an overview of dynamic programming cor@l seminar series joe hartman ise october 14, 2004
TRANSCRIPT

An Overview of Dynamic Programming
COR@L Seminar Series
Joe Hartman
ISE
October 14, 2004

Goals of this Talk
• Overview of Dynamic Programming
• Benefits of DP
• Difficulties of DP– Art vs. Science– Curse of Dimensionality
• Overcoming Difficulties– Approximation Methods

Dynamic Programming
• Introduced by Richard Bellman in the 1950s
• DP has many applications, but is best known for solving Sequential Decision Processes
• Equipment Replacement was one of the first applications.

Sequential Decision Processes
At each stage in a process, a decision is made given the state of the system. Based on the decision and state, a reward or cost in incurred and the system transforms to another state where the process is repeated at the next stage.
Goal is to find the optimal policy, which is the best decision for each state of the system

Stages
• Stages define when decisions are to be made.
• These are defined such that decisions can be ordered.
• Stages are generally discrete and numbered accordingly (1,2,3,…), however they may be continuous if decisions are made at arbitrary times

States
• A state is a description of one of the variables that describe the condition (state) of the system under study
• State space defined by all possible states which the system can achieve
• States may be single variables, vectors, or matrices
• States may be discrete or continuous, although usually made discrete for analysis

Decisions
• For each given state, there is a set of possible decisions that can be made
• Decisions are defined ONLY by the current state of the system at a given stage
• A decision or decision variable is one of the choices available from the decision set defined by the state of the system

Rewards and/or Costs
• Generally, a reward or cost is incurred when a decision is made for a given state in a given stage
• This reward is only based on the current state of the system and the decision

Transformation
• Once a decision has been made, the system transforms from an initial state to its final state according to a transformation function
• The transformation function and decision define how states change from stage to stage
• These transformations may be deterministic (known) or stochastic (random)

Policies
• A decision is made at each stage in the process
• As a number of stages are evaluated, the decisions for each state in each stage comprise a policy
• The set of all policies is the policy space

Returns
• A return function is defined for a given state and policy.
• The return is what is obtained if the process starts at a given state and decisions associated with the policy are used at each state which the process progresses through.
• The optimal policy achieves the optimal return (depends on min or max)

Functional Equation
• These terms are all defined in the functional equation, which is used to evaluate different policies (sets of decisions)
€
f t (λ ) = minx∈X
r(λ , x) + αf t−1(T(λ , x(λ )){ }
StateStage
Decision Set
Decision Reward} }
Transformation Function
Discount Factor

Functional Equation
• May be stochastic in that the resulting state is probabilistic. Note the recursion is backwards here.
€
f t (λ ) = minx∈X
r(λ , x) + α ps f t +1(T(s,λ , x(λ ))S
∑ ⎧ ⎨ ⎩
⎫ ⎬ ⎭}
S represents set of possibleoutcomes with probabilityp for each outcome

Principle of Optimality
• Key (and intuitive) to Dynamic Programming:
If we are in a given state, a necessary condition for optimality is that the remaining decisions must be chosen optimally with respect to that state.

Principle of Optimality
Requires:• Separability of the objective function
– Allows for process to be analyzed in stages
• State separation property– Decisions for a given stage are only dependent
on the current state of the system (not the past)– Markov property

Why Use DP?
• Extremely general in its ability to model systems
• Can tackle various “difficult” issues in optimization (i.e. non-linearity, integrality, infinite horizons)
• Ideal for “dynamic” processes

Why NOT Use DP?
• Curse of dimensionality: each dimension in the state space generally leads to an explosion of possible states = exponential run times
• There is no “software package” for solution• Modeling is often an art… not science

Art vs. Science
• Many means to an end…. Let’s look at an equipment replacement problem.

Replacement Analysis
• Let’s put this all in the context of replacement analysis.
• Stage: Periods when keep/replace decisions are to be made. Generally years or quarters.
• State: Information to describe the system. For simplest problem, all costs are defined by the age of the asset. Thus, age is the state variable
• Decisions: Keep or replace the asset at each stage.

Replacement Analysis
• Reward and/or Costs: – Keep Decision: pay utilization cost– Replace Decision: receive salvage value, pay purchase
and utilization cost
• Transformation: – Keep Decision: asset ages one period from stage to stage– Replace Decision: asset is new upon purchase, so it is
one period old at end of stage
• Goal: Min costs or max returns over horizon

Replacement Analysis
• Let’s start easy, assume stationary costs.
• Assume the following notation:– Age of asset: i– Purchase Cost: P– Utilization Cost: C(i)– Salvage Value: S(i)
• Assume S and P occur at beginning of period and C occurs at end of period.

