apache hawq and apache madlib: journey to apache
TRANSCRIPT

11Pivotal Confidential–Internal Use Only
Apache HAWQ andApache MADlibJourney to Apache
Pivotal San Francisco
Dec 3, 2015

2
Topics
• Journey to Apache
• HAWQ overview
• MADlib overview

33Pivotal Confidential–Internal Use Only
Journey to Apache
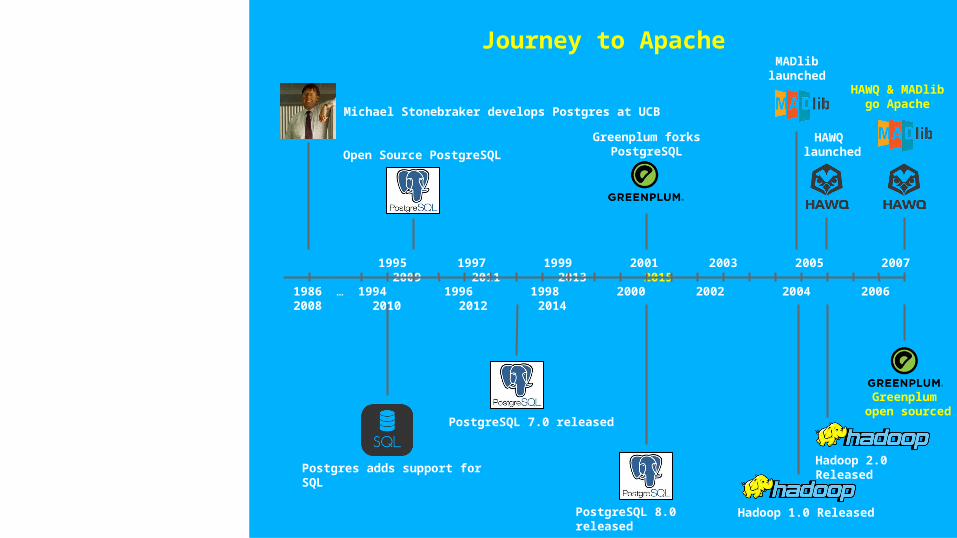
1986 … 1994 1996 1998 2000 2002 2004 2006 2008 2010 2012 2014
1995 1997 1999 2001 2003 2005 2007 2009 2011 2013 2015
Journey to Apache
Michael Stonebraker develops Postgres at UCB
Postgres adds support for SQL
Open Source PostgreSQL
PostgreSQL 7.0 released
PostgreSQL 8.0 released
Greenplum forks PostgreSQL
Hadoop 1.0 Released
HAWQ & MADlibgo Apache
HAWQ launched
Hadoop 2.0 Released
MADliblaunched
Greenplum open sourced

5
Pivotal is Committed to Open Source
Pivotal GemFire Apache Geode (April 2015)
Pivotal HDB Apache HAWQ (Sept 2015)
Pivotal Query Optimizer ComingSoon
MADlib OSS (BSD License)
Apache MADlib (Sept 2015)
Pivotal Greenplum Greenplum Database (Oct 2015)(Apache 2 License)

6
Collaborate on software in open and productive ways Need strong community for innovation MADlib and HAWQ are complementary technologies
Why Apache?

77Pivotal Confidential–Internal Use Only
Apache HAWQ Overview

8
What is Apache HAWQ?

9
Key Featuresof
HAWQ
5

10
5 • Up to 30x SQL-on-Hadoop performance advantage
• Faster time to insight• Massive MPP scalability to petabytes
Benefits: Near real-time latency, complex queries and advanced analytics at scale
1. Advanced Analytics Performance
Key Featuresof
HAWQ

