alphago for disco group of eth zurich
TRANSCRIPT

AlphaGo: Mastering the game of Go
with deep neural networks and tree search
Karel Ha
article by Google DeepMind
ETH Zurich, 9th May 2016

Game AIs
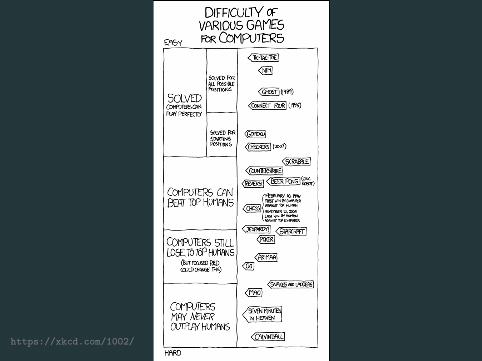

Heads-up Limit Holdem Poker Is Solved!
Cepheus http://poker.srv.ualberta.ca/
0.000986 big blinds per game on expectation
Bowling et al. 2015 1

Heads-up Limit Holdem Poker Is Solved!
Cepheus http://poker.srv.ualberta.ca/
0.000986 big blinds per game on expectation
Bowling et al. 2015 1

Heads-up Limit Holdem Poker Is Solved!
Cepheus http://poker.srv.ualberta.ca/
0.000986 big blinds per game on expectation
Bowling et al. 2015 1

Game Tree

Tree Search
Optimal value v∗(s) determines the outcome of the game:
� from every board position or state s
� under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
� b is the games breadth (number of legal moves per position)
� d is its depth (game length).
Silver et al. 2016 2

Tree Search
Optimal value v∗(s) determines the outcome of the game:
� from every board position or state s
� under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
� b is the games breadth (number of legal moves per position)
� d is its depth (game length).
Silver et al. 2016 2

Tree Search
Optimal value v∗(s) determines the outcome of the game:
� from every board position or state s
� under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
� b is the games breadth (number of legal moves per position)
� d is its depth (game length).
Silver et al. 2016 2

Tree Search
Optimal value v∗(s) determines the outcome of the game:
� from every board position or state s
� under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
� b is the games breadth (number of legal moves per position)
� d is its depth (game length).
Silver et al. 2016 2

Tree Search
Optimal value v∗(s) determines the outcome of the game:
� from every board position or state s
� under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
� b is the games breadth (number of legal moves per position)
� d is its depth (game length).
Silver et al. 2016 2

Tree Search
Optimal value v∗(s) determines the outcome of the game:
� from every board position or state s
� under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
� b is the games breadth (number of legal moves per position)
� d is its depth (game length).
Silver et al. 2016 2

Tree Search
Optimal value v∗(s) determines the outcome of the game:
� from every board position or state s
� under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
� b is the games breadth (number of legal moves per position)
� d is its depth (game length).
Silver et al. 2016 2

Game tree of Go
Sizes of trees for various games:
� chess: b ≈ 35, d ≈ 80
� Go: b ≈ 250, d ≈ 150
⇒ more positions than atoms in the
universe!
That makes Go a googol
[10100] times more complex
than chess.
https://deepmind.com/alpha-go.htmlHow to handle the size of the game tree?
� for the breadth: a neural network to select moves
� for the depth: a neural network to evaluate the current
position
� for the tree traverse: Monte Carlo tree search (MCTS)
Allis et al. 1994 3

Game tree of Go
Sizes of trees for various games:
� chess: b ≈ 35, d ≈ 80
� Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
[10100] times more complex
than chess.
https://deepmind.com/alpha-go.htmlHow to handle the size of the game tree?
� for the breadth: a neural network to select moves
� for the depth: a neural network to evaluate the current
position
� for the tree traverse: Monte Carlo tree search (MCTS)
Allis et al. 1994 3

Game tree of Go
Sizes of trees for various games:
� chess: b ≈ 35, d ≈ 80
� Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
[10100] times more complex
than chess.
https://deepmind.com/alpha-go.html
How to handle the size of the game tree?
� for the breadth: a neural network to select moves
� for the depth: a neural network to evaluate the current
position
� for the tree traverse: Monte Carlo tree search (MCTS)
Allis et al. 1994 3

Game tree of Go
Sizes of trees for various games:
� chess: b ≈ 35, d ≈ 80
� Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
[10100] times more complex
than chess.
https://deepmind.com/alpha-go.htmlHow to handle the size of the game tree?
� for the breadth: a neural network to select moves
� for the depth: a neural network to evaluate the current
position
� for the tree traverse: Monte Carlo tree search (MCTS)
Allis et al. 1994 3

Game tree of Go
Sizes of trees for various games:
� chess: b ≈ 35, d ≈ 80
� Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
[10100] times more complex
than chess.
https://deepmind.com/alpha-go.htmlHow to handle the size of the game tree?
� for the breadth: a neural network to select moves
� for the depth: a neural network to evaluate the current
position
� for the tree traverse: Monte Carlo tree search (MCTS)
Allis et al. 1994 3

Game tree of Go
Sizes of trees for various games:
� chess: b ≈ 35, d ≈ 80
� Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
[10100] times more complex
than chess.
https://deepmind.com/alpha-go.htmlHow to handle the size of the game tree?
� for the breadth: a neural network to select moves
� for the depth: a neural network to evaluate the current
position
� for the tree traverse: Monte Carlo tree search (MCTS)
Allis et al. 1994 3

