big data analytics in linkedin -...
TRANSCRIPT

Big Data Analytics in LinkedIn

2

Brief History of LinkedIn
- Launched in 2003 by Reid Hoffman (https://ourstory.linkedin.com/)
- 2005: Introduced first business lines : Jobs and Subscriptions
- 2006: Launched public profiles (achieved portability/new features)
- 2008: LinkedIn goes GLOBAL! (https://business.linkedin.com/)
- 2012: Site transformation/rapid growth
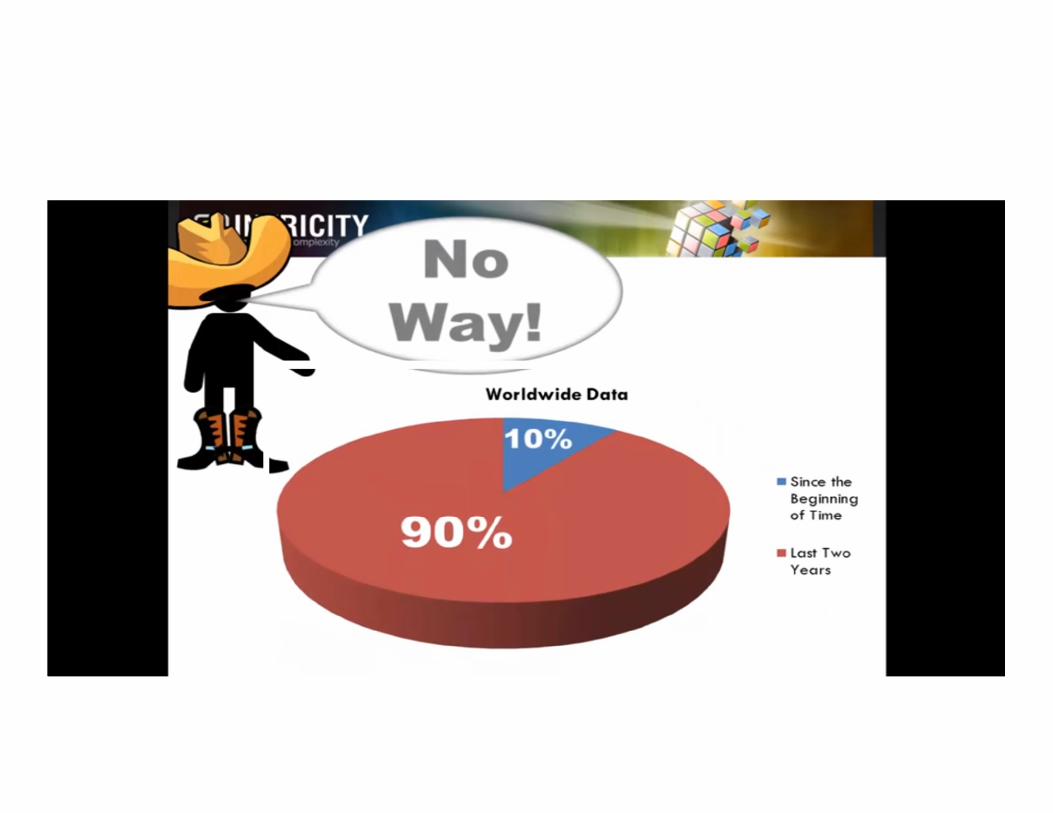
- 2013: ~225 million members (27 % of LinkedIn subscribers are recruiters)
3

4
5
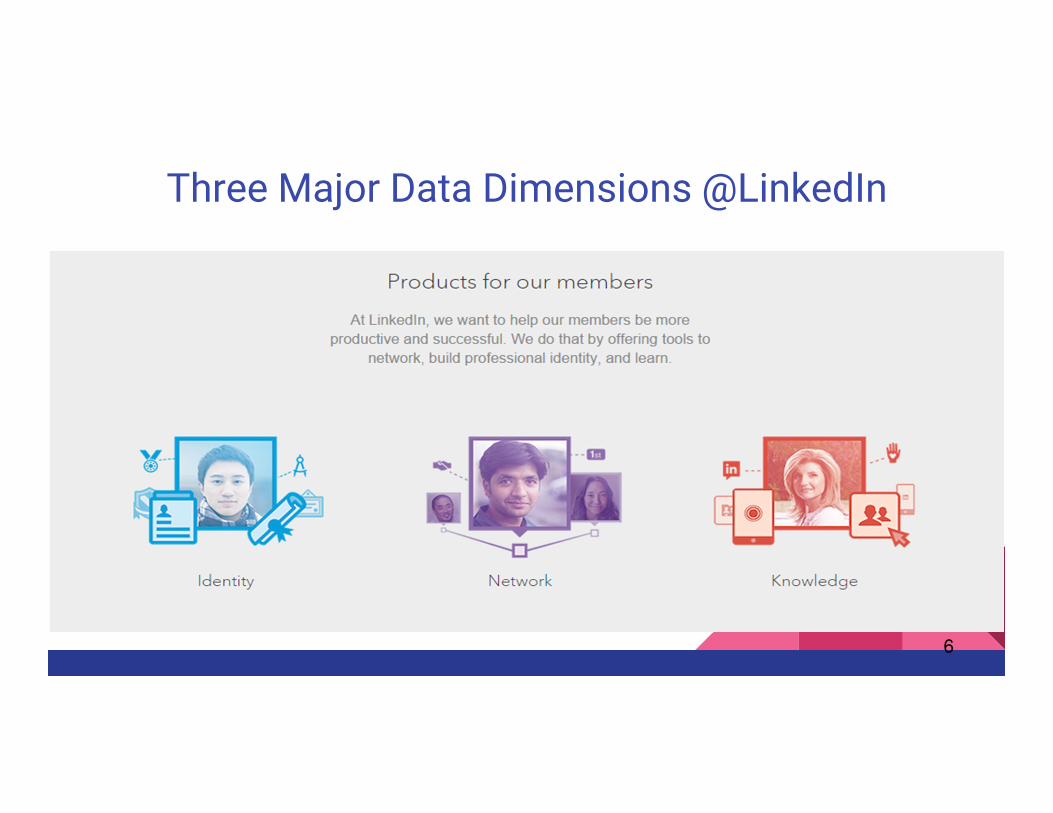
Three Major Data Dimensions @LinkedIn
6

