aws re:invent 2016: case study: librato's experience running cassandra using amazon ebs, enis,...
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Mike Heffner, Data, Librato
Peter Norton, Operations, Librato
Case Study: Librato’s Experience Running
Cassandra Using Amazon EBS, ENIs,
and Amazon VPC
December 1, 2016
CMP213

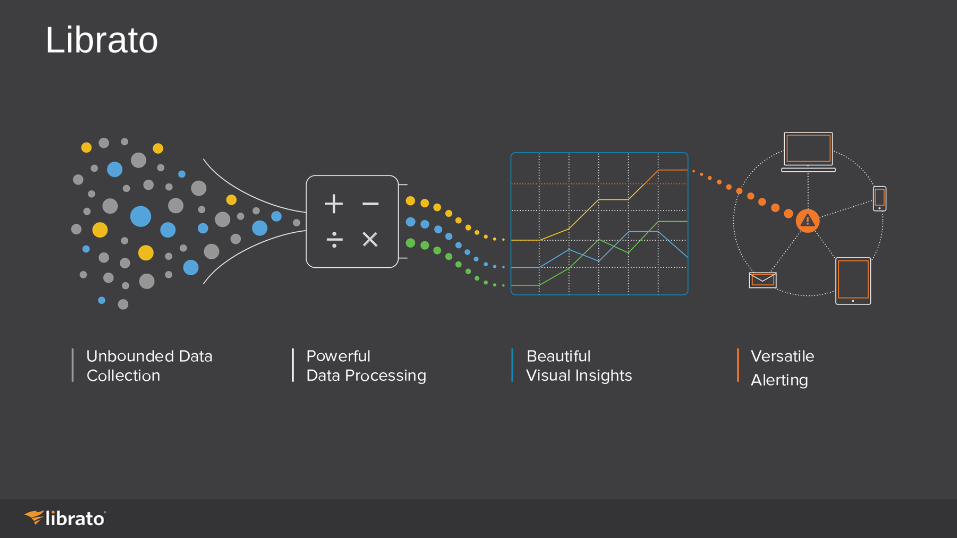
Librato

Collect Some of the integrations with
Amazon CloudWatch support
Visualize
Alert

Cassandra at Librato

Cassandra as a time-series database
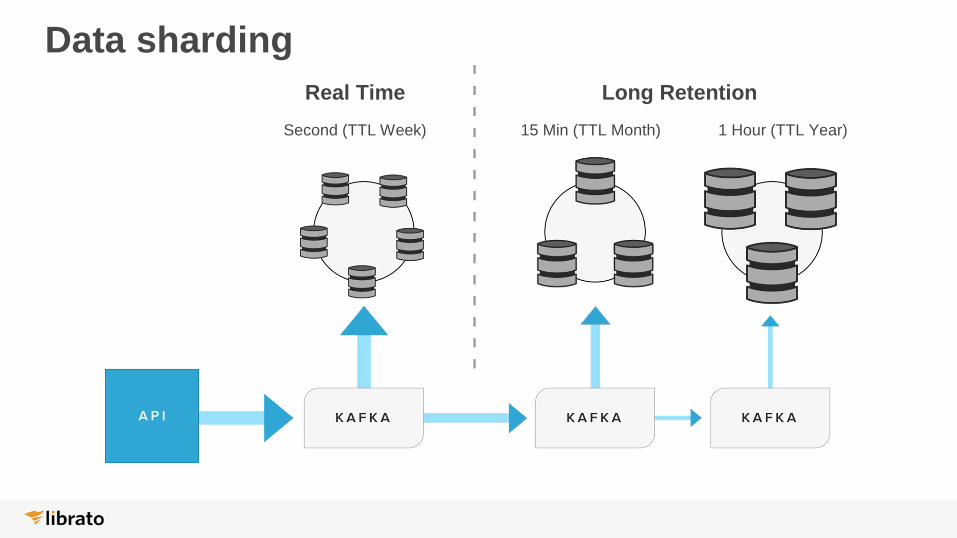
Data sharding
Real Time
Second (TTL Week)
Long Retention
15 Min (TTL Month) 1 Hour (TTL Year)

Librato circa 2015
● Cassandra 2.0.11 + patches
● i2.2xlarge
• DataStax and Netflix preferred instance type
● 160 instances
● Never Amazon EBS – only instance store
● Raid0 over instance store (1.5 TB)

