appunti di logistica - unive.it · 2.2.3 il problema del commesso viaggiatore (tsp) dato un grafo...
TRANSCRIPT

Appunti di Logistica
F. Mason E. Moretti
F. Piccinonno

2

1 Introduzione
La Logistica è una disciplina molto vasta che, in prima approssimazione, si suddivide in logistica interna (alle aziende) e logistica esterna, cioè ambientale.
Quest’ultima, che si interessa di problemi di viabil ità (strade, ponti, gallerie, ferrovie, infrastrutture in genere) e di modalità di trasporto (aereo, terrestre, navale, ecc.) è sicuramente di grande interesse sociale ed economico ed è oggetto di numerosi studi matematico-statistici, ma non si intende trattare tali argomenti in questa sede. Parlando di Logistica noi qui intenderemo la logistica aziendale, cioè quella che riguarda interessi microeconomici. Essa viene generalmente suddivisa a sua volta in materials management e distribution management ed è la scienza che segue i flussi fisici delle merci e delle relative informazioni dall’acquisto delle materie prime fino alla consegna dei prodotti finiti ai clienti e al servizio post-vendita.
Questa definizione è ulteriormente ampliata per comprendere anche la gestione dei flussi presso i clienti e i fornitori.
In ogni caso la Logistica è un settore del management ben definito che riguarda la gestione integrata di varie attività ed è finalizzato a conseguire obiettivi di efficienza globale.
In questi appunti ci occuperemo innanzitutto di logistica distributiva. I l distribution manager si interessa, come è noto, di far giungere ai clienti i prodotti finiti perseguendo i tradizionali obiettivi di efficacia (il servizio alla clientela) e di eff icienza (i costi devono essere minimi). I l suo successo è legato proprio alla capacità di comporre questi obiettivi apparentemente conflittuali .
Nel seguito saranno presentati modelli matematici utili per la risoluzione di alcuni problemi decisionali del distribution manager.
Per far questo sono necessarie delle premesse matematiche descritte nei capitoli 2 e 3, relative alla complessità computazionale e alla teoria dei grafi. I l capitolo 4 affronterà quindi i problemi di logistica distributiva.
Nel conclusivo capitolo 5 saranno affrontati invece i problemi di gestione delle scorte e del magazzino.


2 Problema, modello, algoritmo. Complessità computazionale
Un processo decisionale può essere decomposto nelle seguenti fasi:
1. individuazione del problema;
2. analisi della realtà e raccolta dei dati;
3. costruzione di un modello matematico che descriva gli aspetti essenziali del problema;
4. sviluppo di metodologie matematiche efficienti (algoritmi risolutivi) per determinare una soluzione;
5. analisi dei risultati ottenuti, confronto con la realtà e validazione del modello.
Sono tutte fasi sequenziali anche se a volte può capitare che una di queste fasi richieda modifiche dei risultati ottenuti in fasi precedenti. In particolare, dopo aver analizzato i risultati ottenuti (fase 5), può succedere che ci sia la necessità di ritoccare il modello costruito nella fase 3. I punti 3) e 4) sono quelli più interessanti dal punto di vista matematico.
Individuazione del problema
Analisi della realtà e raccolta dati
Costruzione di modello matematico
Sviluppo algoritmi risolutivi
Analisi dei risultati e validazione del modello

4
2.1 Costruzione di un modello matematico
I l modello è una descrizione logico-matematica della porzione di realtà interessante ai fini del processo decisionale. Una volta descritto il sistema attraverso relazioni matematiche tra variabil i che rappresentano gli elementi del sistema stesso, si tratta di cercare valori per tali variabili che soddisfino i vincoli imposti e che ottimizzino (massimizzino o minimizzino) una funzione obiettivo opportunamente definita. Non va mai dimenticata la diversità esistente tra problema reale e rappresentazione dello stesso tramite il modello: la soluzione di un problema è sempre la soluzione della rappresentazione del problema reale che è stata costruita, cioè del modello. I l modello è dunque in generale una descrizione molto limitata della realtà; nel formularlo si dovrà cercare di rappresentare in modo accurato gli aspetti che interessano ai fini della soluzione del problema decisionale che si sta affrontando.
Per problema si intende una domanda espressa in termini generali , la cui risposta
dipende da un certo numero di parametri e variabili. Esso viene definito per mezzo di:
− una descrizione dei suoi parametri;
− una descrizione delle proprietà che devono caratterizzare la risposta o soluzione che si desidera.
(ES.: trovare il percorso più breve tra due città) Un’ istanza del problema P è una domanda specifica che si ottiene attribuendo un
valore assegnato a ciascun parametro di P. (ES.: trovare il percorso più breve tra Venezia e Padova) Spesso un problema viene definito fornendo l’insieme F delle possibili risposte o
soluzioni. Tale insieme viene detto regione ammissibile e i suoi elementi soluzioni ammissibili. Sulla regione ammissibile viene definita una funzione obiettivo
ℜ→Fc :
che fornisce il costo o il beneficio associato ad ogni soluzione.
Un problema di ottimizzazione è un problema in cui, date la regione ammissibile F e
la funzione obiettivo c, si cerca una soluzione ammissibile (elemento di F) che renda minima oppure massima la funzione obiettivo. Un problema di ottimizzazione verrà indicato usando la seguente notazione:
a) (F, c; min) [min ( ){ }Fxxc ∈: ],
b) (F, c; max) [max ( ){ }Fxxc ∈: ].
Un problema di esistenza (o problema decisionale) è un problema in cui si richiede di determinare una soluzione ammissibile e quindi di verificare se la regione ammissibile è vuota oppure no. Un problema di esistenza verrà indicato usando la seguente notazione:

5
c) (F; ∃) [determinare, se esiste, Fx∈ ].
I problemi a), b) e c) sono equivalenti nel senso che possono essere considerati rappresentazioni alternative di uno stesso problema. Di seguito si dimostra infatti che ciascuna rappresentazione può essere trasformata nelle altre.
a) ↔ b):
min ( ){ }Fxxc ∈: ≡ − max ( ){ }Fxxc ∈− : .
a) ↔ c):
a) → c) sia ( ) ( ){ }FyycxcFxF ∈∀≤∈= ,: * ,
allora (F, c; min) ≡ ( *F ; ∃),
cioè determinare un punto di minimo per la funzione c
nell’insiemeF equivale a determinare un elemento di *F ;
a) ← c) sia { }1,0: →′′ Fc , FF ⊇′ , così definita
( ) ∈
=′;altrimenti ,1
, se ,0 Fxxc
allora (F; ∃) ≡ ( F ′ , c′ ; min),
cioè determinare (se esiste) un elemento di F equivale a determinare un punto di minimo per la funzione c′ in F ′ : se il valore minimo di c′ è 0 significa che Fx∈∃ , se invece il valore minimo di c′ è 1 significa che Fx∈∃/ .
b) ↔ c):
segue da a) ↔ c) e da a) ↔ b).
Dato un problema di ottimo del tipo (F, c; min) [(F, c; max)], si dice problema decisionale ad esso associato, o sua versione decisionale, il problema ( kF ; ∃), dove
( ){ }kxcFxFk ≤∈= : [ ( ){ }kxcFxFk ≥∈= : ], con k intero prefissato. Facendo variare
il parametro k e risolvendo ogni volta un problema di esistenza è possibile determinare il valore ottimo della funzione obiettivo.
Dato un problema decisionale (F; ∃) si dice problema di certificato ad esso
associato il problema seguente:
dato x , determinare se esso è soluzione di (F; ∃), cioè se Fx ∈ .

6
2.2 Esempi
2.2.1 Il problema dello zaino
Sia { }nE ,...,1 = un insieme di oggetti che si vorrebbero caricare nello zaino. Siano
ia e ic rispettivamente il peso e l’utilità dell’elemento i, { }ni ,...,1 ∈ . Si tratta di
determinare un sottoinsieme di elementi di E che abbia utilità totale massima e il cui peso totale non superi la capacità dello zaino, b. Ovviamente, affinché il problema non sia
banale deve necessariamente valere la relazione seguente: ∑=
<<n
iiab
1
0 .
I l problema dello zaino si può formulare come problema di programmazione matematica come segue:
{ } ,,...,1 ,1,0
,
, max
1
1
nix
bxa
xc
i
n
iii
n
iii
=∈
≤∑
∑
=
=
dove
=.altrimenti 0,
zaino, nello inserito viene elementol' se ,1 ixi
I l problema si può formulare come (F, c; max), dove
≤⊆= ∑∈
baESFSi
i: e ( ) ∑∈
=Si
icSc .
La versione decisionale del problema è la seguente:
( ) ? e : kScbaESSi
i ≥≤⊆∃ ∑∈
I l problema di certificato associato è il seguente:
dato ES ⊆ , verificare che ( ) kScbaSi
i ≥≤∑∈
che e .
2.2.2 Ordinamento di lavori su macchine: minimizzazione del tempo di completamento
Siano dati n lavori e m macchine. I l lavoro i, i=1,..,n, può essere svolto su ciascuna macchina e richiede un tempo di lavorazione id , indipendente dalla macchina su cui viene
svolto. Si tratta di assegnare i lavori alle macchine in modo da completare i lavori nel minor tempo possibile.

7
I l problema si può formulare come (F, c; min), dove, dato { }{ }nJE ,...,1⊆= ,
{ }
≤=∅=∩⇒∈⊆=∈
mInJJJIJJEIFIJ
,,..,1 ,,: 2121
�,
( )
= ∑∈∈ Ji
iIJ
dIc max .
2.2.3 I l problema del commesso viaggiatore (TSP)
Dato un grafo completo, simmetrico e ad archi pesati, ( )wEN ,, , con
N insieme dei nodi, nN = ,
E insieme degli archi, ( )2
1−⋅= nnE ,
+ℜ→Ew : funzione che associa ad ogni arco un peso,
si tratta di determinare un circuito hamiltoniano, cioè un circuito che passa per tutti i nodi del grafo una e una sola volta, di costo minimo.
I l problema si formula come (H, w; min), dove
{ }nohamiltonia circuitoun individua : IEIH ⊆= e ( ) ( )∑∈
=Ie
ewIw .
2.2.4 Soddisfacibilità (SAT)
Siano nPPP ,...,, 21 delle proposizioni logiche. Si indichi con jP± la
proposizione jP o la sua negazione jP¬ , per j=1,2,..,n. Siano
ri PPPC ±∨∨±∨±= ...21 , per i=1,..,m e sia mCCCA ∧∧∧= ...21 . Si tratta di
determinare, se esiste, una valore di verità per le proposizioni nPPP ,..,, 21 che
renda vera la formula A.
Come problema di esistenza:
( )∃,F , dove
F è l’insieme degli assegnamenti di verità alle proposizioni che
rendono vera la A.

8
Come problema di ottimo:
(F’ , ν, min), dove
{ }nverofalsoF ,=′ e { }nverofalso, indica il prodotto
cartesiano di { }verofalso, per n volte;
ν è la funzione che conta il numero di clausole non soddisfatte.
Ovviamente una formula è soddisfacibile se e solo se il valore ottimo del problema di ottimo associato (F’ , ν, min) è zero.

9
2.3 Algoritmi e complessità
Una volta che è stato formulato un problema, si tratta di risolverlo e quindi di mettere a punto strumenti di calcolo che, data una qualsiasi istanza, siano in grado di fornire la soluzione in un tempo finito. Tali strumenti si dicono algoritmi. Un algoritmo che risolve un dato problema P è una sequenza finita di istruzioni che, applicata ad una qualsiasi istanza p di P, si arresta dopo un numero finito di passi fornendo una soluzione dell ’istanza p o indicando che l’istanza p non ha soluzioni ammissibil i.
Dato un problema P, una sua istanza p e un algoritmo A che risolve P, si dice costo
(o complessità) di A applicato a p una misura delle risorse utilizzate dall ’esecuzione di A su una macchina per determinare la soluzione di p. Le risorse più interessanti sono di due tipi: la memoria occupata e il tempo di calcolo. Poiché generalmente è il tempo di calcolo la risorsa più critica, è usuale utilizzare il tempo di calcolo come misura della complessità degli algoritmi. Supponendo che tutte le operazioni elementari (operazioni algebriche e confronti) abbiano la stessa durata, si esprime il tempo di calcolo come numero di operazioni elementari effettuate dall ’algoritmo.
Dato un algoritmo è utile disporre di una misura di complessità che consenta di
valutare la bontà dell ’algoritmo stesso ed eventualmente di confrontare questo con algoritmi alternativi. Ovviamente non è possibile conoscere la complessità di un algoritmo A per ognuna delle istanze di P, poiché queste in generale sono in numero non limitato. Si cerca allora di esprimere la complessità come una funzione g(n) che rappresenta il costo necessario per risolvere la più diff icile tra le istanze di dimensione n. Si parla in tal caso di complessità nel caso peggiore. Per dimensione di un’istanza p si intende una misura del numero di bit necessari per rappresentare su calcolatore i dati che definiscono p, cioè una misura della lunghezza del suo input. In realtà, più che la conoscenza esatta della funzione g(n) interessa il suo ordine di grandezza; si parla in tal caso di complessità asintotica. Data una funzione g(x), si dice che g(x) è O(f(x)) se esistono due costanti 1c e 2c tali che
( ) ( ) 21 cxfcxg +≤ . Sia g(x) il numero di operazioni elementari che vengono effettuate da un algoritmo A applicato alla più diff icile istanza, tra tutte quelle che hanno lunghezza di input x, di un dato problema P. Si dice che la complessità di A è O(f(x)) se g(x) è O(f(x)).
Per avere un esempio dell’utili zzo della teoria della complessità, si descrivono di
seguito due diversi algoritmi per l’ordinamento di un insieme di numeri. Esempio Dato un insieme di numeri { }naaaI ,...,, 21= a due a due diversi (non è un’ipotesi
restrittiva), si vogliono ordinare gli elementi di I in senso crescente. Si presentano di seguito due diverse tecniche: l’algoritmo degli scambi e l’algoritmo di ordinamento per sottoinsiemi.
Algoritmo degli scambi Si confrontano a1 e a2. Se a1 < a2, si lascia invariata la loro posizione, altrimenti si
scambiano tra di loro. Si confronta poi a3 con l’elemento che si trova in seconda posizione e se serve con l’elemento che si trova in prima posizione, per trovare la giusta collocazione di a3 rispetto ad a1 e a2. In generale, al k-esimo passo si tratterà di trovare la

10
giusta collocazione per ak+1 rispetto ai primi k elementi già ordinati; siano essi b1, …, bk. Si tratta quindi di confrontare ak+1 con bk, poi se occorre con bk-1, e così via fino a che si individua j tale che bj < ak+1 < bj+1. Ma quanti confronti occorrono complessivamente? Ovviamente questo numero dipende da come gli n numeri sono ordinati inizialmente. Volendo, come è usuale fare, valutare il numero di operazioni elementari che occorrono nel caso peggiore, bisogna supporre che gli n numeri da ordinare dal più piccolo al più grande siano inizialmente ordinati dal più grande al più piccolo. In questo modo ogni elemento sarà costretto a cambiare posizione con tutti gli elementi alla sua sinistra prima di trovare la giusta collocazione rispetto a questi: al k-esimo passo ak+1 subirà k confronti e altrettanti scambi. In totale i confronti sono (l’uguaglianza si dimostra per induzione):
( ) ( )2
11...21
−=−+++ nnn .
Quindi il numero di operazioni elementari da fare nel caso peggiore è un polinomio di grado 2 in n, dove n è il numero di elementi da ordinare e quindi la dimensione
dell ’i stanza. Si dice allora che questo algoritmo ha complessità O( )2 n . Algoritmo di ordinamento per sottoinsiemi (Merge) Si intende illustrare questa seconda procedura mediante un esempio. Si consideri
l’insieme I costituito da 16=24 elementi da ordinare:
I = {20, 8, 11, 3, 15, 7, 30, 2, 18, 31, 4, 25, 9, 40, 10, 35} .
Sia I1 l’insieme che ha come elementi le 8 coppie consecutive ordinate di due elementi consecutivi di I (primo e secondo, terzo e quarto, …):
I1 = {8, 20, 3, 11, 7, 15, 2, 30, 18, 31, 4, 25, 9, 40, 10, 35} .
Sia I2 l’insieme che ha come elementi i 4 insiemi consecutivi ordinati formati ciascuno da 4 elementi consecutivi di I1:
I2 = {3, 8, 11, 20, 2, 7, 15, 30, 4, 18, 25, 31, 9, 10, 35, 40} .
Sia I3 l’insieme che ha come elementi i 2 insiemi consecutivi ordinati formati ciascuno da 8 elementi di I2:
I3 = {2, 3, 7, 8, 11, 15, 20, 30, 4, 9, 10, 18, 25, 31, 35, 40} .
Infine sia I4 l’insieme che si ottiene da I3 ordinando tutti i 16 elementi:
I4 = {2, 3, 4, 7, 8, 9, 10, 11, 15, 18, 20, 25, 30, 31, 35, 40} .
È evidente che se I contiene 2k elementi (nell’esempio I contiene 24 = 16 elementi) si dovranno costruire k insiemi, I1, I2, …, Ik (nell ’esempio I1, I2, I3, I4). Quindi con n = 2k elementi si costruiscono k = log 2 n insiemi (nell’esempio n=16, k=4). Per costruire Ih+1 a partire da Ih si fondono a due a due dei sottoinsiemi adiacenti formati da 2h elementi, ciascuno già ordinato in precedenza. Questa fase richiede al più tante operazioni quanti sono gli elementi da fondere ( � n), infatti per fondere 1a , a2, …, ta con b1, 2b , …, tb si costruisce un elenco di 2t elementi e si procede come segue: si confrontano 1a e b1 e se
1a < 1b si trascrive 1a e si confrontano 2a e b1, altrimenti, se 1a > b1 si trascrive b1 e si

11
confrontano a1 e b2. In generale, quando si confrontano ai e bj, se ai < bj si trascrive ai e si confrontano ai+1 e bj, altrimenti, se ai > bj si trascrive bj e si confrontano ai e bj+1. Poiché ad ogni confronto si trascrive sempre almeno un elemento, 1+hI si ottiene da hI dopo non più di n confronti. Di conseguenza l’algoritmo richiede non più di n log2n operazioni. Si noti che la tecnica non cambia se il numero di elementi da ordinare n è un intero qualunque e non una potenza di 2; si tratterà eventualmente di fondere gruppi aventi numerosità diversa.
Tra le due tecniche descritte è generalmente preferita la seconda in quanto presenta
una complessità inferiore. Si dicono trattabili i problemi per i quali esistono algoritmi la cui complessità è
O(p(x)), con p(x) un polinomio in x, e intrattabili i problemi per i quali un tale algoritmo non si conosce. La Tabella 1 mostra, per diverse funzioni di complessità, come aumentano i tempi di calcolo all ’aumentare della dimensione dell ’istanza, nell' ipotesi che il tempo richiesto per effettuare una operazione elementare mediante calcolatore sia 10-6 sec. Si noti che le funzioni di complessità esponenziali, pur avendo tempi di calcolo confrontabili con quelli polinomiali per dimensione bassa dell’istanza, presentano tempi di calcolo molto elevato all ’aumentare della dimensione dell’istanza.
n=10 n=20 n=40 n=60
G(n)=n 10-5sec 2⋅10-5sec 4⋅10-5sec 6⋅10-5sec
G(n)=n3 10-3sec 8⋅10-3sec 6,4⋅10-2sec 2,16⋅10-1sec
G(n)=n5 10-1sec 3,2sec 102,4sec (1,7min) 777,6sec (13min)
G(n)=2n 1,024⋅10-3sec 1,049sec 1099512sec
(12,7gg)
1,153⋅1012sec
(36500anni)
G(n)=3n 5,9⋅10-2sec 3486,8sec
(0,97ore)
1,22⋅1013sec
(3,9⋅105anni)
4,24⋅1022sec
(1,3⋅1015anni)
Tabella 1: tempi di calcolo con diverse funzioni di complessità e diverse dimensioni dell ' istanza, nell ' ipotesi che il tempo richiesto per una operazione elementare sia 10-6sec
Si definisce classe NP l’insieme di tutti i problemi decisionali il cui associato problema di certificato può essere risolto in tempo polinomiale. Ad esempio il problema del commesso viaggiatore è un problema della classe NP in quanto il problema di certificato associato ad esso può essere risolto con un algoritmo che ha complessità O(n) ovvero in tempo lineare. Nella classe NP è contenuta la classe P, cioè l’insieme di tutti i problemi decisionali per i quali esistono algoritmi risolutivi di complessità polinomiale. I problemi per i quali esistono algoritmi risolutivi di complessità polinomiale si dicono problemi facil i.

12
Dati due problemi decisionali P e Q, si dice che P si riduce in tempo polinomiale a Q, e si scrive QP ∝ , se, supponendo che esista un algoritmo QA che risolve Q in tempo
costante (indipendente dalla lunghezza dell ' input), allora esiste un algoritmo che risolve in tempo polinomiale P utilizzando come sottoprogramma QA . Si parla in tal caso di
riduzione polinomiale di P a Q. La relazione ∝ ha le seguenti proprietà:
i) è riflessiva, cioè PP ∝ ;
ii) è transitiva, cioè QP ∝ e RQ ∝ ⇒ RP ∝ .
Un problema Q è detto NP-completo (o difficile) se Q ∈ NP e se per ogni P ∈ NP si ha che QP ∝ . È possibile dimostrare (teorema di Cook, 1971) che ogni problema
NPP ∈ si riduce polinomialmente al problema della soddisfacibil ità (SAT), quindi la classe dei problemi NP-completi è non vuota, poiché SAT è un problema NP-completo. Se esistesse un algoritmo polinomiale che risolve un problema NP-completo, allora tutti i problemi in NP sarebbero risolubili in tempo polinomiale e si avrebbe NPP = . A tutt’oggi non si sa se esistono problemi in NP che non appartengano anche a P, cioè se
NPP ≠ . Si ritiene che sia molto probabile che NPP ≠ . NP-completi P Classe NP
Un problema che abbia come caso particolare un problema NP-completo ha la proprietà di essere almeno tanto diff icile quanto i problemi NP-completi. Un problema di questo tipo si dice NP-hard. Ad esempio sono NP-hard i problemi di ottimo la cui versione decisionale è un problema NP-completo. In molti casi, a causa della complessità del problema, può risultare troppo oneroso (se non addirittura impossibile) determinare una soluzione ottima del problema. Ci si accontenta allora di cercare delle “buone” soluzioni ammissibil i. Un algoritmo che risolve un problema senza garantirne l’ottimalità della soluzione trovata è detto algoritmo euristico. È evidente che un buon algoritmo euristico deve avere bassa complessità e deve essere in grado di fornire una soluzione che approssima bene la soluzione ottima.

3 Elementi di teoria dei grafi.
3.1 I grafi come metodologia di rappresentazione di sistemi.
La rappresentazione di un sistema mediante un grafo è assai comune ed è a volte utilizzata in maniera inconsapevole. Gli esempi stessi che sono portati per dimostrare come nella storia si sia fatto ricorso a tale rappresentazione lo mettono in evidenza. Dal classico caso di Eulero, che rappresentò con un grafo i quartieri di Koenigsberg e i ponti che li collegavano, alla rappresentazione delle molecole con le formule di struttura o alla descrizione dell’organigramma di un’azienda, si vede come il ri corso a ‘caselle’ o ‘nodi’ o ‘punti’ collegati tra di loro da ‘ linee’ o ‘ frecce’ riguardi ambiti disciplinari molto diversi e tra loro relativamente indipendenti. Gli esempi sopra riportati possono essere anche utili zzati per introdurre problematiche che facendo ricorso a risultati della teoria dei grafi hanno avuto interessanti sviluppi. Ciò per dire che le rappresentazioni mediante grafi descritte sopra non sono fini a se stesse, ma sono servite o possono servire per risolvere problemi o mettere in evidenza proprietà nell’ambito della disciplina interessata. In particolare Eulero con la sua rappresentazione dimostrò che non era possibile individuare un percorso che partendo da uno dei quartieri della città vi ritornasse transitando una ed una sola volta per ognuno dei sette ponti che collegavano i quartieri tra di loro. L’interesse attuale sta nel fatto che vari problemi di igiene urbana (ad es., la raccolta rifiuti, lo spazzamento delle strade ecc.) si possono risolvere sviluppando i ragionamenti di Eulero. Nel caso delle formule chimiche, note proprietà dei grafi portano a escludere l’esistenza di sostanze con molecole formate da determinati numeri di atomi. Infine, la codifica mediante un grafo dell’organigramma di un’azienda mette in evidenza aspetti relativi alla tipologia della organizzazione aziendale, alle modalità del flusso di informazioni e/o degli ordini all’interno della struttura ecc.
Un grafo viene di solito visualizzato mediante un insieme (finito) di punti (in pratica, cerchi o quadrati) collegati tra di loro in vari modi mediante linee o frecce. Questa concezione, tuttavia, fa perdere di vista il fatto che la rappresentazione mediante una figura (un disegno), in quanto tale, non è il grafo: lo stesso grafo può essere rappresentato in maniere diverse, anche se equivalenti. Da un punto di vista matematico, un grafo G consiste in una coppia di insiemi, l’insieme N dei nodi (o vertici) e l’insieme A degli archi. In questa esposizione, per semplicità, useremo i termini ‘nodi’ e ‘vertici’ come sinonimi; così pure intenderemo come sinonimi i termini ‘archi’, ‘ spigoli ’ e ‘ linee’. In letteratura, viceversa, a volte si utilizzano tali concetti con riferimento a contesti diversi (ad es. si parla di archi solo per grafi orientati ecc.), ma il vantaggio che se ne ricava è dubbio. In effetti la teoria dei grafi è relativamente recente e quindi manca ancora di definizioni universalmente accettate. Spesso un articolo o un contributo scientifico che utilizzi i grafi come strumento inizia specificando le definizioni adottate, e ciò è indispensabile elemento di chiarezza nella lettura.

14
Si scrive simbolicamente G = (N, A). Spesso si utilizzano anche i simboli V (per vertici) ed E (per gli archi). Inoltre il grafo stesso viene a volte denominato rete. L’insieme N è non vuoto: esso è rappresentativo di entità tra le quali si intendono evidenziare dei legami a coppie. Gli elementi di N potranno essere indicati con le lettere a, b, c, .... u, v, w, z oppure con v1, v2, ...., vn. L’insi eme A (che, viceversa, può essere anche vuoto) è formato da coppie di elementi di N: se si tratta di coppie ordinate, il grafo si dice orientato o digrafo (directed graph); se le coppie non sono ordinate, il grafo si dice non orientato. Vi sono poi casi in cui alcune coppie sono ordinate mentre altre non lo sono (ad esempio, raffigurando una rete stradale, le strade a senso unico sono rappresentabili con archi orientati, le altre non richiedono orientamento): si ha allora un grafo misto. Tornando all ’osservazione precedente, in base alla quale un grafo è una coppia di insiemi, e non tanto la figura che può servire a rappresentarli , si dice che due raffigurazioni sono isomorfe se rappresentano lo stesso grafo, ma risultano graficamente differenti: evidentemente tra le due si può stabil ire una corrispondenza biunivoca (ad ogni nodo della prima figura corrisponde un nodo della seconda e viceversa in modo tale che l’arco che collega due nodi esiste nella prima rappresentazione se e solo se figura anche nella seconda). Gli elementi di A rappresentano, come si è detto, i legami tra elementi di N. Sulla natura degli elementi di N non si fanno particolari ipotesi: in pratica, in problematiche di trasporto è frequente associare ai nodi gli incroci di una rete stradale e quindi gli archi corrispondono ai tratti stradali che connettono gli incroci stessi, e in questo caso ogni arco rappresenta un’entità fisica. Ma, sempre in relazione a problemi connessi ai trasporti, può succedere che i nodi rappresentino le corse che un’azienda di trasporto pubblico deve effettuare, mentre un arco orientato tra due corse esprime il fatto che uno stesso autobus, dopo aver effettuato la prima corsa può effettuare anche la seconda. In altri casi, i nodi possono rappresentare persone (e gli archi rapporti di parentela) oppure compiti da eseguire (e gli archi precedenze tra compiti) e così via. Un arco che collega i nodi u e v si può rappresentare come coppia (u, v) o anche soltanto con la scrittura uv (a meno che non gli si dia una denominazione, in genere mediante una lettera minuscola: arco ‘a’). Se il grafo è non orientato è evidente che lo stesso arco si potrà rappresentare anche con (v, u) oppure vu. Dato l’arco a = (u, v), si dice che
- u e v sono i due estremi dell ’arco;
- a congiunge u con v:
- u e v sono adiacenti;
- l’arco è incidente in u ed in v;
- u e v sono incidenti nell ’arco a.
Se il grafo è orientato, e quindi necessariamente la coppia (u, v) è ordinata, u è i l
primo estremo o origine dell ’arco, mentre v è il secondo estremo o nodo finale.

