an introduction to parallel computing in econometrics
TRANSCRIPT

Parallel computing: general conceptsOpportunities for parallelization in econometrics
The PelicanHPC Linux distributionBasic MPIMontecarlo
A real problem and a real clusterPractical session: Monte Carlo on PelicanHPC
GMMParameterized Expectations Algorithm
4 Practical Projects
An Introduction to Parallel Computing inEconometrics
Michael Creel
Universitat Autònoma de Barcelona
Master en Economia de la Empresa y Metodos Cuantitativos,UC3M, April 2008
Michael Creel Parallel econometrics

What this presentation does:
The purpose of this presentation (in 3 two hour sessions) is toexplain enough basic concepts and to provide enough examplesso that students are able to:
run parallel code of interest to economistscreate their own clusterwrite new parallel code for basic econometric methodsknow where to look for more information
a link to this presentation is on my homepage(http://pareto.uab.es/mcreel/) in the �presentations�section

What this presentation does:
The purpose of this presentation (in 3 two hour sessions) is toexplain enough basic concepts and to provide enough examplesso that students are able to:
run parallel code of interest to economistscreate their own clusterwrite new parallel code for basic econometric methodsknow where to look for more information
a link to this presentation is on my homepage(http://pareto.uab.es/mcreel/) in the �presentations�section

What this presentation does:
The purpose of this presentation (in 3 two hour sessions) is toexplain enough basic concepts and to provide enough examplesso that students are able to:
run parallel code of interest to economistscreate their own clusterwrite new parallel code for basic econometric methodsknow where to look for more information
a link to this presentation is on my homepage(http://pareto.uab.es/mcreel/) in the �presentations�section

What this presentation does:
The purpose of this presentation (in 3 two hour sessions) is toexplain enough basic concepts and to provide enough examplesso that students are able to:
run parallel code of interest to economistscreate their own clusterwrite new parallel code for basic econometric methodsknow where to look for more information
a link to this presentation is on my homepage(http://pareto.uab.es/mcreel/) in the �presentations�section

What this presentation does:
The purpose of this presentation (in 3 two hour sessions) is toexplain enough basic concepts and to provide enough examplesso that students are able to:
run parallel code of interest to economistscreate their own clusterwrite new parallel code for basic econometric methodsknow where to look for more information
a link to this presentation is on my homepage(http://pareto.uab.es/mcreel/) in the �presentations�section

What this presentation does:
The purpose of this presentation (in 3 two hour sessions) is toexplain enough basic concepts and to provide enough examplesso that students are able to:
run parallel code of interest to economistscreate their own clusterwrite new parallel code for basic econometric methodsknow where to look for more information
a link to this presentation is on my homepage(http://pareto.uab.es/mcreel/) in the �presentations�section

A disclaimer
the presentation is strongly derivative of my own work, anddoes not make much e�ort to explain alternatives.
This is certainly a biased and narrow perspective. The onlyjusti�cation is that time is limited, and I am able to makethese examples work.
There very well may be better ways to do some of this, thoughI do believe that what I present is the fastest and easiest wayto get started.

A disclaimer
the presentation is strongly derivative of my own work, anddoes not make much e�ort to explain alternatives.
This is certainly a biased and narrow perspective. The onlyjusti�cation is that time is limited, and I am able to makethese examples work.
There very well may be better ways to do some of this, thoughI do believe that what I present is the fastest and easiest wayto get started.

A disclaimer
the presentation is strongly derivative of my own work, anddoes not make much e�ort to explain alternatives.
This is certainly a biased and narrow perspective. The onlyjusti�cation is that time is limited, and I am able to makethese examples work.
There very well may be better ways to do some of this, thoughI do believe that what I present is the fastest and easiest wayto get started.

Parallel computing: general conceptsOpportunities for parallelization in econometrics
The PelicanHPC Linux distributionBasic MPIMontecarlo
A real problem and a real clusterPractical session: Monte Carlo on PelicanHPC
GMMParameterized Expectations Algorithm
4 Practical Projects
Outline
1 Parallel computing: general concepts
2 Opportunities for parallelization in econometrics
3 The PelicanHPC Linux distribution
4 Basic MPI
5 Montecarlo
6 A real problem and a real cluster
7 Practical session: Monte Carlo on PelicanHPC
8 GMM
9 Parameterized Expectations Algorithm
10 4 Practical Projects
Michael Creel Parallel econometrics

What is parallel computing?

What is parallel computing (2)
https://computing.llnl.gov/tutorials/parallel_comp/

Share work to get it done faster
Figure: Share the work

Some factors a�ect the performance of a parallelized version
how much of the work is blue/green?
how much communication overhead is introduced?
there may be di�erent ways to parallelize an application, thatlead to di�erent amounts of communications overhead.making a good parallelized application often requiresunderstanding both the application and the technology forparallelization. A single person who understands both willprobably do a better job than 2 people who each understandone of the parts.

Some factors a�ect the performance of a parallelized version
how much of the work is blue/green?
how much communication overhead is introduced?
there may be di�erent ways to parallelize an application, thatlead to di�erent amounts of communications overhead.making a good parallelized application often requiresunderstanding both the application and the technology forparallelization. A single person who understands both willprobably do a better job than 2 people who each understandone of the parts.

Some factors a�ect the performance of a parallelized version
how much of the work is blue/green?
how much communication overhead is introduced?
there may be di�erent ways to parallelize an application, thatlead to di�erent amounts of communications overhead.making a good parallelized application often requiresunderstanding both the application and the technology forparallelization. A single person who understands both willprobably do a better job than 2 people who each understandone of the parts.

Some factors a�ect the performance of a parallelized version
how much of the work is blue/green?
how much communication overhead is introduced?
there may be di�erent ways to parallelize an application, thatlead to di�erent amounts of communications overhead.making a good parallelized application often requiresunderstanding both the application and the technology forparallelization. A single person who understands both willprobably do a better job than 2 people who each understandone of the parts.

Amdahl's Law
In the case of parallelization, Amdahl's law states that if P is theproportion of a program that can be made parallel (i.e. bene�tfrom parallelization), and (1−P) is the proportion that cannot beparallelized (remains serial - the green in the previous �gure) thenthe maximum speedup that can be achieved by using N processorsis
1
(1−P) + PN
In the limit, as N tends to in�nity, the maximum speedup tends to1/(1−P). In practice, performance/price falls rapidly as N isincreased once there is even a small component of (1−P).source: http://en.wikipedia.org/wiki/Amdahl's_law

Amdahl's Law (2)
source: http://en.wikipedia.org/wiki/Amdahl's_law

Multiple cores, clusters, and grids
There are many ways to do parallel computing. A generaloverview is here: http://en.wikipedia.org/wiki/Parallel_computing#Classes_of_parallel_computers
We'll focus on multiple cores and clusters
Grids could also be used for econometrics, but this is outsidethe scope of this course. A grid is a large group ofheterogeneous machines that don't trust eachother. Theyshare CPU capacity when it is available. There is no guaranteethat resources will be available on any speci�c machine at anyparticular time. seti@home or folding@home are wll knownexamples. A promising project that used virtual machines ishttp://www.grid-appliance.org/

Multiple cores, clusters, and grids
There are many ways to do parallel computing. A generaloverview is here: http://en.wikipedia.org/wiki/Parallel_computing#Classes_of_parallel_computers
We'll focus on multiple cores and clusters
Grids could also be used for econometrics, but this is outsidethe scope of this course. A grid is a large group ofheterogeneous machines that don't trust eachother. Theyshare CPU capacity when it is available. There is no guaranteethat resources will be available on any speci�c machine at anyparticular time. seti@home or folding@home are wll knownexamples. A promising project that used virtual machines ishttp://www.grid-appliance.org/

Multiple cores, clusters, and grids
There are many ways to do parallel computing. A generaloverview is here: http://en.wikipedia.org/wiki/Parallel_computing#Classes_of_parallel_computers
We'll focus on multiple cores and clusters
Grids could also be used for econometrics, but this is outsidethe scope of this course. A grid is a large group ofheterogeneous machines that don't trust eachother. Theyshare CPU capacity when it is available. There is no guaranteethat resources will be available on any speci�c machine at anyparticular time. seti@home or folding@home are wll knownexamples. A promising project that used virtual machines ishttp://www.grid-appliance.org/

Multiple cores
A multi-core CPU has two or more cores, which essentially actas separate CPUs
tasks will ordinarily run on a single core
use htop to show that only 1 core is used while running amatrix inversion loop in octave
Using more than 1 core requires specialized methods, such asmulti-threading. Much currently available software will not usethreads, so will run on only one core. Newer software willcertainly start to use threads more widely.
using only 1 core to crunch numbers is very annoying if youhave 3 other mostly idle cores (quad core example)

Multiple cores
A multi-core CPU has two or more cores, which essentially actas separate CPUs
tasks will ordinarily run on a single core
use htop to show that only 1 core is used while running amatrix inversion loop in octave
Using more than 1 core requires specialized methods, such asmulti-threading. Much currently available software will not usethreads, so will run on only one core. Newer software willcertainly start to use threads more widely.
using only 1 core to crunch numbers is very annoying if youhave 3 other mostly idle cores (quad core example)

Multiple cores
A multi-core CPU has two or more cores, which essentially actas separate CPUs
tasks will ordinarily run on a single core
use htop to show that only 1 core is used while running amatrix inversion loop in octave
Using more than 1 core requires specialized methods, such asmulti-threading. Much currently available software will not usethreads, so will run on only one core. Newer software willcertainly start to use threads more widely.
using only 1 core to crunch numbers is very annoying if youhave 3 other mostly idle cores (quad core example)

