analisi forense ed estrazione di elementi probatori da ... · analisi forense ed estrazione di...
TRANSCRIPT

UNIVERSITÀ DEGLI STUDI DI TORINOSCUOLA DI SCIENZE DELLA NATURA
CORSO DI LAUREA IN INFORMATICA
ANNO ACCADEMICO 2012/2013
RELAZIONE DI TIROCINIO
Analisi forense ed estrazione di elementi
probatori da evidenze digitali
Relatore Esterno
Dr. Paolo Dal Checco
Relatore Interno
Prof. Viviana Bono
Candidato
Matteo Ghigo

Abstract
This document describes the topics I learnt and the activities I performed duringthe stage which ends my Italian three-year University Degree in Computer Sci-ence, specialising in Computer and Networks. The stage took place at HQ of the"Digital Forensics Bureau" Consulting Firm in Grugliasco, near Turin, Italy.Once learnt the basis of computer forensincs and observed the issues that mayarise during a digital investigation, I began developing a software designed toautomate the main stages of the investigation, helping the analyst to focus oninformation gathering rather than on repetitive operations.The main tasks of the analysis are: extraction of data from forensic images,deleted files recovery and analysis of email archives (if any) aimed at turningoriginal messages into human readable format.The extraction of data is performed by collecting files from the allocated space andsplitting them into folders, according to their format. The deleted file recoverytakes place by recovering and carving out structured data from the unallocatedspace of the forensic image. As for email messages - the task that took most ofmy efforts - I focused on analysing and parsing three most common file formats,namely PST (Outlook), DBX (Outlook Express) and MSF (Thunderbird), allow-ing the analyst to browse through collected email archives via a comfortable GUI.Upon completion, the data extraction process issues a .CSV file containing usefulinformation drawn from the files founds in the analysed forensic image. A log fileis the output of the deleted files analysis and extraction. As for email process-ing, I developed an HTML graphical user interface similar to a traditional emailclient, which can be used by investigators to browse through email archives andread messages regardless of their original format.The software, which I named "Ermès", makes use of some third-party OpenSource libraries and tools to parse data structures and access data in forensic im-ages in read-only mode, thus preserving the chain of custody of evidences. Thetools and libraries the developed software depends on are distributed under OpenSource licenses, as well as Ermès itself.Python was the programming language chosen for the development of the soft-ware, since Python applications are efficient and facilitate further integration anddevelopment.In conclusion, the software aims to simplify the process of forensic analysis. In

fact, the minimal and clean graphical user interface allows the user to set the pa-rameters of interest and run the analysis and extraction by automating repetitivetasks. The ease of use of the software and variety of gathered information makeErmès an innovative tool, useful for computer forensics experts and analysts.

Indice
1 Motivazioni 3
2 Descrizione dei requisiti 52.1 Posizionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Formulazione del problema . . . . . . . . . . . . . . . . . . 52.1.2 Proposte ed opportunità . . . . . . . . . . . . . . . . . . . 62.1.3 Alternative e concorrenza . . . . . . . . . . . . . . . . . . 6
2.2 Descrizioni delle parti interessate . . . . . . . . . . . . . . . . . . 72.2.1 Riepilogo delle parti interessate . . . . . . . . . . . . . . . 72.2.2 Compatibilità . . . . . . . . . . . . . . . . . . . . . . . . . 72.2.3 Gli strumenti e l’ambiente di sviluppo . . . . . . . . . . . 7
3 Estrazione dei file d’interesse e recupero dei file cancellati 93.1 Estrazione dei file d’interesse . . . . . . . . . . . . . . . . . . . . 9
3.1.1 Input . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.1.2 Strumenti utilizzati . . . . . . . . . . . . . . . . . . . . . . 103.1.3 Il codice . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.1.4 Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Recupero dei file cancellati - carving - . . . . . . . . . . . . . . . . 163.2.1 Strumenti utilizzati . . . . . . . . . . . . . . . . . . . . . . 173.2.2 Input . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2.3 Il codice . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2.4 Output . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4 Analisi delle mail 204.1 La posta elettronica . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1.1 Analisi di un header di una mail . . . . . . . . . . . . . . . 214.1.2 Analisi del body di una mail . . . . . . . . . . . . . . . . . 23
4.2 Analisi delle mail da parte di Ermès . . . . . . . . . . . . . . . . . 264.2.1 Gli archivi dbx . . . . . . . . . . . . . . . . . . . . . . . . 27
1

4.2.2 Gli archivi msf . . . . . . . . . . . . . . . . . . . . . . . . 324.2.3 Gli archivi pst . . . . . . . . . . . . . . . . . . . . . . . . . 384.2.4 Report dell’estrazione delle mail . . . . . . . . . . . . . . . 43
5 L’interfaccia grafica 47
6 Conclusioni 52
7 Gli sviluppi futuri 54
8 Ringraziamenti 55
Bibliografia 56
Sitografia 57
2

Capitolo 1
Motivazioni
L’informatica è una scienza che ha il compito di analizzare e studiare l’infor-mazione e come questa può essere implementata attraverso l’uso di strumentielettronici. La computer forensics, ambito di competenza di questa trattazione,è quella scienza che si occupa della conservazione e del trattamento di quei datiche dovranno essere valutati in un processo giuridico. Durante il mio percorso distudi non ho avuto modo di approfondire tale argomento pertanto ho deciso dieffettuare uno stage per la tesi presso la Di.Fo.B., il più grande studio italianodel settore.La DiFoB offre servizi di consulenze di parte nei procedimenti civili o penali siaper il Pubblico Ministero, sia per i Giudici in ambito istituzionale. Le consulenzepossono vertere su computer forensics analysis, mobile forensics analysis, recupe-ro di file cancellati, OSINT anlaysis1, audio forensics, image and video forensics,mog 231/01, supporto tecnico per la salvaguardia dei dati aziendali.Il ruolo dell’informatico forense è quindi di fondamentale importanza poichè dal-le sue analisi dipendono le sorti delle sentenze. Deve conoscere a fondo i sistemioperativi, la tecnologia con cui son costruiti i dispositivi informatici in analisi esoprattutto deve conoscere tutti quei programmi che possono contenere dati diinteresse da analizzare. La continua evoluzione dei dispositivi informatici creauna forte dinamicità nei lavori con la necessità di aggiornamenti quotidiani.Le nozioni da conoscere sono tantissime, spesso per singoli modelli di computerdevono essere fatte particolari tipi di analisi affinchè siano estratti il maggiornumero di dati in un determinato arco temporale. Alcuni software forensi sonomeglio compatibili con certi modelli di dispositivi mentre altri effettuano analisi
1Open Source INTelligence, è l’attività di raccolta di informazioni mediante la consultazionedi fonti di pubblico accesso. Nella fattispecie vengono cercate tutte le informazioni di ununtente presenti in rete mettendole successivamente in correlazione per formare così un identikittendente ad una vera e propria identità digitale.
3

di medio-alto livello su una vasta gamma di apparecchi elettronici.La forensics si impara sicuramente sul campo con l’esperienza ma è comunquenecessario aggiornarsi continuamente ed avere solide basi teoriche alle spalle. At-tualmente l’informatica forense gode di lavoro continuo poichè qualsiasi procedi-mento penale o civile ha sempre coinvolte persone che dispongono di un telefonocellulare o di un personal computer e spesso all’interno di questi oggetti vi sonole vere prove che possono accusare o scagionare un imputato.
Nel 1979 Hans Jonas scriveva: “la tecnologia assume una rilevanza etica in
virtù della centralità ora occupata nella finalità umana soggettiva”
2.Questo pensiero è sin da subito per il filosofo uno spunto di riflessione sull’im-patto della tecnologia nel tempo che termina con le seguenti parole “è il futuro
indefinito, molto più che non lo spazio contemporaneo dell’azione, a costituire
l’orizzonte rilevante della responsabilità”. Così il filosofo tedesco di origine ebrai-ca invita il genere umano a riflettere sulla tecnologia, sul suo impatto sia tra glialtri uomini sia sullo spazio circostante. Secondo quest’uomo dopo le due grandiguerre mondiali del XX secolo il bilanciamento tra coscienza e sviluppo tecnolo-gico è venuto meno. La necessità di un senso di responsabilità è fondamentalevisto il progresso tecnologico a cui siamo arrivati. La tecnologia mette semprepiù a rischio la civiltà umana e spesso distrugge la natura. È quindi necessario,secondo il filosofo, elaborare una nuova etica della responsabilità profondamentediversa dalle morali tradizionali.Il pensiero di Jonas deve essere anche di spunto per un analista forense, cono-scitore della tecnica (tèchne) e della tecnologia (tèchne-loghìa), affinchè corretteed esaustive analisi dei dati permettano di assegnare la giusta sentenza a chi laresponsabilità non l’ha voluta utilizzare.
2Hans Jonas, Il principio responsabilità. Un’etica per la civiltà tecnologica, Torino, Einaudi,1990, capitolo 1, p. 13-14
4

Capitolo 2
Descrizione dei requisiti
In questa trattazione sarà possibile comprendere ed approfondire le specifiche,le possibilità di utilizzo e le potenzialità del software da me ideato e sviluppatodurante lo stage. Il software in questione prende il nome di Ermès.Codesto programma effettua in modo automatizzato le tre principali analisi com-piute da un informatico forense: estrazione dei dati, recupero dei file cancellatied analisi delle mail.
2.1 Posizionamento
2.1.1 Formulazione del problema
L’era tecnologica in cui siamo profondamente immersi ci porta ad essere conti-nuamente a contatto diretto o indiretto con dispositivi elettronici.A livello giudiziario e legale è oramai diventato impossibile non tenere conto deiruoli e degli effetti che tali dispositivi possono avere all’interno di un’inchiesta. Idispositivi elettronici dotati di memoria possono immagazzinare dati importanti,spesso fondamentali per la corretta formulazione della sentenza.Sempre più avvengono truffe o misfatti incentrati sul commercio elettronico o sulfurto d’identità tramite internet. I molti contesti in cui sono coinvolti queste tipo-logie di manufatti tecnologici portano alla necessità di doverli analizzare in modopreciso ed accurato affinchè le informazioni estrapolate possano essere utilizzatein sede giudiziaria.Il corretto trattamento dei dati digitali è l’oggetto degli studi dell’informaticaforense. I dati vengono analizzati attraverso precise ed accurate tecniche man-tendone lo stato inalterato.La necessità di nuovi strumenti non viene mai meno poichè la tecnologia è in con-
5

tinua evoluzione e spesso certi software non vengono aggiornati rischiando così didiventare obsoleti.E’ inoltre utile poter disporre di software precisi e capaci di effettuare diversi tipidi analisi affinchè possano essere utilizzati in contesti diversi.
2.1.2 Proposte ed opportunità
I software forensi, Ermès nello specifico, si pongono l’obiettivo di analizzare i fileall’interno di un’immagine forense senza alterarne lo stato. I metadati non devonosubire variazioni nemmeno dalla visita di un software forense. Ho cercato di fardistinguere Ermès per la sua semplicità di utilizzo, studiata per essere alla portatadi tutti, capace di produrre documenti ricchi di risultati di facile consultazione.Partendo dalla fase di estrazione fino alla processazione delle mail Ermès procedein modo autonomo. Senza passaggi intermedi il programma estrae i file filtrandolisecondo i propri interessi, recupera i file cancellati ed analizza le mail. Uno deiprimi obbiettivi che mi sono preposto è stato quello di tentare di migliorare leanalisi forensi. Nel momento in cui vengono richieste le informazioni all’utentequeste sono espresse in modo chiaro e conciso. Ogni preferenza dell’analistasarà poi tradotta dal software con le precise azioni sull’immagine forense delreperto. Ogni file presente nell’immagine verrà analizzato e se sarà tra i formatiricercati verrà anche estratto. L’implementazione del programma non escludealcun file d’interesse: ogni singolo file viene analizzato prima di essere estrattoper le successive analisi.
2.1.3 Alternative e concorrenza
Attualmente sul mercato non è disponibile alcune software open source che eseguatutte queste operazioni. Sono disponibili software che effettuano singole operazio-ni. Ho deciso quindi di avvalermi dell’utilizzo di alcuni di questi software di cui houtilizzato solo le loro migliori caratteristiche. Laddove erano presenti delle lacunele ho colmate andando quindi ad arricchire l’analisi ed il numero di informazionidisponibili all’utente.
6

2.2 Descrizioni delle parti interessate
2.2.1 Riepilogo delle parti interessate
Si vuole proporre al mondo dell’open source un nuovo tool che abbia un targetdi utilizzo del settore ma non necessariamente con conoscenze informatiche dialtissimo livello. Le poche ed intuitive fasi di input del programma lo rendonofacilmente fruibile e pertanto aperto ad un ampio bacino di utilizzatori.Parti sicuramente interessate possono essere di vario genere: dalle forze dell’ordinealle agenzie investigative, dai liberi professionisti che effettuano consulenze forensiagli utenti privati.
2.2.2 Compatibilità
Per ora l’ambiente di utilizzo è limitato ai sistemi operativi Linux ma la speranzaè che in futuro lo si possa ampliare. La scelta è stata dettata dall’ampia gammadi strumenti che questa famiglia di sistemi operativi è in grado di fornire. Leinterazioni a basso livello col sistema operativo direttamente a linea di comandomediante l’uso del terminale hanno giocato un ruolo fondamentale nello svilup-po. Questo genere di operazioni ha aumentato considerevolmente le prestazioniaiutando così a migliorare l’efficienza e la produttività del programma stesso.
2.2.3 Gli strumenti e l’ambiente di sviluppo
Il linguaggio di programmazione da me scelto per l’implementazione di Ermès èstato Python. Le motivazioni di questa scelta risiedono nelle grandi oppurtunitàfornite da questo linguaggio, anch’esso cresciuto grazie all’open source, e la pos-sibilità di dialogare direttamente col sistema operativo.Pyhton non è un linguaggio compilato ma bensì un linguaggio interpretato: ognisingola istruzione viene tradotta in linguaggio macchina al momento dell’esecu-zione del programma stesso. Questa sua caratteristica ha fatto sì che moltissimepersone creassero molti loro programmi, detti moduli, facilmente integrabili aipropri programmi. Come per ogni linguaggio di programmazione moderno Py-thon dispone di una vasta gamma di librerie ricche di funzionalità.Per quanto riguarda le documentazioni invece ho fatto due scelte: per i docu-menti di cui era necessaria una semplice visione tabellare ho usato un documentoin formato Comma-Separated Values (CSV) mentre per documenti di maggiorcomplessità ho voluto creare delle pagine html facilmente navigabili.
7

