an information power grid resource management tool
TRANSCRIPT

Computación y Sistemas Vol. 4 No.3 pp. 213 -229@ 2001, CIC -IPN. ISSN 1405-5546 Impreso en México
An Information Power Grid Resource
Management Tool
Luis Miguel Camposl , Fabricio Silval , Isaac Schersonl and Mary Eshaghian21 Dept. oflnformation and Compu,ter Science
University of Califomia-lrvine
Irvine, CA 92697, USA.e-mail: {lcampos, fsilva, isaac}@ics.uci.edu
2 Departament of Computer Engineering
Rochester lnstitute of TechnologyRochester, NY 14623-5603
e-mail: [email protected]
Article received on Februarv 15. 2000: acceoted on Auí!Ust 23. 2000
Introd uction
ground
and Back-1Abstract
Heterogeneous Computing (HC) is defined as a spe-
cial form of parallel and distributed computing.Computations are carried out using a single au-
tonomous computer operating in both SIMD and
MIMD modes, or using a number of connected au-
tonomous computers (a.k.a. Cluster Computing).
Information Power Grid (IPG) a is form of HC in
which high performance computers located at geo-
graphically distributed sites are connected via a high-
speed interconnection network. It is desirable to
make IPG accessible to general users as easily and
seamlessly as electricity from the electric power grid.
The users should be able to submit jobs at any site,
the IPG should be able to handle the computations
using the resources available, and return the results
to the user. One of the many challenges in making
IPG work is the issue of Resource Management. We
present a Resource Management Tool for IPG called
IPG-SaLaD (Static mapper, and Load balancer, and
Dynamic scheduler). This tool uses the Cluster-M
mapping paradigm for initial allocation of tasks of
a given job onto resources. Later as new jobs come
in or as the status of the system changes, the tool
uses the Rate of Change algorithm for load balancing,
and the Concurrent Gang Scheduling for scheduling.
Currentlya window-NT based implementation of the
IPG-SaLaD using PVM is being constructed.
Keywords: Information Power Grid, Heteroge-
neous Computing, Resource Management, Parallel
Job Scheduling, Static Mapping and allocation, Dy-
namic Load Balancing
Since the early 90's, significant amount of attentionhas been given to the type of computing in whichmultiple computers are used concurrently in solvingsingle problems. These computers may be of dif-fe.rent type and brand with different operating sys-tems and capabilities. Furthermore, they may begeographically distributed. A number of differentterms have been used for introducing this conceptsuch as Heterogeneous Computing, Cluster Comput-ing, Meta Computing, Wide-area Computing, andrecently Information Power Grid (IPG) computing.In an IPG environment a national computing infras-tructure allows users to access the information re-sources of the nation in much the same way as oneaccesses electrical power today.
IPG is a topic that has been of interest to N ASAand several other organizations such as DOD, DOEand NSF. To this date, a number of sites have takenpart in IPG, such as Caltech/JPL, ISI/USC, SDSC,and NCSA. IPG offers many benefits such as allow-ing collaborative research among geographically dis-persed teams in a virtual environment, enabling so-lutions of problems that could not be done other-wise, and cost and time savings through optimal useof scarce computing resources. The design issues indeveloping the ipformation technology that enablesIPG, can be classified into four groups: Application,User environment, Execution environment, and Sys-tem integration.
Among the four groups named above, design ofsuitable execution environments for IPG stands per-haps as the most challenging one. IPG requires exe-
*This rese.arch was supported in part by NASA under grantnumber NAG5-2561, and by the Irvine Research Unit in Ad-vanced Computing

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information Power Grid Resource Management Tool.-
Static Allocation oí subtasks in asingle job
cution environments that are portable and scalable.This includes design of efficient resource manage-ment techniques, data storage and migration tech-niques. Tools need to be developed to enable theuse of the execution environment such as automatedtools for porting legacy code, collaborative problem
solving environments, formal, portable programmipgparadigms, languages and tools that express paral-lelism and support synthesis and reuse. These exe-cution environments should support applications forthe future such as application software that uses1000 or 10000 processors. Furthermore, the execu-tion environment, user environment and applicationsall need to be integrated.
1.1
The focus of our work is in the area of execu-tion environment design. More specifically we willconcentrate on an IPG tool for resource manage-ment. The proposed tool called SaLaD (Static allo-cator, and Load balancer, and Dynamic scheduler) ,uses a three step mechanism. During the first step,using the Cluster-M static allocator, it will take aprogram-task (or so called a job) that is entered bythe user (or by a compiler) and will break it intosubtasks and will map/allocate the subtasks ontoavailable processors and or computers so that over-all execution time is minimized. As new jobs ar-rive and/or finish execution, it maybe required toredistributed individual subtasks using the Rate ofChange load balancer. This step guarantees that noprocessing element ever goes idle. Finally the Con-current Gang dynamic scheduler is used to schedulethe execution sequence of multiple independent jobsresiding on the processors. The optimal use of re-sources, and resource allocation based on the work-load contents and site specific capabilities is consis-tent with the IPG objectives specified by NASA. fnthis paper, we will present our preliminary resultstowards the development of this integrated resourcemanagement tool. Currently a simple version whichis NT-window-based and uses PVM is operational.
The rest of the paper is organized as follows. Inthe remaining part of this section we briefly presenta brief background on the three areas studied in thispaper, namely, static allocation, load balancing anddynamic scheduling. In the next section, we presentpreliminary results on Cluster-M (static allocation),Rate of Change (load balancing) , and ConcurrentGang (dynamic scheduling). In Section 3, we willpresent the operation of the three integrated com-ponents of SaLaD, and in section 4, we will describeour current windows-NT implementation of SaLaDusing PVM. In Section 5, we present our concludingremarks.
The mapping problem, in its general form, has beenknown to be NP-complete and has been studied in-tensively for homogeneous parallel computers duringthe past two decades [Ber87, Bok81, CE95, Efe82,ERL90, ES94, LA87, LRG+90, PSD+92, YG94]. Inmapping, an application task and a computing sys-tem are usually modeled in terms of a task flow graphand a system graph. The problem, then, is how tomap efficiently the task flow graph to the systemgraph. A task flow graph is a directed acyclic graph(DAG) that consists ofa set of vertices and a set ofdirected edges. A vertex denotes a task module de-composed from the given task. Each vertex is asso-ciated with a weight that denotes the computationamount within the corresponding task module. Adirected edge joining two task modules denotes thatdata communication and dependency exist betweenthe two task modules. The weight of an edge repre-sents the amount of data communication. While atask flow graph is usually directed, the system graphis usually an undirected graph. A set of vertices ina system graph denote processors and a set of undi-rected edges indicate physical communication linksfor processor pairs. The weight of a vertex (edge)represents the speed (bandwidth) of the correspond-ing processor (communication link). We define agraph as nonuniform if and only if the weights ofall vertices or the weights of all edges are not thesame; otherwise it is uniform.
Mapping can be static or dynamic. In staticmapping, the assignments of the nodes of the taskgraphs onto the system graphs are determined priorto the execution and are not changed until the endof the execution. Static mapping can be classi-fied in two general ways. The first classificationis based on the topology of task and/or systemgraphs [CE95]. Based on this, the mappings can beclassified into four groups: (1) mapping specializedtasks onto specialized systems, (2) mapping special-ized tasks onto arbitrary systems, (3) mapping ar-bitrary tasks onto specialized systems and (4) map-ping arbitrary tasks onto arbitrary systems. Thesecond classification can be based on the unifor-mity of the weights of the nodes and the edges ofthe task and/or the system graphs. Based on this,the mappings can be categorized into the followingfour groups: ( 1) mapping uniform tasks onto uni-form systems [CE95, Bok81, LA87, BS87, ERS90],(2) mapping uniform tasks onto nonuniform systems,(3) mapping nonuniform tasks onto uniform sys-tems [WG90, MG89, Sar89, ERL90, YG94], and (4)mapping nonuniform tasks onto nonuniform systems
214

