bad things happen to good people: how to minimize the … · bad things happen to good people: how...
TRANSCRIPT

© 2013 IBM Corporation
NEODBUG – November 21st, 2013
Bad Things Happen to Good People:How to Minimize the Pain
DB2 for Linux, UNIX, and Windows
Kelly Schlamb ([email protected])Executive IT Specialist, Worldwide Information Management Technical SalesIBM Canada Ltd.

© 2013 IBM Corporation2
© Copyright IBM Corporation 2013. All rights reserved.U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.
THE INFORMATION CONTAINED IN THIS PRESENTATION IS PROVIDED FOR INFORMATIONAL PURPOSES ONLY. WHILE EFFORTS WERE MADE TO VERIFY THE COMPLETENESS AND ACCURACY OF THE INFORMATION CONTAINED IN THIS PRESENTATION, IT IS PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. IN ADDITION, THIS INFORMATION IS BASED ON IBM'S CURRENT PRODUCT PLANS AND STRATEGY, WHICH ARE SUBJECT TO CHANGE BY IBM WITHOUT NOTICE. IBM SHALL NOT BE RESPONSIBLE FOR ANY DAMAGES ARISING OUT OF THE USE OF, OR OTHERWISE RELATED TO, THIS PRESENTATION OR ANY OTHER DOCUMENTATION. NOTHING CONTAINED IN THIS PRESENTATION IS INTENDED TO, NOR SHALL HAVE THE EFFECT OF, CREATING ANY WARRANTIES OR REPRESENTATIONS FROM IBM (OR ITS SUPPLIERS OR LICENSORS), OR ALTERING THE TERMS AND CONDITIONS OF ANY AGREEMENT OR LICENSE GOVERNING THE USE OF IBM PRODUCTS AND/OR SOFTWARE.
IBM's statements regarding its plans, directions, and intent are subject to change or withdrawal without notice at IBM's sole discretion. Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision. The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract. The development, release, and timing of any future features or functionality described for our products remains at our sole discretion.
IBM, the IBM logo, ibm.com, Information Management, DB2, DB2 Connect, DB2 OLAP Server, pureScale, System Z, Cognos, solidDB, Informix, Optim, InfoSphere, and z/OS are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol (® or ™), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at “Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml
Other company, product, or service names may be trademarks or service marks of others.
Disclaimer

© 2013 IBM CorporationOctober 28, 2013
Logging and Recovery

© 2013 IBM Corporation4
What Could Possibly Go Wrong? Famous Last Words.
Underlying storage becomes unusable
Table space is accidentally dropped
Table is accidentally dropped or
data deleted
Database servergoes down (planned
or unplanned)Hardware component
failureDatabase is accidentally dropped
Site disaster
As the Boy Scouts say … "Be prepared!"

© 2013 IBM Corporation5
Develop a Recovery Plan
Some questions to ask yourself when developinga recovery plan– Does the database need to be recoverable?– What are your RPO and RTO requirements?
• Recovery Point Objective – how much data loss is acceptable, if any, if a major incident occurs?
• Recovery Time Objective – what is an acceptable length of time to perform the recovery while the system is unavailable?
– How frequent do the backup operations need to be?– How much storage space can be used for backups and archived logs? – Where do you want the backups and archived logs to go?– Will table space level backups be sufficient, or will full database backups be
necessary? – Do the backups need to be automated?– Is high availability (HA) a consideration?– Is off-site disaster recovery (DR) a consideration?

© 2013 IBM Corporation6
Logging & Log File Management Recommendations
Use archive logging (not circular logging) forproduction environments– Provides better recovery characteristics (lower RPO)– Permits use of online backups (better availability) and table space level
backups (more granular)– Can setup two archive log paths for best protection
Include logs in backup images (default behavior)– Allows restoring of an online backup if all you have is the backup image
(e.g. disaster recovery)
Configure mirrored logging on separate file systems– Protects against file system corruption or accidental deletion of log files
For archive logging, consider using automated log file management– Choose how long to retain recovery objects like backups and archived logs and
when to automatically prune them– See NUM_DB_BACKUPS, REC_HIS_RETENTN, and AUTO_DEL_REC_OBJ
database configuration parameters

© 2013 IBM Corporation7
Backup & Recovery
Various methods and options available for backing up and recovering the data in your databases– Offline or online backups– Database or table space backups– Split mirror / flash copy backups– Incremental backups– Rebuild database from table space backup images– Backup compression
As database size increases, consider using more frequent, onlinetable space level backups
Built-in autonomics for backup command provides optimal values for number of buffers, buffer size, and parallelism– Values calculated based on amount of utility heap memory available, the
number of processors available, and the database configuration
Automatic backup maintenance can be enabled

© 2013 IBM Corporation8
Automatic Backups
Automatic database backups simplify backup managementby ensuring that recent full backup of database is performed
The need to perform a backup is based on one or more of thefollowing criteria
– You have never created a full database backup – The time elapsed since the last full backup is more than a specified number of hours – The transaction log space consumed since the last backup is more than a specified
number of 4 KB pages (in archive logging mode only).
Backups can be configured to be offline or online
Supports disk, tape, TSM, and vendor DLL media types
Feature is enabled/disabled by using auto_db_backup and auto_maintdatabase configuration parameters
Policies can be defined via SYSPROC.AUTOMAINT_SET_POLICY and SYSPROC.AUTOMAINT_SET_POLICYFILE stored procedures