L’ambiente di sviluppo scelto è stato DEFT1, una distribuzione italiana GNU/linuxper usi legali legati alla Computer Forensics ed alla sicurezza informatica. Carat-teristica peculiare e di fondamentale importanza è il suo utilizzo: essa può usarela RAM per essere eseguita. Durante l’accensione del computer, al momento delboot del sistema operativo, DEFT si sostituisce al sistema operativo principaledella macchina.DEFT dispone di una serie di strumenti già preinstallati utili per eseguire analisiforensi. Grazie ad esso è possibile effettuare immagini forensi, estrazione di dati,analisi telefoniche, recupero di file cancellati, analisi delle reti, recupero di pas-sword, OSINT Analisys, database Analysis, generazione di timeline e molto altroancora.Il programma è stato quindi redatto su semplici fogli di testo e poi testato suquesta distribuzione.
1http://www.deftlinux.net/
8

Capitolo 3
Estrazione dei file d’interesse e
recupero dei file cancellati
3.1 Estrazione dei file d’interesse
Nella prima fase di un’analisi forense è necessario poter estrapolare i dati dall’im-magine forense del reperto. L’immagine forense contiene tutti i dati del repertoma questi non sono immediatamente visibili. L’immagine forense, se non monta-ta, non è nemmeno navigabile.Nella prima fase quindi mi son preoccupato di far sì che Ermès estraesse tutti idati oppure solo quelli che l’utente desiderava. La fase di estrazione è un processomolto delicato poichè è fondamentale non modificare in alcun modo i metadati.Sin dal primo istante il dato diventa il baricentro e il software lavora su di essocon la massima attenzione.
3.1.1 Input
Inizialmente l’analista possiede l’immagine forense del reperto da analizzare.Come da procedura non si effettua mai l’intera analisi sul vero reperto ma suun’immagine di esso.Un’immagine forense è una copia bit a bit del dispositivo di memoria del reperto.Durante la generazione della stessa vengono copiati, bit dopo bit, ogni singolosettore, anche quelli non allocati.Ermès prende in input al momento due tipi di immagini Forensi: il formato Raw
DD oppure il formato Expert Witness Format EWF.
9

3.1.2 Strumenti utilizzati
Per poter estrarre i dati da un’immagine forense per prima cosa è necessariomontarla. Montare un immagine significa crearne una struttura navigabile fattadi cartelle e sottocartelle così da rendere possibile l’accesso ai file.Per le immagini RAW è stato usato il comando di terminale mount. La versioneutilizzata è la 2.20.1Per le immagini EWF è stato usato il comando di terminale xmount. La versioneutilizzata è la 0.5.0Le fasi di estrazione dati e generazione report sono avvenute tramite le libreriefornite da Python.
3.1.3 Il codice
Come accennato nel paragrafo precedente la prima azione effettuata in questa faseè il mounting dell’immagine. Questo processo è diverso a seconda dei formati.Nel caso del formato RAW dd attraverso il comando mount, con gli opportuniparametri, si crea in automatico la struttura ad albero necessaria come inputall’estrazione vera e propria.Nel caso di immagini in formato EWF si effettua prima un xmount per ottenereun immagine in formato raw e successivamente si effettua un mount come sopra.Il primo comando, per montare un immagine in formato ewf è il seguente:
xmount� � in ewf [nameImage] [outputFolder] (3.1)
Il primo e secondo parametro [- -in ewf] indicano rispettivamente che verrà pas-sata in input al comando un’immagine forense e quindi bisogna specificarne ilformato.Il terzo parametro [nameImage] indica il path dell’immagine forense (per mon-tare un immagine ewf si passa il path del file .E01)Il quarto ed ultimo parametro [outputFolder] indica la locazione dove verrà in-serita l’immagine in formato raw.Una volta ottenuta la nuova immagine si procede con il montaggio vero e proprioattraverso il seguente commando:
mount� o ro, loop, show_sys_files, streams_interface = windows,
offset = $((length)) [locationImage] [locationDestination](3.2)
dove:
10

• -o ro ! l’immagine viene montata in sola lettura
• loop ! questa opzione determina che il file di output sia un dispositivo ablocchi simile ad una memoria di massa. Grazie a ciò si crea la strutturaad albero navigabile.
• Show_sys_files ! permette di visualizzare i file di sistema
• Streams_interface=windows ! considera anche gli Alternate Data Streams
ovvero dei flussi alternativi dei dati non normalmente visibili in modalitàstandard. Un file possiede quindi un suo flusso principale (quello che vedia-mo normalmente quando navighiamo tra le cartelle del nostro computer)e poi opzionalmente dei flussi secondari non immediatamente raggiungibili:gli ADS. Spesso in questi flussi secondari vengono nascoste informazionidi piccole o grandi dimensioni proprio perchè la loro presenza è quasi deltutto impercettibile: all’aggiunta di uno stream alternato viene modificatala data di ultima modifica del file ma non cambia la grandezza del file.
• offset=length ! per montare la/le partizione/i è necessario fornire il puntodove inizia la partizione. Nella fattispecie si indica un offset rispetto all’im-magine. L’offset si calcola moltiplicando la grandezza di un singolo settorecon il numero del primo settore di collocazione della partizione. Il risultatoè un intero positivo espresso in byte che deve essere inserito al posto di leng-th. Tutte le informazioni per calcolare questo offset le si possono trovaredigitando sul terminale il commando mmls nameImage.dd
• locationImage ! path dell’immagine in format RAW
• locationDestination ! nome della cartella che conterrà l’output del mount
Una volta montate tutte le partizioni saranno presenti sul computer una serie dicartelle dove ognuna ha al suo interno la partizione montata.Contemporaneamente all’estrazione viene creato un file con estensione .csv cheman mano terrà traccia dei file estratti con una serie di informazioni per ognunodi essi.Nello specifico il file .csv presenta le seguenti colonne:
• Original path ! nome completo comprensivo di path assoluto dove è col-locato il file nell’immagine montata
• Actual path ! nome completo comprensivo di path assoluto dove è collo-cato il file dopo l’estrazione
11

• Date and hour creation ! data ed ora di creazione del file
• Date and hour Access ! data ed ora dell’ultimo accesso
• Date and hour Last modify ! data ed ora dell’ultima modifica
Il campo Actual path risponde all’esigenza di estrarre più file aventi lo stessonome ma collocati in cartelle differenti. Attraverso il campo Original path è pos-sibile risalire al nome originale ed alla precisa collocazione nell’immagine forensemontata.Sono presenti inoltre due colonne opzionali:
• Md5 ! calcola l’md5 del file
• Block start ! indica il blocco di partenza del file all’interno dell’immagineforense.
Le ultime due colonne sono definite opzionali perchè l’utente, in fase di scelta dellatipologia di analisi da fare, può scegliere se includere una delle due informazioninel report, oppure tutte due, oppure nessuna di esse. L’opzionalità di quest’ultimeè data dai tempi di esecuzione: il calcolo dell’md5 su un file molto grande puòrichiedere molto tempo.L’md5 viene calcolato con una funzione apposita di Python mentre per il calcolodel primo blocco viene usato il commando ifind della suite Sleutkit1.Sistemato il file di report in formato csv il programma procede con l’estrazionedei file attraverso la funzione
copyF ile(from, to, dictonaryExtension, partition,mode) (3.3)
copyFile () è una funzione che ha come parametri
• La partizione montata che fungerà da input per l’estrazione
• La cartella di destinazione dove risiederanno tutti i files estratti
• Un dizionario contenente tutto l’elenco delle estensioni dei file desiderati
• la partizione in fase di estrazione
• la modalità di elaborazione a seconda delle opzioni selezionate dall’utente.Di default questo campo vale zero e non sono aggiunte opzioni.
1Sleuthkit è un progetto di investigazione digitale open Source dove la figura di riferimentoè Brian Carrier. Per maggiori informazioni http://www.sleuthkit.org/
12

Questo metodo ha il compito di scorrere tutto l’albero delle cartelle e, quandotrova una cartella richiama la stessa funzione sulla cartella altrimenti, se è un file,chiama un’altra funzione: copyExtension () .La copyExtension () viene chiamata solo se il file possiede un’estensione che l’u-tente gradisce estrarre. Attraverso dictonaryExtension, opportunamente settatonell’interfaccia grafica durante la fase di compilazione dei dati di analisi, vienericercata l’estensione del file corrente. Se il file ha un’estensione che corrispondead una voce del dizionario allora la copyExtension viene richiamata su quel filealtrimenti si passa al file successivo.Esiste inoltre una terza modalità dove l’utente sceglie di voler estrapolare tutto ilcontenuto dell’immagine forense e quindi il dizionario dispone di una sola entry:“ all : all ”. Questa entry viene riconosciuta dal programma di estrazione e comeconseguenza la funzione copyExtension () viene chiamata su ogni file.La sua sintassi è la seguente:
copyExtension(src, dest, extension, partition,mode) (3.4)
I parametri sono gli stessi tranne il terzo, extension, che non è un dizionario mauna stringa contenente l’estensione del file che si andrà ad estrarre. Il file vieneestratto solo perchè possiede un’estensione che si trova all’interno del dizionariopassato in parametro alla copyFile (). La copyExtension () si occupa di effettuarerealmente l’estrazione. In questo contesto l’estrazione consiste in una copia par-ticolare che mantiene intatti i metadati dell’originale. La cartella di destinazioneè una cartella che conterrà solo file con quella determinata estensione. Per primacosa viene controllato se esiste già un file con il medesimo nome. Se viene trova-to un file avente il medesimo nome allora lo si copia cambiandogli il nome. Latraccia del cambio nome è presente all’interno del report. Se non si trova alcunfile con il nome identico allora lo si copia direttamente. La funzione di copiautilizzata è la copy2 () di Python che non va a modificarne i metadati. Sel’utente sceglie di cercare file in formato msf allora viene copiata tutta la cartelladove questo file è presente, poichè in fase di processazione delle mail il modulo dianalisi necessiterà dell’intera cartella di origine. È possibile, in rari casi, che visiano dei file danneggiati che non riescono ad essere copiati interamente. Questifile vengono copiati parzialmente e nel report segnalati.
13

3.1.4 Output
Ribadendo il concetto presente nelle righe precedenti l’output di questa fase sono:
• un file csv che tiene traccia di tutto ciò che è stato estratto
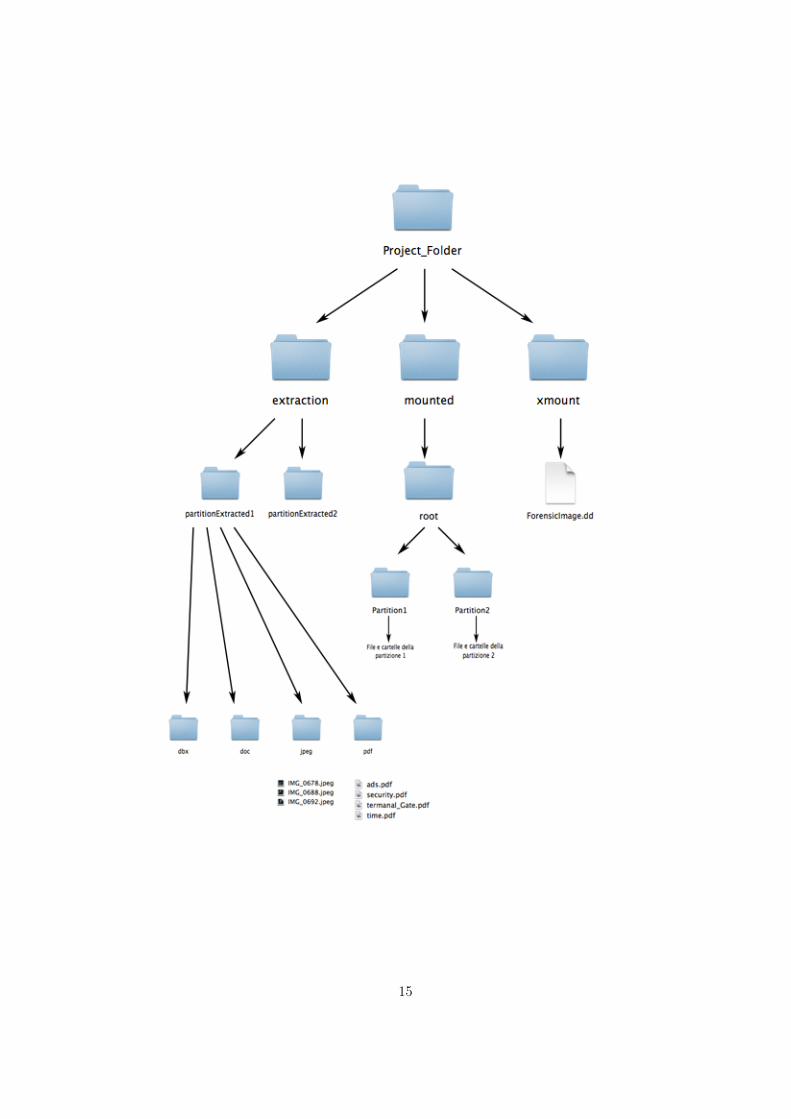
• una cartella dal nome extraction la quale contiene al suo interno tante sotto-cartelle quante sono le partizioni dell’immagine forense. Ognuna di questecartelle ha come prefisso PartitionExtracted a cui viene concatenato un nu-mero intero positivo incrementale che parte da 1. All’interno di ognuna diqueste cartelle di estrazioni di partizione è possibile trovare delle sottocar-telle dove ognuna ha il nome di un’estensione di file. Ogni sottocartellacontiene solo file della stessa estensione.
Nel caso in cui l’immagine forense sia in formato EWF allora vi è anche unaterza cartella dentro la main directory ed ha il nome xmount, la quale contienel’immagine in formato raw.
14
15