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information Power Grid Resource Management Tool
[ST85, Lo88]. In IPG, the task and system graphscan be nonuniform. Therefore, the mapping prob-lem in HC can be viewed as mapping of an arbitrarynonuniform task graph onto an arbitrary nonuniform
system graph.In this paper, we first concentrate on static map-
ping of arbitrary nonuniform task graphs onto arbi-trary nonuniform system graphs. The existing map-ping techniques in this grotlp include EI-Rewini andLewis' mapping heuristic algorithm [ERL90] for di-rected task graphs and Lo's max flow min cut map-ping heuristic [Lo88] for undirected task graphslThe time complexity of these two heuristics areO(M2N3) and O(M4NlogM), respectively, whereM is the number of task modules and N is thenumber of processors. Another algorithm in thiscategory is called Clu8ter-M which can map arbi-trary, nonuniform, architecturally independent, di-rected task graphs onto arbitrary, nonuniform, undi-rected, task-independent system graphs in O(M2)time, where N ~ M. Cluster-M will be explained indetail in 3.1
sponsibility of achieving global load balance. Theother factor often used to classify load balancingstrategies, implicit or explicit, is strictly speaking asystem issue rather than a load balancing one. Im-plicit load balancing refers to load balancing per-formed automatically by the system, whereas ex-plicit means it is up to the user do decide whichtasks should be migrated and when.
Many Dynamic Load Balancing strategies havebeen prop9Sed in the literature. Three of the bestknown are: the gradient model [LK91], the senderinitiated diffusion [WLR93] , and the central job dis-patcher [LHWS96] .The gradient model employs agradient map of the proximities of under-Ioaded pro-cessors in the system to guide the migration of tasksbetween overloaded and under-Ioaded processors.The sender initiated diffusion is a highly distributedlocal approach which makes use of near-neighborload information to apportion surplus load fromheavily loaded processors to under-Ioaded neighborsin the system. Global balancing is achieved astasks from heavily loaded neighborhoods diffuse intolightly loaded areas in the system. In the central jobdispatcher strategy, one of the network processorsacts as a central load balancing master. The dis-patcher maintains a table containing the number ofwaiting tasks in each processor. Whenever a taska:rrives at or departs from a processor, the processornotifies the central dispatcher of its new load state.When a state change message is received or a tasktransfer decision is made, the central dispatcher up-dates the table accordingly. The network bases loadbalancing on this table and notifies the most heav-ily loaded processor to transfer tasks to a requestingprocessor. The network also notifies the requestingprocessor of the decision.
Load Balancingtion oí Subtasks
by Redistribu-1.2
Dynamic Load Balancing (DLB) is an important sys-tem function aimed at distributing workload amongavailable processors to improve throughput and/orexecution times of parallel computer programs eitheruniform ornon-uniform (jobs whose workload variesat run-time in unpredictable ways). Non-uniformcomputation and communication requirements maybog down a parallel computer if no efficient load dis-tribution is effected.
Load balancing strategies fall broadly into eitherone of two classifications, namely static or dynamic.A multicomputer system with static load balanc-ing distributes tasks across the processing elements(PEs) before execution using a priori known taskinformation and the \oad distribution remains un-changed at run time. A multicomputer system withDLB uses no a priori task information, and must sat-isfy changing requirements by making task distribu-tion decisions during run-time. DLB can be furtherclassified as centralized or distributed. In a central-ized strategy, load balancing decisions are made byone PE only, which is responsible for maintainingglobal load information. In distributed strategies,decisions are made locally, load iIiformation is dis-tributed among all PEs and they all share the re-
Dynamic Scheduling oí MultipleJobs or Tasks
1.3
Parallel job scheduling is an important problemwhose solution may lead to better utilization of mod-ern parallel computers, It is defined as: "Given theaggregate of all tasks of multiple jobs in a parallelsystem, find a spatial and temporal allocation to ex-ecute all tasks efficiently" .Each job in a parallel ma-chine is composed by one or more tasks. For the pur-poses of scheduling, we view a computer as a queuingsystem. An arriving job may wait for some time, re-.ceive the required service, and depart [FR98] .Thetime associated with the waiting and service phasesis a function of the scheduling algorithm and theworkload. Some scheduling algorithms may requirethat a job wait in a q1leue until all of its requiredresources become available ( as in variable partition-
1 Mapping of directed task graphs (if there is precedence
relation among the task nodes) is called task scheduling[ERL90]. If the task graphs to be mapped are undirected,then it is called task allocation [ERL90].
215

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information Power Grid Resource Management 1001.-
ing), while in others, like time slicing, the arrivingjob receives service immediately through a processor
sharing discipline.Gang scheduling has been widely used as a prac-
tical solution to the dynamic parallel job schedulingproblem. Parallel tasks of a job are scheduled forsimultaneous execution on a partition of a parallelcomputer. Gang Scheduling has many advantages,such as responsiveness, efficient sharing of resourcesand ease of programming. However, there are twomajor problems associated with gang scheduling:scalability and the decision of what to do when atask blocks.
2 Preliminaries
The IPG tool which is presented in this paper, calledSaLaD consists of three main components. In thenext section we will describe how they work togetherin an integrated fashion. In this section, we presentpreliminary background on each of three componentsnamely the Static Allocator, Load Balancer, and theDynamic Scheduler. The static allocation techniqueused is based on the Cluster-M technique, Load Bal-ancing is achieved using the Rate of Change algo-rithm, and Dynamic Scheduling is performed usinga generalization of gang-scheduling dubbed Concur-rent Gang.
Cluster-M Static Allocation2.1
Cluster-M is a programming tool that facilitates thestatic allocation and mapping of portable parallelprograms [CE95]. Cluster-M has three main compo-nents: the specification module, the representationmodule and the mapping module. In the specifi-cation module, machine-independent algorithms arespecified and coded using the Program Composi-tion Notation (PCN [FT93]) programming language[ES94]. Cluster-M specifications are represented inthe form of a multi-layer clustered task graph calledSpec graph. Each clustering layer in the Spec graphrepresents a set of concurrent computations, calledSpec clusters. A Spec graph can also be obtained byapplying one of the appropriate Cluster-M cluster-ing algorithms to any given task graph. A Cluster-M representation represents a multi-layer partition-ing of a system graph called a Rep graph. Given asystem graph, a Rep graph can be generated usingone of the Cluster-M clustering algorithms. At everypartitioning layer of the Rep graph, there are a num-ber of clusters called Rep clusters. Each Rep clusterrepresents a set of processors with a certain degreeof connectivity. The clustering is done only oncefor a given task (system) graph independent of any
system (task) graphs. It is a machine-independent(application-independent) clustering, therefore it isnot necessary to be repeated for different mappings.For this reason, the time complexities of the cluster-ing algorithms are not included in the time com-plexity of the Cluster-M mapping algorithm. Inthe mapping module, a given Spec graph is mappedonto a given Rep graph. In an earlier publications[CE95, Esh96] two Cluster-M clustering algorithmsand a mapping algorithm were presented for bothuniform an non-uniform graphs.
Below, we present a set of experimental results.The following criteria are used for comparing theperformance of our algorithm with other leadingtechniques: (1) the total time for executing the map-ping algorithm, Tc; (2) the total execution time ofthe generated mappings, Tm; (3) the number of pro-cessors used, Nm; and (4) the total time executingboth clustering (task and system) and mapping al-gorithms, Tcm. From (2) and (3), we can obtain thespeedup Sm = k and efficiency 1] = ~, where Tsis the sequential execution time of the task.
In Table 1, comparison results are shown for map-ping nonuniform random task graphs ranging from100 to 1000 nodes onto the random system graphof size 100, where the speed of the processors andcommunication channels is ranged between 1-5 only.In other words even though there are 100 processorsbut they are very slow, and therefore the speed upis expected to be low. What is really important hereis that both MH and Cluster-M lead to the sametype of results, but Cluster-M is very much fasterthan MH both asymptotically and experimentally.The running time of MH grows significantly as thesize of the task graph grows. Whereas the runningtime of Cluster-M remains relatively stable. In mostcases, Cluster-M obtains a better speedup than MH.But in all cases Cluster-M has a significantly lowertime complexity.
The experimental results shown in this sectionwere obtained by running a set of simulations ona SUN UltraSPARC I workstation, and all runningtimes times (T c , T cm) are measured in millisecondsThe non-uniform task graphs are randomly gener-ated.
2.2 Rate of Change Load Balancing
Previously proposed load balancing strategies castthe problem as one of equalizing the absolute numberof load units among all PEs. Rate of Change loadbalancing algorithm [CS99, Cam99] constitutes adeparture from this classical approach. We defineload balancing as the activity of migrating load unitsfrom one PE to another so that all PEs have at least

