aws re:invent 2016: securing enterprise big data workloads on aws (sec308)
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Nasdaq and the Nasdaq logo are registered and unregistered trademarks, or service marks, of Nasdaq, Inc. or its subsidiaries in the U.S. and other countries.
Hadoop, Hive, Spark, Parquet, and Zeppelin are registered and unregistered trademarks of the Apache Software Foundation in the U.S. and other countries.
Moataz Anany, Solutions Architect, AWS
Nate Sammons, Principal Architect, Nasdaq
November 29, 2016
SEC308
Securing Enterprise Big Data
Workloads on AWS

What to expect from this session
Hybrid enterprise data warehouse: A typical architecture
Apply security controls across this architecture
How it’s done at

A snorkel or a deep dive?

Effective security starts with a plan
“In security engineering, you first need to…
define the threat model, then create a security policy,
and only then choose security technologies that suit”
– Bruce Schneier*
* Secrets and Lies: Digital Security in a Networked World
https://www.amazon.com/Secrets-Lies-Digital-Security-Networked/dp/1119092434/

A hybrid
enterprise data warehouse

A typical hybrid enterprise data warehouse
Corporate data center
Amazon
S3
AWS Direct
Connect
Amazon
RedshiftAmazon
EMR
AWS Cloud
Data
scientists
Business
end users
Enterprise data
sources
Extract,
upload,
and
transform
Explore,
analyze,
and
manipulate
Query
and
visualize
1
2
3
Data
engineers
Amazon QuickSight

A typical hybrid enterprise data warehouse
Corporate data center
Amazon
S3
AWS Direct
Connect
Amazon
RedshiftAmazon
EMR
AWS Cloud
Data
Scientists
Business
end users
Enterprise data
sources
Extract,
upload,
and
transform
Explore,
analyze,
and
manipulate
Query
and
visualize
1
2
3
Data
Engineers
Amazon QuickSight
How do you make it secure?
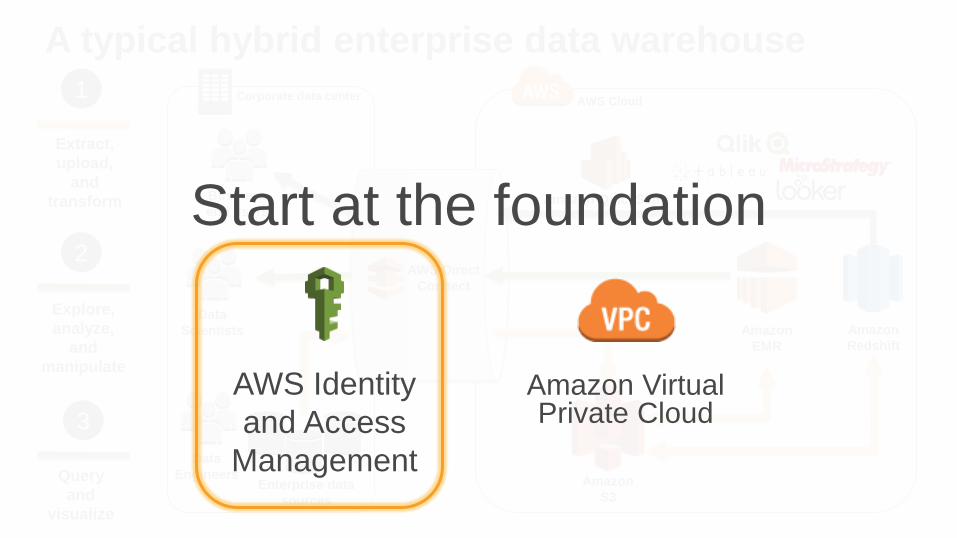
A typical hybrid enterprise data warehouse
Corporate data center
Amazon
S3
AWS Direct
Connect
Amazon
RedshiftAmazon
EMR
AWS Cloud
Data
Scientists
Business
end users
Enterprise data
sources
Extract,
upload,
and
transform
Explore,
analyze,
and
manipulate
Query
and
visualize
1
2
3
Data
Engineers
Amazon QuickSightStart at the foundation
AWS Identity
and Access
Management
Amazon Virtual Private Cloud
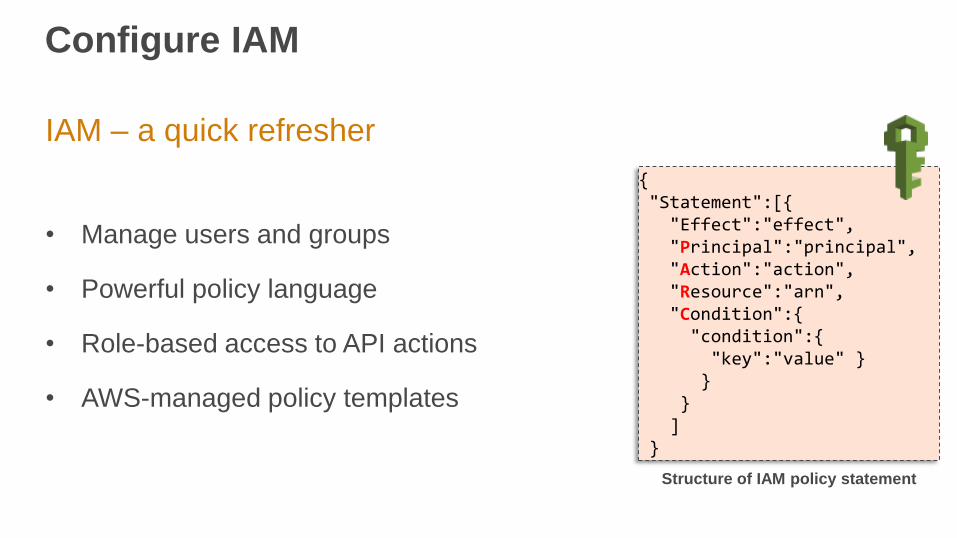
Configure IAM
IAM – a quick refresher
• Manage users and groups
• Powerful policy language
• Role-based access to API actions
• AWS-managed policy templates
{ "Statement":[{
"Effect":"effect","Principal":"principal","Action":"action", "Resource":"arn","Condition":{
"condition":{ "key":"value" }
}}
]}
Structure of IAM policy statement
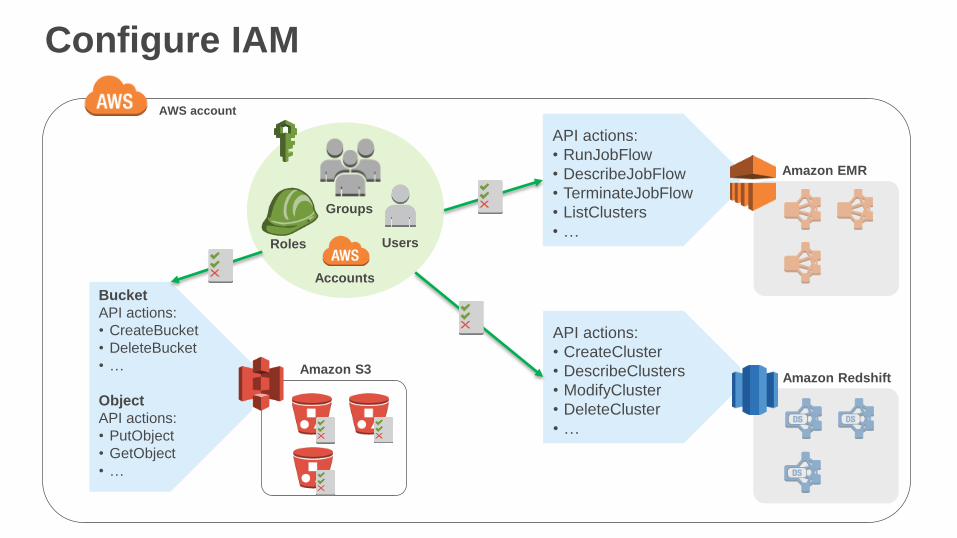
Configure IAM
AWS account
Amazon EMR
Amazon RedshiftAmazon S3
API actions:
• RunJobFlow
• DescribeJobFlow
• TerminateJobFlow
• ListClusters
• …
API actions:
• CreateCluster
• DescribeClusters
• ModifyCluster
• DeleteCluster
• …
Bucket
API actions:
• CreateBucket
• DeleteBucket
• …
Object
API actions:
• PutObject
• GetObject
• …
Roles
Groups
Users
Accounts

