analysis and predictive modeling of body language …zhaojuny/docs/tmm_bodylanguage.pdflanguage...
TRANSCRIPT

1
Analysis and Predictive Modeling of BodyLanguage Behavior in Dyadic Interactions from
Multimodal Interlocutor CuesZhaojun Yang, Student Member, IEEE, Angeliki Metallinou, and Shrikanth Narayanan, Fellow, IEEE
Abstract—During dyadic interactions, participants adjust theirbehavior and give feedback continuously in response to thebehavior of their interlocutors and the interaction context. Inthis paper, we study how a participant in a dyadic interactionadapts his/her body language to the behavior of the interlocutor,given the interaction goals and context. We apply a varietyof psychology-inspired body language features to describe bodymotion and posture. We first examine the coordination betweenthe dyad’s behavior for two interaction stances: friendly andconflictive. The analysis empirically reveals the dyad’s behaviorcoordination, and helps identify informative interlocutor featureswith respect to the participant’s target body language features.The coordination patterns between dyad’s behavior are found todepend on the interaction stances assumed. We apply a GaussianMixture Model (GMM) based statistical mapping in combinationwith a Fisher kernel framework for automatically predicting thebody language of an interacting participant from the speech andgesture behavior of an interlocutor. The experimental resultsshow that the Fisher kernel based approach outperforms methodsusing only the GMM-based mapping, and using the supportvector regression, in terms of correlation coefficient and RMSE.These results suggest a significant level of predictability of bodylanguage behavior from interlocutor cues.
Index Terms—body language, motion capture, dyadic interac-tions, behavior coordination, interaction goals.
I. INTRODUCTION
THE coordination of verbal and nonverbal human behaviorduring interpersonal interactions has been studied in
many diverse areas including neuroscience, engineering, psy-chology and behavioral sciences [1]. Interaction participantsgenerally adjust their behavior and give feedback continuouslybased on the behavior of their interlocutors whom they arehaving conversations with, as well as based on their owninteraction goals and context. The adaptation of behavior,such as facial expressions or body movements, facilitates thecommunication to move smoothly, efficiently and coherently.In addition to understanding the fine details of human in-teraction mechanisms, modeling behavior coordination is im-portant for developing intelligent conversational agents whichcan naturally respond non-verbally in real-time while humaninterlocutors are speaking.
Z. Yang and S. Narayanan are with the Department of Electrical Engineer-ing, University of Southern California, Los Angeles, CA 90089 USA (e-mail:[email protected]; [email protected]).
A. Metallinou was with the Department of Electrical Engineering, Univer-sity of Southern California, Los Angeles, CA 90089 USA. She is now withPearson Knowledge Technologies, 4040 Campbell Ave., Suite 200, MenloPark, CA 94025 USA (e-mail: [email protected]). The workwas supported in part by NSF and DARPA.
Body language is an essential element of nonverbal behaviorin human communication, which includes facial gestures,head, limb and other body postures and movements. It conveysattitudes and emotions of a person towards his/her interlocutor.The adaptation of an interacting participant’s body languageto his/her interlocutor’s behavior depends on their interactiongoals and their nature, including the stance or attitude assumedsuch as being friendly or conflictive. For example, two partici-pants with friendly attitudes may tend to approach each other,while those with conflictive attitudes may avoid each otherand try to terminate the conversation. Hence, the coordinationpattern of a dyad’s behavior is influenced by the nature of theirinteraction goals.
This work focuses on studying how an interacting partici-pant adapts his/her body language to the multimodal behavior,i.e., gesture and speech cues, of the interlocutor, based ontheir communication goals in a dyadic interaction. Our objec-tive is two-fold: 1) to examine the coordination between aninteraction participant’s body language with the interlocutor’smultimodal behavior given the nature of interaction stances(friendliness or conflict); 2) to computationally model thedyadic coordination and automatically predict an interactionparticipant’s body language from the multimodal informationof his/her interlocutor. The estimation of a subject’s bodylanguage based only on the interlocutor’s behavioral cues isa novel research direction. This could lead to the develop-ment of expressive and goal-driven virtual agents that woulddisplay appropriate body language in response to the humaninterlocutor’s behavior such as to increase the human-agentrapport.
In this work, we use the multimodal USC CreativeITdatabase that consists of goal-driven improvised interactions[2]. It contains detailed full body Motion Capture (MoCap)data of both interacting participants in addition to audiodata, providing a rich resource for studying, modeling andpredicting body language patterns in dyadic interactions. Weinvestigate various features inspired by the psychology lit-erature on non-verbal communication [3] to describe bodylanguage behavior, including of head and body position, handand body motion, and relative motion and orientation. Weconsider eight distinct target body language features for mod-eling and predicting the interacting participant’s behavior withrespect to the interlocutor. The eight target features are selectedbecause they capture key aspects of human body language andexpressiveness, viz., body posture, velocity, orientation andrelative motion toward the interlocutor. The dyad’s coordina-

2
tion is investigated using canonical correlation analysis (CCA).We find statistically significant correlations that empiricallyverify the dyad’s behavior coordination. We also rank theinterlocutor’s body language and speech features for eachinteraction stance, according to their importance to the targetparticipant body language feature, using a correlation-basedcriterion. The coordination pattern of the dyad’s behavior foreach interaction type is represented by a list of ranked bodylanguage and speech features. We observe that coordinationpatterns depend on the interaction goals; in our study, wefind that the types of highly ranked interlocutor features varydepending on whether the interaction is friendly or conflictive.
Motivated by these analyses, we propose a method to modelthe coordination of dyadic behavior for each interaction stanceand to automatically predict the target participant body lan-guage features using the multimodal information derived fromthe interlocutor. For this purpose, we adopt a Fisher kernelbased methodology with Gaussian Mixture Model (GMM) tomap from the interlocutor’s behavior to the body language ofthe target participant. Experimental results show that the Fisherkernel based approach outperforms the generative method ofMLE-based mapping and the support vector regression (SVR)model, in terms of both correlation coefficient and Root MeanSquared Error (RMSE) with respect to the ground truth data.In addition, the inclusion of the interlocutor’s speech informa-tion improves the prediction performance, compared to usingonly the interlocutor’s body language. These results indicatea significant level of predictability of body language fromthe interlocutor behavior, which could be exploited towardsinteraction-driven and goal-driven body language synthesis forintelligent virtual agents.
The rest of the paper is organized as follows. Section IIdescribes related work on studying the correlation betweenhuman behavior during communication. Section III introducesthe multimodal database of dyadic interactions, followed bythe description of behavior feature (body language and speech)extraction in Section IV. In Section V, we define the categoriesof behaviors for interlocutor pairs in an interaction, whichare used for analysis and modeling. Based on the behaviorpairs, we analyze how the behavior is coordinated between twointeraction subjects given communication goals in Section VI.Section VII presents the predictive framework for modelingthe behavior coordination according to the interaction goals.Experimental results are presented in Section VIII, and SectionIX provides the conclusion and future work along this researchdirection.
II. RELATED WORK
Body language is an important indicator of emotions orattitudes during social interactions. Ekman extensively studiedthe relation between facial expressions and emotions, andconcluded that an emotional state could be inferred from anexpression with cross-cultural agreement [4]. The analysis ofmovement structure in [5] has demonstrated the dynamic con-gruency between emotion and movement. Conty et al. showedthat the early binding of body gesture, gaze direction andemotion could possibly promote a more adaptive response to
the interlocutor in an interaction [6]. These theoretical founda-tions have inspired studies on automatic emotion recognitionutilizing body language. Affective content has been exploredfrom the dynamics of body movement in [7]. Gunes et al. inte-grated body gestures along with facial expressions to recognizeemotions [8]. Bernhardt and Robinson have attempted to detectaffective information in the knocking motion using derivedmotion primitives [9].
The correlation between body language and speech be-havior has enabled much progress in prosody-driven bodygesture synthesis. Busso et al. have proposed a prosody-driven approach for synthesizing expressive rigid head motion[10] [11]. Mariooryad et al. have built a joint speech andfacial gesture model to generate head and eyebrow motion forconversational agents [12]. Likewise, Sargin et al. synthesizedhead gestures from speech by exploring the joint correlationbetween head gesture and prosody patterns [13]. Frameworksfor full body motion synthesis in real-time, which also useprosody information, have been developed in [14] [15]. Inaddition to the speech-driven methods, emotion-based bodylanguage synthesis has also been studied. Beck et al. generatedemotional body language for robots by investigating the effectof varying the positions of joints on the interpretation of emo-tions [16]. While these works mainly focus on synthesizingbody language of individuals, this paper aims at interaction-driven and goal-driven body language modeling in dyadicsettings, which we believe is important for the developmentof natural human-machine interfaces.