L. M. Campos, F. Silva, Scherson, M. Eshaghian: An Information Power Grid Resource Management Tool
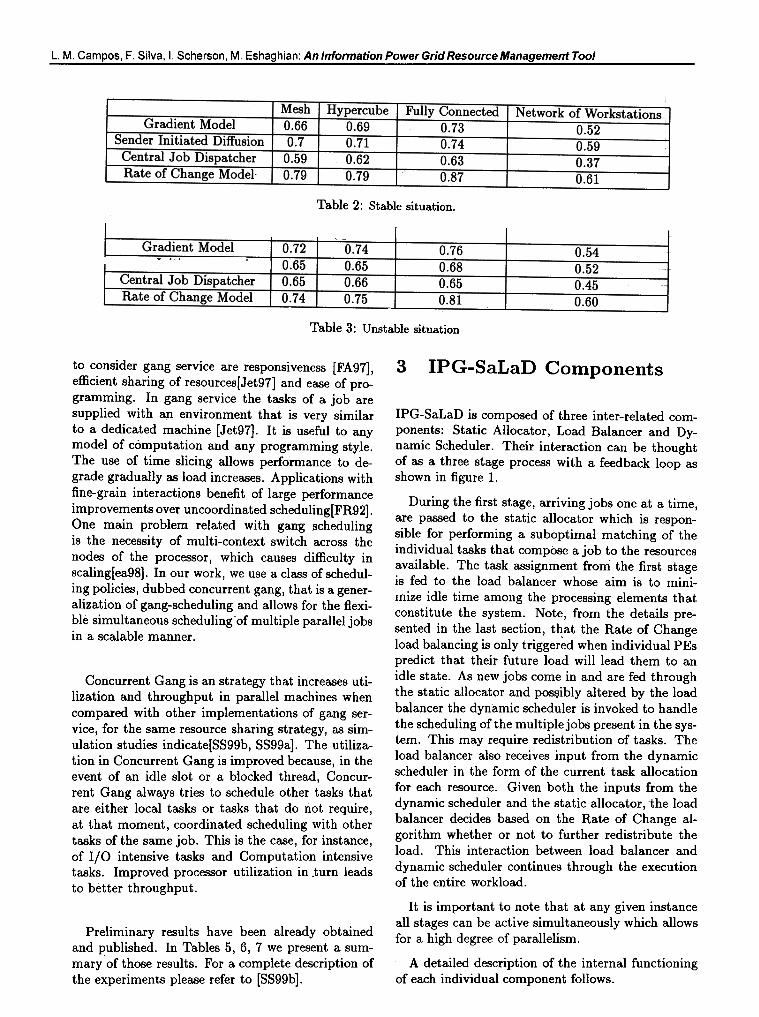
(table 3), the same initial set of tasks was dividedamong only half of the PEswith the remaining beingidle. In both experiments, new applications were notallowed to be submitted to the system. All new taskswere generated internally due to the non-uniform na-ture of the applications being simulated. For thethird experiment ( table 4) , the possibility of arbi-trary arrival times for new jobs was allowed, and thetasks that compose an application were distributedrandomly among all PEs.
The performance metric used in the experi-ments is the normalized performance (NP) as usedin [WLR93, LHWS96] .
Normalized performance (NP) determines the ef-fectiveness of the load balancing strategy (such thatN p -+ O if the strategy is ineffective and N p -+ 1if the strategy is effective). This is a comprehensivemetric; it accounts for the initiallevel of load imbal-ance as well as the load balancing overheads. NP isformally defined as:
N p = ~TnoLB -Tbal)
one load unit at all times. The rationale is that ifany given PE is busy executing tasks then the loaddifferential with respect other PEs is irrelevant sinceno performance gain can be obtained by transferringload. Hence the decision to initiate load transfersshould not depend on a PE's absolute number ofload units, but on how the load changes in time.
Our novel approach uses the Rate of Change(RoC) ()f the load on each PE to trigger any loadbalancing activity. It can be described as a dy-namic, distributed, on demand, preemptive and im-plicit load balancing strategy. Dynamic, becauseit does .'1Ot assume any prior task (unit of load inthis study) information and must satisfy changingrequirements by making task distribution decisionsat run-time. Distributed, because allload balancingdecisions are made locally and asynchronously byeach processor. On demand, because only PEs that" need" tasks are allowed to initiate any migration
activity. Preemptive, because running tasks may besu~pended, moved to another PE and restarted. Im-plicit, because allload balancing activity is done bythe system, without user assistance.
Furthermore, our proposed RoC-Load Balancingstrategy achieves the goal of minimizing proces-sor idling times without incurring into unacceptablyhigh load balancing overhead. It does so by strikinga balance between the cost of evaluating load infor-mation which now is a local activity to each PE, andthe cost of transferring tasks across the system.
Experimental results have been obtained and arebriefly described in here. For a complete descrip-tion of the experiments, algorithm and supportingdata structures please refer to [Csgg, Camgg]. Thefirst experiment (table 2) simulates a stable situa-tion where an initial set oftasks (representing severalcompeting applications) was distributed uniformlyamong all 16 processors. In the second scenario
(TnoLB -Topt)
where TnoLB is the time to complete the work on amulticomputer network without load balancing, Toptis the time to complete the work on one processordivided by the number of processors in the networkand Tbal is the time to complete the work on a mul-ticomputer network wiih load balancing.
2.3 Concurrent Gang Dynamic
Scheduling
Gang scheduling has been widely used as a solu-tion to the dynamic parallel job scheduling problem.Gang service is a paradigm where all tasks of a jobin the service stage are grouped into a gang and con-currently scheduled in distinct processors. Reasons
L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information Power Grid Resource Manageme
Table 2: Stable situation.
Hypercube I Fully Connected Network~f Workstations
I Sender lmtiated D~on I
Table 3: Unstable situation
3to consider gang service are responsiveness [FA97],eflicient sharing of resources[Jet97] and ease of pro-gramming. In gang service the tasks of a job aresupplied with an environment that is very similarto a dedicated machine [Jet97]. It is useful to anymodel of cómputation and any programming style.The use of time slicing allows performance to de-grade gradually as load increases. Applications withfine-grain interactions benefit of large performanceimprovements over uncoordinated scheduling[FR92] .One main problem related with gang schedulingis the necessity of multi-context switch across thenodes of the processor, which causes difliculty inscaling[ea98] .In our work, we use a class of schedul-ing policies, dubbed concurrent gang, that is a gener-alization of gang-scheduling and allows for the flexi-ble simultaneous scheduling.of multiple parallel jobsin a scalable manner .
IPG-SaLaD Components
IPG-SaLaD is composed of three inter-related com-ponents: Static Allocator, Load Balancer and Dy-namic Scheduler. Their interaction can be thoughtof as a three stage process with a feedback loop asshown in figure 1.
During the first stage, arriving jobs one at a time,are passed to the static allocator which is respon-sible for performing a suboptimal matching of theindividual tasks that compbse a job to the resourcesavailable. The task assignment froni the first stageis fed to the load balancer whose aim is to mini-mize idle time among the processing elements thatconstitute the system. Note, from the details pre-sented in the last section, t~at the Rate of Changeload balancing is only triggered when individual PEspredict that their future load will lead them to anidle state. As new jobs come in and are fed throughthe static allocator and poseibly altered by the loadbalancer the dynamic scheduler is invoked to handlethe scheduling ofthe multiplejobs present in the sys-tem. This may require redistribution of tasks. Theload balancer also receives input from the dynamicscheduler in the form of the current task allocationfor each resource. Given both the inputs from thedynamic scheduler and the static allocator, the loadbalancer decides based on the Rate of Change al-gorithm whether or not to further redistribute theload. This interaction between load balancer anddynamic scheduler continues through the executionof the entire workload.
Concurrent Gang is an strategy that increases uti-lization and throughput in parallel machines whencompared with other implementations of gang ser-vice, for the same resource sharing strategy, as sim-ulation studies indicate[SS99b, SS99a]. The utiliza-tion in Concurrent Gang is improved because, in theevent of an idle slot or a blocked thread, Concur-rent Gang always tries to schedule other tasks thatare either local tasks or tasks that do not require,at that moment, coordinated scheduling with othertasks of the same job. This is the case, for instance,of 1/0 intensive tasks and Computation intensivetasks. Improved processor utilization in .turn leadsto better throughput.
Preliminary results have been already obtainedand published. In Tables 5, 6, 7 we present a sum-mary'of those results. For a complete description ofthe experiments please refer to [SS99b].
It is important to note that at any given instanceall stages can be active simultaneously which allowsfor a high degree of parallelism.
A detailed description of the internal functioningof each individual component follows.