Game tree of Go
Sizes of trees for various games:
� chess: b ≈ 35, d ≈ 80
� Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
[10100] times more complex
than chess.
https://deepmind.com/alpha-go.htmlHow to handle the size of the game tree?
� for the breadth: a neural network to select moves
� for the depth: a neural network to evaluate the current
position
� for the tree traverse: Monte Carlo tree search (MCTS)Allis et al. 1994 3

AlphaGo: Neural Networks

Policy and Value Networks
Silver et al. 2016 4

Training the (Deep Convolutional) Neural Networks
Silver et al. 2016 5

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

SL (Supervised Learning) Policy Network
� 13-layer deep convolutional neural network
� goal: to predict expert human moves
� task of classification
� trained from 30 millions positions from the KGS Go Server
� stochastic gradient ascent:
∆σ ∝ ∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
� 44.4% accuracy (the state-of-the-art from other groups)
� 55.7% accuracy (raw board position + move history as input)
� 57.0% accuracy (all input features)
Silver et al. 2016 6

Training the (Deep Convolutional) Neural Networks
Silver et al. 2016 7

Rollout Policy
� Rollout policy pπ(a|s) is faster but less accurate than SL
policy network.
� accuracy of 24.2%
� It takes 2µs to select an action, compared to 3 ms in case
of SL policy network.
Silver et al. 2016 8

Rollout Policy
� Rollout policy pπ(a|s) is faster but less accurate than SL
policy network.
� accuracy of 24.2%
� It takes 2µs to select an action, compared to 3 ms in case
of SL policy network.
Silver et al. 2016 8

Rollout Policy
� Rollout policy pπ(a|s) is faster but less accurate than SL
policy network.
� accuracy of 24.2%
� It takes 2µs to select an action, compared to 3 ms in case
of SL policy network.
Silver et al. 2016 8
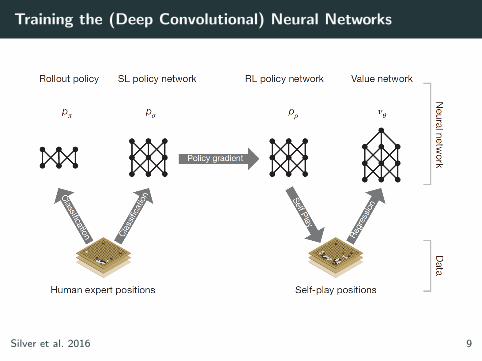
Training the (Deep Convolutional) Neural Networks
Silver et al. 2016 9

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (1/2)
� identical in structure to the SL policy network
� goal: to win in the games of self-play
� task of classification
� weights ρ initialized to the same values, ρ := σ
� games of self-play
� between the current RL policy network and a randomly
selected previous iteration
� to prevent overfitting to the current policy
� stochastic gradient ascent:
∆ρ ∝ ∂ log pρ(at |st)
∂ρzt
at time step t, where reward function zt is +1 for winning and −1 for losing.
Silver et al. 2016 10

RL (Reinforcement Learning) Policy Network (2/2)
Results (retrieved by sampling each move at ∼ pρ(·|st)):
� 80% of win rate against the SL policy network
� 85% of win rate against the strongest open-source Goprogram, Pachi (Baudis and Gailly 2011)
� The previous state-of-the-art, based only on SL of CNN:
11% of “win” rate against Pachi
Silver et al. 2016 11

RL (Reinforcement Learning) Policy Network (2/2)
Results (retrieved by sampling each move at ∼ pρ(·|st)):
� 80% of win rate against the SL policy network
� 85% of win rate against the strongest open-source Goprogram, Pachi (Baudis and Gailly 2011)
� The previous state-of-the-art, based only on SL of CNN:
11% of “win” rate against Pachi
Silver et al. 2016 11

RL (Reinforcement Learning) Policy Network (2/2)
Results (retrieved by sampling each move at ∼ pρ(·|st)):
� 80% of win rate against the SL policy network
� 85% of win rate against the strongest open-source Goprogram, Pachi (Baudis and Gailly 2011)
� The previous state-of-the-art, based only on SL of CNN:
11% of “win” rate against Pachi
Silver et al. 2016 11

RL (Reinforcement Learning) Policy Network (2/2)
Results (retrieved by sampling each move at ∼ pρ(·|st)):
� 80% of win rate against the SL policy network
� 85% of win rate against the strongest open-source Goprogram, Pachi (Baudis and Gailly 2011)
� The previous state-of-the-art, based only on SL of CNN:
11% of “win” rate against Pachi
Silver et al. 2016 11

Training the (Deep Convolutional) Neural Networks
Silver et al. 2016 12

Value Network (1/2)
� similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
� goal: to estimate a value function
vp(s) = E[zt |st = s, at...T ∼ p]
that predicts the outcome from position s (of games played
by using policy p)
� Double approximation: vθ(s) ≈ vpρ(s) ≈ v∗(s).
� task of regression
� stochastic gradient descent:
∆θ ∝ ∂vθ(s)
∂θ(z − vθ(s))
(to minimize the mean squared error (MSE) between the predicted vθ(s) and the true z)
Silver et al. 2016 13

Value Network (1/2)
� similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
� goal: to estimate a value function
vp(s) = E[zt |st = s, at...T ∼ p]
that predicts the outcome from position s (of games played
by using policy p)
� Double approximation: vθ(s) ≈ vpρ(s) ≈ v∗(s).
� task of regression
� stochastic gradient descent:
∆θ ∝ ∂vθ(s)
∂θ(z − vθ(s))
(to minimize the mean squared error (MSE) between the predicted vθ(s) and the true z)
Silver et al. 2016 13

