aplicaciÓn de modelos predictivos para la ......el estudio de la infraestructura persigue la...
TRANSCRIPT

APLICACIÓN DE MODELOS PREDICTIVOS
PARA LA OPTIMIZACIÓN DE SERVICIOS TI
Madrid, 2016
Máster en Big Data y Business Intelligence
Ana Martínez
Daniel Vivas Tutores:
Jaime Ramón Juan Carlos Ibáñez
Laura Figueroa José Carlos García

2
Contenido Contexto y justificación del Proyecto .......................................................................................... 4
Objetivos del Proyecto ............................................................................................................... 6
Aspectos generales de la ejecución del Proyecto ...................................................................... 7
Estudio de las llamadas al CAU ............................................................................................... 11
Estudio diagnóstico .............................................................................................................. 11
Modelado Predictivo ............................................................................................................. 13
Base de Datos MySQL ......................................................................................................... 18
Cuadros de Mando del área del CAU ................................................................................... 20
Estudio de la Infraestructura .................................................................................................... 23
Topología de sistemas ......................................................................................................... 25
Generador de ficheros de log ............................................................................................... 26
Proceso de transporte y análisis de los ficheros ................................................................... 29
Proceso de análisis de los ficheros ....................................................................................... 30
Sistema de monitorización .................................................................................................... 31
Base de datos MySQL .......................................................................................................... 31
Modelado Predictivo ............................................................................................................. 36
Justificación de la selección del modelo ............................................................................ 36
Ajuste del modelo ............................................................................................................. 37
Validación de la fiabilidad del modelo ............................................................................... 39
Cuadro de Mando del área de Infraestructuras ..................................................................... 42
Servidores y componentes con warnings & errores .......................................................... 43
Servidores que no responden ........................................................................................... 43
Alertas prematuras ............................................................................................................ 43
Servidores por estado ....................................................................................................... 44
Indicador de salud de los servidores & componentes ....................................................... 44
Historial de los errores registrados en los últimos 10 minutos ........................................... 45
Valor de Negocio ..................................................................................................................... 46
Retorno económico del estudio de las llamadas ................................................................... 46
Retorno económico del estudio de la Infraestructura ............................................................ 46
Conclusiones ........................................................................................................................... 47
BIBLIOGRAFÍA ........................................................................................................................ 49
ANEXOS .................................................................................................................................. 50
1. Anexo I .......................................................................................................................... 50
1.1. Script para el ajuste del modelo. Parte llamadas CAU............................................ 50
1.2. Script de previsión de llamadas al CAU .................................................................. 51
2. Anexo II ............................................................................................................................ 51

3
2.1 Script para el ajuste del modelo. Parte monitorización sistemas. ................................ 51
2.2 Script de previsión de monitorización sistemas. .......................................................... 51

4
Contexto y justificación del Proyecto
Este proyecto surge de la necesidad de mejorar el nivel de servicio y reducir
los costes derivados, en una organización que da cobertura a un gremio de
profesionales a nivel nacional, que gestiona diferentes servicios TI como son el
correo electrónico corporativo, las aplicaciones de gestión y el alojamiento de
páginas web.
Estos servicios son vitales para el desempeño de los clientes de la
organización, quienes requieren tener disponibilidad de estos servicios en todo
momento.
La organización determinó hace un tiempo la externalización del servicio del
CAU, por resultar más rentable que tener un servicio interno. El acuerdo firmado
con la empresa externa, es pagar un fix por cada llamada atendida.
El uso de los servicios simultáneamente por numerosos usuarios genera
picos en el tráfico, que, en ocasiones, deriva en caídas de rendimiento en los
sistemas que lo hospedan, incluso en pérdidas de servicio. A su vez, la
implementación de cambios en el Software y Hardware asociado a estos servicios,
genera también un elevado número de llamadas de los clientes de la organización
al Centro de Atención del Usuario (CAU), lo que se traduce en un elevado coste que
debe ser contenido, sino reducido, puesto que éste excede por mucho lo esperado
y a la vez, deseado.
Así pues, la justificación del Proyecto viene por la reducción del número de
llamadas de los clientes al CAU, y adicionalmente, la reducción de las caídas de los
sistemas, puesto que generan una mala experiencia para el usuario, quien se
siente insatisfecho con el servicio que recibe, amén de los costes derivados de las
llamadas al CAU por consultas y/o reclamaciones.
Para conseguir estas mejoras se considera vital conocer de antemano cuándo
ocurrirán los picos en la demanda de los servicios por parte de los usuarios, lo cual
permitirá tomar acciones para prevenir la sobresaturación de los sistemas, así
como del propio CAU. Por otra parte, la posibilidad de predecir el comportamiento

5
de los servidores en base a su monitorización constante, permitirá realizar acciones
tempranas destinadas a evitar caídas de los mismos.
Así pues, ante la evidente importancia en la detección temprana de los
factores causantes de los aumentos en las llamadas al servicio externalizado, y en
consecuencia, de sus costes derivados, se hace propicia la utilización de sistemas
de análisis de datos basados en modelos predictivos, tanto en las llamadas al CAU,
como a los provenientes de los servidores.

6
Objetivos del Proyecto
El objetivo general del Proyecto es construir poner a disposición de la
Gerencia una herramienta que le permita adoptar las decisiones oportunas, que
permitan conseguir un ahorro de costes, manteniendo o mejorando el nivel de
calidad del servicio.
Los objetivos específicos del Proyecto son:
1. Estudiar los datos de los reportes de incidencias para entender su composición y
diagnosticar las causas principales de los aumentos de las llamadas.
2. Desarrollar un sistema de modelado de datos que permita predecir o estimar el
número de llamadas al día para orientar el dimensionamiento del CAU.
3. Desarrollar un sistema de ingesta, carga y modelado de datos a partir de los
logs de los servidores que permita prevenir las caídas del servicio para evitarlas o
para tener una respuesta temprana a estas.

7
Aspectos generales de la ejecución del Proyecto
En primer lugar, se llevó a cabo un estudio de diagnóstico de las causas del
aumento en los costes del servicio de atención al usuario externalizado, derivado
del aumento de las llamadas. Para descubrir qué aspectos afectan más a la
demanda del soporte se analizaron tres áreas:
● Comportamiento de los usuarios, mediante:
o Encuesta a usuarios que llamaban al CAU.
o Entrevista a los operadores que dan soporte.
● Análisis de la web a disposición de los clientes, en los aspectos:
o Nivel de usabilidad.
o Grado de accesibilidad de sus contenidos.
o Calidad del contenido.
o Descargas del software.
● Software usado por los usuarios, en los aspectos:
o Facilidad de instalación.
o Fiabilidad.
o Uso/funcionalidad.
Para conseguir el objetivo principal se abrieron dos frentes de acción:
● El primero dirigido a la búsqueda de patrones en los datos provenientes de
los tickets generados por las llamadas de los usuarios.
● El segundo dirigido a mejorar la eficiencia y mantener la estabilidad de la
infraestructura para evitar fallos en los mismos mediante un sistema de
alerta temprana.

8
En el siguiente diagrama se muestra en rasgos generales las dos ramas de
acción del proyecto, así como el tratamiento de los datos que provienen tanto de
las llamadas, como de los servidores, para generar las predicciones que permitan
tomar acciones que mejoren la eficiencia de los recursos en ambas áreas.
Figura 1. Esquema general del sistema de tratamiento de datos.