In social interactions, there exists interpersonal influencealong aspects of speech prosody, body language, and emo-tional states. To accomplish effective communication, peopleoften adapt their interaction behavior to the interlocutor andsuch behavior adaption includes synchronizing in time ordisplaying similar or dissimilar behavior [17]. Chartrand etal. described that humans unconsciously mimic the behaviorof their interaction partners to achieve more effective andpleasant interactions [18]. Ekman found that body languageof interviewees is distinctly different between friendly andhostile job interviews [19]. Neumann et al. reported that theemotions in speech would induce a consistent mood statein the listeners [20]. Kendon qualitatively described detailedinterrelations between movements of the speaker and thelistener by analyzing sound films of social interactions [21].He also found that the movement of the listener might berhythmically coordinated with the speech and movement ofthe speaker in a social interaction.
Many engineering works have also been developed basedon this mutual influence of interaction subjects. Morency etal. predicted head nods for virtual agents from the audio-visual information of a human speaker based on sequentialprobabilistic models [22]. In contrast, our work aims atpredicting more diverse full body movements in response tothe interlocutor’s behavior. Heylen et al. studied what typesof appropriate responses, e.g., facial expressions, an agentshould display when a human user is speaking, to increaserapport in human-agent conversation [23]. Researchers havealso used the emotional state of an interlocutor to inform thatof a speaker by modeling emotional dynamics between two

3
interaction participants [24] [25]. The influence frameworkproposed in [26] models participants in conversational settingsas interacting Markov chains. Lee et al. proposed prosody-based computational entrainment measures to assess the co-ordination in the interactions of married couples [27]. Xiaoet al. studied and modeled the interaction synchrony of headmotion behavior using GMM [28] [29].
A Gaussian mixture model (GMM) based statistical map-ping methodology has been applied in our previous work forinteraction-driven body language prediction [30], i.e., predict-ing the listener’s body language from the speaker’s speech andgestural behavior for both friendly and conflictive interactionstances. A GMM which describes the probability distributionof an overall population is represented by the mixture ofGaussian distributions of subpopulations within an overallpopulation. More details about GMM are described in SectionVII. This GMM-based mapping was based on a methodoriginally proposed for articulatory to acoustic mapping [31]and spectral conversion between speakers [32], and has alsobeen used for continuous emotional state estimation basedon body language and speech [33]. Our preliminary workin [30] showed that the predicted trajectories of the targetbody language features generally follow the trend of theobserved curves. However, this generative approach producesa large difference between the exact values of predicted andobserved body language. To overcome this limitation, weextend this work by applying the Fisher kernel framework[34] to model the interactive behavior coordination. The Fisherkernel technique combines the advantages of generative anddiscriminative approaches. It represents a data sample as a gra-dient vector of the generative model over the data, i.e., GMMin our case, and inputs the representation into a discriminativemodel. Fisher kernels on GMM have been successfully appliedin classification problems, such as image categorization [35],audio classification [36] and speaker verification [37]. In thispaper, we employ them to improve the prediction performanceof the participant’s target body language features from theinterlocutor’s behavior.
III. DATABASE DESCRIPTION
We use the USC CreativeIT database in our experiments,which is a multimodal corpus of dyadic theatrical improvi-sations [2]. The database is freely available for research athttp://sail.usc.edu/data.php. It contains detailed full body Mo-tion Capture (MoCap) data of the two interacting participantsrecorded by 12 Vicon MoCap cameras at 60fps, and audiodata obtained through close-up microphones at 48kHZ with24 bits. The MoCap cameras were located on the ceiling ofthe recording room and the motion capture process retrievedthe (x, y, z) positions of 45 markers for each participant. Themarkers were placed across an actor’s body, as shown inFig. 1(a). Our work is based on the features extracted fromthe MoCap and audio data, which is described in Section IV.The process of collecting and postprocessing the MoCap datain our database requires much effort and is time-consuming.Recently, more advanced and improved techniques have beendeveloped and applied for motion data collection, such as withkinect [38] or the newer Vicon system [39].
The interactions performed by pairs of actors are eitherimprovisations of scenes from theatrical plays or theatricalexercises where actors repeat saying sentences to expressspecific goals featuring specific communication stances orattitudes. In this work, we examine the theatrical exercises, asimplified form of interactions with restricted lexical content(only limited phrases can be used), which encourages richbody language expressions. For example, in a theatrical excer-cise, one actor says Make me smile, and the other one repliesWhy should I. The interactions were guided by a theater expert(professor/director), and were performed following the ActiveAnalysis improvisation technique pioneered by Stanislavsky[40]. According to this technique, the interactions are goal-driven; the pair of actors in each interaction has a pair ofpredefined interaction goals, e.g., to approach vs. to avoid,which they try to achieve through the appropriate use of bodylanguage and speech prosody. The goal pair of each dyaddefines their attitudes towards each other and the content ofthe interaction.
TABLE IFRIENDLY, MEDIUM AND HIGH CONFLICTIVE INTERACTION CASES
Cases Actors’ attitudes Example goal pairsFriendly friendly - friendly to make peace - to comfort
Medium Conflict friendly - conflictive to convince - to rejectHigh Conflict conflictive - conflictive to accuse - to fight back
As described in Section I, our premise is that the dynamicsof interactions differ depending on the stances of interactingparticipants, which may result in distinct coordination patternsof dyad’s behavior. Hence, we group the interactions intothree cases according to the defined goal pairs: friendliness,medium conflict and high conflict. In friendly interactions bothparticipants have friendly attitudes, e.g., one is to make peaceand the other is to comfort; in medium conflict interactions oneparticipant is friendly while the other is creating conflict; andin high conflict interactions the attitudes of both participantsare conflictive. Interactions that do not fit into these categoriesare excluded from our analysis. This grouping is describedin Table I, along with examples of characteristic goal pairs.Friendliness, medium and high conflict groups contain 10, 30and 8 interactions respectively, including 16 actors (9 female).Each interaction has an average length of 3.5 minutes.
IV. FEATURE EXTRACTION
A. Body Language Feature Extraction
The availability of full body MoCap information, as shownin Fig. 1(a), enables us to extract detailed descriptions ofeach actor’s body language expressed during an interaction.The features are motivated from the psychology literaturewhich indicates that body language behaviors, such as lookingat the other, turning away, approaching, touching or handgesturing, are informative of a subject’s attitude and emotiontowards his/her interlocutor [3]. While some of our featurescarry information about an individual’s posture and motion,such as hand or body positions, others describe behaviorsrelative to the interlocutor, e.g., body and head orientation,approaching and moving away. The features are computed in

4
(a) Marker positions (b) Global and local reference systems
(c) Absolute and relative velocity (d) Face orientation angle
Fig. 1. The positions of the Motion Capture markers; the global and localcoordinate systems for body language feature extraction; and examples ofextracted features.
a geometrical manner by defining global and local coordinatesystems illustrated in Fig. 1(b) and by computing Euclideandistances, relative positions, angles and velocities. Similarmovement features have also been applied for analyzing thelink between emotion and gesture dynamics [33] [41].
We extract 24 body language features in total for eachactor in an interaction, as summarized in Table II. Someexample features are illustrated in Fig. 1(c) and (d). Theabsolute velocity of a subject’s body is computed from themovement in one’s local coordinate system, while the relativevelocity towards one’s interlocutor is obtained by projectingthe velocity vector in the direction between the two partners,as shown in Fig. 1(c). Similarly in Fig. 1(d), the angle of asubject’s face towards the other, i.e., cosFace, is the anglebetween the head orientation in one’s local system and thedirection between the two participants. If cosFace is closeto 1, the actor is looking towards the interlocutor, whilecosFace < 0 indicates looking away. Among the 24 bodylanguage features, we selected eight distinct features as thetarget features of the participant which we use for the analysisand prediction from the interlocutor’s full set of 24 features.These target features are marked with * in Table II. Note thatall the 24 body language features including the target ones areused as the interlocutor’s features for analysis and prediction.The eight target features were selected because they capturekey behaviors of human expressiveness, such as body and faceorientations, body posture, hand gesture and relative motiontoward the interlocutor [3]. In future work, the informationconveyed by these selected target features can be used invirtual agent animation.