Operational challenges
● CPU/cost ratio low on i2.2xlarge
• Kept rings hot to maximize efficiency
● Persistent data tied to instance
• Long MTTR to stream large data sets
● Maximum data volume size
• Had to scale rings for data capacity
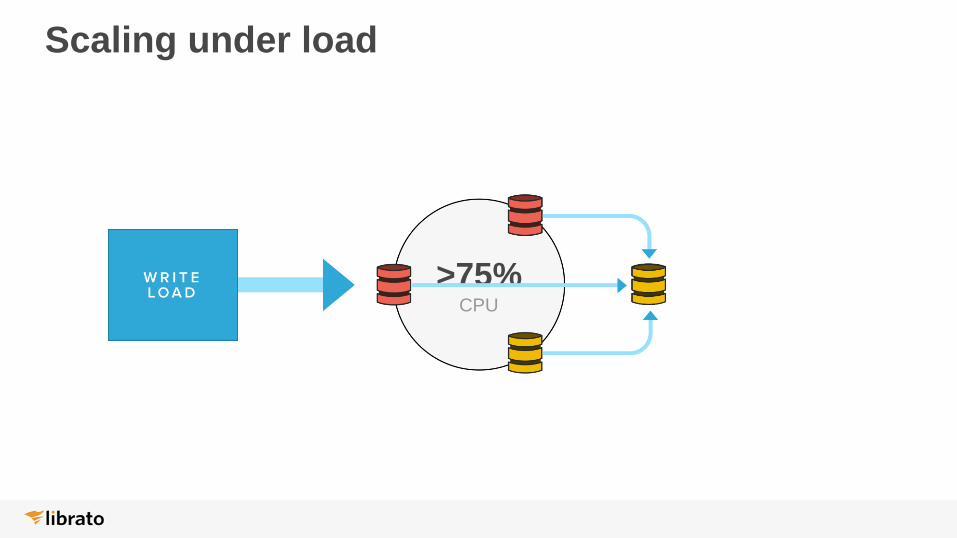
Scaling under load
>75%CPU
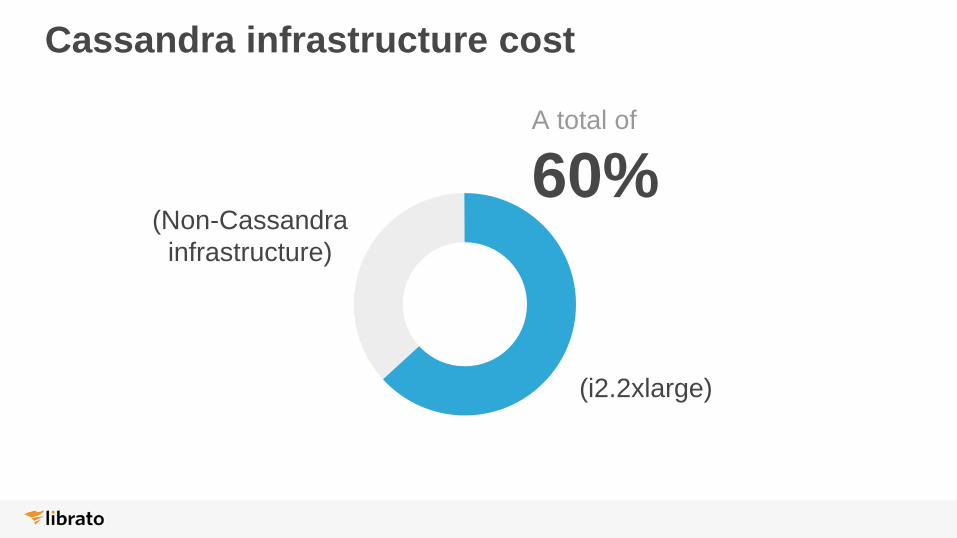
Cassandra infrastructure cost
A total of
60%
(i2.2xlarge)
(Non-Cassandra
infrastructure)

Enter Amazon VPC migration – 3Q 2015
● Librato moving Classic → Amazon VPC
● Code all the things: SaltStack / Terraform / Flask
● Opportunity to overhaul Cassandra
● Emboldened by CrowdStrike Amazon EBS talk
@ re:Invent 2015
• We can do this!
• Anticipating a big win

Initial target spec
● Cassandra 2.2.x
● c4.4xlarge
● EBS GP2
• 4 TB data
• 200 GB commitlog
● XFS
● Ubuntu 14.04 + enhanced networking driver (ixgbevf)
● sysctl, IO, NUMA tuning suggestions from Al Tobey’s guide
● Kernel 3.13