Value Network (1/2)
� similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
� goal: to estimate a value function
vp(s) = E[zt |st = s, at...T ∼ p]
that predicts the outcome from position s (of games played
by using policy p)
� Double approximation: vθ(s) ≈ vpρ(s) ≈ v∗(s).
� task of regression
� stochastic gradient descent:
∆θ ∝ ∂vθ(s)
∂θ(z − vθ(s))
(to minimize the mean squared error (MSE) between the predicted vθ(s) and the true z)
Silver et al. 2016 13

Value Network (1/2)
� similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
� goal: to estimate a value function
vp(s) = E[zt |st = s, at...T ∼ p]
that predicts the outcome from position s (of games played
by using policy p)
� Double approximation: vθ(s) ≈ vpρ(s) ≈ v∗(s).
� task of regression
� stochastic gradient descent:
∆θ ∝ ∂vθ(s)
∂θ(z − vθ(s))
(to minimize the mean squared error (MSE) between the predicted vθ(s) and the true z)
Silver et al. 2016 13

Value Network (1/2)
� similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
� goal: to estimate a value function
vp(s) = E[zt |st = s, at...T ∼ p]
that predicts the outcome from position s (of games played
by using policy p)
� Double approximation: vθ(s) ≈ vpρ(s) ≈ v∗(s).
� task of regression
� stochastic gradient descent:
∆θ ∝ ∂vθ(s)
∂θ(z − vθ(s))
(to minimize the mean squared error (MSE) between the predicted vθ(s) and the true z)
Silver et al. 2016 13

Value Network (2/2)
Beware of overfitting!
� Consecutive positions are strongly correlated.
� Value network memorized the game outcomes, rather than
generalizing to new positions.
� Solution: generate 30 million (new) positions, each sampled
from a seperate game
� almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
Silver et al. 2016 14

Value Network (2/2)
Beware of overfitting!
� Consecutive positions are strongly correlated.
� Value network memorized the game outcomes, rather than
generalizing to new positions.
� Solution: generate 30 million (new) positions, each sampled
from a seperate game
� almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
Silver et al. 2016 14

Value Network (2/2)
Beware of overfitting!
� Consecutive positions are strongly correlated.
� Value network memorized the game outcomes, rather than
generalizing to new positions.
� Solution: generate 30 million (new) positions, each sampled
from a seperate game
� almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
Silver et al. 2016 14

Value Network (2/2)
Beware of overfitting!
� Consecutive positions are strongly correlated.
� Value network memorized the game outcomes, rather than
generalizing to new positions.
� Solution: generate 30 million (new) positions, each sampled
from a seperate game
� almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
Silver et al. 2016 14

Value Network (2/2)
Beware of overfitting!
� Consecutive positions are strongly correlated.
� Value network memorized the game outcomes, rather than
generalizing to new positions.
� Solution: generate 30 million (new) positions, each sampled
from a seperate game
� almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
Silver et al. 2016 14

Elo Ratings for Various Combinations of Networks
Silver et al. 2016 15

AlphaGo: The Main Algorithm

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16

MCTS Algorithm
The next action is selected by lookahead search, using simulation:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of all simulations)
Each edge (s, a) keeps:
� action value Q(s, a)
� visit count N(s, a)
� prior probability P(s, a) (from SL policy network pσ)
The tree is traversed by simulation (descending the tree) from the
root state.
Silver et al. 2016 16
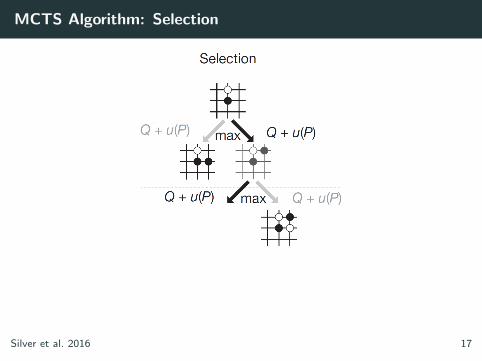
MCTS Algorithm: Selection
At each time step t, an action at is selected from state st
at = arg maxa
(Q(st , a) + u(st , a))
where bonus
u(st , a) ∝P(s, a)
1 + N(s, a)
Silver et al. 2016 17
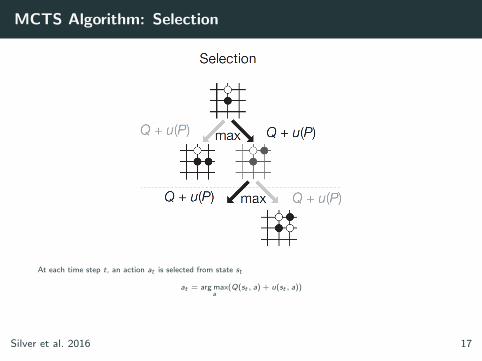
MCTS Algorithm: Selection
At each time step t, an action at is selected from state st
at = arg maxa
(Q(st , a) + u(st , a))
where bonus
u(st , a) ∝P(s, a)
1 + N(s, a)
Silver et al. 2016 17

MCTS Algorithm: Selection
At each time step t, an action at is selected from state st
at = arg maxa
(Q(st , a) + u(st , a))
where bonus
u(st , a) ∝P(s, a)
1 + N(s, a)
Silver et al. 2016 17