B. Audio Feature Extraction
We extract audio features from the speech regions of inter-acting participants, i.e., pitch, energy and 12 Mel FrequencyCepstral Coefficients (MFCCs), which are commonly used bythe affective computing community [42]. Pitch and energy are
TABLE IIEXTRACTED BODY LANGUAGE FEATURES. FEATURES MARKED WITH *WILL BE PREDICTED USING THE INTERLOCUTOR’S FEATURE SET (BOTH
MARKED WITH * AND NOT MARKED).
cosFace* Cosine of subject’s face angle towards the other (Fig. 1(b))HAngle Angle of head looking up and down
cosBody* Cosine of subject’s body orientation angle towards the othercosLean* Cosine of subject’s body leaning angle towards the otherpx, py, pz Subject’s (x,y,z) coord. of body position (global, Fig. 1(b))aVbody* Absolute velocity of subject’s body
aVarmr*,l* Absolute velocity of subject’s right/left armsaVfeetr,l Absolute velocity of subject’s right/left feetrVbody* Relative velocity of subject’s body towards the otherrVhandr,l Relative velocity of subject’s right/left hands towards the otherrVfeetr,l Relative velocity of subject’s right/left feet towards the other
rhandx,y,z Subject’s right hand (x,y,z) coord position (local, Fig. 1(b))lhandx,y,z Subject’s left hand (x,y,z) coord position (local, Fig. 1(b))dHands* Distance between subject’s right and left hands
also used for prosody-based body and head gesture synthesis[11] [14]. We extract these features every 16.67ms with ananalysis window length of 30ms, in order to match with theMoCap frame rate.
V. THE DYAD’S BEHAVIOR PAIR SETUP
Our objective is to investigate how an interaction partici-pant’s body language is influenced as a response to his/herinterlocutor’s speech and body language behavior in a dyadicinteraction. A dyad refers to a group of two individualsand a dyadic interaction defines the communication betweenthe pair of persons in the dyad. In the friendly and highconflictive cases, both actors have the same goal, therefore thebody language of a friendly (conflictive) target participant isanalyzed or predicted with respect to the behavior of a friendly(conflictive) interlocutor. The medium conflictive case includestwo subcategories for analysis and modeling: a friendly targetparticipant interacting with a conflictive interlocutor, and aconflictive target participant interacting with a friendly inter-locutor.
In our work, we pair each target feature of the participant atframe t with the interlocutor’s audio-visual behavioral infor-mation over a window preceding (including) frame t, i.e., weanalyze or estimate the target participant body language fromthe past context information of the interlocutor. Specifically,the interlocutor’s information consists of body language orboth body language and speech, as illustrated in Fig. 2. Similarto [43] that uses utterance-level statistics of prosody featuresfor emotion recognition, we extract 11 statistical functionalsover the context window for each body language (Table II)and speech feature — mean, standard deviation, median,minimum, maximum, range, skewness, kurtosis, first quantile,third quantile and inter-quantile range — to represent contextinformation. Specifically, skewness measures the asymmetryof the data around its sample mean; kurtosis describes thewidth of peak in the probability distribution of a randomvariable; and inter-quantile range is the difference betweenthe third and first quantiles. Because of the high dimensionstatistical functional vector, we reduce the dimensionalityusing Principal Component Analysis (PCA), by preservingabout 90% of the total variance.
5
Fig. 2. Illustration of the dyad’s behavior pair setup.
Our analysis and prediction experiments are performed us-ing dyad’s behavior pair along the entire interaction (whetherthe interlocutor is speaking or not). Context information iscomputed using both body language and speech in the windowif the speech region exceeds 50 percent of the window size.Otherwise, the context information only includes the bodylanguage features in the window.
VI. ANALYSIS OF THE DYAD’S COORDINATION PATTERNS
In this section, we investigate how the coordination patternsof the dyad’s behavior differ depending on the interactiongoals. We approach this problem by examining to whatdegree the participant’s body language is correlated withthe interlocutor’s behavioral context information, and whattypes of interlocutor features are especially informative of theparticipant target body language given interaction attitudes.
We first perform Canonical Correlation Analysis (CCA)between the set of target participant body language features atframe t and the interlocutor information over a window, foreach case of goal pair in Table I. Note that we have four casesfor analysis since the medium category has two subgroups.CCA respectively finds vectors v and u for two sets of data Xand Y with different dimensionalities such that the correlationof Xv and Y u is maximized [44]. It can sequentially seekvectors v′ and u′ by maximizing the correlation of Xv′ andY u′ subject to the constraints vtv′ = 0 and utu′ = 0. Inour case, Y represents the target body language informationand has a dimension of 8 (marked target features in TableII); X contains interlocutor information that is used forprediction CCA then returns min(dimX, dimY ) canonicalcorrelations in a descending order, and each correlation can betested for significance through the F statistic based on Rao’sapproximation [45]. We set the window size in Fig. 2 to be30, 60, 90 and 120 frames. Fig. 3 shows the first (highest)canonical correlation between the dyad’s behavior varyingwith the window size in each interaction case. We can see thatthe correlation respectively achieves the maximum with thewindow size of 60, 120, 30 and 60 in the case of friendliness,high conflict, medium conflict (friendly target participant)and medium conflict (conflictive target participant). In theanalysis and prediction experiments that follow, we fix thewindow size in each case accordingly. Furthermore, we findthat the maximal leading canonical correlation in each case isaround 0.50 (p = 0.000), implying the existence of the dyad’sbehavior coordination in communication. Table III presents thesummary of the statistics for the first canonical correlation ineach interaction case.
30 40 50 60 70 80 90 100 110 1200.46
0.48
0.5
0.52
0.54
0.56
0.58
Window size (frame)
Ca
nonic
al corr
ela
tion
Friendly
Conflictive
Medium Conflictive (friendly participant)
Medium Conflictive (conflictive participant)
Fig. 3. The canonical correlation between the dyad’s body language inrelation to the window size.
TABLE IIISUMMARY OF STATISTICS FOR THE MAXIMAL CANONICAL CORRELATION
UNDER EACH INTERACTION TYPE (p = 0.000 FOR ALL CASES).
Interaction case Statistics
Friendly F (192, 72260) = 422.7
Conflictive F (192, 457100) = 279.5
Medium (Conflictive) F (192, 987700) = 818.5
Medium (Friendly) F (192, 172700) = 833.0
Next, we examine what types of interlocutor features areespecially informative of the target participant body languagefeatures given interaction attitudes. The list of interlocutorfeatures which are ranked according to their informativenessrepresents the coordination pattern of the dyad’s behaviorin each interaction case. The minimal redundancy maximalrelevance criterion (mRMR), introduced in [46], is helpful forus to select informative but decorrelated interlocutor featureswith respect to each target body language feature. The originalmRMR was computed based on mutual information betweenpairs of continuous variables. Inspired by this mutual infor-mation based metric, we compute the minimal redundancymaximal relevance criterion based on correlation instead. Thiscorrelation-based metric is denoted as mRMRc which hasalso been applied for continuous emotion tracking in [33].The final feature set selected by mRMRc contains featuresthat are maximally correlated with the target feature butminimally correlated with each other. In this way, we canavoid collinearity issues among features for later analyses andexperiments.
We average the interlocutor frames over the window andobtain N averaged body language (N = 24) or speech (N =14) features of the interlocutor, denoted as {xi}Ni=1. The targetbody language feature of the participant is denoted as y, andthe correlation between two continuous variables is denotedas C(·). The correlation-based metric mRMRc is defined as:
mRMRc(i) = |C(xi, y)| − 1
N − 1
N∑j=1,j 6=i
|C(xi, xj)|. (1)
A higher mRMRc indicates that the corresponding inter-locutor feature is more correlated with the target feature, andless correlated with other interlocutor features. Hence, we areable to rank the interlocutor’s body language or speech featuresfor each target participant feature in each interaction case. Theabsolute value of the correlation |C(·)| is used in Eq. (1),because we are interested in both highly positive and highly

6
negative relations.Table IV presents the top-5 ranked body language features
of the interlocutor with respect to the target participant featuresin each case, associated with mRMRc values. Overall, wenotice that the types of highly ranked features differ acrossthe goal pairs, implying different coordination patterns fordifferent interaction types (attitudes, stances). Specifically, infriendly situations hand position features are more informa-tive than the others, suggesting the expressiveness of handgestures in these interactions. In contrast, many relative andabsolute velocities of arms, hands and feet, as well as faceorientation features are found informative in medium and highconflict cases, indicating more body motion and approaching-avoidance behaviors in these cases. For speech features, weobserve that pitch and energy of the interlocutor are moreinformative of the target participant features in medium andhigh conflict cases than in the friendly one (detailed results ofspeech features are omitted for the lack of space).
We also investigate the sign of the correlation between theinterlocutor features {xi}Ni=1 and the target body languagefeature y. Table IV presents the sign of the correlation betweeneach feature pair in front of the corresponding interlocutorfeature. Two feature variables with a positive correlation signhave a direct relationship with each other, while variables witha negative correlation sign have an inverse relationship. Forexample, during friendly interactions, a positive relationshipbetween two subjects’ leaning angles (cosLean) is observed,indicating that they tend to lean towards and approach eachother under such condition. In contrary, face orientations(cosFace) or leaning angles (cosLean) of the two interactingpartners are negatively related in the medium conflict cases,suggesting that a friendly participant is more likely to ap-proach, e.g., facing/leaning towards, while the unfriendly oneis more likely to avoid, e.g., facing/leaning away.