Multiple cores
A multi-core CPU has two or more cores, which essentially actas separate CPUs
tasks will ordinarily run on a single core
use htop to show that only 1 core is used while running amatrix inversion loop in octave
Using more than 1 core requires specialized methods, such asmulti-threading. Much currently available software will not usethreads, so will run on only one core. Newer software willcertainly start to use threads more widely.
using only 1 core to crunch numbers is very annoying if youhave 3 other mostly idle cores (quad core example)

Multiple cores
A multi-core CPU has two or more cores, which essentially actas separate CPUs
tasks will ordinarily run on a single core
use htop to show that only 1 core is used while running amatrix inversion loop in octave
Using more than 1 core requires specialized methods, such asmulti-threading. Much currently available software will not usethreads, so will run on only one core. Newer software willcertainly start to use threads more widely.
using only 1 core to crunch numbers is very annoying if youhave 3 other mostly idle cores (quad core example)

High performance computing clusters
A HPC cluster is a set of computers connected with areasonably high speed networking technology, that areprepared to work together to solve a given task.
The goal is to �nish the given task more quickly by sharing thework using parallel computing methods.
Working together on a problem means that the same data andsoftware must be available to each node in the cluster.
Ensuring that this is the case is not always easy, especially asthe cluster agesshared �lesystems that reside on a single server is one way tosyncronize the nodesinstalling and maintaining a cluster is usually a nontrivial jobif you use commercial software, license fees can be veryexpensive if you use many nodes

High performance computing clusters
A HPC cluster is a set of computers connected with areasonably high speed networking technology, that areprepared to work together to solve a given task.
The goal is to �nish the given task more quickly by sharing thework using parallel computing methods.
Working together on a problem means that the same data andsoftware must be available to each node in the cluster.
Ensuring that this is the case is not always easy, especially asthe cluster agesshared �lesystems that reside on a single server is one way tosyncronize the nodesinstalling and maintaining a cluster is usually a nontrivial jobif you use commercial software, license fees can be veryexpensive if you use many nodes

High performance computing clusters
A HPC cluster is a set of computers connected with areasonably high speed networking technology, that areprepared to work together to solve a given task.
The goal is to �nish the given task more quickly by sharing thework using parallel computing methods.
Working together on a problem means that the same data andsoftware must be available to each node in the cluster.
Ensuring that this is the case is not always easy, especially asthe cluster agesshared �lesystems that reside on a single server is one way tosyncronize the nodesinstalling and maintaining a cluster is usually a nontrivial jobif you use commercial software, license fees can be veryexpensive if you use many nodes

High performance computing clusters
A HPC cluster is a set of computers connected with areasonably high speed networking technology, that areprepared to work together to solve a given task.
The goal is to �nish the given task more quickly by sharing thework using parallel computing methods.
Working together on a problem means that the same data andsoftware must be available to each node in the cluster.
Ensuring that this is the case is not always easy, especially asthe cluster agesshared �lesystems that reside on a single server is one way tosyncronize the nodesinstalling and maintaining a cluster is usually a nontrivial jobif you use commercial software, license fees can be veryexpensive if you use many nodes

High performance computing clusters
A HPC cluster is a set of computers connected with areasonably high speed networking technology, that areprepared to work together to solve a given task.
The goal is to �nish the given task more quickly by sharing thework using parallel computing methods.
Working together on a problem means that the same data andsoftware must be available to each node in the cluster.
Ensuring that this is the case is not always easy, especially asthe cluster agesshared �lesystems that reside on a single server is one way tosyncronize the nodesinstalling and maintaining a cluster is usually a nontrivial jobif you use commercial software, license fees can be veryexpensive if you use many nodes

High performance computing clusters
A HPC cluster is a set of computers connected with areasonably high speed networking technology, that areprepared to work together to solve a given task.
The goal is to �nish the given task more quickly by sharing thework using parallel computing methods.
Working together on a problem means that the same data andsoftware must be available to each node in the cluster.
Ensuring that this is the case is not always easy, especially asthe cluster agesshared �lesystems that reside on a single server is one way tosyncronize the nodesinstalling and maintaining a cluster is usually a nontrivial jobif you use commercial software, license fees can be veryexpensive if you use many nodes

High performance computing clusters
A HPC cluster is a set of computers connected with areasonably high speed networking technology, that areprepared to work together to solve a given task.
The goal is to �nish the given task more quickly by sharing thework using parallel computing methods.
Working together on a problem means that the same data andsoftware must be available to each node in the cluster.
Ensuring that this is the case is not always easy, especially asthe cluster agesshared �lesystems that reside on a single server is one way tosyncronize the nodesinstalling and maintaining a cluster is usually a nontrivial jobif you use commercial software, license fees can be veryexpensive if you use many nodes

Parallel computing and econometrics
Not the only source, but a good place to start (gives references):

How to parallelize a nonlinear estimation routine?Let's consider a paradigmatic problem in econometrics: estimationof the parameter of a nonlinear model. Supposing we're trying tominimize sn(θ). Take a second order Taylor's series approximationof sn(θ) about θ k (an initial guess).
sn(θ)≈ sn(θk) +g(θ
k)′(
θ −θk)
+1/2(
θ −θk)′H(θ
k)(
θ −θk)
To attempt to minimize sn(θ), we can minimize the portion of theright-hand side that depends on θ , i.e., we can minimize
s(θ) = g(θk)′θ +1/2
(θ −θ
k)′H(θ
k)(
θ −θk)
with respect to θ . This is a much easier problem, since it is aquadratic function in θ , so it has linear �rst order conditions.These are
Dθ s(θ) = g(θk) +H(θ
k)(
θ −θk)
So the solution for the next round estimate is
θk+1 = θ
k −H(θk)−1g(θ
k)

How to parallelize it?
parallelize the gradient calculation over the parameters? If θ isk dimensional, we could use up to 2k +1 computers tocalculate a central di�erence gradient
use a parallel search algorithm to �nd the best step size?
these ideas work, but poorly.
why?because they generate much inter-node communication. Theyellow areas in Figure 1 become large, and the speedup issmall.you can't use more than 2k +1 computational cores.

How to parallelize it?
parallelize the gradient calculation over the parameters? If θ isk dimensional, we could use up to 2k +1 computers tocalculate a central di�erence gradient
use a parallel search algorithm to �nd the best step size?
these ideas work, but poorly.
why?because they generate much inter-node communication. Theyellow areas in Figure 1 become large, and the speedup issmall.you can't use more than 2k +1 computational cores.

How to parallelize it?
parallelize the gradient calculation over the parameters? If θ isk dimensional, we could use up to 2k +1 computers tocalculate a central di�erence gradient
use a parallel search algorithm to �nd the best step size?
these ideas work, but poorly.
why?because they generate much inter-node communication. Theyellow areas in Figure 1 become large, and the speedup issmall.you can't use more than 2k +1 computational cores.

How to parallelize it?
parallelize the gradient calculation over the parameters? If θ isk dimensional, we could use up to 2k +1 computers tocalculate a central di�erence gradient
use a parallel search algorithm to �nd the best step size?
these ideas work, but poorly.
why?because they generate much inter-node communication. Theyellow areas in Figure 1 become large, and the speedup issmall.you can't use more than 2k +1 computational cores.

How to parallelize it?
parallelize the gradient calculation over the parameters? If θ isk dimensional, we could use up to 2k +1 computers tocalculate a central di�erence gradient
use a parallel search algorithm to �nd the best step size?
these ideas work, but poorly.
why?because they generate much inter-node communication. Theyellow areas in Figure 1 become large, and the speedup issmall.you can't use more than 2k +1 computational cores.

How to parallelize it?
parallelize the gradient calculation over the parameters? If θ isk dimensional, we could use up to 2k +1 computers tocalculate a central di�erence gradient
use a parallel search algorithm to �nd the best step size?
these ideas work, but poorly.
why?because they generate much inter-node communication. Theyellow areas in Figure 1 become large, and the speedup issmall.you can't use more than 2k +1 computational cores.

Econometric models use data
this provides a simple and natural way to parallelize: do calculationson di�erent blocks of data on di�erent computers

MLE
For a sample {(yt ,xt)}n of n observations of a set of dependentand explanatory variables, the maximum likelihood estimator of theparameter θ can be de�ned as
θ = argmaxsn(θ)
where
sn(θ) =1
n
n
∑t=1
ln f (yt |xt ,θ)
Here, yt may be a vector of random variables, and the model maybe dynamic since xt may contain lags of yt .

MLE, continued
As Swann (2002) points out, this can be broken into sums overblocks of observations, for example two blocks:
sn(θ) =1
n
{(n1
∑t=1
ln f (yt |xt ,θ)
)+
(n
∑t=n1+1
ln f (yt |xt ,θ)
)}
Analogously, we can de�ne up to n blocks. Again following Swann,parallelization can be done by calculating each block on separatecomputers.

GMM
For a sample as above, the GMM estimator of the parameter θ canbe de�ned as
θ ≡ argminΘ
sn(θ)
wheresn(θ) = mn(θ)′Wnmn(θ)
and
mn(θ) =1
n
n
∑t=1
mt(yt |xt ,θ)

GMM, continued
Since mn(θ) is an average, it can obviously be computed blockwise,using for example 2 blocks:
mn(θ) =1
n
{(n1
∑t=1
mt(yt |xt ,θ)
)+
(n
∑t=n1+1
mt(yt |xt ,θ)
)}
Likewise, we may de�ne up to n blocks, each of which couldpotentially be computed on a di�erent machine.

Data parallelism
The idea of performing the same computations on di�erentparts of a data set is known as data parallelism, and it is awell-known strategy for parallelization.
See http://en.wikipedia.org/wiki/Data_parallelism
since we always use data in econometrics, this is a naturalplace to start thinking about how to parallelize our work.

Data parallelism
The idea of performing the same computations on di�erentparts of a data set is known as data parallelism, and it is awell-known strategy for parallelization.
See http://en.wikipedia.org/wiki/Data_parallelism
since we always use data in econometrics, this is a naturalplace to start thinking about how to parallelize our work.

