analysis of japanese expressions and semantics based on
TRANSCRIPT

Research ArticleAnalysis of Japanese Expressions and Semantics Based on LinkSequence Classification
Yanyan Shi 1 and Yuting Liang2
1School of Foreign Languages, Harbin University of Commerce, Harbin Heilongjiang 150028, China2Department of Foreign Languages, East University of Heilongjiang, Harbin Heilongjiang 150066, China
Correspondence should be addressed to Yanyan Shi; [email protected]
Received 17 July 2021; Revised 8 August 2021; Accepted 17 August 2021; Published 6 September 2021
Academic Editor: Yuanpeng Zhang
Copyright © 2021 Yanyan Shi and Yuting Liang. This is an open access article distributed under the Creative CommonsAttribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original workis properly cited.
Based on locness corpus, this paper uses Wordsmith 6.0, SPSS 24, and other software to explore the use of temporalconnectives in Japanese writing by Chinese Japanese learners. This paper proposes a method of tense classification basedon the Japanese dependency structure. This method analyzes the results of the syntactic analysis of Japanese dependenceand combines the tense characteristics of the target language to extract tense-related information and construct amaximum entropy tense classification model. The model can effectively identify the tense, and its classification accuracyshows the effectiveness of the classification method. This paper proposes a temporal feature extraction algorithm orientedto the hierarchical phrase expression model. The end-to-end speech recognition system has become the development trendof large-scale continuous speech recognition because of its simplicity and efficiency. In this paper, the end-to-endtechnology based on link timing classification is applied to Japanese speech recognition. Taking into account thecharacteristics of Japanese hiragana, katakana, and Japanese kanji writing forms, through experiments on the Japanese dataset, different suggestions are explored. The final effect is better than mainstream speech recognition systems based onhidden Markov models and two-way long and short-term memory networks. This algorithm can extract the temporalcharacteristics of rules that meet certain conditions while extracting expression rules. These tense characteristics can guidethe selection of rules in the expression process, make the expression results more in line with linguistic knowledge, andensure the choice of relevant vocabulary and the structural ordering of the language. Through the analysis of time seriesand static information, we combine the time and space dimensions of the network structure. Using connectionist temporalclassification (CTC) technology, an end-to-end speech recognition method for pronunciation error detection and diagnosistasks is established. This method does not require phonemic information nor does it require forced alignment. Theextended initials and finals are the error primitives, and 64 types of errors are designed. The experimental results showthat the method can effectively detect the wrong pronunciation, the detection accuracy rate is 87.07%, the false rejectionrate is 7.83%, and the error rate is 87.07%. The acceptance rate is 25.97%. This method uses network information morecomprehensively than traditional methods, and the model is more effective. After detailed experiments, this articleevaluates the prediction effect of this method and previous methods on the data set. This method improves the predictionaccuracy by about 15% and achieves the expected goal of the work in this paper.
1. Introduction
Statistical language expression is one of the challenging fron-tier topics in the field of natural language processing, whichhas a wide range of application value and important com-mercial application prospects [1]. In recent years, statisticallanguage expression technology has developed rapidly, and
a series of impressive results have been achieved. However,in practical applications, how to effectively use linguisticknowledge in statistical language expression models toimprove the quality of expression is still a research hotspot[2]. At present, in the statistical machine expression, theresearch on tense is mainly limited to the aspect of tense rec-ognition, and there are few studies on the expression of tense
HindawiWireless Communications and Mobile ComputingVolume 2021, Article ID 3389643, 12 pageshttps://doi.org/10.1155/2021/3389643

[3]. Temporal information is important linguistic informa-tion, so the tense problem studied in this paper is trans-formed into a problem of incorporating tense and otherlinguistic knowledge into statistical expressions [4]. Drivenby many applications, the research on link prediction hasachieved fruitful results. At present, a method based on nodesimilarity is widely used, and the possibility of link genera-tion is predicted by the size of the similarity score [5]. Inthe static method, the network changes over time areignored. If only the network diagram under the most recenttime snapshot is used, when the network changes frequently,the prediction effect will drop sharply [6]. With the develop-ment of the Internet, there are more and more extensive sce-narios where links occur repeatedly, and the evolution ofnetworks is becoming more and more common. Static linkprediction methods are far from being able to adapt to theneeds of the new situation. Therefore, in recent years, infor-mation has gradually gained attention [7].
In recent years, with the rapid development of the Inter-net at home and abroad and the integration of the worldeconomic market, the amount of network data informationhas increased sharply, international exchanges have becomemore frequent, and the language expression market is broad[8]. Language expression, as an important way to overcomelanguage communication barriers, has a profound impact onthe promotion of political, economic, cultural, and militaryexchanges between countries [9]. Language expression is apowerful guarantee for active and healthy exchanges anddialogues between the two countries. However, traditionalmanual expression is inefficient and costly. For the hugenumber and increasing number of expression tasks, it canno longer meet the needs of society and the market [10].Language expression is the automatic expression of text,which is an important content in text processing, and mostapplications in text processing need to reason and filteraccording to the temporal relationship of text, such as timeextraction and automatic summarization, and tense can pro-vide them important clues, so tense plays an indispensablerole in these applications [11]. Similarly, the correct expres-sion of the tense in the text can convey the information ofthe source language as accurately as possible, but differentlanguages have greater differences in the expression of tense,which is a great challenge to the expression of the tense interms of language [12]. At the technical level, the existinglanguage expression methods are still mainly limited to theuse of rules to solve tense problems. These methods are inef-ficient and costly. Even statistical language expressionmethods cannot solve language well [13].