The Migration JourneyFebruary 2016
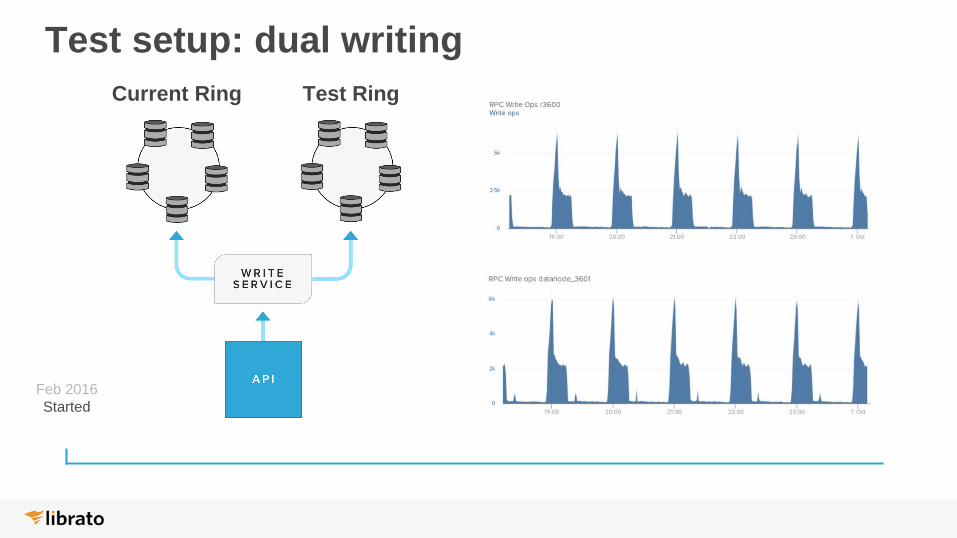
Test setup: dual writing
Feb 2016
Started
Current Ring Test Ring
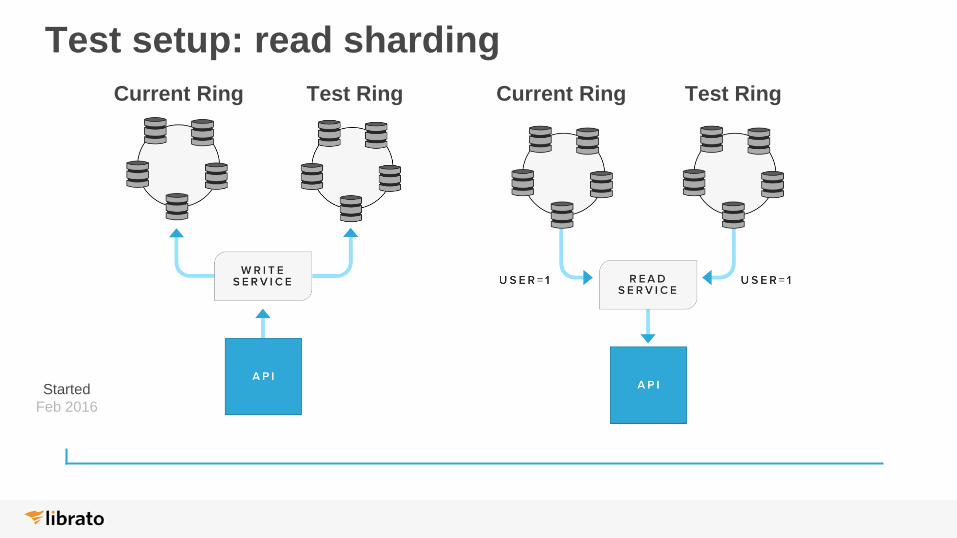
Test setup: read sharding
Started
Feb 2016
Current Ring Test Ring Current Ring Test Ring
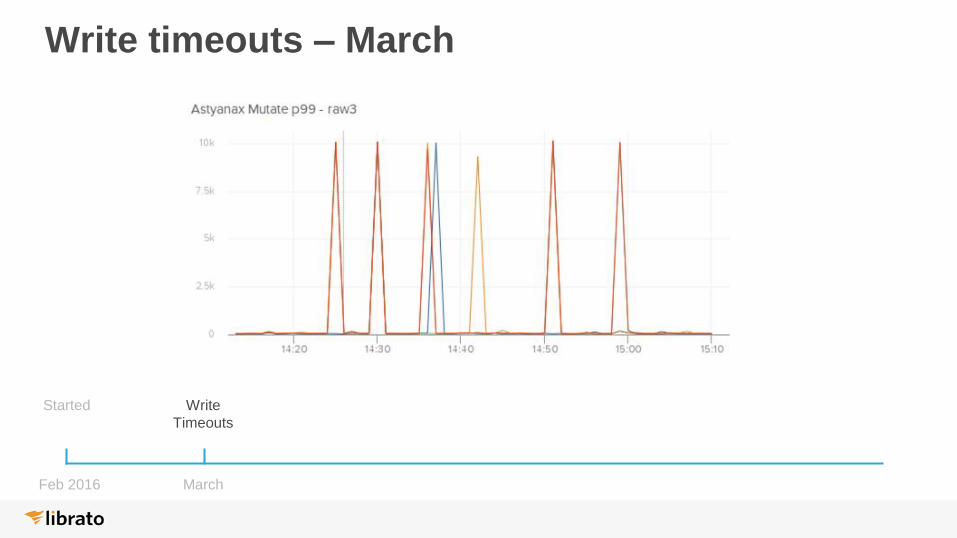
Write timeouts – March
Started Write
Timeouts
Feb 2016 March
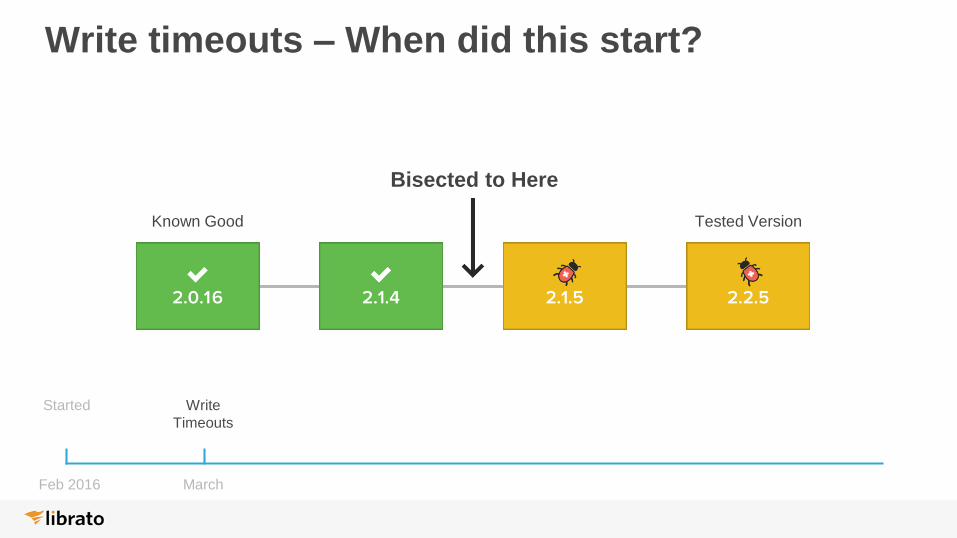
Write timeouts – When did this start?
Started Write
Timeouts
Bisected to Here
Known Good Tested Version
Feb 2016 March
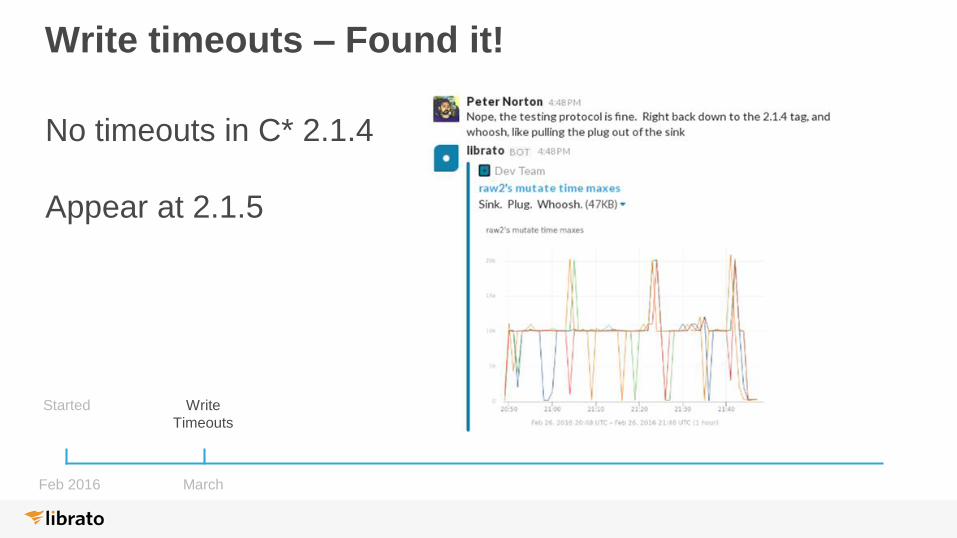
Write timeouts – Found it!
No timeouts in C* 2.1.4
Appear at 2.1.5
Started Write
Timeouts
Feb 2016 March
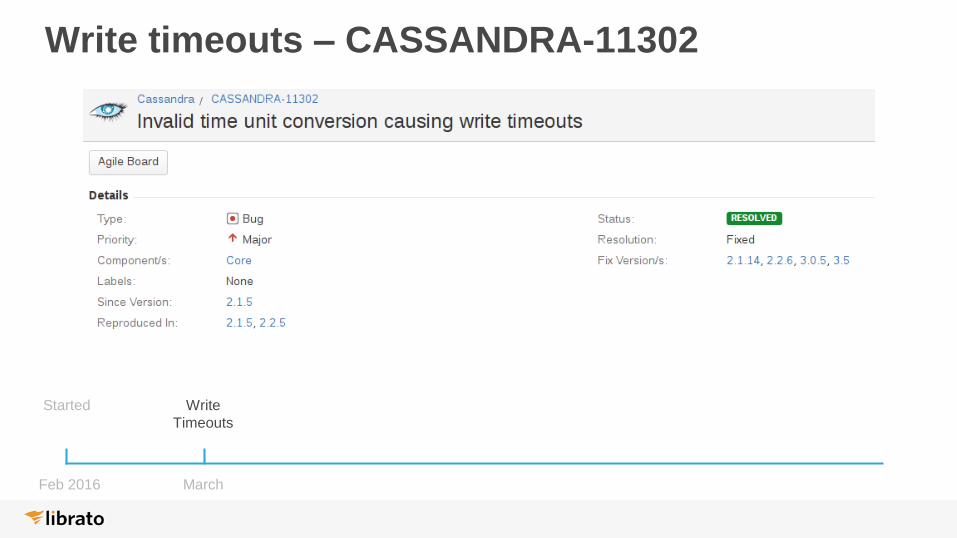
Write timeouts – CASSANDRA-11302
Started Write
Timeouts
Feb 2016 March
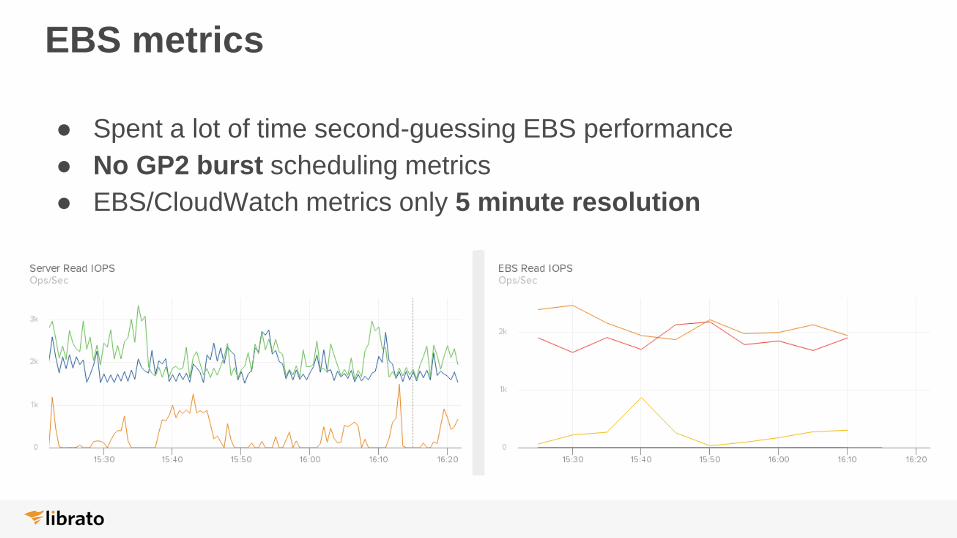
EBS metrics
● Spent a lot of time second-guessing EBS performance
● No GP2 burst scheduling metrics
● EBS/CloudWatch metrics only 5 minute resolution
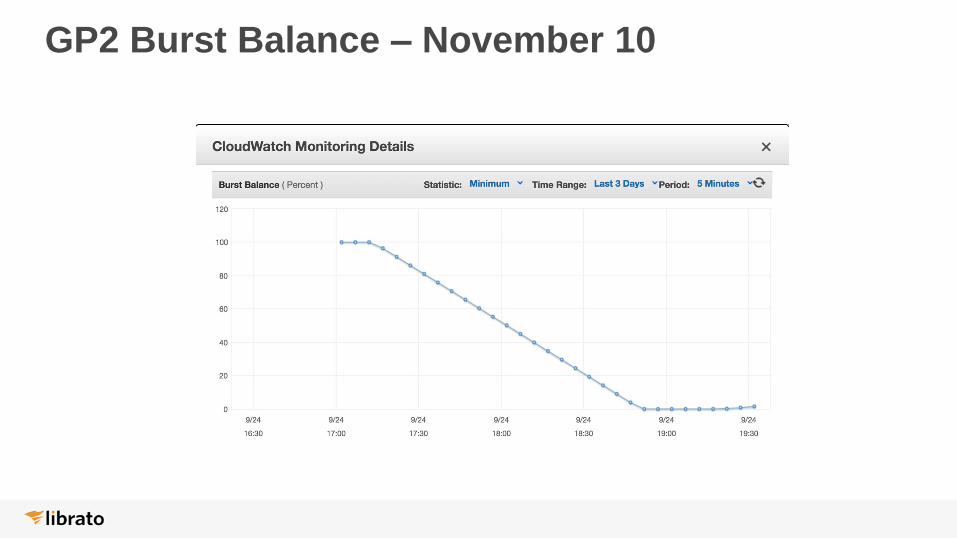
GP2 Burst Balance – November 10

