big-iot.eubig-iot.eu/wp-content/uploads/2016/04/deliverable-4... · the goal of the big iot project...
TRANSCRIPT

BIG IoT – Bridging the Interoperability Gap of the Internet of Things
Deliverable 4.1.a:
Design of Marketplace – First Release Version 1.0
State: Final
Date: 23.12.2016
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 688038.
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 2
Responsible Person and Affiliation Martin Lorenz (Atos)
Due Date / Delivery Date 31.12.2016
State Final
Reviewers Luca Gioppo (CSI)
Ernest Teniente, Juan Hernandez Serrano (UPC)
Version 1.0
Confidentiality Public
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 3
List of Authors
Organisation Authors Main contributions Atos Martin Lorenz Main Editor
Atos Klaus Cinibulk Marketplace Development and Operations
Atos Wolfgang Schwarzott Marketplace Security
Siemens Arne Broering Introduction, Marketplace in Context of the High-level BIG IoT Architecture

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 4
Table of Contents
1 Definition of Terms ............................................................................................ 7
2 Introduction ..................................................................................................... 13
2.1 Scope of this Document ....................................................................................... 13
2.2 Related Work ......................................................................................................... 14 2.2.1 D2.2 (Use Case Definition) .............................................................................................. 14 2.2.2 D2.3 (Requirements Analysis and Specifications) ........................................................... 15 2.2.3 D2.4 (High level architecture specification) ..................................................................... 15 2.2.4 D3.3 (Security and privacy management) ....................................................................... 15 2.2.5 WP3 & WP4 Task Interrelation ........................................................................................ 15
2.3 Structure of the Document .................................................................................. 17
3 Marketplace Overview ..................................................................................... 18
3.1 Marketplace in Context of the High-level BIG IoT Architecture ....................... 18 3.1.1 Core Concepts of the BIG IoT Architecture ..................................................................... 18 3.1.2 BIG IoT Architecture Overview ........................................................................................ 19
3.2 Basic Concepts of the Marketplace .................................................................... 21
4 Marketplace Workflows ................................................................................... 25
4.1 Marketplace Interaction via Portal ...................................................................... 25
4.2 Programmatic Marketplace Interaction .............................................................. 26
5 Marketplace Portal........................................................................................... 28
5.1 Portal Overview..................................................................................................... 28
5.2 Portal Technologies ............................................................................................. 29
5.3 Portal Pages .......................................................................................................... 29 5.3.1 Public Home Page ........................................................................................................... 30 5.3.2 All Offerings Page ............................................................................................................ 30 5.3.3 Public Offering Page ........................................................................................................ 31 5.3.4 Public Provider Page ....................................................................................................... 31 5.3.5 Login Page ....................................................................................................................... 32 5.3.6 Home Page ...................................................................................................................... 33 5.3.7 My Providers Page .......................................................................................................... 34 5.3.8 Empty Provider Page ....................................................................................................... 34 5.3.9 New Offering Page .......................................................................................................... 35 5.3.10 Provider Page .............................................................................................................. 36 5.3.11 My Consumers Page ................................................................................................... 36 5.3.12 Empty Consumer Page ............................................................................................... 37 5.3.13 New Offering Query Page ........................................................................................... 37

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 5
5.3.14 Consumer Page ........................................................................................................... 38 5.3.15 Offering Query Page.................................................................................................... 39
6 Marketplace API ............................................................................................... 40
6.1 GraphQL ................................................................................................................ 40
6.2 Implementation of Marketplace API .................................................................... 41
6.3 Marketplace API Tutorial ...................................................................................... 41 6.3.1 Interactive Exploration of the Marketplace API ................................................................ 42 6.3.2 API documentation .......................................................................................................... 43 6.3.3 Query Example ................................................................................................................ 43 6.3.4 Mutation Example ............................................................................................................ 44 6.3.5 Using the GraphQL endpoint ........................................................................................... 45
7 Marketplace Backend ...................................................................................... 46
7.1 Marketplace Backend Architecture ..................................................................... 46 7.1.1 Command and Query Responsibility Segregation (CQRS) Pattern ................................ 48 7.1.2 Event Sourcing Pattern .................................................................................................... 50 7.1.3 Event Sourcing and CQRS .............................................................................................. 53 7.1.4 Microservices Architecture Pattern .................................................................................. 54 7.1.5 Streaming Middleware based on Apache Kafka .............................................................. 56
7.2 Access Management (AM) ................................................................................... 64 7.2.1 Access Management Domain Model ............................................................................... 64
7.3 Exchange ............................................................................................................... 65 7.3.1 Exchange Domain Model ................................................................................................. 65 7.3.2 Persistence ...................................................................................................................... 66
7.4 Accounting ............................................................................................................ 78
8 Security ............................................................................................................ 79
8.1 Access Control for human users accessing the Marketplace Portal .............. 79
8.2 Access Control for Providers accessing the Marketplace ............................... 79
8.3 Access Control for Consumers accessing the Marketplace ............................ 80
8.4 Access Control for Consumers accessing Provider resources ....................... 80
8.5 Marketplace endpoints TLS settings .................................................................. 81
8.6 Auth0 Configuration ............................................................................................. 81
8.7 Security Tokens .................................................................................................... 82
8.8 Portal Registration................................................................................................ 83
8.9 Portal Login Flow .................................................................................................. 84
8.10 Marketplace Interactions...................................................................................... 85

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 6
9 Marketplace Development and Operations ................................................... 89
9.1 DevOps Concepts ................................................................................................. 89 9.1.1 Automation ....................................................................................................................... 89 9.1.2 Everything as Code ......................................................................................................... 89 9.1.3 Measurement ................................................................................................................... 90
9.2 Docker ................................................................................................................... 90 9.2.1 Docker images and containers ........................................................................................ 90 9.2.2 Docker Registry ............................................................................................................... 91 9.2.3 Docker Compose ............................................................................................................. 92 9.2.4 Docker and DevOps ........................................................................................................ 92
9.3 Provisioning .......................................................................................................... 93 9.3.1 Ansible ............................................................................................................................. 93 9.3.2 Ansible workflow .............................................................................................................. 94
9.4 Hosting Platform ................................................................................................... 95
9.5 Deployment Topology .......................................................................................... 96 9.5.1 Deployment Workflow ...................................................................................................... 97 9.5.2 Visual representation of the Deployment workflow .......................................................... 99
9.6 Logging ............................................................................................................... 100
9.7 Monitoring and Alerting ..................................................................................... 102
9.8 Local Development Environment ...................................................................... 105 9.8.1 Docker Compose ........................................................................................................... 107 9.8.2 Vagrant .......................................................................................................................... 109
10 Conclusions and Future Works ................................................................... 111
11 Appendix ........................................................................................................ 112
11.1 Marketplace GraphQL Schema .......................................................................... 112

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 7
1 Definition of Terms
Accounting
Accounting collects data about each access to an Offering and relates it to the respec-tive Subscription.
BIG IoT API
A set of specifications for
• Providers and Consumers to interact with the BIG IoT Marketplace to authenticate, register, discover and subscribe to Offerings; and perform accounting
• Consumers to directly access the Resources offered by a Provider
The BIG IoT API defines the supported communication protocols, data formats, semantic descriptions, etc. In order to facilitate BIG IoT Applications, Services and Platforms to imple-ment and use the BIG IoT API, dedicated Provider and Consumer Libs (SDKs) are provided for various platforms and programming languages, offering also programming interfaces to de-velopers.
BIG IoT Application (or short Application)
An application software that uses the BIG IoT API to discover Offerings on the BIG IoT Mar-ketplace, subscribe to Offerings and access the offered Resources. A BIG IoT Application acts merely as an Offering Consumer.
BIG IoT Application / Service / Platform Developer (or short BIG IoT Developer)
A software developer that implements or integrates a BIG IoT Service, Applica-tion or Platform.
BIG IoT Application / Service / Platform / Marketplace Provider or Operator
The organization that operates a BIG IoT Application, Service, Platform, Market-place instance. It is hereby not relevant if a particular instance is hosted on the provider organization's own infrastructure or a 3rd party infrastructure.
BIG IoT Core Developer
A software developer that implements or extends BIG IoT Marketplace and/or BIG IoT Lib components.
BIG IoT enabled Platform (or short BIG IoT Platform or just Platform)

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 8
An IoT Platform (or Smart Object Platform) that implements and uses the BIG IoT API to reg-ister Offerings on the BIG IoT Marketplace and provide access to the offered Resources. A BIG IoT Platform acts merely as an Offering Provider.
BIG IoT Marketplace
The BIG IoT Marketplace allows Providers to register their Offerings (based on semantic de-scriptions) and Consumers to discover relevant Offerings (based on semantic queries) at run-time. It also provides accounting support for Consumers and Providers to track the amount of resources accessed, as well as a web portal for developers and administrators to support the implementation and management of their Applications, Services, and Platforms.
BIG IoT Organization (or short Organization)
Participants in the BIG IoT ecosystem are organized in Organizations. Those Organizations are responsible for managing their Providers (with registered Offerings) and Consumers (with registered Queries). Organizations consist of one or more Users to perform that manage-ment.
BIG IoT Service (or short Service)
A BIG IoT Service implements and uses the BIG IoT API to consume and/or pro-vide Offerings via the BIG IoT Marketplace. A BIG IoT Service can act both as an Offering Consumer and Provider. It typically consumes basic Information or Function in order to offer "higher-value" Information or Functions on the BIG IoT Marketplace.
BIG IoT User (or short User)
Part of a BIG IoT Organization that has an account on the BIG IoT Marketplace and can man-age the entities of his Organization there.
Billing
Billing collects Charging data and creates invoices.
Charging
Charging is based on the collected Accounting data. The Charging Service multiplies the ac-counting data with the respective Price data of an Offering, and also takes into account special Consumer (group) pricing models, to compute the final amount to be charged.
Device-level BIG IoT enabled IoT Platform (= Device-level BIG IoT Platform or just Device-level Platform)
A BIG IoT enabled Platform that is implemented directly on a Smart Object, as opposed to on a backend or cloud infrastructure.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 9
Endpoint
An Endpoint in the context of BIG IoT is a web based interface for consumers to access Offer-ings via a Provider. An Endpoint description consists of properties like Endpoint type and URI.
End User
Users of a BIG IoT Application are called End Users. An End User is typically an employee of an Enterprise, SME or Organization (e.g. City Authority), but not limited to that. End Users are not part of the BIG IoT ecosystem and are serviced by the Application Operator of their Application.
Function
Functionality that can be invoked by Consumers and is provided by
• a task on an actuator (as part of an IoT Platform) • a Service that provides some computational functions or higher level functionality
delegating to one or more lower level Functions
Information
Data provided to Consumers by
• a sensor (as part of an IoT Platform) • a Service that takes one or more Information sources and combines them to provide
some added value
IoT Service (or short Service)
Software component enabling interaction with resources through a well-defined interface in order to access or manipulate information or to control entities. An IoT Service can be or-chestrated together with non-IoT services (e.g., enterprise services). Interaction with the service is done via the network. (based on [IoT-A])
IoT Platform (= Smart Object Platform)
A computing and communication system that hosts software components enabling interac-tion with Smart Objects in order to access or manipulate information or to control them. An IoT Platform may be implemented on a backend or cloud infrastructure, or directly on a Smart Object. Interaction with the platform is done via the network.
License
The Provider of an Offering can choose the License terms for the provided Information.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 10
Offering
BIG IoT enables Providers to offer or trade access to Information and Functions with Consumers via the Marketplace. An Offering is defined by an Offering description, which describes a set of Resources offered on the Marketplace. It typically encompasses a set of related Information or Functions. An Offering description pro-vides a semantic description of the Resource(s) provided to a Consumer once the Offering is accessed. The description also entails context and meta information about the Offering, in-cluding information like the Region (e.g. a city or spatial extent) where the Resource(s) relate to, the Price for accessing the Resource(s), the License of the Information provided, input & output data fields, etc.
Offering Consumer (or short Consumer)
A BIG IoT Application or Service that is interested to discover and access IoT resources in order to provide a new service or function. A Consumer discovers and subscribes to rele-vant Offerings via the BIG IoT Marketplace, and accesses the offered resources via the BIG IoT API.
Offering Provider (or short Provider)
A BIG IoT Platform or Service that wants to offer or trade IoT resources via the BIG IoT Mar-ketplace. A Provider registers its Offering(s) on the BIG IoT Marketplace, and provides access to the offered resources via the BIG IoT API.
Offering Query (or short Query)
Consumers are able to discover offerings of interest on the marketplace by providing an (Of-fering) Query. A Query describes the properties of Offerings a client is interested in (Offering type, input & output data fields, Price, License, ...)
Physical Entity
Any physical object that is relevant from a user or application perspective. [IoT-A]
Price
The Provider of an Offering can choose the pricing model (e.g. Free or Per Month or Per Ac-cess) and amount of money (if applicable) a Consumer has to pay when accessing a Resource.
Resource
Abstraction for either Information or Function.
Smart Object (= Thing)

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 11
A Device able to compute and communicate information about itself or related artifacts (Physical Entities) to other devices or computer applications; a Smart Object is typically at-tached to or embedded inside a Physical Entity. Smart Objects either monitor a Physical Entity (sensing) or interact with the physical world through actuators (actuation). Those functions can be either controlled autonomously by local computations or triggered from remote.
Subscription
Agreement to access the Resource(s) of a single Offering. This comprises:
• a Consumer's willingness to access the Offering (he checked License, service level, rating, description, ...)
• the Consumer's consent to pay for the access to the Resources (according to the specified Price), if applicable
Semantic Offerings Composition Recipe (or BIG IoT Recipe)
Semantic Offerings Composition Recipe or shorter Recipe provides description of the com-position of offerings. It is a specification of requirements of an added value service, and hence it represents a template that can be fulfilled by multiple offerings.
BIG IoT Semantic Core Model
BIG IoT Semantic Core Model specifies all important domain concepts in BIG IoT project in-cluding all basic conceptual entities and their relationships. This semantic model is used as basis for (1) the Offering Description to define the capabilities of offerings provided by IoT platforms or services, and (2) the underlying data model of the BIG IoT Marketplace.
Mobility Domain Model
Mobility Domain Model defines a common terms used in the mobility domain. The model aims to improve information exchange and data interoperability between mobility systems, in particular used in Internet of Things applications. This model represents an extended schema.org vocabulary for the mobility domain (mobility.schema.org).
BIG IoT Semantic Application Domain Model
BIG IoT Semantic Application Domain Model defines an application-specific vocabulary that is built on both, BIG IoT Semantic Core Model and Mobility Domain Model, and can be used for annotating Offering Descriptions.
Semantic Recipe Model
Semantic Recipe Model defines a model for BIG IoT Recipes. A Recipe is a specification of requirements of an added value service, and hence it represents a template that can be ful-

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 12
filled by multiple offerings. All terms and their relations, required for specifying Recipes, are defined in Semantic Recipe Model.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 13
2 Introduction
The goal of the BIG IoT project is to ignite a vibrant Internet of Things (IoT) ecosystem. This will be achieved by bridging the interoperability gap between the vertically-oriented IoT Plat-forms through the development of a common BIG IoT API. On top of this mutual API, and as a central pillar for an IoT ecosystem, we are developing a Marketplace for IoT Offerings. While the BIG IoT API provides the building blocks for a syntactically and semantically in-teroperable IoT and inter-platform connectivity and exchange, the Marketplace lays the foundation for an ecosystem of IoT Platforms, Applications, and Services. The Marketplace will enable the advertisement, quality control, and monetization of Offerings from IoT Plat-forms and Services developed on top of the BIG IoT API.
This work is the focus of Work Package 4 (Marketplace & services). Thereby, the Market-place shall act as a B2B (Business to Business) broker for trading access to IoT Information and Functions. A Marketplace can be setup for particular domains, e.g., by a large company for the industry, energy, mobility, or building domain. Access to Platforms and Services are offered through the Marketplace. Further, the Marketplace will support discovery and au-tomated orchestration of Offerings, in order to support successful marketing of IoT Offerings and re-use of software assets in different settings and for different applications. To enable powerful discovery and the orchestration, all entities registered on the Marketplace will be semantically annotated. This allows the conduction of semantic queries and reasoning capa-bilities in the backend.
In order to be able to grow, it is crucial for an IoT ecosystem to be based on future-prove and open technology. Hence, the design of the BIG IoT API is related to currently on going standardization at W3C that will pave the way to advanced collaboration through future IoT APIs. Also, with the BIG IoT Marketplace we are incorporating cutting-edge technologies. We opted for an event based architecture to empower future extensions and chose to adopt emerging container technology to ease the deployment of the final Marketplace and all its related parts. We are combining the power of Semantic Web technologies with the simplici-ty of modern Web interfaces (e.g., GraphQL).
Further, for the Marketplace software infrastructure, we are in the process of elaborating an open source strategy. We expect to release major parts of the Marketplace as open source in mid 2017. This will siginificantly help to strengthen our ecosystem and developer commu-nity.
2.1 Scope of this Document
WP4 is divided into 4 Tasks. Task 4.1 (Design of marketplace) contains the technical design of the Marketplace and the underlying software infrastructure. This comprises the definition of interfaces and internal business logic. It also defines deployment and operations. Further, it will address scale-up and scale-out scenarios as well as Marketplace administration. The Marketplace Portal provides a user interface for administration, management for all in-

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 14
volved entities, and visualization of accounting and charging data. The tasks on Semantic models for the application domain (Task 4.2) and their automated discovery and orchestra-tion (Task 4.3) contribute to this overall design of the Marketplace and the underlying software infrastructure. Finally Task 4.4 (Implementation of marketplace) is dedicated to implementing the Marketplace based on the work done in T4.1, T4.2 and T4.3 and docu-mented in deliverables D4.1, D4.2 and T4.3. This deliverable D4.1a describes the work on designing, implementing, and deploying the Marketplace in the first iteration of WP4. This goes in sync with the first release of the Marketplace implementation (T4.4), scheduled for M16 (April 2017). Future versions of this deliverable (D4.1b, D4.1c) will describe the upcom-ing iterations.
Task 4.1 is about specifying the design of the BIG IoT Marketplace. The Marketplace consists of the following main parts:
• Marketplace Portal: User Interface for visualization and manipulation of all Market-place relevant entities.
• Marketplace API: Web based API for all participants of the BIG IoT ecosystem (includ-ing Marketplace Portal) to access the Marketplace.
• Marketplace Backend: Manages all Marketplace relevant entities and persists them into databases (DBs).
This document describes on the one hand the basic functionality of the Marketplace in the form of general workflows and UI flows, on the other hand it describes the design of the different parts together with some cross-cutting functionalities, such as security and de-ployment. Another major part of this document is the specification of the web based Marketplace API. This specification is necessary for other ecosystem paricipants to be able to use the Marketplace for their needs. Related topics that are the focus of other tasks are only briefly handled and the according deliverables of those tasks are referenced (see chapter Related Work).
The aim of this document is to be published on the Web as a documentation and tutorial for developers interested in collaborating in the IoT ecosystem through the marketplace or con-tributing to the Marketplace code base. Hence, the document is intentionally written in a way that it is easy to understand and quick to read.
2.2 Related Work
Since Task T4.1 (Marketplace & services) incorporates the results of several other tasks, this deliverable is related to the deliverables of those tasks.
The following chapters summarize how this document is related to other deliverables.
2.2.1 D2.2 (Use Case Definition)

