aws innovate: build a data lake on aws- johnathon meichtry
TRANSCRIPT

Building a Data Lake on AWS
Johnathon Meichtry, Principal Solutions Architect
Amazon Web Services


STORAGECOMPUTE

But customers have additional requirements…

The Rise of “Big Data”
Enterprise
data warehouse
Amazon
EMR
Amazon
S3

STORAGECOMPUTE
COMPUTECOMPUTE
COMPUTE
COMPUTE
COMPUTE
COMPUTE
COMPUTECOMPUTE
COMPUTE

Comparison of a Data Lake to an Enterprise Data Warehouse
Complementary to EDW (not replacement) Data lake can be source for EDW
Schema on read (no predefined schemas) Schema on write (predefined schemas)
Structured/semi-structured/Unstructured data Structured data only
Fast ingestion of new data/content Time consuming to introduce new content
Data Science + Prediction/Advanced Analytics + BI
use casesBI use cases only (no prediction/advanced analytics)
Data at low level of detail/granularity Data at summary/aggregated level of detail
Loosely defined SLAs Tight SLAs (production schedules)
Flexibility in tools (open source/tools for advanced
analytics)Limited flexibility in tools (SQL only)
Enterprise DWEMR S3

EMR S3
The New Problem
Enterprise
data warehouse
≠
Which system has my data?
How can I do machine
learning against the DW?
I built this in Hive, can we get
it into the Finance reports?
These sources are giving
different results…
But I implemented the
algorithm in Anaconda…

Dive Into The Data Lake
Enterprise
data warehouseEMR S3
Load Cleansed Data
Export Computed Aggregates
Ingest any data
Data cleansing
Data catalogue
Trend analysis
Machine learning
Structured analysis
Common access tools
Efficient aggregation
Structured business rules

Components of a Data Lake
Storage & Streams
Catalogue & Search
Entitlements
API & UI

STORAGE
High durability
Stores raw data from input sources
Support for any type of data
Low cost
Storage & Streams
Catalogue & Search
Entitlements
API & UI

Amazon Simple Storage ServiceHighly scalable object storage for the Internet
1 byte to 5 TB in size
Designed for 99.999999999% durability, 99.99%
availability
Regional service, no single points of failure
Server side encryption
Key Management Service integration
True object storage
Compute Storage
AWS Global Infrastructure
Database
App Services
Deployment & Administration
Networking
Analytics

Storage Lifecycle Integration
S3 – Standard S3 – Infrequent Access Amazon Glacier

Consider Different Types of Data
Unstructured• Store native file format (logs, dump files, whatever)
• Compress with a streaming codec (LZO, Snappy)
Semi-structured - JSON, XML files, etc.• Consider evolution ability of the data schema (Avro)
• Store the schema for the data as a file attribute (metadata/tag)
Structured• Lots of data is CSV!
• Columnar storage (Orc, Parquet)

STREAMING
Streaming ingest of feed data
Provides the ability to consume any
dataset as a stream
Facilitates low latency analytics
Storage & Streams
Catalogue & Search
Entitlements
API & UI

Amazon KinesisManaged service for real time big data processing
Create streams to produce & consume data
Elastically add and remove shards for performance
Use Amazon Kinesis Worker Library to process data
Integration with S3, Amazon Redshift, and DynamoDB
Compute Storage
AWS Global Infrastructure
Database
App Services
Deployment & Administration
Networking
Analytics

Data
Sources
AW
S E
nd
po
int
Data
Sources
Data
Sources
Data
Sources
S3
App.1
[Archive/
Ingestion]
App.2
[Sliding
Window
Analysis]
App.3
[Data
Loading]
App.4
[Event
Processing
Systems]
DynamoDB
Amazon Redshift
Data
Sources
Availability
Zone
Shard 1
Shard 2
Shard N
Availability
ZoneAvailability
Zone
Amazon Kinesis Architecture

Streaming Storage Integration
Object store
Amazon S3
Streaming store
Amazon
Kinesis
Analytics applicationsRead & write file dataRead & write to streams
Archive
stream
Replay
history

CATALOGUE & SEARCH
Metadata lake
Used for summary statistics and data
Classification management
Simplified model for data discovery &
governance
Storage & Streams
Catalogue & Search
Entitlements
API & UI

Data Catalogue – Metadata Index
• Stores data about your Amazon S3 storage environment
• Total size & count of objects by prefix, data classification,
refresh schedule, object version information
• Amazon S3 events processed by Lambda function
• DynamoDB metadata tables store required attributes

Amazon DynamoDBProvisioned throughput NoSQL database
Fast, predictable, configurable performance
Fully distributed, fault tolerant HA architecture
Integration with Amazon EMR & Hive
Amazon
RDS
Amazon
DynamoD
B
Amazon
Redshift
Amazon
ElastiCache
Managed NoSQL
Compute Storage
AWS Global Infrastructure
Database
App Services
Deployment & Administration
Networking
Analytics

AWS LambdaFully-managed event processor
Node.js or Java, integrated AWS SDK
Natively compile & install any Node.js modules
Specify runtime RAM & timeout
Automatically scaled to support event volume
Events from Amazon S3, Amazon SNS, Amazon
DynamoDB, Amazon Kinesis, & AWS Lambda
Integrated CloudWatch logging
Compute Storage
AWS Global Infrastructure
Database
App Services
Deployment & Administration
Networking
Analytics
Serverless Compute

Data Catalogue – Building Search Index
• Enable DynamoDB
Update Stream for
metadata index table
• Additional AWS
Lambda function reads
Update Stream and
extracts index fields
from S3 object
• Update to search
domain

