architecting for high-availability and multi-cloud environments
TRANSCRIPT

1
Architecting for High-Availability and Multi-Cloud EnvironmentsBrian Adler - Sr. Professional Services Architect, RightScale
June 8th, 2011

2
Real Cloud Experience. Shared.
# 2
Agenda
• Terminology/Level-Setting• Takeaways• Designing for Failure• Cloud and component definitions (more terminology)
• Architectural options and considerations to protect against cloud failures
• Conclusions / Q&A

3
Real Cloud Experience. Shared.
# 3
Terminology• Fault Tolerance
• Designs incorporating redundancy and replication to enable systems to continue operating properly (perhaps at a degraded level) if one or more components fails
• High Availability (HA)• Fault Tolerant systems are measured by their Availability in terms of
planned and unplanned service outages for end users• 99% Availability = 3.65 days of downtime per year• 99.9% Availability = 8.76 hours of downtime per year• 99.99% Availability = 53 minutes of downtime per year• 99.999% Availability = 5.26 minutes of downtime per year
• Disaster Recovery (DR)• The process, policies and procedures related to restoring critical systems
after a catastrophic event

4
Real Cloud Experience. Shared.
# 4
Agenda
• Terminology/Level-Setting• Takeaways• Designing for Failure• Cloud and component definitions (more terminology)
• Architectural options and considerations to protect against cloud failures
• Conclusions / Q&A

5
Real Cloud Experience. Shared.
# 5
Takeaways• Introduction to architectural options for designing highly-
available, fault-tolerant applications• Best Practices for implementation of these architectural options• Multi-Availability Zone (AZ), Multi-Region and Multi-Cloud
• Architectural options• Considerations / pros and cons of these options

6
Real Cloud Experience. Shared.
# 6
Agenda
• Terminology/Level-Setting• Takeaways• Designing for Failure• Cloud and component definitions (more terminology)
• Architectural options and considerations to protect against cloud failures
• Conclusions / Q&A

7
Real Cloud Experience. Shared.
# 7
Designing for Failure (in a good way)
• Large scale failures in the cloud are rare but do happen• Application owners are ultimately responsible for
availability and recoverability• Need to balance cost and complexity of HA efforts against
risk(s) you are willing to bear• Cloud infrastructure has made DR and HA remarkably
affordable versus past options• Multi-Server• Multi-AZ• Multi-Region• Multi-Cloud

8
Real Cloud Experience. Shared.
# 8
Agenda
• Terminology/Level-Setting• Takeaways• Designing for Failure• Cloud and component definitions (more terminology)
• Architectural options and considerations to protect against cloud failures
• Conclusions / Q&A