The analysis results that different coordination patternsare observed in different interaction conditions, reinforce ourhypothesis that conditioning on the goal-pairs reduces some ofthe dyad’s coordination variability in interactions. This alsohelps us to focus on modeling body language coordinationpatterns related to the specific interaction goals of friendlinessand conflict.
VII. FISHER KERNEL FRAMEWORK FOR BODYLANGUAGE MODELING
The observed correlation in the dyad’s behavior, as well asthe distinct coordination patterns under different interactiontypes, imply certain level of predictability of body languagein our goal-driven interactions of interest. We hence aim tomodel the dyad’s behavior coordination according to theirinteraction goals. We apply a Fisher kernel based methodologyfor estimating the participant’s body language patterns fromthe interlocutor’s speech and body language behavior. Agenerative method models the probability distribution of data,focusing on explaining the full relationships between variables.In contrast, a discriminative method focuses on learning func-tions that better discriminate across classes, therefore tends toyield better classification and regression results. The Fisher
kernel approach allows us to combine the benefits from thetwo types of techniques [34].
A. Generative Model: GMM-based Statistical Mapping
This GMM-based method estimates an optimal statisticalmapping, using Maximum Likelihood Estimation (MLE), froma set of observed continuous random variables to a targetcontinuous variable. This method was originally introduced forthe problem of articulatory to acoustic mapping [31]. It can beseen as a general way to produce a mapping between two con-tinuous multidimensional time series, therefore is suitable fora large range of problems. For example, it has been applied forcontinuous emotional state tracking in [33]. In this work, wefocus on the body language prediction problem, where the twomultidimensional time series are body language and speech (ifapplicable) features from two interacting participants.
We denote the interlocutor feature vector (i.e., the contextinformation within the window) at time t by xt, and thecorresponding target behavioral feature of the participant inthe interaction by yt. In [30], we model the joint probabilitydistribution of the dyad’s observed behavioral informationP (xt, yt) as a Gaussian Mixture Model (GMM),
P (xt, yt|θ(x,y)) =
M∑m=1
πmN (xt, yt;µ(xy)m ,Σ(xy)
m ), (2)
where M is the number of mixtures, πm, µ(xy)m and Σ
(xy)m
are the weight, mean vector and covariance matrix of the m-th component, and
∑Mm=1 πm = 1. The GMM-based mapping
method estimates the unknown target feature yt given xt usingMaximum Likelihood Estimation (MLE), by maximizing thecorresponding conditional distribution:
yt = arg maxyt
P (yt|xt,θ(x,y)). (3)
The conditional distribution of yt given the observation xt
is also represented as a GMM:
P (yt|xt,θ(x,y)) =
M∑m=1
βm,tP (yt|xt,m,θ(x,y)),
where βm,t is the occupancy probability P (m|xt,θ(x)),
βm,t =P (m|θ(x))P (xt|m,θ(x))∑Mn=1 P (n|θ(x))P (xt|n,θ(x))
=πmN (xt;µ
(x)m ,Σ
(x)m )∑M
n=1 πnN (xt;µ(x)n ,Σ
(x)n )
,
and according to conditional Gaussian distribution,
P (yt|xt,m,θ(x,y)) =P (yt,xt|m,θ(x,y))
P (xt|m,θ(x))
= N (yt; E(y)m,t,D
(y)m,t),
E(y)m,t = µ(y)
m + Σ(yx)m Σ(xx)−1
m (xt − µ(x)m ),
D(y)m,t = Σ(yy)
m −Σ(yx)m Σ(xx)−1
m Σ(xy)m .
The maximization procedure is achieved through Expec-tation Maximization with the minimum mean squared error

7
TABLE IVTOP-5 RANKED INTERLOCUTOR FEATURES ASSOCIATED WITH mRMRc VALUES IN EACH INTERACTION CASE.
cosBody cosLean cosFace dHands aVarml rVbody aVbody aVarmrFirendly
(-)dHands(0.039) (+)HAngle(0.111) (+)dHands(0.028) (+)dHands(0.053) (+)dHands(0.118) (+)aVhandr(0.199) (+)dHands(0.108) (+)dHands(0.114)(+)rhandz(0.008) (+)lhandz(0.054) (+)rhandx(-0.001) (-)lhandy(0.036) (+)aVarml(0.117) (+)aVhandl(0.193) (+)aVarml(0.098) (+)aVarml(0.113)(-)rhandx(0.006) (+)lhandy(0.032) (+)lhandz(-0.021) (+)pz(0.031) (-)lhandz(0.104) (+)rhandy(0.104) (-)lhandx(0.081) (+)lhandz(0.086)
(+)lhandy(-0.006) (+)cosFace(0.010) (+)rhandz(-0.025) (-)rhandy(0.030) (-)rhandz(0.079) (-)lhandx(0.079) (+)lhandz(0.064) (+)rhandz(0.053)(-)lhandz(-0.013) (+)cosLean(-0.025) (-)lhandx(-0.033) (+)py(0.019) (+)aVbody(0.064) (+)dHands(0.064) (+)rhandz(0.045) (+)aVbody(0.044)
Conflict(-)rVbody(0.06) (-)dHands(0.076) (-)rVbody(0.023) (-)cosLean(0.007) (+)aVarml(0.049) (-)rVbody(0.078) (+)aVbody(0.074) (+)aVarmr(0.084)
(-)rVfeetl(-0.011) (-)cosFace(0.064) (-)rVfeetl(0.008) (+)aVarml(-0.001) (+)aVbody(0.047) (-)aVhandr(0.078) (+)aVarmr(0.072) (+)aVbody(0.081)(-)aVhandl(-0.012) (+)aVarml(0.001) (-)aVhandr(0.004) (-)lhandz(-0.004) (+)aVarmr(0.047) (-)aVhandl(0.056) (+)aVarml(0.067) (+)aVarml(0.075)(-)rVfeetr(-0.019) (+)lhandx(-0.001) (-)rVfeetr(-0.003) (-)pz(-0.023) (+)aVfeetr(0.042) (+)px(0.048) (+)rVfeetr(0.052) (+)aVfeetl(0.071)
(-)aVhandr(-0.023) (+)rhandy(-0.017) (-)aVhandl(-0.004) (-)cosFace(-0.032) (+)aVfeetl(0.023) (-)rVfeetl(0.036) (-)aVfeetl(0.051) (+)aVfeetr(0.045)Medium Conflict (friendly participant)
(-)rVbody(0.008) (-)cosLean(0.265) (-)cosFace(0.027) (+)dHands(0.029) (+)aVarml(0.168) (+)rVbody(0.126) (+)aVbody(0.165) (+)aVarmr(0.189)(+)cosFace(0.002) (+)dHands(0.14) (+)aVarmr(0.018) (-)lhandz(0.013) (+)aVbody(0.156) (+)aVhandl(0.100) (-)aVarml(0.149) (+)aVbody(0.171)
(-)aVfl(-0.006) (+)pz(0.108) (+)rVhandl(-0.014) (-)aVarmr(0.008) (+)aVfeetr(0.093) (+)aVhandr(0.092) (+)aVarmr(0.115) (-)lhandx(0.121)(-)aVfr(-0.007) (-)rhandx(0.049) (-)rhandz(-0.019) (+)dHands(-0.017) (+)aVarmr(0.071) (-)rVfeetr(0.079) (+)aVfeetr(0.092) (+)aVarml(0.084)
(+)rhandz(-0.011) (-)aVbody(-0.019) (-)aVbody(-0.030) (+)lhandy(-0.024) (-)rVhandl(0.070) (-)rVfeetl(0.076) (+)aVfeetl(0.075) (-)rVhandl(0.082)Medium Conflict (conflictive participant)
(+)cosFace(0.039) (-)cosLean(0.242) (-)aVhandr(0.035) (+)cosFace(0.035) (+)aVarmr(0.171) (-)rVbody(0.213) (+)aVarmr(0.170) (+)aVarml(0.179)(-)cosBody(0.026) (-)rhandx(0.192) (-)lhandy(0.016) (+)dHands(0.023) (+)aVarml(0.160) (-)aVarmr(0.165) (+)rVbody(0.164) (+)aVarmr(0.163)(+)rhandz(0.018) (+)dHands(0.100) (-)cosBody(-0.027) (+)aVarmr(-0.029) (+)lhandy(0.132) (-)lhandy(0.162) (+)lhandy(0.144) (+)lhandy(0.135)(-)rVbody(-0.049) (-)cosBody(0.049) (-)rhandx(-0.049) (-)rhandz(-0.039) (+)rVbody(0.103) (-)rVfeetr(0.144) (+)aVarml(0.123) (+)aVhandl(0.085)(-)lhandy(-0.054) (-)rVbody(0.021) (-)rVbody(-0.057) (+)px(-0.069) (-)HAngle(0.089) (-)rVfeetl(0.123) (+)aVbody(0.085) (+)rVbody(0.082)
(MMSE) estimate as the initial value. For more details, werefer readers to [31]. To exploit the continuous nature ofthe observation and target variables, we incorporate dynamicinformation by augmenting xt and yt with their first temporalderivative estimates [31]. We denote this approach as MLE-based mapping.
