Niech h(x, θ) = θ0 + θ1x1 + θ2x2, a czynniki są dwupoziomowe,przyjmujące wartości ±1. Pełny plan czynnikowy tutaj jest planem typu 22 izwykle zapisuje się w postaci tabeli (x0 ≡ 1):
x0 x1 x2
1 1 11 −1 11 1 −11 −1 −1
Realizując pełny plan czynnikowy typu 22 musimy przeprowadzić 4 doświad-czenia. Jeśli wyrzucimy z tabeli niektóre wiersze, to otrzymamy plan ułamkowy.Na przykład wyrzucając dwa ostatnich wierszy otrzymamy plan ułamkowy typu22−1, zgodnie z którym mamy przeprowadzić dwa doświadczenia.

62
Zwykle celem przeprowadzenia doświadczeń jest oszacowanie nieznanych para-metrów modelu, czyli parametrów θ0, {θj}, {θij}. Zakładając, że błędy pomiarówmają zerowe wartości oczekiwane i są nieskorelowane o jednakowej wariancji,otrzymujemy, zgodnie z Twierdzeniem Gaussa-Markowa, estymator MNK wekto-ra parametrów θ = (θ0, θ1, . . . , θm, θ11, . . .)
T w postaci θ = (F TF )−1F Ty, gdziey = (y1, . . . , yn)
T , natomiast F to macierz planu, każdy wiersz której jest odpowie-dnią kombinacją poziomów czynników, dla których należy przeprowadzić doświad-czenia.
Zatem podana w powyższym przykładzie tabela jest pożyteczna również ztego powodu, że podaje wartości elementów macierzy planu F.
W praktyce najpopularniejszymi są (i tylko ich będziemy dalej rozważać)plany dwupoziomowe, gdy czynniki występują tylko na dwóch poziomach (zwykleoznaczamy je ±1). Argumenty ku temu:a) w praktyce przy prowadzeniu doświadczeń typową jest sytuacja, gdy czynnikimogą być obecne (+1) lub też nie (−1), a więc są dwupoziomowe;b) jeśli czynnik występuje na s > 2 poziomach, to zawsze można go zamienićs czynnikami dwupoziomowymi rozważając każdy poziom jako nowy czynnik owartościach: +1 (czynnik obecny), −1 (czynnik nieobecny);c) jeśli czynnik występuje na wielu poziomach (lub wręcz przyjmuje wartości zpewnego przedziału), to często jest sens rozważać tylko dwa skrajnych poziomy.
Rozważmy teraz przypadek k = 3 i najpierw model regresji liniowej postaci
h(x, θ) = θ0 + θ1x1 + θ2x2 + θ3x3.
Pełny plan czynnikowy typu 23 zapisuje się jako
x0 x1 x2 x3
1 1 1 11 −1 1 −11 1 −1 −11 −1 −1 11 1 1 −11 −1 1 11 1 −1 11 −1 −1 −1
=⇒ F =
1 1 1 11 −1 1 −11 1 −1 −11 −1 −1 11 1 1 −11 −1 1 11 1 −1 11 −1 −1 −1
.
Macierz planu F jest wymiaru 8× 4 i rzędu 4. Jak łatwo policzyć,
F TF =
8 0 0 00 8 0 00 0 8 00 0 0 8
,

63
a więc kolumny macierzy F są wektorami ortogonalnymi. Plany, dla którychmacierze planu mają ortogonalne kolumny, nazywamy ortogonalnymi. Są onebardzo wygodne z obliczeniowego punktu widzenia (patrz też Rozdział 4).Stosując wzór na estymator MNK wektora parametrów θ, możemy teraz osza-
cować w sposób nieobciążony wszystkie parametry modelu.Pytanie 1. Mając do oszacowania 4 współczynniki regresji (θ0, θ1, θ2, θ3), jaka
jest najmniejsza liczba doświadczeń, po przeprowadzeniu których możemy oszaco-wać je w sposób nieobciążony? Oczywista odpowiedź: 4. Wystarczy na przykładzastosować plan ułamkowy typu 23−1 postaci
x0 x1 x2 x3
1 1 1 11 −1 1 −11 1 −1 −11 −1 −1 1
(7.9)
(pierwszych cztery wiersze) lub postaci
x0 x1 x2 x3
1 1 1 −11 −1 1 11 1 −1 11 −1 −1 −1
(7.10)
(ostatnich cztery wiersze). Takie plany nazywamy półpowtórzeniami.Pytanie 2. Stosując pełny plan czynnikowy typu 23, ile najwięcej współczynni-
ków regresji możemy oszacować w sposób nieobciążony? Oczywista odpowiedź: 8.Tak na przykład, możemy oszacować w sposób nieobciążony wszystkie parametryw niepełnym modelu kwadratowym postaci
h(x, θ) = θ0 +3∑
j=1
θjxj +∑
i<j
θijxixj ,
gdzie uwzględnione są wszystkie interakcje podwójne (zauważmy, że nie ma sensututaj włączać do modelu składniki typu θjjx
2j , bowiem x
2j ≡ 1). To samo można
powiedzieć o niepełnym modelu sześćściennym postaci
h(x, θ) = θ0 +3∑
j=1
θjxj +∑
i<j
θijxixj + θ123x1x2x3, (7.11)
gdzie uwzględniona również została jedna interakcja potrójna.Wróćmy jeszcze do planów ułamkowych typu (7.9) i (7.10). Jak łatwo zauważyć,
są one planami ortogonalnymi. Oprócz tego, ostatnia kolumna planu (7.9) ma