15
Due archi come h = (u, v) e g = (v, w), aventi un estremo in comune, sono adiacenti.
Oltre a ciò, se il grafo è orientato, h e g considerati nell’ordine sono consecutivi e si dice anche che h precede g e che u è un antenato di w, mentre w si dice discendente di u.
In situazioni particolari occorrono rappresentazioni in cui vi sono più archi paralleli che collegano la stessa coppia di nodi: si parla allora di multigrafo. Un multigrafo potrebbe essere rappresentato indicando per ogni arco (coppia di nodi) la sua molteplicità.
A volte occorre considerare anche archi per i quali i due estremi coincidono: si hanno allora i loop o cappi, archi del tipo (u, u). un multigrafo un cappio In un grafo orientato, due archi del tipo (u, v) e (v, u) si dicono opposti. Se in un grafo orientato per ogni arco è presente anche l’opposto il grafo si dice simmetrico, mentre se ciò non accade mai il grafo si dice antisimmetrico. Un grafo non orientato nel quale esiste un arco per ogni coppia di nodi si dice completo.
Un grafo orientato è completo se per ogni coppia di nodi u e v esistono sia l’arco (u, v) che l’arco (v, u) (e quindi si trat ta anche di un grafo simmetrico).
Non vi è denominazione particolare per indicare la presenza o meno in un grafo,
altrimenti completo, di loop: ciò è detto esplicitamente caso per caso. Si osservi infine che in un grafo completo orientato comprensivo di loop avente n nodi vi sono n2 archi, mentre un grafo non orientato completo privo di cappi contiene n(n-1)/2 archi. A volte, poi, serve dare un’indicazione del fatto che un grafo ha un numero relativamente piccolo di archi oppure, al contrario, che ne contiene molti: si parla rispettivamente di grafo sparso e grafo denso. I due concetti hanno carattere qualitativo (sono termini ‘ sfumati’ o ‘ fuzzy’!): è eccessivo pensare ad un grafo sparso come ad uno che ha meno della metà degli archi di un grafo completo!

16
3.1.1 Sottografi, sottografi indotti e sottografi di supporto.
Dato un grafo G = (N, A), siano N' ⊆ N e A' ⊆ A sottoinsiemi di nodi e archi, rispettivamente, e supponiamo che A' contenga solo archi aventi estremi in N' . Diremo allora che G' = (N' , A' ) è un sottografo di G.
In pratica, per costruire un sottografo di un grafo assegnato G, è sufficiente
cancellare da G alcuni nodi e alcuni archi, con l’accortezza di eliminare tra questi ultimi anche tutti gli archi che hanno uno o entrambi gli estremi tra i nodi cancellati. Come caso limite, è possibile cancellare solo alcuni archi. D’altra parte, si può ritenere ogni grafo come sottografo (improprio) di se stesso.
Si parla di sottografo indotto dai nodi di N' quando il sottografo G' contiene tutti gli archi di A che collegano nodi in N' ; si parla invece di sottografo di supporto quando N' coincide con N (mentre, in generale, A' è un sottoinsieme proprio di A). Infine un concetto che risulta utile in alcune applicazioni pratiche è quello di grafo di sostegno non orientato di un grafo orientato o di un grafo misto. Con tale definizione si intende il grafo (non orientato) che si ottiene eliminando l’orientamento degli archi (in un grafo misto, solo di quell i che lo sono!), eventualmente eliminando le duplicazioni dovute ad archi opposti. Quelli delle figure che seguono sono esempi, rispettivamente, di un grafo non orientato G, di un sottografo e di un sottografo indotto di G stesso. grafo G u v w p q un sottografo di G il sottografo di G indotto da u, v, w, p, q.
u v
w p
q

17
3.1.2 Percorsi in un grafo; connessione.
In un grafo non orientato si dice cammino o catena una successione di archi e1, e2, …, e k, che si possano scrivere nella forma
e1 = (u1, u2), e2 = (u2, u3), ... , ek = (uk, uk+1).
Per comodità diremo che sia gli archi ej che i loro estremi appartengono al cammino.
Poiché il grafo è stato supposto non orientato, si ha lo stesso cammino della
definizione se in alcuni degli archi si scambiano tra loro i due estremi. Pertanto, ad esempio, si ha lo stesso cammino della definizione scrivendo gli archi come e1 = (u1, u2), e2 = (u3, u2), e3 = (u4, u3), ecc. Tuttavia non è corretto definire un cammino come ‘successione di archi che hanno un estremo in comune ciascuno con quello che segue nell’insieme stesso’, perché in tale definizione rientrerebbero altre strutture come la seguente:
e1 = (u1, u2), e2 = (u1, u3), e3 = (u1, u4), …, ek = (u1, uk+1),
che è un grafo particolare (una stella) avente centro u1 e k raggi. Tornando alla definizione data sopra, partendo dal nodo u1, è spontaneo pensare al
cammino come ad un’entità che è possibile percorrere, attraversando via via tutti gli archi e1, e2, ecc., sino ad ek, incontrando successivamente i nodi u2, u3, ecc., e giungendo in uk+1. Da questo punto di vista viene spontaneo anche definire u1 l’origine del cammino ed uk+1 come il termine dello stesso ma, essendo il grafo non orientato, si possono capovolgere i concetti e definire uk+1 come origine e u1 come nodo finale.
Un cammino è semplice se gli archi che contiene sono a due a due diversi, mentre
è elementare se sono a due a due differenti i nodi u1, u2, …, u k, uk+1. Un cammino prende il nome di circuito o ciclo se i vertici u1 ed uk+1 coincidono.
Anche un circuito può essere semplice o elementare. Un cammino (circuito) elementare è anche semplice, ma non necessariamente
viceversa. Si osservi poi che in un grafo non orientato i due termini ‘cammino’ e ‘catena’
sono sinonimi, così come sono considerati sinonimi ‘circuito’ e ‘ciclo’. Si vedrà tra poco come invece nei grafi orientati la cosa non sia più valida.
In un grafo orientato si definisce cammino o sentiero una successione
e1 = (u1, u2), e2 = (u2, u3), ..., ek = (uk, uk+1), nella quale u1 è nodo iniziale del primo arco, uk+1 è nodo finale dell’ultimo, mentre ogni altro nodo uj, per j = 2, 3, … k, è estremo finale di un arco e iniziale per l’arco successivo.
Pertanto, in un cammino di un grafo orientato l’orientamento degli archi è concorde.
I l concetto di catena è più generale, non richiedendo che l’orientamento degli archi sia sempre concorde: una catena è una successione di archi che inducono un cammino nel corrispondente grafo non orientato di sostegno.

18
In pratica, una catena può essere vista come una successione di archi, analoga a
quella che individua un cammino, ma nella quale certi archi siano del tipo ej = (uj+1, uj), cioè orientati in senso opposto a quello ‘naturale’ che va da u1 a uk+1. Il concetto di catena comprende come caso particolare quello di cammino.
Un cammino nel quale u1 e uk+1 coincidono si dice circuito. Una successione di
archi alla quale nel grafo non orientato di sostegno corrisponde un circuito si dice ciclo. Analogamente a quanto evidenziato sopra, in un ciclo è possibile percorrere
qualche arco ‘contromano’, fermo restando che i circuiti sono casi particolari di cicli.
I concetti precedenti consentono di classificare i grafi in conformità a una proprietà, detta di connessione, come segue:
- un grafo orientato per il quale, data una qualunque coppia ordinata di nodi, esiste sempre un cammino che li unisce, si dice for temente connesso;
- un grafo orientato per il quale tra ogni coppia orientata di vertici esiste sempre almeno una catena, ma non un cammino, si dice semplicemente connesso.
In un grafo non orientato, non si distingue tra connessione semplice e forte: - un grafo non orientato è connesso se esiste un cammino tra qualsiasi coppia di
nodi. Se un grafo non orientato G non è connesso si possono ripartire i nodi in classi di
equivalenza sulla base di una proprietà detta di raggiungibilità e individuando dei sottografi di G detti componenti connesse di G stesso.
Operativamente, dato un nodo u1, si tratta di determinare tutti gli altri nodi, u2, u3, …, u h, collegabil i mediante un cammino con u1, cioè raggiungibili da u1: il sottografo indotto da tali nodi costituisce una prima componente connessa G1 di G. Successivamente, considerato uno dei nodi non compresi in G1, che diciamo uh+1, si possono individuare i nodi uh+2, …, u k raggiungibil i da uh+1 che formeranno una seconda componente connessa G2. Se vi sono nodi non ancora compresi nelle componenti connesse sinora individuate, se ne potrà determinare una terza e così via.
Se il grafo G è orientato, si dicono sue componenti connesse i sottografi corrispondenti alle componenti connesse del sostegno non orientato di G.
Sulla rilevanza del concetto di connessione si tornerà in un paragrafo successivo,
insieme con alcune considerazioni legate ai grafi misti.
3.1.3 Gradi.
In un grafo non orientato G si dice grado di un vertice v il numero di archi incidenti in v; se G è orientato si distinguono il grado interno (numero di archi che terminano in v) e grado esterno (numero di archi uscenti da v).

19
I l concetto di grado è importante per alcune problematiche - ad esempio quella relativa alla organizzazione dello sgombero dalla neve di una rete di strade - perché in relazione al grado dei singoli nodi si può stabilire se è possibile attraversare con un circuito tutti gli archi del grafo ciascuno una ed una sola volta, senza ripassare quindi più volte per lo stesso arco, cosa che garantisce il costo minimo.
Un nodo di grado 1 si dice pendente; se ha grado 0 si dice isolato. In qualunque grafo non orientato, la somma dei gradi di tutt i i nodi è un numero pari ed è eguale al doppio del numero degli archi. Infatti, ogni arco contribuisce al grado di due nodi, i suoi due estremi. Di conseguenza i l numero dei nodi aventi grado dispari è un numero pari. Infatti, poiché la somma S di tutti i gradi è pari, detratti da S i gradi dei nodi a grado pari anche la somma dei gradi dei soli nodi a grado dispari è un numero pari e questo richiede necessariamente che i nodi a grado dispari siano in numero pari. In un grafo orientato, la somma dei gradi interni è eguale alla somma dei gradi esterni e tale somma coincide con il numero degli archi del grafo stesso.

20
3.2 Alberi e loro proprietà.
Un albero è un grafo (non orientato) connesso e privo di cicli; un grafo privo di
cicli ma non connesso si dice invece una foresta (e sono alberi le sue componenti connesse). Per gli alberi si può dimostrare la seguente proprietà caratteristica:
Proprietà P: un albero con n nodi ha n-1 archi.
Tale proprietà è condizione necessaria e sufficiente aff inché un grafo connesso sia un albero oppure perché sia un albero un grafo privo di circuiti e può anche essere usata per dare la stessa definizione di albero, nel senso che un albero può alternativamente essere definito come:
- un grafo connesso che ha un arco in meno del numero di nodi;
- un grafo privo di circuiti con un arco in meno del numero di nodi. Partendo comunque dalla definizione data in apertura, ci si può rendere conto della
validità della proprietà P considerando il fatto che un albero può essere disegnato progressivamente tracciando dapprima un nodo e poi aggiungendo alla struttura esistente, uno per volta, un arco ed un altro nodo terminale dell ’arco stesso, sino ad esaurire tutti gli archi. I nodi utilizzati sono tanti quanti gli archi, oltre al nodo da cui il procedimento è partito. Anche se a rigore il concetto di albero si introduce per grafi non orientati, a volte si indica con lo stesso termine un grafo orientato (o anche misto) privo di cicli e (semplicemente) connesso. Per i grafi orientati si definisce il concetto di arborescenza: è tale una struttura nella quale esiste un nodo r, detto radice, che è origine (comune) di un certo numero di cammini che raggiungono tutti gli altri nodi e non vi sono cicli . In un albero non esiste, a rigore, una radice. Tuttavia in varie applicazioni può tornare utile attribuire il ruolo di radice ad un particolare nodo a partire dal quale poi individuare dei cammini che congiungano la radice stessa a tutti o parte dei nodi restanti. Caratteristica comune di alberi ed arborescenze è la presenza di un unico cammino (o di una unica catena) tra ogni coppia fissata di nodi, e quindi il problema di individuare il percorso più breve tra due nodi in un albero è banale. Sistemi di trasporto che hanno struttura ad albero (o ad arborescenza) sono piuttosto rari: una rete fluviale può essere di questo tipo, ma in genere la presenza di canali navigabil i o diramazioni nel delta introducono circuiti. Ha in genere struttura ad albero l’insieme dei tratti autostradali che è possibile percorrere a partire da un dato casello di entrata sino ad incontrare un altro casello o una barriera : qui acquista importanza proprio il requisito della unicità del percorso tra due nodi, in modo che si abbia con certezza un unico pedaggio da pagare. Gli alberi sono uno strumento utile in algoritmi risolutivi di alcuni problemi (in particolare, per gli scopi di questa esposizione, nel Problema del Commesso Viaggiatore).

21
Un albero di k+1 nodi (con k>1) dei quali uno ha grado k mentre tutti gli altri sono pendenti (di grado 1) si dice stella. In un grafo orientato, l’insieme degli archi uscenti da un vertice v si dice stella uscente (forward star) da v, mentre l’insieme degli archi entranti in v si dice stella entrante (backward star) in v.
3.2.1 Grafi bipartiti.
Si dicono bipartiti i grafi in cui è possibile ripartire l’insieme N dei nodi in due sottoinsiemi (disgiunti), U e V, in modo tale che gli archi del grafo collegano solo nodi del primo sottoinsieme U con nodi del secondo sottoinsieme V. Un grafo bipartito, di conseguenza, si indica anche con una scrittura del tipo G = (U, V, A). I l concetto è formulato per grafi non orientati. Spesso si rappresenta un grafo bipartito evidenziando i nodi dei due insiemi su due colonne e gli archi collegano solo nodi della colonna di sinistra con nodi della colonna di destra. Ciò, comunque, non deve trarre in inganno perché può essere bipartito anche un grafo con una rappresentazione differente: ad es., sono bipartiti entrambi i grafi della figura che segue (nella figura di destra, come sottoinsiemi U e V si possono assumere, rispettivamente, i nodi bianchi e neri).
Se ogni nodo di U è adiacente ad ogni nodo di V allora il grafo bipartito si dice completo (e se U= m, mentre V= n, allora A= m × n).
È immediato constatare che è bipartito ogni albero. Nel caso di grafi non connessi, essi sono bipartiti se e solo se lo sono tutte le loro componenti connesse.
In genere, in un grafo bipartito i due insiemi di nodi rappresentano due gruppi di
elementi di natura diversa, tra i quali vi sono dei legami di natura logica. Ad esempio, i l primo insieme può rappresentare dei compiti che devono essere svolti, mentre il secondo delle persone che devono svolgere tali compiti. Un arco che collega un nodo u ∈ U con un altro nodo v ∈ V esprime allora il fatto che il compito u può essere svolto dalla persona v.
I l concetto di grafo bipartito sarà utilizzato nel problema di assegnazione.

22
Si può dimostrare che vale il teorema seguente: I circuiti di un grafo bipartito hanno un numero pari di archi. Si tratta di una condizione necessaria e suff iciente.
3.2.2 Grafi misti e connessione.
Si è visto in precedenza come un grafo misto sia caratterizzato dalla presenza simultanea di archi orientati e archi non orientati ed è la rappresentazione più ovvia di una struttura quale una rete stradale in cui alcuni tratti sono non orientati (strade a doppio senso di circolazione) mentre altre vie sono dei sensi unici. In alcuni problemi è possibile sostituire a un grafo misto G un grafo orientato G' sostituendo ad ogni arco non orientato di G una coppia di archi opposti in G'. Diremo grafo orientato di sostegno del grafo misto il grafo così ottenuto.
Occorre prestare attenzione al fatto che questa operazione non deve cambiare la natura del problema che si sta studiando.
Ad esempio, nel caso della raccolta dei rifiuti, una strada a doppio senso di circolazione in cui vi sono contenitori di rifiuti deve essere percorsa ma non necessariamente più di una volta (un unico passaggio può bastare per raccogliere i cassonetti posti su entrambi i lati): solo se vi è uno spartitraffico, o se il mezzo effettua caricamento laterale sul lato destro, si rende necessario un passaggio in entrambi i sensi di marcia. Questo doppio passaggio diverrebbe comunque un obbligo se nella rappresentazione mediante grafo all’arco non orientato si sostituisse una coppia di archi orientati opposti.
Un discorso analogo vale per la distribuzione della posta: vi sono casi nei quali l’agente può ripetutamente attraversare la strada e percorrerla in definitiva solo in una delle due direzioni, mentre in altri casi occorre seguire il flusso consentito del traffico. In problemi di organizzazione del traff ico occorre a volte decidere quali tratti stradali rendere a senso unico per agevolare alcuni itinerari o, viceversa, per scoraggiarne altri. L’operazione in ogni caso deve mantenere la completa raggiungibil ità reciproca tra tutte le coppie di nodi della rete stessa. Questo richiede che rimanga fortemente connesso il grafo di sostegno orientato corrispondente al grafo misto alla fine della operazione. In effetti, gli uffici del traffico considerano anche un problema di raggiungibil ità più ristretta, nel senso che spesso si cerca di evitare che, con l’ introduzione di sensi unici e svolte obbligate, determinati punti della rete (vicini fisicamente) siano troppo distanti tra di loro per un qualsiasi veicolo. In pratica ci si avvale di vari accorgimenti, quali ad es. l’inserimento di raccordi o bretelle per consentire inversioni di marcia. Da un punto di vista teorico, si possono studiare problemi di raggiungibilità entro un fissato numero di archi e la cosa può essere risolta utilizzando le matrici di adiacenza tra nodi (o matrici nodi-nodi) che saranno introdotte nel prossimo paragrafo. Infine va segnalato il fatto che, per modellizzare situazioni di emergenza, anziché sostituire ad un grafo misto il corrispondente sostegno orientato, si può effettuare l’operazione inversa di cancellazione dell’orientamento degli archi che lo presentano, nella misura in cui dei mezzi di soccorso li possono attraversare anche contromano (ovviamente con tutte le cautele del caso!).

23
3.2.3 Grafi pesati: lunghezze e distanze.
Nei problemi di ottimizzazione su rete il grafo rappresentativo di un sistema è generalmente pesato o valutato, nel senso che ai suoi elementi, nodi e/o archi, sono associati dei coeff icienti o dei pesi: il significato di questi (utilità, penalità o importanza) dipende dal contesto in cui il problema stesso sorge. Indicheremo con wu il peso associato al (generico) nodo u e con cij o lij il peso associato all ’arco (i, j). I l peso associato ad un arco, in problemi di minimo, è detto costo dell’arco stesso oppure, anche senza particolari riferimenti a problemi di percorso, lunghezza. La lunghezza di un arco può anche essere un numero ≤ 0. I l peso associato ad un nodo v può rappresentare l’importanza del nodo stesso: la popolazione residente in una località; la frequenza con cui il nodo esprime una certa domanda di beni o di servizi, ecc. Il peso associato ad un arco, può rappresentare la lunghezza di un tratto stradale che gli corrisponde, il numero di utenze distribuite lungo lo stesso tratto, il tempo necessario per percorrerlo o il guadagno che se ne può ricavare. Non è escluso, infine, che ad uno stesso arco siano associati più pesi. In un grafo si introducono due differenti concetti di lunghezza di un cammino e di conseguenza di distanza tra due nodi. I due concetti fanno riferimento rispettivamente solo alla struttura di adiacenze del grafo oppure ad un sistema di pesi associati agli archi. In un grafo (non pesato) si dice lunghezza di un cammino il numero di archi che lo compongono. Si dice poi distanza tra due nodi la lunghezza del cammino che li collega avente lunghezza minore. Si vede come con queste definizioni si prende in considerazione solo la struttura algebrica del grafo: ciò è utile specialmente nei casi in cui gli archi indicano solo dei legami che non sono altrimenti quantificabili (non corrispondono a realtà passibili di una misurazione fisica). In un grafo ad archi pesati si dice lunghezza di un cammino la somma delle lunghezze degli archi che lo compongono; distanza tra due nodi u e v è la lunghezza del cammino più breve (se esiste) tra i nodi stessi. Indicheremo la distanza dal nodo u al nodo v con una delle due scritture d(u, v) oppure duv. Ovviamente il concetto di lunghezza è trasferibile anche ai cammini chiusi, cioè ai circuiti. Tuttavia è il caso di osservare che, con archi di lunghezza negativa, può risultare negativa la somma delle lunghezze degli archi che compongono il circuito stesso e ciò può avere forti ripercussioni pratiche, come sarà evidenziato tra poco. In presenza di archi con lunghezza negativa, il cammino più breve tra due nodi u e v può non essere definito. Infatti, se vi è un circuito di lunghezza negativa e questo, in un percorso da u verso v, può essere attraversato almeno una volta, ripetendo il circuito stesso un numero adeguato di volte, si ottiene un cammino di lunghezza negativa, arbitrariamente grande in valore assoluto Ovviamente, in problemi di massimo, sono i circuiti di lunghezza positiva che rendono la soluzione ottima non definita.

24
Situazioni concrete che portano a rappresentazioni con queste proprietà (cammini di lunghezza infinita) sono rare e comunque, in genere, risultato di situazioni anomale e instabil i. Un esempio è dato dall ’arbitraggio spaziale nei cambi tra valute. Rappresentando con nodi un insieme di valute e associando agli archi i logaritmi dei tassi di cambio tra due monete, non è diff icile che in un determinato istante, per le inevitabil i approssimazioni nelle cifre decimali dei tassi stessi, un cambio ‘a circuito’ di una moneta (ad es., con lire acquistare dollari, con questi marchi e poi riconvertire il ricavato in li re) dia luogo a un guadagno rispetto alla cifra iniziale. Allora immettendo nel circuito una somma di denaro che lo percorra un numero adeguato di volte, si può pervenire a un risultato grande a piacere. (Si noti che il ricorso a pesi logaritmici è l’accorgimento che consente di mantenere come definizione di lunghezza del circuito quella di somma delle lunghezze degli archi che lo compongono). In realtà, a parte la difficoltà di individuare il circuito e la presenza dei costi di transazione, non appena l’operazione diventa rilevante provoca essa stessa le inevitabili reazioni per cui il circuito di ‘guadagno illim itato’ è distrutto. Quello che segue è un esempio in cui il cammino di lunghezza minima tra la coppia di nodi u e v non esiste. y 1 -7 u 8 t 5 w 3 v
Infatti, nel grafo in figura, il circuito formato dagli archi (t,w), (w,y), (y,t) ha lunghezza negativa e quindi non esiste il cammino più breve da u sino a v.
Nei grafi in cui sono stati introdotti pesi sia per i nodi che per gli archi si definisce anche il concetto di distanza pesata.
Supponiamo che le lunghezze degli archi siano numeri non negativi. La distanza pesata da un nodo u ad un altro nodo v è definita come il prodotto della distanza da u a v moltiplicata per il peso w(v) del nodo v. Se indichiamo la distanza pesata con dw(u, v), si pone:
dw (u, v) = d(u, v) w(v).
I l concetto di distanza pesata è utilizzato quando un percorso da un nodo ad un altro deve essere valutato un numero di volte proporzionale ad un coeff iciente (peso) del nodo di arrivo. Ad esempio, se da una centrale telefonica si vuole collegare via cavo una località (ad es., una frazione di un comune) oltre che calcolare la distanza chilometrica occorre considerare il numero di utenti da raggiungere, perché ciascuno di questi richiede una propria coppia di cavi: nella determinazione della lunghezza complessiva dei cavi

25
necessari per i collegamenti si deve allora moltiplicare la distanza fisica tra la frazione e la centrale per il numero di utenti della frazione stessa.
Analogamente, se si desidera collocare un centro da cui erogare un servizio che serve varie località, non basta individuare le distanze dai vari utenti, ma occorre anche considerare la frequenza con la quale il servizio è richiesto. Lunghezze degli archi e distanze tra nodi di un grafo si possono riassumere in opportune matrici, come sarà illustrato alla fine del paragrafo che segue. In particolare, le distanze si possono riassumere in tabelle triangolari, come tipicamente si descrivono le distanze tra varie località negli atlanti stradali. Occorre però prestare attenzione al fatto che operativamente è indispensabile indicare non soltanto il valore delle distanze stesse, ma anche i cammini (più brevi) che le implicano.
Da questo punto di vista generalmente le pubblicazioni geografiche sono carenti perché in genere i cammini minimi (che definiscono le distanze) non sono indicati esplicitamente e sono lasciati alla intuizione del lettore il quale li può rintracciare con esattezza solo risolvendo nuovamente il problema di percorso minimo.
3.2.4 Grafi hamiltoniani e grafi euleriani.
Spesso le aziende di trasporto devono individuare dei percorsi di costo minimo con caratteristiche opportune. Di frequente uno stesso veicolo deve raggiungere quanti più clienti può o passare per più strade con uno stesso viaggio che è generalmente un circuito, con arrivo e partenza presso un deposito o presso la residenza del conducente (e passaggio obbligato per il deposito). Due casi limite sono dati dall’obbligo di transitare per tutti i nodi di una rete oppure per tutti gli archi. Se il grafo rappresentativo è fortemente connesso, è evidente che esiste almeno un circuito (in generale non semplice e tanto meno elementare) che consente di visitare tutti i nodi come pure esistono circuiti che consentono di attraversare tutti gli archi. I l problema è che in questi circuiti alcuni nodi e, rispettivamente, alcuni archi dovranno essere visitati più volte.
Distingueremo innanzi tutto due categorie di problemi. Se si tratta di determinare uno o più circuiti che raggiungono tutti i nodi di un grafo si parla di problemi di tipo hamiltoniano. Vengono in genere impostati come problemi hamiltoniani quelli legati alla distribuzione di merci a clienti. Invece, se occorre garantire il servizio lungo tutti gli archi di un grafo (o per un sottoinsieme di archi ben individuato a priori), si parla di problemi di tipo euleriano. Sono rappresentati come problemi euleriani, di solito, quelli che riguardano la pulizia delle strade (dalla neve, ad esempio), la raccolta dei rifiuti solidi urbani, la distribuzione della posta o di altri beni a utenti dislocati lungo le strade o le vie di una città. È evidente come sia la situazione specifica a suggerire la rappresentazione più adatta per la risoluzione di un problema particolare. I problemi hamiltoniani saranno approfonditi in occasione della discussione dei modell i che risolvono casi di logistica distributiva, mentre quelli euleriani trovano il loro

26
principale campo di applicazione nell’ambito dei problemi di organizzazione della raccolta di rifiuti. Si danno le seguenti definizioni:
- si dice hamiltoniano un grafo nel quale è possibile individuare un circuito che passa per tutti i nodi esattamente una volta;
- si dice euleriano un grafo nel quale esiste un circuito che passa per tutti gli archi esattamente una volta.
Sia nei grafi hamiltoniani che in quell i euleriani, il circuito della definizione può non essere unico. Ma se il costo dei percorsi è misurato dalla lunghezza degli archi, nel caso dei grafi hamiltoniani si pone anche il problema di trovare il circuito hamiltoniano di costo minimo, mentre nei grafi euleriani ogni circuito euleriano ha lo stesso costo.
3.2.5 Rappresentazione di un grafo mediante matrice.
Grafi di dimensioni ridotte possono essere facilmente disegnati e sulla rappresentazione stessa si possono condurre semplici elaborazioni ma, sia a scopi di calcolo relativamente sofisticato che per la memorizzazione di grafi di dimensioni non banali occorre ricorrere a strumenti rappresentativi consistenti tipicamente in opportune matrici o in vettori che consentano l’uso del mezzo elettronico per la impostazione e risoluzione dei problemi. Un grafo può essere codificato in vari modi tra i quali segnaliamo: la matrice di adiacenza o matrice nodi-nodi; la matrice di incidenza o matrice nodi-archi e le liste di adiacenza. Un discorso a parte meritano alberi ed arborescenze, per i quali è possibile una rappresentazione mediante un unico vettore. La scelta della rappresentazione è legata sia al problema che alle caratteristiche del grafo: come possono incidere queste ultime sarà messo in evidenza volta per volta. La matrice di adiacenza per un grafo G = (N, A) di n nodi è una matrice quadrata nxn, avente una riga ed una colonna per ciascun nodo. L’elemento generico aij vale 1 se e solo se esiste l’arco dal nodo i al nodo j: in caso contrario vale 0.
La matrice di adiacenza può essere usata sia per grafi orientati che non orientati, (anche se in quest’ultimo caso risulta ridondante essendo necessariamente simmetrica) ed è uno strumento più comodo con grafi densi, mentre con grafi sparsi è preferibile ricorrere alla matrice di incidenza. L’esempio che segue illustra la matrice di adiacenza di un particolare grafo.

27
b c a b c d e f g a 0 1 0 1 1 0 0 a b 1 0 1 0 0 1 1 d c 0 1 0 0 0 1 1 d 1 0 0 0 1 0 0 g e 1 0 0 1 0 0 1 f 0 1 1 0 0 0 0 f e g 0 1 1 0 1 0 0 grafo G matrice di adiacenza di G
La matrice di incidenza, invece, è formata da tante righe quanti sono i nodi e tante colonne quanti sono gli archi. In un grafo non orientato, per ogni arco sono indicati con 1 i due nodi estremi; gli altri elementi sono null i. Invece se il grafo è orientato si indica con 1 il nodo origine e con -1 il nodo destinazione.
La attribuzione del valore negativo ai nodi destinazione è convenzionale, ma
risulta più comoda per la impostazione di particolari problemi. Da un punto di vista mnemonico, si può pensare al nodo destinazione come ad un elemento che ‘consuma’ o ‘divora’ un determinato bene, da cui il segno negativo.
Nella figura che segue sono rappresentati un grafo orientato (costituito da 6 nodi ed
altrettanti archi) e la sua matrice di incidenza. b c u v w p q r a 1 0 0 0 0 0 b -1 -1 0 1 0 0 c 0 1 -1 0 -1 0 a d d 0 0 0 0 0 -1 e 0 0 0 -1 1 1 f 0 0 1 0 0 0 f e La matrice di incidenza, come si è detto, è utile, evidentemente, quando sono poco numerosi gli archi, ma anch’essa utilizza una notevole quantità di memoria rispetto alle informazioni che fornisce. La matrice nodi-archi ha particolari proprietà in relazione alla struttura del grafo. Ad esempio, se vi sono circuiti o catene le colonne corrispondenti agli archi che li compongono sono linearmente dipendenti.