© 2013 IBM Corporation9
Incremental BackupsIncremental backups contain data changed since previous backups (depending on the type of backup – incremental or delta)
– In addition to data, each incremental backup image also contains all of the database metadata
Incremental (cumulative) backup image– Contains all database data that has changed since the most recent, successful, full
backup operation– Cumulative because a series of incremental backups taken over time will each have the
contents of the previous incremental backup image
Delta backup image– Contains a copy of all database data that has changed since the last successful backup
(full, incremental, or delta) of the table space in question
Combinations of database and table space incremental backups arepermitted, in both online and offline modes of operation
To restore a database or table space to a consistent state, the recovery process must begin with a consistent image of the object to be restored, followed by the application of the appropriate incremental backup images
TRACKMOD database configuration parameter must be set to YES

© 2013 IBM Corporation10
Incremental Backups: Examples
Weekly full backups, daily incremental (cumulative) backups:
Weekly full backups, daily delta backups:
Weekly full backups (Sunday), incremental (cumulative) backup half-way through week, delta backups all other days:
Recovery required (prior to Saturday's delta being taken):

© 2013 IBM Corporation11
Database Rebuild
Automatic restoring of necessary backup images
Rebuild a database from table space backup images– Means no longer having to take as many full database backups, which is
becoming less possible as databases grow in size– Instead, take more frequent table space backups
In a recovery situation, if you need to bring a subset of table spaces online faster than others, you can do a partial database rebuild– May also be used for
• Creating a separate database for QA purposes• Data recovery purposes
Can choose which table spaces to restore as part of the rebuild– All table spaces in the database at a time that the backup was taken– All table spaces included in a selected table space backup– A specific list of table spaces specified as part of the restore command– All table spaces except those in the specific list provided

© 2013 IBM Corporation12
Database Disaster Recovery using Rebuild
Necessary table spaces will be restored automatically based on recovery history data
SalesDB
SMS01
BackupDatabase SALESDB
SYSCATSPACE
DMS01 DMS02
SUN MON TUE WED THU FRI SAT
BackupTS DMS01
BackupTS DMS02
BackupTS DMS01
DatabaseFails !
1. RESTORE DB SALESDB REBUILD WITH ALL TABLESPACES IN DATABASE TAKEN AT <Friday>(DB2 restores Friday, Sunday and Thursday)
2. ROLLFORWARD DB SALESDB TO END OF LOGS AND STOP
Recovery History File
1
2
3

© 2013 IBM Corporation13
Database Recovery - Rebuild from Table Space Backups
Database recovery using multiple table space backups
SalesDB
SMS01SYSCATSPACE
DMS01 DMS02
SUN MON TUE WED THU FRI SAT
BackupTS SMS01
SYSCATSPACEBackup
TS DMS02DMS01
BackupTS DMS01 Database
Fails !
1. RESTORE DB SALESDB REBUILD WITH ALL TABLESPACES IN DATABASE TAKEN AT <Friday>(DB2 restores Friday, Tuesday and Thursday)
2. ROLLFORWARD DB SALESDB TO END OF LOGS AND STOP
Recovery History File
1
23
BackupTS DMS02
DMS01

© 2013 IBM Corporation14
Database Partial Copy using Rebuild
Can create a database copy with a subset of table spaces
SalesDB
BackupDatabase SALESDB
SYSCATSPACE
DMS01
SUN MON TUE WED THU FRI SAT
BackupTS DMS01
BackupTS DMS02
BackupTS DMS01
Copy for testing
1. RESTORE DB SALESDB REBUILD WITH TABLESPACE(SYSCATSPACE,DMS01) TAKEN AT Friday(DB2 Restores Friday, and Sunday (just SYSCATSPACE TS)
RESTORE DB SALESDB REBUILD WITH ALL TABLESPACES IN DATABASE EXCEPT TABLESPACE(SMS01,DMS02) TAKEN AT Friday
2. ROLLFORWARD DB SALESDB TO END OF LOGS AND STOP
SalesDBSYSCATSPACE
DMS01
SMS01
DMS02
1
2
OR

© 2013 IBM Corporation15
Transportable Schemas
Efficient schema movement between databases
Using a backup image as the source, allows you to copy a set of table spaces and SQL schemas from one database into another
A database schema must be transported in its entirety– If a table space contains both the schema you want to transport, as well as
another schema, you must transport all data objects from both schemas– These self contained (from a table space perspective) sets of schemas that
have no references to other database schemas are called transportable sets
Restore will do multiple operations under the covers– Restore SYSCATSPACE and specified table spaces from backup image– Roll them forward to a point of consistency– Validate the schemas specified– Transfer ownership of the specified table spaces (including containers) to the
target database– Recreate the schema in the target database

© 2013 IBM Corporation16
Transportable Schemas: Example
The database contains the following valid transportable sets:mydata1: schema1 + schema2 mydata2 + myindex: schema3 multidata1 + multiuser2 + multiindex1: schema4 + schema5Any combination of the above transportable sets
To Move All Table Spaces:restore db old_db \tablespace (“mydata1”,”mydata2”,”myindex”,”multidata1”,”multiindex1”,”multiuser2”)\schema (“schema1”,”schema2”,”schema3”,”schema4”,”schema5”) transport into new_db
Not a valid transportable set Valid transportable set