3.1

I Simulation time
Seconds
5000
10000
20000
30000
40000
Table 7: Experimental results -Synchronization inténsive workload
is as follows: if any given PE is busy executing tasksthen the load differential with respect to any otherPE is irrelevant since no performance gain can be ob-tained by load transfer. Moreover the decision fac-tor to initiate a load transfer request should not bea PE's absolute load but instead how much its loadhas changed since the previous time interval. Ourgoal is then to minimize processor idling time with-out incurring high load balancing overhead. To doso, an optimal tradeoff between the processing ( costof evaluating load information to determine task mi-gration) and communication (cost of acquiring loadinformation and informing other PEs of load migra-tion decisions) overhead and the degree of knowledgeused in the balancing process must be sought.
The load balancing problem can be thought of asa four phase decision process, namely:
When to initiate task migration
.Where, which PE, to send the task migration
request
.How many tasks to migrate
.Which tasks to migrate
In RoC- LB these four phases occur asyn-chronously at each PE and are purely distributed.
The When Phase3.2.1
this point. First, each PE may calculate this quan-tity independently from other PEs in the system, i.e.there is no concept of global synchronous clock in thesystem. Second, the length of the sample intervalmay vary with time for a given PE, depending, forinstance, on the number of load requests received ornetwork traffic. As a consequence different PEs mayuse different sampling intervals at any given time.The sampling interval is therefore an adaptive pa-rameter. The sampling interval is usually measuredas a multiple of the time slice duration. The finerthe sampling the faster we detect the need for loadbalancing, but the greater overhead we incur .
Each PE uses its own DL as a predictor for howmanytasks will finish in subsequent intervals. EachPE assumes that DL will remain the same forever .Given that it calculates the .number of sampling in-tervals it will take to reach an idle state (no tasks toprocess). If the number of intervals (times its dura-tion) is less than the network delay (ND), then thePE will initiate a migration request.
From the above, one can conclude that only whenDL is negative (reduction in load) will a PE considerrequesting load from other PEs. Network delay isan adaptive parameter. It is defined as the time ittakes between the initiation of a load request and thereception of load. It may vary with time and eachPE may use a different value depending on its ownrecord of past load requests. Initially, before anyrequest has been made, ND is set to an arbitrary(positive) value.
There are two exceptions to the general rules de-scribed above. The first exception is the situationin which a PE will initiate a request for load eventhough it does not predict it will reach the idle state.
At the beginning of eachcalculates the change in iinterval. Let us call thisload (DL). Two key obser
sample interval, each PEts load since the previousquantity the difference invations should be made at

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information PowerGrid Resource Management Tool
Clustering Nonuniform Undirected Graphs (CNUG) AlgorithmFor all nodesPi dobegin Make a cluster for Pi at clustering layer 1
Set the parameters of the cluster to be (1, Bi, 0,0)endSet cluster layer L to be 1While there is at least one edge linkingtwo clusters of layer L dobegin Sort all edges linking any two clusters in descending order
While sorted edge list is not empty, dobegin Take the first edge (Ci,Cj) from sorted edge list
Delete the edge from the listMerge ci and Cj into cluster C' at layer (L + 1)Calculate the parameters of C'Delete clusters ci and Cj from current layer LFor each edge ( Cx , Cy) in sorted edge listbegin
If ( C;r is a sub-cluster of c') and(Cy is not a sub-cluster of any cluster) and(Cy is connected to all other sub-clusters of c') thenbegin Merge Cy into c'
Recalculate the parameters of c'Delete (C;r, Cy) from edge list
endEtse if Cx and Cy are sub-clusters of two different clusters at layer (L + 1), thenbegin Add the weight of ( Cx , Cy) to the edge between the two super-clusters
Delete (cx, Cy) from edge listend
endend
Increment clustering layer L by 1
end
Figure 2: Clustering Nonuniform Undirected Graphs (CNUG) algorithm,
In order to understand why it chooses to do so, letus introduce the three thresholds used by the algo-rithm. High threshold (HT) and Low threshold (LT)are used to determine the load status of the proces-sor. If a PE's load is greater or equal to HT it isconsidered a Source PE. If on the other hand it isless or equal to LT it is considered a Sink PE. If itsload lies between these two thresholds then the PE isin a neutral state. If however a PE's load falls belowa Critical threshold (CT) the PE immediately ini-tiates a request for load regardless of the predictedfuture load based upon the current DL value. Wedecide to request load even though we do not expectto reach the idle state since even a small change inload at this level will result in immediate task star-vation by the PE. The only exception to this rule isthat if a PE has already a request pending in thenetwork it will not issue another until either load isreceived from other PE(s) or the request comes backas unfulfilled. This last observation applies in everycase even when a DL 's value would deem necessaryto issue another request. The other exception to thegeneral rule is the situation when a PE's load level isabove HT. In that case even if the value of DL pre-dicts that the PE will reach an idle state we do not
initiate a load request because at this load value thevalue of DL necessary to force the PE to become idlemust be quite high. There is a good chance that sucha value is rare and short lived in which case duringthe next sample interval the newly calculated DLwill be such that it does not warrant an initiationof a transfer request. By delaying any action untilthe load value falls below HT we are immune to anyspikes in load that may occur over time.
The Where Phase3.2.2
Each PE keeps two local tables containing systemload information. One contains information regard-ing the location of sink PEs, called Sink table theother of source PEs, called Source table. Any PEthat initiates a request for load is considered to bea sink by the receivjng PE(s). This is true regard-less of the level of load at the time the request forload transfer was issued. Selecting the PE to whichsend a load request is a simple operation. The sinkPE (request initiator) selects a source PE from itssource table ( the first entry in the table) and sends amessage requesting load to it. Every time the staticallocator produces a task-to-resource mapping for a
221