9
El Estudio de las Llamadas consiste principalmente en el modelado de los
datos provenientes de la base de datos del CAU, sobre los que se aplican modelos
predictivos desarrollados en R, destinados a hacer predicciones del comportamiento
de la afluencia de llamadas.
Figura 2 . Flujo de los datos procedentes de las llamadas del CAU

10
El Estudio de la Infraestructura persigue la optimización del
funcionamiento de los sistemas con el objeto de evitar su caída, basándose en la
predicción del comportamiento de cada uno de sus componentes de hardware y
software. Para ello se lleva a cabo una ingesta de los datos procedentes de los
sistemas, utilizando la herramienta Flume, enviándolos a un clúster HDFS, sobre
los cuales se aplican procesos Spark para su análisis, cuyo resultado es almacenado
en una base de datos MySQL, donde confluyen con los datos provenientes de la
monitorización externa. Sobre éstos se aplica un modelo predictivo en R capaz de
predecir el comportamiento de los componentes en los siguientes 1, 5 y 15
minutos.
Figura 3. Flujo de los datos procedentes de los servidores y el sistema de monitorización.
En ambos casos se utiliza la herramienta Power BI para la visualización de
los datos y las predicciones, y para su análisis.

11
Estudio de las llamadas al CAU
Estudio diagnóstico
Se hizo un estudio sobre el volumen de las llamadas recibidas y su
correspondiente registro de tickets en el sistema de ticketing del CAU, con el fin de
conocer la tendencia y previsiones con las condiciones actuales, y, por otra parte,
de adelantarse al aumento o disminución de la demanda si se cambia el escenario
actual.
Se tomaron en cuenta otros aspectos relacionados con la funcionalidad del
software, como son:
● Tamaño y variedad de la infraestructura que soportan los servicios ofrecidos.
● Software de terceros que afectan al funcionamiento.
Figura 4. Representación esquemática de los aspectos estudiados.
También se incorpora el aspecto de mejorar la formación a los usuarios
mediante plataformas on-line y aumentar el uso de las redes sociales para informar
a los usuarios.
12
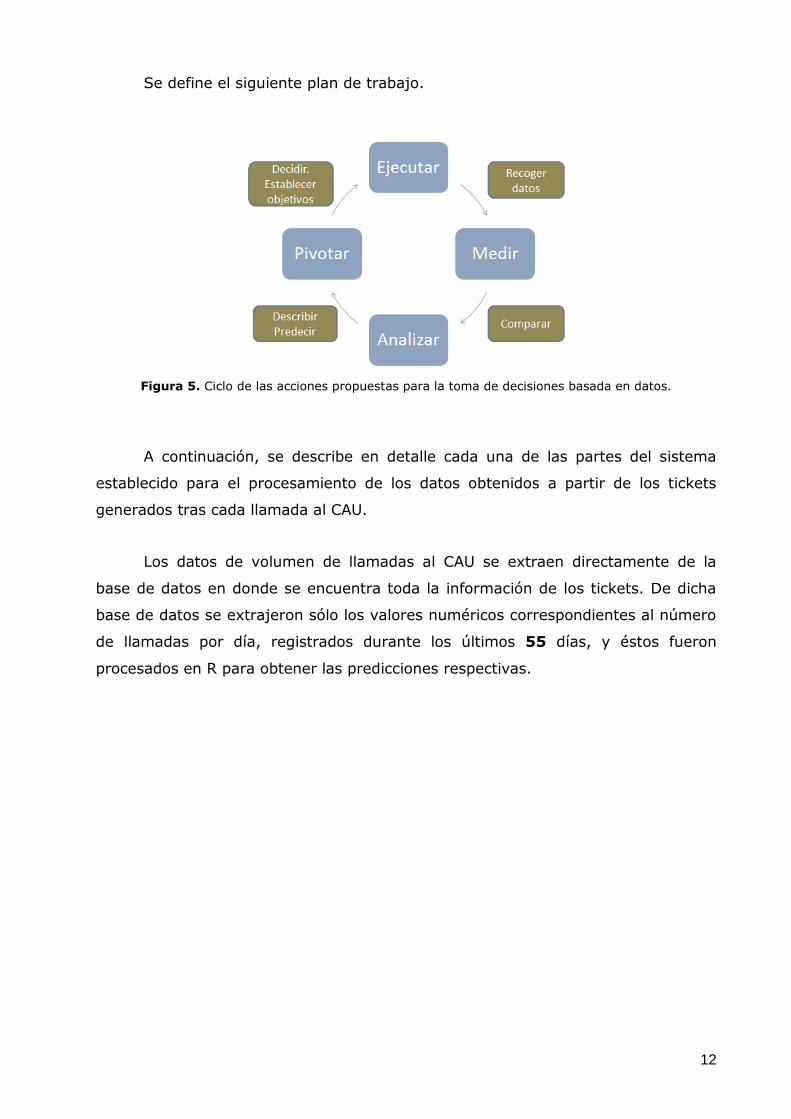
Se define el siguiente plan de trabajo.
Figura 5. Ciclo de las acciones propuestas para la toma de decisiones basada en datos.
A continuación, se describe en detalle cada una de las partes del sistema
establecido para el procesamiento de los datos obtenidos a partir de los tickets
generados tras cada llamada al CAU.
Los datos de volumen de llamadas al CAU se extraen directamente de la
base de datos en donde se encuentra toda la información de los tickets. De dicha
base de datos se extrajeron sólo los valores numéricos correspondientes al número
de llamadas por día, registrados durante los últimos 55 días, y éstos fueron
procesados en R para obtener las predicciones respectivas.

13
Modelado Predictivo
Después de un estudio probando diferentes modelos predictivos para
conseguir el mejor ajuste y con ello la mayor fiabilidad, se optó por un modelo
ARIMA (1,0,0) debido a las características de la serie con la que trabajamos.
Modelo Arima: (order=c(1,0,0), seasonal = c(1,1,0), lambda=0.5)
El proceso de decisión consistió en desarrollar un modelo comparativo
(entrenamiento), utilizando el lenguaje de programación R. El modelo usa los datos
históricos del año actual para hacer las previsiones.
Figura 6. Representación de datos originales 10 meses.
Figura 7. Representación de las variaciones, en escala logarítmica, entre medidas consecutivas.

14
Figura 8. Gráfico de serie temporal, ACF y PACF, para 10 meses.
A través del factor ACF y PACF se comprueba la clara estacionalidad semanal
de los datos. Sabiendo esto, se transforma la serie para recoger datos en periodos
semanales.
Figura 9. Representación de la serie transformada en semanas.

15
Figura 10. Representación de las variaciones, en escala logarítmica, entre medidas consecutivas,
para la serie transformada en semanas.
Figura 11. Gráfico de serie temporal, ACF y PACF, para la serie transformada en semanas.

16
Una vez definida la serie temporal con la que trabajar, se desarrolla un script
que permita comparar diferentes modelos ARIMA combinados con diferentes
tamaños de muestras.
Modelo1:order=c(1,0,0), seasonal = c(1,1,0)
Modelo2:order=c(1,0,0), seasonal = c(1,0,1)
Modelo3:order=c(1,0,0), seasonal = c(0,1,1)
Modelo4:order=c(1,0,1), seasonal = c(1,1,0)
Modelo5:order=c(1,0,1), seasonal = c(1,0,1)
Modelo6:order=c(0,1,1), seasonal = c(0,1,1)
Una vez obtenidos resultados se comparan. Como se ve en la imagen
inferior, y aplicando un suavizado de media móvil para interpretar mejor los
resultados, se deduce que el número de registros óptimos a tomar para realizar la
previsión es de 55.
Figura 12. Media móvil en tramos de 14 medidas, representando el factor de ajuste versus el tamaño de la muestra.
El eje X contiene el tamaño de la muestra necesaria para realizar la
previsión, en el eje Y el factor de ajuste. Este factor de ajuste se ha calculado
mediante la siguiente fórmula:
Dónde:
● RMSETr: Root Mean Square Error del grupo de entrenamiento. ● RMSETe: Root Mean Square Error del grupo de test.
● FAjuste: tiene que ser lo más cercano a 0 y estable posible.