© 2013 IBM Corporation17
DB2's Dropped Table Recovery Feature
Recover the contents of a dropped table using DB2'stable space restore and rollforward operations– When rolling forward through the drop of the table, the data is
exported prior to the replay of the drop
Requires that the table space be enabled for dropped table recovery– Enabled by default at table space creation time
When a table is dropped, an entry is made in the transaction log files as well as in the recovery history file
You can recover a dropped table by doing the following:1. Identify the dropped table by invoking the LIST HISTORY DROPPED TABLE command2. Restore a database- or table space-level backup image taken before the table
was dropped3. Create an export directory to which files containing the table data are to be written4. Roll forward to a point in time after the table was dropped (or to end of logs) by using the RECOVER DROPPED TABLE parameter on the ROLLFORWARD DATABASE command
5. Re-create the table by using the CREATE TABLE statement from the recovery history file6. Import the table data that was exported during the rollforward operation into the table

© 2013 IBM Corporation18
Proactive Checking of Database and Recovery Objects
db2dart – Database analysis and reporting tool– Examines database for architectural correctness
INSPECT – Database inspection command– Inspects database for architectural integrity– Can be run while the database is online
db2ckbkp – Check backup command– Test the integrity of a backup image
db2cklog – Check archive log file validity command– Check the validity of archive log files in order to determine whether or not the
log files can be used during rollforward recovery of a database or table space

© 2013 IBM Corporation19
IBM DB2 Recovery ExpertGranular and Flexible Data Recovery
Faster– Simplifies and optimizes database recovery by reducing disruption during the
recovery process• DBAs can quickly restore or correct erroneous data
– Log Analysis enables organizations to monitor changes that allow for quick recovery
Smarter– Provides intelligent analysis of DB2 and DB2 recovery assets to find the most
efficient recovery pathSimpler – Facilitates process of rebuilding data assets to a specified point in time, often
without taking operations offline
“AFS is establishing a disaster recovery policy with our Vision Application. DB2 Recovery Expert provides us with the functionality to roll back both databases to a point where the tables are
consistent. This will help us meet 100% of our needs for this project. The product itself is awesome and WEB UI is very nice.”
-Kirk B. Spadt, Principal Architect, Automated Financial Systems
Part of the DB2Advanced
Recovery Feature

© 2013 IBM Corporation20
IBM DB2 Merge Backup (MBK)
Merge full DB2 backups with DB2 incremental/deltabackups to build a new up-to-date full DB2 backup image
Eliminates the need to take DB2 full backups
Use online or offline, and table space or database backup images
Split out table space backup images from a full backup image
Run MBK on the database server or on a standalone remote machine
Benefits include– Reduce backup intensive resources on the database server– Reduce backup storage footprint
• Eliminate full DB2 backups by backing up only what needs to be backed up– Reduce number of objects required during recovery
• Simplify recovery process through restore of up-to-date full backup images• Speed up recovery with up-to-date more recent full backup images
Part of the DB2Advanced
Recovery Feature
© 2013 IBM Corporation21
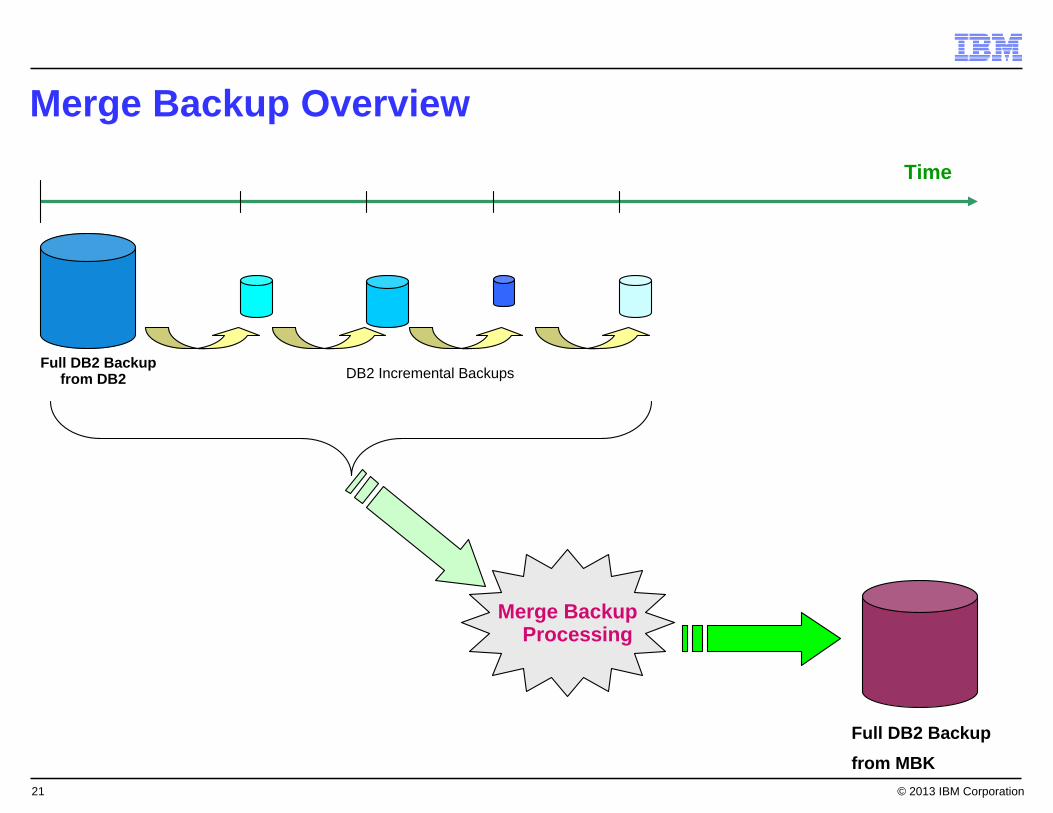
Merge Backup Overview
Merge BackupProcessing
Time
Full DB2 Backup from DB2
Full DB2 Backup from MBK
DB2 Incremental Backups

