big data berlin - criteo
TRANSCRIPT

From 6 hours to 1 minute... in 2 days! How we managed to stream our (long) Hadoop batches
1
Sofian DJAMAA - Software engineer @sdjamaa

Phase 1 - Buy displaysPhase 2 - Sell clicksPhase 3 - ???Phase 4 - Profit
Criteo

How does it work?What’s
on Bild website today?
user
We gather the information for the retargeting process
Let’s go on Amazon!! The website
contains a « pixel » used
to put information on the user
cookie
user
eCommerce website
publisher website
Using the information we have on the user, tagged
by a cookie, we display the right ad
Advertiser sidePublisher side

HOW DO THEY KNOOOOOOOOWW????

Our constraints
6 datacenters !3 billions events a day !+50 PB of data in our Hadoop cluster !800K HTTP requests/second !JIRA ticket generation

How do we use the data? Where’s my money?
WHERE’S MY F@*#
MONEY?!?!
Where’s my client’s money?
finance
sales
business devinternal reports
client reports
billing
(heavy) data transformation
clicks, displays, purchases…
client
YAY!! MAKIN’
MONEY!!
client dashboard (web)

But this takes time…

Where goes the data? There’s an issue… let’s
investigate
WTF?!?!?
business escalation
relase management
Data not aggregated cross-DC !Granularity limited due to the volume of data !Load time can be huge even if we bulk insert (or move files)
clicks, displays, purchases…
IIS web servers
SQL Server DBs (multiple instances
per DC)
Graphite monitoring
Scaling is limited therefore only the most aggregated level is kept in Graphite
production alert

Up to 6 hours for some metrics !
Volume being huge, processing and storage takes time (SQL Server
replication hell…) !
Multiple datacenters containing data with latency issues

6 hours to get business data + 1 hour to check data/raise alerts + 1 hour to find root cause !
- SSome big money (up to million €)

finance
sales
release management
(heavy) data transformation
PBs of data to replay
client
A lot of people need the same aggregated data but all with their own constraints…
Consistency required
Quick feedback

Batching on Hadoop or SQL Server doesn’t fill the requirement !
We need to have our checks as soon as something wrong happens !
We need to handle both real-time and batch mode

But who can do it?


Some amazing projects such as: !
- Ads in GIF format !
- Embedded ad banners in movies !
- Streaming service stopping several times a movie to display an ad !
- Ponys !
- And something about Chuck Norris (‘cause he’s awesome)
Internal hackathon

No team wanted to take the responsibility of project so we built our own: !
- 3 1/2 developers !
- 1 business release manager (as a product owner) !
- 2 business intelligence engineers (the guys that write SQL queries all day long) !
- 1 business developer (doesn’t code a business layer obviously) !
- 1 creative !
- 1 release manager !
- 1 technical solution guy (the guy who helps in putting the pixels)
Turbo

What people think a hackathon is…

What really a hackathon is….


SummingBird computations
Metric aggregations at banner/zone level - Clicks, displays, sales, revenue… !Real-time part Aggregates are updated and sent after each event 30K messages/second !Batch part Computes the expected trend of data for each period (reference data) Using lasso: sum of squared errors, with a bound on the sum of the absolute values of the coefficients

data processing is done in batches on each side
when an offline batch is ready, it becomes the truth for the whole system
online batches are computed in streaming
batch #1 (e.g. 1H)
batch #2 batch #3
insert AND update aggregated results for each event
insert aggregated results for 1 hour of events

