assessing the impact of cyber attacks using game theory · assessing the impact of cyber attacks...
TRANSCRIPT

Assessing the Impact of Cyber
Attacks Using Game Theory
João P.
Hespanha
Kyriakos G.
Vamvoudakis
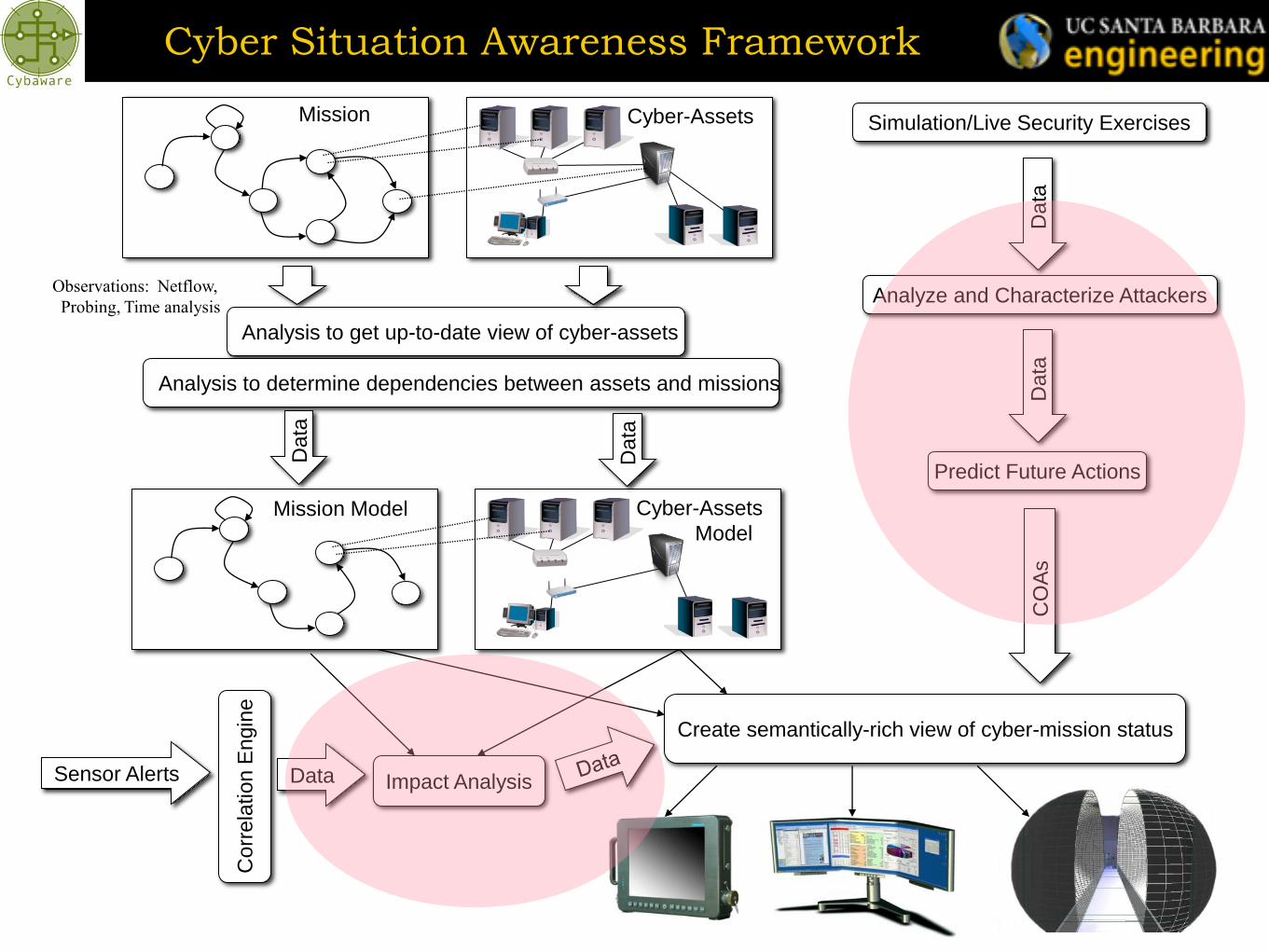
Mission Cyber-Assets
CO
As
Mission Model Cyber-Assets
Model
Sensor Alerts
Co
rre
latio
n E
ng
ine
Analysis to get up-to-date view of cyber-assets
Analysis to determine dependencies between assets and missions
Impact Analysis
Create semantically-rich view of cyber-mission status
Simulation/Live Security Exercises
Predict Future Actions
Analyze and Characterize Attackers
Da
ta
Da
ta
Data
Da
ta
Da
ta
Observations: Netflow,
Probing, Time analysis
Cyber Situation Awareness Framework

Outline...
Large-scale cyber-security games (summary of new results)
Estimation and detection in adversarial environments
Online optimization for real-time attack prediction