28
Le liste di adiacenza, infine, indicano quali sono i nodi adiacenti ad un nodo fissato, e questo per tutti i nodi del grafo. Per illustrarne l’uso, si consideri il caso seguente. b c a b c d e b a c a d c a b d e f d a c e e a c d f f c e f e grafo G lista di adiacenza di G Una lista di adiacenza presenta lo svantaggio che, in genere, il numero di nodi adiacenti ad un nodo fissato varia al variare di quest’ultimo e quindi, se si desidera trasformare la lista stessa in un vettore, occorre individuare in qualche modo (ad esempio, mediante un insieme di puntatori) dove, nel vettore complessivo, hanno inizio e termine i nodi adiacenti a ciascuno dei nodi del grafo.
Nel caso dell ’esempio precedente, è chiaro che un vettore come
(b c d e a c a b d e f a c e a c d f c e)
presenta una certa ambiguità. L’inserimento di barre ( ) può essere suff iciente a chiarire la situazione: (b c d e a c a b d e f a c e a c d f c e)
anche se nel caso specifico l’ordine (alfabetico) con cui sono stati scritti i nodi adiacenti a ciascuno dei 6 nodi può essere d’aiut o. Senza elementi separatori, tuttavia, non c’è comunque possibil ità di esprimere l’esistenza di eventuali nodi isolati. Per rappresentare un albero o una arborescenza si può ricorrere ad un unico vettore che sintetizza le informazioni necessarie, evitando l’uso di matrici.
Se il grafo è una arborescenza, il vettore dovrà contenere n-1 componenti, una per ciascun nodo eccettuata la radice. La generica componente corrispondente ad un nodo u contiene il predecessore di u, cioè l’origine dell ’(unico) arco che ha u come nodo finale.
Banalmente, si tratta del principio in base al quale, in coda per una visita dal
medico di famiglia, è sufficiente sapere che ognuno sappia chi gli sta immediatamente davanti perché sia rispettato l’o rdine di priorità complessivo. In tal caso, tuttavia, la arborescenza è addirittura un cammino.
Si può ovviamente, se torna più agevole, utilizzare un vettore di n componenti associando alla radice un simbolo convenzionale, come ad es. ∅).

29
La figura che segue rappresenta una arborescenza e il relativo vettore. r n k m h p g a f b d e c r a b c d e f g h k m n p ∅ p p b c b p r r r k k r
Come si è già detto, è possibile definire altre due matrici associate ad un grafo: la matrice delle lunghezze degli archi e la matrice delle distanze tra nodi. La matrice delle lunghezze degli archi è sostanzialmente la matrice di adiacenza (o matrice nodi-nodi) nella quale al posto del valore 1, che indica la esistenza di un arco tra due nodi, è indicata la lunghezza dell’arco in questione. Se tra due nodi non esiste l’arco che li collega, non si potrà però più utilizzare il valore 0, che sarebbe interpretato come ‘ lunghezza nulla’.
Occorrerà piuttosto un valore, adeguato alle circostanze, che di fatto faccia sì che l’arco sia riconosciuto inesistente o comunque non utili zzato: in un problema di ottimizzazione con funzione oggetto da minimizzare, è opportuno usare valori numerici molto elevati, mentre occorrerà una quantità negativa grande in valore assoluto nel caso di problemi di massimo. L’uso di valori elevati in valore assoluto e di segno appropriato è necessario ogni volta che si ricorre all ’uso dell ’elaboratore in un problema che è più facile impostare su un grafo completo, ma che si deve talvolta risolvere mancando qualche arco. Lo stesso vale se si deve forzare o , al contrario, impedire l’inserimento nella soluzione di un particolare arco. In letteratura questi valori ‘elevati’ vengono a volte indicati con una lettera, ad es., M.
I l valore da usare effettivamente va scelto con un certo equili brio. Da un lato deve essere sufficientemente grande da garantire che l’arco in questione sia effettivamente escluso o scelto, a seconda di quello che si desidera.
D’altra parte, va evitato l’uso di grandezze esageratam ente grandi (in valore assoluto) perché questo potrebbe condurre a errori nella soluzione finale dovuti alle approssimazioni effettuate dall ’elaboratore alle prese, simultaneamente, con numeri molto grandi e numeri molto piccoli . La matrice delle distanze riporta per ogni elemento dij la distanza tra i nodi i e j. Mentre dalla matrice delle lunghezze è possibile risalire al grafo corrispondente, (proprio attraverso la interpretazione dei valori indicanti ‘arco non esistente’) la matrice delle distanze non lo consente. L’ultima affermazione vale anche se alla matrice delle distanze si aggrega una matrice dei cammini minimi a partire da ciascun nodo, cioè una matrice avente per ogni

30
riga il vettore che rappresenta la arborescenza con radice nel nodo stesso. Infatti, può succedere che qualche arco (u,v) non sia il cammino più breve tra i due estremi u e v e quindi esso non compare in nessuna delle arborescenze in questione. Ciò è legato ad una proprietà, sulla quale si tornerà in seguito, e cioè la proprietà triangolare: essa vale se e solo se per ogni terna di nodi i, j, k vale la relazione:
cij ≤ cik + ckj cioè se il cammino più breve tra due nodi è comunque l’arco che li collega. La proprietà triangolare rende banali i problemi di percorso minimo non vincolato (in effetti, di solito, questi sono risolti in casi in cui non esistono tutti gli archi del grafo). La stessa proprietà, se non è verificata, può essere ‘ forzata’ se si sostituisce all’arco (i,j) di costo c ij un nuovo arco (fittizio) avente costo
min cik + ckj. k

31
3.3 Appendice: Dimostrazioni
Proprietà (pag. 20): Un albero con n nodi ha n-1 archi. Dimostrazione. La dimostrazione si sviluppa mostrando prima che la condizione è necessaria e quindi che è anche sufficiente.
a) (condizione necessaria: se un grafo è un albero, vale la proprietà P).
Si procede per induzione completa sul numero di nodi. Se l’albero ha 1 nodo, evidentemente non può avere archi, mentre se ha due nodi, essendo connesso e privo di circuiti non può che avere un solo arco. Pertanto la proprietà P è vera per n=1 e n=2. Supponiamo allora di avere un albero T con k > 2 nodi e supponiamo che la proprietà P sia vera per tutti gli alberi aventi un numero di nodi ≤ k-1. Dimostriamo che la proprietà vale anche per T.
Infatti, eliminando un arco da T si rompe la connessione (se ciò non succedesse vi sarebbero circuiti, contro la definizione di albero) e si ottengono due sottografi a loro volta connessi e privi di circuiti T1 e T2, che sono quindi anch’essi due alberi: sia j il numero di nodi del primo e k-j quello del secondo. Sia j sia k-j saranno compresi tra 1 e k-1 e quindi, per l’ipotesi induttiva, T 1 ha j-1 archi mentre T2 ne contiene k-j-1. Complessivamente l’albero T contiene un numero di archi dato da (j -1) + (k-j-1) + 1 = k-1 (perché avrà tutti gli archi dei due sottoalberi oltre all ’arco che era stato eliminato). b) (condizione sufficiente s1: se vale la proprietà P in un grafo connesso G, il grafo G è un albero). Occorre dimostrare che G è privo di circuiti. In effetti, se per assurdo vi fossero circuiti, se ne potrebbe considerare uno qualunque, C1, e ‘romperlo’ eliminando un arco (u, v). Con questo il grafo rimarrebbe connesso, perché tra ogni coppia di nodi rimane almeno un cammino, che eventualmente utilizza la parte di C che non comprendeva (u,v) e conterebbe n nodi ma n-2 archi. D’altra parte, il grafo che resta dopo l’eliminazione di (u, v) non può essere un albero (perché allora, per la dimostrazione precedente dovrebbe avere n-1 archi), e quindi dovrebbe contenere almeno un altro circuito, C2. Ciò comporterebbe che è possibile eliminare un altro arco, stavolta da C2, ancora senza rompere la connessione e iterando il procedimento si giungerebbe, sempre mantenendo la connessione, ad eliminare tutti gli archi. Ma ciò è assurdo perché alla fine del procedimento resterebbero solo n nodi isolati. E’ impossibile quindi supporre che nel grafo vi siano dei circuiti. c) (condizione sufficiente s2: se vale la proprietà P in un grafo G privo di circuiti, G è un albero). Stavolta occorre dimostrare che G è connesso. Infatti, se non lo fosse, avrebbe più componenti connesse (almeno due) e tutte per ipotesi prive a loro volta di circuiti: per definizione si tratterebbe di alberi. D’altra parte a ciascuna di esse si potrebbe applicare la dimostrazione a), per cui varrebbe la proprietà P e se h è il numero di nodi della componente, gli archi sono h-1. Ma allora, se diciamo n il numero complessivo di nodi di

32
G, il numero di archi sarebbe inferiore a n-1 (con k componenti connesse, gli archi di G sarebbero, precisamente, n-k) contro l’ipotesi. Pertanto è assurdo ipotizzare che il grafo non sia connesso. Si noti infine come, oltre alla minore ‘ linearità’ delle dimostrazioni b) e c) � entrambe condotte per assurdo � le stesse sono complicate dalla necessità di collegare la proprietà P ad una delle altre due caratteristiche degli alberi, la connessione e l’aci clicità.
�
Teorema (pag. 22): I circuiti di un grafo bipartito hanno un numero pari di archi. Dimostrazione: Sarà dimostrato che si tratta di una condizione necessaria e sufficiente. Supporremo per semplicità che il grafo in questione sia connesso: l’estensione ai grafi non connessi è comunque immediata.
a) (Se un grafo G ha solo circuiti con un numero pari di archi è bipartito). Si consideri un albero di supporto T di G e si scelga una radice r. Si ponga r∈U e
poi si attribuiscano di conseguenza tutti i restanti nodi dell’albero T ai due insiemi U e V. Si considerino gli archi di G che non figurano nell ’albero. Ognuno di questi, se aggiunto a T, deve creare un circuito (se non fosse così, T non sarebbe di supporto). D’altra parte i circuiti sono solo di cardinalità pari e quindi qualunque arco aggiunto può collegare solo un nodo di U con uno in V (in caso contrario si avrebbe un circuito di cardinalità dispari). Pertanto, anche dopo la aggiunta degli archi che creano i circuiti il grafo rimane bipartito.
b) (Se un grafo è bipartito ha solo circuiti con un numero pari di archi). Infatti, ogni circuito deve iniziare e terminare in uno stesso nodo, e supponiamo
che come riferimento si tratti di un nodo di U. Poiché gli archi collegano solo nodi di U con nodi di V, con un numero dispari di archi si hanno solo cammini che iniziano in U e finiscono in V, ma non si possono avere mai circuiti.
�

4 Logistica distr ibutiva.
4.1 Generalità
La logistica distr ibutiva studia i problemi connessi con la distribuzione delle merci, partendo dal luogo di produzione, ad eventuali magazzini intermedi e poi alla domanda finale. L’obiettivo è quello di minimizzare i costi, garantendo al cliente un servizio adeguato alle sue richieste. Problemi di logistica distributiva si presentano sia alle aziende che fanno del trasporto merci il loro ‘core business’, sia alle aziende che effettuano in proprio il trasporto dei beni prodotti. Si tratta di prendere decisioni che coinvolgono sia aspett i strategici (quali , ad esempio, la costituzione di magazzini intermedi o piattaforme di consolidamento dei carichi), sia aspett i operativi (quali percorsi compiere e quando presentarsi ai clienti, visto che questi ultimi, in generale, desiderano essere visitati in specifici momenti della giornata). Gli elementi di costo da considerare sono molteplici: da un lato vi sono i costi di magazzino, che hanno dei riflessi sul ritmo delle spedizioni e, a monte, della stessa produzione; d’altro canto vi sono ovviamente i costi di trasporto, che hanno implicazioni sulla progettazione degli itinerari di distribuzione e più in generale sulle caratteristiche dei viaggi. Una corretta gestione della logistica distributiva deve considerare tutti questi elementi: l’ottimizzazione combinatoria si presta bene soprattutto per formulare e risolvere problemi ‘ fini’ di determinazione dei percorsi una volta che le frequenze di viaggio, se non anche le zone, siano già state stabil ite.
In realtà, l’ottimizzazione in senso stretto del processo di distribuzione dovrebbe tenere conto simultaneamente di tutti i fattori sopra descritti. Il procedere a fasi successive è solo una necessità dettata dalla complessità del problema.
Si aggiunga poi che all’atto pratico non sempre è il caso di andare subito in dettaglio e di cercare immediatamente quale è il circuito ottimale per visitare una clientela: eccellenti risultati si possono ottenere con modell i approssimati che ignorano i dettagli topografici. È un’opera di raffinamento successivo quel la che può permettere, delineato a grandi tratti il sistema nel suo complesso, di raggiungere risultati ancora migliori.
Nella esposizione che segue saranno proposti soprattutto strumenti utili per l’ultima fase di messa a punto operativa, ma sarà dato anche spazio ad elementi di progettazione ‘a grandi linee’ del sistema di distribuzione. Riteniamo infatti, che un (possibile) addetto ai lavori in questo campo, abbia la consapevolezza di poter disporre sia di mezzi piuttosto grezzi, di primo approccio al problema, sia di strumenti di ‘ sintonia fine’.
Questo non deve autorizzare ad esprimere giudizi negativi su modell i ‘ raffinati’,
perché, in molti casi, è stata proprio l’analisi dei risultati ottenuti con modell i ‘f ini’ a suggerire proprietà generali che hanno portato a formule approssimate (ma non troppo!) per le performance medie di un sistema di distribuzione.
I l tipico modello che si adatta particolarmente bene alle problematiche di trasporto in Logistica Distributiva è il Vehicle Routing Problem con Time Windows, VRPTW. Su questo modello, che può essere considerato un punto d’arrivo nel settore, esiste una vasta letteratura, anche se spesso si è costretti ad apportare alle varie versioni studiate delle modifiche per tenere presenti particolarità aziendali, derivanti da normative, esigenze della clientela, caratteristiche del territorio servito, ecc.

34
Per affrontare il Vehicle Routing Problem con Time Windows, e adeguarlo al contesto, tuttavia, è necessario sviluppare vari argomenti che sono dei prerequisiti: si tratta dei problemi di percorso ottimo, della costruzione di alberi ottimi, del problema di assegnazione (Assignment Problem) e infine dei modell i di circuito ottimo, particolarmente quelli di tipo hamiltoniano quali il TSP (Travelling Salesman Problem) e il problema del Vehicle Routing (senza finestre temporali). In questi ultimi problemi di percorso rientrano i problemi di routing nei quali è richiesto che siano visitati tutti i nodi di un grafo oppure un loro sottoinsieme ben determinato.

35
4.2 I l Problema di Assegnazione (AP).
L’ordine della esposizione che segue è dettato dalla esigenza di non costringere il lettore ad affrontare il materiale scorrendo il testo ‘avanti e indietro’. Pertanto il modello di assegnazione, che risulta relativamente indipendente dai restanti modell i più specifici di percorso, è affrontato per primo.
4.2.1 Generalità: dai problemi di matching all ’AP.
Definiremo di matching i problemi nei quali si tratta di determinare in un grafo un insieme di archi a due a due non adiacenti, che soddisfano prefissate proprietà. Queste possono ricondursi a due requisiti: cardinalità ott ima e peso ott imo (massimi oppure minimi, in entrambi i casi). A sua volta il grafo su cui è impostato il problema può essere generico oppure bipartito. Come sinonimo di matching si userà anche il termine accoppiamento: in ogni caso gli archi scelti individueranno delle coppie di nodi di G, ed è escluso che uno stesso nodo si trovi in coppie differenti. In questo contesto si possono formulare problemi che hanno una risoluzione banale ed altri che invece hanno interesse concreto. Sono banali i problemi di cardinalità minima senza ulteriori vincoli i n quanto basta assumere come soluzione l’insieme vuoto, ∅. Sono egualmente banali i problemi di peso minimo se i pesi sono tutti positivi, sempre se non si impongono altri vincoli. Viceversa hanno interesse, sia teorico che applicativo, i seguenti problemi: − matching di cardinalità massima in un grafo generale (non completo); − matching di cardinalità massima in un grafo bipartito (non completo); − matching di peso massimo in un grafo generale ad archi pesati, con pesi qualsiasi; − accoppiamento di peso minimo (o massimo) ed assegnata cardinalità n in un grafo bipartito completo G = (U, V, A) tra gli i nsiemi U e V, di n nodi ciascuno (problema di assegnazione). I problemi sopra descritti sono tutti di classe P, e quindi risolubil i con algoritmi di complessità polinomiale. Sono comunque relativamente più facil i da risolvere i problemi in grafi bipartiti. I l problema più interessante per le applicazioni che saranno considerate è il problema di assegnazione, detto anche AP (assignment problem), nella versione classica di minimo. Per la sua risoluzione è utile premettere alcune nozioni e risultati sui problemi di cardinalità massima (specialmente per grafi bipartiti), argomento cui saranno dedicati i prossimi paragrafi.
4.2.2 Accoppiamenti di cardinalità massima e cammini aumentanti.
Come si è detto, è utile distinguere i problemi di accoppiamento di cardinalità massima in grafi bipartiti da quell i in grafi non bipartiti. Nel secondo caso il numero di archi che si possono individuare se il grafo G ha n nodi non può superare n/2, se n è pari; (n-1)/2, se n è dispari. In un grafo bipartito, la massima cardinalità non può essere superiore al numero di nodi dell ’insieme (U o V) che contiene meno elementi.

36
In entrambi i casi, come vedremo, la determinazione di un accoppiamento di cardinalità massima si può effettuare individuando particolari sottografi che diremo cammini ed alberi aumentanti.
Introduciamo di seguito alcune definizioni, necessarie a definire le proprietà
caratteristiche di un accoppiamento massimo. - dato un grafo G, indicheremo con il simbolo M un insieme di archi a due a due
non adiacenti, che costituiscono quindi un accoppiamento tra (alcuni) nodi di G e parleremo ‘ tout court’ dell ’ accoppiamento M;
- dato un accoppiamento M, un nodo u di G estremo di un arco di M si dice
accoppiato, mentre se u non è incidente in alcun arco di M si dice esposto; se in un accoppiamento M tutti i nodi di G sono accoppiati, M si dice completo;
- un cammino elementare di G i cui archi, alternativamente, fanno parte di un
accoppiamento M e non ne fanno parte, si dice cammino alternante; - un cammino alternante i cui vertici iniziale e finale sono esposti, si dice
cammino aumentante (sempre, ovviamente, rispetto al matching M!). Vale il seguente teorema: un accoppiamento M in un grafo G è di cardinalità massima se e solo se in G non esistono cammini aumentanti r ispetto a M. I l teorema appena enunciato, la cui dimostrazione si trova in appendice al capitolo, suggerisce un algoritmo (semplice ma non efficiente!) per la ricerca di un matching ottimo M*. Infatti, si può pensare di costruire un matching iniziale M (anche di un solo arco, se non addirittura vuoto) e migliorarlo ricercando ripetutamente cammini aumentanti tra nodi esposti: quando si constata che non ve ne sono più, il matching è ottimo. Tuttavia questa procedura richiede l’esame di tutte le coppie di nodi esposti e la ricerca di cammini aumentanti tra essi, e potrebbe essere eccessivamente onerosa. Sono state viceversa messe a punto delle tecniche che prevedono una ricerca simultanea di cammini aumentanti da un nodo esposto utilizzando altri due concetti contenuti nelle seguenti definizioni:
- un sottoalbero di un grafo G in cui si sia individuato un matching M si dice albero alternante se ha come radice r un vertice esposto e i cammini uscenti dalla radice sono tutti alternanti;
- un albero alternante avente un altro nodo esposto, oltre alla radice, si dice
albero aumentante. I nodi degli alberi alternanti ed aumentanti si possono distinguere in due sottoinsiemi: infatti, la radice r e tutti i nodi di posto dispari in un qualsiasi cammino possono avere grado qualunque, mentre i nodi di posto pari non possono che avere grado minore o uguale a 2. In altre parole, le ‘diramazioni’ di questi alberi si manifestano solo nei nodi di posizione dispari (oltre che in r). Si definiscono allora esterni la radice e i nodi di (possibile) diramazione; gli altri nodi si dicono interni.

37
È evidente che la presenza di un albero aumentante garantisce la possibil ità, come nel caso del cammino aumentante, di incrementare di un’unità la cardinalità dell ’accoppiamento corrente. La figura che segue mette in evidenza le caratteristiche di un albero alternante: in essa con le sigle E ed I si indicano i nodi esterni ed interni.
4.2.3 Matching di cardinalità massima in un grafo bipartito.
In un grafo bipartito G = (U, V, A) ogni cammino contiene alternativamente nodi dei due insiemi U e V: se il cammino ha un numero dispari di archi, necessariamente inizia in uno dei due insiemi e finisce nell’altro. Pertanto, ogni cammino aumentante (che contiene appunto un numero dispari di archi) collega due nodi esposti che stanno uno in U e l’altro in V. Ne consegue allora anche il fatto che una ricerca esaustiva dei cammini aumentanti può limitarsi a esaminare solo i nodi esposti di uno dei due insiemi, U o V.
Come annunciato nell ’ul timo paragrafo, la procedura più efficiente di ricerca di un cammino aumentante rispetto ad un matching iniziale M (anche vuoto) è condotta attraverso la costruzione di un albero alternante T, come segue:
- Passo 1: si individua un nodo esposto u ∈ U; se non ve ne sono STOP,
altrimenti andare al Passo 2 (u è la radice dell ’albero T); - Passo 2: si inseriscono in T tutti gli archi (u, v) uscenti da u; (nessuno di questi
fa parte di M); andare al Passo 3; - Passo 3: se uno (almeno) dei nodi v è esposto, si è individuato in T un
cammino aumentante: si aggrega l’arco (u, v) al matching M. Cancellare T e tornare al Passo 1; se nessuno dei nodi v è esposto andare al Passo 4;
- Passo 4: ampliare l’albero T aggregando per ciascuno dei nodi interni v (che
non sono esposti!) l' (unico) arco del matching incidente in v: si individuano dei nodi u’ in U; andare al Passo 5;
- Passo 5: ampliare ancora l’albero T aggregando tutti gli archi del tipo (u’, v’),
incidenti in nodi v’ che non facciano già parte di T, uscenti dai nodi u ’ individuati al Passo 4; se non ve ne sono, STOP; altrimenti andare al Passo 6;
E
E
E
E
E
E
I
I
I
I
I
I
I

38
- Passo 6: se uno dei vertici v’ è esposto, si è individuato un cammino aumentante; aumentare il matching, cancellare T e tornare al Passo 1; se nessuno lo è ripetere il Passo 4 ed il Passo 5 ponendo v = v’.
Consideriamo un esempio. Sia dato il grafo bipartito (non completo) della figura
che segue, nella quale è evidenziato anche un matching iniziale M.
u1 v1
u2 v2
u3 v3
u4 v4
u5 v5
u6 v6
Considerato il nodo esposto u2, si costruisce l’albero alternante aggregando i due
archi uscenti da u2; poi, visto che i nodi v3 e v5 sono accoppiati, si amplia T con gli archi (v3, u1) e (v5, u6); poi si aggiungono i due archi (u1, v1), uscente da u1, e (u6, v4), uscente da u6: non si aggrega (u6, v3) perché v3 fa già parte dell ’albero. Si prosegue aggregando gli archi del matching (v1, u3) e (v4, u4). Infine partendo da u4 si aggrega l’arco incidente nel nodo v6, che è un nodo esposto: l’albero alternante è anche aumentante, ed è quello della figura che segue:
v3 u1 v1 u3 u2
v5 u6 v4 u4 v6
I l cammino aumentante è il seguente:
u2, v5, u6, v4, u4, v6 e può essere usato per aumentare di uno la cardinalità del matching corrente. In un grafo G non bipartito valgono tutte le proprietà finora stabil ite ma la tecnica di ricerca con gli alberi aumentanti va opportunamente adattata.

39
4.2.4 I l problema di assegnazione come problema di programmazione intera e di programmazione lineare.
Ripetendo quanto già detto in precedenza e utilizzando le definizioni poste, il Problema di Assegnazione (Assignment Problem, AP), consiste nella determinazione di un accoppiamento completo di costo minimo in un grafo bipartito completo G = (U, V, A) nel quale i due sottoinsiemi U e V contengono ciascuno n nodi e ad ognuno degli n2 archi è associato un peso. Supponiamo che gli n nodi di U rappresentino n compiti da eseguire e che gli n nodi di V rappresentino n macchine. La risoluzione dell’AP è di notevole importanza in problematiche di routing, che con il concetto di ‘accoppiamento’ non hanno collegamenti evidenti.
Sull ’argomento esiste una letteratura piuttosto ampia alla quale si rinvia per approfondimenti. Formalmente, l’input è una matrice quadrata C n×n il cui generico elemento cij è il costo da sostenere se il compito i-mo è attribuito alla macchina j-ma.
Le variabil i di decisione, binarie, saranno indicate con xi j e possono quindi assumere solo valore 0 oppure 1. Se xij = 1, il compito i è assegnato alla macchina j, mentre se xij = 0 questo non avviene. I l problema si può allora scrivere:
∑ij
ijij xcmin
con i vincoli : Σj xij = 1 per ogni indice i; Σi xij = 1 per ogni indice j; xij ∈ {0, 1} per ogni indice i e j
Si osservi che i vincoli sono 2n, oltre a quelli relativi alla interezza delle variabil i. A volte può essere interessante risolvere un problema analogo all ’AP, ma con la
variante di una funzione oggetto di massimo, anziché di minimo. I l nuovo problema è tuttavia equivalente all ’AP di minimo, in quanto è sufficiente cambiare di segno tutti i coefficienti di costo, che poi possono essere ricondotti tutti a numeri positivi aggiungendo ad ogni cij una stessa costante Q sufficientemente grande.
Si tenga presente che con questo la soluzione ottima non cambia in quanto il problema di assegnazione richiede di scegliere nel modo migliore uno ed un solo elemento per ciascuna riga e ciascuna colonna di C.
I l Problema di Assegnazione rientra nella categoria dei problemi di programmazione intera (non si tratta di un problema di programmazione lineare, almeno nel suo significato originario), ma presenta caratteristiche tali per cui può essere risolto con tecniche adatte alla programmazione lineare.
Infatti, la matrice dei coefficienti dei vincoli gode della proprietà della totale unimodularità, consistente nel fatto che ogni sottomatrice quadrata della matrice dei coefficienti stessa ha determinante che vale 0 oppure 1 o –1. Ne segue che un vertice ottimo ha componenti intere, che non possono che essere 0 oppure 1.
Pertanto il problema sostanzialmente non cambia se nella formulazione precedente
si sostituiscono ai vincoli di interezza i vincoli (rilassati) di non negatività

40
xi j ≥ 0. Un vincolo aggiuntivo del tipo xij ≤ 1 è superfluo, in quanto la non negatività delle variabil i e i due insiemi di vincoli precedenti impediscono comunque a qualsiasi variabile di assumere un valore superiore a 1. Con tale variazione nei vincoli, il problema di assegnazione può essere trattato in tutto e per tutto come un problema di programmazione lineare e si può quindi, per la sua risoluzione, ricorrere a qualsiasi tecnica di programmazione lineare, anche se in realtà la particolare struttura di AP ha portato alla costruzione di algoritmi polinomiali ‘ad hoc’.
4.2.5 Problema di Assegnazione e circuiti hamiltoniani.
I l Problema di Assegnazione presenta stretti legami con i problemi di ricerca di circuiti o sottocircuiti hamiltoniani di costo complessivo minimo, in un grafo completo ad archi pesati, ed è questo il motivo che giustifica, nell ’impostazione scelta per quest’esposizione, il fatto di ricollegarlo alle problematiche di logistica distributiva. In questo paragrafo mostreremo, infatti, come:
- ad ogni circuito hamiltoniano in un grafo or ientato G di n nodi si può far corrispondere una soluzione ammissibile in un problema di assegnazione in un grafo non orientato G’ di 2n nodi; - ad ogni soluzione del problema di assegnazione nel grafo G’ di 2n nodi corrisponde (più in generale) un insieme di sottocircuiti che ricoprono tutto un grafo G di n nodi, nel senso che ogni nodo del grafo stesso appartiene esattamente ad un sottocircuito (eventualmente, un loop). Per quanto riguarda la prima affermazione, dato un circuito hamiltoniano in un
grafo G = (N, A) di n nodi, che numeriamo da 1 a n, costruiamo un grafo bipartito G’ = (U, V, E) di 2n nodi con U ={1’, 2’, ..., n’ } e V ={1”, 2” , ..., n”}: all ’arco (i, j) del circuito in G corrisponde l’arco (i’, j” ) di G’. Ad esempio, al circuito hamiltoniano della figura che segue:
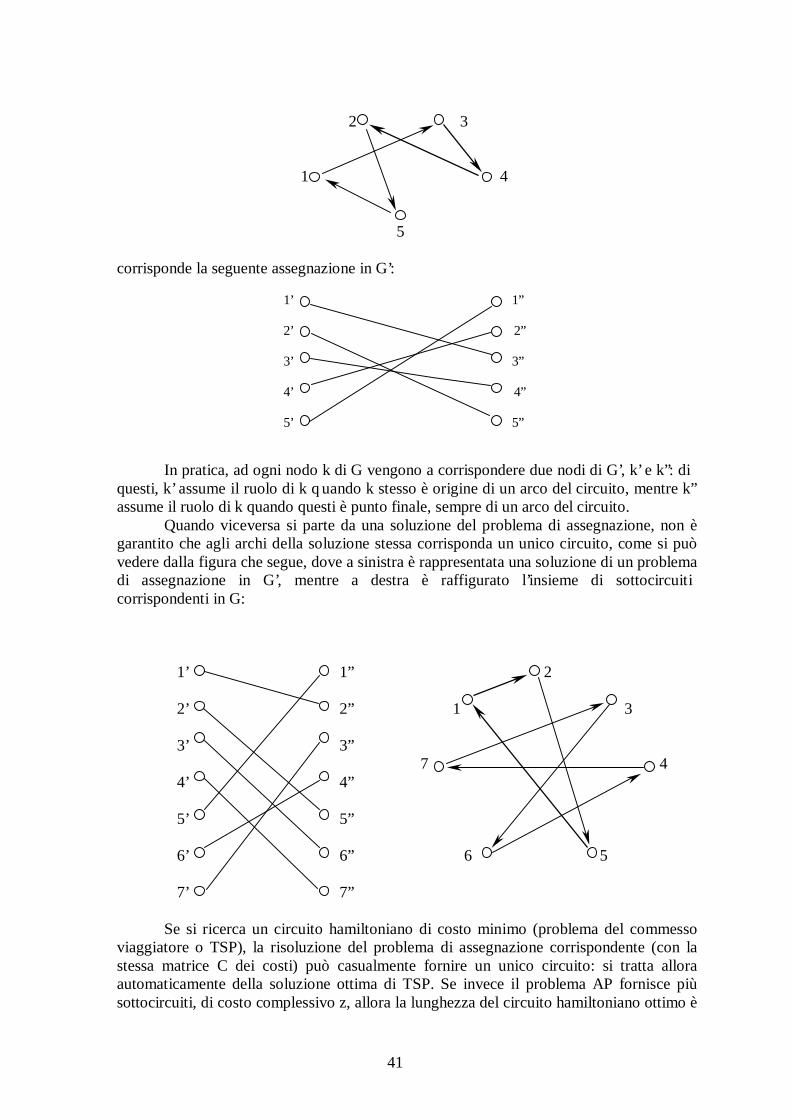
41
2 3 1 4 5 corrisponde la seguente assegnazione in G’: 1’ 1” 2’ 2” 3’ 3” 4’ 4” 5’ 5” In pratica, ad ogni nodo k di G vengono a corrispondere due nodi di G’, k’ e k”: di questi, k’ assume il ruolo di k quando k stesso è origine di un arco del circuito, mentre k” assume il ruolo di k quando questi è punto finale, sempre di un arco del circuito. Quando viceversa si parte da una soluzione del problema di assegnazione, non è garantito che agli archi della soluzione stessa corrisponda un unico circuito, come si può vedere dalla figura che segue, dove a sinistra è rappresentata una soluzione di un problema di assegnazione in G’, mentre a destra è raffigurato l’insieme di sottocircuiti corrispondenti in G: 1’ 1” 2 2’ 2” 1 3 3’ 3” 7 4 4’ 4” 5’ 5” 6’ 6” 6 5 7’ 7” Se si ricerca un circuito hamiltoniano di costo minimo (problema del commesso viaggiatore o TSP), la risoluzione del problema di assegnazione corrispondente (con la stessa matrice C dei costi) può casualmente fornire un unico circuito: si tratta allora automaticamente della soluzione ottima di TSP. Se invece il problema AP fornisce più sottocircuiti, di costo complessivo z, allora la lunghezza del circuito hamiltoniano ottimo è

42
certamente superiore a z (e z è pertanto un confine inferiore per il valore della soluzione stessa.