11
5 • ANSI SQL-92, -99, -2003• All 99 TPC-DS queries tested, no
modifications• Plus, OLAP extensions• Complete ACID integrity and reliability
Benefits: 100% SQL compliant No risk to SQL applications All native on HDP via HAWQ
2. 100% ANSI SQL Compliant
Key Featuresof
HAWQ
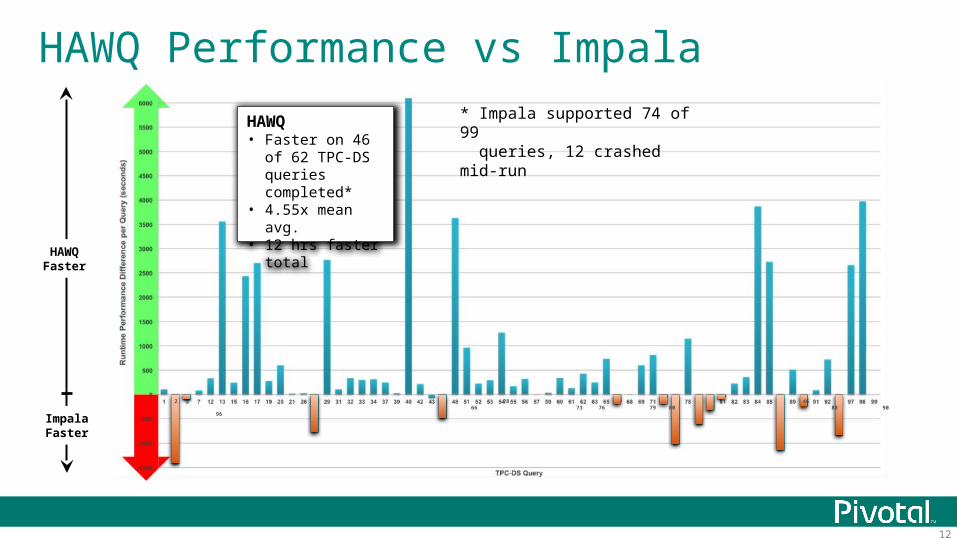
12
HAWQ Performance vs Impala
HAWQFaster
ImpalaFaster
2 28 46 66 73 76 79 80 88 90 96
HAWQ• Faster on 46 of 62
TPC-DS queries completed*
• 4.55x mean avg.• 12 hrs faster total
* Impala supported 74 of 99 queries, 12 crashed mid-run

13
HAWQ vs Apache Hive w/Tez
HAWQFaster
HiveFaster
3 7 15 25 27 34 46 48 76 79 89 90 96
HAWQ• Faster on 45 of 60
TPC-DS queries completed*
• 3.44x mean avg.• 9 hrs faster total
* Hive supported 65 of 99 queries, 5 crashed mid-run

14
5• Advanced machine learning for big data• Local, in-database operation• Exceptional MPP/parallel performance• Open source, Postgres-based
Benefits: Advanced, highly scalable, machine learning, directly on data in Hadoop
3. Integrated Machine Learning
Key Featuresof
HAWQ

15
5 • HDP, PHD, other ODPi-derived distros• Easily managed via Ambari• On premises, in cloud, or PaaS• HBase, Avro, Parquet and more• Connectors to make HAWQ data
available to other SQL query tools
Benefits: Flexibility Accessibility Portability
4. Flexible Deployment
Key Featuresof
HAWQ
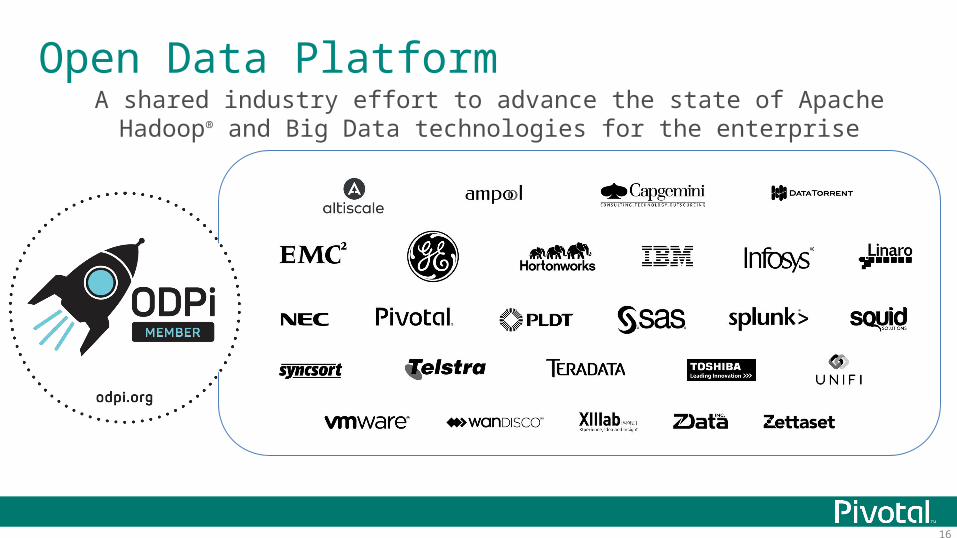
16
Open Data PlatformA shared industry effort to advance the state of Apache Hadoop® and Big Data
technologies for the enterprise
17The open ecosystem of big data
September 25, 2015
http://odpi.org