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 15
The use cases for the BIG IoT ecosystem are described in Chapter 3 (BIG IoT Ecosystem Use Cases). The use cases that involve the Marketplace are implemented in WP4 and the design for it are described in this document.
2.2.2 D2.3 (Requirements Analysis and Specifications)
The requirements for the BIG IoT ecosystem are described in Chapter 3 (BIG IoT Ecosystem Requirements). The requirements that involve the Marketplace are implemented in WP4 and the design for it are described in this document.
2.2.3 D2.4 (High level architecture specification)
The high level architecture describes several interfaces in the BIG IoT ecosystem in abstract form. The interfaces related to the Marketplace are specified in detail in this document.
2.2.4 D3.3 (Security and privacy management)
All the security concepts specified in D3.3 that are related to the Marketplace are specified in detail in this document.
2.2.5 WP3 & WP4 Task Interrelation
The tasks of WP3 and WP4 are highly interrelated, however, their deliverables have each their own, clear responsibilites. The figure below follows the general BIG IoT architecture description in D2.4 and illustrates at hand of this architecture the scope of each of the dif-ferent deliverables of the tasks 3.1, 3.2, 4.1, 4.2, and 4.3.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 16
Figure: Relation of deliverables.
D3.1 covers the description of the BIG IoT API. This entails a specification of the Web API (e.g., interaction model, and encodings) as well as description of the programmatic API that is implemented as part of consumer and provider lib of the SDK.
D4.1 describes the architecture of the BIG IoT Marketplace. This includes the general design, the workflows of interactions, the GraphQL-based API of the marketplace, as well as the user interface of the portal to utilize the marketplace. Also contained in this deliverable is a de-scription on how to map between the GraphQL API of the marketplace frontend and its SPARQL based triple store backend.
D3.2 describes the model and schema of the BIG IoT Semantic Core Model. This semantic model is used as a basis for (1) the Offering Description to define the capabilities of offerings provided by IoT platforms or services, and (2) the underlying data model of the BIG IoT Mar-ketplace.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 17
D4.2 builds up on the core semantic model of D3.2 and defines the BIG IoT Semantic Appli-cation Domain Model, which specifies a vocabulary of terms that can be used in Offering Descriptions, and in the triple store of the marketplace.
D4.3 addresses the orchestration and composition of the offerings of BIG IoT providers (i.e., platforms or services). A composition of offerings can be specified by defining a Recipe. The Recipe Semantic Model and examples of such recipes is the scope of this deliverable.
2.3 Structure of the Document
The content of this document is divided into the following chapters:
Chapter 1 is a brief introduction to the most important terms used.
Chapter 2 gives an introduction to the document, includes an executive summary, defines the scope and structure of the document and relates this document with other documents created in the BIG IoT project.
Chapter 3 introduces the most important concepts of the Marketplace and gives an over-view of the Marketplace functionality.
Chapter 4 shows in more detail the typical workflows how the different participants of the BIG IoT ecosystems communicate with the Marketplace and with each other.
Chapter 5 describes the concepts of the Marketplace Portal and gives an overview of the different pages to manage the Marketplace entities.
Chapter 6 first describes the concept and the technologies used for the Marketplace API and then gives a detailed specification of the API clients have to use to access the Marketplace.
Chapter 7 introduces the technologies used for the Marketplace Backend and describes all the services that are part of it.
Chapter 8 is about the cross-cutting concern of security. It describes how the security con-cepts, defined in task T3.3, are implemented on the Marketplace.
Chapter 9 gives an overview about the development environment, deployment and opera-tion of the Marketplace and the local development environment.
Chapter 10 concludes the document and gives an outlook on some future works.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 18
3 Marketplace Overview
3.1 Marketplace in Context of the High-level BIG IoT Architecture
This section introduces the high-level architecture of BIG IoT in order to give the necessary background for the Marketplace design. The full specification of the BIG IoT Architecture - Release 1 is provided in Deliverabe D2.4a.
3.1.1 Core Concepts of the BIG IoT Architecture
This section summarizes the underlying concepts of the BIG IoT architecture and the interac-tions between them, namely Offerings, (Offering) Providers and Consumers, and the interactions of registering and discovering offerings via a Marketplace, and accessing the Resources offered by a Provider (see Figure).
An Offering encompasses a set of IoT Resources, typically a set of related Information (e.g. low-level sensor data like temperature or aggregate information across a region) or Func-tions (e.g. actuation tasks like open a gate or computational functions like compute a route), that are offered on a Marketplace.
Providers register their Offerings on a Marketplace and provide access to the offered Re-sources via a common API. A Provider can be either a Platform or a Service instance that offers available Resources, i.e., some Information or access to Functions that it wants to share or trade on the Marketplace (e.g. an IoT Platform of a parking lot provider). Consumers discover and subscribe to Offerings of interest via a Marketplace in order to access the Re-sources. A Consumer can be either an Application or Service instance that requires access to IoT Resources in order to implement an intended service or function (e.g., a smart parking service provided by the city).
In technical terms, a Provider registers its Offerings on the Marketplace by providing an Of-fering description for each Offering. An Offering can for example entail parking information for a city and include data such as geo location or address of the parking lot, the type of lot (e.g. garage or on-street), available spots, occupied spots, etc. In order to increase interop-erability between different IoT Platforms, the Offering description is provided in a machine interpretable manner. All relevant communication metadata is provided on how the Offering can be accessed (e.g., Endpoint URL, which HTTP method, etc.). As a default vocabulary set, the Offering description includes a local identifier (unique to a provider), a name of the Of-fering, and the input and/or output data fields provided to a Consumer when the Offering is accessed. The description may also include information about the region (e.g. the city or spa-tial extent) where the resources relate to, the Price for accessing the Resources, the License of the data provided, the access control list, etc.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 19
Figure: Core Concepts
Consumers discover Offerings of interest on the Marketplace by providing an (Offering) Que-ry. The Query entails a specification of the type of Offerings the Consumer is interested in. For example, a Consumer can provide a description of the desired Resources (such as type of parking information), and also define the maximum Price, the desired License types, the re-gion, etc. Upon a discovery request, the marketplace identifies all matching Offerings and returns them to the Consumer. The Consumer can then choose the Offerings of interest and subscribe to those on the Marketplace. Since the discovery can take place at run-time, a Consumer is able to identify and subscribe to newly offered Resources as they emerge. Final-ly, to limit the data to be transmitted upon accessing an Offering, a Consumer can also provide a filter in the request.
3.1.2 BIG IoT Architecture Overview
This section provides an overview of the BIG IoT architecture. As shown in the figure below, we distinguish the following 5 core building blocks:
1.) BIG IoT enabled Platform – this IoT Platform implements (as a Provider) the common API, which is called the BIG IoT API, to register offerings on a BIG IoT Marketplace, and grants BIG IoT Services or Applications (as Consumers) access to the offered Resources.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 20
2.) BIG IoT Application – this application software implements and uses the BIG IoT API, (as a Consumer) to discover offerings on a BIG IoT Marketplace, and to access the resources pro-vided by one or more BIG IoT Services or Platforms (as Providers).
3.) BIG IoT Service – this IoT Service implements and uses the BIG IoT API to register offer-ings on a BIG IoT Marketplace (as a Provider) and/or to discover and access Offerings provided via a BIG IoT Marketplace (as a Consumer).
4.) BIG IoT Marketplace – this composite system consists of sub-components: The Market-place API serves as an entry point for all communications and interactions with the Marketplace; the Identity Management Service (IdM) which authenticates and authoriz-es providers and consumers; the Exchange, which allows registration and discovery of offerings using semantic technologies; the Web Portal for users of the Marketplace; and the Charging Service, which collects accounting information.
5.) BIG IoT Lib – this is an implementation of the BIG IoT API that supports platform, service and application developers. The BIG IoT Lib consists of a Provider Lib and a Consumer Lib part. It translates function calls from the respective application or service logic, or the platform code into interactions with the Marketplace, or peer Services or Platforms. The Provider Lib allows a Platform or Service to authenticate itself on a Marketplace and to register Offerings. The Consumer Lib allows an application or service to authenticate itself on a Marketplace, to discover available Offerings based on semantic queries, and to subscribe to Offerings of interest. The use of semantic technologies enables the Exchange to perform semantic matching even in case providers and consumers use different semantic models or formats, as long as a common meta-model defines the relations/mapping between the dif-ferent semantic models and converters for the different semantic formats are supported.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 21
Figure: The BIG IoT architecture.
3.2 Basic Concepts of the Marketplace
The BIG IoT Marketplace is a B2B (Business to Business) broker for trading access to IoT In-formation and Functions.
Human actors involved in Marketplace interactions are
• Platform Providers operating a BIG IoT Platform • Service Providers operating a BIG IoT Service • Application Providers operating a BIG IoT Application
Those human actors interact with the Marketplace via the Portal as described in more detail in chapter 5 Marketplace Portal:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 22
Software artifacts that are part of the BIG IoT ecosystem can act in one of the following roles:
• Offering Provider (or short Provider) provides Offerings on the Market-place: Platform or Service
• Offering Consumer (or short Consumer) consumes Offerings discovered on the Mar-ketplace: Service or Application
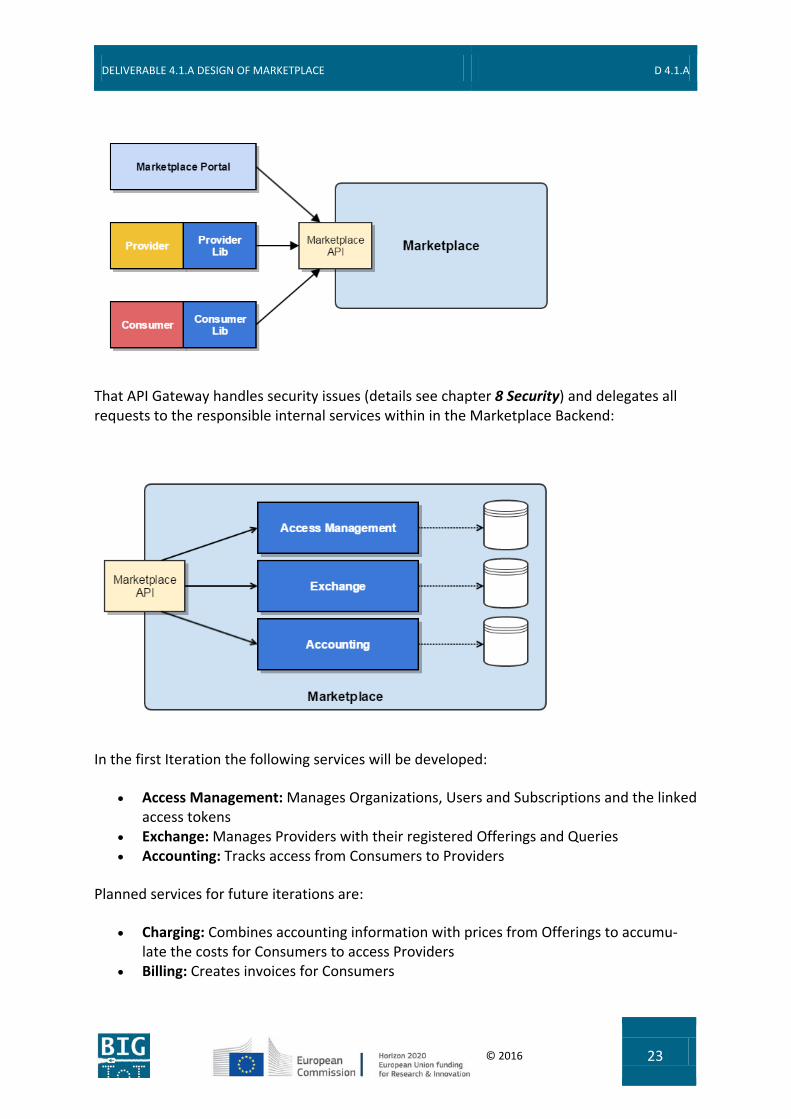
An API Gateway (see chapter 6 Marketplace API) is provided for all interested parties in the BIG IoT ecosystem to access the Marketplace. Provider and Consumer are enabled to access the Marketplace with the help of Provider and Consumer Libs, resp. (as described in deliverable D3.1):
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 23
That API Gateway handles security issues (details see chapter 8 Security) and delegates all requests to the responsible internal services within in the Marketplace Backend:
In the first Iteration the following services will be developed:
• Access Management: Manages Organizations, Users and Subscriptions and the linked access tokens
• Exchange: Manages Providers with their registered Offerings and Queries • Accounting: Tracks access from Consumers to Providers
Planned services for future iterations are:
• Charging: Combines accounting information with prices from Offerings to accumu-late the costs for Consumers to access Providers
• Billing: Creates invoices for Consumers

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 24
All services are described in chapter 7 Marketplace Backend.
The major use cases for the Marketplace are the following:
• Create an Offering by providing an Offering description • Activate an Offering • Create a Query by providing a Query description • Subscribe one or more Offerings that match a Query • Get access token for each Subscription to access Offerings
Details about the defined workflows are given in the next chapter 4 Marketplace Work-flows.
Another important topic that is handled in this document is the development, build, de-ployment and operations of the Marketplace as described in chapter 9 Marketplace Development and Operations.
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 25
4 Marketplace Workflows
The following diagrams describe the basic Marketplace interactions. We use as an example a BIG IoT Platform as an Offering Provider and a BIG IoT Application as an Offering Consumer.
A more detailed view of the given scenarios with a focus on security is shown in chapter 8 Security.
4.1 Marketplace Interaction via Portal
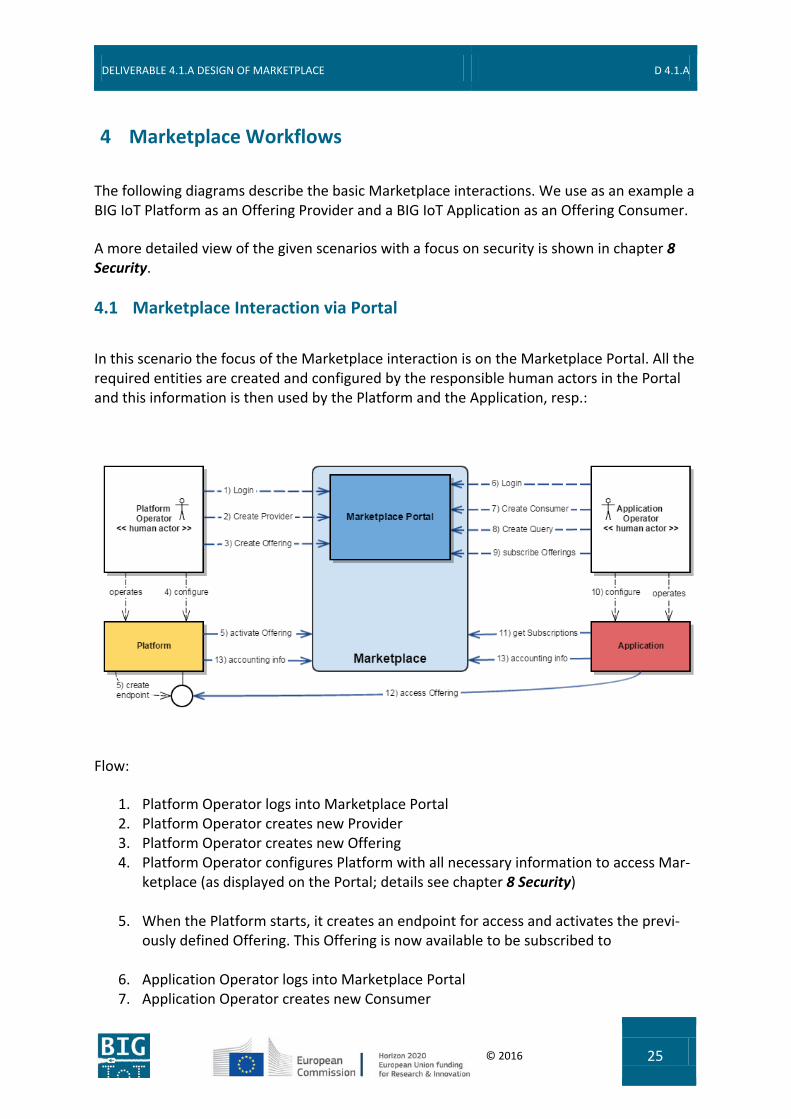
In this scenario the focus of the Marketplace interaction is on the Marketplace Portal. All the required entities are created and configured by the responsible human actors in the Portal and this information is then used by the Platform and the Application, resp.:
Flow:
1. Platform Operator logs into Marketplace Portal 2. Platform Operator creates new Provider 3. Platform Operator creates new Offering 4. Platform Operator configures Platform with all necessary information to access Mar-
ketplace (as displayed on the Portal; details see chapter 8 Security)
5. When the Platform starts, it creates an endpoint for access and activates the previ-ously defined Offering. This Offering is now available to be subscribed to
6. Application Operator logs into Marketplace Portal 7. Application Operator creates new Consumer

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 26
8. Application Operator creates new Query and all matching Offerings are shown 9. Application Operator subscribes to an Offering 10. Application Operator configures Application with all necessary information to access
Marketplace
11. When the Application starts, it retrieves its Subscriptions and gets back endpoint info and token to access the subscribed Offering
12. Application accesses the provided endpoint 13. Both Application and Platform notify Accounting about that access
4.2 Programmatic Marketplace Interaction
In this scenario the focus is more on the non-human interaction with the Marketplace.
The Platform programmatically creates and configures the Offering and the Application then (also programmatically) creates a Query and subscribes to the Offering it is interested in:
Prerequisite:
• Platform and Application are configured with all necessary information to access Marketplace
Flow:
1. Platform creates a new Offering 2. Platform creates an endpoint for access and activates created Offering
3. Application creates new Offering Query and gets back matching Offerings

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 27
4. Application subscribes to Offering and gets back endpoint info and token to access the subscribed Offering
5. Application accesses the provided endpoint 6. Both Platform and Application notify Accounting about that access