Outline...
Large-scale cyber-security games (summary of new results)
Estimation and detection in adversarial environments
Online optimization for real-time attack prediction
Prandini-Milano
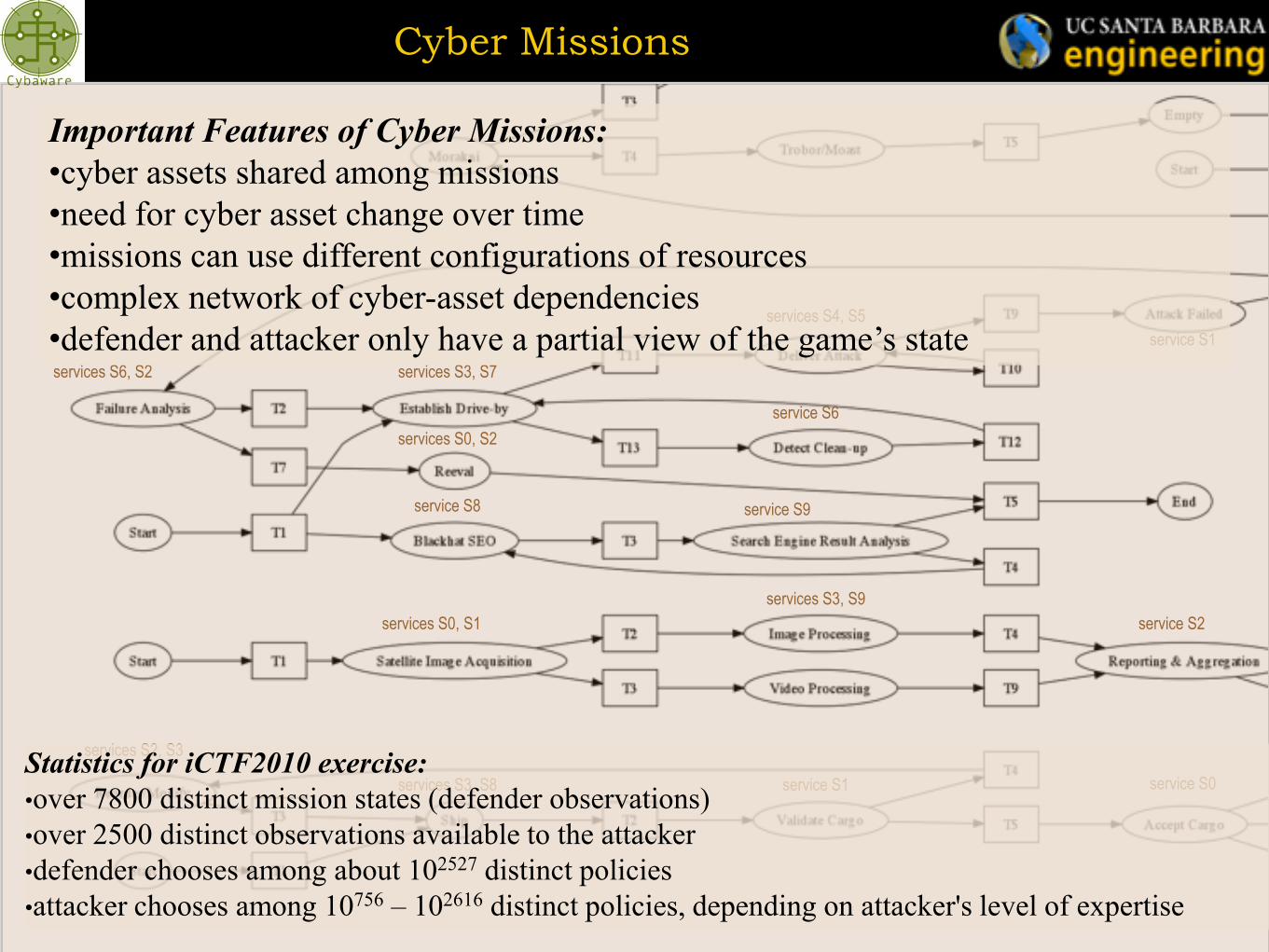
Cyber Missions
services S3, S7
services S4, S5
services S0, S2
service S6
service S1
services S6, S2
service S9 service S8
services S0, S1
services S3, S9
service S2
service S0 service S1 services S3, S8
services S2, S3
Important Features of Cyber Missions:
•cyber assets shared among missions
•need for cyber asset change over time
•missions can use different configurations of resources
•complex network of cyber-asset dependencies
•defender and attacker only have a partial view of the game’s state
Statistics for iCTF2010 exercise:
•over 7800 distinct mission states (defender observations)
•over 2500 distinct observations available to the attacker
•defender chooses among about 102527 distinct policies
•attacker chooses among 10756 – 102616 distinct policies, depending on attacker's level of expertise

Zero-Sum Matrix Games
Two players:
P1 - minimizer
P2 - maximizer
Each player selects a policy:
S1 - set of available policies for P1
S2 - set of available policies for P2
All possible game outcomes can be encoded in a matrix (2D-array),
jointly indexed by the actions of the players
P1‘s
policy
P2‘s policy
game outcome when
P1 selects policy i
P2 selects policy j
We are interested in games in which, at least one (possibly both)
dimensions of this matrix are very large
=> precise security levels impossible to compute
Mixed security level for P1 (minimizer):
What is the worst outcome, assuming my best response?