17
Aplicando el modelo ARIMA, la imagen siguiente refleja la previsión a 3 semanas de
las llamadas que se recibirán en el CAU.
Figura 13. Previsión de las llamadas a 3 semanas utilizando el modelo ARIMA. En la gráfica se representa el número de llamadas histórico en función de las semanas, seguido de la predicción.
Una vez aplicado el modelo se ha obtenido una gráfica en la que se observa
el número de llamadas histórico seguido de la predicción. En el histórico se puede
observar un comportamiento periódico, que se explica porque los sábados se
reciben menos llamadas, y también se observa un pico que se debe a la
implementación de un cambio en el servicio, que por ser un acontecimiento
puntual, no será considerado a efectos de este estudio. En cuanto a la predicción
(representada en color azul) se ha obtenido un comportamiento estable con un
valor cercano a las 500 llamadas.

18
Base de Datos MySQL
La base de datos del estudio toma el nombre bdbiproject, y tiene las
siguientes tablas para el área del CAU:
Figura 14. Tablas correspondientes al CAU contenidas en la Base de Datos.
Dónde:
● forecast_cau: contiene las previsiones relacionadas con el CAU, tickets o
llamadas. Las previsiones en este caso se hacen a 1 día, 7 y 14 días ya que
el periodo (frecuencia) de estos datos es semanal.
o ID: Autonumérico incremental.
o FECHAREFERENCIA: Fecha de la previsión (timestamp).
o IDSERVICIO. Servicio sobre el cual se está haciendo la previsión.
o IDTIPODATO: Identifica si la previsión es sobre llamadas o tickets,
o FC1: Previsión a 1 día.
o FC7: Previsión a 7 días.
o FC14: Previsión a 14 días.
● cat_servicios: alberga el catálogo codificado de los servicios que da soporte
el CAU.
● cat_tipodato_cau: alberga el catálogo codificado del tipo de dato que se
maneja en el CAU: Llamadas o tickets.
● Llamadas_cau: contiene las llamadas recibidas en CAU agrupadas por día.

19
● Tickets: Tabla donde se registran los tickets en tiempo real abiertos por los
operadores que atienden las llamadas.
o ID: Identificador de la incidencia. Lo da el sistema automáticamente
siguiendo un código.
o TIPO: Naturaleza de la llamada. Petición, Consulta Incidencia.
o IDSERVICIO: Código del servicio al que hace referencia la llamada.
o SERVICIO: Descripción del servicio.
o FECHACREACION: Fecha y hora en la que se abre el ticket en el
sistema.
o CIUDAD: Nombre de la ciudad origen de la llamada.
o DIA: Día del mes de apertura del ticket.
o HORA: Hora (sin minutos) de apertura del ticket.
o DIASEMANA: Día de la semana en el cual se ha abierto el ticket.
o MES: Mes de apertura del ticket.
o ANIO: Año de apertura.

20
Cuadros de Mando del área del CAU
Los cuadros de mando del área del CAU se componen de 5 páginas
En la primera página tenemos la monitorización del registro de incidencias y de llamadas, así
como la distribución de ambas por origen y tipo de servicio.
En la segunda página tenemos la evolución de los costes, por periodos y por servicio.
21
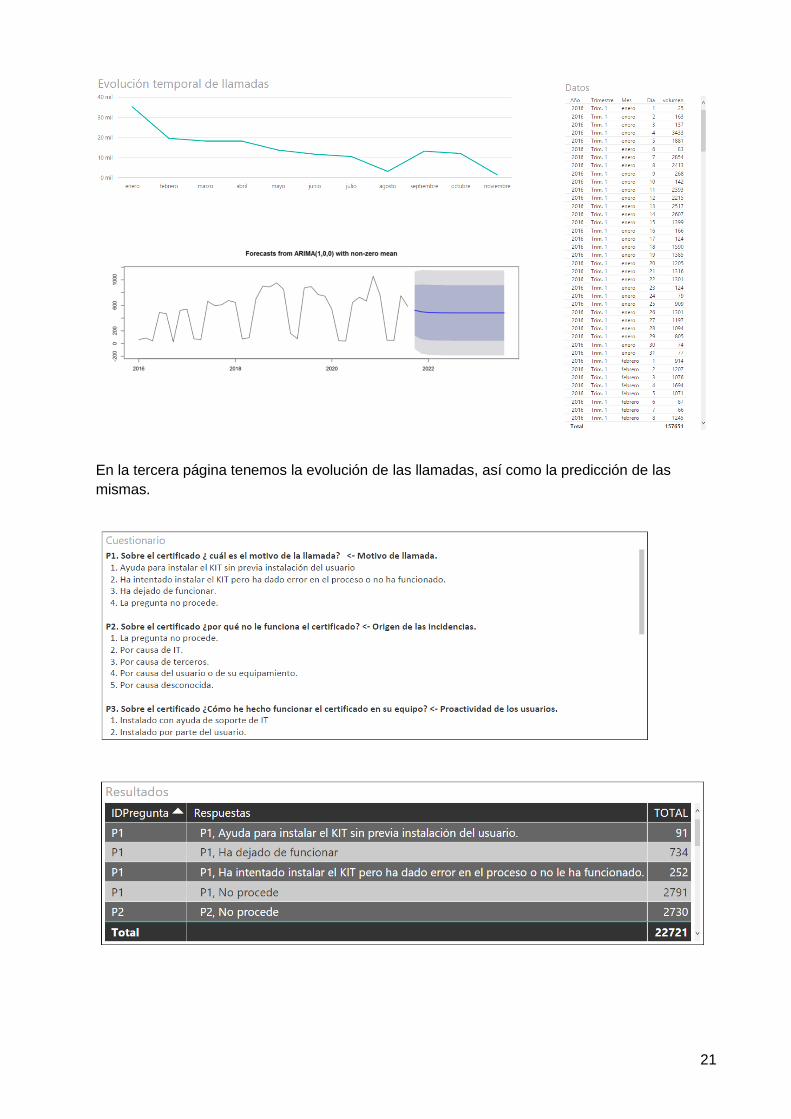
En la tercera página tenemos la evolución de las llamadas, así como la predicción de las
mismas.

22
En la cuarta y quinta página tenemos la visualización de los resultados de la encuesta que
hacen los operadores a los usuarios para medir la satisfacción del servicio.

