bayesian classifiers: applications in vision -...
TRANSCRIPT

1 L.E. Sucar
Bayesian Classifiers: ���Applications in Vision
Luis Enrique Sucar
Computer Science DepartmentInstituto Nacional de Astrofísica, Óptica y Electrónica (INAOE)
Puebla, MÉXICO

2 L.E. Sucar
Research areas• Probabilistic graphical models
• Multidimensional / Hierarchical classifiers• Causal graphical models
• Motor Rehabilitation• Incorporate affective aspects• Automatic evaluation• Monitoring patients at home
• Video surveillance• People / vehicle detection and recognition• Activity recognition• Implementation in the “cloud” (FIWARE)
• Service Robots• Mapping and localization in dynamic environments• Robocup@home

3 L.E. Sucar
Contents
• Introduction
• Semi-naive Bayes• Skin classification
• Multidimensional classifiers• Rehabilitation - automatic evaluation
• Hierarchical classifiers• Galaxy classification
• Toolkit • Project / Thesis ideas

4 L.E. Sucar
Naive Bayes Classifier
• The NBC makes the assumption that the attributes are independent given the hypothesis:
P(E1, E2, ...EN | H) = P(E1 | H) P(E2 | H) ... P(EN | H)
• Thus, the posterior probability can be calculated as:
P(H | E1, E2, ...EN) = P(H) P(E1 | H) P(E2 | H) ... P(EN | H) P(E)
• Now the complexity is linear!

5 L.E. Sucar
Naive Bayes Classifier
• It is not necessary to calculate the denominator (constant):
P(H | E1, E2, ...EN) ~ P(H) P(E1 | H) P(E2 | H) ... P(EN | H)
• P(H) is the prior probability, P(Ei | H) is known as the likelihood, and P(H | E1, E2, ...EN) is the posterior probability

6 L.E. Sucar
NBC
• Despite it simplicity the NBC obtains very good results in many applications; it is particularly useful in domains where there are hundreds or even thousands of attributes (text classification, genomics, etc.)
• However, its performance degrades if the independence assumption is not correct; in this case there are two main alternatives:• TAN, BAN classifiers: they model the dependency between
attributes; resulting in more complex models• Semi-Naive: it considers the dependencies and at the same
time tries to maintain the efficiency of the NBC

7 L.E. Sucar
Semi-Naive Bayesian Classifier • It modifies the Naive classifier by:
• Eliminating irrelevant attributes (feature selection)
• Verifying the conditional independence relations between attributes, and modifyng the structure of the model if these are not satisfied. Alternatives:
• Node elimination • Node combination • Node insertion

8 L.E. Sucar
Feature Selection • Eliminate those attributes that do not contribute much
information to the class, these are irrelevant. • For this we can measure the mutual information between
each attribute and the class, and eliminate those with “low” value
C
A2A1 A4A3

9 L.E. Sucar
Structural Improvement
• Estimate the conditional mutual information (CMI) between each pair of attributes given the class. If the CMI is “high” (not independent), then apply one of the following:
1. Elimination: remove one of the two attributes 2. Combination: obtain a new a attribute by combining
the values of the two original ones 3. Insertion: insert a new, “virtual”, variable between the
attributes and the class.
L. E. Sucar, D. F. Gillies, D. A. Gillies, "Objective Probabilities in Expert Systems", Artificial Intelligence Journal, Vol. 61 (1993) 187-208

10 L.E. Sucar
Structural Improvement
Y X
Z
X
Z
XY
Z W
Z
Y X

11 L.E. Sucar
Example – skin classification
• A fast and simple way to detect persons in an image is to find “skin pixels” – a binary classification problem.
• There are several color models, which one is the best?

