best practices in recommender system challenges
TRANSCRIPT

Recommender Systems
Challenges
Best Practices
Tutorial & Panel
ACM RecSys 2012
Dublin September 10, 2012

About us
• Alan Said - PhD Student @ TU-Berlin o Topics: RecSys Evaluation
o @alansaid
o URL: www.alansaid.com
• Domonkos Tikk - CEO @ Gravity R&D o Topics: Machine Learning methods for RecSys
o @domonkostikk
o http://www.tmit.bme.hu/tikk.domonkos
• Andreas Hotho - Prof. @ Uni. Würzburg o Topics: Data Mining, Information Retrieval, Web Science
o http://www.is.informatik.uni-wuerzburg.de/staff/hotho

General Motivation
"RecSys is nobody's home conference. We
come from CHI, IUI, SIGIR, etc."
Joe Konstan - RecSys 2010
RecSys is our home conference - we
should evaluate accordingly!

• Tutorial o Introduction to concepts in challenges
o Execution of a challenge
o Conclusion
• Panel
Experiences of participating in and
organizing challenges Yehuda Koren
Darren Vengroff
Torben Brodt
Outline

What is the motivation
for RecSys Challenges?
Part 1
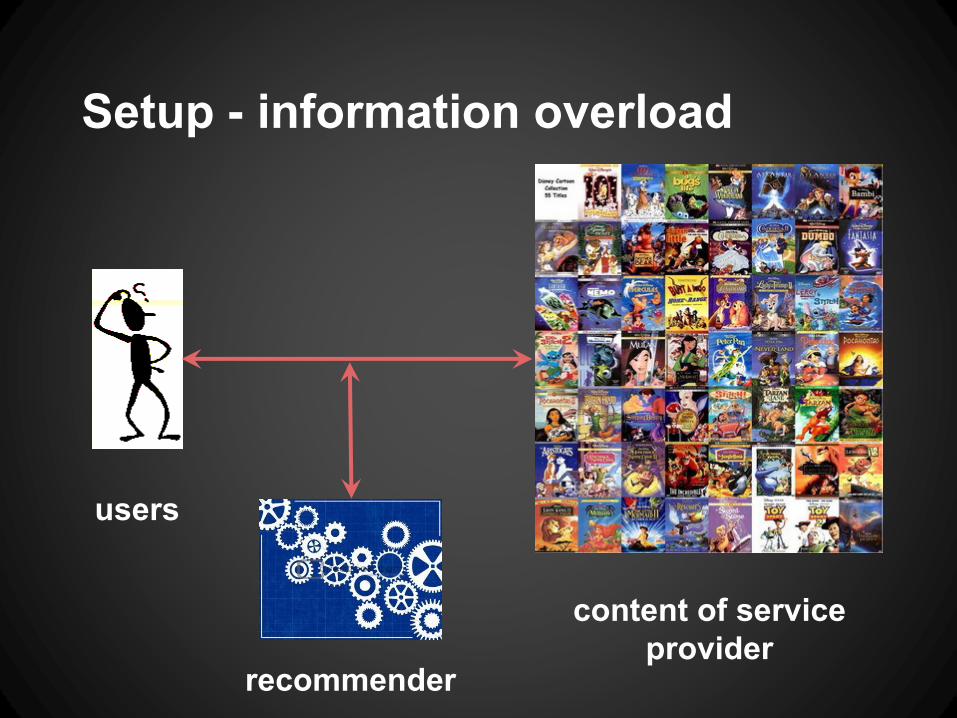
Setup - information overload
users
content of service
provider recommender
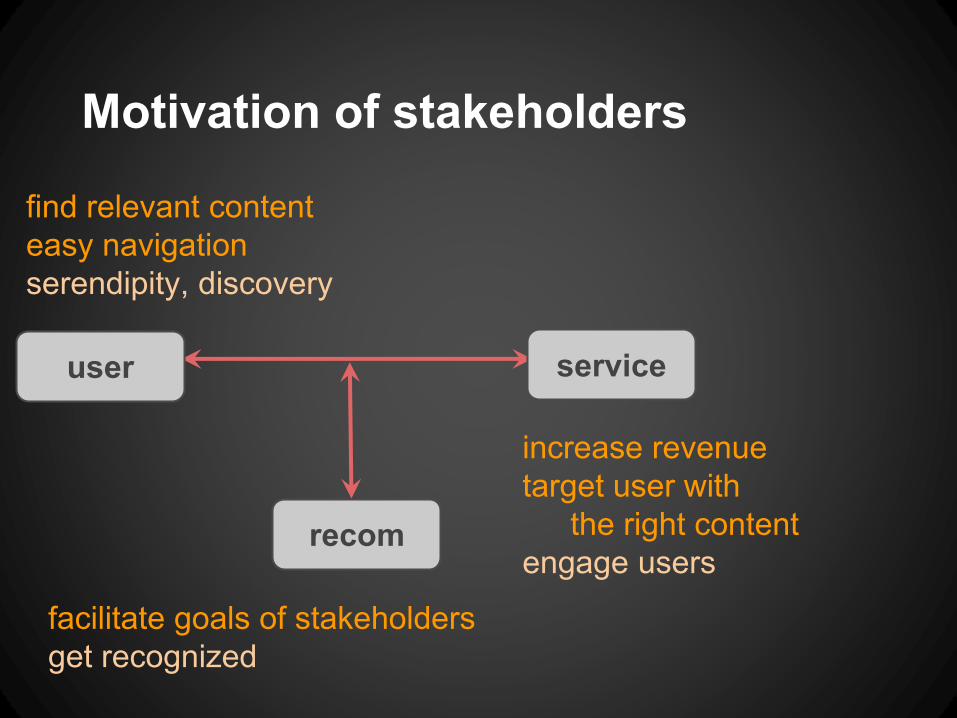
Motivation of stakeholders
service
recom
user
increase revenue
target user with
the right content
engage users
find relevant content
easy navigation
serendipity, discovery
facilitate goals of stakeholders
get recognized
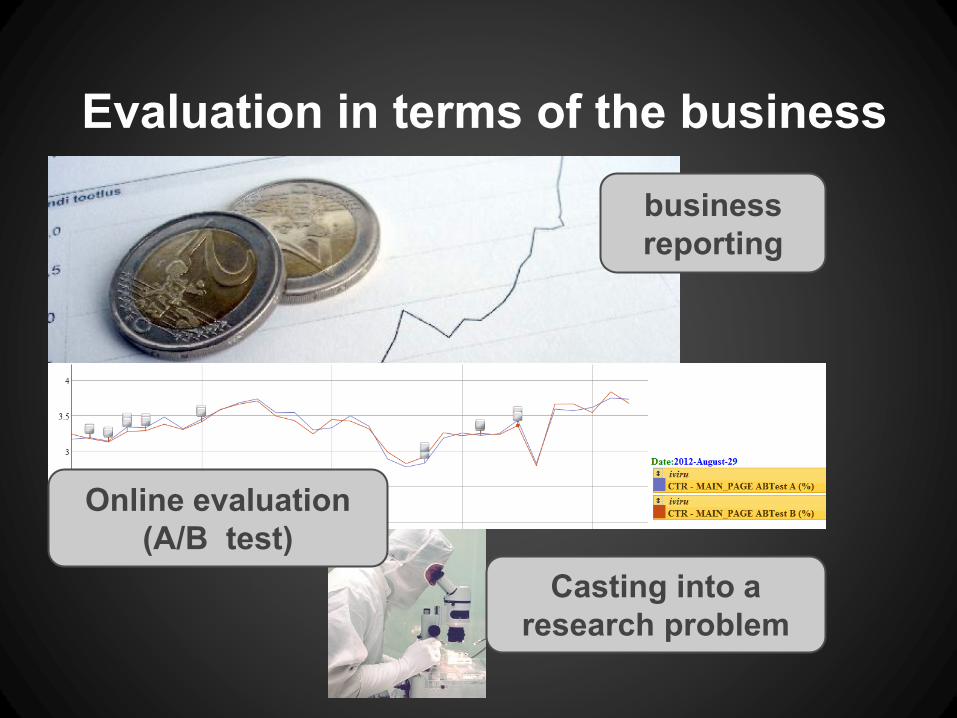
Evaluation in terms of the business
business
reporting
Online evaluation
(A/B test)
Casting into a
research problem

