apache spark session
TRANSCRIPT


Sandeep GiriHadoop
Apache
A fast and general engine for large-scale data processing.
• Really fast Hadoop • 100x faster than Hadoop MapReduce in memory, • 10x faster on disk.
• Builds on similar paradigms as Hadoop • Integrated with Hadoop

Sandeep GiriHadoop
Apache

Sandeep GiriHadoop
Login as root
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0-bin-hadoop2.4.tgz
tar zxvf spark-1.1.0-bin-hadoop2.4.tgz && rm spark-1.1.0-bin-hadoop2.4.tgz;
mv spark-1.1.0-bin-hadoop2.4 /usr/lib/
cd /usr/lib;
ln -s spark-1.1.0-bin-hadoop2.4/ spark
Login as student
/usr/lib/spark/bin/pyspark
INSTALLING ON YARNAlready Installed on hadoop1.knowbigdata.com
Sandeep GiriHadoop
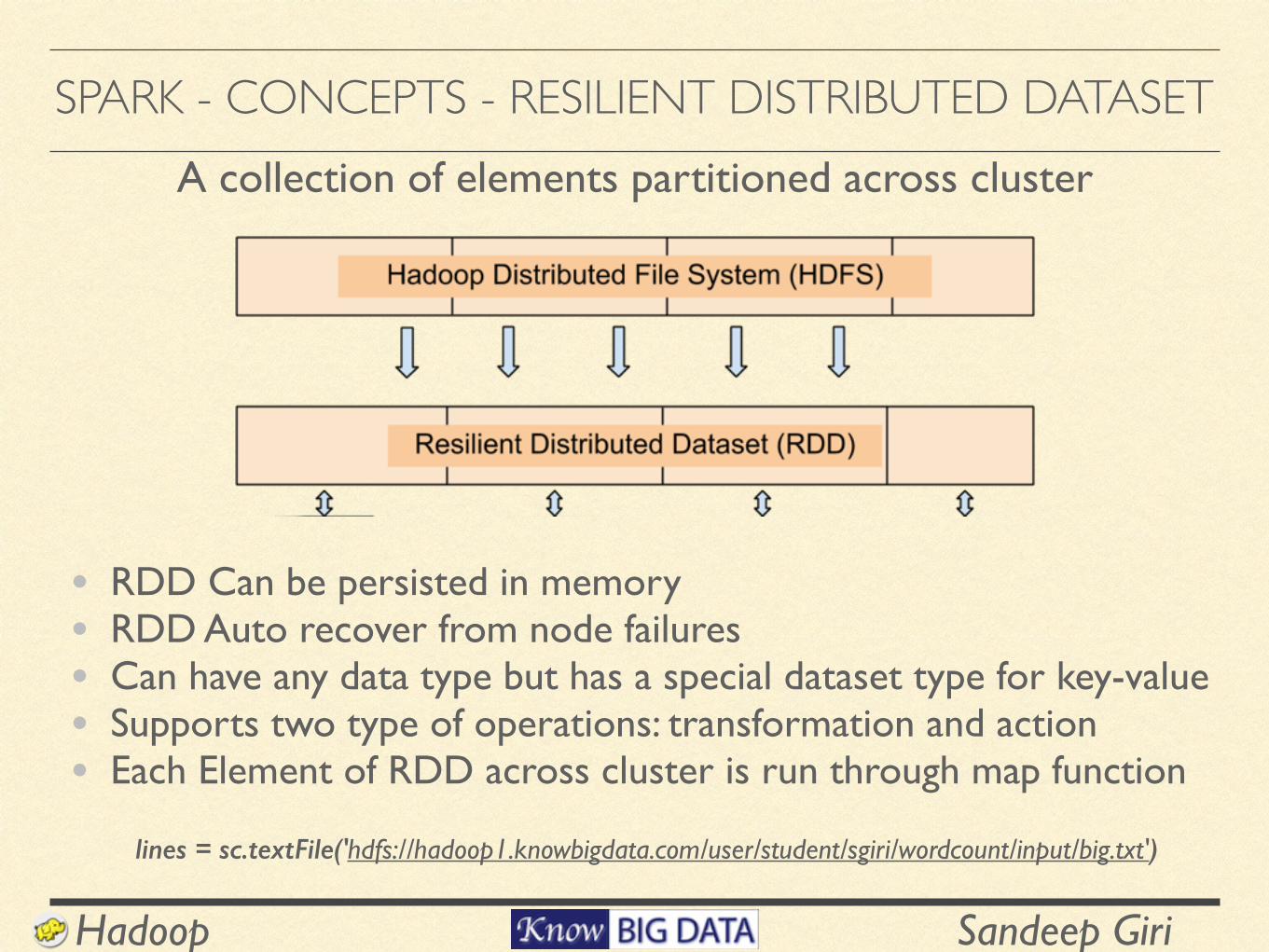
SPARK - CONCEPTS - RESILIENT DISTRIBUTED DATASETA collection of elements partitioned across cluster
lines = sc.textFile('hdfs://hadoop1.knowbigdata.com/user/student/sgiri/wordcount/input/big.txt')
• RDD Can be persisted in memory • RDD Auto recover from node failures • Can have any data type but has a special dataset type for key-value • Supports two type of operations: transformation and action • Each Element of RDD across cluster is run through map function