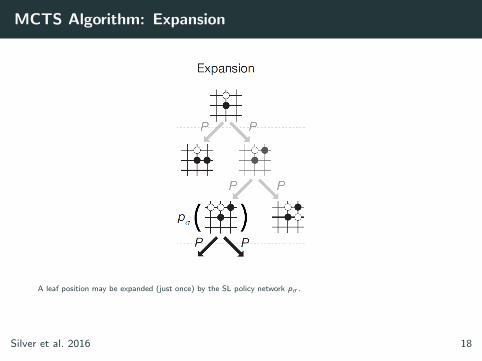
MCTS Algorithm: Expansion
A leaf position may be expanded (just once) by the SL policy network pσ .
The output probabilities are stored as priors P(s, a) := pσ(a|s).
Silver et al. 2016 18
MCTS Algorithm: Expansion
A leaf position may be expanded (just once) by the SL policy network pσ .
The output probabilities are stored as priors P(s, a) := pσ(a|s).
Silver et al. 2016 18

MCTS Algorithm: Expansion
A leaf position may be expanded (just once) by the SL policy network pσ .
The output probabilities are stored as priors P(s, a) := pσ(a|s).
Silver et al. 2016 18

MCTS: Evaluation
� evaluation from the value network vθ(s)
� evaluation by the outcome z using the fast rollout policy pπ until the end of game
Using a mixing parameter λ, the final leaf evaluation V (s) is
V (s) = (1− λ)vθ(s) + λz
Silver et al. 2016 19

MCTS: Evaluation
� evaluation from the value network vθ(s)
� evaluation by the outcome z using the fast rollout policy pπ until the end of game
Using a mixing parameter λ, the final leaf evaluation V (s) is
V (s) = (1− λ)vθ(s) + λz
Silver et al. 2016 19

MCTS: Evaluation
� evaluation from the value network vθ(s)
� evaluation by the outcome z using the fast rollout policy pπ until the end of game
Using a mixing parameter λ, the final leaf evaluation V (s) is
V (s) = (1− λ)vθ(s) + λz
Silver et al. 2016 19

MCTS: Evaluation
� evaluation from the value network vθ(s)
� evaluation by the outcome z using the fast rollout policy pπ until the end of game
Using a mixing parameter λ, the final leaf evaluation V (s) is
V (s) = (1− λ)vθ(s) + λz
Silver et al. 2016 19

MCTS: Evaluation
� evaluation from the value network vθ(s)
� evaluation by the outcome z using the fast rollout policy pπ until the end of game
Using a mixing parameter λ, the final leaf evaluation V (s) is
V (s) = (1− λ)vθ(s) + λz
Silver et al. 2016 19

MCTS: Backup
At the end of simulation, each traversed edge is updated by accumulating:
� the action values Q
� visit counts N
Silver et al. 2016 20

MCTS: Backup
At the end of simulation, each traversed edge is updated by accumulating:
� the action values Q
� visit counts N
Silver et al. 2016 20

Once the search is complete, the algorithm
chooses the most visited move from the root
position.
Silver et al. 2016 20

Principal Variation (Path with Maximum Visit Count)
The moves are presented in a numbered sequence.
� AlphaGo selected the move indicated by the red circle;
� Fan Hui responded with the move indicated by the white square;
� in his post-game commentary, he preferred the move (labelled 1) predicted by AlphaGo.
Silver et al. 2016 21

Principal Variation (Path with Maximum Visit Count)
The moves are presented in a numbered sequence.
� AlphaGo selected the move indicated by the red circle;
� Fan Hui responded with the move indicated by the white square;
� in his post-game commentary, he preferred the move (labelled 1) predicted by AlphaGo.
Silver et al. 2016 21

Principal Variation (Path with Maximum Visit Count)
The moves are presented in a numbered sequence.
� AlphaGo selected the move indicated by the red circle;
� Fan Hui responded with the move indicated by the white square;
� in his post-game commentary, he preferred the move (labelled 1) predicted by AlphaGo.
Silver et al. 2016 21

Principal Variation (Path with Maximum Visit Count)
The moves are presented in a numbered sequence.
� AlphaGo selected the move indicated by the red circle;
� Fan Hui responded with the move indicated by the white square;
� in his post-game commentary, he preferred the move (labelled 1) predicted by AlphaGo.
Silver et al. 2016 21

AlphaGo: Distributed Computing

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Scalability
� asynchronous multi-threaded search
� simulations on CPUs
� computation of neural networks on GPUs
AlphaGo (on a single-machine):
� 40 search threads
� 40 CPUs
� 8 GPUs
Distributed version of AlphaGo (on multiple machines):
� 40 search threads
� 1202 CPUs
� 176 GPUs
Silver et al. 2016 22

Elo Ratings for Various Combinations of Threads
Silver et al. 2016 23

AlphaGo: Results

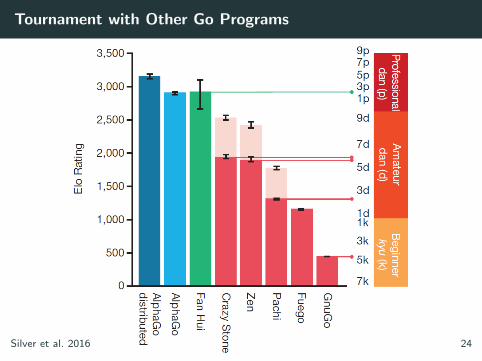
Tournament with Other Go Programs
Silver et al. 2016 24