B. The Fisher Kernel
The Fisher kernel was originally introduced in [34] and hasbeen applied to a variety of classification problems, such asimage categorization [35] and audio classification [36]. Ratherthan estimating the value of the target variable directly fromthe generative model, the Fisher kernel technique transforms asample data into the Fisher score from the generative model,i.e., a gradient vector of the log-likelihood. This represen-tation (gradient vector) can be in turn used as input to adiscriminative model. This technique is hence able to takeadvantage of both generative and discriminative approachesby embedding the generative information in the representationwhich can be conveniently exploited by discriminative meth-ods. Let P (xt|θ(x)) be a probability model of a sequence ofthe interlocutor’s behavior feature vectors X = {xt}Tt=1. Thenthe sample xt can be characterized by the gradient vector:
Ux = ∇θlogP (xt|θ(x)). (4)
This gradient vector Ux describes how the parameters ofthe generative model contribute to the process of generating aparticular sample. For the exponential family of distributions,the gradients also form sufficient statistics for the samples.Ux can be further normalized as the natural gradient Fx by
the Fisher information matrix I:
Fx = I−12Ux, (5)
I = Ex{UxUTx }, (6)
where I defines the Riemannian manifold Mθ of P (x|θ(x))[47], and the distance metric on Mθ measures a distancebetween P (x|θ(x)) and P (x|λ(x)) [34].
C. Fisher Kernels for Predicting Body Language
In our case, the probability distribution P (xt|θ(x)) ismodeled as GMM, and parameters θ(x) include the weights{π(x)
m }Mm=1, the component mean vectors {µ(x)m }Mm=1 and
covariance matrices {Σ(x)m }Mm=1. To save computation cost,
we assume the covariance matrices are diagonal, and denotethe variance vector by σ2
m = diag(Σ(x)m ). The log-likelihood
of the generative model is:
L(xt;θ(x)) = logP (xt|θ(x)). (7)
Let the index d denotes the d-th dimension of the interlocu-tor feature vector xt. Based on the generative model (GMM)of X = {xt}Tt=1, we can derive the gradient of the log-likelihood with respect to parameters θ(x):
∂L(xt;θ(x))
∂πm=βm,tπm− β1,t
π1(m ≥ 2), (8)
∂L(xt;θ(x))
∂µm(d)= βm,t(
xt(d)− µm(d)
σm(d)2), (9)
∂L(xt;θ(x))
∂σm(d)= βm,t(
(xt(d)− µm(d))2
σm(d)3− 1
σm(d)). (10)
The Fisher information matrix I can be approximated asa diagonal matrix with diagonal coefficients Iπm
, Iµm(d)
and Iσm(d), corresponding to the derivatives ∂L(xt;θ(x))
∂πm,
∂L(xt;θ(x))
∂µm(d) and ∂L(xt;θ(x))
∂σm(d) . Perronnin et al. approximated Iin a closed form and detailed derivations can be found in theappendix of [35]:
Iπm =1
πm+
1
π1, (11)

8
Iµm(d) =πm
σm(d)2, (12)
Iσm(d) =2πm
σm(d)2. (13)
According to Eq. (5) and (11) – (13), the final normalizedFisher score vector is:
Fx = diag([Iπm, Iµm(d), Iσm(d)])
− 12
· [∂L(xt;θ(x))
∂πm;∂L(xt;θ
(x))
∂µm(d);∂L(xt;θ
(x))
∂σm(d)]
=[I− 1
2πm
∂L(xt;θ(x))
∂πm; I− 1
2
µm(d)
∂L(xt;θ(x))
∂µm(d); I− 1
2
σm(d)
∂L(xt;θ(x))
∂σm(d)].
Once the interlocutor feature vector xt has been transformedinto Fx, we apply a discriminative regression model to predictthe corresponding target behavior yt. In our work, we useSupport Vector Regression (SVR) as the regression model [48]where the objective is to minimize the soft margin L2-loss.
VIII. EXPERIMENTS AND RESULTS
In this section, we present our experimental results ofpredicting body language of an interaction participant fromthe interlocutor’s body language and speech (if applicable).The prediction performance of each target body languagefeature marked with * in Table II is examined in all interactionconditions. In our experiments, we use 4-fold cross-validationby randomly leaving interactions out, and the cross-validationperformance is averaged over all the 4 folds. On average, weuse about 5040000 frames for training and 1680000 frames fortesting. For the MLE-based mapping, we use full covarianceGMMs which perform better compared to the diagonal ones.We apply the diagonal covariance GMMs to the Fisher kernelbased approach to simplify the gradient derivation procedure,as described in Section VII-C.
To examine the effectiveness of the interlocutor’s speechfeatures in predicting the participant’s body language, wecompare the performance with visual (the interlocutor’s bodylanguage behavior) only information, and with audio-visual(the interlocutor’s body language and speech behavior) infor-mation. For each target body language feature and for eachgoal pair, we compute the interlocutor’s context informationby selecting the top 6, 12, 18, 24 visual and the top 6, 12audio interlocutor features respectively, according to the listof ranked features in Section VI. When we use only visualfeatures for prediction, the set of 12 visual features performsthe best. When we use audio-visual information for prediction,the combination of 12 visual features and 6 audio featuresprovides the best performance, where the audio and visualfeatures are fused by concatenation at the feature level.
We use two measures to evaluate the prediction perfor-mance: correlation coefficient ρ to assess how well the trend ofbody language trajectories is captured, and RMSE to examinehow well the actual values are estimated,
ρ =
∑Tt=1(xt − x)(xt − ¯x)√∑T
t=1(xt − x)2√∑T
t=1(xt − ¯x)2, (14)
RMSE =
√√√√ 1
T
T∑t=1
(xt − xt)2, (15)
where T is the number of frames, xt is the observed bodylanguage value at time t, xt is the estimated value, and x, ¯x arethe average of the observed and estimated values, respectively.A higher ρ value indicates that the predicted body languagecurve follows better the trend of the observed trajectory, whilea lower RMSE value tells that the estimated values are closerto the observed ones.
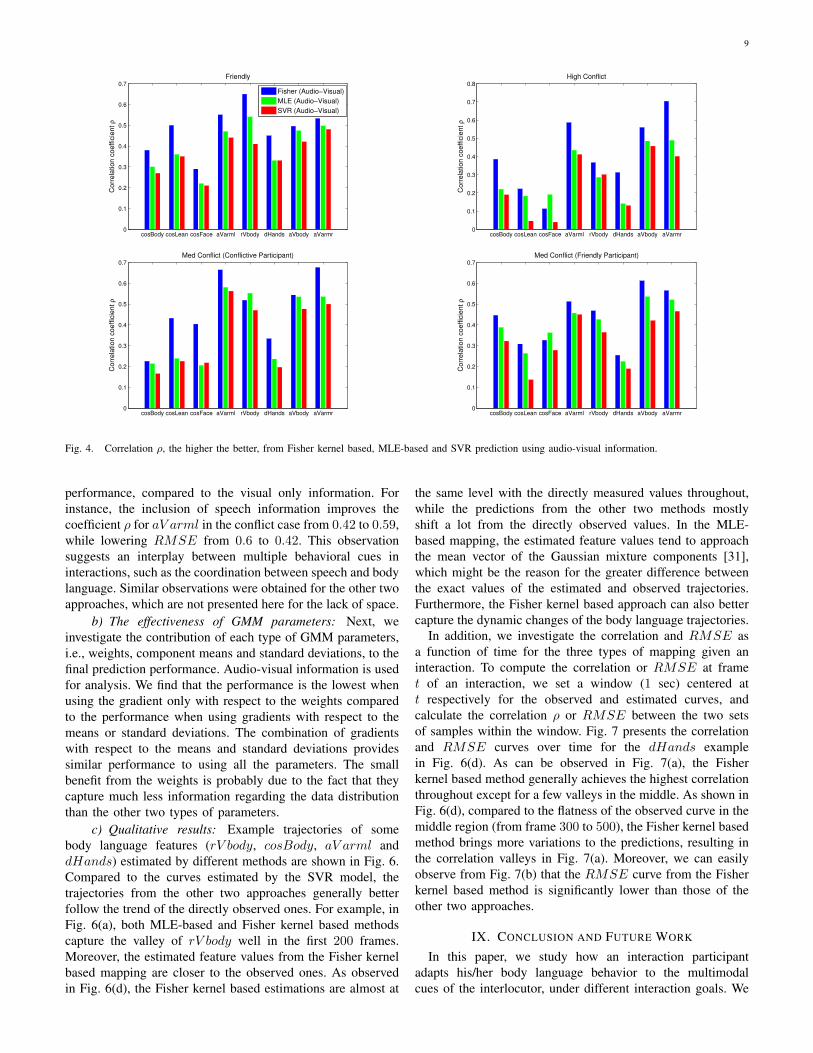
a) Prediction performance: Fig. 4 and 5 present theprediction performance evaluated by correlation and RMSErespectively, under different interaction conditions. In eachinteraction case, we compare the performance of the Fisherkernel based, MLE-based and the basic SVR approaches usingthe audio-visual interlocutor features. The x-axis in these twofigures represents the eight target features which have beenselected in Section IV-A, i.e., cosBody, cosFace, cosLean,aV arml, rV body, dhands, aV body and aV armr. The y-axis represents the correlation value in Fig. 4 and the RMSEvalue in Fig. 5 respectively.