© 2013 IBM Corporation22
Eliminate the Need to Take Full DB2 Backups
. . .
MBKMBK
MBK
Full DB2Backup
Full DB2Backup
Full DB2Backup
Full DB2Backup

© 2013 IBM CorporationOctober 28, 2013
High Availability and Disaster Recovery

© 2013 IBM Corporation24
18.25 days95%3.65 days99%
8 hours, 45 minutes99.9%52 minutes99.99%5 minutes99.999%
Downtime per YearAvailability
What Does Downtime Mean To Your Business?
Breach ofSLA/ContractBreach of
SLA/Contract
Reduced End-UserProductivity
Reduced End-UserProductivity
Loss of Market Shareto Competitors
Loss of Market Shareto Competitors
CustomerDissatisfaction
CustomerDissatisfaction
Negative PressNegative Press
Reduced Company/Shareholder Value
Reduced Company/Shareholder Value
Damaged ReputationDamaged Reputation
Reduced IT/EmployeeProductivity
Reduced IT/EmployeeProductivity
Lost RevenueLost Revenue
* ITIC Paper "Two-Thirds of Corporations Now Require 99.99% Database Uptime, Reliability ", Laura DiDio, July 10th, 2013
64% of organizations require that their databases deliver a minimum of 99.99% or better uptime for their most mission
critical applications *

© 2013 IBM Corporation25
DB2 Has the Right Solution to Meet Your HA Needs
pureScalepureScaleHADRHADR IntegratedIntegrated
ClusteringClustering
HADRCFCF

© 2013 IBM Corporation26
High Availability and/or Disaster Recovery Options
Server failover– Shared disk or remote disk mirroring
HADR– High Availability and/or Disaster Recovery– Easy to set up and manage– Automatic failover with TSA integration– Fast failover
Q-Replication– Flexible – can handle database subsets– Active/Active– Asynchronous
pureScale (Active / Active)– Continuous Availability– Load Balancing– Easy to set up and manage

© 2013 IBM Corporation27
tx
Server-Based Failover
DB2 ships with an integrated TSA cluster manager
– Node Failure Detection– Disk takeover– IP takeover– Restart DB2
Management framework included to keep the cluster topology in sync
Active Server
tx

© 2013 IBM Corporation28
Storage Replication
Uses remote disk mirroring technology– Maximum distance between sites is typically 100s of km
(for synchronous, 1000s of km for asynchronous)– For example: IBM Metro Mirror, EMC SRDF
Transactions run against primary site only,DR site is passive– If primary site fails, database at DR site can be brought online
All data and logs must be mirrored to the DR site– Synchronous replication guarantees no data loss– Writes are synchronous and therefore ordered, but “consistency groups” are
still needed• If failure to update one volume, don’t want other volumes to get updated (leaving data
and logs out of sync)

© 2013 IBM Corporation29
High Availability Disaster Recovery (HADR)
Provides local High Availability and/or Disaster Recovery– Keeps two copies of a database in sync with each other on two
different servers
Simple to setup and manage
DB2 9.5 adds an integrated cluster manager for automatic failover
DB2 10 adds multiple standbys, time delay and log buffering to handle network spikes

© 2013 IBM Corporation30
HADR: DB2 Delivers Fast Failover at Low Cost
Redundant copy of the database to protect against site or storage failureSupport for Rolling UpgradesFailover typically under 15 seconds
Example: Real SAP workload, 600 SAP users – database available in 11 sec.100% performance after primary failure
TSA for server monitoringBuilt in cluster managerMonitors primary & performs takeover
txtxtxtx Network Connection
Standby Server
HADRKeeps the two servers in sync
Automatic Client RerouteClient application transparently resumes on Standby
txtx
Standby ServerPrimary Server

© 2013 IBM Corporation31
HADR Synchronization Modes
log
file
log writer
HADR
log
file
HADR
Commit Succeeded
Synchronous
Near- Syn
chronousAsynchronous
Synchronous, Near Synchronous, Asynchronous and Super Asynchronous
receive()send()
Commit RequestSuper Asynchronous

© 2013 IBM Corporation32
HADR Failover
Single command called "TAKEOVER" – Change the standby into a primary – Switch the roles of a healthy primary-standby pair – No db2start / restart database / rollforward etc.
Integrated TSA provides heartbeat monitoring & automated “TAKEOVER”– Set up for you during DB2 installation– Use a network tiebreaker to avoid split brain scenarios– Configuration is available in this whitepaper
Automatic client re-route (ACR) provides transparent failover– And will rerun the statement that was running when the failure occurred as long
as it’s the first statement of a transaction with no data yet returned

