application of instruction analysis/scheduling techniques · pdf file ·...
TRANSCRIPT

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 1
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of
Superscalar Processors
Ing-Jer Huang and Ping-Huei XieDepartment of Computer Science and Engineering
National Sun Yat-Sen UniversityKaohsiung, TAIWAN 804, R. O. C.EMAIL: [email protected]
PHONE: (886-7) 525-2000 EXT. 4315
Abstract
This paper presents the development of instruction analysis/sched-uling CAD techniques to measure the distribution of functional unitusage and the micro operation level parallelism (MLP), whichtogether determine the proper functional unit allocation for super-scalar microprocessors, such as the x86 microprocessors. The pro-posed techniques fit in the early design exploration phase in whichthe trace or microarchitecture simulator hasn’t been available yet.The techniques have been applied to analyze several popularWindows95 applications such as Word, Excel, Communicator, etc.for their MLP and distribution of functional unit usage. The resultsare used to evaluate the resource allocation of several existing x86superscalar microprocessors and suggest future extension.
Keywords: instruction set analysis, micro operation level parallelism, superscalar archi-tecture, resource allocation
1. Introduction
The superscalar microarchitecture has been found as a good solution to improve micropro-cessors’ performance while keeping backward software compatibility. One important design issueof superscalar architectures is the resource allocation problem: such as how many integer units,load/store units, branch unit, floating point units are necessary? How to allocate resourcesbetween the register renaming unit and branch prediction unit? The keys to answer these ques-tions are the micro operation level parallelism (MLP) and the distribution of functional unit usagederived from typical and real application software. Such measurements can be obtained with aparameterized microarchitecture simulator or a trace simulator. However, during the early design
This paper is supported by NSC under 85-2262-E-009-010R and 86-2262-E-009-009.

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 2
exploration phase of a superscalar microprocessor, such simulators might not be available. Inaddition, the overheads in constructing the runtime environment support and the long simulationtime (typically tens to hundreds of simulated instructions per second) may also hinder the use ofthe simulators in the early design exploration phase. Therefore, other approaches are necessary.
We participate in a research project to build a high performance superscalar x86 compati-ble microprocessor and face the aforementioned problem. Motivated by the problem, we havedeveloped a time-saving approach based on our instruction set CAD system x86 Workshop, con-sisting of three tools: x86Bench, State Mapper, and ASIA-II. x86Bench is an x86 application anal-ysis system which produces disassembled x86 basic blocks annotated with their execution counts.State Mapper is an automatic retargeting tool which maps a given instruction set to MOPs for thegiven microarchitecture. Both x86Bench and State Mapper serve as the front end of ASIA-II,which is a second generation of our instruction synthesis tool ASIA [1]. ASIA-II enables us toinvestigate many interesting instruction behaviors in typical superscalar architectures, includingthe distribution of functional unit usage, MLP, CPI (cycle per instruction), etc. Note that thesetechniques, except x86Bench, are retargetable tools which can be applied to other superscalararchitectures, in addition to the x86 architecture reported in this paper.
In this paper we present the approach and its experimental results. Section 2 reviewsrelated work. Section 3 provides a superscalar architecture model for efficient x86 instructionexecution. Section 4 describes the CAD framework and individual tools for the x86 instructionanalysis. Section 5 presents the analysis of x86 application software and the results. Section 6draws conclusions for this study and points out future direction.
2. Related work
Instruction level parallelism (ILP) and machine parallelism have been among the hot top-ics in computer architecture. See, for example, [11], [12], [13], [15], [16], [17], and [18]. Most ofthe research works are based on simulation. For example, the work of Shinatani et al. is based onan RTL simulator that takes the instruction trace of benchmark programs [13]. Hara et al. build atrace-driven simulator to simulate three different superscalar architectures and obtain the func-tional unit utilization [12]. There are difficulties in applying these typical techniques to the x86study with real application programs as explained in the introduction section. One way to over-come the inefficiency and overhead problems of simulation-based approaches is to instrument theapplication programs and execute them on the real hardware and environment. The instrumentedprograms will generate profiling information while performing their normal operations. Forexample, Davidson and Jinturakar use a MIPS R4000 architecture measurement tool to instru-

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 3
ment the code and measure the dynamic instruction counts and latency of benchmarks [15]. How-ever, this approach is applicable only when high level source code is available for instrumentingand recompiling. In the x86 world, most of the frequently used application programs are commer-cial ones of which the source code is unavailable.
As for the studies specific to the x86 architecture, Adams et al. analyze x86 instructionusage in the MS-DOS environment, based on the interrupt mechanism of the x86 microprocessors[11]. The analysis is performed at the mnemonic code level, which is insufficient to superscalarstudy. For example, a mnemonic instruction mov may turn into a memory load, a memory store, aregister to register move, or an immediate to register move. These variations use different hard-ware resources in a superscalar microarchitecture. Huang and Peng conduct a similar butextended experiments for modern applications under both MS-DOS and Windows95 applicationprograms [6]. In their study, mnemonic code is further differentiated according to their actualhardware usage. However, further improvements, such as taking into account the effects of regis-ter renaming and branch predication, are necessary in order to explore the superscalar configura-tions.
Bhandarkar et al. measure the instruction set usage and compare the performance betweena Pentium processor and a Pentium Pro processor under the WindowsNT environment [14]. Theinstruction execution information is obtained by using special x86 instructions to access perfor-mance monitoring information that are automatically collected by the processors and stored insidethe processors. Although the information is very accurate, it is not applicable to estimate the per-formance of superscalar configurations other than the one implemented in the chip.
3. A Superscalar Model for x86 Instruction Execution
The general practice to speed up x86 instruction execution is a two-layered microarchitec-ture, as shown in Figure1. The outer layer fetches x86 instructions from the instruction cache,and translates the x86 instructions into MOP’s or RISC-like instructions which are executed in theinner layer of the microarchitecture. The inner layer, the area surrounded by the dashed line,