Catalogue & Search Architecture

ENTITLEMENTS
Encryption
Authentication
Authorisation
Chargeback
Quotas
Data masking
Regional restrictions
Storage & Streams
Catalogue & Search
Entitlements
API & UI

IAM Policy Language
Example: Allow a user to access a private part of the data lake
{"Version": "2012-10-17","Statement": [{"Action": ["s3:ListBucket"],"Effect": "Allow","Resource": ["arn:aws:s3:::mydatalake"],"Condition": {"StringLike": {"s3:prefix": ["${aws:username}/*"]}}
},{"Action": ["s3:GetObject","s3:PutObject"
],"Effect": "Allow","Resource": ["arn:aws:s3:::mydatalake/${aws:username}/*"]
}]
}
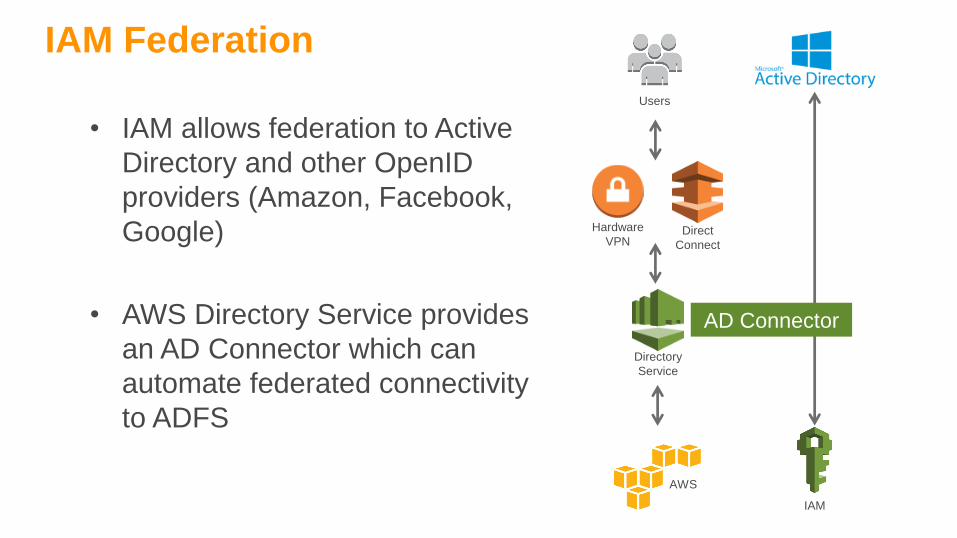
IAM Federation
• IAM allows federation to Active
Directory and other OpenID
providers (Amazon, Facebook,
Google)
• AWS Directory Service provides
an AD Connector which can
automate federated connectivity
to ADFS
IAM
Users
AWS
Directory
Service
AD Connector
Direct
Connect
Hardware
VPN

Data Encryption
AWS CloudHSM
Dedicated Tenancy SafeNet Luna SA HSM
Device
Common Criteria EAL4+, NIST FIPS 140-2
AWS Key Management Service
Automated key rotation & auditing
Integration with other AWS services
AWS server side encryption
AWS managed key infrastructure

Entitlements – Access to Encryption Keys
Customer
Master Key
Customer
Data Keys
Ciphertext
Key
Plaintext
Key
IAM Temporary
Credential
Security Token
Service
MyData
MyData
S3
S3 Object
…
Name: MyData
Key: Ciphertext Key
…

Secure Data Flow
IAM
Amazon S3
API Gateway
Users
Temporary
Credential
Temporary
Credential
s3://mydatalake/${YYY-MM-DD}/
${resource}/${resourceID}
Encrypted
Data
Metadata
Index -
DynamoDB
TVM - Elastic
Beanstalk
Security Token
Service

API & UI
Exposes the data lake to customers
Programmatically query catalogue
Expose search API
Ensures that entitlements are respected
Storage & Streams
Catalogue & Search
Entitlements
API & UI

Amazon API Gateway
Host multiple versions and stages of APIs
Create and distribute API keys to developers
Leverage AWS Sigv4 to authorize access to APIs
Throttle and monitor requests to protect the backend
Leverages AWS Lambda

An API Call Flow
Internet
Mobile Apps
Websites
Services
API
Gateway
AWS Lambda
functions
AWS
API Gateway
cache
Endpoints on
Amazon EC2
Any other publicly
accessible endpointAmazon
CloudWatch
monitoring
Amazon
CloudFront

API & UI Architecture
API Gateway
UI - Elastic
Beanstalk
AWS Lambda Metadata IndexUsersIAM
TVM - Elastic
Beanstalk

Storage & Streams
Amazon
Kinesis
Amazon S3 Amazon Glacier
Entitlements
IAM
Encrypted
Data
Security Token
Service
Data Catalogue & Search
AWS Lambda
Search
Index
Metadata
Index
API & UI
API GatewayUsers UI - Elastic
Beanstalk
TVM - Elastic
Beanstalk
KMS

Online Labs & Training
Gain confidence and hands-on
experience with AWS.
Watch free Instructional Videos and
explore Self-Paced Labs
Instructor Led Classes
Learn how to design, deploy and
operate highly available, cost-effective
and secure applications on AWS in
courses led by qualified AWS
instructors
Validate your technical expertise
with AWS and use practice
exams to help you prepare for
AWS Certification
AWS Certification
More info at http://aws.amazon.com/training

Thank You for Attending AWS Innovate
We hope you found it interesting!
Do provide us with your feedback for the session and complete the feedback form.
Let us know your thoughts of today’s event and how we can improve the event
experience for you in the future.