In majority of interaction cases, the Fisher kernel basedmethod generally achieves better performance than the othertwo approaches. For example, the correlation coefficient ρand RMSE for rV body in the friendly case are about0.54 and 0.70 respectively by employing the MLE-basedmethod, and are about 0.41 and 0.52 with the SVR model.The performance improves to 0.72 (increase in ρ) and 0.44(decrease in RMSE) with the Fisher kernel based approach.We can further observe that MLE-based approach has a highercorrelation performance than the SVR model, while the SVRmodel generally outperforms the MLE-based approach interms of RMSE. The results show that the Fisher kernelbased method is helpful in both tracking the trends while si-multaneously reducing the difference of actual values betweenthe predicted and observed curves. This results from the factthat it leverages the advantages of both the generative anddiscriminative approaches.
In general, the velocity features of arms and body, i.e.,aV arml, rV body, aV body and aV armr, are better predictedthan the other features in all the conditions. A potential appli-cation of this result to future animation work would be to usethe predicted velocity values as constraints for body motionanimation of a virtual agent. This could make the animationmore consistent with the desired interaction type. We can alsoobserve that the friendly case has a better performance ofpredicting the orientation features, i.e., cosBody, cosLeanand cosFace, in terms of both correlation and RMSE. Therelatively higher predictability of orientation body language inthe friendly case indicates that people with friendly attitudestend to adapt more to the behavior of their interlocutors. Thisalso agrees with the observation in [49] that the degree ofvocal entrainment is higher for interaction participants with apositive affective state.
In Table V, we compare the performance with visual onlyand with audio-visual information respectively using the Fisherkernel based method. It is interesting to observe that thefusion of audio and visual information generally improves the
9
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Co
rre
latio
n c
oe
ffic
ien
t ρ
Friendly
Fisher (Audio−Visual)
MLE (Audio−Visual)
SVR (Audio−Visual)
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Co
rre
latio
n c
oe
ffic
ien
t ρ
High Conflict
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Co
rre
latio
n c
oe
ffic
ien
t ρ
Med Conflict (Conflictive Participant)
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Co
rre
latio
n c
oe
ffic
ien
t ρ
Med Conflict (Friendly Participant)
Fig. 4. Correlation ρ, the higher the better, from Fisher kernel based, MLE-based and SVR prediction using audio-visual information.
performance, compared to the visual only information. Forinstance, the inclusion of speech information improves thecoefficient ρ for aV arml in the conflict case from 0.42 to 0.59,while lowering RMSE from 0.6 to 0.42. This observationsuggests an interplay between multiple behavioral cues ininteractions, such as the coordination between speech and bodylanguage. Similar observations were obtained for the other twoapproaches, which are not presented here for the lack of space.
b) The effectiveness of GMM parameters: Next, weinvestigate the contribution of each type of GMM parameters,i.e., weights, component means and standard deviations, to thefinal prediction performance. Audio-visual information is usedfor analysis. We find that the performance is the lowest whenusing the gradient only with respect to the weights comparedto the performance when using gradients with respect to themeans or standard deviations. The combination of gradientswith respect to the means and standard deviations providessimilar performance to using all the parameters. The smallbenefit from the weights is probably due to the fact that theycapture much less information regarding the data distributionthan the other two types of parameters.
c) Qualitative results: Example trajectories of somebody language features (rV body, cosBody, aV arml anddHands) estimated by different methods are shown in Fig. 6.Compared to the curves estimated by the SVR model, thetrajectories from the other two approaches generally betterfollow the trend of the directly observed ones. For example, inFig. 6(a), both MLE-based and Fisher kernel based methodscapture the valley of rV body well in the first 200 frames.Moreover, the estimated feature values from the Fisher kernelbased mapping are closer to the observed ones. As observedin Fig. 6(d), the Fisher kernel based estimations are almost at
the same level with the directly measured values throughout,while the predictions from the other two methods mostlyshift a lot from the directly observed values. In the MLE-based mapping, the estimated feature values tend to approachthe mean vector of the Gaussian mixture components [31],which might be the reason for the greater difference betweenthe exact values of the estimated and observed trajectories.Furthermore, the Fisher kernel based approach can also bettercapture the dynamic changes of the body language trajectories.
In addition, we investigate the correlation and RMSE asa function of time for the three types of mapping given aninteraction. To compute the correlation or RMSE at framet of an interaction, we set a window (1 sec) centered att respectively for the observed and estimated curves, andcalculate the correlation ρ or RMSE between the two setsof samples within the window. Fig. 7 presents the correlationand RMSE curves over time for the dHands examplein Fig. 6(d). As can be observed in Fig. 7(a), the Fisherkernel based method generally achieves the highest correlationthroughout except for a few valleys in the middle. As shown inFig. 6(d), compared to the flatness of the observed curve in themiddle region (from frame 300 to 500), the Fisher kernel basedmethod brings more variations to the predictions, resulting inthe correlation valleys in Fig. 7(a). Moreover, we can easilyobserve from Fig. 7(b) that the RMSE curve from the Fisherkernel based method is significantly lower than those of theother two approaches.
IX. CONCLUSION AND FUTURE WORK
In this paper, we study how an interaction participantadapts his/her body language behavior to the multimodalcues of the interlocutor, under different interaction goals. We

10
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.5
1
1.5
RM
SE
Friendly
Fisher (Audio−Visual)
MLE (Audio−Visual)
SVR (Audio−Visual)
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.5
1
1.5
RM
SE
High Conflict
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.5
1
1.5
RM
SE
Med Conflict (Conflictive Participant)
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr0
0.5
1
1.5
RM
SE
Med Conflict (Friendly Participant)
Fig. 5. RMSE, the lower the better, from Fisher kernel based, MLE-based and SVR prediction using audio-visual information.
TABLE VCORRELATION ρ AND RMSE USING AUDIO-VISUAL AND VISUAL ONLY INFORMATION FOR THE FISHER KERNEL BASED APPROACH.
cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmr cosBody cosLean cosFace aVarml rVbody dHands aVbody aVarmrCorrelation Coefficient ρ
Friendly High ConflictA-V 0.38 0.50 0.29 0.55 0.65 0.45 0.50 0.53 0.39 0.22 0.11 0.59 0.37 0.31 0.56 0.70
Visual 0.39 0.40 0.29 0.43 0.53 0.32 0.49 0.50 0.34 0.10 0.04 0.42 0.36 0.19 0.53 0.66Medium Conflict (Conflictive Participant) Medium Conflict (Friendly Participant)
A-V 0.23 0.43 0.40 0.66 0.52 0.33 0.54 0.68 0.45 0.31 0.33 0.51 0.47 0.25 0.61 0.56Visual 0.14 0.43 0.32 0.51 0.53 0.23 0.49 0.52 0.37 0.20 0.33 0.52 0.34 0.18 0.48 0.52
RMSEFriendly High Conflict
A-V 0.46 0.89 0.40 0.53 0.39 0.67 0.51 0.51 0.85 0.43 0.47 0.46 0.41 0.56 0.44 0.43Visual 0.64 0.92 0.32 0.69 0.45 0.90 0.68 0.40 0.86 0.26 0.88 0.60 0.57 0.42 0.57 0.54
Medium Conflict (Conflictive Participant) Medium Conflict (Friendly Participant)A-V 0.14 0.43 0.32 0.51 0.52 0.13 0.28 0.33 0.94 0.45 0.56 0.88 0.75 0.88 0.51 0.94
Visual 0.44 0.58 0.20 0.66 0.72 0.69 0.83 0.75 0.99 0.56 0.85 0.94 0.81 0.95 0.76 0.97
adopt a variety of psychology-inspired features to describethe body language behavior of participants, including bodymotion, posture and relative orientation [3]. Our work focusis two-fold: 1) to systematically examine the coordinationbetween the participant’s body language and the interlocutor’smultimodal speech and body language behavior for the inter-action stances of friendliness and conflict; 2) to automaticallypredict an interaction participant’s body language from themultimodal behavior of the interlocutor for specific interactiongoals. The coordination analysis empirically corroborated thecorrelation between the dyad’s behavior. It also showed thatthe interlocutor features that are especially informative ofthe participant’s target body language features differ acrossinteraction types. This implies that the coordination patternsdepend on the overarching interaction goals. Further, we pro-posed a methodology that combines Gaussian Mixture Model(GMM) based statistical mapping, and Fisher kernels, inorder to automatically predict body language of an interactionparticipant from the multimodal speech and gesture cues of the
interlocutor. The experimental results showed that the Fisherkernel based approach generally outperforms the generativemodel of MLE-based mapping and the basic SVR model interms of both correlation coefficient and RMSE computedbased on the ground truth. These promising results suggest thatthere is a significant level of predictability of body languagein the examined goal-driven improvisations, which could beexploited for interaction-driven and goal-driven body languagesynthesis.