64
własność: x3 = x1x2, a ostatnia kolumna planu (7.10) ma własność: x3 = −x1x2(tu i dalej mamy na myśli mnożenie kolumn jako wektorów, po współrzędnych).Właśnie zwykle w taki sposób tworzymy plany ułamkowe: najpierw bierzemy planpełny dla mniejszej liczby czynników (pierwsze trzy kolumny w (7.9) lub (7.10)),a potem następne kolumny tworzymy przez mnożenie kolumn poprzednich. Takakonstrukcja jest dostatecznie prosta i pozwala na zachowanie ortogonalności.Rozważmy teraz model (7.11) i plan ułamkowy 23−1 postaci (patrz (7.9)):
x0 x1 x2 x3 x1x2 x1x3 x2x3 x1x2x3
1 1 1 1 1 1 1 11 −1 1 −1 −1 1 −1 11 1 −1 −1 −1 −1 1 11 −1 −1 1 1 −1 −1 1
(7.12)
Plan (7.12) został skonstruowany w sposób następujący: dla czynników x1 i x2były wzięte wszystkie możliwe kombinacje wartości, natomiast x3 = x1x2, awszystkie pozostałe kolumny obliczone zostały na podstawie pierwszych.Pytanie 3. Czy możemy w tej sytuacji stosując plan (7.12) oszacować w sposób
nieobciążony wszystkie 8 parametrów? Oczywiście że nie, ponieważ przeprowadza-my tylko 4 doświadczenia. A co możemy oszacować w sposób nieobciążony stosującplan (7.12)?Zauważmy, że pierwsza kolumna jest równa ósmej, druga siódmej, trzecia
szóstej, czwarta piątej. A więc stosując ten plan nie rozróżniamy wartości: x0i x1x2x3, x1 i x2x3, x2 i x1x3, x3 i x1x2, tzn. mamy
x0 = x123, x1 = x23, x2 = x1x3, x3 = x1x2. (7.13)
Oznacza to, że możemy na podstawie tego planu oszacować w sposób nieobciążonytylko 4 tzw. współczynniki regresji mieszane:
θ0 + θ123, θ1 + θ23, θ2 + θ13, θ3 + θ12.
Jak łatwo zrozumieć, wszystkie relacje (7.13) można uzyskać mając tylkoostatnią, tzn. x3 = x1x2. Dlatego nazywamy ją relacją generującą. Znając relacjegenerujące dla planu ułamkowego postaci 2m−p (tych relacji jest dokładnie p),możemy odtworzyć ten plan.
Zadanie domowe.Odtworzyć plan ułamkowy typu 23−1 mając relację generującąpostaci x3 = −x1x2 i podać współczynniki regresji mieszane, które w tym przypad-ku możemy oszacować w sposób nieobciążony.
Oprócz pojęcia relacji generującej, pożytecznym jest też pojęcie relacji określa-jącej. Relacja określająca to równość, w której po lewej stronie stoi iloczyn pew-nych czynników, z plusem lub z minusem, a po prawej – jedynka. W przypadkuplanu (7.12) mamy jedną relację określającą: x1x2x3 = 1, którą uzyskamy mnożąc

