aprendizagem de mÁquina para previsÃo de demanda em um sistema de compartilhamento de bicicletas
TRANSCRIPT

APRENDIZAGEM DE MÁQUINA PARA PREVISÃO
DE DEMANDA EM UM SISTEMA DE
COMPARTILHAMENTO DE BICICLETAS
Tr a b a l h o d e G r a d u a ç ã o G r a d u a ç ã o e m C i ê n c i a d a
C o m p u t a ç ã o C I n - U F P E
A l u n o : R a f a e l F e l i p e N a s c i m e n t o d e A g u i a r < r f n a @ c i n . u f p e . b r >
O r i e n t a d o r : P r o f . G e r m a n o C r i s p i m V a s c o n c e l o s < g c v @ c i n . u f p e . b r >
R e c i f e , J u l h o d e 2 0 1 5

•Contexto e Objetivo
•Características do Conjunto de Dados
•Estimadores
•Parametrização
•Engenharia de Variáveis
•Overview do Pipeline de Aprendizagem
•Resultados
•Conclusão
TÓPICOS

A
B
CONTEXTO

•Previsão de Demanda através de aprendizagem de máquina
•Dada uma data e hora do dia, qual o número total de bicicletas retiradas?
•Aprendizagem de Máquina Supervisionada
•Regressão
•Técnicas exploradas: Ensembles, Random Forest, Gradient Tree Boosting, Rede Neural (rprop+), Rede Neural (momentum)
OBJETIVO

•Fonte: Capital Bikeshare, Washington - DC, 2011-2012
•Registros: ^10k (train), ^6k (test)
•Variáveis:
CARACTERÍSTICA DO CONJUNTO DE DADOS
Season Holiday Working day Weather Temp aTemp
Tipo Categórico Booleano Booleano Categórico Numérico Numérico
Valores 1 a 4 0 ou 1 0 ou 1 1 a 4 0.8ºC a 41ºC 0.7ºC a 45ºC
Humidity Windspeed Casual Registered Count DateTime
Tipo Numérico Numérico Numérico Numérico Numérico
String
Valores 0% a 100% 0 a 57 km/h 0 ou 367 0 ou 886 1 a 997 2011-01-01 12:00:00 AM a 2012-11-02
12:00:00 AM

CARACTERÍSTICA DO CONJUNTO DE DADOS
Count = Casual + Registered

CARACTERÍSTICA DO CONJUNTO DE DADOS
Count = Casual + Registered

1. Ensemble
2. Random Forest
3. Gradient Tree Boosting
4. Rede Neural (Rprop+)
5. Rede Neural (Momentum)
ESTIMADORES

ENSEMBLE
•I d é i a : v e n c e r b i a s - v a r i a n c e t r a d e o f f u t i l i z a n d o e s t i m a d o r e s f r a c o s
•C o n s t r u ç ã o : •B a g g i n g ( B o o t s r a p A g g r e g a t i n g ) •B o o s t i n g

RANDOM FOREST

GRADIENT TREE BOOSTING

REDES NEURAIS

•Backpropagation (backward propagation of errors) é um método para aprender pesos de uma rede neural e costuma ser utilizado em conjunto com um método de otimização (e.g., gradiente descendente).
Δwij = −α ∂E∂wij
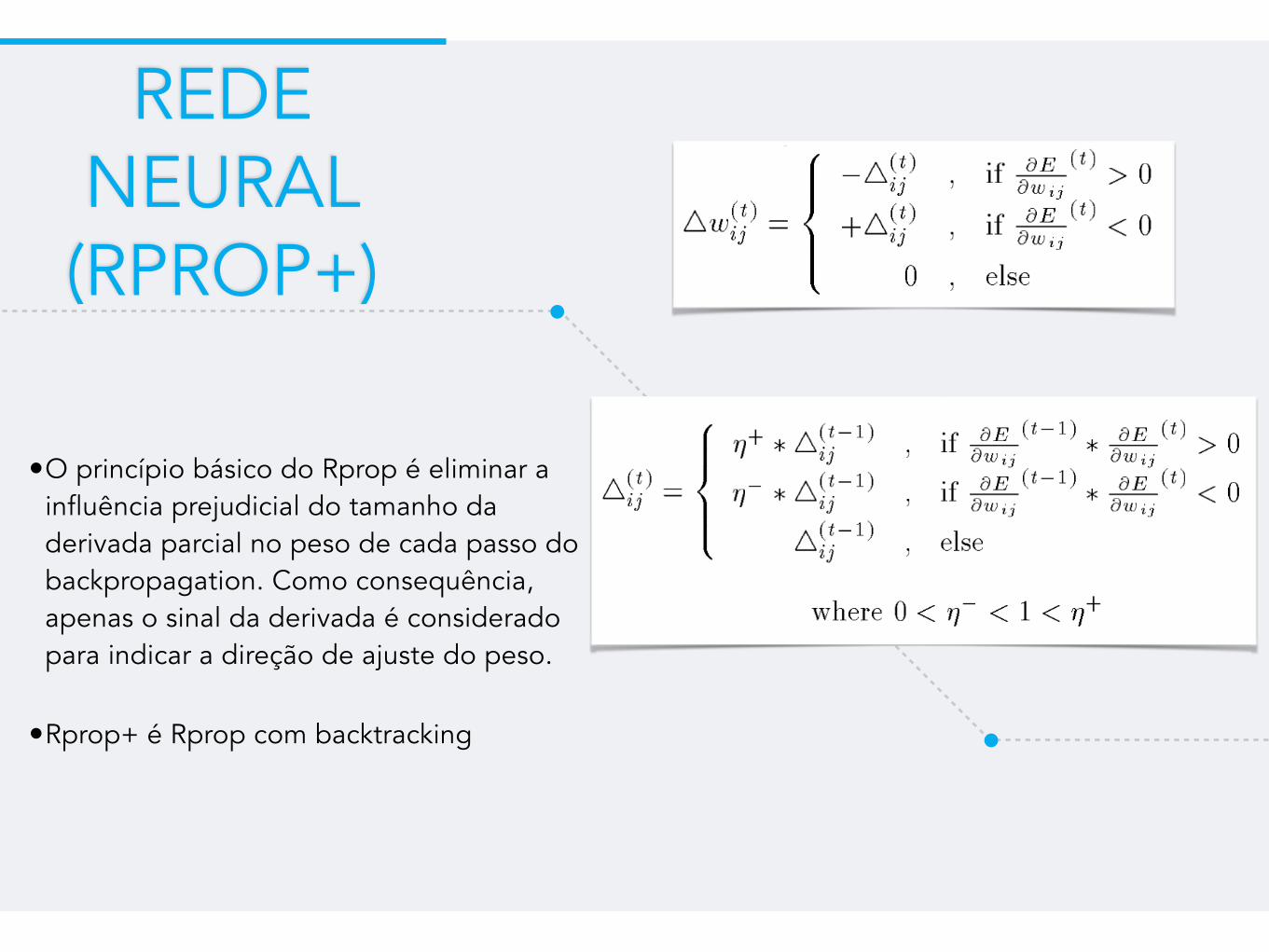
REDE NEURAL (RPROP+)
•O princípio básico do Rprop é eliminar a influência prejudicial do tamanho da derivada parcial no peso de cada passo do backpropagation. Como consequência, apenas o sinal da derivada é considerado para indicar a direção de ajuste do peso.
•Rprop+ é Rprop com backtracking