Sandeep GiriHadoop
SPARK - TRANSFORMATIONS
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() { public Integer call(String s) { return s.length(); } });
Creates a new dataset
persist()cache()

Sandeep GiriHadoop
SPARK - TRANSFORMATIONSmap(func)
Return a new distributed dataset formed by passing each element of the source through a function func.
Analogous to foreach of pig.
filter(func)Return a new dataset formed by selecting those
elements of the source on which func returns true.
flatMap( func)
Similar to map, but each input item can be mapped to 0 or more output items
groupByKey ([numTasks])
When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs.
See More: sample, union, intersection, distinct, groupByKey, reduceByKey, sortByKey,join https://spark.apache.org/docs/latest/api/java/index.html?org/apache/spark/api/java/JavaPairRDD.html
Sandeep GiriHadoop
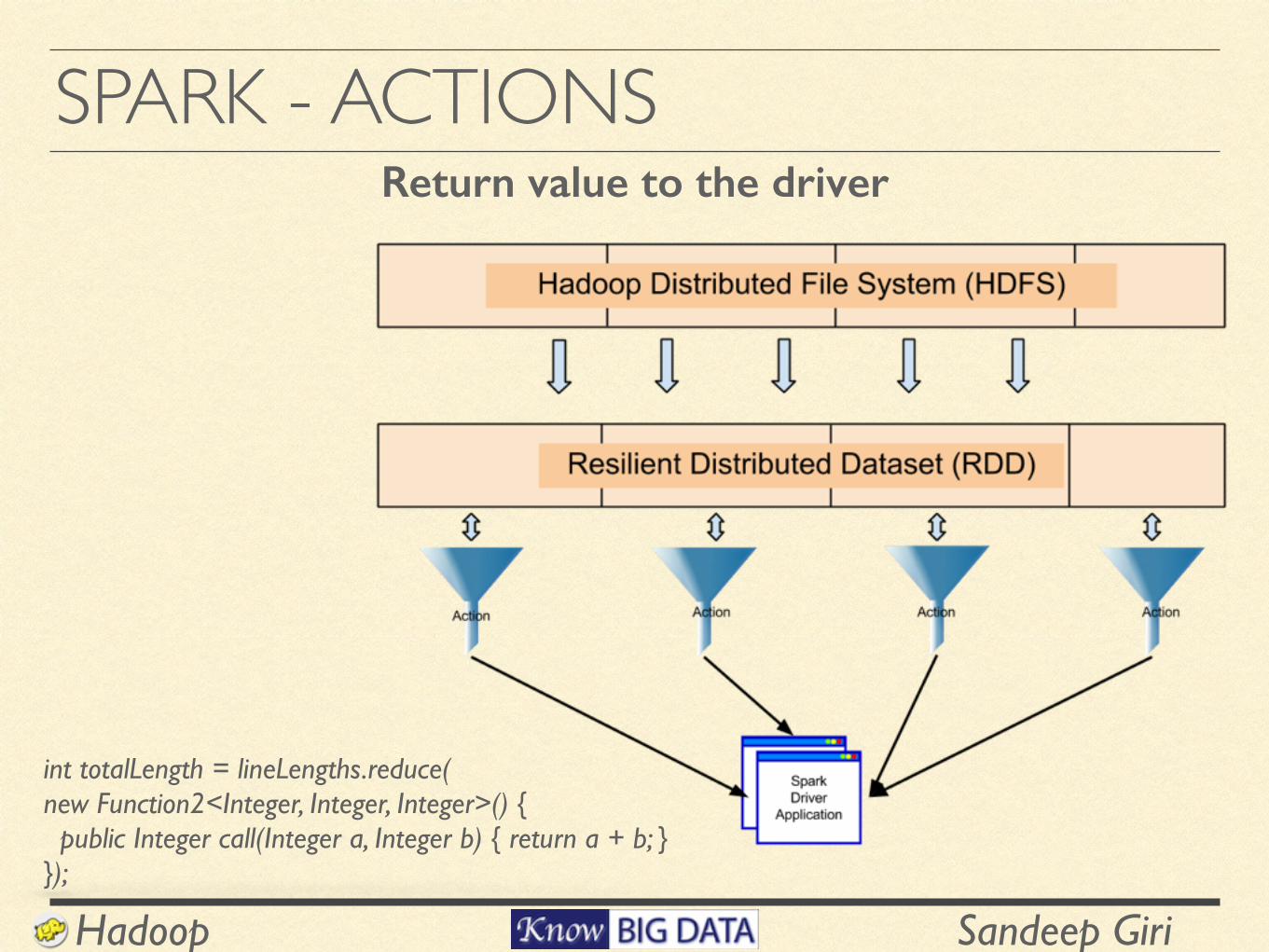
SPARK - ACTIONS
int totalLength = lineLengths.reduce( new Function2<Integer, Integer, Integer>() { public Integer call(Integer a, Integer b) { return a + b; } });
Return value to the driver