Fan Hui
� professional 2 dan
� European Go Champion in 2013, 2014 and 2015
� European Professional Go Champion in 2016� biological neural network:
� 100 billion neurons
� 100 up to 1,000 trillion neuronal connections
https://en.wikipedia.org/wiki/Fan_Hui 25

Fan Hui
� professional 2 dan
� European Go Champion in 2013, 2014 and 2015
� European Professional Go Champion in 2016� biological neural network:
� 100 billion neurons
� 100 up to 1,000 trillion neuronal connections
https://en.wikipedia.org/wiki/Fan_Hui 25

Fan Hui
� professional 2 dan
� European Go Champion in 2013, 2014 and 2015
� European Professional Go Champion in 2016� biological neural network:
� 100 billion neurons
� 100 up to 1,000 trillion neuronal connections
https://en.wikipedia.org/wiki/Fan_Hui 25

Fan Hui
� professional 2 dan
� European Go Champion in 2013, 2014 and 2015
� European Professional Go Champion in 2016
� biological neural network:
� 100 billion neurons
� 100 up to 1,000 trillion neuronal connections
https://en.wikipedia.org/wiki/Fan_Hui 25

Fan Hui
� professional 2 dan
� European Go Champion in 2013, 2014 and 2015
� European Professional Go Champion in 2016� biological neural network:
� 100 billion neurons
� 100 up to 1,000 trillion neuronal connections
https://en.wikipedia.org/wiki/Fan_Hui 25

Fan Hui
� professional 2 dan
� European Go Champion in 2013, 2014 and 2015
� European Professional Go Champion in 2016� biological neural network:
� 100 billion neurons
� 100 up to 1,000 trillion neuronal connections
https://en.wikipedia.org/wiki/Fan_Hui 25

Fan Hui
� professional 2 dan
� European Go Champion in 2013, 2014 and 2015
� European Professional Go Champion in 2016� biological neural network:
� 100 billion neurons
� 100 up to 1,000 trillion neuronal connectionshttps://en.wikipedia.org/wiki/Fan_Hui 25

AlphaGo versus Fan Hui
AlphaGo won 5:0 in a formal match in October 2015.
[AlphaGo] is very strong and stable, it seems
like a wall. ... I know AlphaGo is a computer,
but if no one told me, maybe I would think
the player was a little strange, but a very
strong player, a real person.
Fan Hui
26

AlphaGo versus Fan Hui
AlphaGo won 5:0 in a formal match in October 2015.
[AlphaGo] is very strong and stable, it seems
like a wall. ... I know AlphaGo is a computer,
but if no one told me, maybe I would think
the player was a little strange, but a very
strong player, a real person.
Fan Hui
26

AlphaGo versus Fan Hui
AlphaGo won 5:0 in a formal match in October 2015.
[AlphaGo] is very strong and stable, it seems
like a wall. ... I know AlphaGo is a computer,
but if no one told me, maybe I would think
the player was a little strange, but a very
strong player, a real person.
Fan Hui 26

Lee Sedol “The Strong Stone”
� professional 9 dan
� the 2nd in international titles
� the 5th youngest (12 years 4 months) to become
a professional Go player in South Korean history
� Lee Sedol would win 97 out of 100 games against Fan Hui.
� biological neural network comparable to Fan Hui’s (in number
of neurons and connections)
https://en.wikipedia.org/wiki/Lee_Sedol 27

Lee Sedol “The Strong Stone”
� professional 9 dan
� the 2nd in international titles
� the 5th youngest (12 years 4 months) to become
a professional Go player in South Korean history
� Lee Sedol would win 97 out of 100 games against Fan Hui.
� biological neural network comparable to Fan Hui’s (in number
of neurons and connections)
https://en.wikipedia.org/wiki/Lee_Sedol 27

Lee Sedol “The Strong Stone”
� professional 9 dan
� the 2nd in international titles
� the 5th youngest (12 years 4 months) to become
a professional Go player in South Korean history
� Lee Sedol would win 97 out of 100 games against Fan Hui.
� biological neural network comparable to Fan Hui’s (in number
of neurons and connections)
https://en.wikipedia.org/wiki/Lee_Sedol 27

Lee Sedol “The Strong Stone”
� professional 9 dan
� the 2nd in international titles
� the 5th youngest (12 years 4 months) to become
a professional Go player in South Korean history
� Lee Sedol would win 97 out of 100 games against Fan Hui.
� biological neural network comparable to Fan Hui’s (in number
of neurons and connections)
https://en.wikipedia.org/wiki/Lee_Sedol 27

Lee Sedol “The Strong Stone”
� professional 9 dan
� the 2nd in international titles
� the 5th youngest (12 years 4 months) to become
a professional Go player in South Korean history
� Lee Sedol would win 97 out of 100 games against Fan Hui.
� biological neural network comparable to Fan Hui’s (in number
of neurons and connections)
https://en.wikipedia.org/wiki/Lee_Sedol 27

Lee Sedol “The Strong Stone”
� professional 9 dan
� the 2nd in international titles
� the 5th youngest (12 years 4 months) to become
a professional Go player in South Korean history
� Lee Sedol would win 97 out of 100 games against Fan Hui.
� biological neural network comparable to Fan Hui’s (in number
of neurons and connections)https://en.wikipedia.org/wiki/Lee_Sedol 27

