april 21, 2010 stat 950 chris wichman. motivation every ten years, the u.s. government conducts a...
TRANSCRIPT

Section 3.7:Finite Population Sampling
April 21, 2010STAT 950
Chris Wichman

MotivationEvery ten years, the U.S. government conducts
a population census, and every five years the U. S. National Agricultural Statistics Service conducts an Agriculture Census.
Notice, that for the given “moment in time” that the census is taken, the total population, N, is known. In the intervening years, the numbers from each census are used to make inferences. For example, mean population in urban areas, and farm output (average bushels/acre).

MotivationOf interest is an intervening year population
average:
Two statistics commonly employed in these situations:The ratio estimator:
The regression estimator:
N
j jxN1
1
n
jN
ratjjrat
n
nNrat u
tux
nn
fv
u
xut
1)1(
)1( ceest varian with
n
j jjregNreg uxnn
fvut
1
21010 )ˆˆ(
)2(
)1( ceest varian with ˆˆ

Sample AverageWithout Replacement SamplesPopulation Average , where the
unbiased estimator of μ is
When is based on a sample taken without replacement, the true variance of is:
the unbiased estimator of which is:
NyN
j j
1
nyYn
j j
1
N
nf
nf
Nn
y
fYVar
N
jj
where;)1(
)1(
)(
)1()(2
1
2
YY
n
sf
nn
yy
fYVar
n
jj 2
1
2
)1( )1(
)(
)1()(

The Problem with the Ordinary BootstrapRecall, when a resample, is taken
with replacement from the original sample then:
Note that the only matches the form of if the sampling fraction, .
In other words, the ordinary bootstrap fails to realize the “contraction” in .
**1 nYY
nyy 1
2
1
2
2
2***
)()1()()ˆ|(
n
yy
n
snYVarFYVar
n
j j
)( ** YVar )(YVar
nf
1
)(YVar

Proposed Resampling MethodsModified Sample Size
With replacementWithout replacement
Mirror Match
Population
Superpopulation

Modified Sample SizeFind a resampling size such that the
is approximately matched by .
Process:Find the form of Take the expected value of and set
equal toSolve for
)(YVar
)( ** YVar
)( ** YVar
)( ** YVar )(YVar
n
n

Modified Sample SizeWith-ReplacementFor with replacement resampling, the
bootstrapped variance of is:
this leads to a modified sample size > than n
n
sn
nYVar
2** )1(1)(
)1(
)1(
f
nn
*Y
n
fn
sEn
nYVarE
22** )1(
)1(1)(
nf
n
n
n
22
)1()1(1

Modified Sample SizeWithout-replacementFor without-replacement resampling, notice
that the effective N for each resample is really n.
The making the obvious
choice for one in which
n
sn
nfYVar
2** )1(1
)1()(
nfn
nn
nf

Mirror MatchGoals:
Capture the dependence due to sampling without-replacement
Minimize the instability of the resampled statistic, by matching the original sample size
Process:SupposeThen simply concatenate k resamples of size m
together to form an
numbers wholeare / and , mnknfm
nn

Mirror MatchWhen m and k are not integers:
Round m = nf to the nearest whole number
Choose k such that
Randomly select either k or (k+1) without-replacement resamples of size m from . Sampling probabilities should be chosen to match f
mknkm )1(
nyy 1

Population BootstrapIf is an integer:
create a fake population Y*, by repeating k times.
Generate R replicate samples of size n, by sampling without-replacement from Y*.
Each resample will have the same sampling fraction as the original sample.
nNk
nyy 1

Population BootstrapIf is not an integer:
Find k and l such that N = nk + l, and .
create a fake population Y*, by repeating k times and joining it with a without replacement sample of size l from . This step is repeated R times.
Generate R replicate samples of size n, by sampling without-replacement from Y*.
Each resample will have the same sampling fraction as the original sample.
nNk
nyy 1
nl 0
nyy 1

Superpopulation BootstrapFor each resample, 1,. . .,R
Create a fake population, Y*, of size N, by resampling with replacement from , N times.
From each Y1*, . . . , YN* take a without replacement sample of size n.
Each resample will have the same sampling fraction as the original sample.
nyy 1

Example 3.15: City Population DataA Comparison of Confidence IntervalsIn this example, the normal approximation
C.I. refers to the bias corrected interval:
The remaining intervals are Studentized confidence intervals :
zvtzvt bsbs5.0
)1(5.0 ˆˆ
*))1((
5.0*))1)(1((
5.0 RR zvtzvt

Example 3.15: City Population DataTable 3.7
ResamplingScheme Ratio Regression
Normal 132.65 175.18 128.48 161.09
Modified Size, n' = 2 46.55 298.93 NA NA
Modified Size, n' = 11 109.14 209.42 111.31 283.13
Mirror Match, m = 2 118.42 174.79 117.06 245.09
Population 116.72 199.18 113.56 267.37
Superpopulation 107.7 204.17 110.43 300.64
ResamplingScheme Ratio Regression
Normal 137.8 174.7 123.7 152
Modified Size, n' = 2 58.9 298.6 NA NA
Modified Size, n' = 11 111.9 196.2 114 258.2
Mirror Match, m = 2 115.6 196 112.8 258.7
Population 118.9 193.3 116.1 240.7
Superpopulation 120.3 195.9 114 255.4

