authors: bhavana bharat dalvi, meghana kshirsagar, s. sudarshan presented by: aruna keyword search...
TRANSCRIPT

Authors: Bhavana Bharat Dalvi, Meghana Kshirsagar, S. Sudarshan
Presented By: Aruna
Keyword Search on External Memory Data Graphs

2
Outline
Introduction
Modeling
Graph Model
2-stage Graph Model
Multi-granular Graph Representation
Algorithms
Iterative Expansion Search
Incremental Expansion Search
Experiments
Conclusion

3
Keyword Search
Keyword search A very simple and easy-to-use mechanism to get
information from databases.
Keyword search queries A set of keywords.
Allows users to find interconnected tuple structures containing the given keywords in an relational database.
Combines data from multiple data sources.

4
Keyword Search on Graph Data (1/2)
Query result Rooted trees that connect nodes matching the
keywords.
Keyword searches – ambiguous and query results may be irrelevant to a user Ranking function
Top-k answers to keyword query.

5
Keyword Search on Graph Data (2/2)
Keyword search on databases Information may split across the tables/tuples due to normalization. Use of artificial documents. Use of data graphs in the absence of schema.
Graph Data Model: Lowest common denominator. Integrates data from multiple sources from different
schemas. Enables novel systems for heterogeneous data integration
and search. Query result
A subtree where no node or edge can be removed without losing keyword matches.
Most of the previous work assumes graph fits in memory.

6
External memory data graph (1/2)
Problem with in-memory algorithms - if graph size is more than memory.
Solutions :1. Virtual memory
Significant I/O cost Thrashing
2. SQL For relational data only Not good for top-k query answer generation

7
External memory data graph (2/2)
Goal of the paper: Use a compressed graph representation to reduce
IO. Graphs which are larger than memory.
Solution uses Multi-granular graph Two approaches
1. Iterative approach2. Incremental approach

8
Graph Model (1/2)
Nodes: Every node has an associated set of keywords, with weights or prestige. Influences the rank of answers containing the node.
Edges: directed and weighted.
Keyword query : a set of terms ki, i=i….n.
Answer tree: a set-of-paths model, with one path per keyword. Each path (root to a node) contains the keyword.

9
Graph Model (2/2)
Node score : sum of the leaf/root node weights.
Edge score of an answer: sum of the path lengths.
Answer score : a function of the node score and the edge score of the answer tree.
10
Keyword Search
Steps to generate top-k answers: Looking up an inverted keyword index to get
the node-ids of nodes. Keyword nodes
Use of a graph search algorithm to find out trees connecting the keyword nodes found above. Finds rooted answer trees, which should be
generated in ranked order.
11
SuperEdges
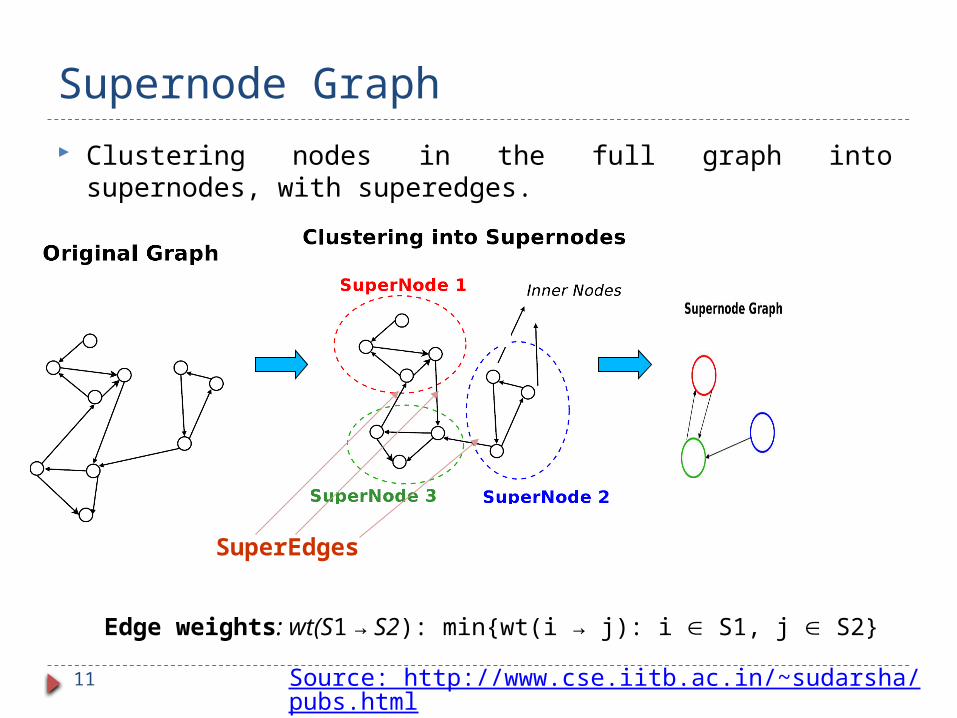
Supernode Graph
Edge weights: wt(S1 → S2): min{wt(i → j): i S1, j S2}
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html
Clustering nodes in the full graph into supernodes, with superedges.