This article takes Japanese as the research object andstudies the expression of tense from the perspectives ofJapanese-Chinese. Japanese belongs to the cohesive languagefamily, and its tense is determined by the deformation of thepredicate ending, and the changes of the predicate endingare various. There are similar endings in different simulta-neous expressions, which leads to the low accuracy of thetense expression of statistical expressions. In response tothe above problems, this article proposes a statistical expres-sion method that incorporates tense characteristics. The dif-ference between a recursive network and a feedforward
network lies in this feedback loop that constantly uses itsown output at the last moment as input. The purpose ofadding memory to the neural network is the sequence itselfcontains information, and the recursive network can use thisinformation to complete tasks that the feedforward networkcannot complete. This sequence information is stored in thehidden state of the recursive network and is continuouslypassed to the previous layer, spanning many time steps,affecting the processing of each new sample. Human mem-ory will continue to cycle invisible in the body, affectingour behavior without showing a complete appearance, andinformation will also circulate in the hidden state of therecursive network. This method uses a deep control gatingfunction to connect multilayer LSTM units and introduceslinear correlation between the upper and lower layers inthe recurrent neural network, which can build a deeper voicemodel. At the same time, we use the training criteria of link-ing time series classification for model training. We build anend-to-end speech recognition system to solve the hiddenMarkov model’s need to force the alignment of labels andsequences and use CTC training criteria to realize an end-to-end speech system, by combining with the traditionalLSTM-CTC model. The model is compared to verify theeffectiveness of the deep LSTM neural network [14, 15] inspeech recognition.
2. Related Work
Rule-based expression technology is highly dependent onhumans. It mainly relies on linguists to summarize rulesand manually compile the rules. The workload is large, andproblems such as rule conflicts are prone to occur, and it isdifficult to cope with large-scale expression tasks. Thecorpus-based method pays more attention to automaticallyobtaining rules from a large-scale corpus, which has theadvantages of language independence and automatic knowl-edge acquisition, which greatly improves the efficiency ofexpression. With the increase of the amount of networkinformation, the rule-based method has become more andmore limited, and the corpus-based method has more andmore obvious advantages, has developed rapidly, and hasachieved a series of remarkable results [16]. Allen et al.[17] proposed an expression model based on word align-ment, which entered the development stage of languageexpression and marked the birth of modern statisticalexpression methods. McCune [18] proposed the phraseexpression model, which greatly improved the expressioneffect. This phrase expression model used a logarithmic lin-ear model and its weight tuning method, which has made agreat contribution to the expression performance improve-ment of the phrase expression model. At the same time,due to its strong ease of use and other advantages, the phraseexpression model has begun to attract wide attention fromall walks of life. In practical applications, the online transla-tion systems of large domestic and foreign Internet compa-nies such as Baidu and Google all use this model asbackend support, which has certain commercial value. How-ever, this model uses phrases as the basic processing unit,and its ability to adjust order is limited, and the quality of
2 Wireless Communications and Mobile Computing

long sentences is not good, which needs further improve-ment. Izard et al. [19] introduced the concept of generalizedvariables. A hierarchical phrase expression model was furtherproposed, which used hierarchical phrase rules to achieveexpression, which made the entire expression process morehierarchical, to a certain extent, alleviates the problem of insuf-ficient global ordering ability in the phrase expression model,and solved other problems of ordering. The method of theproblem has a certain guiding effect. As an expression modelbased on formal grammar, this model introduces more effec-tive information for the expression process. Similarity can bedescribed by many methods. According to the type of infor-mation used, link prediction mainly includes similaritymethods based on network topology and similarity methodsbased on node attributes. The network topology can bedivided into local information and global information. Asa-hara and Matsumoto [20] also considered the number ofneighbors in common neighbors. Later, these neighbor-based methods were also extended, not only consideringwhether there is a link between neighbors but also the numberof links, that is, the addition based on the basic neighbormethod. In addition to neighbor-based methods, global infor-mation was also often used for link prediction, such as pathinformation between nodes. Another way to consider globalinformation is the random walk model. This model can beconsidered a general expression based on the neighbormethod and the path-based method, which can better reflectthe network topology information. The similarity methodbased on node attributes is rarely used solely for link predic-tion. Because on the one hand, node attributes are often usedin specific types of networks, and the processing is relativelycomplicated; on the other hand, node attributes may be sub-jective and sometimes not as reliable as the network topology.However, node attributes and network topology, respectively,reflect information from different aspects of the network,and combining the two can often achieve a better effect. Inaddition to node attributes and network topology, communityinformation has recently been shown to be helpful for linkprediction. At present, various types of information in net-works such as local information, global information, and com-munity information are often targeted at specific fields, andthe relatively comprehensive and comprehensive similarityscore model is not very satisfactory.
Since tenses have different and complex expressions indifferent languages, it is very difficult to maintain the sametense information from the source language to the target lan-guage in terms of expression. In the machine expression sys-tem based on intermediate language conversion [21], thetense information of the source language was first convertedinto language-independent abstract expressions. For exam-ple, in the study of Chinese-Japanese tense expression,Cheng et al. [22] proposed Lexical Conceptual Structures(LSC) based on two levels of knowledge expression are usedto assist language expression, combining tense and lexicalsemantics, and through some rule transformations in theexpression process, it can generate Japanese sentences withcorrect tenses for Chinese sentences expression. However,the above research is based on a language expression systembased on intermediate language conversion. It is a rule-based
language expression. It is not only highly subjective but alsohighly dependent on language types, and it is difficult toexpand. It is also significantly different from the existingSMT system. On this basis, others jointly build a temporalmodel with the context of the target end. First, they syntac-tically analyzed the bilingual parallel corpus and used thesyntactic analysis result to automatically extract the tempo-ral information contained in the sentence, and then accord-ing to the temporal continuity and text classification, atemporal model based on the classifier was proposed. Inthe SMT system, someone proposed a corpus-based methodto study Japanese and Chinese tense expression, but mainlydemonstrated that bilingual corpus contains rich tense infor-mation, which can help solve the problem of Japanese andChinese tense expression. On this basis, we can considerintegrating bilingual tense information to solve the problemof tense expression [23]. In the statistical language expressionsystem, on the one hand, there is less research on the expres-sion of tense. On the other hand, the expression research onthe integration of linguistic knowledge is in its infancy. Vari-ous methods need to be further improved. The full use of lin-guistic knowledge in the research of machine translation hasimportant value and also has important guiding significancefor the research of tense in this article.