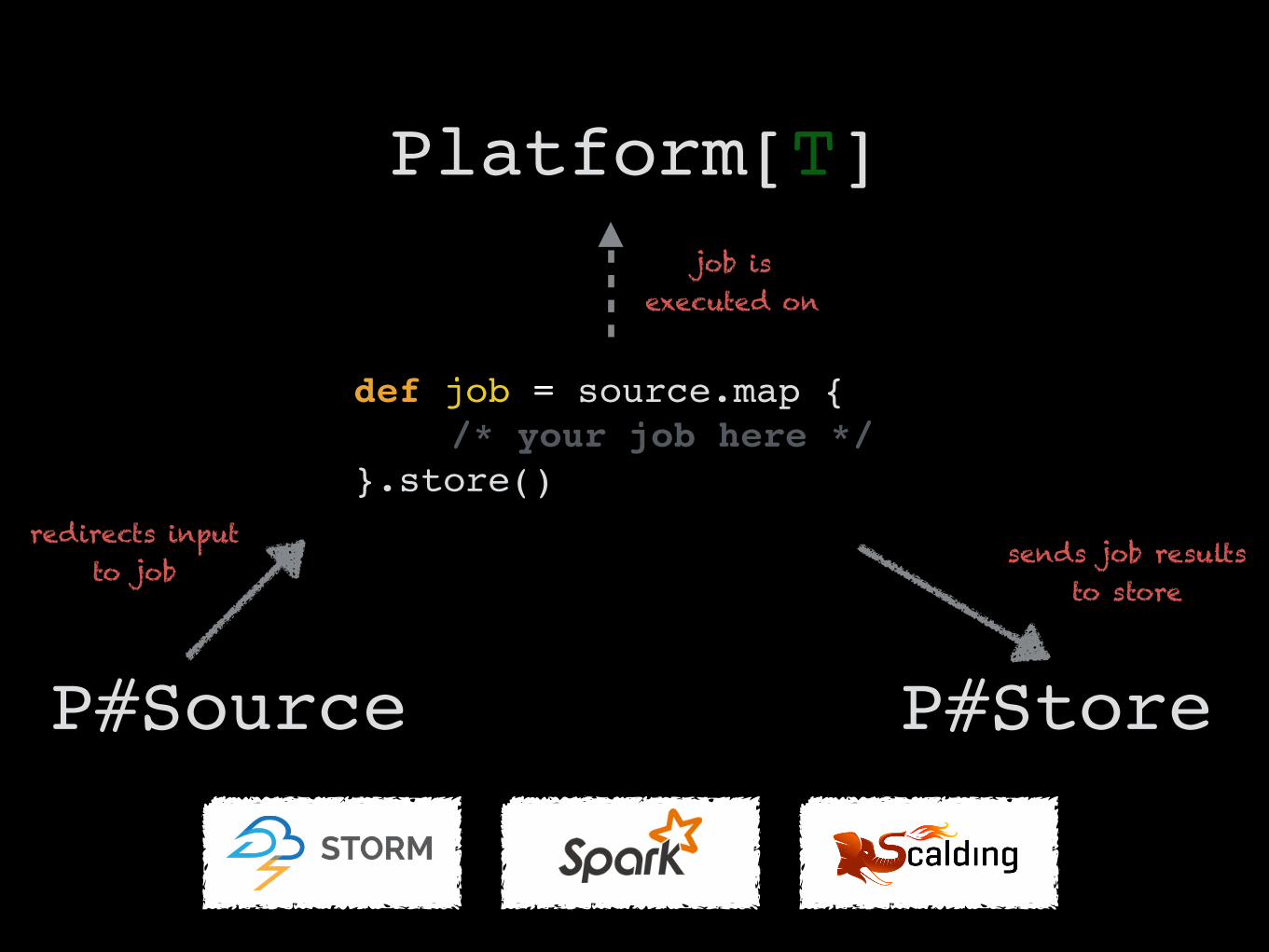
Platform[T]
def job = source.map { !/* your job here */ "
}.store()
P#Source P#Store
job is executed on
sends job results to store
redirects input to job

Why not streaming everything then ?
Streaming costs a lot of infrastructure !Sometimes we need to replay (backfilling) events from the past to correct a bug or adjust a formula !With PBs of data generated per day, a streaming architecture needs to be massively parallelized (much more than a batching architecture) for replays !Lambda Architecture is a good way to move towards a full streaming architecture

Rule engine
Developed in Prolog !
10K decisions/minute !
Linked to the real-time flow to compute the discrepancies with expected values and tag abnormal data

Vizatra
In-house analytic visualization stack: world map, graphs, real-time curves… !AngularJS, Bootstrap, Scala, Finagle, any DB supporting SQL !Web-component oriented: easy customization !Query deconstruction and NOT query building :-) !Open-source release coming soon

Riemann
Monitoring system with a « powerful stream processing language » (nah, just Clojure configuration files) !Sends alerts based on tags sent by the rule engine !Scoped alerts !Alerts are emails and SMS to on-duty people !JIRA ticket generation

Awesomeness
✓ Data granularity
- Checks at banner/zone levels for better investigations
✗ Data granularity - Checks only at publisher website level (only on RTB) - No checks on the client side
✗ Latency up to 6 hours ✓ Latency of 1 minute
✗ Data aggregated hourly ✓ Data aggregated in 5-min period
✗ Money in the bank: $ ✓ Money in the bank: $$$$$

Even more…
Thanks to the hackathon, we are now able to provide real-time feedback to sales, business developers, MDs and VPs which led us to : !- Getting more clients as they love having a quick feedback on
their campaigns !
- Adjust CPC in real-time - For special occasions like sales - To test aggressively our prediction models in an A/B test !
- And more…

Some feedbacks
✗ Exponential learning curve with all frameworks
✗ A lot of features are missing (e.g. stores)
✗ Very limited documentation or tutorial
✗ Testing the error rate between Hadoop and Storm is really too long for a 2 day development period
✗ Cassandra was a bad choice because of the data model needed for the visualization part (lot of joins)

#Paris, #BigData, #MachineLearning, #NerfGuns, #Hadoop, #Storm, #Spark, #Cassandra, #MongoDB, #Riemann, #Scala, #C# (?!), #Java
31
Sofian DJAMAA - Software engineer @sdjamaa
WE RECRUIT!!!!
We have many open positions in the R&D: !
•Data Processing Systems Manager
•Senior Software Engineer (Grenoble)
•Software Development lead/Manager
•SRE OPS Manager
•Senior Software Engineer – Palo Alto, CA.
•Python Software Lead Engineer - Paris
•Software Development Engineer –Paris
•Machine Learning Scientist