12
2-Phase Search (1/2)
First-Attempt Algorithm: Phase 1 :
Search on supernode graph to get top-k results (containing supernodes) Using any search algorithm
Expand all supernodes from supernode results.
Phase 2 : Search on this expanded component of graph to get
final top-k results.
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html

13
2-Phase Search (2/2)
Top-k on expanded component may not be top-k on full graph.
Experiments show poor recall.

14
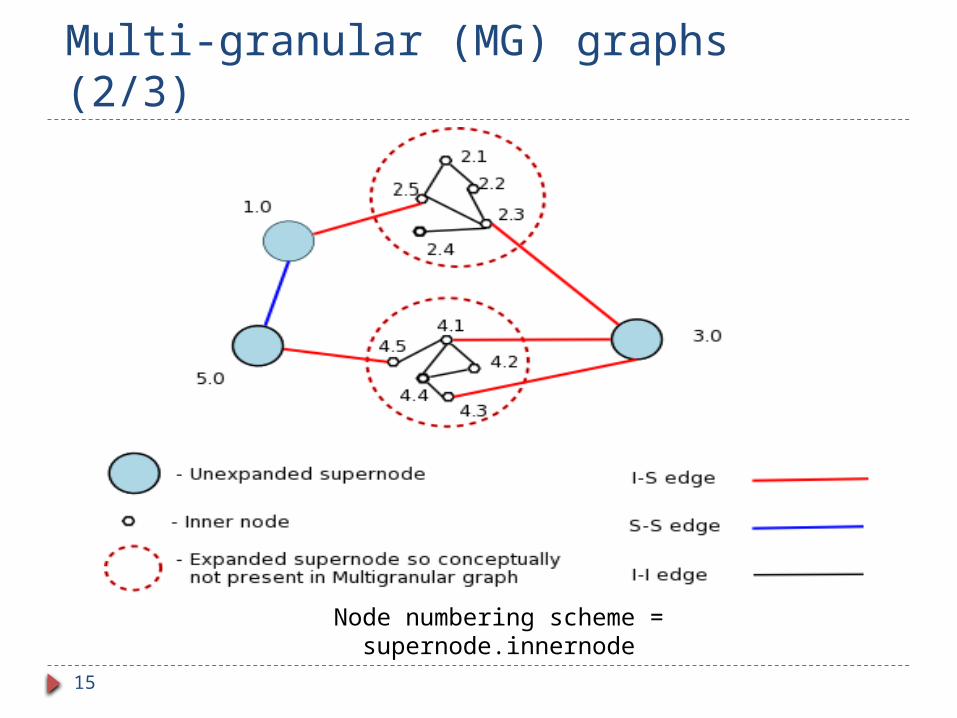
Multi-granular (MG) graphs (1/3)
Combines a condensed version of the graph (the “supernode graph”) Always memory resident.
Supernode graph: Clustering nodes in the full graph into supernodes,
with superedges.
All information about the part of the full graph, currently available in memory.
15
Multi-granular (MG) graphs (2/3)
Node numbering scheme = supernode.innernode