● Started with 200 GB GP2 volume
● 600 IOPS max
● Hit bottlenecks during test (15-30 min+)
● Workaround
• Bumped to 1 TB commitlog volume (3k IOPS)
• Tested with sharing commitlog on data disk
Commitlog scaling – April 2016
Write
Timeouts
Started Commitlog
Scaling
Feb 2016 March April
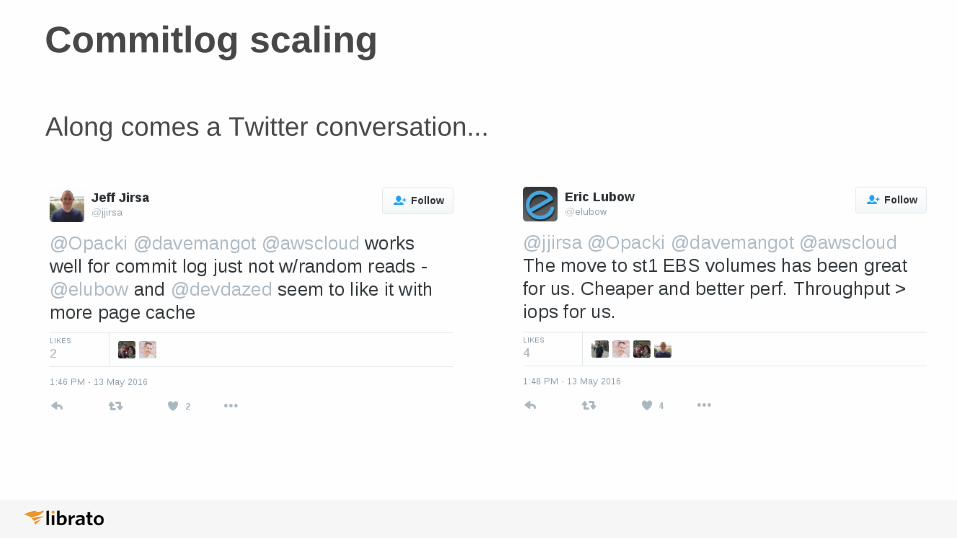
Commitlog scaling
Along comes a Twitter conversation...

