alphago in depth
TRANSCRIPT

1
AlphaGoinDepth
byMarkChang
1

Overview• AIinGamePlaying• MachineLearningandDeepLearning• ReinforcementLearning• AlphaGo'sMethods
2

AIinGamePlaying• AIinGamePlaying– AdversarialSearch–MiniMax– MonteCarloTreeSearch– MulI-ArmedBanditProblem
3
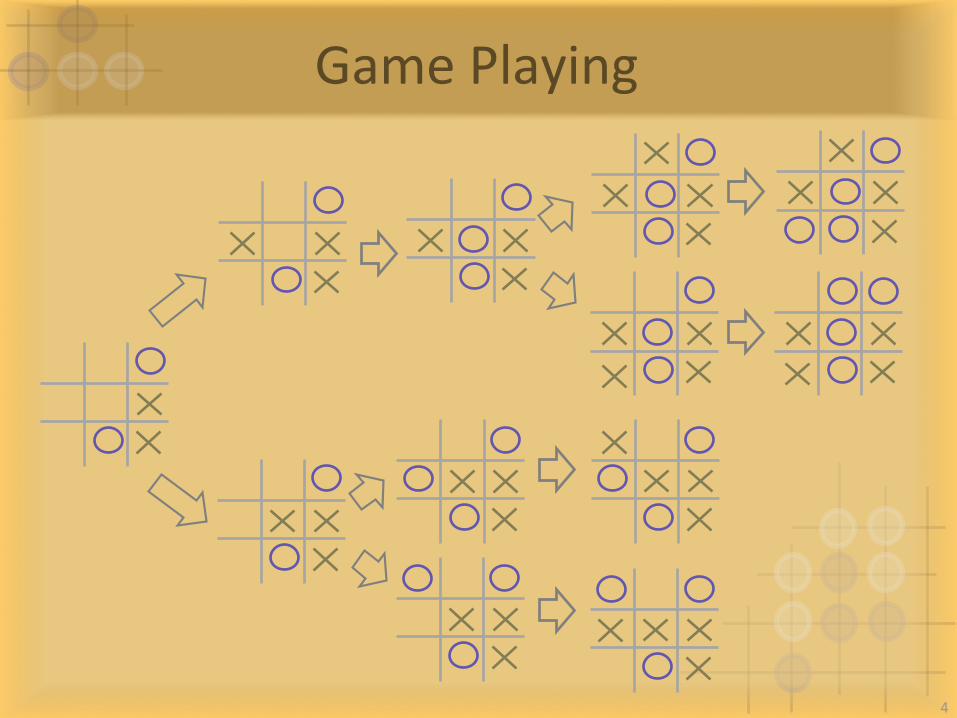
GamePlaying
4

AdversarialSearch–MiniMax
-1 0
1 0
0 0 -1 -1 -1 -1
1 1
5
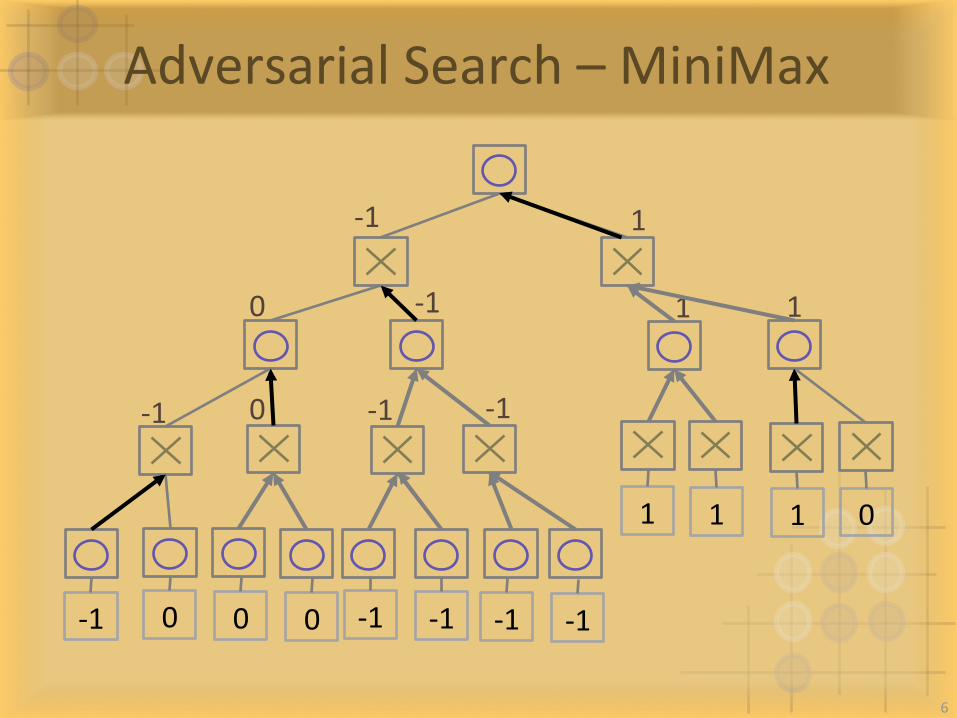
AdversarialSearch–MiniMax
-1 0
1 0
0 0 -1 -1 -1 -1
1 1
-1 0 -1 -1
1 10 -1
1-1
6
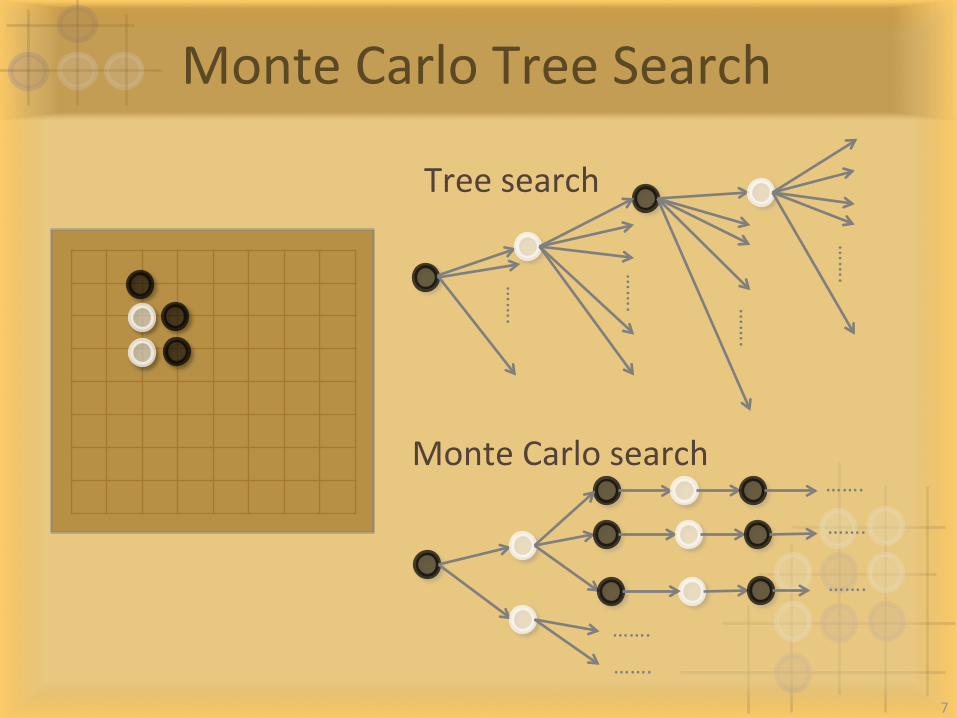
MonteCarloTreeSearch
…….
……. …….
…….
…….
…….
…….
…….
Treesearch
MonteCarlosearch
…….
7

MonteCarloTreeSearch• TreeSearch+MonteCarloMethod– SelecIon– Expansion– SimulaIon– Back-PropagaIon
3/5
1/22/3
0/1
whitewins/total
1/21/1 1/1
1/1 0/1
8
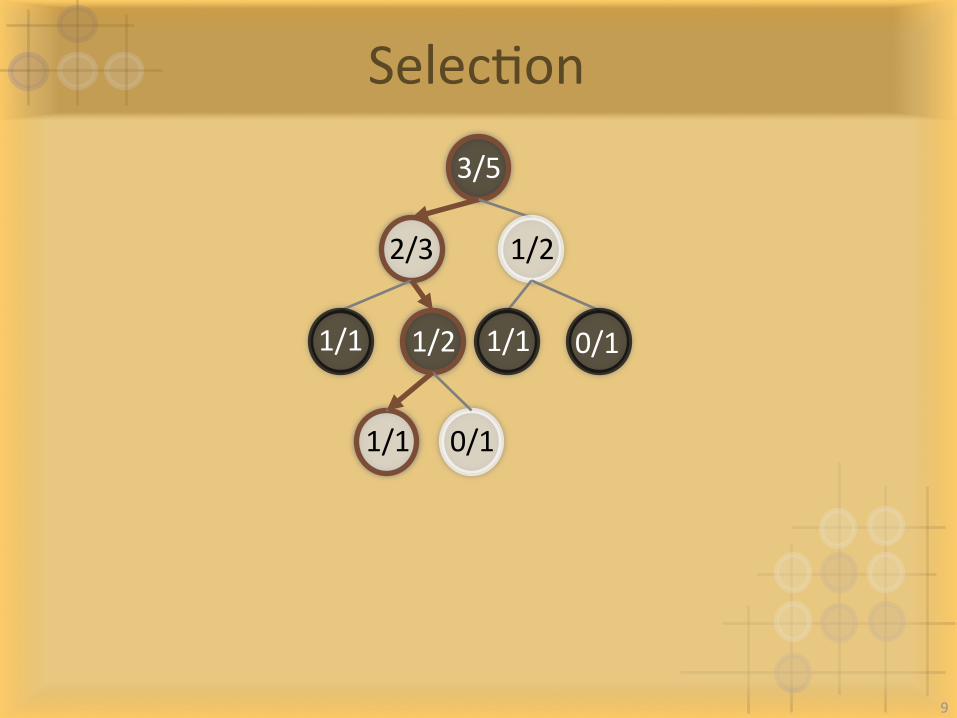
SelecIon
3/5
1/22/3
0/11/21/1 1/1
1/1 0/1
9
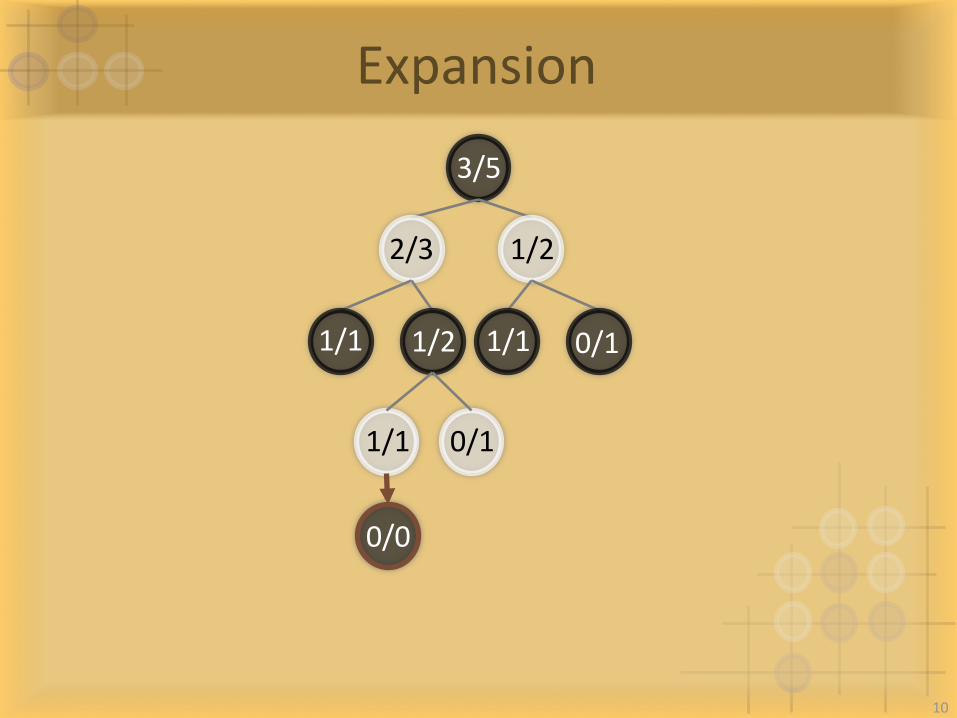
Expansion
3/5
1/22/3
0/11/21/1 1/1
1/1 0/1
0/0
10
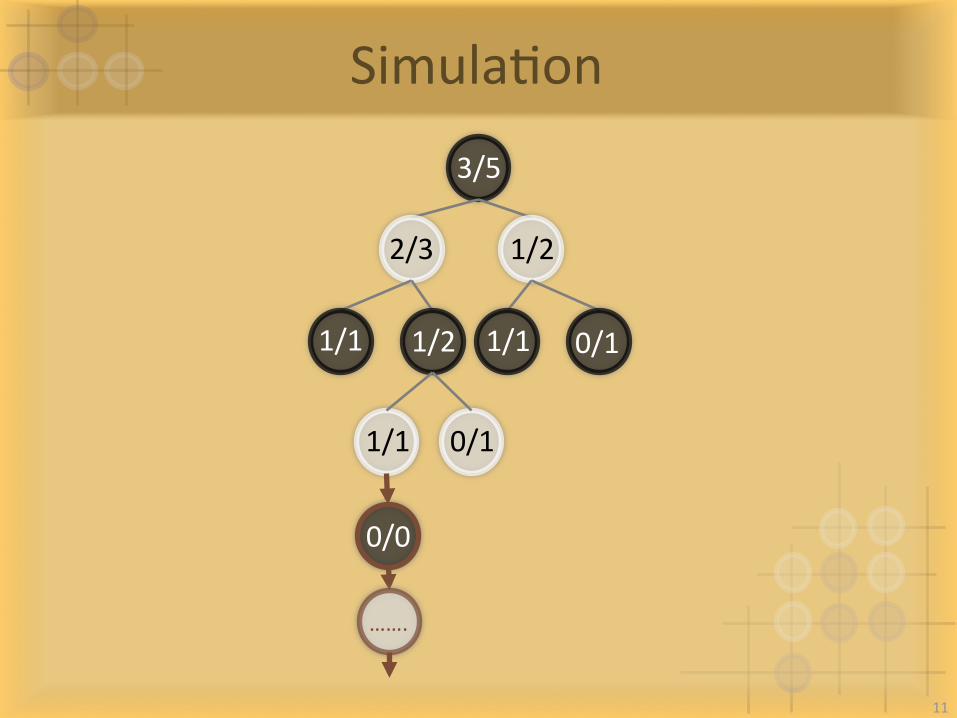
SimulaIon
0/0
…….
3/5
1/22/3
0/11/21/1 1/1
1/1 0/1
11
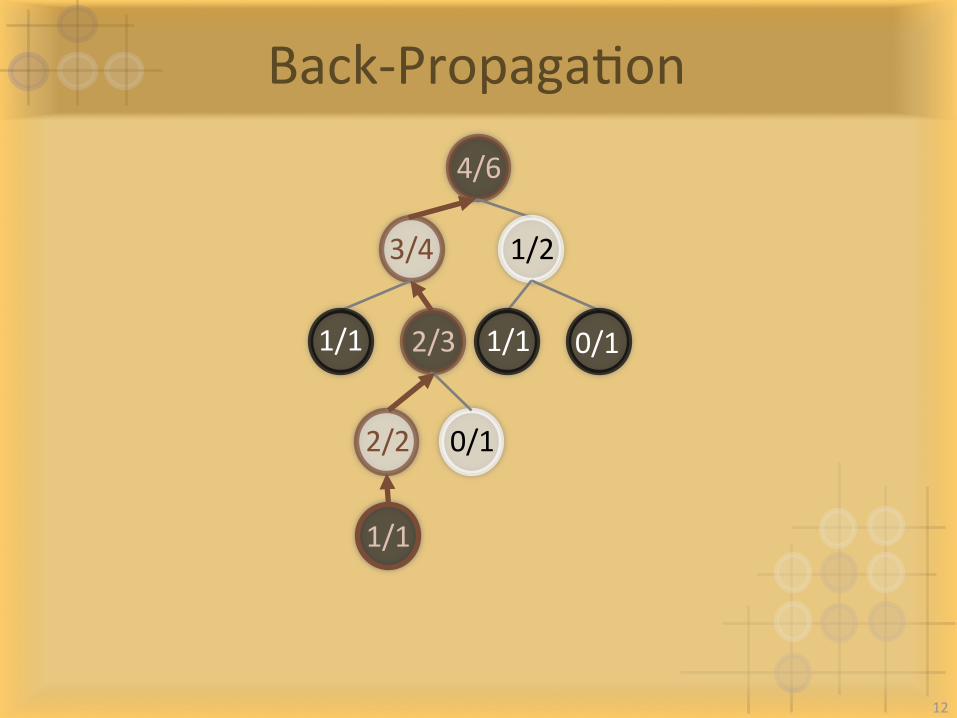
Back-PropagaIon
4/6
1/23/4
0/12/31/1 1/1
2/2 0/1
1/1
12
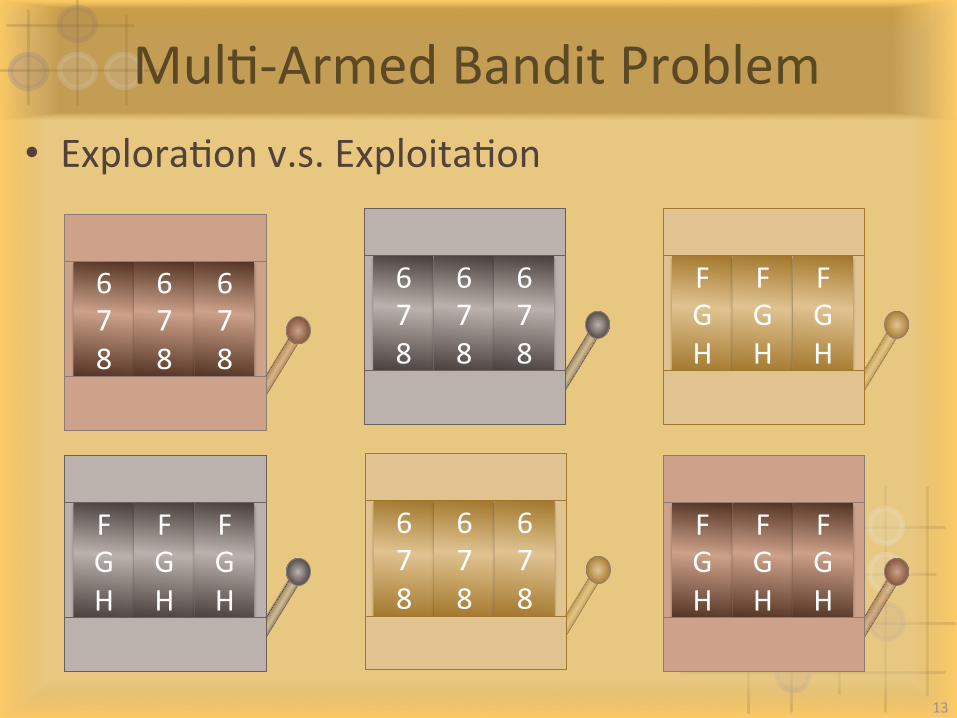
MulI-ArmedBanditProblem• ExploraIonv.s.ExploitaIon
678
678
678
678
678
678
678
678
678
FGH
FGH
FGH
FGH
FGH
FGH
FGH
FGH
FGH
13
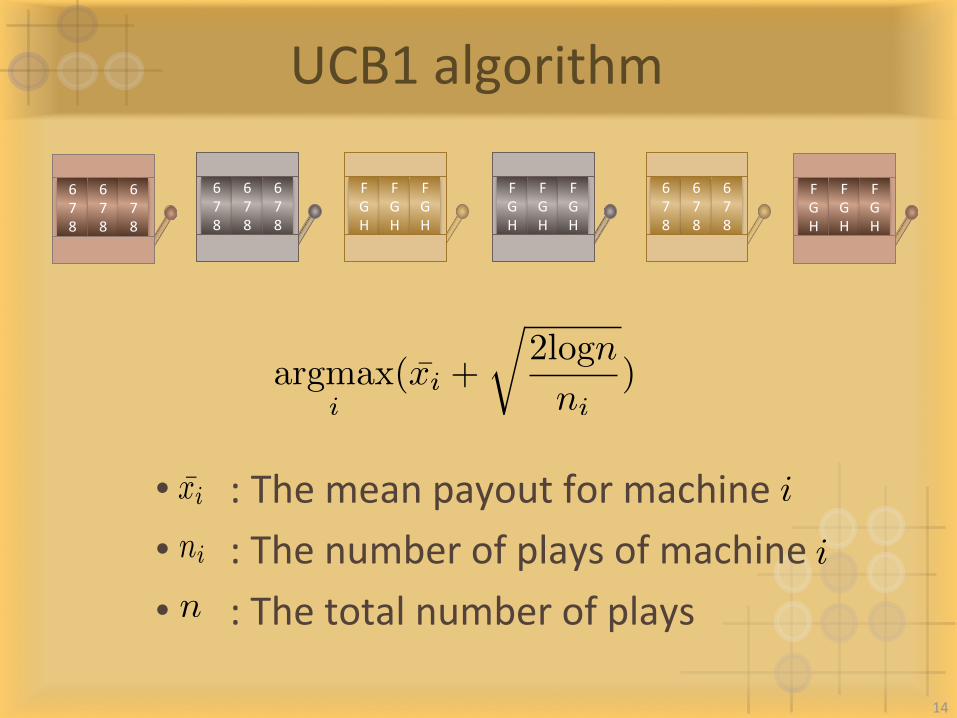
UCB1algorithm
argmax
i(x̄i +
r2logn
ni)
• :Themeanpayoutformachine• :Thenumberofplaysofmachine• :Thetotalnumberofplays
x̄i +
r2logn
nix̄i +
r2logn
ni
i
i
n
678
678
678
678
678
678
FGH
FGH
FGH
678
678
678
FGH
FGH
FGH
FGH
FGH
FGH
14
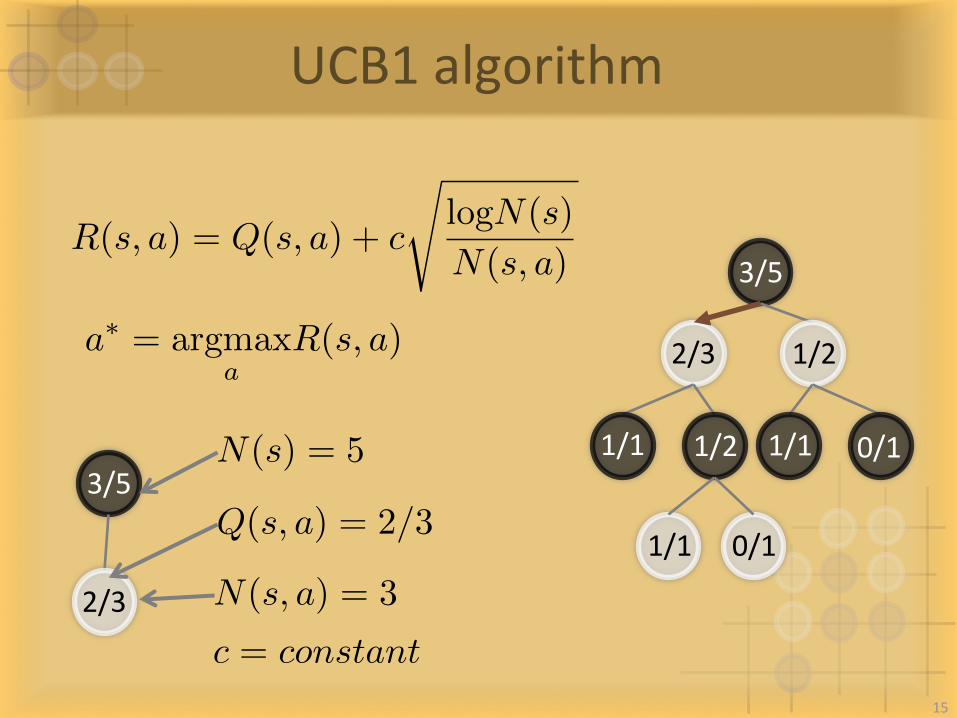
UCB1algorithm
R(s, a) = Q(s, a) + c
slogN(s)
N(s, a) 3/5
1/22/3
0/11/21/1 1/1
1/1 0/1
a⇤ = argmax
aR(s, a)
3/5
2/3 N(s, a) = 3
N(s) = 5
c = constant
Q(s, a) = 2/3
15