LinkedIn Challenges for Web-scale OLAP
● Horizontally scalable
○ currently over 200+ million users
○ adding 2 new members per second
● Quick response time to user’s queries
● High availability
● High read & write throughput (billions of monthly page views)
● Heavy dependency on slowest node’s response as data is spread across
various nodes 7

Current OLAP Solutions - not suited for high-traffic website
● What is OLAP - Online Analytical Processing○ Long transactions
○ Complex queries
○ Mining and analyzing large amounts of data
○ Infrequent updates of data
Traditional for Business Intelligence (i.e. SAP, Oracle and etc)
retrieve & consolidate partial results across nodes (causing slow responses)
Distributed (problems: w/latency, availability and cost)
Materialized Cubes (loading billions of page views - load too high)
8

Avatara: solution for Web-scale Analytics Products
● Provides fast scalable OLAP system
○ handles small cubes scenarios
○ simple grammar for cube construction and query at scale
○ sharding of cube dimension into key-value model
○ leverage distributed key-value store for low-latency
○ high availability access to cubes
○ leverages hadoop for joins
9

Avatara: solution for Web-scale Analytics Products
● Two examples of analytics features:
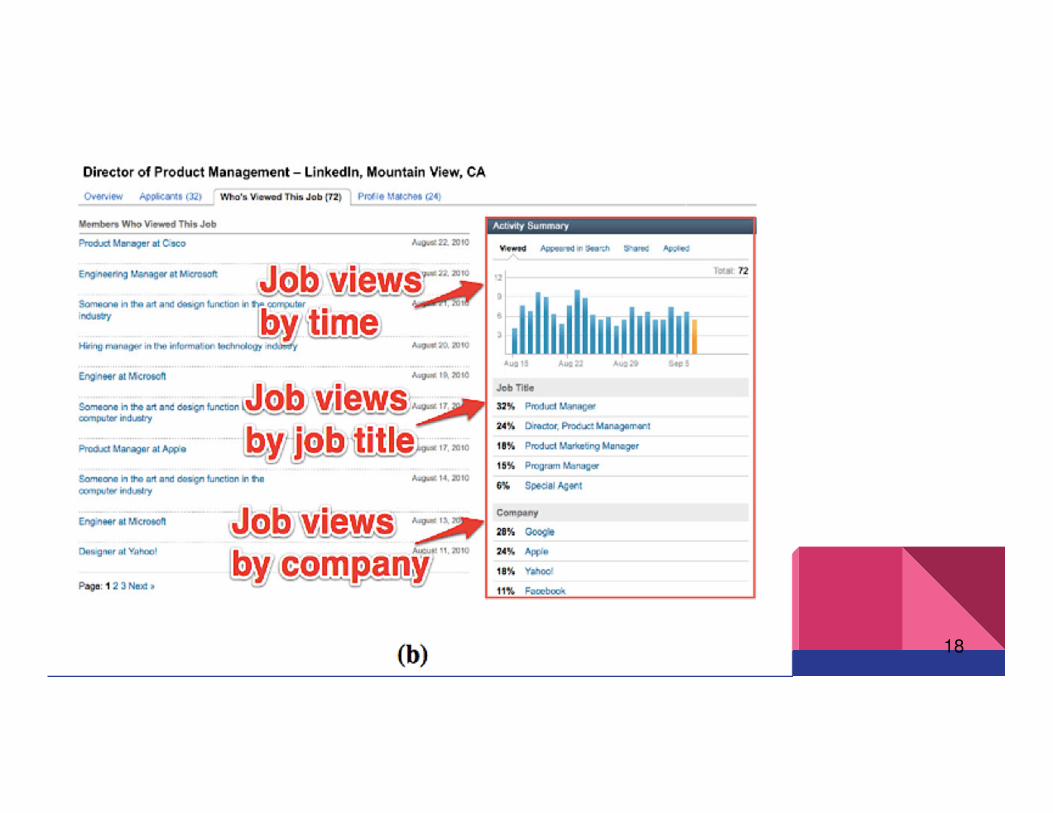
○ WVMP - cube sharded by member ID
■ Who’s viewed my profile? (WVMP)
○ WVTJ - cube sharded across jobs
■ Who’s viewed this job? (WVTJ)
10

