分散処理基盤apachehadoop入門とhadoopエコシステムの最新技術動向(osc2015...
TRANSCRIPT

Copyright © 2015 NTT DATA Corporation
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向
株式会社 NTTデータ 基盤システム事業本部OSSプロフェッショナルサービス 鯵坂 明
2015/08/08OSC 2015 Kansai@Kyoto

2Copyright © 2015 NTT DATA Corporation
NTTデータ社員 (2011/04~現在)
担当でHadoopを利用したシステムを数多く構築
その利用者からのQ&A対応
Apache Hadoop Committer (2014/12~現在)
ソースコードの変更権限を持つ
世界に100人程度、日本企業だと初
自己紹介:鯵坂 明 (あじさか あきら)

3Copyright © 2015 NTT DATA Corporation
Hadoop概要 ~これまでのHadoop~
Hadoopの最新動向
NTTデータのHadoopコミュニティに対する取り組み
アジェンダ

Copyright © 2015 NTT DATA Corporation 4
Hadoop概要 ~これまでのHadoop~

5Copyright © 2015 NTT DATA Corporation
Hadoopとは?
オープンソースの大規模分散処理フレームワーク• Googleの基盤ソフトウェアのオープンソース版クローン (GFS, MapReduce)
• Apacheプロジェクト (http://hadoop.apache.org/)
Yahoo Research の Doug Cutting 氏(現 Cloudera社)が Java で開発
『扱うデータがビッグ(大容量・多件数)であるために、従来のITアーキ
テクチャでは難しかった、もしくは超高コストでしか実現できなかった
データ活用が可能となる』
Dougさんのお子さんのお気に入りだったぬいぐるみ

6Copyright © 2015 NTT DATA Corporation
集中管理型の分散システム
Hadoopの構成
Hadoopマスタサーバ
Hadoopスレーブサーバ群
Hadoopクライアント
NameNodeDataNode
DataNode
DataNode
DataNode
JobTracker
TaskTracker
TaskTracker
TaskTracker
TaskTracker
スレーブサーバは、分散処理の実行やデータの実体を保存
データ管理や分散処理ジョブの管理は
マスタサーバが実施

7Copyright © 2015 NTT DATA Corporation
大きく2つのコンポーネントで構成
分散ファイルシステム
HDFS
並列分散処理フレームワーク
MapReduceフレームワーク
Hadoopの構成するコンポーネント
データを貯める機能を
提供
貯めたデータを処理する機能を
提供

8Copyright © 2015 NTT DATA Corporation
Hadoopとは
集中管理型の分散システムで
HDFSとMapReduceフレームワークの2つのコンポーネントにより
並列分散処理を実現するミドルウェア

9Copyright © 2015 NTT DATA Corporation
分散ファイルシステム
HDFSとは
NameNode
DataNode
DataNode
DataNode
DataNode
DataNode
一つのファイルシステムを構成
複数のサーバを束ねて、

10Copyright © 2015 NTT DATA Corporation
外から見ると、1つの巨大なファイルシステム
HDFSの外からの見え方
NameNode
DataNode
DataNode
DataNode
DataNode
DataNodeHadoopクライアント
hdfs dfs -put
HDFSへの命令

11Copyright © 2015 NTT DATA Corporation
外から見ると、1つの巨大なファイルシステム
HDFSの外からの見え方
NameNode
DataNode
DataNode
DataNode
DataNode
DataNodeHadoopクライアント
hdfs dfs -ls
-rw-r--r-- 3 tester hadoop 129 2015-02-28 12:00 /user/tester/test.txt
所有者権限 作成日時

12Copyright © 2015 NTT DATA Corporation
分散ファイルシステムの舞台裏では
HDFSの舞台裏
NameNode
DataNode
DataNode
DataNode
DataNode
DataNodeHadoopクライアント
入力ファイルは、ブロックサイズで分割される※分割したものをブロックと呼ぶ
④
①
②
③

13Copyright © 2015 NTT DATA Corporation
分散ファイルシステムの舞台裏では
HDFSの舞台裏
NameNode
DataNode
DataNode
DataNode
DataNode
DataNodeHadoopクライアント
各ブロックは複製(レプリケーション)され、スレーブサーバに格納される
④
①
②
③
①
①
①
②
②
②
③
③
③
④
④
④
レプリカは異なる3サーバに配置される

14Copyright © 2015 NTT DATA Corporation
MapReduceアルゴリズム
大量の件数のデータがあった時に、複数ワーカーで 並列に処理できる仕組み
例として、選挙の開票作業を想定
- 複数人で作業を分担して実施
- 最初に、投票用紙を分けて、みんなで並行して候補者別に用紙を仕分ける
- 次に、候補者別の用紙を1カ所にまとめて、それぞれの枚数を数える
MapReduceって?

15Copyright © 2015 NTT DATA Corporation
MapReduce (アルゴリズム)
①用紙を適当に3つに分ける第1段階
第2段階
第3段階
a氏 e氏
③候補者ごとに用紙を集める
d氏c氏b氏
Aさん Bさん Cさん
・・・
・・・
・・・
a氏 b氏 e氏 a氏 b氏 e氏 a氏 b氏 e氏
②3人で並行して、候補者ごとに用紙を仕分ける
④3人で並行して、候補者ごとに枚数を数える
a氏の得票数
b氏の得票数
d氏の得票数
e氏の得票数
c氏の得票数
投票結果
Bさん CさんAさん