UCB1algorithm
3/5
1/22/3
0/11/21/1 1/1
1/1 0/1
R(s, a1) = 2/3 + 0.5
rlog5
3
= 1.3029
R(s, a2) = 1/2 + 0.5
rlog5
2
= 0.9485s
a1 a2R(s, a1) > R(s, a2)
a⇤ = argmax
aR(s, a) = a1
16

MachineLearningandDeepLearning• MachineLearningandDeepLearning:– SupervisedMachineLearning– NeuralNetworks– ConvoluIonalNeuralNetworks– TrainingNeuralNetworks
17
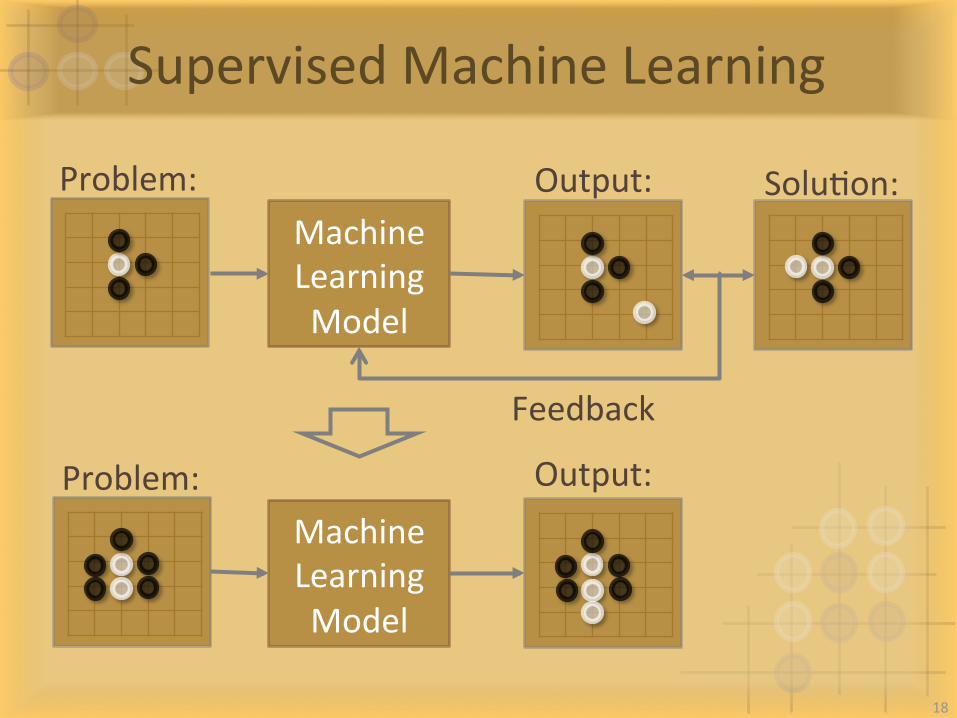
SupervisedMachineLearning
MachineLearningModel
Problem: SoluIon:Output:
Problem: Output:MachineLearningModel
Feedback
18
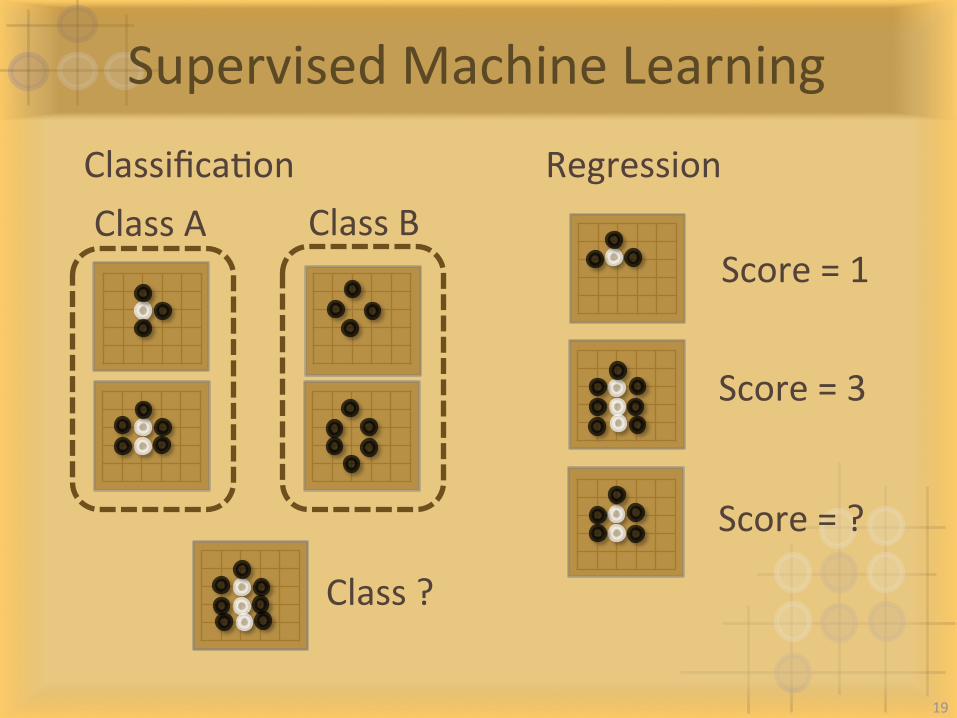
SupervisedMachineLearning
ClassificaIon RegressionClassA ClassB
Score=1
Score=?
Score=3
19
Class?
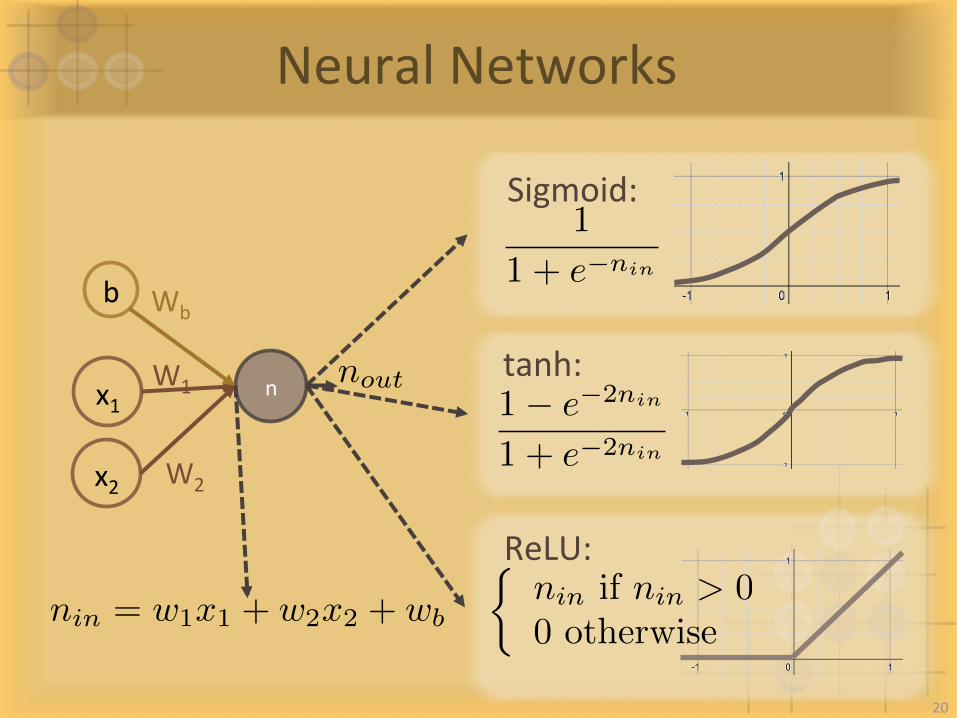
NeuralNetworks
n W1
W2
x1
x2
b Wb
nin = w1x1 + w2x2 + wb
Sigmoid:nout
=1
1 + e�nin
nout
1� e�2nin
1 + e�2nin
tanh:
ReLU:⇢nin if nin > 0
0 otherwise
20
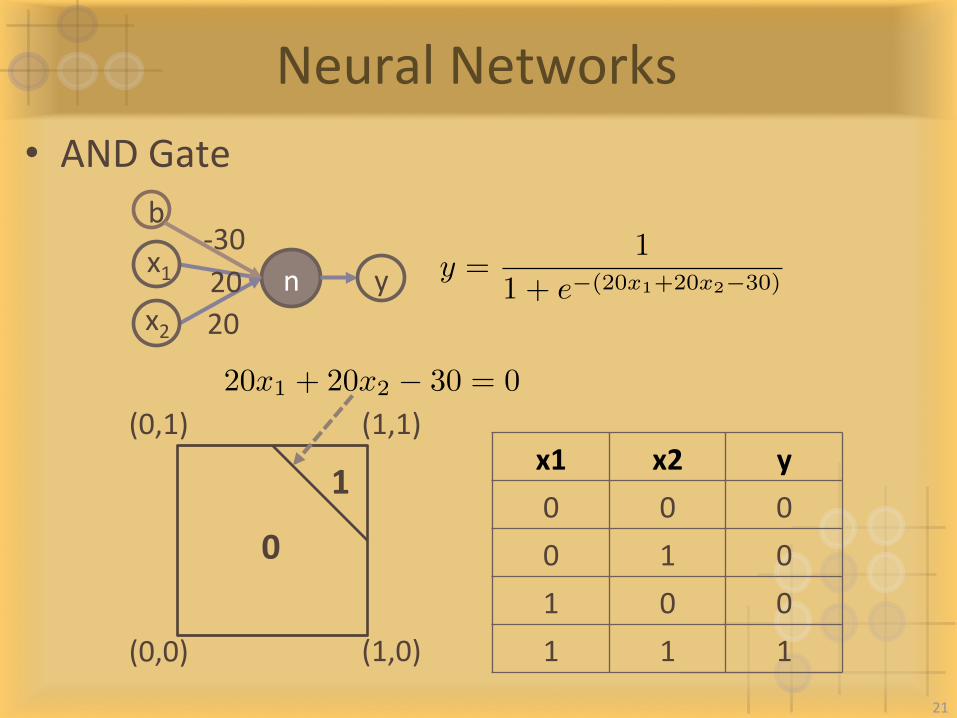
NeuralNetworks• ANDGate
x1 x2 y 0 0 0 0 1 0 1 0 0 1 1 1 (0,0)
(0,1) (1,1)
(1,0)
0
1
n
b-30
y x1x2
20 20
y =1
1 + e�(20x1+20x2�30)
20x1 + 20x2 � 30 = 0
21
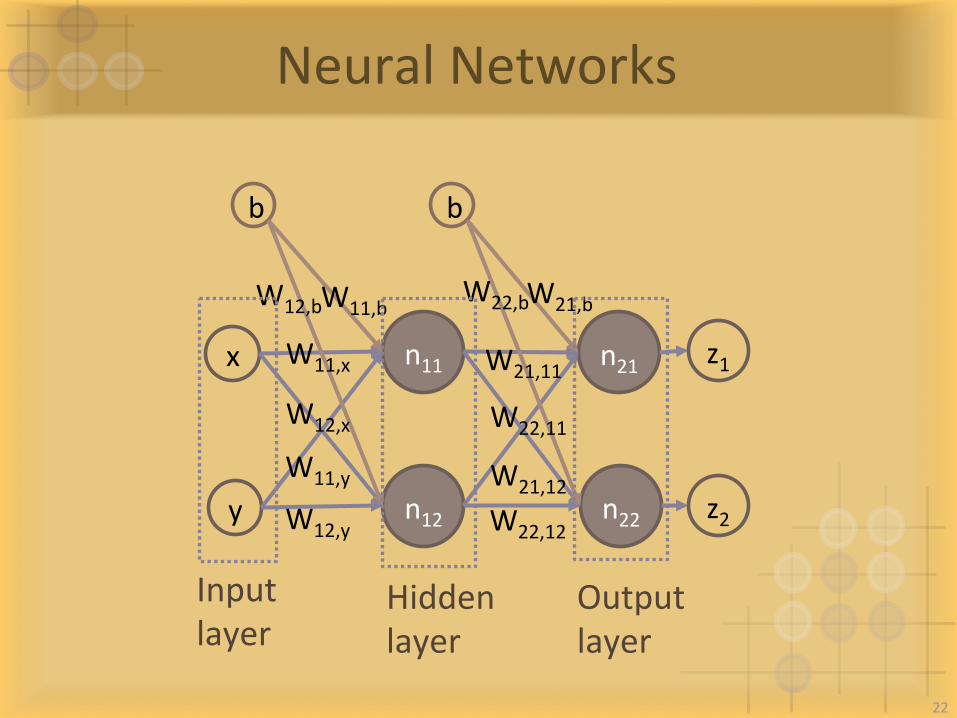
NeuralNetworks
x
y
n11
n12
n21
n22
b b
z1
z2 W12,y
W12,x
W11,y
W11,b W12,b
W11,x W21,11
W22,12
W21,12
W22,11
W21,b W22,b
Inputlayer
Hiddenlayer
Outputlayer
22
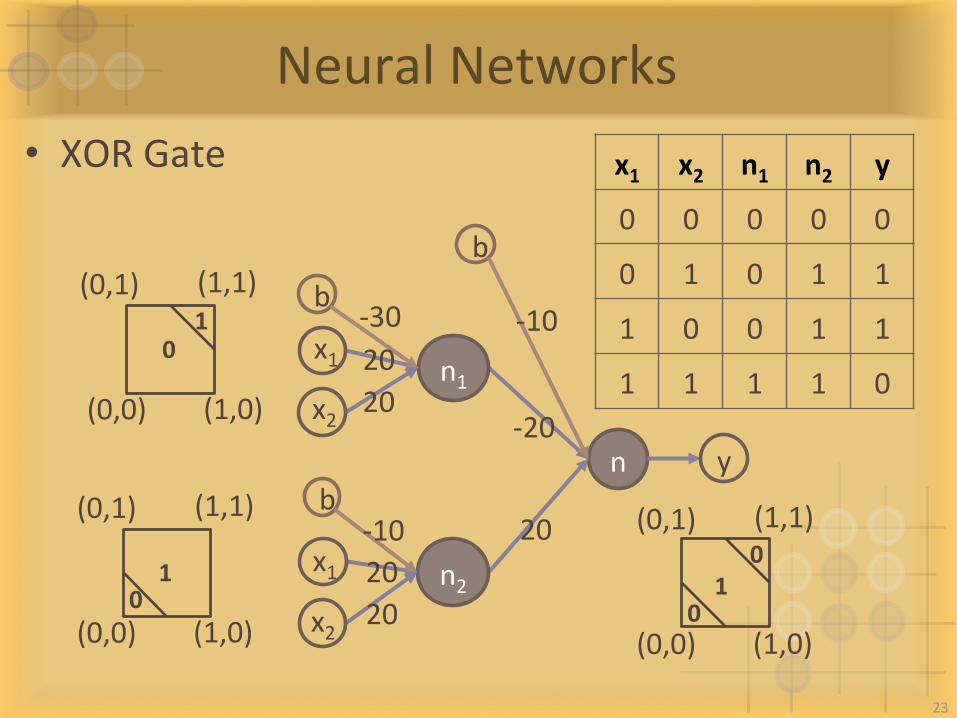
NeuralNetworks• XORGate
n -20
20
b
-10
y
(0,0)
(0,1) (1,1)
(1,0)
0 1
(0,0)
(0,1) (1,1)
(1,0)
1 0
(0,0)
(0,1) (1,1)
(1,0) 0
0 1
n1
b-30 20 20
x1
x2
n2
b-10 20 20
x1
x2
x1 x2 n1 n2 y
0 0 0 0 0
0 1 0 1 1
1 0 0 1 1
1 1 1 1 0
23