Context of the contest
• Selection of metrics
• Domain dependent
• Offline vs. online evaluation
• IR centric evaluation
o RMSE
o MAP
o F1

Latent user needs

Recsys Competition Highlights
• Large scale
• Organization
• RMSE
• Prize • 3-stage setup
• selection by review
• runtime limits
• real traffic
• revenue increase
• offline
• MAP@500
• metadata available
• larger in dimensions
• no ratings

Recurring Competitions
• ACM KDD Cup (2007, 2011, 2012)
• ECML/PKDD Discovery Challenge (2008
onwards)
o 2008 and 09: tag recommendation in social
bookmarking (incl. online evaluation task)
o 2011: video lectures
• CAMRa (2010, 2011, 2012)

Does size matter?
• Yes! – real world users
• In research – to some extent

Research & Industry
Important for both
• Industry has the data and research needs
data
• Industry needs better approaches but this
costs
• Research has ideas but has no systems
and/or data to do the evaluation
Don't exploit participants
Don't be too greedy

Part 2
Running a Challenge

• organizer defines the recommender setting e.g.
tag recommendation in BibSonomy
• provide data o with features or
o raw data
o construct your own data
• fix the way to do the evaluation
• define the goal e.g. reach a certain
improvement (F1)
• motivate people to participate:
e.g. promise a lot of money ;-)
Standard Challenge Setting

• offline o everyone gets access to the dataset
o in principle it is a prediction task, the user can't be influenced
o privacy of the user within the data is a big issue
o results from offline experimentation have limited predictive power
for online user behavior
• online o after a first learning phase the recommender is plugged into a real
system
o user can be influenced but only by the selected system
o comparison of different system is not completely fair
• further ways o user study
Typical contest settings
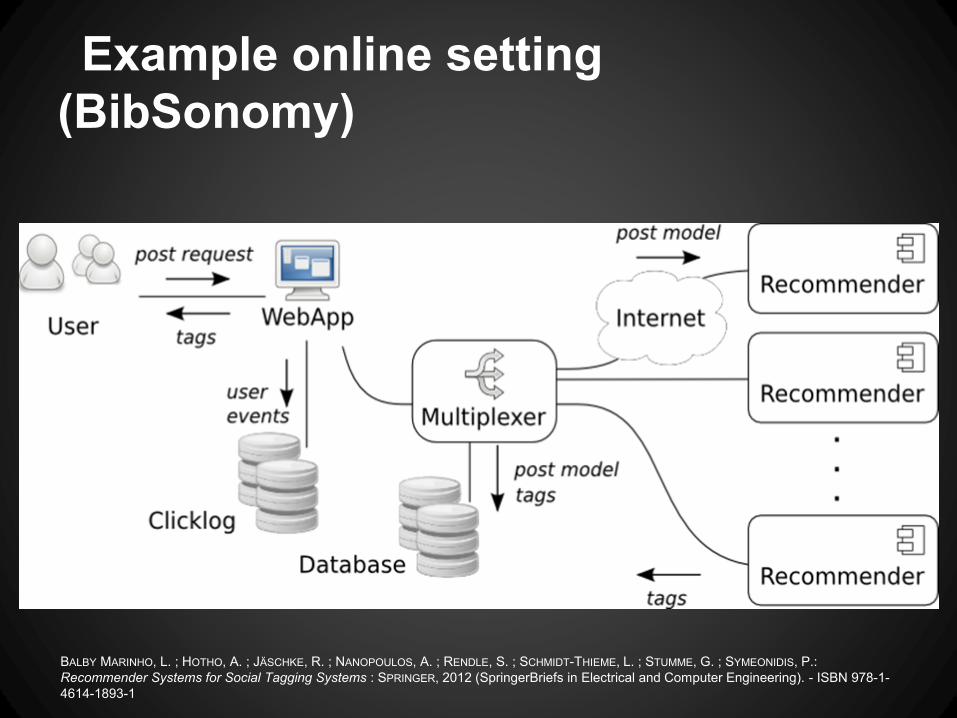
Example online setting
(BibSonomy)
BALBY MARINHO, L. ; HOTHO, A. ; JÄSCHKE, R. ; NANOPOULOS, A. ; RENDLE, S. ; SCHMIDT-THIEME, L. ; STUMME, G. ; SYMEONIDIS, P.:
Recommender Systems for Social Tagging Systems : SPRINGER, 2012 (SpringerBriefs in Electrical and Computer Engineering). - ISBN 978-1-
4614-1893-1