Configure IAM
Build IAM policies that match common activities
Access to Amazon S3 Administration (IAM)
Data read/write (IAM)
Access to Amazon EMR Cluster management (IAM)
Running batch transient jobs (IAM)
In-cluster activity (Hadoop AuthN/AuthZ)
Client access (Hadoop AuthN/AuthZ)
Access to Amazon Redshift Cluster management (IAM)
Authorizing COPY/UNLOAD (IAM)
In-cluster activity (Amazon Redshift
AuthN/AuthZ)

Configure IAM
Define AWS Identities and attach policies
• Define IAM users, groups, and roles
• Provide least privilege IAM access to Amazon S3, EMR, and Amazon Redshift
• Simulate and verify IAM policies
AWS
Identity
S3
Prefix “/…/...”
Amazon Redshift
Cluster “aaa”Amazon EMR AWS IAM
User X <Policy doc IDs> No Access No Access No Access
Group Y <Policy doc IDs> <Policy doc IDs> <Policy doc IDs> <Policy doc IDs>
Role Z <Policy doc IDs> <Policy doc IDs> No Access No Access
…

Configure IAM
Layer security controls around sensitive API actions
Use IAM policy conditions to...
• Require MFA for destructive API actions
s3:DeleteBucket
redshift:DeleteCluster
elasticmapreduce:TerminateJobFlow
• Add pre-conditions such as source IP address
or time of day
MFA
Policy conditions
Sensitive APIs
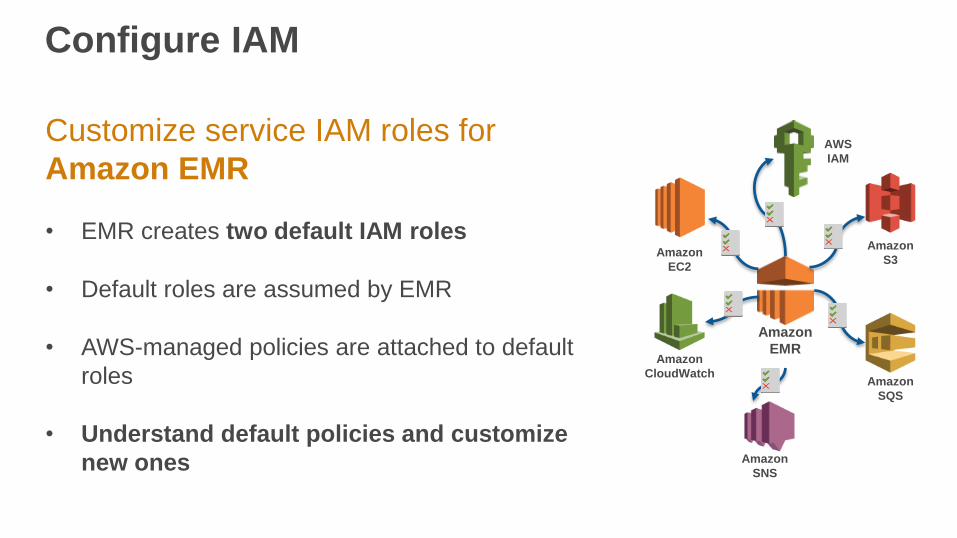
Configure IAM
Customize service IAM roles for
Amazon EMR
• EMR creates two default IAM roles
• Default roles are assumed by EMR
• AWS-managed policies are attached to default
roles
• Understand default policies and customize
new ones
Amazon
S3Amazon
EC2
Amazon
SQS
AWS
IAM
Amazon
EMR
Amazon
SNS
Amazon
CloudWatch
A typical hybrid enterprise data warehouse
corporate data center
Amazon
S3
AWS Direct
Connect
Amazon
RedshiftAmazon
EMR
AWS Cloud
Data
Scientists
Business
end users
Enterprise data
sources
Extract,
upload,
and
transform
Explore,
analyze,
and
manipulate
Query
and
visualize
1
2
3
Data
Engineers
Amazon QuickSightStart at the foundation
AWS Identity
and Access
Management
Amazon Virtual Private Cloud
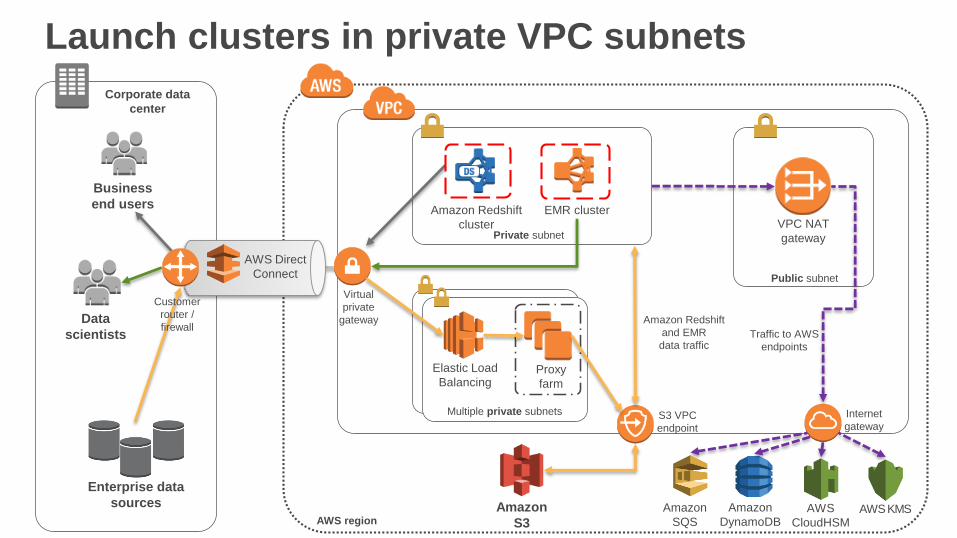
Launch clusters in private VPC subnets
Corporate data
center
Amazon
S3
Data
scientists
AWS region
Business
end users
Private subnet
AWS
CloudHSM
AWS Direct
Connect
Enterprise data
sourcesAWS KMS
S3 VPC
endpoint
EMR cluster
Public subnet
Customer
router /
firewall
Virtual
private
gateway
Amazon
DynamoDB
Internet
gateway
VPC NAT
gateway
Traffic to AWS
endpoints
Amazon
SQS
Amazon Redshift
cluster
Amazon Redshift
and EMR
data traffic
Elastic Load
BalancingProxy
farm
Multiple private subnets