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information Power Grid Resource Management 7001~. ,... ~~...t'~~, , , ~~
Figure 3: Clustering Nonuniform Directed Graphs (CNDG) algorithm
given job, the entries in the source/sink tables areupdated with this new information. The selectionprocess described above is used by all PEs alike,w:hether they are the request initiator or the recip-ient of a load transfer message who might need toselect a source PE to whom forward the message to.
cost [HBD90] Age in this cage refers to the CPUtime a tagk hag used thus far and not how long ago.the tagk wag created meagured in wall time clock.
Figure 5 shows the internal data structures in-volved during the load transfer update process.
3.3 SaLaD Dynamic Scheduling
In this section we describe the Concurrent Gangalgorithm. We first introduce the concepts of CY-cle, slice, period and slot, which are fundamental tounderstand the internal workings of our algorithm.Then we describe the task classification that is madeby the algorithm; we shall see that this task classifi-cation is used by Concurrent Gang to decide locallywhich task to schedule if the current task blocks. In3.3.3 the algorithm itself is detailed, with the de--scription of the components of a Concurrent GangScheduler .
3.2.3 The How Many Phase
At the beginning of each sample interval each PEcalculates its DL. Using DL it computes how manytasks it would have, assuming DL would stay con-stant, after a length oftime equal to ND. Let us ca"this quantity Predicted Load (PL). If PL is greateror equal to zero then the PE does not expect to be-come idle within the next ND period and thereforedoes not initiate a request for load. If on the otherhand PL is lesser than zero the PE requests load, ac-cording to the mechanism described in 3.2.2, in theamount of abs(PL). On the receiver side, a PE wi"only transfer tasks if its load is above the HT level,in which case it transfers tasks above this value upto the requested transfer amount.
3.3.1 Time Utilization
In parallel job scheduling, as the number of proces-sors is larger than one, the time utilization as well asthe spatial utilization can be better visualized withthe help of a bi-dimensional diagram dubbed tracediagram. One dimension represents processors whilethe other dimension represents time. Through thetrace diagram it is possible to visualize the time uti-lization of the set of processors given a scheduling
3.2.4 The Which Phase
Finally, to answer the question of which tasks tomigrate, we have decided to migrate older tasksbecause these tasks have a higher probability ofliving long enough to amortize their migration
222

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information Power Grid Resource Management Tool
Mapping AlgorithmFor each layer of Spec graph (starting from maximallayer number) dobegin
Sort all Spec clusters at current layer in descending order of uS!A .SS!A .nsu. and 7rS!A .Sort all Rep cllisters at current layer in descending order of u Rj SRj. nRj. and 7r Rj .Calculate f(u,ti) , if f(u,ti) > 1, let f(u,ti) = 1.Calculate the required size of the Rep cluster matching S't to be f(u,ti) xuS'tFor each Spec cluster at current layer sorted list. dobegin If the cluster has only one sub-cluster, then
Go to a lower layer where there are multiple or no sub-clustersIf at least a Rep cluster of required size is found, thenbegin Select the Rep cluster of required size with minimum estimated execution time
Match the Spec cluster to the Rep clusterDelete the Spec and Rep cluster from Spec and Rep list
endendFor each unmatched Spec cluster. dobegin If the size of the first Rep cluster > the required size. then
begin Split the Rep cluster into two parts with one part of the required sizeMatch the Spec cluster to this partInsert the other part to proper position of the sorted Rep cluster list
endElse begin
Merge Rep clusters with largest size until the sum of sizes :?: the required sizeIf =, thenMatch the Spec cluster to the merged Rep clusterElsebegin Split the merged Rep cluster into two parts with one of required size
match the Spec cluster to this partInsert the other part to the sorted Rep list
endend
endFor each matching pair of Spec cluster and Rep cluster, dobegin If the Rep cluster contains only one processor, then
Map all the modules in the Spec cluster to the processorElse if Inequality is satisfied, then
begin Select the sub-cluster of the Spec cluster with the largest sizeEmbed the nodes of other sub-clusters to the connected nodes of the selected sub-clusterto the connected nodes of the selected sub-clusterembed these sub-clusters onto the selected oneCalculate the parameters for the new clusterInsert it into the sorted Spec cluster list
endElsebegin Delete the Spec cluster from Spec cluster list
Delete the Rep cluster from Rep cluster listGo to the sub-clusters of the Spec and Rep cluster (thus they are pushed to current layer)Call the same mapping algorithm forthese clusters
endend
end
Figure 4: Mapping algorithm.
223

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian. An Information PowerGrid Resource Management Tool
algorithm. One such diagram is illustrated in figure6. A Workload change occurs at the arrival of a newjob, the completion of an existing one, or through thevariation of the number of eligible tasks of a job tobe scheduled. The time between workload changesis defined as a cycle. Between workload changes, wemay define a period that depends on the workloadand the spatial allocation. The period is the mini-mum interval of time where all jobs are scheduled atleast once. A cycle/period is composed of slices; aslice corresponds to a time slice in a partition thatincludes all processors of the machine. Observe thatthe duration of the slice for Concurrent Gang is de-fined by the period of the global clock. A slot is theprocessors' view of a slice. A Slice is composed of Nslots, for a machine with N processors. If a processorhas no assigned task during its slot in a slice, then wehave an idle slot. The number ofidle slots in a perioddivided by the total number of slots in that perioddefines the Idling Ratio. Note that workload changesare detected between periods. If, for instance, a jobarrives in the middle of a period, corresponding ac-tion of allocating the job isonly taken by the end ofthe period.
Figure 5: "°ad Transfer Update Process
3.3.2 Task Classification
In Concurrent Gang, each pE classifies each one ofits allocated tasks into classes. Examples of suchclasses are: 1/0 intensive, Synchronization intensive,and computation intensive. Each one of these classesis" similar to a fuzzy set [Zad65] .A fuzzy set asso-ciated with a class A is characterized by a member-ship function f A ( x) with associates each task T toa real number in the interval [0,1], with the value off A (T) representing the "grade of membership" of Tin A. Thus, the nearer the value of F A (T) to unity,the higher the grade of membership of T in A. Forinstance, consider the class of 1/0 intensive tasks,
with its respective characteristic function fIO(T). Avalue of fIO(T) = 1 indicates that the task T onlyhave 1/0 statements, while a value offIO(X) = O in-dicates that the task T have executed no 1/0 state-ment at all.
In principIe, four major classes are possible: 1/0
intensive, Computing intensive, Communications(point to point) intensive and synchronization inten-sive. We will see in the next subsection that only asubset of them are used in Concurrent Gang.
3.3.3 Description of Concurrent Gang
A Concurrent Gang scheduler is composed by a set of
local schedulers, one for each PE, and a mechanism
Arriving Jobs
sraric,Allocaror I,Task-ro- Rcsourcc IMapping
Load Balancer
~~nDynamic Schcdulcr
--r-~Dcparring Jobs
CUrrcnt Task Allocation
Period -1-Peri-¡ Period-1 -Period-
Tinle
* I die Slols
Figure
ponents
Interaction between the different SaLaD com
Figure 6: Definition of slice, slot, period and cyclj
224