MulI-ClassClassificaIon• SogMax
n1
n2
n3
n1,out =en1,in
en1,in + en2,in + en3,in
n2,out =en2,in
en1,in + en2,in + en3,in
n3,out =en3,in
en1,in + en2,in + en3,in
n1,in
n2,in
n3,in
24
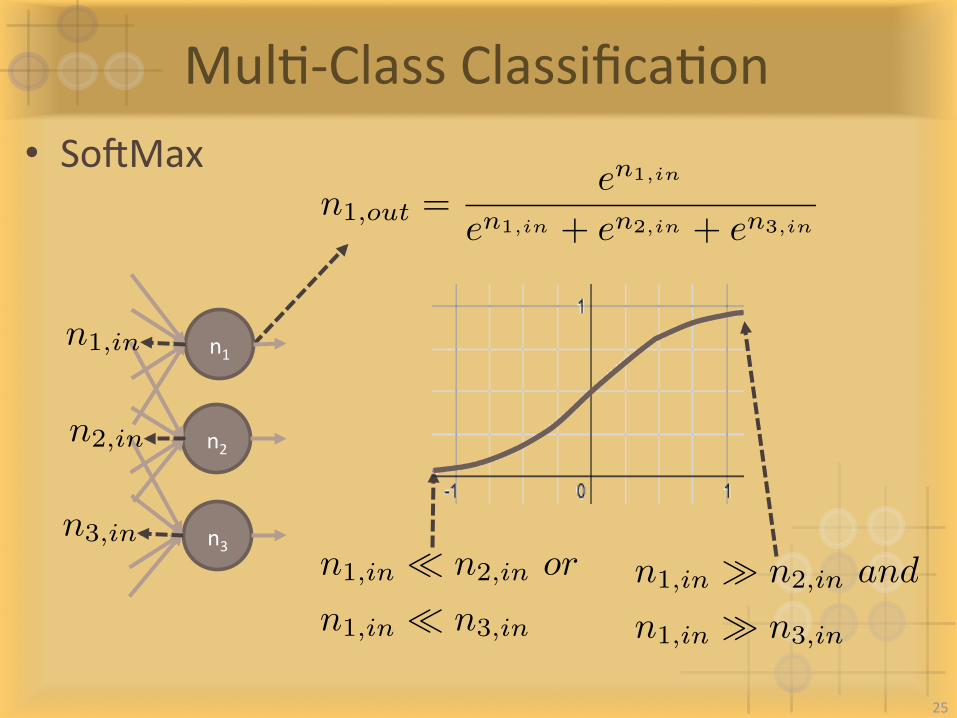
MulI-ClassClassificaIon• SogMax
n1,out =en1,in
en1,in + en2,in + en3,in
n1
n2
n3
n1,in
n2,in
n3,in
25
n1,in � n2,in and
n1,in � n3,in
n1,in ⌧ n2,in or
n1,in ⌧ n3,in
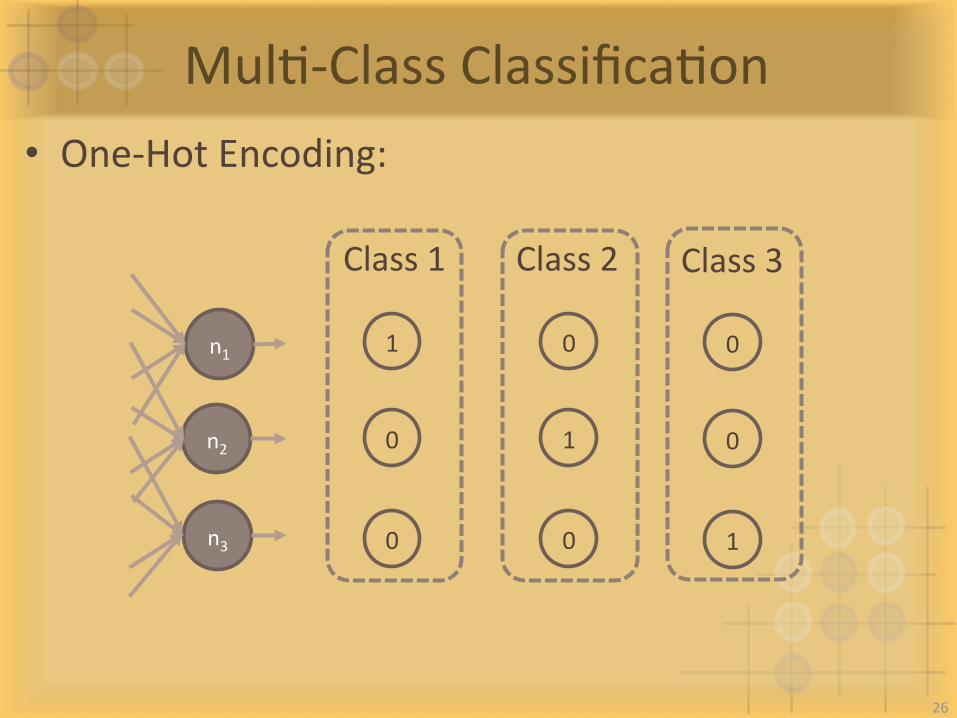
MulI-ClassClassificaIon• One-HotEncoding:
Class1 Class2 Class3
1
0
0
0
1
0
0
0
1
n1
n2
n3
26
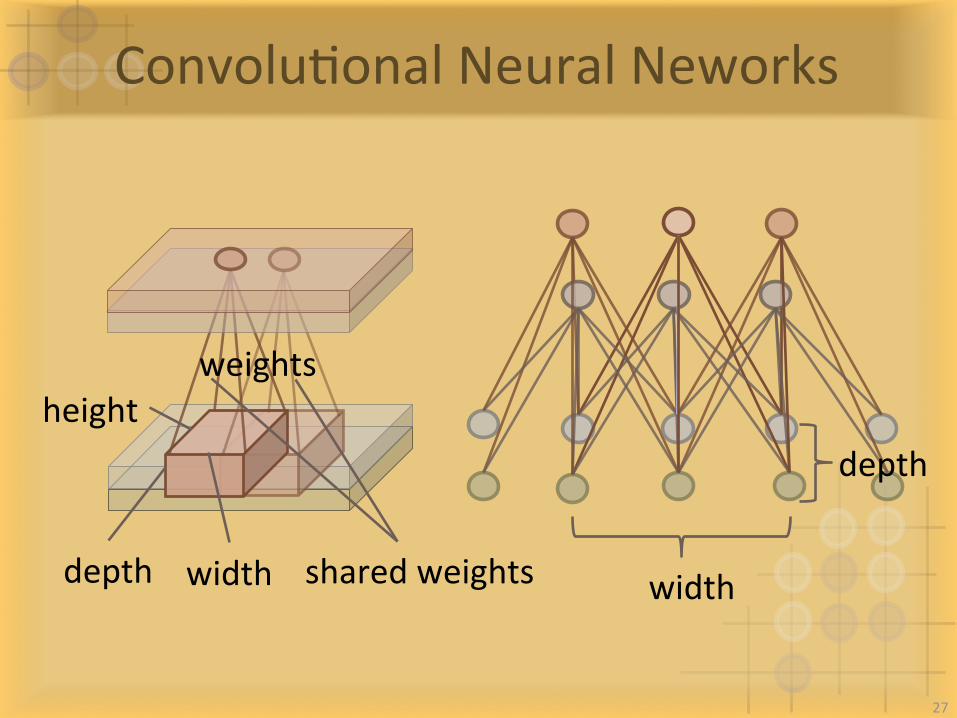
ConvoluIonalNeuralNeworks
depth
widthwidthdepth
weightsheight
sharedweights
27
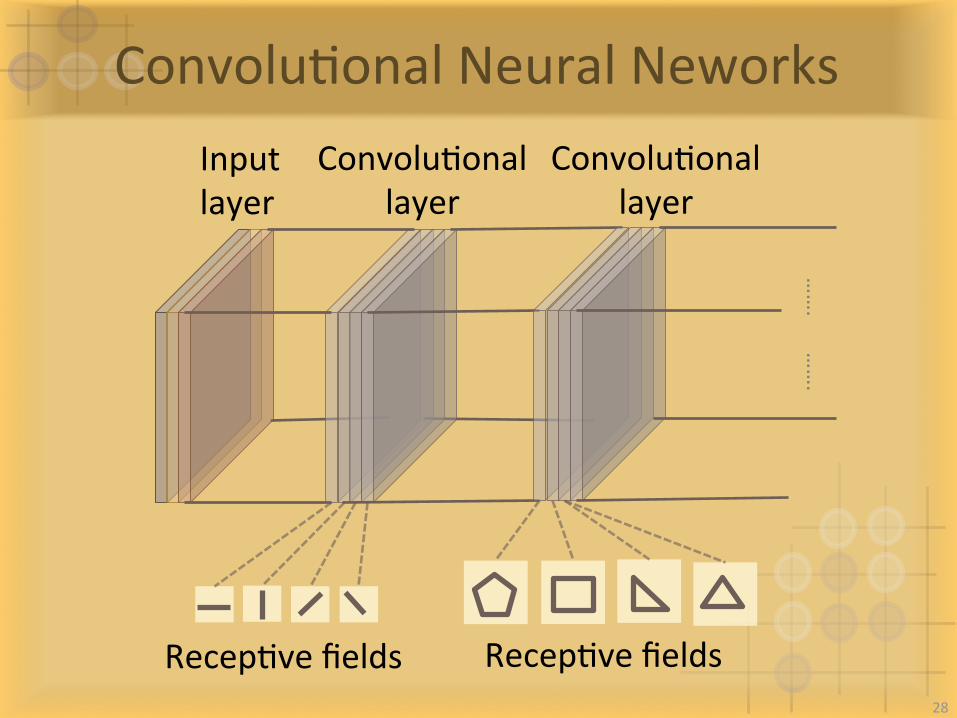
ConvoluIonalNeuralNeworksConvoluIonal
layer
RecepIvefields RecepIvefields
Inputlayer
ConvoluIonallayer
…….
…….
28
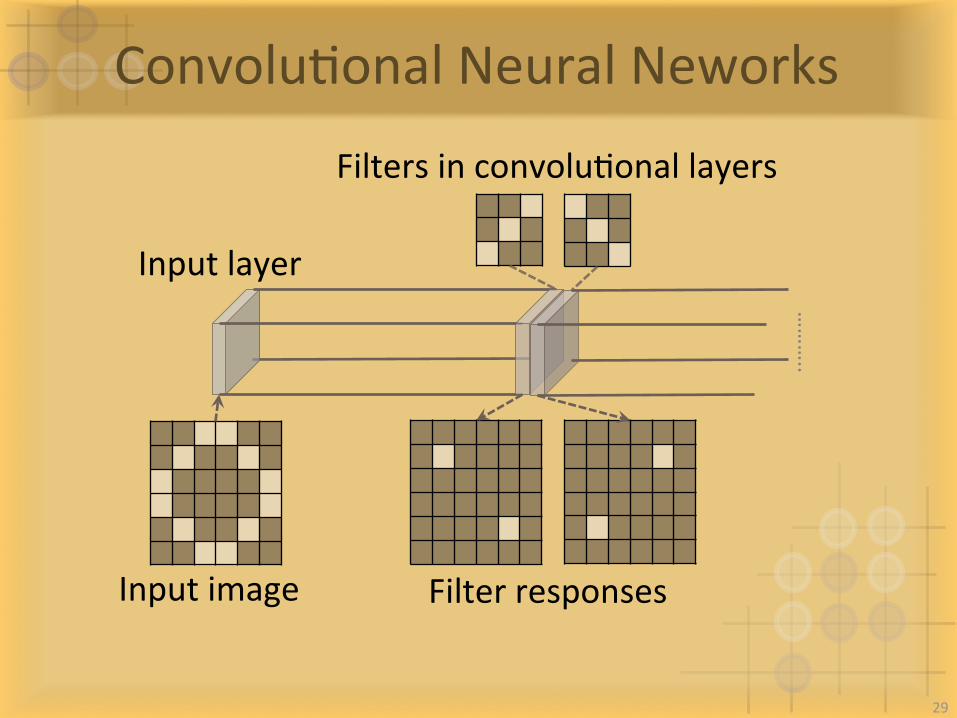
ConvoluIonalNeuralNeworks
Inputlayer
FilterresponsesInputimage
FiltersinconvoluIonallayers………..
29
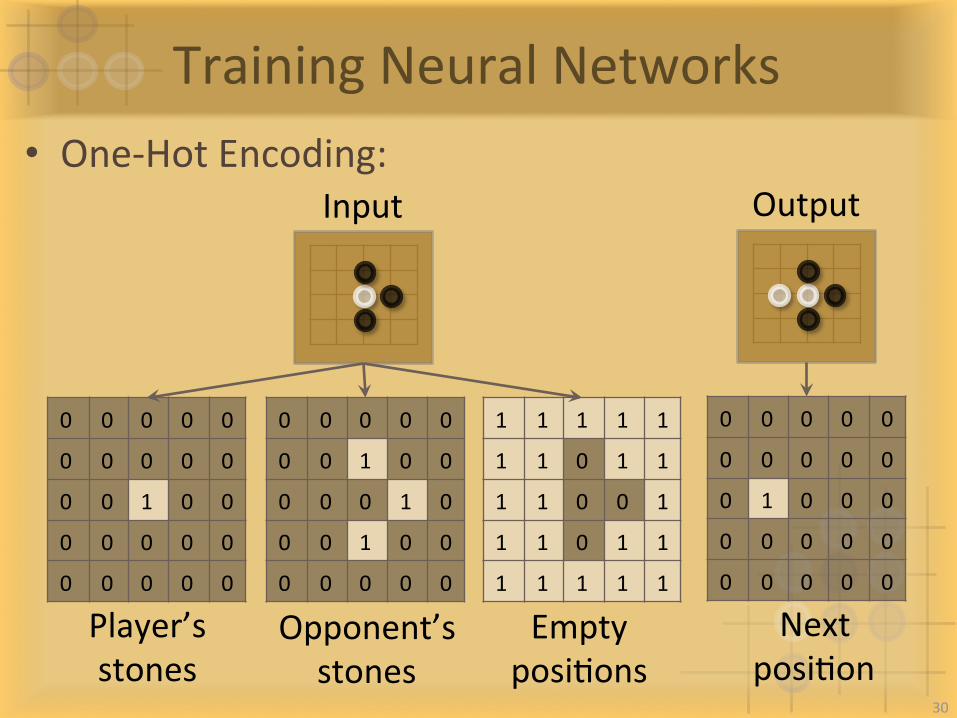
TrainingNeuralNetworks• One-HotEncoding:
0 0 0 0 0
0 0 0 0 0
0 0 1 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 1 0 0
0 0 0 0 0
1 1 1 1 1
1 1 0 1 1
1 1 0 0 1
1 1 0 1 1
1 1 1 1 1
0 0 0 0 0
0 0 0 0 0
0 1 0 0 0
0 0 0 0 0
0 0 0 0 0
Player’sstones
Opponent’sstones
EmptyposiIons
NextposiIon
Input Output
30
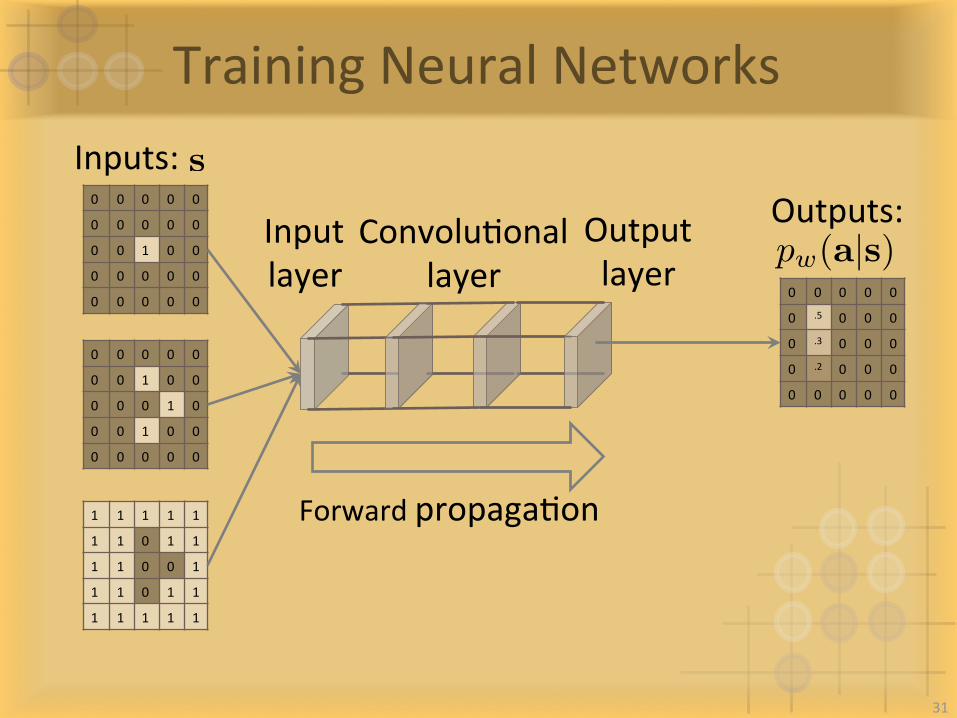
TrainingNeuralNetworks
0 0 0 0 0
0 0 0 0 0
0 0 1 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 1 0 0
0 0 0 0 0
1 1 1 1 1
1 1 0 1 1
1 1 0 0 1
1 1 0 1 1
1 1 1 1 1
0 0 0 0 0
0 .5 0 0 0
0 .3 0 0 0
0 .2 0 0 0
0 0 0 0 0
ForwardpropagaIon
pw(a|s)
Inputs:
Inputlayer
ConvoluIonallayer
Outputlayer
Outputs:s
31
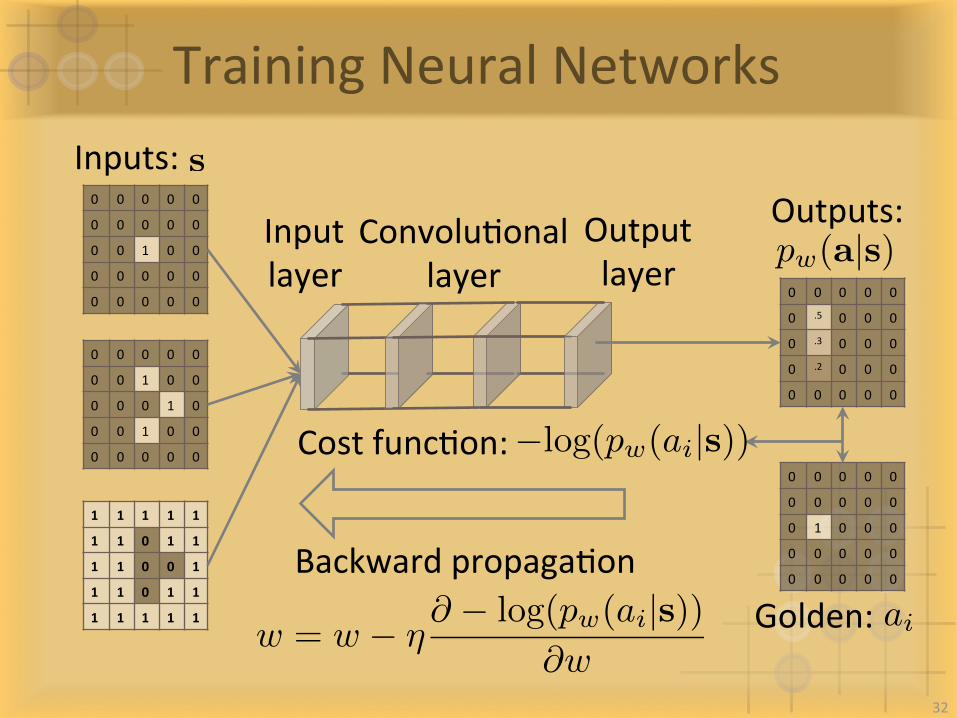
TrainingNeuralNetworks
0 0 0 0 0
0 0 0 0 0
0 0 1 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 1 0 0
0 0 0 0 0
1 1 1 1 1
1 1 0 1 1
1 1 0 0 1
1 1 0 1 1
1 1 1 1 1
0 0 0 0 0
0 .5 0 0 0
0 .3 0 0 0
0 .2 0 0 0
0 0 0 0 0
Inputs:
Inputlayer
ConvoluIonallayer
Outputlayer
Outputs:s
pw(a|s)
0 0 0 0 0
0 0 0 0 0
0 1 0 0 0
0 0 0 0 0
0 0 0 0 0
Golden:BackwardpropagaIon
CostfuncIon:
aiw = w � ⌘@ � log(pw(ai|s))
@w32
�log(pw(ai|s))
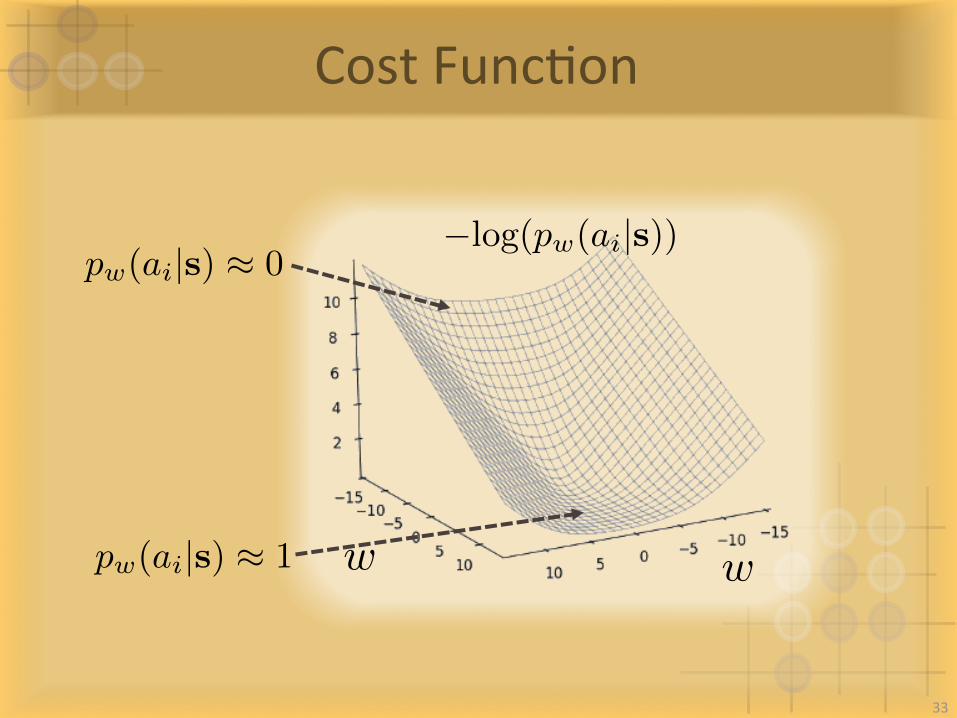
CostFuncIon
w w
pw(ai|s) ⇡ 0
pw(ai|s) ⇡ 1
�log(pw(ai|s))
33
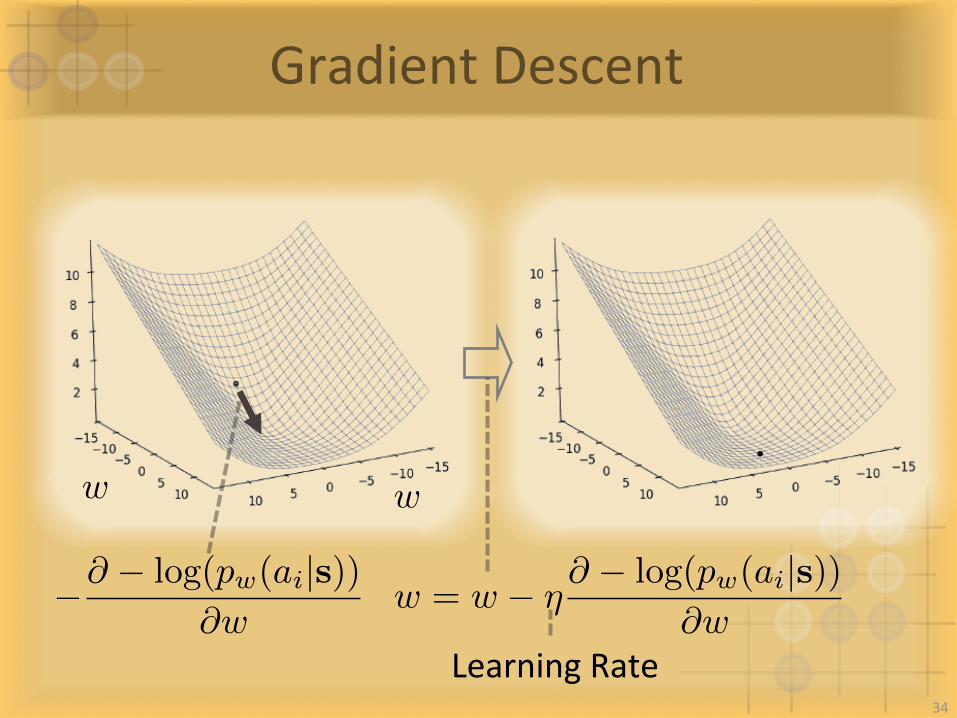
GradientDescent
w w
LearningRate
w = w � ⌘@ � log(pw(ai|s))
@w�@ � log(pw(ai|s))
@w
34
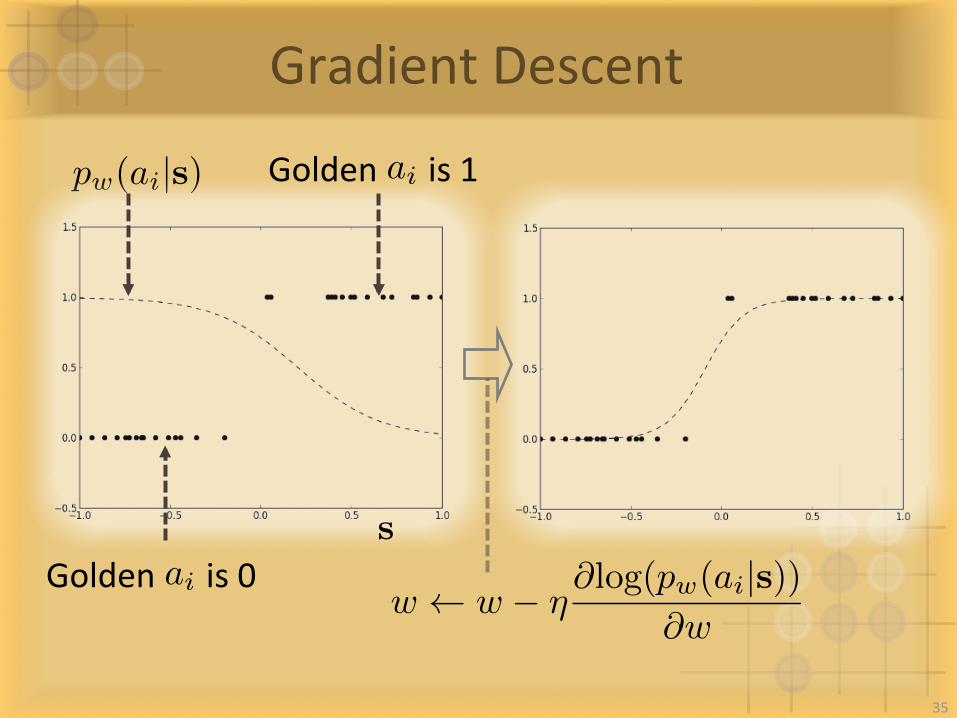
GradientDescent
pw(ai|s)
s
w w � ⌘@log(pw(ai|s))
@w
35
ai = 1Goldenis1
ai = 1Goldenis0
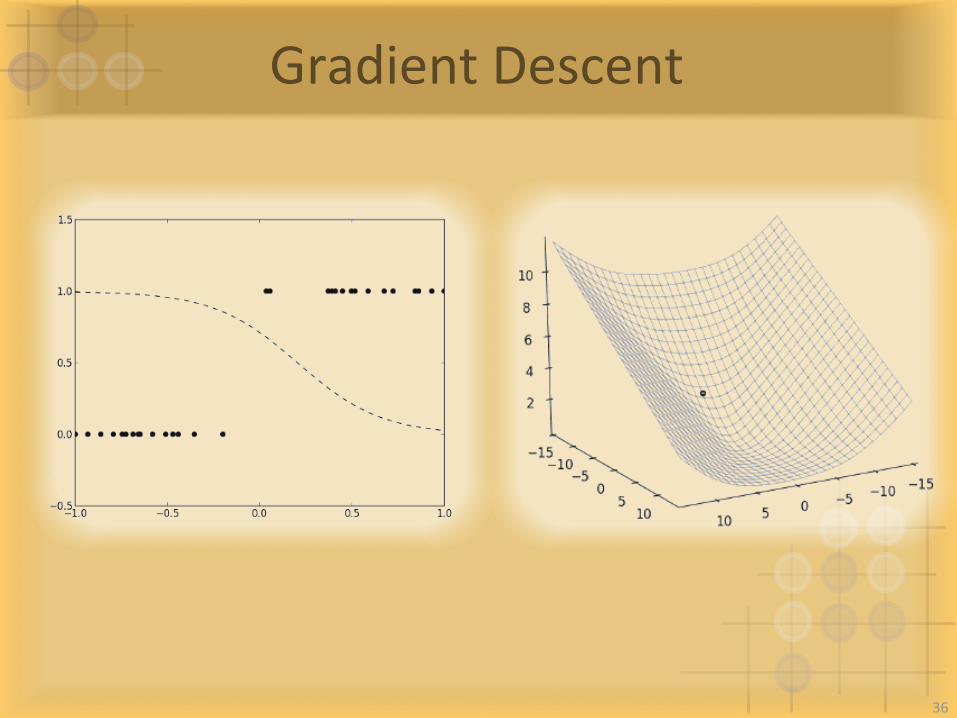
GradientDescent
36
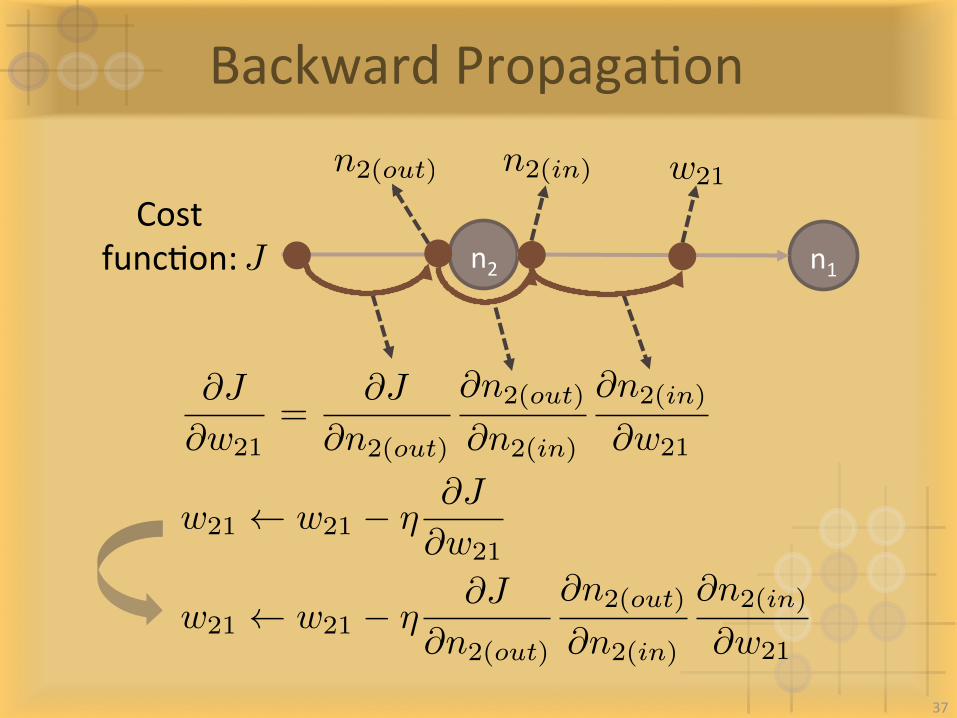
BackwardPropagaIon
n2 n1 JCost
funcIon:
n2(out) n2(in) w21
37
@J
@w21=
@J
@n2(out)
@n2(out)
@n2(in)
@n2(in)
@w21
w21 w21 � ⌘@J
@w21
w21 w21 � ⌘@J
@n2(out)
@n2(out)
@n2(in)
@n2(in)
@w21