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 4
adopts a superscalar core to speed up performance by simultaneously dispatching, executing andcommitting multiple MOP’s.
The x86 instruction decoders in the outer layer are classified into three types: simple
decoders, general decoders, and a sequencer. The simple decoders handle simple x86 instruc-tions, which are x86 instructions consisting of only a small number of MOP’s. The general decod-ers are capable of handling any x86 instructions, ranging from simple to very complex. Bothsimple and general decoders are active when the core is executing in its superscalar mode. On theother hand, there are some complex x86 instructions, called sequential instructions in this paper,which are not suitable for superscalar execution, such as ENTER, POPA, PUSHA, etc. In such case,the superscalar core waits until all pending operations are completed and then enters the sequen-tial (scalar) mode. In the sequential mode, only one x86 instruction is active, as opposed to thesuperscalar mode in which multiple instructions can be simultaneously active. The sequentialinstruction is decoded by a sequencer (a micro ROM). The operations of the instruction are exe-cuted sequentially. The superscalar core resumes the superscalar mode after the completion of thesequential instruction.
The decoders translate x86 instructions into MOP’s. These MOP’s are logged into thereorder buffer (ROB) to make sure that they can be retired in the sequential program order. Thenthese MOPs wait in the reservation station until all of their source operands become available. Ineach cycle, more than one MOPs can be dispatched as long as their source operands and their cor-responding functional units are ready for execution. While MOPs are logged into the ROB, their
Figure 1. The superscalar architecture for x86 instruction execution
instru
ction
cach
e
Reservation Station
load/storeunit
branchunit FP unit
Result bus
X86Instructions
General decoder
Simple decoder
ReorderBuffer
Micro Operations (RISC-like opeations)
RegisterFile
integerALU
Sequencer(µROM)

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 5
operands are renamed if they hold anti data dependency or output dependency with MOPs whichhave been in the ROB.
The execution results of functional units (such as load/store units, integer ALU, branchunit, floating point unit, etc.) are written into the reorder buffer through the result bus. If opera-tions waiting in the reservation station also need the computed results, then the results are alsoforwarded to the reservation station. The results in the reorder buffer are finally written into theregister file upon retirement.
Note that the superscalar core incorporates the branch predication mechanism and registerrenaming mechanism to increase the number of MOP’s available for execution per cycle (microoperation level parallelism).
The objective of this study is to develop proper CAD tools for application software analy-sis in order to determine the allocation of functional units in the superscalar core, as depicted inthe grey area.
4. The x86 Instruction Set CAD System: x86 Workshop
4.1 Framework
The framework of the x86 instruction set CAD system x86 Workshop is shown Figure2.x86 Workshop consists of three tools: x86 Bench, State Mapper and ASIA-II. x86 Bench andState Mapper serve as the front-end of ASIA-II, which investigates superscalar features. Note that
Figure 2. The x86 inst. set CAD system: x86 Workshop
x86 Bench
x86 Program Input Data
x86 Inst. Freq.x86 Code
ASIA-II
State Mapper
x86 Instr. Set Micro-ops (MOP)
DisassembledMapping Tablex86-to-MOP
Functional Unit UsageDistribution of
ParallelismMOP Level
MicroarchitectureSuperscalar
FunctionObjective

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 6
all of our tools are retargetable to other instruction sets and microarchitectures except X86 Benchwhich has been developed specifically for the x86 study. In this paper we present the overallframework and the details of ASIA-II. Details of x86 Bench and State Mapper can be found in [6]and [7], respectively.
x86 Bench is an instruction analysis tool for the x86 instruction set, which is built aroundIntel’s performance tuning tool VTune [10]. x86 Bench accepts an x86 program and its input data.The x86 program can be a DOS or Windows95 application. The tool can analyze x86 programseither with or without source code (high level language source code). For a given x86 programand its input data, the tool generates the x86 instruction usage frequencies and the disassembledcode annotated with basic blocks’ execution counts. Currently we are able to analyze instructionsbelonging to the application programs but not instructions belonging to the operating system. Toanalyze instructions in the operating system we need the symbol files for the Windows95 kernelwhich are not available to general public [9].
State Mapper is an instruction retargeting tool. It translates a given assembly code fromone instruction set to another instruction set, based on a machine state transition notation. It canbe configured to solve our x86 problem as well, as illustrated in Figure 2. Each x86 instruction,due to its CISC nature, is considered as an assembly code, which is to be translated into asequence of MOP’s (i.e., micro sequence, or micro program). The MOP’s of the superscalar archi-tecture is considered as the target instruction set for State Mapper. The generated micro sequencescan be viewed as the entries of the x86-to-MOP mapping table.
ASIA-II reads in the disassembled instruction sequences generated by x86 Bench andmaps the instruction sequences into MOP’s, according to the x86-to-MOP mapping table gener-ated by State Mapper. ASIA-II then schedules the MOP’s into time steps, subject to constraints oftheir dependencies and the constraints of the given superscalar microarchitecture model. Thesuperscalar microarchitecture model describes the supported micro-operations, operational delaysand the topology of data path components (i.e., the achievable data movements in the data path).The numbers of data path resources, such as read/write ports of the register file, memory ports andfunctional units can be given as the resource constraints. The numbers of data path componentscan also be left unspecified, letting the tool search for the best combination (w.r.t. to the givenobjective function). The objective function controls how the MOP’s are scheduled. It can be con-figured to optimize for performance (as in the experiment of this paper), functional unit cost, or acombination of both. MOPs scheduled into the same time step represent MOPs that are executedin parallel in the superscalar core. From the scheduled MOP’s, the MLP and the distribution offunctional unit usage can be obtained. In the following sub-section, we present ASIA-II, theinvestigation tool for superscalar microarchitecture, in more detail.