Data parallelism
The idea of performing the same computations on di�erentparts of a data set is known as data parallelism, and it is awell-known strategy for parallelization.
See http://en.wikipedia.org/wiki/Data_parallelism
since we always use data in econometrics, this is a naturalplace to start thinking about how to parallelize our work.

Monte Carlo �ts a job-based framework
A Monte Carlo study involves repeating a random experimentmany times under identical conditions. Several authors havenoted that Monte Carlo studies are obvious candidates forparallelization (Doornik et al. 2002; Bruche, 2003) sinceblocks of replications can be done independently on di�erentcomputers.
Job-based parallelism is the idea of executing independentparts of an overall computation on di�erent CPUs. Seehttp://en.wikipedia.org/wiki/Task_parallelism

Monte Carlo �ts a job-based framework
A Monte Carlo study involves repeating a random experimentmany times under identical conditions. Several authors havenoted that Monte Carlo studies are obvious candidates forparallelization (Doornik et al. 2002; Bruche, 2003) sinceblocks of replications can be done independently on di�erentcomputers.
Job-based parallelism is the idea of executing independentparts of an overall computation on di�erent CPUs. Seehttp://en.wikipedia.org/wiki/Task_parallelism

Monte Carlo, continued
if we need 1000 Monte Carlo replications, we can do half onone computer and half on another
it would be nice to have a convenient way of organizing this
use many computers
centralized reporting of results
recovery if some particular computer fails or crashes

Monte Carlo, continued
if we need 1000 Monte Carlo replications, we can do half onone computer and half on another
it would be nice to have a convenient way of organizing this
use many computers
centralized reporting of results
recovery if some particular computer fails or crashes

Monte Carlo, continued
if we need 1000 Monte Carlo replications, we can do half onone computer and half on another
it would be nice to have a convenient way of organizing this
use many computers
centralized reporting of results
recovery if some particular computer fails or crashes

Monte Carlo, continued
if we need 1000 Monte Carlo replications, we can do half onone computer and half on another
it would be nice to have a convenient way of organizing this
use many computers
centralized reporting of results
recovery if some particular computer fails or crashes

Monte Carlo, continued
if we need 1000 Monte Carlo replications, we can do half onone computer and half on another
it would be nice to have a convenient way of organizing this
use many computers
centralized reporting of results
recovery if some particular computer fails or crashes

the concepts of data parallelism and job-parallelism are notentirely separate. A real problem usually has elements of each.
The important thing is to think carefully about your problemto �nd the best way to parallelize it
what does �best� mean? There are a number of competingfactors:
code that runs fastcode that is easy to write and maintaincode that can be re-usedcode that is easy enough to understand so that othereconometricians can use it

the concepts of data parallelism and job-parallelism are notentirely separate. A real problem usually has elements of each.
The important thing is to think carefully about your problemto �nd the best way to parallelize it
what does �best� mean? There are a number of competingfactors:
code that runs fastcode that is easy to write and maintaincode that can be re-usedcode that is easy enough to understand so that othereconometricians can use it

the concepts of data parallelism and job-parallelism are notentirely separate. A real problem usually has elements of each.
The important thing is to think carefully about your problemto �nd the best way to parallelize it
what does �best� mean? There are a number of competingfactors:
code that runs fastcode that is easy to write and maintaincode that can be re-usedcode that is easy enough to understand so that othereconometricians can use it

the concepts of data parallelism and job-parallelism are notentirely separate. A real problem usually has elements of each.
The important thing is to think carefully about your problemto �nd the best way to parallelize it
what does �best� mean? There are a number of competingfactors:
code that runs fastcode that is easy to write and maintaincode that can be re-usedcode that is easy enough to understand so that othereconometricians can use it

the concepts of data parallelism and job-parallelism are notentirely separate. A real problem usually has elements of each.
The important thing is to think carefully about your problemto �nd the best way to parallelize it
what does �best� mean? There are a number of competingfactors:
code that runs fastcode that is easy to write and maintaincode that can be re-usedcode that is easy enough to understand so that othereconometricians can use it

the concepts of data parallelism and job-parallelism are notentirely separate. A real problem usually has elements of each.
The important thing is to think carefully about your problemto �nd the best way to parallelize it
what does �best� mean? There are a number of competingfactors:
code that runs fastcode that is easy to write and maintaincode that can be re-usedcode that is easy enough to understand so that othereconometricians can use it

the concepts of data parallelism and job-parallelism are notentirely separate. A real problem usually has elements of each.
The important thing is to think carefully about your problemto �nd the best way to parallelize it
what does �best� mean? There are a number of competingfactors:
code that runs fastcode that is easy to write and maintaincode that can be re-usedcode that is easy enough to understand so that othereconometricians can use it

Advantages and drawbacks of parallel computing
parallelized code is obviously more di�cut to write thannormal serial code. This will become clear soon.
new compilers may automatically parallelize part of code touse multiple core CPUs
many (most?) interesting research problems are not socomputationally demanding so as to require parallel computing
however, once you know how to use parallel computing, maybeyour idea of what is a feasible and interesting research projectmight change. The tools we have in�uence the researchagenda.

Advantages and drawbacks of parallel computing
parallelized code is obviously more di�cut to write thannormal serial code. This will become clear soon.
new compilers may automatically parallelize part of code touse multiple core CPUs
many (most?) interesting research problems are not socomputationally demanding so as to require parallel computing
however, once you know how to use parallel computing, maybeyour idea of what is a feasible and interesting research projectmight change. The tools we have in�uence the researchagenda.

Advantages and drawbacks of parallel computing
parallelized code is obviously more di�cut to write thannormal serial code. This will become clear soon.
new compilers may automatically parallelize part of code touse multiple core CPUs
many (most?) interesting research problems are not socomputationally demanding so as to require parallel computing
however, once you know how to use parallel computing, maybeyour idea of what is a feasible and interesting research projectmight change. The tools we have in�uence the researchagenda.

Advantages and drawbacks of parallel computing
parallelized code is obviously more di�cut to write thannormal serial code. This will become clear soon.
new compilers may automatically parallelize part of code touse multiple core CPUs
many (most?) interesting research problems are not socomputationally demanding so as to require parallel computing
however, once you know how to use parallel computing, maybeyour idea of what is a feasible and interesting research projectmight change. The tools we have in�uence the researchagenda.

Some speedup resultsTaken from Michael Creel �User-Friendly Parallel Computationswith Econometric Examples� Computational Economics, 2005, vol.26, issue 2, pages 107-128

Speedup for kernel regression
The Nadaraya-Watson kernel regression estimator of a functiong(x) at a point x is
g(x) =∑nt=1 ytK [(x− xt)/γn]
∑nt=1K [(x− xt)/γn]
≡n
∑t=1
wtyy
We see that the weight depends upon every data point in thesample. To calculate the �t at every point in a sample of size n, onthe order of n2k calculations must be done, where k is thedimension of the vector of explanatory variables, x . Racine (2002)demonstrates that MPI parallelization can be used to speed upcalculation of the kernel regression estimator by calculating the �tsfor portions of the sample on di�erent computers.
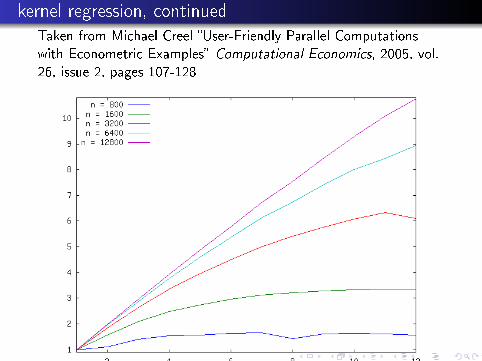
kernel regression, continuedTaken from Michael Creel �User-Friendly Parallel Computationswith Econometric Examples� Computational Economics, 2005, vol.26, issue 2, pages 107-128

PelicanHPC
PelicanHPC is a live CD image that let's you set up a HPCcluster for parallel computing in about 10 minutes.
The homepage ishttp://pareto.uab.es/mcreel/PelicanHPC/ (make sureto look at the tutorial)
I will use this to present examples. You can get the examplesand run them from the CD.

PelicanHPC
PelicanHPC is a live CD image that let's you set up a HPCcluster for parallel computing in about 10 minutes.
The homepage ishttp://pareto.uab.es/mcreel/PelicanHPC/ (make sureto look at the tutorial)
I will use this to present examples. You can get the examplesand run them from the CD.

PelicanHPC
PelicanHPC is a live CD image that let's you set up a HPCcluster for parallel computing in about 10 minutes.
The homepage ishttp://pareto.uab.es/mcreel/PelicanHPC/ (make sureto look at the tutorial)
I will use this to present examples. You can get the examplesand run them from the CD.

ParallelKnoppix
You might prefer to work with ParallelKnoppix(http://pareto.uab.es/mcreel/ParallelKnoppix/)which is a bit more user friendly.
However, it is older and no longer developed, and willeventually become obsolete.

ParallelKnoppix
You might prefer to work with ParallelKnoppix(http://pareto.uab.es/mcreel/ParallelKnoppix/)which is a bit more user friendly.
However, it is older and no longer developed, and willeventually become obsolete.