Example
• Many solutions approaches to problem -- even with DP!
• Map out decision possibilities and analyze by solving recursion backwards.
• Define the initial state and solve forwards (with reaching)

Decision MapDecision Map
i
1
1
1
2
2
3i+1
i+2
i+3
K
K
K
K
K
K
R
R
R
R
R
R
0 1 2 3 T

Example Decision MapExample Decision Map
4
1
1
2
5
6
7
K
K
K
K
K
K
R
R
R
R
R
R
0 1 2 3 T
1
2
3
1
2
3
8
4
1
2
3
5
4
4 5

Functional Equation
• Write functional equation:
• Write a boundary condition for the final period (where we sell the asset):
• Traditional approach: solve backwards.
fT (i) =−ST ( j)
€
f t (i) = minKeep : αCt (i) + αf t +1(i +1)
Replace : Pt - St (i) +αCt (0) + αf t +1(1)
⎧ ⎨ ⎩

Functional Equation
• Or the problem can be solved forwards, or with reaching.
• Functional equation does not change:
• Write a boundary condition for the initial period:
• Benefit: don’t have to build network first.
f0(i) =0€
f t (i) = minKeep : αCt (i) + αf t−1(i +1)
Replace : Pt - St (i) +αCt (0) + αf t−1(1)
⎧ ⎨ ⎩

Art vs. Science
• However, there are more approaches…

Replacement Analysis II
• A new approach which mimics that of lot-sizing:
• Stage: Decision Period.• State: Decision Period.• Decisions: Number of periods to retain an
asset.

Example Decision MapExample Decision Map
1 2 3 4 5K1 K1 K1 K1
K2K2
K2
K3
K3
K4

Functional Equation
• Can be solved forwards or backwards.
• Write a boundary condition for the final period:
€
f (T) = 0€
f (t) = minn≤N
Pt + α jCt + j ( j)j=1
n
∑ −α nSt +n (n) + α n f (t + n) ⎧ ⎨ ⎪
⎩ ⎪
⎫ ⎬ ⎪
⎭ ⎪

Replacement Analysis III
• A new approach which mimics that of solving integer knapsack problems:
• Stage: One for each possible age of asset.• State: Number of years of accumulated
service.• Decisions: Number of times an asset is
utilized for a given length of time over the horizon.
• Note: this is only valid for stationary costs.

Example Decision MapExample Decision Map
i
T/i
3i
2i
0
i
i+T/j
i+2j
i+j
0

Functional Equation
• Can be solved forwards or backwards.
• Where:
• Write a boundary condition for the first period:
€
f (0) = 0
€
f i(t) = minm:mn i ≤ t
α t−mn i α ( j−1)n i p(ni)j=1
m
∑ + f i−1(t − mni) ⎧ ⎨ ⎪
⎩ ⎪
⎫ ⎬ ⎪
⎭ ⎪
€
p(ni) = Pt + α jC( j)j=1
n i
∑ −α n i S(ni)

Art vs. Science
• Age as the state space:– Conceptually simple, easy to explain.
• Period as the state space:– Computationally efficient– Can be generalized to non-stationary costs,
multiple challengers easily
• Length of service as the state space:– Easy to bound problem– Relates to infinite horizon solutions

Curse of Dimensionality
• To given an idea of state space explosion, consider a fleet management problem:– Assign trucks to loads– Loads must move from one destination to another
within some given time frame– The arrivals of loads are probabilistic
• State space: number of trucks (given type) at each location in time.

Approximation Methods
• These can generally be categorized as follows:– Reduction in granularity– Interpolation– Policy Approximation – Bounding/Fathoming – Cost to Go Function Approximations
• Unfortunately, art wins over science here too. Requires intimate knowledge of problem.

Decision NetworkDecision Network
0 1 2 3 T
1
2
3
5
4
1
2
3
5
4
4 5
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4

Adjusting Granularity
• Simply remove the number of possible states. Instead of evaluating 1,2,3,…,10, evaluate 1,5,10.
• Advocate: Bellman
1
5
3
1
5
3
1
5
3
1
5
3
1
5
3
1
5
3

Granularity continued…• Solve continuously finer granularity problems
based on previous solution
• Advocates: Bean and Smith (Michigan), Bailey (Pittsburgh)
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4

Interpolation
• Solve for some of the states exactly and then interpolate solutions for “skipped” states
• Advocates: Kitanidis (Stanford)
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4

Interpolation
• Solve for some of the states exactly and then interpolate solutions for “skipped” states
• Advocates: Kitanidis (Stanford)
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
SolveExactly.