3.2 Recupero dei file cancellati - carving -
In una analisi forense i file cancellati spesso sono più importanti rispetto a quellinon cancellati. I dati, grazie al file system, sono organizzati e memorizzati inmodo ordinato all’interno della memoria secondaria. Un file system possiede me-morizzato dentro di sé una serie di informazioni tra cui il numero dei blocchi2 diun disco e i blocchi liberi con le rispettive locazioni. Nello specifico, le strutturepresenti sempre in un file system di interesse per questa trattazione sono il bloccodei volumi, le strutture delle directory ed i blocchi di controllo dei file.Il blocco dei volumi (volume control block) ha dentro di sé tutte le informazionirelative al volume o alla partizione. Proprio qui sono presenti informazioni sulnumero dei blocchi del disco, la loro grandezza, i blocchi liberi con i puntatoriad essi. Nei file system Solaris questa sezione prende il nome di superbloccomentre nell’attuale file system utilizzato da windows, NTFS, si chiama tabellaprincipale dei file (master file table).Le strutture delle directory per Solaris, corrispondono una lista di nomi di file acui è associato un inode mentre in ntfs queste informazioni sono contenute all’in-terno della master file table.I blocchi di controllo dei file contengono dettagli sui file tra cui i permessi diaccesso, i proprietari, le dimensioni e le locazioni dei blocchi di dati. In Solaris iblocchi di dati sono gli inode mentre in ntfs anche questi dati sono memorizzatinella tabella principale dei file. Tutte queste strutture sono memorizzate nelleprime aree del disco in modo che siano facilmente accessibili.L’accesso ad un file non avviene quindi in modo diretto ma si passa tramite questestrutture che possiedono i puntatori ai blocchi contenenti i dati. Adottare questatecnica risponde all’esigenza di risolvere problemi di efficienza: se per cercare unfile fosse necessario leggere ogni singolo blocco del disco le velocità si ridurrebberodrasticamente. Per ogni file invece è presente o un inode o una entry nella masterfile table quindi il tempo di ricerca di esso è pari al numero di file presenti nel filesystem (⇥n).
2I dischi sono formati da una serie di piatti paralleli che hanno le medesime sembianzedei CD. Entrambe le superfici dei piatti sono ricoperte da materiale magnetico ed è possibilememorizzarvi informazioni. A fianco alle testine vi è un braccio di lettura da cui fuoriescono unaserie di testine, una per ogni lato dei dischi,che hanno il compito di leggere/scrivere i dati. Lasuperficie dei dischi è suddivisa logicamente in tracce circolari che a loro volta son suddivise insettori. Ad alto livello però, quando si vuole effettuare una scrittura, non si ragiona in terminedi settori ma di blocchi. Il blocco è l’unità minima di trasferimento ed è solitamente grande512 byte. Un disco corrisponde ad una serie di blocchi logici i quali sono composti da una seriedi settori consecutivi.Una cartella è considerata anch’essa un file ma con proprietà differenti. Dentro il file checorrisponde ad una cartella vi saranno i puntatori ai singoli file che sono al suo interno.
16

Il file system possiede inoltre un meccanismo di gestione dello spazio libero at-traverso l’utilizzo del vettore di bit grande tanti bit quanti sono i blocchi deldisco. Se l’n-esimo bit vale 1 il blocco n del disco è libero, se l’n-esimo bit vale0 il blocco n è occupato. Quando un file viene memorizzato sul disco si cercanoi blocchi ad 1 all’interno del vettore, se ne scelgono tanti quanti sono necessari aseconda del metodo di allocazione prestabilito per quel file system e si scrive inquei blocchi. I blocchi utilizzati per la scrittura avranno il loro bit nel vettore deibit a 0. Se invece si decide di cancellare un file si aggiorna solamente il vettoredei bit, convertendo tutti i bit dei blocchi dei file da 0 a 1.In altre parole quando ci si accinge a cancellare un file in realtà si elimina unpuntatore al file, non il file. La cancellazione del solo puntatore ha la conseguen-za che il file risulta irraggiungibile dal file system e in futuro verrà sovrascritto incaso di successive allocazioni.Il principio di cancellazione standard è efficiente nei tempi ma non adatto se dav-vero si desidera non lasciare tracce dei file non più d’interesse.Il processo di cancellazione completa dei dati prende il nome di wiping. Colwiping oltre a cancellare il puntatore viene cancellato anche il file. Nello specificoogni singolo blocco del file viene sovrascritto con una serie di zero consecutivi dimodo che qualsiasi analisi successiva non possa risalire al file originale.I sistemi operativi non eseguono normalmente il wiping dei file per questioni diefficienza. Sono però oramai disponibili su mercato moltissimi software gratuitiche effettuano questa operazione. L’utilizzo scorretto o con superficialità di questiultimi può causare danni irreversibili.Un programma che analizza file cancellati va a cercare all’interno del disco tuttigli spazi allocati privi di puntatore alla tabella di allocazione e tenta di recupe-rarli. Alle volte sono presenti solo porzioni di file poichè se un file è diviso inblocchi è possibile che parte di essi siano stati sovrascritti da nuove allocazioni.
3.2.1 Strumenti utilizzati
Il programma utilizzato per effettuare questa fase di analisi è PhotoRec, unsoftware free open source multipiattaforma sviluppato da Christophe Grenier ingrado di analizzare un dispositivo di memoria non in base al file system, maandando a scansionare settore per settore alla ricerca di file cancellati. La ricercaè basata sugli header delle estensioni dei file che conosce e, se ne trova uno alloratenta il recupero blocco dopo blocco. Giunto alla fine verifica la consistenza esalva il file.PhotoRec accede ai dati sempre solo in sola lettura per preservare i metadati.
17

La versione utilizzata è la 6.13 rilasciata nel novembre 2011 ed è inoltre uno deitool preinstallati nella distribuzione DEFT.
3.2.2 Input
Per effettuare il carving dei dati di un immagine forense è necessaria l’immaginestessa.
3.2.3 Il codice
In questa fase viene impostata una chiamata a terminale di Photorec dove l’o-biettivo è di far effettuare un analisi dello spazio libero all’interno dell’immagineforense, alla ricerca di tutti i file recuperabili.
La funzione che effettua tale operazione è la seguente:
photorec /debug /log /logname carving.log /d [destinationAnalisys] carving
/cmd [ForensicsImage] freespace, search(3.5)
dove:
• /debug ! attiva la modalità di debug
• /log ! rilascia un file di log con il risultato dell’analisi
• /logname carving.log ! il file di log avrà il nome “carving.log”
• /d destinationAnalisys carving ! indica il path assoluto della cartella con-tenente i file estratti. Questi file vengono posizionati in sottocartelle. Ognisottocartella avrà come nome il prefesso “carving” a cui è concatenato unnumero intero positivo che si incrementa di volta in volta. Si parte da1. Viene anteposto un punto ( “.” ) all’intero positivo. (es: carving.1 -carving.2 ecc.)
• /cmd ! permette di eseguire in modo automatico l’analisi
• forensicsImage ! contiene il path dell’immagine forense su cui si effettueràcarving
• freespace ! specifica che la ricerca dei file è solo da effettuarsi nello spaziolibero
• search ! avvia l’analisi
18
3.2.4 Output
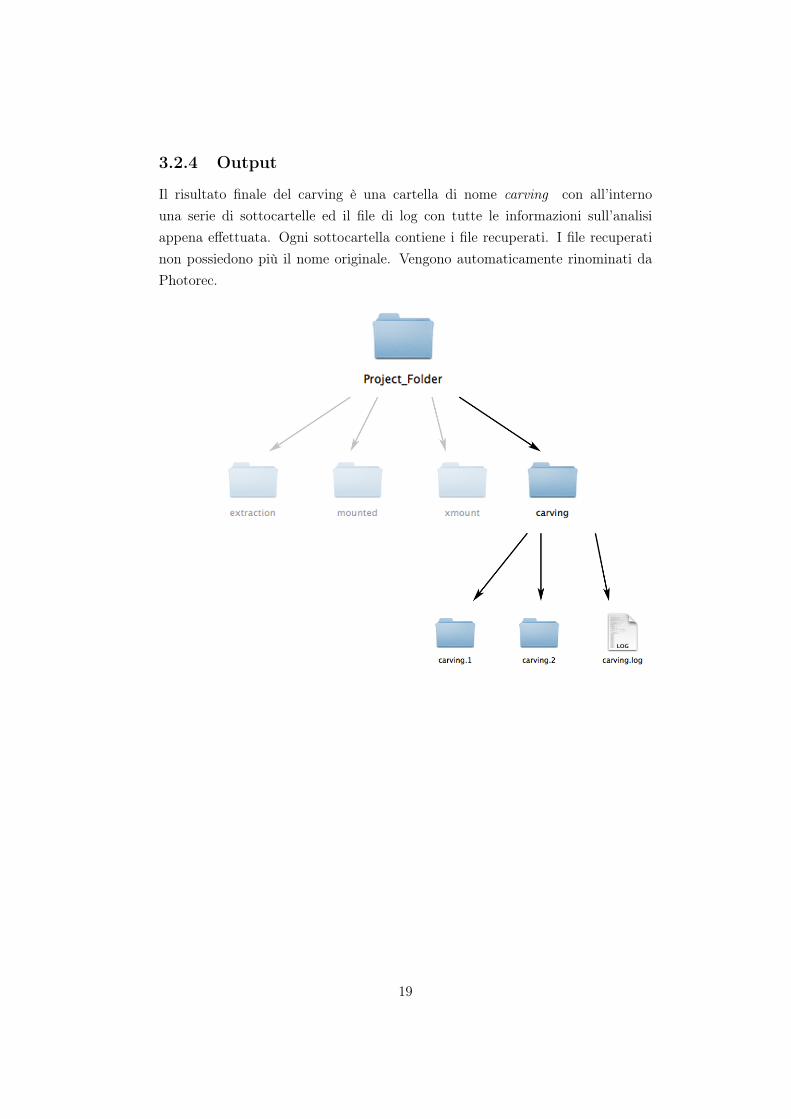
Il risultato finale del carving è una cartella di nome carving con all’internouna serie di sottocartelle ed il file di log con tutte le informazioni sull’analisiappena effettuata. Ogni sottocartella contiene i file recuperati. I file recuperatinon possiedono più il nome originale. Vengono automaticamente rinominati daPhotorec.
19

Capitolo 4
Analisi delle mail
Il fulcro del progetto Ermès consiste nella parte relativa all’analisi delle email.L’internazionalizzazione delle comunicazioni e degli affari ha portato la societàa modificare le modalità di comunicazione optando verso la propagazione di in-formazioni in digitale mediante la rete internet. Lo strumento in rete analogo alservizio postale è la posta elettronica.
4.1 La posta elettronica
Ogni Internet Service Provider (ISP) o altri fornitori di servizi online permet-tono agli utenti privati e di pubbliche imprese di aprirsi una propria casella diposta elettronica dove poter inviare e ricevere messaggi, anche allegati. La postaelettronica è consultabile in due modalità:
• Nel sito internet di riferimento �! stiamo quindi parlando di webmail
• All’interno di un programma client di posta elettronica che, settato oppor-tunamente, scarica da internet la posta di uno o più account.
A livello forense è difficile recuperare delle email se l’utente consulta la posta soloonline perchè le mail rimangono nella rete e non vengono scaricate sul computer.Con un colpo di fortuna si potrebbero recuperare delle tracce di alcune mail vi-sionate attraverso l’analisi della cache del browser.Nel secondo caso invece tutto l’archivio di posta viene scaricato sul computeral momento della configurazione dell’account. Periodicamente il client di postaeffettua controlli per verificare la presenza di nuovi messaggi in arrivo. In questocaso la Computer forensic può intervenire effettuando analisi sugli archivi, cer-cando di estrapolare la maggior parte dei dati possibile.
20

I numerosi formati di posta attualmente utilizzati, tenendo anche conto della pos-sibilità di visualizzare le proprie mail sui telefonini e tablet, rendono ostiche leprocedure di mail analisys.Pensare ad un’analisi standard è un’utopia poichè ogni formato è organizzatonella propria maniera, ottimizzato per funzionare al meglio nei client di postaproprietari.All’inizio del progetto ho effettuato numerose riflessioni riguardo la possibilità diuniformare il più possibile ogni singola analisi. La prima riflessione che è affio-rata è stata la seguente: ogni client di posta si scambia il medesimo “oggetto” equesto oggetto è la mail. Ogni client di posta organizza quindi stessi contenutiin modalità differenti. Una mail è composta da un header, un body contenenteil corpo del messaggio ed eventualmente degli allegati. Il cuore delle analisi diuna mail viene fatta nella prima delle tre componenti. L’header è una sezionedella mail che contiene una serie di intestazioni che servono a controllare l’inviodel messaggio oltre a tenere uno storico del percorso effettuato prima dell’arrivoal destinatario.
4.1.1 Analisi di un header di una mail
Un header di una mail si presenta nel seguente modo1:
Delivered-To: [email protected]: by 10.218.111.222 with SMTP id m78zs52525wei;Wed, 16 Jun 2010 10:39:19 -0700 (PDT)Received: by 10.216.91.7 with SMTP id g7mr996235wef.93.1276709959223;Wed, 16 Jun 2010 10:39:19 -0700 (PDT)Return-Path: <[email protected]>Received: from mrqout1.tiscali.it (mrqout1-sorbs.tiscali.it [195.115.228.3])by mx.google.com with ESMTP id x45si7853472weq.196.2010.06.16.10.39.18;Wed, 16 Jun 2010 10:39:19 -0700 (PDT)Received-SPF: pass (google.com: domain of [email protected] designates195.145.188.7as permitted sender) client-ip=195.115.228.3;Authentication-Results: mx.google.com;spf=pass (google.com: domain of [email protected] 195.145.188.7as permitted sender) [email protected]
1Collaborazione alla redazione del Capitolo 9, “il decisivo ruolo probatorio della documen-tazione extracontabile digitale nella ricostruzione dell’ipotesi di esterovestizione”, in “ Estero-vestizione societaria. Disciplina tributaria e profili tecnico-operativi”, AA.VV., Sacchetto C. (acura di), Giappichelli Editore, Torino, 2013, pp. 215-237
21