Which evaluation measures?
• Root Mean Squared Error (RMSE)
• Mean Absolute Error (MAE)
• Typical IR measures
o precision @ n-items
o recall @ n-items
o False Positive Rate
o F1 @ n-items
o Area Under the ROC Curve (AUC)
• non-quality measures
o server answer time
o understandability of the results

Discussion of measures?
RMSE - Precision
• RMSE is not necessarily the king of metrics
as RMSE is easy to optimize on
• What about Top-n?
• but RMSE is not influenced by popularity as
top-n
• What about user-centric stuff?
• Ranking-based measure in KDD Cup 2011,
Track 2

Results influenced by ...
• target of the recommendation (user, resources, etc...)
• evaluation methodology (leave-one-out, time based split, random
sample, cross validation)
• evaluation measure
• design of the application (online setting)
• the selected part of the data and its preprocessing (e.g.
p-core vs. long tail)
• scalability vs. quality of the model
• feature and content accessible and usable for the
recommendation

Don't forget..
• the effort to organize a challenge is very big
• preparing data takes time
• answering questions takes even more time
• participants are creative, needs for reaction
• time to compute the evaluation and check the
results
• prepare proceedings with the outcome
• ...

Part 3
What have we learnt?
Conclusion

Challenges are good since they...
• ... are focused on solving a single problem
• ... have many participants
• ... create common evaluation criteria
• ... have comparable results
• ... bring real-world problems to research
• ... make it easy to crown a winner
• ... they are cheap (even with a 1M$ prize)

Is that the complete truth?
No!

Is that the complete truth?
• Why?
Because using standard information retrieval metrics we
cannot evaluate recommender system concepts like:
• user interaction
• perception
• satisfaction
• usefulness
• any metric not based on accuracy/rating prediction
and negative predictions
• scalability
• engineering
We can't catch everything offline
Scalability
Presentation
Interaction

The difference between IR and RS
Information retrieval systems answer to a need
Recommender systems identify the user's needs
A Query

Should we organize more
challenges?
• Yes - but before we do that, think of o What is the utility of Yet Another Dataset - aren't
there enough already?
o How do we create a real-world like challenge
o How do we get real user feedback

Take home message
• Real needs of users and content providers are better
reflected in online evaluation
• Consider technical limitations as well
• Challenges advance the field a lot
o Matrix factorization & ensemble methods in the
Netflix Prize
o Evaluation measure and objective in the KDD Cup
2011

Related events at RecSys
• Workshops o Recommender Utility Evaluation
o RecSys Data Challenge
• Paper Sessions
o Multi-Objective Recommendation and Human
Factors - Mon. 14:30
o Implicit Feedback and User Preference - Tue. 11:00
o Top-N Recommendation - Wed. 14:30
• More challenges:
o www.recsyswiki.com/wiki/Category:Competition

Part 4
Panel

Panel
• Torben Brodt o Plista
o Organizing Plista Contest
• Yehuda Koren o Google
o Member of winning team of the Netflix Prize
• Darren Vengroff o RichRelevance
o Organizer of RecLab Prize

Questions
• How does recommendation influence the
user and system?
• How can we quantify the effects of the UI?
• How should we translate what we've
presented into an actual challenge?
• should we focus on the long tail or the short
head?
• Evaluation measures, click rate, wtf@k
• How to evaluate conversion rate?