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 28
5 Marketplace Portal
This chapter describes the Marketplace Portal as planned for the first iteration of the Mar-ketplace implementation in M16. Future iterations will improve on that in functionality and user experience. Those changes will be documented in future releases of this document.
5.1 Portal Overview
The Marketplace Portal is the User Interface (UI) for the Marketplace. All users participating in the BIG IoT ecosystem can use this UI for the following use cases (among others):
• login to the Marketplace • create and manage your organization • invite other users to your organization • view available Offerings • manage Offering Providers • manage Offerings • manage Offering Consumers • manage Offering Queries • manage Subscriptions to Offerings
The Portal communicates to the Marketplace Backend via the Marketplace API using GraphQL (details see chapter 6 Marketplace API).
The Marketplace Portal currently uses the external Identity Provider Auth0 (https://auth0.com) for authentication using the OAuth2 protocol. The free Auth0 ac-count big-iot allows up to 7000 active users and 2 social identity providers (currently GitHub and Google) with unlimited logins and allows sign up of local Auth0 users. Auth0 offers a dashboard for monitoring logins and supports Rules for easy customization of Auth0's capa-bilities.
Details are described in chapter 8 Security.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 29
5.2 Portal Technologies
The Portal is implemented as a Single Page Application (SPA, https://en.wikipedia.org/wiki/Single-page_application), i.e. a web application that fits on a single web page with the goal of providing a user experience similar to that of a desktop ap-plication. All necessary code – HTML, JavaScript, and CSS – is retrieved with a single page load. The most notable difference between a regular website and an SPA is the reduced amount of page refreshes. SPAs have a heavier usage of AJAX - a way to communicate with back-end servers without doing a full page refresh - to get data loaded into our application. As a result, the process of rendering pages happens on the client-side.
As the JavaScript library to build the UI we use React.js (https://facebook.github.io/react). It allows the UI code to be
• Declarative: React makes it painless to create interactive UIs. Design simple views for each state in your application, and React will efficiently update and render just the right components when your data changes. Declarative views make your code more predictable, simpler to understand, and easier to debug.
• Component-Based: Build encapsulated components that manage their own state, then compose them to make complex UIs. Since component logic is written in JavaS-cript instead of templates, you can easily pass rich data through your app and keep state out of the DOM.
To connect the Portal to the GraphQL based Backend we use Relay.js (https://facebook.github.io/relay). Relay is a JavaScript framework for building data-driven React applications with the following main features:
• Declarative: Never again communicate with your data store using an imperative API. Simply declare your data requirements using GraphQL and let Relay figure out how and when to fetch your data.
• Colocation: Queries live next to the views that rely on them, so you can easily reason about your app. Relay aggregates queries into efficient network requests to fetch on-ly what you need.
• Mutations: Relay lets you mutate data on the client and server using GraphQL muta-tions, and offers automatic data consistency, optimistic updates, and error handling.
5.3 Portal Pages
The following chapters describe the current functionality of the Marketplace Portal with the help of screen shots. Keep in mind, that the development is an ongoing process, so the look of the Portal will change in the future and the screen shots are just provided to give you an understanding of that functionality and not an exact look of the pages.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 30
The following functionalities are not yet implemented and so there are no screen shots shown (will be part of the next iteration D4.1b):
• create and manage your organization • invite other users to your organization • manage Offering Providers • manage Offering Consumers
Currently the Portal is offered at port 8082 for HTTP on a locally running Marketplace in-stance (http://localhost:8082 or http://172.17.17.11:8082 if you are running in a VM as described in chapter 9.8 Local Development Environment) and at port 8083 for HTTPS (https://localhost:8082 or https://172.17.17.11:8083). This URL will change, when the Mar-ketplace will be deployed in the cloud.
5.3.1 Public Home Page
When you open the Portal in your web browser, the BIG IoT Marketplace home page is shown. You are not yet logged in, so the only available menu entry is to show All Offerings.
5.3.2 All Offerings Page
On the All Offerings page you can see a list of all currently registered Offerings with some properties like city, type, license and price. With the drop down box in the top you can filter the Offerings by Offering type.
When you click on the Offering link in the first column, you open the public Offering page with more details about that Offering.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 31
5.3.3 Public Offering Page
On this page the publically visible details about an Offering are shown. Details about input and output data fields and endpoints are displayed here.
After clicking on the Provider link you are forwarded to the public Provider page.
5.3.4 Public Provider Page
On the public Provider page all publically visible details about a Provider are shown. The Li-cense and Price fields show default license and price for all Offerings registered by this Provider, resp.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 32
The list of Offerings below includes only Offerings that were registered by this Provider.
You cannot change Offerings or create new Offerings from this page because you have to be logged in to be allowed to do that.
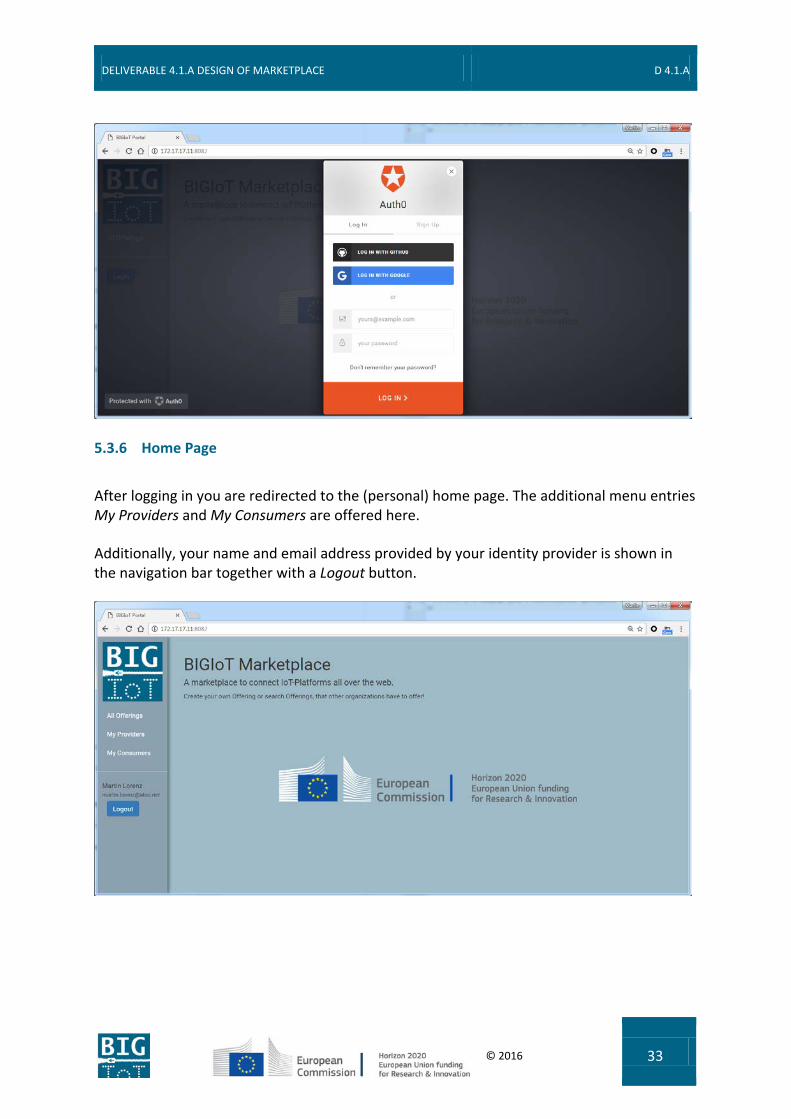
5.3.5 Login Page
When you press the Login button in the left navigation bar, the Login popup appears.
If you already have a local account you can enter your email address and password here or if you prefer to login with your existing GitHub or Google account, you can do so here and are redirected to the according login page (or are automatically logged in if you are already logged in on the chosen social identity provider).
If you neither have a local account nor a GitHub or Google account, you can choose here to sign up for a new account, by selecting the Sign Up tab.
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 33
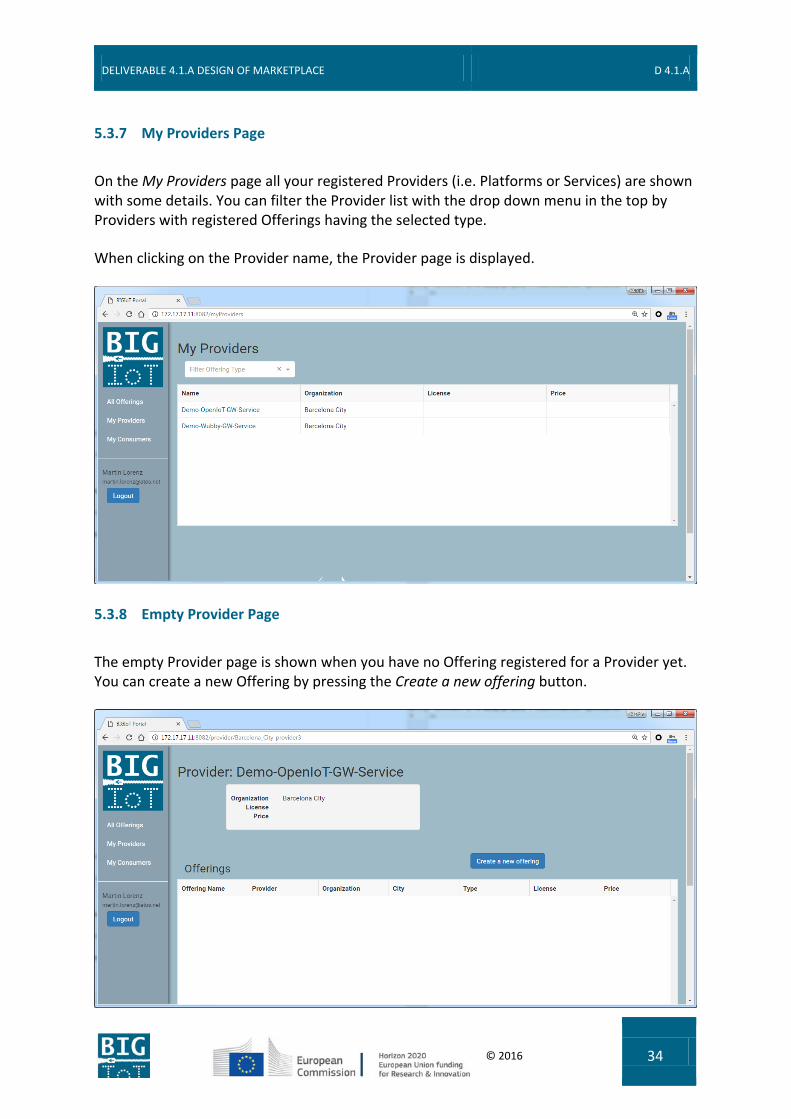
5.3.6 Home Page
After logging in you are redirected to the (personal) home page. The additional menu entries My Providers and My Consumers are offered here.
Additionally, your name and email address provided by your identity provider is shown in the navigation bar together with a Logout button.
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 34
5.3.7 My Providers Page
On the My Providers page all your registered Providers (i.e. Platforms or Services) are shown with some details. You can filter the Provider list with the drop down menu in the top by Providers with registered Offerings having the selected type.
When clicking on the Provider name, the Provider page is displayed.
5.3.8 Empty Provider Page
The empty Provider page is shown when you have no Offering registered for a Provider yet. You can create a new Offering by pressing the Create a new offering button.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 35
5.3.9 New Offering Page
Fill in the parameters on this page to create a new Offering.
You have to enter the following information here:
• Offering Name (mandatory): This name is shown in all Offering lists • City (optional): Location of that Offering • Type (mandatory): Semantic Offering type • Output Data (zero or more): Enter output fields with optional name and mandatory
data type • Input Data (zero or more): Enter input fields with optional name and mandatory data
type • Endpoint (one or more): Enter access interface type and URL for all endpoints to ac-
cess this Offering • License (mandatory): Select one of the supported licenses • Price (mandatory): Select one of the supported pricing models and the amount, if
applicable
For all fields that allow multiple entries you can delete and add a new entry with the buttons on the right.
Names for input and output fields are optional because the data type of the fields must be unique and so the fields can be differentiated by type. If you give a name then automatic mapping is supported.
When you have entered all necessary information, press the Save button to create that Of-fering on the Marketplace.
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 36
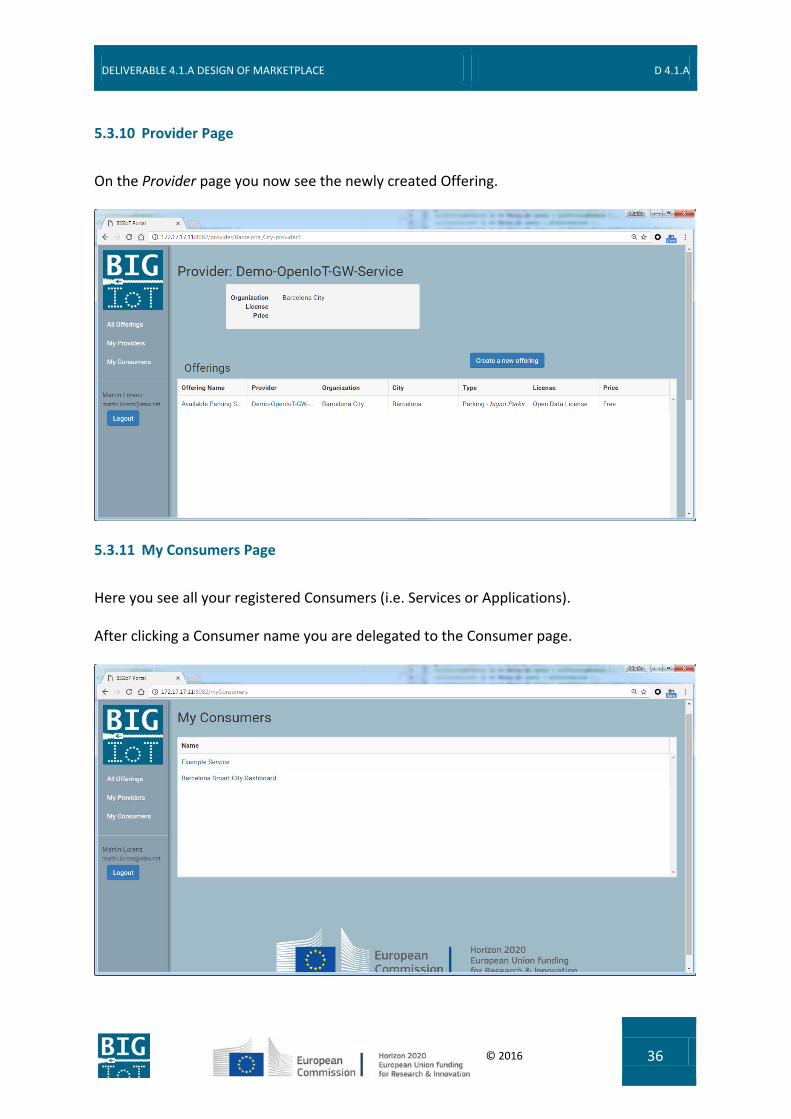
5.3.10 Provider Page
On the Provider page you now see the newly created Offering.
5.3.11 My Consumers Page
Here you see all your registered Consumers (i.e. Services or Applications).
After clicking a Consumer name you are delegated to the Consumer page.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 37
5.3.12 Empty Consumer Page
This page is shown if you haven't created any Offering Query for this Consumer yet. To cre-ate one press the Create new offering query button.
5.3.13 New Offering Query Page
To create a new Offering Query you have to fill in the information in this form:
• Offering Query Name (mandatory): This name is shown in the list of Offering Queries • City (optional): Enter city here if you want to restrict the query to Offerings located in
that city • Type (optional): Enter Offering type here if you want to restrict the query to Offer-
ings of that type • Output Data (zero or more): Enter optional name and mandatory data type for out-
put data fields here if you want to restrict the query to Offerings returning that output field(s)
• Input Data (zero or more): Enter optional name and mandatory data type for input data fields here if you want to restrict the query to Offerings accepting that input field(s)
• License (optional): Select License here if you want to restrict the query to Offerings using that license
• Price (optional): Select Pricing Model and amount (if applicable) here if you want to restrict the query to Offerings with that maximum price
For all fields that allow multiple entries you can delete and add a new entry with the buttons on the right.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 38
Names for input and output fields are optional because the data type of the fields must be unique and so the fields can be differentiated by type. If you give a name then automatic mapping is supported.
When you have entered all necessary information, press the Save button to create that Of-fering Query on the Marketplace.
5.3.14 Consumer Page
After creating a new Offering Query it is displayed on the Consumer page.
If you click on the Offering Query name you are delegated to the Offering Query page.
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 39
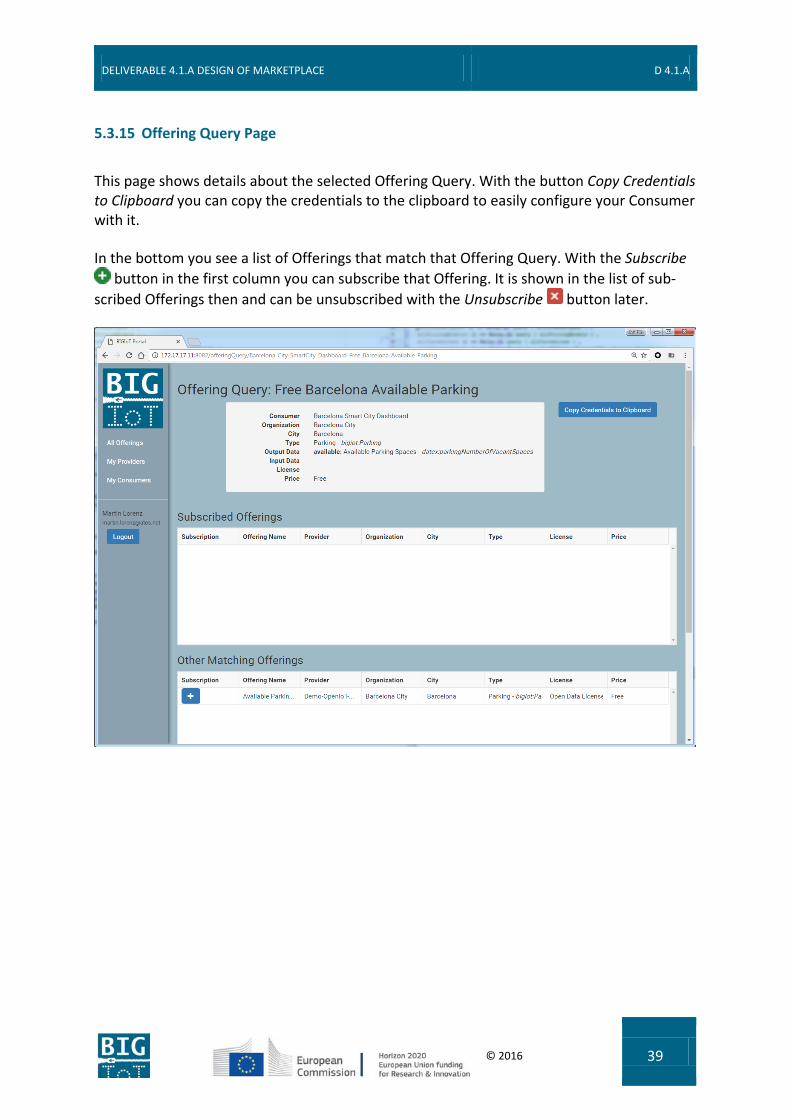
5.3.15 Offering Query Page
This page shows details about the selected Offering Query. With the button Copy Credentials to Clipboard you can copy the credentials to the clipboard to easily configure your Consumer with it.
In the bottom you see a list of Offerings that match that Offering Query. With the Subscribe button in the first column you can subscribe that Offering. It is shown in the list of sub-
scribed Offerings then and can be unsubscribed with the Unsubscribe button later.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 40
6 Marketplace API
The Marketplace API is the implementation of the interfaces M1 (authentication & authori-zation), M2 (register), M3 (lookup / subscribe) and M4 (accounting) as described in Task 3.1 - Specification of BIG IoT API. It is an aggregator that collects data from the Marketplace internal services (Access Management, Exchange, Accounting, Charging) and provides it to clients like the Marketplace Portal, Offering Providers, Offering Consumers and tests.
This API is based on GraphQL to allow clients to fetch and manipulate Marketplace data as described in the Exchange Domain Model. This domain model is hierarchically structured as a tree of entities. Clients can retrieve exactly that part of the tree that they need for their purposes, e.g. the Marketplace Portal fetches all data it needs to display one complete page of the UI with one access.
GraphQL is not to be confused with other query languages like SPARQL. It is only used to fetch and manipulate data over the API. SPARQL will be used internally in the Exchange for accessing semantic data in a triple store.
A full listing of the current schema can be found in the appendix in chapter 11.1 Market-place GraphQL Schema.
6.1 GraphQL
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your ex-isting data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
GraphQL was created by Facebook in 2012 and provides a common interface between the client and the server for data fetching and manipulations: http://graphql.org. It helps to ad-dress some of the more common headaches developers are faced when building a REST API -backed application:
• Issue #1: Multiple round trips. • Issue #2: Overfetching of data. • Issue #3: Documenting your API (discover and explore your API)
GraphQL itself is only a specification (http://facebook.github.io/graphql) but there are sev-eral open source implementations for both client and server side available: https://github.com/chentsulin/awesome-graphql
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 41
6.2 Implementation of Marketplace API
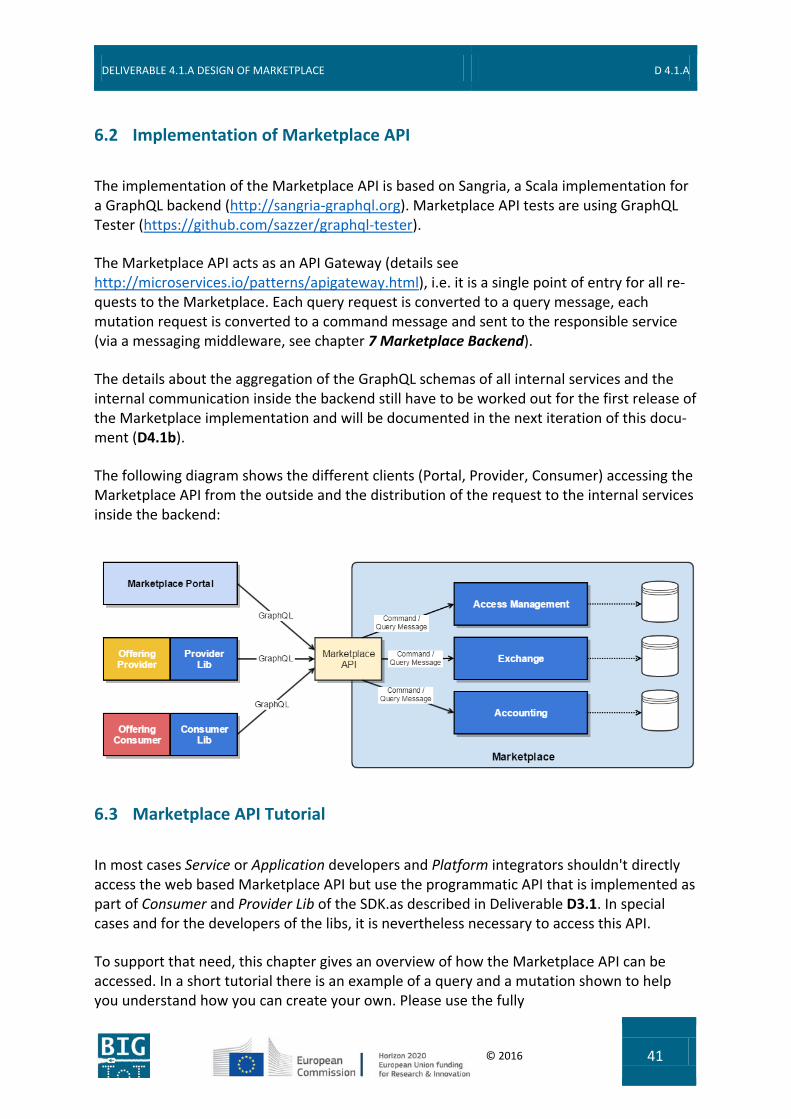
The implementation of the Marketplace API is based on Sangria, a Scala implementation for a GraphQL backend (http://sangria-graphql.org). Marketplace API tests are using GraphQL Tester (https://github.com/sazzer/graphql-tester).
The Marketplace API acts as an API Gateway (details see http://microservices.io/patterns/apigateway.html), i.e. it is a single point of entry for all re-quests to the Marketplace. Each query request is converted to a query message, each mutation request is converted to a command message and sent to the responsible service (via a messaging middleware, see chapter 7 Marketplace Backend).
The details about the aggregation of the GraphQL schemas of all internal services and the internal communication inside the backend still have to be worked out for the first release of the Marketplace implementation and will be documented in the next iteration of this docu-ment (D4.1b).
The following diagram shows the different clients (Portal, Provider, Consumer) accessing the Marketplace API from the outside and the distribution of the request to the internal services inside the backend:
6.3 Marketplace API Tutorial
In most cases Service or Application developers and Platform integrators shouldn't directly access the web based Marketplace API but use the programmatic API that is implemented as part of Consumer and Provider Lib of the SDK.as described in Deliverable D3.1. In special cases and for the developers of the libs, it is nevertheless necessary to access this API.
To support that need, this chapter gives an overview of how the Marketplace API can be accessed. In a short tutorial there is an example of a query and a mutation shown to help you understand how you can create your own. Please use the fully
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 42
listed Marketplace GraphQL Schema to find out what queries and mutations are currently supported on the Marketplace API.
You can create and experiment with GraphQL queries and mutations by using the integrated GraphiQL IDE as described in the next chapter.
6.3.1 Interactive Exploration of the Marketplace API
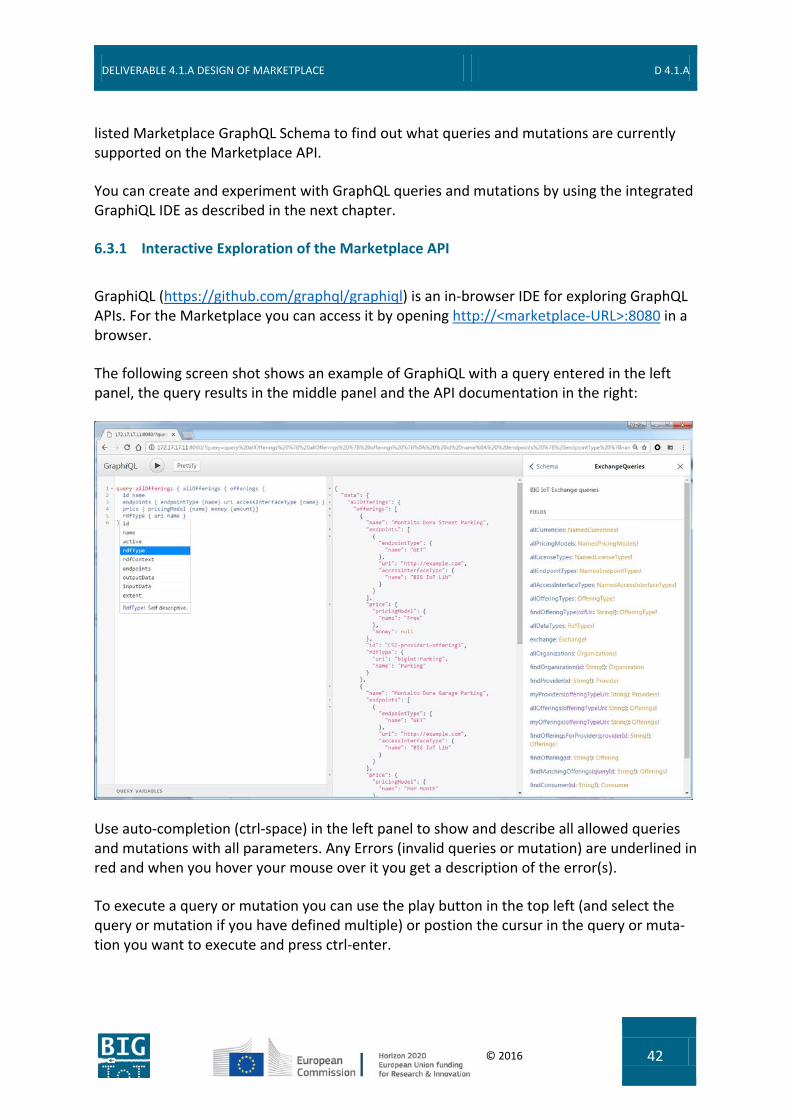
GraphiQL (https://github.com/graphql/graphiql) is an in-browser IDE for exploring GraphQL APIs. For the Marketplace you can access it by opening http://<marketplace-URL>:8080 in a browser.
The following screen shot shows an example of GraphiQL with a query entered in the left panel, the query results in the middle panel and the API documentation in the right:
Use auto-completion (ctrl-space) in the left panel to show and describe all allowed queries and mutations with all parameters. Any Errors (invalid queries or mutation) are underlined in red and when you hover your mouse over it you get a description of the error(s).
To execute a query or mutation you can use the play button in the top left (and select the query or mutation if you have defined multiple) or postion the cursur in the query or muta-tion you want to execute and press ctrl-enter.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 43
6.3.2 API documentation
When you click Docs in the top right of GraphiQL you can browse the full (generated) docu-mentation for the Exchange API. All queries, mutations and types with parameters, return types and fields are described there.
Fields with a type ending with an exclamation mark (e.g. String!) are mandatory fields, all others are optional. Fields with types in brackets (e.g. [String]) are arrays of entries with the given type.
6.3.3 Query Example
The following listing shows an example of a GraphQL query to return all registered Offerings:
allOfferings Query query q1 { allOfferings { offerings { id name } } }
The keyword query starts the query statement, followed by the name of this statement, q1. You only need to specify that statement name if you want to enter multiple statements at one time in the left panel.
In braces you enter one or more queries with the necessary parameters in parenthesis, if applicable, as described in the API documentation. In this case the defined query allOfferings is called, that takes no parameters.
After that you have to specify in what return values you are interested in by hierarchically giving all the field names with all the sub-fields in braces. In this example we are interested in the offerings field with the sub-fields id and name. You can dive as deep into the hierarchy of return values as you need.
Please have a look at the API documentation what queries are defined and what values will be returned as a result.
When you execute that query you get back a JSON result similar to the following:
allOfferings Query Result { "data": { "allOfferings": { "offerings": [ { "id": "CSI-provider1-offering3", "name": "Montalto Dora Street Parking" },