23
Estudio de la Infraestructura
Esta parte del Proyecto es consecuencia del análisis realizado en el área del
CAU, puesto que una de las conclusiones obtenidas de la encuesta y del análisis de
datos fue que un número importante de llamadas y tickets abiertos venían, directa
o indirectamente, del rendimiento de los sistemas. Es por ello que se consideró
necesario abrir una nueva línea de estudio centrada en el comportamiento
puramente técnico.
Esta parte del Proyecto persigue la optimización del funcionamiento de la
infraestructura, así como mantener su fiabilidad en niveles óptimos, evitando su
caída, con la consecuente pérdida de servicio. Para ello el estudio se basa en la
predicción del comportamiento de los servidores y cada uno de sus componentes,
tanto de Hardware como de Software.
Para ello se analizan los visores de eventos de los servidores, la información
registrada en los LOGs de las aplicaciones, los registros de los sistemas de
monitorización que vigilan, entre otras: la conectividad de los sistemas, la
evolución de los indicadores que denotan un colapso de los mismos (ej. el aumento
en los tiempos de respuesta de una aplicación), y los indicadores de los
componentes que pueden manifestar igualmente una tendencia al colapso (ej. el %
de ocupación de la CPU o de los discos).
La canalización y procesado de toda esta cantidad ingente de información es
donde se centran las acciones asociadas al Big Data, que revierten en una base de
datos donde se explotará para su análisis y visualización, como parte de las
acciones asociadas al Business Intelligence.
Debido a la confidencialidad de la empresa en estudio, no se ha podido
disponer de un conjunto de datos reales, por lo que se ha programado un
simulador que genera toda la información referida. Así pues, a efectos del presente
trabajo, al hacer mención a los datos de los servidores, se estará refiriendo a los
datos generados por este programa.
La ingesta de datos registrados en los visores de eventos, así como de los
LOGs de las aplicaciones se realiza en tiempo real mediante la herramienta Flume.

24
En el estudio se ha definido un conector Flume para cada uno de estos
ficheros en cada uno de los servidores, que transportan en tiempo real la
información al clúster HDFS, formado por 3 nodos. Depositando así toda la
información en un único punto sobre el cual se ejecutarán diversos procesos Spark
que buscan y contabilizan sobre los ficheros con la información del último minuto,
el número de veces que aparecen palabras clave que puedan denotar problemas,
como por ejemplo ERROR.
La salida de los procesos Spark es almacenada de un modo estructurado en
una base de datos MySQL, donde, junto a los datos generados por el sistema de
monitorización, que también se almacenan en la misma base de datos, conforman
el oráculo de conocimiento sobre el cual actúa el modelo de análisis de información
en R, que se muestra a través de cuadros de mando sobre Power BI, la información
que permitirá a los responsables de los sistemas, la toma de decisiones más
adecuada.
El modelo elegido para calcular las previsiones del comportamiento de los
componentes es el de suavizado exponencial doble, a través del cual se generan
predicciones de las variables del sistema con 1, 5 y 15 minutos de antelación,
mediante las cuales se pretende obtener una detección temprana de los fallos en
los mismos, que ayude a evitar problemas técnicos sobre componentes
deteriorados, con el objeto de realizar las acciones que solucionen lo antes posible
la situación derivada, evitando su pérdida funcional y en consecuencia, la pérdida
del servicio del sistema al que está asociado.
En los siguientes apartados se detalla cada etapa del procesamiento de los
datos que proceden de los servidores, su procesado, el cálculo de sus previsiones
de comportamiento, hasta la visualización de alertas tempranas, no sin antes
explicar cómo se ha realizado la generación de estos datos simulando la actividad
de seis servidores.

25
Topología de sistemas El estudio se centra sobre el conjunto de servidores que componen los
servicios de SharePoint y FTP corporativos en la empresa. El servicio de SharePoint
se compone de dos frontales Web (WSSPFRONT1 y WSSPFRONT2), dos servidores
de aplicaciones (WSSPAPP1 y WSSPAPP2) y un indexador de contenidos
(WSSPCRW). Por otra parte, el servicio de FTP se compone de un único servidor
(WSFTP).
Para el estudio se cuenta con un clúster de tres servidores virtuales Linux de
distribución Cloudera, con los servicios HDFS y Spark configurados. Se dispone
también de un servidor de monitorización de los sistemas (WSMONITOR), y de un
servidor de MySQL (WSMYSQL)
Figura 15. Representación esquemática del flujo de datos entre los servidores, la base de datos, el
cluster HDFS & Spark, y el terminal de monitorización.

26
Generador de ficheros de log Como se ha indicado anteriormente, debido a la confidencialidad de la
empresa en estudio, no se ha podido disponer de un conjunto de datos reales, por
lo que se ha programado un simulador que genera toda la información referida
para el estudio, y la vierte directamente en la base de datos en MySQL. Simulando
la captura de los ficheros procedentes de los visores de eventos y LOGs de los
servidores, así como su transporte hasta el clúster HDFS, a través de procesos
Flume. Simula también la ejecución de los procesos Spark que contarían el
número de Errores y/o palabras reservadas sujetas a monitorización que se
registran en estos ficheros, para volcar finalmente el resultado de estos procesos
Spark en la base de datos MySQL.
Gracias al simulador se ha podido generar más de 3 millones de registros, lo
que equivale a 3 meses de información, y un volumen de datos lo suficientemente
representativo, para simular el comportamiento de cada uno de sus componentes,
simulando aleatoriamente y dentro de unos parámetros, aquellos valores que
tendrían tanto en condiciones de buen funcionamiento de los servidores, como en
caso de fallos.
El programa ha sido desarrollado en Java, y simula la siguiente actividad:
Servidor web de SharePoint (WSSPFRONT1)
● CPU: Incrementa su ocupación diaria entre las 00:00 y las 00:50, hasta el
96%, por la carga masiva diaria de contenidos.
● Unidad C: Incrementa su ocupación diaria entre las 00:00 y las 23:55 en un 2%, por el registro de información del sistema. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene estable
hasta las 00:00.
● Unidad D: Incrementa su ocupación espacio en disco diaria entre las 00:00 y las 00:50, del 12%, por la carga masiva diaria de contenidos. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene
estable hasta las 00:00.
● IIS: incrementa los tiempos de transferencia entre las 00:00 y las 00:50 hasta 12 segundos, por la carga masiva de contenidos. A partir de las 00:50 hasta las 08:10 los tiempos se mantienen en 3 segundos. Desde las 08:10
hasta las 18:30 se mantienen entre los 3 y los 8 segundos. Entre las 18:30 hasta las 00:00 se mantienen en 3 segundos.

27
Servidor web de SharePoint (WSSPFRONT2)
● CPU: Incrementa su ocupación diaria entre las 00:00 y las 00:50, hasta el 92%, por la carga masiva diaria de contenidos.
● Unidad C: Incrementa su ocupación diaria entre las 00:00 y las 23:55 en un
2%, por el registro de información del sistema. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene estable hasta las 00:00.
● Unidad D: Incrementa su ocupación espacio en disco diaria entre las 00:00 y
las 00:50, del 12%, por la carga masiva diaria de contenidos. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene estable hasta las 00:00.
● IIS: Incrementa los tiempos de transferencia entre las 00:00 y las 00:50
hasta 11 segundos, por la carga masiva de contenidos. A partir de las 00:50 hasta las 08:10 los tiempos se mantienen en 2 segundos. Desde las 08:10 hasta las 18:30 se mantienen entre los 3 y los 8 segundos. Entre las 18:30
hasta las 00:00 se mantienen en 4 segundos.
Servidor de Aplicaciones de SharePoint (WSSPAPP1)
● CPU: Incrementa su ocupación diaria entre las 00:00 y las 00:50, hasta el
95%, por la carga masiva diaria de contenidos.
● Unidad C: Incrementa su ocupación diaria entre las 00:00 y las 23:55 en un 1,2%, por el registro de información del sistema. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene estable
hasta las 00:00.
● Unidad D: Incrementa su ocupación espacio en disco diaria entre las 00:00 y las 00:50, del 8%, por la carga masiva diaria de contenidos. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene
estable hasta las 00:00.
● APP: Incrementa el número de errores entre las 00:00 y las 00:50 hasta 8, por la carga masiva de contenidos. A partir de las 00:50 hasta las 08:10 los
errores se mantienen en 2. Desde las 08:10 hasta las 18:30 se mantienen entre los 3 y los 8 errores. Entre las 18:30 hasta las 00:00 se mantienen en 2 errores.
Servidor de Aplicaciones de SharePoint (WSSPAPP2)
● CPU: Incrementa su ocupación diaria entre las 00:00 y las 00:50, hasta el 93%, por la carga masiva diaria de contenidos.
● Unidad C: Incrementa su ocupación diaria entre las 00:00 y las 23:55 en un
1,6%, por el registro de información del sistema. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene estable hasta las 00:00.
● Unidad D: incrementa su ocupación espacio en disco diaria entre las 00:00 y
las 00:50, del 8%, por la carga masiva diaria de contenidos. A las 23:55 se