Scherson, M. Eshaghian: An Information Power Grid Resource Management ToolM. C~mpos. F. Silva,
bership of a task to each one of the major classesdescribed in the previous subsection. Formally, thepriority of a task T in a PE is defined as:
Pr(T) = max(Q x >.l0,>.COMP) (1)
Where >.10, >.COM P are the grade for membershipof task T to the classes 1/0 intensive and Com-putation intensive. The objective of the parame-ter Q is to give higher priority to 1/0 bound jobs( Q > 1) .The choices made in equation 1 intendto give high priority to 1/0 intensive jobs and com-putation intensive job, since such jobs can benefitthe most from uncoordinated scheduling. The mul-tiplication factor Q for the class 1/0 intensive giveshigher priority to 1/0 bound tasks over computationintensive tasks, since those jobs have a higher proba-bly to block when sclieduled than computing boundtasks. By other side, synchronization intensive andcommunication intensive jobs have low priority sincethey require coordinated scheduling to achieve effi-cient execution and machine utilization[FR92, ea98] .A synchronization intensive or communication inten-sive phase will reflect negatively over the grade ofmembership of the class computation intensive, re-ducing the possibility of a task be scheduled by thelocal task scheduler. Among a set of tasks of thesame priority, the local task scheduler uses a roundrobinstrategy. The local task scheduler also definesa minimum priority {3. If no parallel task has prioritylarger than {3, the local task scheduler considers thatall tasks are either communication or synchroniza-tion intensive, thus requiring coordinated schedul-
mg.In practice the operation of the Concurrent Gang
scheduler at each processor will proceed as follows:The reception of the global clock signal will generatean interruption that will make each processing ele-ment schedule tasks as defined in the trace diagram.If a task blocks, control will be passed to anothertask as a function of the priority assigned to eachone of the tasks until the arrival of the next clocksignal. The task chosen is the one with higher pri-
ority. ,In the event of a job arrival, a .job termination or
a job changing its number of eligible tasks the frontend Concurrent Gang Scheduler will :
for the coordination of the global context switch inthe machine, which can be either a central controlleror aglobal synchronizer .
A local scheduler in Concurrent Gangis composedof two main parts: the Gang scheduler and the lo-cal task scheduler. The Gang Scheduler defines thenext task to be scheduled by the arrival of the globalcontext switch signal coming from a synchronizer ora central controller. The local task scheduler is re-sponsible for scheduling sequential tasks and paralleltasks that do not need global coordination, as de-scribed in the next paragraph, and it is similar toa UNIX scheduler. The Gang Scheduler has prece-dence over the local task scheduler .
We may consider two types of parallel tasks ina concurrent gang scheduler: Those that shouldbe scheduled as a gang with other tasks in otherprocessors and those that gang scheduling is notmandatory. Examples of the first class are tasksthat compose a job with fine grain synchroniza-tion ínteractions [FR92] and communication inten-sive jobs[ea98] .Second class task examples are localtasks or tasks that compose an 1/0 bound paralleljob, for instance. On other side a traditional UNIXscheduler does a good job in scheduling 1/0 boundtasks since it gives high priority to 1/0 blocked taskswhen the data became available from disk. As thosetasks typically run for a small amount of time andthen blocks again, giving them high priority meansrunning the task that will take the least amountof time before blocking, which is coherent to thetheory of uniprocessors scheduling where the bestscheduling strategy possible under total completiontime is Shortest Job First [MPT94]. In the localtask scheduler of Concurrent Gang, such high prior-ity is preserved. Another example ofjobs where gangscheduling is not mandatory are embarrassingly par-allel jobs. As the number of iterations among tasksbelonging to this class of jobs are small, the basicrequirement for scheduling a embarrassingly paralleljob is to give those jobs the larger fraction of CPUtime possible, even in an uncoordinated manner.
Differentiation among tasks that should be gangscheduled and those that a more flexible scheduleris better is made using- the grade of membership in-formation computed by the local scheduler ( as ex-plained in the last subsection) about each task asso-ciated with the respective processor. The grade ofmembership of the task previously scheduled is thencomputed at the next machine-wide context switch,and is that information that is used to decide if gangscheduling is mandatory or not for a specific task.
The local task scheduler defines a priority for eachtask allocated to the corresponding PE. The priorityof each task is defined based on the grade of mem-
2
3
Update Eligible task listAllocate Tasks of First Job in General QueueWhile not end of Job Queue
Allocate all tasks of remaining parallel jobsusing a defined spatial sharing strategy
Run4
225