Received: from [10.23.116.88]by mrq-1 with esmtp (Exim)id 1OOwLh-0002kI-My; Wed, 16 Jun 2010 19:24:25 +0200Received: from ps23 (10.39.75.93) by mail-8.mail.tiscali.sys (8.0.031)id 4BF3B10F009F2F83 for [email protected];Wed, 16 Jun 2010 19:24:25 +0200Message-ID:<27243525.49621276709064749.JavaMail.defaultUser@defaultHost>Date: Wed, 16 Jun 2010 19:24:22 +0200 (CEST)From: [email protected] <[email protected]>Reply-To: [email protected] <[email protected]>To: [email protected]: <[email protected]>Subject: I: Riepilogo situazione aziendaleMIME-Version: 1.0Content-Type: multipart/mixed;boundary=----=_Part_3112_30806331.1276709062485xOriginalSenderIP: 95.236.201.23X-Priority: 1X-MSMail-Priority: HighX-Mailer: Microsoft Outlook Express 6.00.2900.5843Disposition-Notification-To: [email protected] [email protected]: Produced By Microsoft MimeOLE V6.00.2900.5579
Un header va letto dal basso verso l’alto. Partendo dalle informazioni prin-cipali, risalendo verso la cima dell’header è quindi possibile ricostruire tutto ilpercorso fatto dalla mail prima di giungere al destinatario. Le righe che eviden-ziano questo percorso sono quelle che iniziano con la parola chiave Received. Traparentesi tonde ( ) e quadre [ ] si trovano gli indirizzi IP che forniscono ulterio-ri informazioni sulle locazioni geografiche del computer/server. Dopo il bloccodi informazioni contrassegnate dalla parola “Received” sono presenti altri campifornitori di informazioni differenti:
• From - fornisce l’infomazione della casella di posta del mittente.
• To - indica il destinatario.
• Cc - destinatari in copia carbone [per conoscenza].
22

• Bcc - destinatari in copia carbone nascosta.
• Date - data ed ora al momento dell’invio.
• Subject - oggetto del messaggio.
• Importance o X-priority - priorità del messaggio [ se c’è il valore 1 ! altapriorità, 2 ! media priorità, 3 ! normale priorità ].
• X-Mailer - programma usato per inviare la mail. (se si usa una webmailquesto campo non è presente).
Altra riga da tenere in considerazione è quella preceduta dalla parola Mime.Il Mime (Multipurpose Internet Mail Extensions) è un protocollo definito peril trasferimento e l’interpretazione dei dati non codificati in ASCII. Il Mime sioccupa anche del trasferimento di allegati in qualsiasi formato, ad esempio fileaudio, file video, file testo di qualsiasi formato.
4.1.2 Analisi del body di una mail
Subito dopo l’header di un messaggio viene inserito il body. Il body corrispondeal testo del messaggio. Spesso troviamo testi con delle immagini o dei piccolivideo. Tutto ciò è possibile grazie al linguaggio html.Andando infatti a visionare un esempio di body:
Content-Type: multipart/mixed; boundary=047d7b2e109170ca5b04e42b6de6
--047d7b2e109170ca5b04e42b6de6Content-Type: multipart/alternative;boundary=047d7b2e109170ca5604e42b6de4
--047d7b2e109170ca5604e42b6de4Content-Type: text/plain; charset=ISO-8859-1
ecco i dati di mio padre (compilati da lui apposta per te )
--047d7b2e109170ca5604e42b6de4Content-Type: text/html; charset=ISO-8859-1
<div dir=“ltr”>ecco i dati di mio padre (compilati da lui apposta per te)
23

<br></div>--047d7b2e109170ca5604e42b6de4 ---047d7b2e109170ca5b04e42b6de6Content-Type: application/pdf;name=“tessera_sanitaria.pdf”Content-Disposition: attachment;filename=“tessera_sanitaria.pdf”Content-Transfer-Encoding: base64X-Attachment-Id: 2fa57bb50712ddcd_0.1
JVBERi0xLjQNJeLjz9MNCjEgMCBvYmoNCjw8L1cGUgL1BhZ2VzQovUmVzb3VyY2VzIDMgMCBSDQovTWkaWFCb3ggWzACA1OTUuMjcNiA4NDEuODg5OF0NCi9Db3VudCAxDQovS2lkQ0KLcyBddSWNCAwIFJDQo+Pg0KZW5kb2JqDQoyIDAgb2JqDQo8PC9DYXGluZXMgAwIFINCi9QWdlcyAxIDAgUg0KL01ldGFkYXRhIDggMCBSDQovTwMzI3NjggMyNY4IDFDQovVmlld2VyUHJlZmVyZW5jZXMgPDwvQ2VuVyV2luZG93IHRdWUNCi90Rpc3BsYXlEb2NUaXRsZSBmYWxzZQ0KLpdFdpbmRvdyBmWxzZQ060ovSGlkZVRvb2xiYXIgZmFsc2UNCi9IaWR2luZG93VUkgZmFc2UNCi9Ob2gL1VzZU5vbmUNCi9QcmludEFyZWEgNyb3BCb3gNCi9QcmldFNjYWxpbmcgL0FwcERlZmF1bHQNCi9WaWVXJlYSAvQ3JvcEJveAKL1ZpZS4tDQo+Pg0KL1BhNlIC9Vc2VOb25lDQoGFnZUxheW91dCAvT2lQ29sdW1uDQo...--047d7b2e109170ca5b04e42b6de6-
Il messaggio di posta elettronica in formato standard utilizza solo la codificaASCII a 7 bit. Il MIME, oltre a permettere l’invio di allegati, permette l’invio dimail testuali con delle formattazioni personalizzate, in lingue diverse dall’inglesequindi aventi caratteri accentati oppure anche usando una modalità decorata datag html. Nella prima riga, attraverso l’opzione Content-Type: multipart/mixed;
si evidenzia che questa mail conterrà diverse parti aventi però componenti se-parate. Ogni componente avrà a sua volta una propria intestazione con un suoContent-type ed altre opzioni. Per poter delimitare una parte dall’altra si usa unastringa univoca che è dichiarata subito dopo il Content-type nel modo seguente:boundary=[stringa] Ad ogni occorrenza della stringa a cui viene anteposto “--”inizia una nuova parte del messaggio. Ad ogni occorrenza di “ - - stringa - ” si de-limita la fine di quella sottoparte e l’inesistenza di un’altra nuova. All’interno diuna parte possono esserci delle sottoparti, proprio come nell’esempio soprastante.Il meccanismo di suddivisione in sottoparti è il medesimo.
24

Il grafico esemplificativo evidenzia come la mail contenga una parte con iltesto del messaggio ed un altra con l’allegato. La parte contenente il messaggioè a sua volta suddivisa in due sottoparti. Dando uno sguardo a tutto l’esempiosi nota che la frase “ecco i dati di mio padre (compilati da lui apposta per te )”
compare due volte. Se visualizzassimo questa mail la frase comparirebbe solo unavolta. La dichiarazione del Content-Type alla riga 3 è multipart/alternative, ciòsignifica che lo stesso messaggio è stato composto in modalità diverse. A secondadi come sono implementate le impostazioni di visualizzazione dei messaggi deiclient di posta la mail sarà visualizzata in una modalità piuttosto che un’altra.Non è l’utente che effettua queste operazioni ma sono i client di posta che lo fannoper questioni di retrocompatibilità con vecchi software oppure per migliorare lavisualizzazione da smartphone o tablet. Nella seconda parte del body del mes-saggio è presente l’allegato. Un allegato è per forza un documento non in formatoASCII pertanto necessita di essere convertito per poter essere trasferito. Questostrumento deve anche essere presente nel destinatario e deve saper ricostruire ilfile uguale all’originale. Mime si occupa proprio di ciò, convertendo qualsiasi tipoallegato. I formati in cui converte sono diversi, basta che contengano solo carat-teri ASCII. Nelle immagini, video e file audio il formato utilizzato è la base64 checonsiste in una trasformazione in cui ogni gruppo di 24 bit (3 byte) viene trasfor-mato in quattro caratteri (4 byte). Per poter istruire il Mime del destinatario alla
25

ricostruzione del file, vengono poste prima dell’allegato una serie di intestazionicon diverse informazioni:
• Content-type ! indica la tipologia di file
• Name ! nome dell’allegato
• Content-Transfer-Encoding ! indica la codifica di trasferimento.
• Z-Attachment-id ! id univoco dell’allegato.
4.2 Analisi delle mail da parte di Ermès
Dopo un’attenta analisi sono giunto alla conclusione che tutte le mail dispongonodi un formato standard anche se molto variegato. Andando ad analizzare i metodidi archiviazione dei vari formati di posta elettronica nessuno di essi modifica esalva nei suoi archivi le mail modificando la struttura del messaggio. In nessunformato di mail analizzato vengono effettuate modifiche a runtime della strutturadel messaggio per permetterne l’invio.Ho quindi potuto convenire che è possibile riuscire a creare un software di analisidelle mail dove per ogni formato la modalità di estrazione delle informazioni tendead essere il più similare possibile. Nei prossimi capitoli verranno dettagliate lemodalità di analisi da me scelte ed implementate per i tre formati che attualmenteErmès supporta: dbx - msf - pst.
26

4.2.1 Gli archivi dbx
Il formato di posta dbx è stato creato per il client di posta Outlook Express svi-luppato da Microsoft. I sistemi operativi che hanno preinstallato questo clientsono Windows98, Windows 2000, Windows Millenium e Windows XP. In Win-dows 95 l’installazione era facoltativa. Negli anni in cui questi sistemi operativisono entrati nel mercato, l’informatica si è diffusa a macchia d’olio. Grazie alleloro interfacce user friendly anche coloro che non possedevano conoscenze infor-matiche avanzate cominciarono ad acquistare i computer. Ad oggi, nei paesi adalto tasso di sviluppo, si registra che per ogni famiglia vi siano almeno 1-2 com-puter. Anche se quei sistemi operativi oggi sono superati da altre nuove versioni,la loro vastissima diffusione li rende ancora presenti nelle case e nelle aziende,soprattutto per quanto riguarda Windows XP. Durante un’analisi risulta quindifondamentale avere uno strumento di acquisizione ed elaborazione di file dbx. Laprobabilità di trovare un computer con uno dei sistemi operativi sopra elencati èalta, soprattutto nelle aziende dove gli upgrade sono costosi e gli investimenti insoftware sono spesso agli ultimi posti nell’elenco delle spese prioritarie.
4.2.1.1 Strumenti utilizzati
Per l’estrapolazione delle mail da un archivio in formato dbx ho scelto di utilizzareUnDBX, un tool di estrazione e recupero di messaggi cancellati di OutlookExpress. Il padre del progetto è Avi Rozen2 e la versione utilizzata è la 0.20 delnovembre 2011. Un archivio dbx contiene una serie di file in formato eml, unoper ogni mail. UnDBX estrae ogni singola mail e poi le inserisce in una cartellaavente lo stesso nome dell’archivio.Il processo di parsificazione dei messaggi ottenuti dopo l’estrazione madiantel’UnDBX è stato da me sviluppato.
4.2.1.2 Input
Se nell’immagine forense sono presenti degli archivi in formato dbx, durante laprecedente fase di estrazione questi file sono stati estratti e riposti all’interno diuna cartella dal nome “dbx”, la quale si trova all’interno di un’altra cartella de-nominata “extraction”. Questa fase vuole quindi in input la cartella di estrazionedel progetto già iniziato e la cartella dove salvare i risultati dell’analisi.
27

4.2.1.3 Il codice
Ogni partizione estratta verrà analizzata. Se nella partizione è presente la cartella“dbx” allora procede, altrimenti non esegue nulla. Viene creata una nuova cartellanella directory principale del progetto dal nome “MailAnalisys” e al suo internosi crea un’altra cartella contenente il nome della partizione in analisi. All’internodi questa cartella si crea una cartella denominata “dbx”. La memorizzazione delleinformazioni riguardanti le mail avviene in tre dizionari annidati. I dizionari sonodelle strutture dati simili alle tabelle di hash in cui è possibile salvare un coppia<chiave, valore>. Non possono esserci due coppie con chiavi uguali. L’annida-mento avviene nel modo seguente: nel dizionario più esterno le chiavi non sonodizionari, mentre i valori sono a loro volta dei dizionari. Il dizionario più esternopossiede le coppie <nome partizione : dizionario degli archivi dbx >.Il dizionario degli archivi dbx possiede le coppie <nome archivio dbx : dizionariofile eml >.Il dizionario dei file eml, ovvero di tutte le mail presenti nell’archivio dbx possiedele coppie <numero mail : dati della mail >. È quello più interno.
Dopo aver analizzato le partizioni, attraverso la funzione processPartitonDbxFol-
der () si analizzano gli archivi dbx. Per ogni archivio viene chiamata la funzioneundbx che ha la seguente sintassi:
undbx [file.dbx] [destinationFolder] (4.1)
28