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 7
4.2 ASIA-II for Superscalar Architecture
ASIA-II is the second generation of our instruction set analysis/synthesis tool ASIA(Automatic Synthesis of Instruction set Architecture) [1], which analyzes and synthesizes applica-tion specific instruction sets for pipelined uni-processors. Since the internal superscalar core in
Figure 1 can be regarded as an application specific RISC-based core with its sole application as anx86 instruction set emulator, ASIA-II, with the enhancements described in this section, can betuned to study many design issues of x86 compatible microprocessors, such as the design of theinternal RISC-based instruction set [8] and the resource allocation problem for the superscalar
core, which is the focus of this paper. With the last paragraph of Section 4.1 describing the basicoperations of ASIA-II, this section focuses on the necessary techniques adopted in ASIA-II forsuperscalar architecture study.
4.2.1 The basic scheduling algorithm
Using an instruction scheduling tool to investigate MLP and distribution of functional unitusage for superscalar architecture is a convenient approach but requires special care. Otherwise,
non-optimal designs may results. For example, Figure3 (a) shows a piece of MOP code. Figure3(b) (five MOPs in time step 1 and one MOP in time step 2) and Figure3 (c) (three MOPs in timestep 1 and three MOPs in time step 2) are two versions of its scheduled MOPs. Both versions taketwo time steps to finish. Both also have the same MLP of three (# of MOP’s / # of time steps, 6/2).
However, Figure3 (b) requires five ALU’s (to support the five MOP’s in time step 1) to sustainsuch parallelism while Figure3 (c) requires only three. This observation suggests that a schedul-ing algorithm which also tries to balance the resource usage while optimizing for performance isdesirable to explore superscalar design space.
In addition, in a superscalar core, the relative order of incoming operations is usually pre-served during execution unless there are dependencies or there are some operations which takemuch more cycles than others to finish, as observed in Chapter 2 in Johnson’s famous book on
superscalar microprocessor [18]. For example, it is very unlikely that the sixth MOP (sub r15r16 r17) in Figure3 (a) is executed in time step 1 while the second MOP (add r4 r5 r6)being executed in time step 2, although the dependency relationship allows so. Therefore, thescheduling algorithm should also try to preserve the relative order while optimizing for perfor-
mance.
To take care of the above two issues, ASIA-II adopts a scheduling algorithm based onlocal compaction with a simulated annealing approach [19]. Figure 4 lists the basic structure of

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 8
the simulated annealing algorithm. The major inputs of the algorithm are an initial schedule of thegiven MOP’s and their scheduling constraints. The output of the algorithm is an optimized sched-ule by adjusting the positions of MOP’s with the simulated annealing process. There are two iter-ation loops in the algorithm. The outer loop (between lines 2 and 13) implements the coolingoperation of the annealing process by lowering the current temperature in each iteration until anequilibrium state is reached. The inner loop (between lines 4 and 11) improves the schedule byrepeatedly selecting MOP’s from the current schedule and displacing them to other time steps,subjected to dependency and resource constraints, as shown in line 6. The selection and displace-ment of MOP’s are accepted as long as the resulted value of the objective function is improved(e.g., when the total number of time steps is reduced), as shown in lines 7 and 8. However, inferiorselection or displacement may be occasionally accepted, based on the annealing condition asshown in line 9, in the hope to escape from a local optimal solution to a global optimal solution.As the current temperature gets lower, the chance with which inferior selection or displacement ofMOP’s is accepted becomes lower. When the annealing process reaches the end, the algorithmaccepts only good selection and displacement of MOP’s and thus produces the final optimalschedule.
The scope of the possible locations (time steps) of a MOP is intentionally constrained tobe within the basic block where the MOP belongs to. The displacement distance is limited. There-fore, a MOP will stay close to its original position as long as it does not lengthen the schedule. Itis possible to displace a MOP further away from its original location through many iterations ofdisplacements. However, such long range displacement is performed only when functional unitsare unavailable in the nearby locations. As a result, ASIA-II produces optimized schedules withbetter distribution of functional unit usage as in the case of Figure3 (c).
We understand that other scheduling algorithms, such as the trace scheduling algorithm[23] or the force-directed scheduling algorithm [24], are also capable of investigating the sameproblem. Therefore, we don’t claim any novelty for our simulated-annealing based schedulingalgorithm over other algorithms. It is adopted in our work because it is easy to implement and it is
Figure 3. MOP schedules and distribution of functional unit usage
1.add r1 r2 r32.add r4 r5 r63.add r7 r8 r94.sub r10 r1 r115.sub r12 r13 r146.sub r15 r16 r17
(a) original MOPs
1.add r1 r2 r3;add r4 r5 r6;add r7 r8 r9;sub r12 r13 r14;sub r15 r16 r17
2.sub r10 r1 r11
(b) scheduled MOPs-I
1.add r1 r2 r3;add r4 r5 r6;add r7 r8 r9
2.sub r10 r1 r11;sub r12 r13 r14;sub r15 r16 r17
(c) scheduled MOPs-II

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 9
easy to incorporate necessary modifications to accommodate various advanced superscalar fea-tures, which are discussed in the following sub sections.
4.2.2 Register renaming
The superscalar core in Figure1 supports the register renaming mechanism in order toboost parallelism. Register renaming eliminates anti (write after read) and output (write afterwrite) dependencies between a pair of operations by redirecting the write operation (the lateroperation in the dependent pair) to a different location. Later operations that read the write resultare also redirected to the new location.
The register renaming feature is supported in ASIA-II by ignoring the anti and outputdependencies among the MOP’s during scheduling, as also commonly practiced in [21] and [22].
4.2.3 Sequentially executed complex instructions
As explained in Section 3, sequential instructions are executed sequentially in the super-scalar core. Such instructions effectively reduce the basic block sizes. In addition, they also incurcycle penalty since they have to wait until all pending operations are completed. The effect ofsuch instructions on the superscalar performance can be modeled as splitting of basic blocks.
Figure 4. The basic simulated annealing algorithm
/* Basic simulated annealing process */1: GIVEN: schedule S, , scheduling constraints R, current temperature T, max.
movement M per temperature;
2: while (not achieving equilibrium state)3: { C=0;4: while (C < M) /* repeat for M times */5: { 6: Snext = Generate_Next_Schedule(S); /* Local Compaction */7: ∆ = cost(Snext) - cost(S); /* compute the cost improvement */
8: if (∆ < 0 ) then S = Snext; /* a good movement */9: else S= Snext with the probability exp-(∆/Τ);
/* accept a bad movement occasionally */10: C = C + 1;11: };12: T = Update(T); /* lower the current temperature */13: }