16Copyright © 2015 NTT DATA Corporation
MapReduce (アルゴリズム)
Aさん Bさん Cさん
①用紙を適当に3つに分ける
・・・
・・・
・・・
a氏 b氏 e氏 a氏 b氏 e氏 a氏 b氏 e氏
②3人で並行して、候補者ごとに用紙を仕分ける
第1段階
第2段階
第3段階
a氏 e氏
③候補者ごとに用紙を集める
d氏c氏b氏
④3人で並行して、候補者ごとに枚数を数える
a氏の得票数
b氏の得票数
d氏の得票数
e氏の得票数
c氏の得票数
投票結果
Bさん CさんAさん
Map処理データを分類・仕分け
Reduce処理分類・仕分けされたデータごとに処理

17Copyright © 2015 NTT DATA Corporation
MapReduce (アルゴリズム)
Aさん Bさん Cさん
①用紙を適当に3つに分ける
・・・
・・・
・・・
a氏 b氏 e氏 a氏 b氏 e氏 a氏 b氏 e氏
②3人で並行して、候補者ごとに用紙を仕分ける
第1段階
第2段階
第3段階
a氏 e氏
③候補者ごとに用紙を集める
d氏c氏b氏
④3人で並行して、候補者ごとに枚数を数える
a氏の得票数
b氏の得票数
d氏の得票数
e氏の得票数
c氏の得票数
投票結果
Bさん CさんAさん
M人でやれば M倍のスピード(相互に影響を受けずに作業できる)
N人でやれば 約N倍のスピード(相互に影響を受けずに作業できる)
18Copyright © 2015 NTT DATA Corporation
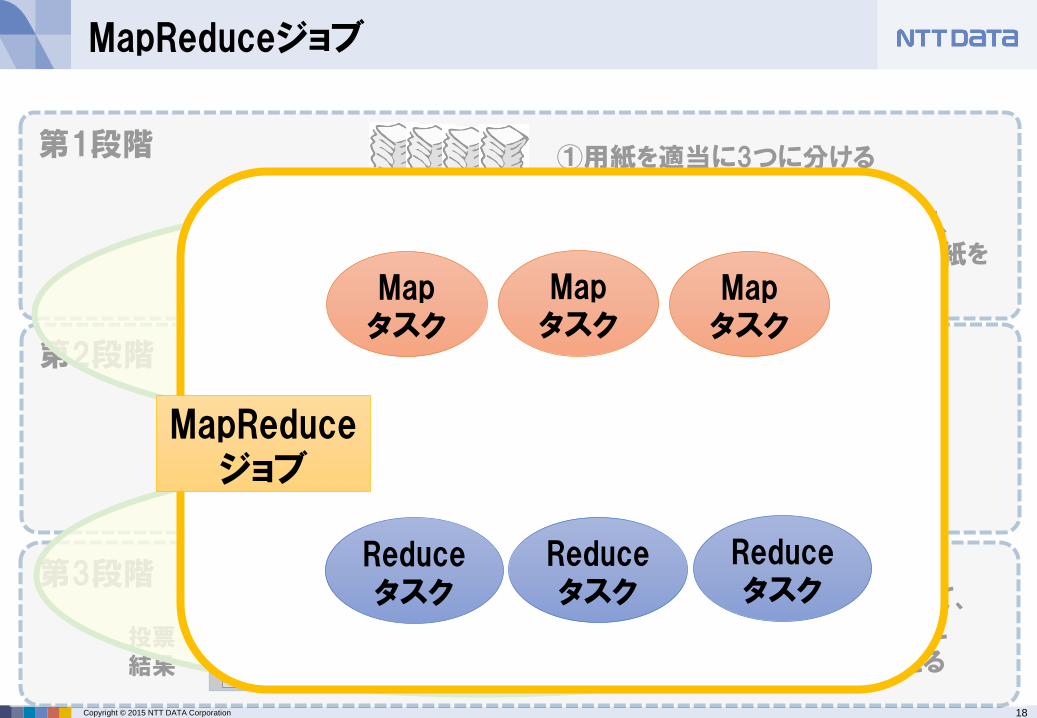
MapReduceジョブ
Aさん Bさん Cさん
①用紙を適当に3つに分ける
・・・
・・・
・・・
a氏 b氏 e氏 a氏 b氏 e氏 a氏 b氏 e氏
②3人で並行して、投票者別に用紙を仕分ける
第1段階
第2段階
第3段階
a氏 e氏
③投票者ごと用紙を集める
d氏c氏b氏
④3人で並行して、投票者ごとに枚数を数える
a氏の得票数
b氏の得票数
d氏の得票数
e氏の得票数
c氏の得票数
投票結果
Bさん CさんAさん
Map処理データを分類・仕分け
Reduce処理分類・仕分けされたデータごとに処理
MapReduceジョブ
Mapタスク
Mapタスク
Mapタスク
Reduceタスク
Reduceタスク
Reduceタスク
19Copyright © 2015 NTT DATA Corporation
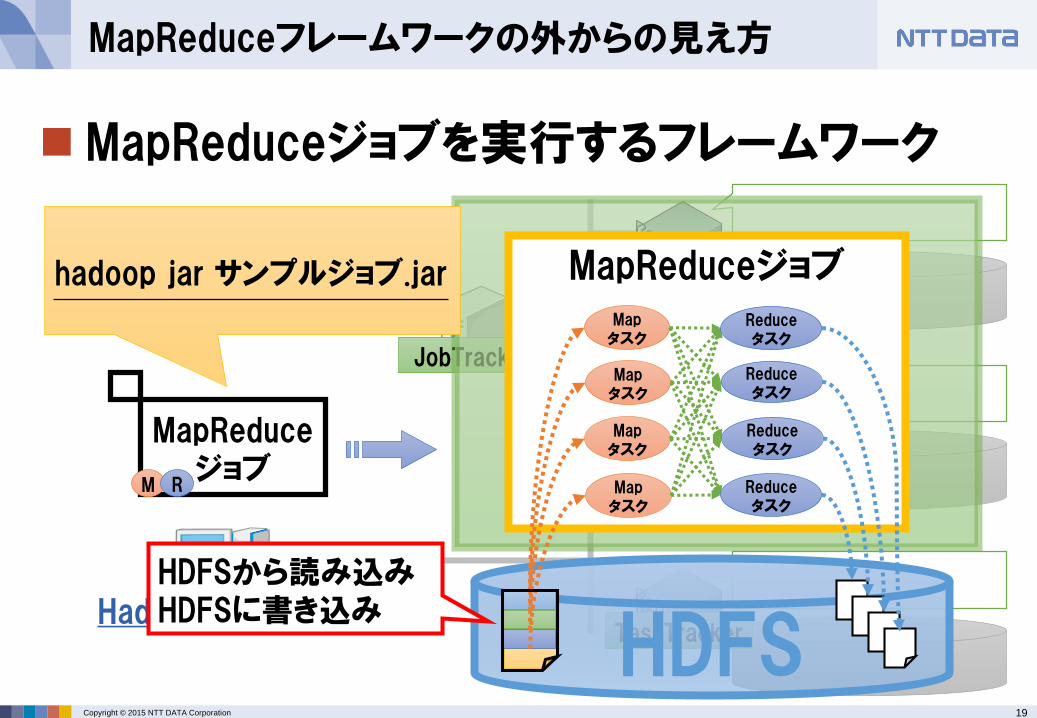
MapReduceジョブを実行するフレームワーク
MapReduceフレームワークの外からの見え方
JobTracker
TaskTracker
TaskTracker
TaskTrackerHadoopクライアント
MapReduceジョブ
HDFS
MapReduceジョブhadoop jar サンプルジョブ.jar
M R
Mapタスク
Mapタスク
Mapタスク
Mapタスク
Reduceタスク
Reduceタスク
Reduceタスク
Reduceタスク
HDFSから読み込みHDFSに書き込み