• File.dbx corrisponde al path assoluto dell’archivio dbx
• destinationFolder corrisponde al path assoluto della cartella contenente lemail estratte.
Si ricorda che l’output della funzione undbx è una cartella avente come nomelo stesso nome del file dbx, come contenuto tutte le mail presenti nell’archivioognuna in formato .eml. Per ogni archivio dbx viene chiamata la funzione proces-
sDbxPostUndbx () che avrà come parametro la cartella destinazione dell’istruzioneundbx del file dbx Nella processDbxPostUndbx () si analizza ogni singola mail,ognuna in formato eml. Per ogni mail si costruisce un array avente i seguentielementi posti nell’ordine sottoelencato:
• Mittente
• Destinaratio
• Data e ora
• Oggetto
• Testo
• Path del file .eml
• Path degli allegati (un path di un allegato per ogni cella dell’array)
Il terzo dizionario, quello più interno, avrà come chiave un numero incrementa-le identificativo univoco della mail, come valore l’array contenente i dati sopraelencati. Per l’analisi delle mail è stato utilizzato il modulo email di Python. An-dando a lavorare sul file eml per prima cosa viene rinominato, assegnando comenome un numero intero positivo incrementale per risolvere problemi di codifi-ca. Successivamente verrà spiegato il perchè di questa scelta. Subito dopo vieneestratto il testo, sia quello standard sia quello in html. Successivamente vengonoestratti, nella rispettiva codifica, mittente destinatario, data ed oggetto. Questiultimi quattro vengono inseriti uno in coda all’altro all’interno dell’array. Subitodopo viene inserito il messaggio ed il path del file eml.Giunti a questo punto, rimane l’analisi degli allegati. Per ogni allegato si crea unfile e si scrive dentro di esso la sequenza di dati, decodificandoli dal formato incui si trovano: base64, usato oramai quasi per tutti gli allegati. Ecco l’istruzione:
out.write(base64.b64decode(message.get_payload())) (4.2)
29

Ogni file ha quindi il seguente nome:
nome file eml00__00stringa univoca che contraddistingue il file00.00estensione
(es : 1661__58d4c21f � ef47� 4666� 9506� bbfe2d230505.pdf)
Terminata l’analisi dei file eml termina la funzione processDbxPostUndbx () e sipassa all’archivio successivo. Terminati anche gli archivi di quella partizione sipassa alla partizione successiva. Man mano che l’analisi procede il dizionario siriempie di dati. Una volta analizzate tutte le partizioni si arriva alla fase finale. Sedopo l’analisi vi è un dizionario contente almeno una mail, viene creato un nuovofile JSON dal nome “ElencoMailDBX.json” e tutto il dizionario viene memoriz-zato al suo interno. JSON (JavaScript Object Notation) è un formato adattoper lo scambio di dati nelle applicazioni client-server. Nella fattispecie linguaggicome Javascript, Ajax e Jquery riconoscono questi file e, se ben formati, possonoleggerli e manipolarli. I dizionari Python, all’interno di un file JSON diventanoarray associativi. Il file json in questo progetto sono il ponte che collega la partedi back-end di analisi in Python con la visualizzazione delle mail in formato html.Generato il file json viene creata una cartella dentro MailAnalisys dal nome “Re-port” dove dentro vengono inseriti una serie di file presi direttamente dai file diconfigurazione di Ermès. Questi file serviranno per la corretta e gradevole visua-lizzazione delle mail. Infine, il file ElencoMailDBX.json viene spostato all’internodella cartella Report.
4.2.1.4 Output
L’output di questa fase è una cartella contenente un file dal nome “Report.html”.Una volta aperto il file sarà possibile visionare le mail come se si fosse su unclient di posta. Grazie a Javascript il file JSON viene analizzato rendendo facileed agevole l’estrapolazione dei dati. Già nella fase di scrittura all’interno di unfile json ma anche comunque per poterlo leggere è fondamentale che questo siaben formato, cioè deve contenere caratteri codificati solo in utf-8. Le lettere ac-centate, ad esempio non possono essere inserite.Mentre tutto ciò che concerne i dati delle mail sono stati codificati automati-camente, proprio per non avere caratteri non validi, i nomi delle mail e degliallegati son stati controllati manualmente. Il controllo manuale si è trasformatoin una ridenominazione automatica di tutti i file così da mantenere l’efficienza. Imeccanismi di ridenominazione sono stati spiegati precedentemente. Per quantoriguarda l’interfaccia grafica e la modalità di navigazione all’interno di essa, è
30
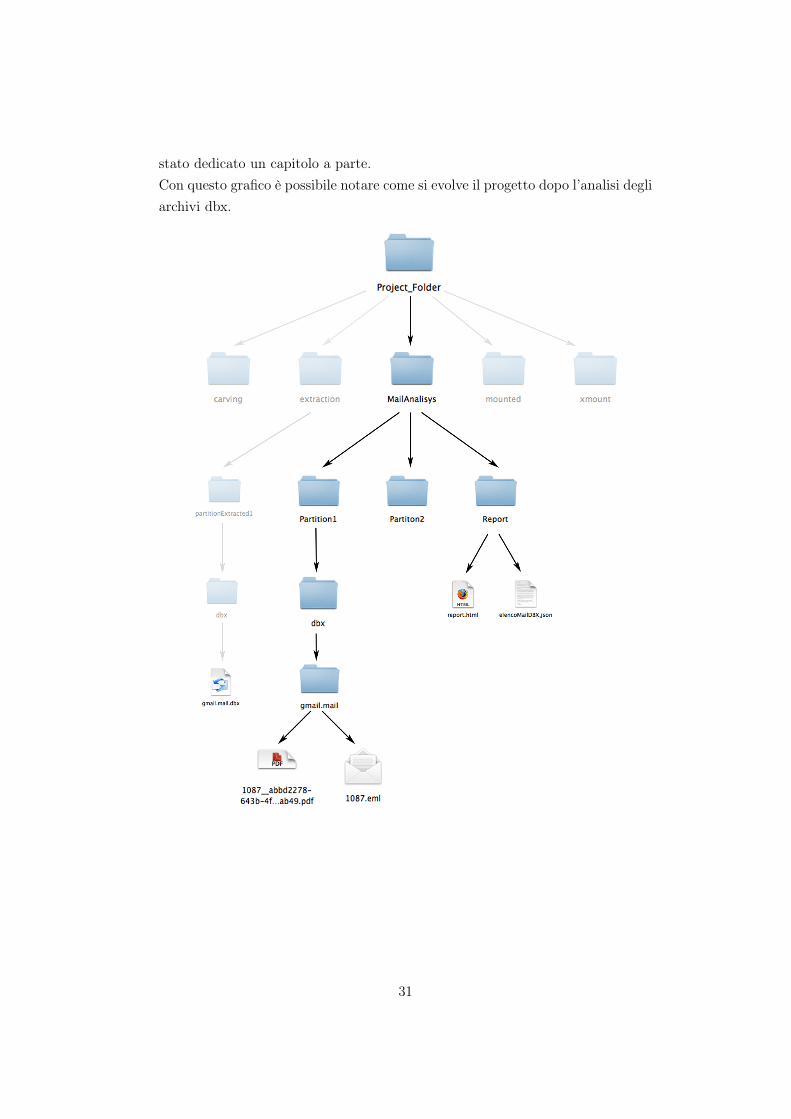
stato dedicato un capitolo a parte.Con questo grafico è possibile notare come si evolve il progetto dopo l’analisi degliarchivi dbx.
31
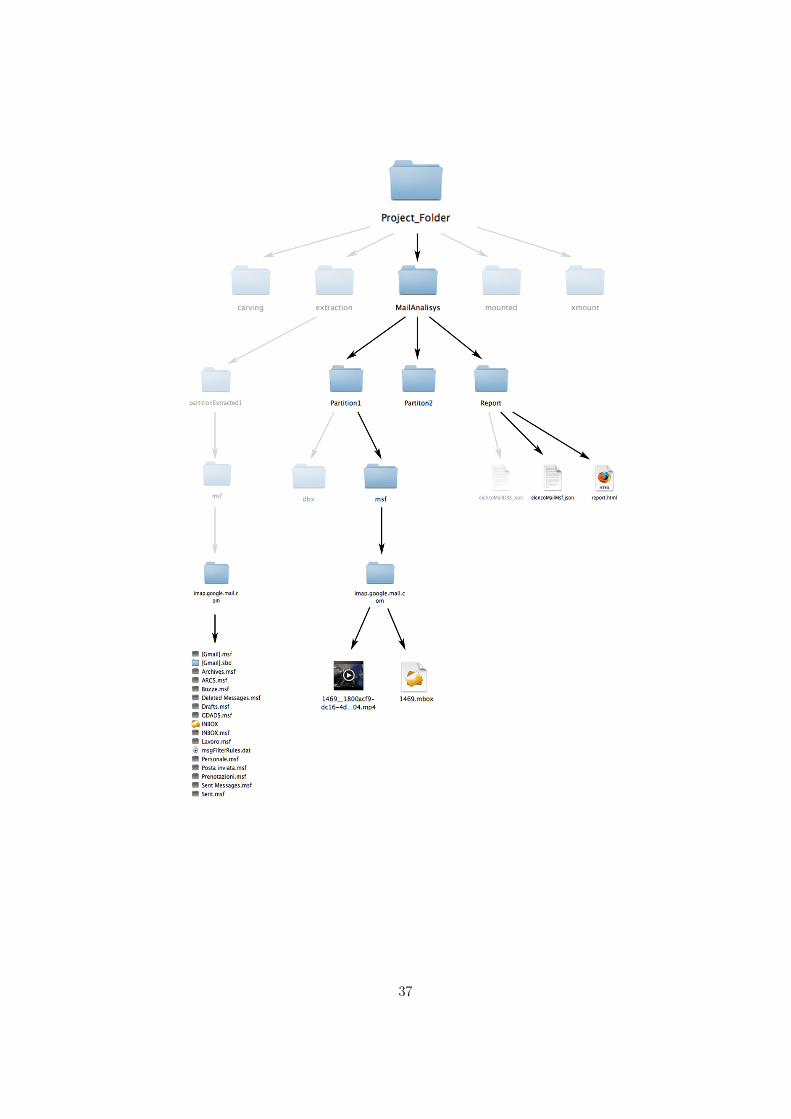
4.2.2 Gli archivi msf
Nel dicembre 2004 Mozilla Foundation3 rilasciò le versione stabile 1.0 di un clientdi posta totalmente free: Thunderbird. Grazie al successo del browser Firefox,anche Thunderbird cominciò ad essere utilizzato dagli utenti, soprattutto da colo-ro che nutrivano risentimenti nei confronti di Microsoft e il suo Outlook Express.Mozilla Foundation è un associazione no-profit che da sempre ha avuto comeobiettivo l’innovazione tecnologica aperta a tutti. Anche se Outlook Express èun software gratuito, per averlo era necessario acquistare un computer con siste-ma operativo Windows, unica piattaforma compatibile. Thunderbird invece è unclient multipiattaforma, installabile su qualsiasi sistema operativo.
4.2.2.1 La metodologia di archiviazione di Thunderbird
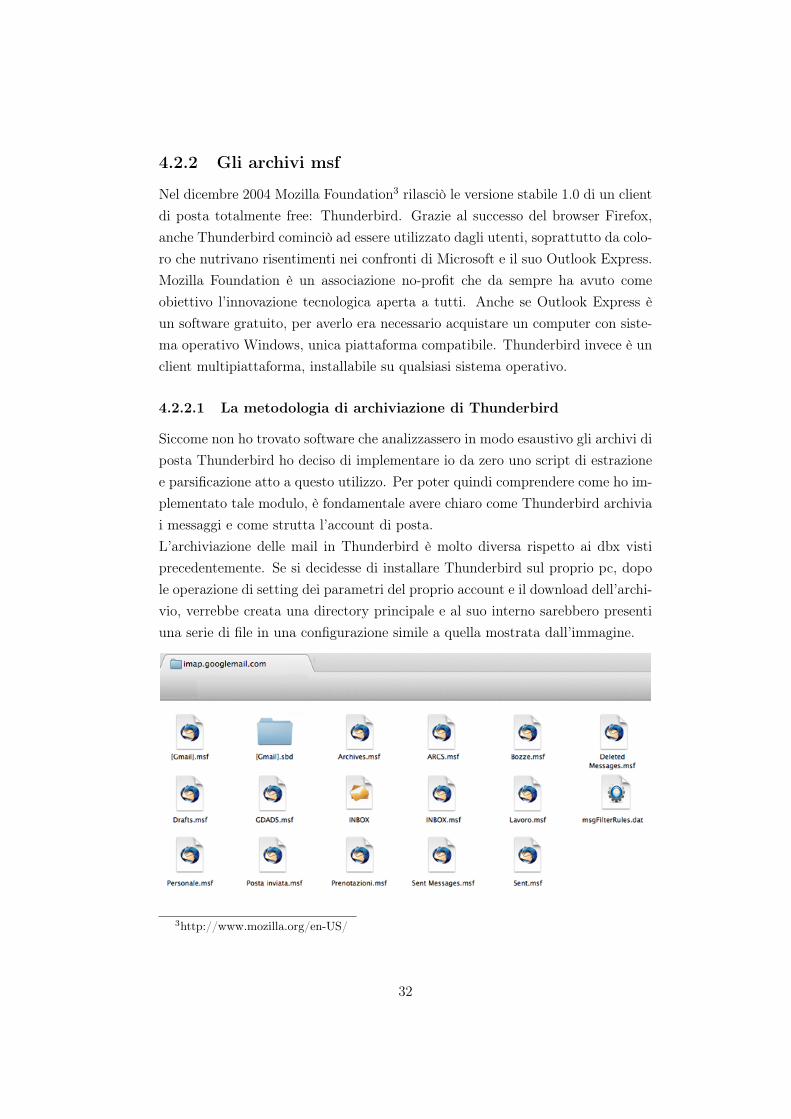
Siccome non ho trovato software che analizzassero in modo esaustivo gli archivi diposta Thunderbird ho deciso di implementare io da zero uno script di estrazionee parsificazione atto a questo utilizzo. Per poter quindi comprendere come ho im-plementato tale modulo, è fondamentale avere chiaro come Thunderbird archiviai messaggi e come strutta l’account di posta.L’archiviazione delle mail in Thunderbird è molto diversa rispetto ai dbx vistiprecedentemente. Se si decidesse di installare Thunderbird sul proprio pc, dopole operazione di setting dei parametri del proprio account e il download dell’archi-vio, verrebbe creata una directory principale e al suo interno sarebbero presentiuna serie di file in una configurazione simile a quella mostrata dall’immagine.
3http://www.mozilla.org/en-US/
32