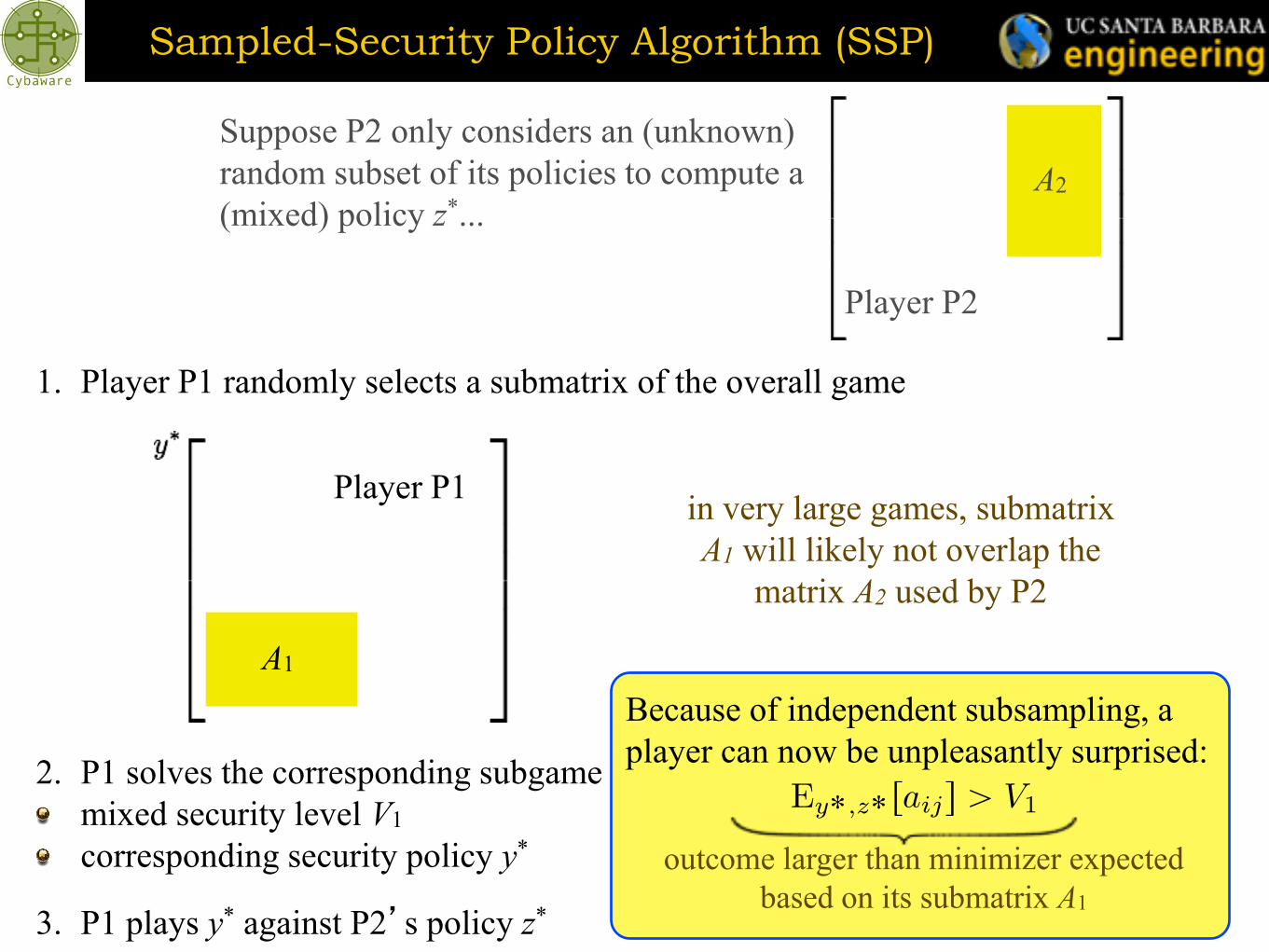
Sampled-Security Policy Algorithm (SSP)
1. Player P1 randomly selects a submatrix of the overall game
Player P1
2. P1 solves the corresponding subgame (as if it was the whole game) and computes
mixed security level V1
corresponding security policy y*
A1
3. P1 plays y* against P2’s policy z*
in very large games, submatrix
A1 will likely not overlap the
matrix A2 used by P2
A2
Player P2
P1‘s
policy
P2‘s policy
Suppose P2 only considers an (unknown)
random subset of its policies to compute a
(mixed) policy z*...
Sampled-Security Policy Algorithm (SSP)
1. Player P1 randomly selects a submatrix of the overall game
Player P1
2. P1 solves the corresponding subgame (as if it was the whole game) and computes
mixed security level V1
corresponding security policy y*
A1
3. P1 plays y* against P2’s policy z*
in very large games, submatrix
A1 will likely not overlap the
matrix A2 used by P2
A2
Player P2
Suppose P2 only considers an (unknown)
random subset of its policies to compute a
(mixed) policy z*...
Because of independent subsampling, a
player can now be unpleasantly surprised:
outcome larger than minimizer expected
based on its submatrix A1
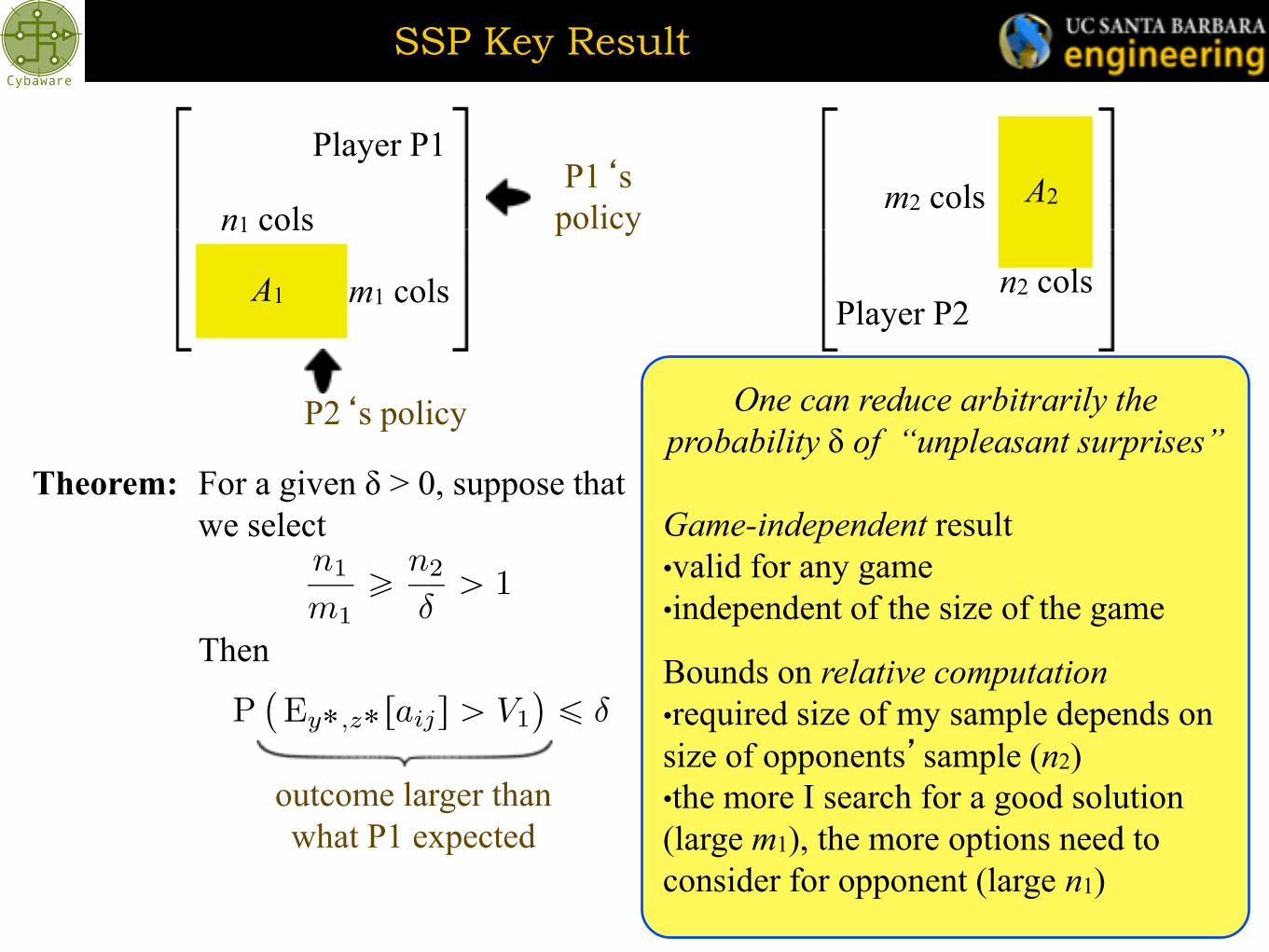
SSP Key Result
A2
Player P2
m2 cols
n2 cols
Theorem: For a given δ > 0, suppose that
we select
Then
A1
Player P1
n1 cols
m1 cols
P1‘s
policy
P2‘s policy
outcome larger than
what P1 expected
One can reduce arbitrarily the
probability δ of “unpleasant surprises”
Game-independent result
•valid for any game
•independent of the size of the game
Bounds on relative computation
•required size of my sample depends on
size of opponents’sample (n2)
•the more I search for a good solution
(large m1), the more options need to
consider for opponent (large n1)