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 10
Figure 5 (a) shows a basic block of which the instructions s_instr_1, s_instr_M ands_instr_N are simple (or general) instructions whose micro-operations can be executed in thesuperscalar mode and the instruction seq_instr is a sequential instruction that has to be exe-cuted in the sequential mode. The effect of the sequential instruction on the basic block can bevisualized as in Figure5 (b). The basic block containing the sequential instruction is split intothree smaller basic blocks: the simple (general) instructions before the sequential instruction, thesequential instruction itself, and the simple instructions after the sequential instruction.
4.2.4 Hardware branch prediction
Branch instructions impede the instruction fetcher’s capability to supply instructions at asufficient rate to keep functional units busy. When the outcome of a branching instruction is notknown, the instruction fetcher has to stall or incorrect instructions are fetched. A stalled instruc-tion fetcher or incorrectly fetched instructions decrease the number of instructions ready to exe-cute in parallel.
Hardware branch prediction aims to reduce the branch penalty by predicting, with hard-ware support, the direction of the current branch instruction based on its previous branch out-comes before the result of the current branch is known. If the branches are successfully predicted,the instruction fetcher is stalled for less times, and a smaller number of incorrect instructions arefetched. The functional units in the data path would see more instructions ready for parallel exe-cution. Therefore, branch predication reclaims potential parallelism which is undermined bybranch instructions.
From the viewpoint of the instruction fetcher, the benefit of branch prediction is that thelength of the instruction sequence which the instruction fetcher can keep fetching without beeninterrupted becomes longer. Since the boundary of uninterrupted fetching is mainly marked by thebranching related instructions1, which also mark the boundaries of basic blocks, the effect of
s_instr_1::
s_inst_Mseq_instrs_instr_N
::
seq_instr
s_instr_N::
s_instr_1::
s_inst_M
(a) (b)
Figure 5. The effect of sequential instructions on basic block formation

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 11
branch prediction can be regarded as the enlargement of basic blocks’ sizes. The more levels ofbranches are successfully predicted, the larger the resulting basic block. The larger the basicblock, the more chances the superscalar core can find instructions to execute in parallel.
1. Other factors include internal exceptions, I/O interrupts, cache misses, resource conflicts, etc., which are not the focus of this work.
Figure 6. ASIA-II’s approach to support branch prediction
pushmov
pushpush
movmov
movcmp
jbe
stdadd
addtest
mov
addcmp
jb
cmp
jbe
cmpjbe
test
jnz
testjnz
movand
pushmov
pushpush
mov
movmov
cmpjbe
testjnz
cmpjbe
mov
andsub
pushmov
pushpush
mov
movmov
cmpjbe
movadd
cmpjb
std
addadd
test
pushmov
pushpush
mov
movmov
cmpjbe
testjnz
cmpjbe
mov
poppop
(a) Original x86 code
(b) Basic Block Expansion
(c) Compacted MOP
A+B+D+H
A+B+D+I
A+C+F
EBlock1
mov
poppop
mov
andsub
A
B C
DF G
H IJ K
pushmov
pushpush
mov
movmov
cmpjbe
movadd
cmpjb
test
jnzcmp
jbe
A+C+G+J
pushmov
pushpush
mov
movmov
cmpjbe
movadd
cmpjb
test
jnzmov
and
A+C+G+K
subin
mov
subin
ld
ld
stld
subandi
subinbrn
mov
stbrn
subiandi
stbrn
sub
subin
mov
subin
ld
ldld
subin
mov
sub
addadd
st
brnsub
add
st
stbrn
oriandi
subin
mov
subin
ld
ldst [ esp ],ebp
subin esp , esp, 4
stld
sub
addi
brnandi
ld
brnsubi
ld
ld
stbrn
addi
A+B+D+H
A+B+D+I
A+C+F
subin
mov
subin
ld
ldld
st
movandi
subadd
brn
sub
subinbrn
stst
brnsubi
brn
A+C+G+J
subin
mov
ldld
ld
andirr
add
sub
subin
brnst
movsub
subin
brn
st
andbrn
st
A+C+G+K
EBlock1 EBlock2 EBlock4 EBlock5 EBlock6
8291
6340 1951
2480
2054 426
426 1525
391 1134
2054 426 426 391 1134
mov
andshr
jmp
E3860
pushmov
pushpush
mov
movmov
cmpjbe
testjnz
movand
shr
jmp
A+B+E
3860
2054426 426
3911134
subin
mov
ldld
ld
stsubin
sub
subin
brnandi
mov
stst
brnandi
shri
brn
EBlock3
3860
EBlock2 EBlock4 EBlock5 EBlock6EBlock3
A+B+E