20Copyright © 2015 NTT DATA Corporation
HDFS 大量データを高スループットに読み込める
サーバが故障しても、データの安全性は担保
サーバ数を増やせば、格納できるデータ量はスケールする
MapReduceフレームワーク Mapタスク、Reduceタスクのみ指定すれば、
(原則はJavaで処理を記述)あとはフレームワークが並列分散処理を実現
サーバが故障しても、タスクが再実行され、ジョブは成功
サーバ数を増やせば、処理性能は基本スケールする
Hadoopの特徴

21Copyright © 2015 NTT DATA Corporation
HDFS 大量データを高スループットに読み込める
サーバが故障しても、データの安全性は担保
サーバ数を増やせば、格納データ量はスケールする
MapReduce Mapタスク、Reduceタスクのみ指定すれば、
(原則はJavaで処理を記述)あとはフレームワークが並列分散処理を実現
サーバが故障しても、タスクが再実行され、ジョブは成功
サーバ数を増やせば、処理性能は基本スケールする
Hadoopの特徴
並列分散処理の面倒な部分を解決してくれるミドルウェア

22Copyright © 2015 NTT DATA Corporation
Hadoopは「貯める」「処理する」機能に特化。Hadoopを活用した大量データ分析を実現するため、様々な周辺ツールが出現。エコシステムが広がった。
エコシステムを形成

23Copyright © 2015 NTT DATA Corporation
MapReduceフレームワークを直接Javaで記述すると、コード行数が増えることは避け難く、アプリケーションの生産性が課題となる。
分散処理を記述するためのAPIは提供されているが、適切なプログラムの記述のためにはアプリ実装者が覚えることが多いのも事実…
エコシステム ~アプリ記述の抽象化・ライブラリ化~
Map?Reduce?
Partitioner??Combiner??

24Copyright © 2015 NTT DATA Corporation
Apache HiveHiveQLというSQLライクな言語でMapReduceを実行
Apache PigPig Latinという独自の言語でMapReduceを実行
Apache Mahout機械学習アルゴリズムのMapReduce実装のライブラリ
エコシステム ~アプリ記述の抽象化・ライブラリ化~
hive> SELECT COUNT(uid) FROM access_log GROUP BY date;
A = LOAD 'data' USING PigStorage() AS (f1:int, f2:int, f3:int); B = GROUP A BY f1;(省略)
$ mahout kmeans --input inputfile --output outputfile

25Copyright © 2015 NTT DATA Corporation
HDFS HDFSHDFS
よくある疑問
MapReduceフレームワークの縛りは厳しそうだけど、SQLのような複雑な処理を実現できるの?
YES!MapReduceを複数段組み合わせることで、様々な処理が実現できる
M R
M R
M RM
GROUP BY + 集約関数
JOIN(結合処理)
SELECT(射影)やWHERE(選択)
HDFS
JOIN(結合処理)

26Copyright © 2015 NTT DATA Corporation
分析対象のデータをHDFSに格納することも課題となる
既存のRDBMSに格納したデータを移動して利用したい
Webアクセスログやシステムログなど、多数のサーバで発生するログを効率よく収集したい
エコシステム ~データ連携~
処理毎に使い捨てスクリプトを書く?エラーハンドリングや耐障害性など担保すべきことも多い…

27Copyright © 2015 NTT DATA Corporation
Apache SqoopRDBMS-Hadoop間のデータ連携ツール
Apache Flumeログ収集のための分散フレームワーク
エコシステム ~データ連携~
MapReduce
SqoopRDBMS
HDFS
import
export
内部的にはMapReduceが動作。並列でRDBとテーブルの情報をやりとりする。
HDFS
ログ
ログ
ログ