New Results
1. Pure policies (not involving randomization):
Theorem: For a given δ > 0, suppose that we select
Then
outcome larger than
what P1 expected
no longer linear on m1
(much smaller # of
samples needed)
total # of game outcomes
2. Opponent algorithms:
All results independent of the algorithm used by opponent to select its policy z*
3. Opponent sampling:
Results have been generalized to mismatched sampling distributions
Theorem: For a given δ > 0, suppose that we select
Then
mismatch factor
(measures distance between distributions)
S. Bopardikar, A. Borri, J. Hespanha, et. al. Randomized Sampling for Large Zero-Sum Games. To appear in Automatica.

Outline...
Large-scale cyber-security games (summary of new results)
Estimation and detection in adversarial environments
Online optimization for real-time attack prediction
Sinopoli-CMU Y. Mo-CMU

Estimation in Adversarial Environments
How to interpret & access the reliability of “sensors” that have been manipulated?
“Sensors” relevant to cyber missions?
•Measurement sensors (e.g., determine presence/absence of friendly troops)
•Computational sensors (e.g., weather forecasting simulation engines)
•Data retrieval sensors (e.g., database queries)
•Cyber-security sensors (e.g., IDSs)
Domains
• Deterministic sensors:
with n sensors, one can get correct answer as long as m < n/2 sensors
have been manipulated

Estimation in Adversarial Environments
How to interpret & access the reliability of “sensors” that have been manipulated?
“Sensors” relevant to cyber missions?
•Measurement sensors (e.g., determine presence/absence of friendly troops)
•Computational sensors (e.g., weather forecasting simulation engines)
•Data retrieval sensors (e.g., database queries)
•Cyber-security sensors (e.g., IDSs)
Domains
• Deterministic sensors:
with n sensors, one can get correct answer as long as m < n/2 sensors
have been manipulated
• Stochastic sensors without manipulation:
solution given by hypothesis testing/estimation
• Stochastic sensors with potential manipulation: open problem?

Problem formulation
X – binary random variable to be estimated
for simplicity
(papers treats general case)
Y1, Y2, …, Yn – “noisy” measurements of X produced by n sensors
per-sensor error probability
(not necessarily very small)
Z1, Z2, …, Zn – measurements actually reported by the n sensors
at most m sensors attacked
pattack – probability that we are under attack (very hard to know!)
interpretation of sensor data should be mostly independent of pattack

Game Theoretical Approach
X – binary random variable to be estimated
Y1, Y2, …, Yn – “noisy” measurements of X produced by n sensors
Z1, Z2, …, Zn – measurements actually reported by the n sensors
Players:
P1 (minimizer) – selects estimation policy
Goal: minimize
estimate
of X
P2 (maximizer) – selects attack policy larger if we include selection of
which sensors to attack
previous results amenable to this problem, but we can do better…

Result
Theorem:
perr
pattack
The optimal estimator can guarantee
optimal attack free
prob. error
prob. error degradation due to attack
• essentially linear growth with pattack
• essentially exponential grow with m (#attacked sensors)
K. G. Vamvoudakis, J. P. Hespanha, B. Sinopoli, Y. Mo, “Adversarial Detection as a
Zero-Sum Game,” to appear in IEEE Conference on Decision and Control, 2012
How to interpret &
access the reliability of
“sensors” that have been
manipulated?