Pelican - basic use
boot up a virtual master node (with home already set up onhard disk)
do setup, and boot a real compute node
run a basic example
encourage students to try it out before the next session

Pelican - basic use
boot up a virtual master node (with home already set up onhard disk)
do setup, and boot a real compute node
run a basic example
encourage students to try it out before the next session

Pelican - basic use
boot up a virtual master node (with home already set up onhard disk)
do setup, and boot a real compute node
run a basic example
encourage students to try it out before the next session

Pelican - basic use
boot up a virtual master node (with home already set up onhard disk)
do setup, and boot a real compute node
run a basic example
encourage students to try it out before the next session

What is MPI?
MPI is the �message passing interface�.http://www.mpi-forum.org/ This is a speci�cation for ameans of parallel computing.
there are many implementations of MPI.
LAM/MPI http://www.lam-mpi.org/ and OpenMPIhttp://www.open-mpi.org/ are the ones on PelicanHPC,and are what we will use.An implementation can be optimized for a particular platform.MPI implementations exist for Linux, Windows, MacOS, etc.

What is MPI?
MPI is the �message passing interface�.http://www.mpi-forum.org/ This is a speci�cation for ameans of parallel computing.
there are many implementations of MPI.
LAM/MPI http://www.lam-mpi.org/ and OpenMPIhttp://www.open-mpi.org/ are the ones on PelicanHPC,and are what we will use.An implementation can be optimized for a particular platform.MPI implementations exist for Linux, Windows, MacOS, etc.

What is MPI?
MPI is the �message passing interface�.http://www.mpi-forum.org/ This is a speci�cation for ameans of parallel computing.
there are many implementations of MPI.
LAM/MPI http://www.lam-mpi.org/ and OpenMPIhttp://www.open-mpi.org/ are the ones on PelicanHPC,and are what we will use.An implementation can be optimized for a particular platform.MPI implementations exist for Linux, Windows, MacOS, etc.

What is MPI?
MPI is the �message passing interface�.http://www.mpi-forum.org/ This is a speci�cation for ameans of parallel computing.
there are many implementations of MPI.
LAM/MPI http://www.lam-mpi.org/ and OpenMPIhttp://www.open-mpi.org/ are the ones on PelicanHPC,and are what we will use.An implementation can be optimized for a particular platform.MPI implementations exist for Linux, Windows, MacOS, etc.

MPI is portable
It will run on a desktop computer, on any of a number ofoperating systems. You can use all available cores.
The same code will run on a cluster on PCs
The same code will run on a supercomputer

MPI is portable
It will run on a desktop computer, on any of a number ofoperating systems. You can use all available cores.
The same code will run on a cluster on PCs
The same code will run on a supercomputer

MPI is portable
It will run on a desktop computer, on any of a number ofoperating systems. You can use all available cores.
The same code will run on a cluster on PCs
The same code will run on a supercomputer

Binding functions
MPI implementations typically provide libraries for Fortran andC/C++
However, there are numerous collections of bindings for otherlanguages, such as Matlab, Ox, R, Python and GNU Octave.
this lets you make calls to MPI functions from the high levellanguages. The high level language dynamically loads the Cfunctions when needed. The binding functions provide theinterface.

Binding functions
MPI implementations typically provide libraries for Fortran andC/C++
However, there are numerous collections of bindings for otherlanguages, such as Matlab, Ox, R, Python and GNU Octave.
this lets you make calls to MPI functions from the high levellanguages. The high level language dynamically loads the Cfunctions when needed. The binding functions provide theinterface.

Binding functions
MPI implementations typically provide libraries for Fortran andC/C++
However, there are numerous collections of bindings for otherlanguages, such as Matlab, Ox, R, Python and GNU Octave.
this lets you make calls to MPI functions from the high levellanguages. The high level language dynamically loads the Cfunctions when needed. The binding functions provide theinterface.

MPITB for GNU Octave
GNU Octave http://www.gnu.org/software/octave/ issimilar to Matlab. Most Matlab code will run on Octavewithout modi�cation.
Octave is free software. What does �free� mean here?
�free� also means you don't have to pay for it.This is important if you want to run 30 copies on a cluster.
MPITB is the �message passing interface toolbox� for GNUOctave. http://atc.ugr.es/javier-bin/mpitb
this lets you use MPI in Octave scripts.

MPITB for GNU Octave
GNU Octave http://www.gnu.org/software/octave/ issimilar to Matlab. Most Matlab code will run on Octavewithout modi�cation.
Octave is free software. What does �free� mean here?
�free� also means you don't have to pay for it.This is important if you want to run 30 copies on a cluster.
MPITB is the �message passing interface toolbox� for GNUOctave. http://atc.ugr.es/javier-bin/mpitb
this lets you use MPI in Octave scripts.

MPITB for GNU Octave
GNU Octave http://www.gnu.org/software/octave/ issimilar to Matlab. Most Matlab code will run on Octavewithout modi�cation.
Octave is free software. What does �free� mean here?
�free� also means you don't have to pay for it.This is important if you want to run 30 copies on a cluster.
MPITB is the �message passing interface toolbox� for GNUOctave. http://atc.ugr.es/javier-bin/mpitb
this lets you use MPI in Octave scripts.

MPITB for GNU Octave
GNU Octave http://www.gnu.org/software/octave/ issimilar to Matlab. Most Matlab code will run on Octavewithout modi�cation.
Octave is free software. What does �free� mean here?
�free� also means you don't have to pay for it.This is important if you want to run 30 copies on a cluster.
MPITB is the �message passing interface toolbox� for GNUOctave. http://atc.ugr.es/javier-bin/mpitb
this lets you use MPI in Octave scripts.

MPITB for GNU Octave
GNU Octave http://www.gnu.org/software/octave/ issimilar to Matlab. Most Matlab code will run on Octavewithout modi�cation.
Octave is free software. What does �free� mean here?
�free� also means you don't have to pay for it.This is important if you want to run 30 copies on a cluster.
MPITB is the �message passing interface toolbox� for GNUOctave. http://atc.ugr.es/javier-bin/mpitb
this lets you use MPI in Octave scripts.

MPITB for GNU Octave
GNU Octave http://www.gnu.org/software/octave/ issimilar to Matlab. Most Matlab code will run on Octavewithout modi�cation.
Octave is free software. What does �free� mean here?
�free� also means you don't have to pay for it.This is important if you want to run 30 copies on a cluster.
MPITB is the �message passing interface toolbox� for GNUOctave. http://atc.ugr.es/javier-bin/mpitb
this lets you use MPI in Octave scripts.

MPI_Init and MPI_Finalize
MPI programs start with MPI_Init, and end withMPI_Finalize.
when using MPITB, we also need to clear variables out ofmemory between successive calls to MPI_Init,
see �rst.m

MPI_Init and MPI_Finalize
MPI programs start with MPI_Init, and end withMPI_Finalize.
when using MPITB, we also need to clear variables out ofmemory between successive calls to MPI_Init,
see �rst.m

MPI_Init and MPI_Finalize
MPI programs start with MPI_Init, and end withMPI_Finalize.
when using MPITB, we also need to clear variables out ofmemory between successive calls to MPI_Init,
see �rst.m

MPI_Comm_size and MPI_Comm_rank
an MPI communicator is a set of ranks (nodes, processes) thatcan work in a group. It is isolated from other sets of ranks, sothat messages stay within the communicator.
It is possible to use multiple communicators, but we'll use justone. Its name in MPITB is �MPI_COMM_WORLD�
the size of an MPI communicator is the number of ranks thatit holds.
ranks are processes that run on CPUs. Any number of rankscan run on any number of CPUS. The speci�c way that ranksare spread over CPUs is part of the design of the parallelprogram, and can have an important e�ect on performance.With a homogeneous cluster of single core CPUs, a typicalstarting point would be to assign one rank to each CPU. Fordual core CPUs, one should probably have a rank for each core.
see second.m

MPI_Comm_size and MPI_Comm_rank
an MPI communicator is a set of ranks (nodes, processes) thatcan work in a group. It is isolated from other sets of ranks, sothat messages stay within the communicator.
It is possible to use multiple communicators, but we'll use justone. Its name in MPITB is �MPI_COMM_WORLD�
the size of an MPI communicator is the number of ranks thatit holds.
ranks are processes that run on CPUs. Any number of rankscan run on any number of CPUS. The speci�c way that ranksare spread over CPUs is part of the design of the parallelprogram, and can have an important e�ect on performance.With a homogeneous cluster of single core CPUs, a typicalstarting point would be to assign one rank to each CPU. Fordual core CPUs, one should probably have a rank for each core.
see second.m

MPI_Comm_size and MPI_Comm_rank
an MPI communicator is a set of ranks (nodes, processes) thatcan work in a group. It is isolated from other sets of ranks, sothat messages stay within the communicator.
It is possible to use multiple communicators, but we'll use justone. Its name in MPITB is �MPI_COMM_WORLD�
the size of an MPI communicator is the number of ranks thatit holds.
ranks are processes that run on CPUs. Any number of rankscan run on any number of CPUS. The speci�c way that ranksare spread over CPUs is part of the design of the parallelprogram, and can have an important e�ect on performance.With a homogeneous cluster of single core CPUs, a typicalstarting point would be to assign one rank to each CPU. Fordual core CPUs, one should probably have a rank for each core.
see second.m

MPI_Comm_size and MPI_Comm_rank
an MPI communicator is a set of ranks (nodes, processes) thatcan work in a group. It is isolated from other sets of ranks, sothat messages stay within the communicator.
It is possible to use multiple communicators, but we'll use justone. Its name in MPITB is �MPI_COMM_WORLD�
the size of an MPI communicator is the number of ranks thatit holds.
ranks are processes that run on CPUs. Any number of rankscan run on any number of CPUS. The speci�c way that ranksare spread over CPUs is part of the design of the parallelprogram, and can have an important e�ect on performance.With a homogeneous cluster of single core CPUs, a typicalstarting point would be to assign one rank to each CPU. Fordual core CPUs, one should probably have a rank for each core.
see second.m

MPI_Comm_size and MPI_Comm_rank
an MPI communicator is a set of ranks (nodes, processes) thatcan work in a group. It is isolated from other sets of ranks, sothat messages stay within the communicator.
It is possible to use multiple communicators, but we'll use justone. Its name in MPITB is �MPI_COMM_WORLD�
the size of an MPI communicator is the number of ranks thatit holds.
ranks are processes that run on CPUs. Any number of rankscan run on any number of CPUS. The speci�c way that ranksare spread over CPUs is part of the design of the parallelprogram, and can have an important e�ect on performance.With a homogeneous cluster of single core CPUs, a typicalstarting point would be to assign one rank to each CPU. Fordual core CPUs, one should probably have a rank for each core.
see second.m

Creating child Octaves
To increase the size of the communicator, we need to createmore threads that run Octave, and integrate them into thecommunicator. The LAM_Init command will do this for us.
Using LAM_Init and spawning child Octaves is only one wayto use MPITB. We do not have time to explore other options.The method we use here works fairly well, however.
see third.m Important reminder to self - all nodes should beon one machine to see the messages.