16
Multi-granular (MG) graphs (3/3) Edge-weights:
S1 S2: Min {edge-weight n1 n2 | n1 S1 and n2 S2}
S i : Min {edge-weight s i | s S}
I I: Edge weight is same as in original graph.
Supernode answer: Answer containing supernodes if we execute search on
the MG graph.
Pure answer: Answer that does not contain any supernodes.

17
Iterative Expansion Search (1/3)
Input : a MG graph.
Output : top k pure results.
Iterative search on MG graph Repeat
Search on current MG graph using any search algorithm, to find top results.
Expand super nodes in top results. Until top k answers are all pure.
18
Iterative Expansion Search (2/3)
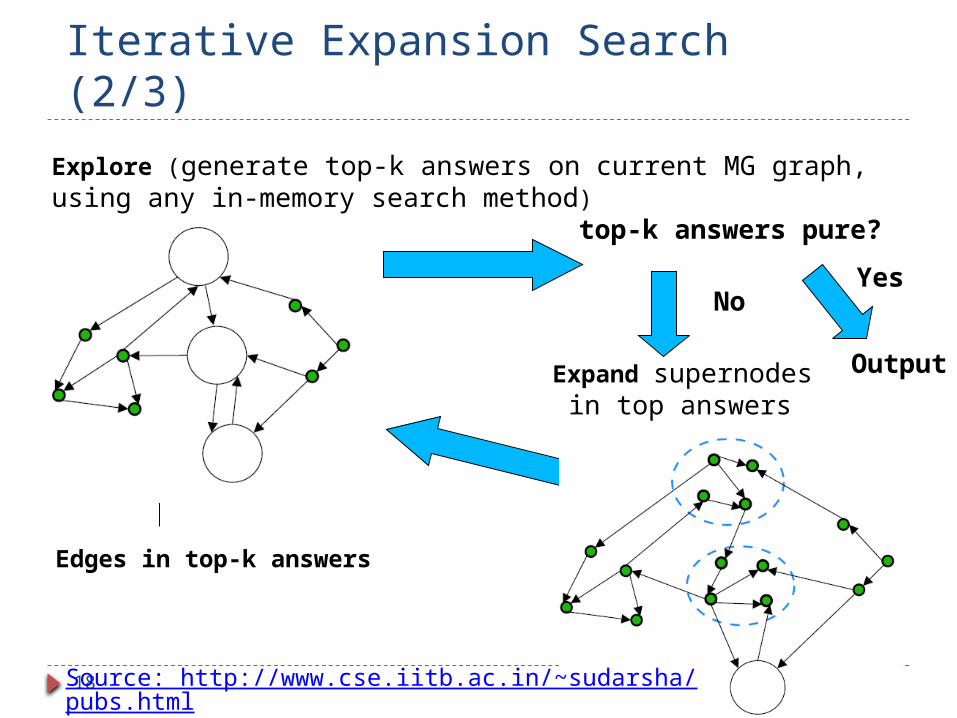
Yes
Output
No
Expand supernodes in top answers
Edges in top-k answers
Explore (generate top-k answers on current MG graph, using any in-memory search method)
top-k answers pure?
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html

19
Iterative Expansion Search (3/3)
Guarantees finding top- k answers Very good IO efficiency compared to search using
virtual memory.
Nodes expanded above never evicted from “virtual memory” cache. Expanded nodes retain in logical MG graph, re-
fetch as required. Can cause thrashing.
But high CPU cost due to repeated work.