Result
Theorem:
perr
pattack
The optimal estimator is
go with the majority of the (potentially manipulated) sensor readings
go with the majority, EXCEPT if there is consensus
The optimal estimator is largely independent of pattack (hard to know)

Result
Theorem:
perr
pattack
The optimal estimator is
go with the majority of the (potentially manipulated) sensor readings
go with the majority, EXCEPT if there is consensus
The optimal estimator is largely independent of pattack (hard to know)
What about larger prob. of
sensor errors/prob. of attack ?

General case
Theorem: For every perr, pattack the estimator
threshold like rule
is away from optimal, at most by,
• All of this is independent of pattack (hard to know)
• Deterministic bounds on probability of being fooled by attacker
small when we have enough sensors
(needed to overcome large perr)
K. G. Vamvoudakis, J. P. Hespanha, B. Sinopoli, Y. Mo, “Detection in Adversarial
Environments,” in preparation for IEEE Transactions on Automatic Control, 2012.

Additional Results
General formulation:
1. Estimate distribution of a random variable X with two possible distributions
2. Given measurement Z = X + Y, where distribution of Y is determined by adversary
3. Compute attack/defense policies that minimize probability of error
Omniscient adversary:
1. Estimate value of binary random variable X
2. Given continuous measurements
with the understanding that attacker knows values of all measurements when
she chooses Zi
3. Compute attack/defense policies that minimize probability of error
K. G. Vamvoudakis, J. P. Hespanha, B. Sinopoli, Y. Mo, “Detection in Adversarial
Environments,” in preparation for IEEE Transactions on Automatic Control, 2012.
additive noise (e.g., Gaussian)
Yilin Mo, J. Hespanha, Bruno Sinopoli. Robust Detection in the Presence
of Integrity Attacks. In Proc. of the 2012 Amer. Contr. Conf., June 2012.

Outline...
Large-scale cyber-security games (summary of new results)
Estimation and detection in adversarial environments
Online optimization for real-time attack prediction
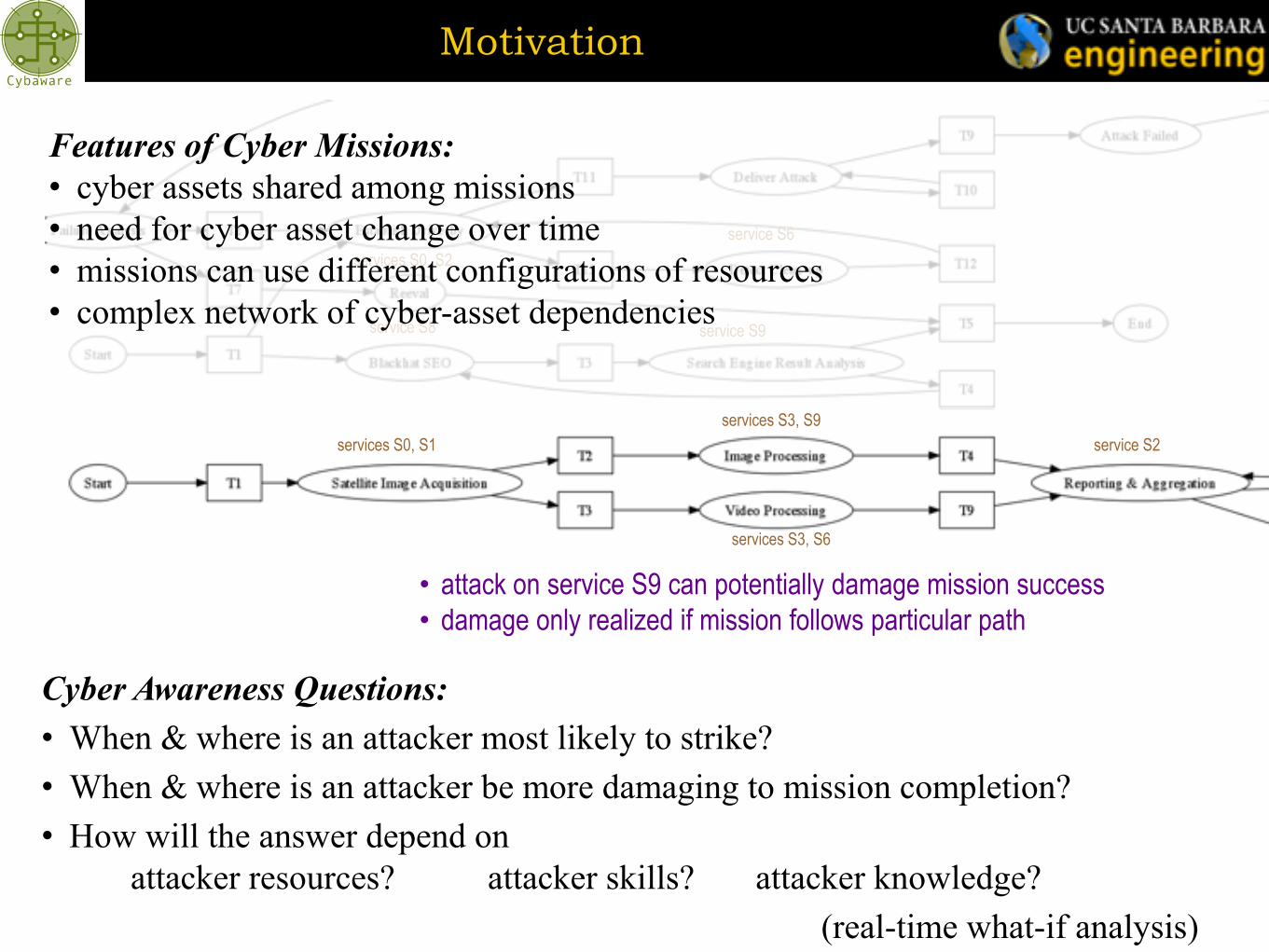
Motivation
services S0, S2
service S6
service S9 service S8
services S0, S1
services S3, S9
service S2
• attack on service S9 can potentially damage mission success
• damage only realized if mission follows particular path
services S3, S6
Features of Cyber Missions:
• cyber assets shared among missions
• need for cyber asset change over time
• missions can use different configurations of resources
• complex network of cyber-asset dependencies
Cyber Awareness Questions:
• When & where is an attacker most likely to strike?
• When & where is an attacker be more damaging to mission completion?
• How will the answer depend on
attacker resources? attacker skills? attacker knowledge?
(real-time what-if analysis)