3. Japanese Language Expression and SemanticModel Construction Based on LinkTiming Classification
3.1. Link Timing Classification. Time series has achievedgood results in describing time information. There are twomain ways to represent the network information of eachtime period in history as discrete time series diagrams andlink predictions. Link timing classification (CTC) is mainlyused to deal with timing classification tasks, especially whenthe alignment result between the input signal and the targetlabel is unknown. Link timing classification technology canperform label prediction at any point in the entire inputsequence, which solves the problem of forced alignment intraditional speech recognition. The criterion for neural net-work training by linking time series classification technologyis called the CTC criterion. Figure 1 shows the hierarchicaldistribution of link timing classification.
The existing information of the static method is a graph.According to the link between nodes x and y and othernodes, the similarity scores of x and y are calculated to pre-dict the current unlinked node pair (x, y) will be generated inthe next time period possibility of linking.
X t½ � =1 0 00 ⋯ 00 0 t
2664
3775, ð1Þ
Y xð Þ = x 1ð Þ + 2 × x 2ð Þ+⋯+t × x tð Þ: ð2ÞOne is the time series of the number of links between
nodes, which only predicts the future link situation basedon the past links between nodes, and achieves similar results
3Wireless Communications and Mobile Computing

to the static method. Combining it with the static methodcan further improve the prediction effect.
C t, sð Þ = t ∈ A : s tð Þ = t ∗ t − 1ð Þ, t⟶Nf g: ð3Þ
For new links, because the time series of link times islost, the hybrid model is downgraded to a static similaritymethod; in addition, the hybrid model multiplies the finalstatic method prediction value with the time series predic-tion value, which makes it difficult to describe the networkin each time period.
z =i × x tð Þ + x t − 1ð Þð Þ, t > i,i × x tð Þ − x t − 1ð Þð Þ, t < i,
(ð4Þ
H x½ � = x 1ð Þ⋯ x tð Þ½ � ×x tð Þ⋯
x 1ð Þ
2664
3775: ð5Þ
The existing information of this method is from the firsttime period in history to the current time period t, a total oft pictures. According to (x, y) historical link situation(including the bold dashed line at time t), we establish aunary time series model to predict the link situation in thenext time period. The probability number of links is greaterthan 0 is the link probability.
p t ∣ xð Þ −YTt=1
H xð Þ × x tð Þ − �xð Þ = 0, ð6Þ
∂ ln p z ∣ xð Þ∂x
× p z ∣ xð Þ ×H xð Þ = 1: ð7Þ
However, because the model is too simple and fails todescribe the relationship between the similarity score andthe number of links, the changing laws of the two are differ-ent, and the results obtained by the mixed model are not asgood as just using the similarity score time series.
3.2. Temporal Feature Extraction. Time series is a sequenceof ordered data recorded in chronological order. We observethe time series in order to find the law of its developmentand change, and then, we select a suitable model to fit theobservations to complete the prediction of the future valuebased on the model. The application of time series analysisand forecasting methods is very rich, such as forecastingthe load of the power system and the price of a stock inthe stock market.
Figure 2 shows the flow of sentence temporal featureextraction. The first part is the input layer, which acceptsthe acoustic characteristics of the input. As a branch ofmathematical statistics, time series has its own set of analysisand prediction methods. In the unary time series model, inorder to predict the future value, the historical value of theseries itself is the research focus. Different from the unitarytime series, in addition to its own influence, the changinglaws of some series are also related to other series. The nextis the batch normalization layer and the zero-filling layer.The reason for adding the zero-filling layer is to ensure batchprocessing with the same length; the second part is convolu-tion, which contains 10 CNN layers, 5 maxpool layers, thenthe batch normalization layer, and the dropout layer. Thefunction of the dropout layer is to prevent overfitting andimprove generalization ability during training; the third partis the fully connected layer (dense layer), each neuron in thefully connected layer is connected with all neurons in theprevious pooling layer, and the fully connected layer inte-grates the classification features of the convolution and
Link 1
A B
A BSimilarity score
Similarity score
Y1
Likelihoodprediction
LikelihoodpredictionTime series
Time period networkinformation
Historical linksituationSememe analysis
End-to-end speech recognition with a single deepnetwork architecture
Module-basedarchitecture
Dynamic adjustmentparameters
X1 X1
X1 X1
X1 X1
X1
X1
X1 Link 2
Link 1
Link 2
Link 1
Link 2
Link 1
Link 2
Y1
Y1
Y1
Y1
Y1
Y1
Y1
Y1
Figure 1: Hierarchical distribution of link timing classification.
4 Wireless Communications and Mobile Computing

pooling layers and distinguishes them. The activation func-tion of each neuron uses the linear rectification function.The output value of the last layer is passed to the softmaxlogistic regression for classification. Finally, the CTC outputlayer is used to generate the predicted phoneme sequence.This method also tries to compare the similarity score calcu-lated by the entire network between nodes and the actualoccurrence between nodes. Combining the number of links,the hybrid model normalizes the similarity score of eachtime period and adds the number of links, which is used asthe input of the time series.
3.3. Phrases and Semantic Fusion. The language model of theencoder-decoder structure [24] integration is only reflectedin the prediction of the current moment by using the predic-tion of the previous moment during decoding. There are cer-tain limitations and cannot make full use of linguisticinformation. Therefore, in order to explicitly introduce itin the decoding process in the language model, we furtherimprove the performance of speech recognition. Based onthe transformer structure, this article removes the decoderpart and combines the encoder with the link timing classifi-cation as the end-to-end model used in this article. The mainbody of the entire model is composed of several identicalcoding layers stacked, and each coding layer is divided intotwo parts: multihead attention [25, 26] and feed-forwardnetwork. The main method of current speech recognitionis to train the acoustic model by combining the recurrentneural network (RNN) and its variants with the hidden Mar-kov model. The cyclic neural network uses the past informa-tion to input the output of the hidden layer at the lastmoment into the hidden layer at the current moment,retaining the previous information. As a time series, thespeech signal has a strong context dependence, so the recur-
rent neural network is quickly applied to speech recognition.Theoretically, RNN can handle arbitrarily long sequences,but due to the disappearance of the gradient, the RNN can-not use the information at a longer time. A residual connec-tion is added after each part, and then, layer normalization isperformed. Figure 3 shows the three-dimensional histogramof the residuals in the coding layer of the language model. Inaddition, the model also includes a downsampling andupsampling module, a position encoding module, and anoutput layer. The output adopts the link timing classificationcriterion and predicts a label for each frame of speech tominimize the CTC loss function.