28
reduce al volumen original por una tarea de mantenimiento y se mantiene estable hasta las 00:00.
● APP: Incrementa el número de errores entre las 00:00 y las 00:50 hasta 9,
por la carga masiva de contenidos. A partir de las 00:50 hasta las 08:10 los errores se mantienen en 2. Desde las 08:10 hasta las 18:30 se mantienen
entre los 4 y los 9 errores. Entre las 18:30 hasta las 00:00 se mantienen en 2 errores.
Servidor de Indexado de Contenidos de SharePoint (WSSPCRW)
● CPU: Mantiene su ocupación diaria entre el 40 y el 60%. El domingo, entre las 00:00 y las 07:00, llega hasta el 95%, por la indexación completa.
● Unidad C: Incrementa su ocupación diaria entre las 00:00 y las 23:00 en un 0,5%, por el registro de información del sistema. A las 23:00 se reduce un
0,5% por una tarea de mantenimiento y se mantiene estable hasta las 00:00.
● Unidad D: Incrementa su ocupación diaria entre las 00:00 y las 23:55 en un 2,8%, por el registro de información del sistema. A las 23:55 se reduce al
volumen original por una tarea de mantenimiento y se mantiene estable hasta las 00:00.
● APP: Incrementa el número de errores entre las 00:00 y las 00:50 hasta 7,
por la carga masiva de contenidos. A partir de las 00:50 hasta las 08:10 los errores se mantienen en 1. Desde las 08:10 hasta las 18:30 se mantienen
entre los 2 y los 4 errores. Entre las 18:30 hasta las 00:00 se mantienen en 2 errores.
El servidor de FTP (WSFTP)
● Servidor: Simula la pérdida de servicio por mantenimiento del diario servidor entre las 00:05 y las 00:19. No habiendo recibido PING en ese intervalo de tiempo. En consecuencia, de todos sus componentes (CPU, UNIT C, UNIT D y
el IIS), no se ha registrado información durante ese espacio de tiempo.
● CPU: Mantiene su ocupación entre el 20 y el 68% las 24h / día.
● Unidad C: Incrementa su ocupación diaria entre las 00:00 y las 23:55 en un 0,5%, por el registro de información del sistema. A las 23:55 se reduce al volumen original por una tarea de mantenimiento y se mantiene estable
hasta las 00:00.
● Unidad D: Incrementa su ocupación entre el 0,05 y el 0,1% por minuto las 24h / día.
● APP: Mantiene el número de errores diarios, entre los 0 y los 4 errores por minuto.

29
Proceso de transporte y análisis de los ficheros
Como se indicaba en el punto anterior, el simulador emula el conjunto de
procesos Flume que leen y transportan al cluster HDFS el contenido de los ficheros
procedentes de los visores de eventos de los servidores y de los LOGs de las
aplicaciones que en ellos se ejecutan.
El hecho de carecer de LOGs, no ha impedido realizar pruebas de concepto
para validar la solución técnica seleccionada. En la fase de análisis se han valorado
y probado diversas soluciones tecnológicas, y finalmente se ha adoptado una
solución basada en Flume sobre HDFS, por su funcionalidad, rendimiento y
tolerancia a errores.
La solución técnica pasa por declarar un servicio Flume en cada servidor,
configurando un origen por cada tipo de fichero a transportar. Para su lectura se ha
optado por el tipo exec, que a través del comando tail irá leyendo los datos
añadidos en los ficheros a transportar.
A su vez, todos los agentes Flume depositarán los ficheros en la misma
estructura de carpetas del clúster HDFS, en aras de facilitar su gestión y
explotación. Bajo la carpeta flume (en nuestro caso, el directorio raíz del clúster
HDFS), se encuentran dos directorios, uno llamado logs y otro events. El primero
albergará los ficheros de log y el segundo los ficheros de eventos. Los separamos
para facilitar su explotación posterior.
Los ficheros son organizados por fechas, horas y minutos, tal como ilustra la
siguiente imagen.
Figura 16. Captura de pantalla de una de las carpetas del clúster HDFS para ilustrar como están
organizados los directorios.

30
A continuación, podemos ver un fichero de configuración de los agentes. En
este caso, se trata del agente que transporta el LOG del IIS del servidor
WSSPFRONT1 hasta el clúster HDFS:
# Source a1.sources = src1 a1.channels = channel1 a1.sinks = sink1 a1.sources.src1.type = exec a1.sources.src1.command = tail -F /logs/WSSPFRONT1_log.dat_20160809_050001 a1.sources.src1.channels = channel1 #Chanel a1.channels.channel1.type = memory a1.channels.channel1.capacity = 10000 a1.channels.channel1.transactionCapacity = 10000 a1.channels.channel1.byteCapacityBufferPercentage = 20 a1.channels.channel1.byteCapacity = 800000 #Sink a1.sinks.sink1.type = hdfs a1.sinks.sink1.channel = channel1 a1.sinks.sink1.hdfs.path = flume/logs/%Y%m%d/%H%M a1.sinks.sink1.hdfs.filePrefix = WSSPFRONT1_log.dat_20160809_050001 a1.sinks.sink1.hdfs.round = true a1.sinks.sink1.hdfs.roundValue = 10 a1.sinks.sink1.hdfs.roundUnit = minute a1.sinks.sink1.hdfs.useLocalTimeStamp = true
Proceso de análisis de los ficheros
Homónimamente, el simulador también emula la ejecución de los procesos
Spark que contarían el número de Errores y/o palabras reservadas sujetas a
monitorización que se registran en estos ficheros, para volcar finalmente el
resultado de estos procesos Spark en la base de datos bdbiproject en MySQL.

31
Sistema de monitorización
La empresa dispone de un sistema de monitorización a través del cual se
vigilan entre otros:
● La conectividad de los sistemas (PING)
● La ejecución de servicios
● La evolución de los indicadores que denotan un colapso de los mismos:
o Tiempos de respuesta de una aplicación
o % de ocupación de la CPU
o % de ocupación de los discos.
Todos estos valores son configurados en el producto GFI Network Server
Monitor, por cada uno de los servidores. De tal modo que además de enviar un
email a la lista de distribución programada informando de las excepciones, registra
en la base de datos MySQL cada una de las monitorizaciones. En nuestro caso, la
base de datos bdbiproject.
Base de datos MySQL
En la fase de análisis del estudio se ha determinado que, para la volumetría
esperada tanto para la parte del CAU como de sistemas, el motor de base de datos
MySQL y sus capacidades de escalar, son lo suficientemente potentes para
gestionar tanto la carga por el número de transacciones por minuto, como el
volumen de la información almacenado.
Por cuanto a las inserciones, considerando que tenemos 30 componentes y
de ellos se registra al menos una medición por cada minuto, lo que representa 30
inserciones de registros por minuto.
Por otra parte, para efectuar el cálculo de las previsiones de los valores que
puede tomar cada uno de los componentes, teniendo en cuenta que para ello se
requiere obtener los datos de cada uno de ellos en los últimos 200 minutos. Esto
representa 30 consultas que recuperan 200 registros, y 30 inserciones que
almacenan el resultado de la previsión calculada por cada uno de los 30
componentes.