© 2013 IBM Corporation33
HADR Multiple Standbys
Allows for one standby for high availability and up to two other standbys for disaster recovery
– Rolling fix pack updates of standbys and primary without losing HA
Reads on standby supported on all standbys
TSA Automation for takeover is only to Principal Standby
Takeover (forced and non-forced) supported from any standby– After takeover, configuration parameters on new primary’s standbys will be changed
automatically so they point to the new primary
Principal Standby
Auxiliary Standby
Auxiliary StandbyPrimary
Any sync mode
Super async mode
Super async mode

© 2013 IBM Corporation34
HADR Log Spooling on the Standby
When enabled, allows the standby to spool log records arriving from the primary
Decouples log replay on the standby from receiving of the log datafrom the primary
Supported with any synchronization mode
34
StandbyPrimary
Any sync mode
Spooled logson standby
© 2013 IBM Corporation35
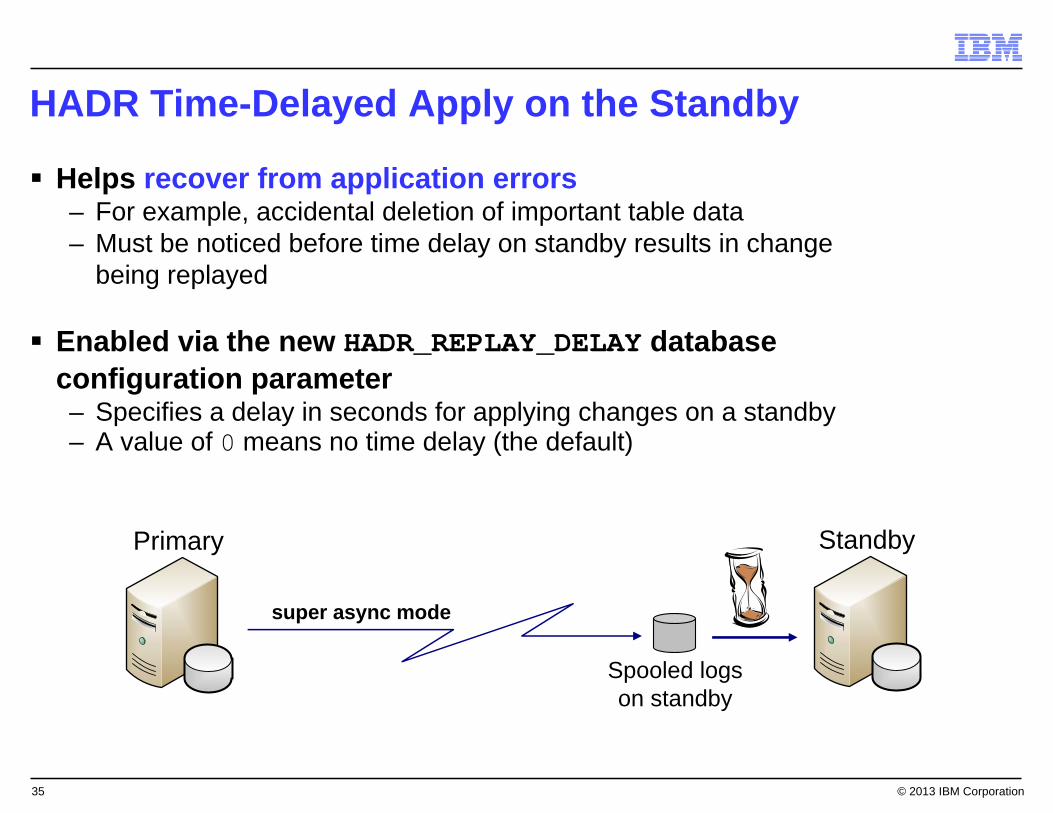
HADR Time-Delayed Apply on the Standby
Helps recover from application errors– For example, accidental deletion of important table data – Must be noticed before time delay on standby results in change
being replayed
Enabled via the new HADR_REPLAY_DELAY databaseconfiguration parameter– Specifies a delay in seconds for applying changes on a standby– A value of 0 means no time delay (the default)
StandbyPrimary
super async mode
Spooled logson standby
© 2013 IBM Corporation36
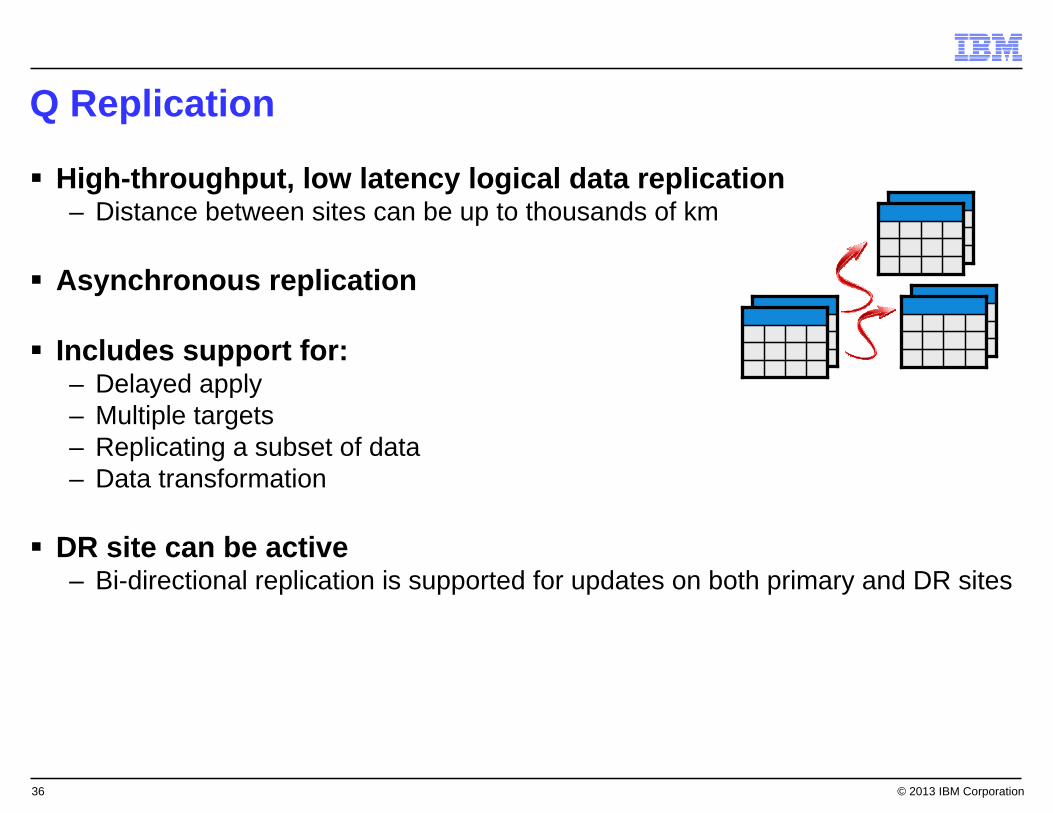
Q Replication
High-throughput, low latency logical data replication– Distance between sites can be up to thousands of km
Asynchronous replication
Includes support for:– Delayed apply– Multiple targets– Replicating a subset of data– Data transformation
DR site can be active– Bi-directional replication is supported for updates on both primary and DR sites