9
Real Cloud Experience. Shared.
# 9
What do we mean by “Cloud”?
• A cloud is a physical datacenter entity behind an API endpoint
• What does that really mean?• Amazon Web Services is not a cloud• EC2 is not a cloud• Eucalyptus, Cloud.com, OpenStack are not clouds• EC2 US-East, Rackspace, ‘my private cloud’… these are clouds• An availability zone is not a cloud (but it is part of one)
Think of a cloud as a “resource pool” accessed via an API
10
Real Cloud Experience. Shared.
# 10
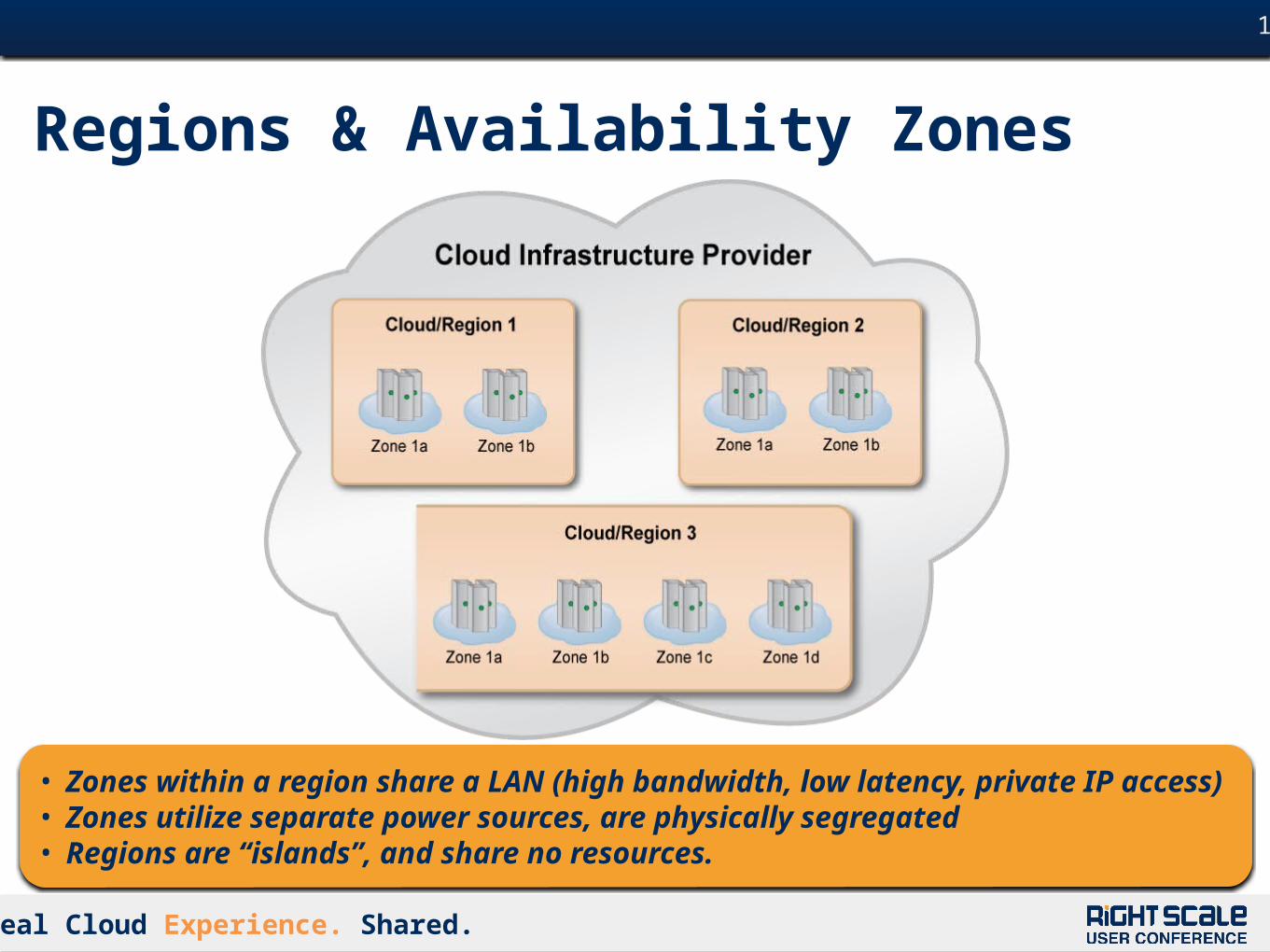
Regions & Availability Zones
• Zones within a region share a LAN (high bandwidth, low latency, private IP access)
• Zones utilize separate power sources, are physically segregated • Regions are “islands”, and share no resources.

11
Real Cloud Experience. Shared.
# 11
Overcoming Multi-Cloud Pain Points• APIs differ
• Different sets of available resources• Different formats, encodings and versions
• Abstractions and features differ• Network architectures differ: VLANs, security groups, NAT, IPs, ACLs, …• Storage architectures differ: local/attachable disks, backup, snapshots, …• Hypervisors, machine images, cost models, billing, reporting… etc.
Each cloud is unique in some/many/all respects, with differentaccess mechanisms and varying functionalities providedby the managed resources.