32
Resumen de operaciones por minuto: 60 inserciones y 30 consultas de 200
registros.
La base de datos del estudio toma el nombre bdbiproject, y tiene las
siguientes tablas para el área de Infraestructuras:
Figura 17. Estructura de la Base de Datos MySQL
Dónde:
● Components, alberga el inventario de componentes que participan en el
estudio. Por cada uno de ellos se dispone de su descripción, su función, el
tiempo entre registro y registro de monitorización (utilizado para el cálculo
de las previsiones), los umbrales de warning y critical, utilizados para lanzar
alertas online como para calcular las alertas prematuras.
En la siguiente imagen se puede observar tanto la relación entre servidor y
componentes, como los valores definidos como warning y críticos.

33
Figura 18. Captura de pantalla de la base de datos mostrando su composición
idcomponent: Identificador del componente. Autonumérico
parent_componentid: Los componentes pueden estar asociados a un componente superior. Para vincularlos se utiliza la columna
parent_component. De tal modo que un servidor se considera entidad superior y por lo tanto tiene este campo sin informar, mientras que sus
componentes (CPU, DISCO C, DISCO D, IIS), sí lo tienen informado, tomando éste el identificador del servidor al cual están adscritos. type: Tipo de componente: SERVER, CPU, HD, WEB, APP.
description: Descripción del componente
function: Función del componente
status: Estado del componente, donde:
0 = Disponible
1 = En mantenimiento
2 = Parado
3 = Dado de baja
monitoring_interval: Tiempo de monitorización en el que se espera recibir información del componente, expresado en minutos
warning_value: Valor a partir del cual las mediciones recibidas serán
consideradas como advertencia. critical_value: Valor a partir del cual las mediciones recibidas serán
consideradas como crítico.
● Current_traq, alberga los registros recibidos en las últimas 5 horas, y sirve
como conjunto de consulta rápido sobre los datos recibidos tanto de los
procesos Spark como del sistema de monitorización. Es sobre esta tabla
sobre la cual se realizan las lecturas por parte de los procesos de predicción
R. Su estructura es idéntica a la tabla historic_traq, si bien su cometido y por
lo tanto, información difiere.
idcurrent_traq: Identificador del registro. Autonumérico.
idcomponent: Identificador del componente del cual se está registrando una medición. timestamp: Instante en el cual ha sido tomada la medición del componente.
category: Categoría de la cual se registra una medición. value: Valor registrado en la medición.
● Historic_traq, alberga todos registros recibidos al sistema, y sirve como
repositorio histórico de los datos recibidos tanto de los procesos Spark como
del sistema de monitorización.

34
En la siguiente imagen se puede observar un ejemplo de los datos
registrados sobre alguno de los servidores y componentes del estudio.
Figura 19. Captura de pantalla de la tabla de historic_traq
idcurrent_traq: Identificador del registro. Autonumérico. idcomponent: Identificador del componente del cual se está registrando una
medición. timestamp: Instante en el cual ha sido tomada la medición del componente.
category: Categoría de la cual se registra una medición. value: Valor registrado en la medición.
● Components_forecast, alberga las previsiones calculadas por cada uno de
los componentes en base al intervalo definido de la tabla components. EN el
caso del estudio, todos los componentes tienen un intervalo de 1 minuto.
Esto representa que por cada componente en cada minuto se hace la
previsión de los valores que va a tomar por dentro de 1 minuto, 5 minutos y
15 minutos. Y, en base a los valores informados en el componente como
umbral de warning y critical, se registra un 0 si no supera el valor a 1
minuto, 5 minutos y 15 minutos, tanto para con el warning como para el
critical.
En la siguiente imagen se puede observar un ejemplo de las
previsiones obtenidas para 5 componentes en el minuto 11 del día 11 de
noviembre del 2016. Ninguno de ellos supera el umbral de warning o critical,
por lo que las columnas warning y error están a cero.

35
Figura 20. Captura de pantalla de la tabla de Components_forecast
idforecast: Identificador de la previsión. Autonumérico.
idcomponent: Identificador del componente sobre el cual se realiza la previsión. timestamp: Instante sobre el cual se realiza la previsión.
forecast_1: Valor predecido a 1 minuto. forecast_5: Valor predecido a 5 minutos.
forecast_15 Valor predecido a 15 minutos. warning_1: Previsión de alerta en 1 minuto (0 = Falso / 1 = Verdadero) warning_5: Previsión de alerta en 5 minutos (0 = Falso / 1 = Verdadero)
warning_15: Previsión de alerta en 15 minutos (0 = Falso / 1 = Verdadero) error_1: Previsión de error en 1 minuto (0 = Falso / 1 = Verdadero)
error_5: Previsión de error en 5 minutos (0 = Falso / 1 = Verdadero)
error_15: Previsión de error en 15 minutos (0 = Falso / 1 = Verdadero)

36
Modelado Predictivo
Como se mencionaba al principio del documento, el estudio de los servidores
persigue, entre otros objetivos, la optimización del funcionamiento de los mismos,
así como mantener su fiabilidad en niveles óptimos, evitando su caída, con la
consecuente pérdida de servicio. Para ello el estudio se basa en la predicción del
comportamiento de los servidores y cada uno de sus componentes, tanto de
Hardware como de Software.
Para ello se ha empleado el suavizado exponencial doble, a través del cual, y
con una población determinada de “n” mediciones anteriores al minuto actual, el
modelo facilita los valores previstos para el minuto siguiente, para dentro de cinco
minutos y para dentro de quince minutos. Con ello se obtiene una alerta temprana
del comportamiento de cada uno de los componentes de los servidores.
Para la realización del modelado predictivo de las variables, se estudia tanto
las mediciones del comportamiento de los componentes, como son el porcentaje de
ocupación de la CPU, el porcentaje de ocupación del disco y los tiempos de
transferencia. Como el número de errores registrados por minuto en los logs de los
servidores.
Justificación de la selección del modelo
Si se tuviera que pronosticar un modelo con tendencia usando suavización
exponencial simple, el pronóstico tendría una reacción retrasada al crecimiento.
Entonces, el pronóstico tendería a subestimar la demanda real. Para corregir esto
se puede estimar la pendiente y multiplicar la estimación por el número de periodos
futuros que se quieren pronosticar.
Una simple estimación de la pendiente daría la diferencia entre las demandas
en dos periodos sucesivos; sin embargo, la variación aleatoria inherente hace que
esta estimación sea mala. Para reducir el efecto de la aleatoriedad se puede usar la
diferencia entre los promedios calculados en dos periodos sucesivos. Usando
suavización exponencial, la estimación del promedio en T, es St, de manera que la
estimación de la pendiente en el tiempo t será:
BT = ST - ST-1