The “multihead attention” module is composed of sev-eral identical layers stacked, and each layer is a self-attention mechanism that uses scaled dot-product attention(scaled dot-product attention). Self-attention is a mecha-nism that uses the connection between different positionsof the input sequence to calculate the input representation.Specifically, it has three inputs, queries, keys, and values,which can be understood as the speech feature after encod-ing. The output of query is obtained by the weighted sum-mation of value, and the weight of each value is calculatedby the design function of query and its related key. The“multihead” mechanism is used to combine multiple differ-ent layers. The self-attention representation of that is calcu-lated, and h represents the number of “heads”. Figure 4shows the fusion of linguistic expressions and sememe char-acters. Combining the characters in the word with spaces asseparators to form character pairs, we combine word fre-quency and count all character pairs and their appearancefrequency. We select the pair of characters with the highestfrequency, remove the spaces in the middle, and mergethem. The resulting character sequence is used as a newsymbol to replace the original character pair.
1 2
3 4
A B
C D
A A A A
B B B B
C C C C
D D D D
1 1 1 1
2 2 2 2
3 3 3 3
4 4 4 4
Output tag sequenceInput tag sequence
Link time sequence classification expression sememe
Link
Link
Cycl
icla
yer
Cycl
icla
yerTime series
forecast analysisSentence input
layerSentence output
layer
Figure 2: Sentence temporal feature extraction process.
5Wireless Communications and Mobile Computing

Then, we repeat the two steps of counting the frequencyof character pairs and merging the most frequent characterpairs until the number of merging reaches the specifiednumber. We output the merged character pairs accordingto the statistical frequency from high to low, then use thecharacter pair list generated in the previous section. The cor-pus that needs to be processed is segmented. When segment-ing is performed, the same word is used as the unit, and thecharacters are first segmented. Then, the character pairs aremerged in the order of the frequency of appearance in thecharacter pair list from high to low. Finally, it is retained thatdoes not appear in units in the list of character pairs andindividual characters not participating in the merging.
4. Application and Analysis of JapaneseLanguage Expression and Semantic ModelBased on Link Timing Classification
4.1. Link Timing Score Prediction. In the LSTM-based end-to-end speech recognition system, we use a bidirectional long andshort-term memory network to model the timing of speechfeatures, and the output uses the link timing classification cri-terion to directly predict the label sequence. In this experi-ment, we use 3 hidden layers. They are combined with a
LSTM network with 1024 hidden nodes in each layer and108-dimensional filterbank features for acoustic model train-ing. The modeling unit uses ub-word units. The 3-gram lan-guage model is combined when decoding. Figure 5 showsthe sentence level accuracy deviation box type figure. In rec-ognition, in order to use the knowledge of Japanese linguis-tics to further improve the recognition performance, wecombined the traditional language model when decodingand unified the dictionary, language model, and acousticmodel to decode, and the system recognition performancewas significantly improved. On the Japanese data set, usingthe algorithm recommended in this article, the recognitionperformance is significantly better than the current main-stream hybrid system based on the hidden Markov modeland the end-to-end model based on the bidirectional longand short-term memory network. In order to reduce thememory occupied during model training and speed up thetraining, we first downsample the original speech featureframe and, then, encode it through the linear layer. At thesame time, because the output adopts the CTC criterion, itis necessary to predict a label for each frame of speech, sothe speech feature is performed before the output layerOne-step upsampling operation restores the length of thespeech frame to the original length. In this way, while speed-ing up the calculation and reducing memory requirements, it
0
0.2
0.4
0.6
Resid
ual v
alue
1
0.8
1
2Link index
D3
C
Text group4 B
A
Figure 3: Three-dimensional histogram distribution of residuals in the coding layer of the language model.
6 Wireless Communications and Mobile Computing

also ensures the accuracy of the model and improves the rec-ognition performance.
For the CTC-based end-to-end model described in thisarticle, in the experiment, we use 6 layers of coding, the“multihead” attention part uses 8 “heads,” and the original
speech features are 108-dimensional filterbank features. Fordownsampling, the dimension after encoding is 512 dimen-sions, and then, the position-coding information is added asthe input of the network. The feedforward network dimen-sion uses 1024 dimensions. Algorithm utilization for the idea
Time series batch normalization layer
Query Key Value
B CA
0 0 0 1
0 0 1 0
0 1 0 0
1 0 0 0
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1
0 1 0 0
0 1 0 0
0 0 1 0
0 0 1 0
0 1 0 1 0 0 1 1
Sentence sememe segmentation
Node 1
Node 2
Node 3
Static prediction
Excitation function
Number of links
Figure 4: The fusion of expressions and semantic characters.
1 2 3 4 5 6Statement group
0
0.2
0.4
0.6
0.8
1
Accu
racy
dev
iatio
n (%
)
Figure 5: Box plot of sentence level accuracy deviation.