Launch clusters in private VPC subnets
corporate data
center
Amazon
S3
Data
Scientists
AWS region
Business
end users
Private VPC subnet
AWS
CloudHSM
AWS Direct
Connect
Enterprise data
sources AWS KMS
Amazon
Redshift
S3 VPC endpoint
Amazon
EMR Custer
Public VPC subnet
Internet
Gateway
VPC NAT Gateway
Customer
Gateway
Virtual
Private
Gateway
Amazon
DynamoDB
Communication
with AWS
service
endpoints
Amazon
SQS
Key security benefits
• Data flows are private; traversing your VPC
• Multiple network traffic “choke points”
• Traffic logging with VPC Flow Logs
• Dedicated tenancy is possible
A typical hybrid enterprise data warehouse
corporate data center
Amazon
S3
AWS Direct
Connect
Amazon
RedshiftAmazon
EMR
AWS Cloud
Data
Scientists
Business
end users
Enterprise data
sources
Extract,
upload,
and
transform
Explore,
analyze,
and
manipulate
Query
and
visualize
1
2
3
Data
Engineers
Amazon QuickSight
Protect your data with
access control
Amazon
S3
Amazon
Redshift
Amazon
EMR
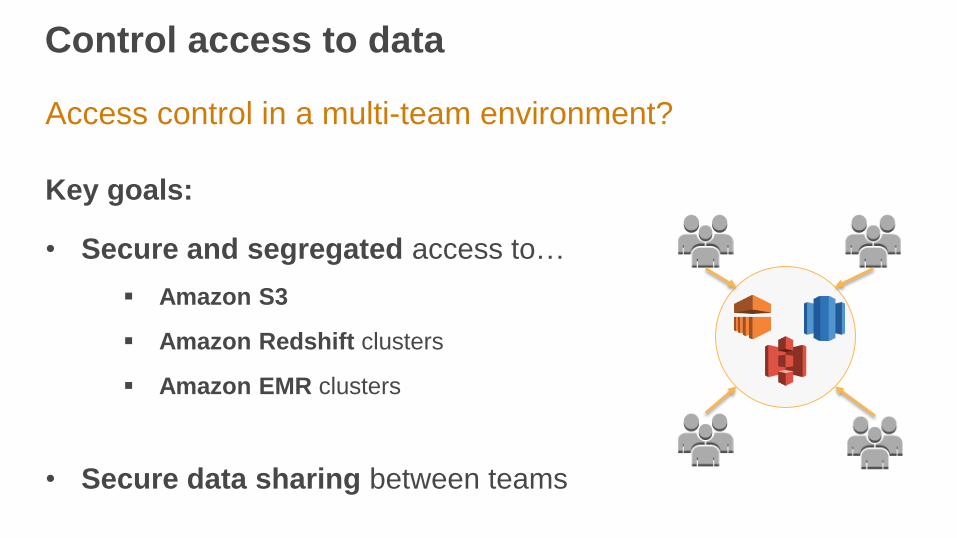
Control access to data
Access control in a multi-team environment?
Key goals:
• Secure and segregated access to…
Amazon S3
Amazon Redshift clusters
Amazon EMR clusters
• Secure data sharing between teams
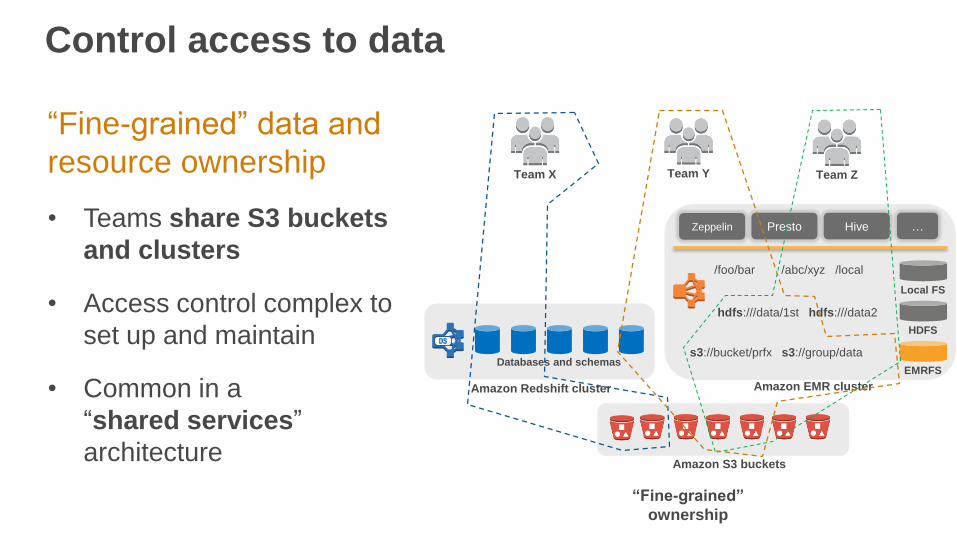
Control access to data
“Fine-grained” data and
resource ownership
• Teams share S3 buckets
and clusters
• Access control complex to
set up and maintain
• Common in a
“shared services”
architecture
Team X Team Y Team Z
Amazon EMR cluster
Amazon S3 buckets
Local FS
HDFS
EMRFS
Amazon Redshift cluster
Databases and schemas
/foo/bar /abc/xyz /local
hdfs:///data/1st hdfs:///data2
s3://bucket/prfx s3://group/data
Zeppelin Presto Hive …
“Fine-grained”
ownership
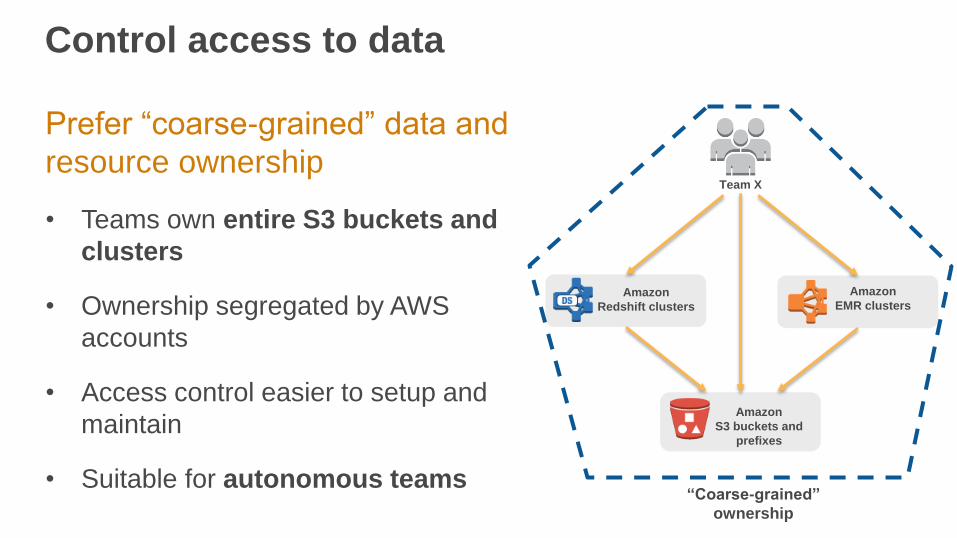
Control access to data
Amazon
S3 buckets and
prefixes
Amazon
EMR clusters
Team X
Amazon
Redshift clusters
Prefer “coarse-grained” data and
resource ownership
• Teams own entire S3 buckets and
clusters
• Ownership segregated by AWS
accounts
• Access control easier to setup and
maintain
• Suitable for autonomous teams“Coarse-grained”
ownership
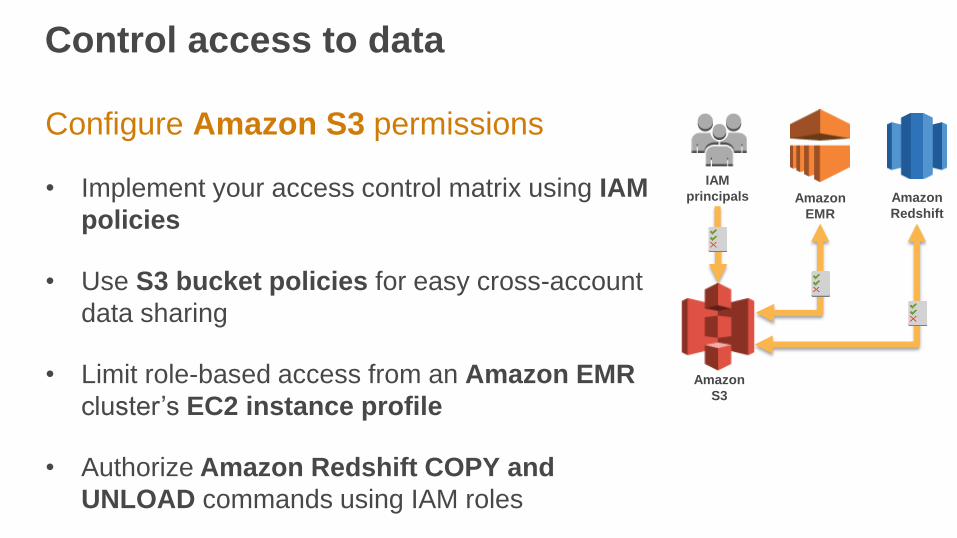
Control access to data
Configure Amazon S3 permissions
• Implement your access control matrix using IAM
policies
• Use S3 bucket policies for easy cross-account
data sharing
• Limit role-based access from an Amazon EMR
cluster’s EC2 instance profile
• Authorize Amazon Redshift COPY and
UNLOAD commands using IAM roles
Amazon
S3
Amazon
RedshiftAmazon
EMR
IAM
principals