43
4.3 Alberi di supporto ott imi.
4.3.1 Generalità: la costruzione di un albero di supporto.
Ricordiamo che, dato un grafo G = (V, A), si dice albero di supporto di G qualunque sottografo di G che sia un albero e che contenga tutti i nodi di G. Condizione evidente per l’esistenza di alberi di supporto per un grafo è che lo stesso sia connesso. In caso contrario, si possono costruire foreste di supporto. La costruzione di alberi di supporto ha notevole interesse applicativo: in particolare, se il grafo è ad archi pesati, si può porre il problema di costruzione di un albero di supporto nel quale la somma dei pesi degli archi sia minima (o, in altri contesti, massima). Un albero di supporto di lunghezza minima è indicato con la sigla SST (Shortest Spanning Tree) e può rappresentare, in tema di comunicazioni, la rete meno costosa per collegare tutti i nodi del grafo: questo non significa che si ottengano così i percorsi più brevi tra i vari nodi, ma se l’elemento prevalente è il costo di costruzione della rete, un SST comporta il costo minimo di connessione.
Mentre il problema di costruzione di un qualsiasi albero di supporto si pone per un grafo generico, la ricerca di uno SST si effettua avendo come dato standard in ingresso un grafo completo del quale è data la matrice delle lunghezze degli archi.
Se il grafo non è completo, ci si può ricondurre a tale circostanza introducendo gli
archi mancanti, con l’accortezza di dare loro peso molto elevato, in modo che un algoritmo risolutivo non li prenda in considerazione.
Rinviando ai prossimi paragrafi la trattazione dei problemi relativi ad alberi ottimi,
affrontiamo qui la questione della costruzione di un qualsiasi albero di supporto per un grafo generico G. A tale scopo è suff iciente scegliere nel grafo n-1 archi, in modo tale che non si creino circuiti: se ciò non risulta possibile, si otterrà una foresta di supporto, ogni componente della quale risulterà un albero di supporto di una componente connessa di G. La procedura per ottenere tale risultato è denominata algoritmo di coloritura, perché questo è solitamente descritto ipotizzando di usare due colori, per indicare gli archi che fanno parte (ad es. blu) e quelli che non fanno parte (ad es. rossi) dell ’albero, e consiste nei passi seguenti.
Passo 1) Scegliere un primo arco dal grafo e colorarlo in blu. Inserire i due nodi estremi dell’arco in un insieme S1. Andare al Passo 2.
Passo 2) Scegliere un arco (u, v) non ancora esaminato e testare i due nodi estremi. Se questi non sono mai stati incontrati in precedenza, andare al Passo 3. Se uno dei due estremi, ad es. u, è stato individuato in precedenza, andare al Passo 4. Se ambedue i nodi estremi u e v sono già stati incontrati in precedenza andare al Passo 5.

44
Passo 3) Colorare l’arco in blu. Detto k il numero di insiemi S iii finora costruiti, definire un nuovo insieme Sk+1 e inserirvi entrambi i nodi u e v. Andare al Passo 6.
Passo 4) Colorare l’arco in blu. Se u ∈ Si, inserire in Si anche v. Andare al Passo 6.
Passo 5) Se u e v appartengono ad uno stesso insieme Si, colorare l’arco in rosso e andare al Passo 6. Se u ∈ Si mentre v ∈ Sj, colorare l’arco in blu, trasferire tutti gli elementi di Sj in Si, porre Sj = ∅ e andare al Passo 6.
Passo 6) Se sono stati colorati in blu n-1 archi STOP: gli archi blu costituiscono un grafo di supporto. Se sono stati colorati in blu meno di n-1 archi e non vi sono più archi STOP: gli archi blu costituiscono una foresta di supporto. Se sono stati colorati in blu meno di n-1 archi e vi sono ancora archi da esaminare, tornare al Passo 2.
I sottoinsiemi Si che si creano o modificano contemporaneamente alla accettazione di archi (coloriture in blu) individuano ciascuno un insieme di nodi connessi in uno stesso sottoalbero: alla fine del procedimento, se il grafo è connesso, sono tutti vuoti, tranne uno che comprende tutti i nodi. Se ve ne sono due o più non vuoti, ciascuno identifica i nodi di uno stesso sottoalbero nella foresta di supporto. I sottoinsiemi Si si possono individuare ricorrendo ad un sistema di etichette attribuite ai nodi: ognuno di essi riceve come etichetta l’indice dell’insieme cui appartiene. Ad un nodo non ancora inserito in un insieme si potrà dare un’etichetta ‘ad hoc’, ad esempio, l’etichetta 0. Le quattro eventualità che figurano al Passo 2 implicano, rispettivamente: - (passo 3): la creazione di un nuovo sottoalbero, formato da un unico arco, avendo trovato due nodi mai esaminati sinora; - (passo 4): l’ampliamento di un sottoalbero, per aggregazione di un nodo finora mai trovato; - (passo 5): il rifiuto di un arco che creerebbe un circuito o la riunione di due sottoalberi in un sottoalbero unico (eventualmente nell’albero finale cercato), mediante un arco tra due nodi facenti parte di due sottoinsiemi diversi. Per quanto riguarda la complessità computazionale, il procedimento richiede un numero di operazioni dell’ordine di n2. Infatti, se dividiamo a priori gli archi in due categorie, quell i rifiutati e quell i scelti, si può osservare come i primi siano dell’ordine di n2 ed il rifiuto avviene semplicemente riconoscendo che i due vertici appartengono allo stesso insieme (come si è già detto, l’appartenenza ad uno degli S i può essere memorizzata con un sistema di etichette apposte ai nodi), quindi con una sola operazione di confronto. Invece, leggermente più complessa è la gestione degli archi accettati, che sono n-1. In questo caso, la situazione che richiede un maggior numero d’operazioni è quella in cui i due nodi estremi, u e v, appartengono a due insiemi diversi, u ∈ Si e v ∈ Sj. In questo caso, occorre scorrere l’elenco dei nodi e cambiare tutte le etichette ‘ j’ facendole diventare ‘ i’ (o anche, se si vuole, cambiare tutte le ‘ i’ in ‘ j’). Questo può richiedere al più n confronti: nel complesso, anche per gli archi accettati si devono fare O(n2) operazioni.

45
4.3.2 Principi teorici per la costruzione di alberi ott imi.
Dato un grafo G = (V, A) ad archi pesati, se alcuni archi hanno lo stesso peso si possono avere differenti SST, aventi tutti lo stesso costo minimo. Alla base delle varie tecniche proposte si può porre il seguente Teorema: Siano noti k sottoalberi disgiunti di un grafo G, che indicheremo con T1, T2, ..., Tk, contenenti complessivamente tutt i i nodi di G e si conosca con certezza che essi sono parte di uno stesso albero di supporto di lunghezza minima T* di G. Allora:
i) un arco di lunghezza minima tra quelli che collegano due sottoalberi diversi può essere inserito in un SST; ii ) fissato un particolare sottoalbero Th, i l più corto tra gli archi che collegano vertici in Th con vertici di altr i sottoalberi può essere inserito in un SST.
4.3.3 Gli algoritmi di Prim e di K ruskaal.
L’algoritmo di Prim procede ampliando un solo sottoalbero, al quale sono aggregati con singoli archi, progressivamente, tutti i restanti nodi. Per questo può essere definito una tecnica a ‘macchia d’olio’. Indichiamo con Tk il sottoalbero quando contiene k nodi (1 ≤ k ≤ n-1). Inoltre, sempre nel corso della procedura, associeremo ad ogni nodo v ∈ G non ancora aggregato al sottoalbero, un’etichetta del tipo (u, hv), dove u rappresenta un (opportuno) nodo del sottoalbero corrente e hv la lunghezza dell’arco (u, v). L’algoritmo prevede i seguenti passi: Passo 1: scegliere arbitrariamente un nodo iniziale u, che costituisce il primo sottoalbero T1; attribuire ad ogni altro nodo v del grafo l’etichetta (1, hv), dove hv = l(1, v); andare al passo 2; Passo 2: detto Tk-1 l’albero sinora costruito, per ottenere T k, determinare il nodo y ∉ Tk-1, di etichetta (i, hv), con hv minimo; porre Tk = Tk-1 ∪ { (i, y)} ; cancellare l’etichetta di y e andare al passo 3; Passo 3: se k = n-1, STOP; altrimenti aggiornare le etichette dei nodi v che non stanno in Tk ponendo h’ v = min (hv; l(y, v)), dove y è l’ultimo nodo aggregato all ’albero; porre hv = h’ v e tornare al passo 2. Si noti che l’etichetta del generico nodo v contiene due indicazioni: il nodo dell ’albero sinora costruito che è collegabile con l’arco più corto a v e la lunghezza h v di questo stesso arco. L’aggiornamento consiste nell’analizzare, sempre per il generico nodo v non ancora aggregato all ’albero, se conviene ancora raggiungerlo con l’arco trovato in precedenza oppure se è più corto l’arco che collega v all’ultimo nodo y inserito nell’albero.

46
I l procedimento alterna una fase di scelta di un nodo con etichetta minima e una fase di aggiornamento delle etichette: da ciò si può facilmente dedurre la complessità, che è dell ’ordine di n2. Infatti, a parte la scelta iniziale di un nodo e la prima attribuzione di etichette, occorre poi: - scegliere tra n-1 nodi il primo nodo da aggregare a quello iniziale (n-2 confronti); - aggiornare le n-2 etichette dei nodi rimanenti (n-2 confronti); - scegliere il terzo nodo da aggregare, tra gli n-2 rimasti (adesso i confronti richiesti sono n-3); e così via, sino ad aggiornare l’etichetta di un solo nodo, l’ultimo rimasto (con un ultimo confronto). Si ha complessivamente un numero di confronti dato da
2·{(n-2) + (n-3) + ... + 2 + 1 } = 2·(n-2)·(n-1)/2. L’algoritmo di Kruskaal coincide con l’algoritmo di coloritura applicato ad un
ordinamento degli archi in senso di lunghezza crescente: pertanto per la sua descrizione si può fare riferimento a quanto già detto nel paragrafo 4.3.1.
Per quanto riguarda la sua complessità computazionale, osservato che in un grafo completo gli archi sono n(n-1)/2, si vede come l’operazione più onerosa sia proprio l’ordinamento degli archi, che richiede un numero di confronti dell ’ordine di
n2·log n2 = 2·n2·log n.
4.3.4 Osservazioni ed esempi.
Tra i due algoritmi, la complessità computazionale farebbe propendere per quello di Prim. In realtà, nei casi concreti in cui il grafo di partenza non è completo, la situazione può capovolgersi. Se il numero di archi è abbastanza basso (cioè, nei cosiddetti grafi sparsi), essendo piccolo il numero di archi da ordinare, può essere più conveniente l’algoritmo di Kruskaal. Per grafi invece con molti archi, cioè nei grafi densi, la scelta torna sulla tecnica di Prim.
È possibile pensare anche a una tecnica di tipo ibrido, quando non sono note a priori le caratteristiche del grafo. Si può procedere a macchia d’olio accrescendo un sottoalbero parziale fino a quando include un certo numero prefissato di nodi, e poi proseguire con la tecnica di Kruskaal.

47
Come esempli ficazione, si consideri il seguente grafo a griglia, ove accanto agli archi sono riportati i relativi pesi:
a b c d 5 1 11
9 9 13 4 e f g h
7 10 12
6 15 3 8 k m n p 2 14 7
15 9 10 16 q 4 r 8 s 12 t
Con la procedura di Kruskaal, si procede all ’ordinamento degli archi secondo
lunghezza crescente, ottenendo la lista riportata a sinistra, e quindi si accettano gli archi indicati con * . L’albero ottenuto è raffigurato a destra. (b, c) * 1 (b, f) 9 (k, m) * 2 (m, r)* 9 (g, n) * 3 (f, g)* 10 (d, h) * 4 (n, s) 10 (q, r) * 4 (c, d) 11 (a, b) * 5 (g, h) 12 (e, k) * 6 (s, t)* 12 (e, f) * 7 (c, g) 13 (n, p) * 7 (m, n) 14 (h, p) * 8 (f, m) 15 (r, s) * 8 (k, q) 15 (a, e) * 9 (p, t) 16
Procedendo con l’algoritmo di Prim e iniziando con il nodo in alto a sinistra, si aggregano gli archi nell ’ordine indicato dai numeri tra parentesi:
(1) (2)
(3) (14) (6) (10)
(4) (11) (13) (5) (12)
(7) (8) (9) (15)

48
4.3.5 Alberi di lunghezza minima e circuiti hamiltoniani.
La ricerca di alberi di lunghezza minima in una grafo nel quale si vuole risolvere il problema del circuito hamiltoniano più breve (TSP) ha un forte interesse perché varie tecniche, sia euristiche sia esatte, utili zzano appunto degli SST come punto di partenza per costruire la soluzione del TSP. In effetti, se da un circuito hamiltoniano si elimina un qualsiasi arco, si ottiene un albero di supporto (in altre parole, è un albero di supporto qualunque cammino hamiltoniano di un grafo). Non vale invece il viceversa perché, dato un SST, la aggiunta di un arco crea certamente un circuito, ma in questo sottografo di n archi vi saranno in generale nodi con grado maggiore di 2 (un circuito hamiltoniano, viceversa, ha tutti i nodi di grado esattamente 2). Rinviando ad un successivo paragrafo, la esposizione di tecniche che sfruttano le proprietà sopra descritte, osserviamo come il TSP si trovi in una posizione intermedia tra il problema di assegnazione AP e il problema dell ’albero di supporto di peso minimo, SST. Una soluzione di AP, vista come insieme di sottocircuiti ha come elemento favorevole il fatto che il grado di ogni nodo è 2, ma come elemento sfavorevole la non connessione dei sottocircuiti stessi. Invece, una soluzione di SST, integrata con un ulteriore arco per avere un circuito, in maniera simmetrica, ha la proprietà di connessione ma pecca per il fatto che alcuni nodi hanno grado inferiore o superiore a 2. È chiaro che due linee di ‘attacco’ per avere una soluzione del TSP sono costituite da: - soluzione di particolari adattamenti del problema AP in modo da forzare la presenza di un unico circuito (eliminando sottocircuiti e avere la connessione); - soluzione di problemi di SST e aggiunta opportuna di un arco, con espedienti per forzare il grado dei nodi, aff inché questo sia per tutti eguale a 2. Queste due filosofie diverse possono essere prese come base per costruire algoritmi di ricerca della soluzione ottima del TSP.

49
4.4 Modell i per problemi di percorso: modelli non vincolati.
4.4.1 Generalità.
I modelli di percorso ottimo su un grafo hanno un’evidente applicazione nell’ambito dei problemi di comunicazione e tr asporto. La terminologia adottata di modell i non vincolati si riferisce al fatto che il percorso ottimo che si vuole individuare, al di là dei punti iniziale e finale, non ha altra limitazione che l’uso di archi del grafo (seguendone l’orientamento). In s eguito si analizzeranno altri modelli nei quali vi sono anche obblighi di passaggio, per archi e/o per nodi, che comportano in genere un maggiore grado di diff icoltà nella soluzione. I l paradigma adottato più frequentemente è quello in cui la funzione oggetto deve essere minimizzata. Non mancano tuttavia dei casi in cui si ricerca il percorso più lungo: tutto dipende dal significato dei coeff icienti di peso degli archi (dei nodi) che, come già detto in precedenza, possono rappresentare sia dei costi o penalità (lunghezze fisiche, tempi di percorrenza) che guadagni. Se il grafo presenta archi di lunghezza negativa e si ha un problema di minimo, può non esistere la soluzione del problema (quando esistono circuiti di lunghezza negativa), mentre se il problema è di massimo diff icoltà sorgono con circuiti positivi: non vi sono difficoltà di sorta se il grafo è aciclico, cioè privo di circuiti. I classici problemi (modelli) di percorso ottimo (minimo) non vincolato sono quelli nei quali si vogliono determinare: - (a) il cammino minimo tra due nodi fissati u e v; - (b) i cammini minimi da un nodo u a tutti gli altri del grafo (albero dei cammini minimi di radice u); - (c) i cammini minimi tra tutte le coppie di nodi. Si osservi la differenza tra i due concetti di albero minimo o SST e albero dei cammini minimi di fissata radice. Si può costatare facilmente, su opportuni esempi, come in genere i due siano differenti.
4.4.2 I l cammino minimo tra due nodi e l’albero dei cammini minimi.
Le tecniche risolutive del problema (a), ricerca del cammino minimo tra due nodi fissati u e v, forniscono in genere, in tutto o in parte, anche l’albero dei cammini minimi di radice u, per cui dal punto di vista degli algoritmi risolutivi i due problemi (a) e (b) coincidono. Un procedimento ‘ad hoc’ per trovare il cammino più breve da u a v con archi di lunghezza non negativa è la risoluzione di un problema di programmazione intera a variabil i 0 - 1, come segue:

50
min Σ cij xij s.t.
Σk xuk = 1, Σk xki = Σk xik, per ogni nodo i ≠ u, v Σk xkv = 1, xi j ∈{0, 1}.
Per il generico arco (i, j), la variabile xij indica se l’arco stesso fa par te o meno del cammino. I vincoli esprimono che, mentre per i due nodi estremi u e v devono esservi, rispettivamente, un solo arco in uscita ed un solo arco in entrata, per gli altri nodi i l numero di archi entranti deve essere eguale al numero di archi uscenti (in pratica, o un solo arco o nessuno). L’albero dei cammini minimi da un nodo a tutti gli altri di un grafo G (orientato completo) è caratterizzato dal seguente Teorema: Sia T(r) un albero di supporto di G avente come radice r e, per ogni nodo v di G, sia d(v) la distanza di v da r misurata lungo T(r). Sia l(u, v) la lunghezza del generico arco (u, v) di G. Condizione necessaria e sufficiente affinché T(r) sia un albero dei cammini minimi di radice r è che per qualsiasi arco (u, v) di G valga la diseguaglianza:
d(v) ≤≤ d(u) + l(u, v) Si noti che, se da un lato nell ’enunciato non esistono condizioni sulla lunghezza degli archi, d’altra parte, poiché si parla di distanza tra r ed altri nodi si esclude la presenza di circuiti di lunghezza negativa. I l teorema appena enunciato è punto di partenza di vari algoritmi risolutivi che possono essere visti a loro volta come varianti della tecnica generale che segue:
- porre la distanza della radice da sé stessa pari a zero: d(r) = 0; porre la distanza di ogni altro nodo dalla radice pari a infinito: d(u) = + ∞ per ogni u∈V, u ≠ r;
- verificare la condizione d(v) ≤ d(u) + l(u, v) per ogni arco del grafo: se è sempre verificata, STOP; altrimenti correggere d(v) e ripetere la verifica per tutti gli archi.
Se vi sono circuiti di lunghezza negativa, un procedimento di questo tipo non si arresta mai: gli algoritmi effettivamente usati o richiedono la garanzia a priori che tali circuiti non esistono oppure sono tali da arrestarsi non appena un circuito negativo viene scoperto. Prima di esporre, nei prossimi paragrafi, algoritmi per cammini minimi, osserviamo che i problemi di percorso non vincolati sono banali se per le lunghezze degli archi vale la proprietà tr iangolare, cioè se per ogni terna di nodi u, v, w si ha:
l(u, w) ≤ l(u, v) + l(v, w) che, viceversa, è verificata in parecchie circostanze concrete nelle quali però si tratta di determinare percorsi con passaggi obbligati (ad es., hamiltoniani o euleriani).

51
Infine va osservato che la diff icoltà dei problemi non vincolati è minore rispetto a quelli con obblighi di transito: i problemi (a), (b) e (c) sono facil i (di classe P), mentre in genere quell i con vincoli sono NP-completi.
4.4.3 L’algoritmo di Dijkstra.
Si applica quando le lunghezze di tutti gli archi sono numeri non negativi. È una procedura nella quale ai nodi vengono attribuite delle etichette, modificabil i nel corso dell ’algoritmo, che indicano la lunghezza del cammino più breve trovato sino a quel momento dalla radice r al nodo in questione. L’etichetta del generico nodo v contiene due elementi: la distanza più breve sinora trovata da u a v e il penultimo nodo del percorso corrispondente. Pertanto essa assume la forma:
(d(v), j)
dove d(v) è la distanza del nodo v dalla radice r e j è il penultimo nodo del percorso di lunghezza d(v) da r a v, individuato sino al momento. Le etichette vengono distinte in provvisorie e definitive: un’etichetta è provvisoria finché è ancora potenzialmente migliorabile, mentre diventa definitiva quando si è certi che la lunghezza in essa contenuta è minima. L’algoritmo consiste nei passi seguenti:
- Passo 1. Porre d(r) = (0, r); d(v) = (+ ∞, r) per ogni v ≠ r. Dichiarare definitiva l’etichetta di r e provvisorie tutte le altre. Andare al passo 2.
- Passo 2. Detto w l’ultimo vertice la cui etichetta è stata dichiarata definitiva, si
considerino tutti gli archi (w, v) uscenti da w e si aggiornino le etichette degli estremi v di questi archi sulla base della formula: d’(v) = min {d(v); d(w) + l(w,v)}, dove d’(v) rappresenta la nuova distanza. Se d’(v) = d(v), cioè se la distanza più breve rimane la precedente, l’etichetta non varia, mentre se d’(v) < d(v), cambiare l’etichetta in (d’(v), w). Andare al passo 3.
- Passo 3. Individuare tra tutti i vertici a etichetta provvisoria il vertice v per cui
d(v) è minima e dichiarare la sua etichetta definitiva. Se tutte le etichette sono definitive, STOP. Altrimenti tornare al passo 2.
Si noti che i percorsi di lunghezza minima dal nodo radice r agli altri nodi vengono
individuati in ordine di distanza crescente.

52
Per illustrare l’algoritmo si consideri il grafo della figura che segue. w 7 z 8 5 u 1 4 2 s 5 3 7 v t
Si vuole individuare un albero dei cammini minimi di radice u. Le etichette da attribuire ai vari nodi si possono organizzare in una tabella, come
segue.
u v w z t s (passo 1) (0, u)* (+∞,u) (+∞,u) (+∞,u) (+∞,u) (+∞,u)
(passi 2 e 3) (5, u)* (8, u) (+∞,u) (+∞,u) (+∞,u) (id.) (6, v)* (+∞,u) (12, v) (+∞,u) (id.) (13, w) (10,w)* (+∞,u) (id.) (12, t)* (13, t) (id.) (13, t)*
STOP L’albero dei percorsi minimi è quello della figura che segue:
w z u 1 4 2 s 5 3 v t
Per individuare quest’albero, si utilizzano le indicazioni delle etichette. L’algoritmo di Dijkstra presenta strette analogie con l’algoritmo di Prim, sia come struttura sia come complessità computazionale, che è, anche in questo caso, dell ’ordine di n2.

53
4.4.4 I percorsi minimi tra tutte le coppie di nodi: l’algoritmo di Floyd.
In presenza di archi di lunghezza negativa si può calcolare la matrice delle distanze relativa ad un grafo G, e parallelamente tutti gli alberi dei cammini minimi aventi radice in ciascun nodo, con una tecnica detta algoritmo di Floyd. La matrice delle distanze, in effetti, è uno strumento utile da un punto di vista operativo in diverse situazioni, sia in problematiche di trasporto che in molti altri problemi tipici della Ricerca Operativa.
L’algor itmo, applicato ad un grafo (fortemente connesso) di n nodi, opera aggiornando la matrice delle lunghezze degli archi in n iterazioni successive.
Parallelamente, si possono costruire altrettante matrici i cui generici elementi indicano dei nodi, l’ultima delle quali , in ogni riga, fornisce l’albero dei cammini minimi avente per radice il nodo associato alla riga stessa. Come detto all ’inizio, la tecnica può essere utilizzata anche con archi di lunghezza l(u ,v) < 0, nel qual caso, con elementari accorgimenti che non alterano la complessità, viene segnalata anche l’eventuale presenza in G di circuiti di lunghezza negativa. Prima di procedere con la presentazione dell’algoritmo, ipotizziamo che G contenga n nodi, che indicheremo con i numeri interi da 1 a n, e che L rappresenti la matrice delle lunghezze degli archi. A partire da L si costruiscono n matrici, che diremo C1, C2, …, C n. Per uniformità di notazioni, poniamo L = C0. Costruiamo poi altre n+1 matrici quadrate di ordine n, Q0, Q1, Q2, …, Q n, la prima delle quali è definita come:
��� ���� ��colonne
0
n...nnn
...............
3...333
2...222
1...111
Q
n
=
mentre le successive sono aggiornamenti progressivi di Q0. L’algoritmo consiste in n iterazioni: nella generica, k -esima (k=1, 2, …, n), avendo a disposizione Ck-1 e Qk-1, si costruiscono le matrici Ck e Qk. I l generico elemento, che diremo ck
ij, della matrice Ck è dato da
ckij = min { ck-1
ij; ck-1
ik + ck-1kj}.
Ad esempio la costruzione di C1, a partire da C0, si effettua fissando in C0 la prima
riga e la prima colonna. Per ogni altra riga i e colonna j per trovare l’elemento nella
generica posizione (i, j) si calcola la somma 01
01 ji cc + : se questa somma è inferiore al
valore 0ijc allora 0
101
1jiij ccc += (in C1 l’elemento viene aggiornato sostituendolo con la
somma appena calcolata); in caso contrario 01ijij cc = (l’elemento quindi resta invariato).

