apache mahout - introduction
TRANSCRIPT

Jackson Oliveira@cyber_jso
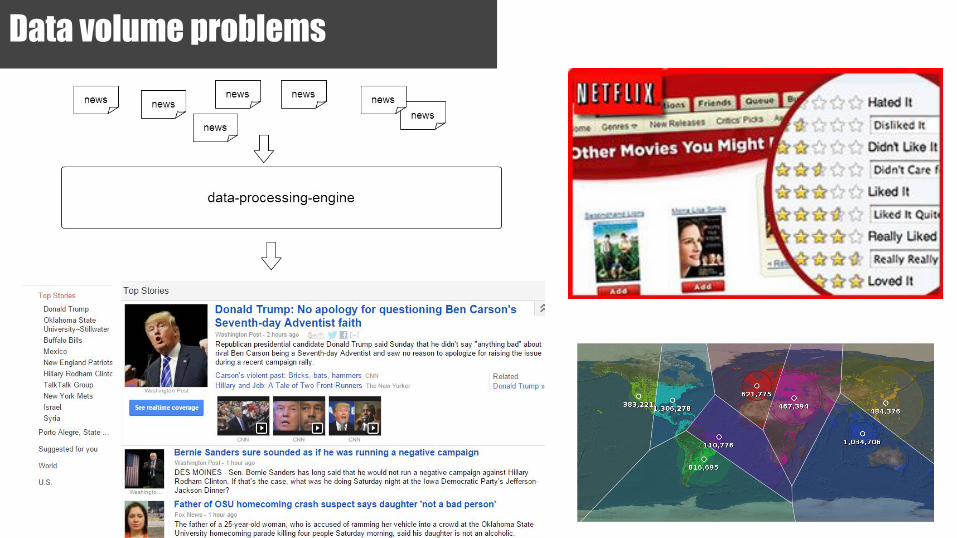
Data volume problems
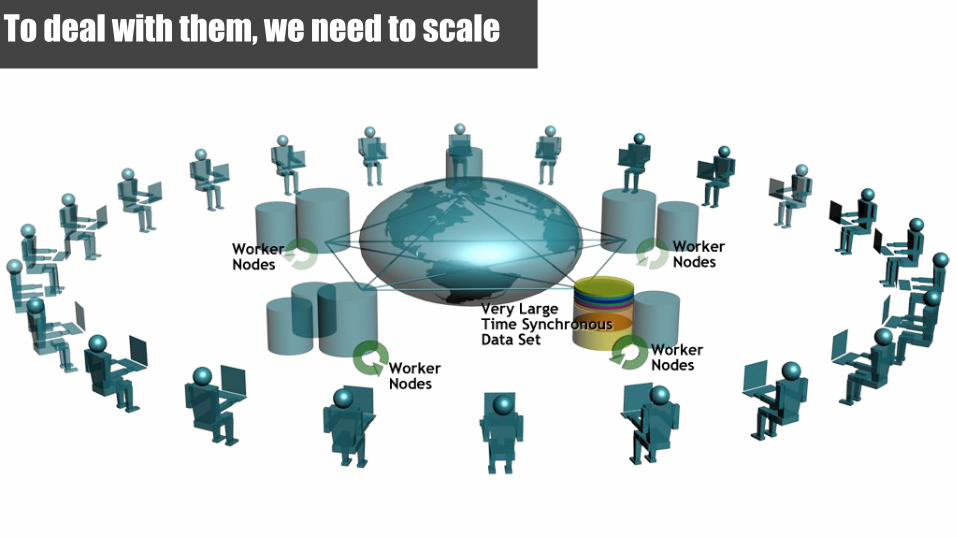
To deal with them, we need to scale