Quantifying Mission Damage
Attack Resources (AR) affect
• Potential for damage (PD)
• Probability that potential realizes into actual damage to mission (p)
total damage
to mission
projection to interval [0,1]
Damage equation:
attack
resources
potential
damage
Uncertainty equation:
attack
resources
probability of
realizing damage

Damage Dynamics
• Mission requires multiple services
• Mission reliance on services varies with time
total damage
to mission
Damage equation:
attack
resources potential
damage
Uncertainty equation:
attack
resources
probability of
realizing damage
Equation parameters typically
vary with time according to
complex equations
•Finite-state machines
•Markov chains
•Auto-regressive models
•…

Optimal Attacks
Damage equation:
• Attack resources are constrained
• Attacker allocates resources to maximize damage
attack
resources potential
damage
Uncertainty equation:
attack
resources
probability of
realizing damage
total damage
to mission total attack
resources
Equation parameters typically
vary with time according to
complex equations
•Finite-state machines
•Markov chains
•Auto-regressive models
•…
total attack
resources at time t
maximize constrained by:

Optimal Attacks
Lemma: Previous optimization is equivalent to following concave maximization
maximize
subject to
numerically very
well behaved
How effective are these optimizations on predicting real attacks?

2011 iCTF
• Distributed, wide-area security exercise to test the security skills of the
participants, organized yearly by Prof. Giovanni Vigna (UCSB)
• The 2011 iCTF involved 89 teams from around the world (1000+ participants)
• Cyber assets shared among missions
• Mission needs (in terms of cyber assets) change over time
• Attackers (teams)
• receive cues about importance of cyber assets (payoff & cut)
• receive cues about uncertainty in inflicting damage (risk)
• must decide how to efficiently use resources (money)
• Team that produces most damage wins (points)
described in
more detail in
G. Vigna’s talk

How did we get the parameters?
Damage equation:
attack
resources potential
damage
Uncertainty equation:
attack
resources
probability of
realizing damage
Equation parameters typically
vary with time according to
complex equations
•Finite-state machines
•Markov chains
•Auto-regressive models
•…
Q: How did we get the equation parameters?
A: Black box identification
used low-order state-
space models to
predict the complex
dynamics of the
equation parameters