28Copyright © 2015 NTT DATA Corporation
Hadoopコア部分に加えてエコシステムが充実することで、データの収集や分析など、「大量データ活用」を身近なものにした。
エコシステムの浸透
HDFS
MapReduce
PigHive MahoutHBase
SqoopRDBMS
外部システム
Flume

Copyright © 2015 NTT DATA Corporation 29
Hadoopの最新動向

30Copyright © 2015 NTT DATA Corporation
Hadoopとエコシステムはユーザーとともに進化を遂げた。活用事例の増加や取り巻く環境の変化から、新たな潮流が生まれる…
Hadoopと周辺環境の変化
•一部のユーザは数千台クラスのHadoopクラスタを構築・利用クラスタ”超”巨大化
•企業の利用拡大に伴い、Hadoopにアクセスしてデータ分析をする利用者が増えたアクセスユーザ増加
•大量データ活用が一般的になるにつれて、「速報値を知りたい」「もっとインタラクティブに分析したい」といった要求が生まれるデータ処理高速化の追求
•Hadoop黎明期はサーバあたりのメモリ4~8Gが一般的だったが、現在は100GB以上のメモリを積んだサーバも普及。ハードウェアの進化
主な”変化”の例

31Copyright © 2015 NTT DATA Corporation
近年のHadoopおよびエコシステムについて、
以下の3点について最新動向を紹介
近年のHadoopの潮流
クラスタ”超”巨大化
アクセスユーザ増加
データ処理高速化の追求
ハードウェアの進化
1.YARN登場
2.新たな並列分散処理エンジンの出現
3.非機能面の強化

32Copyright © 2015 NTT DATA Corporation
YARNの前に:Hadoop1系、Hadoop2系について
Hadoop1系は2007年から開発が始まり、安定化志向。2014年6月に開発は凍結。 Hadoop2系は2012年に分岐。根本のアーキテクチャに変更を入れ、現在も進化を続けている。
20142010 2011 201320122009
branch-2
2.2.0
2.3.0
2.4.02.0.0-alpha
2.1.0-beta
branch-1(branch-0.20)
1.0.0 1.1.0 1.2.1(stable)0.20.1 0.20.205
0.22.00.21.0
New append
Security
0.23.0
0.23.11(final)NameNode Federation, YARN
NameNode HA
2015
2.5.0
2.6.0
これまでお伝えした範囲
これからお伝えする範囲
2.7.0

33Copyright © 2015 NTT DATA Corporation
YARN = Yet Another Resource Negotiator
YARN登場
分散ファイルシステム
HDFS
バッチ処理MapReduce
Hadoop 1
分散ファイルシステム
HDFS
バッチ処理MapReduceV2
Hadoop 2
リソース制御YARN
「蓄積+処理」の構成からリソース制御を切り出した

34Copyright © 2015 NTT DATA Corporation
MRv1とMRv2との比較 (ノード構成)
JobHistoryServer
NodeManager
TaskTracker
タスクプロセスタスクプロセスタスクプロセス
Hadoop 1系 Hadoop 2系
HDFS HDFS
JobTracker
ResourceManager
TaskTracker
NodeManagerジョブ履歴
管理
リソース管理
タスクプロセス
MRv1
MRv2
YARN
リソース管理
ジョブ・タスク管理
TimelineServer
コンテナ
Application Master
コンテナコンテナコンテナコンテナ タスクプロセス

35Copyright © 2015 NTT DATA Corporation
YARNの意義
リソース制御を分離することで…つまり何が嬉しいの?
柔軟なリソース制御によるスループット向上
Hadoopのスケーラビリティをさらに向上させる
MapReduce以外の分散処理を実行できる

36Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
TaskTracker
ジョブ/アプリケーション管理のイメージ
JobTracker
TaskTracker TaskTracker TaskTracker TaskTracker
Hadoop1系
クライアント ジョブAお願いします。

37Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
TaskTracker
ジョブ/アプリケーション管理のイメージ
JobTracker
TaskTracker TaskTracker TaskTracker TaskTracker
Hadoop1系
クライアント了解です。
Aさんは○○、Bさんは○○をお願いします。定期的に進捗報告もお願いします。

38Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
TaskTracker
ジョブ/アプリケーション管理のイメージ
JobTracker
TaskTracker TaskTracker TaskTracker TaskTracker
ジョブAのタスク1、50%終わりました。
余裕あります。
ジョブAのタスク2、30%終わりました。
忙しいです。
ジョブ Hadoop1系