12
Real Cloud Experience. Shared.
# 12
Overcoming Multi-Cloud Pain Points• Navigating the obstacles
• Design using generic concepts (“durable storage”) yet deploy using cloud specifics (“EBS volumes”)
• Have tools that translate your concepts to cloud-specific ones (e.g. scripts/recipes that choose the correct provider for the desired resource)
• Think of how to share resources across clouds (i.e. data sharing)

13
Real Cloud Experience. Shared.
# 13
Agenda
• Terminology/Level-Setting• Takeaways• Designing for Failure• Cloud and component definitions (more terminology)
• Infrastructure abstraction and automation as building blocks for highly available applications
• Architectural options and considerations to protect against cloud failures
• Conclusions / Q&A

14
Real Cloud Experience. Shared.
# 14
HA/DR Checklist for Risk Mitigation
Determine who owns the architecture, DR process and testing. Develop expertise in-house and / or get outside help. Conduct a risk assessment for each application. Specify your target Recovery Time Objective
and Recovery Point Objective. Design for failure starting with application architecture. This will help
drive the infrastructure architecture. Implement HA best practices balancing cost, complexity and risk.
Automate infrastructure for consistency and reliability.
Document operational processes and automations. Test the failover... then test it again. Release the Chaos Monkey.

15
Real Cloud Experience. Shared.
# 15
Application Architecture Deployment Options