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 44
{ "id": "CSI-provider1-offering2", "name": "Montalto Dora Garage Parking" }, { "id": "CSI-provider1-offering1", "name": "Montalto Dora Traffic counter" } ] } } }
Please note that all GraphQL query results are wrapped at least twice:
• an object always called data • an object named by the query name, in this case allOfferings • if the query returns a list of items then it is wrapped in an additional object
(called offerings in this example).
6.3.4 Mutation Example
Here you can see an example for a GraphQL mutation to create a new Offering in the Mar-ketplace:
createOffering Mutation mutation m1 { createOffering(input: { providerId: "Barcelona_City-provider3" localId: "newOffering" name: "name" rdfUri: "bigiot:Parking" licenseType: "CREATIVE_COMMONS" price: { pricingModel: "PER_ACCESS" money: { amount:1 currency:"EUR" }} }) { offering { id name } } }
The keyword mutation starts the mutation statement, followed by the name of this state-ment, m1.
In braces you enter one or more mutations with the necessary parameters in parentheses, in this case the defined mutation createOffering is called, with all the given parameters. For the return value you just want to get back the id and name of the newly created Offering.
Please have a look at the API documentation what mutations are defined and what values will be returned as a result.
When you execute that mutation you get back a JSON result similar to the following:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 45
createOffering Mutation Result { "data": { "createOffering": { "offering": { "id": "Barcelona_City-provider3-newOffering", "name": "name" } } } }
The ids are created in a hierarchical way, that is by combining the parent id and the child id with a separator "-" in between. The child id for an entity to be created is either given explic-itly as localId or calculated from the name (by replacing spaces and special characters with "_"). If neither localId nor name is given a unique id is created.
6.3.5 Using the GraphQL endpoint
After you have designed your query or mutation with the help from GraphiQL you can use that query string to access the Marketplace API running on http://<marketplace-URL>:8080/graphql
Here is an example query by accessing the http://localhost:8080/graphql endpoint using curl:
curl -X POST localhost:8080/graphql -H "Content-Type:application/json" -d "{\"query\": \"{ allOfferings { offerings {name} } } \"}"

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 46
7 Marketplace Backend
This chapter first describes the architecture of the Marketplace Backend and then gives a short overview of the planned services.
7.1 Marketplace Backend Architecture
The development of the Marketplace Backend is an ongoing process and the details still have to be defined. This chapter nevertheless describes the corner-stones of the envi-sioned architecture. Not all parts of that architecture will be already implemented in the first release of the Marketplace.
The goal is to develop a set of backend services that on one hand fulfill the current require-ments of the BIG IoT project, on the other hand can be developed further in the future without having to be completely redesigned. The Marketplace will be deployed in a reduced mode in the beginning (merely to support pilot development and open call) and should be prepared to scale up later when the Marketplace will be in full operation.
It has to be possible to make parts of the services open source and keep some services as closed source to allow business models like a Freemium model (see Task 7.1 - Impact Crea-tion and exploitation - Business Models).
The basic idea to achieve these goals is to develop all services as loosely coupled microservices that are connected asynchronously through message queues (called topics in Apache Kafka). Each service is based on domain events and these events are used to com-municate with other services (Event Sourcing). Services consist of a separate update model (Command Handler) and a query model (Query Handler), as proposed in Command and Que-ry Responsibility Segregation (CQRS). Those two models are synchronized by the domain events.
These concepts are shown in the following diagram:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 47
Each of the Microservices consists of the following parts:
• Command topic • Command Handler • Event topic • Queries topic (optional) • Query Handler • Query DB
The Marketplace API converts the GraphQL mutation requests (see chapter 6 Marketplace API) into commands that are sent to the Apache Kafka Commands topic of the responsible service. The Command Handler of that service validates the request, creates an according event (that is stored in an event log) and sends the event to the Events topic of that service. By subscribing to that Events topic, the Query DB of that service and other services can be updated, if necessary. This supports a very loose coupling between the services.
Each service has to provide a Query Handler that handles all queries for that service with the help of a service specific Query DB. Those queries between the Marketplace API and the Query Handler can either be implemented as direct REST request (e.g. for the Access Man-agement that has to be available to validate the access token of the request) or decoupled via a Queries topic (e.g. Exchange).
The planned architectural concepts Command and Query Responsibility Segregation (CQRS), Event Sourcing, Microservices and Apache Kafka are described in more detail in the follow-ing chapters.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 48
7.1.1 Command and Query Responsibility Segregation (CQRS) Pattern
This chapter is taken from Microsoft MSDN (https://msdn.microsoft.com/en-us/library/dn568103.aspx).
Segregate operations that read data from operations that update data by using separate interfaces. This pattern can maximize performance, scalability, and security; support evolu-tion of the system over time through higher flexibility; and prevent update commands from causing merge conflicts at the domain level.
Context and Problem
In traditional data management systems, both commands (updates to the data) and queries (requests for data) are executed against the same set of entities in a single data repository. These entities may be a subset of the rows in one or more tables in a relational database such as SQL Server.
Typically, in these systems, all create, read, update, and delete (CRUD) operations are ap-plied to the same representation of the entity. For example, a data transfer object (DTO) representing a customer is retrieved from the data store by the data access layer (DAL) and displayed on the screen. A user updates some fields of the DTO (perhaps through data bind-ing) and the DTO is then saved back in the data store by the DAL. The same DTO is used for both the read and write operations, as shown in the figure:
Figure: A traditional CRUD architecture (Source: Microsoft)
Traditional CRUD designs work well when there is only limited business logic applied to the data operations. Scaffold mechanisms provided by development tools can create data access code very quickly, which can then be customized as required.
However, the traditional CRUD approach has some disadvantages:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 49
• It often means that there is a mismatch between the read and write representations of the data, such as additional columns or properties that must be updated correctly even though they are not required as part of an operation.
• It risks encountering data contention in a collaborative domain (where multiple ac-tors operate in parallel on the same set of data) when records are locked in the data store, or update conflicts caused by concurrent updates when optimistic locking is used. These risks increase as the complexity and throughput of the system grows. In addition, the traditional approach can also have a negative effect on performance due to load on the data store and data access layer, and the complexity of queries required to retrieve information.
• It can make managing security and permissions more cumbersome because each en-tity is subject to both read and write operations, which might inadvertently expose data in the wrong context.
Solution
Command and Query Responsibility Segregation (CQRS) is a pattern that segregates the op-erations that read data (Queries) from the operations that update data (Commands) by using separate interfaces. This implies that the data models used for querying and updates are different.
Compared to the single model of the data (from which developers build their own conceptu-al models) that is inherent in CRUD-based systems, the use of separate query and update models for the data in CQRS-based systems considerably simplifies design and implementa-tion.
The query model for reading data and the update model for writing data may access the same physical store, perhaps by using SQL views or by generating projections on the fly. However, it is common to separate the data into different physical stores to maximize per-formance, scalability, and security; as shown in the figure below.
Figure: A CQRS architecture with separate read and write stores (Source: Microsoft)
The read store can be a read-only replica of the write store, or the read and write stores may have a different structure altogether. Using multiple read-only replicas of the read store can considerably increase query performance and application UI responsiveness, especially in

