bellwether analysis hierarchies in data mining raghu ramakrishnan [email protected] chief...
TRANSCRIPT

Bellwether Analysis
Hierarchies in Data Mining
Raghu Ramakrishnan
Chief Scientist for Audience and Cloud Computing
Yahoo!

2Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
About this Talk
• Common theme—multidimensional view of data:– Reveals patterns that emerge at coarser
granularity• Widely recognized, e.g., generalized association rules
– Helps handle imprecision• Analyzing imprecise and aggregated data
– Helps handle data sparsity• Even with massive datasets, sparsity is a challenge!
– Defines candidate space of subsets for exploratory mining
• Forecasting query results over “future data” • Using predictive models as summaries • Potentially, space of “mining experiments”?

4Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Background: The Multidimensional Data Model
Cube Space

5Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Star Schema
SERVICEpidtimeidlocidrepair
PRODUCTpidpnameCategoryModel
TIMEtimeiddateweekyear
LOCATIONlocidcountryregionstate
“FACT” TABLE
DIMENSION TABLES

6Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Dimension Hierarchies
• For each dimension, the set of values can be organized in a hierarchy:
PRODUCT TIME LOCATION
category week month region
model date state
year
automobile quarter country

7Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Multidimensional Data Model
• One fact table =(X,M)– X=X1, X2, ... Dimension attributes
– M=M1, M2,… Measure attributes
• Domain hierarchy for each dimension attribute:– Collection of domains Hier(Xi)= (Di
(1),..., Di(k))
– The extended domain: EXi = 1≤k≤t DXi(k)
• Value mapping function: γD1D2(x)
– e.g., γmonthyear(12/2005) = 2005
– Form the value hierarchy graph– Stored as dimension table attribute (e.g., week for a time
value) or conversion functions (e.g., month, quarter)

8Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
MA
NY
TX
CAW
est
Eas
t
ALL
LOC
AT
ION
Civic SierraF150Camry
TruckSedan
ALL
Automobile
Model
Category
Re
gio
n
Sta
te
ALL
AL
L
1
3
2
2 1 3
FactID Auto Loc Repair
p1 F150 NY 100
p2 Sierra NY 500
p3 F150 MA 100
p4 Sierra MA 200
Multidimensional Data
p3
p1
p4
p2
DIMENSIONATTRIBUTES

9Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Cube Space
• Cube space: C = EX1EX2…EXd
• Region: Hyper rectangle in cube space– c = (v1,v2,…,vd) , vi EXi
– E.g., c1= (NY, Camry); c2 = (West, Sedan)
• Region granularity:– gran(c) = (d1, d2, ..., dd), di = Domain(c.vi)– E.g., gran(c1) = (State, Model); gran(c2) = (State, Category)
• Region coverage: – coverage(c) = all facts in c
• Region set: All regions with same granularity

10Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
OLAP Over Imprecise Data
with Doug Burdick, Prasad Deshpande, T.S. Jayram, and Shiv Vaithyanathan
In VLDB 05, 06 joint work with IBM Almaden

11Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
MA
NY
TX
CAW
est
Eas
t
ALL
LOC
AT
ION
Civic SierraF150Camry
TruckSedan
ALL
Automobile
Model
Category
Re
gio
n
Sta
te
ALL
AL
L
1
3
2
2 1 3
FactID Auto Loc Repair
p1 F150 NY 100
p2 Sierra NY 500
p3 F150 MA 100
p4 Sierra MA 200
p5 Truck MA 100
p5
Imprecise Data
p3
p1
p4
p2

12Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Querying Imprecise Facts
p3
p1
p4
p2
p5
MA
NY
SierraF150FactID Auto Loc Repair
p1 F150 NY 100
p2 Sierra NY 500
p3 F150 MA 100
p4 Sierra MA 200
p5 Truck MA 100
Truck
East
Auto = F150Loc = MASUM(Repair) = ??? How do we treat p5?

13Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
p3
p1
p4
p2
p5
MA
NY
SierraF150FactID Auto Loc Repair
p1 F150 NY 100
p2 Sierra NY 500
p3 F150 MA 100
p4 Sierra MA 200
p5 Truck MA 100
Truck
East
Allocation (1)

14Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
p3
p1
p4
p2
MA
NY
SierraF150
ID FactID Auto Loc Repair Weight
1 p1 F150 NY 100 1.0
2 p2 Sierra NY 500 1.0
3 p3 F150 MA 100 1.0
4 p4 Sierra MA 200 1.0
5 p5 F150 MA 100 0.5
6 p5 Sierra MA 100 0.5
Truck
East
Allocation (2)
p5 p5
(Huh? Why 0.5 / 0.5? - Hold on to that thought)

15Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
p3
p1
p4
p2
MA
NY
SierraF150
ID FactID Auto Loc Repair Weight
1 p1 F150 NY 100 1.0
2 p2 Sierra NY 500 1.0
3 p3 F150 MA 100 1.0
4 p4 Sierra MA 200 1.0
5 p5 F150 MA 100 0.5
6 p5 Sierra MA 100 0.5
Truck
East
Allocation (3)
p5 p5
Auto = F150Loc = MASUM(Repair) = 150 Query the Extended Data Model!

16Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Allocation Policies
• Procedure for assigning allocation weights is referred to as an allocation policy– Each allocation policy uses different information to
assign allocation weight
• Key contributions:– Appropriate characterization of the large space of
allocation policies (VLDB 05)– Designing efficient algorithms for allocation policies
that take into account the correlations in the data (VLDB 06)

17Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
SierraF150
Truck
MA
NY
East
p1
p3
p5
p4
p2
Motivating Example
We propose desiderata that enable appropriate definition of query semantics for imprecise data
We propose desiderata that enable appropriate definition of query semantics for imprecise data
Query: COUNT

18Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Desideratum I: Consistency
• Consistency specifies the relationship between answers to related queries on a fixed data set
SierraF150
Truck
MA
NY
East
p1
p3
p5
p4
p2

19Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Desideratum II: Faithfulness
• Faithfulness specifies the relationship between answers to a fixed query on related data sets
SierraF150
MA
NY
p3
p1
p4
p2
p5
SierraF150
MA
NY
p3
p1
p4
p2
p5
SierraF150
MA
NY
p3
p1
p4
p2
p5
Data Set 1 Data Set 2 Data Set 3

20Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
p3
p1
p4
p2
p5
MA
NY
SierraF150
SierraF150
MA
NY
p4
p1
p3 p5
p2
p1p3
p4p5
p2
p4
p1p3
p5
p2
MA
NY
MA
NY
SierraF150SierraF150
p3 p4
p1
p5
p2
MA
NY
SierraF150
w1
w2 w3
w4
Imprecise facts lead to many possible worlds[Kripke63, …]

21Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Query Semantics
• Given all possible worlds together with their probabilities, queries are easily answered using expected values– But number of possible worlds is exponential!
• Allocation gives facts weighted assignments to possible completions, leading to an extended version of the data– Size increase is linear in number of (completions of)
imprecise facts– Queries operate over this extended version

Bellwether Analysis
Dealing with Data Sparsity
Deepak Agarwal, Andrei Broder, Deepayan Chakrabarti, Dejan Diklic, Vanja Josifovski, Mayssam
Sayyadian
Estimating Rates of Rare Events at Multiple Resolutions, KDD 2007

31Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Motivating ApplicationContent Match Problem
• Problem: – Which ads are good on what pages– Pages: no control; Ads: can control
• First simplification:– (Page, Ad) completely characterized by a
set of high-dimensional features• Naïve Approach:
– Experiment with all possible pairs several times and estimate CTR.
• Of course, this doesn’t work• Most (ad, page) pairs have very few
impressions, if any,• and even fewer clicksSevere data sparsity
pages ads

32Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Estimation in the “Tail”
• Use an existing, well-understood hierarchy– Categorize ads and webpages to leaves of the
hierarchy– CTR estimates of siblings are correlatedThe hierarchy allows us to aggregate data
• Coarser resolutions– provide reliable estimates for rare events– which then influences estimation at finer resolutions
Similar “coarsening”, different motivation:Mining Generalized Association RulesRamakrishnan Srikant, Rakesh Agrawal , VLDB 1995

34Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Sampling of Webpages
• Naïve strategy: sample at random from the set of URLsSampling errors in impression volume AND click
volume
• Instead, we propose:– Crawling all URLs with at least one click, and– a sample of the remaining URLsVariability is only in impression volume

35Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Imputation of Impression Volume
Z(0)
Z(i)
Page hierarchy Ad hierarchy
• Region node= (page node, ad node)
• Build a Region HierarchyA cross-product of the page
hierarchy and the ad hierarchy
Page leaves Ad leaves
Leaf Region

36Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Exploiting Taxonomy Structure
• Consider the bottom two levels of the taxonomy
• Each cell corresponds to a (page, ad)-class pair
Key point : Children under a parent node are alike and expected to have similar CTRs (i.e., form a cohesive block)

37Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Imputation of Impression Volume
For any level Z(i)
Ad classes
Pag
e cl
asse
s
sums to #impressions on ads of this ad class
[column constraint]
sums to ∑nij + K.∑mij
[row constraint]
sums toTotal impressions
(known)
#impressions = nij + mij + xij
Clicked pool
Sampled Non-clicked
pool
Excess impressions(to be imputed)
38Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
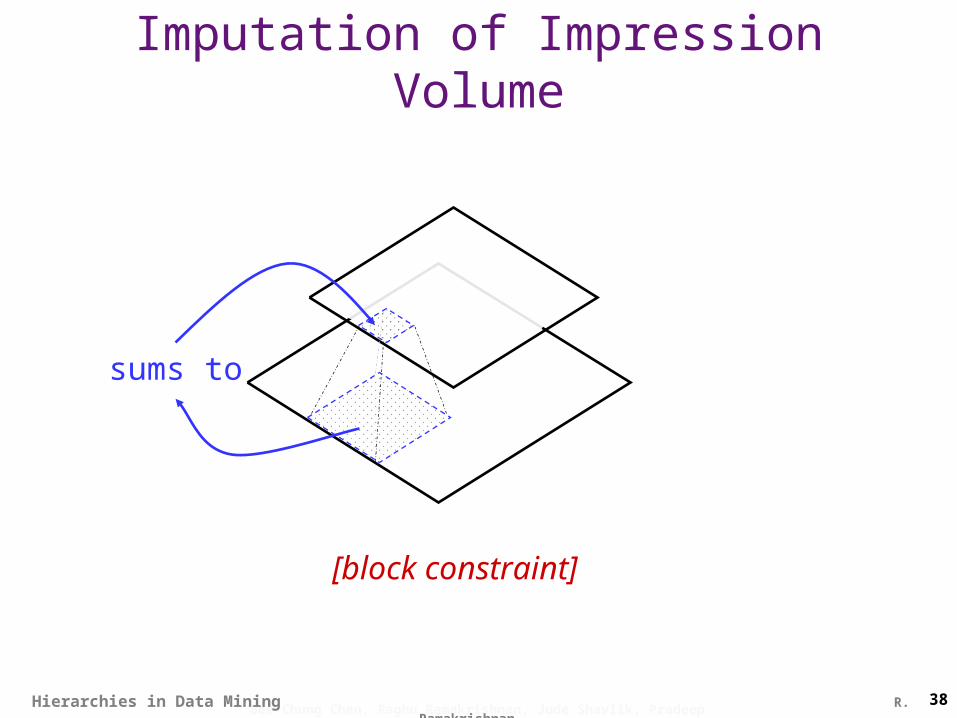
Imputation of Impression Volume
sums to
[block constraint]

39Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Imputing xij
Z(i)
Z(i+1)
Iterative Proportional Fitting [Darroch+/1972]
Initialize xij = nij + mij
Top-down:
• Scale all xij in every block in Z(i+1) to sum to its parent in Z(i)
• Scale all xij in Z(i+1) to sum to the row totals
• Scale all xij in Z(i+1) to sum to the column totals
Repeat for every level Z(i)
Bottom-up: Similar
blockPage classes Ad classes

40Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Imputation: Summary
• Given– nij (impressions in clicked pool)
– mij (impressions in sampled non-clicked pool)
– # impressions on ads of each ad class in the ad hierarchy
• We get– Estimated impression volume
Ñij = nij + mij + xij
in each region ij of every level Z(.)