● Throughput Optimized HDD (st1)
● Use a 600 GB st1 partition
● Cost <50% of GP2
● Commitlog separate from data
New commitlog config
Started Write
Timeouts
Commitlog
Scaling
st1 GA st1 Testing
Feb 2016 March April April 9 May
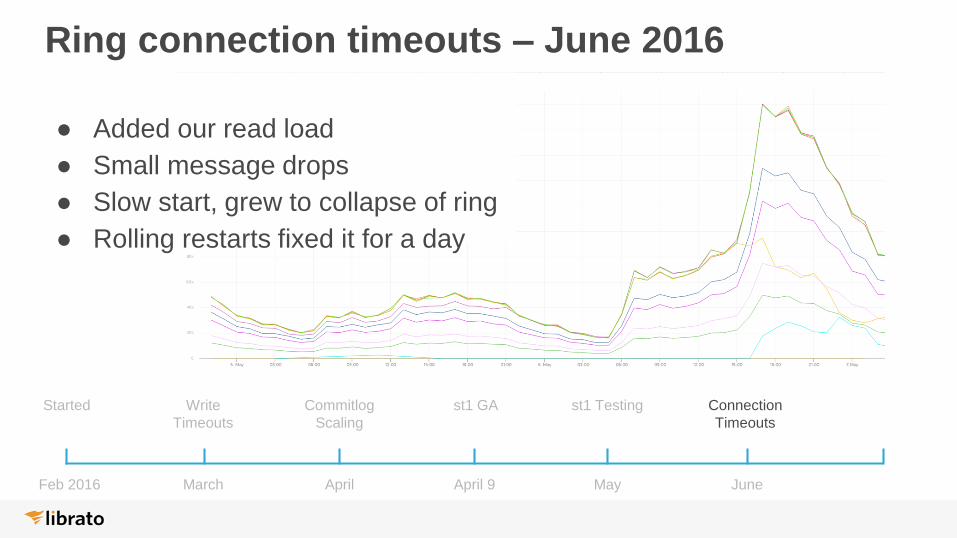
Ring connection timeouts – June 2016
● Added our read load
● Small message drops
● Slow start, grew to collapse of ring
● Rolling restarts fixed it for a day
Started Write
Timeouts
Commitlog
Scaling
st1 GA st1 Testing Connection
Timeouts
Feb 2016 March April April 9 May June

Send help!