I heard Google DeepMind’s AI is surprisingly
strong and getting stronger, but I am
confident that I can win, at least this time.
Lee Sedol
...even beating AlphaGo by 4:1 may allow
the Google DeepMind team to claim its de
facto victory and the defeat of him
[Lee Sedol], or even humankind.
interview in JTBC
Newsroom
27

I heard Google DeepMind’s AI is surprisingly
strong and getting stronger, but I am
confident that I can win, at least this time.
Lee Sedol
...even beating AlphaGo by 4:1 may allow
the Google DeepMind team to claim its de
facto victory and the defeat of him
[Lee Sedol], or even humankind.
interview in JTBC
Newsroom
27

I heard Google DeepMind’s AI is surprisingly
strong and getting stronger, but I am
confident that I can win, at least this time.
Lee Sedol
...even beating AlphaGo by 4:1 may allow
the Google DeepMind team to claim its de
facto victory and the defeat of him
[Lee Sedol], or even humankind.
interview in JTBC
Newsroom
27

AlphaGo versus Lee Sedol
In March 2016 AlphaGo won 4:1 against the legendary Lee Sedol.
AlphaGo won all but the 4th game; all games were won
by resignation.
The winner of the match was slated to win $1 million.
Since AlphaGo won, Google DeepMind stated that the prize will be
donated to charities, including UNICEF, and Go organisations.
Lee received $170,000 ($150,000 for participating in all the five
games, and an additional $20,000 for each game won).
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol 28

AlphaGo versus Lee Sedol
In March 2016 AlphaGo won 4:1 against the legendary Lee Sedol.
AlphaGo won all but the 4th game; all games were won
by resignation.
The winner of the match was slated to win $1 million.
Since AlphaGo won, Google DeepMind stated that the prize will be
donated to charities, including UNICEF, and Go organisations.
Lee received $170,000 ($150,000 for participating in all the five
games, and an additional $20,000 for each game won).
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol 28

AlphaGo versus Lee Sedol
In March 2016 AlphaGo won 4:1 against the legendary Lee Sedol.
AlphaGo won all but the 4th game; all games were won
by resignation.
The winner of the match was slated to win $1 million.
Since AlphaGo won, Google DeepMind stated that the prize will be
donated to charities, including UNICEF, and Go organisations.
Lee received $170,000 ($150,000 for participating in all the five
games, and an additional $20,000 for each game won).
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol 28

AlphaGo versus Lee Sedol
In March 2016 AlphaGo won 4:1 against the legendary Lee Sedol.
AlphaGo won all but the 4th game; all games were won
by resignation.
The winner of the match was slated to win $1 million.
Since AlphaGo won, Google DeepMind stated that the prize will be
donated to charities, including UNICEF, and Go organisations.
Lee received $170,000 ($150,000 for participating in all the five
games, and an additional $20,000 for each game won).
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol 28

AlphaGo versus Lee Sedol
In March 2016 AlphaGo won 4:1 against the legendary Lee Sedol.
AlphaGo won all but the 4th game; all games were won
by resignation.
The winner of the match was slated to win $1 million.
Since AlphaGo won, Google DeepMind stated that the prize will be
donated to charities, including UNICEF, and Go organisations.
Lee received $170,000 ($150,000 for participating in all the five
games, and an additional $20,000 for each game won).
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol 28

AlphaGo versus Lee Sedol
In March 2016 AlphaGo won 4:1 against the legendary Lee Sedol.
AlphaGo won all but the 4th game; all games were won
by resignation.
The winner of the match was slated to win $1 million.
Since AlphaGo won, Google DeepMind stated that the prize will be
donated to charities, including UNICEF, and Go organisations.
Lee received $170,000 ($150,000 for participating in all the five
games, and an additional $20,000 for each game won).
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol 28

Who’s next?
28
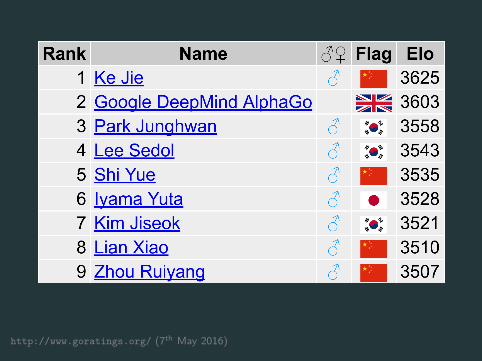

AlphaGo versus Ke Jie?
� professional 9 dan
� the 1st in (unofficial) world ranking list
� the youngest player to win 3 major international tournaments
� head-to-head record against Lee Sedol 8:2
� biological neural network comparable to Fan Hui’s, and thus
by transitivity, also comparable to Lee Sedol’s
https://en.wikipedia.org/wiki/Ke_Jie 29

AlphaGo versus Ke Jie?
� professional 9 dan
� the 1st in (unofficial) world ranking list
� the youngest player to win 3 major international tournaments
� head-to-head record against Lee Sedol 8:2
� biological neural network comparable to Fan Hui’s, and thus
by transitivity, also comparable to Lee Sedol’s
https://en.wikipedia.org/wiki/Ke_Jie 29

AlphaGo versus Ke Jie?
� professional 9 dan
� the 1st in (unofficial) world ranking list
� the youngest player to win 3 major international tournaments
� head-to-head record against Lee Sedol 8:2
� biological neural network comparable to Fan Hui’s, and thus
by transitivity, also comparable to Lee Sedol’s
https://en.wikipedia.org/wiki/Ke_Jie 29