37
Con esta idea una vez más, se puede usar suavizamiento exponencial para
actualizar la estimación de la tendencia, lo que lleva al suavizamiento exponencial
doble, representado por el siguiente conjunto de ecuaciones:
ST = α dT + (1-α) (ST-1 + BT)
BT = β (ST - ST-1) + (1-β) BT-1
FT+K = ST + k BT
El pronóstico para k periodos futuros consiste en la estimación de la
pendiente más una corrección por tendencia.
Debe elegirse uno de los dos parámetros α y β, para el suavizamiento
exponencial doble.
Los modelos de suavización exponencial ajustada tienen todas las ventajas
de los modelos de suavizado exponencial simple; además, proyectan en el futuro
(por ejemplo, para el periodo t + 1) agregando un incremento de corrección de
tendencia Tt, para el promedio suavizado del promedio suavizado del periodo
presente F (Sipper y Bulfin, 1999).
Ajuste del modelo
En el proceso de ajuste se desarrolló un modelo comparativo
(entrenamiento) utilizando el lenguaje de programación R. Se tomó un conjunto de
medidas de cada componente y sobre este conjunto se realizaron las pruebas y test
de ajuste del modelo.
El proceso consistió en ir ampliando el tamaño de muestra hasta comprobar
que el aumento de la muestra no aporta más valor ni mejoraba los resultados
obtenidos con los tamaños de muestra anteriores. Cada uno de los datos obtenidos
en la ejecución del script se grababa en ficheros de texto para su posterior análisis.
Los datos recogidos en los ficheros fueron los siguientes:
● i: tamaño de la muestra, número de registros históricos tomados para hacer
la previsión, n-x.
● RMSETr1: Root Mean Square Error del conjunto de entrenamiento para una
previsión de 1 día.

38
● RMSETe1: Root Mean Square Error del conjunto de test para una previsión
de 1 día.
● RMSETr5: Root Mean Square Error del conjunto de entrenamiento para una
previsión de 5 días.
● RMSETe5: Root Mean Square Error del conjunto de test para una previsión
de 5 días.
● RMSETr15: Root Mean Square Error del conjunto de entrenamiento para una
previsión de 15 días.
● RMSETe15: Root Mean Square Error del conjunto de test para una previsión
de 15 días.
Una vez recogidas las previsiones se pasó al estudio de la exactitud y
fiabilidad del modelo en función del tamaño de la muestra.
La exactitud de cada una de las pruebas se mide en función del siguiente
cálculo.
Figura 21. Ilustración de la tabla de los errores cuadráticos medios de los conjuntos de entrenamiento y de prueba, y sus diferencias, para cada tamaño de la muestra.
Figura 22. Gráfica de la diferencia entre el error cuadrático medio del conjunto de entrenamiento y el del conjunto de prueba para N + 1.

39
Una vez obtenidos resultados se comparan. Como se ve en la imagen
inferior, y aplicando un suavizado de media móvil para interpretar mejor los
resultados, se deduce que el número de registros óptimos a tomar para realizar la
previsión es de 140.
Figura 23. Gráfica de la media móvil, donde se representa el factor de ajuste en función del tamaño de la muestra.
El eje X contiene el tamaño de la muestra necesaria para realizar la
previsión, en el eje Y el factor de ajuste. Este factor de ajuste se ha calculado
mediante la siguiente fórmula:
Dónde:
● RMSETr: Root Mean Square Error del grupo de entrenamiento. ● RMSETe: Root Mean Square Error del grupo de test.
● El valor absoluto de FAjuste: tiene que ser lo más cercano a 0 y estable posible.
Validación de la fiabilidad del modelo
El siguiente paso es comprobar la fiabilidad de las previsiones obtenidas.
Para ello se hace un cruce de datos entre la previsión hecha en Pn para Pn+1 y
contrastarla con la medida real en Rn+1.
Ejemplo de fiabilidad para una previsión a 1 minuto.
● TimestampFC: momento en el cual se hace la predicción. ● Forecast: previsión estimada para TimestampFC+1.
● Lectura: Lectura real para el momento TimestampFC+1. ● Diferencia: resultado de calcular Forecast – Lectura.
● WFC: Este campo informa si en función de la previsión realizada salta la alerta de warning.

40
● WM: Este campo informa si realmente saltó o no la alerta de warning. ● EFC Este campo informa si en función de la previsión realizada salta la alerta
de error. ● EM: Este campo informa si realmente saltó o no la alerta de error.
● WACIERTO: Campo que indica si el modelo ha acertado en lanzar el warning. Valor a 1 ha acertado, a 0 ha fallado.
● EACIERTO: Idem que el anterior punto, pero con el error.
Tabla 1. Valores de referencia para las alertas de warning y ciritical. Parametrizables por variable.
Tabla 2. Verificación de aciertos en las previsiones a +1 minutos.
En este caso se observa que para las primeras previsiones el modelo no
acierta debido que las medidas reales no sufren una variación importante y el
modelo no le ha dado tiempo de tener en cuenta la tendencia, sin embargo, en el
siguiente cuadro, pasado un tiempo, los resultados cambian y empieza a aumentar
el número de aciertos.
Tabla 3. Verificación de aciertos en las previsiones a +1 minutos (después de 35 minutos).

41
La fiabilidad de la previsión a +1 minutos del modelo en un periodo de 1.000
minutos es:
Tabla 4. Fiabilidad a +1 minuto.
Siguiendo la misma mecánica las previsiones para 5 minutos y 15 minutos
respectivamente son las siguientes.
Tabla 5. Fiabilidad a +5 minutos.
y
Tabla 6. Fiabilidad a +15 minutos.
La fiabilidad se centra en los parámetros de Warning y Error ya que son los
indicadores referentes para tomar las acciones oportunas para evitar caídas y
ralentizaciones de los sistemas.
El control y seguimiento de las medidas puntuales de cada timestamp y el
control de la fiabilidad del sistema se llevará a cabo con los cuadros de mando
desarrollados para tal objetivo, en los cuales se incorporan las medidas reales,
previsiones y alertas.

42
Cuadro de Mando del área de Infraestructuras
Se utiliza la herramienta Power BI para la visualización y monitorización del
comportamiento de los servidores y sus componentes. Se ha elegido este producto
por sus características funcionales y la alineación con el motor de base de datos
elegido.
El cuadro de mando de sistemas ofrece una visión general del estado de los
servidores y sus componentes (HW & SW). Compuesto de 6 elementos visuales,
permite identificar fácilmente la desviación de los valores funcionales que estar
mermando su capacidad o disponibilidad.
En la siguiente imagen podemos ver una visión general del cuadro de mando
del área de Infraestructuras:
Figura 24. Captura de pantalla de la vista general del cuadro de mando de infraestructura.
A continuación, se describe cada uno de los elementos visuales:

43
Servidores y componentes con warnings & errores
Muestra la lista de servidores y componentes con valores registrados en el
último minuto, que superan los umbrales de warning y/o error definidos.
Por cada uno de ellos se identifica el nivel de criticidad, el servidor al que
pertenece (en caso de tratarse de un componente), el nombre del
servidor/componente, su funcionalidad, la categoría que ha superado el umbral, el
valor registrado, los umbrales de referencia warning y critical, así como el instante
en el que fue registrada la medición.
Servidores que no responden
Muestra la lista de servidores que no responden y no están ni en
mantenimiento, ni en parada registrada. Bien porque haya un problema de
comunicación con él (PING), bien porque se hayan apagado sin previo aviso, o
cualquier otra situación.
Alertas prematuras
Muestra la lista de servidores y componentes sobre cuyos valores
registrados, el sistema predice que se van a superar los umbrales de warning y/o
critical, en los próximos 1, 5 y 15 minutos.

44
Servidores por estado
Muestra el número de servidores y componentes monitorizados por su estado, que
pueden ser:
● Activos ● En mantenimiento
● Parados
Indicador de salud de los servidores & componentes
Permite identificar visualmente aquellos servidores y/o componentes cuyos valores
registrados en el último minuto, que superan los umbrales de warning y/o error
definidos.
Permite la navegación drill down para visualizar el tipo de error del servidor.