REDE NEURAL (MOMENTUM)
•O gradiente da função de erro é então calculado com base na média ponderada entre o gradiente atual e o gradiente ajustado anterior de acordo com a equação ao lado.
•Teoricamente, essa abordagem deveria proporcionar um processo de busca com um tipo de inércia que poderia ajudar a evitar oscilações excessivas em vales estreitos da função de erro (Rojas 1996)

•Poucos parâmetros:
•Random Forest - # árvores, max_features
•Gradient Tree Boosting - # árvores, taxa de aprendizagem
•Muitos Parâmetros:
•Dificuldade: espaço de busca muito grande!
•Rede Neural (rprop+) - # camadas, # neurônios por camada, taxa de aprendizagem
•Rede Neural (momentum) - # camadas, # neurônios por camada, taxa de aprendizagem, taxa de momentum
• Biggest mistake: não fazer a otimização de parâmetros com CV em paralelo
PARAMETRIZAÇÃO

•Redimensionamento de variáveis
•Criação de variáveis simplificadas
•Transformação log (variáveis dependentes)
•Variáveis por agrupamento
ENGENHARIA DE VARIÁVEIS

VARIÁVEIS POR AGRUPAMENTO

VARIÁVEIS POR AGRUPAMENTO
Variável / Grupo
Ano Estação do Ano
Condição de Tempo
Mês Hora
Tamanhomédiodo grupo*
5443 2722 2722 907 454
count 0.46 0.44 0.45 0.44 0.44
casual 0.44 0.44 0.44 0.44 0.43
registered 0.44 0.44 0.44 0.42 0.42
*Ensembles por agrupamento de dados tiveram baixo desempenho.

VARIÁVEIS POR AGRUPAMENTO
Casual
Registered
OVERVIEW DO
PIPELINE DE
APRENDIZAGEM



RESULTADOSRandom Forest
Gradient Tree Boosting
Ensemble (RF, GB)
Rede Neural (rprop+)
Rede Neural (Momentum)
Erro de Validação
0.41852 0.40162 0.38787 0.39646 0.39008
Erro de Teste 0.38561 0.38219 0.37106 (80th)
0.41244 (368th)
0.39633
Tempo de Execução (Conjunto de Testes)
34s 6s 50s 2h 11min 1h 39 min
Parâmetros #árvores =1000
#árvores =100
#árvores =100
1 camada intermediária com 10 nós;
taxa de aprendizagem
=0.001
1 camada intermediária
com 5 nós; taxa de
aprendizagem=0.001; taxa de
momentum =0.001

•Detalhada investigação de técnicas de aprendizagem de máquina para resolução de um problema real através de:
•Um estudo comparativo de diferentes técnicas de regressão
•Uma análise de seus desempenhos (erros de validação e teste), tempos de execução e particularidades de otimização
•Uma cuidadosa manipulação (criação e modificação) de variáveis
CONCLUSÃO

•Trabalhos futuros:
•Melhor parametrização através de técnicas automatizadas que efetivamente diminuam o espaço de busca
•Implementação de redes neurais em GPU ou uso de alternativas ao backpropagation (e.g., LM)
•Problema sob uma ótica de séries temporais: investigação de retardos temporais no valor das variáveis dependentes
CONCLUSÃO

DÚVIDAS?