12 L.E. Sucar
Skin Classification An alternative is to combine several models and then “optimize” the initial NBC via structural improvement Initial model: 9 attributes, 3 models: RGB, HSV, YIQ
S
GR B IY QSH V
13 L.E. Sucar
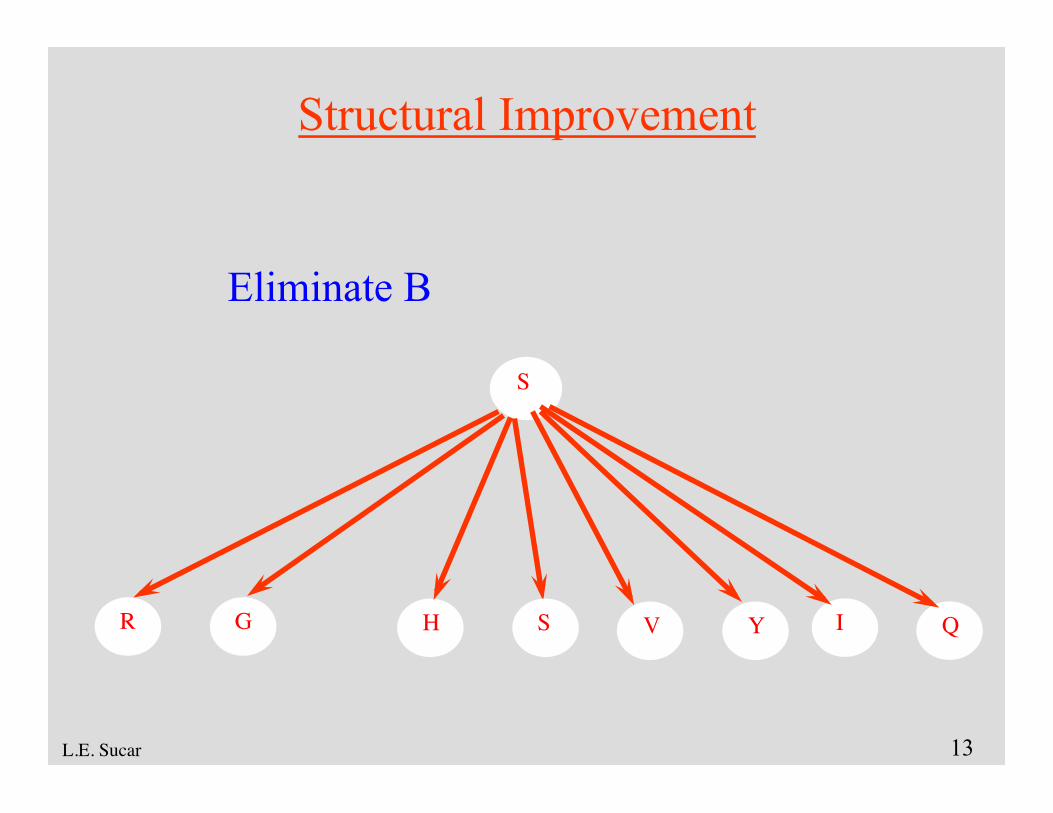
Structural Improvement
S
GR IY QSH V
Eliminate B

14 L.E. Sucar
S
GR IYSH V
Eliminate Q

15 L.E. Sucar
S
GR IYS V
Eliminate H

16 L.E. Sucar
S
RG IYS V
Join RG

17 L.E. Sucar
S
RG IYS
Eliminate V

18 L.E. Sucar
S
RG IY
Eliminate S
Accuracy: initial 94% final 98%
M. Martínez, L.E. Sucar, “Learning an optimal naive Bayesian classifier”, ICPR, 2006
M. Marítnez, L.E. Sucar, H.G. Acosta, N. Cruz, Bayesian Model Combination and Its Application to Cervical Cancer Detection, Lecture Notes in Computer Science 4140, Springer-Verlag, 622-631, 2006.

19 L.E. Sucar
Dynamic Semi-Naïve Bayesian Classifiers
This method can be extended to dynamic models (similar to HMM)We have apply it to gesture recognition.
St St
At1
At2 At
3
Hidden Markov model
(At1,At
2,At3)
Dynamic naive Bayesian Classifier
M. Martínez, L.E. Sucar, Learning Dynamic Naive Bayesian Classifiers, Florida Artificial Intelligence Research Symposium (FLAIRS-21), pp. 655-659, May 2008.
M. A. Palacios-Alonso, C. A. Brizuela and L. E. Sucar, Evolutionary Learning of Dynamic Naive Bayesian Classiers, Journal of Automated Reasoning, pp. 21-37, 2010.