Component
DNS
Load Balancing
Storage
Server Array
Database
Options/Considerations
DNS APIs for dynamic configuration (DynDNS, Route 53, DNS Made Easy)
HAProxy, Zeus, aiCache, ELB
Local storage, EBS, S3, CloudFiles, GlusterFS, etc.
Scalable tiers; scale up and down conservatively
MySQL, PostgreSQL, SQL Server, RDS, NoSQL

16
Real Cloud Experience. Shared.
# 16
General HA Best Practices
Avoid single points of failure. Always place (at least) one of each component (load balancers,
app servers, databases) in at least two AZs. Maintain sufficient capacity to absorb AZ / cloud failures.
Reserved Instances – guarantee capacity is available in a separate region/cloud
Replicate data across AZs and backup or replicate across clouds/regions for failover.
Setup monitoring, alerts and operations to identify and automate problem resolution or failover process.
Design stateless applications for resilience to reboot / relaunch.
17
Real Cloud Experience. Shared.
# 17
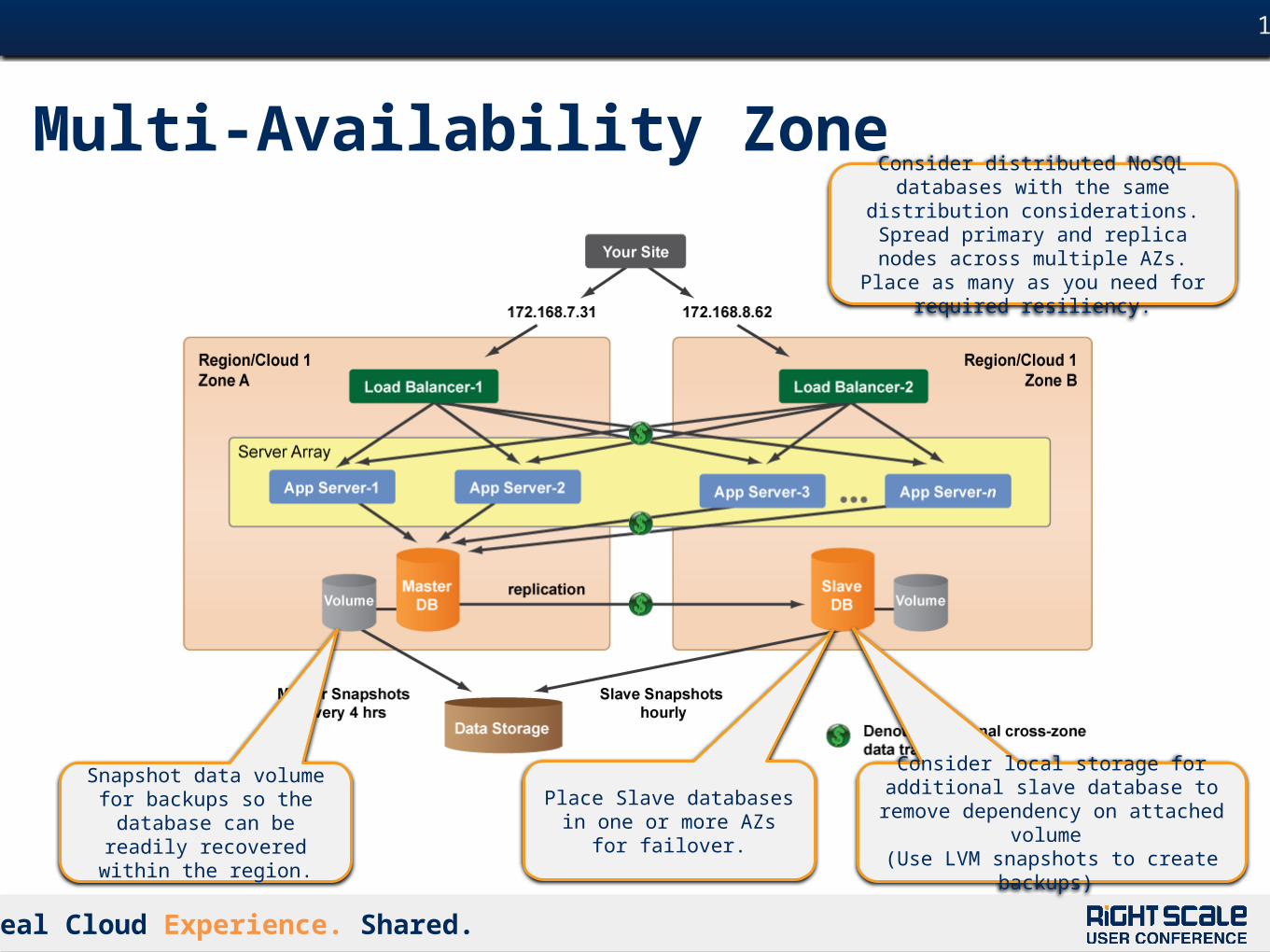
Multi-Availability Zone
Snapshot data volume for backups so the database can
be readily recovered within the region.
Place Slave databases in one or more AZs for failover.
Consider distributed NoSQL databases with the same distribution considerations. Spread primary and replica nodes across multiple AZs. Place as many as you need
for required resiliency.
Consider local storage for additional slave database to remove dependency
on attached volume (Use LVM snapshots to create backups)