Hadoop was built with these ideas in mind
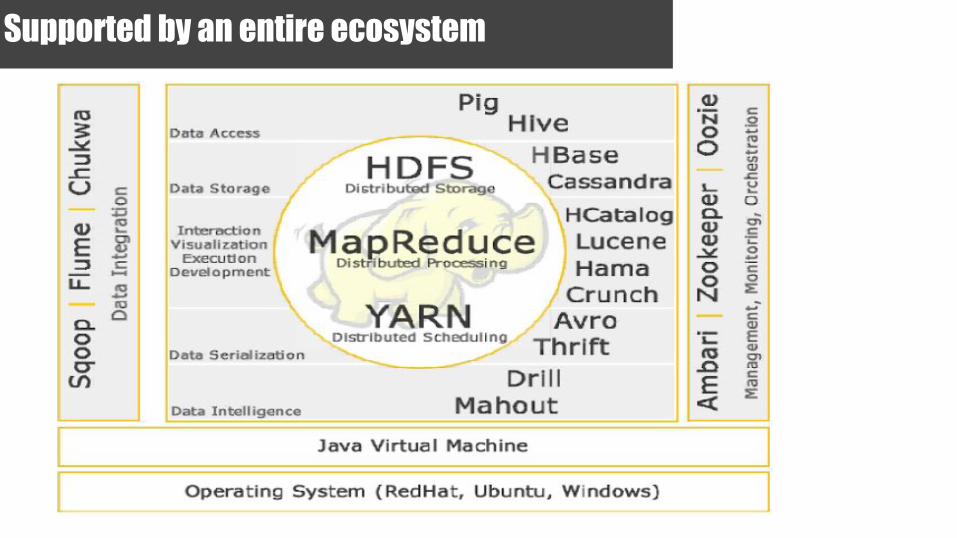
Supported by an entire ecosystem

Mahout was built on top of hadoop.., The Elephant Rider

It was born as Lucene subproject… But It grew quickly
Became top level project on 2010
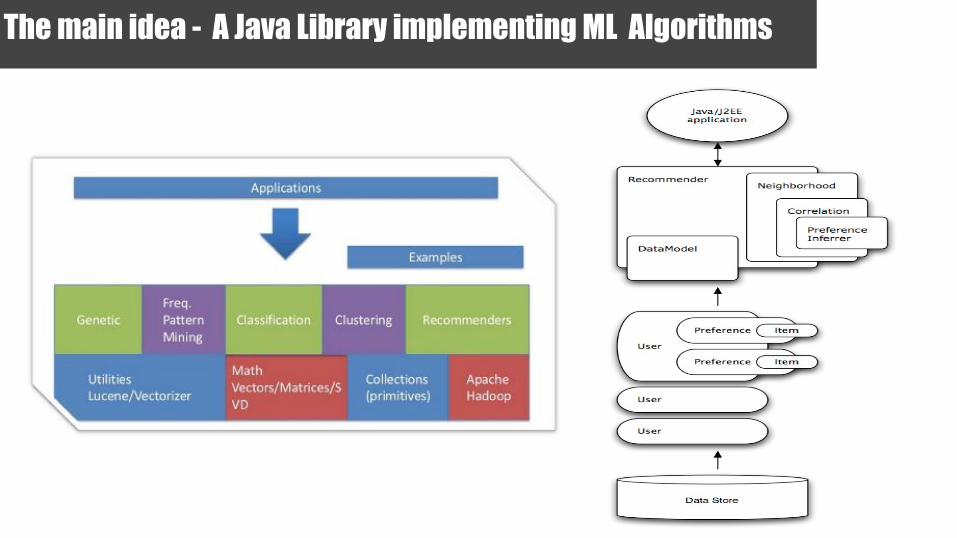
The main idea - A Java Library implementing ML Algorithms
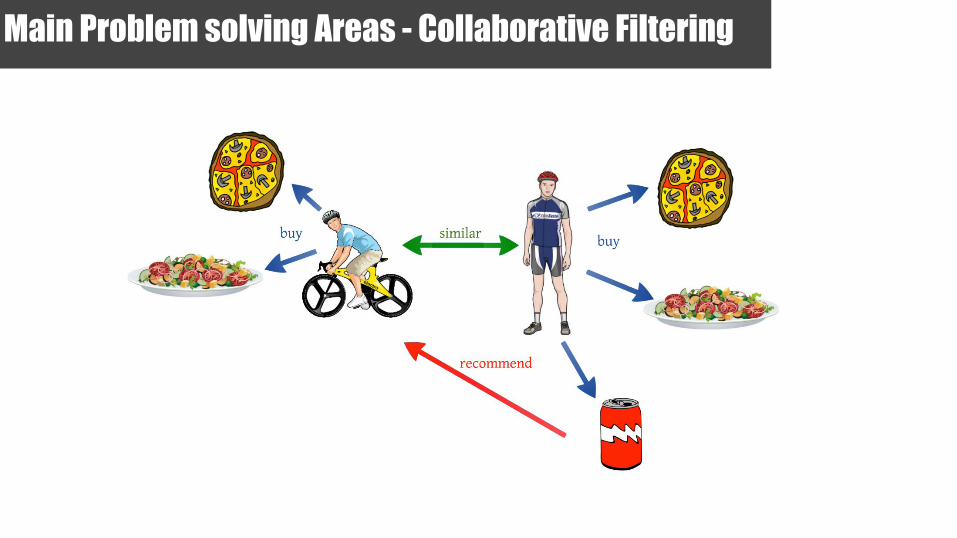
Main Problem solving Areas - Collaborative Filtering