Experimental results also showed that the predictability oforientation body language is lower in the conflictive interac-tions than in the friendly ones. It is possible that conflictive be-havior cues are inherently more self-initiated whereas friendlyones are more synchronized with the interlocutor cues. We alsoobserved that the participant’s body language is influenced byother behavioral cues than merely the body language. Thiswas reflected in our experimental results, where the use ofboth speech and body language of the interlocutor improvedprediction performance over using only body language. Other

11
0 100 200 300 400 500−3
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
1.5
Frame
rVbody
Friendly
(a)0 100 200 300 400 500 600 700 800
−3
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
Frame
cosB
ody
High Conflict
(b)
0 100 200 300 400 500 600−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
3
Frame
aV
arm
l
Med Conflict (Friendly Participant)
(c)0 100 200 300 400 500 600 700
−3
−2.5
−2
−1.5
−1
−0.5
0
0.5
1
Frame
dH
ands
Med Conflict (Conflictive Participant)
Ground truth
Fisher
MLE
SVR
(d)
Fig. 6. Examples of body language features trajectories estimated by theFisher kernel based, MLE-based and SVR methods using the audio-visualinformation.
0 100 200 300 400 500 600 700−1.5
−1
−0.5
0
0.5
1
1.5
Frame
Co
rre
latio
n ρ
Fisher
MLE
SVR
(a) Correlation curve0 100 200 300 400 500 600 700
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Frame
RM
SE
Fisher
MLE
SVR
(b) RMSE curve
Fig. 7. Correlation (left) and RMSE (right) curves over time between theobserved values and estimations by the Fisher kernel based, MLE-based andSVR methods for the dHands example in Fig. 6(d).
cues, such as facial expressions, could also be an indicatorof the interlocutor’s behavior. A further detailed study of theinterplay between the various multimodal cues is a topic forfuture work.
Also, in the future, this work could be combined with moretraditional synthesis approaches that are based on discretebody language units. For example, the interlocutor multimodalcues could be used to generate constraints on a virtual agent’sbody language during data-driven, unit-based animation. Inparticular, the predicted velocities from the interlocutor infor-mation can be used as constraints for body motion animationfor a virtual agent, which could make the animation moreconsistent with the desired interaction type. We are currentlystudying how interaction attitudes are conveyed by handgesture dynamics based on data-driven gesture units [50]. Theresults in [50] demonstrate that the unit-based hand gesture dy-namics can well discriminate interaction attitudes and that suchderived gesture units can be used for gesture synthesis withattitudes. Our long-term goal is to work towards interaction-driven and goal-driven body language synthesis, e.g., creatingintelligent virtual characters with specific interaction goals
which would display expressive body language in responseto the human user’s audio-visual input behavior.
REFERENCES
[1] E. Delaherche, M. Chetouani, A. Mahdhaoui, C. Saint-Georges, S. Vi-aux, and D. Cohen, “Interpersonal synchrony: A survey of evaluationmethods across disciplines,” IEEE Transactions on Affective Computing,vol. 3, no. 3, pp. 349–365, 2012.
[2] A. Metallinou, C.-C. Lee, C. Busso, S. Carnicke, and S. Narayanan,“The USC CreativeIT database: A multimodal database of theatricalimprovisation,” in Proc. of Multimodal Corpora: Advances in Capturing,Coding and Analyzing Multimodality, 2010.
[3] J. Harrigan, R. Rosenthal, and K. Scherer, The new handbook of Methodsin Nonverbal Behavior Research. Oxford Univ. Press, 2005.
[4] P. Ekman, “Facial expression and emotion.” American Psychologist,vol. 48, no. 4, p. 384, 1993.
[5] M. Sheets-Johnstone, “Emotion and movement. a beginning empirical-phenomenological analysis of their relationship,” Journal of Conscious-ness Studies, vol. 6, no. 11-12, pp. 11–12, 1999.
[6] L. Conty, G. Dezecache, L. Hugueville, and J. Grezes, “Early bindingof gaze, gesture, and emotion: neural time course and correlates,” TheJournal of Neuroscience, vol. 32, no. 13, pp. 4531–4539, 2012.
[7] G. Castellano, S. D. Villalba, and A. Camurri, “Recognising humanemotions from body movement and gesture dynamics,” in Affectivecomputing and intelligent interaction, 2007, pp. 71–82.
[8] H. Gunes and M. Piccardi, “Bi-modal emotion recognition from ex-pressive face and body gestures,” Journal of Network and ComputerApplications, vol. 30, no. 4, pp. 1334–1345, 2007.
[9] D. Bernhardt and P. Robinson, “Detecting affect from non-stylised bodymotions,” in Affective Computing and Intelligent Interaction, 2007, pp.59–70.
[10] C. Busso, Z. Deng, M. Grimm, U. Neumann, and S. Narayanan, “Rigidhead motion in expressive speech animation: Analysis and synthesis,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 15,no. 3, pp. 1075–1086, 2007.
[11] S. Mariooryad and C. Busso, “Generating human-like behaviors usingjoint, speech-driven models for conversational agents,” IEEE Transac-tions on Audio, Speech, and Language Processing, vol. 20, no. 8, pp.2329–2340, 2012.
[12] C. Busso, Z. Deng, U. Neumann, and S. Narayanan, “Natural headmotion synthesis driven by acoustic prosodic features,” Journal ofComputer Animation and Virtual Worlds, vol. 16, pp. 283–290, 2005.
[13] M. Sargin, E. Erzin, Y. Yemez, A. Tekalp, A. Erdem, C. Erdem,and M. Ozkan, “Prosody-driven head-gesture animation,” in Proc. ofICASSP, 2007.
[14] S. Levine, C. Theobalt, and V. Koltun, “Real-time prosody-drivensynthesis of body language,” ACM Transactions on Graphics, vol. 28,no. 5, p. 172, 2009.
[15] S. Levine, P. Krahenbuhl, S. Thrun, and V. Koltun, “Gesture controllers,”ACM Transactions on Graphics, vol. 29, no. 4, p. 124, 2010.
[16] A. Beck, L. Canamero, and K. A. Bard, “Towards an affect space forrobots to display emotional body language,” in Proc. of RO-MAN, IEEE,2010, pp. 464–469.
[17] J. K. Burgoon, L. A. Stern, and L. Dillman, Interpersonal adaptation:Dyadic interaction patterns. Cambridge University Press, 2007.
[18] T. L. Chartrand and J. A. Bargh, “The chameleon effect: The perception-behavior link and social interaction,” Journal of Personality and SocialPsychology, vol. 76, pp. 893–910, 1999.
[19] P. Ekman, “Body position, facial expression and verbal behavior duringinterviews,” Journal of Abnormal and Social Psychology, vol. 63, 1964.
[20] R. Neumann and F. Strack, “” mood contagion”: the automatic transferof mood between persons.” Journal of personality and social psychology,vol. 79, no. 2, p. 211, 2000.
[21] A. Kendon, “Movement coordination in social interaction: Some exam-ples described,” Acta psychologica, vol. 32, pp. 101–125, 1970.
[22] L. Morency, I. de Kok, and J. Gratch, “A probabilistic multimodalapproach for predicting listener backchannels,” Journal of AutonomousAgents and Multi-Agent Systems, vol. 20, no. 1, pp. 70–84, 2010.
[23] D. Heylen, E. Bevacqua, C. Pelachaud, I. Poggi, J. Gratch, andM. Schroder, “Generating listening behaviour,” in Emotion-OrientedSystems, 2011, pp. 321–347.