20 L.E. Sucar
Multidimensional Bayesian Classifiers

21 L.E. Sucar
Multidimensional Classifiers • In several domains, an object could be assigned several classes
at the same time; so in that case we want to maximize the probability of the set of classes given the attributes:
ArgH [ Max P(H1, H2, …Hm | E1, E2, ...EN) ] • Some applications are: music genre classification, image
annotation, document classification, genomics, etc.
Rock Pop Latin E1 E2 E31 1 0 … … …
1 1 1 … … …
0 0 1 … … …

22 L.E. Sucar
Basic Approaches
• There are two basic ways to solve the multidimensional classification problem:
• Binary relevance: a separate classifier is built for each class and the results are combined (does not consider the dependencies between classes)
• Power set: a single classifier is built for all the combinations of classes (computational complexity – it is exponential to the number of classes)

23 L.E. Sucar
Basic Approaches

24 L.E. Sucar
Alternative Bayesian Approaches• Under a Bayesian framework, there are two main
alternatives:• Multidimensional Bayesian Network Classifiers: a
model that considers the dependency relation between classes and between attributes; the problem is again computational complexity
• Bayesian Chain Classifiers: they incorporate in certain way the dependencies by adding other classes as additional attributes, maintaining a similar complexity to binary relevance

25 L.E. Sucar
Chain Classifiers
• As in binary relevance, a classifier is built for each class; but it incorporates as additional attributes some of the other classes according to certain order
• The order is defined by considering a “chain” between the classes, such that the results (class) from previous classes in the chain are added as additional attributes
poprock latin
Read, et al., “Classifier chains for multilabel classification”, ECML/PKDD, 2009

26 L.E. Sucar
Chain Classifiers - example
• Limitations of the original chain classifier:• How to define the order of the classes?• The number of additional attributes
R
A1 An…
P
A1 RAn…
L
AnA1 PR…

27 L.E. Sucar
Bayesian Chain Classifiers • The relations (dependencies) between classes are
modelled using a Bayesian network – which could be learned from data
• This model can be used to define the order of the chain and also to limit the number of additional attributes
Zaragoza, Sucar, Morales, Larrañaga, Bielza, “Bayesian chain classifiers for multidimensional classification”, IJCAI, 2011

28 L.E. Sucar
Simple BCC• The joint probability of the classes is then:
• For each class a Naive Bayes classifier is learned, including the parent class as an additional attribute
• For classification, the outputs of the d Naive Bayes are combined to produce a class vector

29 L.E. Sucar
Automatic Evaluation for Virtual Rehabilitation

30 L.E. Sucar
Objective
• Develop an automatic evaluation system for assessing the progress of a patient in rehabilitation of the upper limbs:• Clinical acceptance: the scoring system should be
understandable and comparable by clinicians and therapists.
• Sensor independence: the system must be able to work with a variety of sensors available.
• Unobtrusiveness: the system should use sensing technology that does not hinder the person movements.

31 L.E. Sucar
Clinical Scale
• Fugl-Meyer Assessment (FMA)• Clinically accepted.• Commonly used.• Highly objective.• Fast to perform.• Standardized.• Independent for Upper
extremities and Lower extremities.

32 L.E. Sucar
Representation
S) Sensor data acquired by a range sensing conguration. f) Limb segment orientation (illustrative). g) Normalized data from different FMA scores. h) Projection of salient components using t-SNE

33 L.E. Sucar
Pilot Study
• Sensor setup:• IMU at upper arm.• IMU inside custom gripper.• Kinect at 2m at a height of 85cm.• Video recording during session.
• Data obtained:• 10 FMA exercises.• 5 repetitions.• 15 subjects.• 3 levels of FMA.• 2250 samples in total.

34 L.E. Sucar
Multidimensional Classification
• Given that the different exercises are not independent – they are usually similar for the same patient –, we are developing a multidimensional chain classifier
• The values of the different movements in the FM evaluation depend on the stage in the therapy – there is a natural evolution; we are using this knowledge to model the dependencies between the different exercises (classes)

35 L.E. Sucar
Multidimensional Classificationl The rela(onships among classes was obtained from medical experts according to the expected dependencies between the exercises
l It is reptresented as a DAG (Bayesian network)
l Each class inherits as addi(onal aAributes the ancestors in the class DAG

36 L.E. Sucar
ResultsThe average accuracy using mul(dimensional classifica(on increases 4% and the S.D. is reduced by 2 points.
Independent c las s ifiers multidimens ional chain c las s ifier80
82
84
86
88
90
92
94
96
98
100Average c lassification
Accu
racy

37 L.E. Sucar
Hierarchical Classification

38 L.E. Sucar
Hierarchical Classification• A subtype of multidimensional classification in which
the classes are organized in a hierarchy• Hierarchies are used in several domains: animals,
genes, musical genres, galaxies, …• The structure of the hierarchy can be used to improve
classification