L. M. Campos, F. Silva, 1; Scherson, M. Eshaghian: An Information Power Grid Resource Manaqement Tool
Between Workload Changes-If a task blocks or in the case of an idle slot, the
local task scheduler is activated, and it will decideto schedule a new task based on:
.Availability of the task (task ready
.Priority of the task defined by the local taskscheduler .
AII processors change context at same time dueto a global clock signal coming from a central syn-chronizer. The local queue positions represents slotsin the trace diagram. The local queue length is thesame for all processors and is equal to the number ofslices in a period of the schedule. It is worth notingthat in the case of a workload change, only the PEsconcerned by the modification in the trace diagramare notified.
It is clear that once the first job, if any, in thegeneral queue is allocated, the remaining availableresources can be allocated to other eligible tasks byusing a predefined partitioning strategy.
In the case of creation of a new task by a paralleltask, or parallel task completion, it is up to the localscheduler to inform the front end of the workloadchange. The front end will then take tlie appropriateactions depending on the pre-defined space sharing
strategy.
4 Implementation ofCurrent
SaLaD
Software solutions for IPG are still in their infancy.As examples of some experimental meta-computingsystems we have the NOW project 2 and Legion3,
which enable users to use resources across multiplemachines. A number of attempts are being madeto address the problem of allowing programmers towrite portable code that will run across networksof computers. One such to.ol is HENCE4 (Hetero-geneous Network Computing Environment), an x-window based software environment designed to as-sist in developing parállel programs that run on anetwork of computers. HENCE allows a user to layout tasks in a graphical format and execute them.HENCE uses a static table of costs tha.t describesthe cost of executing various program modules onvarious machines. Selection is then done using thistable so that the overall cost is minimized.
In this section, a Windows NT based implemen-tation of the SaLaD tool for distributed executionof arbitrary heterogeneous tasks onto arbitrary suiteof heterogeneous systems using PVM is presented.The main components of this tool are the Cluster-M Clustering and Mapping Module, the Rate ofChange Module, the Concurrent Gang SchedulingModule,the Graphical User Interface Module and thePVM based Distribution Module. The user inputsthe task and system graphs using the tool 's Graph-ical User Interface module, where the Nodes of atask graph represent an arbitrary executable pro-gram written in C, C++ or Fortran, and the Nodesof the System Graph represent any system with aPVM implementation. Once the mapping is done,the Distribution Module using PVM dispatches thetasks on the underlying heterogeneous systems anddisplays the results graphically. Next, the Rate ofChange Load Balancer and Concurrent Gang Sched-uler will redistribute the jobs and the tasks as nec-
essary.
The current implementation of SaLAD requiresthe application programs to be described by graphs.SaLaD graphs are variants of directed acyclic graphs,or DAGS. There are two kinds of graphs namely Taskand System graphs. Nodes of the task graph repre-sent executables and the arcs represent data depen-dencies between the executables. Similarly Nodes ofthe system graph represent computer systems andthe arcs represent the communication bandwidthavailable between them. SaLaD uses the Cluster-M algorithms for clustering and mapping of the taskgraphs and the system graphs in an efficient way,based on the data dependency between the tasks andthe communication capacity available between thesystems. Once the tasks have been mapped onto thesystems, individual tasks ar~ distributed using PVM.As the load of the system changes and/ or as new jobscome in the Rate of Change load balancer and Con-current Gang scheduler are invoked and they will re-distribute the tasks using PVM. SaLaD is composedof integrated graphical tools for creating, executing,and analyzing parallel programs. During execution,SaLaD displays an event-ordered animation of appli-cation execution. Through SaLaD, a user can easilyschedule and execute applications written in any lan-guage over an existing collection of workstations orsupercomputers. SaLaD depends on PVM and hencethe task graph modules can reside on any Computersystem for which a PVM implementation is avail-able.
The SaLaD tool runs on the Windows NT, Win-dows 95 environments. PVM implementations forWin32 must be installed before using SaLaD. Thetask graph the user draws is a directed graph in
2Network of Workstations (UC Berkeley Project)3Vlsit http:/ /www.cs.virginia.edu/ legion4 Heterogeneous Network Computing Environment (X.
Windows based network programming tool)

L. M. Campos, F. Silva, Scherson, M. Eshaghian: An Information Power Grid Resource Management Tool
Gang Dynamic-scheduler. In section 3, we presentedhow these three components operate in an integratedfashion, and section 4 we preseJlted a simple imple-mentation of SaLaD using PVM which distributesthe tasks to the locations determined by the map-
per.We propose to extend the windows-NT based im-
plementation of SaLaD using PVM with a portableprogramming interface. Currently a user has tospecify a set of threads which can be C or C++ code,and their interdependency. Then SaLaD takes thisinformation and produces a mapping using Cluster-M mappingroutines, and then the load balancer anddynamic schedulers are triggered as needed. We pro-pose a portable programming interface such that theuser just enters the program and then the programis decomposed into a task graph showing the depen-dencies and extracted parallelisms, and then thatinformation gets supplied to the Cluster-M mapper.One way of pursuing this would be to use a portableparallellanguage from beginning such as PCN. Ourinitial investigation shows that clustering constructscan be implemented in PCN so that the process ofclustering the graphs is automated. Another ap-proach would be to use a Functional and/or objectoriented programming language such as SISAL orJAVA.
which nodes represent executables written in C orFortran. Arcs represent execution ordering con-straints. A node may execute when all nodes thatprecede it in the graph have executed. The restric-tion placed on the task modules is that they shouldbe using the PVM library to send back results to theSaLaD tool, if it has to be passed to other depen-dent modules. If the task modules have dependen-cies in the order of execution but do not have to passdata amongst themselves, then no change needs tobe done to the executables. The above restriction isplaced due to the fact those unlike tools where userswrite their programs graphically, SaLaD is more ofa Cluster-M scheduling tool for executable modules.Unlike Task modules there is no restriction on thesystems. Any system for which a PVM implementa-tion is available can be part of the system graph.
When the SaLaD executable is run the openingscreen is divided into four windows as follows:1.Information Window -Shows the names of thecurrently loaded task and system graphs.2.Drawing Window -Used to draw task and system
graphs.3.Map Window -Shows the result of the Cluster-M
mapping.4.Run Window -Show the results of executing thetasks (graph) on the systems (graph) using PVM.
The steps a user must perform to create and run)a parallel program under SaLaD are as follows: 1.Draw a task and system graph in the Drawing Win-dow that shows the desired parallel structure. 2.Once the Task and system graphs have been drawn,use the " Map" menu command to Map the task
graph on the system graph. Once the mapping isdone, the Rep and Spec Clusters and the Mappingresults are displayed in the mapping informationwindow. 3. After the tasks have been mapped, theycan be executed on the respective systems by us-ing the "Run" Menu command. The Run ResultsWindow displays the status of the execution as it
progresses.
References
[Ber87: F. Berman. Experience with an auto-matic solution to the mapping problem.In L. H. Jamieson, D. B. Gannon, andR. J. Douglass, editors, The Character-istics of Parallel Algorithms, pages 307-334. MIT Press, Cambridge, MA, 1987.
[Bok81 ]s. H. Bokhari. On the mapping prob-lem. IEEE Trans. on Computers, c-30(3):207-214, March 1981.
[BS87] F. Berman and L. Snyder. On mappingparallel algorithms into parallel architec-tures. Journal of Parallel and DistributedComputing, pages 439-458, April1987 .
5 Conclusion and Future Work
The main goal of our studies has been to concen-trate on the development of tools that can be usedin the execution environment of IPGs. Mainly, ourfocus is to complete building the SaLaD tool thatis intellded to automate the execution of a pro-gram inputed by a user of IPG, so that it is dis-tributed among available resources minimizing to-tal execution time. SaLad can be viewed as hav-ing three components, Cluster-M Static-allocatorthe Rate-of-Change Load-balancer, and Concurrent-
[Cam99] L. M. Campos. Resource ManagementTechniques for Parallel and DistributedSystems. PhD thesis, University 0[ Cali-[ornia at Irvine, 1999.
[CE95] s o Chen and M o Eshaghian o A fast recur-
sive mapping algorithmo Concurrencyo
Practice and Experience, 7(5):391-409
August 19950