ReinforcementLearning• ReinforcementLearning:– Policy&Value– PolicyGradientMethod
38
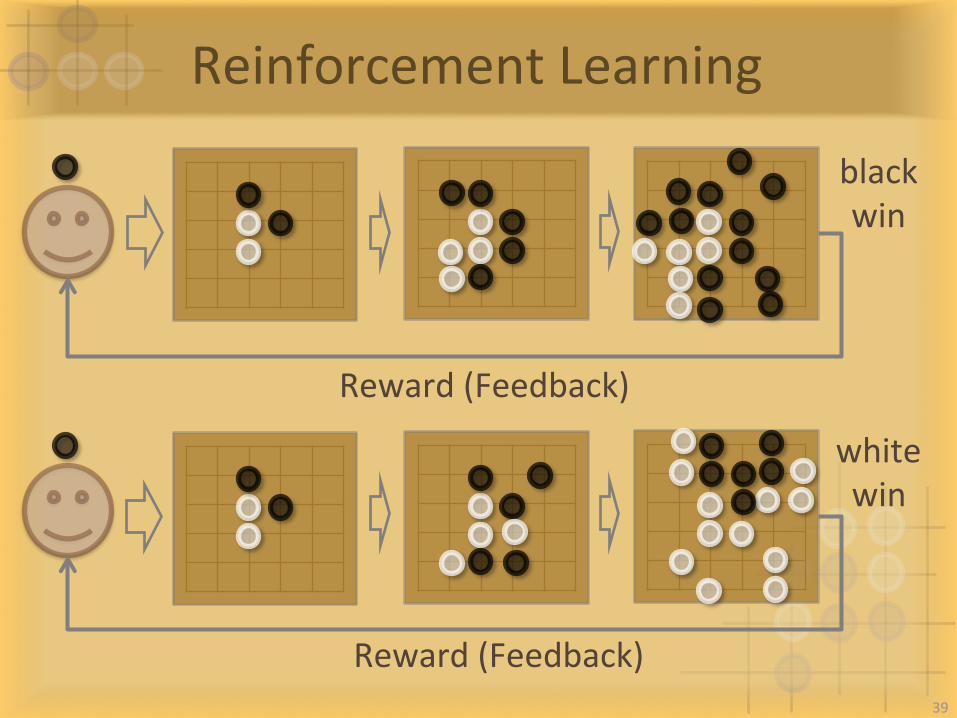
ReinforcementLearning
Reward(Feedback)
Reward(Feedback)
whitewin
blackwin
39
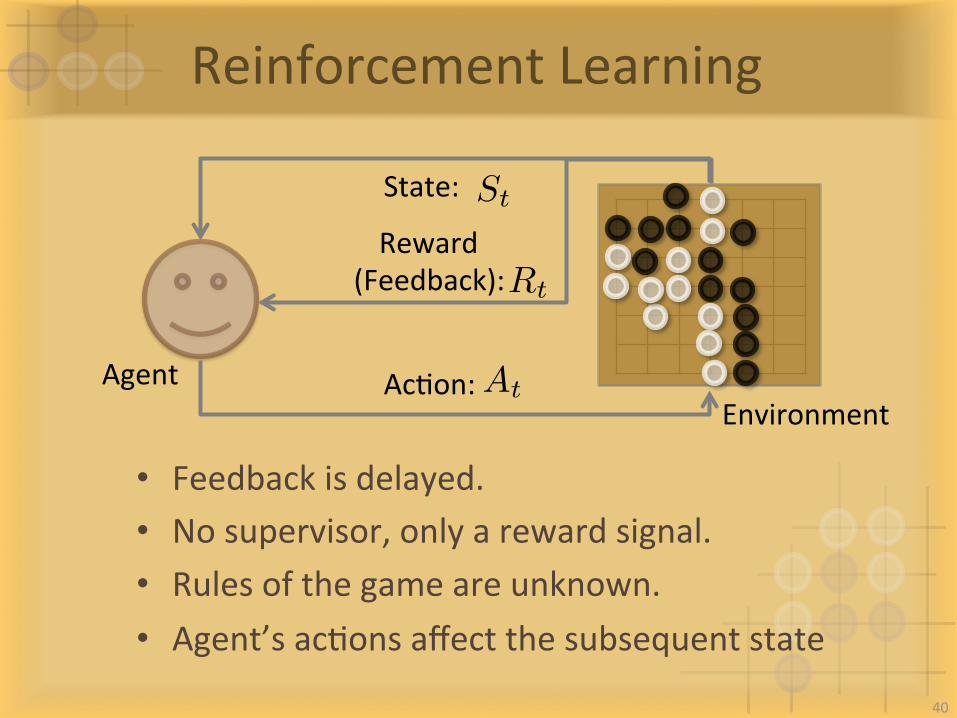
ReinforcementLearning
State: St
Reward(Feedback):Rt
AcIon:At
• Feedbackisdelayed.• Nosupervisor,onlyarewardsignal.• Rulesofthegameareunknown.• Agent’sacIonsaffectthesubsequentstate
AgentEnvironment
40
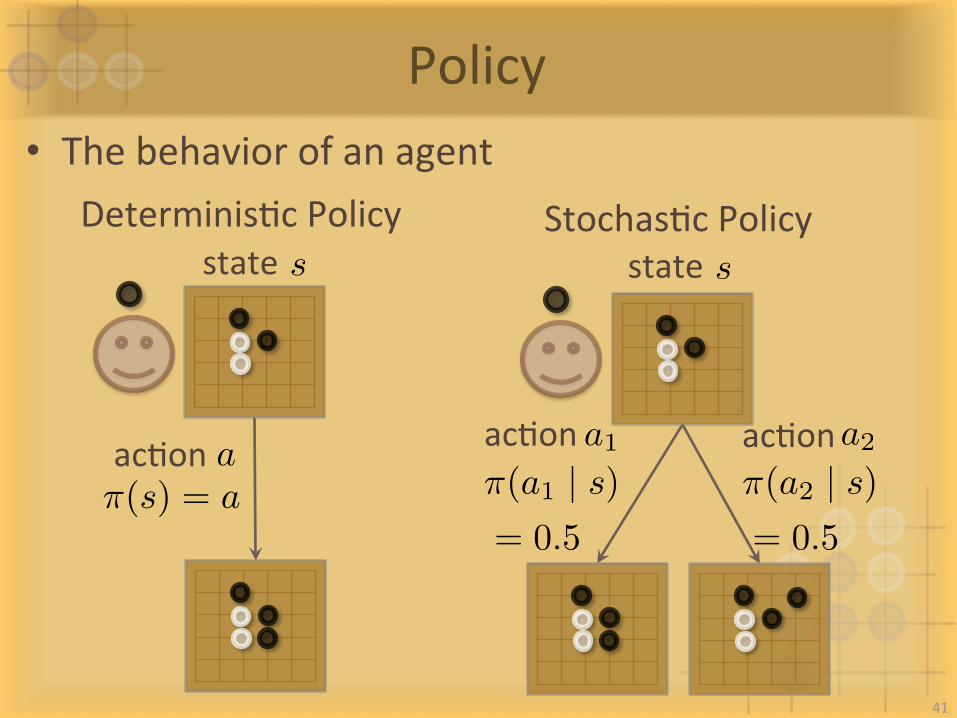
• Thebehaviorofanagent
Policy
sstate
a1acIon a2acIon⇡(a2 | s)= 0.5
⇡(a1 | s)= 0.5
StochasIcPolicysstate
DeterminisIcPolicy
⇡(s) = aacIona
41
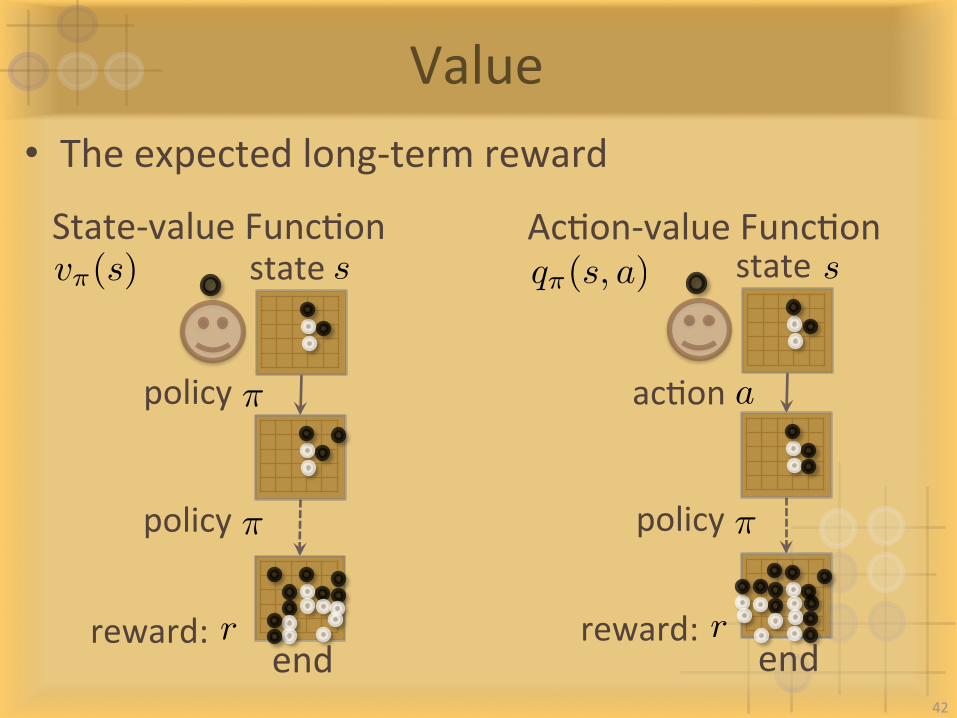
Value• Theexpectedlong-termreward
sstate q⇡(s, a)v⇡(s)
acIona⇡policy
State-valueFuncIon AcIon-valueFuncIon
rreward:
⇡policy
sstate
rreward:
⇡policy
end end42