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 50
distributed scenarios where read-only replicas are located close to the application instances. Some database systems provide additional features such as failover replicas to maximize availability.
Separation of the read and write stores also allows each to be scaled appropriately to match the load. For example, read stores typically encounter a much higher load that write stores.
Issues and Considerations
Consider the following points when deciding how to implement this pattern:
• Dividing the data store into separate physical stores for read and write operations can increase the performance and security of a system, but it can add considerable complexity in terms of resiliency and eventual consistency. The read model store must be updated to reflect changes to the write model store, and it may be difficult to detect when a user has issued a request based on stale read data—meaning that the operation cannot be completed.
• A typical approach to embracing eventual consistency is to use event sourcing in con-junction with CQRS so that the write model is an append-only stream of events driven by execution of commands. These events are used to update materialized views that act as the read model.
7.1.2 Event Sourcing Pattern
This chapter is taken from Microsoft MSDN (https://msdn.microsoft.com/en-us/library/dn589792.aspx).
Use an append-only store to record the full series of events that describe actions taken on data in a domain, rather than storing just the current state, so that the store can be used to materialize the domain objects. This pattern can simplify tasks in complex domains by avoid-ing the requirement to synchronize the data model and the business domain; improve performance, scalability, and responsiveness; provide consistency for transactional data; and maintain full audit trails and history that may enable compensating actions.
Context and Problem
Most applications work with data, and the typical approach is for the application to maintain the current state of the data by updating it as users work with the data. For example, in the traditional create, read, update, and delete (CRUD) model a typical data process will be to read data from the store, make some modifications to it, and update the current state of the data with the new values - often by using transactions that lock the data.
The CRUD approach has some limitations:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 51
• The fact that CRUD systems perform update operations directly against a data store may hinder performance and responsiveness, and limit scalability, due to the pro-cessing overhead it requires.
• In a collaborative domain with many concurrent users, data update conflicts are more likely to occur because the update operations take place on a single item of da-ta.
• Unless there is an additional auditing mechanism, which records the details of each operation in a separate log, history is lost.
Solution
The Event Sourcing pattern defines an approach to handling operations on data that is driv-en by a sequence of events, each of which is recorded in an append-only store. Application code sends a series of events that imperatively describe each action that has occurred on the data to the event store, where they are persisted. Each event represents a set of chang-es to the data (such as AddedItemToOrder).
The events are persisted in an event store that acts as the source of truth or system of rec-ord (the authoritative data source for a given data element or piece of information) about the current state of the data. The event store typically publishes these events so that con-sumers can be notified and can handle them if needed. Consumers could, for example, initiate tasks that apply the operations in the events to other systems, or perform any other associated action that is required to complete the operation. Notice that the application code that generates the events is decoupled from the systems that subscribe to the events.
Typical uses of the events published by the event store are to maintain materialized views of entities as actions in the application change them, and for integration with external systems. For example, a system may maintain a materialized view of all customer orders that is used to populate parts of the UI. As the application adds new orders, adds or removes items on the order, and adds shipping information, the events that describe these changes can be handled and used to update the materialized view.
In addition, at any point in time it is possible for applications to read the history of events, and use it to materialize the current state of an entity by effectively “playing back” and con-suming all the events related to that entity. This may occur on demand in order to materialize a domain object when handling a request, or through a scheduled task so that the state of the entity can be stored as a materialized view to support the presentation lay-er.
The following figure shows a logical overview of the pattern, including some of the options for using the event stream such as creating a materialized view, integrating events with ex-ternal applications and systems, and replaying events to create projections of the current state of specific entities.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 52
Figure: An overview and example of the Event Sourcing pattern (Source: Microsoft)
Event sourcing is commonly combined with the CQRS pattern by performing the data man-agement tasks in response to the events, and by materializing views from the stored events.
Issues and Considerations
Consider the following points when deciding how to implement this pattern:
• The system will only be eventually consistent when creating materialized views or generating projections of data by replaying events. There is some delay between an application adding events to the event store as the result of handling a request, the events being published, and consumers of the events handling them. During this pe-riod, new events that describe further changes to entities may have arrived at the event store.
• The event store is the immutable source of information, and so the event data should never be updated. The only way to update an entity in order to undo a change is to add a compensating event to the event store, much as you would use a negative transaction in accounting. If the format (rather than the data) of the persisted events needs to change, perhaps during a migration, it can be difficult to combine existing events in the store with the new version. It may be necessary to iterate through all the events making changes so that they are compliant with the new format, or add new events that use the new format. Consider using a version stamp on each version of the event schema in order to maintain both the old and the new event formats.
• Multi-threaded applications and multiple instances of applications may be storing events in the event store. The consistency of events in the event store is vital, as is the order of events that affect a specific entity (the order in which changes to an en-

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 53
tity occur affects its current state). Adding a timestamp to every event is one option that can help to avoid issues. Another common practice is to annotate each event that results from a request with an incremental identifier. If two actions attempt to add events for the same entity at the same time, the event store can reject an event that matches an existing entity identifier and event identifier.
• There is no standard approach, or ready-built mechanisms such as SQL queries, for reading the events to obtain information. The only data that can be extracted is a stream of events using an event identifier as the criteria. The event ID typically maps to individual entities. The current state of an entity can be determined only by re-playing all of the events that relate to it against the original state of that entity.
• The length of each event stream can have consequences on managing and updating the system. If the streams are large, consider creating snapshots at specific intervals such as a specified number of events. The current state of the entity can be obtained from the snapshot and by replaying any events that occurred after that point in time.
• Even though event sourcing minimizes the chance of conflicting updates to the data, the application must still be able to deal with inconsistencies that may arise through eventual consistency and the lack of transactions. For example, an event that indi-cates a reduction in stock inventory might arrive in the data store while an order for that item is being placed, resulting in a requirement to reconcile the two operations; probably by advising the customer or creating a back order.
• Event publication may be “at least once,” and so consumers of the events must be idempotent. They must not reapply the update described in an event if the event is handled more than once. For example, if multiple instances of a consumer maintain an aggregate of a property of some entity, such as the total number of orders placed, only one must succeed in incrementing the aggregate when an “order placed” event occurs. While this is not an intrinsic characteristic of event sourcing, it is the usual implementation decision.
7.1.3 Event Sourcing and CQRS
This chapter is taken from Microsoft MSDN (https://msdn.microsoft.com/en-us/library/dn568103.aspx).
The CQRS pattern is often used in conjunction with the Event Sourcing pattern. CQRS-based systems use separate read and write data models, each tailored to relevant tasks and often located in physically separate stores. When used with Event Sourcing, the store of events is the write model, and this is the authoritative source of information. The read model of a CQRS-based system provides materialized views of the data, typically as highly denormalized views. These views are tailored to the interfaces and display requirements of the application, which helps to maximize both display and query performance.
Using the stream of events as the write store, rather than the actual data at a point in time, avoids update conflicts on a single aggregate and maximizes performance and scalability. The events can be used to asynchronously generate materialized views of the data that are used to populate the read store.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 54
Because the event store is the authoritative source of information, it is possible to delete the materialized views and replay all past events to create a new representation of the current state when the system evolves, or when the read model must change. The materialized views are effectively a durable read-only cache of the data.
7.1.4 Microservices Architecture Pattern
This chapter is taken from http://microservices.io/patterns/microservices.html.
Context
You are developing a server-side enterprise application. It must support a variety of different clients including desktop browsers, mobile browsers and native mobile applications. The application might also expose an API for 3rd parties to consume. It might also integrate with other applications via either web services or a message broker. The application handles re-quests (HTTP requests and messages) by executing business logic; accessing a database; exchanging messages with other systems; and returning a HTML/JSON/XML response.
The application has either a layered or hexagonal (http://alistair.cockburn.us/Hexagonal+architecture) architecture and consists of different types of components:
• Presentation components - responsible for handling HTTP requests and responding with either HTML or JSON/XML (for web services APIS)
• Business logic - the application’s business logic • Database access logic - data access objects responsible for access the database • Application integration logic - messaging layer, e.g. based on Spring integration.
There are logical components corresponding to different functional areas of the application.
Problem
What’s the application’s deployment architecture?
Forces
• There is a team of developers working on the application • New team members must quickly become productive • The application must be easy to understand and modify • You want to practice continuous deployment of the application • You must run multiple copies of the application on multiple machines in order to sat-
isfy scalability and availability requirements • You want to take advantage of emerging technologies (frameworks, programming
languages, etc)

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 55
Solution
Architect the application by functionally decomposing the application into a set of collabo-rating services. Each service implements a set of narrowly, related functions. For example, an application might consist of services such as the order management service, the customer management service etc.
Services communicate using either synchronous protocols such as HTTP/REST or asynchro-nous protocols such as AMQP.
Services are developed and deployed independently of one another.
Each service has its own database in order to be decoupled from other services. When nec-essary, consistency is between databases is maintained using either database replication mechanisms or application-level events.
Resulting context
This solution has a number of benefits:
• Each microservice is relatively small o Easier for a developer to understand o The IDE is faster making developers more productive o The web container starts faster, which makes developers more productive,
and speeds up deployments • Each service can be deployed independently of other services - easier to deploy new
versions of services frequently • Easier to scale development. It enables you to organize the development effort
around multiple teams. Each (two pizza) team is responsible a single service. Each team can develop, deploy and scale their service independently of all of the other teams.
• Improved fault isolation. For example, if there is a memory leak in one service then only that service will be affected. The other services will continue to handle requests. In comparison, one misbehaving component of a monolithic architecture can bring down the entire system.
• Each service can be developed and deployed independently • Eliminates any long-term commitment to a technology stack
This solution has a number of drawbacks:
• Developers must deal with the additional complexity of creating a distributed system. o Developer tools/IDEs are oriented on building monolithic applications and
don’t provide explicit support for developing distributed applications. o Testing is more difficult o Developers must implement the inter-service communication mechanism.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 56
o Implementing use cases that span multiple services without using distributed transactions is difficult
o Implementing use cases that span multiple services requires careful coordina-tion between the teams
• Deployment complexity. In production, there is also the operational complexity of deploying and managing a system comprised of many different service types.
• Increased memory consumption. The microservices architecture replaces N mono-lithic application instances with NxM services instances. If each service runs in its own JVM (or equivalent), which is usually necessary to isolate the instances, then there is the overhead of M times as many JVM runtimes. Moreover, if each service runs on its own VM (e.g. EC2 instance), as is the case at Netflix, the overhead is even higher.
One challenge with using this approach is deciding when it makes sense to use it. When de-veloping the first version of an application, you often do not have the problems that this approach solves. Moreover, using an elaborate, distributed architecture will slow down de-velopment. This can be a major problem for startups whose biggest challenge is often how to rapidly evolve the business model and accompanying application. Using functional de-composition might make it much more difficult to iterate rapidly. Later on, however, when the challenge is how to scale and you need to use functional decomposition, the tangled dependencies might make it difficult to decompose your monolithic application into a set of services.
Ideally, each service should have only a small set of responsibilities. (Uncle) Bob Martin talks about designing classes using the Single Responsibility Principle (SRP, http://www.objectmentor.com/resources/articles/srp.pdf). The SRP defines a responsibility of a class as a reason to change, and states that a class should only have one reason to change. It makes sense to apply the SRP to service design as well.
Another analogy that helps with service design is the design of Unix utilities. Unix provides a large number of utilities such as grep, cat and find. Each utility does exactly one thing, often exceptionally well, and can be combined with other utilities using a shell script to perform complex tasks.
7.1.5 Streaming Middleware based on Apache Kafka
This chapter is taken from the Apache Kafka introduction (https://kafka.apache.org/intro).
Kafka is a distributed streaming platform. What exactly does that mean?
We think of a streaming platform as having three key capabilities:
1. It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.
2. It lets you store streams of records in a fault-tolerant way.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 57
3. It lets you process streams of records as they occur.
What is Kafka good for?
It gets used for two broad classes of application:
1. Building real-time streaming data pipelines that reliably get data between systems or applications
2. Building real-time streaming applications that transform or react to the streams of data
To understand how Kafka does these things, let's dive in and explore Kafka's capabilities from the bottom up.
First a few concepts:
• Kafka is run as a cluster on one or more servers. • The Kafka cluster stores streams of records in categories called topics. • Each record consists of a key, a value, and a timestamp.
Kafka has four core APIs:
• The Producer API allows an application to publish a stream records to one or more Kafka topics.
• The Consumer API allows an application to subscribe to one or more topics and pro-cess the stream of records produced to them.
• The Streams API allows an application to act as a stream processor, consuming an in-put stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
• The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a con-nector to a relational database might capture every change to a table.
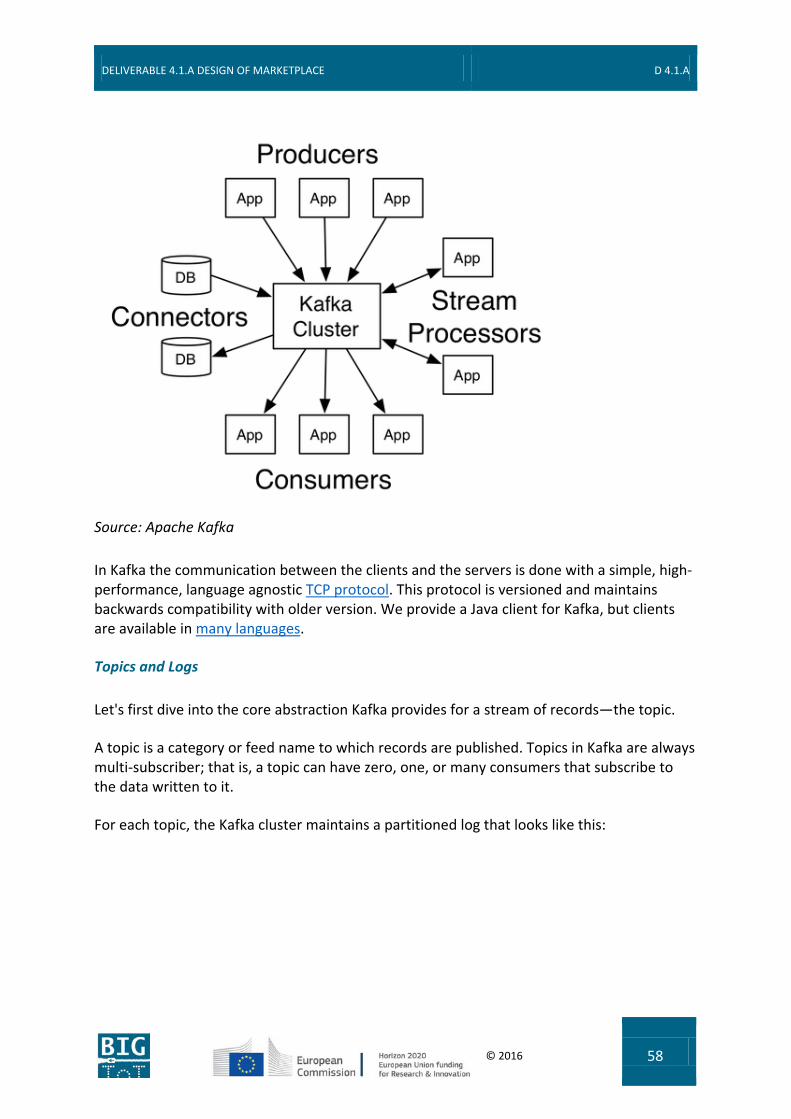
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 58
Source: Apache Kafka
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. This protocol is versioned and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many languages.
Topics and Logs
Let's first dive into the core abstraction Kafka provides for a stream of records—the topic.
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log that looks like this:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 59
Source: Apache Kafka
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
The Kafka cluster retains all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
Source: Apache Kafka
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will ad-vance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 60
an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to "tail" the contents of any topic without changing what is con-sumed by any existing consumers.
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
Distribution
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
Each partition has one server which acts as the "leader" and zero or more servers which act as "followers". The leader handles all read and write requests for the partition while the fol-lowers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
Producers
Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition func-tion (say based on some key in the record). More on the use of partitioning in a second!
Consumers
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Con-sumer instances can be in separate processes or on separate machines.
If all the consumer instances have the same consumer group, then the records will effective-ly be load balanced over the consumer instances.
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 61
Source: Apache Kafka
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Con-sumer group A has two consumer instances and group B has four.
More commonly, however, we have found that topics have a small number of consumer groups, one for each "logical subscriber". Each group is composed of many consumer in-stances for scalability and fault tolerance. This is nothing more than publish-subscribe semantics where the subscriber is a cluster of consumers instead of a single process.
The way consumption is implemented in Kafka is by dividing up the partitions in the log over the consumer instances so that each instance is the exclusive consumer of a "fair share" of partitions at any point in time. This process of maintaining membership in the group is han-dled by the Kafka protocol dynamically. If new instances join the group they will take over some partitions from other members of the group; if an instance dies, its partitions will be distributed to the remaining instances.
Kafka only provides a total order over records within a partition, not between different parti-tions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over records this can be achieved with a topic that has only one partition, though this will mean only one con-sumer process per consumer group.
Guarantees
At a high-level Kafka gives the following guarantees:
• Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
• A consumer instance sees records in the order they are stored in the log.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 62
• For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.
More details on these guarantees are given in the design section of the documentation.
Kafka as a Messaging System
How does Kafka's notion of streams compare to a traditional enterprise messaging system?
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each record goes to one of them; in publish-subscribe the record is broadcast to all consumers. Each of these two models has a strength and a weakness. The strength of queuing is that it allows you to divide up the processing of data over multiple consumer instances, which lets you scale your processing. Unfortunately, queues aren't multi-subscriber—once one process reads the data it's gone. Publish-subscribe allows you broadcast data to multiple processes, but has no way of scaling processing since every message goes to every subscriber.
The consumer group concept in Kafka generalizes these two concepts. As with a queue the consumer group allows you to divide up processing over a collection of processes (the mem-bers of the consumer group). As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
The advantage of Kafka's model is that every topic has both these properties—it can scale processing and is also multi-subscriber—there is no need to choose one or the other.
Kafka has stronger ordering guarantees than a traditional messaging system, too.
A traditional queue retains records in-order on the server, and if multiple consumers con-sume from the queue then the server hands out records in the order they are stored. However, although the server hands out records in order, the records are delivered asyn-chronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the records is lost in the presence of parallel consumption. Messaging systems often work around this by having a notion of "exclusive consumer" that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
Kafka does it better. By having a notion of parallelism - the partition - within the topics, Kaf-ka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many con-sumer instances. Note however that there cannot be more consumer instances in a consumer group than partitions.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 63
Kafka as a Storage System
Any message queue that allows publishing messages decoupled from consuming them is effectively acting as a storage system for the in-flight messages. What is different about Kaf-ka is that it is a very good storage system.
Data written to Kafka is written to disk and replicated for fault-tolerance. Kafka allows pro-ducers to wait on acknowledgement so that a write isn't considered complete until it is fully replicated and guaranteed to persist even if the server written to fails.
The disk structures Kafka uses scale well - Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server.
As a result of taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation.
Kafka for Stream Processing
It isn't enough to just read, write, and store streams of data, the purpose is to enable real-time processing of streams.
In Kafka a stream processor is anything that takes continual streams of data from input top-ics, performs some processing on this input, and produces continual streams of data to output topics.
For example, a retail application might take in input streams of sales and shipments, and output a stream of reorders and price adjustments computed off this data.
It is possible to do simple processing directly using the producer and consumer APIs. Howev-er for more complex transformations Kafka provides a fully integrated Streams API. This allows building applications that do non-trivial processing that compute aggregations off of streams or join streams together.
This facility helps solve the hard problems this type of application faces: handling out-of-order data, reprocessing input as code changes, performing stateful computations, etc.
The streams API builds on the core primitives Kafka provides: it uses the producer and con-sumer APIs for input, uses Kafka for stateful storage, and uses the same group mechanism for fault tolerance among the stream processor instances.
Putting the Pieces Together
This combination of messaging, storage, and stream processing may seem unusual but it is essential to Kafka's role as a streaming platform.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 64
A distributed file system like HDFS allows storing static files for batch processing. Effectively a system like this allows storing and processing historical data from the past.
A traditional enterprise messaging system allows processing future messages that will arrive after you subscribe. Applications built in this way process future data as it arrives.
Kafka combines both of these capabilities, and the combination is critical both for Kafka us-age as a platform for streaming applications as well as for streaming data pipelines.
By combining storage and low-latency subscriptions, streaming applications can treat both past and future data the same way. That is a single application can process historical, stored data but rather than ending when it reaches the last record it can keep processing as future data arrives. This is a generalized notion of stream processing that subsumes batch pro-cessing as well as message-driven applications.
Likewise, for streaming data pipelines the combination of subscription to real-time events make it possible to use Kafka for very low-latency pipelines; but the ability to store data reli-ably make it possible to use it for critical data where the delivery of data must be guaranteed or for integration with offline systems that load data only periodically or may go down for extended periods of time for maintenance. The stream processing facilities make it possible to transform data as it arrives.
7.2 Access Management (AM)
The Access Management service supports the Marketplace API in checking authorization for requests coming from the Marketplace Portal or from clients like Providers and Consumers to the Marketplace Backend on one hand, and also manages subscriptions for handling ac-cess between Consumers and Providers on the other hand. Details about the security concepts are described in chapter 8 Security.
7.2.1 Access Management Domain Model
Access Management is responsible for managing
• Users (identified by their email address) and their Organizations • Subscriptions (identified by SubscriptionId) between Subscribers and Subscribables
and the linked SubscriptionTokens for authorizing access between Consumers and Providers
• Access Tokens and Client Secrets for clients (identified by ClientId) accessing the Marketplace (Producers and Consumers)
as shown in the following diagram:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 65
The Subscription model is an abstraction of the Offering Query (acting as Subscriber) and an Offering (acting as a Subscribable).
This model is work in progress. Details will be described in the next iteration D4.1b of this document.
7.3 Exchange
The Exchange service manages
• Providers • Offerings with their semantic annotations (Offering descriptions) • Consumers • Offering Queries to support semantic discovery of Offerings
It persists its entities with the help of a semantic store to enable semantic queries.
The following chapters show the domain model of the Exchange service and describe details about the way the entities of that model are persisted.
7.3.1 Exchange Domain Model
The following diagram shows the domain model for the Exchange:
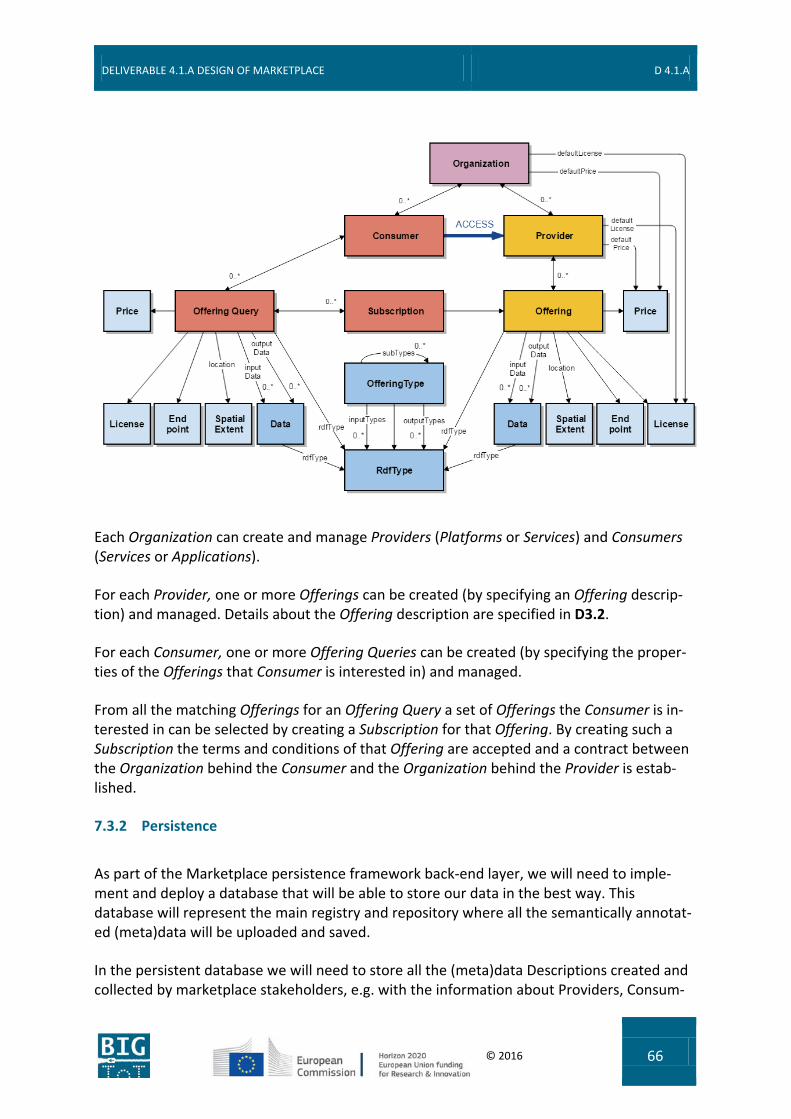
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 66
Each Organization can create and manage Providers (Platforms or Services) and Consumers (Services or Applications).
For each Provider, one or more Offerings can be created (by specifying an Offering descrip-tion) and managed. Details about the Offering description are specified in D3.2.
For each Consumer, one or more Offering Queries can be created (by specifying the proper-ties of the Offerings that Consumer is interested in) and managed.
From all the matching Offerings for an Offering Query a set of Offerings the Consumer is in-terested in can be selected by creating a Subscription for that Offering. By creating such a Subscription the terms and conditions of that Offering are accepted and a contract between the Organization behind the Consumer and the Organization behind the Provider is estab-lished.
7.3.2 Persistence
As part of the Marketplace persistence framework back-end layer, we will need to imple-ment and deploy a database that will be able to store our data in the best way. This database will represent the main registry and repository where all the semantically annotat-ed (meta)data will be uploaded and saved.
In the persistent database we will need to store all the (meta)data Descriptions created and collected by marketplace stakeholders, e.g. with the information about Providers, Consum-