Avatara: solution con’t
● Sharding (i.e horizontal scaling)○ divides the data set and distributes the data over multiple servers. Each
shard is an independent database and together the shards make up a single logical database■ sharding on a primary key (turning a big cube into smaller ones)
● Store cube data’s in one location requires a single disk fetch
● Offline Batch Engine○ High throughput○ Batch processing (Hadoop Jobs)
● Online Query Engine○ low latency, high availability○ key-value paradigm for storing data (Voldemort)
11
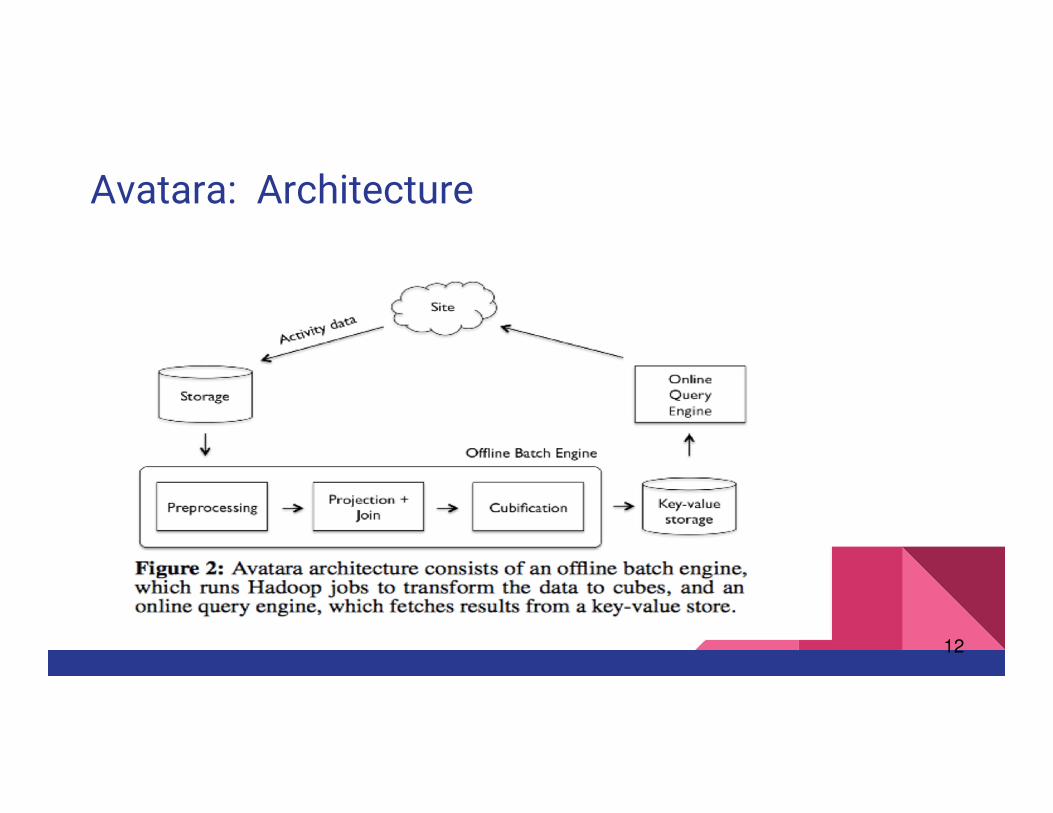
Avatara: Architecture
--
12

Avatara: Offline Batch Engine - Three Phases- driven by a simple configuration file
Phase 1: Preprocessing
○ preparing the data
○ using built-in functions to roll up data
○ customized scripting for further processing
● Phase 2: Projections and Joins
○ builds the dimension & fact tables
○ a join key ties dimension & fact tables
13

Avatara: Offline Batch Engine - Three Phases
● Phase 3: Cubification
○ partitions the data by cube shard key & produces small cubes
○ data can be retrieved in a single disk fetch for faster responses
○ cubes are bulk loaded into a distributed key-value store (i.e. Voldemort)
14

Avatara: Online Query Engine
Serves queries in real time
Retrieves & processes data from key-value store (i.e. Voldemort)
Fast retrieval because of compact cubes per sharded key (i.e. member_id)
SQL-like syntax for clients
Supports select, where, group-by, having, order and etc. operations
Simplifies development for developers 15

Cube Thinning● Avatara’s mechanism for thinning cubes too large to process on page load
(such as: President Obama or Lebron James)
● Allows developers to do the following:
○ set priorities and constraints
■ on dimensions aggregated to a specific value (such as “other” category)
○ drop data across pre-defined dimensions
■ ex: WVMP can opt to drop data across time dimension
● resulting in a shorter history!16

17
18

In SummaryAvatara has been working several years at LinkedIn (i.e. in-house OLAP system)
Allows developers to build OLAP cubes with a single configuration file
Hybrid offline/online strategy combined with sharding into key-value store
Powers large web-scale applications such as: WVMP, WVTJ and Jobs You May
Be Interested In
Avatara uses Hadoop for batch computing infrastructure
SQL-like query interaction
Hadoop batch engine can handle TBs of data & process in less than hrs of time
Voldemort can respond to online queries in milliseconds19