© 2013 IBM Corporation37
Q Replication
Each message represents a transaction
Highly parallel apply process
Differentiated conflict detection and resolution
© 2013 IBM Corporation38
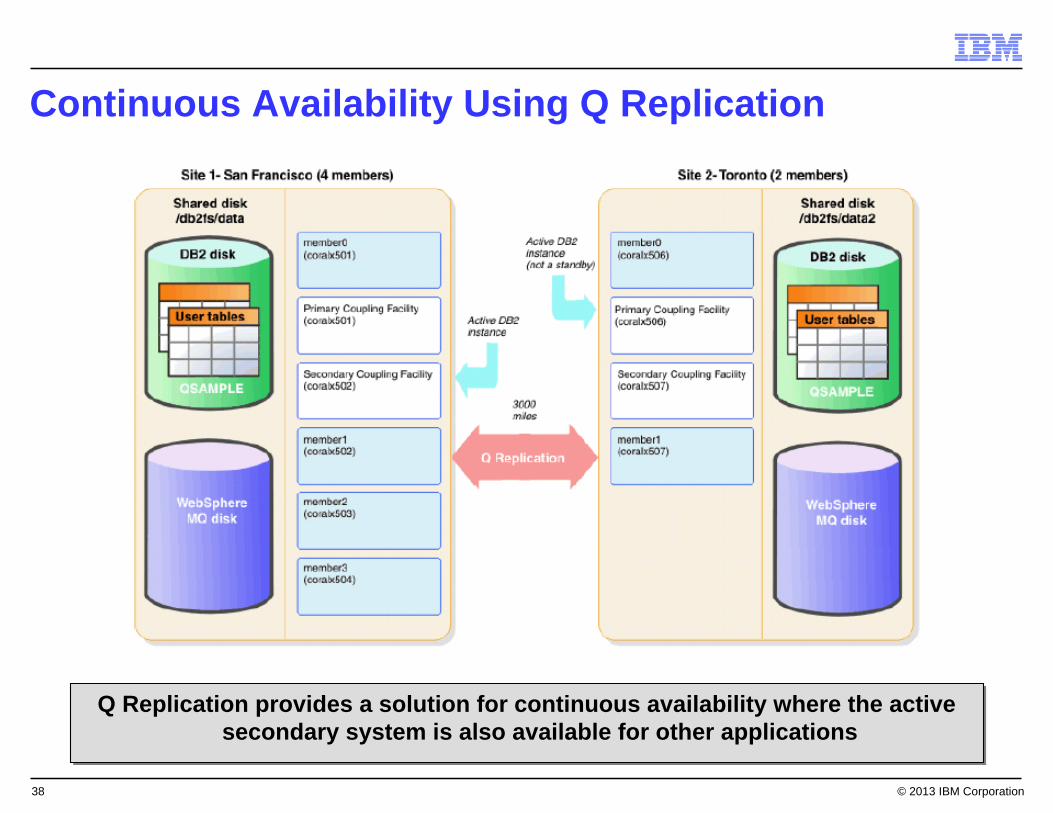
Continuous Availability Using Q Replication
Q Replication provides a solution for continuous availability where the active secondary system is also available for other applications
Q Replication provides a solution for continuous availability where the active secondary system is also available for other applications

© 2013 IBM Corporation39
Learning from the undisputed Gold Standard... System z
Introducing DB2 pureScale
Extreme capacity– Buy only what you need,
add capacity as your needs grow
Application transparency– Avoid the risk and cost of
application changes
Continuous availability– Deliver uninterrupted access to your
data with consistent performance

