alexander panchenko - human and machine judgements about russian semantic relatedness
TRANSCRIPT

Human and Machine Judgementsabout Russian Semantic Relatedness
A. Panchenko, D. Ustalov, D. Paperno, C. Meyer, N. Konstantinova, N. Loukachevitch, Ch. Bieman

Motivation A semantic similarity measure is a specific kind of similarity measure for nouns or multiword expressions.
… high values for synonyms, hyponyms, free associations, etc. … low values for unrelated pairs
Applications: information retrieval, document clustering, topic detection, question
answering, word sense disambiguation, text summarization…
Most datasets, approaches were proposed for English
2015 Russe The First International Workshop on Russian Semantic Similarity
Evaluation (RUSSE) 19 participants, 105 runs, special session at the Dialog-2015 conference.

Russian Datasets for Measuring Word Semantic Similarity
• Human Judgement dataset (HJ dataset)– Word pairs with human judgements
• Russian Thesaurus dataset (RT dataset)– synonyms and hypernyms from RuThes thesaurus
• Associative Thesaurus dataset (AE dataset)– cognitive associations between words
• Machine Judgements– combination of submissions from a shared task on Russian
semantic similarity
• Russian Distributional Thesaurus

Human judgements about semantic similarity (HJ)
This is the standard way to assess a semantic similarity measure.
The HJ dataset contains word pairs translated from the widely used benchmarks for English: Miller-Charles set – 30 word pairs Rubenstein, H., Goodenough – 65 word pairs WordSim – 353 word pairs:
Additionally subdivided into similarity set and relatedness set
Evaluation: Correlations with human judgments in terms of Spearman’s rank correlation
Agreement in ordering
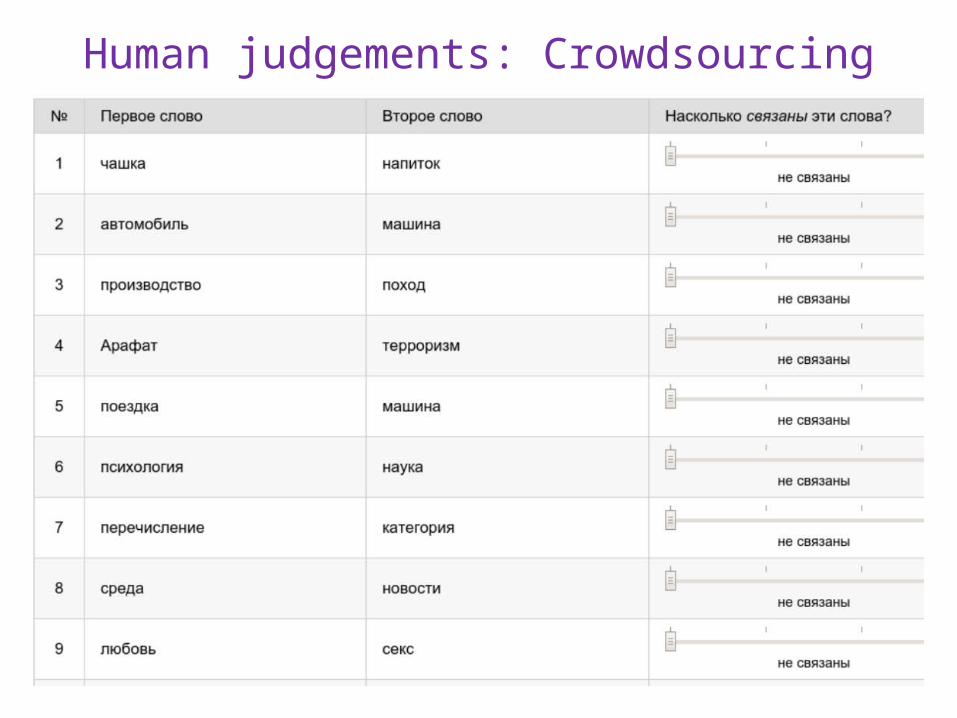
Human judgements: Crowdsourcing

Example of human judgements about semantic similarity (HJ)

RuThes Lingustic Ontology http://www.labinform.ru/pub/ruthes/index.htm
• 96 thousand unique words and expressions– Synonyms– Conceptual relations: class-subclass, part-whole, conceptual
dependence
•The dataset contains 114 066 relations for 6 832 nouns.
•Half of these relations are synonyms and hypernyms from the RuThes-lite thesaurus•half of them are unrelated words.

Thesaurus Sociation.org
•Non-commercial Internet-project
• contains 325,863 associations for 37,463 words