AlphaGo versus Ke Jie?
� professional 9 dan
� the 1st in (unofficial) world ranking list
� the youngest player to win 3 major international tournaments
� head-to-head record against Lee Sedol 8:2
� biological neural network comparable to Fan Hui’s, and thus
by transitivity, also comparable to Lee Sedol’s
https://en.wikipedia.org/wiki/Ke_Jie 29

AlphaGo versus Ke Jie?
� professional 9 dan
� the 1st in (unofficial) world ranking list
� the youngest player to win 3 major international tournaments
� head-to-head record against Lee Sedol 8:2
� biological neural network comparable to Fan Hui’s, and thus
by transitivity, also comparable to Lee Sedol’s
https://en.wikipedia.org/wiki/Ke_Jie 29

AlphaGo versus Ke Jie?
� professional 9 dan
� the 1st in (unofficial) world ranking list
� the youngest player to win 3 major international tournaments
� head-to-head record against Lee Sedol 8:2
� biological neural network comparable to Fan Hui’s, and thus
by transitivity, also comparable to Lee Sedol’s
https://en.wikipedia.org/wiki/Ke_Jie 29

I believe I can beat it. Machines can be very
strong in many aspects but still have
loopholes in certain calculations.
Ke Jie
Now facing AlphaGo, I do not feel the same
strong instinct of victory when I play a
human player, but I still believe I have the
advantage against it. It’s 60 percent in
favor of me.
Ke Jie
Even though AlphaGo may have defeated
Lee Sedol, it won’t beat me.
Ke Jie
29

I believe I can beat it. Machines can be very
strong in many aspects but still have
loopholes in certain calculations.
Ke Jie
Now facing AlphaGo, I do not feel the same
strong instinct of victory when I play a
human player, but I still believe I have the
advantage against it. It’s 60 percent in
favor of me.
Ke Jie
Even though AlphaGo may have defeated
Lee Sedol, it won’t beat me.
Ke Jie
29

I believe I can beat it. Machines can be very
strong in many aspects but still have
loopholes in certain calculations.
Ke Jie
Now facing AlphaGo, I do not feel the same
strong instinct of victory when I play a
human player, but I still believe I have the
advantage against it. It’s 60 percent in
favor of me.
Ke Jie
Even though AlphaGo may have defeated
Lee Sedol, it won’t beat me.
Ke Jie
29

Conclusion

Difficulties of Go
� challenging decision-making
� intractable search space
� complex optimal solution
It appears infeasible to directly approximate using a policy or value function!
Silver et al. 2016 30

Difficulties of Go
� challenging decision-making
� intractable search space
� complex optimal solution
It appears infeasible to directly approximate using a policy or value function!
Silver et al. 2016 30

Difficulties of Go
� challenging decision-making
� intractable search space
� complex optimal solution
It appears infeasible to directly approximate using a policy or value function!
Silver et al. 2016 30

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31

AlphaGo: summary
� Monte Carlo tree search
� effective move selection and position evaluation
� through deep convolutional neural networks
� trained by novel combination of supervised and reinforcement
learning
� new search algorithm combining
� neural network evaluation
� Monte Carlo rollouts
� scalable implementation
� multi-threaded simulations on CPUs
� parallel GPU computations
� distributed version over multiple machines
Silver et al. 2016 31
Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Novel approach
During the match against Fan Hui, AlphaGo evaluated thousands
of times fewer positions than Deep Blue against Kasparov.
It compensated this by:
� selecting those positions more intelligently (policy network)
� evaluating them more precisely (value network)
Deep Blue relied on a handcrafted evaluation function.
AlphaGo was trained directly and automatically from gameplay.
It used general-purpose learning.
This approach is not specific to the game of Go. The algorithm
can be used for much wider class of (so far seemingly)
intractable problems in AI!
Silver et al. 2016 32

Thank you
for the music
of your attention!
Happy to be here,
in your DISCO group!
32

Thank you
for the music
of your attention!
Happy to be here,
in your DISCO group!
32

Thank you
for the music
of your attention!
Happy to be here,
in your DISCO group!
32

Thank you
for the music
of your attention!
Happy to be here,
in your DISCO group!
32

Thank you
for the music
of your attention!
Happy to be here,
in your DISCO group!
32

Backup Slides

SL Policy Network: Accuracy vs. Win Rate
Small improvements in accuracy led to large improvements
in playing strength
Silver et al. 2016

Evaluation Accuracy in Various Stages of a Game
Move number is the number of moves that had been played in the given position.
Each position evaluated by:
� forward pass of the value network vθ
� 100 rollouts, played out using the corresponding policySilver et al. 2016

Input features for rollout and tree policy
Silver et al. 2016

Selection of Moves by the SL Policy Network
move probabilities taken directly from the SL policy network pσ (reported as a percentage if above 0.1%).
Silver et al. 2016

Selection of Moves by the Value Network
evaluation of all successors s′ of the root position s, using vθ(s)
Silver et al. 2016

Tree Evaluation from Value Network
action values Q(s, a) for each tree-edge (s, a) from root position s (averaged over value network evaluations only)
Silver et al. 2016

Tree Evaluation from Rollouts
action values Q(s, a), averaged over rollout evaluations only
Silver et al. 2016

Percentage of Simulations
percentage frequency with which actions were selected from the root during simulations
Silver et al. 2016

Results of a tournament between different Go programs
Silver et al. 2016

Results of a tournament between AlphaGo and distributed Al-
phaGo, testing scalability with hardware
Silver et al. 2016