Future Work
○ Near real-time cubing
○ Streaming joins
○ Dimension and schema changes
20
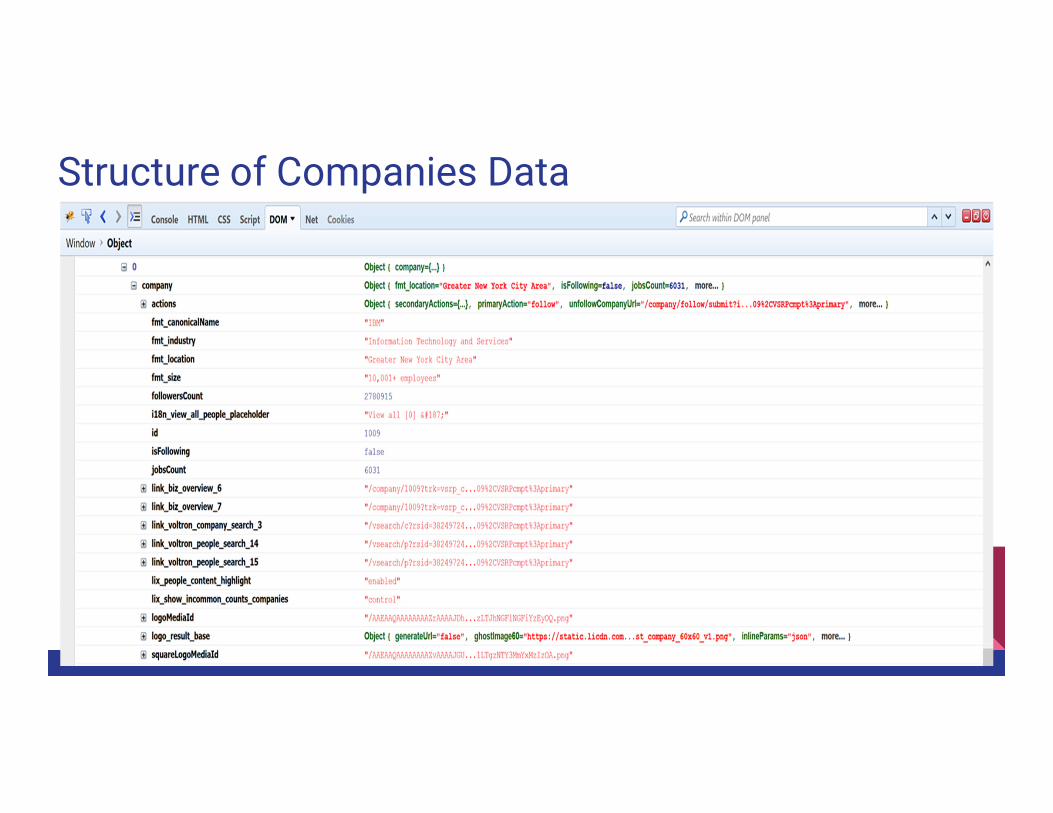
Structure of Companies Data
21
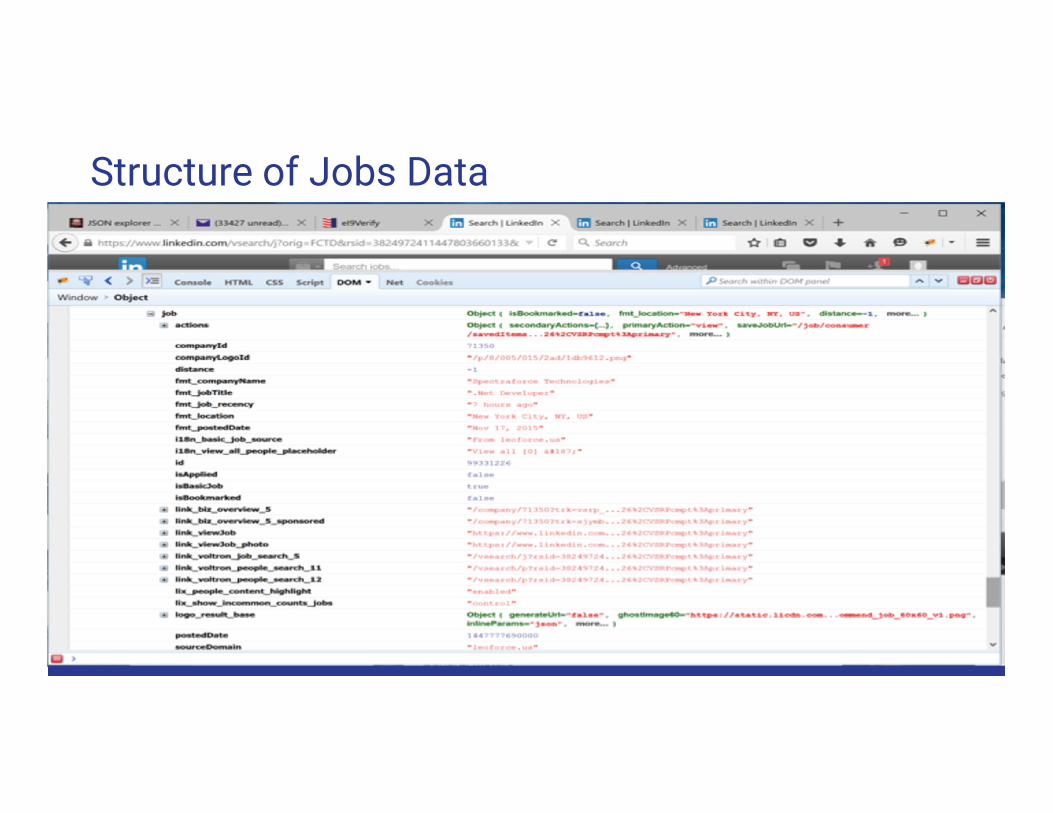
Structure of Jobs Data
22
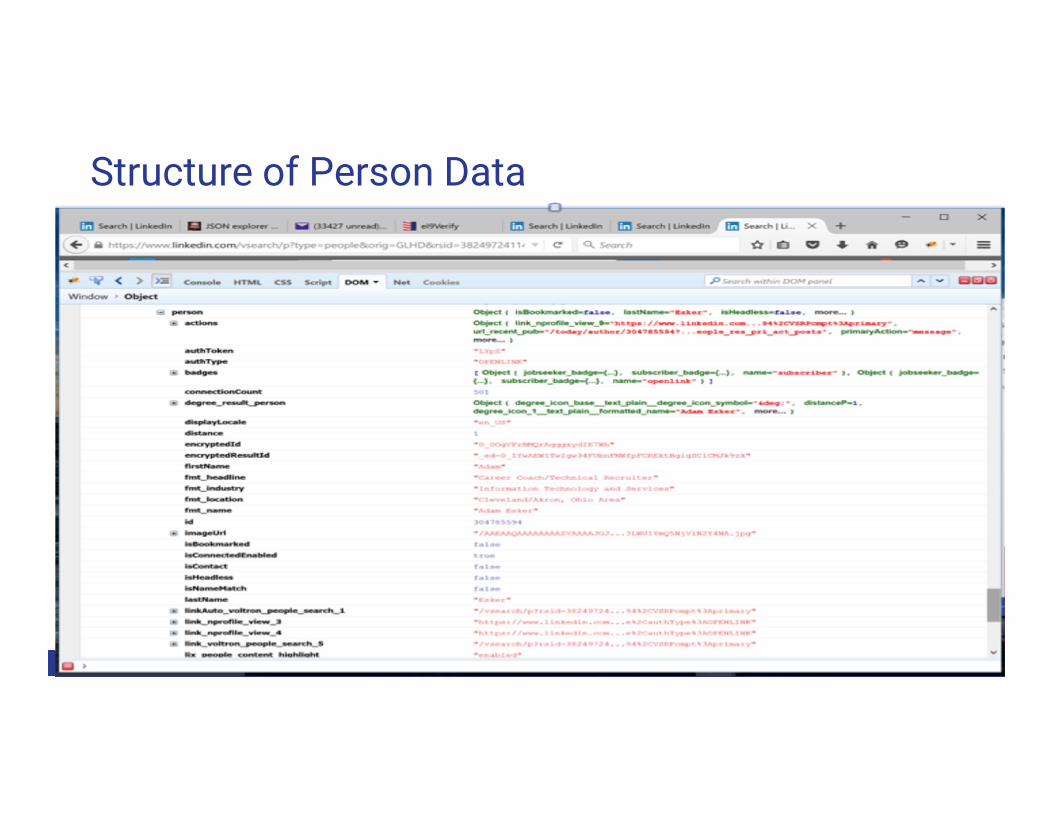
Structure of Person Data
23