39 L.E. Sucar
Approaches for Hierarchical Classification
Global Local – per parent
Local –per level
Local –per node

40 L.E. Sucar
Top-Down Approach: Classification• The first classifier decides the branch to follow by the
example in the hierarchy• This is repeated until the example reaches a leaf node• An error in a prediction is propagated to all its
descendants in the hierarchy (inconsistency problem)

41 L.E. Sucar
Chained Path Evaluation• Predicts a single path (from the root to a leaf node) for tree
hierarchies, and multiple paths for DAGs.• Estimates the probability of each path by combing LCPNs,
incorporating two additional features: Ø A weighting scheme that gives more
importance to correct predictions at the top levels;
Ø An extension of the chain idea for hierarchical classification, incorporating the label of the parent nodes as additional attributes.
• An extension for non mandatory leaf node prediction (NMLNP) was developed
Mallinali Ramrez-Corona, L Enrique Sucar, Eduardo F Morales, “Multi-label Classication for Tree and Directed Acyclic Graphs Hierarchies”, Probabilistic Graphical Models , pp.
409-425, 2014

42 L.E. Sucar
Classification• The predictions from the local classifiers are combined to obtain a score for each path (root to leaf) in the hierarchy• The merging rule considers the level in the hierarchy:

43 L.E. Sucar
Example - weights
root
1 6
2 3
4
7 10
5
8 9
1-(1/4) =0.75 0.75
1-(2/4) =0.5 0.5 0.5 0.5
1-(2.5/4) = 0.375
1-(3/4) =0.25
0.25
1-(3.5/4) =0.125

44 L.E. Sucar
Example - probabilities
root
y1 y6
y2 y3
y4
y7 y10
y5
y8 y9
P(y1=1|xe)
=0.4
P(y6=1|xe)
=0.5
P(y2=1|xe,y1)
=0.3
P(y3=1|xe,y1)
=0.4
P(y4=1|xe,y3,y6)
=0.7
P(y5=1|xe,y4)
=0.5
P(y8=1|xe,y7)
=0.1
P(y9=1|xe,y7)
=0.5
P(y7=1|xe,y6)
=0.4
P(y10=1|xe,y6)
=0.2

45 L.E. Sucar
Example - scoresroot
0.75*log(0.4) 0.75*log(0.5)
0.5*log(0.3) 0.5*log(0.4)
0.375*log(0.7)
0.5*log(0.4) 0.5*log(0.2)
0.125*log(0.5)
0.25*log(0.1) 0.25*log(0.5)
+ +
+
+
+
+ +
+ +=
=
= =
-0.560
-0.819
-0.675 -0.5
-0.575
=

46 L.E. Sucar
Galaxy Classification

47 L.E. Sucar
• Galaxy classification is important …• To produce catalogs• To discover underlying physics• To help astronomers
• Classification can be:• Morphological• Spectral
• Morphological classification – main problems:• Imbalance between classes• Poor accuracy when many classes are considered
• Proposed solutions:• Generate artificial examples• Use hierarchical classifiers
Introduction

48 L.E. Sucar
• Based on shape• Elliptical (E)• Lenticular (S0)• Spiral (S)
• Normal (Sa)• Barred (SBa)
• Irregular (Irr)
Hubble’s classification SCHEME
Galaxy
Elliptical Lenticular Spiral Irregular
Normal BarredE0 E0 E0 E0 E0 E0 E0
Sa Sb Sc SBa SBb SBc