54
I l generico elemento qkij di Qk coincide con quello di Qk-1, cioè con qk-1
ij, se risulta ck
ij = ck-1ij, mentre in caso contrario, cioè se ck
ij < ck-1ij, si pone
qk
ij = qk-1kj.
L’algoritmo è assai semplice (bastano poche istruzioni per programmarlo). È relativamente più laborioso dimostrare che esso fornisce effettivamente le distanze minime ed i percorsi più brevi tra tutte le coppie di vertici. Inizialmente, la matrice C0 contiene le lunghezze degli archi: esse costituiscono le distanze minime se s’impone che per andare da un vertice ad un qualsiasi altro non si possa passare per alcun altro vertice intermedio. La matrice Q0, viceversa, esprime il fatto che nel percorso sin qui determinato da un vertice i al vertice j, formato da un solo arco, il penultimo vertice prima di j è, inevitabilmente, i. Con la prima iterazione si verifica se convenga o no, per andare dal generico vertice i al generico vertice j, utilizzare come nodo intermedio di passaggio il nodo 1. Con l’iterazione generica, k -esima, si verifica se per andare da i a j, oltre a poter utilizzare come nodi intermedi i nodi 1, 2, …, k -1, conviene utilizzare, sempre come nodo intermedio, anche il nodo k. Può nascere il dubbio che così facendo, si sia condizionati dall ’ordine con cui s’inseriscono le possibil ità intermedie di transito per i vari nodi del grafo. In realtà, così non è: chiariamo quest’affermazione con un esempio. Si supponga che in un grafo G di 9 nodi il cammino più breve per andare dal nodo 4 al nodo 7 sia il seguente:
4 → 5 → 1 → 8 → 7.
Premettiamo un’osservazione: ogni sottocammino del cammino minimo tra due nodi costituisce a sua volta il percorso ottimo tra i nodi estremi del sottocammino. In altre parole, posto che il cammino minimo dal nodo 4 al nodo 7 sia quello descritto, allora si può anche affermare che il cammino più breve da 5 a 8 è 5 → 1 → 8, e così via. L’algoritmo in pratica identifica (e costruisce) il percor so in questione come segue:
- al passo 1, si constata come per andare da 5 a 8 non conviene l’arco (5, 8), ma conviene invece passare per il nodo 1;
- al passo 5, si vede come per andare da 4 a 8 il cammino più breve è quello che
utilizza come nodo intermedio il nodo 5 (da 5 a 8 le cose sono già state assestate, come si è visto, in precedenza);
- al passo 8 si evidenzia come per andare da 4 a 7 conviene passare per 8 (ma,
anche in questo caso, si deve osservare che il percorso da 4 a 8 è stato definito in precedenza come un cammino che utilizza a sua volta anche i nodi 1 e 5).
Nella matrice Q9, che è quella finale degli alberi dei cammini minimi, sulla quarta
riga si legge come predecessore di 7 nel cammino minimo da 4 a 7 sia il nodo 8; predecessore del nodo 8 nel cammino minimo da 4 a 8 è il nodo 1; predecessore di 1 è 5 ed infine predecessore di 5 è 4. Questo consente di ricostruire tutto il cammino da 4 a 7.

55
La quarta riga assume in altre parole l’aspetto:
colonne → 1 2 3 4 5 6 7 8 9 … … … … … … … … …
riga 4a 5 … … … 4 … 8 1 … … … … … … … … … …
L’aggiornamento delle matrici Q si giustifica osservando che, quando si riconosce che per andare da i a j conviene inserire come passaggio intermedio il nodo k, allora:
i → … → j diventa i → … → k → … → j, e quindi il penultimo nodo nel percorso da i a j diviene quello che si è trovato (sinora) nel percorso più breve da k a j. Questo comporta la sostituzione
qij → qkj. In presenza di archi di lunghezza negativa, l’aggiornamento degli elementi sulla diagonale delle matrici C segnala l’eventuale presenza di circuiti di lunghezza negativa: non appena per qualche k risulta ck
ii < 0, allora il procedimento può essere arrestato. In tal caso la matrice Q degli alberi dei cammini minimi perde di significato. Prima di proporre un esempio applicativo, osserviamo che se gli archi hanno tutti lunghezza non negativa, si può evitare di aggiornare gli elementi sulla diagonale principale delle matrici C (questi possono essere posti eguali a 0, o anche, se si vuole evidenziare che non vi sono loop, eguali ad un valore arbitrariamente grande M, significativo del fatto che l’arco non esiste).
Se invece vi sono archi di lunghezza negativa, gli elementi sulla diagonale devono essere aggiornati, a prescindere dal valore che è stato loro attribuito inizialmente in C0. Si consideri il seguente esempio. È dato il grafo in figura 2 10 15 40 20 1 30 3 8 2 4 Le matrici C e Q risultano le seguenti:

56
C0 C1 C2 C3 C4 0 10 30 M 0 10 30 M 0 10 25* 30* 0 10 25 27* 0 10 25 27 40 0 15 20 40 0 15 20 40 0 15 20 40 0 15 17* 25* 0 15 17 M M 0 2 M M 0 2 M M 0 2 M M 0 2 10* 20* 0 2 8 M M 0 8 18* 38* 0 8 18 33* 0 8 18 33 0 8 18 33 0
Q0 Q1 Q2 Q3 Q4 1 1 1 1 1 1 1 1 1 1 2* 2* 1 1 2 3* 1 1 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3* 4* 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4* 1* 3 3 4 4 4 4 4 1* 1* 4 4 1 2* 4 4 1 2 4 4 1 2 4 L’algoritmo di Floyd, in un grafo di n nodi, richiede, come si è visto, n iterazioni, in ciascuna delle quali si aggiornano tutti gli n2 elementi di una opportuna matrice C. Ogni aggiornamento richiede una somma ed un confronto, per cui complessivamente le operazioni sono 2·n3, e quindi la complessità è O(n3). Ai fini del calcolo della complessità, l’aggiornamento della matrice Q può essere trascurato, perché effettuato sulla base degli stessi confronti che si compiono per la matrice C.

57
4.5 I l problema del commesso viaggiatore, TSP.
4.5.1 Generalità.
I l problema del commesso viaggiatore, noto anche con la sigla TSP, Travell ing Salesman Problem, consiste nella determinazione del circuito hamiltoniano di lunghezza minima, vale a dire, del circuito più corto che, in un grafo completo ad archi pesati, attraversa tutti i nodi, passando per ciascuno una ed una sola volta.
I l problema può essere studiato anche su un grafo non completo, ma evidentemente
in tal caso occorre che sia garantita l’esistenza di (almeno) un circuito hamiltoniano. A sua volta, l’esistenza di tale circuito è un problema, detto CH, studiato a fondo nella teoria dei grafi, ma non completamente risolto, nel senso che si conoscono varie condizioni sufficienti affinché un grafo contenga un tale circuito, ma non sono note condizioni che siano al tempo stesso suff icienti e anche necessarie. Si può dimostrare che la ricerca di un circuito hamiltoniano in un grafo non completo è un problema diff icile, per la cui risoluzione esistono tecniche non polinomiali.
I l TSP deve la sua denominazione al caso ipotetico di un agente di commercio che,
dovendo visitare una certa clientela con il minimo costo di viaggio, è interessato ad individuare l’ordine di visita che comporti la lunghezza più breve del percorso complessivo. Tuttavia lo stesso problema si presenta in altre situazioni, che non sono propriamente di organizzazione di percorsi.
Nella formulazione del TSP non compaiono altri vincoli particolari, che si
presentano invece nella maggior parte dei casi reali , quali tempi obbligati per le varie visite o vincoli di capacità per i carichi da trasportare verso o da i clienti, per cui potrebbero essere necessari più agenti o più circuiti dello stesso agente, per completare le visite. Pertanto, come modello, è relativamente semplice e un po’ lontano da molte realtà.
Tuttavia il TSP è un problema difficile, risolubile per dimensioni limitate delle istanze. In pratica, si riescono a risolvere in maniera esatta istanze con un numero di nodi dell ’ordine delle centinaia (poche centinaia!). In alternativa esistono numerose tecniche approssimate.
In quest’esposizione, dopo aver discusso il problema di esistenza CH, sarà descritta la impostazione del TSP come problema di programmazione intera, per metterne in evidenza i collegamenti con l’AP.
4.5.2 La ricerca di un circuito hamiltoniano in un grafo.
La determinazione di un circuito hamiltoniano in un grafo, problema NP-completo può essere affrontata con l’algoritmo di Robert e Flores, tecnica di enumerazione implicita, che nel worst case ha complessità esponenziale.
In linea di principio, per individuare se in un grafo G di n nodi esiste un circuito
hamiltoniano, si può pensare di compilare l' elenco di tutte le n! permutazioni dei nodi stessi e verificare se ciascuna di esse corrisponde o meno ad un circuito: in pratica, per

58
ognuna di queste, come (a, b, c, d, …, n) , si tratta di vedere se esistono gli archi (a, b), (b, c), (c, d) e così via, sino ad (n, a). Il procedimento, all ’atto pratico, non è utilizzabile, per il numero di verifiche da effettuare, ingestibile non appena il numero di nodi superi la decina. La tecnica di Robert Flores riduce il numero delle verifiche in questione sulla base di un’osservazione molto semplice, per non dire banale: se in G non esiste un arco, poniamo sia l’arco (c, d), non è il caso di fare verifiche sulle permutazioni che contengono i nodi c, d in successione e quindi, tutte le permutazioni che contengono (…, c, d, …) possono essere scartate in blocco. In altre parole, la tecnica analizza solo permutazioni (o parti di permutazione) che corrispondano ad archi effettivamente esistenti.
L’algoritmo utilizza la rappresentazione del grafo mediante una lista di adiacenze
(cioè una tabella nella quale sono elencati, in corrispondenza a ciascun nodo v, i successori di v se G è orientato o i nodi adiacenti a v se G è non orientato), che supporremo organizzata su colonne: ogni colonna si riferisce ad un nodo.
Passo 1: scegliere un vertice iniziale v e porre S = {v}. Passo 2: sulla colonna dell’ultimo vertice inserito in S, scegliere un vertice che non
stia ancora in S e inserirvelo; se un vertice di questo tipo non esiste andare al passo 3; se esiste, ripetere il passo 2;
Passo 3: se S contiene n vertici, si è trovato un cammino hamiltoniano; se esiste l’arco tra l’ultimo nodo inserito in S ed il nodo v, esiste anche un circuito hamiltoniano (STOP); se S contiene meno di n vertici oppure se non si è trovato un circuito, andare al passo 4;
Passo 4: detti w e u, rispettivamente, il penultimo e l’ultimo dei nodi inseriti in S, cioè avendo S = {…, w, u }, togliere da S il nodo u e cercare nella colonna di w un altro vertice non ancora inserito in S, diverso da u; se tale operazione è possibile, ripetere il Passo 2; se l’operazione non è possibile, eliminare u e ripetere il passo 4; se S rimane vuoto, non esistono circuiti hamiltoniani.
Si noti che al Passo 2 converrà adoperare un certo ordine nella scelta dell ’elemento
da inserire in S. La regola più semplice potrebbe essere quello di seguire l’ordine con cui di fatto sono elencati i nodi nella lista di adiacenza.
I l procedimento consiste essenzialmente di due fasi che si alternano: una di
accrescimento di un cammino che tocca i nodi di G, senza ripetizioni, cercando di raggiungerne il maggior numero possibile (passo 2), ed una (detta di backtracking) di cancellazione di parte del cammino sinora costruito (passo 4), perché non ha dato buon risultato, allo scopo di ripartire in un’altra direzione, ancora con la prima fase.
L’algoritmo (che ha complessità esponenziale) riesce a trattare solo grafi con
qualche decina di nodi. Può essere accelerato con accorgimenti basati sull’analisi delle adiacenze tra nodi.
Consideriamo il seguente esempio. È dato il grafo nella figura di sinistra, mentre a
destra compare la lista di adiacenza relativa.

59
b c a b c d e f
- - - - - - - - - - - - - - - - - - a d b c a c c a
- e d f d b - - - - - c
e f Si inseriscono successivamente in S i nodi a, b, c. Dopo il nodo c, si deve scegliere d (perché a fa già parte di S); quindi il nodo f (il nodo c fa anch’esso già parte di S). A questo punto, S = {a, b, c, d, f}, ma non si può proseguire in quanto i successori di f sono i nodi a, b, c, tutti già inseriti in S, mentre S non contiene ancora tutti i nodi. Si deve quindi andare al Passo 4 e procedere con il backtracking: si eliminano successivamente f, d, c, sempre perché da nessuno di essi è possibile effettuare altre scelte, oltre a quelle già viste. Si può però ripartire dal nodo b, perché da esso è possibile scegliere l’altro nodo, e. Si aggiungono adesso, nell’ordine, c, d, f, così S = {a, b, e, c, d, f}. Poiché esiste l’arco (f, a), si è individuato un circuito hamiltoniano. Volendo, si può effettuare un’altra fase di backtracking, per cercare altri circuiti hamiltoniani (nel caso in questione, il circuito trovato non è unico: se ne individua un secondo).
La successione delle operazioni, ipotizzando di partire dal vertice a, può essere schematizzata nelle liste seguenti (che rappresentano gli elementi dell ’insieme S nelle varie fasi). a a b a b c a b c d a b c d f a b c d a b c a b a b e a b e c a b e c d a b e c d f (cammino hamiltoniano) (a b e c d f a → circuito hamiltoniano) a b e c d a b e c a b e a b e d a b e d f a b e d f c (secondo cammino hamiltoniano) (a b e d f c a → secondo circuito hamiltoniano). Continuando ancora si scoprirebbe che non ci sono altri circuiti, perché la fase di backtracking porterebbe ad un insieme S vuoto.

60
4.5.3 Il TSP come problema di programmazione intera.
I l Problema del Commesso Viaggiatore può essere formulato come problema di programmazione intera assumendo come dato in input una matrice quadrata C, il cui generico elemento cij indica la lunghezza dell’arco (i, j), e come variabile di decisione un vettore di variabil i booleane xij, la generica delle quali assume il valore 1 se l’arco corrispondente (i, j) fa parte di una soluzione ammissibile del problema (vale a dire, di un circuito hamiltoniano), mentre vale 0 in caso contrario.
La funzione oggetto consiste nella minimizzazione della somma delle lunghezze degli archi usati per costruire il circuito. I vincoli impongono che:
- (a) per ogni nodo si usino due archi, uno entrante ed uno uscente dal nodo stesso; - (b) il percorso, che comprende tutti i nodi, costituisca un unico circuito. La proprietà (b) non è conseguenza della proprietà (a). Quest’ultima, da sola, lascia aperta la possibil ità che la soluzione consista in più sottocircuiti.
È opportuno che nella matrice C si ponga cii = +∞. Questo evita che nella soluzione
possano comparire i sottocircuiti costituiti da singoli loop. I l Problema del Commesso Viaggiatore si può scrivere come:
min Σ cij xi j
con i vincoli Σj xij = 1, per ogni i; Σi xij = 1, per ogni j;
x ∈ S, e i vincoli d’interezza
xi j ∈ {0, 1}.
I primi due insiemi di vincoli impongono la proprietà (a), e cioè che nella soluzione il grado di ogni nodo sia 2. La scrittura ‘x ∈ S’ è, invece, un modo puramente formale di esprimere il requisito (b): ogni soluzione deve consistere in un unico circuito. Vi sono infine le condizioni d’interezza delle variabil i, che devono assumere solo uno dei due valori, 0 o 1.
Se si prescinde dai vincoli che vietano i sottocircuiti, la formulazione del TSP coincide con quella del Problema di Assegnazione: questo è un fatto importante che sta alla base di alcune procedure risolutive.
Vi sono più modi di imporre, con opportuni vincoli, che nella soluzione non vi siano sottocircuiti. Alcune di queste impostazioni rivestono particolare interesse perché è seguendo la loro logica che si costruiscono certe procedure risolutive (esatte). Una prima tecnica è quella di considerare tutte le partizioni dei nodi di V in due sottoinsiemi non vuoti, A e V-A, e di richiedere che per ogni partizione i due sottoinsiemi siano connessi da almeno un arco:
Σ i∈A Σ j∈V-A xij ≥ 1.

61
Vi sono 2n-1 – 1 vincoli di questo tipo: i sottoinsiemi di V sono in numero di 2n, ma occorre anche tenere conto del fatto che, per ogni A, le coppie (A, V-A) e (V-A, A) sono equivalenti per i nostri scopi e che inoltre occorre escludere la coppia (V, ∅) e la sua simmetrica. Un secondo modo si basa sul fatto che, se esiste un sottoinsieme A ⊆ V di cardinalità k e vi sono k archi che collegano nodi di A, allora tra i nodi di A stesso esiste (almeno) un sottocircuito. S’impone all ora che
Σ i∈A Σ j∈A xij ≤ k-1, per ogni sottoinsieme proprio e non vuoto A dell ’insieme V di tutti i nodi tale che |A|=k. I vincoli di questo tipo sono 2n – 1, tanti quanti i sottoinsiemi non vuoti di V. Si possono giustificare anche osservando che, se tra i k nodi dell’insieme A vi sono al più k-1 archi, allora certamente qualche nodo di A è adiacente, nella soluzione, ad un nodo in V-A. Vi sono ancora altre tecniche di esclusione dei sottocircuiti, per le quali rinviamo alla letteratura.
Come già osservato in precedenza, è il caso di ripetere che il Problema del
Commesso Viaggiatore, TSP, limitatamente ai vincoli i ndicati sopra esplicitamente, coincide con quello di Assegnazione, AP, e questo è appunto alla base di alcune delle tecniche risolutive esatte che si trovano in letteratura.
4.5.4 Tecniche approssimate per la r isoluzione del TSP: generalità.
Le tecniche approssimate per la risoluzione del TSP si possono suddividere in varie classi, non del tutto esaustive nel senso che alcuni procedimenti sfuggono a questa classificazione, potendosi considerare trasversali .
Si distinguono fondamentalmente algoritmi di tipo tour building e algoritmi di tipo tour improvement: nei primi si costruisce passo passo la soluzione, mentre nei secondi si migliora una soluzione preesistente (che può essere a sua volta ottenuta con una tecnica ‘ tour building’).
Vi è una vasta letteratura sull ’argomento. Le tecniche euristiche sono da valutare da due punti di vista: la loro complessità
computazionale (che in ogni modo ha senso solo se polinomiale) e la prestazione, sia nel caso medio sia nel caso peggiore. Sovente l’analisi del worst case dà risultati deludenti: sono numerosi i casi di errori percentuali , rispetto al valore corrispondente alla soluzione ottima, molto elevati, dell’ordine del 100% o 200% e più. Si tratta però di capire anche se le istanze particolari che si studiano non presentino caratteristiche tali da indurre a ritenere che si sia lontani dalle prestazioni del worst case.
Nei paragrafi che seguono viene dapprima discussa, assieme alla cosiddetta proprietà triangolare, la problematica della valutazione delle tecniche euristiche. Vengono quindi accennate alcune di tali procedure, che costituiscono oramai un ‘classico’ in materia di soluzione di TSP. Infine viene presentata con maggior grado di dettaglio l’euristica che garantisce, sempre nel worst case, l’errore percentuale minore.

62
4.5.5 La proprietà tr iangolare e la valutazione di un’euristica.
Un elemento spesso presente nelle analisi delle procedure risolutive per problemi di percorso ottimo è l’ipotesi che le lunghezze degli archi soddisfino la proprietà tr iangolare. Questa vale se, per ogni terna di nodi u, v, w, si ha:
cuv ≤ cuw + cwv,
e quindi se il percorso più breve tra due nodi è costituito dall ’arco che l i collega.
Se un grafo non è completo, ovviamente, la proprietà triangolare non può essere soddisfatta, anche se essa può essere introdotta apportando al grafo stesso modifiche opportune, che non alterano la soluzione di problemi di interesse pratico. Una situazione in cui ci si trova ad effettuare questa operazione si ha quando in un grafo si vuole individuare un circuito di lunghezza minima che passi per ogni nodo almeno una volta, piuttosto che esattamente una volta. Questo problema costituisce una variante particolare del TSP, che si presenta con una certa frequenza nelle applicazioni di logistica distributiva. In effetti, un mezzo che distribuisce della merce con il vincolo di visitare tutti i clienti, e con l’obiettivo di minimizzare la distanza percorsa, ripassa anche per lo stesso nodo più volte, se questo gli consente di abbreviare il cammino (può addirittura essere costretto a farlo, se il grafo non è hamiltoniano).
Si può ad ogni modo fare rientrare facilmente questo caso nello schema tipico del TSP: basta inserire tra ogni coppia di nodi non adiacenti un nuovo arco fittizio, di lunghezza eguale a quella del cammino di lunghezza minima tra i nodi stessi. In questo modo si conseguono contemporaneamente vari obiettivi: da un lato il grafo diventa completo, e si possono applicare quindi le tecniche tipiche per ottenere la soluzione del Problema del Commesso Viaggiatore e in secondo luogo il grafo acquista la proprietà triangolare, con tutte le implicazioni sulla approssimazione della soluzione ottenuta che si vedranno in seguito.
Più in generale, in grafi completi, si può ottenere la proprietà triangolare con l’espediente di sostituire ad eventuali archi (u, v) che non la soddisfano un solo arco di lunghezza eguale a quella del cammino più breve da u a v.
Si osservi infine che la proprietà può essere ottenuta forzatamente anche con l’espediente di aggiungere al costo di tutti gli archi una costante K sufficientemente elevata. In questo modo la soluzione ottima di problemi che richiedano un numero fissato di archi (come in TSP) rimane invariata (perché tutte le soluzioni ammissibili sono penalizzate allo stesso modo), mentre d’altra parte, se per qualche terna di nodi, prima della introduzione della costante additiva, risultava
cuv ≥ cuw + cwv ,
in seguito all ’aggiunta di un K > 0 e sufficientemente grande si ha:
cuv + K ≤ cuw + cwv + 2*K. La valutazione della differenza tra il valore zeur, che indica il valore della funzione oggetto ottenuto con la soluzione restituita da una procedura euristica, e il valore ottimo vero e proprio z* è un elemento di evidente interesse. Tale grado di approssimazione è spesso collegato al fatto che valga o no la proprietà triangolare di cui si è detto.

63
La maniera più ovvia di valutare l’efficacia di una tecnica di soluzione approssimata è quella di calcolare lo scarto relativo tra zeur e z* . Questo chiaramente non è possibile se non si dispone della stessa soluzione ottima, cosa a sua volta ragionevole solo su problemi test di piccole dimensioni. Per problemi di interesse concreto, si riesce spesso a definire dei confini sui margini di errore, e si parlerà quindi di errore non superiore ad un fissato ammontare. L’impostazione merita comunque una serie di precisazioni.
L’indice accennato poco sopra è dato, in formule, dal rapporto
r = (zeur - z* ) / z*
Occorre però tenere presente che il modello TSP si applica anche a casi nei quali i costi degli archi non hanno limitazioni di segno, e quindi potrebbero anche essere dei numeri negativi. A sua volta la lunghezza del circuito minimo potrebbe essere un numero di segno qualsiasi, se non addirittura zero! L’indice appena introdotto potrebbe perdere di significato o non essere definito.
Si può allora preferire ad r un indicatore che non dipenda dal segno delle lunghezze degli archi come il seguente:
e = (zeur - z* ) / (zmax – z*),
dove zmax indica la lunghezza del circuito di lunghezza massima. Questo rapporto esprime di quanto si scosta la soluzione trovata rispetto a quella ottima in una scala che assume come unità di misura la differenza tra la lunghezza del circuito più lungo e di quello minimo. È facile constatare come il rapporto in questione non risenta della introduzione di costanti additive come quelle cui si è accennato sopra ed è quindi più ‘neutrale’ rispet to alla proprietà triangolare. Naturalmente, anche per l’indicatore “ e” valgono considerazioni analoghe a quelle espresse in precedenza, e cioè che esso richiede la conoscenza sia della soluzione ottima sia della lunghezza del circuito peggiore ottenibile.
4.5.6 Le euristiche per il TSP.
Una delle più note procedure euristiche di tipo costruttivo è probabilmente quella del nodo più vicino: fissato un nodo u, si individua l’arco più corto uscente da u, e questo costituisce il nucleo iniziale di un cammino che viene allungato progressivamente aggregandogli l ’arco più corto che esce dall’ultimo nodo raggiunto. Quando sono stati inglobati tutti i nodi, si aggiunge l’arco che congiunge l’ultimo nodo a quello di partenza. Si tratta di un procedimento miope, in quanto si sceglie sempre l’arco più corto immediatamente disponibile, senza però tenere conto delle implicazioni future di tale scelta.
In particolare, è evidente che può facilmente capitare di perdere gran parte dei vantaggi conseguiti con le scelte degli archi più corti quando si tratta di tornare dall ’ultimo nodo a quello di partenza. Inoltre, può capitare facilmente di lasciare al di fuori del

64
percorso parziale nodi periferici che si visitano alla fine con una specie di ‘ recupero’ a sua volta relativamente costoso.
Una altra categoria di procedure, sempre di tipo costruttivo, prevede di ampliare un (sotto)circuito iniziale interponendo, tra due nodi adiacenti del circuito, un nodo non ancora visitato. Si parla appunto di tecniche di inserimento. Gli elementi che contraddistinguono le tecniche una dall’altra sono i criteri di scelta della coppia tra cui effettuare l’inserimento di un nuovo nodo ed il nodo stesso da inserire. Occorre in altre parole decidere ad ogni passo sia il nodo da inserire, sia la coppia di nodi adiacenti dove effettuare l’operazione di ampliamento del circuito. Si possono sfruttare in queste circostanze, per ottimizzare le scelte, particolari proprietà del grafo su cui si lavora: ad es., se le distanze sono euclidee (e gli archi rappresentano percorsi in linea retta) si può dimostrare che il percorso ottimo non può prevedere che due archi si incrocino al di fuori di un nodo e così via.
Tra le procedure di miglioramento figura la tecnica degli scambi di Lin e Kernighan, che suggerisce, dato un circuito, ovvero una permutazione dell’insieme dei nodi, di effettuare su quest’ultima delle variazioni equivalenti allo scambio di alcuni archi del circuito con altri che non ne fanno parte, in modo da diminuire la lunghezza complessiva.
La tecnica può essere usata limitandosi ad eliminare dal circuito due archi, per sostituirli con altri due, ma si può procedere all ’eliminazione e sostituzione di un numero di archi maggiore: quanto più elevato è il numero di archi che sono sostituiti, tanto più si ha la possibilità di ottenere la soluzione ottima o una soluzione più vicina all’ottimo, ma contemporaneamente cresce la complessità computazionale dell’algoritmo, aumentando sia le combinazioni del numero degli archi da eliminare che le combinazioni degli archi da inserire.
Una variante della procedura di scambio prevede che non si fissi a priori il numero di archi scartati e sostituiti, ma che questo parametro sia una conseguenza di valutazioni progressive effettuate sulla funzione oggetto: a mano a mano che si eliminano e sostituiscono archi, si valuta se conviene individuare un altro arco da scartare o se fermarsi e chiudere il circuito.
È il caso di osservare che con le tecniche di scambio assume rilievo la circostanza
della tipologia del grafo, se orientato o no. In effetti, la sostituzione di due archi con altri due in un circuito che comprenda tutti i nodi provoca spesso un’inversione nell’ordine con cui un certo insieme di nodi viene visitato. Questo non crea problemi, se il grafo è non orientato, viceversa va gestito con attenzione. La cosa ha particolare rilevanza se, come si vedrà in modell i più elaborati, subentrano fattori temporali, in particolare indicazioni su periodi nei quali i clienti vanno visitati.
Tecnica difficilmente catalogabile, ma che è stata sperimentata largamente con
buoni risultati e numerose varianti, è quella detta dei savings o dei risparmi, spesso applicata anche al Vehicle Routing Problem (vedi oltre il paragrafo 4.6.2).
Per introdurre il concetto di risparmio, occorre definire innanzitutto nel grafo G un nodo che sarà detto deposito D dal quale (convenzionalmente) si parte per procedere alla visita dei restanti n-1 nodi separatamente, con n-1 viaggi di andata e ritorno dal deposito stesso.
La scelta del deposito, nella risoluzione di un TSP, può essere arbitraria. Non lo è
più quando nell ’impostazione del problema si deve individuare un nodo che funge proprio

65
da punto obbligato da cui devono partire e nel quale devono rientrare diversi mezzi per effettuare non più un unico circuito, ma un insieme di sottocircuiti che complessivamente ricoprano tutti i nodi.
È evidente che per molte coppie di nodi è più conveniente comprendere i due nodi
stessi in un unico (sotto)circuito piuttosto che visitarli ciascuno per conto proprio. Si definisce risparmio sij, appunto, quanto si guadagna dal visitare due fissati nodi i e j con un unico percorso, che partendo dal deposito visiti prima i e poi j, anziché separatamente:
sij = ciD + cDj - cij,
come si può vedere dalla figura che segue: i D j La tecnica prevede di costruire un percorso, che transiti per il deposito una sola volta, riunendo progressivamente i sottocircuiti, a partire da quelle aggregazioni che comportano i risparmi più elevati.
Una volta effettuata un’aggregazione, cioè dopo aver riunito due nodi i e j in un unico circuito, occorre procedere all ’aggiornamento dell ’elenco dei risparmi, perché, un sottocircuito può essere ampliato solo inserendo un nodo tra il deposito ed il primo nodo visitato oppure tra l’ultimo nodo ed il deposito mentre due sottocircuiti vengono riuniti solo cancellandone il primo e/o l’ultimo arco (vedi la figura che segue).
i j
D
4.5.7 Euristiche basate sulla costruzione di SST: la tecnica di Christofides.
È già stato osservato in precedenza come un possibile approccio alla soluzione del TSP sia quello di costruire un albero di supporto di lunghezza minima del grafo, cioè un SST, e di trasformarlo in un circuito in maniera opportuna. In effetti, sono stati proposti, tra gli altri, due algoritmi euristici che si basano su questa filosofia, algoritmi che si possono concepire logicamente in successione, nel senso che la seconda tecnica, dovuta a