I file di estensione msf possiedono il formato proprietario di Thunderbird. È bennoto a tutti che le cartelle principali presenti in una casella di posta elettronicasono: Posta in Arrivo, Posta in uscita, Posta Inviata, Bozze, Posta cancellatae Spam. L’utente può inoltre crearsi delle proprie cartelle dove organizzare almeglio messaggi e non avere la cartella della posta in arrivo intasata da messaggiappartenenti ad argomenti differenti.Ognuno dei file con estensione msf rappresenta proprio l’insieme di queste dueclassi di cartelle. Andando ad aprire uno dei file in formato msf, con grandestupore, non si troveranno delle mail ma diverse stringhe che appaiono essereparametri di configurazione.
Se dentro un file msf non son presenti le mail per come sono state presentateall’inizio del capitolo, allora si può supporre che questi parametri corrispondanoad indici, i quali puntano a tutte le mail presenti nella cartella.Dove sono quindi le mail? Tra i vari file presenti nella cartella uno di essi, “Inbox”,è privo di estensione. Andando a vedere le proprietà del file si scopre che possiedel’estensione mbox, un formato standard per l’archiviazione di mail. Aprendoloè possibile trovare proprio tutte le mail, concatenate una dopo l’altra. Occorrenotare che nell’immagine relativa alla struttura dei file in msf è presente unacartella dal nome [Gmail].sbd ed un file msf con lo stesso nome: [Gmail].msf.Questi due file raccontano parte della storia dell’account qui presente. L’account,essendo di google, prima di essere stato importato in Thunderbird era utilizzatonel client online di Google, Gmail per l’appunto. Dentro questa cartella infatti
33

vi sono a loro volta una serie di file in formato msf, le cartelle principali standarddel web client Gmail [quelle standard di tutti i client di posta già elencate sopra].Nella directory principale è presente ancora un file con estensione .dat. Que-sto file contiene parametri di configurazioni standard non inerenti alla strutturadell’account.
4.2.2.2 Input
Durante la fase di estrazione, quando il programma incontrava un file in formatomsf, non procedeva all’estrazione del singolo msf. In quel caso veniva estrattatutta la cartella laddove era contenuto il file. Le motivazioni nascono dal fattoche il file in formato mbox non ha lo stesso nome dell’account di posta (delladirectory principale). È cosa certa che dove vi è un file msf vi è anche un filein formato mbox contenente tutte le mail. L’unico caso in cui ciò è falso è nellesottocartelle della directory principale dell’account. Dentro di essa vi sono solofile in formato msf.In questa fase l’input richiesto è il path della cartella di estrazione, come per ilcaso dell’analisi degli archivi dbx.
4.2.2.3 Il codice
Dopo un’analisi del numero di partizioni estratte, per ognuna di esse si verificala presenza di una cartella denominata “msf”. L’analisi proseguirà solo nelle par-tizioni dove questa cartella è presente.Anche per questa analisi verrà utilizzato un dizionario Python dove al suo internosono annidati altri due dizionari. Si ricorda che il primo dizionario, il piu esterno,contiene le coppie <partizione, dizionario delle cartelle contenenti file msf>.Nel secondo dizionario sono presenti le coppie <nome dell’account msf, dizionariodelle mail>.Nel terzo dizionario, quello più interno, sono presenti le coppie <numero mail,dati della mail>.Ogni sottocartella dentro la cartella msf viene analizzata dalla funzione proces-
sPartitionMSFFolder () che vuole due parametri: Il primo è il path della cartellamsf della partizione, il secondo è il path della cartella dove destinare l’output del-l’analisi. La funzione processPartitionMSFFolder () ha solo il compito di cercareil file mbox. Se il file viene trovato allora sarà chiamata la funzione processM-
boxfile () che vuole anch’essa due parametri: il primo è il path del file mbox, ilsecondo è il path della cartella di destinazione dell’analisi, identico al secondoparametro della processPartitionMSFFolder ().
34

Nella processPartitionMSFFolder () avviene effettivamente l’analisi delle mail.Le mail si trovano tutte all’interno del file mbox per poterle analizzare una aduna è necessario spacchettare l’archivio, così da processare una mail per volta.Tutte le mail archiviate da Thunderbird hanno una prima parte comune:
From - [data ed ora]
X-Mozilla-Status: [numero]
X-Mozilla-Status2: [numero]
Ogni qual volta nel file mbox compare la stringa ad inizio riga “From - ” ini-zia una nuova mail. Per separare ogni mail è stata utilizzata una struttura datiad hoc: un array dove per ogni cella è presente una ed una sola mail tutta inte-ra. Una volta ottenuto l’array si passa all’analisi di ognuna di esse. L’analisi èpraticamente la stessa fatta nel caso dei file dbx, cioè per prima cosa si estrapolail testo nei suoi formati alternativi, poi si procede alla ricerca di mittente, de-stinatario, data ed ora ed infine viene cercato l’oggetto. Viene sempre utilizzatoil modulo email di Python. Tutti i dati sono concatenati in un unico array edil testo della mail si trova sempre al fondo per ora. Nell’analisi dei dbx, nellacella dell’arrray dei dati della singola mail, dopo il testo viene inserito il pathdella mail. Nel nostro caso le mail si trovano tutte nella stesso file mbox e, se simettesse il path di questo archivio si incontrerebbero successivamente una seriedi problemi: Sarebbe difficile aprirlo date le sue dimensione e sarebbe difficilericercare la mail in mezzo ad altre centinaia o migliaia. A costo di occupare piùspazio sul disco, per ogni mail, viene creato un nuovo file in formato mbox checontenga solo la mail analizzata. Per ogni mail analizzata vi sarà un corrispetti-vo file in formato mbox, ed il suo path sarà inserito nell’array dopo il testo delmessaggio. Questo è il codice che esegue tali operazioni:
pathSingleMail = dest+ str(numMail) +00 .mbox00
with open(pathSingleMail,00 w00)assingleMail :
singleMail.write(listOfMail[numMail � 1])
singleMail.close()
arrayDati.append(pathSingleMail)
(4.3)
I dati non ancora analizzati sono gli allegati. Anch’essi sono disposti allo stessomodo e necessitano di essere convertiti nella loro codifica di origine ed inseritidentro ad un file con la giusta estensione. Per maggiori delucidazioni è possibileleggere la parte di estrazione degli allegati nell’analisi degli archivi dbx.
35

Terminate le tre analisi (ricerca partizione - ricerca mbox- analisi mail), se tuttoè andato a buon fine, allora il rispettivo dizionario viene aggiornato. Terminatal’analisi delle partizioni il dizionario è completo. Se questo è vuoto allora nonerano presenti alcuni file msf e quindi l’analisi termina, altrimenti il dizionarioviene inserito all’interno di un file JSON dal nome “elencoMailMsf”.Come per i dbx viene creata una cartella “Report” (se questa fosse già presente ifile doppi vengono sovrascritti) ed infine il file json viene spostato in questa car-tella. Nel grafico della pagina successiva si evidenzia nuovamente l’avanzamentodel progetto.
4.2.2.4 Output
L’output di questa fase è un file in formato html dal nome “report.html”. Nellacartella MailAnalisys è possibile trovare una cartella denominata “Report” con ilfile all’interno. Attraverso il file html è possibile visionare sia le mail provenientida archivi dbx sia provenienti da archivi msf.In questa versione, tutte le mail provenienti dal formato msf si trovano raggruppa-te secondo il loro archivio di provenienza, non divise per cartelle. Con la prossimaversione si cercherà di studiare a fondo questi file affinchè si possa migliorare ilsoftware.
36
37

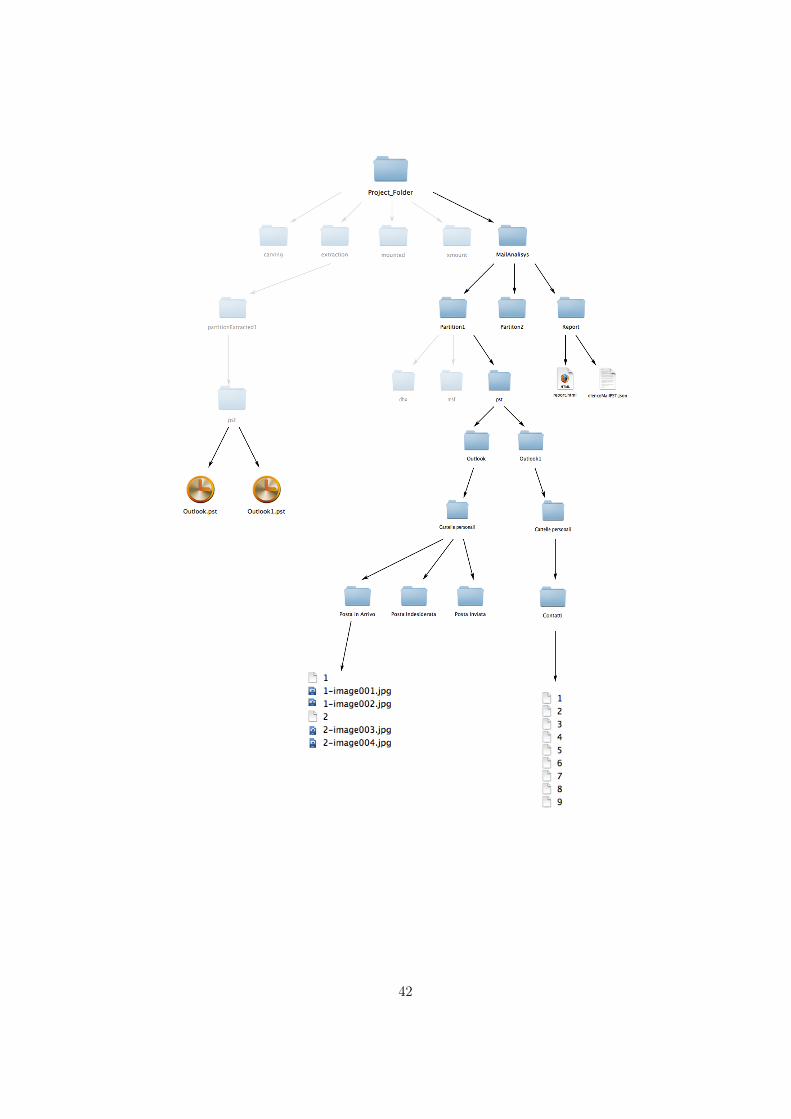
4.2.3 Gli archivi pst
Visto il successo avuto da Outlook Express, vista la diffusione in larga scala delsevizio di scambio di mail tra gli utenti, Microsoft lanciò sul mercato Outlook,una versione nuova del software. Uno dei primi cambiamenti fu proprio il formatodell’archiviazione delle mail: da archvi dbx si passò ad archivi in formato PST(Personal Storage Table). Mentre un archivio dbx poteva arrivare fino ad unacapienza massima di 2 Gb, nei pst non vi sono limiti di capacità.Il servizio Outlook inoltre possiede caratteristiche innovative, quali il dialogo conMicrosoft Exchange e quindi la gestione delle rubriche. Microsoft Exchange è unprodotto di target aziendale studiato per la messaggistica aziendale. L’idea dimigrare un software da un semplice uso di scambio mail ad un sofisticato metododi gestione delle comunicazione e degli impegni di molti utenti ha rivoluzionatoil concetto di archivio di messaggi di posta elettronica.Oltre alla gestione dei contatti, Microsoft Outlook gestisce il calendario, l’agendadelle attività e le note personali. Ora Outlook non è più compreso nella suite diun sistema operativo Microsoft. È incorporato nella suite Microsoft Office.
4.2.3.1 Strumenti utilizzati
Per analizzare gli archivi pst ho deciso di utilizzare una libreria esterna:ReadPST versione 0.6.54L’istruzione della readpst per l’estrazione dei dati dei file pst è la seguente:
Readpst � rSD [Path Pst F ile] [path destination Folder] (4.4)
Dove le opzioni
• r ! per fare un analisi all’interno del file
• S ! stabilisce l’output dell’estrazione. Per ogni file viene generata unacartella dove all’interno vi sono tanti file in formato MHTML quante sonole mail analizzate. A questi file viene assegnato come nome un numero in-crementale da 1 in poi. I file MHTML non contengono gli allegati perchèquesti vengono automaticamente estratti dalla funzione readpst. Agli alle-gati viene assegnato come nome il numero di mail a cui appartengono e poiviene concatenato il nome originale dell’allegato.
• D ! recupera anche le mail cancellate presenti nell’archivio
38