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 12
ASIA-II adopts the basic block enlargement approach to account for the hardware branchprediction effect. Shown in Figure6 is a small example taken from the MS-Word7.0 (Word97)application. In Figure6 (a) there is a control flow graph consisting of eleven basic blocks Athrough H. The number next to the basic block is its execution count. For example, basic block Ais executed for 8291 times, out of which 6340 times jumps to basic block B and 1951 times jumpsto basic block C. This control flow graph can be differentiated into six versions of extended basic
blocks (called Eblocks), as shown in Figure 6 (b). The Eblocks are derived by tracing down everypath in the control flow graph. While constructing the Eblocks, ASIA-II also derives their execu-
tion counts. For example, Eblock 1 is obtained by concatenating basic blocks A, B D and H.Eblock 1 is executed for 2054 times. An Eblock annotated with its derived execution count iscalled an annotated Eblock.
ASIA-II provides a user defined parameter, called extension distance, which controls howfar ASIA-II should travel to construct Eblocks. The larger the number, the more Eblocks will beconstructed. For example, if the parameter is set to two instructions, there will be only twoEblocks (A+B and A+C) derived from basic block A. If the parameter is set to eight, there will besix Eblocks derived, as shown in Figure6 (b). When the parameter is set too small, some potentialparallelism may be lost. On the other hand, when the parameter is set too large, the number andsizes of Eblocks would grow significantly and the experiments could not be accomplished withina reasonable time. We have experimented with several possible values for the parameter, such as2, 4, 8, 12, 16 and 32, and conclude that 8 is a good number; there is no significant performanceimprovement beyond this number.
The above observation suggests that scheduling with the annotated Eblock approach, witha medium extension distance parameter, provides practically the same parallelism measurementfor the micro-operations executed in typical superscalar architectures as scheduling with entireinstruction traces. On the other, scheduling annotated Eblocks requires much less computing timethan scheduling entire traces. Therefore, we conclude that the annotated Eblock approach is a fea-sible solution to design exploration for superscalar architectures.
4.2.5 Derivation of distribution and parallelism
After the construction of Eblocks, Eblocks are then mapped into MOP’s and the MOP’sare scheduled into time steps, as shown in Figure6 (c). The Eblocks are optimally scheduled into7, 7, 7, 7, 9 and 8 time steps, respectively. Note that in the third time step of Eblock 1, two MOP’swriting into the same register esp are scheduled into the same time step. It’s a legal schedulesince the second MOP (subin) will be renamed by hardware.

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 13
From the MOP patterns in the time steps, the distribution of functional unit usage can bederived. For example, the MOP’s in the third time step of Eblock 1 need three load/store units andone integer unit, which accounts for 3.4% (2054/(7*2054+7*426+7*3860+7*426+9*391+8*1134)) of exe-cuted time steps. Figure7 shows the distribution of functional unit usage of all Eblocks. Note thatthe most significant functional unit usage pattern is 1A0M0B0F, (A: integer unit; M: memoryunit; B: branch unit; F: floating unit) which is contributed by the first time step in all Eblocks. Thetotal MLP is 2.66 which is calculated with the following equation EQ1. The weights in the equa-tion specify the relative frequencies of the programs executed in a typical workload environment.In this example, the weight is set to one since there is only one program (the flow graph inFigure 6 (a)).
EQ 1
Figure 7. Distribution of functional unit usage in the schedules of Figure6 (c)Notation: A: integer unit, M: memory, B: branch unit, F: floating unit
Functional Unit Usage
8.3%
7.1%
1.9%
9.7%
21.9%
2.0%
9.5%
4.1%
3.4%
6.4%
6.4%
3.3%
4.1%
7.1%
2.6%
2.0%
0.0% 5.0% 10.0% 15.0% 20.0% 25.0%
0A,0M,0B,0F
0A,0M,1B,0F
0A,1M,1B,0F
0A,3M,0B,0F
1A,0M,0B,0F
1A,0M,1B,0F
1A,1M,1B,0F
1A,2M,1B,0F
1A,3M,0B,0F
2A,0M,1B,0F
2A,1M,0B,0F
2A,1M,1B,0F
2A,2M,0B,0F
2A,2M,1B,0F
3A,0M,0B,0F
Other
MOP Parallelism
Weightp Execution Counte× number of MOPse×e
Eblocks
∑p
Programs
∑
Weightp Execution Counte× number of time stepse×e
Eblocks
∑p
Programs
∑--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------=

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 14
5. Analysis of x86 Application Software
In this section, we apply x86 Workshop to measure the potential MLP, the distribution offunctional unit usage and the performance characterization of several commercial Windows95
applications. Table1 lists the Windows95 applications used in this experiment. These applicationsare typical programs used by graduate students of computer engineering. In the table we list thenumbers of executed instructions of the programs and the weights of programs which represent
the relative frequencies of these applications used in a typical work environment. Note that Wordand Excel execute relatively less instructions than some other applications, because they are inter-active programs which spend most of the time in idle and waiting for users’ inputs. The total num-
ber of instructions executed is over 524 million.
The superscalar core under measurement is based on the superscalar model in Section 3.In order to obtain the maximal available MLP, which is used to serve as the upper bounds for the
design space exploration, we adopt the following assumptions. The assumptions are similar to theones used in Section 3.3.3 of [18] and Chapter 4 of [20] for superscalar architecture exploration.
1. The cache is 100% hit; i.e., there is no delay cycles caused by cache miss.
2. The branch prediction is 100% accurate.
Program Executed Instructions*
*. User instructions only, not including the service of operating system
Weight
MS-Excel 7.0 3,249,987 10
MS-Word 7.0 8,222,279 20
Netscape Communicator 4.03 70,573,959 15
Winzip 6.3 97,064,114 2
Winrar 2.02 79,824,168 1
Notepad 260,898 5
PhotoShop 4.0 46,780,538 1
Calculator 123,848 2
Visio 4.5 26,451,451 2
ACDSee 3.2.3 351,109 2
WinTune 13,215,050 1
Turbo95 187,063,542 1
TOTAL 524,180,953
Table 1. Description of Windows95 applications under experiment

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 15
3. The instruction fetcher and decoders are fast enough to provide and decode sufficientinstructions, in order to sustain the maximal MLP.
4. All the functional units are pipelined and the execution latency of functional units is onecycle, except the load/store unit which requires two cycles (the first cycle computing theeffective address while the second cycle accessing the cache).
5. The reservation station is large enough to accommodate all ready MOPs and perform allnecessary register renaming.
The experiments of ASIA-II take about 24 hours of computing time on four UltraSparcworkstations (one at 143MHz, two at 200MHz, and one at 270MHz)
5.1 Micro operation level parallelism (MLP)
Table2 lists the MLP’s for the given software programs, which are derived with the equa-tion EQ1 and with the weights given in Table1. Two versions of MLP’s are measured. One con-siders the existence of sequential instructions in the given programs. The other ignores theexistence. The experiment shows that, on the average, the existence of the sequential instructionsdegrades the MLP by about 20%. This indicates that the sequential instructions severely impairthe performance by forcing the superscalar core to enter the sequential mode frequently. Sincethere is no hardware solution to the problem (the semantics of such instructions demand sequen-tial implementation), software programmers should try to avoid using such instructions as muchas possible.
Note that Turbo95 has the highest MLP. It is a PC performance measurement tool. Its pro-gram structure is a lot simpler than other programs, with a smaller number of function calls. Theaverage basic block size is larger. That’s why more MLP can be found. On the other hand, Winzip