39Copyright © 2015 NTT DATA Corporation
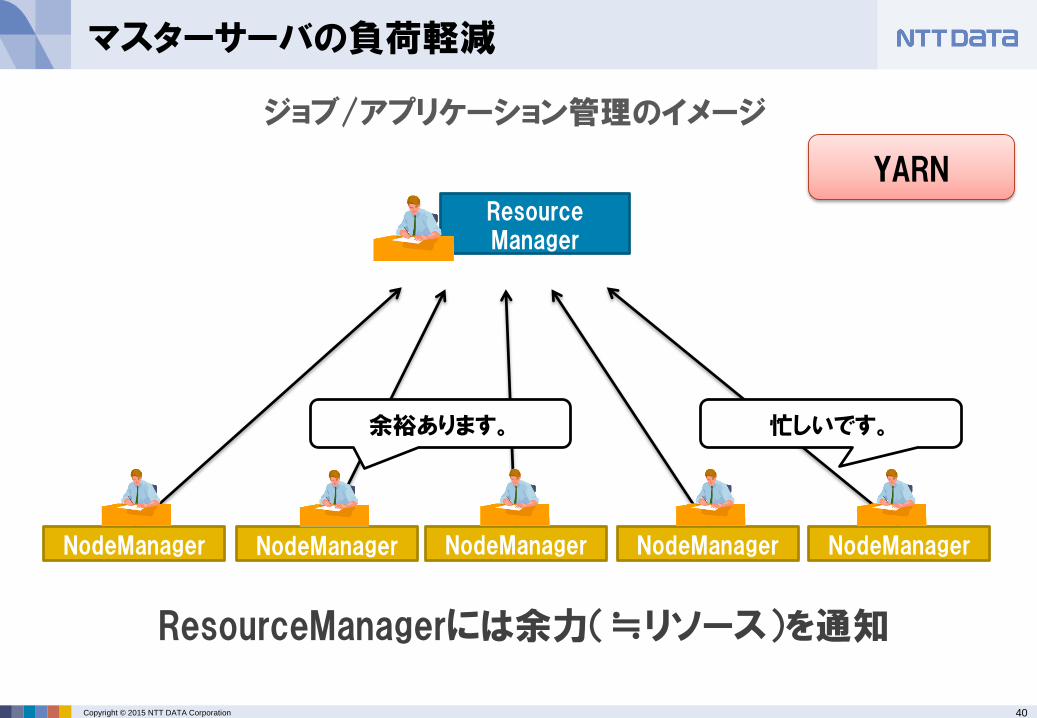
マスターサーバの負荷軽減
TaskTracker
ジョブ/アプリケーション管理のイメージ
JobTracker
TaskTracker TaskTracker TaskTracker TaskTracker
ジョブAのタスク02を50%終わりました。ジョブCのタスク01を完了しました。
余裕あります。
ジョブAのタスクA30%終わりました。ジョブBのタスクBを50%終わりました。
忙しいです。
ジョブ
マスターサーバの管理コストが多く、メンバが増えるとボトルネックに…
Hadoop1系
3000~4000ノードで限界といわれている
40Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
余裕あります。 忙しいです。
YARN
ResourceManagerには余力(≒リソース)を通知

41Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
YARN
アプリAお願いします。クライアント
YARNではジョブ× → アプリケーション○

42Copyright © 2015 NTT DATA Corporation
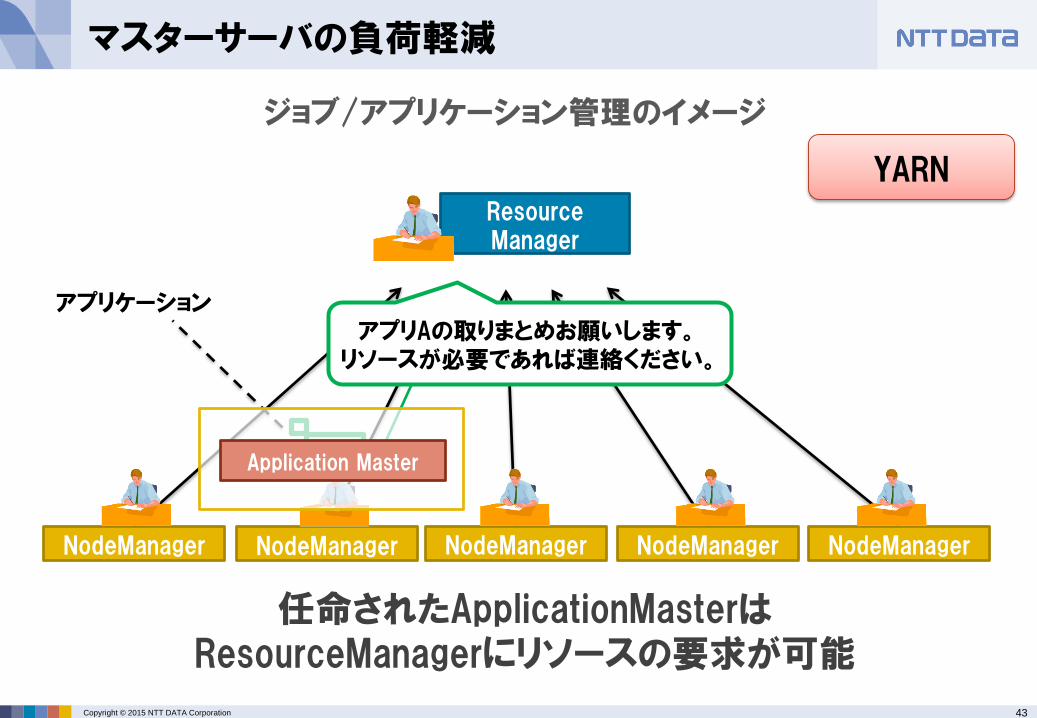
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
アプリAの取りまとめお願いします。リソースが必要であれば連絡ください。
アプリケーション
YARN
仕事(アプリケーション)の管理はメンバに依頼取りまとめ役(ApplicationMaster)になる
43Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
アプリAの取りまとめお願いします。リソースが必要であれば連絡ください。
アプリケーション
YARN
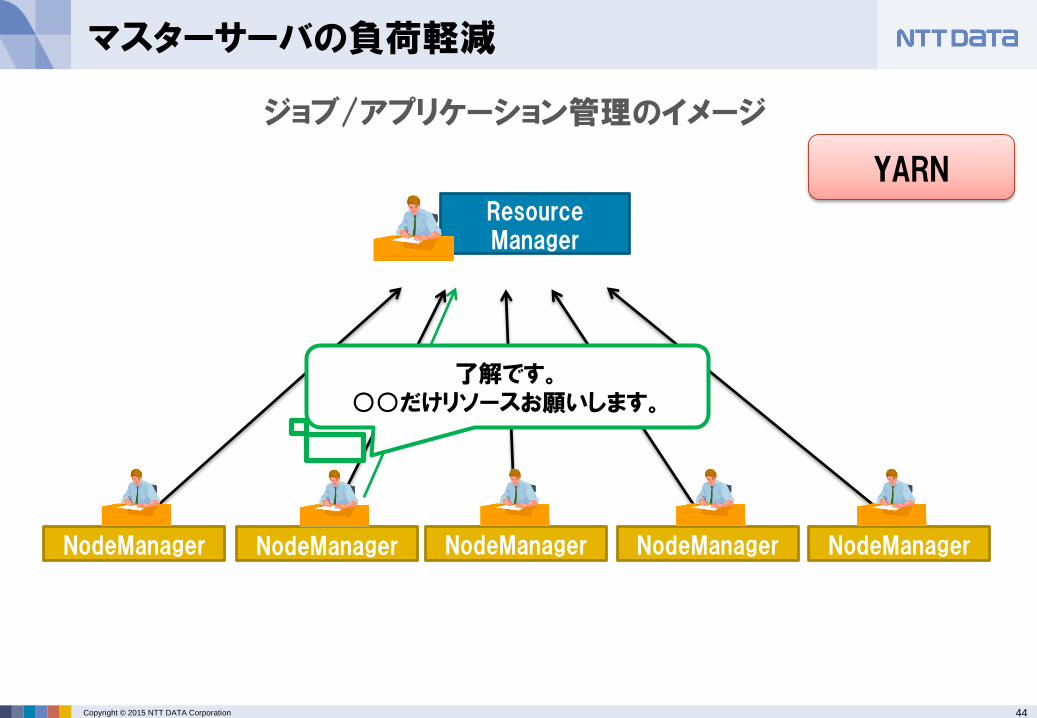
任命されたApplicationMasterはResourceManagerにリソースの要求が可能
Application Master
44Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
了解です。○○だけリソースお願いします。
YARN

45Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
○割の仕事はBさんの指示に従ってください。
YARN
46Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
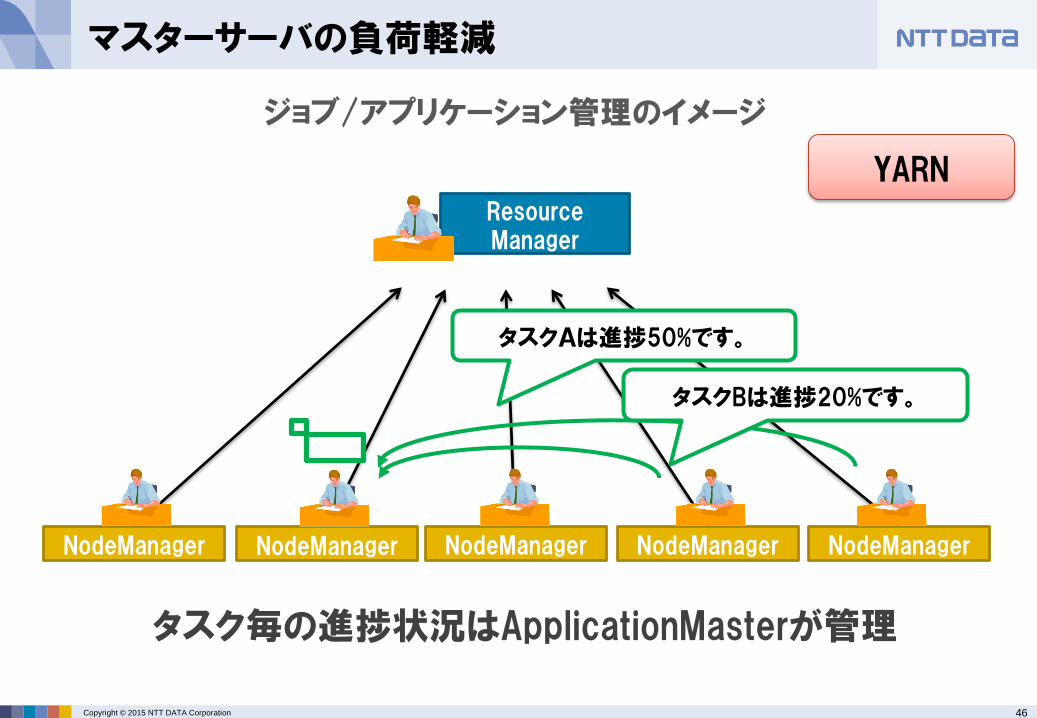
タスクAは進捗50%です。
タスクBは進捗20%です。
YARN
タスク毎の進捗状況はApplicationMasterが管理

47Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
YARN
ApplicationMasterはアプリケーションの進捗状況をRMに通知
アプリAの進捗70%です

48Copyright © 2015 NTT DATA Corporation
マスターサーバの負荷軽減
NodeManager
ジョブ/アプリケーション管理のイメージ
ResourceManager
NodeManager NodeManager NodeManager NodeManager
マスターサーバの管理コストが減り、多数のメンバを管理できる(スケーラビリティ向上)
アプリAの進捗70%ですアプリBの進捗30%です
YARN
10000ノード程度のクラスタも構成可能に!