Bellwether Analysis
Dealing with Data Sparsity
Deepak Agarwal, Pradheep Elango, Nitin Motgi, Seung-Taek Park, Raghu Ramakrishnan, Scott Roy,
Joe Zachariah
Real-time Content Optimization through Active User Feedback, NIPS 2008

42Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Yahoo! Home Page Featured Box
• It is the top-center part of the Y! Front Page
• It has four tabs: Featured, Entertainment, Sports, and Video

43Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Novel Aspects• Classical: Arms assumed fixed over time
– We gain and lose arms over time • Some theoretical work by Whittle in 80’s; operations research
• Classical: Serving rule updated after each pull– We compute optimal design in batch mode
• Classical: Generally. CTR assumed stationary– We have highly dynamic, non-stationary CTRs

44Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Bellwether Analysis:Global Aggregates from Local Regions
with Beechung Chen, Jude Shavlik, and Pradeep TammaIn VLDB 06

45Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Motivating Example
• A company wants to predict the first year worldwide profit of a new item (e.g., a new movie)– By looking at features and profits of previous (similar) movies, we
predict expected total profit (1-year US sales) for new movie• Wait a year and write a query! If you can’t wait, stay awake …
– The most predictive “features” may be based on sales data gathered by releasing the new movie in many “regions” (different locations over different time periods).
• Example “region-based” features: 1st week sales in Peoria, week-to-week sales growth in Wisconsin, etc.
• Gathering this data has a cost (e.g., marketing expenses, waiting time)
• Problem statement: Find the most predictive region features that can be obtained within a given “cost budget”

46Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Key Ideas
• Large datasets are rarely labeled with the targets that we wish to learn to predict– But for the tasks we address, we can readily use OLAP
queries to generate features (e.g., 1st week sales in Peoria) and even targets (e.g., profit) for mining
• We use data-mining models as building blocks in the mining process, rather than thinking of them as the end result– The central problem is to find data subsets
(“bellwether regions”) that lead to predictive features which can be gathered at low cost for a new case

47Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Motivating Example
• A company wants to predict the first year’s worldwide profit for a new item, by using its historical database
• Database Schema:
Profit Table
TimeLocationCustIDItemIDProfit
Item Table
ItemIDCategoryR&D Expense
Ad Table
TimeLocationItemIDAdExpenseAdSize
• The combination of the underlined attributes forms a key

48Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
A Straightforward Approach
• Build a regression model to predict item profit
• There is much room for accuracy improvement!
Profit Table
TimeLocationCustIDItemIDProfit
Item Table
ItemIDCategoryR&D Expense
Ad Table
TimeLocationItemIDAdExpenseAdSize
ItemID Category R&D Expense Profit
1 Laptop 500K 12,000K
2 Desktop 100K 8,000K
… … … …
By joining and aggregating tables in the historical database we can create a training set:
Item-table features Target
An Example regression model:Profit = 0 + 1 Laptop + 2 Desktop + 3 RdExpense

49Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Using Regional Features
• Example region: [1st week, HK]• Regional features:
– Regional Profit: The 1st week profit in HK– Regional Ad Expense: The 1st week ad expense in HK
• A possibly more accurate model:
Profit[1yr, All] = 0 + 1 Laptop + 2 Desktop + 3 RdExpense +
4 Profit[1wk, HK] + 5 AdExpense[1wk, HK]
• Problem: Which region should we use?– The smallest region that improves the accuracy the most– We give each candidate region a cost– The most “cost-effective” region is the bellwether region

52Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Basic Bellwether Problem
1 2 3 4 5 … 52
KR
USA
…
WI
WY
... …
ItemID Category … Profit[1-2,USA] …
… … … … …
i Desktop 45K
… … … … …
Aggregate over data recordsin region r = [1-2, USA]
Features i,r(DB)
ItemID Total Profit
… …
i 2,000K
… …
Target i(DB)
Total Profitin [1-52, All]
For each region r, build a predictive model hr(x); and then choose bellwether region:
• Coverage(r) fraction of all items in region minimum coverage support • Cost(r, DB) cost threshold
• Error(hr) is minimized
r

53Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Experiment on a Mail Order Dataset
0
5000
10000
15000
20000
25000
30000
5 25 45 65 85Budget
RM
SE
Bel Err Avg Err
Smp Err
• Bel Err: The error of the bellwether region found using a given budget
• Avg Err: The average error of all the cube regions with costs under a given budget
• Smp Err: The error of a set of randomly sampled (non-cube) regions with costs under a given budget
[1-8 month, MD]
Error-vs-Budget Plot
(RMSE: Root Mean Square Error)

54Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Experiment on a Mail Order Dataset
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
5 25 45 65 85Budget
Fra
ctio
n of
indi
stin
guis
able
s
Uniqueness Plot
• Y-axis: Fraction of regions that are as good as the bellwether region– The fraction of regions that
satisfy the constraints and have errors within the 99% confidence interval of the error of the bellwether region
• We have 99% confidence that that [1-8 month, MD] is a quite unusual bellwether region
[1-8 month, MD]

55Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Basic Bellwether Computation
• OLAP-style bellwether analysis– Candidate regions: Regions in a data cube
– Queries: OLAP-style aggregate queries
• E.g., Sum(Profit) over a region
• Efficient computation:
– Use iceberg cube techniques to prune infeasible regions (Beyer-Ramakrishnan, ICDE 99; Han-Pei-Dong-Wang SIGMOD 01)
• Infeasible regions: Regions with cost > B or coverage < C
– Share computation by generating the features and target values for all the feasible regions all together
• Exploit distributive and algebraic aggregate functions• Simultaneously generating all the features and target values
reduces DB scans and repeated aggregate computation
1 2 3 4 5 … 52
KR …
USA
WI
... WY

57Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Subset-Based Bellwether Prediction
• Motivation: Different subsets of items may have different bellwether regions– E.g., The bellwether region for laptops may be
different from the bellwether region for clothes
• Two approaches:
R&D Expense 50K
YesNo
Category
Desktop Laptop
[1-2, WI] [1-3, MD]
[1-1, NY]
Bellwether Tree Bellwether Cube
Low Medium High
Software OS [1-3,CA] [1-1,NY] [1-2,CA]
… ... … …
Hardware Laptop [1-4,MD] [1-1, NY] [1-3,WI]
… … … …
… … … … …
R&D Expenses
Cat
egor
y

69Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Characteristics of Bellwether Trees & Cubes
Dataset generation:• Use random tree to generate different bellwether regions for different subset of itemsParameters:• Noise• Concept complexity: # of tree nodes
Result:• Bellwether trees & cubes have better accuracy than basic bellwether search• Increase noise increase error• Increase complexity increase error
0
0.5
1
1.5
2
2.5
3
0.05 0.5 1 2Noise
RM
SE
basic
cube
tree
0
0.5
1
1.5
2
3 7 15 31 63Number of nodes
RM
SE
basic
cube
tree
15 nodes Noise level: 0.5

70Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Efficiency Comparison
0
500
1000
1500
2000
2500
3000
100 150 200 250 300Thousands of examples
Sec
naive cube
naive tree
RF tree
single-scancube
optimizedcube
Naïve computationmethods
Our computationtechniques

71Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Scalability
0
200
400
600
800
1000
1200
2.5 5 7.5 10Millions of examples
Sec
single-scancube
optimizedcube
0
1000
2000
3000
4000
5000
6000
7000
2.5 5 7.5 10Millions of examples
Sec RF tree

72Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Exploratory Mining:Prediction Cubes
with Beechung Chen, Lei Chen, and Yi LinIn VLDB 05

73Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
The Idea
• Build OLAP data cubes in which cell values represent decision/prediction behavior– In effect, build a tree for each cell/region in the cube—
observe that this is not the same as a collection of trees used in an ensemble method!
– The idea is simple, but it leads to promising data mining tools
– Ultimate objective: Exploratory analysis of the entire space of “data mining choices”
• Choice of algorithms, data conditioning parameters …

74Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Example (1/7): Regular OLAP
Location Time # of App.
… … ...AL, USA Dec, 04 2
… … …WY, USA Dec, 04 3
Goal: Look for patterns of unusually high numbers of applications:
Z: Dimensions Y: Measure
All
85 86 04
Jan., 86 Dec., 86
All
Year
Month
Location Time
All
Japan USA Norway
AL WY
All
Country
State

75Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Example (2/7): Regular OLAP
Location Time # of App.
… … ...AL, USA Dec, 04 2
… … …WY, USA Dec, 04 3
Goal: Look for patterns of unusually high numbers of applications:
……………………
………108270USA
……3025502030CA…Dec…JanDec…Jan…20032004
Cell value: Number of loan applications
Z: Dimensions Y: Measure
…………
…9080USA
…90100CA…0304
Roll up
Coarserregions
………………
………10WY
……5…
………55ALUSA
…1535YT
…2025…
…151520AB
CA
…Dec…Jan…2004
Drilldown
Finer regions

76Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Model h(X, Z(D))E.g., decision tree
No…FBlackDec, 04WY, USA
………………
Yes…MWhiteDec, 04AL, USA
Approval…SexRaceTimeLocation
Example (3/7): Decision AnalysisGoal: Analyze a bank’s loan decision process
w.r.t. two dimensions: Location and Time
All
85 86 04
Jan., 86 Dec., 86
All
Year
Month
Location Time
All
Japan USA Norway
AL WY
All
Country
State
Z: Dimensions X: Predictors Y: Class
Fact table D
Cube subset

77Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Example (3/7): Decision Analysis
• Are there branches (and time windows) where approvals were closely tied to sensitive attributes (e.g., race)?
– Suppose you partitioned the training data by location and time, chose the partition for a given branch and time window, and built a classifier. You could then ask, “Are the predictions of this classifier closely correlated with race?”
• Are there branches and times with decision making reminiscent of 1950s Alabama?
– Requires comparison of classifiers trained using different subsets of data.

78Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Model h(X, [USA, Dec 04](D))E.g., decision tree
Example (4/7): Prediction Cubes
2004 2003 …
Jan … Dec Jan … Dec …
CA 0.4 0.8 0.9 0.6 0.8 … …
USA 0.2 0.3 0.5 … … …
… … … … … … … …
1. Build a model using data from USA in Dec., 1985
2. Evaluate that model
Measure in a cell:• Accuracy of the model• Predictiveness of Race measured based on that model• Similarity between that model and a given model
N…FBlackDec, 04WY, USA
………………
Y…MWhiteDec, 04AL ,USA
Approval…SexRaceTimeLocation
Data [USA, Dec 04](D)

79Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
No…FBlackDec, 04WY, USA
………………
Yes…MWhiteDec, 04AL, USA
Approval…SexRaceTimeLocation
Data table D
Example (5/7): Model-Similarity
Given: - Data table D - Target model h0(X) - Test set w/o labels
…MBlack
………
…FWhite
…SexRace
Test set
……………………
………0.90.30.2USA
……0.50.60.30.20.4CA
…Dec…JanDec…Jan
…20032004
Level: [Country, Month]
The loan decision process in USA during Dec 04 was similar to a discriminatory decision model
h0(X)
Build a model
Similarity
No
…
Yes
Yes
…
Yes

80Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Location Time Race Sex … Approval
AL, USA Dec, 04 White M … Yes
… … … … … …
WY, USA Dec, 04 Black F … No
Example (6/7): Predictiveness
2004 2003 …
Jan … Dec Jan … Dec …
CA 0.4 0.2 0.3 0.6 0.5 … …
USA 0.2 0.3 0.9 … … …
… … … … … … … …
Given: - Data table D - Attributes V - Test set w/o labels
Race Sex …White F …
… … …
Black M …
Data table D
Test set
Level: [Country, Month]Predictiveness of V
Race was an important predictor of loan approval decision in USA during Dec 04
Build models
h(X) h(XV)
YesNo..No
YesNo..Yes

81Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Example (7/7): Prediction Cube
2004 2003 …
Jan … Dec Jan … Dec …
CA 0.4 0.1 0.3 0.6 0.8 … …
USA 0.7 0.4 0.3 0.3 … … …
… … … … … … … …
………………………
…………0.80.70.9WY
………0.10.10.3…
…………0.20.10.2AL
USA
………0.20.10.20.3YT
………0.30.30.10.1…
……0.20.10.10.20.4AB
CA
…Dec…JanDec…Jan
…20032004
Drill down
…………
…0.30.2USA
…0.20.3CA
…0304Roll up
Cell value: Predictiveness of Race

82Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Efficient Computation
• Reduce prediction cube computation to data cube computation– Represent a data-mining model as a distributive or
algebraic (bottom-up computable) aggregate function, so that data-cube techniques can be directly applied

83Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Bottom-Up Data Cube Computation
1985 1986 1987 1988
Norway 10 30 20 24
… 23 45 14 32
USA 14 32 42 11
1985 1986 1987 1988
All 47 107 76 67
All
Norway 84
… 114
USA 99
All
All 297
Cell Values: Numbers of loan applications

84Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Functions on Sets
• Bottom-up computable functions: Functions that can be computed using only summary information
• Distributive function: (X) = F({(X1), …, (Xn)})
– X = X1 … Xn and Xi Xj =
– E.g., Count(X) = Sum({Count(X1), …, Count(Xn)})
• Algebraic function: (X) = F({G(X1), …, G(Xn)})
– G(Xi) returns a length-fixed vector of values
– E.g., Avg(X) = F({G(X1), …, G(Xn)})
• G(Xi) = [Sum(Xi), Count(Xi)]
• F({[s1, c1], …, [sn, cn]}) = Sum({si}) / Sum({ci})

85Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Scoring Function
• Represent a model as a function of sets
• Conceptually, a machine-learning model h(X; Z(D)) is a scoring function Score(y, x; Z(D)) that gives each class y a score on test example x– h(x; Z(D)) = argmax y Score(y, x; Z(D))
– Score(y, x; Z(D)) p(y | x, Z(D))
Z(D): The set of training examples (a cube subset of D)

87Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Machine-Learning Models
• Naïve Bayes:– Scoring function: algebraic
• Kernel-density-based classifier:– Scoring function: distributive
• Decision tree, random forest:– Neither distributive, nor algebraic
• PBE: Probability-based ensemble (new)– To make any machine-learning model distributive– Approximation

88Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Probability-Based Ensemble
1985
Jan … Dec
WA…
…
…
1985
Jan … Dec
WA…
…
…
Decision trees built on the lowest-level cells
Decision tree on [WA, 85]PBE version of decision
tree on [WA, 85]

94Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Efficiency Comparison
0
500
1000
1500
2000
2500
40K 80K 120K 160K 200K
RFex
KDCex
NBex
J48ex
NB
KDC
RF-PBE J48-PBE
Using exhaustivemethod
Using bottom-upscore computation
# of Records
Exe
cuti
on T
ime
(sec
)

Bellwether Analysis
Conclusions

96Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Related Work: Building Models on OLAP Results
• Multi-dimensional regression [Chen, VLDB 02]– Goal: Detect changes of trends– Build linear regression models for cube cells
• Step-by-step regression in stream cubes [Liu, PAKDD 03]
• Loglinear-based quasi cubes [Barbara, J. IIS 01]– Use loglinear model to approximately compress dense regions of
a data cube
• NetCube [Margaritis, VLDB 01]– Build Bayes Net on the entire dataset of approximate answer
count queries

97Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Related Work (Contd.)
• Cubegrades [Imielinski, J. DMKD 02]– Extend cubes with ideas from association rules– How does the measure change when we rollup or drill down?
• Constrained gradients [Dong, VLDB 01]– Find pairs of similar cell characteristics associated with big
changes in measure
• User-cognizant multidimensional analysis [Sarawagi, VLDBJ 01]– Help users find the most informative unvisited regions in a data
cube using max entropy principle
• Multi-Structural DBs [Fagin et al., PODS 05, VLDB 05]• Experiment Databases: Towards an Improved
Experimental Methodology in Machine Learning [Blockeel & Vanschoren, PKDD 2007]

98Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Take-Home Messages
• Promising exploratory data analysis paradigm:– Can use models to identify interesting subsets– Concentrate only on subsets in cube space
• Those are meaningful subsets, tractable
– Precompute results and provide the users with an interactive tool
• A simple way to plug “something” into cube-style analysis:– Try to describe/approximate “something” by a distributive or
algebraic function

100Bee-Chung Chen, Raghu Ramakrishnan, Jude Shavlik, Pradeep TammaHierarchies in Data Mining R. Ramakrishnan
Conclusion
• Hierarchies are widely used, and a promising tool to help us deal with– Data sparsity– Data imprecision and uncertainty– Exploratory analysis– “Experiment” planning and management
• Area is as yet under-appreciated– Lots of work on taxonomies and how to use them,
but there are many novel ways of using them that have not received enough attention