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 16
and Winrar also have higher MLP’s. It is because that these two programs are computation inten-sive jobs, while other programs are interactive ones.
5.2 Functional unit usage
Figure 8 shows the overall distribution of functional unit usage of the MOP’s in the time
steps for these programs. Each bar represents the frequency of the corresponding pattern of func-tional unit usage in the programs. To save space, distributions of insignificant functional unitusage patterns (<1.0%) are lumped together and listed under the label “others.” The most frequentpatterns are 1A0M0B0F (10.6%), 1A1M0B0F (8.5%), 1A2M0B0F (7.2%) and 2A0M1B0F(7.1%). The result suggests that integer units and load/store (memory) units are the most critical
functional units for efficient x86 execution. Note that these programs are mainly integer applica-tions. The use of floating point units and MMX are very insignificant. Therefore, we will not dis-cuss floating point and MMX units in the rest of the discussion.
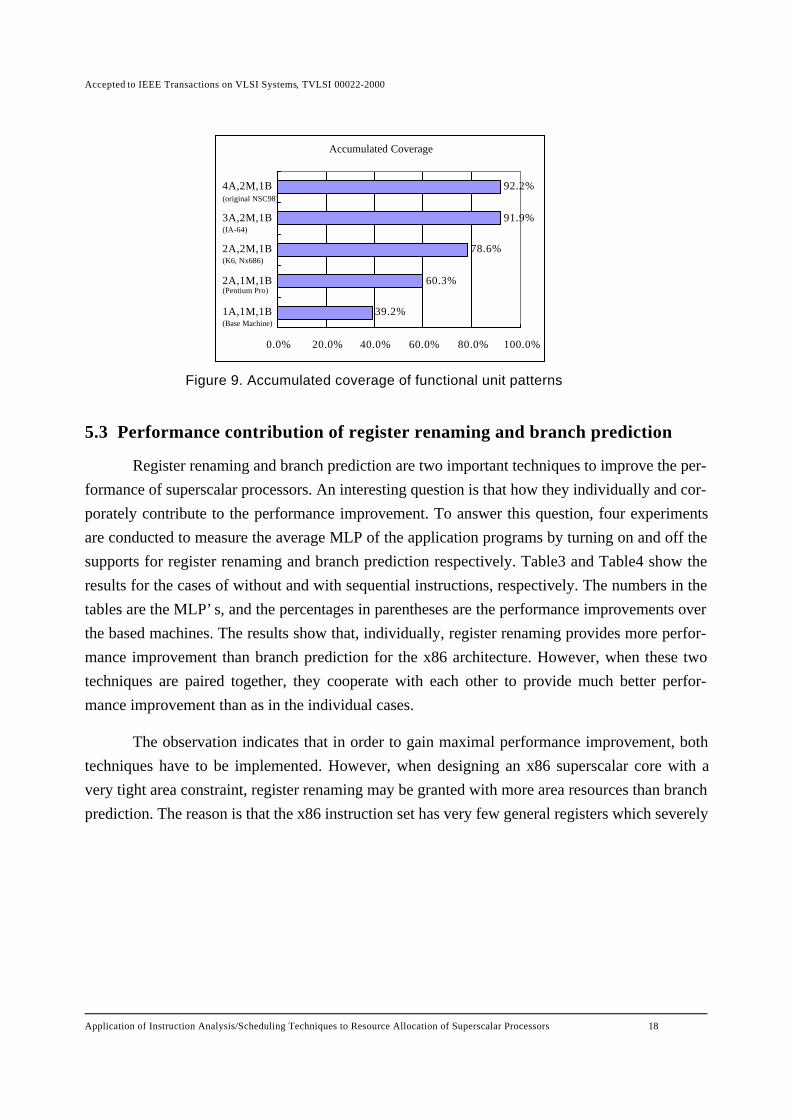
A functional unit pattern can cover some other patterns. For example, the time steps of the
pattern 1A0M0B0F can also be accommodated by the pattern 2A1M1B1F. Therefore, we need tocalculate the accumulated coverage of time steps for possible allocations of functional units thatwe are considering. Figure9 shows the accumulated coverage of several functional unit alloca-tions found in existing x86 compatible microprocessors such as Pentium Pro (2A1M1B), K6
Program MLP(excl. sequential instr.)
MLP(incl. sequential instr.)
MS-Excel 7.0 2.28 1.62
MS-Word 7.0 2.28 1.50
Netscape Communicator 4.03 2.59 2.19
Winzip 6.3 3.04 2.61
Winrar 2.02 3.32 3.22
Notepad 2.21 1.55
PhotoShop 4.0 2.50 1.98
Calculator 2.17 1.49
Visio 4.5 2.08 2.08
ACDSee 3.2.3 2.39 1.95
WinTune 2.57 2.01
Turbo95 4.91 4.96
AVERAGE 2.64 2.20
Table 2. Measured MLP’s