49 L.E. Sucar
Dataset: INAOE’s plate collection
50 L.E. Sucar
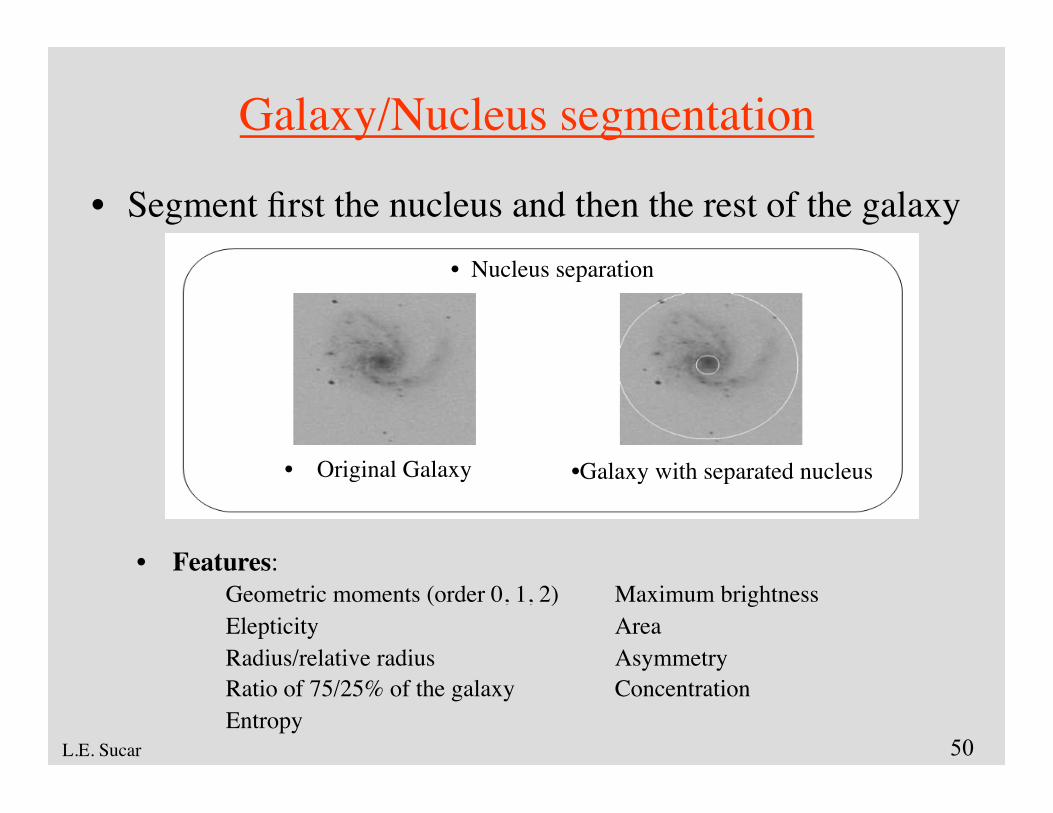
• Segment first the nucleus and then the rest of the galaxy
Galaxy/Nucleus segmentation
• Nucleus separation
• Original Galaxy • Galaxy with separated nucleus
• Features:Geometric moments (order 0, 1, 2) Maximum brightnessElepticity AreaRadius/relative radius AsymmetryRatio of 75/25% of the galaxy ConcentrationEntropy

51 L.E. Sucar
Results
Flat (%) Hierarhical (%)Data 22.09 42.85Data + over-sampling 29.99 42.86Data + artificial examples + over-sampling 39.44 53.57
Results: Based on INAOE’s collection of photographs with9 types of galaxies considered
MA Marin, LE Sucar, JA González, R Diaz, “A hierarchical model for morphological galaxy classification”, The Twenty-Sixth International FLAIRS Conference, 2013

52 L.E. Sucar
Toolkit
• We have developed a toolkit under Weka/Meka that includes the code for the different types of Bayesian classifiers:• Semi-Naive Bayes Classifier• BCC (Multidimensional Classification)• CPE (Hierarchical Classification)
• All 3 are implemented in Weka (and Meka), and as such, configuring the classifier options is the same as in Weka.

53 L.E. Sucar
Project / Thesis Ideas
• Apply multidimensional / heirarchical classifier for object recognition / content based image retrieval
• Incorporate hierarchical constraints using a graphical model (BN or MRF) for hierarchical classification
• Extend semi-naive dynamic classifier for hierarchical classification and apply it to action / activity recognition

54 L.E. Sucar
Additional information …
• L. E. Sucar, Probabilistic Graphical Models: Principles and Applications, Springer-Verlag, 2015
• Course on PGMs: http://ccc.inaoep.mx/~esucar/Clases-mgp/mgp.html

55 L.E. Sucar
AcknowledgementsCollaborators:• Felipe Orihuela, Eduardo Morales, Jesús González, Raquel
Díaz, Mallinali Ramírez, Julio Zaragoza, Julio Hernández, Patrick Heyer, Joel Rivas, Lindey Fielder - INAOE, Mexico
• Jorge Hernández, Lorena Palafox, INNN, Mexico• Miriam Martínez, Antonio Montero, ITA, Mexico• Héctor Acosta, Nicandro Cruz (UV)• Nadia Bianchi-Berthouzie, M. Aung - UCL, UK• Oscar Mayora, CREATE-NET, Italy• Pedro Larrañaga, Concha Bielza, UPM, Spain