AlphaGo versus Fan Hui: Game 1
Silver et al. 2016

AlphaGo versus Fan Hui: Game 2
Silver et al. 2016
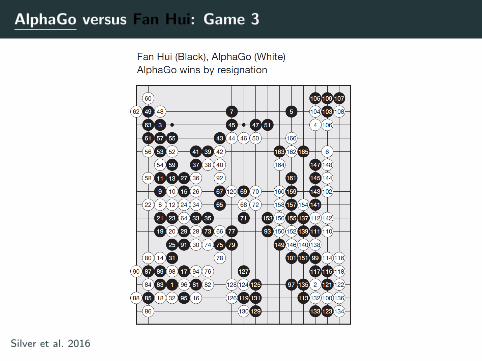
AlphaGo versus Fan Hui: Game 3
Silver et al. 2016

AlphaGo versus Fan Hui: Game 4
Silver et al. 2016

AlphaGo versus Fan Hui: Game 5
Silver et al. 2016

AlphaGo versus Lee Sedol: Game 1
https://youtu.be/vFr3K2DORc8
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol

AlphaGo versus Lee Sedol: Game 2 (1/2)
https://youtu.be/l-GsfyVCBu0
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol

AlphaGo versus Lee Sedol: Game 2 (2/2)
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol

AlphaGo versus Lee Sedol: Game 3
https://youtu.be/qUAmTYHEyM8
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol

AlphaGo versus Lee Sedol: Game 4
https://youtu.be/yCALyQRN3hw
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol

AlphaGo versus Lee Sedol: Game 5 (1/2)
https://youtu.be/mzpW10DPHeQ
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol

AlphaGo versus Lee Sedol: Game 5 (2/2)
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol

Further Reading I
AlphaGo:
� Google Research Blog
http://googleresearch.blogspot.cz/2016/01/alphago-mastering-ancient-game-of-go.html
� an article in Nature
http://www.nature.com/news/google-ai-algorithm-masters-ancient-game-of-go-1.19234
� a reddit article claiming that AlphaGo is even stronger than it appears to be:
“AlphaGo would rather win by less points, but with higher probability.”
https://www.reddit.com/r/baduk/comments/49y17z/the_true_strength_of_alphago/
� a video of how AlphaGo works (put in layman’s terms) https://youtu.be/qWcfiPi9gUU
Articles by Google DeepMind:
� Atari player: a DeepRL system which combines Deep Neural Networks with Reinforcement Learning (Mnih
et al. 2015)
� Neural Turing Machines (Graves, Wayne, and Danihelka 2014)
Artificial Intelligence:
� Artificial Intelligence course at MIT
http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/
6-034-artificial-intelligence-fall-2010/index.htm

Further Reading II
� Introduction to Artificial Intelligence at Udacity
https://www.udacity.com/course/intro-to-artificial-intelligence--cs271
� General Game Playing course https://www.coursera.org/course/ggp
� Singularity http://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html + Part 2
� The Singularity Is Near (Kurzweil 2005)
Combinatorial Game Theory (founded by John H. Conway to study endgames in Go):
� Combinatorial Game Theory course https://www.coursera.org/learn/combinatorial-game-theory
� On Numbers and Games (Conway 1976)
� Computer Go as a sum of local games: an application of combinatorial game theory (Muller 1995)
Chess:
� Deep Blue beats G. Kasparov in 1997 https://youtu.be/NJarxpYyoFI
Machine Learning:
� Machine Learning course
https://youtu.be/hPKJBXkyTK://www.coursera.org/learn/machine-learning/
� Reinforcement Learning http://reinforcementlearning.ai-depot.com/
� Deep Learning (LeCun, Bengio, and Hinton 2015)
Further Reading III
� Deep Learning course https://www.udacity.com/course/deep-learning--ud730
� Two Minute Papers https://www.youtube.com/user/keeroyz
� Applications of Deep Learning https://youtu.be/hPKJBXkyTKM
Neuroscience:
� http://www.brainfacts.org/

References I
Allis, Louis Victor et al. (1994). Searching for solutions in games and artificial intelligence. Ponsen & Looijen.
Baudis, Petr and Jean-loup Gailly (2011). “Pachi: State of the art open source Go program”. In: Advances in
Computer Games. Springer, pp. 24–38.
Bowling, Michael et al. (2015). “Heads-up limit holdem poker is solved”. In: Science 347.6218, pp. 145–149. url:
http://poker.cs.ualberta.ca/15science.html.
Conway, John Horton (1976). “On Numbers and Games”. In: London Mathematical Society Monographs 6.
Graves, Alex, Greg Wayne, and Ivo Danihelka (2014). “Neural turing machines”. In: arXiv preprint
arXiv:1410.5401.
Kurzweil, Ray (2005). The singularity is near: When humans transcend biology. Penguin.
LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton (2015). “Deep learning”. In: Nature 521.7553, pp. 436–444.
Mnih, Volodymyr et al. (2015). “Human-level control through deep reinforcement learning”. In: Nature 518.7540,
pp. 529–533. url:
https://storage.googleapis.com/deepmind-data/assets/papers/DeepMindNature14236Paper.pdf.
Muller, Martin (1995). “Computer Go as a sum of local games: an application of combinatorial game theory”.
PhD thesis. TU Graz.
Silver, David et al. (2016). “Mastering the game of Go with deep neural networks and tree search”. In: Nature
529.7587, pp. 484–489.