Creating child Octaves
To increase the size of the communicator, we need to createmore threads that run Octave, and integrate them into thecommunicator. The LAM_Init command will do this for us.
Using LAM_Init and spawning child Octaves is only one wayto use MPITB. We do not have time to explore other options.The method we use here works fairly well, however.
see third.m Important reminder to self - all nodes should beon one machine to see the messages.

Creating child Octaves
To increase the size of the communicator, we need to createmore threads that run Octave, and integrate them into thecommunicator. The LAM_Init command will do this for us.
Using LAM_Init and spawning child Octaves is only one wayto use MPITB. We do not have time to explore other options.The method we use here works fairly well, however.
see third.m Important reminder to self - all nodes should beon one machine to see the messages.

NumCmds_Send
the method uses the NumCmds protocol for communication.
NumCmds_Send is used to send Octave objects to all ranks,along with a command to executeafter executing a command, the ranks loop, waiting for a newcommand to execute
see fourth.m:

NumCmds_Send
the method uses the NumCmds protocol for communication.
NumCmds_Send is used to send Octave objects to all ranks,along with a command to executeafter executing a command, the ranks loop, waiting for a newcommand to execute
see fourth.m:

NumCmds_Send
the method uses the NumCmds protocol for communication.
NumCmds_Send is used to send Octave objects to all ranks,along with a command to executeafter executing a command, the ranks loop, waiting for a newcommand to execute
see fourth.m:

NumCmds_Send
the method uses the NumCmds protocol for communication.
NumCmds_Send is used to send Octave objects to all ranks,along with a command to executeafter executing a command, the ranks loop, waiting for a newcommand to execute
see fourth.m:

Sending and receiving
once we have more than one rank, we need to know how theycan communicate
the simplest form is point-to-point communication, usingMPI_Send and MPI_Recv
see �fth.m
you can send Octave objects of any type - for example,
matrices. See sixth.m

Sending and receiving
once we have more than one rank, we need to know how theycan communicate
the simplest form is point-to-point communication, usingMPI_Send and MPI_Recv
see �fth.m
you can send Octave objects of any type - for example,
matrices. See sixth.m

Sending and receiving
once we have more than one rank, we need to know how theycan communicate
the simplest form is point-to-point communication, usingMPI_Send and MPI_Recv
see �fth.m
you can send Octave objects of any type - for example,
matrices. See sixth.m

Sending and receiving
once we have more than one rank, we need to know how theycan communicate
the simplest form is point-to-point communication, usingMPI_Send and MPI_Recv
see �fth.m
you can send Octave objects of any type - for example,
matrices. See sixth.m
Checking if a message is ready
sometimes you don't want to block execution to wait for amessage to arrive. To check if a message has arrived, you canuse MPI_Iprobe (use Octave's help).
examine and run seventh.m
this is used in montecarlo.m.

Checking if a message is ready
sometimes you don't want to block execution to wait for amessage to arrive. To check if a message has arrived, you canuse MPI_Iprobe (use Octave's help).
examine and run seventh.m
this is used in montecarlo.m.

Checking if a message is ready
sometimes you don't want to block execution to wait for amessage to arrive. To check if a message has arrived, you canuse MPI_Iprobe (use Octave's help).
examine and run seventh.m
this is used in montecarlo.m.

montecarlo.m
MPI_Iprobe is used so that results can be received in theorder they are ready.
the frontend node does not participate in the generation ofresults, it only gathers them.
for this reason, the number of compute nodes (not countingthe frontend) should be set equal to the number of CPU coresavailable.
The frontend will run rank 0, which uses very little CPU time.Mostly it is polling the others to see if they have results.The frontend also runs one of the computational ranks, tokeep its CPU busythe computational nodes run a rank on each CPU core theyhave
The goal is to keep all CPUs in the cluster fully occupied.

montecarlo.m
MPI_Iprobe is used so that results can be received in theorder they are ready.
the frontend node does not participate in the generation ofresults, it only gathers them.
for this reason, the number of compute nodes (not countingthe frontend) should be set equal to the number of CPU coresavailable.
The frontend will run rank 0, which uses very little CPU time.Mostly it is polling the others to see if they have results.The frontend also runs one of the computational ranks, tokeep its CPU busythe computational nodes run a rank on each CPU core theyhave
The goal is to keep all CPUs in the cluster fully occupied.

montecarlo.m
MPI_Iprobe is used so that results can be received in theorder they are ready.
the frontend node does not participate in the generation ofresults, it only gathers them.
for this reason, the number of compute nodes (not countingthe frontend) should be set equal to the number of CPU coresavailable.
The frontend will run rank 0, which uses very little CPU time.Mostly it is polling the others to see if they have results.The frontend also runs one of the computational ranks, tokeep its CPU busythe computational nodes run a rank on each CPU core theyhave
The goal is to keep all CPUs in the cluster fully occupied.

montecarlo.m
MPI_Iprobe is used so that results can be received in theorder they are ready.
the frontend node does not participate in the generation ofresults, it only gathers them.
for this reason, the number of compute nodes (not countingthe frontend) should be set equal to the number of CPU coresavailable.
The frontend will run rank 0, which uses very little CPU time.Mostly it is polling the others to see if they have results.The frontend also runs one of the computational ranks, tokeep its CPU busythe computational nodes run a rank on each CPU core theyhave
The goal is to keep all CPUs in the cluster fully occupied.

montecarlo.m
MPI_Iprobe is used so that results can be received in theorder they are ready.
the frontend node does not participate in the generation ofresults, it only gathers them.
for this reason, the number of compute nodes (not countingthe frontend) should be set equal to the number of CPU coresavailable.
The frontend will run rank 0, which uses very little CPU time.Mostly it is polling the others to see if they have results.The frontend also runs one of the computational ranks, tokeep its CPU busythe computational nodes run a rank on each CPU core theyhave
The goal is to keep all CPUs in the cluster fully occupied.

montecarlo.m
MPI_Iprobe is used so that results can be received in theorder they are ready.
the frontend node does not participate in the generation ofresults, it only gathers them.
for this reason, the number of compute nodes (not countingthe frontend) should be set equal to the number of CPU coresavailable.
The frontend will run rank 0, which uses very little CPU time.Mostly it is polling the others to see if they have results.The frontend also runs one of the computational ranks, tokeep its CPU busythe computational nodes run a rank on each CPU core theyhave
The goal is to keep all CPUs in the cluster fully occupied.

montecarlo.m
MPI_Iprobe is used so that results can be received in theorder they are ready.
the frontend node does not participate in the generation ofresults, it only gathers them.
for this reason, the number of compute nodes (not countingthe frontend) should be set equal to the number of CPU coresavailable.
The frontend will run rank 0, which uses very little CPU time.Mostly it is polling the others to see if they have results.The frontend also runs one of the computational ranks, tokeep its CPU busythe computational nodes run a rank on each CPU core theyhave
The goal is to keep all CPUs in the cluster fully occupied.

montecarlo_nodes.m

mc_example3
look at the code for this

mc_example1.m

mc_example2.m

Homework
write GNU Octave code to do a Monte Carlo study of the OLSestimator of ρ in the model
yt = α + ρyt−1 + εt
use n = 30 observations, with the true parameter valuesα = 0;ρ = 0.95 and εt ∼IIN(0,1)your code should make use of montecarlo.m

Homework
write GNU Octave code to do a Monte Carlo study of the OLSestimator of ρ in the model
yt = α + ρyt−1 + εt
use n = 30 observations, with the true parameter valuesα = 0;ρ = 0.95 and εt ∼IIN(0,1)your code should make use of montecarlo.m

Homework
write GNU Octave code to do a Monte Carlo study of the OLSestimator of ρ in the model
yt = α + ρyt−1 + εt
use n = 30 observations, with the true parameter valuesα = 0;ρ = 0.95 and εt ∼IIN(0,1)your code should make use of montecarlo.m

A real problem and a real cluster
let's look at a research problem that requires a lot ofcomputational power
when you have access to computing power your researchagenda might change
once you learn how to do this, there's no reason not to try toget time on a supercomputer like Marenostrum to reallyincrease the scale

A real problem and a real cluster
let's look at a research problem that requires a lot ofcomputational power
when you have access to computing power your researchagenda might change
once you learn how to do this, there's no reason not to try toget time on a supercomputer like Marenostrum to reallyincrease the scale

A real problem and a real cluster
let's look at a research problem that requires a lot ofcomputational power
when you have access to computing power your researchagenda might change
once you learn how to do this, there's no reason not to try toget time on a supercomputer like Marenostrum to reallyincrease the scale

The DLV model
Billio and Monfort (2003)
DLV:
{yt = rt
(y t−1,y∗t ,εt ;θ
)y∗t = r∗t
(y t−1,y∗t−1,ε∗t ;θ
) (1)
y t−1 is notation for(y ′1, ...,y ′t−1
)′{εt} and {ε∗t } are two independent white noises with knowndistributions
θ is a vector of unknown parameters