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 67
ers, Offering Descriptions and Recipes. In our research for a semantic interoperability in BIG IoT we decided to model our Providers, Consumers, Offering Descriptions and Recipes fol-lowing an RDF schema model, annotated with our BIG IoT Semantic Core Model and represent and exchange data in Json-ld serialization format.
So due to the nature of such kind of (meta) data we need to choose the best solution for storing, managing, accessing and retrieving information.
The semantic descriptions are generated following the BIG IoT Semantic Core Model and mapped with the BIG IoT Semantic Application Domain Model vocabularies and then will be loaded into an RDF Triple-Store.
RDF triple-store is a type of graph database that stores semantic facts. Being a graph data-base, triple-store stores data as a network of objects with materialised links between them. This makes RDF triple-store a preferred choice for managing highly interconnected data. Triple-stores are more flexible and less costly than a relational database, for example.
The RDF database, often called a semantic graph database, is also capable of handling pow-erful semantic queries and of using inference for uncovering new information out of the existing relations. In contrast to other types of graph databases, RDF triple-store engines support the concurrent storage of data, meta-data and schema models (e.g. the so called ontologies). Models/Ontologies allow for formal description of the data. They specify both object classes and relationship properties, and their hierarchical order as we use our BIG IoT models to describe our resources.
This allows to create a unified knowledge base grounded on common semantic models that allows to combine all meta-data coming from different sources making them semantically interoperable to
• create coherent queries independently from the source, format, date, time, provider, etc.
• enable the implementation of more efficient semantic querying features • enrich the data, make it more complete, more reliable, more accessible • enable to perform inference as triple materialization from some of the relations
In the following paragraphs we are going to give some more information and examples about the semantic data formalization, query interface and the interface of the seman-tic framework back-end layer with the Marketplace API.
RDF: Data Model & Serialisation Formats
Linked Data is based around describing real world things using the Resource Description Framework (RDF). The following paragraphs introduce the basic data model, and then out-line existing formats to serialize data model in RDF.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 68
RDF Data Model
RDF is a very simple, flexible, and schema-less to express and process a series of simple as-sertions. Consider the following example: “Sensor A measures 21C.” Each statement, i.e. piece of information, is represented in the form of triples (RDF triples) that link a subject (“Sensor A”), a predicate (“measures”), and an object (“21C”). The subject is the thing that is described, i.e. the resource in question. The predicate is a term used to describe or modify some aspect of the subject. It is used to denote relationships between the subject and the object. The object is, in RDF, the “target” or “value” of the triple. It can be another resource or just a literal value such as a number or word.
In RDF, resources are represented by Uniform Resource Identifiers (URIs). The subject of RDF triples must always be a resource. The typical way to represent an RDF triple is a graph, with the subject and object being nodes and the predicate a directed edge from the subject to the object. So the above example statement could be turned into an RDF triple illustrated in the figure below:
Figure: RDF triple in graph representation describing “Sensor A measures 21.8°C.”
Since objects can also be a resource with predicates and objects on their own, single triples are connected to a so-called RDF graph. In terms of graph theory, the RDF graph is a labeled and directed graph. As the illustration we extend the previous example, replacing the literal “21.8C” by a resource “Measurement” for the object in the RDF triple in the following figure. The resource itself has two predicates assigning a unit and the actual value to the measure-ment. The unit is again represented by a resource and the value is numerical literal. The resulting RDF graph looks as follows:
Figure: Simple RDF graph including the example RDF triple

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 69
Serialisation Formats
The RDF data model itself does not describe the format in which the data, i.e. the RDF graph structure, is stored, processed, or transferred. Several formats exist that serialize RDF data; the following overview lists the most popular formats, including a short description of their main characteristics and examples. Figure 2 shows a simple RDF graph to serve as the basis.
RDF/XML: The RDF/XML syntax is standardized by the W3C and is widely used to publish Linked Data on the Web. On the downside, however, the XML syntax is also viewed as diffi-cult for humans to read and write. This recommends consideration of (a) other serialization formats in data management and control workflows that involve human intervention and (b) the provision of alternative serializations for consumers who may wish to examine the raw RDF data. The RDF/XML syntax is described in detail as part of the W3C RDF Primer. The MIME type that should be used for RDF/XML within HTTP content negotiation is applica-tion/rdf+xml. The listing below shows the RDF/XML serialization for the RDF graph .
RDF/XML Serialisation Example <?xml version="1.0"?> <rdf:RDF xmlns:ex="http://www.example.org/" <rdf:Description rdf:about=" http://www.example.org/Sensor_A"> <ex:title>21.8°C</ex:title> </rdf:Description> </rdf:RDF>
Turtle: Turtle (Terse RDF Triple Language) is a plain text format for serializing RDF data. It has support for namespace prefixes and other shorthands, making Turtle typically the serial-ization format of choice for reading RDF triples or writing them by hand. A detailed introduction to Turtle is given in the W3C Team Submission document Turtle. It was accept-ed as a first working draft by the World Wide Web Consortium (W3C) RDF Working Group in August 2011, and parsing and serializing RDF data is supported by a large number of RDF toolkits. The following listing shows the serialization listing for the example RDF graph in Turtle syntax.
Turtle Serialisation Example @prefix : <http://www.example.org/> . :Sensor_A :measures “21.8°C”
N-Triples: The N-Triples syntax is a subset of Turtle, excluding features such as namespace prefixes and shorthands. Since all URIs must be specified in full in each triple, this serializa-tion format involves a lot of redundancy, typically resulting in large N-Triples particularly compared to Turtle but also to RDF/XML. This redundancy, however, enables N-Triples files to be parsed one line at a time, benefitting the loading and processing of large data files that will not fit into main memory. The redundancy also allows compressing N-Triples files with a high compression ratio, thus reducing network traffic when exchanging files. These two fac-tors make N-Triples the de facto standard for exchanging large dumps of Linked Data. The complete definition of the N-Triples syntax is given as part of the W3C RDF Test Cases rec-

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 70
ommendation. The following listing in Table 3 represents the N-Triples serialization of the example RDF graph.
N-Triples Serialisation Example <http://www.example.org/Sensor_A> <http://www.example.org/measures> “21.8°C”@en-UK .
JSON-LD: Many developers have little or no experience with Linked Data, RDF or common RDF serialization formats such as N-Triples and Turtle. This produces extra overhead in the form of a steeper learning curve when integrating new systems to consume linked data. To counter this, the project consortium decided to use a format based on a common serializa-tion format such as XML or JSON. Thus, the two remaining options are RDF/XML and JSON-LD. JSON-LD was chosen over RDF/XML as the data format for all Linked Data items in BigIoT. JSON-LD is a JSON- based serialization for Linked Data with the following design goals:
• Simplicity: There is no need for extra processors or software libraries, just the knowledge of some basic keywords.
• Compatibility: JSON-LD documents are always valid JSON documents, so the stand-ard libraries from JSON can be used.
• Expressiveness: Real-world data models can be expressed because the syntax serial-izes a directed graph.
• Terseness: The syntax is readable for humans and developers need little effort to use it.
• Zero Edits: Most of the time JSON-LD can be devolved easily from JSON- based sys-tems.
• Usable as RDF: JSON-LD can be mapped to / from RDF and can be used as RDF with-out having any knowledge about RDF.
From the above, terseness and simplicity are the main reasons why JSON-LD was chosen over RDF/XML. JSON-LD also allows for referencing external files to provide context. This means contextual information can be requested on-demand and makes JSON-LD better suit-ed to situations with high response times or low bandwidth usage requirements. We think that using JSON-LD will reduce the complexity of BigIoT development by (1) making it possi-ble to reuse a large number of existing tools and (2) reduce the inherent complexity of RDF documents. Ultimately, this will increase BigIoT’s uptake and success. In the following, we give a short overview of the main JSON-LD features and concepts. More information can be found in http://json-ld.org/.
The data model underlying JSON-LD is a labeled, directed graph. There are a few important keywords, such as @context, @id, @value, and @type. These keywords are the core part of JSON-LD. Four basic concepts should be considered:
• Context: A context in JSON-LD allows using shortcut terms to make the JSON-LD file shorter and easier to read (as well as increasing its resemblance with pure JSON). The context maps terms to IRIs. A context can also be externalized and reused for multi-ple JSON-LD files by referencing its URI.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 71
• IRIs: Internationalised Resource Identifiers (IRIs) are used to identify nodes and prop-erties in Linked Data. In JSON-LD two kinds of IRIs are used: absolute IRIs and relative IRIs. JSON-LD also allows defining a common prefix for relative IRIs using the keyword @vocab.
• Node Identifiers: Node identifiers (using the keyword @id) reference nodes external-ly. As a result of using @id, any RDF triples produced for this node would use the given IRI as their subject. If an application follows this IRI it should be able to find some more information about the node. If no node identifier is specified, the RDF mapping will use blank nodes.
• Specifying the Type: It is possible to specify the type of a distinct node with the key-word @type. When mapping to RDF, this creates a new triple with the node as the subject, a property rdf:type and the given type as the object (given as an IRI).
JSON-LD Example [{"@id":"http://www.example.org/Sensor_A","http://www.example.org/measures":[{"@value":"21.8C"}]}]
SPARQL
SPARQL (SPARQL Protocol and RDF Query Language) is the most popular query language to retrieve and manipulate data stored in RDF, and became an official W3C Recommendation in 2008. Depending on the purpose, SPARQL distinguishes the following for query variations:
• SELECT query: extraction of (raw) information from the data
• CONSTRUCT query: extraction of information and transformation into RDF
• ASK query: extraction of information resulting a True/False answer
• DESCRIBE query: extraction of RDF graph that describes the resources found
Given that RDF forms a directed, labeled graph for representing information, the most basic construct of an SPARQL query is a so-called basic graph pattern. Such a pattern is very simi-lar to an RDF triple with the exception that the subject, predicate or object may be a variable. A basic graph pattern matches a subgraph of the RDF data when RDF terms from that subgraph may be substituted for the variables and the result is RDF graph equivalent to the subgraph. Using the same identifier for variables also allow combining multiple graph patterns. To give an example, one of BigIoT offering discovery queries, the SPARQL query below returns all the organizations and their offerings
Simple SPARQL query utilizing basic graph patterns PREFIX schema: <http://schema.org/> PREFIX bigiot: <http://big-iot.eu/ns#> PREFIX datex: <http://vocab.datex.org/terms#> SELECT ?orgName ?proName ?offName

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 72
FROM <http://big-iot.eu/offerings#> WHERE{ ?org a schema:Organisation. ?org rdfs:label ?orgName. ?provider schema:organisations ?org. ?provider bigiot:offering ?offering. ?provider rdfs:label ?proName. ?offering schema:name ?offName. }
Besides aforementioned graph patterns, the SPARQL 1.1 standard also supports the sorting (ORDER BY), and the limitation of result sets (LIMIT, OFFSET), the elimination of duplicates (DISTINCT), the formulation of conditions over the value of variables (FILTER), and the possi-bility to declare a constraint as OPTIONAL. The SPARQL 1.1 standard significantly extended the expressiveness of SPARQL. In more detail the new features include:
• Grouping (GROUP BY), and conditions on groups (HAVING) • Aggregates (CONT, SUM, MIN, MAX, AVG, etc.) • Subqueries to embed SPARQL queries directly within other queries • Negation to, e.g., check for the absence of data triples • Project expression, e.g., to use numerical result values in the SELECT clause within
mathematical formulas and assign new variable names to the result • Update statements to add, change, or delete statements • Variable assignments to bind expressions to variables in a graph pattern • New built-in functions and operators, including string functions (e.g., CONCAT, CON-
TAINS), string digest functions (e.g., MD5, SHA1), numeric functions (e.g., ABS, ROUND), or date/time functions (e.g., NOW, DAY, HOURS)
To give a short example, the query below counts for each organization the number of offer-ings. The results are sorted with respect to the number of offerings in a descending manner.
Example SPARQL 1.1 query PREFIX schema: <http://schema.org/> PREFIX bigiot: <http://big-iot.eu/ns#> PREFIX datex: <http://vocab.datex.org/terms#> SELECT ?orgName count(?offering) as ?numberOfOffers FROM <http://big-iot.eu/offerings#> WHERE{ ?org a schema:Organisation. ?org rdfs:label ?orgName. ?provider schema:organisations ?org. ?provider bigiot:offering ?offering. ?provider rdfs:label ?proName. }GROUP BY ?org ORDER BY DESC(COUNT(?offering))
BIG IoT Semantic Model
The BIG IoT Semantic Core Model that defines also the main RDF data schema of the stored information is described in D3.2.a. It is the semantic model used as a basis for (1) the Offer-

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 73
ing Description to define the capabilities of Offerings provided by IoT Platforms or Services, (2) the metadata description of other entities e.g. Providers, Consumers, and (3) the underly-ing data model of the BIG IoT Marketplace.
In D4.2.a the BIG IoT Semantic Application Domain Model is defined, which specifies vo-cabulary of terms that will be used in semantically annotating the Offering Descriptions, and in the triple store of the Marketplace.
And in D4.3.a there are the specifications of the Semantic Recipe Model and examples of BIG IoT Recipes that will be stored in our repository.
GraphQL <-> SPARQL Integration
In our ecosystem the Marketplace uses the Marketplace API as an aggregator that collects data from the Marketplace internal services (Access Management, Exchange, Accounting, Charging) and provides it to clients like the Marketplace Portal, e.g. the Marketplace Portal fetches all data it needs to display one complete page of the UI with one access.
Considering that the Portal UI needs a simple query language to retrieve the data used to populate the graphical user interface, it was decided to utilize an API interface based on GraphQL, a query language for APIs, that has proven to be a very simple and easy framework to use and implement for this scope.
However, considering our next implementation of a triple store, as the main "database" for our semantic (meta)data and for leveraging the power and functionalities of semantic que-ries we need to implement a SPARQL query engine on top of it.
Once the data is expressed in RDF, the use of SPARQL, as query processor engine, to find specific knowledge information is extensible effective. These queries can go from simple to more complex and select whole documents or sub-patterns that match conditions defined on data content and structure.
For this purpose, in order to integrate the two interfaces, we need to enable a way to ac-quire, translate and map the queries between GraphQL and SPARQL.
In the following part we present a first development implementation of this mapping and translation process.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 74
Example 1: Querying All Organizations and accounting info
Request
The following GraphQL request queries for all organizations registered at the eXchange.
GraphQL - Query query { allOrganizations { organisations { id name price { pricingModel { name } } } } }
On the backend, this GraphQL query translates to the following Sparql query:
Sparql - Query prefix bigiot: <http://big-iot.eu/core#> prefix schema: <http://schema.org/> select ?organisationId ?organisationName ?accountingModel from <http://big-iot.eu/offering#> where{ ?offering schema:organisation ?organisation. ?organisation schema:name ?organisationName. ?organisation bigiot:organizationId ?organisationId. ?offering schema:priceSpecification ?price. ?price bigiot:pricingModel ?pricingModel. }
Response
The response of the GraphQL query above looks like this:
GraphQL - Response { "data": { "allOrganizations": { "organisations": [ { "id": "Barcelona_City", "name": "Barcelona City", "price": { "pricingModel": { "name": "Free" }