66
Christofides, può essere vista come un raffinamento della prima. L’algoritmo di Christofides, poi, è di notevole interesse in quanto, attualmente, tra tutte le tecniche approssimate, è quella che – in un grafo dove valga la proprietà triangolare - garantisce il minore errore relativo, errore che è, nel caso peggiore, non superiore al 50% della lunghezza del percorso ottimo (in genere assai inferiore nei casi concreti). Viceversa, la prima tecnica che sarà presentata garantisce un errore relativo al più del 100%, cioè nel caso peggiore si può individuare un circuito che è lungo il doppio di quello ottimale, ma, giova ripetere, si tratta anche qui del caso peggiore. Proprio perché si parte da un SST, si tratta in entrambi i casi di algoritmi ideati originariamente per TSP su grafi non orientati (o per TSP simmetrici): è possibile tuttavia adattarli al caso di grafi orientati, come verrà detto più avanti.
Le due tecniche differiscono per il modo con cui, partendo dall ’SST, si ricava un circuito. Si basano entrambe sul fatto che il circuito ottimale del TSP, privato di un arco, diventa un cammino che è anche un albero di supporto del grafo poiché non ha circuiti e contiene tutti i vertici del grafo stesso. Si tratta comunque di un albero particolare in quanto in esso tutti i nodi hanno grado due, tranne un paio di grado 1. L’idea di fondo è allora quella di costruire un albero di supporto di lunghezza minima (che in generale non è un cammino, avendo alcuni nodi di grado superiore a due) e trasformarlo in un circuito hamiltoniano, con opportuni accorgimenti. a) Euristica del raddoppio degli archi.
Costruito l’SST, si tratta di duplicarne tutti gli archi e quindi individuare un circuito che attraversi gli archi stessi esattamene una volta (circuito euleriano). Si tratta poi di trasformare il circuito euleriano in uno hamiltoniano eliminando i passaggi ripetuti che si sono creati per i vari nodi. Passo 1. Si costruisce un SST per il grafo G. Passo 2. Si duplicano tutti gli archi di SST, ottenendo il multigrafo G’. Passo 3. Si individua in G’ un circuito che passa per ogni arco una ed una sola volta cioè un circuito euleriano (l’operazione può essere effettuata in genere in più modi diversi). Passo 4. Si eliminano i passaggi multipli per gli stessi nodi, evitando cioè nodi già incontrati in precedenza (fase di skipping).
Si osservi che nel passo 3 il circuito euleriano non è necessariamente unico. In relazione al particolare circuito euleriano che si costruisce cambia in generale la soluzione finale che si ottiene per il TSP originario.
I l seguente esempio può chiarire la procedura. Supponiamo di avere individuato,
come albero di supporto minimale in un grafo G (completo), quello in figura:

67
c d a b e I l procedimento di raddoppio degli archi porta al multigrafo che segue: c d a b e
Un circuito euleriano, nel multigrafo così ottenuto, è quello evidenziato nella figura che segue: c d a b e Si tratta adesso di eliminare i passaggi multipli. Scelto come nodo (arbitrario) di partenza il vertice a, il circuito precedente può essere descritto dalla successione di nodi:
a b e b c d c b a. Se da tale elenco si omettono i nodi ripetuti, si ottiene la seguente successione:
a b e c d a. Questa corrisponde ad una delle soluzioni del TSP fornite dall’algoritmo (ripetiamo che la soluzione ottenibile non è unica):

68
c d a b e
L’errore massimo in grafi nei quali valga la proprietà triangolare è del 100% in quanto, con l’operazione di duplicazione degli archi, si raddoppia in realtà la lunghezza dell ’SST.
La successiva fase di eliminazione dei passaggi multipli riduce il margine d’errore, ma di una quantità che non è determinabile a priori. b) Algoritmo di Christofides.
Coincide inizialmente con il precedente, ma, anziché costruire un multigrafo con la duplicazione degli archi di G, si individuano i nodi di SST di grado dispari per congiungerli a coppie con archi di lunghezza totale minima (in altre parole, si individua un accoppiamento completo di costo minimo tra i nodi di grado dispari). Si tenga presente che i nodi di grado dispari sono sempre in numero pari.
A questo punto, sono gli archi dell’accoppiamento ad essere aggiunti a G, per poi
determinare un circuito euleriano e quindi eliminare i passaggi multipli eventuali per uno stesso nodo. Passo 1. Si costruisce, come per l’algoritmo precedente, l’albero di supporto di lunghezza minima del grafo, SST. Passo 2. Si individuano i nodi di grado dispari di SST: essi sono certamente in numero pari. Passo 3. Si individua l’accoppiamento completo di costo minimo M* tra i nodi di grado dispari cioè l’insieme M* di archi che collegano tali nodi a due a due e che ha la lunghezza complessiva minima. Si aggiungono al grafo gli archi dell’accoppiamento M*. Passo 4. Si individua un circuito (euleriano) che passi per tutti gli archi. Passo 5. Si termina con una fase di skipping cioè eliminando, anche in questo secondo caso, i passaggi multipli del circuito per i nodi del grafo. Si osservi che al Passo 3 l’accoppiamento che si deve determinare tra i nodi dispari può essere impostato come problema di matching in un grafo non bipartito, e quindi non si tratta di un Problema di Assegnazione. Tuttavia, anche per problemi di matching non bipartito sono state messe a punto tecniche efficienti (si tratta di un problema facile, nel senso chiarito nel capitolo sulla complessità).

69
Con riferimento allo stesso esempio usato per illustrare la prima procedura, una volta ottenuto l’albero di supporto, si individuano i nodi di grado dispari, che nel caso in questione sono a, b, d, e. Si collegano questi a due a due con gli archi di costo complessivo minore. Supponiamo si tratti di (a, b) e (d, e). Tali archi vengono aggiunti all ’albero: c d a b e Individuato poi un percorso euleriano, come quello che segue: c d a b e si opera la fase di eliminazione dei passaggi multipli e si perviene alla soluzione finale: c d a b e Teorema:
L ’errore relativo commesso dall’algoritmo di Christofides è al massimo del 50% del valore della soluzione ott ima. I l livello dell ’approssimazione garantita deriva dal fatto che l’aggiunta degli archi che accoppiano i nodi di grado dispari comporta un incremento nella lunghezza complessiva rispetto a quella dell’SST minore appunto del 50% rispetto alla l unghezza del circuito ottimo.
4.5.8 Varianti e conclusioni.
I l problema del commesso viaggiatore, come si è accennato in precedenza, ha ricevuto una vasta attenzione da parte degli studiosi. La letteratura in merito comprende non solo contributi su aspetti particolari, ma anche opere di rassegna dello stato dell ’arte,

70
che per altro è in continua evoluzione. Per concludere questa esposizione, accenniamo ad alcune varianti, oltre a quanto detto in precedenza e ad alcuni risultati che possono essere utili nell ’affrontare un problema di logistica distributiva, nei suoi aspetti non solo operativi, ma anche a livello strategico.
In applicazioni pratiche può avere interesse individuare soluzioni ammissibil i per il TSP, cioè circuiti hamiltoniani, per i quali siano raggiunti obiettivi diversi dalla lunghezza minima: in particolare, a volte si cerca un circuito nel quale la tappa più lunga sia la più corta possibile (problema A), oppure un circuito nel quale sia minima la differenza tra l’arco più lungo e quello più corto che vengono utili zzati, bilanciando così i costi dei vari tratti (problema B). In effetti, anche nel problema A si ottiene il risultato di ridurre il divario tra l’arco più lungo e quello più corto. I l primo problema viene detto TSP con obiettivo minimax (o bott leneck); i l secondo problema viene detto TSP con obiett ivo di bilanciamento (o balancing). Una giustificazione del primo obiettivo può essere quella di avere a disposizione un mezzo con un serbatoio limitato in una zona in cui vi sono pochi distributori di carburante, ad esempio concentrati solo nei nodi. Può essere allora importante contenere la lunghezza massima delle varie tappe per non superare l’autonomia del mezzo. Un obiettivo di bilanciamento vero e proprio può sorgere per ragioni di equità di carico di lavoro. Altro caso interessante è quello in cui la lunghezza di un arco varia (in modo deterministico, in prima istanza) al trascorrere del tempo: si parla in questo caso di time – dependent TSP. Rinviamo in ogni modo alla letteratura per un approfondimento di questi temi. Viceversa, introduciamo un’altra problematica, a carattere strategico, di notevole interesse nelle applicazioni. Un importante risultato a questo riguardo si riferisce alla valutazione a priori del valore della soluzione di un TSP, a prescindere dalla posizione precisa dei nodi e quindi dalla lunghezza effettiva dei singoli archi. Già nel 1959 era stata stabilita una formula per la lunghezza attesa L del circuito ottimo, in una superficie rettangolare di area R, contenente n punti da visitare, nell’ipotesi che questi siano uniformemente distribuiti nella superficie stessa:
L = k * (n *R)1/2. Nella espressione figura la costante k il cui valore è stato stimato in 0.57, circa, se le distanze sono misurate in linea retta, diventa circa 0.82 se si usa una metrica Manhattan (cioè se ogni coppia di nodi è collegata da una spezzata con i lati paralleli ai due assi ortogonali di riferimento), mentre può essere assunto 0.765 nei casi reali di percorsi effettivi stradali.
La formula è interessante in quanto, come si vedrà, in sede di progettazione di una rete distributiva, l’opportunità di istituire dei punti di transito dei carichi o di suddivisione in zone deve essere valutata senza poter calcolare i percorsi ottimi nel dettaglio, anche perché spesso, nelle applicazioni, occorre fissare una ripartizione in zone che sia stabile nel tempo, mentre i punti da visitare all’interno di ogni zona possono variare da un giorno all ’altro, pur restando uniformemente distribuiti nella zona stessa. Un’impostazione di questo tipo è seguita da C.F. Daganzo, che in numerosi lavori analizza le varie possibil ità di rete logistica per assumere decisioni di carattere strategico, valutando le varie strutture

71
mediante l’utilizzo della approssimazio ne di cui sopra, per tenere conto della lunghezza dei circuiti di visita.

72
4.6 Problemi hamiltoniani con più veicoli.
4.6.1 I l Problema del Commesso Viaggiatore multiplo: m-TSP.
I l Problema del Commesso Viaggiatore Multiplo, o m-TSP, costituisce un’estensione del TSP classico che è meglio adatta alle situazioni reali quando, in effetti, i veicoli che possono visitare i nodi sono più di uno e quindi possono ripartirsi il carico di lavoro. Questo modello, tuttavia, non include alcuna considerazione riguardo alla capacità dei mezzi ed alle domande dei clienti, né tanto meno considera vincoli temporali. S’ipotizza che vi sia un nodo particolare, il deposito, che indicheremo con la lettera D, dal quale partono ed al quale devono ritornare m mezzi, con m fissato, con l’obiettivo di rendere minima la lunghezza complessiva dei percorsi effettuati. Ogni nodo deve comparire in uno ed uno solo dei circuiti. Una soluzione di questo problema assume il seguente aspetto:
Non è previsto esplicitamente alcun meccanismo di equilibrio per quanto riguarda
la lunghezza e il numero dei nodi dei singoli circuiti, nel senso che può succedere che i vari mezzi debbano effettuare percorsi di costo molto diverso e visitare un numero differente di clienti.
La risoluzione di m-TSP può essere ricondotta a quella del TSP con l’espediente di
introdurre nel grafo G alcuni nodi e archi fittizi. Le modifiche al grafo di partenza sono le seguenti: - si sostituisce il deposito (unico) D con un insieme di m nodi, che
continueremo a chiamare depositi, D1, D2, ...., Dm, collegati tra loro da archi di lunghezza infinita;
- si collega ciascuno degli m depositi D1, D2, ..., Dm con ciascun nodo v
del grafo con un arco avente la stessa lunghezza di quello che collegava originariamente v con D.

73
Se G inizialmente contiene n nodi, oltre al deposito, nel grafo modificato, che diremo G’, i nodi sono n+m e di conseguenza diventa (n+m) ×(n+m) la dimensione della matrice delle lunghezze degli archi di G’. A questo punto la risoluzione di m-TSP in G si ottiene determinando il circuito di lunghezza minima in G’. Infatti, il circuito hamiltoniano ottimo di G’ non può prevedere depositi adiacenti, perché l’arco che li collega ha lunghezza infinita. Viceversa, in tale circuito, tutte le successioni di nodi comprese tra due depositi consecutivi corrispondono ad uno dei sottocircuiti che gli m veicoli devono compiere.
Ad es., se in un problema con 3 veicoli e 9 nodi (oltre al nodo deposito) si ottiene la soluzione (nel grafo modificato)
D1, 2, 4, 7, D2, 1, 5, D3, 8, 6, 3, 9, D1
allora il primo veicolo visiterà i nodi 2, 4, 7; il secondo i nodi 1 e 5; il terzo i nodi 8, 6, 3 e 9, nell ’ordine.
I l modello corrispondente al problema del commesso viaggiatore multiplo è adatto alle situazioni in cui il deposito è relativamente centrale rispetto ai nodi (clienti) da visitare e questi sono distribuiti in maniera abbastanza omogenea nel piano. Allora, di fatto, i sottocircuiti comprendono all ’incirca lo stesso numero di nodi e risultano quindi equilibrati. Viceversa, se vi sono problemi di ripartizione equa di clienti tra mezzi di servizio, occorre ricorrere ad altri modell i, in particolare a quello del Vehicle Routing Problem.
4.6.2 Il Vehicle Routing Problem.
Introducendo nel problema del commesso viaggiatore multiplo le ipotesi che i mezzi a disposizione siano dotati di una capacità limitata, la stessa per tutti i veicoli, mentre ciascun nodo presenta una domanda di servizio, sempre con l’obiettivo di minimizzare la lunghezza complessiva dei percorsi per visitare tutti i clienti, si ottiene il Vehicle Routing Problem.
I l modello è più complesso dei precedenti, pur presentando ancora serie limitazioni rispetto a molte realtà, in quanto la flotta è omogenea (spesso, invece, si hanno a disposizione vari tipi di mezzi, di capacità diversa) e il servizio è di sola consegna o sola raccolta. Volendo rimuovere queste sempli ficazioni, si ottengono modelli più realistici, ma ovviamente, via via più diff icil i da trattare.
Risolvere il Vehicle Routing Problem significa individuare m sottocircuiti, tutti aventi origine e termine nel deposito D, di lunghezza complessiva minima, ciascuno dei quali deve essere percorso da un veicolo: la somma delle domande dei clienti di un circuito deve essere compatibile con la capacità del veicolo.
Per precisare la soluzione, occorre anche stabilire cosa succede quando la capacità di un veicolo non coincide con la somma delle domande di un insieme di clienti: la capacità residua può andare perduta oppure può essere utilizzata per servire un ulteriore cliente in maniera parziale, e allora questo cliente dovrà essere visitato da due veicoli diversi. Può anche capitare che la domanda di un cliente sia maggiore della capacità dei mezzi, in tal caso necessariamente più veicoli visitano il cliente in questione.

74
Il Vehicle Routing Problem può essere formulato in termini di Programmazione Intera a variabil i 0-1, analogamente a quanto visto per il TSP. Occorre tuttavia introdurre un ulteriore elemento di diversificazione e cioè il particolare veicolo che transita per ciascun arco: si utilizzano quindi delle variabil i del tipo xij
v, la generica delle quali vale 1 se e solo se l’arco (i, j) è percorso dal veicolo v. La formulazione dovrà poi comprendere i vincoli relativi alla capacità del mezzo a fronte delle domande dei clienti. La formulazione accennata è alla base di tecniche risolutive esatte, che però riescono a dominare istanze di dimensione notevolmente ridotta rispetto a quanto si riesce a fare per il TSP. Numerose sono le tecniche euristiche prospettate dalla letteratura. Esse si possono classificare in vari modi. Uno dei più usati distingue le procedure:
- cluster first, route second; - route first, cluster second.
Nelle prime si procede dapprima ad una ripartizione dei clienti in sottoinsiemi (cluster) ciascuno avente somma delle domande non superiore alla capacità dei veicoli. Quindi all ’interno dei cluster si risolve un problema di circuito minimo (un TSP) di dimensioni generalmente assai inferiori a quelle del problema di partenza, e quindi notevolmente più facile. Nel secondo approccio si costruisce inizialmente un unico circuito (detto anche giant tour) comprendente tutti i nodi, e quindi non ammissibile, per poi suddividerlo in tante sezioni quanti sono i veicoli : ogni sezione è formata da un cammino che va ricollegato, all ’inizio ed alla fine, con il deposito. L’approccio che prevede per prima cosa la costruzione dei cluster è in genere preferito e dà risultati migliori: costruendo viceversa il giant tour, da un lato si incontra subito un problema (TSP) di grandi dimensioni e poi capita spesso di perdere molto della sua ottimalità con l’introduzione degli archi che collegano le varie parti del circuito al deposito. Tuttavia vi sono casi in cui la conformazione della zona da servire rende efficace anche il secondo approccio. In ogni caso, ottenuta una soluzione con una di queste euristiche, si può tentare di migliorarla con tecniche di scambio, rimuovendo clienti dai rispettivi circuiti per ricollocarli i n circuiti diversi. Sempre con il VRP, è possibile usare, adattata opportunamente, la tecnica dei risparmi (saving), già descritta a proposito del problema del Commesso Viaggiatore. Descriveremo ora un approccio risolutivo euristico di tipo cluster first, e cioè la tecnica di Gillet e Miller, che si può a ragione definire tecnica dell’orologio. Passo 1. Tracciare un raggio, che non tocchi alcun vertice, uscente dal nodo deposito; andare al passo 2. Passo 2. Scegliere una direzione di rotazione del raggio (ad es., il verso orario); andare al passo 3. Passo 3. Far ruotare il raggio nel verso prescelto, calcolando la somma progressiva delle domande dei nodi incontrati dal raggio stesso. Ogni volta che la somma delle domande satura la capacità di un veicolo, si è individuato un cluster e si ricomincia con un nuovo veicolo, a partire dal primo nodo successivo incontrato dal raggio. Passo 4. Determinare il circuito ottimale (di TSP) per ogni cluster. Come ci si può facilmente rendere conto, al passo 3 occorre specificare che cosa succede nel caso in cui l’ultimo nodo u incontrato dal raggio è quello che porta a superare

75
la capacità del veicolo corrente, e quindi determina il completamento di un cluster da assegnare ad un veicolo v. Se è possibile spezzare la domanda del nodo u, si può saturare il veicolo v e far fronte alla domanda ancora inevasa di u stesso con il veicolo successivo, che partirà quindi proprio da u (in questo modo due circuiti vicini potranno avere un nodo in comune). In caso contrario, la capacità del veicolo v resterà in parte non utilizzata e tutta la domanda del nodo u sarà trasferita sul veicolo seguente. I l procedimento può essere ripetuto, per ottenere soluzioni diverse, capovolgendo il verso di rotazione del raggio oppure facendo variare la posizione del raggio iniziale. È buona regola far seguire al procedimento dell ’orologio una tecnica di miglioramento, ad esempio con eventuali scambi di nodi tra cluster adiacenti. Può capitare infatti che il raggio, in una delle posizioni in cui si riempie un mezzo di trasporto, venga a spezzare due o più sottoinsiemi di clienti che conviene viceversa servire ciascuno con lo stesso mezzo, come si vede facilmente dall ’esempio che segue: raggio r
È evidente come convenga raggruppare nello stesso cluster, rispettivamente, i nodi di A e di B piuttosto che rispettare la partizione individuata dal raggio r.
4.6.3 Routing e scheduling.
I l termine routing fa riferimento alla costruzione di percorsi; il termine scheduling si adopera quando si tratta di organizzare delle operazioni, di vario genere, nel tempo. Pertanto sono problematiche di scheduling sia quelle di organizzazione della produzione, quando si deve stabil ire l’ordine di lavorazione di articoli su una o più macchine, sia quelle di compilazione di orari, ad esempio dell’orario scolastico di un istituto o dei turni del personale in un’azienda di trasporto.
Quando si usa la dizione mista routing e scheduling si ha a che fare con la ricerca di percorsi per i quali occorre tenere conto anche di elementi temporali : ad esempio, frequentemente succede che i nodi da visitare debbano essere toccati solo in certi momenti della giornata oppure in certi periodi o intervalli temporali (se si violano questi tempi, l’operazione diventa impossibile oppure, altre volte, si deve subire una penalità).
Questo è il contesto più frequente nel caso della logistica distributiva, cioè dell ’organizzazione dei trasporti di merce da magazzini a clienti o dettaglianti. Solo quando le finestre sono talmente ampie da essere rispettate da qualsiasi successione di visita dei clienti o nei (pochi) casi in cui i clienti stessi accettano che la merce sia depositata all ’aperto, al di fuori della loro sede, il problema diventa soltanto di percorso.
A
B

76
Viceversa si ha il classico problema detto di Vehicle Routing e Scheduling con Time Windows, in breve, VRSPTW, che è appunto un problema misto, di ottimizzazione dei percorsi ma anche con un’organizzazione che rispetti precisi vincoli temporali.
4.6.4 Le finestre temporali.
Prende il nome di finestra temporale (time window) qualsiasi intervallo di tempo, desiderato e specificato dal cliente, nel quale deve cadere la visita al cliente stesso (e quindi il passaggio per il corrispondente nodo) per la consegna o il ritiro di merce (o per la conclusione di un viaggio di una persona).
Si è soliti distinguere due categorie di finestre temporali: finestre forti e finestre deboli. Le finestre temporali forti (strong time windows) sono intervall i di tempo nei quali necessariamente deve accadere l’evento ‘visita del nodo’. In altri termini, una finestra forte non può essere violata. Se il visitatore si presenta prima dell’inizio della finestra, egli deve attendere il periodo di tempo necessario per l’apertura della finestra stessa, mentre se si presenta dopo che la finestra si è chiusa, la visita non può avvenire. Le finestre temporali deboli , invece, sono finestre alle quali si può derogare pagando una penalità: questa, in genere, è legata all ’entità della violazione.
Dal punto di vista formale, in un problema di routing e scheduling con finestre temporali, al generico nodo i sono associati due valori, ei e li, che costituiscono gli i stanti di inizio e fine della finestra corrispondente.
Non sono escluse le due possibil ità ei = -∞, oppure li = +∞, corrispondenti,
rispettivamente, ad una finestra temporale aperta a sinistra, oppure ad una aperta a destra (nei due casi, il cliente indica solo un limite massimo alla operazione, oppure uno minimo, rispettivamente). Nella generica formulazione del problema, anche per il deposito sono dati due istanti, eD e lD, di apertura e chiusura, rispettivamente, della finestra.
Soprattutto nel caso di finestre deboli , a volte si indica anche il valore di un
parametro wmax, attesa massima, che rappresenta una limitazione superiore per la attesa che il mezzo può effettuare presso un cliente prima di visitarlo, nel caso in cui si arrivi prima dell ’apertura della finestra. La funzione oggetto ha natura differente, a seconda che si tratti di un problema con finestre forti o deboli. Anche la specificazione della soluzione ha natura diversa nei due casi.
Con finestre temporali forti, non vi sono penalizzazioni legate al disservizio percepito dal cliente: tuttavia gli elementi di costo sono più di uno, perché oltre alla lunghezza dei percorsi occorre tenere conto del numero di mezzi, del personale necessario e dal trade-off tra la sosta inoperosa presso un cliente, in attesa della apertura della finestra, e il trasferimento presso clienti più lontani, ma visitabili non appena raggiunti. Per quanto riguarda la soluzione, questa consiste semplicemente nell ’ordine con cui ciascuno dei mezzi disponibil i visita i vari nodi.
Con finestre temporali deboli interviene pesantemente un elemento di diff icile valutazione e cioè la qualità percepita del servizio. Questa dovrebbe essere tradotta in una funzione che dovrebbe esprimere, in funzione dell’orario di arrivo, la penalità rapportata in termini monetari per l’(eventuale) infrazione della finestra. Questa funzione dovrebbe essere nulla per tutto il tratto [ei, li], decrescente sino a ei, crescente da li in poi:

77
Penalità ei li ora di arrivo Si noti che non è detto si debba trattare di una funzione simmetrica: i ritardi
potrebbero ‘costare’ di più degli anticipi. Vi sono due esigenze contrapposte: ridurre per quanto possibile le penalità, e cioè
contenere gli anticipi e i ritardi nelle visite e d’altro canto tenere presente l’esigenza di minimizzare le distanze percorse.
Nella soluzione vanno specificati sia l’ordine di visita dei clienti, sia l’entità della (eventuale) sosta, nel caso in cui si arrivi in anticipo.
Infatti, può essere conveniente infrangere la finestra, effettuando un servizio in
anticipo, ma dopo aver aspettato comunque per un certo periodo di tempo, una volta arrivati presso il cliente, per diminuire la penalità.
La sosta ha implicazioni sia sulla penalità per l’anticipo nella visita del cliente (questo tende a fare attendere quanto più possibile l’apertura della sua finestra temporale) sia sui costi dell’attesa del conducente e sulle (eventuali) penalit à che si possono venire a sostenere per i clienti successivi.
Analogamente a quanto succede quando non si hanno vincoli di tempo, nel caso di routing e scheduling con finestre temporali si hanno vari problemi (modell i) tra cui evidenziamo il TSPTW, problema del commesso viaggiatore con finestre temporali , ove non ci sono vincoli di capacità, e il VRSPTW, (vehicle routing and scheduling problem with time windows), per il quale si deve tenere conto esplicitamente della flotta a disposizione e delle capacità dei veicoli. La difficoltà di questi problemi è intuibile.
Nel caso di routing con finestre forti, è addirittura NP-completo già il solo problema di individuare se esiste una soluzione ammissibile, cioè se esiste un circuito per il quale tutte le finestre sono rispettate. A maggior ragione, è difficile il problema di individuare una soluzione ottima. D’altro canto, le finestre deboli , pur consentendo in generale una più ampia gamma di soluzioni ammissibil i, come si è visto, pongono in concreto il problema di specificare funzioni di penalità che siano realistiche. Descriveremo nel prossimo paragrafo alcune euristiche per il VRSPTW.
4.6.5 Algoritmi per il VRSPTW: l’inserimento di un nuovo cliente.
Seguendo l’impostazione di Solomon, che ha pubblicato i suoi risultati verso la fine degli anni ’80, diamo innanzi tutto alcune definizioni, oltre a quelle già viste d’istante di apertura (ei) e chiusura (li) della finestra temporale del nodo (cliente) i.
Diremo, sempre con riferimento al cliente corrispondente al nodo i:

78
- bi l’istante nel quale ha inizio il servizio; - si la durata del servizio stesso, vale a dire delle operazioni di carico o scarico.
Diremo poi - t ij il tempo necessario per andare dal cliente i al cliente j. L’istante in cui ha inizio la visita del cliente i è dato dalla formula ricorsiva:
bi = max {ei , bh + sh + thi } dove h è il cliente che precede i, bh è l’istante di inizio del servizio presso h, sh la durata del servizio stesso e thi il tempo necessario per il trasferimento da h ad i. Nel caso in cui ei > bh + sh + thi, allora si pone
wi = (ei - bh - sh - thi). Più in generale, wi = max {0, (ei - bh - sh - thi)}.
La variabile wi indica l’attesa (eventuale) del mezzo presso il cliente i-esimo prima che si apra la sua finestra temporale.
È appena il caso di notare che si inizia a visitare il cliente i-esimo non appena si è arrivati, se l’apertura della sua finestra ei è avvenuta prima dell’istante di arrivo presso il cliente stesso, altrimenti si deve attendere proprio l’istante di apertura. I l costo connesso alla visita del cliente i, sempre supponendo che prima si sia visitato h, può essere formulato con l’espressione seguente:
chi = p dhi + q (bi - bh)
dove p e q sono opportuni parametri e dhi rappresenta la distanza (fisica) da h ad i. L’espressione stessa indica come vi siano due elementi di costo, uno legato alla distanza e l’altro al tempo. Se p = 0, il problema diventa un puro problema di scheduling, nel quale si cerca di minimizzare il tempo di completamento delle operazioni. Invece se si pone q = 0, l’unica cosa che interessa è minimizzare la distanza totale percorsa. Più in generale, come detto poco sopra, si cercherà di tenere conto sia dei tempi, evitando attese eccessive, sia delle distanze percorse ed i due parametri hanno lo scopo di rendere omogenee le unità di misura (e ricondurre tutto a importi monetari).
I l primo risultato che prenderemo in considerazione è un teorema che permette di determinare se l’ interposizione di un nuovo cliente tra due già visitati in un percorso parziale ammissibile, è essa stessa ammissibile. Infatti, c’è il rischio che per qualcuno dei clienti successivi non siano più rispettate le finestre temporali .
Questo è indispensabile per mettere in atto procedure di tipo ‘ tour building’, inserendo progressivamente altri clienti in un tour parziale già costruito.
Supponiamo allora si debba inserire, in un circuito parziale ammissibile che ha origine e termine nel deposito
D, v1, v2, … v p-1 , vp, vp+1, …, v m, D, un nuovo nodo u tra i nodi vp-1 e vp:
D, v1, v2, … v p-1, u, vp, vp+1, …, v m, D,

79
Per semplificare i calcoli, si suppone anche che il veicolo che effettua il servizio parta da D all ’apertura della finestra eD (eventualmente aspetta presso il primo cliente).
Si noti che l’ammissibil ità del circuito parziale implica che ei ≤ bi ≤ li, per i = 1, 2, …, m, e quindi le differenze w i = bi - ei sono tutte ≥ 0.
I l servizio presso u può iniziare all’istante bu = max {eu , bp-1 + sp-1 + tp-1,u}: una prima condizione per l’ammissibil ità dell’inse rimento è, ovviamente, che risulti
bu ≤≤ lu. (C)
L’inserimento di u immediatamente prima di v p provoca poi, in generale, uno slittamento in avanti del tempo di inizio del servizio per tutti i clienti dal p-esimo in poi: potrebbe anche richiedere uno spostamento all ’indietro dei tempi di visita dei clienti precedenti, ma è proprio l’ipotesi che il veicolo parta da D all ’istante eD che fa escludere questa possibil ità.
In effetti, con tale ipotesi, fissato l’ordine di visita, nessun cliente è visitabile in anticipo rispetto a quanto si ottiene sulla base delle formule viste sopra.
Se la condizione (C) è rispettata, occorre vedere cosa succede per i clienti successivi, a partire dal p-esimo. L’istante di (possibile) inizio del servizio presso di lui diventa adesso:
b’p = max {ep , bu + su + tup}.
Calcolato questo nuovo istante b’p, se vale la proprietà triangolare per i percorsi tra i vari nodi, sarà ovviamente b’p ≥ bp. Affinché l’inserimento sia ammissibile occorre che b’p ≤ lp. Se anche questa seconda condizione è verificata, occorre calcolare il nuovo istante di inizio del cliente (p+1)-esimo, e via di seguito.
Per specificare tutte le condizioni di ammissibil ità dell ’inserimento di u, Solomon definisce allora la quantità, che denomina push forward,
PFp = b’ p - bp che risulterà, per quanto già osservato, ≥ 0. Se PFp = 0, non vi sono conseguenze, vale a dire slittamenti nei tempi di visita, né per il cliente p-esimo né per i successivi. Se invece PFp > 0, come si è già detto, occorre procedere alla verifica del rispetto della finestra temporale del cliente p stesso e ricalcolare via via anche i tempi dei clienti successivi, dal (p+1)-esimo in poi.
Per tali clienti, come si può dimostrare, vale la formula ricorsiva
PFj = b’j - bj = max {{0, PFj-1 - wj}}
Infatti, si ricordi innanzi tutto che bj = max {ej, bj-1 + sj-1 + tj-1,j }, perché il servizio inizia o all ’apertura della finestra o all ’arrivo dopo il trasferimento dal cliente precedente, mentre l’attesa prima di servire il cliente j -esimo è data da wj = max {0, ej - bj-1 - sj-1 - tj-
1,j}, cioè è 0 se si arriva dopo che la finestra si era aperta mentre è positiva se si arriva prima.