© 2013 IBM Corporation40
DB2 pureScale Scalability, Performance, and Always Available Transactions
DB2 pureScale– Robust infrastructure for OLTP workloads – Provides improved availability, performance
and scalability– Application transparency – Scales to >100 members– Leverages z/OS cluster technology
Highlights of pureScale enhancementsin DB2 10.5– Rich disaster recovery options, now including
integrated HADR support – Backup and restore between pureScale and non-pureScale environments– Online fix pack updates – Add members online for additional capacity– Included in Advanced Workgroup and Advanced Enterprise editions
© 2013 IBM Corporation40

© 2013 IBM Corporation41
DB2 pureScale
• Multiple DB2 members for scalable and available database environment
• Client application connects into any DB2 member to execute transactions
• Automatic workload balancing
• Shared storage for database data and transaction logs
• Cluster caching facilities (CF) provide centralized global locking and pagecache management for highest levels of availability and scalability
• Duplexed, for no single point of failure
• High speed, low latency interconnect for efficient and scalable communication between members and CFs
• DB2 Cluster Services provides integrated failure detection, recovery automation and the clustered file system
Shared Storage
Database
Logs Logs LogsLogs
Cluster Interconnect
MemberCS
MemberCS
MemberCS
MemberCS
Primary CF
CFCSSecondary CF
CFCS
Clients
DB2 pureScale Cluster (Instance)
Architected for extreme scale and availability

42
Scale with Ease
Log LogLogLog
Addmemberonline
Scale up or out… without changingyour applications
– Efficient coherency protocols designedto scale without application changes
– Applications automatically andtransparently workload balancedacross members
– Up to 128 members
Without impacting availability– Members can be added while
cluster remains online
Without administrative complexity– No data redistribution required
Log
MemberMemberMemberMemberMember
CF CF
“DB2 pureScale is the only solution we found that provided near linear scalability... It scales 100 percent, which means when I add servers and resources to the cluster, I get 100 percent of the benefit. Before, we had to ‘oversize’ our servers, and used only 50 - 60 percent of the available capacity so we could scale them when we needed.”-- Robert M. Collins Jr. (Kent), Database Engineer, BNSF Railway Inc.

Online Recovery from Failures
DB2 pureScale design point is to maximize availability duringfailure recovery processing
When a database member fails, only in-flight data remains locked until member recovery completes
– In-flight = data being updated on the failed member at the time it failed
Target time to availability of rows associated with in-flight updates on failed member in seconds
% o
f Dat
a A
vaila
ble
Time (~seconds)
Only data in-flight updates locked during recovery
Database member failure
100
50
“We pulled cards, we powered off systems, we uninstalled devices, we did everything we could do to make the cluster go out of service, and we couldn’t make it happen.”-- Robert M. Collins Jr. (Kent), Database Engineer, BNSF Railway Inc.
CFCF
X

© 2013 IBM Corporation44
Stealth System MaintenanceAllows DBAs to apply system maintenance without negotiatingan outage window
Example: Upgrade the OS in arolling fashion across the cluster
Procedure:1. Drain (a.k.a. Quiesce)
Wait for transactions to end theirlife naturally; new transactionsrouted to other members
2. Remove & maintain 3. Reintegrate into cluster
Workload balancing startssending it work as a leastloaded machine
4. Repeat until done
Single Database View
DB2 DB2 DB2 DB2

© 2013 IBM Corporation45
Rolling Database Fix Pack Updates
Transparently install pureScale fix packs or perform system maintenance in an online rolling fashion
No outage experienced by applications
Single installFixPack commandrun on each member/CF for fix pack update– Quiesces member
• Existing transactions allowed to finish(configurable timeout)
• New transactions sent to other members– Installs binaries– Updates instance
• Member still behaves as if running on previous fix pack level– Unquiesces member
Final installFixPack command to complete and commit updates– Instance now running at new fix pack level
CFCF
New inDB2 10.5

© 2013 IBM Corporation46
> installFixPack –check_commit> installFixPack –check_commit6
Rolling Fix Pack Updates (cont.)
CF S
Code level: GA
CF P
Code level: GA
Member
Code level: GA
Member
Code level: GA
Member
Code level: GA FP1 FP1
FP1
FP1
FP1
Cluster is effectively running at: GA FP1
> installFixPack –online> installFixPack –online1 > installFixPack –online> installFixPack –online2
> installFixPack –online> installFixPack –online3 > installFixPack –online> installFixPack –online4 > installFixPack –online> installFixPack –online5
> installFixPack –commit_level7
Transactions routed away from member undergoing maintenance, so no application outages experienced. Workload balancing brings work back after maintenance finished
Cluster not running at new level until commit is performed

© 2013 IBM Corporation47
Disaster Recovery Options for pureScale
Variety of disaster recoveryoptions to meet your needs– HADR (new in DB2 10.5)– Storage Replication– Q Replication– InfoSphere Change Data
Capture (CDC)– Geographically Dispersed
pureScale Cluster (GDPC)– Manual Log Shipping