Sandeep GiriHadoop
SPARK - ACTIONS
reduce(func)Aggregate elements of dataset using a function:
• Takes 2 arguments and returns one • Commutative and associative for parallelism
count() Return the number of elements in the dataset.
collect() Return all elements of dataset as an array at driver. Used for small output.
take(n)Return an array with the first n elements of the dataset.
Not Parallel.
See More: first(), takeSample(), takeOrdered(), saveAsTextFile(path) https://spark.apache.org/docs/latest/api/java/index.html?org/apache/spark/api/java/JavaPairRDD.html

Sandeep GiriHadoop
SPARK - EXAMPLE - REDUCE SUM FUNCTION//Single Node lines = ["san giri g", "san giri", "giri", "bhagwat kumar", "mr. shashank sharma", "anto"] lineLengths = [11, 9, 4, 14, 20, 4] sum = ??? !//Node1 lines = ["san giri g", "san giri", "giri"] lineLengths = [11, 9, 4] !totalLength = [20, 4] totalLength = 24 //sum or min or max or sqrt(a*a + b*b) !//Node2 lines = ["bhagwat kumar"] lineLengths = [14] totalLength = 14 !//Node3 lines = ["mr. shashank sharma", "anto"] lineLengths = [20, 4] totalLength = 24 !!//Driver Node lineLengths = [24, 14, 24] lineLength = [38, 24] lineLength = [62]
Sandeep GiriHadoop
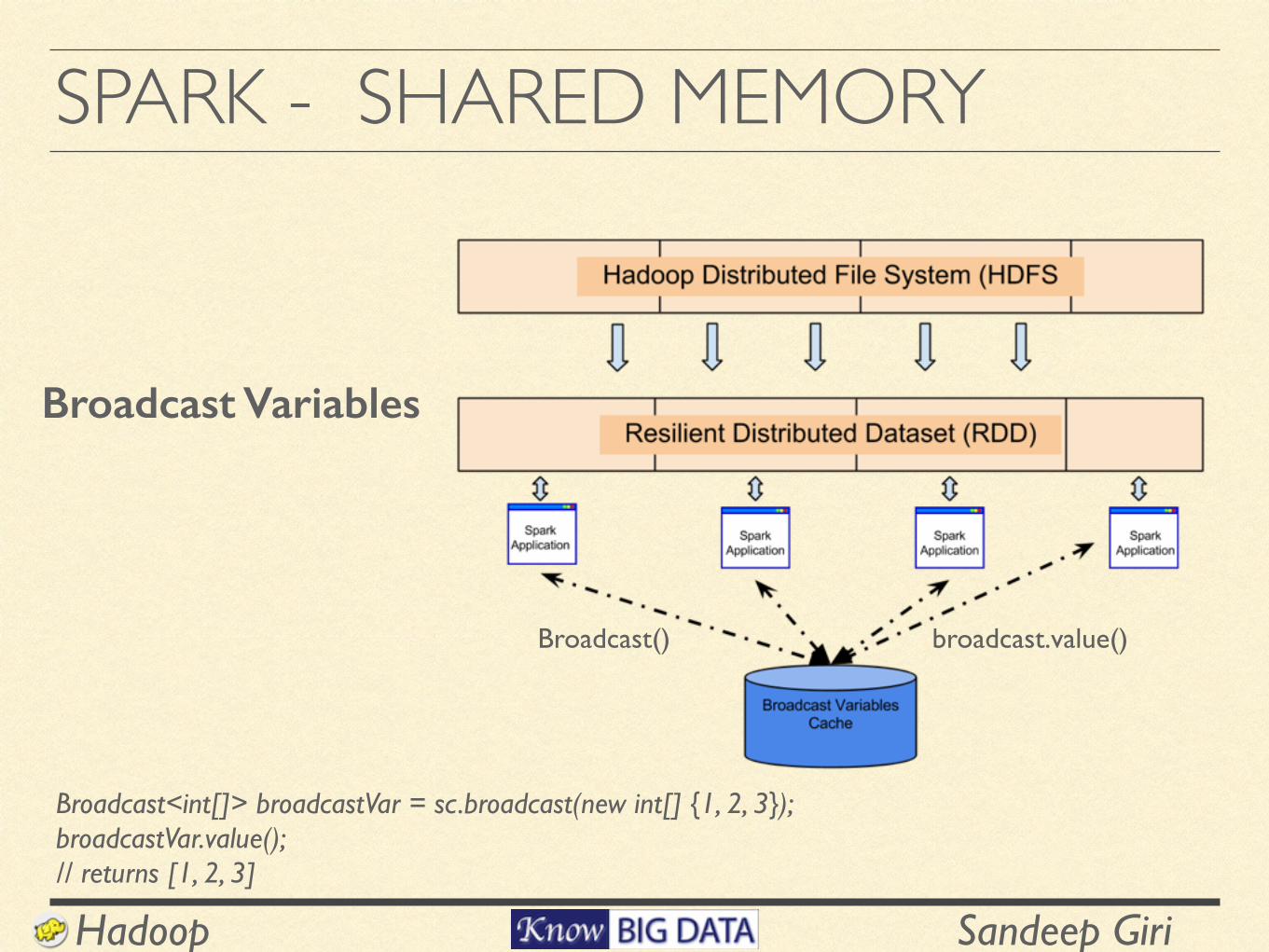
SPARK - SHARED MEMORY
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3}); broadcastVar.value(); // returns [1, 2, 3]
Broadcast Variables
Broadcast() broadcast.value()