Come per gli archivi dbx, ho utilizzato una libreria esterna per estrapolare le mailmentre il parsificatore l’ho interamente sviluppato io.
4.2.3.2 Input
Anche in questo caso, come per gli altri archivi, la funzione vuole due input: lacartella di estrazione della prima fase e la cartella del progetto.
4.2.3.3 Il codice
L’analisi preliminare che viene fatta avviene attraverso la ricerca della presenzadella cartella denominata “pst” all’interno delle cartelle di estrazione delle parti-zioni.Anche per i pst vengono usati tre dizionari annidati per salvare i dati. Siccomein questa analisi è possibile tenere traccia della divisione in cartelle delle mail, lecoppie dei dizionari sono diverse.Il primo dizionario contiene le coppie <nome dell’archivio pst, dizionario dellecartelle dell’archivio >.Il secondo dizionario contiene le coppie <nome della cartella, dizionario delle mailcontenute in quella cartella >.Il terzo dizionario, il più interno, contiene le coppie <nome della mail, dati dellamail >.Se sono stati estratti degli archivi pst nella fase di estrazione allora viene chia-mata la funzione mailLab () che vuole come parametri la cartella pst di quellapartizione e la cartella destinazione di salvataggio. La struttura di salvataggiodelle mail è analoga ai due casi precedenti cioè dentro la cartella mailAnalisysvengono create tante cartelle quante sono le partizioni e dentro di esse vi sarà lacartella “pst” con i dati salvati in modo ordinato.La funzione mailLab () si occupa di eseguire il comando da terminale della readp-st per ogni archivio pst. L’output di destinazione possiede come main directoryla cartella pst, poi per ogni archivio vi è una sottocartella avente lo stesso nome.Dentro ognuna di queste cartelle vi è la main directory originale dell’archivio eancora all’interno troviamo le varie suddivisioni in cartelle dell’archivio. Dentroqueste ultime cartelle sarà possibile trovare le mail e tutti gli allegati.
39

Dopo l’esecuzione della readpst viene analizzato il messaggio di output e vengonosalvati tutti i dati riguardanti l’estrazione. Per ogni archivio dove all’interno visono delle mail, viene chiamata la funzione mailLab2 () che prende come para-metri il nome della cartella dell’archivio, il numero di mail presenti al suo internoe la cartella genitore (quella con il nome dell’archivio pst).La funzione mailLab2 () si occupa di estrapolare tutti i dati dalle mail. Comegià detto nella parte introduttiva gli archivi pst non contengono solo mail maanche ad esempio i contatti. Questo analizzatore riesce anche ad analizzare icontatti. Se l’archivio pst ha il nome “contatti” allora l’analisi sarà diversa. Perogni contatto di un file e dentro di essi vi sono le informazioni. Per ogni file vieneestrapolato il nome ed il numero di telefono.Per tutti gli altri archivi si tenta l’estrazione delle mail. Le mail, come già detto,si trovano una ad una dentro il rispettivo file mhtml - mime html - un formatodi archiviazione dati multimediale. Ognuno di questi file è sottoposto ad analisimediante il modulo email di Python dove si tenta di estrarre mittente, destinata-rio, data e ora, oggetto e testo. Tutti questi dati vengono posti all’interno di unarray. Successivamente viene inserito anche il path del file mhtml per permetterela consultazione dell’originale in caso di necessità.Rimangono solamente gli allegati. Questa volta non è necessario cercarli all’inter-no del file mhtml. Essi sono già stati estratti dalla readpst pertanto sono presentitra i file della cartella in analisi. Ricordando che ogni allegato ha come primaparte del nome il nome della mail a cui fa riferimento, trovarli tutti è abbastanzasemplice grazie ai comandi del terminale. Il comando usato è il seguente:
ls [this directory] | grep ˆ[�] (4.5)
40

Si richiede di listare tutti i file contenuti nella cartella ma di estrarre solo quelliche iniziano (ˆ) con il numero della mail [i] a cui è concatenato il trattino.Ad ogni nome corrisponde un allegato, quindi viene costruito il suo path edinserito in un array di supporto. Questo array, infine, verrà inserito come ultimoelemento dell’array dei dati della mail.Se in ogni fase tutto precede bene e vengono trovati dei dati, i dizionari rispettivivengono aggiornati. Anche in questo caso il dizionario Python funge da strumentoper creare un file json ben formato: elencoMailPST.json. In fase conclusiva il jsonviene creato e, se non ancora presente, costruita tutta la struttura della cartellacontenente i file di configurazione per il report.
4.2.3.4 Output
L’output è un report in html che permette la navigazione all’interno delle variecaselle di posta estratte. È possibile consultare la versione originale della mailcosì come è anche possibile visionare gli allegati. Se precedentemente erano statefatte analisi di altri archivi di altri formati questi saranno presenti prima o dopogli archivi pst. Ogni tipologia di archivio è graficamente distinguibile dagli altri.Il consueto grafico di fine capitolo aiuta a riepilogare lo stato del progetto al ter-mine della seguente fase.
41
42

4.2.4 Report dell’estrazione delle mail
Dopo un’accurata analisi delle mail l’utente ha possibilità di visualizzare il risulta-to andando ad aprire il report in formato html. Attraverso le funzioni Javascriptdi manipolazione degli oggetti json è possibile recuperare tutte le informazioniordinate nei file generati durante le fasi di mail analysis. I layout grafici che hocreato sono stati fatti sia con CSS 2 ma soprattutto con la libreria Bootstrap4
versione 2.3.2 sviluppata da Marc Otto (@mdo) e Jacob (@fat). Bootsrap non èsolo una libreria che fornisce pezzi di codice di elementi grafici, offre anche unaserie di layout animati grazie all’integrazione di Javascript.A questa tipologia di report ho deciso di applicare un layout grafico molto simileai client di posta di successo.
Nella parte sinistra sono presenti le cartelle e gli archivi analizzati, nella parte inalto a destra è possibile visionare l’elenco delle mail mentre in quella in basso èpossibile visionare la singola mail selezionata.All’atto di apertura del report vengono analizzati i file json e successivamentecaricati nella colonna di sinistra tutti i file presenti all’interno.Una barra di attesa invita l’utente ad aspettare a proseguire fino a che tutti gliarchivi non vengono caricati.In seguito viene riportato il caso d’uso dettagliato.
4http://www.getbootstrap.com/2.3.2/
43

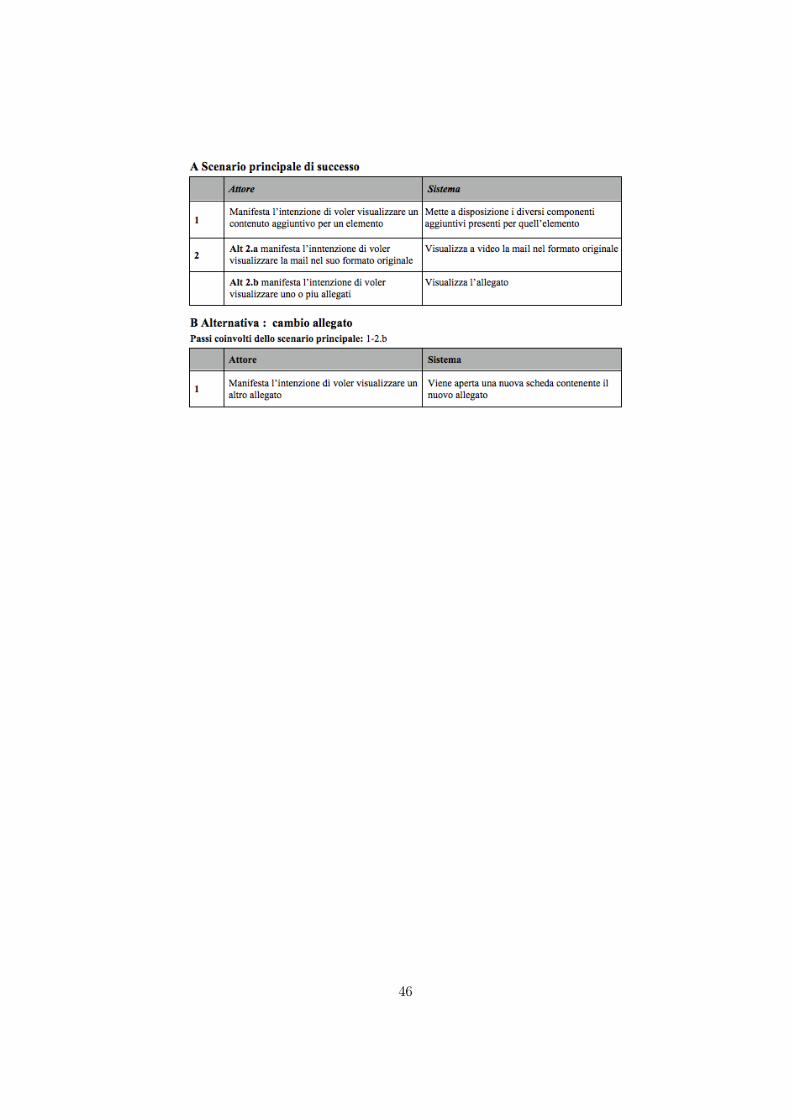
Nome caso d’uso: VisualizzaArchiviAnalizzatiPortata: SistemaLivello: Obiettivo AnalistaAttore Principale: analistaParti Interessate: analista forense - forze dell’ordine - informatico genericoPre-condizioni: È stata fatta un’analisi forense con il software Ermès, sono statitrovati archivi in formato pst e/o dbx e/o msf.Garanzie di successo: viene visualizzato l’output dell’analisi
Dopo aver caricato tutti gli archivi l’utente è libero di scegliere l’archivio di inte-resse e verrà visualizzato il suo contenuto. Il suo caso d’uso dettagliato:Nome caso d’uso: VisualizzaContenutoArchivioPortata: SistemaLivello: Obiettivo AnalistaAttore Principale: analistaParti Interessate: analista forense - forze dell’ordine - informatico genericoPre-condizioni:essere all’interno del file di report ed aver visualizzato gli archivianalizzati dal software Ermès.
44

Per ogni contenuto contenuto di ogni archivio, è possibile visualizzare ogni singoloelemento, che siano mail o che siano contatti personali. Ecco il caso d’uso:
Nome caso d’uso: VisualizzaDettagliElementoPortata: SistemaLivello: Obiettivo AnalistaAttore Principale: analistaParti Interessate: analista forense - forze dell’ordine - informatico genericoPre-condizioni:Vi è un archivio mail o contatti non vuoto
Nella fattispecie per le mail vi è una intestazione dove vengono riassunti mittente,destinatario, data ed ora, oggetto, mail originale ed eventuali allegati. L’analistapuò scegliere di non limitarsi a visualizzare le mail ma anche gli allegati e la mailoriginale presente nell’archivio. Ecco il caso d’uso:
Nome caso d’uso: VisualizzaComponentiAggiuntiviPortata: SistemaLivello: Obiettivo AnalistaAttore Principale: analistaParti Interessate: analista forense - forze dell’ordine - informatico genericoPre-condizioni:Vi è un archivio mail o contatti non vuoto e si sta visualizzandoun singolo elemento
45
46

Capitolo 5
L’interfaccia grafica
Diversi software di informatica forense sono utilizzabili dagli utenti mediante ilterminale, a linea di comando. L’utilizzo del terminale è un prerequisito limitatoad un gruppo di persone aventi una cospicua conoscenza dell’informatica. Vistoperò che il mio obiettivo era quello di poter permettere al maggior numero dipersone possibile di utilizzare il mio software, ho provveduto a creare un’inter-faccia grafica semplice ed intuitiva. Grazie ad essa l’analista potrà sin da subitoprendere confidenza col programma e in poche e semplici interazioni riuscirà adavviare l’analisi. L’unico punto di comunicazione tra l’utente, l’analista, ed ilsoftware è l’interfaccia grafica. Per facilitare l’apprendimento e l’interazione, l’in-terfaccia possiede una sola schermata con unicamente le informazioni necessariealla corretta esecuzione delle analisi. L’use case diagram dell’analista mostra sinda subito quali sono le operazioni che può effettuare
Per visualizzare l’interfaccia grafica è necessario aprire una nuova finestra del ter-minale, passare in modalità root (attraverso il comando sudo su) e poi lanciare ilmodulo di Python Ermes_gui.py
47

Affinchè l’analisi possa iniziare, devono essere soddisfatte tre condizioni:
1. Deve essere indicato il path dell’immagine forense
2. Deve essere indicata la cartella di destinazione laddove verranno salvatitutti i dati
3. È obbligatorio selezionare almeno un files di interesse da analizzare
Per prima cosa è necessario inserire l’immagine forense. All’atto dell’inseri-mento viene chiamato il metodo SelectForensicsImage (). Eccone il caso d’uso:Nome caso d’uso: SelectForensicsImagePortata: SistemaLivello: Obiettivo AnalistaAttore Principale: analistaParti Interessate: analista forense - forze dell’ordine - informatico generico
48
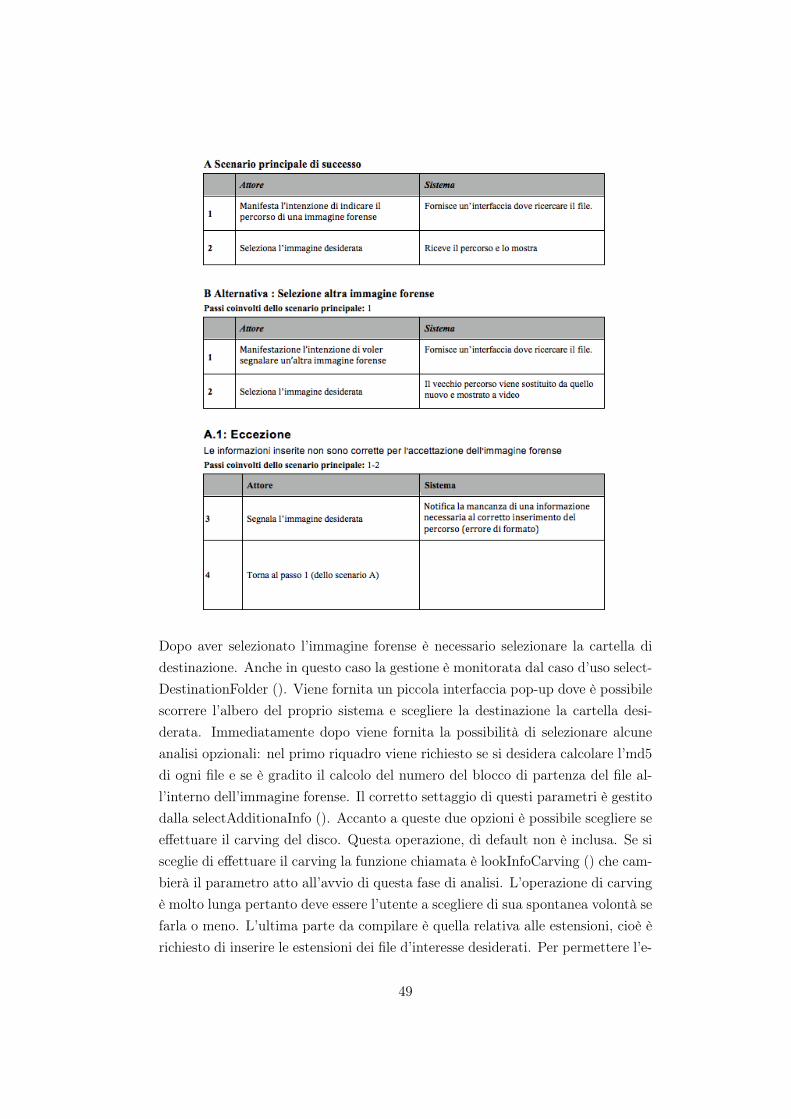
Dopo aver selezionato l’immagine forense è necessario selezionare la cartella didestinazione. Anche in questo caso la gestione è monitorata dal caso d’uso select-DestinationFolder (). Viene fornita un piccola interfaccia pop-up dove è possibilescorrere l’albero del proprio sistema e scegliere la destinazione la cartella desi-derata. Immediatamente dopo viene fornita la possibilità di selezionare alcuneanalisi opzionali: nel primo riquadro viene richiesto se si desidera calcolare l’md5di ogni file e se è gradito il calcolo del numero del blocco di partenza del file al-l’interno dell’immagine forense. Il corretto settaggio di questi parametri è gestitodalla selectAdditionaInfo (). Accanto a queste due opzioni è possibile scegliere seeffettuare il carving del disco. Questa operazione, di default non è inclusa. Se sisceglie di effettuare il carving la funzione chiamata è lookInfoCarving () che cam-bierà il parametro atto all’avvio di questa fase di analisi. L’operazione di carvingè molto lunga pertanto deve essere l’utente a scegliere di sua spontanea volontà sefarla o meno. L’ultima parte da compilare è quella relativa alle estensioni, cioè èrichiesto di inserire le estensioni dei file d’interesse desiderati. Per permettere l’e-
49