18
Real Cloud Experience. Shared.
# 18
Multi-Cloud Cold / Warm / Hot DR Options
Cold DR
Warm DR
Hot DR
Multi-Cloud HANo Downtime
> 5 Minutes
> 1 Hour
> Few Hours
$ $$ $$$ $$$$
(Most Common)
(Recommended)
(Least Common)
(Live/Live Config)

19
Real Cloud Experience. Shared.
# 19
Multi-Cloud Cold DRStaged Server Configuration and generally no staged data
Data Copy Mechanism
• Not recommended if rapid recovery is required • Slow to replicate data to other cloud• Slow to bring database to an operational state

20
Real Cloud Experience. Shared.
# 20
Multi-Cloud Warm DRStaged Server Configuration, pre-staged data and running Slave Database Server
• Generally recommended DR solution
• Minimal additional cost • Allows fairly rapid recovery

21
Real Cloud Experience. Shared.
# 21
Multi-Cloud Hot DRParallel Deployment with all servers running but all traffic going to primary
• Not recommended. Very high additional cost• Allows rapid recovery, but not significantly faster than “warm” configuration
22
Real Cloud Experience. Shared.
# 22
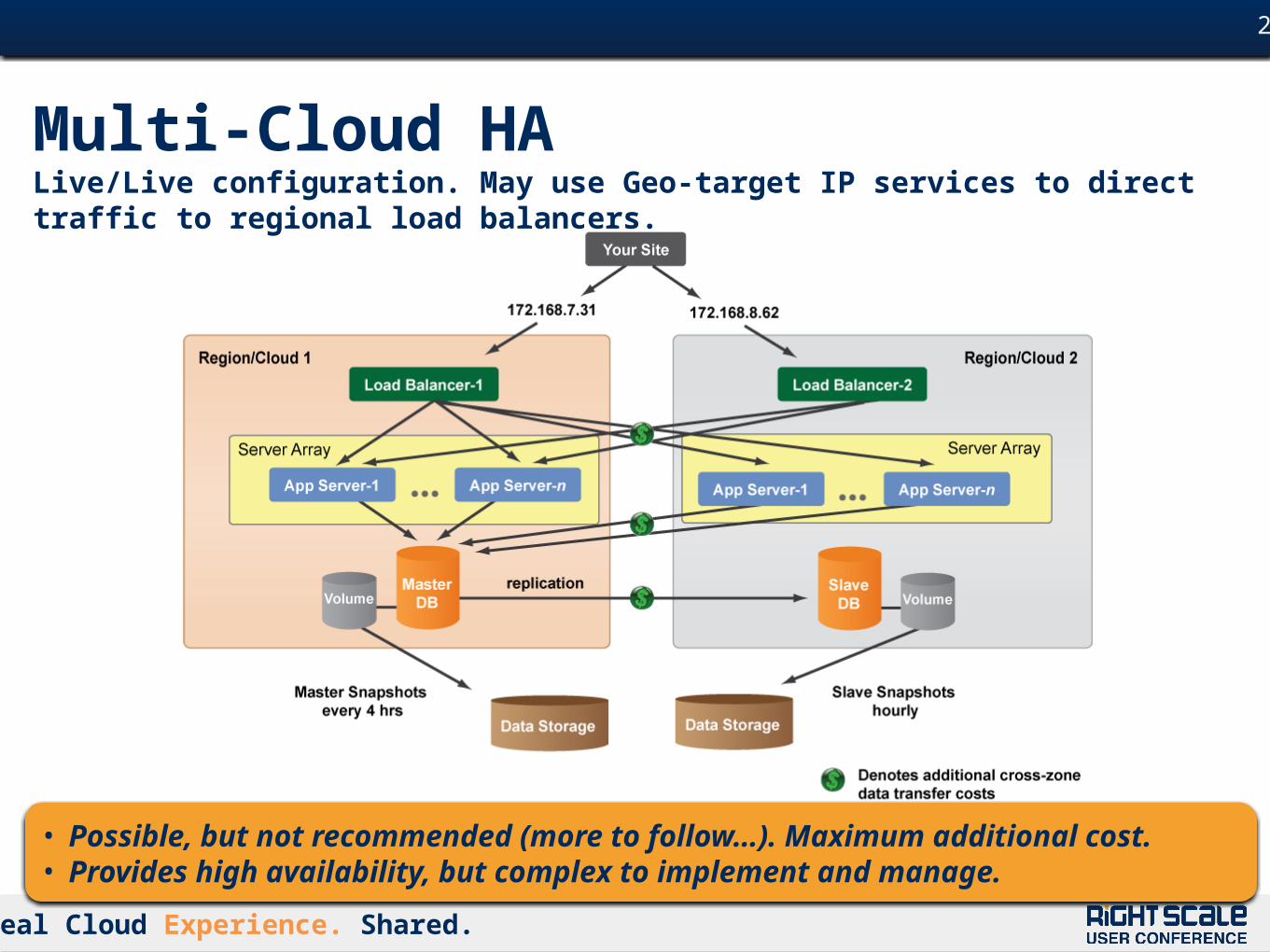
Multi-Cloud HALive/Live configuration. May use Geo-target IP services to direct traffic to regional load balancers.
• Possible, but not recommended (more to follow…). Maximum additional cost. • Provides high availability, but complex to implement and manage.
23
Real Cloud Experience. Shared.
# 23
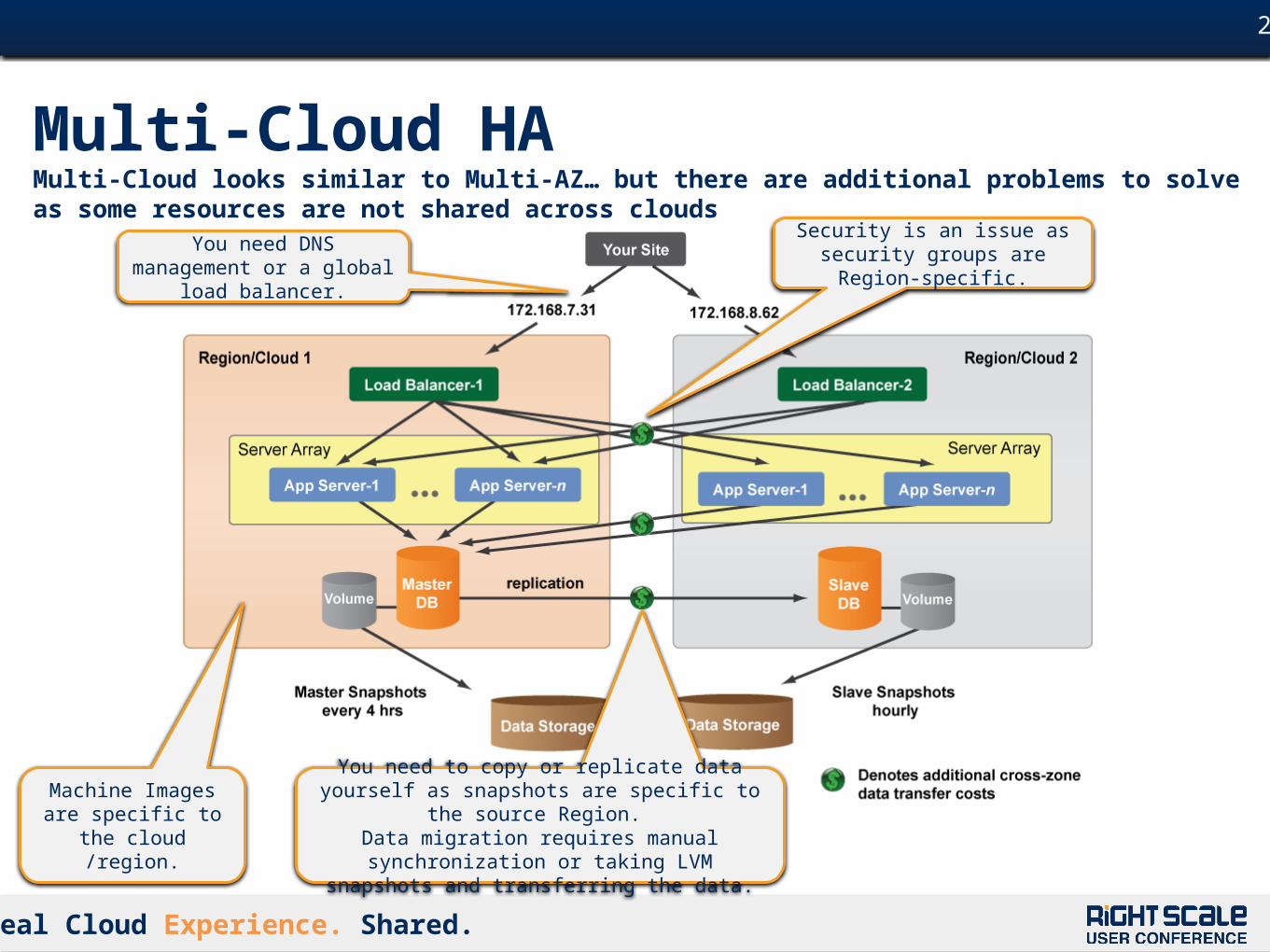
Multi-Cloud HAMulti-Cloud looks similar to Multi-AZ… but there are additional problems to solve as some resources are not shared across clouds
You need DNS management or a global load balancer.