Control access to data
Configure AuthN and AuthZ in Amazon EMR
• Enable “Secure Mode” in Hadoop
• Setup and configure Kerberos authentication
• Configure Hadoop ACLs for authorization
• Optionally integrate EMR with Apache Ranger or a
similar security framework
MIT Kerberos

Control access to data
Configure AuthN and AuthZ in Amazon Redshift
• Amazon Redshift is based on PostgreSQL
• GRANT or REVOKE fine-grained permissions databases, schemas,
tables, and other objects
• Set secure default privileges for new objects using the ALTER
DEFAULT PRIVILEGES command
• Verify privileges using SET SESSION AUTHORIZATION command
A typical hybrid enterprise data warehouse
corporate data center
Amazon
S3
AWS Direct
Connect
Amazon
RedshiftAmazon
EMR
AWS Cloud
Data
Scientists
Business
end users
Enterprise data
sources
Extract,
upload,
and
transform
Explore,
analyze,
and
manipulate
Query
and
visualize
1
2
3
Data
Engineers
Amazon QuickSight
Protect your data with
encryption
Amazon
S3
Amazon
Redshift
Amazon
EMR

Encrypt data at rest
In a nutshell…
1. Decide on an encryption key management strategy
2. Pick encryption mode for Amazon S3 objects
3. Configure encryption in Amazon EMR
4. Launch an encrypted Amazon Redshift cluster
Encrypt data at rest
Decide on an encryption key management strategy
AWS Key
Management Service
(AWS KMS)
AWS service managed
keysCustom key
management system
AWS CloudHSM

Encrypt data at rest
What is AWS KMS?
• Simplifies creation, import, control, rotation, deletion, and use
of encryption keys
• Integrated with AWS client-side and server-side encryption
• Integrated with AWS CloudTrail

Encrypt data at rest
Decide on an encryption key management strategy
Do I have to
manage my
encryption keys?
Do I need dedicated
key management
hardware?
Do I have to manage
my keys on premises? Strategy
No No No Use AWS service managed
Yes No No Use AWS KMS
Yes Yes No Use AWS CloudHSM
Yes No Yes Use own KMS
Yes Yes Yes Use own HSM

Encrypt data at rest
Pick encryption mode for Amazon S3 objects
Where and when do I need to encrypt my data for S3?
• Before upload, after download – S3 client-side encryption
• After upload, before download – S3 server-side encryption