49Copyright © 2015 NTT DATA Corporation
コンテナ単位でリソースを柔軟に払い出す
Hadoop 1系 Hadoop 2系
TaskTracker NodeManager
Mapタスク
Mapタスク
Mapタスク
Reduceタスク
Reduceタスク
Mapタスク
Mapタスク
Mapタスク
Reduceタスク
Mapタスク、Reduceタスクの並列数は、それぞれに設定したスロット数で制限される。
利用可能な仮想CPU、メモリを制限したコンテナという単位でリソースを払いだす。(Map、Reduceの区別は無い)
Mapスロット Reduceスロット コンテナ
単一サーバ上での並列実行数管理のイメージ
リソース(VCPU / メモリ)
Application Master
柔軟なリソース管理やリソースオーバーコミット防止は、スループットの向上につながる

50Copyright © 2015 NTT DATA Corporation
MapReduceは、ディスクIOを並列化することでスループットを最大化するが、低レイテンシな処理は苦手。
新たな並列分散処理エンジンの出現
M RM R
Reduce処理
MapReduceジョブ ・・・
M
M R
M R M R
・・・
・・・
・・・
・・・
Map処理
・・・・・・
HDFS
HDFSHDFS
HDFSApplicationMaster
MapReduceのフレームワークの縛りの中で複雑な処理を行うには、多数のMapReduceを組み合わせることになる。都度HDFSに中間データを書き出すためのオーバーヘッドや、ジョブ(ApplicationMaster)の起動のオーバーヘッドは分析処理の遅延に繋がる。
HiveやPig(on MapReduce)による一連の処理のイメージ
HDFSに書き出しHDFSから読み出し

51Copyright © 2015 NTT DATA Corporation
MapReduceで実現が難しいデータ処理の課題に対して、新たな分散処理フレームワーク・実行エンジンが出現。
新たな並列分散処理エンジンの出現
次ページより概要を紹介します!
分散ストリーム処理
SQLライクなインターフェース+ 実行エンジン
分散機械学習フレームワーク
分散処理エンジン
52Copyright © 2015 NTT DATA Corporation
Apache Spark : Hadoop上で動作する低レイテンシ技術
Apache Spark : 大規模データの分散処理をオンメモリで実現
• データ処理を極力メモリ上で実現するため、高速な処理を実現
• Hadoop MapReduceが不得意な繰り返し処理に威力を発揮
• 機械学習やHadoop MapReduceよりも短時間で処理したいものが得意領域
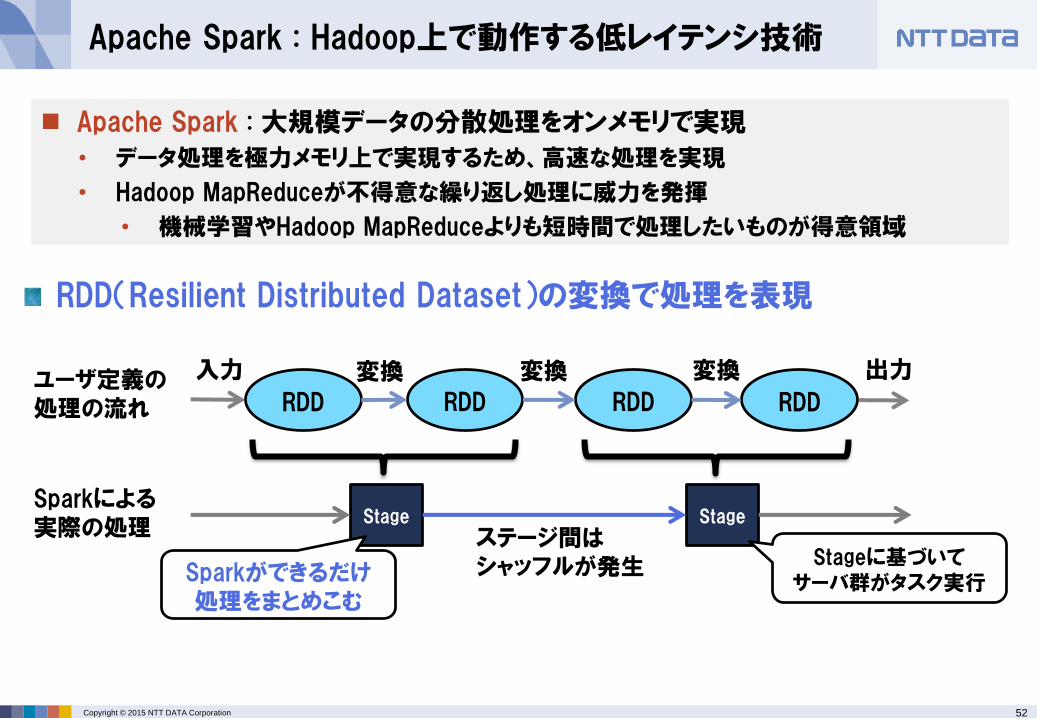
RDD(Resilient Distributed Dataset)の変換で処理を表現
RDD RDD RDD
Stage Stage
RDD
Sparkができるだけ処理をまとめこむ
ユーザ定義の処理の流れ
Sparkによる実際の処理 ステージ間は
シャッフルが発生
変換 変換 変換 出力入力
Stageに基づいてサーバ群がタスク実行

53Copyright © 2015 NTT DATA Corporation
Apache Spark : コアを中心に成り立つライブラリ
Apache Spark(コア)
Spark SQLSpark
StreamingMLlib GraphX
SQLで書ける ストリーム処理できる
機械学習できる統計処理できる グラフ処理できる
Scala、Java、Pythonで分散処理を書ける
高度な処理を実現するための標準ライブラリが充実
メモリを活用したアーキテクチャ、インタラクティブにも処理を記述できる仕組み、便利なライブラリなど、分析担当者に嬉しい機能が多い。

54Copyright © 2015 NTT DATA Corporation
SparkやStormは元々Hadoopとは独立したプロジェクトだったが、機能追加によりYARN上での動作が可能に。(TezはYARNでの実行を前提としている)
メリット- 専用のクラスタを構築する必要が無く、必要なリソースを払いだしながら多様
な分析処理を実行できる
- 同一のデータ(HDFS)にアクセスできる。(データを移動させる必要が無い)
YARNで、Hadoopに乗る
MRv2
PigHive
HDFS
YARN
Tez Spark Storm
MLlib Streaming
…
SQL GraphX
スケーラブルなデータストアの上で、様々な分析処理のワークロードが動作。「Hadoopはビッグデータの”OS”カーネル」という声も。
http://itpro.nikkeibp.co.jp/article/NEWS/20140708/569985/