45
Y finalmente, el componente afectado.
Historial de los errores registrados en los últimos 10 minutos
Permite visualizar la tendencia de errores registrados, así como del tiempo
de respuesta en las aplicaciones, a lo largo de los últimos 10 minutos.

46
Valor de Negocio
Retorno económico del estudio de las llamadas
El establecimiento de un sistema para procesar los datos del volumen de
llamadas y hacer predicciones sobre el comportamiento de estos valores permitirá
tomar las decisiones oportunas en los siguientes aspectos:
● mejorar el software en aquellos puntos que penalizan más a los usuarios
● disminuir el abanico de plataformas soportadas
● identificar software obsoleto y problemático.
Una vez se tenga el presupuesto de los desarrollos necesarios para mejorar
el producto, se comparará con el futuro ahorro que se obtendrá en el CAU para ver
la rentabilidad de la inversión en la calidad del software.
Retorno económico del estudio de la Infraestructura
El beneficio de crear el sistema desarrollado en el presente Proyecto es que este
proporciona la información necesaria tomar las decisiones acertadas para:
● Reducir las llamadas al servicio de CAU relacionadas con caídas en los
servidores.
● Reducir las penalizaciones de incumplimiento de SLAs con los clientes.
● Pérdida de ingresos por abandono de los usuarios por lentitud de los
servicios que ofrece.
Otros beneficios indirectos de implementar esta solución se relacionan con la
posibilidad de investigar ciertos aspectos del desempeño de los servidores, que
permitan mejorar la infraestructura, a saber:
● Estudios de impactos ante cambios tanto hardware como software. Se puede
“materializar” el impacto del cambio, por ejemplo, de la compra de una
cabina de discos de nueva generación o comparar la inversión realizada en la
optimización del software con la mejora del rendimiento que produce.
● Conocer las correlaciones entre componentes, es decir, si el componente C
está trabajando anormalmente, qué servicios está afectando, o por el
contrario, si se mejora el componente C qué servicios se aprovechan de este
cambio.

47
Conclusiones
● Se llevó a cabo exitosamente un estudio / análisis diagnóstico de las
principales causas de los aumentos en las llamadas al CAU, gracias al cual se
identificaron deficiencias en la infraestructura y derivando en un estudio de
la infraestructura y en el desarrollo de un sistema de alertas tempranas para
evitar incidencias en los servidores.
● Se desarrolló satisfactoriamente un modelo predictivo para la estimación el
volumen diario de llamadas, encontrando que el modelo que mejor se ajusta
a este tipo de datos es el ARIMA, para el cual se hizo un ajuste del tamaño
muestral obteniendo un “n” óptimo de 55 registros.
● Este modelo permitió evidenciar que las llamadas tienen una estacionalidad
semanal. La información arrojada por el modelado predictivo permite
orientar decisiones referentes al dimensionamiento del CAU. Para ir un paso
más adelante, consideramos que se podría usar este sistema como base para
hacer simulaciones de acontecimientos que se sabe que causan una
saturación de los sistemas (ej. la introducción de un nuevo sistema
operativo) y ver la posible respuesta, para tomar acciones a tiempo.
● Se desarrolló con éxito un sistema de big data para la ingesta y carga de los
datos provenientes de los servidores, acoplado a un programa de modelado
predictivo que es capaz de proporcionar alertas tempranas en caso de fallos
en la infraestructura, con una fiabilidad del 75 % en el peor de los casos. Se
encontró que el modelo óptimo para este tipo de datos es el suavizado
exponencial doble y que el número de registros óptimos para realizar la
previsión es de 140.
● Se logró diseñar y estructurar una base de datos organizada y coherente que
recoge y proporciona acceso a información actualizada y precisa, tanto de los
datos de las llamadas, como de los correspondientes a los servidores.
● Se configuró un conjunto de cuadros de mando intuitivo y concreto, que
aporta toda la información necesaria para la toma de decisiones tanto en el
área de llamadas como en el área de infraestructura.

48
● Se sugiere que para futuros estudios que profundicen en este tema, se
podrían buscar posibles correlaciones entre los fallos del servidor y los picos
en las llamadas al CAU. Del mismo modo, sugiere realizar la migración de los
datos del servidor a un modelo de datos en grafo para estudiar las relaciones
existentes entre la información disponible de estas fuentes.

49
BIBLIOGRAFÍA
Esteban, A. y Lorenzo, C. (2013). Dirección Comercial .Madrid, ESIC.
Sherman, R. (2015). Business Intelligence Guidebook: From data integration to
analytics. Morgan Kauffman
Sipper, D., Bulfin, R. (1999). Planeación y control de la producción. Mexico D.F.,
Mc. Graw Hill.
Apache Mahout (2016) http://www.tutorialspoint.com/mahout/index.htm
Apache Flume https://flume.apache.org/
Apache Spark http://spark.apache.org/
Cloudera http://www.cloudera.com/

50
ANEXOS
1. Anexo I
A continuación, se presentan los códigos en R utilizados en el proyecto y su
aplicación al proyecto.
1.1. Script para el ajuste del modelo. Parte llamadas CAU
Consultar fichero ForecastDefinicionTrainSetCAU.R incorporado en la
documentación del proyecto.
Este proceso consistió en recoger en diferentes ficheros de texto los resultados de
las previsiones e indicadores necesarios para hacer el análisis. Una vez recogida
toda la información se utilizó un Excel para realizar la comparativa.
Dónde:
● Muestra: número de registros históricos tomados para hacer la previsión, n-
x.
● RMSETr1: Root Mean Square Error del conjunto de entrenamiento para una
previsión de 1 día.
● RMSETe1: Root Mean Square Error del conjunto de test para una previsión
de 1 día.
● RMSETr5: Root Mean Square Error del conjunto de entrenamiento para una
previsión de 5 días.
● RMSETe5: Root Mean Square Error del conjunto de test para una previsión
de 5 días.
● RMSETr15: Root Mean Square Error del conjunto de entrenamiento para una
previsión de 15 días.
● RMSETe15: Root Mean Square Error del conjunto de test para una previsión
de 15 días.

51
Sobre este estudio se obtiene la gráfica mostrada en el punto 5.3
1.2. Script de previsión de llamadas al CAU
Consultar fichero ForecastCAU.R incorporado en la documentación del proyecto.
Este script realiza la previsión a n días (parametrizable por variable) e inserta los
resultados en la base de datos del proyecto junto con las previsiones de estado de
los sistemas y servicios.
Este fichero se ejecutará a demanda cuando se requiera ver la previsión. Este script
junto el cuadro de mando desarrollado para hacer el seguimiento del volumen de
llamadas serán las herramientas utilizadas para controlar y obtener las
conclusiones de la estrategia establecida.
2. Anexo II
A continuación, se presentan los códigos en R utilizados en el proyecto y su
aplicación al proyecto.
2.1 Script para el ajuste del modelo. Parte monitorización sistemas.
Consultar fichero ForecastDefinicionTrainSetComponentes.R incorporado en la
documentación del proyecto.
Este fichero ejecuta un bucle el suavizado exponencial doble para diferentes
tamaños de muestra. Los resultados se guardan en ficheros csv para el posterior
análisis de exactitud y fiabilidad.
2.2 Script de previsión de monitorización sistemas.
Consultar fichero ModeloForecastNComponentesOnline.R incorporado en la
documentación del proyecto.