strazione totale di tutta l’immagine si può subito premere in corrispondenza dellacheckbox “all the files into the image”. Come conseguenza tutte le checkbox elen-canti i singoli formati di maggior interesse vengono disabilitate poichè la selezionefatta comprende già questi formati. Se non si è interessati a tutti i file dentrol’immagine forense, si procede con la selezione uno a uno dei file desiderati tra lecheckbox a disposizione. All’atto di selezione di un estensione viene chiamato ilmetodo OptionExtensionExtraction () che l’aggiunge ad un dizionario sintattica-mente uguale a quello delle estensioni della prima fase d’analisi. Se viene toltoil check da una delle checkbox allora anche il dizionario perde quella voce. Unavolta compilato tutto con un semplice click sul pulsante “Analize” l’analisi inizia.Per non permettere interferenze con l’analisi in corso quest’ultimo bottone vienedisabilitato e per poterlo riavviare si dovrà eseguire nuovamente il programmada capo. Un box sottostante tiene traccia dello stato dell’analisi corrente e, unavolta terminata, lo segnala. Il caso d’uso StartAnalysis riassume quanto dettoprecedentemente:Nome caso d’uso: StartAnalysisPortata: SistemaLivello: Obiettivo AnalistaAttore Principale: analistaParti Interessate: analista forense - forze dell’ordine - informatico generico
50
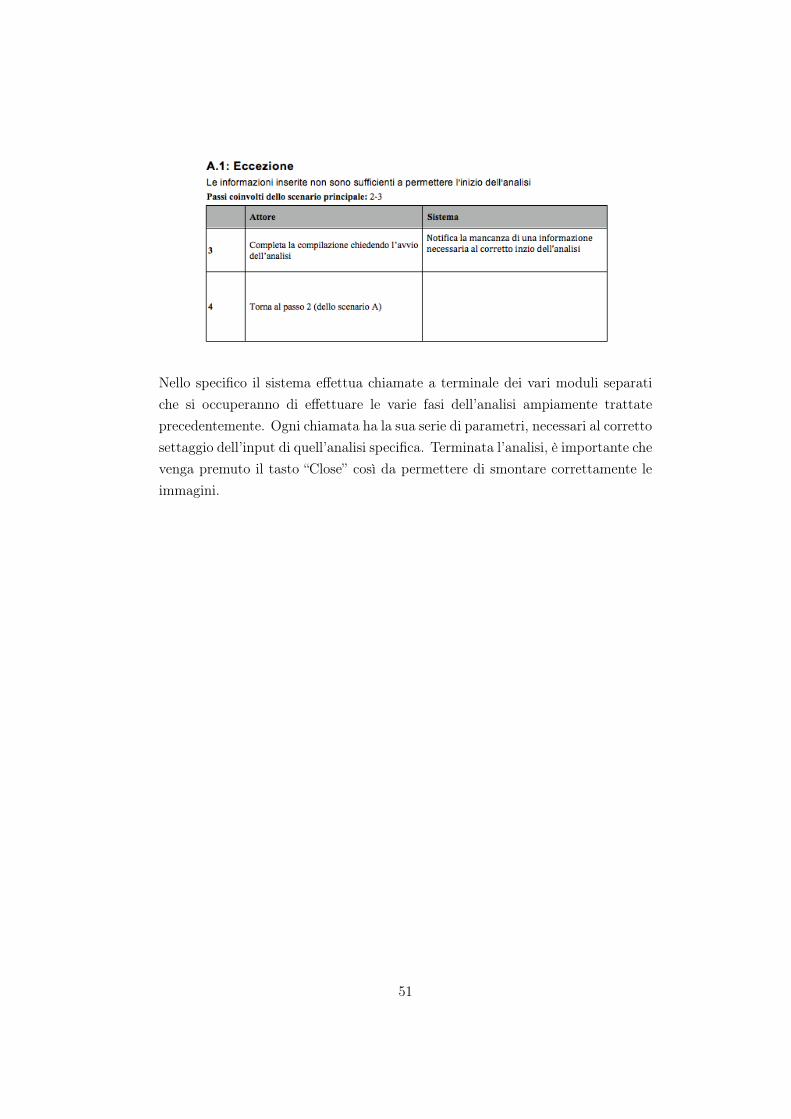
Nello specifico il sistema effettua chiamate a terminale dei vari moduli separatiche si occuperanno di effettuare le varie fasi dell’analisi ampiamente trattateprecedentemente. Ogni chiamata ha la sua serie di parametri, necessari al correttosettaggio dell’input di quell’analisi specifica. Terminata l’analisi, è importante chevenga premuto il tasto “Close” così da permettere di smontare correttamente leimmagini.
51

Capitolo 6
Conclusioni
Ermès, il software da me realizzato, può davvero risultare assai utile in tutti queicontesti laddove sia necessaria un’analisi dei dati di un computer, un server, unnas, una chiavetta usb o una memory card. I punti di forza del programma sonola catalogazione dei file per formato, la ricerca dei file cancellati e l’analisi del-le mail. In un’indagine non è strettamente detto che tutte tre siano necessariecontemporaneamente ma solitamente sono azioni che rispecchiano la metodologiastandard di analisi di un analista forense.In caso di analisi preliminari questo programma può risultare assai utile poichèè in grado di effettuare in modo automatico un’analisi globale con un grado dicompletezza tale da poter far capacitare subito l’utilizzatore riguardo la quantitàdi dati presenti nell’immagine forense, il sistema di scambio di mail utilizzato equali mail nello specifico venivano scambiate.Ad oggi sono riuscito a far estrapolare ad Ermès qualsiasi file all’interno di un’im-magine forense oppure solo quelli di interesse dell’utente. Ogni file estratto vienecatalogato in un documento visualizzabile successivamente.Mi sono anche occupato di far ricercare ad Ermès i file cancellati in una fase dianalisi separata.La parte per cui ho impiegato maggiori sforzi riguarda l’analisi delle mail. At-tualmente i tre formati di archivi di posta che ho analizzato sono dbx, pst emsf. Vengono analizzati i file estrapolati dalla fase di estrazione. Sono esclusigli archivi recuperati durante la fase di carving. Negli archivi di mail in formatopst, grazie al software ReadPST che ho utilizzato per l’estrazione, son riuscitoa ricostruire la struttura originale delle cartelle all’interno dell’account di posta.Sono inoltre riuscito a recuperare i contatti della rubrica dell’account e a crearneuna lista. Se si è alla ricerca di un numero telefonico e questo è all’interno dellarubrica, sarà possibile visualizzarlo assieme ai dati del contatto nel report delle
52

mail.Nei formati dbx ed msf, al momento, vengono analizzati tutti i file singolarmenteestraendo le mail e raggruppandole archivio per archivio.
53

Capitolo 7
Gli sviluppi futuri
Di fronte a questo progetto si è generato un entusiasmo tale da non far terminareil progetto con questa tesi anzi, sarà immediatamente ripreso, rivisto ed ampliato.Le collaborazioni saranno importanti per portare nuove idee e nuove strategie peranalisi sempre più precise ed efficienti.Siccome questo programma utilizza moduli esterni per eseguire piccole fasi dianalisi non si escludono future integrazioni con nuovi programmi. Se esiste giàun software open source che effettua bene una parte dell’analisi che si vuole in-serire nel proprio progetto non è saggio risviluppare un modulo che effettua lemedesime azioni. Si considera una scelta più utile quella di usare direttamentequel modulo e di integrarlo.Ciò che risulta davvero importante e necessita di essere sviluppato con metico-losità in questo contesto sono gli output visibili all’utente. I report di analisie le interfacce di navigazione dovranno essere continuamente migliorate da chisviluppa Ermès e sarà praticamente impossibile trovare programmi esterni inte-grabili. La ricerca di visualizzazioni user-friendly ma comunque complete è unodegli obiettivi di questo progetto. Lavorando sodo su questo obiettivo sarà pos-sibile allargare il bacino di utenti che usufruirà del programma.L’obiettivo finale che vorrei raggiungere è quello di avere un semplice strumentoma comunque completo, capace di analizzare il maggior numero di formati dimail possibile e che sia in grado di essere integrato mano mano con nuovi scriptrelativi ai singoli archivi di posta analizzabili.Un software può diventare grande solo se ci sono diverse menti che lo hanno pen-sato e sviluppato. L’evoluzione delle tecnologie e dei sistemi operativi obbligheràad effettuare aggiornamenti continui al programma. Sarà importate avere unapanoramica completa sulle ultime uscite su mercato di dispositivi, programmi esistemi operativi.
54

Capitolo 8
Ringraziamenti
Le persone da ringraziare sono sempre molte: spero di ricordare di tutti senzafare torti ad alcuno. Andando a ritroso i miei primi ringraziamenti vanno alDr. Paolo Dal Checco che ha saputo darmi i consigli giusti per non andare fuo-ri strada durante l’ideazione del software e la redirezione della tesi. Ringrazioinoltre il Dr. Giuseppe Dezzani e i miei colleghi Ivano, Stefano ed in particolarmodo Sebastiano che, ai primi approcci con Python, mi ha fornito numerosi con-sigli sulla programmazione agile in questo linguaggio. Ringrazio inoltre Monicae Cristina, per aver sopportato i miei continui andirivieni in ufficio. Ringrazio laprofessoressa Viviana Bono, il mio relatore interno, per il supporto al seguenteprogetto e le rifiniture alla relazione. Altri ringraziamenti vanno a Mattia concui ho condiviso moltissimi momenti in università e assieme abbiamo preparatonumerosi esami. Ringrazio l’amico Stefano per avermi fatto da supporto intel-lettuale alla lettura di questa trattazione. Ringrazio anche gli avvocati CamilloSacchetto e Fabio Montalcini. Grazie a loro ho avuto la possibilià di misurarminel mondo accademico prima della laurea sia facendo piccole lezioni davanti adun cospicuo pubblico, sia mediante la partecipazione alla scrittura di un manuale.Un grazie speciale va ad Alessandra, punto di riferimento, con cui quest’anno hocondiviso tantissimi momenti di studio nei posti, nei momenti e nelle condizionipiù variegate.Uno dei ringraziamenti più grandi va ai miei genitori. Durante i periodi degliesami e lezioni/stage, la mia tensione era alta ed a volte poteva sfociare in nervo-sismo che loro hanno compreso e capito con grande pazienza. Li ringrazio inoltreper l’aiuto concreto durante tutto il periodo degli studi. Senza di loro, con lavorisaltuari, non sarei riuscito a permettermi questo titolo di studio. Ringrazio infineil dottor Bruno Ramondetti per avermi aiutato a ritrovare e percorrere la stradagiusta per inseguire al meglio il mio obiettivo.
55

Bibliografia
[1] Lutz Marc, Learning Pythton - 4th edition, Sebastopol (USA), O’Reilly, 2009
[2] Silberschatz - Galvin - Gagne - Sistemi operativi. Concetti ed esempi. Ottavaedizione, Milano, Pearson, 2009
[3] Ghirardini Andrea, Faggioli Gabriele, Computer Forensics, Milano, Apogeo,2009
56

Sitografia
[1] http://docs.python.it/paper-a4/ref.pdf
[2] http://infohost.nmt.edu/tcc/help/pubs/tkinter.pdf
[3] http://linuxdidattica.org/docs/altre_scuole/msm_p/txs_01.html
[4] http://it.diveintopython.net/xml_processing/command_line_arguments.html
[5] http://wwwcdf.pd.infn.it/
[6] http://code.google.com/p/undbx/
[7] http://www.cgsecurity.org/wiki/PhotoRec
[8] http://www.five-ten-sg.com/libpst/rn01re01.html
[9] http://docs.python.org/2.7/
[10] http://api.jquery.com/jQuery.getJSON/
57