[CS99] [HBD90]L. M. Campos and I. D. Scherson. Rateof change load balancing on distributedand parallel systems. In Proceedings ofthe Second Merged. IPPS/SPDP, pages
701-707, Apri11999.
M. Harchol-Ealter and A. E. Downey.Exploiting process lifetime distributionsfor dynamic load balancing. ACMTransactions on Computer Systems,15(3):253-285, 1990.
[Jet97]P. G. Solbalvarro et al. DynamicCoscheduling on Workstation Clusters,Job Scheduling Stmtegies for ParallelProcessing, LNCS 1459:231-256, 1998.
M. A. Jet te. Períormoí Gang Scheduling IEnvironments. In p1997.
[LA87] s. Lee and J. K. Aggarwal. A mappingstrategy for parallel processing. IEEETrans. on Computers, 36:433-442, April1987.
[Efe82] K. Efe. Heuristic models of task assign-ment scheduling in distributed systems.IEEE Computer, 15(6):50-56, 1982.
[ERL90] H. EI-Rewini and T. G. Lewis. Schedul-ing parallel program tasks onto arbitrarytarget machines. Journal of Parallel andDistributed Computing, pages 138-153,September 1990.
[LHWS96] P.K.K. Loh, W. J. Hsu, C. Wentong,and N. Sriskanthan. .How networktop,ology affects dynamic load balancing.IEEE Parallel and Distributed Technol-ogy, 4(3):25-35, 1996.
[ERS90] .F. Ercal, J. Ramanujam, and P. Sa-dayappan. Task allocation anta a hyper-cube by recursive mincut bipartitianing.Journal of Parallel and Distributed Com-puting, pages 33-44, October 1990.
[LK91] F. C. H. Lin and R. M. Keller. The gradi-ent modelload balancing method. IEEETmns. Software Eng., 13(1}:32-38,1991.
[1088] v. M. Lo. Heuristic algorithms for taskassignment in distributedsystems. IEEETrans. on Computers, C-37(11):!384-1397, November 1988.
M. Eshaghian and M. Shaaban. Cluster-M parallel programming paradigm. In-ternational Journal of High Speed Com-puting, 6(2):287-309, June 1994. [LRG+90] V. M. Lo, S. Rajopadhye, S. Gupta,
D. Keldsen, M. A. Mohamed, and J. A.Telle. Oregami: Software tools for map-ping parallel computations to paralle~ ar-chitectures. In Proc. International Con-ference on Parallel Processing, 1990.
[Esh96] M. M. Eshaghia,n. Heterogeneous Com-puting. Artech House, 1996.
D. Feitelson and M. A.Jette. Im-proved Utiliz~tion and Responsivenesswith Gang Scheduling. Job SchedulingStrategies for Pamllel Processing, LNCS
1291:238-261,1997.
[FA97]
[MG89] C. McCreary and H. Gill. Automaticdetermination of gLain size for efficientparallel processing. Communications ofA CM, 32(9):1073-1078, September 1989.
D. Feitelson and L. Rudolph. GangScheduling Performance Benefits forFine-Grain Synchronization. Journalof Parallel and Distributed Computing,16:306-318, 1992.
[FR921R. Motwani, S. Phillips, and E. Torng.Non-clairvoyant scheduling. Theoretical
Computer Science, 130(1):17-47,1994.
[MPT94]
[PSD+92] R. Ponnusamy, J. Saltz, R. Das, C. Koel-bel, and A. Choudhary. A runtimedata mapping scheme for irregular prob-lems. In Proc. Scalable High Per-
formance Computing Conference, pages216-219, May 1992.
D. Feitelson and L. Rudolph. Met-rics and Bechmarking for Parallel JobScheduling. Job Scheduling. Stmtegiesfor Parallel Processing, LNCS 1459:1-24,
1998.
[FR98]
v. Sarkar. Partitioning and Scheduling
Parallel Programs for Execution on Mul-
tiprocessors. The MIT Press, Cambridge,
MA, 1989.
[Sar89]I. Foster and S. Tuecke. Parallel pro-gramming with PCN. Technical report,Argonne National Laboratory, Univer-sity of Chicago, January 1993.
228
lance Characteristicsn Multiprogrammed
'roceedings of SC'97,

L. M. Campos, F. Silva, I. Scherson, M. Eshaghian: An Information Power Grid Resource Management Tool
[SS99a] [WG90]F .A.B. Silva and I.D. Scherson. Improv-
ing Throughput and Utilization in Paral-lel Machines Through Concu,rrent Gang.In Proceedings of the IEEE/ACM In-ternational Parallel and Distributed Pro-
cessing Symposium 2000, 1999. [WLR93]
M. Y. Wu and D. Gajski. Hypertool:A programming aid for message-passingsystems. IEEE Trans. on Parallel andDistributed Systems, 1(3):101-119, 1990.
M. H. Willebeek-LeMair and A. P.Reeves. Strategies for dynamic loadbalancing on highly parallel computers.IEEE Trans. Parallel Distributed. Sys-
tems, 4(9):979-993, 1993.
[SS99b] F .A.B. Silva and I.D. Scherson. To-wards Flexibility and Scalability in Par-allel Job Scheduling. In Proceedings ofthe 1999 IASTED Conference on Paral-lel and Distributed Computing Systems,1999.
[YG94] T. Yang and A. Gerasoulis. DSC:
Scheduling parallel tasks on an un-bounded number of processors. IEEETrans. on Parallel and Distributed Sys-
tems, 5(9):951-967, September 1994.
[ST85] c. Shen and W. Tsai. A graph match-ing approach to optimal task assignmentin distributed comptIting systems using aminmax criterion. IEEE Trans. on Com-
puters, c-34(3):197-203, March 1985.
[Zad65] L. A. Zadeh. Fuzzy Sets. lnformationand Control, 8:338-353, 1965.
Lujs Mjguel Campos recejved hjs Ph.D.. degree jn Computer Scjence from the Unjversjty ofCalifornja Irvjnejn 1999. where he hjs currently a faculty member. Dr. Campos. jnterests are jnthe area of resource management jn djstrjbuted and parallel systems and mobjle agents. He hjsthe co-author of the computer language Tea and the web appljcatjon server I*Tea.He hjs aformer Fulbrjght scholar.
Fabr;c;o S;lva received hi$ Ph.D. degree in Computer Science from Universite Pierre et Marie Curie in2000. He is currently a postdoctoral researcher at the University ofCalifornia at Irvine. Dr. Silva is amember of IEEE and A CM and has authored numerous scientific articles.
Isaac D. Scherson is currently a Professor in the Deptartments of Information and Computer Science andElectrical and Computer Engineering at the University ofCalifornia. Irvine. He received BSEE and MSEEdegrees from the National University of Mexico (UNAM) and a Ph.D. in Applied Mathematics (ComputerScience) from the Weizmann Institute ofScience. Rehovot. Israel. He heldfaculty positions in the Dept. ofElectrical and Computer Engineering ofthe University ofCalifornia at Santa Barbara (J983-J987). and inthe Dept. ofElectrical Engineering at Princeton University (J 987- J 99 J). Dr. Scherson has been a member ofthe Technical Program Committee for several professional conferences and served as Workshops Chair forFrontiers .92. He is the editor ofthe book that resultedfrom the Frontier .s 92 workshop and a co-editor of anJEEE Tutorial on Jnterconnection Networks. He was the Guest Editor ofthe Special Jssue ofThe VisualComputer on Foundations ofRay Tracing (June 1990.). Dr. Scherson is a member ofthe JEEE ComputerSociety and ofthe ACM Since July. J992. he has contributed to the JEEE as member ofthe JEEE ComputerSociety Technical Committee on Computer Architecture. His research interests include concurrent computingsystems (parallel and distributed). scalable server architectures. scheduling and load balancing, interconnectionnetworks, performance evaluation. and algorithms and their complexity.
Mary M. Eshaghian received her Ph.D. degree in Computer Engineeringfrom the University ofSouthernCalifornia in J 988. She is currently Professor ofComputer Engineering at the Rochester Jnstitute ofTechnology. Dr. Eshaghian has chaired and served on many program committees of internationalconferences and workshops in the area of parallel processing. She has edited several special volumes
and has authored numerous scientific articles.
~
229