Optimal attacks
Lemma: Previous optimization is equivalent to following concave maximization
maximize
subject to
How effective are these optimizations on predicting real attacks?
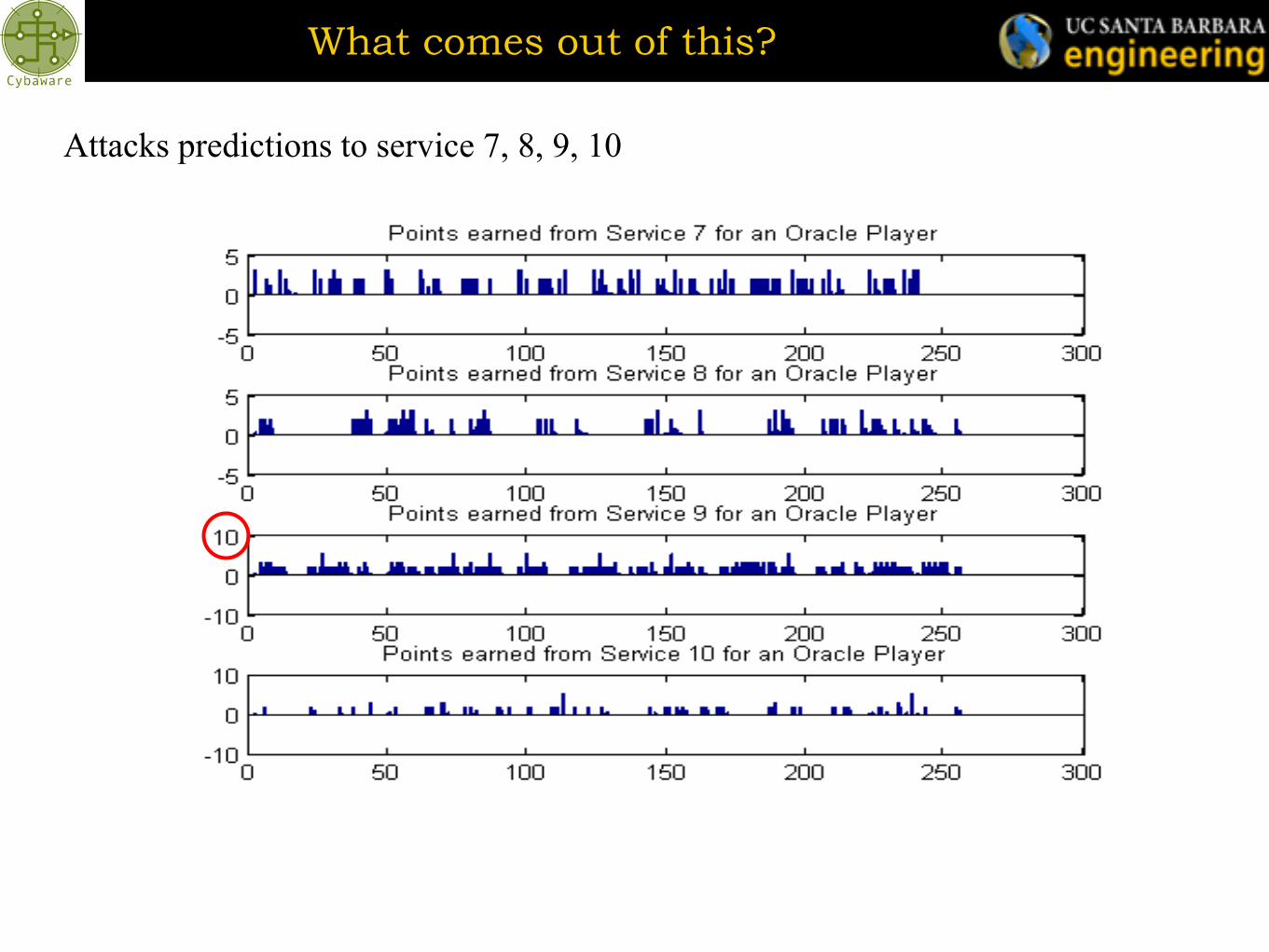
What comes out of this?
Attacks predictions to service 7, 8, 9, 10
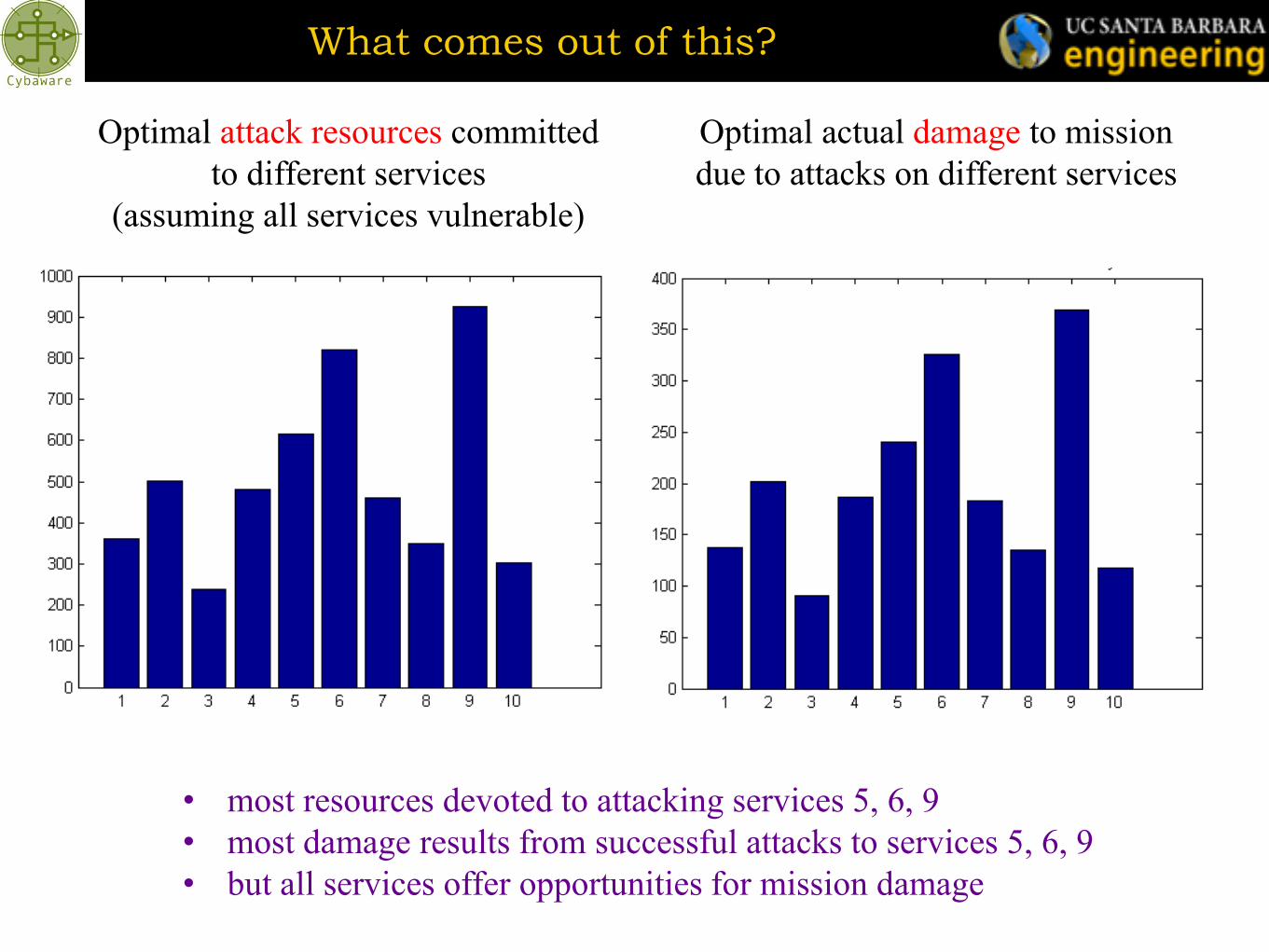
What comes out of this?
Optimal attack resources committed
to different services
(assuming all services vulnerable)
Optimal actual damage to mission
due to attacks on different services
• most resources devoted to attacking services 5, 6, 9
• most damage results from successful attacks to services 5, 6, 9
• but all services offer opportunities for mission damage
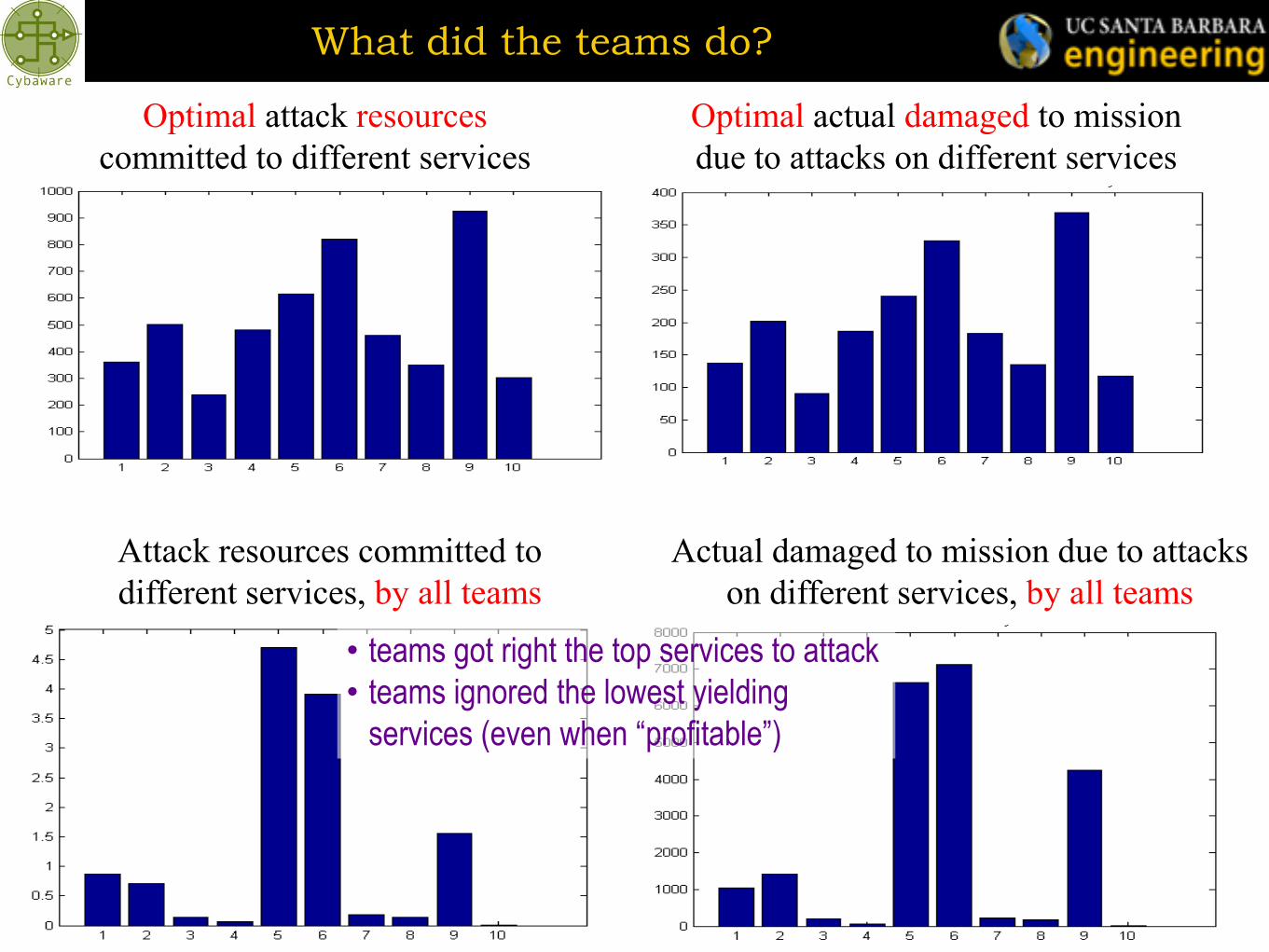
What did the teams do?
Optimal attack resources
committed to different services
Optimal actual damaged to mission
due to attacks on different services
Attack resources committed to
different services, by all teams
Actual damaged to mission due to attacks
on different services, by all teams
• teams got right the top services to attack
• teams ignored the lowest yielding
services (even when “profitable”)

What did the teams do?
Optimal actual damaged to mission
due to attacks on different services
Actual damaged to mission due to attacks
on different services, by all teams
Actual damaged to mission due to attacks
on different services, by top 10 teams
• teams got right the top services to attack
• teams ignored the lowest yielding
services (even when “profitable”)
• top teams correctly identified the best 4
services to attack & invested resources
more judisciously

Summary of Accomplishments (Y3)
Large-scale cyber-security games
• new results regarding pure policies, sampling mismatch
Estimation and detection in adversarial environments
• stochastic sensors with potential manipulation
• estimation/detection algorithms/assessing risk
Online optimization for real-time attack prediction
• concave optimization for online prediction of attacks and damage to mission
• evaluation in iCTF 2011 game
• results incorporated in visualization tools (more on Tobias Hollerer’s presentation)
Focus in next review period
Estimation/detection for more general design problems
Learning-based approaches to solving minimax problems
Develop numerical algorithms for fast (real-time) attack prediction
Generalization of framework for real-time attack prediction