Example 3.15: City Population DataTable 3.8
Recreated in R Coverage Length
Lower Upper Overall Average SD
Normal 6 88 82 22.35 7.62
Modified Size, n' = 2 0 96 96 164.48 143.2
Modified Size, n' = 11 1 94 93 38.09 20.97
Mirror Match, m = 2 1 86 85 26.77 14.87
Population 1 91 90 34.75 19.61
Superpopulation 0 94 94 39.08 21.29
From BMA pg 96 Coverage Length
Lower Upper Overall Average SD
Normal 7 89 82 23 8.2
Modified Size, n' = 2 1 98 98 151 142
Modified Size, n' = 11 2 91 89 34 19
Mirror Match, m = 2 3 91 88 33 19
Population 2 91 89 36 21
Superpopulation 1 92 91 41 24

Example 3.15: City Population DataFigure 3.6
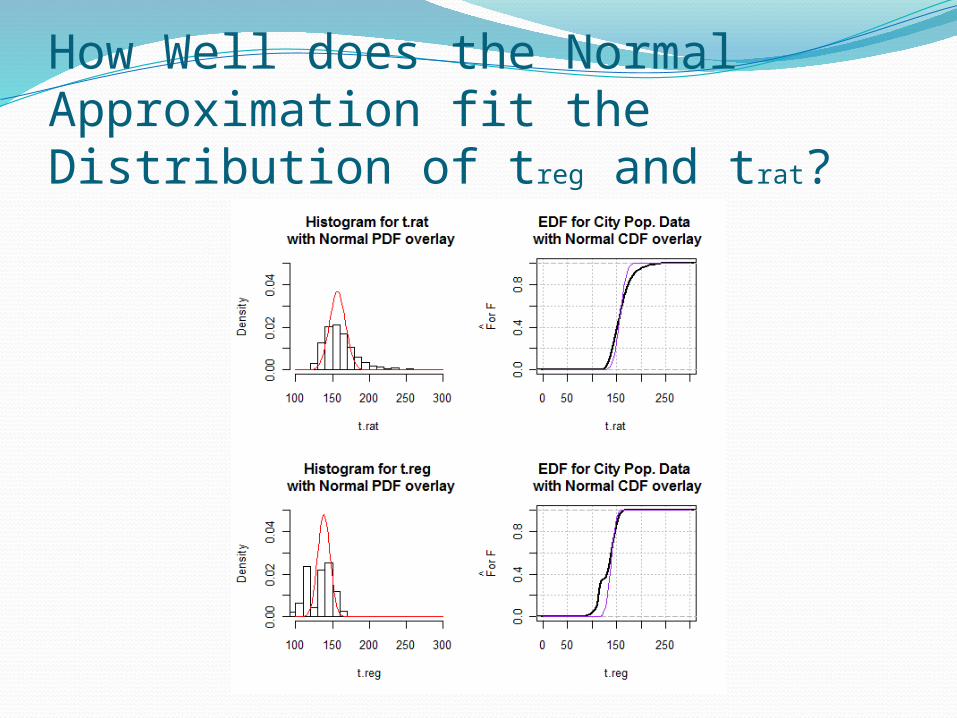
How Well does the Normal Approximation fit the Distribution of treg and trat?

How Well does the Normal Approximation fit the Distribution of treg and trat?

Conclusions About trat and tregThe normal approximation for the ratio and
regression estimators performs poorly. The estimated expected length of confidence
intervals based on the normal approximation are very short relative to the other resampling methods.
The estimated variance of the regression estimator is unstable, potentially causing huge swings in z* ultimately affecting the bounds of Studentized confidence intervals.

Stratified SamplingSuppose the population of interest is divided
into k strata, then the population total,
Each strata now has it’s own sampling fraction,
Each strata represents proportion of the population.
kNNN 1
i
ii N
nf
kiN
Nw ii ,,1 ;

trat for a Stratified SampleOf interest is the overall mean:
The ratio estimator for a stratified population becomes:
k
i
N
j ijxN1 1
1
ni
j ijiijii
iirat
k
ii
iNiirat utx
nn
fwv
u
xuwt
1
2
1.
.
)1(
)1( ceest varian with

Example 3.17: Stratified RatioHere, Davison and Hinkley drop the
regression estimator, due to the potential instability of the variance affecting the bootstrapped confidence intervals.
They also drop the Modified Sample, because they felt it was a “less promising” finite population resampling scheme.
nfn

Example 3.17: MethodologySimulate N pairs (u, x) divided into k strata of
sizes
“small-k”: k = 3, Ni = 18, ni = 6“small-k”: k = 5, Ni = 72, ni = 24“large-k”: k = 20, Ni = 18, ni = 6
1000 different samples of size were taken from the dataset(s) produced above. For each sample, R=199 resamples were used to compute confidence intervals for θ.
knnn 1
kNN ,,1

All methods were used on the sample as described in example 3.15, with the exception of superpopulation resampling, which was conducted for each strata.
Example 3.17: Methodology
BMA Table 3.9 k=20, N=18 k=5, N=72 k=3, N=18
L U O L U O L U O
Normal 5 93 88 4 94 90 7 93 86
Modified Sample Size 6 94 89 4 94 90 6 96 90
Mirror-match 9 92 83 8 90 82 6 94 88
Population 6 95 89 5 95 90 6 95 89
Superpopulation 3 97 95 2 98 96 3 98 96

Conclusions: Stratified SampleThe estimated coverage for Normal, Modified
Sample Size, and Population resampling methods are all close to the nominal 90% desired. The “tail” probabilities are each roughly 5%.
Neither the Mirror-match (estimated coverage of 83%), nor the Superpopulation (estimated coverage of 95%) performed very well.
Due to their ease of calculation, Davison and Hinkley conclude that the Population and Modified Sample Size perform the best.