7Wireless Communications and Mobile Computing

of the greedy algorithm is an efficient data compressionalgorithm. In the process of data compression, the BPE algo-rithm searches for the byte pair that appears most frequentlyin the program code on the target memory (RAM) page; thesingle-byte token that appears in the specific code replacesthe byte pair. In order to compare with the traditionalHMM-based Mandarin speech recognition method, theHMM-based Mandarin recognition is performed under thesame data set, in which the acoustic features use 39-dimensional MFCC features (dimensional cepstral coeffi-cient features, dimensional energy feature, and its first andsecond order differences), the word error rate based onmonophones in the experimental results is 50.9%, which isworse than the results in the text, indicating that the methodin the text is superior to the monophone based on HMM inMandarin speech recognition method. The method in thetext does not require the use of pronunciation dictionariesand language models, which simplifies the implementationprocess of the speech recognition system. We repeat thesetwo steps until all byte pairs are replaced or no byte pairsappear with a frequency greater than 1, and finally, the com-pressed data is output. With the dictionary containing all thereplaced byte pairs, the dictionary is used to restore the data.
4.2. Expression and Semantic Simulation. This article con-ducts experiments on the King-ASR-450 data set. The data-base collects 79,149 voice data in a quiet environment, whichis 121.3 hours long. The dictionary formed by the tran-scribed text contains a total of 66027 Japanese words. Allvoice data are 8KHz sampling rate, 16bit, single-channelformat. In the experiment, 76.6 k voice data (117.45 h) wereselected as the training set, 0.5 k voice data (0.77 h) wereused as the development set, and 2.0 k speech data (3.07 h)are as the test set. This paper uses them as the experimental
platform to compare the experimental effects under differentmodels and explore the improved the impact of the unit onthe recognition performance. In the experiment, we builtthree systems for comparison. The first is the mainstreamLSTM-HMM-based baseline system, and the second systemis the LSTM-based CTC end-to-end recognition system, andthe third is the CTC end-to-end recognition system based onLSTM. The system is the SA-CTC end-to-end recognitionsystem proposed in this paper. Figure 6 shows the compari-son of the word data recognition error rate.
In the experiment, 39 Mel-Frequency Cepstral Coeffi-cients (MFCC characteristics) are used as the input signalof the GMM-HMM hybrid system. In the GMM-HMM sys-tem, the final number of bound states is 3334 throughGaussian splitting and decision tree clustering. The modelforcibly aligns the training data to obtain frame-level labels,which are used as training data for the subsequent neuralnetwork. In the LSTM-HMM training, 108-dimensional fil-terbank features are used for training, and 40 frames ofspeech data are used before and after the current frame toobtain the before and after information. The network has 3hidden layers, the hidden layer nodes are 1024, and themodeling unit is the bound 3334 states. Considering theimpact of resource sparseness on the experimental results,we use a pronunciation dictionary and use phonemes asmodeling units to conduct experiments. There are 237 pho-nemes in the data set. After blank is added, the output nodeof the network is 238, and the frequency of each phoneme iscounted. The relative balance is better, and the trainedmodel should be more robust. The 3-gram language modelis combined when decoding.
In order to evaluate the performance of the pronuncia-tion error detection system, the article refers to the hierar-chical evaluation structure developed in the literature, and
100 200 300 400 500 600 700Sentence training set
0
2
4
6
8
10
Sam
plin
g er
ror r
ate (
%)
Sample 1Sample 2
Figure 6: Line chart of comparison of term data recognition error rate.
8 Wireless Communications and Mobile Computing
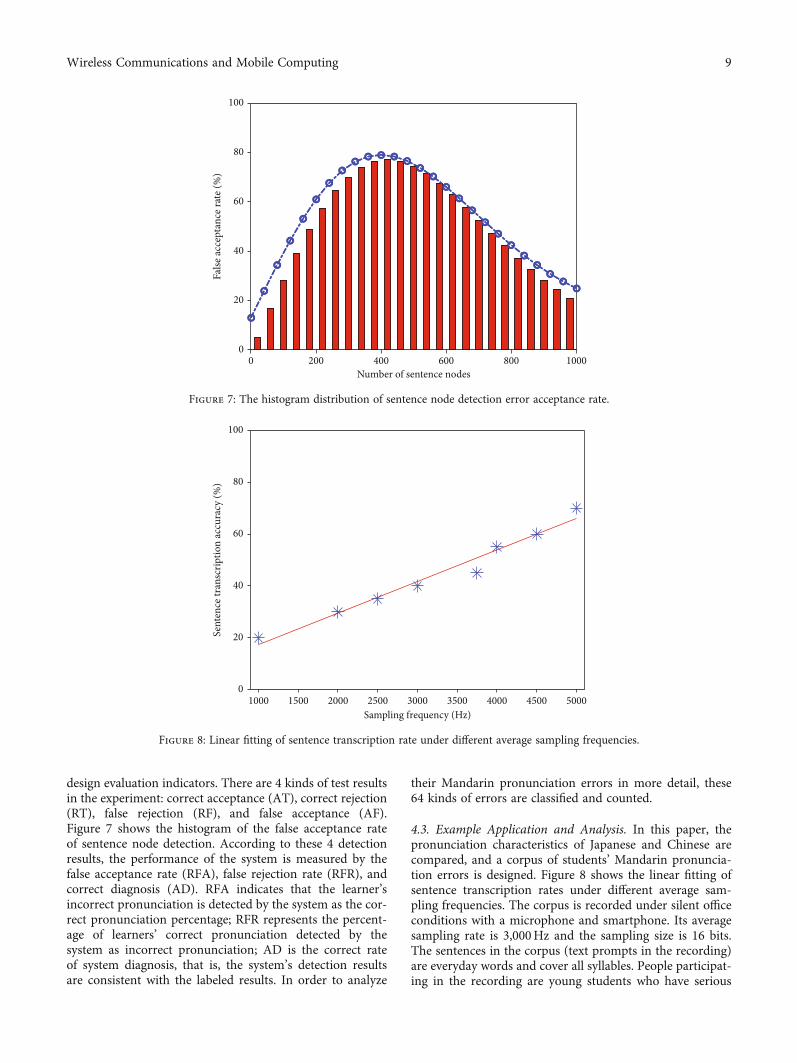
design evaluation indicators. There are 4 kinds of test resultsin the experiment: correct acceptance (AT), correct rejection(RT), false rejection (RF), and false acceptance (AF).Figure 7 shows the histogram of the false acceptance rateof sentence node detection. According to these 4 detectionresults, the performance of the system is measured by thefalse acceptance rate (RFA), false rejection rate (RFR), andcorrect diagnosis (AD). RFA indicates that the learner’sincorrect pronunciation is detected by the system as the cor-rect pronunciation percentage; RFR represents the percent-age of learners’ correct pronunciation detected by thesystem as incorrect pronunciation; AD is the correct rateof system diagnosis, that is, the system’s detection resultsare consistent with the labeled results. In order to analyze
their Mandarin pronunciation errors in more detail, these64 kinds of errors are classified and counted.