Machine Images are specific to the cloud
/region.
You need to copy or replicate data yourself as snapshots are specific to the source Region.
Data migration requires manual synchronization or taking LVM snapshots and transferring the data.
Security is an issue as security groups are Region-specific.

24
Real Cloud Experience. Shared.
# 24
Agenda
• Terminology/Level-Setting• Takeaways• Designing for Failure• Cloud and component definitions (more terminology)
• Infrastructure abstraction and automation as building blocks for highly available applications
• Architectural options and considerations to protect against cloud failures
• Conclusions / Q&A

25
Real Cloud Experience. Shared.
# 25
So What’s Best?• Design for failure
• Assume everything will fail and architect a solution capable of handing each and every failure condition
• No one size fits all solution is available• Every application has its own architecture
• Not all infrastructure building blocks fit well with all applications
• Tradeoffs between levels of resiliency and cost
• The options available in the cloud today are unprecedented• Capabilities for global redundancy• Time to access• Investment required
• Follow our High Availability Checklist (or create your own)• Multi-AZ configurations with a solid DR plan are generally the
most viable and cost-conscious solutions

26
Questions?
Brian Adler - Sr. Professional Services Architect, RightScale
June 8th, 2011

27
We hope to see you at our next RightScale User Conference!
See all presentations and videos at RightScale.com/Conference.