Main Problem solving Areas - Collaborative Filtering
Algorithm Single machine MR Spark
Item based
User Based
Matrix Factorization
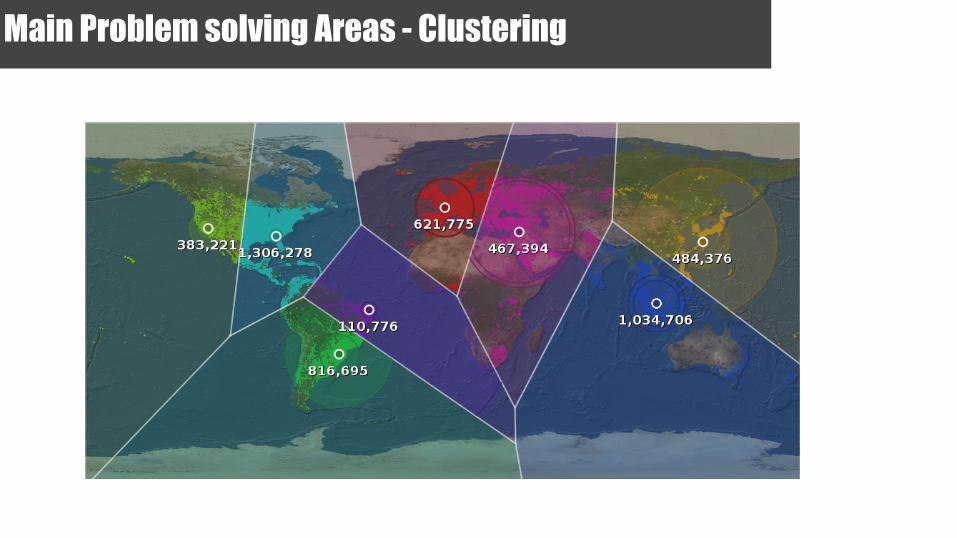
Main Problem solving Areas - Clustering

Main Problem solving Areas - Clustering
Algorithm Single machine MR Spark
K-Means
Fuzzy K-Means
Streaming K-Means
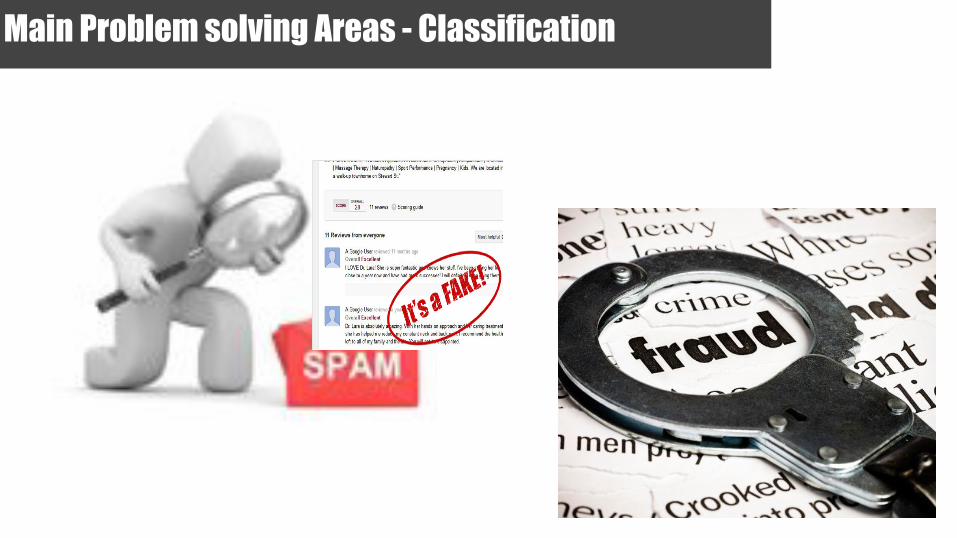
Main Problem solving Areas - Classification