Ring connection timeouts
● Called The Last Pickle
otc_coalescing_strategy: DISABLED
Started Write
Timeouts
Commitlog
Scaling
st1 GA st1 Testing Connection
Timeouts
Feb 2016 March April April 9 May June
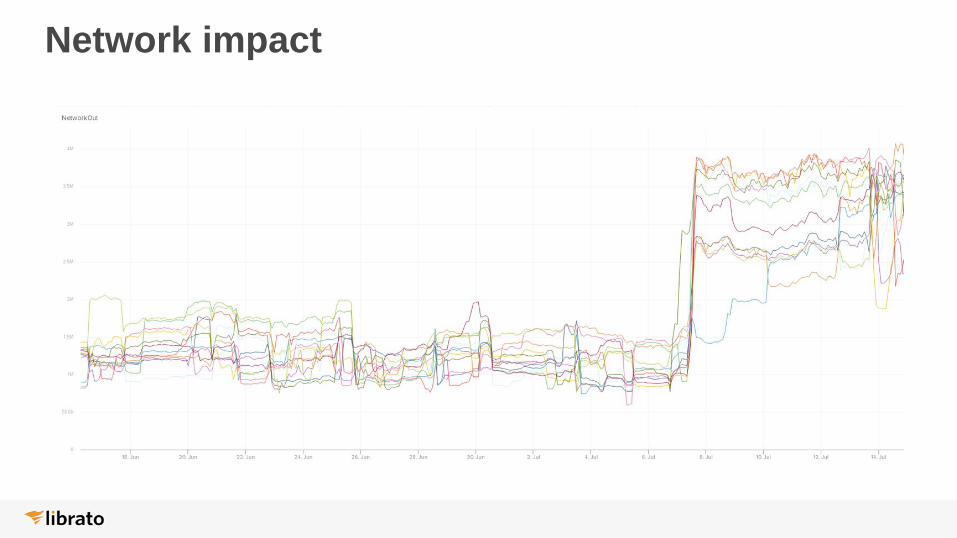
Network impact
Production reached! – July 2016
We’ll live with more network traffic for now
Write
Timeouts
Commitlog
Scaling
Started st1 GA st1 Testing Connection
Timeouts
In Prod!
Feb 2016 March April April 9 May June July 2016
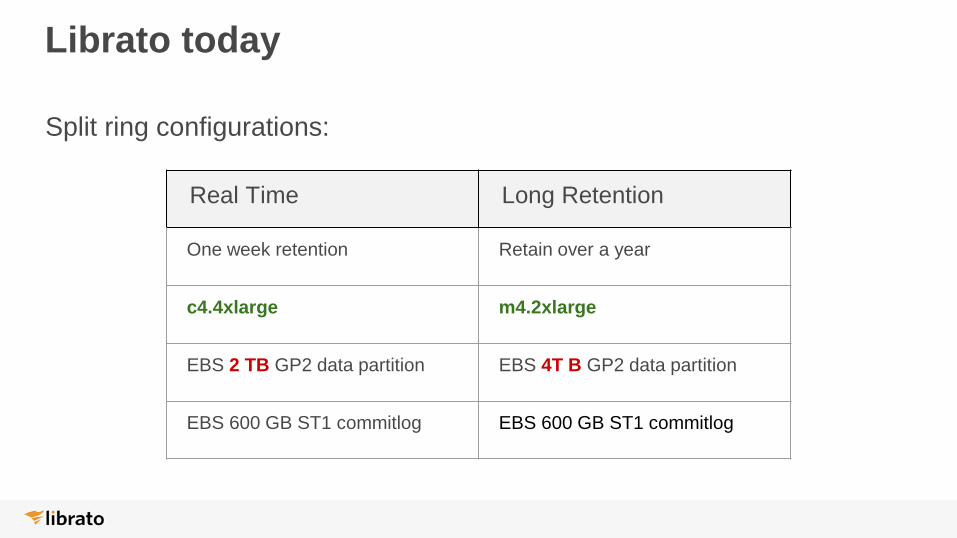
Librato today
Real Time Long Retention
One week retention Retain over a year
c4.4xlarge m4.2xlarge
EBS 2 TB GP2 data partition EBS 4T B GP2 data partition
EBS 600 GB ST1 commitlog EBS 600 GB ST1 commitlog
Split ring configurations:
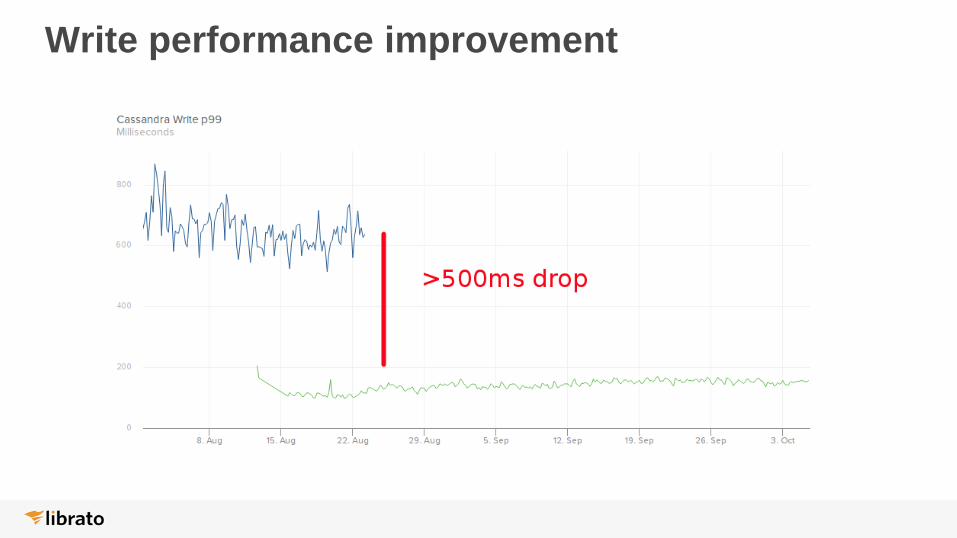
Write performance improvement