4.3. Example Application and Analysis. In this paper, thepronunciation characteristics of Japanese and Chinese arecompared, and a corpus of students’ Mandarin pronuncia-tion errors is designed. Figure 8 shows the linear fitting ofsentence transcription rates under different average sam-pling frequencies. The corpus is recorded under silent officeconditions with a microphone and smartphone. Its averagesampling rate is 3,000Hz and the sampling size is 16 bits.The sentences in the corpus (text prompts in the recording)are everyday words and cover all syllables. People participat-ing in the recording are young students who have serious
0 200 400 600 800 1000Number of sentence nodes
0
20
40
60
80
100
False
acce
ptan
ce ra
te (%
)
Figure 7: The histogram distribution of sentence node detection error acceptance rate.
1000 1500 2000 2500 3000 3500 4000 4500 5000Sampling frequency (Hz)
0
20
40
60
80
100
Sent
ence
tran
scrip
tion
accu
racy
(%)
Figure 8: Linear fitting of sentence transcription rate under different average sampling frequencies.
9Wireless Communications and Mobile Computing
accents in their pronunciation. The recorded corpus is cross-labeled by 10 graduate students majoring in phonetics.When there are inconsistencies, phonetics experts will beasked to judge them. This corpus is only used for testing.
In the DNN-based acoustic model modeling process, 75-dimensional fiherbank features are used, and the networktrained with 10000 h Japanese corpus is used as the initialnetwork, which effectively avoids the local optimal solutionin network training. The DNN model [27–29] includes 6hidden layers, each layer includes 2,048 nodes, and the out-put layer includes 6,004 nodes. In order to improve the dis-tinguishing degree of the DNN model, the input layer adoptsthe framing operation, and the input nodes are 825 (11 × 75)nodes. In addition, the HMMs acoustic model is forced toalign the training data to obtain frame-level annotationsfor DNN training [30, 31].
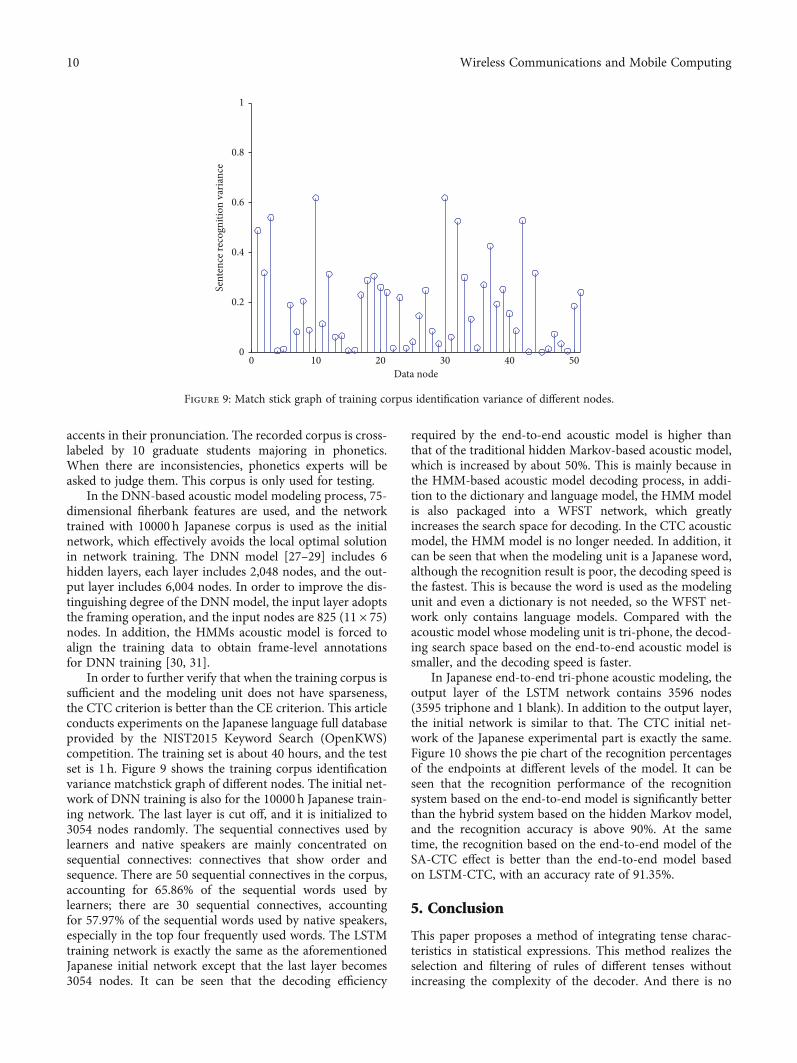
In order to further verify that when the training corpus issufficient and the modeling unit does not have sparseness,the CTC criterion is better than the CE criterion. This articleconducts experiments on the Japanese language full databaseprovided by the NIST2015 Keyword Search (OpenKWS)competition. The training set is about 40 hours, and the testset is 1 h. Figure 9 shows the training corpus identificationvariance matchstick graph of different nodes. The initial net-work of DNN training is also for the 10000h Japanese train-ing network. The last layer is cut off, and it is initialized to3054 nodes randomly. The sequential connectives used bylearners and native speakers are mainly concentrated onsequential connectives: connectives that show order andsequence. There are 50 sequential connectives in the corpus,accounting for 65.86% of the sequential words used bylearners; there are 30 sequential connectives, accountingfor 57.97% of the sequential words used by native speakers,especially in the top four frequently used words. The LSTMtraining network is exactly the same as the aforementionedJapanese initial network except that the last layer becomes3054 nodes. It can be seen that the decoding efficiency
required by the end-to-end acoustic model is higher thanthat of the traditional hidden Markov-based acoustic model,which is increased by about 50%. This is mainly because inthe HMM-based acoustic model decoding process, in addi-tion to the dictionary and language model, the HMM modelis also packaged into a WFST network, which greatlyincreases the search space for decoding. In the CTC acousticmodel, the HMM model is no longer needed. In addition, itcan be seen that when the modeling unit is a Japanese word,although the recognition result is poor, the decoding speed isthe fastest. This is because the word is used as the modelingunit and even a dictionary is not needed, so the WFST net-work only contains language models. Compared with theacoustic model whose modeling unit is tri-phone, the decod-ing search space based on the end-to-end acoustic model issmaller, and the decoding speed is faster.