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 17
(2A2M1B), Nx686 (2A2M1B), IA-64 (3A2M1B) and the original NSC98 (4A2M1B). The1A1M1B stands for a base machine with one resource for each functional unit. It covers about39.2% of available parallelism. With an additional integer unit, Pentium Pro is able to cover60.3% of the available parallelism. Adding an extra load/store unit to Pentium Pro, as in K6 andNx686, can increase the coverage up to 78.6%. By adding one more integer unit to K6 or Nx686,IA-64 can covers 91.9%. Finally, by adding additional integer unit to the IA-64 may cover up to92.2%. We observe that the originally planned hardware configuration of 4A2M1B provides onlyvery little additional parallelism coverage than that of the IA-64 (3A2M1B). Based on the experi-ments, a suggestion has been made to the NSC98 architect to reduce the hardware configurationto the same as the IA-64.
Figure 8. Distribution of functional unit usage
Functional Unit Usage
4.1%
3.6%
2.9%
3.6%
1.6%
10.6%
5.1%
8.5%
3.6%
7.2%
2.1%
1.2%
5.1%
7.1%
5.6%
3.3%
2.7%
1.0%
3.8%
1.7%
6.4%
9.0%
0.0% 2.0% 4.0% 6.0% 8.0% 10.0% 12.0%
0A,0M,1B,0F
0A,1M,0B,0F
0A,1M,1B,0F
0A,2M,0B,0F
0A,2M,1B,0F
1A,0M,0B,0F
1A,0M,1B,0F
1A,1M,0B,0F
1A,1M,1B,0F
1A,2M,0B,0F
1A,2M,1B,0F
1A,3M,0B,0F
2A,0M,0B,0F
2A,0M,1B,0F
2A,1M,0B,0F
2A,1M,1B,0F
2A,2M,0B,0F
2A,2M,1B,0F
3A,0M,0B,0F
3A,0M,1B,0F
3A,1M,0B,0F
Other
Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 18
5.3 Performance contribution of register renaming and branch prediction
Register renaming and branch prediction are two important techniques to improve the per-formance of superscalar processors. An interesting question is that how they individually and cor-porately contribute to the performance improvement. To answer this question, four experimentsare conducted to measure the average MLP of the application programs by turning on and off thesupports for register renaming and branch prediction respectively. Table3 and Table4 show theresults for the cases of without and with sequential instructions, respectively. The numbers in thetables are the MLP’s, and the percentages in parentheses are the performance improvements overthe based machines. The results show that, individually, register renaming provides more perfor-mance improvement than branch prediction for the x86 architecture. However, when these twotechniques are paired together, they cooperate with each other to provide much better perfor-mance improvement than as in the individual cases.
The observation indicates that in order to gain maximal performance improvement, bothtechniques have to be implemented. However, when designing an x86 superscalar core with avery tight area constraint, register renaming may be granted with more area resources than branchprediction. The reason is that the x86 instruction set has very few general registers which severely
Figure 9. Accumulated coverage of functional unit patterns
Accumulated Coverage
39.2%
60.3%
78.6%
91.9%
92.2%
0.0% 20.0% 40.0% 60.0% 80.0% 100.0%
1A,1M,1B
2A,1M,1B
2A,2M,1B
3A,2M,1B
4A,2M,1B(original NSC98)
(IA-64)
(K6, Nx686)
(Pentium Pro)
(Base Machine)

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 19
prevent the parallelism to be exploited, and hence register renaming unlocks the hidden parallel-ism.
5.4 Comparison with related approaches
Our approach is an approximate method to obtain a large amount of superscalar measure-ments with greater flexibility and less preparation and computing time. It is usually used for adesign exploration in which possible design points have to be quickly evaluated and compared.Although it may be less accurate, it is desired that its approximated data fall within a reasonablerange and show trends similar to the trends found in data obtained by more accurate (but possiblymuch slower) approaches. Here we compare our results with other related research. Due to thelimited accessibility of the experiment material and our resources, we could not repeat theirexperiments locally; instead, our comparison relies solely on published data.
Bhandarkar and Ding present performance characterization of the Pentium Pro processor,measured on the real chip [14]. They show that the average number of micro-operations perinstruction (MPI) is 1.35, whereas our approximation shows 1.26 [6], with only 6% differencebetween the two approaches. Regarding the trends among data, the MPI of Microsoft’s Excel isabout 11% higher than Microsoft’s Word in their experiment, whereas our approximation shows8% (computed from data in [6]). Both the data ranges and trends between the two approaches arevery close.
On the other hand, we compare our analysis of performance contributions in Section 5.3with a similar analysis for the MIPS superscalar architecture based on a trace simulation approach
Without Register Renaming With Register Renaming
Without Branch Prediction 1.31 (Base Machine)
2.00(+53%)
With Branch Prediction 1.66(+27%)
2.64(+102%)
Table 3. Performance contribution in MLP (without sequential instructions) of register renaming and branch prediction
Without Register Renaming With Register Renaming
Without Branch Prediction 1.07 (Base Machine)
1.56(+46%)
With Branch Prediction 1.32(+23%)
2.20(+106%)
Table 4. Performance contribution in MLP (with sequential instructions) of register renaming and branch prediction

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 20
[18]. In this related work the measured performance contributions of register renaming andbranch prediction are 36% and 30%, whereas ours are 46% and 23% (in Table4). There are twoobservations. First, both results show the same trend: register renaming provides higher perfor-mance improvement than branch prediction. Second, our approximation shows that the contribu-tion of register renaming is more significant in the x86 superscalar architecture than in the MIPSsuperscalar architecture. It is reasonable because the x86 architecture has only eight general pur-pose registers while the MIPS architecture has thirty-two general purpose registers. There is morepotential parallelism locked by the limited number of registers in the x86 architecture than by thenumber of registers in the MIPS architecture. Therefore, by releasing the heavily locked parallel-ism, register renaming contributes more to the x86 architecture than to the MIPS architecture.
Based upon previous discussions, we found that our quick approximation approach pro-duces the same trends as the related approaches which are more accurate but more complicated,and our data fall within a reasonable range of their data. For the data which exhibit significantdeviation, we are able to explain that the main reason is due to the differences in the processorarchitecture features under investigation, not due to our approximation. Therefore, our approxi-mate approach is a quick and viable solution for design space exploration.
6. Conclusions
We have developed an x86 instruction set CAD system x86 Workshop to measure the dis-tribution of functional unit usage and the micro operation level parallelism (MLP), which togetherdetermine the proper hardware allocation in the x86 compatible superscalar architecture. x86Workshop consists of three tools: x86 Bench, State Mapper and ASIA-II. x86 Bench is an instruc-tion analysis tool for the x86 instruction set. It produces disassembled code for a givenWindows95 program and its input data, annotated with execution counts for the basic blocks inthe disassembled code. State Mapper automatically generates the mapping table to map the x86instruction set to MOP’s for a given superscalar architecture.
ASIA-II reads in the disassembled x86 code generated by x86 Bench and maps the x86code into MOP’s, according to the x86-to-MOP mapping table generated by State Mapper. ASIA-II then schedules the MOP’s into time steps. From the scheduled MOP’s, the distribution of func-tional unit usage and average MLP can be measured. We have presented the necessary mecha-nisms in ASIA-II in order to support several superscalar features, such as register renaming,branch prediction, etc.
x86 Workshop has been successfully applied to analyze several popular Windows95applications such as Word, Excel, Communicator, etc. The MLP’s, distribution of functional unit