Structure of the semantic relation classification (RT, AE) benchmarks
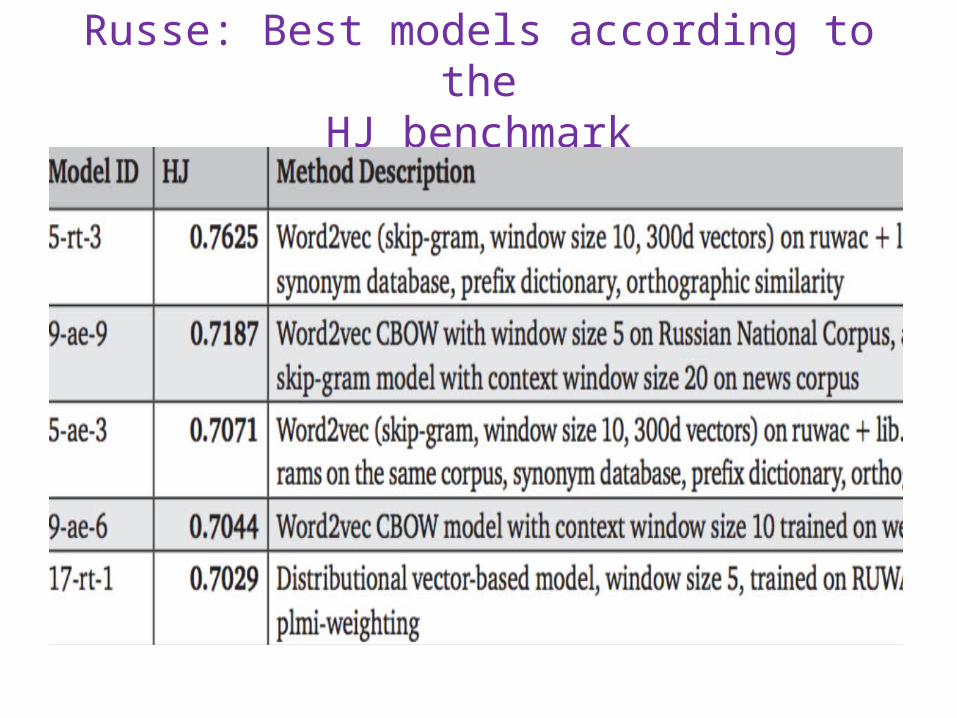
Russe: Best models according to theHJ benchmark

MJ: Machine Judgements of Word Pairs from the RUSSE Shared Task
• This dataset contains 12 886 word pairs coming from HJ, RT, and AE datasets
• The pairs have continuous relatedness scores• To estimate these scores we averaged 105
submissions of the shared task on Russian semantic similarity, RUSSE.
• Each run consisted of 12 886 word pairs along with their similarity scores.

Gathering Machine Judgements
• Select one best submission for each of 19 participating teams for HJ, RT and AE datasets
• Rank the 19 best submissions. The best one has rank r1 = 19; the worst has rank r19 = 1
• Combine scores of these 19 best submissions– The score of a pair is equal to sum of run scores
multiplied by run weight– Run weight: rank, exponent of rank, or square root of
rank
• Combined approach is better than single submission
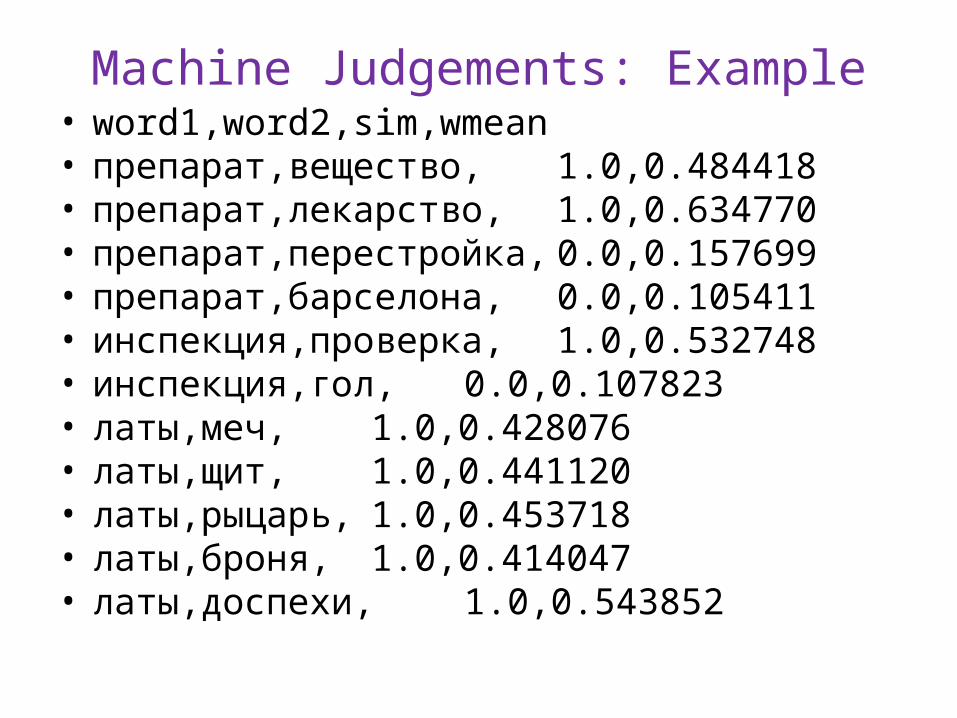
Machine Judgements: Example• word1,word2,sim,wmean• препарат,вещество, 1.0,0.484418• препарат,лекарство, 1.0,0.634770• препарат,перестройка, 0.0,0.157699• препарат,барселона, 0.0,0.105411• инспекция,проверка, 1.0,0.532748• инспекция,гол, 0.0,0.107823• латы,меч, 1.0,0.428076• латы,щит, 1.0,0.441120• латы,рыцарь, 1.0,0.453718• латы,броня, 1.0,0.414047• латы,доспехи, 1.0,0.543852

DT: Open Russian Distributional Thesaurus
• skip-gram model (Mikolov et al., 2013)• trained on a 12.9 billion word collection of books
in Russian– minimal word frequency -- 5, – number of dimensions in a word vector -- 500, – Context window size: 10 words– For the most frequent 932,000 words, 250 nearest
neighbours with the cosine similarity between word vectors are calculated.
– These related words were lemmatized using PyMorphy2.


Conclusion• We presented new Russian resources for evaluating of
semantic relatedness measures Russian HJ datasets: Miller-Charles, Rubenstein, Goodenough;
WordSim-353 RuThes dataset and Human associations dataset Machine Judgements Dataset and Distributional Thesaurus
• The resources can be obtained from• http://panchenko.me/rsr/
• The semantic similarity and relatedness are useful in many NLP and information retrieval applications