18
5 • Cost-based query optimization • Robust query plan optimization • Complex big data management
Benefits: Optimize performance and costs Maximize Hadoop cluster resources Offload EDW w/o compromise
5. Query Optimization Options
Key Featuresof
HAWQ
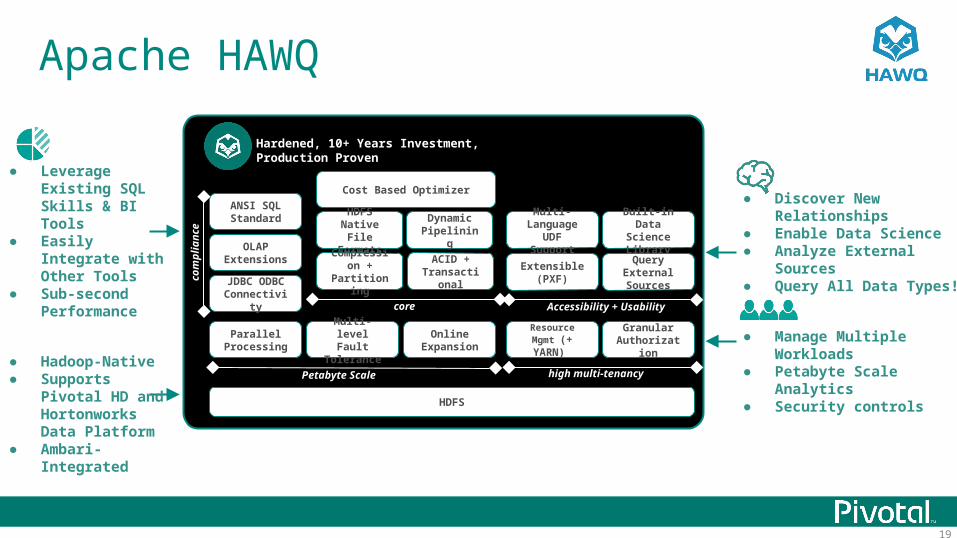
19
Apache HAWQ
● Discover New Relationships● Enable Data Science ● Analyze External Sources● Query All Data Types!
Multi-level Fault Tolerance
Granular Authorization
Resource Mgmt (+ YARN)
high multi-tenancy
ANSI SQL Standard
OLAP Extensions
JDBC ODBCConnectivity
Parallel Processing
Online Expansion
HDFS
Petabyte Scale
Cost Based Optimizer
Dynamic Pipelining
ACID + Transactional
Multi-Language
UDF Support
Built-in Data Science Library
Extensible (PXF)
Query External Sources
Hardened, 10+ Years Investment, Production Proven
Accessibility + Usability
HDFS Native File Formats
● Manage Multiple Workloads● Petabyte Scale Analytics● Security controls
● Leverage Existing SQL Skills & BI Tools
● Easily Integrate with Other Tools
● Sub-second Performance Compression
+ Partitioning
core
com
plia
nce
● Hadoop-Native● Supports Pivotal HD
and Hortonworks Data Platform
● Ambari-Integrated