80
Se il tempo d’attesa dell ’apertura della finestra del cliente j, w j (prima dell ’inserimento di u) era superiore al push forward PFj-1, (caso a) in fig.) allora il nuovo orario d’inizio di servizio di j coincide con quello vecchio (e coincide con l’apertura della finestra, ej) e quindi b’ j = bj e PFj = 0; se invece vi era un’attesa inferiore a PFj, o se non vi era attesa, allora la nuova attesa di fronte al cliente j è, in ogni caso, w’ j=0 e la differenza (PFj-1 - wj) rappresenta lo spostamento in avanti dell ’inizio del servizio presso il cliente j. A quest’ultimo riguardo si possono distinguere due situazioni diverse ( casi b) e c)): se wj>0, parte del push forward è compensato dalla precedente attesa (PF si riduce); se invece l’attesa era nulla, tutto il PF relativo al cliente j -1 si trasferisce anche al cliente j-esimo. a) attesa wj > PFj-1: cliente j-1 ej-1 bj-1 b’ j-1 bj-1+sj-1 b’ j-1+sj-1 lj-1 PFj-1 t j-1,j cliente j ej=bj=b’ j lj wj
b) attesa wj ≤ PFj-1, con wj>0: cliente j-1 ej-1 bj-1 b’ j-1 bj-1+sj-1 b’ j-1+sj-1 lj-1 PFj-1 t j-1,j cliente j wj PFj
ej=bj b’ j lj c) attesa wj = 0: cliente j-1 ej-1 bj-1 b’ j-1 bj-1+sj-1 b’ j-1+sj-1 lj-1 PFj-1 t j-1,j cliente j PFj
ej bj b’ j lj In ogni caso, il nuovo istante di inizio del servizio presso il cliente j-esimo può essere espresso anche con la formula:
b’j = bj + PFj.
Possiamo quindi verificare l’ammissibil ità del nuovo orario semplicemente controllando che sia
b’j ≤≤ lj.
Questo procedimento di controllo si può arrestare non appena si individua il primo cliente j, successivo al p-esimo, per il quale il push forward PFj = b’j - bj = 0.

81
Infatti, da quel cliente in avanti tutti i push forward risultano anch’essi null i.
Se invece i push forward rimangono positivi, alla fine si deve verificare che anche l’istante di ritorno al Deposito sia compatibile con la finestra di rientro: la verifica è del tutto analoga alle precedenti. In pratica, il procedimento può essere formalizzato con i seguenti passi:
- Passo 1: porre j = p; calcolare PFj = b’ j - bj; andare al Passo 2; - Passo 2: se PFj = 0, allora STOP: l’inserimento è ammissibile; se PF j>0,
andare al Passo 3; - Passo 3: controllare se la finestra temporale del cliente j è rispettata: se
non lo è, STOP: l’inserimento non è ammissibile; se la finestra è rispettata, incrementare j di una unità e andare al Passo 4;
- Passo 4: se j = m+1, controllare la ammissibil ità dell ’istante di rientro al Deposito: STOP; se j ≤ m, calcolare PFj e tornare al passo 2.
Sintetizzando quanto illustrato sinora, si può enunciare il teorema che segue: condizione necessaria e suff iciente aff inché si mantenga la ammissibilità temporale quando un cliente u viene inserito tra i clienti p-1 e p, 1 ≤≤ p ≤≤ m, in un percorso parziale ammissibile (D, v1, v2, … vp-1 , vp, vp+1, …, vm, D), è che valgano le relazioni: 1) bu ≤≤ lu 2) bj + PFj ≤≤ lj (p ≤≤ j ≤≤ m).
3) bD ≤≤ lD dove, per ogni j , bj indica l’istante in cui è possibile iniziare il servizio al cliente j dopo l’inserimento di u e bD indica l’istante di r ientro al deposito.
Si noti che, con questa impostazione, è fondamentale arrivare prima della chiusura della finestra, dopo di che il servizio può protrarsi anche oltre la chiusura stessa.
4.6.6 Euristiche per il VSRPTW.
In questo paragrafo vengono delineate alcune delle euristiche proposte in letteratura per la risoluzione del VRSPTW, in particolare quelle proposte da Solomon, analoghe come impostazione a tecniche risolutive già introdotte per problemi di percorso di tipo hamiltoniano, mettendo in evidenza le varianti necessarie per tenere conto delle finestre temporali.
È in ogni caso da ricordare che, a differenza dei problemi di puro Routing (e di puro Scheduling), la funzione oggetto del Vehicle Scheduling and Routing Problem with Time Windows, anche con finestre forti, non può prescindere dalle particolarità del caso specifico: dovendosi considerare sia elementi di distanza sia di tempo, per risolvere concretamente un’istanza di VRSPTW, il decisore dovrà precisare che peso intende dare ai due elementi di costo.
Si vedrà in effetti come le euristiche presentate comprendano dei criteri di valutazione, a volte in alternativa, che cercano di aiutare il decisore a tenere conto dei vari elementi in gioco.

82
Si tenga presente che, in generale, si tratta di costruire più sottocircuiti: si parlerà
quindi di costruzione e ampliamento di subtour, ognuno dei quali può richiedere una propria fase di inizializzazione.
Una delle euristiche più semplici e facilmente implementabil i per la risoluzione di
un VRSPTW, sempre nel caso di finestre forti, è quella del nodo più vicino o del nearest neighbor , che si basa su un principio analogo a quello della tecnica di eguale denominazione già introdotta per il caso del TSP.
Essa, a partire dal Deposito D, costruisce sequenzialmente i percorsi necessari a visitare tutti i clienti inserendo di volta in volta il cliente più vicino all ’ultimo nodo dell ’ultimo route parziale costruito sinora, fino a che questo è possibile: in caso contrario inizia a costruire un nuovo sottocircuito, fino a che tutti i clienti non sono stati raggiunti.
I l concetto di vicinanza va però ridefinito perché vanno considerati sia aspetti spaziali sia temporali . A questo scopo Solomon suggerisce di usare una variabile di decisione cij che è la somma pesata di tre elementi:
- la distanza dij dall’ultimo nodo v i incluso nel route parziale in costruzione al possibile successore vj ;
- l’intervallo temporale T ij tra la fine del servizio presso vi e l’inizio del servizio presso vj, dato dalla espressione Tij = bj - (bi + si); quest’ultimo comprende sia il tempo necessario al trasferimento che l’eventuale attesa della apertura della finestra temporale in vj;
- l’urgenza ννij di servire vj una volta servito vi, definita come tempo che rimarrebbe prima della chiusura della finestra temporale di vj; νij è data dalla espressione νij = lj - (bi + si + tij).
Vengono considerati come possibil i successori di vi solo i clienti per i quali i
parametri Tij e νij risultano positivi. La variabile cij è definita come:
cij = k1 dij + k2 T ij + k3 ννij ,
dove i pesi k1, k2 e k3 sono numeri non negativi e di somma 1. I l cliente ‘più vicino’ è quello che presenta il valore più basso di c ij. La procedura, oltre che di facile implementazione, può dar luogo a soluzioni diverse cambiando i pesi attribuiti ai tre elementi di ‘ vicinanza’.
Si può notare come il criterio di scelta diventi semplicemente quello di un problema m-TSP (commesso viaggiatore multiplo) se k2 = k3 = 0. In generale, invece, l’espressione di c ij permette di tenere conto sia del tempo necessario per il trasferimento (elemento che potrebbe anche essere trascurato, perché lo si può ritenere proporzionale alla distanza dij) sia, soprattutto, dell ’esigenza di visitare i clienti con finestre temporali ‘strette’ in tour che comprendano anche altri clienti, evitando di adoperare troppi autoveicoli . Le euristiche di inserimento, come nel caso del TSP, prevedono innanzi tutto una fase di inizializzazione di ogni subtour e successivamente l’inserimento nello stesso di altri utenti, fino a che questo è possibile. Nella prima fase, il cliente iniziale, che dà origine ad un (nuovo) sottocircuito

83
deposito → cliente → deposito
potrebbe essere il cliente (non ancora servito) più lontano, oppure quello (sempre tra i clienti ancora da servire) la cui finestra temporale si chiude prima delle altre. La seconda fase prevede di inserire iterativamente clienti nel circuito parziale applicando ogni volta due criteri:
- il primo serve per determinare per ogni cliente u non inserito (ma inseribile!) la posizione migliore, all ’interno del route in costruzione;
- il secondo serve per individuare il cliente da inserire.
I l primo criterio è dovuto al fatto che per uno stesso cliente u potrebbe risultare ammissibile l’inserimento in differenti posizioni nella sequenza già costruita
D, v1, v2, …, v m, D,
I l secondo criterio, invece, permetterà di scegliere, nell ’elenco dei possibil i clienti candidati (ciascuno dei quali associato al proprio inserimento ottimo) quale effettivamente utilizzare per ampliare il subtour. L’ottica è chiaramente di tipo greedy: l’effettivo inserimento del cliente, sul quale la tecnica non prevede di ritornare, altera in generale le condizioni per gli inserimenti successivi. Per quanto riguarda l’espressione dei due criteri, ancora una volta le proposte combinano tra loro elementi di costo in termini di distanza percorsa e di tempo impiegato. Una delle alternative di Solomon è la seguente: a) (fissato un cliente u non ancora visitato) per ogni coppia (vi, vj) di clienti adiacenti nel tour parziale calcolare una media pesata dell ’incremento di percorso e dello slittamento temporale (push forward) di vj:
c1(i(u), u, j(u)) = α(diu + duj – k dij) + β( b’ j - bj), dove k ≥ 0, α ≥ 0,β ≥ 0, α + β = 1, e individuare la coppia (vi, vj) per cui c1 è minima; b) (fissata la posizione migliore per ogni cliente) scegliere il cliente u per il quale è minima l’espressi one
c2(i, u, j) = λ d0u - c1(i, u, j), dove λ è un parametro ≥ 0. Si noti l’abbondanza di pesi soggettivi: k è un fattore di correzione introdotto nell’euristica dei saving (risparmi) già vista a proposito del TSP multiplo e del VRP, che determina la forma dei sottocircuiti che si vengono a creare; α e β, ovviamente, oltre che ‘pesare’ costi diversi, hanno lo scopo di rendere omogenee le unità di misura.

84
Con la funzione c2 si valuta in effetti quanto costa visitare il cliente u con un giro a se stante, piuttosto che introdurlo nel circuito parziale che si sta costruendo.
Infine accenniamo all’adattamento al VRSPTW della tecnica sweep di Gillett e Miller. Fissato il raggio di partenza e la direzione di rotazione (ad esempio, il verso orario), nella prima fase si procede alla individuazione del primo cluster C1. Si costruisce poi un tour T1 entro questo cluster, ad esempio con una procedura di inserimento. Questo tour lascerà, in generale, alcuni clienti non visitati, per i vincoli dovuti alle finestre temporali. Si tratta di inserirli in altri percorsi. Si eliminano i clienti inseriti nel primo tour T1 e si procede alla creazione del secondo cluster C2. Per recuperare clienti non serviti del primo tour e mantenere una certa coesione geografica nei tour stessi, si suggerisce di costruire C2 facendo partire il raggio dalla bisettrice del primo settore (sempre in senso orario): così facendo i clienti non serviti nella parte di sinistra di C1 verranno inseriti successivamente (alla fine del procedimento)
Clienti non ancor serviti
Clienti serviti con T1

85
4.7 Appendice: Dimostrazioni dei teoremi
Teorema (pag. 36): Un accoppiamento M in un grafo G è di cardinalità massima se e solo se in G non esistono cammini aumentanti r ispetto a M. Dimostrazione. È pressoché evidente che se in G esiste un cammino aumentante C rispetto al matching M, M non può essere di cardinalità massima. Infatti, in tal caso C contiene un numero dispari di archi e quindi, posto che gli archi in C ∩ M siano k, gli archi di C che non fanno parte del matching M sono k+1. Basta allora togliere da M i k archi che fanno anche parte del cammino C e inserire in M viceversa gli archi (k+1) di C che prima non erano nell ’accoppiamento: nel nuovo matching che si ottiene, M’, gli archi sono aumentati di un’unità rispetto a M.
Più laborioso è provare che se un accoppiamento M in G non è di cardinalità massima, allora in G esiste anche un cammino aumentante rispetto a M. Sinteticamente, a tale scopo si considera innanzi tutto un matching massimo di G che diremo M* e poi il grafo G’ degli archi che stanno in uno ed uno solo dei due matching, M ed M* (si escludono quindi da G’ tutti gli archi che fanno parte di entrambi i matching). G’ n on può essere vuoto (visto che M* ha più archi di M). Si costata che G’ non può avere circuiti (né di cardinalità pari né dispari: in entrambi i casi si arriva a contraddire il modo con il quale G’ è stato costruito). G’ (che in generale non è connesso) può solo contenere cammini in cui si alternano archi di M ed M* e in questi cammini il primo e l’ultimo arco sono necessariamente in M* (gli altri casi ipotetici porterebbero ancora a contraddizioni con la natura di G’). Questi cammini risultano così aumentanti (rispetto a M) ed è quello cui si voleva arrivare.
�
Teorema (pag. 45): Siano noti k sottoalberi disgiunti di un grafo G, che indicheremo con T1, T2, ..., Tk, contenenti complessivamente tutt i i nodi di G e si conosca con certezza che essi sono parte di uno stesso albero di supporto di lunghezza minima T* di G. Allora:
i) un arco di lunghezza minima tra quelli che collegano due sottoalberi diversi può essere inserito in uno SST; ii ) fissato un particolare sottoalbero Th, i l più corto tra gli archi che collegano vertici in Th con vertici di altr i sottoalberi può essere inserito in uno SST. Dimostrazione. i) Sia e un arco di lunghezza minima tra due sottoalberi diversi e siano Tj e Tk i due sottoalberi collegati da e (si noti anche come questi dipendano da e, e non siano determinati a priori!).
Se, per assurdo, non fosse ottimale usare l’arco e per collegare i due sottoalberi, (e non fosse ottimale nemmeno usare alcuno degli altri archi lunghi quanto e per unire le rispettive coppie di sottoalberi), Tj e Tk sarebbero in ogni caso connessi in qualche altra maniera, anche non direttamente, mediante altri archi di peso superiore ad e: diciamo tali archi e’ , e” , ecc.

86
Ma allora l’albero ottenuto alla fine del procedimento non sarebbe ottimo perché in esso si potrebbe cancellare e’ (rompendo la connessione) e sostituirlo con e (ristabilendo la connessione in altra forma) diminuendone la lunghezza (vedi la figura che segue). e Tj Th e” e’ ii ) Analogamente a quanto visto nel caso precedente, è evidente che un fissato Th deve essere connesso con il resto del grafo attraverso uno (ed un solo) arco. Se a tale scopo non si usa l’arco (o uno degli archi) più corto uscente da T h si cade nello stesso tipo di contraddizione di cui nella dimostrazione per i). � Teorema (pag.50): Sia T(r) un albero di supporto di G avente come radice r e per ogni nodo v di G diciamo d(v) la distanza di v da r misurata lungo T(r). Sia l(u, v) la lunghezza del generico arco (u, v) di G. Condizione necessaria e sufficiente affinché T(r) sia un albero dei cammini minimi di radice r è che per qualsiasi arco (u, v) di G valga la diseguaglianza:
d(v) ≤≤ d(u) + l(u, v) Dimostrazione. i) Condizione necessaria. Sia T(r) albero dei cammini minimi e dimostriamo che valgono le condizioni del teorema. Se l’arco (u, v) ∈ T(r), la relazione vale come eguaglianza. Se invece (u, v) non fa parte dell ’albero, si vede come non possa mai essere vera la relazione
d(v) > d(u) + l(u, v), perché allora sarebbe possibile individuare un percorso da r a v (passante per u) più breve di quello individuato dall ’albero T(r), e questo in contraddizione con l’ottimalità di T(r) (vedi la figura che segue).

87
u r v ii ) Condizione sufficiente. Si deve dimostrare che se valgono le condizioni del teorema per ogni arco in relazione ad un certo albero T(r), allora questo è proprio l’albero dei cammini minimi uscenti da r. Procederemo (per assurdo!) supponendo di avere un albero T’(r) che non sia quello dei cammini minimi e provando che allora almeno per un arco le condizioni del teorema non valgono. Se T’(r) non è albero dei cammini minimi, esisterà almeno un nodo w di G tale che la distanza d(w) misurata da r a w lungo T’(r) è superiore alla lunghezza del cammino più breve da r a w in G. Ma allora in tale cammino più breve esisterà (almeno) un arco che non fa parte di T’(r): sia (u, v) l’arco di questo tipo più vicino ad r. Ne segue che, poiché tratti parziali di un cammino ottimo sono a loro volta ottimi relativamente ai loro estremi, anche per andare da r a v l’albero T’(r) non esprime il cammino più breve, che viceversa utili zza l’arco (u, v), per cui deve valere la diseguaglianza d(v) > d(u) + l(u, v). � Teorema (pag.69)
L ’errore relativo commesso dall’algoritmo di Christofides è al massimo del 50% del valore della soluzione ott ima. Dimostrazione. Innanzi tutto occorre notare che l’albero di supporto di lunghezza minima è certamente di peso complessivo (strettamente) inferiore alla lunghezza del circuito hamiltoniano ott imo. Infatti, se si elimina dal circuito hamiltoniano ottimo un arco, si ricava un albero di supporto, che, tra tutti gli alberi di supporto, non è detto sia quello di peso minimo. L’eliminazione dell ’arco rende più forte la diseguaglianza
l(SST) < l(CH*). D’altra parte, all ’albero di supporto minimo vengono poi aggiunti gli archi di un accoppiamento, quello di costo minimo tra i nodi di grado dispari. Ora tale accoppiamento M* viene ottenuto con gli archi che collegano direttamente a due a due i nodi dispari, e ciò nella maniera più conveniente. Se si schematizza il circuito ottimo (hamiltoniano) lungo una circonferenza e si evidenziano i nodi dispari con dei pallini neri come segue:
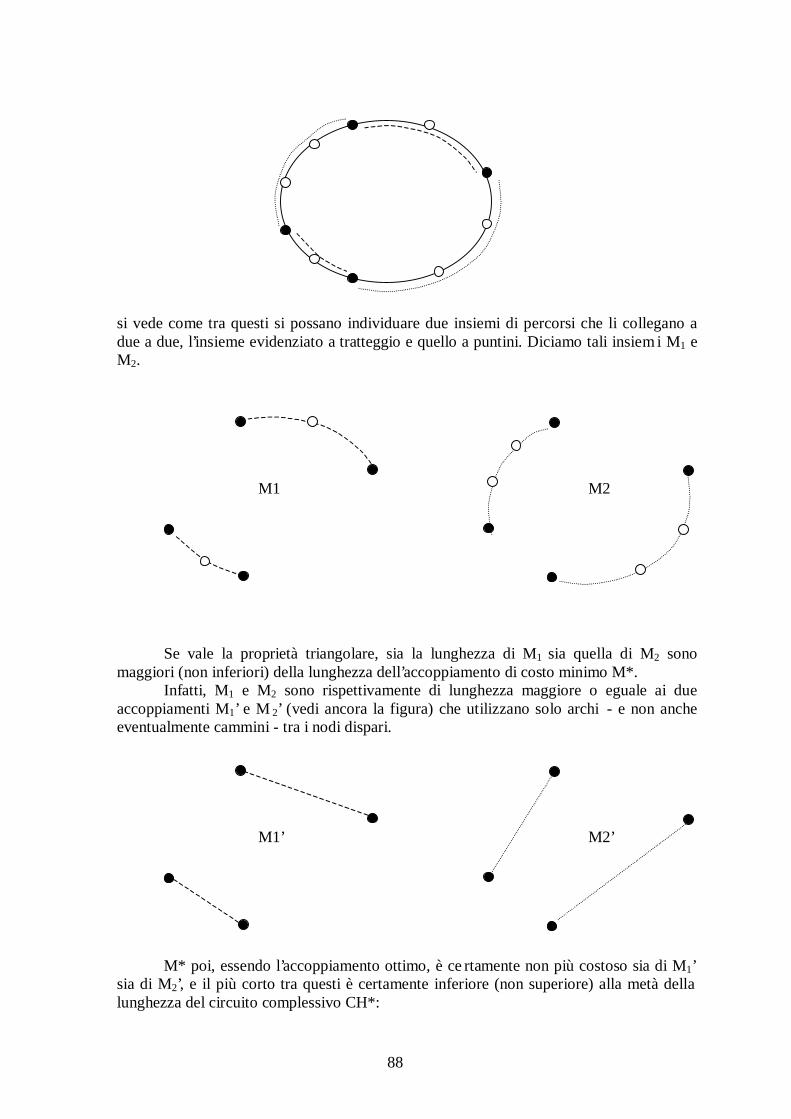
88
si vede come tra questi si possano individuare due insiemi di percorsi che li collegano a due a due, l’insieme evidenziato a tratteggio e quello a puntini. Diciamo tali insiemi M1 e M2. M1 M2
Se vale la proprietà triangolare, sia la lunghezza di M1 sia quella di M2 sono maggiori (non inferiori) della lunghezza dell’accoppiamento di costo minimo M*.
Infatti, M1 e M2 sono rispettivamente di lunghezza maggiore o eguale ai due accoppiamenti M1’ e M 2’ (vedi ancora la figura) che utili zzano solo archi - e non anche eventualmente cammini - tra i nodi dispari. M1’ M2’
M* poi, essendo l’accoppiamento ottimo, è certamente non più costoso sia di M1’
sia di M2’, e il più corto tra questi è certamente inferiore (non superiore) alla metà della lunghezza del circuito complessivo CH*:

89
l(M*) ≤ min (l(M1’), l(M 2’)) ≤ min (l(M1), l(M2)) ≤ 1/2 l(CH*).
Pertanto si può concludere che la lunghezza di SST sommata a quella dell ’accoppiamento M* è complessivamente non superiore a una volta e mezza la lunghezza del cammino hamiltoniano ottimo CH*. Anche stavolta la fase di skipping, sempre se vale la proprietà triangolare, può portare ad un ulteriore miglioramento della soluzione, ma di una quantità non definibile a priori. �

90
5 La gestione delle scorte
5.1 Generalità
Le scorte sono i materiali all’interno del processo logistico produttivo che aspettano di essere utilizzati, lavorati, assemblati per essere distribuiti, venduti, adoperati o consumati. Più precisamente le scorte possono essere materie prime oppure semilavorati o subassemblati ma possono essere anche prodotti finiti pronti per la vendita; le situazioni che si possono presentare sono le più svariate a seconda degli scenari considerati. 5.2 Motivazioni delle scorte
I motivi per cui vengono mantenute delle scorte sono essenzialmente i seguenti tre:
- motivo transazionale: producendo o ordinando grandi lotti di merce i costi fissi (ad esempio quell i di trasporto) possono essere ridotti e si possono realizzare delle economie di scala perchè i costi sono meno che proporzionali alla quantità;
- motivo precauzionale e/o di smoothing: le scorte possono offrire delle garanzie contro le incertezze dei fornitori, dei trasporti, della produzione e più in generale del mercato perchè le scorte disaccoppiano processi contigui cioè ne riducono la mutua influenza e ne facil itano la gestione;
- motivo speculativo: è vantaggioso disporre di scorte se sono previsti aumenti di valore o di costo nel prossimo futuro.
5.3 Costi delle scorte
Sono stati sopra esposti i motivi per cui vengono mantenute delle scorte tuttavia è chiaro che le scorte non producono valore aggiunto e soprattutto costano anche perchè i costi vanno oltre lo specifico costo della merce considerata; quindi ci sono anche dei motivi per non mantenere delle scorte e quando è possibile conviene attuare delle politiche che riducano la necessità di scorte oppure distribuiscano i costi fissi. Vediamo ora più in dettaglio quali siano i costi delle scorte. Questi possono essere specificati come segue:
- oneri finanziari; - costi di opportunità (costi di immobilizzo del capitale con sacrificio di investimenti
alternativi); - oneri da rischio (obsolescenza, furto, danneggiamento, ...); - costi assicurativi; - costi di immagazzinamento (spazi, movimentazione); - costi gestionali (strutture, sicurezza, personale, amministrazione).
5.4 Modellamento dei costi
I costi delle scorte vengono modellati in tre grandi famiglie: costo di mantenimento, costo di r ifornimento, costo di penuria. Essi possono essere classificati