The DLV model
Billio and Monfort (2003)
DLV:
{yt = rt
(y t−1,y∗t ,εt ;θ
)y∗t = r∗t
(y t−1,y∗t−1,ε∗t ;θ
) (1)
y t−1 is notation for(y ′1, ...,y ′t−1
)′{εt} and {ε∗t } are two independent white noises with knowndistributions
θ is a vector of unknown parameters

The DLV model
Billio and Monfort (2003)
DLV:
{yt = rt
(y t−1,y∗t ,εt ;θ
)y∗t = r∗t
(y t−1,y∗t−1,ε∗t ;θ
) (1)
y t−1 is notation for(y ′1, ...,y ′t−1
)′{εt} and {ε∗t } are two independent white noises with knowndistributions
θ is a vector of unknown parameters

The DLV model
Billio and Monfort (2003)
DLV:
{yt = rt
(y t−1,y∗t ,εt ;θ
)y∗t = r∗t
(y t−1,y∗t−1,ε∗t ;θ
) (1)
y t−1 is notation for(y ′1, ...,y ′t−1
)′{εt} and {ε∗t } are two independent white noises with knowndistributions
θ is a vector of unknown parameters

The DLV model
Billio and Monfort (2003)
DLV:
{yt = rt
(y t−1,y∗t ,εt ;θ
)y∗t = r∗t
(y t−1,y∗t−1,ε∗t ;θ
) (1)
y t−1 is notation for(y ′1, ...,y ′t−1
)′{εt} and {ε∗t } are two independent white noises with knowndistributions
θ is a vector of unknown parameters

The DLV model
Billio and Monfort (2003)
DLV:
{yt = rt
(y t−1,y∗t ,εt ;θ
)y∗t = r∗t
(y t−1,y∗t−1,ε∗t ;θ
) (1)
y t−1 is notation for(y ′1, ...,y ′t−1
)′{εt} and {ε∗t } are two independent white noises with knowndistributions
θ is a vector of unknown parameters

The DLV model
Billio and Monfort (2003)
DLV:
{yt = rt
(y t−1,y∗t ,εt ;θ
)y∗t = r∗t
(y t−1,y∗t−1,ε∗t ;θ
) (1)
y t−1 is notation for(y ′1, ...,y ′t−1
)′{εt} and {ε∗t } are two independent white noises with knowndistributions
θ is a vector of unknown parameters

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

DLV models are often impossible to estimate using classicalmethods
Calculation of the likelihood function requires �nding thedensity of yn
this involves integrating out all of the y∗t , of which there are n.It is in general an untractable problem
Without the density of the observable variables, analyticmoments cannot be computed
Without the density function, maximum likelihood isunavailable
Without moments, moment-based estimation methods are notavailable

Why is SMM ine�cient?
SMM is ine�cient for DLV models, since conditional momentscan't be used. Why not?
It's because we can't sample the latent variables conditional onthe history of the observed variables. Recall the model:
DLV:{yt = rt
(y t−1,y∗t ,εt ;θ
)(2)
If we could sample from y∗t |y t−1, we could substitute thedraw into the DLV to get a draw from yt |y t−1
For Markovian models, the Markov chain Monte Carlo methodcan be used to sample from y∗t |y t−1, since in this caseinformation about the distant past is not needed to sample thelatent variables. Fiorentini, Sentana and Shephard (2004) is anexample.

Why is SMM ine�cient?
SMM is ine�cient for DLV models, since conditional momentscan't be used. Why not?
It's because we can't sample the latent variables conditional onthe history of the observed variables. Recall the model:
DLV:{yt = rt
(y t−1,y∗t ,εt ;θ
)(2)
If we could sample from y∗t |y t−1, we could substitute thedraw into the DLV to get a draw from yt |y t−1
For Markovian models, the Markov chain Monte Carlo methodcan be used to sample from y∗t |y t−1, since in this caseinformation about the distant past is not needed to sample thelatent variables. Fiorentini, Sentana and Shephard (2004) is anexample.

Why is SMM ine�cient?
SMM is ine�cient for DLV models, since conditional momentscan't be used. Why not?
It's because we can't sample the latent variables conditional onthe history of the observed variables. Recall the model:
DLV:{yt = rt
(y t−1,y∗t ,εt ;θ
)(2)
If we could sample from y∗t |y t−1, we could substitute thedraw into the DLV to get a draw from yt |y t−1
For Markovian models, the Markov chain Monte Carlo methodcan be used to sample from y∗t |y t−1, since in this caseinformation about the distant past is not needed to sample thelatent variables. Fiorentini, Sentana and Shephard (2004) is anexample.

Why is SMM ine�cient?
SMM is ine�cient for DLV models, since conditional momentscan't be used. Why not?
It's because we can't sample the latent variables conditional onthe history of the observed variables. Recall the model:
DLV:{yt = rt
(y t−1,y∗t ,εt ;θ
)(2)
If we could sample from y∗t |y t−1, we could substitute thedraw into the DLV to get a draw from yt |y t−1
For Markovian models, the Markov chain Monte Carlo methodcan be used to sample from y∗t |y t−1, since in this caseinformation about the distant past is not needed to sample thelatent variables. Fiorentini, Sentana and Shephard (2004) is anexample.

Why is SMM ine�cient?
SMM is ine�cient for DLV models, since conditional momentscan't be used. Why not?
It's because we can't sample the latent variables conditional onthe history of the observed variables. Recall the model:
DLV:{yt = rt
(y t−1,y∗t ,εt ;θ
)(2)
If we could sample from y∗t |y t−1, we could substitute thedraw into the DLV to get a draw from yt |y t−1
For Markovian models, the Markov chain Monte Carlo methodcan be used to sample from y∗t |y t−1, since in this caseinformation about the distant past is not needed to sample thelatent variables. Fiorentini, Sentana and Shephard (2004) is anexample.

The GMM estimator
Error functions are of the form
ε(yt ,xt ;θ) = yt −φ(xt ;θ), (3)
Moment conditions are de�ned by interacting a vector ofinstrumental variables z(xt) with error functions:
m(yt ,xt ;θ) = z(xt)⊗ ε(yt ,xt ;θ) (4)
Average moment conditions are
mn(Zn;θ) =1
n
n
∑t=1
m(yt ,xt ;θ) (5)
The objective function is
sn(Zn;θ) = m′n(Zn;θ)W (τn)m′n(Zn;θ) (6)

The GMM estimator
Error functions are of the form
ε(yt ,xt ;θ) = yt −φ(xt ;θ), (3)
Moment conditions are de�ned by interacting a vector ofinstrumental variables z(xt) with error functions:
m(yt ,xt ;θ) = z(xt)⊗ ε(yt ,xt ;θ) (4)
Average moment conditions are
mn(Zn;θ) =1
n
n
∑t=1
m(yt ,xt ;θ) (5)
The objective function is
sn(Zn;θ) = m′n(Zn;θ)W (τn)m′n(Zn;θ) (6)

The GMM estimator
Error functions are of the form
ε(yt ,xt ;θ) = yt −φ(xt ;θ), (3)
Moment conditions are de�ned by interacting a vector ofinstrumental variables z(xt) with error functions:
m(yt ,xt ;θ) = z(xt)⊗ ε(yt ,xt ;θ) (4)
Average moment conditions are
mn(Zn;θ) =1
n
n
∑t=1
m(yt ,xt ;θ) (5)
The objective function is
sn(Zn;θ) = m′n(Zn;θ)W (τn)m′n(Zn;θ) (6)

The GMM estimator
Error functions are of the form
ε(yt ,xt ;θ) = yt −φ(xt ;θ), (3)
Moment conditions are de�ned by interacting a vector ofinstrumental variables z(xt) with error functions:
m(yt ,xt ;θ) = z(xt)⊗ ε(yt ,xt ;θ) (4)
Average moment conditions are
mn(Zn;θ) =1
n
n
∑t=1
m(yt ,xt ;θ) (5)
The objective function is
sn(Zn;θ) = m′n(Zn;θ)W (τn)m′n(Zn;θ) (6)

The GMM estimator
Error functions are of the form
ε(yt ,xt ;θ) = yt −φ(xt ;θ), (3)
Moment conditions are de�ned by interacting a vector ofinstrumental variables z(xt) with error functions:
m(yt ,xt ;θ) = z(xt)⊗ ε(yt ,xt ;θ) (4)
Average moment conditions are
mn(Zn;θ) =1
n
n
∑t=1
m(yt ,xt ;θ) (5)
The objective function is
sn(Zn;θ) = m′n(Zn;θ)W (τn)m′n(Zn;θ) (6)

The GMM estimator
Error functions are of the form
ε(yt ,xt ;θ) = yt −φ(xt ;θ), (3)
Moment conditions are de�ned by interacting a vector ofinstrumental variables z(xt) with error functions:
m(yt ,xt ;θ) = z(xt)⊗ ε(yt ,xt ;θ) (4)
Average moment conditions are
mn(Zn;θ) =1
n
n
∑t=1
m(yt ,xt ;θ) (5)
The objective function is
sn(Zn;θ) = m′n(Zn;θ)W (τn)m′n(Zn;θ) (6)

The GMM estimator
Error functions are of the form
ε(yt ,xt ;θ) = yt −φ(xt ;θ), (3)
Moment conditions are de�ned by interacting a vector ofinstrumental variables z(xt) with error functions:
m(yt ,xt ;θ) = z(xt)⊗ ε(yt ,xt ;θ) (4)
Average moment conditions are
mn(Zn;θ) =1
n
n
∑t=1
m(yt ,xt ;θ) (5)
The objective function is
sn(Zn;θ) = m′n(Zn;θ)W (τn)m′n(Zn;θ) (6)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator
Consider a long simulation from the DLV model, ZS .
Kernel regression may be used to �t φ(xt ;θ), using thissimulated data
φS(xt ; ZS(θ)) =S
∑s=1
ws ys(θ) (7)
the weight ws is
ws =K(xt−xs(θ)
hS
)∑Ss=1K
(xt−xs(θ)
hS
) (8)
φS(xt ; ZS(θ))a.s.→ φ(xt ,θ), for almost all xt , as S → ∞.
S can be made as large as we like! (Jump back to last slide)