Interpolation
• Solve for some of the states exactly and then interpolate solutions for “skipped” states
• Advocates: Kitanidis (Stanford)
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
SolveExactly.
Interpolate.

Interpolation
• Interpolations over the entire state space often called spline methods. Neural networks also used.
• Advocates: Johnson (WPI), Bertsekas (MIT)
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
1
2
3
5
4
SolveExactly.
Interpolate.

Policy Approximation
• Reduce the number of possible decisions to evaluate
• This merely reduces the number of arcs in the network
• Advocates: Bellman

Fathoming Paths
• Like branch and bound: use an upper bound (to a minimization problem) to eliminate inferior decisions (paths)
• Note: typical DP must be solved completely in order to find an upper bound to a problem
• Most easily implemented in “forward” solution problems (not always possible)
• Advocate: Martsen

Approximating Cost to Go Functions
• This is the hot topic in approximation methods
• Highly problem specific• Idea:
– Solving a DP determines the “cost-to-go” value for each state in the system -- value or cost to move from that state in a given stage to the final state in the final stage.
– If I know this function a priori (or can approximate), then I don’t need to solve the entire DP
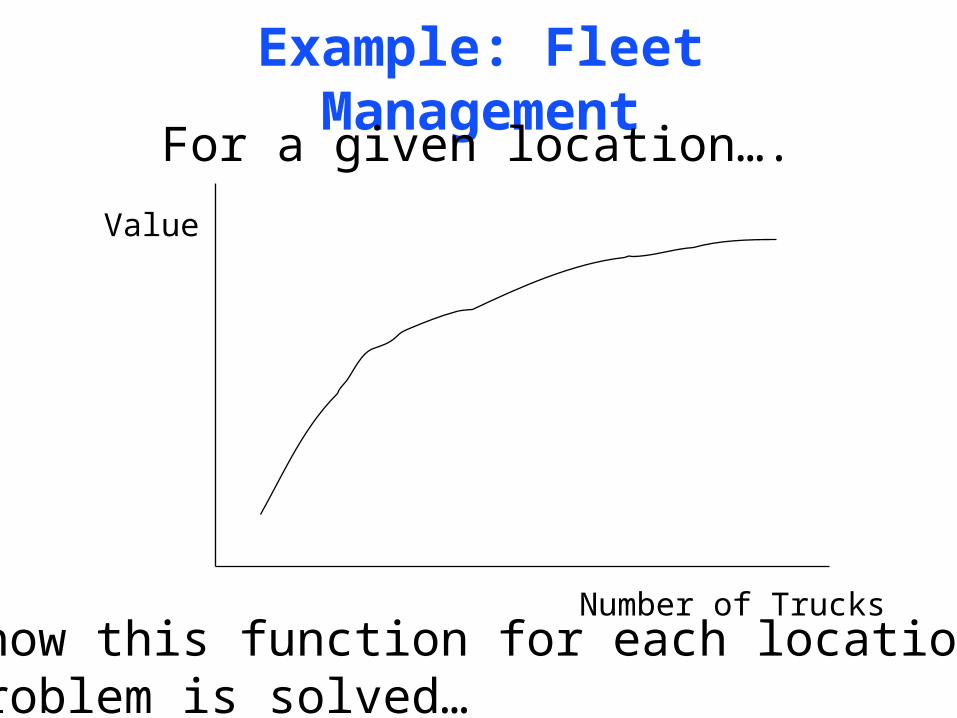
Example: Fleet Management
Number of Trucks
Value
For a given location….
If I know this function for each location, thenthis problem is solved…

How Approximate?
• Helps to know what the function looks like (can find by plotting small instances)
• Powell (Princeton): Simulate demand and solve the deterministic problem (as a network flow problem)– Repeat and take average of values of each state to
approximate functions– Use dual variables from network solutions to build cost-
to-go functions

How Approximate?
• Bertsimas (MIT) proposes the use of heuristics to approximate the value function
• Specifically, when solving a multidimensional knapsack problem, the value function is approximated by adaptively rounding LP relaxations to the problem.

Implementing Approximations
• Can use to approximate the final period values and then solve “full” DP from there
• Can use approximations for each state and just “read” solution from table (always approximating and updating approximations)

Summary• DP is a very useful and powerful modeling
tool• Ideal for sequential decision processes• Can handle various situations: integrality,
non-linearity, or stochastic problems• DP is limited by:
– Art vs. science in modeling– Curse of dimensionality– No commercial software
• But approximation approaches show promise