HQL (Hive Query Language)Top companies with highest # followers
Top locations with highest job count
Job title and count per location
Top job titles recently listed
Location of jobs listed “1 day ago”
Comparison of # of connections of people with and without profile image
Comparison Profile Headlines with Highest Connection Count vs those with lower
connection count
Query visualization done in Tableau
24
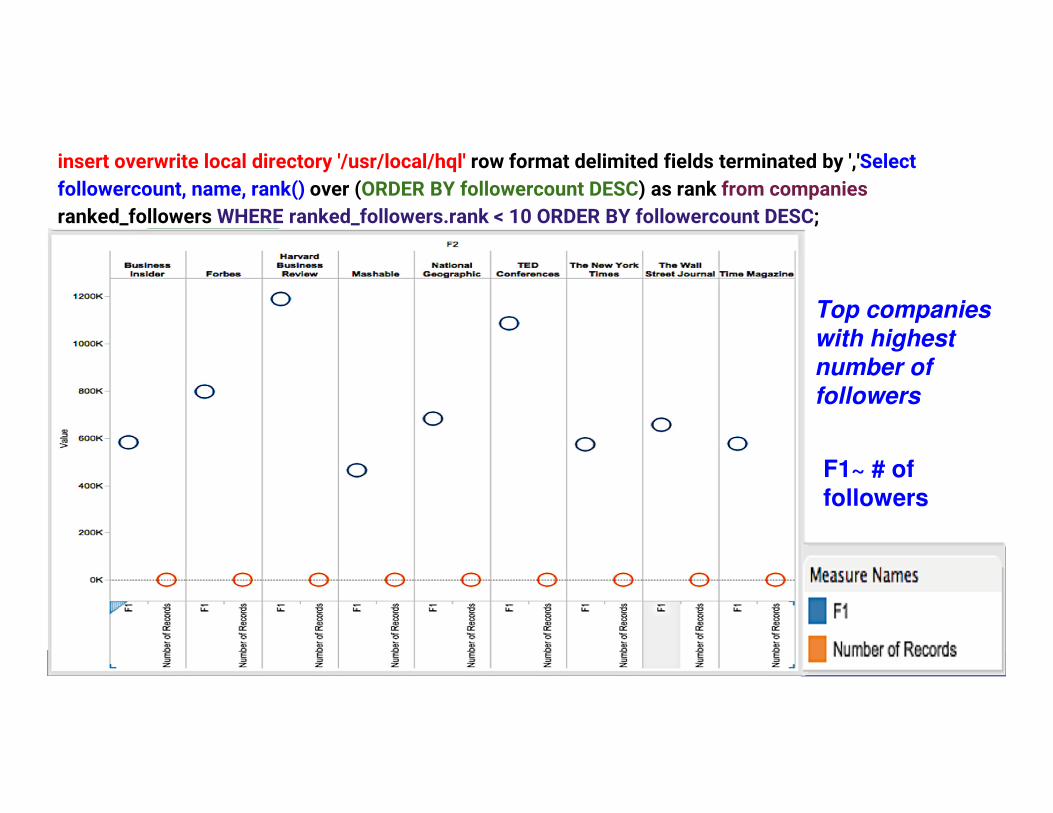
insert overwrite local directory '/usr/local/hql' row format delimited fields terminated by ','Select
followercount, name, rank() over (ORDER BY followercount DESC) as rank from companies
ranked_followers WHERE ranked_followers.rank < 10 ORDER BY followercount DESC;
25
Top companies with highest
number of
followers
F1~ # of
followers