Encrypt data at rest
Pick encryption mode for Amazon S3 objects
CSE - KMS CSE - C
SSE - KMS SSE - C SSE - S3Server side
Client side
AWS KMS S3 built-inCustom KMS
Key
management?
Encryption
point?
Encrypt data at rest
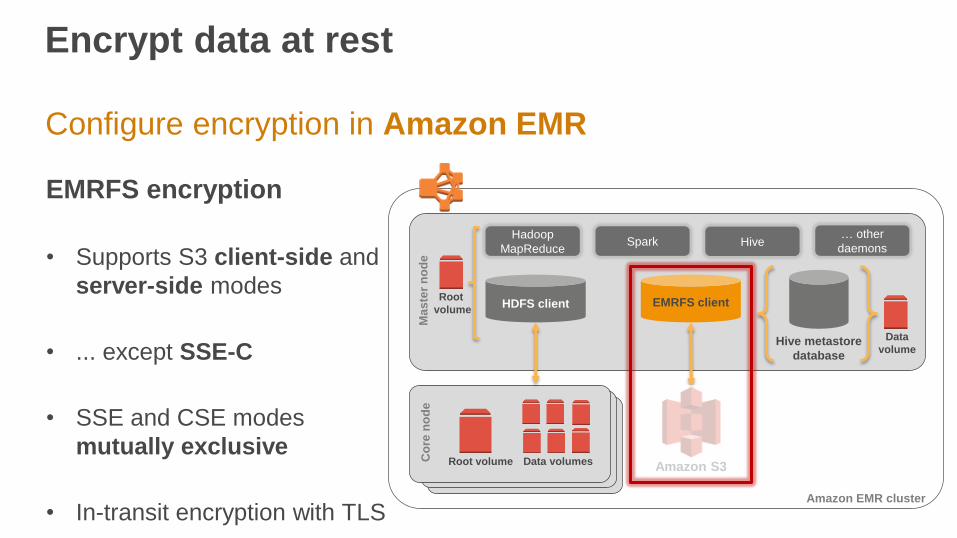
Configure encryption in Amazon EMR
EMRFS encryption
• Supports S3 client-side and
server-side modes
• ... except SSE-C
• SSE and CSE modes
mutually exclusive
• In-transit encryption with TLS
Co
re n
od
e
Root volume Amazon S3
EMRFS clientHDFS client
Hive metastore
database
HiveHadoop
MapReduceSpark
… other
daemons
Data volumes
Ma
ste
r n
od
e
Root
volume
Amazon EMR cluster
Data
volume
Encrypt data at rest
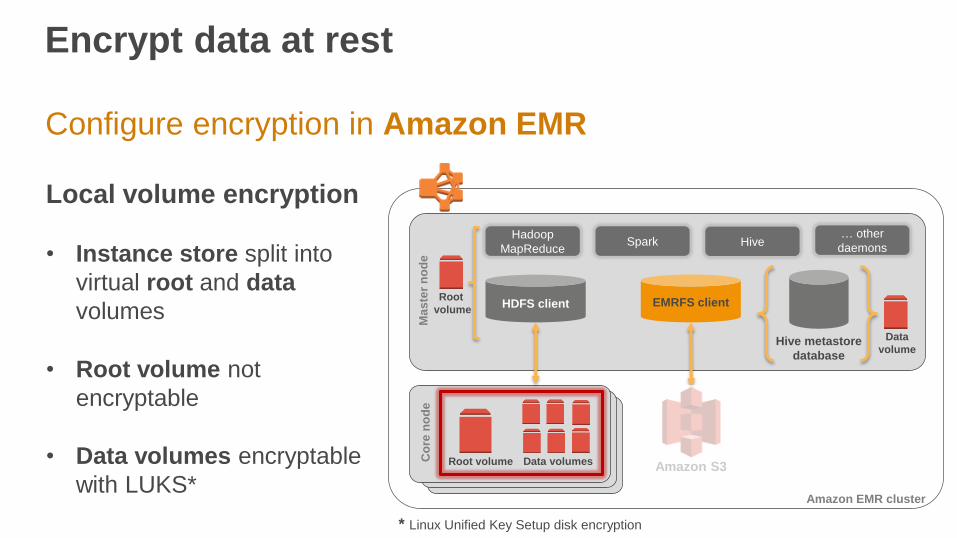
Configure encryption in Amazon EMR
Local volume encryption
• Instance store split into
virtual root and data
volumes
• Root volume not
encryptable
• Data volumes encryptable
with LUKS*
Co
re n
od
e
Data volumesRoot volume Amazon S3
EMRFS clientHDFS client
Hive metastore
database
HiveHadoop
MapReduceSpark
… other
daemons
Ma
ste
r n
od
e
Root
volume
Amazon EMR cluster
Data
volume
* Linux Unified Key Setup disk encryption
Encrypt data at rest
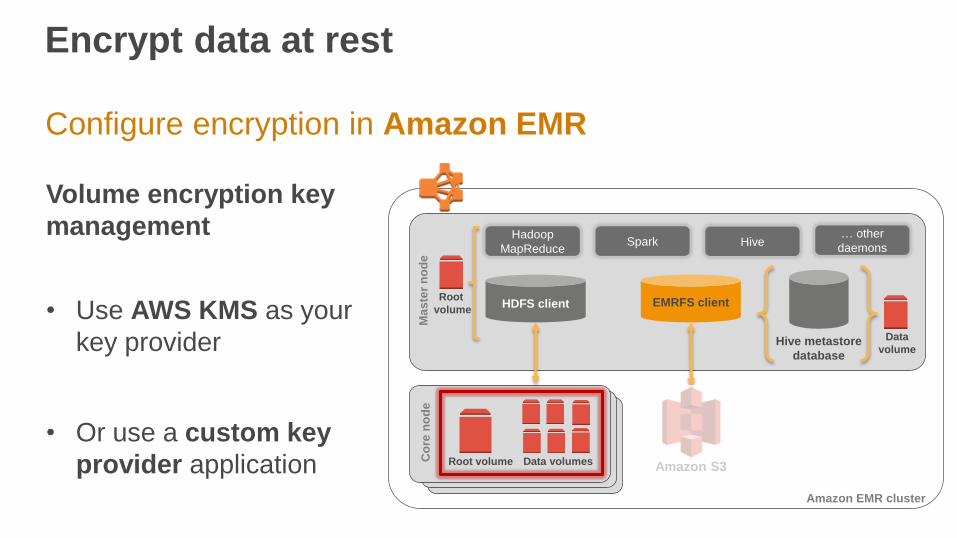
Configure encryption in Amazon EMR
Volume encryption key
management
• Use AWS KMS as your
key provider
• Or use a custom key
provider application Co
re n
od
e
Data volumesRoot volume Amazon S3
EMRFS clientHDFS client
Hive metastore
database
HiveHadoop
MapReduceSpark
… other
daemons
Ma
ste
r n
od
e
Root
volume
Amazon EMR cluster
Data
volume
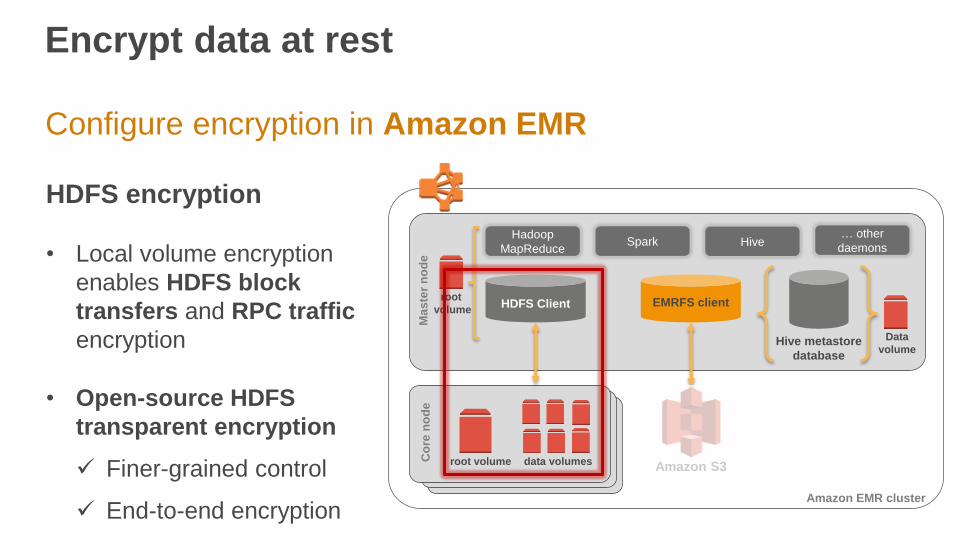
Encrypt data at rest
Configure encryption in Amazon EMR
HDFS encryption
• Local volume encryption
enables HDFS block
transfers and RPC traffic
encryption
• Open-source HDFS
transparent encryption
Finer-grained control
End-to-end encryption
Co
re n
od
e
data volumesroot volume Amazon S3
EMRFS clientHDFS Client
Hive metastore
database
HiveHadoop
MapReduceSpark
… other
daemons
Ma
ste
r n
od
e
root
volume
Amazon EMR cluster
Data
volume

Encrypt data at rest
Configure encryption in Amazon EMR
Create a managed “security configuration” object...
• Configure EMRFS and local-volume encryption at rest
• Configure encryption in transit
At cluster creation time...
• Reference a managed security configuration
• If needed, configure HDFS transparent encryption