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 75
} }, { "id": "CSI", "name": "CSI", "price": { "pricingModel": { "name": "Per Month" } } } ] } } }
This GraphQL response has been created based on the following Sparql response in HTML Table:
organisationId organisationName accoutingModel "Barcelona_City" "Barcelona City" "FREE"
"CSI" "CSI" "PER MONTH"
or in JSON:
SPARQL Response { "head": { "link": [], "vars": [ "organisationId", "organisationName", "accoutingModel" ] }, "results": { "distinct": false, "ordered": true, "bindings": [ { "organisationId": { "type": "literal", "value": "Barcelona_City" }, "organisationName": { "type": "literal", "value": "Barcelona City" }, "pricingModel": { "type": "literal", "value": "FREE" } }, { "organisationId": { "type": "literal",

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 76
"value": "CSI" }, "organisationName": { "type": "literal", "value": "CSI" }, "pricingModel": { "type": "literal", "value": "PER_MONTH" } } ] } }
Example 2: Querying All the offerings
Request
The following GraphQL request queries for all organizations registered at the eXchange.
GraphQL - Query query q1 { allOfferings { offerings { id name } } }
On the backend, this GraphQL query translates to the following Sparql query:
Sparql - Query prefix bigiot: <http://big-iot.eu/core#> prefix schema: <http://schema.org/> select ?offeringId ?offeringName from <http://big-iot.eu/offering#> where{ ?offering a bigiot:Offering. ?offering schema:name ?offeringName. ?offering bigiot:offeringId ?offeringId. }
Response
The response of the GraphQL query above looks like this:
GraphQL - Response { "data": { "allOfferings": {

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 77
"offerings": [ { "id": "Barcelona_City-provider3-offering3", "name": "Barcelona Parking Sensors" }, { "id": "CSI-provider1-offering2", "name": "Montalto Dora Parking Sensors" }, { "id": "CSI-provider1-offering1", "name": "Montalto Dora Traffic counter" } ] } } }
This GraphQL response has been created based on the following Sparql response in HTML Table:
offeringId offeringName "Barcelona_City-provider3-offering3" "Barcelona Parking Sensors" "CSI-provider1-offering2" "Montalto Dora Parking Sensors" "CSI-provider1-offering1" "Montalto Dora Traffic counter"
or in JSON:
SPARQL Response { "head": { "link": [], "vars": [ "offeringId", "offeringName" ] }, "results": { "distinct": false, "ordered": true, "bindings": [ { "offeringId": { "type": "literal", "value": "Barcelona_City-provider3-offering3" }, "offeringName": { "type": "literal", "value": "Barcelona Parking Sensors" } }, { "offeringId": { "type": "literal", "value": "CSI-provider1-offering2" },

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 78
"offeringName": { "type": "literal", "value": "Montalto Dora Parking Sensors" } }, { "offeringId": { "type": "literal", "value": "CSI-provider1-offering1" }, "offeringName": { "type": "literal", "value": "Montalto Dora Traffic counter" } } ] } }
7.4 Accounting
The Accounting service collects information about each access of any Consumer to any Of-fering via the corresponding Providers. It is notified by both the Consumer Lib on the client side and the Provider Lib on the server side of that connection about each access to be able to recognize and handle fraud.
The Marketplace Portal will visualize the accounting data to show Providers how their Offer-ings are utilized and show Consumers what Resources where necessary for their services.
Accounting data will later also be the base for the Charging service to calculate costs caused by Consumers and revenues created by Providers.
Details about this service will be specified in the next iteration D4.1b of this document.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 79
8 Security
This section is a work in progress, and reflects the current state of the discussion in the con-text of BIG IoT Marketplace and API implementation.
At the time of writing, Auth0 (https://auth0.com) is used as an OAuth 2.0 Authorization Server implementation. Details can be found at https://auth0.com/how-it-works.
Authentication is relayed to external Identity Providers authentication services (Google, GitHub) and no user credentials (user names, passwords) are stored in the BIG IoT Market-place System.
All requests accessing the Marketplace API have to be authorized. Responsible for that au-thorization on the Marketplace is the Marketplace Access Management (AM) service (see chapter 7.2 Access Management).
The Marketplace will use the following concepts to achieve security for authentication and authorization (all tokens mentioned are JSON Web Tokens (JWT)):
8.1 Access Control for human users accessing the Marketplace Portal
Identification:
• The user identities are stored in the external Identity Provider systems and are based on the user's email address
Authentication:
• The external Identity Provider is responsible for validating the correct user creden-tials (user name and password)
Authorization:
• The Auth0 authorization server delivers the access token for the Marketplace Portal to access the Marketplace API
• Marketplace AM can validate the access token that is signed with the Marketplace secret (shared secret between Auth0 and Marketplace)
8.2 Access Control for Providers accessing the Marketplace
Identification:
• Identification is based on provider id issued by the Marketplace AM

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 80
Authentication:
• When a Provider wants to access the Marketplace, it sends an Authorization Request with the provider id and gets back a provider token, that is encrypted with the pro-vider secret (shared between Marketplace AM and Provider)
Authorization:
• Marketplace AM can authorize the requests from a Provider by validating the given provider token
8.3 Access Control for Consumers accessing the Marketplace
Identification:
• Identification is based on consumer id issued by the Marketplace AM
Authentication:
• When a Consumer wants to access the Marketplace, it sends an Authorization Re-quest with the consumer id and gets back a consumer token, that is encrypted with the consumer secret (shared between Marketplace AM and Consumer)
Authorization:
• Marketplace AM can authorize the requests from a Consumer by validating the giv-en consumer token
8.4 Access Control for Consumers accessing Provider resources
Identification:
• Identification is based on subscription id issued by the Marketplace AM
Authentication:
• When a Consumer wants to access an Offering, it first has to create a Subscription for that Offering on the Marketplace
• For each Subscription it gets back the endpoint information and the subscription to-ken issued by the Marketplace AM
• This subscription token is signed by the provider secret (shared between Marketplace AM and Provider) and contains among others the subscription id
Authorization:

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 81
• The Marketplace AM authorizes the Consumer by issuing an subscription token to the Consumer per Subscription
• The Provider Lib validates the signature of the subscription token that is signed with the provider secret
8.5 Marketplace endpoints TLS settings
To be protected against eavesdropping or hijacking of sessions, the use of TLS is mandatory when using OAuth 2.0. The Marketplace will use HTTPS (HTTP over SSL/TLS) endpoints se-cured by:
• a server certificate issued by an trusted certification authority to prove its identity • the use of a strong transport layer security protocol (e.g. TLS 1.2) • the use of a strong key exchange algorithm (e.g. ECDH) • the use of strong ciphers (e.g. AES_256_GCM) to protect the communication channel
8.6 Auth0 Configuration
The Portal is administrated in Auth0 as a single page application, the client id and client se-cret (marketplace secret) are generated by Auth0 and the Marketplace Access Management is configured with that information by the Marketplace Operator.
The administrated Allowed Callback URLs define the allowed endpoints where the user may be redirected to after being successfully authenticated via the external Identity Provider.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 82
8.7 Security Tokens
User Token
The user token is used to authorize the Platform/Service/Application Operator access to the Marketplace. The token is issued by the Auth0 Authorization Server after validating the user credentials via an authentication redirect to the IdP.
Provider Token
The provider token is used to authorize the Provider access to the Marketplace. The token is issued by the Marketplace AM and is delivered to the Provider encrypted with the provider secret (shared between the Provider and the Marketplace).
Consumer Token
The consumer token is used to authorize the Consumer access to the Marketplace. The token is issued by the Marketplace AM and is delivered to the Consumer encrypted with the consumer secret (shared between the Consumer and the Marketplace).
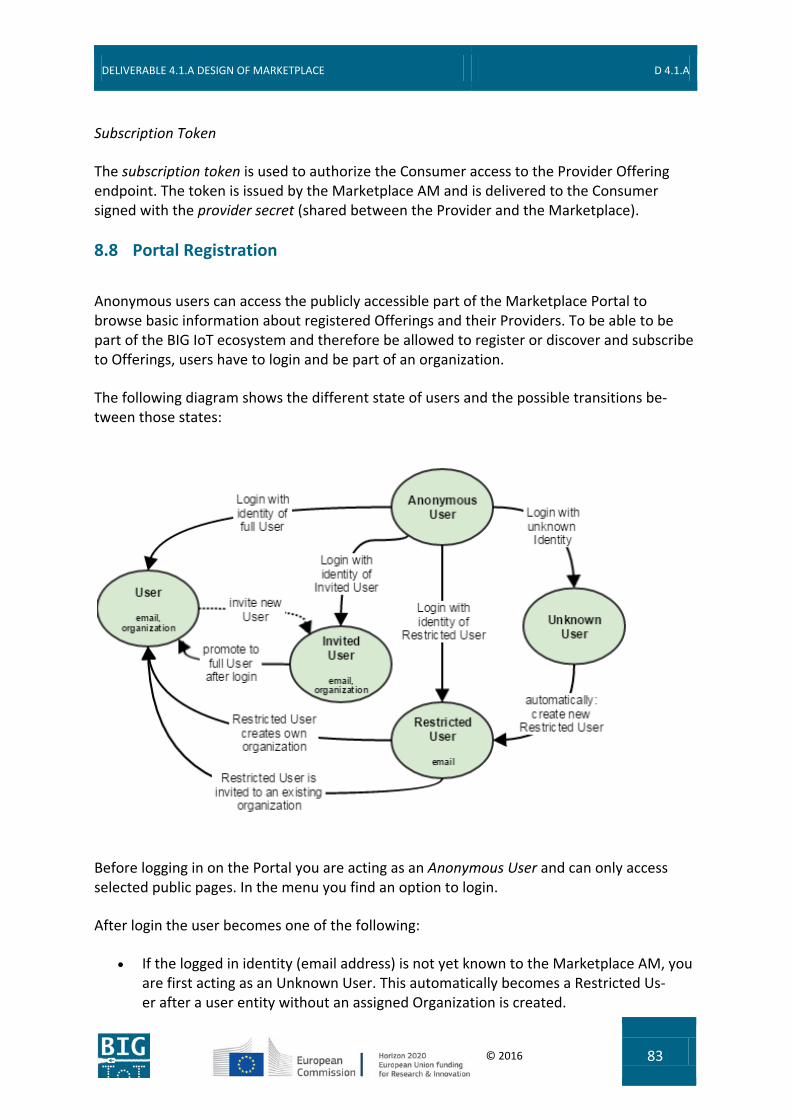
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 83
Subscription Token
The subscription token is used to authorize the Consumer access to the Provider Offering endpoint. The token is issued by the Marketplace AM and is delivered to the Consumer signed with the provider secret (shared between the Provider and the Marketplace).
8.8 Portal Registration
Anonymous users can access the publicly accessible part of the Marketplace Portal to browse basic information about registered Offerings and their Providers. To be able to be part of the BIG IoT ecosystem and therefore be allowed to register or discover and subscribe to Offerings, users have to login and be part of an organization.
The following diagram shows the different state of users and the possible transitions be-tween those states:
Before logging in on the Portal you are acting as an Anonymous User and can only access selected public pages. In the menu you find an option to login.
After login the user becomes one of the following:
• If the logged in identity (email address) is not yet known to the Marketplace AM, you are first acting as an Unknown User. This automatically becomes a Restricted Us-er after a user entity without an assigned Organization is created.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 84
• If the identity is connected to a Restricted User, you are now acting as such a Restricted User and have no Organization assigned. The only additional permission you now have compared to an Anonymous User is that you can create your own Or-ganization.
• If the identity is connected to an Invited User, it becomes promoted to a full User (see below).
• If the identity is connected to a full User, you are from now on acting as a fully quali-fied User with an assigned organization. This User has permission to manage all entities already assigned to this Organization (Provider, Offering, Consumer, Query, Subscription) and to create new such entities.
The only way to assign a Restricted User to an existing Organization is by invitation, i.e. you can invite a new User to your Organization by giving his identity (email address) when you are already logged in. If you are inviting an identity that is not connected to a Restricted Us-er, a new Invited User with that identity is created and will be promoted to a full User on the first login.
8.9 Portal Login Flow
Operators (Developer or User of a Provider/Consumer Organization referred as operator later on) access the Marketplace Portal, for registering themselves for the first time or login, will hit the Portal Login page and will get a redirect via the Auth0 authorization server to the administrated federated identity providers (external site e.g. GitHub or Google) to provide their corresponding credentials (e.g. user name and password).
Prerequisite:
• The operator has a valid account on Auth0 or on one of the supported external Iden-tity Providers (IdP). Alternatively he can also sign up for a new account using the Login Page.
Flow:
• The operator accesses the Marketplace Portal URL by the means of a web browser and the Marketplace Portal single page application (SPA) will be downloaded to the user's browser environment.
• The Portal SPA will present the login dialog with the list of enabled IdPs • The operator chooses the IdP and the Marketplace SPA redirects to the federated IdP • The operator authenticates with the IdP and after successful verification of the cre-
dentials (based on Oauth2 Implicit Grant Type) one will be redirected to the Marketplace Portal SPA with an OAuth 2.0 bearer token, the user token.
• The Browser obtains the user token, which is saved in local storage and used in sub-sequent accesses to the Marketplace (in the authorization header of the HTTP request)

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 85
8.10 Marketplace Interactions
The following section describes the Marketplace interactions from the security point of view. The same scenario that was already introduced in chapter 4 Marketplace Workflows is used here and is enriched with details about security.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 86
Prerequisite:
• The operators have a valid account on one of the supported Identity Providers (IdP) • The users connected to that accounts are already assigned to Organizations in the
Marketplace • Both Offering Consumer and Provider are registered with the Marketplace • Offering registration through the Provider takes place prior to the Consumer query • The Consumer and Provider Libs are capable to communicate with the Marketplace
API. • The marketplace endpoints are up and running (TLS 1.2 secured endpoints)
Flow:
1. Platform Operator logs in (details see above in Portal Login Flow) 2. Platform Operator creates new Provider
1. User opens New Provider page and enters Provider description 2. Portal sends Create Provider request to Marketplace API including provider
description (authorized by the user token) 3. Exchange creates Provider with provider id and registers Provider with AM 4. AM generates provider secret 5. Marketplace API returns the Provider information (provider id and provider
secret) 6. Portal provides provider id and provider secret for configuration of Platform
3. Platform Operator creates new Offering (or alternatively Platform creates new Offer-ing)
1. User opens New Offering page and enters Offering description 2. Portal sends Create Offering request to Marketplace API including offering de-
scription (authorized by the user token) 3. Exchange creates Offering with offering id 4. Marketplace API returns offering id 5. Portal provides offering id for configuration of Platform
4. Platform Operator configures the Platform (acting as an Offering Provider) with the provider id, provider secret and offering id (with out of band means, e.g. copy/paste)
5. When the Platform starts, 1. Provider Lib creates Offering endpoint 2. Provider Lib sends an Authorization Request to the Marketplace API contain-
ing the provider id 3. Marketplace AM issues an provider token encrypted by the provider secret 4. Marketplace API returns the encrypted provider token 5. Provider Lib decrypts and saves the provider token for further use 6. Platform sends Activate Offering request to Marketplace API includ-
ing offering id (authorized by the provider token) 7. Exchange activates the Offering with offering id. This Offering is now available
to be subscribed to

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 87
6. Application Operator logs in (details see above in Portal Login Flow) 7. Application Operator creates new Consumer
1. User opens New Consumer page and enters Consumer description 2. Portal sends Create Consumer request to Marketplace API including consumer
description (authorized by the user token) 3. Exchange creates Consumer with consumer id and registers Consumer with
AM 4. AM generates consumer secret 5. Marketplace API returns the Consumer information (consumer id and con-
sumer secret) 6. Portal provides consumer id and consumer secret for configuration of Applica-
tion 8. Application Operator creates new Query (or alternatively Application creates new
Query) 1. User opens New Query page and enters Query description 2. Portal sends Create Query request to Marketplace API including query de-
scription (authorized by the user token) 3. Exchange creates Query with query id 4. Marketplace API returns query id and matching Offerings 5. Portal provides query id for configuration of Application
9. Application Operator subscribes to one or more Offerings for that Query (or alterna-tively Application subscribes to Offerings)
1. User selects Offerings to subscribe 2. Portal sends Subscribe Offerings request to Marketplace API including query
id and offering ids of selected Offerings (authorized by the user token) 3. Marketplace AM creates a new Subscription with subscription id for each sub-
scribed Offering (containing query id and offering id) 4. Marketplace AM issues a subscription token signed with the provider secret
(containing subscription id, query id and offering id together with expiration and scope)
10. Application Operator configures the Application (acting as an Offering Consumer) with the consumer id, consumer secret and query id (with out of bands means, e.g. copy/paste)
11. When the Application starts, it requests its Subscriptions form the Marketplace 1. Consumer Lib sends an Authorization Request containing the consumer id 2. Marketplace AM issues a consumer token encrypted by the consumer secret 3. Marketplace API returns the encrypted consumer token 4. Consumer Lib decrypts and saves the consumer token for further use 5. Application sends Get Subscriptions with query id to the Marketplace API (au-
thorized by the consumer token) 6. Marketplace returns for each Subscription the Offering endpoint information,
the subscription id and the subscription token
12. Consumer accesses the Offering

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 88
1. Consumer Lib accesses the Offering endpoint providing input data fields (au-thorized by the subscription token)
2. Provider Lib validates the signature of the subscription token with the provid-er secret and also checks expiration and scope
3. Provider Lib saves subscription id from subscription token for accounting 4. Provider Lib calls the Platform with given input data fields 5. Provider Lib returns resulting output data fields
13. Accounting 1. Provider Lib sends Accounting Information to the Marketplace API provid-
ing subscription id (authorized by the provider token) 2. Consumer Lib sends Accounting Information to the Marketplace API provid-
ing subscription id (authorized by the consumer token) 3. Marketplace Accounting collects accounting information for Subscription with
subscription id

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 89
9 Marketplace Development and Operations
In this chapter the development- and deployment-specific aspects of the Marketplace appli-cation are defined, which are
• DevOps Concepts • Docker • Provisioning • Hosting Platform • Provisioning strategy • Deployment Topology • Deployment workflow • Logging • Monitoring and Alerting • Local development environment
9.1 DevOps Concepts
Essentially, DevOps is the practice of operations and development engineers participating together in the entire service lifecycle, from design through the development pro-cess to production support. For the development of the Marketplace a DevOps approach shall be used. Although we might not be able to employ the complete DevOps idea in its full beauty (due to resource constraints), we will utilize some of the key concepts and principles throughout the implementation.
9.1.1 Automation
A fully automated deployment pipeline will be established to enable frequent updates of the components of the Marketplace. The stages of the deployment pipeline comprise
• the GitLab repository, • the automated build service provided by GitLab CI (automated build, unit test, docu-
mentation generation) • and finally a test environment on the hosting platform where the build artifacts
(=Docker images) are deployed after a successful build.
9.1.2 Everything as Code
The idea behind the Everything as Code concept is that infrastructure and operations related building blocks are all described and treated like application code such that they follow the same software development lifecycle practices. Infrastructure is codified in a declarative specification such as so called "resource templates" for Azure Cloud or "Cloud Formation templates" for AWS cloud. Ansible playbooks are used for setting up the hosting and devel-