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 21
usage and performance contribution of register renaming and branch prediction are measured forthese applications. The measurements are used to evaluate the allocation of functional units inseveral existing x86 superscalar processors and suggest the improvement to our planned NSC98x86 compatible superscalar microprocessor.
In the future, we’d like to conduct experiments to cover a much wider spectrum ofWindows95 applications. In addition, we’d like to extend the capability of x86 Workshop toaddress other superscalar design issues, such as instruction pairing (instruction folding), elimina-tion of short conditional branches, instruction decoder allocation, branch prediction depth, etc.
Acknowledgment : This paper is supported by NSC under 85-2262-E-009-010R and 86-2262-E-009-009. The authors would like to thank the comments and suggestions of the reviewersfor the improvement of the final manuscript.
References
[1] I. J. Huang and A. Despain, “Synthesis of Application Specific Instruction Sets,” IEEETransactions on Computer-Aided Design, June 1995
[2] Dick Pountain, “Pentium: More RISC Than CISC,” Byte Magazine, Sept. 1993.[3] Linley Gwennap. “Intel’s P6 Uses Decouple Superscalar Design,” Microprocessor Report
Vol. 9, No. 2, February 16, 1995.[4] AMD’s K5, http://www.amd.com/products/cpg/k5[5] Cyrix’s 6x86 (M1), http://www.cyrix.com/process/prodinfo/legacy[6] I. J. Huang and T. C. Peng, “Analysis of x86 Instruction Set Usage for DOS/Windows Ap-
plications and Its Implication on Superscalar Design,” Proceedings of the InternationalConference on Computer Design, 1998.
[7] I. J. Huang and W. F. Kao, “Instruction Retargeting Based on the State Pair Notation,”Proc. of the Asia-Pacific Conference on Hardware Description Languages, Aug., 1997.
[8] I. J. Huang and J. M. Shiu, “Design of RISC-based Instructions for Efficient x86 Emula-tion,” Proc. of National Computer Symposium, Taiwan, Dec. 1997
[9] Private communication with an engineer of Intel’s VTUNE team, 1997[10] Mark Atkins and Ramesh Subramaniam. PC Software Performance Tuning. IEEE Com-
puter, August 1996 [11] Thomas L. Adams and Richard E. Zimmerman. “An analysis of 8086 Instruction Set Us-
age in MS DOS Program”, ASPLOS-III Proceedings, pp.152-160, 1989[12] Tetsuya Hara, Hideki Ando, Chikako Nakanishi, Masao Nakaya, “Performance Compari-
son of ILP Machines with Cycle Time Evaluation” 23rd annual International Symposiumon Computer Architecture , Vol 3, No 5, pp.213-224, 1996
[13] Yooichi Shintani, Kiyoshi Inoue, Eiki Kamada, and Toru Shonai, “A Performance andCost Analysis of Applying Superscalar Method to Mainframe Computer”, IEEE transac-tion on Computers, VOL. 44, NO. 7, pp.891-901, JULY 1995

Accepted to IEEE Transactions on VLSI Systems, TVLSI 00022-2000
Application of Instruction Analysis/Scheduling Techniques to Resource Allocation of Superscalar Processors 22
[14] Dileep Bhandarkar and Jason Ding, “Performance Characterization of the Pentium ProProcessor”, proceedings of the IEEE High Performance Computer Architecture, pp.288-297, 1997.
[15] J. W. Davidson and S. Jinturakar, “Improving Instruction-level Parallelism by Loop Un-rolling and Dynamic Memory,” IEEE MICRO-28, pp.125-132, 1995.
[16] N. P. Jouppi and D. W. Wall, “Available Instruction-Level Parallelism for Superscalar andSuperpipeliend Machine,” Proceedings of the Third International Conference on Architec-tural Support for Programming Languages and Operating Systems, pp. 272-282, April1989.
[17] M. P. Jouppi, “The Distribution of Instruction-Level and Machine Parallelism and Its Ef-fect on Performance,” IEEE Transactions on Computers, Vol. 38, No. 12, pp. 1645-1658,December, 1989.
[18] N. Johnson, Superscalar Microprocessor Design, Prentice Hall, 1991.[19] D. F. Wong, H. W. Leong and C. L. Liu, Simulated Annealing for VLSI Design, Kluwer
Academic Publishers, 1988.[20] J. Hennessy and D. Patterson, Computer Architecture: A Quantitative Approach, 2nd ed.,
Morgan Kaufmann Publishers, 1995.[21] J. Smith and G. Sohi, “The Microarchitecture of Superscalar Processors,” Proceedings of
the IEEE, Vol. 83, No. 12, pp. 1609-1624, Dec. 1995.[22] D. Sima, “Superscalar Instruction Issue,” IEEE Micro Magazine, pp. 28-39, Sept./Oct.
1997.[23] J. Fisher, “Trace Scheduling: A Technique for Global Microcode Compaction,” IEEE
Transactions on Computers, Vol. 30, No. 7, 1981.[24] P. G. Paulin and J. P. Knight, “Force-Directed Scheduling for the Behavioral Synthesis of
ASIC’s,” IEEE Transactions on Computer-Aided Design, Vol. 8, No. 6, June 1989.