Sandeep GiriHadoop
SPARK - SHARED MEMORY
Accumulator<Integer> accum = sc.accumulator(0); sc.parallelize(Arrays.asList(1, 2, 3, 4)).foreach(x -> accum.add(x)); accum.value(); // returns 10
Accumulators
+= 10 += 20
• are only “added” to • through associative operation • assoc.: (2+3)+4=2+(3+4)=9

Sandeep GiriHadoop
!#Import regular expression import re; !#load file lines = sc.textFile('hdfs://hadoop1.knowbigdata.com/user/student/sgiri/wordcount/input/big.txt') !#Split line into multiple lines fm = lines.flatMap(lambda lines: lines.split(" ")); !#Keep only alphanumerics m = fm.map(lambda word: ( re.sub(r"[^A-Za-z0-9]*", ""), word.lower()), 1)) !#Run Reduce counts = m.reduceByKey(lambda a, b: a + b) counts.count(); counts.saveAsTextFile('hdfs://hadoop1.knowbigdata.com/user/student/sgiri/wordcount/output/spark')
Word Count example

Sandeep GiriHadoop
import re; lines = sc.textFile('hdfs://hadoop1.knowbigdata.com/user/student/sgiri/wordcount/input/big.txt'); common = sc.broadcast({"a":1, "an":1, "the":1, "this":1, "that":1, "of":1, "is":1}); accum = sc.accumulator(0); !fm = lines.flatMap(lambda lines: lines.split(" ")); m = fm.map( lambda word: ( re.sub( r"[^A-Za-z0-9]*", "", word.lower() ), 1) ) !def filterfunc(k): accum.add(1); return k[0] not in common.value; !cleaned = m.filter(filterfunc); cleaned.take(10) counts = cleaned.reduceByKey(lambda a, b: a + b) counts.count(); counts.saveAsTextFile('hdfs://hadoop1.knowbigdata.com/user/student/sgiri/wordcount/output/spark')
WordCount with Accumulator and broadcast