20
Incremental Expansion Search
Motivation : Repeated restarts of search in iterative search.
Basic idea: Search on MG graph Expand supernode(s) in top answer. Unlike iterative search
Update the state of the search algorithm when a supernode is expanded, and
Continue search instead of restarting. Run search algorithm until top k answers are all pure.
State update depends on search algorithm. Use of backward expanding search.Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.ht
ml

21
Backward Expanding Search
Based on Dijkstra’s single-source shortest path algorithm. One shortest path search iterator per keyword. Runs n copies of this algorithm concurrently.
Explored nodes: nodes for which shortest path already found.
Fringe nodes: unexplored nodes adjacent to explored nodes.
SPI tree: shortest path iterator tree Tree containing explored and fringe nodes. Edge uv if (current) shortest path from u to keyword passes through
v.

22
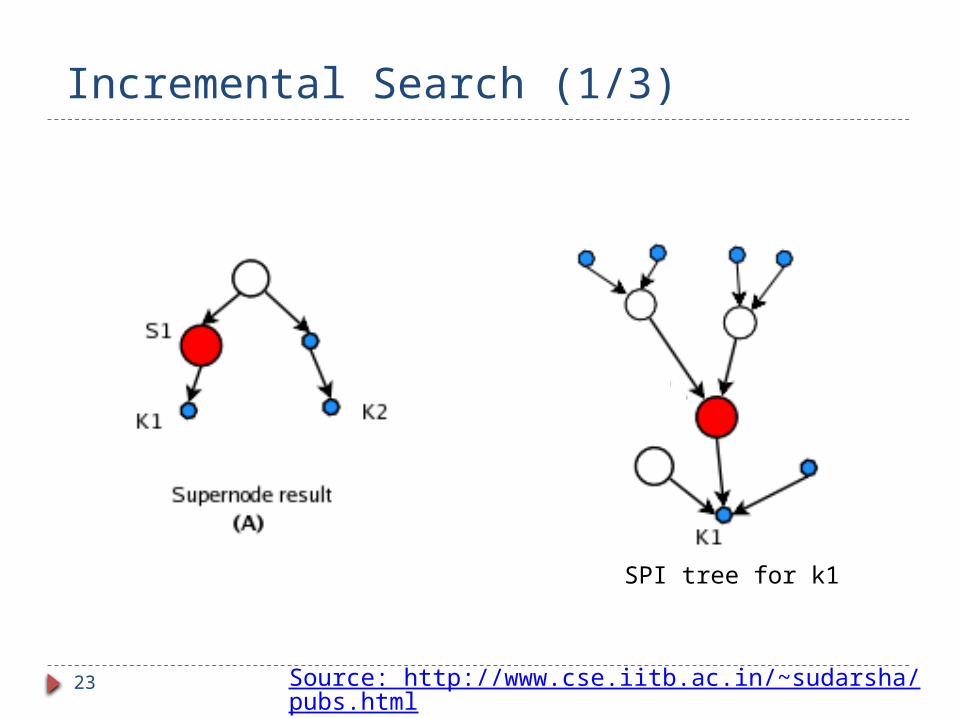
Incremental backward search
Backward search run on multi-granular graph
Algorithm: Repeat
Find next best answer on current multi-granular graph.
If answer has supernodes Expand supernode(s)
Update the state of backward search, i.e. all SPI trees, to reflect state change of multi-granular graph due to expansion
Until top-k answers on current multi-granular graph are “pure” answersSource: http://www.cse.iitb.ac.in/~sudarsha/pubs.ht
ml
23
Incremental Search (1/3)
SPI tree for k1
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html
24
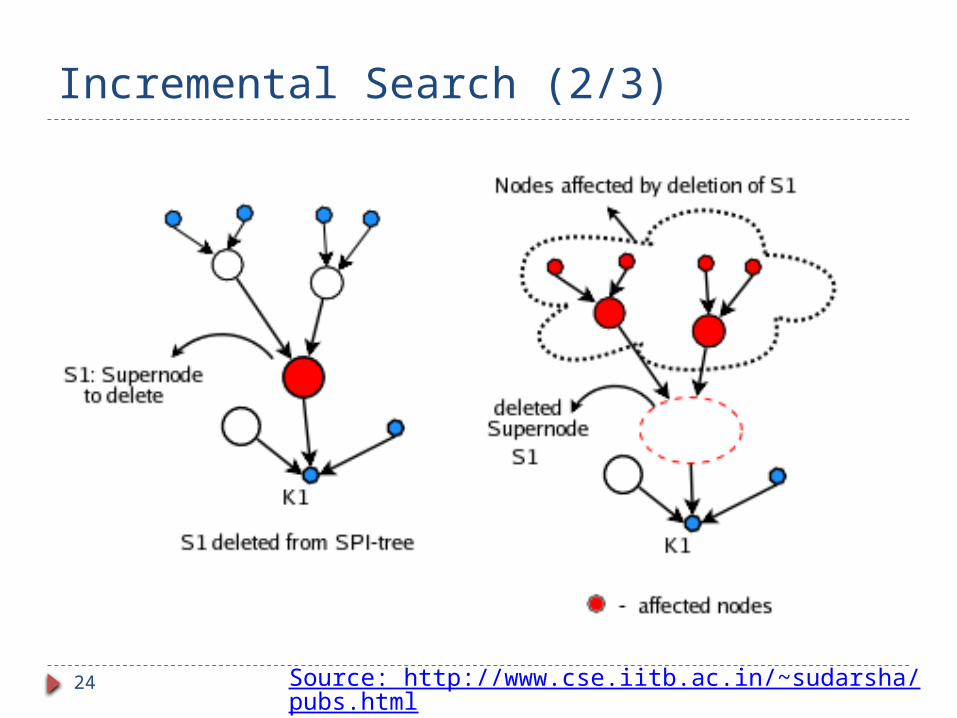
Incremental Search (2/3)
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html
25
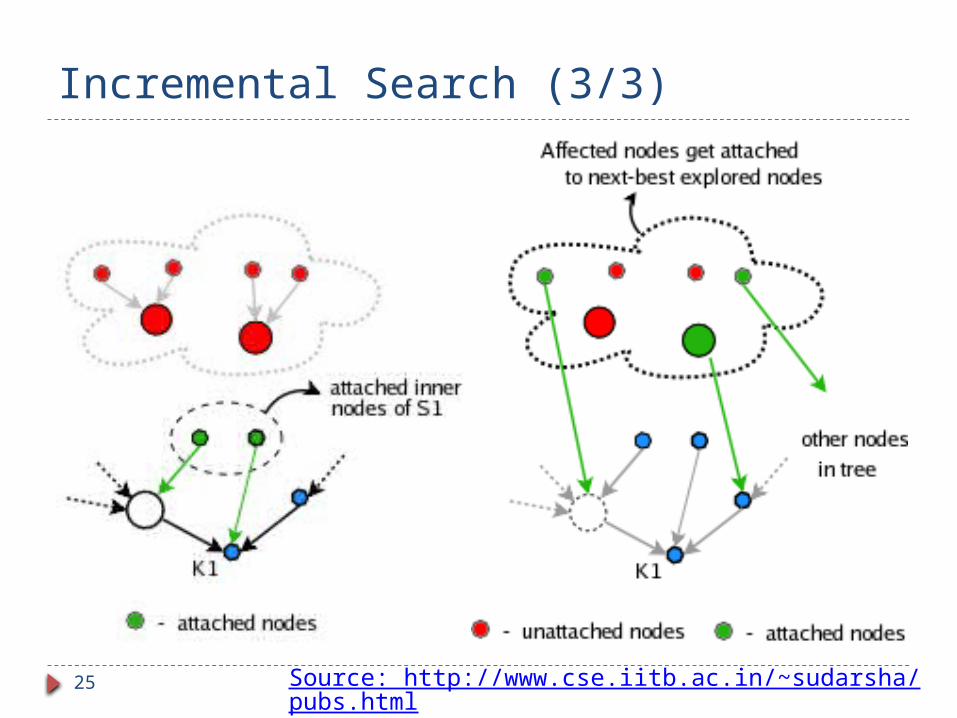
Incremental Search (3/3)
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html