20
Apache HAWQ 2.0 (in beta)Areas of Enhancement New Features
Elastic & Scalable Architecture
Hadoop-Native Integrations
Simplified External Data Access/Queries
Performance & Optimizations
On-Demand Virtual Segments
Flexible Query Dispatch on subset nodes
3 Tier RM: YARN level>User>Query-Operator
Dynamic Cluster Expansion (no redistribute)
New Fault Tolerance Service
HCatalog integration - Read Access
HDFS Catalog Cache
Per Table Directory storage (user friendly)
Single physical segment per node
Easier Administration/Usage
Cloud-ReadySimpler Management Commands
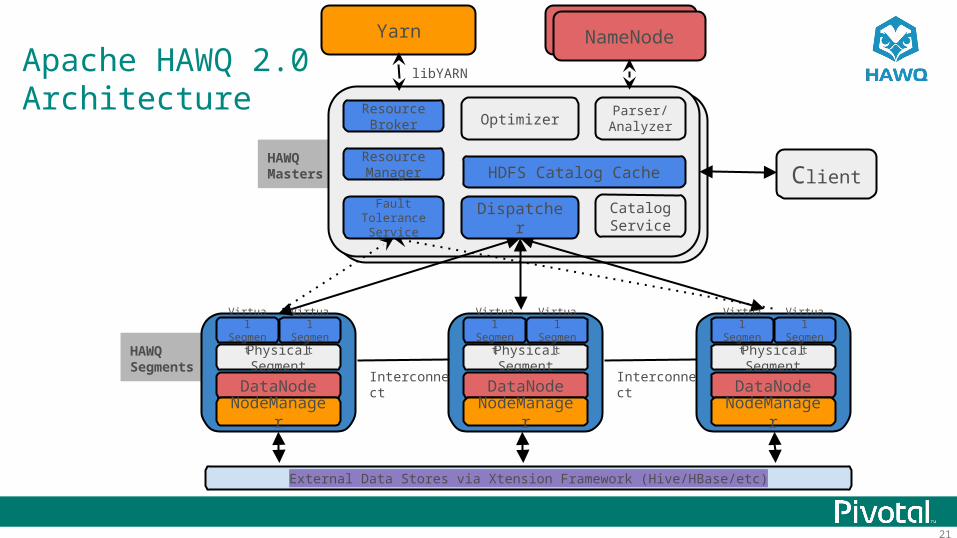
21
HAWQ Segments
HAWQ Masters
Yarn
Physical Segment
Client
Parser/AnalyzerOptimizer
Dispatcher
DataNode
NodeManager
NameNodeNameNode
External Data Stores via Xtension Framework (Hive/HBase/etc)
Resource Manager
Fault Tolerance Service
CatalogService
VirtualSegment
VirtualSegment
Physical Segment
DataNode
NodeManager
VirtualSegment
VirtualSegment
Physical Segment
DataNode
NodeManager
VirtualSegment
VirtualSegment
Resource Broker
libYARN
HDFS Catalog Cache
Interconnect Interconnect
Apache HAWQ 2.0Architecture

22
Example Use CasesSmart/connected car• PHD, HAWQ• Ability to have numerous data
in Hadoop• Generate new business models• Predictive analytics
Network & Call Center Analysis• PHD, HAWQ• Store and maintain 2B records/day• Analyze drop and completed calls• Analyze networks, care-center
responsiveness• 5X capacity of EDW at half the cost
Revenue Prediction• PHD, HAWQ, GPDB• Predict ad revenue
to within 1%• Transform into data-driven
company that builds close relationships withcustomers
Archive Analytics, CustomerBehavior Analytics• PHD, HAWQ• Mainframe alternative• Archive analytics• Customer behavior
profiling and analytics

2323Pivotal Confidential–Internal Use Only
Apache MADlib Overview

24
Scalable, In-Database Machine Learning
• Open Source https://github.com/apache/incubator-madlib• Supports Greenplum DB, Apache HAWQ/HDB and PostgreSQL• Downloads and Docs: http://madlib.incubator.apache.org/
Apache (incubating)

25
History
MADlib project was initiated in 2011 by EMC/Greenplum architects and Joe Hellerstein from Univ. of California, Berkeley.
• MAD stands for:
• lib stands for SQL library of:• advanced (mathematical, statistical, machine learning)• parallel & scalable in-database functions
UrbanDictionary.com:mad (adj.): an adjective used to enhance a noun.
1- dude, you got skills.2- dude, you got mad skills.