Encrypt data at rest
Launch an encrypted Amazon Redshift cluster
• Four-tier key hierarchy
• AES algorithm with 256-bit keys
• Use AWS KMS or HSM
• Control rotation of encryption keys
• Blocks backed up to S3 are encrypted
10 GigE
(HPC)
Backup
JDBC/ODBC
At rest
Four-tier key
hierarchy
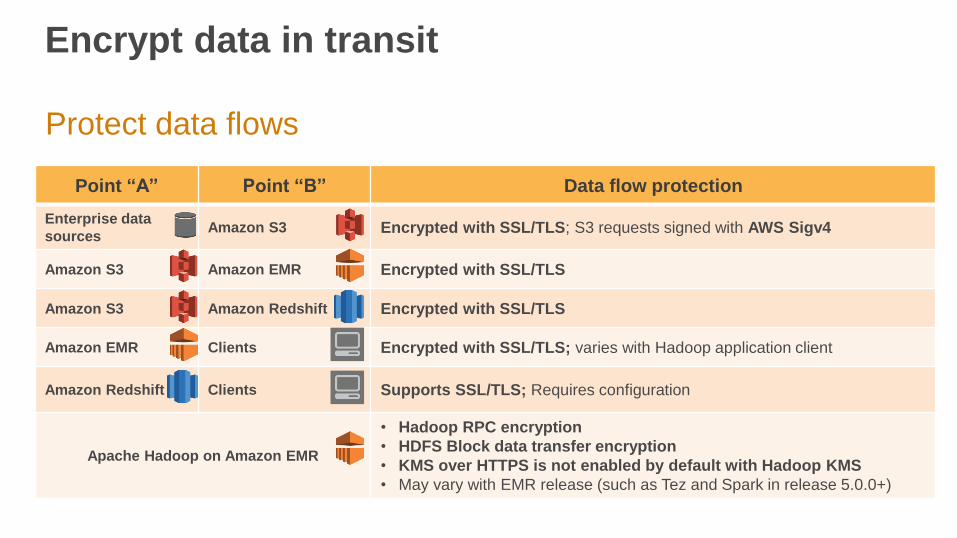
Encrypt data in transit
Protect data flows
Point “A” Point “B” Data flow protection
Enterprise data
sourcesAmazon S3 Encrypted with SSL/TLS; S3 requests signed with AWS Sigv4
Amazon S3 Amazon EMR Encrypted with SSL/TLS
Amazon S3 Amazon Redshift Encrypted with SSL/TLS
Amazon EMR Clients Encrypted with SSL/TLS; varies with Hadoop application client
Amazon Redshift Clients Supports SSL/TLS; Requires configuration
Apache Hadoop on Amazon EMR
• Hadoop RPC encryption
• HDFS Block data transfer encryption
• KMS over HTTPS is not enabled by default with Hadoop KMS
• May vary with EMR release (such as Tez and Spark in release 5.0.0+)

How it’s done at

What to expect from this session
Introduction
Choices made on our path:
• Amazon Redshift
• Amazon EMR
Future directions for big data at

NASDAQ LISTS3 , 7 0 0 G L O B A L C O M P A N I E S
IN MARKET CAP REPRESENTING
WORTH $9.3TRILLION
DIVERSE INDUSTRIES AND
MANY OF THE WORLD’SMOST WELL-KNOWN AND
INNOVATIVE BRANDSMORE THAN U.S.1 TRILLIONNATIONAL VALUE IS TIEDTO OUR LIBRARY OF MORE THAN
43,000 GLOBAL INDEXES
N A S D A Q T E C H N O L O G Y
IS USED TO POWER MORE THAN
IN 50 COUNTRIES100 MARKETPLACES
OUR GLOBAL PLATFORM
CAN HANDLE MORE THAN
1 MILLIONMESSAGES/SECONDAT SUB-40 MICROSECONDS
AV E RAG E S P E ED S
1 C L E A R I N G H O U S E
WE OWN AND OPERATE
33 MARKETS
5 CENTRAL SECURITIES
DEPOSITORIES
INCLUDING
ACROS S AS S E T C L A S SE S
& GEOGRAPHIES