insert overwrite local directory '/usr/local/hql' row format delimited fields terminated by ',' Select location, jobcount FROM (select location, rank() over (ORDER BY jobcount DESC) as rank, jobcount from companies) ranked_jobs WHERE ranked_jobs.rank < 51 ORDER BY location, jobcount DESC;
26
Top
locations that have
the highest
number of
jobs
F2~ # of jobs
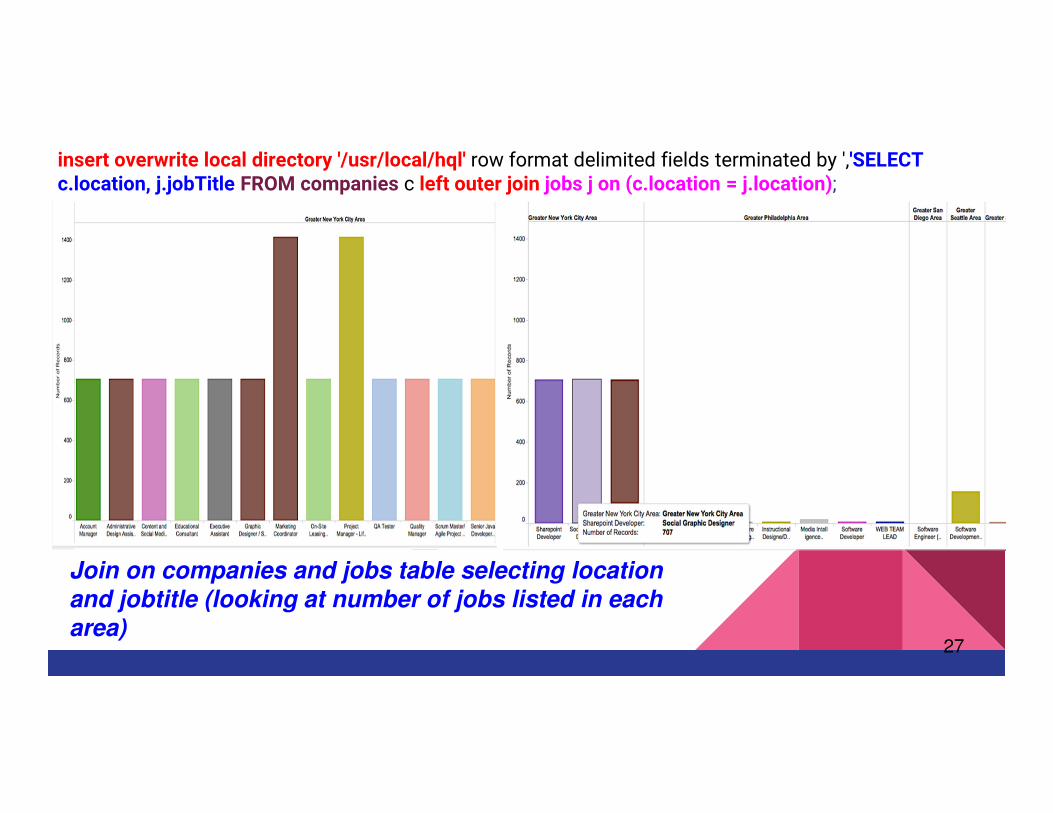
insert overwrite local directory '/usr/local/hql' row format delimited fields terminated by ','SELECT c.location, j.jobTitle FROM companies c left outer join jobs j on (c.location = j.location);
27
Join on companies and jobs table selecting location
and jobtitle (looking at number of jobs listed in each area)