55Copyright © 2015 NTT DATA Corporation
エンタープライズ用途でより活用されるために、高い非機能要求に対応するための機能拡張も進んでいる
以下の観点で、Hadoop2系で追加された機能を紹介します
可用性
セキュリティ
堅牢なHadoopに向けて

56Copyright © 2015 NTT DATA Corporation
Hadoop1系まではマスターサーバはSPOF(単一障害点)
他のHA系コンポーネントを組み合わせることで冗長化していた
現在は、Hadoopの機能としてマスタサーバのHA機能を提供
他のHA系コンポーネントと組み合わせるよりも少ないダウンタイムでフェールオーバが可能に
MRv2やTezのジョブ実行中にフェールオーバが発生しても、処理は正常に継続する
ユーザがジョブを再投入する必要はない
可用性 : SPOFは無い!

57Copyright © 2015 NTT DATA Corporation
Hadoopクラスタへアクセスするユーザ・組織の増加や、クリティカルなデータをHadoopで保持する事例も増え、セキュリティ機能も強化されている。
HDFS Transparent Encryption ファイルを暗号化してDataNodeに書き込む
HDFS ACL 細かな粒度でHDFSへのアクセス権限を制御する
セキュリティ : 暗号化 / ACL
-rw-r--r-- 3 tester hadoop 129 2015-02-27 12:00 /user/tester/test.txt
例: $ hdfs dfs –setfacl –m group:hive:rw- /user/tester/test.txt上記のコマンドで、hiveグループにも書き込みの権限を付与可能。アクセス制御が柔軟に。
DataNode
DataNode中のデータに直接アクセスしても読めない
クライアントやアプリケーションからは透過的にデータが読める

58Copyright © 2015 NTT DATA Corporation
お話した内容
YARN登場
新たな並列分散処理エンジンの出現
非機能面の強化
Hadoopの最新動向のまとめ
根本的なアーキテクチャも見直しを入れてHadoopはさらに進化をつづけている
Hadoopがユーザへ浸透することで生まれた新たな課題に対しても、様々なエコシステムが生まれ活用されている
大量データ保持・活用の様々な課題に対するHadoopの適用領域は広がりつづけている

Copyright © 2015 NTT DATA Corporation 59
NTTデータのHadoopコミュニティに対する取り組み

60Copyright © 2015 NTT DATA Corporation
Hadoopを多数運用してきたことで得られた知見をもとに、改善提案をコミュニティにフィードバックしています
運用上特に問題となるバグの改修- HDFS-6833: データロストが起こる可能性がある問題の修正
- HDFS-6945: NameNodeのメモリリークの修正
利用者向けのドキュメントの拡充- HADOOP-10139: 擬似分散クラスタ構築用ドキュメントの更改
- HADOOP-6350, YARN-2157: メトリクスのドキュメントを追加
運用、トラブルシュートを便利にする機能の開発- HDFS-5274: HDFSにTracingの機能を実装
- HDFS-5978: OfflineImageViewerにREST APIを実装
コミュニティへの貢献

61Copyright © 2015 NTT DATA Corporation
開発面におけるHadoopコミュニティへの貢献
NTTデータはHadoopコミュニティにおいて世界有数のコントリビュータ(貢献企業)として活動しています。
商用環境においてHadoopを多数運用してきたことで得られた知見をもとに、Hadoopに対する改善提案をコミュニティにフィードバックしています。事象の報告にとどまらずHadoop本体への開発も行っています。運用上特に問題となるバグの改修や、利用者向けのドキュメントの拡充のためのパッチを投稿し、コミュニティに貢献しています。
解決済みissue数
2014年 Hadoopコミュニティ貢献指標
Hadoop専業ベンダのHortonworksやCloudera、Hadoopを開発したYahoo! Inc.に次いで、NTTデータもHadoopコミュニティにグローバルレベルで貢献しています。
貢献コード行数
244,975
131,609
30,595
第6位
21,78023,197 30,595 20,54014,764 14,534
第4位370
274
195
85
174
11972
45 45

62Copyright © 2015 NTT DATA Corporation
小沢 健史 日本電信電話株式会社ソフトウェアイノベーションセンタ
鯵坂 明 株式会社NTTデータ 基盤システム事業本部
岩崎 正剛 株式会社NTTデータ 基盤システム事業本部
猿田 浩輔 NEW! 株式会社NTTデータ 基盤システム事業本部
コミッタ(主要開発者)に就任
Hadoop
Hadoop
HTrace
Spark

63Copyright © 2015 NTT DATA Corporation
Hadoopは1台のマシンで扱えない規模の大量データを高速に処理するためのフレームワークです 数台から始めて、数千台(データ量にして数十PB)までスケールアウトします
Hadoopエコシステムの開発の勢いは今も活発です 性能面、運用面で便利な機能がどんどん追加されています
より低レイテンシな分散処理フレームワークや分析のためのライブラリも充実し、大量データ活用の可能性を広げています
NTTデータも、Hadoopの開発に参戦しています バグフィックスや、運用を便利にするための機能開発に取り組んでいます
国内初のコミッタ輩出!さらなる開発力の向上を目指しています
まとめ

Copyright © 2011 NTT DATA Corporation
Copyright © 2015 NTT DATA Corporation
お問い合わせ先:株式会社NTTデータ 基盤システム事業本部OSSプロフェッショナルサービスURL: http://oss.nttdata.co.jp/hadoopメール: [email protected] TEL: 050-5546-2496