PolicyGradientMethod• REINFOCE– theREwardIncrement=NonnegaIveFactorOffsetReinforCEment
weightsinpolicyfuncIon
reward baseline(usually=0)
learningrate
43
w w + ↵(r � b)@log⇡(a|s)
@w
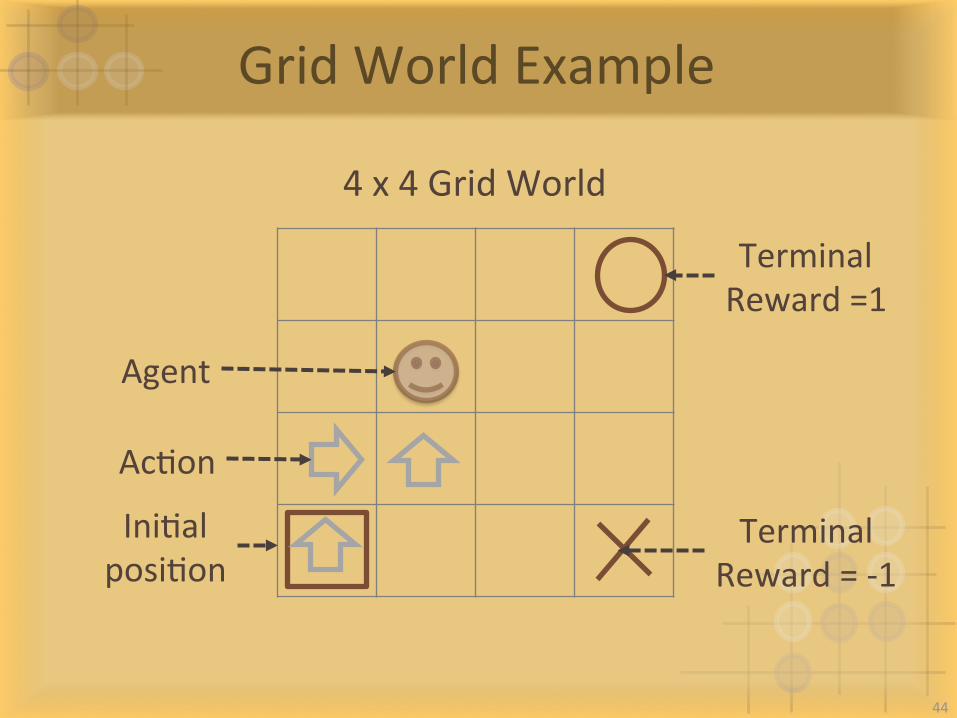
GridWorldExample
4x4GridWorld
TerminalReward=1
TerminalReward=-1
IniIalposiIon
AcIon
Agent
44
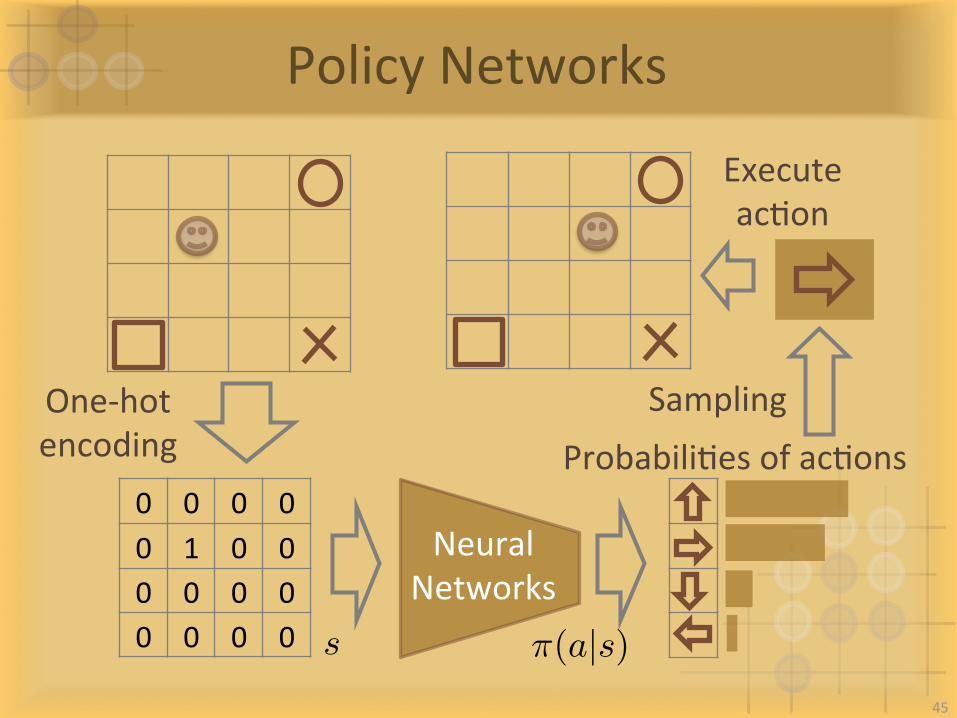
PolicyNetworks
0 0 0 00 1 0 00 0 0 00 0 0 0
One-hotencoding ProbabiliIesofacIons
Sampling
ExecuteacIon
NeuralNetworks
s ⇡(a|s)45
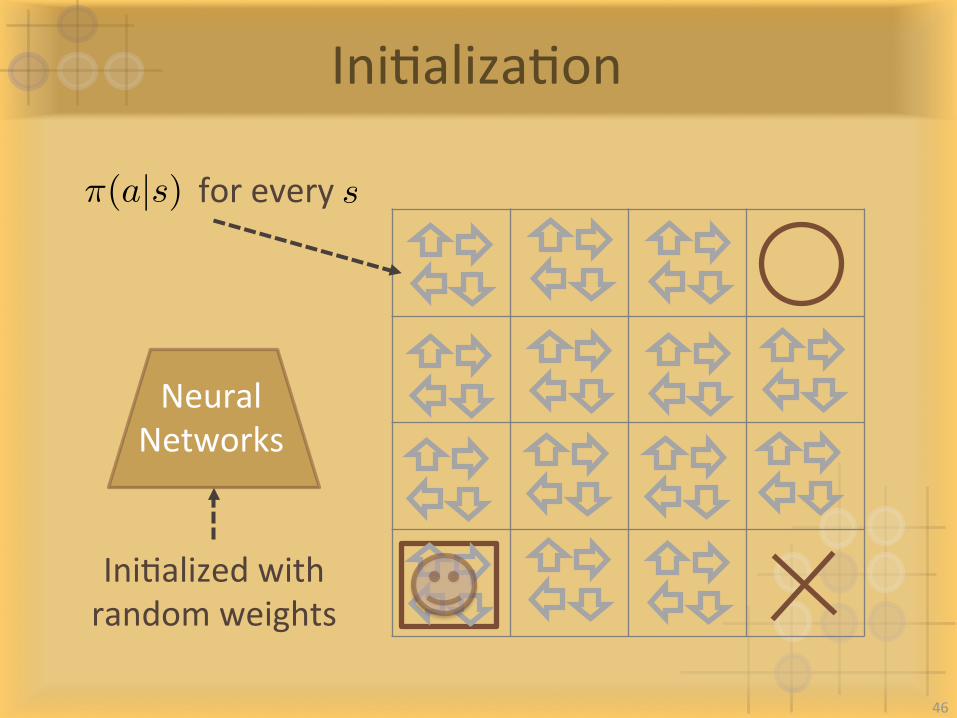
IniIalizaIon
NeuralNetworks
IniIalizedwithrandomweights
⇡(a|s) foreverys
46
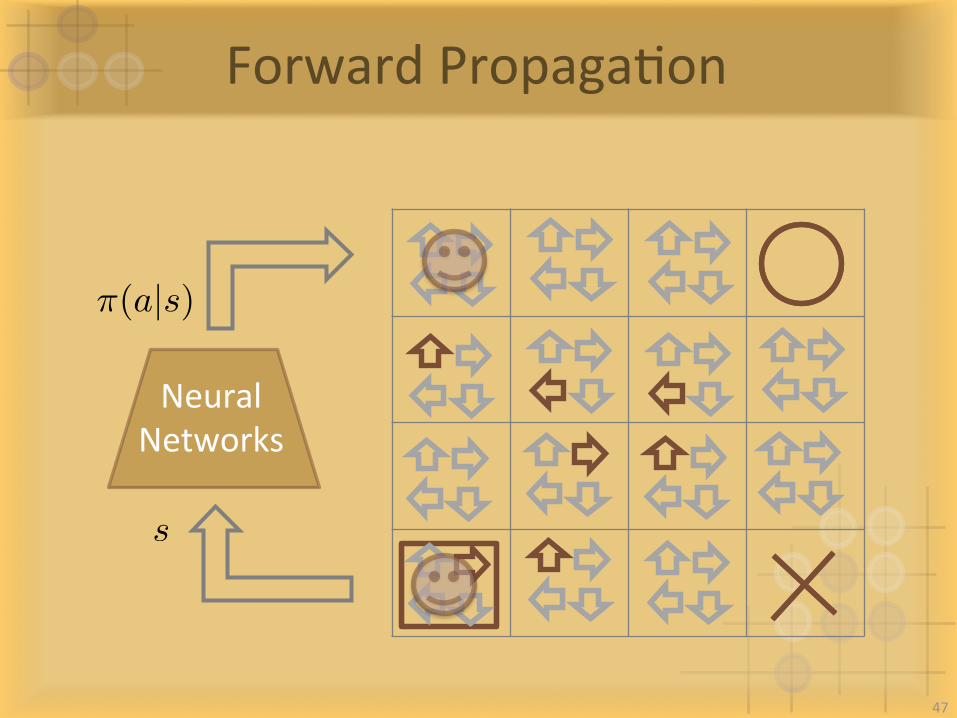
ForwardPropagaIon
NeuralNetworks
⇡(a|s)
s
47
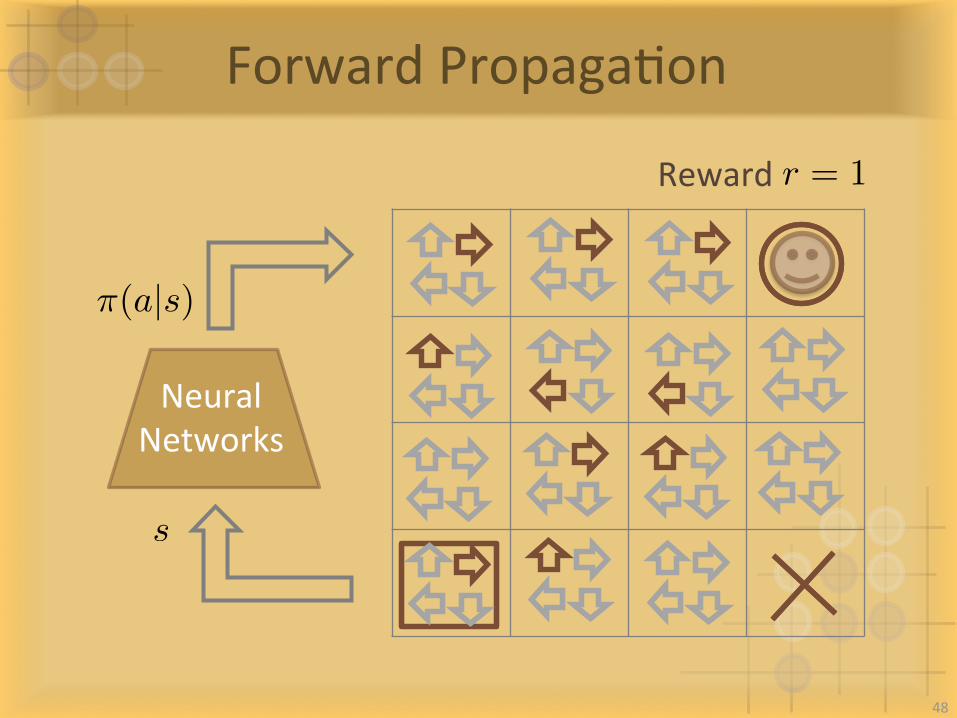
ForwardPropagaIon
NeuralNetworks
⇡(a|s)
s
Rewardr = 1
48
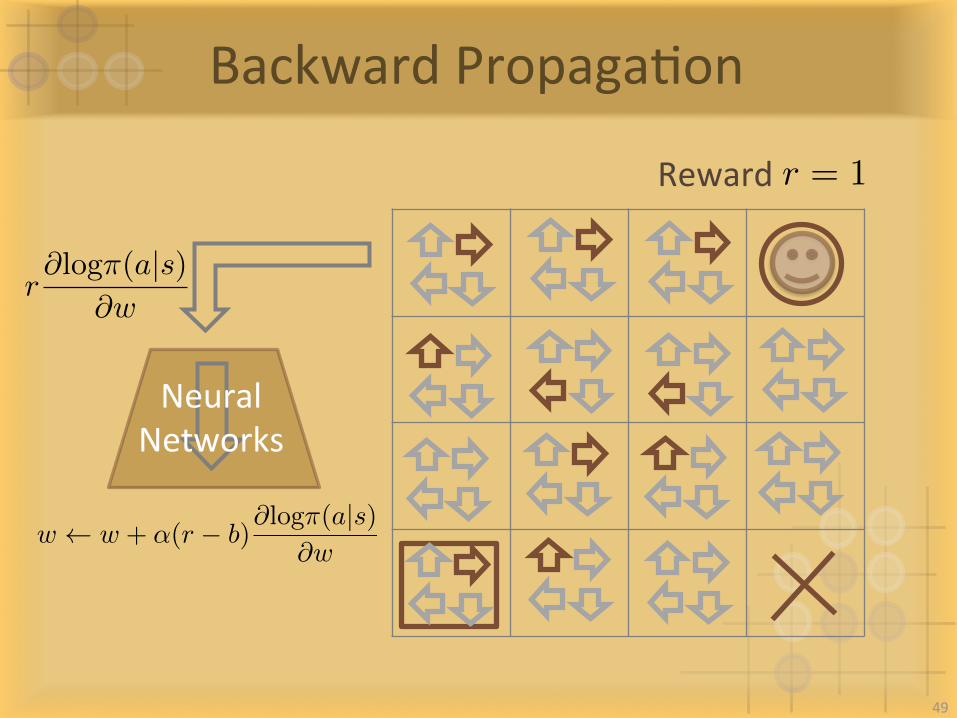
BackwardPropagaIon
NeuralNetworks
Rewardr = 1
49
w w + ↵(r � b)@log⇡(a|s)
@w
r@log⇡(a|s)
@w
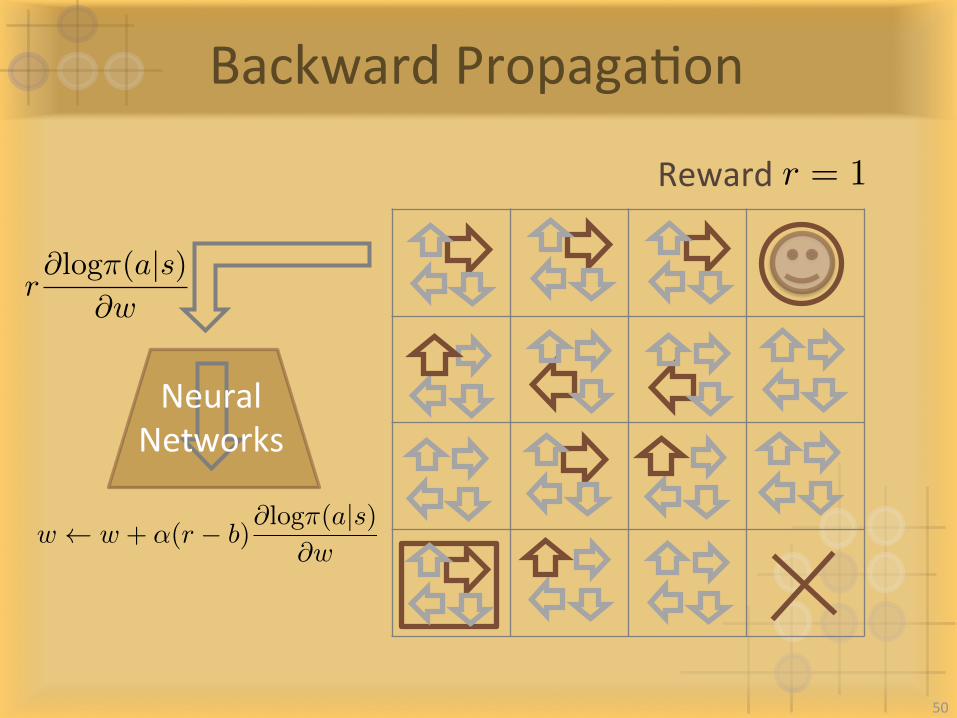
BackwardPropagaIon
NeuralNetworks
Rewardr = 1
50
w w + ↵(r � b)@log⇡(a|s)
@w
r@log⇡(a|s)
@w
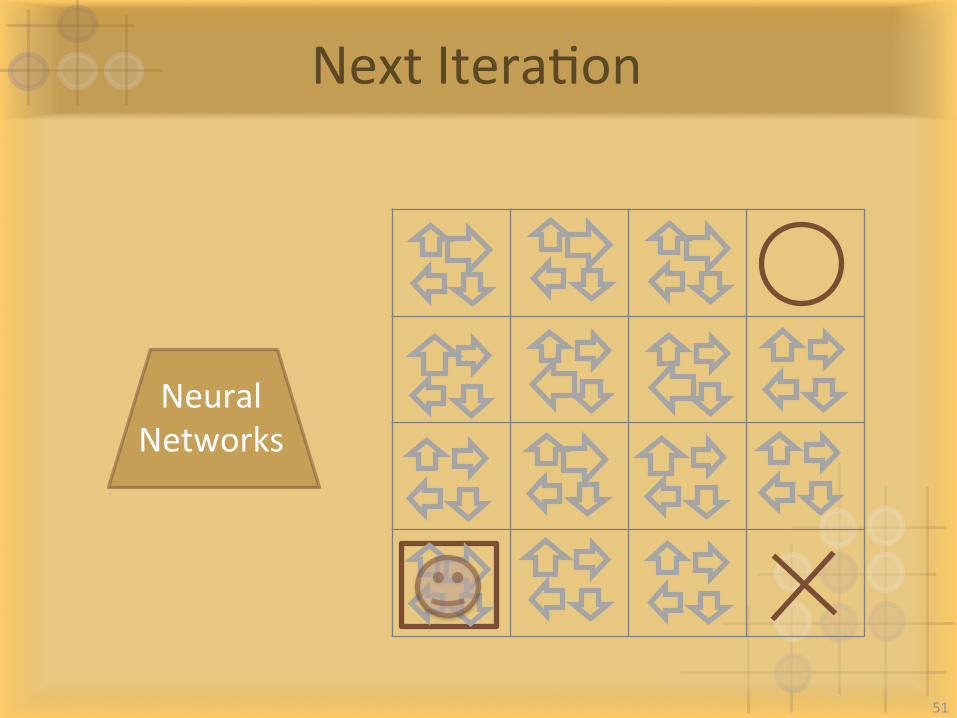
NextIteraIon
NeuralNetworks
51
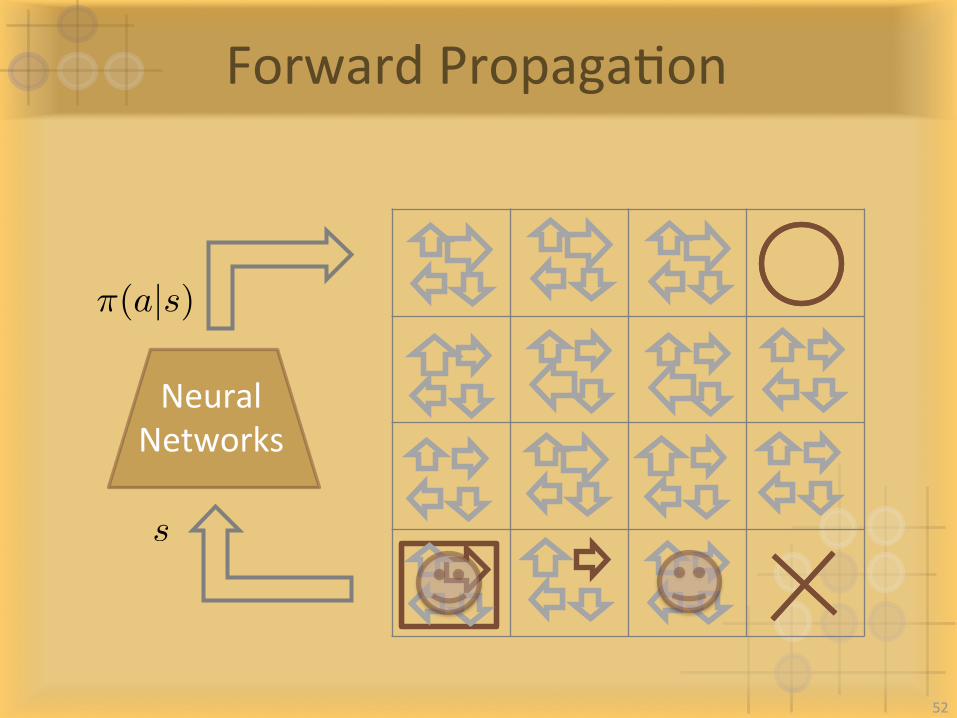
ForwardPropagaIon
NeuralNetworks
⇡(a|s)
s
52
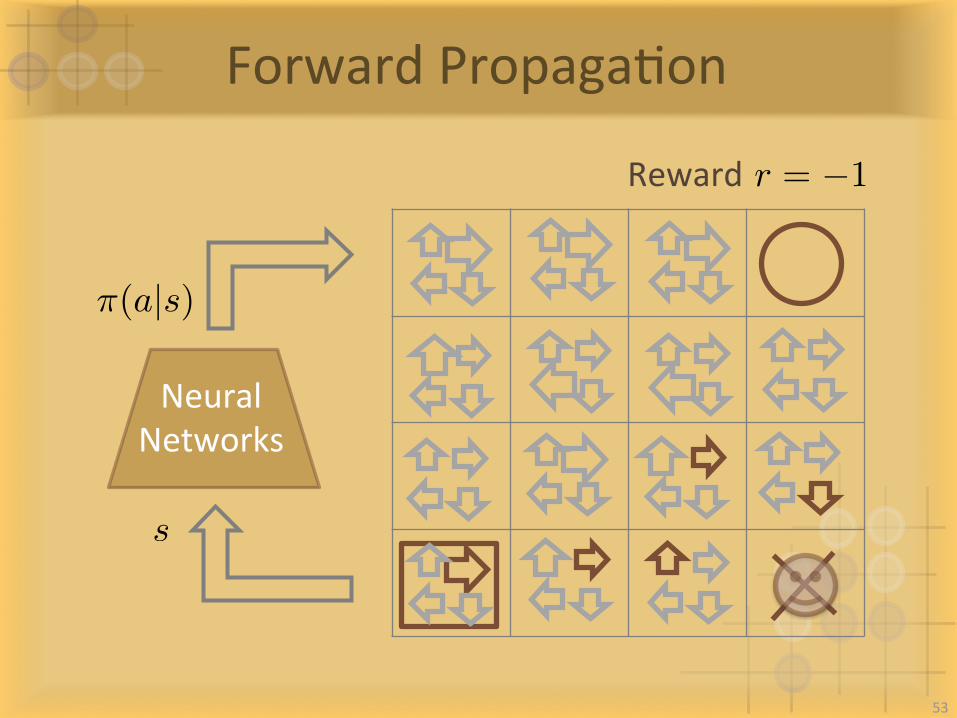
ForwardPropagaIon
NeuralNetworks
⇡(a|s)
s
Rewardr = �1
53