65
obie części relacji generującej przez x3. Relacji określających jest, na ogół, conajmniej tyle, ile generujących. Wszystkie relacje określające można uzyskaćw sposób następujący: z każdej relacji generującej można uzyskać bezpośredniojedną relację określającą poprzez mnożenie obu części relacji generującej na odpo-wiedni czynnik. Dalej mnożąc już uzyskane relacje określające same na siebie,można otrzymać nowe (o ile nie będą się one powtarzać).Relacje określające są pożyteczne, ponieważ pozwalają szybko odpowiedzieć
na pytanie: z jakimi współczynnikami będzie mieszany wybrany współczynnikregresji przy estymacji w sposób nieobciążony na podstawie zadanego planuułamkowego? Istotnie, na przykład dla znalezienia współczynników regresji, zktórymi będzie mieszany współczynnik θ1, mamy pomnożyć lewą i prawą stronykażdej relacji określającej przez x1; odpowiednie współczynniki odczytujemy zlewych stron otrzymanych równości biorąc efekty współdziałań odpowiednichczynników.
Przykład 7.2. Wypisać relacje określające i podać współczynniki regresji, zktórymi będą mieszane efekty główne w przypadku planu ułamkowego typu 25−2
i relacji generujących postaci: x4 = x1x2x3, x5 = x1x2.Relacje określające to: x1x2x3x4 = 1, x1x2x5 = 1, x3x4x5 = 1. Przy korzysta-
niu z zadanego planu, efekty główne będą mieszane tak:
θ1 + θ25 + θ234 + θ1345, θ2 + θ15 + θ134 + θ2345, θ3 + θ45 + θ124 + θ1235,
θ4 + θ35 + θ123 + θ1245, θ5 + θ12 + θ34 + θ12345.
Analogicznie postępujemy też w przypadku k > 3. W praktyce, wybierającplan ułamkowy korzystamy ze wszystkich wiadomości na temat badanego zjawiska,mając na celu wyodrębnienie tych efektów głównych i interakcji, wpływ którychna zmienną odpowiedzi jest istotny. Przy tym, na przykład, współczynniki regresji,które są istotne, mieszamy ze współczynnikami (na przykład interakcjami wysokie-go rzędu), które nie są istotne lub wręcz nieobecne w modelu.

66
Bibliografia
Podstawowa:
1 Koronacki J., Mielniczuk J. Statystyka. WNT, Warszawa, 2006.
2 Larose D. T. Metody i modele eksploracji danych. PWN, Warszawa, 2008.
Dodatkowa:
3 Ahrens H. Analiza wariancji. PWN, Warszawa, 1970.
4 Krysicki W., Bartos J., Dyczka W., Królikowska K., Wasilewski M. Rachu-nek Prawdopodobieństwa i Statystyka Matematyczna w Zadaniach. Cześć II.Statystyka Matematyczna. PWN, Warszawa, 1995.
5 Rao C. R.Modele liniowe statystyki matematycznej. PWN, Warszawa, 1982.
6 Stanisz A. Przystępny kurs statystyki. Tom 2. StatSoft Polska, Kraków,2000.
7 Zieliński W. Analiza regresji. Rozwój SGGW, Warszawa, 1998.

Spis treści
Rozdział 1. Wprowadzenie do analizy regresji 3
Rozdział 2. Klasyczny model regresji liniowej 7
2.1. Estymacja parametrów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2. Testowanie hipotez. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.3. O współczynniku determinacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1
Rozdział 3. Przypadek niespełnienia założeń klasycznego modelu
regresji liniowej 24
3.1. Niespełnienie założenia dotyczącego macierzy Cov y . . . . . . . . . . . . . 243.2. Niespełnienie obu założeń . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Rozdział 4. Regresja wielomianowa 29
Rozdział 5. Prosta regresja liniowa 35
5.1. Estymacja parametrów i testowanie hipotez o nich . . . . . . . . . . . . . . 355.2. Problem prognozy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375.3. Analiza wartości resztowych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.4. Klasyfikacja obserwacji nietypowych . . . . . . . . . . . . . . . . . . . . . . . . 395.5. O liniowej regresji wielokrotnej . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
Rozdział 6. O regresji nieliniowej 45
6.1. Regresja logistyczna. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 456.2. O metodach szacowania parametrów regresji nieliniowej. . . . . . . . . . . 49
Rozdział 7. Analiza wariancji 52
7.1. Analiza jednoczynnikowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 527.2. Analiza dwuczynnikowa. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 577.3.∗ O planowaniu doświadczeń czynnikowych. . . . . . . . . . . . . . . . . . . . .60
Literatura 66