26
1. Affected nodes get detached.
2. Inner-nodes get attached (as fringe nodes) to adjacent explored nodes based on shortest path to K1.
3. Affected nodes get attached (as fringe nodes) to adjacent explored nodes based on shortest path to K1.
State Update on Supernode Expansion

27
Effects of supernode expansion Differences from Dijkstra's shortest-path
algorithm:For Explored nodes: Path-costs of explored nodes may increase. Explored nodes may become fringe nodes.
For Fringe nodes: Incremental Expansion: Path-costs may increase or
decrease.
Invariant SPI trees reflect shortest paths for explored nodes in
current multi-granular graph.
Theorem: Incremental backward expanding search generates correct top-k answers.

28
Heuristics
Thrashing Control : Stop supernode expansion on cache full. Use only parts of the graph already expanded for
further search.
Intra-supernode edge weight
Heuristics can affect recall Recall at or close to 100% for relevant answers,
with heuristics, in the experiments.
29
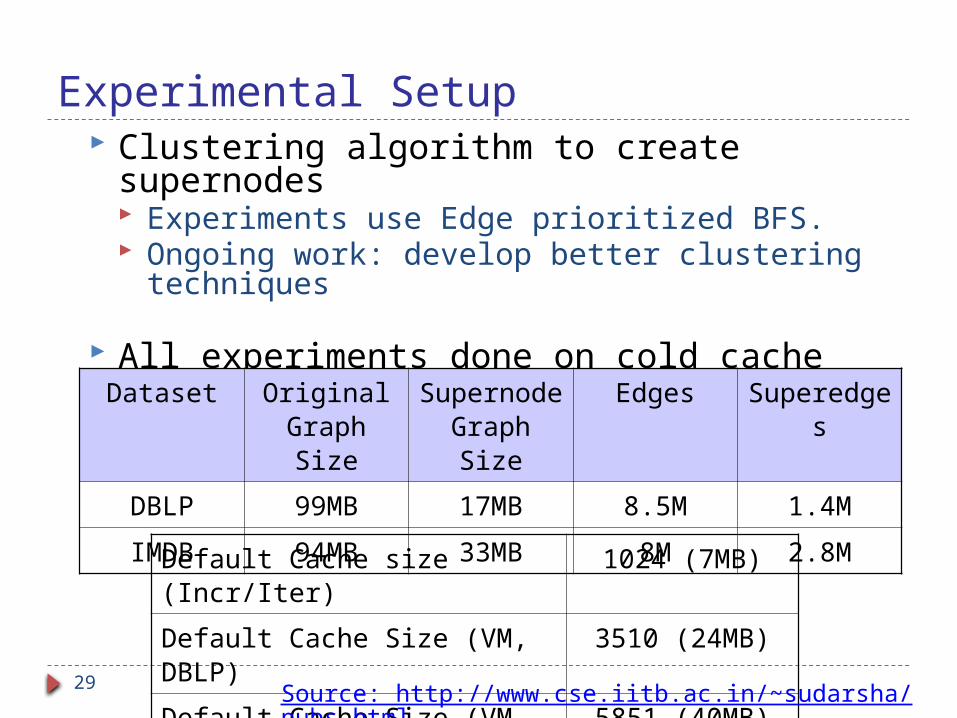
Experimental Setup Clustering algorithm to create supernodes
Experiments use Edge prioritized BFS. Ongoing work: develop better clustering
techniques
All experiments done on cold cache
Dataset Original Graph Size
Supernode Graph Size
Edges Superedges
DBLP 99MB 17MB 8.5M 1.4M
IMDB 94MB 33MB 8M 2.8M
Default Cache size (Incr/Iter) 1024 (7MB)
Default Cache Size (VM, DBLP) 3510 (24MB)
Default Cache Size (VM, IMDB) 5851 (40MB)
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html