BackwardPropagaIon
NeuralNetworks
Rewardr = �1
54
w w + ↵(r � b)@log⇡(a|s)
@w
r@log⇡(a|s)
@w
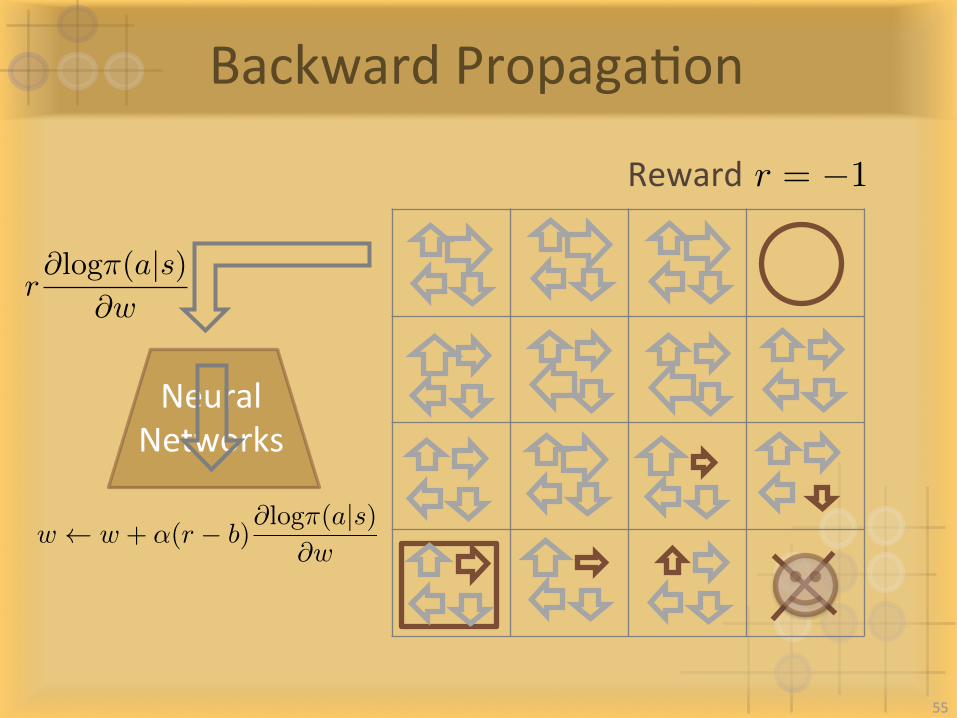
BackwardPropagaIon
NeuralNetworks
Rewardr = �1
55
w w + ↵(r � b)@log⇡(a|s)
@w
r@log⇡(a|s)
@w
NextIteraIon…
NeuralNetworks
56