Before
● 120 * i2.2xlarge
● Instance cost: $62k monthly*
Real-time rings: before and after
After
● 66 * c4.4xlarge
● 2 TB GP2 + 600 GB ST1
● Instance cost: $25k monthly*
● EBS cost: $15k monthly
● Total: $40k monthly
Total savings
35%(*) 1 year up-front

Before
● 36 * i2.2xlarge
● Instance cost: $19k monthly*
Long retention rings: before and after
After
● 30 * m4.2xlarge
● 4 TB GP2 + 600 GB ST1
● Instances: $6k monthly*
● EBS cost: $13k monthly
● Total: $19k monthly
Even cost
2x+ more disk capacity
(*) 1 year up front

Operational Simplicity

Reducing MTTR
● Two critical pieces of state for Cassandra:
• Data files (commitlog and sstables)
• Network interface
● Data now on EBS
● ENI provides detached IP address (Amazon VPC only)
● Mobility provides a lot of flexibility

Bring them up, bring them down
● Now new rings are brought up fast
● Easier to automate
When not in use
● Shut down nodes
● Park the disks
… Or just destroy them

We’ve grown up: managing resources with
Terraform
● Query Terraform for state
● Create EBS
● Create ENI
● Create Security groups

Organized to let us remove resources
Keeps us from being cloud hoarders. When we’re done with a ring, we
can remove resources easily.
● Remove EBS
● Remove ENI
● Remove Security groups
Snapshots are still available in case we need them.
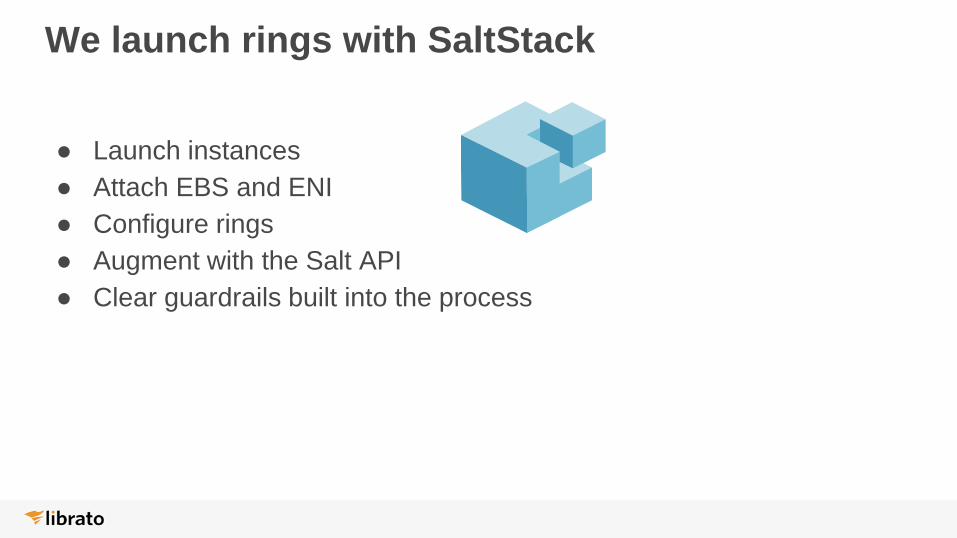
● Launch instances
● Attach EBS and ENI
● Configure rings
● Augment with the Salt API
● Clear guardrails built into the process
We launch rings with SaltStack
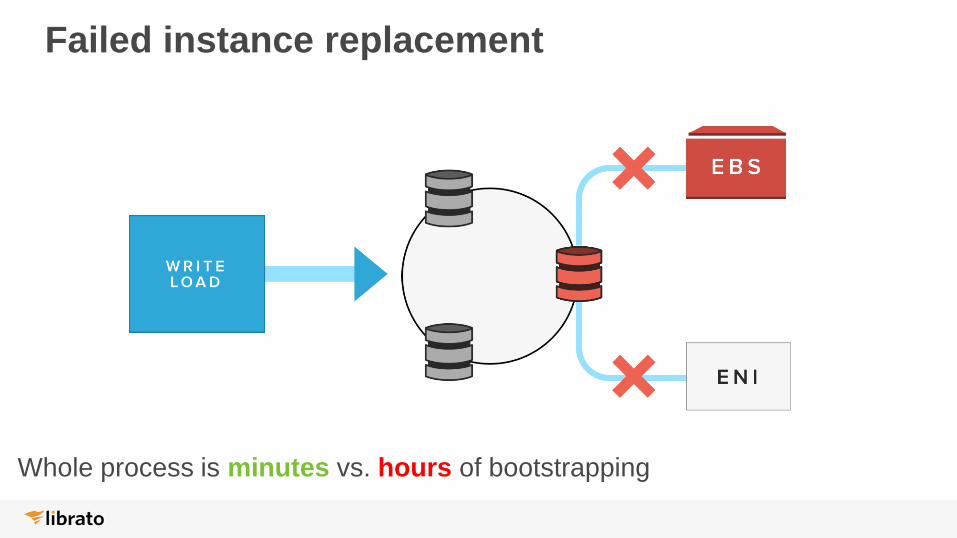
Failed instance replacement
Whole process is minutes vs. hours of bootstrapping