91
in costi fissi, i quali sono pressoché indipendenti dal volume delle attività, e costi variabili, che in prima approssimazione sono proporzionali al volume delle attività.
5.4.1 Costo di mantenimento
I l costo di mantenimento modella tutti i costi legati alla presenza di merci in magazzino, quali gli oneri finanziari, i costi opportunità, gli oneri da rischio, i costi assicurativi, i costi di immagazzinamento e i costi gestionali . I l costo di mantenimento dipende dal livello di scorte e dal loro tempo di permanenza in magazzino ed è un costo variabile.
5.4.2 Costo di rifornimento
I l costo di rifornimento, detto anche costo d’ordine, modella tutti i costi legati all ’emissi one e all’esecuzione di un ordine di rifornimento, quali i costi del personale, i costi accessori (stampati, ammortamento macchine), i costi di trasporto e i costi di acquisto. In generale si ritiene che il costo di rifornimento abbia una componente fissa ed una variabile proporzionale alle dimensioni dell ’ordine, se vengono presi in considerazione i costi di acquisto.
5.4.3 Costo di penuria
I l costo di penuria quantifica economicamente le motivazioni di mantenimento delle scorte quali il rischio di rottura di scorta, il blocco della produzione o la mancata vendita con conseguente disaffezione del cliente. I l costo di penuria è ritenuto variabile e proporzionale alla quantità non soddisfatta (lost sales) o alla quantità non soddisfatta e al tempo di attesa se è possibile una vendita in ritardo (back order).
Si osservi che da quanto si è detto scorte eccessive comportano oneri economici e spreco di risorse mentre scorte ridotte inducono disequilibrio nel ciclo produttivo e impossibil ità di rispondere alla domanda del cliente quindi la gestione ottimale delle scorte è di fondamentale importanza per una azienda.
Osserviamo infine che il costo di ordine è legato alle relazioni tra magazzino e fornitore mentre il costo di penuria è legato alle relazioni tra magazzino e cliente. Inoltre ridurre le scorte riduce i costi di mantenimento, ma aumenta i costi di penuria e di ordine mentre scorte più elevate aumentano i costi di mantenimento, ma riducono quelli di rifornimento e di penuria.
I costi sono quindi interdipendenti e il problema consiste nel trovare il punto di equilibrio più conveniente. 5.5 Articoli a domanda regolare
Gli articoli a domanda regolare sono quelli che presentano i minori problemi di gestione perchè, non essendo soggetti a moda o stagionalità, hanno un consumo abbastanza prevedibile e, non essendo deperibil i possono essere riordinati nelle quantità
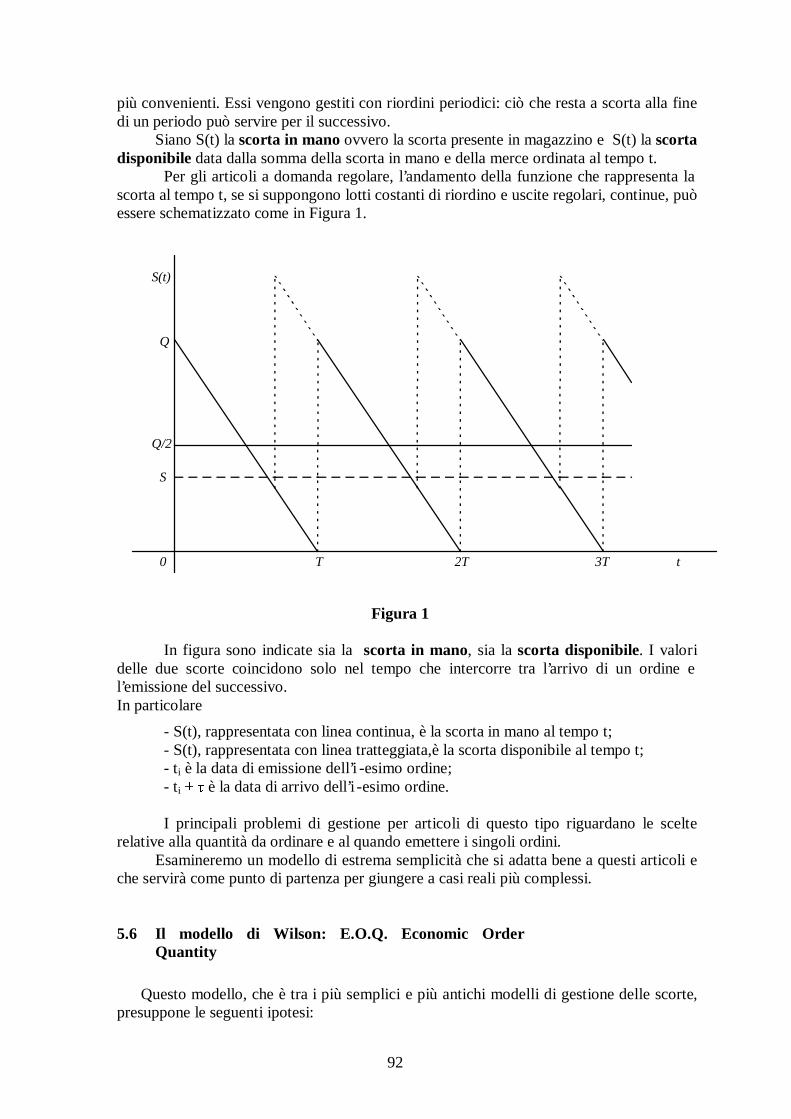
92
più convenienti. Essi vengono gestiti con riordini periodici: ciò che resta a scorta alla fine di un periodo può servire per il successivo.
Siano S(t) la scorta in mano ovvero la scorta presente in magazzino e S(t) la scorta disponibile data dalla somma della scorta in mano e della merce ordinata al tempo t.
Per gli articoli a domanda regolare, l’andamento della funzione che rappresenta la scorta al tempo t, se si suppongono lotti costanti di riordino e uscite regolari, continue, può essere schematizzato come in Figura 1.
Q
0 t
Q/2
S
S(t)
T 3T2T
Figura 1
In figura sono indicate sia la scorta in mano, sia la scorta disponibile. I valori delle due scorte coincidono solo nel tempo che intercorre tra l’arrivo di un ordine e l’emissione del successivo. In particolare
- S(t), rappresentata con linea continua, è la scorta in mano al tempo t; - S(t), rappresentata con linea tratteggiata,è la scorta disponibile al tempo t; - ti è la data di emissione dell’i -esimo ordine; - ti � � è la data di arrivo dell ’i -esimo ordine. I principali problemi di gestione per articoli di questo tipo riguardano le scelte
relative alla quantità da ordinare e al quando emettere i singoli ordini. Esamineremo un modello di estrema semplicità che si adatta bene a questi articoli e
che servirà come punto di partenza per giungere a casi reali più complessi. 5.6 Il modello di Wilson: E.O.Q. Economic Order
Quantity
Questo modello, che è tra i più semplici e più antichi modell i di gestione delle scorte, presuppone le seguenti ipotesi:

93
1. per quanto concerne le entrate (acquisto, trasporto, ingresso della merce): - il prezzo-costo è noto, costante nel tempo e non dipende dal numero delle
unità acquistate; -
������������ ����������� �������� �������è l’intervallo che intercorre tra il momento in cui
si accerta la necessità di emettere l’ordine e l’arrivo della merce è noto e costante. Sia cl il costo unitario per ordine;
2. per quanto concerne le uscite: - l’articolo ha domanda nota con intensità costante nel tempo; d è la quantità
domandata nell’unità di tempo; - si vuole soddisfare tutta la domanda senza far attendere i clienti cioè non
sono ammesse rotture di scorte; 3. per quanto concerne la conservazione dell’articolo:
- la conservazione della merce comporta spese che si ritengono proporzionali al valore e al tempo di giacenza; sia cs il costo di conservazione per unità di merce e di tempo
Dalle ipotesi poste deriva che, essendo la domanda costante nel tempo, la quantità
da acquistare sarà pure costante: la chiameremo lotto e la indicheremo con Q. Parimenti l’intervallo tra due arrivi successivi o due emissioni di ordini sarà pure
costante: lo chiameremo tempo di riciclaggio e lo indicheremo con T. Poiché tutto è noto a priori non conviene avere scorta in mano quando arriva un
ordine perché ciò comporterebbe inutili costi di conservazione. Pertanto S(t) varia linearmente tra il valore massimo Q e il valore minimo 0.
Se in un periodo di ampiezza unitaria si consuma d, la quantità Q si consumerà in un tempo T per il quale valga la proporzione:
d : 1 = Q : T. I l tempo di riciclaggio è pertanto:
T = Q/d e il suo reciproco 1/T dà il numero di ordini al periodo. Indicandolo con n si ha:
n = d/Q . I l valore ottimo di Q è quello che minimizza il costo totale di ordinazione e di
magazzino relativo ad un intervallo unitario. Indicando con y(Q) la somma totale dei costi di ordinazione e di magazzino la
funzione obbiettivo da minimizzare è y(Q) = cl d/Q + cs Q/2 Q>0.
I l primo termine della funzione rappresenta il costo totale di ordinazione mentre il secondo termine è il costo totale di magazzino, perchè Q/2 rappresenta la quantità media di merce presente in magazzino nell ’intervallo unitario di tempo.
Studiando la derivata prima e seconda di y(Q) facilmente si dimostra che questa funzione è convessa ed il punto di minimo è
sc
2dcQ l=
espressione generalmente nota con il nome di formula di Wilson o lotto economico o EOQ Economic Order Quantity, che in seguito indicheremo con Qw.
L’andamento della funzione y(Q) si può ricavare da quello degli addendi che la compongono; il costo totale annuo di ordinazione è funzione decrescente convessa e tende a zero per Q che tende all ’infinito, mentre i l costo totale annuo di magazzino è funzione crescente rappresentata da una retta passante per l’origine.
94
y(Q)
Q w0 Q
y(Q)
Figura 2
La funzione somma è pertanto una funzione convessa, con un solo punto di minimo ed ha l’andamento rappresentato in Figura 2.
Si è ora in grado di rispondere alle domande poste inizialmente: in merito al quanto, rispondiamo che conviene ordinare la quantità Qw, mentre l’intervallo ottimo di riciclaggio è
Tw=Qw/d e il numero ottimo di ordini è
nw=1/Tw .
5.6.1 Quando ordinare?
Osserviamo innanzitutto che normalmente si risponde a questa domanda non indicando un istante nel tempo ma un livello di scorta.
Questo livello che indica la necessità di procedere all ’emissione dell’ordine, viene detto punto d’ordine.
I l punto d’ordine è dunque il livello di scorta al raggiungimento del quale è necessario avviare le operazioni di r iordino.
Nel presente modello, poichè si è supposto di non voler scorta in mano quando arriva un nuovo lotto, il punto d’ordine è esattamente uguale al consumo nel tempo di riordino.
Detto S0 il punto d’ordine, si ha S0=d � ������������ ������������������������ ����������!��#" $�%'&�(*)�$�+�,�-�%�& .&0/�&0/�(01�2�2�&�-�354-�6�-'2�.1�6�%�$�7�78$
indipendenti; la prima dipende sostanzialmente dalla volontà dei fornitori mentre la seconda è il risultato di una ottimizzazione aziendale.

95
5.7 I l caso di domanda aleatoria
5.7.1 Generalità
Supponiamo ora che la domanda e/o il tempo di riordino non siano così regolari da essere noti a priori, ma siano variabili casuali note, cioè variabili con assegnate distribuzioni di probabil ità.
Una variabile casuale si r itiene nota quando se ne conoscono valori e relative probabilità o, se è continua, la funzione di densità o di r ipartizione: nel nostro caso, se la conoscenza va intesa in questi termini, difficilmente potremo dire di conoscere le variabil i casuali che entrano nei problemi di scorte.
Tuttavia per procedere supporremo di conoscere le variabil i casuali che ci interessano e in un primo momento ammetteremo che esse siano statiche, cioè indipendenti dal tempo.
Quando si formulano ipotesi di questo tipo, cioè quando si ammette che le grandezze varino unicamente in dipendenza della loro legge di probabil ità e non anche del tempo, si dice che il problema è formulato in ipotesi statica; altrimenti è formulato in ipotesi dinamica.
5.7.2 Classificazione dei tipi di gestione
Se la domanda e/o il tempo di riordino sono variabil i, una gestione, comunque la si attui, non può risultare così regolare come previsto dal modello di Wilson, nel quale sia i lotti sia i cicli risultavano costanti. In queste nuove ipotesi, o si vorranno costanti i lotti e allora varieranno gli i ntervall i tra una emissione e la successiva, o si vorranno cicli costanti e allora si ordineranno quantità variabil i.
Con ciò non si vuole escludere che molto spesso si adottano soluzioni miste, cioè riordino di quantità variabil i a intervall i variabil i. Tuttavia numerosi tipi di politiche si possono ricondurre ai seguenti due fondamentali :
- riordino di quantità costanti ogni volta che la scorta raggiunge il punto d’ordine (sistemi di gestione a punto d’ordine)
- r iordino ad intervalli fissi di quantità generalmente variabili (sistemi di gestione a r iordino periodico).
Presentiamo ora due modelli validi per il primo e per il secondo tipo di politica.
5.7.3 Sistemi a punto d’ordine: la politica (Q, S0) o dei due magazzini
Questa politica consiste nel r iordinare la quantità costante Q ogni volta che la scorta scende sotto il punto d’ordine S0.
Questo tipo di gestione è detto anche politica dei due magazzini perchè si può pensare di realizzarla in questo modo.
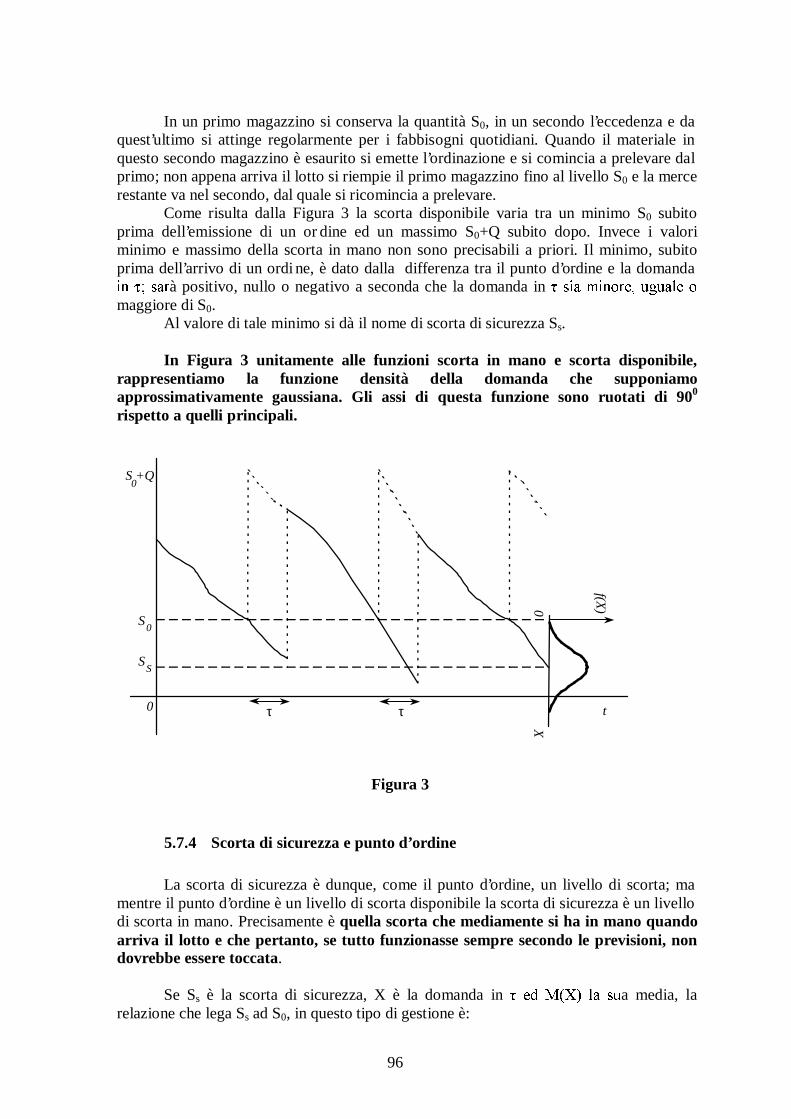
96
In un primo magazzino si conserva la quantità S0, in un secondo l’eccedenza e da
quest’ultimo si attinge regolarmente per i fabbisogni quotidiani. Quando il materiale in questo secondo magazzino è esaurito si emette l’ordinazione e si comincia a prelevare dal primo; non appena arriva il lotto si riempie il primo magazzino fino al livello S0 e la merce restante va nel secondo, dal quale si ricomincia a prelevare.
Come risulta dalla Figura 3 la scorta disponibile varia tra un minimo S0 subito prima dell’emissione di un or dine ed un massimo S0+Q subito dopo. Invece i valori minimo e massimo della scorta in mano non sono precisabili a priori. I l minimo, subito prima dell ’arrivo di un ordi ne, è dato dalla differenza tra il punto d’ordine e la domanda ����� �����
à positivo, nullo o negativo a seconda che la domanda in � ������������������������� ����maggiore di S0.
Al valore di tale minimo si dà il nome di scorta di sicurezza Ss. In Figura 3 unitamente alle funzioni scorta in mano e scorta disponibile,
rappresentiamo la funzione densità della domanda che supponiamo approssimativamente gaussiana. Gli assi di questa funzione sono ruotati di 900 r ispetto a quell i principali.
S +Q0
S
0
SS
0
τ tτ
0X
f(X)
Figura 3
5.7.4 Scorta di sicurezza e punto d’ordine
La scorta di sicurezza è dunque, come il punto d’ordine, un livello di scorta; ma mentre il punto d’ordine è un livello di scorta disponibile la scorta di sicurezza è un livello di scorta in mano. Precisamente è quella scorta che mediamente si ha in mano quando arriva il lotto e che pertanto, se tutto funzionasse sempre secondo le previsioni, non dovrebbe essere toccata.
Se Ss è la scorta di sicurezza, X è la domanda in ! "�#%$%&('*),+�-/.10 a media, la relazione che lega Ss ad S0, in questo tipo di gestione è:

97
Ss = S0 - M(X). La scorta di sicurezza è così chiamata perchè assicura, almeno entro certi limiti, ������������� �����������������������������������������������������������! �"$#������������%����&%���'�)(*��������� �&�������� rischio
di sbagliare e si pone perciò S0 > M(X)
e la scorta di sicurezza risulta positiva. Tuttavia resta aperto il problema della definizione di S0 oppure se si vuole di Ss .
Esso è rilevante perchè un elevato punto d’ordine dà tranquill ità contro i rischi di non poter soddisfare i clienti durante il tempo di riordino, ma causa alti costi di giacenza; viceversa un basso punto d’ordine, che sembra economico, lo è solo in apparenza perchè causa mancate vendite.
Osserviamo che nella politica (Q,S0) l’ampiezza dell ’intervallo di tempo durante il quale si corre il rischio di rottura di scorta è +�����-,." infatt i si va sottoscorta se il punto d’ordine non è suff iciente a coprire i consumi del tempo di r iordino.
Per questo è rilevante la conoscenza della variabile casuale /$0�132�4$/$265�4 7 che abbiamo chiamato X, mentre della domanda nell ’unità di tempo è sufficiente conoscere il valor medio.
5.7.5 Quando acquistare? Quanto acquistare?
Le risposte che si danno a queste domande differiscono in funzione dell’obbiettivo che ci si prefigge.
Infatti in un problema, quando sono presenti una o più variabil i casuali non è immediato individuare la politica ottima. In condizioni di incertezza non si ha una sola funzione obiettivo, ma più funzioni ognuna con una propria probabil ità di verificarsi e ognuna ottima per dati valori della o delle variabili d’azione.
I l problema generalmente si supera considerando come obiettivo da ottimizzare il valor medio di tutte le possibil i funzioni obiettivo (in pratica il costo o il guadagno medio) oppure scegliendo quella politica che consente di raggiungere un dato risutato con una certa sicurezza.
Accenniamo ad alcuni tra i più usati criteri di determinazione della politica di scorte ottima.
Determinazione congiunta di Q e di S0
Con questo metodo si determinano congiuntamente i valori di Q e di S0 minimizzando il costo totale medio di gestione. I l metodo comporta qualche difficoltà di analisi e di calcolo per cui non è molto applicato in pratica. Per ulteriori approfondimenti, si rimanda alla letteratura sull ’argomento.
Determinazione separata di Q e di S0
Con questo secondo metodo i valori di Q e di S0 si determinano separatamente e di solito si procede così;
1. La dimensione del lotto si fissa in modo da minimizzare i costi medi di
ordinazione e di magazzino. Pertanto come quantità ottima da ordinare si assume quella indicata dalla formula di Wilson. Naturalmente in questo caso il simbolo d che compare nella formula indica la domanda media nell’unità di tempo.

98
2. I l punto d’ordine può essere fissato in p iù modi alternativi varianti in funzione dell ’obiettivo che si sceglie. Ne elenchiamo alcuni:
a. fissare S0 in modo da assicurare alla clientela un certo livello minimo di servizio;
b. fissare S0 in modo da avere un certo coefficiente minimo di sicurezza; c. fissare S0 in modo da minimizzare i costi medi di giacenza e di penuria.
Descriviamo in particolare il criterio “a” e per gli altri rimandiamo alla letteratura
sull ’argomento.
Determinazione di S0 in modo da assicurare alla clientela un certo livello di servizio. Precisiamo innanzitutto cosa si intende per livello di servizio. Generalmente si
ritiene che una buona misura del livello di serviziosia data dalla probabil ità di soddisfare le richieste che si presentano durante il tempo di riordino, cioè della cosiddetta probabilità di copertura.
Fissare il livello di servizio per un certo prodotto al 90% significa volere che, ogni volta che si lancia un ordine, ci sia almeno il 90% di probabil ità di soddisfare la domanda.
Per determinare quale livello di punto d’ordine dia questa sicurezza, indichiamo con X un valore della domanda nel tempo di riordino, con F(x) la funzione di ripartizione, con p(x) la relativa probabil ità se si tratta di variabile casuale discreta e con f(x) la densità se si tratta di variabile casuale continua; è necessario allora determinare il minore valore della variabile casuale in corrispondenza del quale risulta:
F(S0) ��� dove L è il li vello di servizio desiderato.
Questa disequazione può scriversi più semplicemente come:
Lp(x)0S
0
≥∑=x
se la variabile casuale è discreta, oppure come :
Lf(x)dx0S
0
≥∫
se la variabile casuale è continua. La risoluzione dell’equazione F(S0)=L può effettuarsi con uno o l’altro dei due
metodi seguenti:
- determinare l’ascissa corrispondente ad una data ordinata L della funzione di ripartizione F(X), la quale esprime il livello di servizio desiderato;
- determinare l’asc issa in corrispondenza della quale l’area che sta al disotto della funzione di densità f(X) e che risulta tratteggiata in Figura 4 vale L.
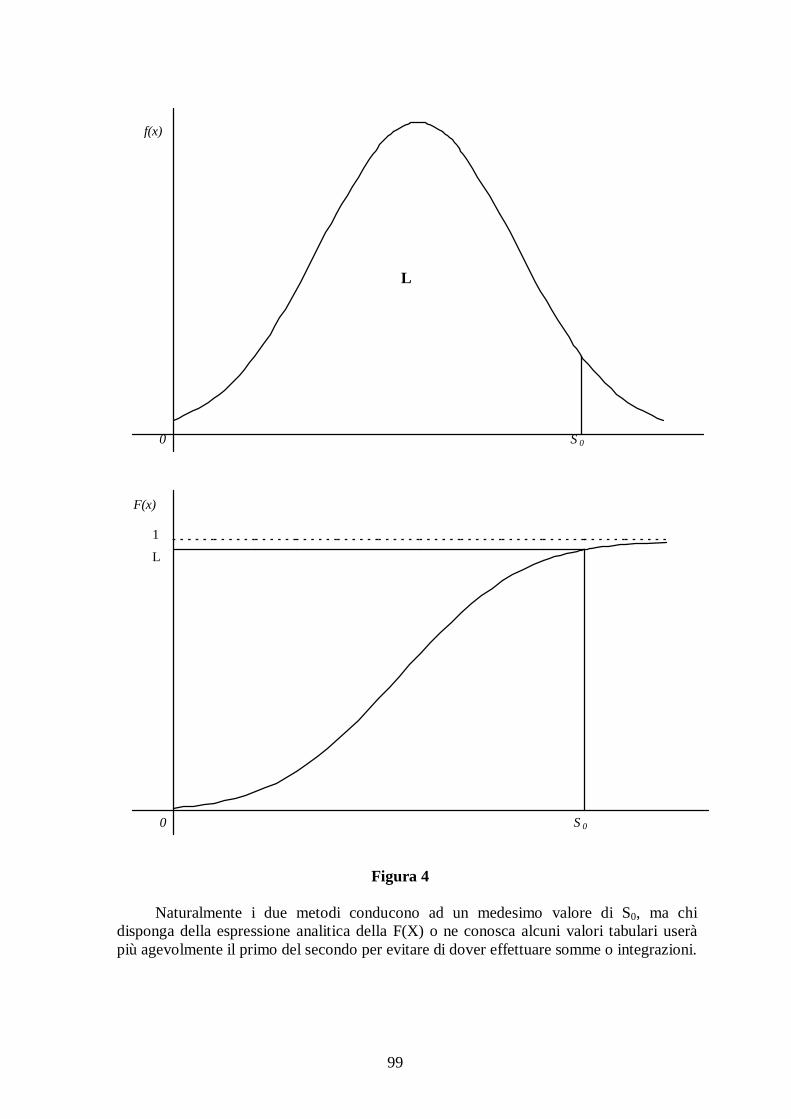
99
0
f(x)
S 0
L
0
F(x)
S 0
L
1
Figura 4
Naturalmente i due metodi conducono ad un medesimo valore di S0, ma chi disponga della espressione analitica della F(X) o ne conosca alcuni valori tabulari userà più agevolmente il primo del secondo per evitare di dover effettuare somme o integrazioni.

100
5.8 Sistemi di r iordino periodico: la politica (T,S)
Questa politica consiste nel riordinare a intervalli costanti di ampiezza T la quantità che serve per riportare la scorta disponibile al li vello S, detto anche livello massimo o scorta massima.
In questo tipo di gestione risultano costanti gli i ntervall i tra due successive emissioni di ordini e variabil i invece le quantità ordinate ogni volta.
La scorta disponibile varia tra un massimo S, che raggiunge subito dopo l’emissione di ogni ordine e un minimo (S –Qi ) subito prima dell ’arrivo dell ’ordine successivo. Tale valore non è precisabile a priori perchè Qi varia ad ogni intervallo dipendendo dai consumi che si sono avuti nell’intervallo medesimo.
Incognite in questo tipo di gestione sono l’ampiezza dell ’intervallo tra due successivi riordini T e la scorta massima S.
Questi due valori possono essere fissati con diversi criteri seguendo concetti analoghi a quelli indicati per la gestione a punto d’ordine.
Per ulteriori approfondimenti rimandiamo alla letteratura sull ’argomento.
5.9 Articoli a domanda non regolare
5.9.1 Generalità
I l prodotto che diciamo a domanda non regolare è tipicamente un prodotto deperibile e fortemente stagionale; è oggetto di una gestione non ripetitiva nel senso che ciò che resta a scorta dopo un periodo non può essre utili zzato nel periodo successivo.
Perciò questi prodotti vengono detti di gestione a periodo singolo. Appartengono a questa categoria:
- tutti quegli articoli per cui la domanda è fortemente concentrata in un dato periodo dell ’anno ed è pressocchè inesi stente altrimenti;
- tutti gli articoli deperibil i fisicamente; - tutti i prodotti soggetti a rapida obsolescenza.
Generalmente questi articoli vengono acquistati con un’unica ordinazione e non è
possibile, se la domanda supera la merce in mano, effettuare riordini all ’ultimo momento. Dunque la domanda non verte sul quando emettere l’ordine, ma solo sul quanto
acquistare. Presentiamo un semplice modello che si adatta a questi problemi detto modello del
venditore di giornali o del venditore di alberi di Natale.
5.9.2 I l modello del venditore di alberi di Natale
Ammettiamo le seguenti ipotesi: - il prodotto può essere acquistato una sola volta all’inizio di ogni periodo e
il suo prezzo è indipendente dal numero delle unità acquistate;

101
- i costi di conservazione sono trascurabili perchè essendo la merce deperibile in senso fisico o economico, il prodotto non può essere conservato a lungo;
- se si presenta una richiesta superiore alla quantità acquistata la vendita è persa e ogni unità mancante determina un costo di penuria cp;
- viceversa, se la richiesta è inferiore alla quantità acquistata ogni unità restante a fine periodo va svenduta e determina un costo di rimanenza cv.
Essendo trascurabil i costo di ordinazione e di conservazione il problema è quello
di scegliere la quantità che conviene acquistare all’inizio del periodo in modo da evitare una eccessiva rimanenza invenduta alla fine e da non restare senza merce durante il periodo.
Indichiamo con X la domanda relativa all’intervallo in esame e supponiamo che essa sia variabile casuale continua con funzione di densità f(x); indichiamo inoltre con s la quantità incognita che conviene acquistare all ’inizio periodo. Si ha allora:
- se è x < s a fine periodo resta una quantità invenduta (s – x ) e si sostiene un costo
cv ( s – x ); - se è x > s a fine periodo si ha una penuria di entità ( x – s ) e si sostiene un
costo cp ( x – s ).
Come funzione obiettivo si assume il costo medio di rimanenza e penuria relativa al periodo in esame.
Si ha
∫ ∫∞
+=s
0 s
pv s)f(x)dx-x(cx)f(x)dx -s(cy(s) .
Si dimostra che questa funzione è minima per quel valore di s che verifica la seguente eguaglianza:
pv
p
cc
cF(s)
+= ,
avendo indicato come sempre con F(s) la funzione di ripartizione della variabile casuale X.
Quindi se si vogliono minimizzare i costi medi di rimanenza e di penuria, si deve ordinare una quantità che dà una probabil ità di copertura uguale al rapporto tra il costo unitario di penuria e la somma dei costi unitari di penuria e di rimanenza.
Osservazioni
Essendo la funzione di ripartizione strettamente monotona la soluzione della esiste ed è unica.
Tale soluzione dipende unicamente dal rapporto cp/cv come si mette in evidenza dividendo numeratore e denominatore del secondo membro della per cp. Si ha :
p
v
c
c1
1F(s)
+=

102
Valgono i seguenti limiti
1F(s) lim0
c
c
p
v
=→
0F(s) lim
p
v
c
c=
+∞→
il cui significato economico è evidente. Il primo dice che la quantità da acquistare è tanto più elevata quanto minore è il costo di rimanenza o più alti i danni derivanti da stockout.
I l secondo dice che quando non si teme la penuria oppure sono particolarmente elevati i costi di rimanenza conviene ridurre al minimo la quantità che si acquista.

103
Indice
1 Introduzione.............................................................................................................1 2 Problema, modello, algoritmo. Complessità computazionale .................................... 3
2.1 Costruzione di un modello matematico .............................................................4 2.2 Esempi..............................................................................................................6 2.3 Algoritmi e complessità....................................................................................9
3 Elementi di teoria dei grafi. .....................................................................................13 3.1 I grafi come metodologia di rappresentazione di sistemi. .................................13 3.2 Alberi e loro proprietà......................................................................................20 3.3 Appendice: Dimostrazioni ...............................................................................31
4 Logistica distributiva. ..............................................................................................33 4.1 Generalità........................................................................................................33 4.2 I l Problema di Assegnazione (AP). ..................................................................35 4.3 Alberi di supporto ottimi..................................................................................43 4.4 Modelli per problemi di percorso: modelli non vincolati. .................................49 4.5 I l problema del commesso viaggiatore, TSP.....................................................57 4.6 Problemi hamiltoniani con più veicoli ..............................................................72 4.7 Appendice: Dimostrazioni dei teoremi .............................................................85
5 La gestione delle scorte...........................................................................................90 5.1 Generalità........................................................................................................90 5.2 Motivazioni delle scorte...................................................................................90 5.3 Costi delle scorte.............................................................................................90 5.4 Modellamento dei costi ....................................................................................90 5.5 Articoli a domanda regolare.............................................................................91 5.6 I l modello di Wilson: E.O.Q. Economic Order Quantity ..................................92 5.7 I l caso di domanda aleatoria.............................................................................95 5.8 Sistemi di riordino periodico: la politica (T,S)...............................................100 5.9 Articoli a domanda non regolare....................................................................100
Indice............................................................................................................................103