Main Problem solving Areas - Classification
Algorithm Single machine MR Spark
Naive Bayes/ Complementary Naive Bayes
Random Forest
Multilayer Perception

Recommendations (CF) - User recommendation
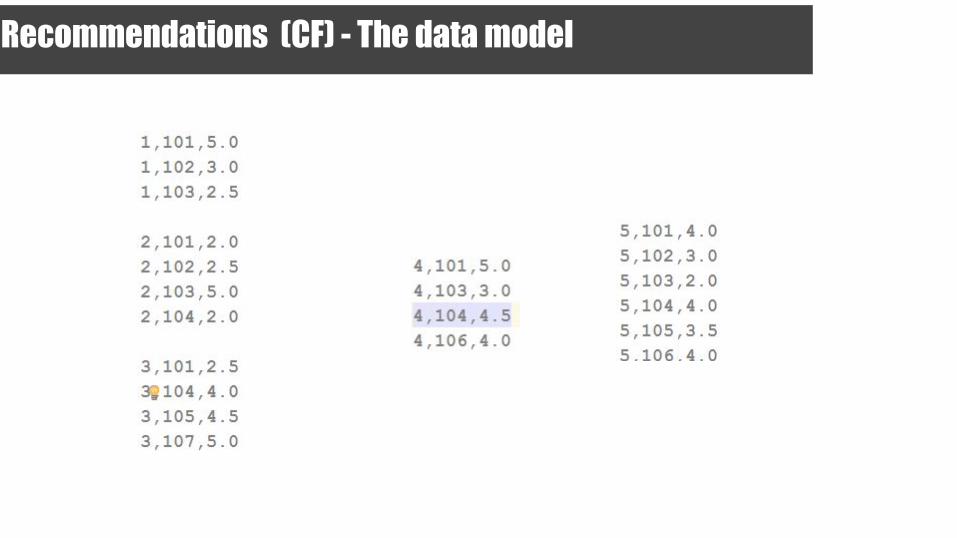
Recommendations (CF) - The data model
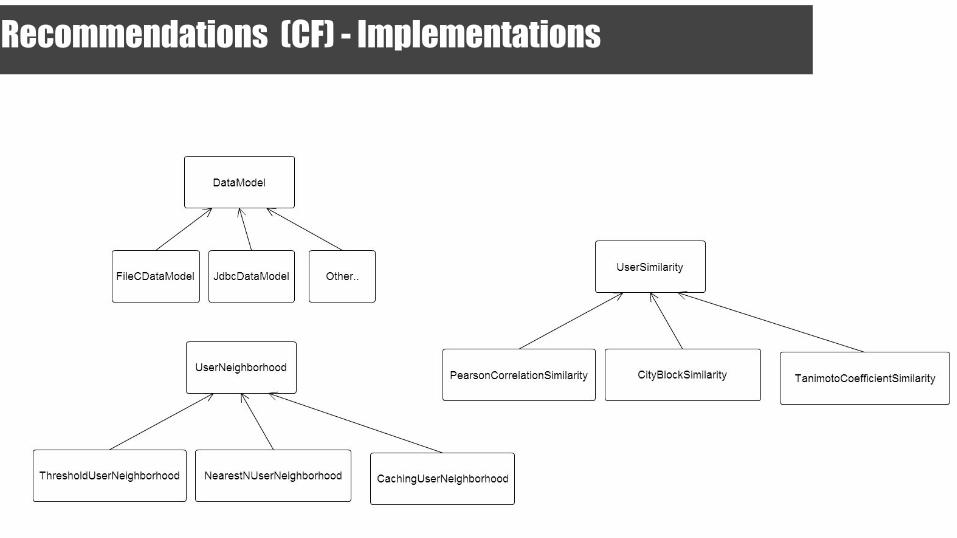
Recommendations (CF) - Implementations

Who is using Mahout in production

Goods and bads
● Several algorithms implementations ready to use● Well documented java API● More robust when compared to weeka● Startup overhead when compared to Spark MLIB● API target for programmers rather than data scientists● Extensible API

What comes next?

Jackson Oliveira@cyber_jso
Thank you!