Amazon Redshift at Nasdaq
• In use since Amazon Redshift was in beta
• Nasdaq’s main data warehousing workhorse
• Daily ingest from 100s of internal sources, 6-20B rows/day
• Current footprint: 18x ds2.8xlarge instances, 3 trillion rows
• Highly sensitive data:
• All orders, quotes, trades, etc. from all Nasdaq exchanges
• Membership and ownership information
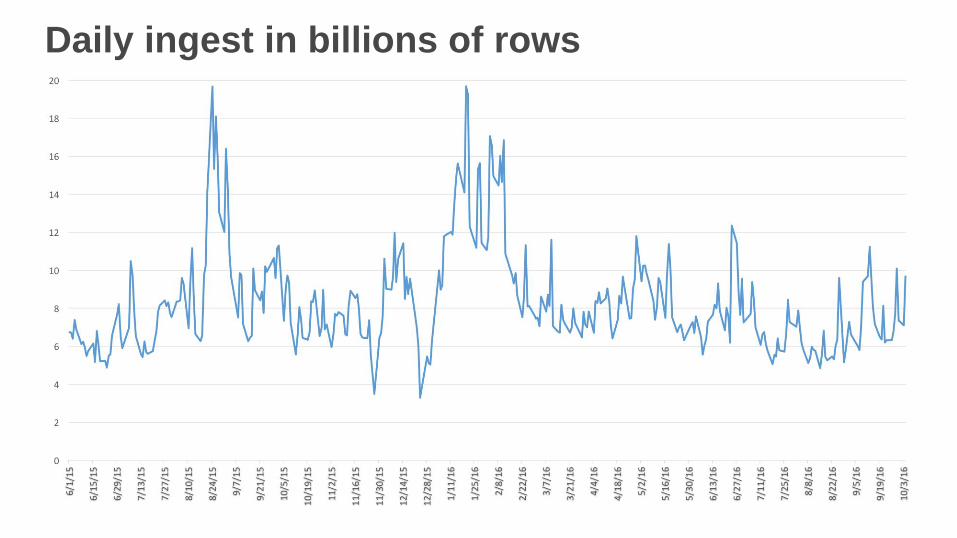
Daily ingest in billions of rows
Amazon Redshift workloads
• Billing and reporting
• Market surveillance
• Economic research
• Trade history queries
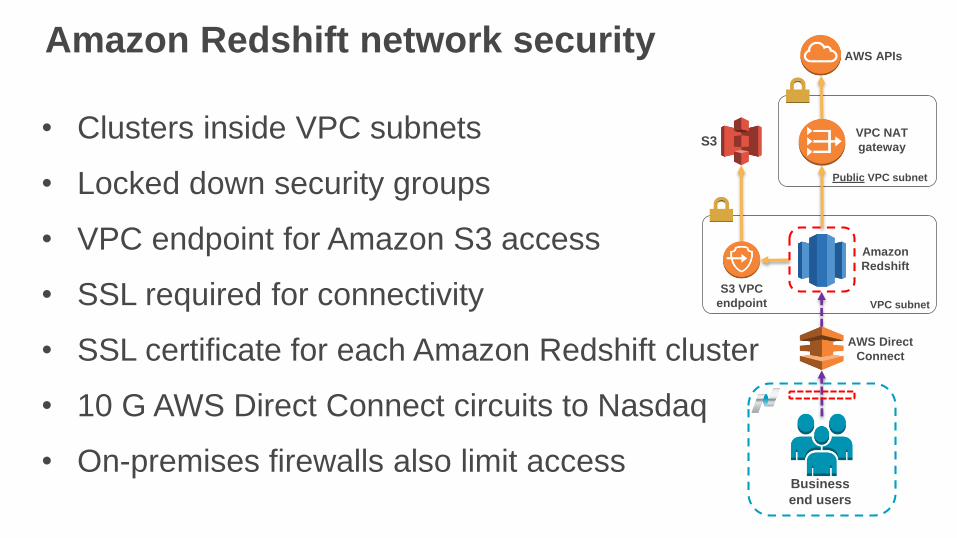
Amazon Redshift network security
• Clusters inside VPC subnets
• Locked down security groups
• VPC endpoint for Amazon S3 access
• SSL required for connectivity
• SSL certificate for each Amazon Redshift cluster
• 10 G AWS Direct Connect circuits to Nasdaq
• On-premises firewalls also limit accessBusiness
end users
AWS Direct
Connect
Amazon
Redshift
Public VPC subnet
VPC NAT
gateway
S3 VPC
endpoint
AWS APIs
VPC subnet
S3
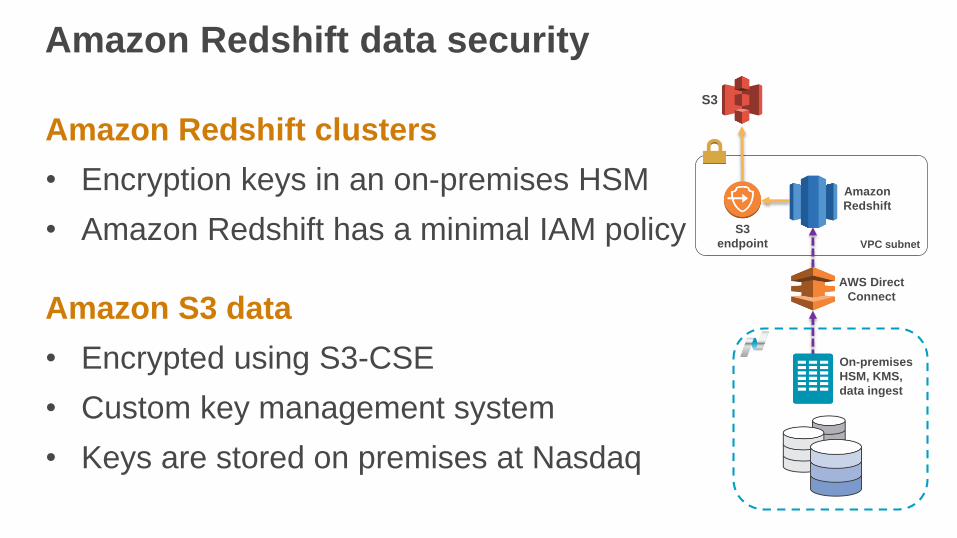
Amazon Redshift data security
Amazon Redshift clusters
• Encryption keys in an on-premises HSM
• Amazon Redshift has a minimal IAM policy
Amazon S3 data
• Encrypted using S3-CSE
• Custom key management system
• Keys are stored on premises at Nasdaq
AWS Direct
Connect
Amazon
Redshift
VPC subnet
S3
endpoint
On-premises
HSM, KMS,
data ingest
S3
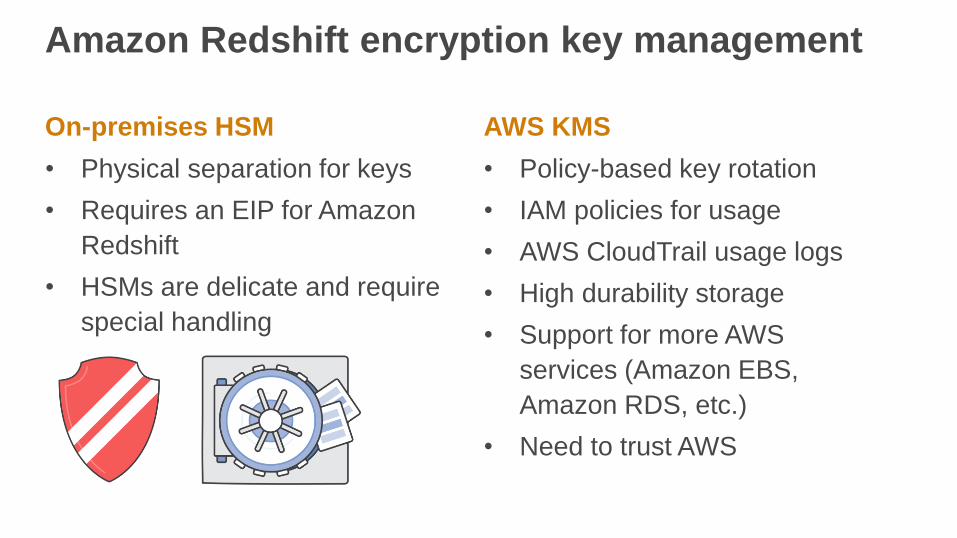
On-premises HSM
• Physical separation for keys
• Requires an EIP for Amazon
Redshift
• HSMs are delicate and require
special handling
Amazon Redshift encryption key management
AWS KMS
• Policy-based key rotation
• IAM policies for usage
• AWS CloudTrail usage logs
• High durability storage
• Support for more AWS
services (Amazon EBS,
Amazon RDS, etc.)
• Need to trust AWS

Amazon Redshift access control and monitoring
• Write access allowed only for the data ingest system
• Users granted access to specific schemas
• Users granted specific WLM constraints
• Monitor STL_CONNECTION_LOG for access
• Logs in S3 pulled on-premises for analysis
• Amazon Redshift activity logging
• CloudTrail API logs
• VPC Flow Logs
AWS CloudTrailAmazon S3
Amazon
CloudWatch
Amazon
Redshift

Managing Amazon Redshift cluster resources
Initially we never purged any data
• Led to growing clusters once per quarter
Now we maintain a 1-year rolling window in Amazon
Redshift
• Older data is accessed infrequently
• Resizing a large Amazon Redshift cluster is not instantaneous
• Grow clusters based on market volumes, acquisitions
• This led us to extend our warehouse to EMR and S3

Amazon EMR at Nasdaq
Gaining traction internally
• Building an open data platform
• Parallel daily loads of data for Amazon EMR and
Amazon Redshift
• Data stored as encrypted Parquet files in Amazon S3
Keep data “forever”
• Current footprint is 5.1 million objects, 500 TB
• Approximately 6.5 trillion rows since January 2014
• Backfilling data from the 1990s, around 1.5 PB

Hadoop file formats
Evaluated Parquet and ORC
• Arrived at Apache Parquet
Benefits
• Modern columnar format with good compression
• “Self-describing” format
• Growing support across open source projects
• Works with our two main use cases: Spark and Presto
• Good performance when encrypted

Amazon EMR workloads
Apache Spark and Zeppelin
• Economic research
• Market surveillance
• Machine learning
Presto from Facebook
• Trade history queries
• BI and reporting (experimental)