In Japanese end-to-end tri-phone acoustic modeling, theoutput layer of the LSTM network contains 3596 nodes(3595 triphone and 1 blank). In addition to the output layer,the initial network is similar to that. The CTC initial net-work of the Japanese experimental part is exactly the same.Figure 10 shows the pie chart of the recognition percentagesof the endpoints at different levels of the model. It can beseen that the recognition performance of the recognitionsystem based on the end-to-end model is significantly betterthan the hybrid system based on the hidden Markov model,and the recognition accuracy is above 90%. At the sametime, the recognition based on the end-to-end model of theSA-CTC effect is better than the end-to-end model basedon LSTM-CTC, with an accuracy rate of 91.35%.
5. Conclusion
This paper proposes a method of integrating tense charac-teristics in statistical expressions. This method realizes theselection and filtering of rules of different tenses withoutincreasing the complexity of the decoder. And there is no
0 10 20 30 40 50Data node
0
0.2
0.4
0.6
0.8
1
Sent
ence
reco
gniti
on v
aria
nce
Figure 9: Match stick graph of training corpus identification variance of different nodes.
10 Wireless Communications and Mobile Computing

dependence on language, only need to choose to integratemonolingual tense features or bilingual tense featuresaccording to the difference of language grammar. In theend, the recognition performance of the SA-CTC-basedend-to-end model surpasses the HMM-based hybrid modeland the BiLSTM-based end-to-end model, and the recogni-tion accuracy reaches 91.35%. This paper studies the end-to-end technology based on the self-attention mechanismand link timing classification and builds a complete speechrecognition system on the Japanese data set. At the sametime, according to the characteristics of Japanese largevocabulary, the algorithm is introduced, and the subwordunit is used as Japanese recognition modeling unit. Theexperimental results of Japanese-Chinese and Japanese-Japanese expressions show that the method proposed in thispaper can not only effectively improve the tense expressionaccuracy of the hierarchical phrase model but also achievethe purpose of word sense disambiguation and improvementof sentence structure adjustment. In response to the aboveshortcomings, this paper proposes a new link predictionmethod SOTS (Similarities and Occurrences Time Series)based on the combination of node similarity and link times.First, calculate the similarity score between the nodes in eachtime period through a trending random walk and, then, usethe time series model to combine it with the actual numberof links between the nodes in each time period to predict theoccurrence of each node pair in the next time period possi-bility of linking. Through two combined time series models,this paper studies the relationship between the similarityscores between nodes and the actual number of links. Thismethod can be used to predict new links and recurring linksin the evolving network in the future.
Data Availability
The data used to support the findings of this study areincluded within the article.
Conflicts of Interest
All the authors do not have any possible conflicts of interest.
References
[1] H. Brock, I. Farag, and K. Nakadai, “Recognition of non-manual content in continuous Japanese sign language,” Sen-sors, vol. 20, no. 19, p. 5621, 2020.
[2] M. Asahara, S. Kato, H. Konishi, M. Imada, and K. Maekawa,“BCCWJ-TimeBank: temporal and event information annota-tion on Japanese text,” Journal of Computational Linguistics &Chinese Language, vol. 4, pp. 20–24, 2019.
[3] N. Laokulrat, M. Miwa, Y. Tsuruoka, and T. Chikayama,“Uttime: temporal relation classification using deep syntacticfeatures,” Lexical and Computational Semantics, vol. 3,pp. 88–92, 2019.
[4] R. Bansal, M. Rani, H. Kumar, and S. Kaushal, “Temporalinformation retrieval and its application: a survey,” in Emerg-ing Research in Computing, Information, Communicationand Applications, pp. 251–262, Springer, Singapore, 2019.
[5] J. Pustejovsky, R. Knippen, J. Littman, and R. Saurí, “Temporaland event information in natural language text,” LanguageResources and Evaluation, vol. 39, no. 2, pp. 123–164, 2020.
[6] M. Verhagen, R. Gaizauskas, F. Schilder, M. Hepple,J. Moszkowicz, and J. Pustejovsky, “The TempEval challenge:identifying temporal relations in text,” Language Resourcesand Evaluation, vol. 43, no. 2, pp. 161–179, 2019.
[7] N. Osaka, M. Osaka, M. Morishita, H. Kondo, andH. Fukuyama, “A word expressing affective pain activatesthe anterior cingulate cortex in the human brain: an fMRIstudy,” Behavioural Brain Research, vol. 153, no. 1, pp. 123–127, 2020.
[8] K. E. Moore, “Ego-perspective and field-based frames of refer-ence: temporal meanings of FRONT in Japanese, Wolof, andAymara,” Journal of Pragmatics, vol. 43, no. 3, pp. 759–776,2019.
[9] T. Ogihara, “The ambiguity of the-te iru form in Japanese,”Journal of East Asian Linguistics, vol. 7, no. 2, pp. 87–120,2018.