The SNM estimator is the GMM estimator if S is largeenough
Classical linear model
Linear Model:
y = β1 + β2x + ε
x ∼ U(0,1)
ε ∼ N(0,1)
(9)
SNM estimation with S = 500000, 1000 Monte Carlo reps

The SNM estimator is the GMM estimator if S is largeenough
Classical linear model
Linear Model:
y = β1 + β2x + ε
x ∼ U(0,1)
ε ∼ N(0,1)
(9)
SNM estimation with S = 500000, 1000 Monte Carlo reps

The SNM estimator is the GMM estimator if S is largeenough
Classical linear model
Linear Model:
y = β1 + β2x + ε
x ∼ U(0,1)
ε ∼ N(0,1)
(9)
SNM estimation with S = 500000, 1000 Monte Carlo reps

...continuation
β1(SNM) =−0.00106912(0.00023012)
+ 1.00292(0.00030566)
β1(GMM)−0.00267236(0.00050332)
β1
T = 1000 R2 = 0.9999 F (2,997) = 8.5632e+6 σ = 0.0036169
(standard errors in parentheses)
β2(SNM) = 2.50475e-5(0.00038392)
+ 1.00389(0.00029626)
β2(GMM)−0.000178451(0.00073023)
β2
T = 1000 R2 = 0.9999 F (2,997) = 6.9636e+6 σ = 0.0061481
(standard errors in parentheses)

...continuation
β1(SNM) =−0.00106912(0.00023012)
+ 1.00292(0.00030566)
β1(GMM)−0.00267236(0.00050332)
β1
T = 1000 R2 = 0.9999 F (2,997) = 8.5632e+6 σ = 0.0036169
(standard errors in parentheses)
β2(SNM) = 2.50475e-5(0.00038392)
+ 1.00389(0.00029626)
β2(GMM)−0.000178451(0.00073023)
β2
T = 1000 R2 = 0.9999 F (2,997) = 6.9636e+6 σ = 0.0061481
(standard errors in parentheses)

...continuation
β1(SNM) =−0.00106912(0.00023012)
+ 1.00292(0.00030566)
β1(GMM)−0.00267236(0.00050332)
β1
T = 1000 R2 = 0.9999 F (2,997) = 8.5632e+6 σ = 0.0036169
(standard errors in parentheses)
β2(SNM) = 2.50475e-5(0.00038392)
+ 1.00389(0.00029626)
β2(GMM)−0.000178451(0.00073023)
β2
T = 1000 R2 = 0.9999 F (2,997) = 6.9636e+6 σ = 0.0061481
(standard errors in parentheses)

SNM is computationally demanding
to �t n points using S simulated points, we need to doapproximately knS calculations
when S is very large, this is a lot of work
all of this is required for a single evaluation of the GMMcriterion function. When this is embedded in a quasi-Newtonmethod, many evaluations are required.
the GMM criterion is not globally convex - need to usesomething like simulated annealing to avoid local minima, thenuse quasi-Newton to re�ne
doing Monte Carlo adds a layer of computations

SNM is computationally demanding
to �t n points using S simulated points, we need to doapproximately knS calculations
when S is very large, this is a lot of work
all of this is required for a single evaluation of the GMMcriterion function. When this is embedded in a quasi-Newtonmethod, many evaluations are required.
the GMM criterion is not globally convex - need to usesomething like simulated annealing to avoid local minima, thenuse quasi-Newton to re�ne
doing Monte Carlo adds a layer of computations

SNM is computationally demanding
to �t n points using S simulated points, we need to doapproximately knS calculations
when S is very large, this is a lot of work
all of this is required for a single evaluation of the GMMcriterion function. When this is embedded in a quasi-Newtonmethod, many evaluations are required.
the GMM criterion is not globally convex - need to usesomething like simulated annealing to avoid local minima, thenuse quasi-Newton to re�ne
doing Monte Carlo adds a layer of computations

SNM is computationally demanding
to �t n points using S simulated points, we need to doapproximately knS calculations
when S is very large, this is a lot of work
all of this is required for a single evaluation of the GMMcriterion function. When this is embedded in a quasi-Newtonmethod, many evaluations are required.
the GMM criterion is not globally convex - need to usesomething like simulated annealing to avoid local minima, thenuse quasi-Newton to re�ne
doing Monte Carlo adds a layer of computations

SNM is computationally demanding
to �t n points using S simulated points, we need to doapproximately knS calculations
when S is very large, this is a lot of work
all of this is required for a single evaluation of the GMMcriterion function. When this is embedded in a quasi-Newtonmethod, many evaluations are required.
the GMM criterion is not globally convex - need to usesomething like simulated annealing to avoid local minima, thenuse quasi-Newton to re�ne
doing Monte Carlo adds a layer of computations

Check the Pelican cluster at the UAB
made up of two servers, each has two quad core CPUs.
A total of 16 cores. 1 server runs the PelicanHPC CD, theother is netbooted from the �rstcost was about 4500 euroskeeping CPU density high is important
ssh to pareto, then to pelican
run estimate_fg, and look at htop on second screen
run mc.m for SV1, look at htop on second screen

Check the Pelican cluster at the UAB
made up of two servers, each has two quad core CPUs.
A total of 16 cores. 1 server runs the PelicanHPC CD, theother is netbooted from the �rstcost was about 4500 euroskeeping CPU density high is important
ssh to pareto, then to pelican
run estimate_fg, and look at htop on second screen
run mc.m for SV1, look at htop on second screen

Check the Pelican cluster at the UAB
made up of two servers, each has two quad core CPUs.
A total of 16 cores. 1 server runs the PelicanHPC CD, theother is netbooted from the �rstcost was about 4500 euroskeeping CPU density high is important
ssh to pareto, then to pelican
run estimate_fg, and look at htop on second screen
run mc.m for SV1, look at htop on second screen

Check the Pelican cluster at the UAB
made up of two servers, each has two quad core CPUs.
A total of 16 cores. 1 server runs the PelicanHPC CD, theother is netbooted from the �rstcost was about 4500 euroskeeping CPU density high is important
ssh to pareto, then to pelican
run estimate_fg, and look at htop on second screen
run mc.m for SV1, look at htop on second screen

Check the Pelican cluster at the UAB
made up of two servers, each has two quad core CPUs.
A total of 16 cores. 1 server runs the PelicanHPC CD, theother is netbooted from the �rstcost was about 4500 euroskeeping CPU density high is important
ssh to pareto, then to pelican
run estimate_fg, and look at htop on second screen
run mc.m for SV1, look at htop on second screen

Check the Pelican cluster at the UAB
made up of two servers, each has two quad core CPUs.
A total of 16 cores. 1 server runs the PelicanHPC CD, theother is netbooted from the �rstcost was about 4500 euroskeeping CPU density high is important
ssh to pareto, then to pelican
run estimate_fg, and look at htop on second screen
run mc.m for SV1, look at htop on second screen

Check the Pelican cluster at the UAB
made up of two servers, each has two quad core CPUs.
A total of 16 cores. 1 server runs the PelicanHPC CD, theother is netbooted from the �rstcost was about 4500 euroskeeping CPU density high is important
ssh to pareto, then to pelican
run estimate_fg, and look at htop on second screen
run mc.m for SV1, look at htop on second screen

Using PelicanHPC
PelicanHPC is an image �le for a bootable CDROM.
You can boot a computer using the CDROMusing the CDROM does not a�ect anything installed on yourcomputer, when you reboot, your computer is just as it wasbefore using PelicanHPC
PelicanHPC allows you to create a cluster for parallelcomputing using MPI
other computers in the cluster are booted using their ethernetinterfaces
netboot must be enabled for this to work, It is an option in theBIOS setup routine
basic instructions for using PelicanHPC are athttp://pareto.uab.es/mcreel/PelicanHPC/Tutorial/
PelicanTutorial.html
Using PelicanHPC
PelicanHPC is an image �le for a bootable CDROM.
You can boot a computer using the CDROMusing the CDROM does not a�ect anything installed on yourcomputer, when you reboot, your computer is just as it wasbefore using PelicanHPC
PelicanHPC allows you to create a cluster for parallelcomputing using MPI
other computers in the cluster are booted using their ethernetinterfaces
netboot must be enabled for this to work, It is an option in theBIOS setup routine
basic instructions for using PelicanHPC are athttp://pareto.uab.es/mcreel/PelicanHPC/Tutorial/
PelicanTutorial.html

Using PelicanHPC
PelicanHPC is an image �le for a bootable CDROM.
You can boot a computer using the CDROMusing the CDROM does not a�ect anything installed on yourcomputer, when you reboot, your computer is just as it wasbefore using PelicanHPC
PelicanHPC allows you to create a cluster for parallelcomputing using MPI
other computers in the cluster are booted using their ethernetinterfaces
netboot must be enabled for this to work, It is an option in theBIOS setup routine
basic instructions for using PelicanHPC are athttp://pareto.uab.es/mcreel/PelicanHPC/Tutorial/
PelicanTutorial.html

Using PelicanHPC
PelicanHPC is an image �le for a bootable CDROM.
You can boot a computer using the CDROMusing the CDROM does not a�ect anything installed on yourcomputer, when you reboot, your computer is just as it wasbefore using PelicanHPC
PelicanHPC allows you to create a cluster for parallelcomputing using MPI
other computers in the cluster are booted using their ethernetinterfaces
netboot must be enabled for this to work, It is an option in theBIOS setup routine
basic instructions for using PelicanHPC are athttp://pareto.uab.es/mcreel/PelicanHPC/Tutorial/
PelicanTutorial.html