AgerSeveralIteraIons…
57

AlphaGo’sMethods• Training:– Supervisedlearning:ClassificaIon– Reinforcementlearning– Supervisedlearning:Regression
• Searching:– Searchingwithpolicyandvaluenetworks– Distributedsearch
58
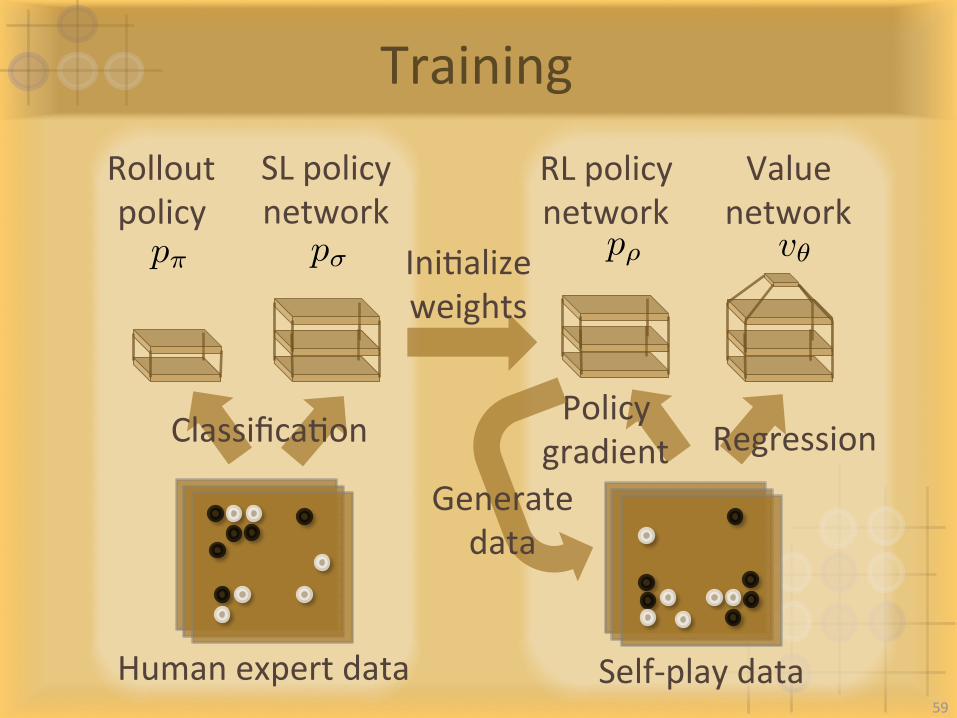
Training
Humanexpertdata Self-playdata
Rolloutpolicy
SLpolicynetwork
RLpolicynetwork
Valuenetwork
ClassificaIon RegressionPolicy
gradientGeneratedata
IniIalizeweights
p⇡ p� p⇢ v✓
59
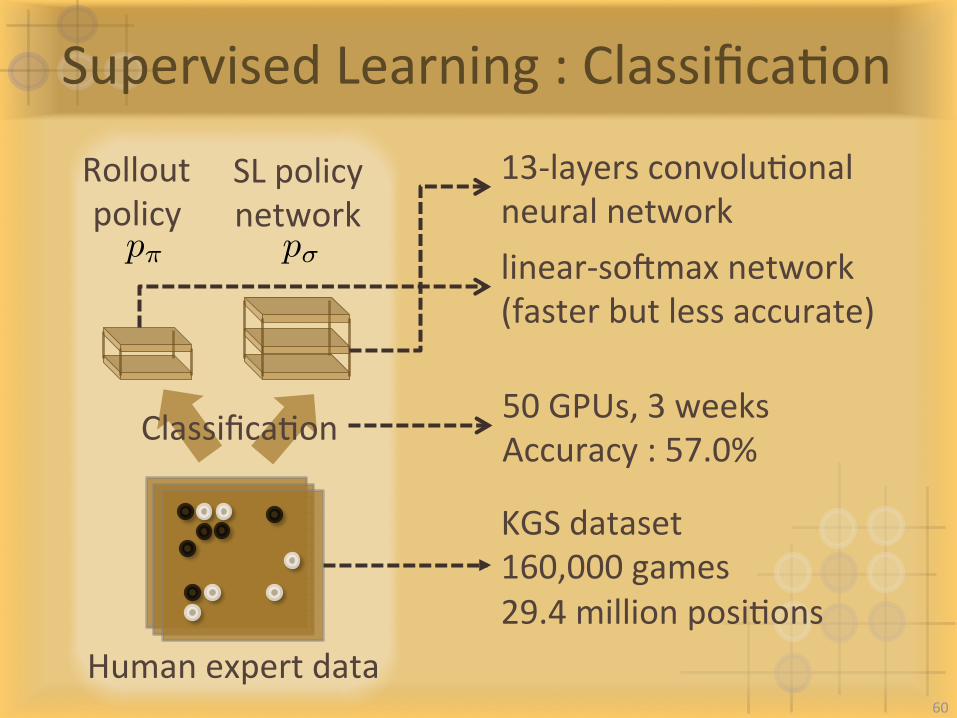
SupervisedLearning:ClassificaIon
Humanexpertdata
Rolloutpolicy
SLpolicynetwork
ClassificaIon
p⇡ p�
KGSdataset160,000games29.4millionposiIons
linear-sogmaxnetwork(fasterbutlessaccurate)
13-layersconvoluIonalneuralnetwork
50GPUs,3weeksAccuracy:57.0%
60
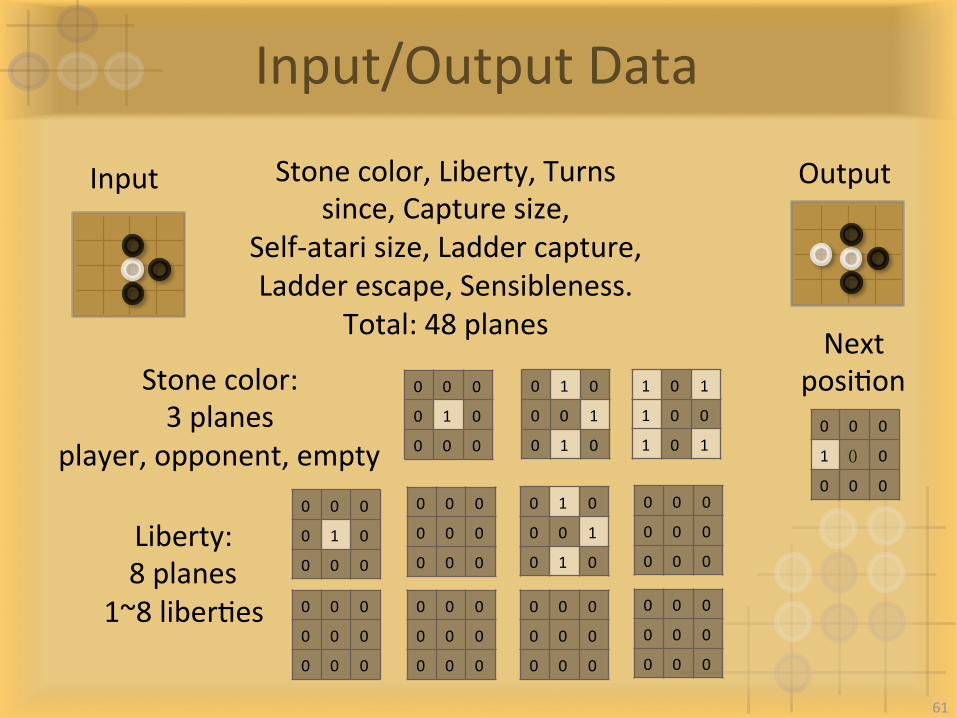
Input/OutputData
0 0 0
0 1 0
0 0 0
0 1 0
0 0 1
0 1 0
1 0 1
1 0 0
1 0 1
Input
NextposiIon
Output
0 0 0
1 0 0
0 0 0
Stonecolor:3planes
player,opponent,empty
Liberty:8planes
1~8liberIes
Stonecolor,Liberty,Turnssince,Capturesize,
Self-atarisize,Laddercapture,Ladderescape,Sensibleness.
Total:48planes
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 1 0
0 0 0
0 1 0
0 0 1
0 1 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
61
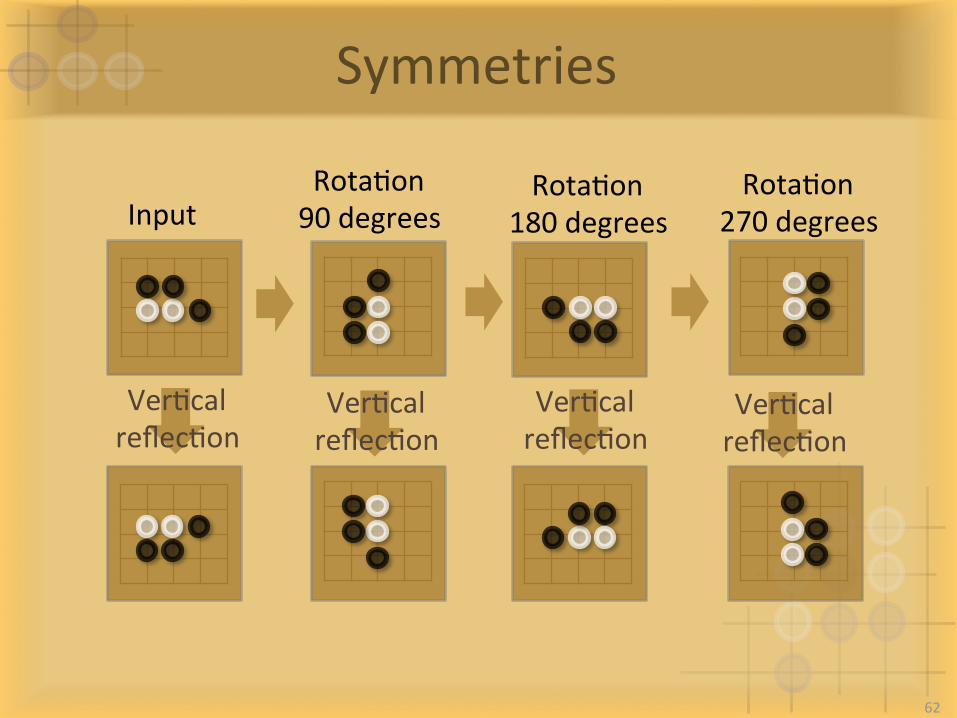
Symmetries
62
InputRotaIon90degrees
RotaIon180degrees
RotaIon270degrees
VerIcalreflecIon
VerIcalreflecIon
VerIcalreflecIon
VerIcalreflecIon
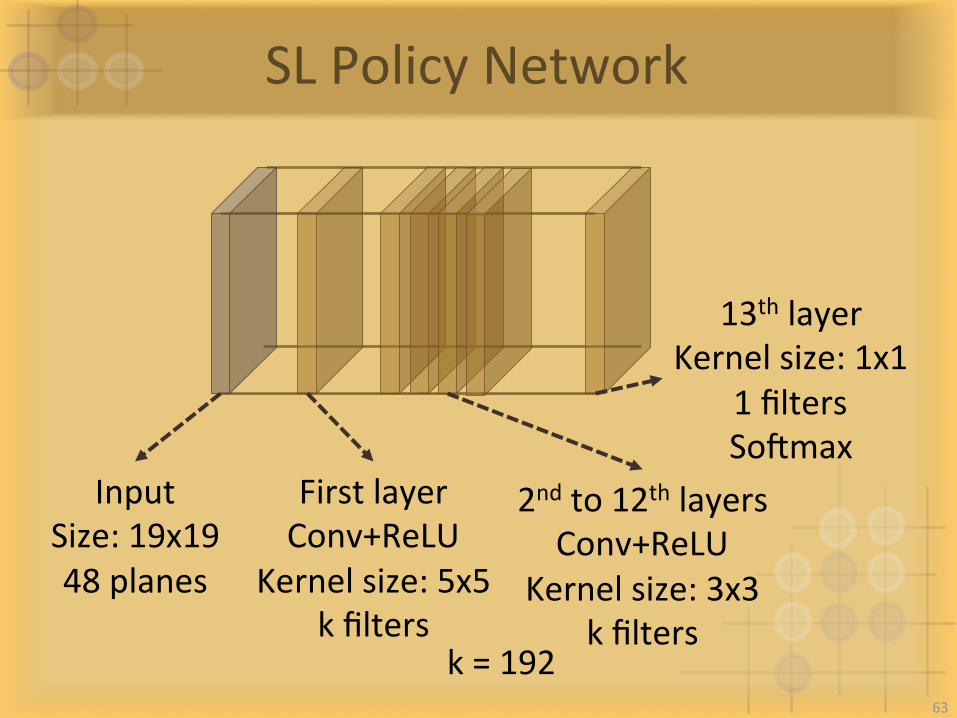
SLPolicyNetwork
InputSize:19x1948planes
FirstlayerConv+ReLU
Kernelsize:5x5kfilters
2ndto12thlayersConv+ReLU
Kernelsize:3x3kfilters
13thlayerKernelsize:1x1
1filtersSogmax
k=19263
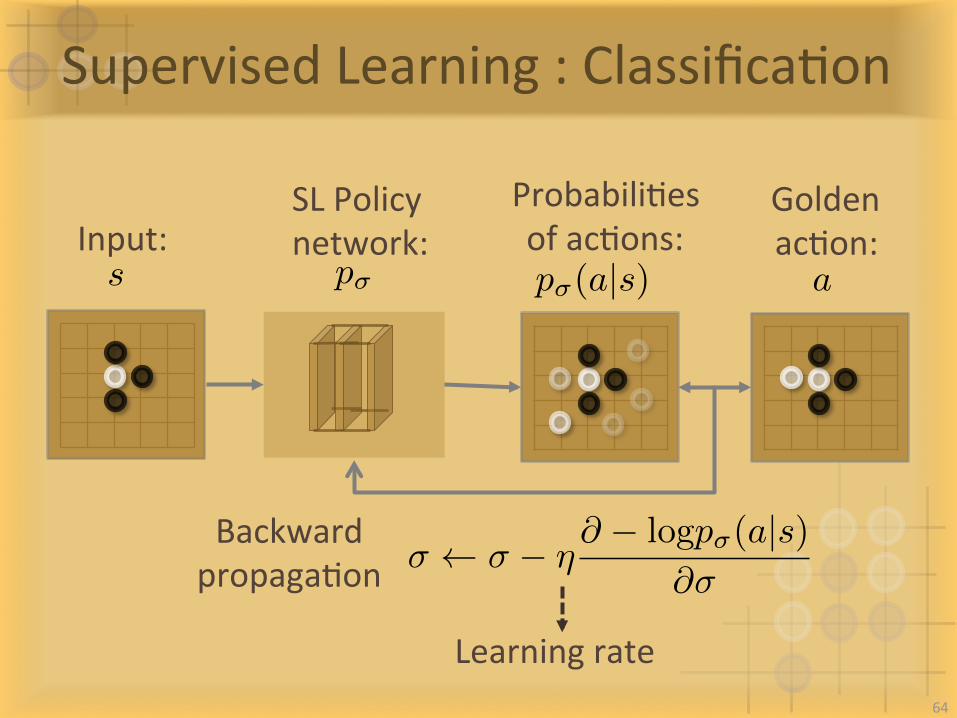
SupervisedLearning:ClassificaIon
Input:GoldenacIon:
BackwardpropagaIon
p�
SLPolicynetwork:
s ap�(a|s)
ProbabiliIesofacIons:
Learningrate
� � � ⌘@ � logp�(a|s)
@�
64
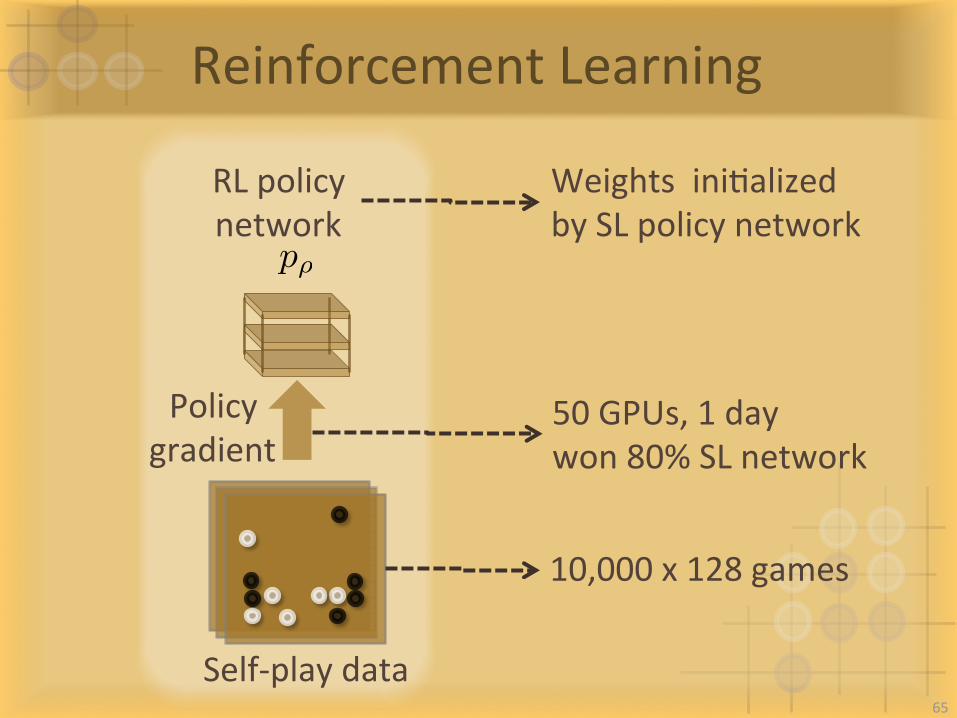
ReinforcementLearning
Self-playdata
RLpolicynetwork
Policygradient
p⇢
50GPUs,1daywon80%SLnetwork
10,000x128games
WeightsiniIalizedbySLpolicynetwork
65
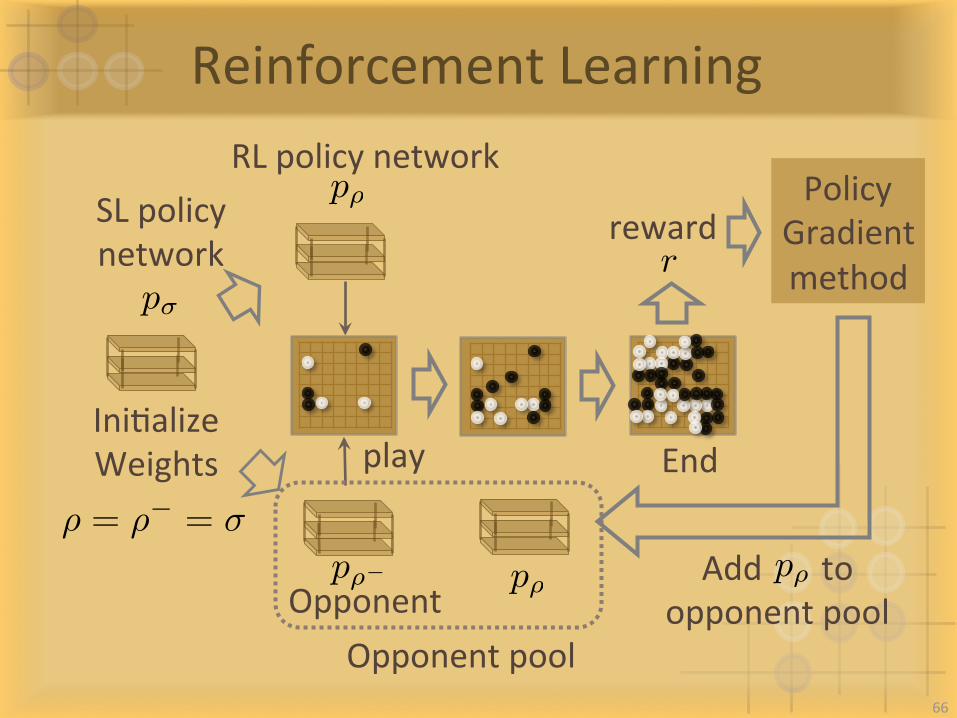
ReinforcementLearning
p⇢SLpolicynetwork
p�
p⇢�
RLpolicynetwork
Opponent
IniIalizeWeights
⇢ = ⇢� = �
play End
PolicyGradientmethod
p⇢
Opponentpool
Addtoopponentpool
p⇢
rreward
66
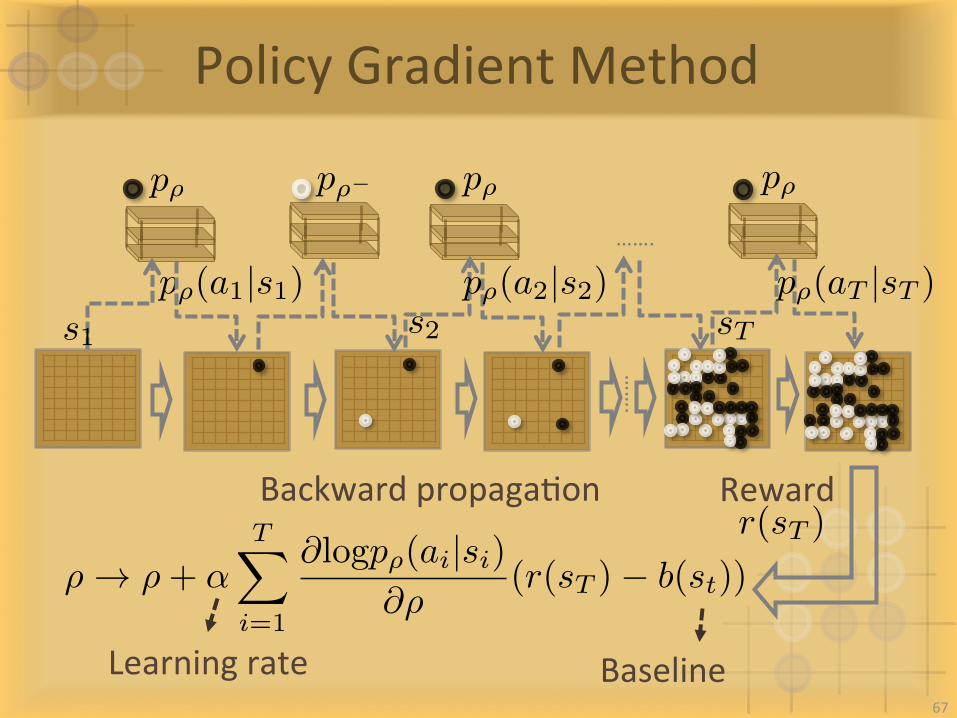
PolicyGradientMethod
p⇢ p⇢� p⇢ p⇢
p⇢(a1|s1) p⇢(a2|s2) p⇢(aT |sT )s1 s2 sT
r(sT )
…….
…….
RewardBackwardpropagaIon
Learningrate Baseline67
⇢ ! ⇢+ ↵TX
i=1
@logp⇢(ai|si)@⇢
(r(sT )� b(st))
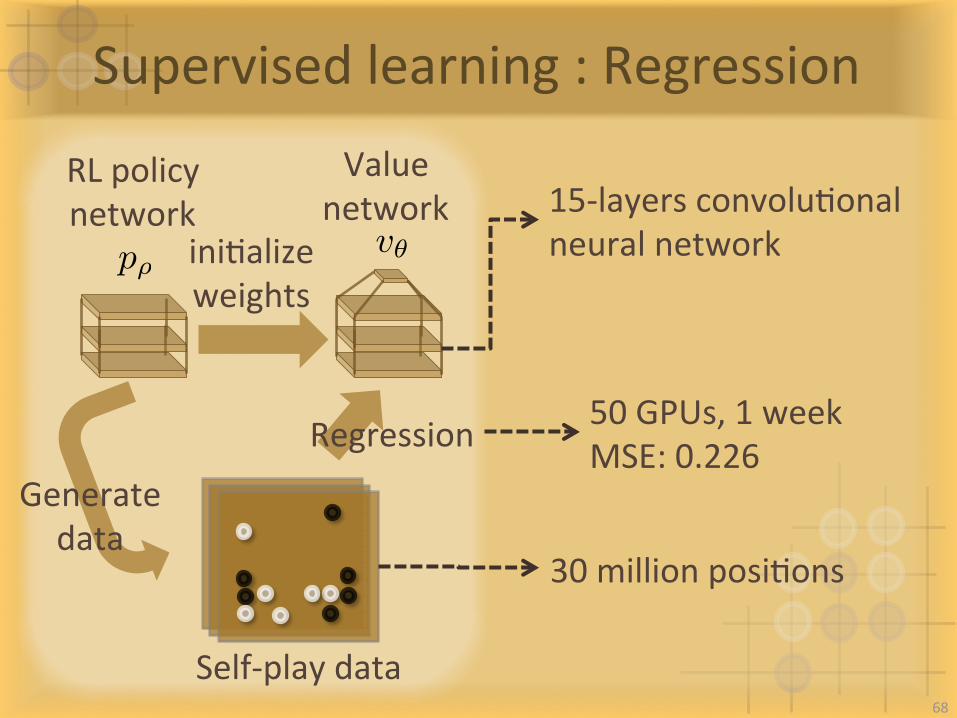
Supervisedlearning:Regression
Self-playdata
RLpolicynetwork
Valuenetwork
Regression
Generatedata
p⇢v✓
30millionposiIons
50GPUs,1weekMSE:0.226
iniIalizeweights
15-layersconvoluIonalneuralnetwork
68
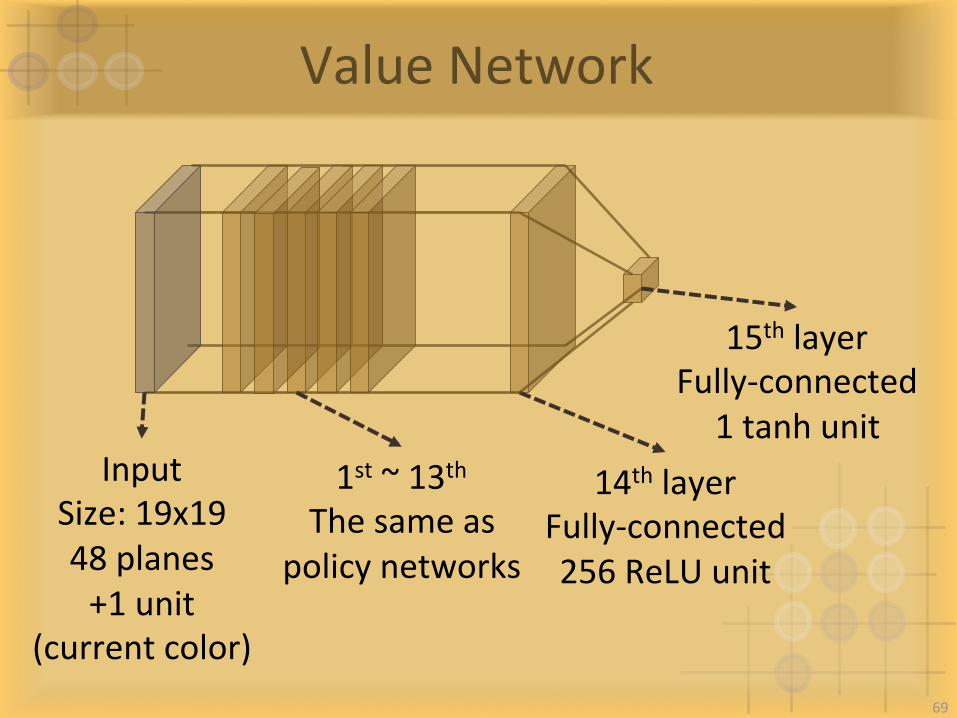
ValueNetwork
InputSize:19x1948planes
14thlayerFully-connected256ReLUunit
1st~13thThesameas
policynetworks
15thlayerFully-connected
1tanhunit
+1unit(currentcolor)
69
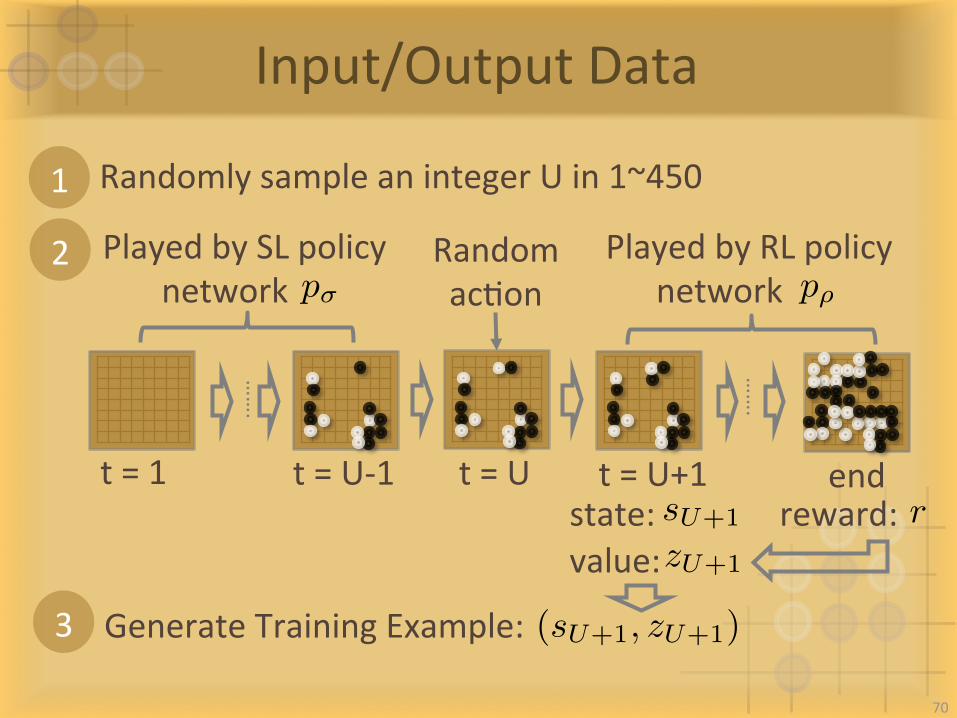
Input/OutputData
…….
PlayedbyRLpolicynetwork p⇢
PlayedbySLpolicynetworkp�
RandomlysampleanintegerUin1~4501
2
t=1 t=U-1 t=U+1 end
RandomacIon
t=U
3 GenerateTrainingExample:
sU+1state: rreward:value:zU+1
(sU+1, zU+1)
…….
70
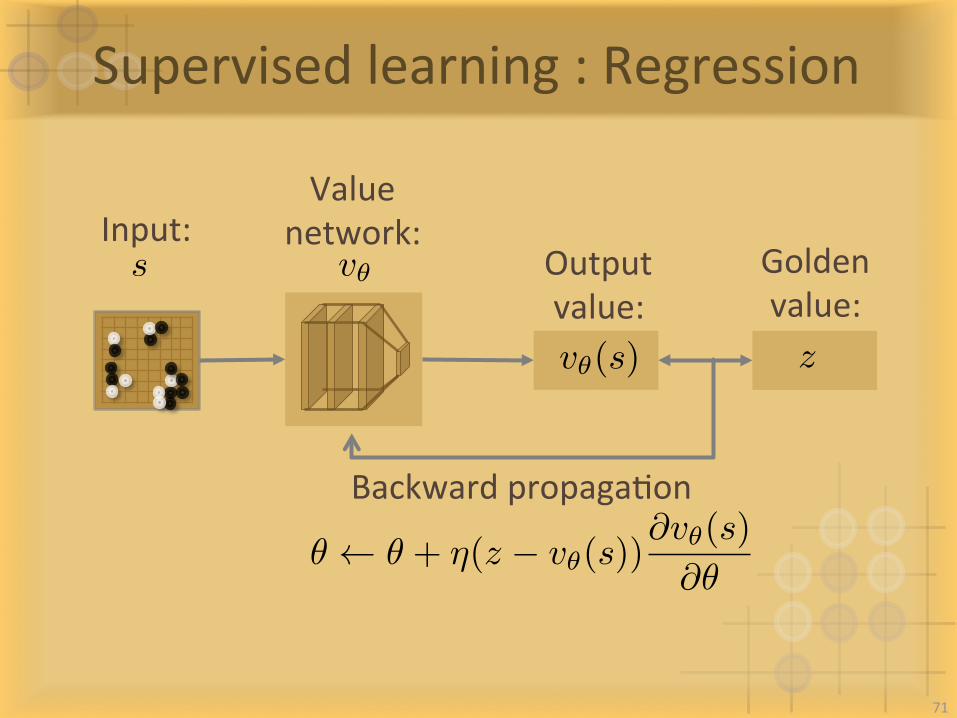
Supervisedlearning:Regression
Input:Goldenvalue:
BackwardpropagaIon
Valuenetwork:
s v✓
v✓(s)
Outputvalue:
z
✓ ✓ + ⌘(z � v✓(s))@v✓(s)
@✓
71
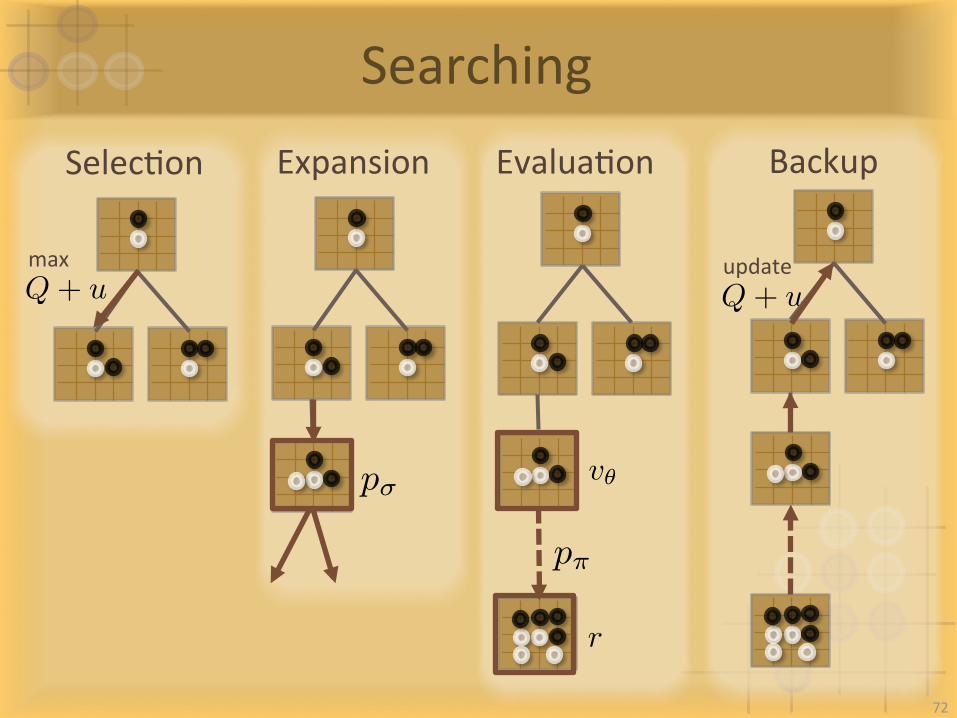
SearchingSelecIon Expansion EvaluaIon Backup
Q+ umax
r
v✓
Q+ uupdate
p�
p⇡
72