Amazon EMR data strategy
Decouple storage and compute
• Scale each as needed
• Data stored centrally in Amazon S3
Hive directory structure in S3
• Easy partitioning of time series data by date
• Fine-grained access control using bucket policies
• Cross-account access using bucket policies
• Use “MSCK REPAIR TABLE” to rebuild metastore
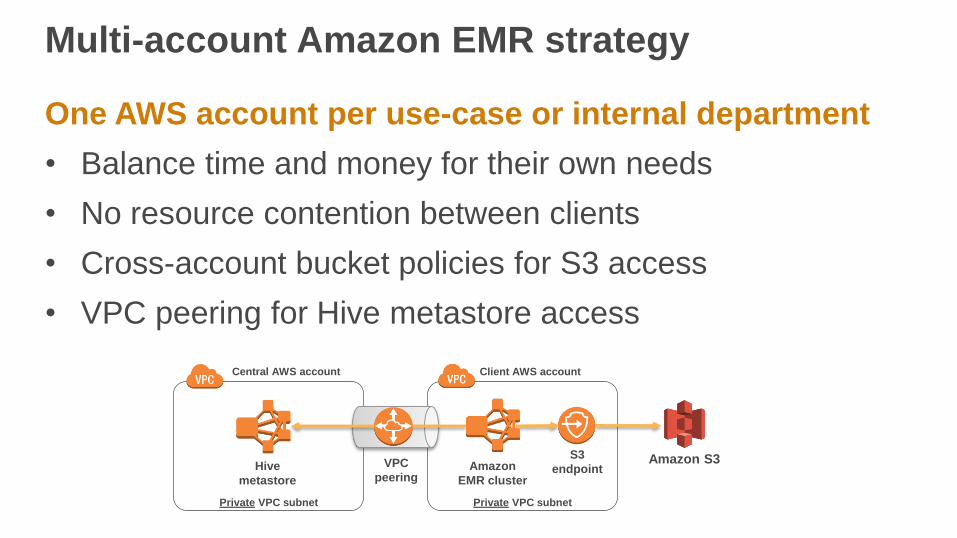
Multi-account Amazon EMR strategy
One AWS account per use-case or internal department
• Balance time and money for their own needs
• No resource contention between clients
• Cross-account bucket policies for S3 access
• VPC peering for Hive metastore access
Private VPC subnet
S3
endpointAmazon
EMR cluster
Private VPC subnet
Hive
metastore
VPC
peering
Client AWS accountCentral AWS account
Amazon S3
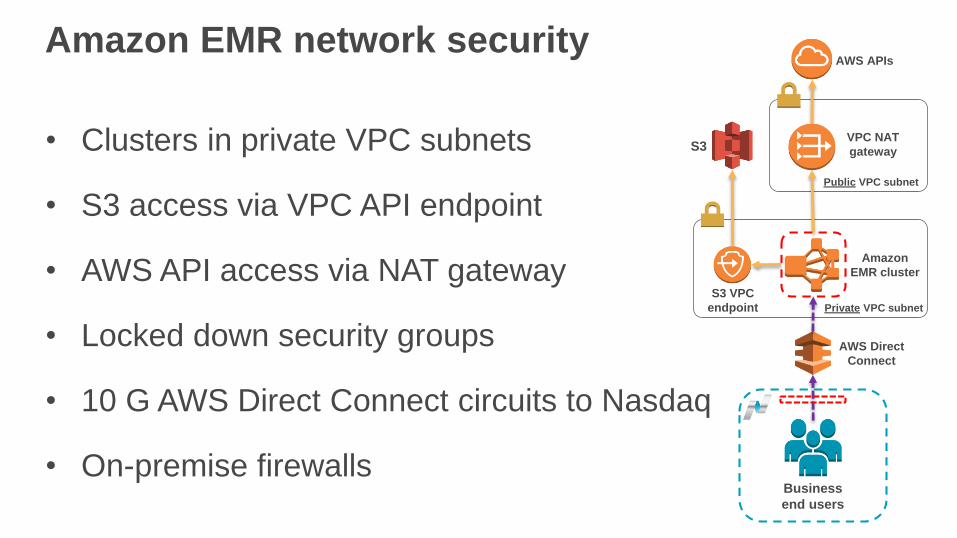
Amazon EMR network security
• Clusters in private VPC subnets
• S3 access via VPC API endpoint
• AWS API access via NAT gateway
• Locked down security groups
• 10 G AWS Direct Connect circuits to Nasdaq
• On-premise firewalls
AWS Direct
Connect
Amazon
EMR cluster
Private VPC subnet
Public VPC subnet
VPC NAT
gateway
S3 VPC
endpoint
AWS APIs
Business
end users
S3
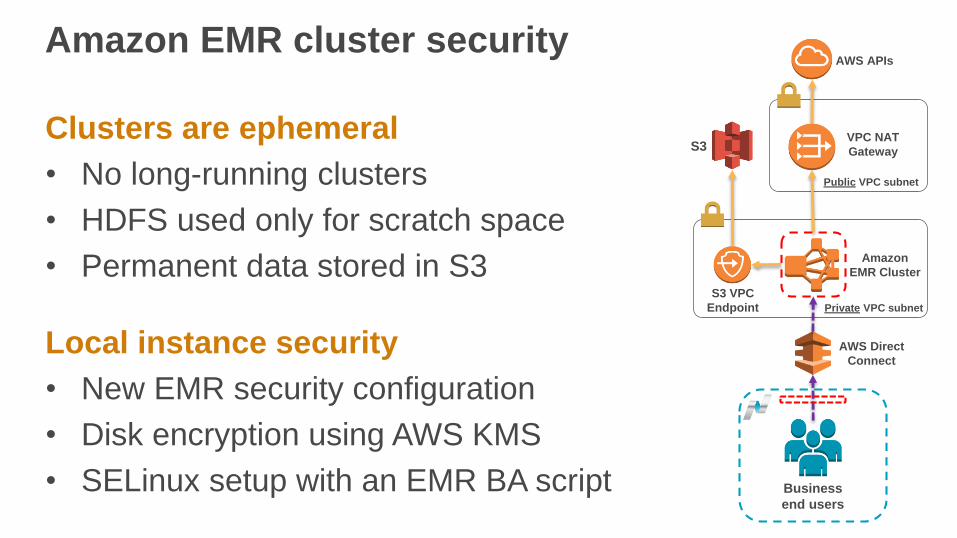
Amazon EMR cluster security
Clusters are ephemeral
• No long-running clusters
• HDFS used only for scratch space
• Permanent data stored in S3
Local instance security
• New EMR security configuration
• Disk encryption using AWS KMS
• SELinux setup with an EMR BA script
AWS Direct
Connect
Amazon
EMR Cluster
Private VPC subnet
Public VPC subnet
VPC NAT
Gateway
S3 VPC
Endpoint
AWS APIs
Business
end users
S3

Amazon S3 data security with EMR
EMRFS: Amazon S3 as HDFS
• S3-CSE integrated as part of EMRFS
• Custom S3 encryption materials provider jar
• Requests to “seek” within objects stored in S3 works well
and is critical for performance
Multi-account access control
• S3 bucket policies control access
• Able to limit access to specific schemas and tables

Apache Spark data security
EMRFS on S3 “just works” with Spark
• Simple configurations for S3-CSE
• EMR security configuration for local disk encryption
Apache Zeppelin notebook storage in S3
• Nasdaq contributed S3-CSE support
• Custom KMS and AWS KMS supported as of 0.6.0
https://github.com/apache/zeppelin/pull/886

Presto data security
Presto does not use EMRFS
• PrestoS3FileSystem is part of the Hive connector
• EMR security configuration for local disk encryption
Nasdaq contributed S3-CSE support to Presto
• Support for S3-CSE with custom KMS merged in 0.129
https://github.com/prestodb/presto/pull/3802
• Support for S3-CSE-KMS merged in 0.153
https://github.com/prestodb/presto/pull/5701

Coming next: Data community
• Clients perform analytics on shared data
• New datasets created in their local account
• Amazon SQS messages from a “staging” S3 bucket
trigger data ingest in the central warehouse account
• Maintains centralized write access to the warehouse
• Client accounts generate Parquet output
• Automatically categorize and catalog data

Thank you!

Remember to complete
your evaluations!