Using PelicanHPC
PelicanHPC is an image �le for a bootable CDROM.
You can boot a computer using the CDROMusing the CDROM does not a�ect anything installed on yourcomputer, when you reboot, your computer is just as it wasbefore using PelicanHPC
PelicanHPC allows you to create a cluster for parallelcomputing using MPI
other computers in the cluster are booted using their ethernetinterfaces
netboot must be enabled for this to work, It is an option in theBIOS setup routine
basic instructions for using PelicanHPC are athttp://pareto.uab.es/mcreel/PelicanHPC/Tutorial/
PelicanTutorial.html

Using PelicanHPC
PelicanHPC is an image �le for a bootable CDROM.
You can boot a computer using the CDROMusing the CDROM does not a�ect anything installed on yourcomputer, when you reboot, your computer is just as it wasbefore using PelicanHPC
PelicanHPC allows you to create a cluster for parallelcomputing using MPI
other computers in the cluster are booted using their ethernetinterfaces
netboot must be enabled for this to work, It is an option in theBIOS setup routine
basic instructions for using PelicanHPC are athttp://pareto.uab.es/mcreel/PelicanHPC/Tutorial/
PelicanTutorial.html

Using PelicanHPC
PelicanHPC is an image �le for a bootable CDROM.
You can boot a computer using the CDROMusing the CDROM does not a�ect anything installed on yourcomputer, when you reboot, your computer is just as it wasbefore using PelicanHPC
PelicanHPC allows you to create a cluster for parallelcomputing using MPI
other computers in the cluster are booted using their ethernetinterfaces
netboot must be enabled for this to work, It is an option in theBIOS setup routine
basic instructions for using PelicanHPC are athttp://pareto.uab.es/mcreel/PelicanHPC/Tutorial/
PelicanTutorial.html

A virtual cluster
this uses VMware server(http://www.vmware.com/download/server/). This is free(as in free beer) software that works on Linux and Windows.
it lets you use Pelican without actually rebooting yourcomputer
the virtual frontend node can be used to boot a cluster of realcompute nodes
the compute nodes can also be virtual: it is possible to havean entirely virtual PelicanHPC cluster running on a set ofWindows machines
go on to demonstrate Pelican, running the Monte Carloexamples.

A virtual cluster
this uses VMware server(http://www.vmware.com/download/server/). This is free(as in free beer) software that works on Linux and Windows.
it lets you use Pelican without actually rebooting yourcomputer
the virtual frontend node can be used to boot a cluster of realcompute nodes
the compute nodes can also be virtual: it is possible to havean entirely virtual PelicanHPC cluster running on a set ofWindows machines
go on to demonstrate Pelican, running the Monte Carloexamples.

A virtual cluster
this uses VMware server(http://www.vmware.com/download/server/). This is free(as in free beer) software that works on Linux and Windows.
it lets you use Pelican without actually rebooting yourcomputer
the virtual frontend node can be used to boot a cluster of realcompute nodes
the compute nodes can also be virtual: it is possible to havean entirely virtual PelicanHPC cluster running on a set ofWindows machines
go on to demonstrate Pelican, running the Monte Carloexamples.

A virtual cluster
this uses VMware server(http://www.vmware.com/download/server/). This is free(as in free beer) software that works on Linux and Windows.
it lets you use Pelican without actually rebooting yourcomputer
the virtual frontend node can be used to boot a cluster of realcompute nodes
the compute nodes can also be virtual: it is possible to havean entirely virtual PelicanHPC cluster running on a set ofWindows machines
go on to demonstrate Pelican, running the Monte Carloexamples.

A virtual cluster
this uses VMware server(http://www.vmware.com/download/server/). This is free(as in free beer) software that works on Linux and Windows.
it lets you use Pelican without actually rebooting yourcomputer
the virtual frontend node can be used to boot a cluster of realcompute nodes
the compute nodes can also be virtual: it is possible to havean entirely virtual PelicanHPC cluster running on a set ofWindows machines
go on to demonstrate Pelican, running the Monte Carloexamples.

make_pelican
PelicanHPC ISO images are made by running a single script:make_pelican
if you use Debian Linux (or a derivative), you can install thelive_helper package, and then use the script to make your ownversion
this allows you to specify a password, select software packagesyou want, place the home directory on permanent storage, etc.this is probably not something to try until you are morefamiliar with the basics - it's just information to be aware of incase you become interested

make_pelican
PelicanHPC ISO images are made by running a single script:make_pelican
if you use Debian Linux (or a derivative), you can install thelive_helper package, and then use the script to make your ownversion
this allows you to specify a password, select software packagesyou want, place the home directory on permanent storage, etc.this is probably not something to try until you are morefamiliar with the basics - it's just information to be aware of incase you become interested

make_pelican
PelicanHPC ISO images are made by running a single script:make_pelican
if you use Debian Linux (or a derivative), you can install thelive_helper package, and then use the script to make your ownversion
this allows you to specify a password, select software packagesyou want, place the home directory on permanent storage, etc.this is probably not something to try until you are morefamiliar with the basics - it's just information to be aware of incase you become interested

make_pelican
PelicanHPC ISO images are made by running a single script:make_pelican
if you use Debian Linux (or a derivative), you can install thelive_helper package, and then use the script to make your ownversion
this allows you to specify a password, select software packagesyou want, place the home directory on permanent storage, etc.this is probably not something to try until you are morefamiliar with the basics - it's just information to be aware of incase you become interested

GMM
gmm_results.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_results.m
gmm_estimate.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_estimate.m
gmm_obj.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_obj.m
average_moments.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/average_moments.m
sum_moments_nodes.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/sum_moments_nodes.m
GMM
gmm_results.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_results.m
gmm_estimate.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_estimate.m
gmm_obj.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_obj.m
average_moments.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/average_moments.m
sum_moments_nodes.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/sum_moments_nodes.m
GMM
gmm_results.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_results.m
gmm_estimate.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_estimate.m
gmm_obj.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_obj.m
average_moments.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/average_moments.m
sum_moments_nodes.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/sum_moments_nodes.m

GMM
gmm_results.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_results.m
gmm_estimate.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_estimate.m
gmm_obj.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_obj.m
average_moments.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/average_moments.m
sum_moments_nodes.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/sum_moments_nodes.m

GMM
gmm_results.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_results.m
gmm_estimate.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_estimate.m
gmm_obj.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/gmm_obj.m
average_moments.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/average_moments.m
sum_moments_nodes.mhttp://pareto.uab.es/mcreel/Econometrics/
MyOctaveFiles/Econometrics/GMM/sum_moments_nodes.m

Solving macroeconomic models
An example is a forthcoming paper

PEA
uses a long simulation from a model, conditional on aparameterized model of expectations
the parameterized model of expectations is �t to the generateddata
when the generated data is consistent with the model ofexpectations, the model has been solved
both making a long simulation and �tting the model ofexpectations can easily be parallelized
is is possible to speed up a simple model by more than 80%.More complicated models should give even better results

PEA
uses a long simulation from a model, conditional on aparameterized model of expectations
the parameterized model of expectations is �t to the generateddata
when the generated data is consistent with the model ofexpectations, the model has been solved
both making a long simulation and �tting the model ofexpectations can easily be parallelized
is is possible to speed up a simple model by more than 80%.More complicated models should give even better results

PEA
uses a long simulation from a model, conditional on aparameterized model of expectations
the parameterized model of expectations is �t to the generateddata
when the generated data is consistent with the model ofexpectations, the model has been solved
both making a long simulation and �tting the model ofexpectations can easily be parallelized
is is possible to speed up a simple model by more than 80%.More complicated models should give even better results

PEA
uses a long simulation from a model, conditional on aparameterized model of expectations
the parameterized model of expectations is �t to the generateddata
when the generated data is consistent with the model ofexpectations, the model has been solved
both making a long simulation and �tting the model ofexpectations can easily be parallelized
is is possible to speed up a simple model by more than 80%.More complicated models should give even better results

PEA
uses a long simulation from a model, conditional on aparameterized model of expectations
the parameterized model of expectations is �t to the generateddata
when the generated data is consistent with the model ofexpectations, the model has been solved
both making a long simulation and �tting the model ofexpectations can easily be parallelized
is is possible to speed up a simple model by more than 80%.More complicated models should give even better results

Speedups

Go look at the code
pea_example.mhttp://pareto.uab.es/mcreel/Econometrics/Examples/
Parallel/pea/example/pea_example.m
note use of C++ to write the model
run the examples

Go look at the code
pea_example.mhttp://pareto.uab.es/mcreel/Econometrics/Examples/
Parallel/pea/example/pea_example.m
note use of C++ to write the model
run the examples

Go look at the code
pea_example.mhttp://pareto.uab.es/mcreel/Econometrics/Examples/
Parallel/pea/example/pea_example.m
note use of C++ to write the model
run the examples

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.

4 projectsThe last two hours will be used working on the following fourprojects.
1 Create a real cluster1 at least two students, and 2 laptop computers. Need a copy of
the Pelican CD and a crossover cable.
2 Create a virtual cluster1 at least 1 student with a laptop computer. Need a copy of
VMware server and the Pelican ISO image.
1 Install VMware server to allow bridged, NAT and host only
networking.2 create a virtual machine with 2 NICs, �rst bridged, second
NAT. Use it to boot CD image3 create a virtual machine with bridged NIC, use it to PXE boot
the compute node
3 Run a Monte Carlo study1 boot up Pelican and use only the frontend. Do the AR1 Monte
Carlo suggested above.
4 Do GMM estimation1 boot up Pelican and use only the frontend. Make hausman.m
run on 2 ranks.