© 2013 IBM Corporation48
Geographically Dispersed pureScale Clusters (GDPC)
A “stretch” or geographically dispersed pureScale cluster spans two sites– At distances of tens of km– Active/active DR, where half of the cluster is at site A, other half at site B– Enables a level of DR support suitable for many types of disasters– Supported for AIX (using InfiniBand) and RedHat Linux (using 10 Gigabit Ethernet)
Both sites active and available for transactions during normal operation
On failures, client connections are automatically redirected to surviving members– Applies to both individual members within sites and total site failure
M1 M3 M2 M4CFSCFP
Site A Site B
Tens of km
Workload fully balanced
M1 M3 M2 M4CFSCFP
Site A Site B
Tens of km
Workload rebalanced on hardware failure
M1 M3 M2 M4CFSCFP
Site A Site B
Tens of km
Workload rebalanced on site failure

© 2013 IBM CorporationOctober 28, 2013
HA & DR Scenarios

© 2013 IBM Corporation50
Local Cluster Failover
DB1
HA Cluster
Primary Database
Local StandbyDatabase
Pros:Inexpensive local failover solutionProtection from software and server failureDB2 9.5 integrated TSA cluster manager
Cons:No protection from disk failureNo protection from site failureFailover times vary from 5 to 15 minutes
DB2 automation with built-in cluster manager

© 2013 IBM Corporation51
HADR Local or Remote with Read on Standby
Pros:Inexpensive local failover or DR solutionProtection from software, server, storage, and site failuresSimple to setup and monitorFailover time in the range of 30 secReporting on standby without increase in failover time
Cons:Two full copies of the database (a plus from a redundancy perspective)Only read transactions can run on
standby
Primary Connection
DB1
HADR Cluster
Primary Database
StandbyDatabase
DB1a Read only

© 2013 IBM Corporation52
Pros:Very fast local failover with DR capabilityProtection from software, server, storage, and site failuresLocal failover time in the range 30 seconds
HADR With Disk Mirroring to Remote DR Site
Primary Connection
DB1
HADR Cluster
Primary Database
Local StandbyDatabase
Automatic client rerouteDisaster RecoverySite
Remote Disk Mirror Technology
DB1a DB1aa
Cons:Three full copies of the database (a plus from a redundancy perspective)More costly than HADR for just DR

© 2013 IBM Corporation53
Pros:Very fast local failover with DR capabilityProtection from software, server, storage, and site failuresAllows for time delay on auxiliary standbysLocal failover time in the range 30 seconds
HADR With Multiple Standby’s (DB2 10)
Primary Connection
DB1
HADR Cluster
Primary Database
Local StandbyDatabase
Automatic client rerouteDisaster RecoverySite
Remote Standby DB1a DB1aa
Cons:Three full copies of the database (a plus from a redundancy perspective)Super Async only for DR site

© 2013 IBM Corporation54
DB3
Q Replication
Primary Connection
Multiple alternate standby servers
Site ASite B
DB1
Primary Database
Q-based SQL replication to logical standby’s
DB2
Remote Standby
Site C…
Read/Write write on standby
Pros:Protected from software, server, storage, and site failuresFailover time is “instant”Standby can be full or subset and is fully accessible (read and/or write)Multiple standby servers
Cons:More complex to setup and monitor (but
more flexibility) vs. HADRAsynchronous

© 2013 IBM Corporation55
High Availability Disaster Recovery (HADR) OptionsLocal HA – fast failover with server and storage protection
Disaster Recovery – server, storage and site protection
Both – fast local failover with server, storage and site protection
ServerA
ServerB
Primary Standby
Site A
ServerA
ServerB
Primary Standby
Site A Site BAny Distance
ServerA
Primary Standby
Site A Site B
Any Distance
ServerB
Standby
ServerC

© 2013 IBM Corporation56
HADR with Replication – Best Practice for HA and DR
HADR Pairs with Replication
Delivers:– Fast Local Failover– Active / Active DR– Rolling patch upgrades– Rolling version upgrades– Online database on-disk modifications– Schema modifications online/rolling
Can replace HADR at each site with pureScale for even better HA
ServerA
Primary Active
Site A Site B
Q ReplicationAny DistanceServer
B
Standby
ServerC
ServerD
Standby

© 2013 IBM Corporation57
DB2 pureScale Availability OptionsLocal only – Online recovery, active-active, protection from server failure
Geographically dispersed cluster– Online recovery, active-active, protection from server, storage and site failure
Local pureScale plus DR replication– Online recovery, active-active, protection from server, storage and site failure
Member1
Member2Site A CF CF
Member1
Member2Site A CF
Member3
Member4
Site BCF
Member1
Member2Site A CF CF
Member1
Member2
Site BCF CF
< 80km
Any distance
Disk Replicationor
IBM Replication Server

© 2013 IBM Corporation58
DB2 pureScale Availability Option in DB2 10.5DB2 10.5 supports HADR with pureScale – Online recovery, protection from server, storage and site failure– Easy to set up and manage– Any distance (ASYNC or SuperAsync)
Member1
Member2Site A CF CF
Member1
Member2
Site BCF CF
Any distance
HADR

© 2013 IBM Corporation59
HA & DR Summary
When it comes to HA and DR, one size does not fit all
There are many availability options, each with their own advantages– Server failover– HADR– Q-Replication– pureScale– More likely a combination of several of the above
Choose the one that best suits your deployment– Determine the right solution considering
• Cost (hardware/software/network/site)• Availability requirements• Management costs• Application requirements

© 2013 IBM Corporation60
Kelly Schlamb ([email protected])Executive IT Specialist, Worldwide Information Management Technical SalesIBM Canada Ltd.