Disaster recovery
● Previously
• Tablesnap to Amazon S3
• Required constant pruning (tablechop)
• Amazon S3 bill high
● Now
• EBS snapshots
• Cron job to snapshot EBS via Ops API
• Cron job to clean old snapshots via Ops API
• Block differences: no pruning needed

In-place ring scale up
Now we have a button to push
● Sudden load change
● Rolling operation to scale up instances
● Example: scale from c4.4xl → c4.8xl
After comfortable with capacity, we can still scale ring out with
bootstrap

Data Access Impacts on EBS

Disk access mode
● MMap (4 KB faults) and Standard (read/write syscalls)
● MMap works well for small, random-access row reads
● Read ahead kept small for performant small reads
● Large compaction operations are sequential I/O
● What does this mean?
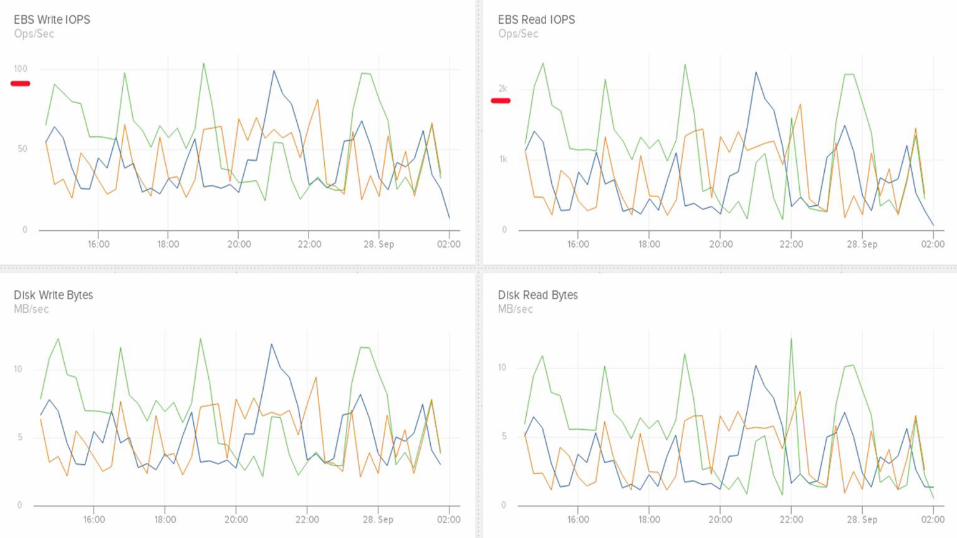


This impacts cost
● We must provision for a high base IOP load
● Disk size much larger than used capacity
● EBS GP2 IOP size is 256 KB
● What can be done?
Hybrid disk access mode
● MMap reads for row queries
● Standard mode (read/write) during compaction
● Ensure reads are chunked
● Chunk size configurable by disk (eg., 256 KB for GP2)
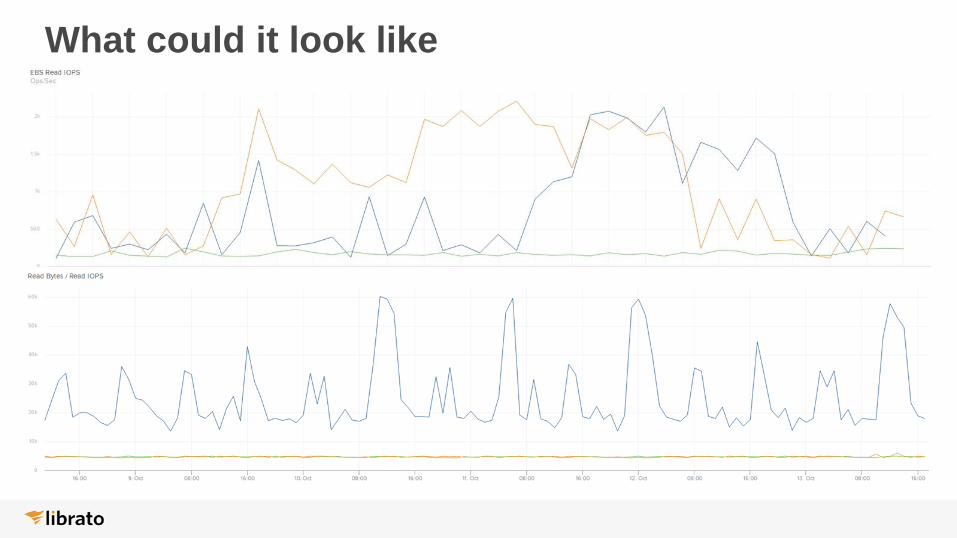
What could it look like

Closing

Wrapup
● Make it easy to test
production traffic
● Instance flexibility with EBS
● Operational simplicity and
reduced MTTR
● Reduced cost and increased
headroom
Future
● Debug network coalescing
● Cassandra 3.0
● More testing of hybrid disk
access models

Thank you!
@mheffner and @petercnorton
Come see us at SolarWinds booth #818

Remember to complete
your evaluations!