26
Functions
Predictive Modeling Library
Linear Systems• Sparse and Dense Solvers• Linear Algebra
Matrix Factorization• Singular Value Decomposition (SVD)• Low Rank
Generalized Linear Models• Linear Regression• Logistic Regression• Multinomial Logistic Regression• Cox Proportional Hazards Regression• Elastic Net Regularization• Robust Variance (Huber-White), Clustered
Variance, Marginal Effects
Other Machine Learning Algorithms• Principal Component Analysis (PCA)• Association Rules (Apriori)• Topic Modeling (Parallel LDA)• Decision Trees• Random Forest• Support Vector Machines• Conditional Random Field (CRF)• Clustering (K-means) • Cross Validation• Naïve Bayes• Support Vector Machines (SVM)
Descriptive Statistics
Sketch-Based Estimators• CountMin (Cormode-Muth.)• FM (Flajolet-Martin)• MFV (Most Frequent Values)CorrelationSummary
Support Modules
Array OperationsSparse VectorsRandom SamplingProbability FunctionsData PreparationPMML ExportConjugate Gradient
Inferential Statistics
Hypothesis Tests
Time Series• ARIMA
Oct 2014

27
MADlib Advantages
Better parallelism– Algorithms designed to leverage MPP and
Hadoop architecture
Better scalability– Algorithms scale as your data set scales
Better predictive accuracy– Can use all data, not a sample
ASF open source (incubating)– Available for customization and optimization
28
Supported Platforms
GPDB PostgreSQLPHDHDP
Other ODPi distros
Scale-out machine learning now available on open source, MPP execution engines.
Now open source !
Now open source !
Has always been
open source

29
Example UsageTrain a model
Predict for new data
30
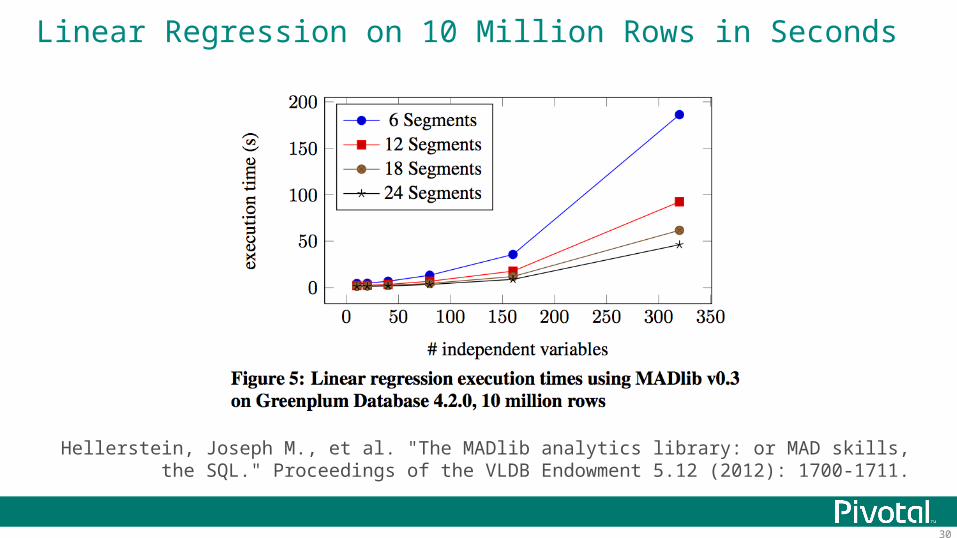
Linear Regression on 10 Million Rows in Seconds
Hellerstein, Joseph M., et al. "The MADlib analytics library: or MAD skills, the SQL." Proceedings of the VLDB Endowment 5.12 (2012): 1700-1711.

31
Pivotal is very proud to deepenour relationship with the ASF to advance SQL-on-Hadoop and machine learning technologies.
Please join us!

32
Contributors Welcome!
• Web sites– http://hawq.incubator.apache.org/– http://madlib.incubator.apache.org/– https://cran.r-project.org/web/packages/PivotalR/index.html
• Github– https://github.com/apache/incubator-hawq– https://github.com/apache/incubator-madlib– https://github.com/pivotalsoftware/PivotalR