[10] I. Cohen, N. Sebe, A. Garg, L. S. Chen, and T. S. Huang, “Facialexpression recognition from video sequences: temporal andstatic modeling,” Computer Vision and Image Understanding,vol. 91, no. 1-2, pp. 160–187, 2019.
[11] F. Cheng and Y. Miyao, “Classifying temporal relations bybidirectional lstm over dependency paths,” ComputationalLinguistics, vol. 7, pp. 1–6, 2019.
[12] S. Kita, A. Özyürek, S. Allen, A. Brown, R. Furman, andT. Ishizuka, “Relations between syntactic encoding and co-speech gestures: implications for a model of speech and gestureproduction,” Language and cognitive processes, vol. 22, no. 8,pp. 1212–1236, 2017.
[13] L. Chen-Hafteck, “Music and language development in earlychildhood: integrating past research in the two domains,”Early Child Development and Care, vol. 130, no. 1, pp. 85–97,2019.
[14] Y. Peng, N. Kondo, T. Fujiura et al., “Dam behavior patterns inJapanese black beef cattle prior to calving: automated detectionusing LSTM-RNN,” Computers and Electronics in Agriculture,vol. 169, p. 105178, 2020.
[15] K. Nishikawa, R. Hirakawa, H. Kawano, K. Nakashi, andY. Nakatoh, “Detecting system Alzheimer’s dementia by 1dCNN-LSTM in Japanese speech,” in 2021 IEEE InternationalConference on Consumer Electronics (ICCE), Las Vegas, NV,USA, 2021, January.
18.75%
11.25%33.75%
13.75%15%
7.5%
Endpoint 1Endpoint 2Endpoint 3
Endpoint 4Endpoint 5Endpoint 6
Figure 10: Fan chart of the recognition proportions of endpoints atdifferent levels of the model.
11Wireless Communications and Mobile Computing

[16] A. Bender, A. Rothe-Wulf, L. Hüther et al., “Moving forwardin space and time: how strong is the conceptual link betweenspatial and temporal frames of reference?,” Frontiers in Psy-chology, vol. 3, p. 486, 2012.
[17] S. Allen, A. Özyürek, S. Kita et al., “Language-specific and uni-versal influences in children’s syntactic packaging of mannerand path: a comparison of Japanese, Japanese, and Turkish,”Cognition, vol. 102, no. 1, pp. 16–48, 2018.
[18] L. McCune, “A normative study of representational play in thetransition to language,” Developmental Psychology, vol. 31,no. 2, p. 198, 2019.
[19] C. E. Izard, “Innate and universal facial expressions: evidencefrom developmental and cross-cultural research,” LanguageSciences, vol. 9, pp. 4–9, 2019.
[20] M. Asahara and Y. Matsumoto, “Constructing a temporal rela-tion tagged corpus of Chinese based on dependency structure,”Japanese Society for Artificial Intelligence, vol. 7, pp. 311–315,2020.
[21] M. Sotirova‐Kohli, D. H. Rosen, S. M. Smith, P. Henderson,and S. Taki‐Reece, “Empirical study of Kanji as archetypalimages: understanding the collective unconscious as part ofthe Japanese language,” Journal of Analytical Psychology,vol. 56, no. 1, pp. 109–132, 2019.
[22] F. Cheng, M. Asahara, I. Kobayashi, and S. Kurohashi,“Dynamically updating event representations for temporalrelation classification with multi-category learning,” in Find-ings of the Association for Computational Linguistics: EMNLP2020, pp. 1352–1357, 2020.
[23] P. Pettenati, K. Sekine, E. Congestrì, and V. Volterra, “A com-parative study on representational gestures in Italian and Jap-anese children,” Journal of Nonverbal Behavior, vol. 36, no. 2,pp. 149–164, 2019.
[24] N. T. Ly, C. T. Nguyen, and M. Nakagawa, “An attention-based row-column encoder-decoder model for text recogni-tion in Japanese historical documents,” Pattern RecognitionLetters, vol. 136, pp. 134–141, 2020.
[25] Y. Koizumi, K. Yatabe, M. Delcroix, Y. Masuyama, andD. Takeuchi, “Speech enhancement using self-adaptationand multi-head self-attention,” in ICASSP 2020 - 2020 IEEEInternational Conference on Acoustics, Speech and SignalProcessing (ICASSP), pp. 181–185, Barcelona, Spain, 2020,May.
[26] R. Imaizumi, R. Masumura, S. Shiota, and H. Kiya, “Dialect-aware modeling for end-to-end Japanese dialect speech recog-nition,” in In 2020 Asia-Pacific signal and information process-ing association annual summit and conference (APSIPA ASC),pp. 297–301, Honolulu, Hawaii, 2020, December.
[27] Z. Huang, P. Zhang, R. Liu, and D. Li, “Immature apple detec-tion method based on improved Yolov3,” ASP Transactions onInternet of Things, vol. 1, no. 1, pp. 9–13, 2021.
[28] J. Zhang, J. Sun, J. Wang, and X. G. Yue, “Visual object track-ing based on residual network and cascaded correlation fil-ters,” Journal of Ambient Intelligence and HumanizedComputing, vol. 12, pp. 8427–8440, 2021.
[29] W. Chu, P. S. Ho, and W. Li, “An adaptive machine learningmethod based on finite element analysis for ultra low-k chippackage design,” IEEE Transactions on Components, Packag-ing and Manufacturing Technology, pp. 1–1, 2021.
[30] E. Yamada, “Fostering criticality in a beginners’ Japanese lan-guage course: a case study in a UK higher education modernlanguages degree programme,” Language Learning in HigherEducation, vol. 6, no. 2, pp. 453–471, 2020.
[31] L. Mealier, G. Pointeau, and S. Mirliaz, “Narrative construc-tions for the organization of self experience: proof of conceptvia embodied robotics,” Frontiers in Psychology, vol. 8,p. 1331, 2017.
12 Wireless Communications and Mobile Computing