[24] A. Metallinou, A. Katsamanis, and S. Narayanan, “A hierarchical frame-work for modeling multimodality and emotional evolution in affectivedialogs,” in Proc. of ICASSP, 2012.

12
[25] C. Lee, C. Busso, S. Lee, and S. Narayanan, “Influence of interlocutoremotion states in dyadic spoken interactions,” in Proc. of InterSpeech,2009.
[26] S. Basu, T. Choudhury, B. Clarkson, and A. Pentland, “Learning humaninteractions with the influence model,” MIT Media Lab: Cambridge,MA., 2001.
[27] C. Lee, A. Katsamanis, M. Black, B. Baucom, P. Georgiou, andS. Narayanan, “An analysis of PCA-based vocal entrainment measures inmarried couples’ affective spoken interactions,” in Proc. of InterSpeech,2011.
[28] B. Xiao, P. G. Georgiou, B. Baucom, and S. S. Narayanan, “Datadriven modeling of head motion toward analysis of behaviors in coupleinteractions,” in Proc. of ICASSP, 2013.
[29] B. Xiao, P. G. Georgiou, B. Baucom, and S. Narayanan, “Head motionsynchrony and its correlation to affectivity in dyadic interactions,” inProc. of ICME, 2013.
[30] Z. Yang, A. Metallinou, and S. Narayanan, “Towards body languagegeneration in dyadic interaction settings from interlocutor multimodalcues,” in Proc. of ICASSP, 2013.
[31] T. Toda, A. W. Black, and K. Tokuda, “Statistical mapping betweenarticulatory movements and acoustic spectrum using a gaussian mixturemodel,” Speech Communication, vol. 50, pp. 215–227, 2008.
[32] T. Toda, A. Black, and K. Tokuda, “Voice conversion based on maximumlikelihood estimation of spectral parameter trajectory,” IEEE Transac-tions on Audio, Speech and Language Processing, vol. 15, pp. 2222–2235, 2007.
[33] A. Metallinou, A. Katsamanis, and S. Narayanan, “Tracking continuousemotional trends of participants during affective dyadic interactionsusing body language and speech information,” Image and Vision Com-puting, 2012.
[34] T. S. Jaakkola and D. Haussler, “Exploiting generative models indiscriminative classifiers,” Advances in neural information processingsystems, pp. 487–493, 1999.
[35] F. Perronnin and C. Dance, “Fisher kernels on visual vocabularies forimage categorization,” in Proc. of CVPR, 2007, pp. 1–8.
[36] P. J. Moreno and R. Rifkin, “Using the fisher kernel method for webaudio classification,” in Proc. of ICASSP, vol. 6, 2000, pp. 2417–2420.
[37] V. Wan and S. Renals, “Speaker verification using sequence discriminantsupport vector machines,” IEEE Transactions on Speech and AudioProcessing, vol. 13, no. 2, pp. 203–210, 2005.
[38] I. Oikonomidis, N. Kyriazis, and A. A. Argyros, “Tracking the articu-lated motion of two strongly interacting hands,” in Proc. of CVPR, 2012,pp. 1862–1869.
[39] http://www.vicon.com.[40] S. M. Carnicke, Stanislavsky in Focus: An Acting Master for the Twenty-
First Century. Routledge, UK, 2008.[41] A. Kapur, A. Kapur, N. Virji-Babul, G. Tzanetakis, and P. F. Driessen,
“Gesture-based affective computing on motion capture data,” in AffectiveComputing and Intelligent Interaction, 2005, pp. 1–7.
[42] D. Ververidis and C. Kotropoulos, “Emotional speech recognition:Resources, features, and methods,” Speech Communication, vol. 48, pp.1162–1181, 2006.
[43] C. Busso, Z. Deng, S. Yildirim, M. Bulut, C. M. Lee, A. Kazemzadeh,S. Lee, U. Neumann, and S. Narayanan, “Analysis of emotion recog-nition using facial expressions, speech and multimodal information,” inProc. of ICMI, 2004, pp. 205–211.
[44] F. Bach and M. Jordan, “A probabilistic interpretation of canonicalcorrelation analysis,” Technical Report 688, Department of Statistics,University of California, Berkeley, 2005.
[45] M. Bartlett, “The statistical significance of canonical correlations,”Biometrika, vol. 32, no. 1, pp. 29–37, 1941.
[46] H. Peng, F. Long, and C. Ding, “Feature selection based on mu-tual information criteria of max-dependency, max-relevance, and min-redundancy,” IEEE Transactions on Pattern Analysis and MachineIntelligence, vol. 27, no. 8, pp. 1226–1238, 2005.
[47] S.-I. Amari, “Natural gradient works efficiently in learning,” Neuralcomputation, vol. 10, no. 2, pp. 251–276, 1998.
[48] A. J. Smola and B. Scholkopf, “A tutorial on support vector regression,”Statistics and computing, vol. 14, no. 3, pp. 199–222, 2004.
[49] C.-C. Lee, A. Katsamanis, M. P. Black, B. R. Baucom, A. Christensen,P. G. Georgiou, and S. S. Narayanan, “Computing vocal entrainment: Asignal-derived pca-based quantification scheme with application to affectanalysis in married couple interactions,” Computer Speech & Language,2012.
[50] Z. Yang, A. Metallinou, E. Erzin, and S. Narayanan, “Analysis ofinteraction attitudes using data-driven hand gesture phrases,” in Proc.of ICASSP, 2014.
Zhaojun Yang is a Ph.D. student in ElectricalEngineering at the University of Southern California(USC). She received her B.E. Degree in ElectricalEngineering from University of Science and Tech-nology of China (USTC) 2009 and M.Phil. Degree inSystems Engineering and Engineering Managementfrom Chinese University of Hong Kong (CUHK)2011. Her research interests include multimodalemotion recognition and analysis, interaction mod-eling and spoken dialog system.
Angeliki Metallinou received her Diploma in Elec-trical and Computer Engineering from the NationalTechnical University of Athens, Greece, in 2007,and her Master’s and PhD degrees in ElectricalEngineering in 2009 and 2013 respectively, fromUniversity of Southern California (USC). Between2007 and 2013 she was a member of the SignalAnalysis and Interpretation Lab (SAIL) at USC,working on spoken and multimodal emotion recogni-tion and analysis, and computational approaches forhealthcare applications, including autism. She also
interned at Microsoft Research working on state tracking for spoken dialogsystems. She is currently working as a research scientist at Pearson KnowledgeTechnologies, on automatic speech recognition, spoken language assessmentand written essay grading for education applications. Her research interestsinclude speech and multimodal signal processing, automatic speech recogni-tion, affective computing, machine learning, natural language processing, anddialog systems.
Shrikanth (Shri) Narayanan (StM’88-M’95-SM’02-F’09) is Andrew J. Viterbi Professor of En-gineering at the University of Southern California(USC), and holds appointments as Professor of Elec-trical Engineering, Computer Science, Linguisticsand Psychology and as the founding director ofthe Ming Hsieh Institute. Prior to USC he waswith AT&T Research from 1995-2000. At USChe directs the Signal Analysis and InterpretationLaboratory (SAIL). His research focuses on human-centered signal and information processing and sys-
tems modeling with an interdisciplinary emphasis on speech, audio, language,multimodal and biomedical problems and applications with direct societalrelevance. [http://sail.usc.edu]
Prof. Narayanan is a Fellow of the Acoustical Society of America andthe American Association for the Advancement of Science (AAAS) and amember of Tau Beta Pi, Phi Kappa Phi, and Eta Kappa Nu. He is also anEditor for the Computer Speech and Language Journal and an Associate Editorfor the IEEE TRANSACTIONS ON AFFECTIVE COMPUTING, APSIPATRANSACTIONS ON SIGNAL AND INFORMATION PROCESSING andthe Journal of the Acoustical Society of America. He was also previouslyan Associate Editor of the IEEE TRANSACTIONS OF SPEECH AND AU-DIO PROCESSING (2000-2004), IEEE SIGNAL PROCESSINGMAGAZINE(2005-2008) and the IEEE TRANSACTIONS ON MULTIMEDIA (2008-2011). He is a recipient of a number of honors including Best TransactionsPaper awards from the IEEE Signal Processing Society in 2005 (with A.Potamianos) and in 2009 (with C. M. Lee) and selection as an IEEESignal Processing Society Distinguished Lecturer for 20102011. Papers co-authored with his students have won awards at Interspeech 2013 SocialSignal Challenge, Interspeech 2012 Speaker Trait Challenge, Interspeech 2011Speaker State Challenge, InterSpeech 2013 and 2010, InterSpeech 2009-Emotion Challenge, IEEE DCOSS 2009, IEEE MMSP 2007, IEEE MMSP2006, ICASSP 2005 and ICSLP 2002. He has published over 600 papers andhas been granted sixteen U.S. patents.