30
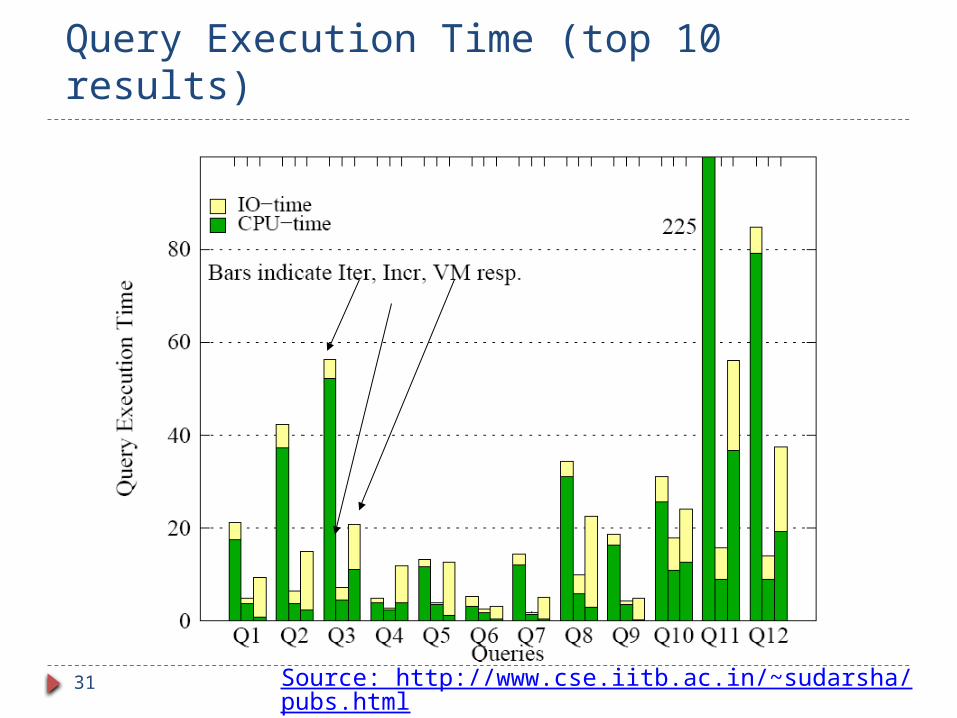
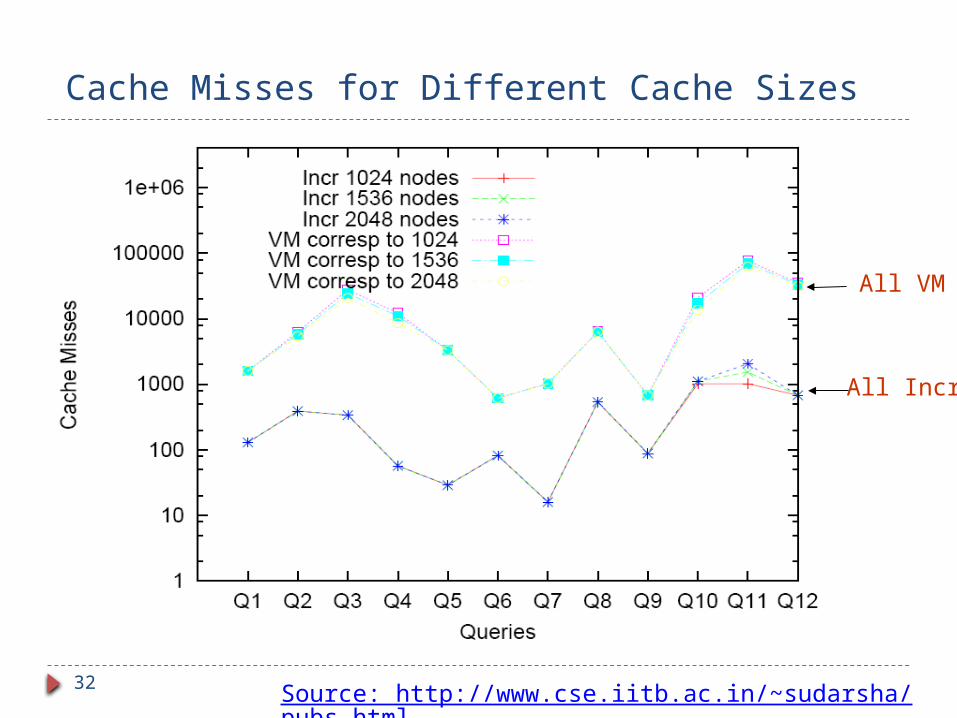
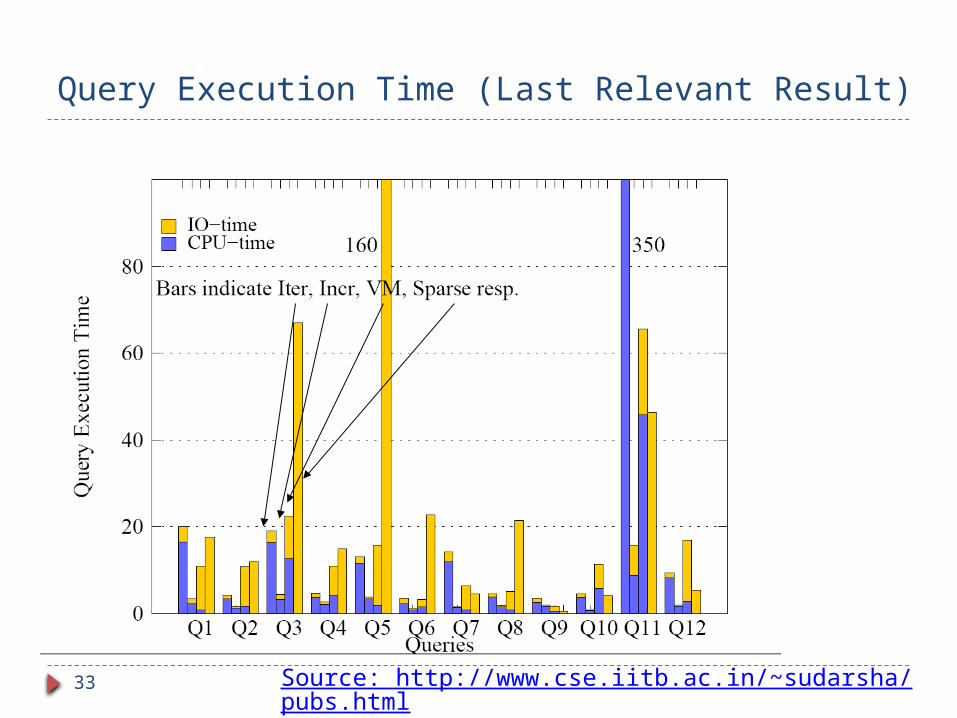
External memory search: performance Supernode graph very effective at minimizing IO
Cache misses with incremental often less than no. of nodes matching keywords.
Iterative algorithm High CPU cost.
VM (backward search with cache as virtual memory) has high IO cost. Use same clustering as for supernode graph. Fetch cluster into cache whenever a node is accessed.
Evicting LRU cluster if required.
Search code unaware of clustering/caching. Gets “Virtual Memory” view.
Incremental combines low IO cost with low CPU cost.
31
Query Execution Time (top 10 results)
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html
32
Cache Misses for Different Cache Sizes
All Incr.
All VM
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html
33
Query Execution Time (Last Relevant Result)
Source: http://www.cse.iitb.ac.in/~sudarsha/pubs.html

34
Conclusions
Graph summarization coupled with a multi-granular graph representation shows promise for external memory graph search.
Ongoing/Future work Applications in distributed memory graph search. Improved clustering techniques. Extending Incremental to bidirectional search and
other graph search algorithms. Testing on really large graphs.