insert overwrite local directory '/usr/local/hql' row format delimited fields terminated by ',' SELECT companyName, jobTitle, jobRecency FROM (select companyName, jobTitle, rank() over (ORDER BY jobRecency DESC) as rank, jobRecency from jobs) ranked_jobTitles WHERE ranked_jobTitles.rank < 11 ORDER BY jobTitle, jobRecency DESC;
28
Top Job titles
recently listed
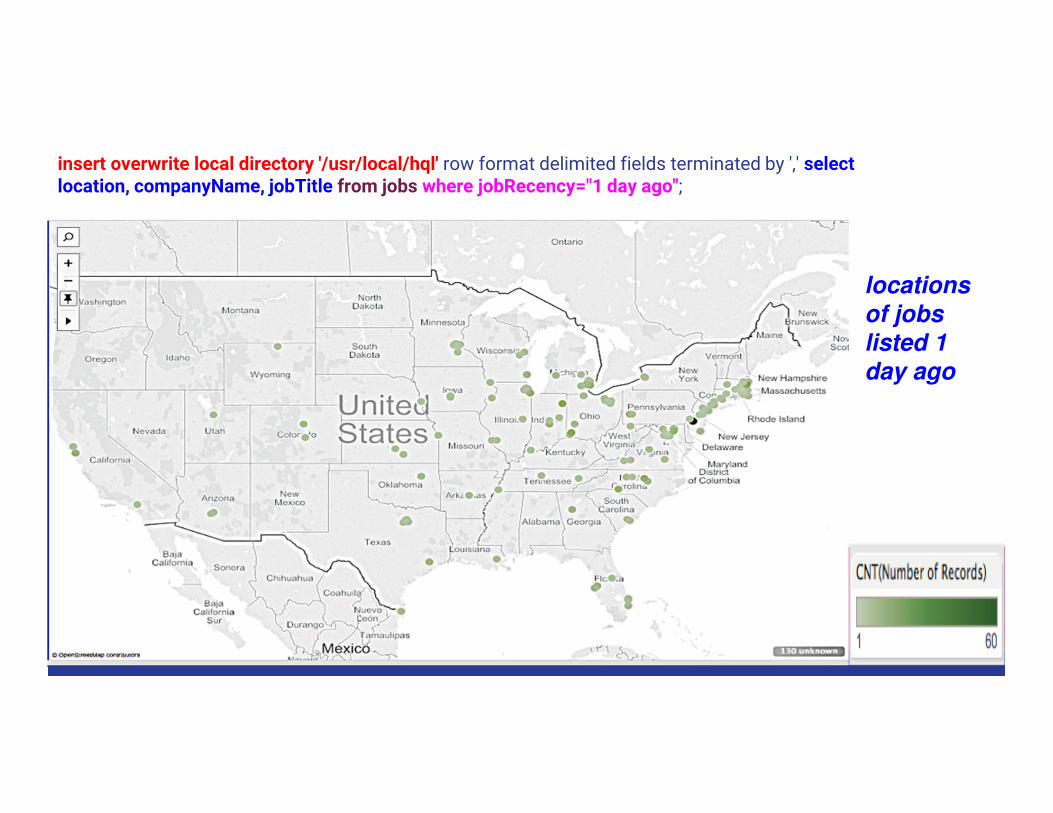
insert overwrite local directory '/usr/local/hql' row format delimited fields terminated by ',' select location, companyName, jobTitle from jobs where jobRecency="1 day ago";
29
locations
of jobs listed 1
day ago
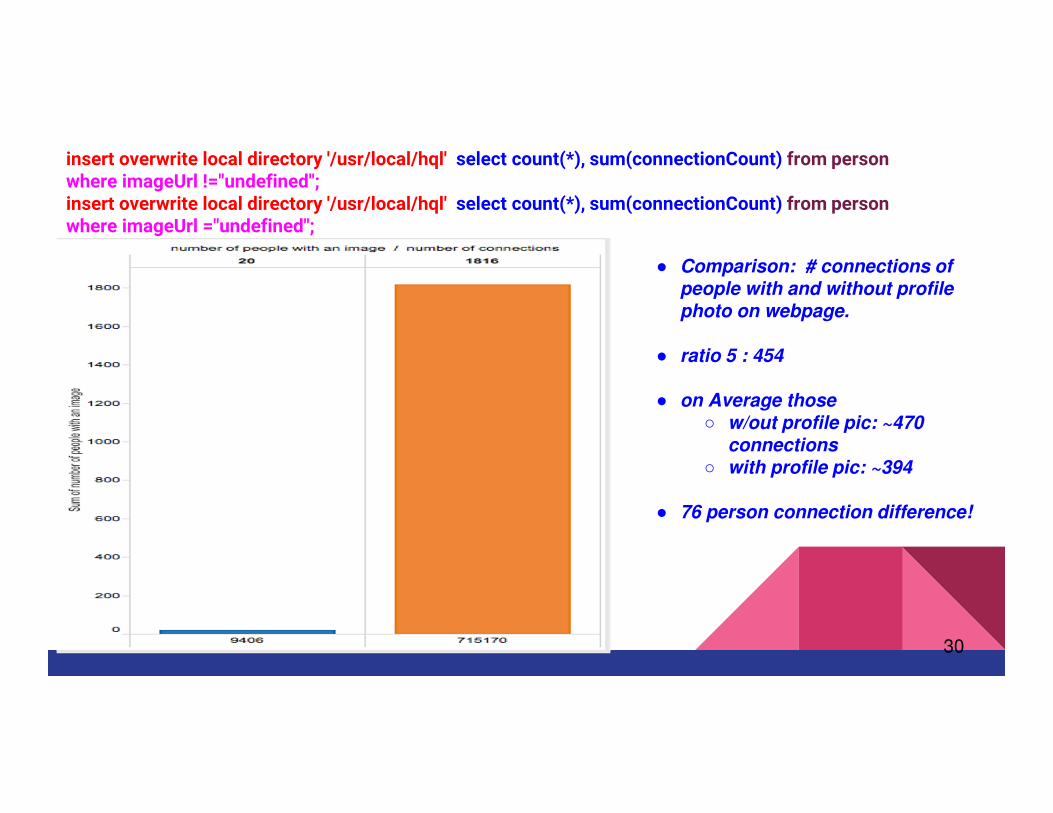
insert overwrite local directory '/usr/local/hql' select count(*), sum(connectionCount) from person where imageUrl !="undefined";insert overwrite local directory '/usr/local/hql' select count(*), sum(connectionCount) from person where imageUrl ="undefined";
30
● Comparison: # connections of people with and without profile photo on webpage.
● ratio 5 : 454
● on Average those ○ w/out profile pic: ~470
connections○ with profile pic: ~394
● 76 person connection difference!
31
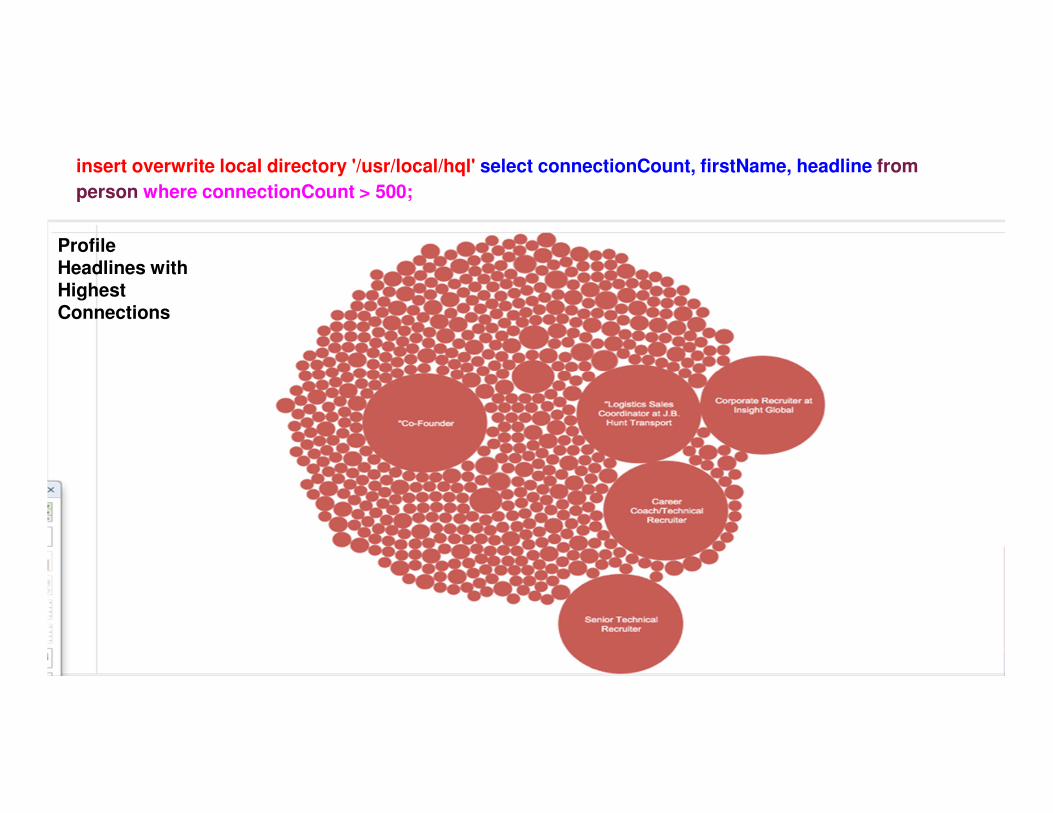