• EachedgestoresasetofstaIsIcs• :combinedmeanacIonvalue• :priorprobabilityevaluatedby• :esImatedacIonvalueby• :esImatedacIonvalueby• :countsofevaluaIonsby• :countsofevaluaIonsby
Searching
P (s, a)
Nv(s, a)
Nr(s, a)
Wr(s, a)
Wv(s, a)
Q(s, a)s
a
v✓(s)
p⇡(a|s)
v✓(s)
p⇡(a|s)
p�(a|s)
73
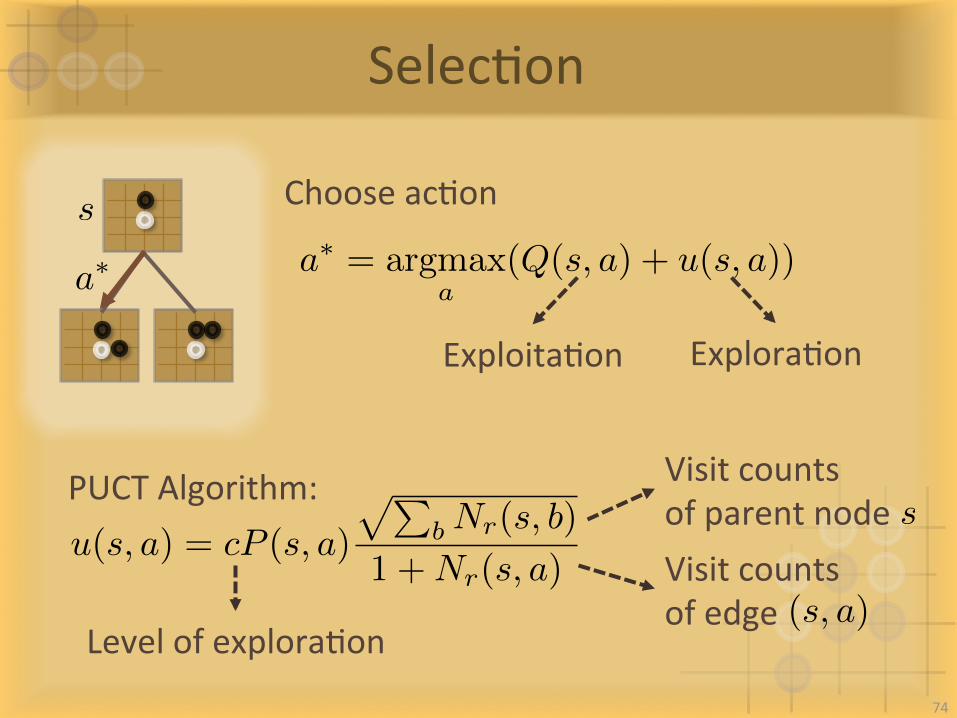
SelecIon
a⇤ = argmax
a(Q(s, a) + u(s, a))
u(s, a) = cP (s, a)
pPb Nr(s, b)
1 +Nr(s, a)
ChooseacIon
a⇤
PUCTAlgorithm:
ExploitaIon ExploraIon
VisitcountsofparentnodesVisitcountsofedge(s, a)
LevelofexploraIon
s
74
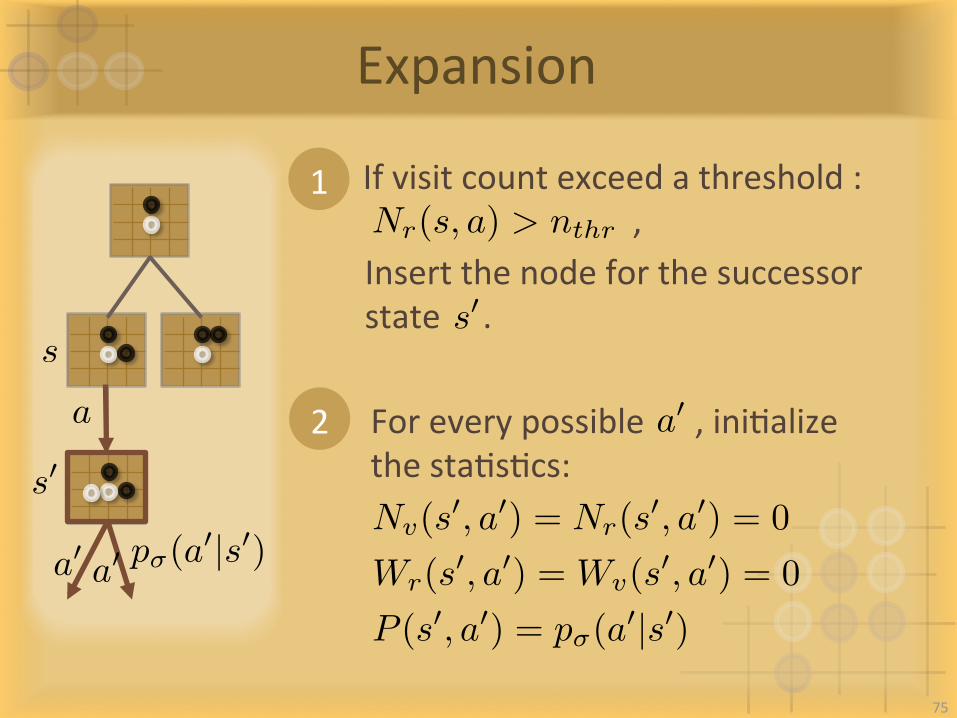
Expansion
s
a
s0
Insertthenodeforthesuccessorstate.s0
1
2
Nv(s0, a0) = Nr(s
0, a0) = 0
Wr(s0, a0) = Wv(s
0, a0) = 0
P (s0, a0) = p�(a0|s0)
p�(a0|s0)
Ifvisitcountexceedathreshold:,Nr(s, a) > nthr
a0 a0
Foreverypossible,iniIalizethestaIsIcs:
a0
75
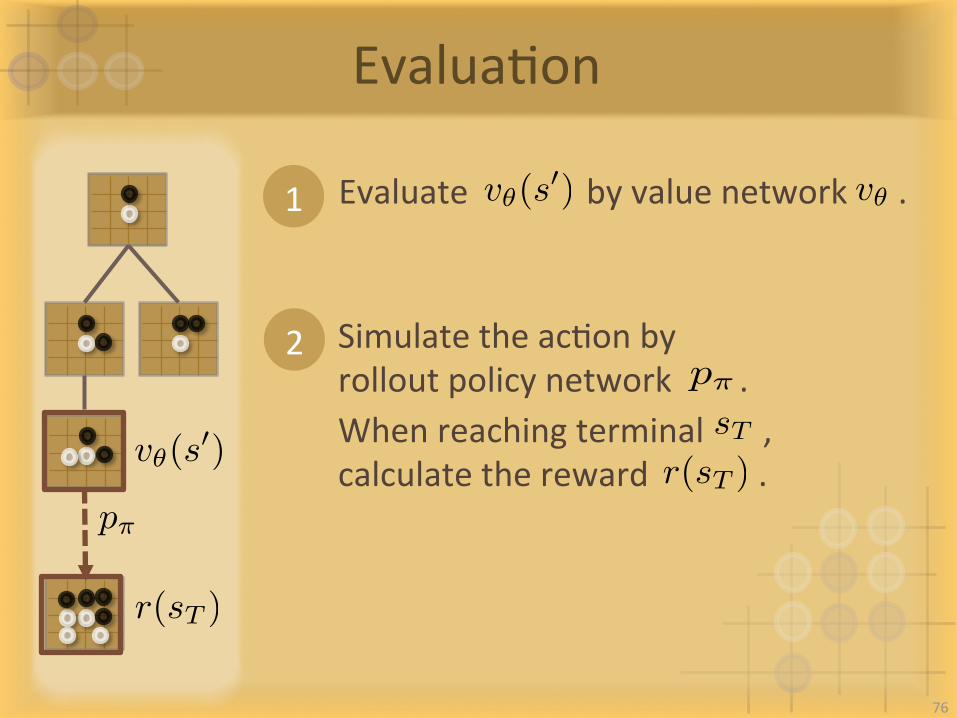
EvaluaIon
p⇡
1
2 SimulatetheacIonbyrolloutpolicynetwork.p⇡
Evaluatebyvaluenetwork.v✓(s0) v✓
r(sT )
v✓(s0) Whenreachingterminal,
calculatethereward.sT
r(sT )
76

Backup
s
a
r(sT )
v✓(s0)s0
UpdatethestaIsIcsofeveryvisitededge:(s, a)
Nr(s, a) Nr(s, a) + 1
Wr(s, a) Wr(s, a) + r(sT )
Nv(s, a) Nv(s, a) + 1
Wv(s, a) Wv(s, a) + v✓(s0)
Q(s, a) = (1� �)Wv(s, a)
Nv(s, a)+ �
Wr(s, a)
Nr(s, a)
InterpolaIonconstant
77
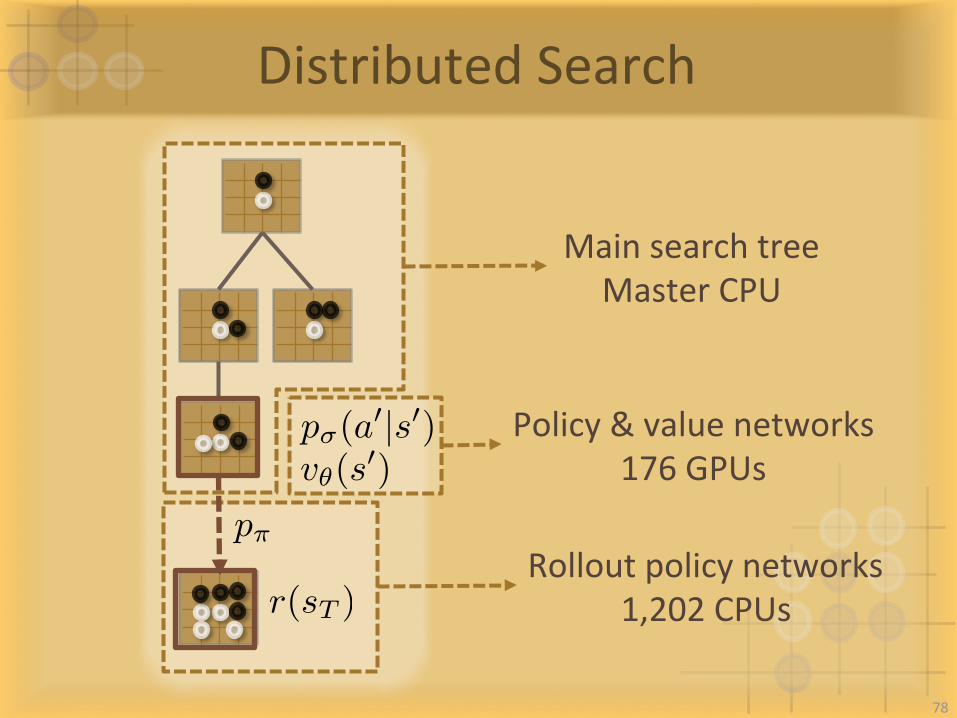
DistributedSearch
p⇡
r(sT )
v✓(s0)
p�(a0|s0)
MainsearchtreeMasterCPU
Policy&valuenetworks176GPUs
Rolloutpolicynetworks1,202CPUs
78

Reference• MasteringthegameofGowithdeepneuralnetworksandtreesearch– hqp://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
79

FurtherReading• MonteCarloTreeSearch– hqps://jesradberry.com/posts/2015/09/intro-to-monte-carlo-tree-search/
• NeuralNetworksBackwardPropagaIon– hqp://cpmarkchang.logdown.com/posts/277349-neural-network-backward-propagaIon
• ConvoluIonalNeuralNetworks– hqp://cs231n.github.io/convoluIonal-networks/
• PolicyGradientMethod:REINFORCE– hqps://www.cs.cmu.edu/afs/cs/project/jair/pub/volume4/kaelbling96a-html/node37.html
80

AbouttheSpeaker
• Email:ckmarkohatgmaildotcom• Blog:hqp://cpmarkchang.logdown.com• Github:hqps://github.com/ckmarkoh
F.C.C
MarkChang
• Facebook:hqps://www.facebook.com/ckmarkoh.chang• Slideshare:hqp://www.slideshare.net/ckmarkohchang• Linkedin:hqps://www.linkedin.com/pub/mark-chang/85/25b/847
81