insert overwrite local directory '/usr/local/hql' select connectionCount, firstName, headline from
person where connectionCount > 500;
Profile Headlines with Highest Connections
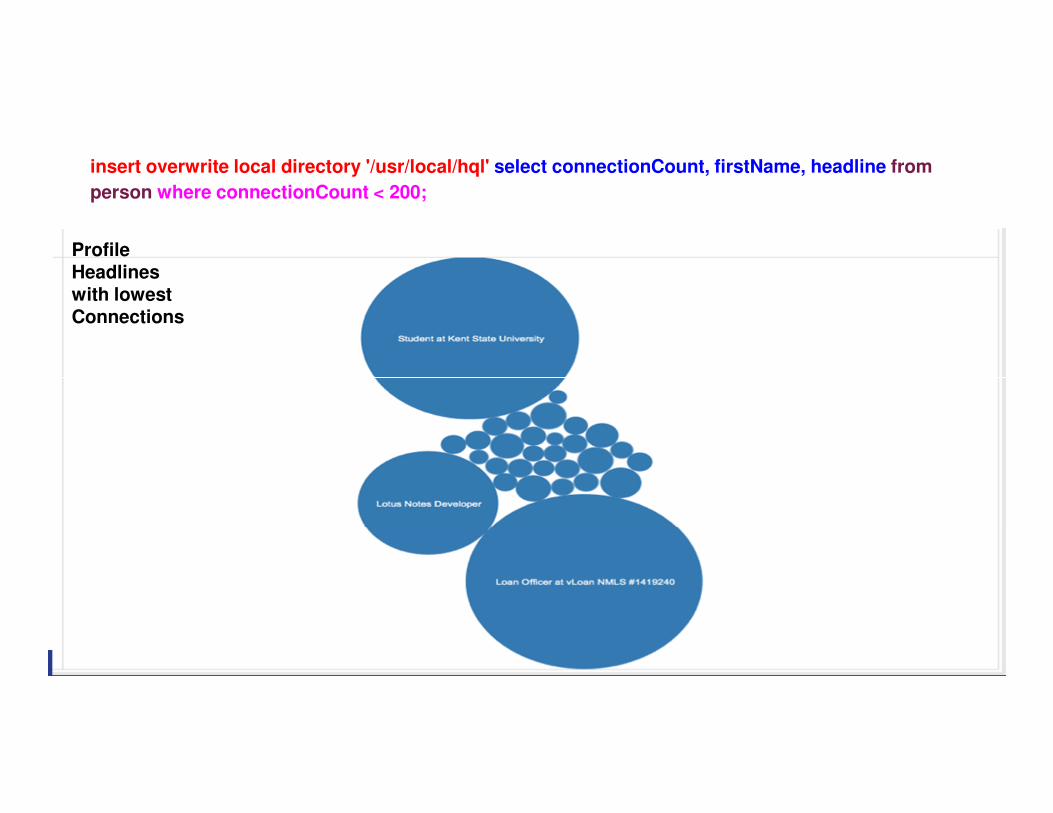
insert overwrite local directory '/usr/local/hql' select connectionCount, firstName, headline from
person where connectionCount < 200;
32
Profile Headlines with lowestConnections

Interested in trying on your own?
Links:
FireBug add-on to FireFox:
https://addons.mozilla.org/en-us/firefox/addon/firebug/
Jase Clamp tutorial “Extracting Data From LinkedIn”:
https://www.youtube.com/watch?v=S-9BWrtxoDw
Data Extraction Script on Github:
https://gist.github.com/jaseclamp/2c74062bac1cc4dd929f\
Tableau Download:
http://www.tableau.com/products/desktop/download?os=windows
33

Sources
1. http://vldb.org/pvldb/vol5/p1874_liliwu_vldb2012.pdf
2. http://www.slideshare.net/liliwu/avatara-olap-for-webscale-analytics-products
3. https://ourstory.linkedin.com/#year-2004
4. http://www.slideshare.net/MichaelLi17/how-business-analytics-drives-business-
value-teradata-partners-conference-nashvile-2014?next_slideshow=1
5. https://engineering.linkedin.com/olap/avatara-olap-web-scale-analytics-products
6. https://www.youtube.com/watch?v=9s-vSeWej1U
34