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 90
opment environments. For the local development environment Vagrant and Docker Com-pose are used. Configuration files/templates of all those tools are kept in the project's Git repository to track and make changes to infrastructure and applications in a predictable, governed manner.
9.1.3 Measurement
In order to know how the components are performing at any point in time a monitoring so-lution based on Prometheus will be set up. On the one hand constant improvement and optimization is only possible if it is based on valid facts. On the other hand watching metrics carefully shall ensure that no degradation happens as releases with increasing frequency are pushed out. Measurement takes place not only on application/platform level but also on the level of the deployment pipeline (and ideally even on process/organizational level).
9.2 Docker
This chapter describes - very briefly - the basic principles of Docker and why it is useful to leverage the power of this tool for the Marketplace development. The detailed description of Docker and its components and workflows are beyond the scope of this document. Nu-merous online resources exist with in-depth documentation. Docker (http://www.docker.com/) is the state-of-the-art container technology with a high penetra-tion in the IT landscape.
9.2.1 Docker images and containers
A Docker image is a binary that includes all of the requirements for running a single Docker container, as well as metadata describing its needs and capabilities. It can be considered as a stack of read-only file system layers that form the container's root file system. Docker con-tainers are the runtime instance of a Docker image which adds a read-write layer on top of the image's read-only layers. Docker containers only have access to resources defined inside the image, unless the container is given additional access when creating it (e.g. directories of the host file system or a network storage volume can be mapped into a container). Dock-er containers sit on top of the host OS and share the host OS kernel. This is an important difference compared to traditional virtual machines. When a container is removed, the read-write layer is removed as well, leaving the host system in its previous state.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 91
By deploying the same image in multiple containers across multiple hosts - even with differ-ent operating systems - and load balancing between them, you gain redundancy and horizontal scaling for a service packaged into an image. Once built, the docker container runs on any platform that is supported by the Docker Engine, thus making them extremely porta-ble ("build once, run everywhere").
A comprehensive overview about images and containers is available at https://docs.docker.com/engine/userguide/storagedriver/imagesandcontainers/.
9.2.2 Docker Registry
A Docker registry is a service for storing ("pushing") and retrieving ("pulling") Docker images. A registry contains a collection of one or more Docker image repositories. Each image repos-itory contains one or more tagged images. For the Marketplace development, the private registry of GitLab will be used.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 92
A docker image is identified by an URL as shown above. Multiple images of the same image repository are differentiated by using different image tags. The Docker images generated during the build process are tagged with the Git commit hash. This clearly relates a Docker image with corresponding commit that triggered the build.
Note: If the registry host is omitted, the host name of the public Docker registry at https://hub.docker.com is used implicitly.
9.2.3 Docker Compose
Docker Compose (https://docs.docker.com/compose/) is a utility for defining and running multi-container applications. For the Marketplace development Docker Compose is used to run the Docker containers in the local development environment. Docker compose lets you specify the characteristics of how multiple Docker containers work together and takes care of automatic updates of single containers. As usual the specification of a multi-container application is written in YAML. See chapter Local Development Environment for a detailed example of a Docker compose file.
9.2.4 Docker and DevOps
Since Docker images contain all dependencies that are required to run the corresponding container, Docker simplifies continuous deployment workflows. This is due to the fact that a docker container can be spun up on any node running a docker engine without the need to configure the host system in advance.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 93
Another important aspect is that a Docker image can be removed from a host without leav-ing artifacts that may lead to unpredictable behavior the next time the container starts to run. This is especially useful in testing scenarios. By using Docker containers for test runs it is ensured that the tests always start in a predictable environment.
Every deployment unit of the Marketplace service will be packaged as a Docker image and stored in the project's Docker registry at GitLab. 3rd-party products such as components of the ELK stack, Cassandra, Kafka, etc. will be pulled from the official Docker repositories at Docker Hub (https://hub.docker.com/).
9.3 Provisioning
It has to be ensured that the Infrastructure components required to host and run the mar-ketplace application containers are created, configured and provisioned automatically and in reproducible manner. This is even more important in public cloud environments where lots of different resources have to be setup properly (and repeatedly). At its core these are
• virtual machines • load balancers • firewalls (security groups) • virtual networks • storage volumes • and so on and so forth
Doing this manually is error-prone and will in most cases lead to different configurations. Thus it is essential to stick to the paradigm of "Infrastructure as Code" (IaC) which is the pro-cess of managing and provisioning computing infrastructure and their configuration through machine-processable definition files rather than through interactive configuration tools (i.e. Web GUIs). One open source utility that supports this idea is Ansible (https://www.ansible.com/) which will be used in this project.
See also https://en.wikipedia.org/wiki/Infrastructure_as_Code.
9.3.1 Ansible
Ansible is a quite young automation tool that has many advantages compared to products like Chef or Puppet
• Very few dependencies (in fact there are exactly 2) o The systems that shall be managed by Ansible must have Python installed o The systems that shall be managed by Ansible must be reachable via standard
SSH (public key authentication) • Declarative configuration language that is very easy to learn
o YAML o Plain text "Playbooks" stored and versioned in Git
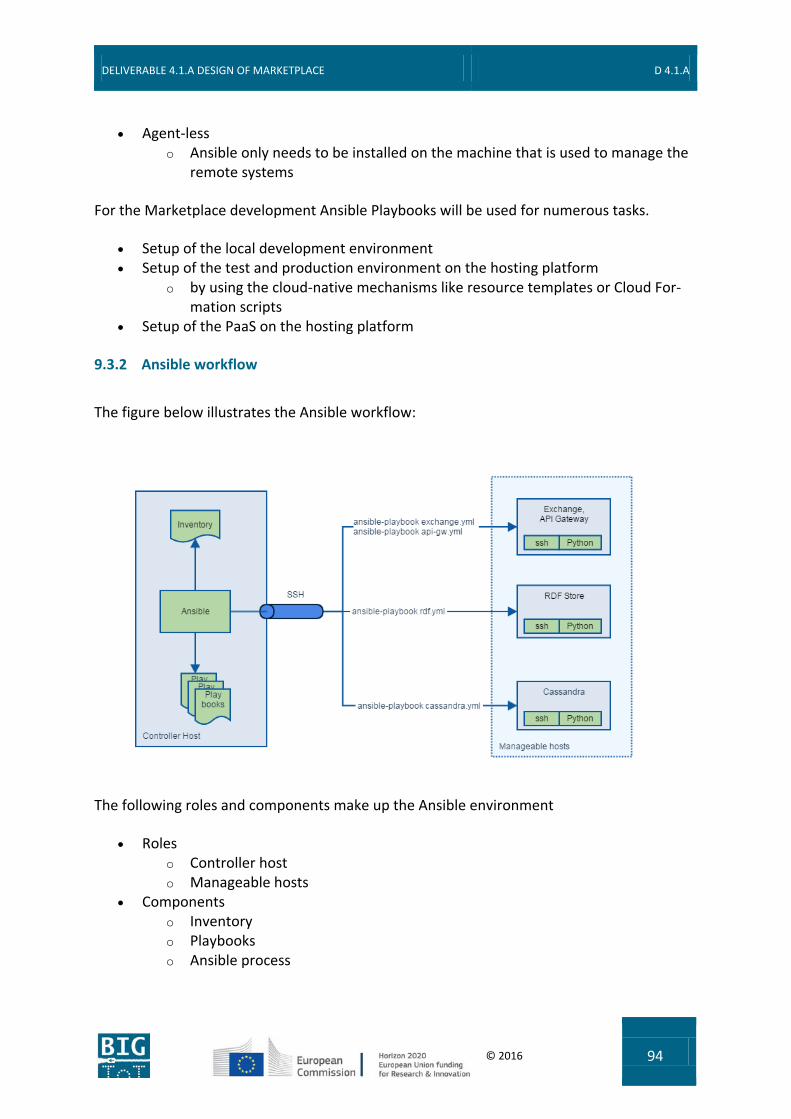
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 94
• Agent-less o Ansible only needs to be installed on the machine that is used to manage the
remote systems
For the Marketplace development Ansible Playbooks will be used for numerous tasks.
• Setup of the local development environment • Setup of the test and production environment on the hosting platform
o by using the cloud-native mechanisms like resource templates or Cloud For-mation scripts
• Setup of the PaaS on the hosting platform
9.3.2 Ansible workflow
The figure below illustrates the Ansible workflow:
The following roles and components make up the Ansible environment
• Roles o Controller host o Manageable hosts
• Components o Inventory o Playbooks o Ansible process

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 95
The controller host is the machine where Ansible is installed and playbooks are executed. The manageable hosts are all machines that shall be provisioned with Ansible. The funda-mental requirements for manageable hosts are that ssh and Python are installed.
The inventory is a INI-style text file where groups of host names or IP addresses of the man-ageable hosts are listed. For all major public environments there are so called "dynamic inventories" available. As hosts come and go with different IP addresses, static configuration of inventories might be cumbersome.
Playbooks are the essential building blocks which describe "desired states" of manageable hosts in declarative style. Again, YAML files are used here. Playbooks contain so called "plays" and plays consist of a list of tasks. The code snipped below shows a simple playbook with 2 plays and several tasks.
--- - hosts: frontend tasks: - name: ensure nginx is installed apt: name=nginx state=latest tags: [installation] - name: ensure nginx is enabled service: name=nginx enabled=yes state=started tags: [installation] - name: ensure nginx is running service: name=nginx state=restarted tags: [installation, restart] - hosts: rdfhosts tasks: - ...
The first block starting with "- host" defines a "play" that is dedicated to the hosts in the group "frontend". This play consists of a list of tasks for installing and managing the Nginx service. The first task says that the latest version of nginx shall be installed while second task declares that nginx shall be enabled in the OS's init system. Finally, the third task specifies state=restarted meaning that if this task gets executed the service nginx will be restarted regardless if it is already running or not. The first time the playbook is run, Ansible will try to establish the desired state. If Ansible is run a second time then all tasks will be skipped which are already in the desired state.
9.4 Hosting Platform
The first release of the Marketplace application along with all its required sub-components (databases, monitoring and logging services) are hosted in the Microsoft Azure Cloud.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 96
9.5 Deployment Topology
The figure below shows the logical view of the Marketplace deployment. In this context "log-ical" means, that each service is not necessarily associated with a single physical node. Rather it represents one or multiple Docker containers running on one or multiple virtual machines. For instance, API Gateway and portal server may run on the same node in the first release. Similarly, the monitoring and logging frontends may share the same node.
The entire infrastructure is deployed in a virtual network (or virtual private cloud) on the hosting platform. From a networking point-of-view two subnets are used, a frontend subnet for the internet-facing services and a backend subnet for the backend services. Access to both subnets is protected by security groups (layer 4 access control lists).

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 97
The application gateway in the frontend subnet fullfills several roles. Basically it acts as re-verse proxy which performs SSL termination and forwards the decrypted requests to the corresponding frontend services based on the URL path of the HTTPS request. The internal load balancer in the backend subnet distributes requests from the frontend to the backend accordingly.
Mapping of URL paths to frontend services
URL path Frontend service
/api API Gateway
/portal Portal Server
/monitor Monitoring Frontend
/log Logging Frontend
9.5.1 Deployment Workflow
In this chapter, the workflow that is used for the deployment of the Marketplace software components is described. This workflow aims to empower a continuous deployment ap-proach by automating most of the stages of the deployment pipeline. The components of the deployment pipeline are described in the subsequent chapters.
GitLab source repository
The entire source code of the Marketplace software components is stored in GitLab (https://gitlab.com/). There are separate repositories for both the Exchange and the API Gateway services.
GitLab CI
GitLab provides an integrated CI (Continuous Integration) facility, which provides automatic build, test and deployment of the build artifacts. In GitLab CI, deployment pipelines are spec-ified in a plain text YAML file, named .gitlab-ci.yml, which is stored in the root folder of the project repository. As soon as a Git push happens the CI pipeline is executed.
GitLab Runner
A GitLab runner is a process that executes the build pipeline as specified in the .gitlab-ci.yml file. GitLab offers two kinds of runners, shared and specific. Shared runners are shared among different GitLab projects and have some restrictions, especially when dealing with Docker builds. Due to these facts we use specific runners for every Marketplace project. They are running on dedicated machines on the hosting platform.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 98
GitLab Docker Registry
Build artifacts - which are Docker images - are stored in the Docker registry of GitLab where-as each GitLab project has its own dedicated registry. To be able to correlate Docker images with the corresponding contents of the Git commit, a naming scheme for Docker images is introduced that uses the commit hash as the tag for the Docker image, e.g.:
Name Tag Docker Image ID registry.gitlab.com/big-iot/exchange 1dcc8d33e0015dc6be8160ff25c12a0337c46fb2 00e7d410c registry.gitlab.com/big-iot/exchange latest 00e7d410c
In the example above the image name would be:
registry.gitlab.com/big-iot/exchange
whereas the image tag (which is the same as the commit hash) is
1dcc8d33e0015dc6be8160ff25c12a0337c46fb2
Note that one Docker image (same Docker Image ID) may have several tags. For instance, the "latest" tag is used to mark the most recent Docker image.
Hosting Platform
The Marketplace software will be deployed in a cloud environment. The assumption is that Microsoft Azure will be used for the first deployment of the Marketplace.
PaaS - Platform as a Service
The PaaS layer is responsible for the management and orchestration of the Docker contain-ers and its dependent components. This includes
• Rolling upgrade of containers with zero downtime • Scaling of containers • Replication of containers • Automatic restart of containers • Service Discovery
In order to save resources for the first release of the Marketplace it might be decided to use the cloud providers native orchestration systems instead of using a cloud-provider-independent solution like Kubernetes, Mesos/Marathon or Nomad.
Test Environment
After a component has been built and unit-tested successfully, it is automatically deployed into the test environment. The test environment is completely decoupled from the produc-
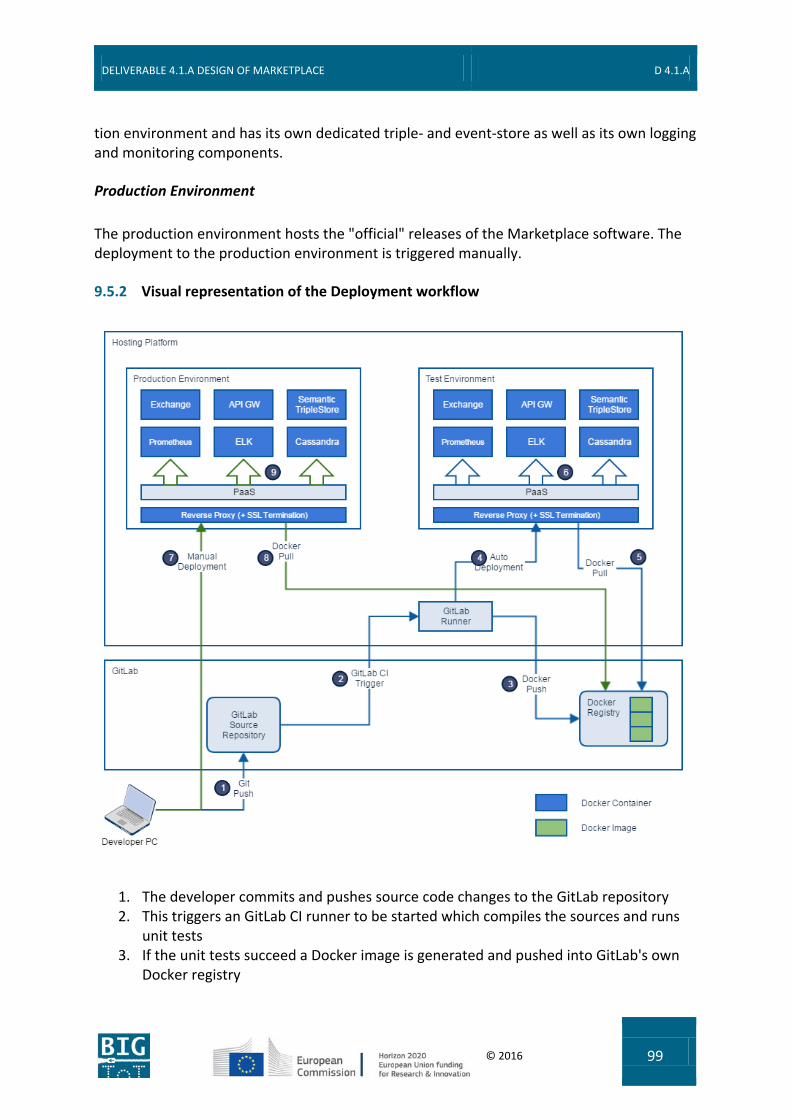
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 99
tion environment and has its own dedicated triple- and event-store as well as its own logging and monitoring components.
Production Environment
The production environment hosts the "official" releases of the Marketplace software. The deployment to the production environment is triggered manually.
9.5.2 Visual representation of the Deployment workflow
1. The developer commits and pushes source code changes to the GitLab repository 2. This triggers an GitLab CI runner to be started which compiles the sources and runs
unit tests 3. If the unit tests succeed a Docker image is generated and pushed into GitLab's own
Docker registry

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 100
4. After the Docker image has been successfully pushed to the Docker registry, a de-ployment request is sent to the PaaS software of the test environment
5. The PaaS software pulls the Docker image to be deployed from the Docker registry 6. The PaaS software performs a rolling upgrade of the Docker container. After the up-
grade has completed the newly deployed software can be tested in the test environment
7. If the new software is considered to be stable it is promoted to the production envi-ronment by manually sending a deployment request to the PaaS software of the production environment
8. The PaaS software pulls the Docker image to be deployed from the Docker registry 9. The PaaS software of the production environment performs a rolling upgrade of the
Docker container. As soon as the upgrade has completed the new version of the software is immediately available in the production environment
9.6 Logging
A centralized logging approach is inevitable for distributed (cloud-)applications in order to perform efficient system and error analysis by correlation log information from different sources in a common place.
In the past years the Elastic Stack (https://www.elastic.co/) has gained massive popularity in the domain of log collection, processing, analytics and visualization in near real time. The Elastic Stack is a collection of Open Source tools and will be used for log processing in the Marketplace deployment environment. Essentially, the core Elastic Stack (formerly called ELK Stack) consists of 4 components:
• Beats • Logstash • Elasticsearch • Kibana
Beats are lightweight agents that are basically running on nodes where logs should be col-lected from. Beats come in different flavors like FileBeat, which reads log messages from log files or TopBeat, which scans typical operating system metrics like CPU load, memory usage, disk I/O, etc. In the Marketplace logging infrastructure FileBeat will be used for collecting log messages from application and system log files.
Logstash is a data ingestion and enrichment utility that is capable of receiving logs from Beats (and many other sources which are out of scope for our purpose). Messages received by Logstash can be enriched with arbitrary data or even be transformed to completely new message formats. Finally, Logstash sends data to Elasticsearch for persistent storage.
Elasticsearch is essentially a distributed search and analytics engine. It provides a RESTful API for querying and analyzing data. From an operations point-of-view it is easily scalable to higher workloads but can be run as a single instance on a development host as well.
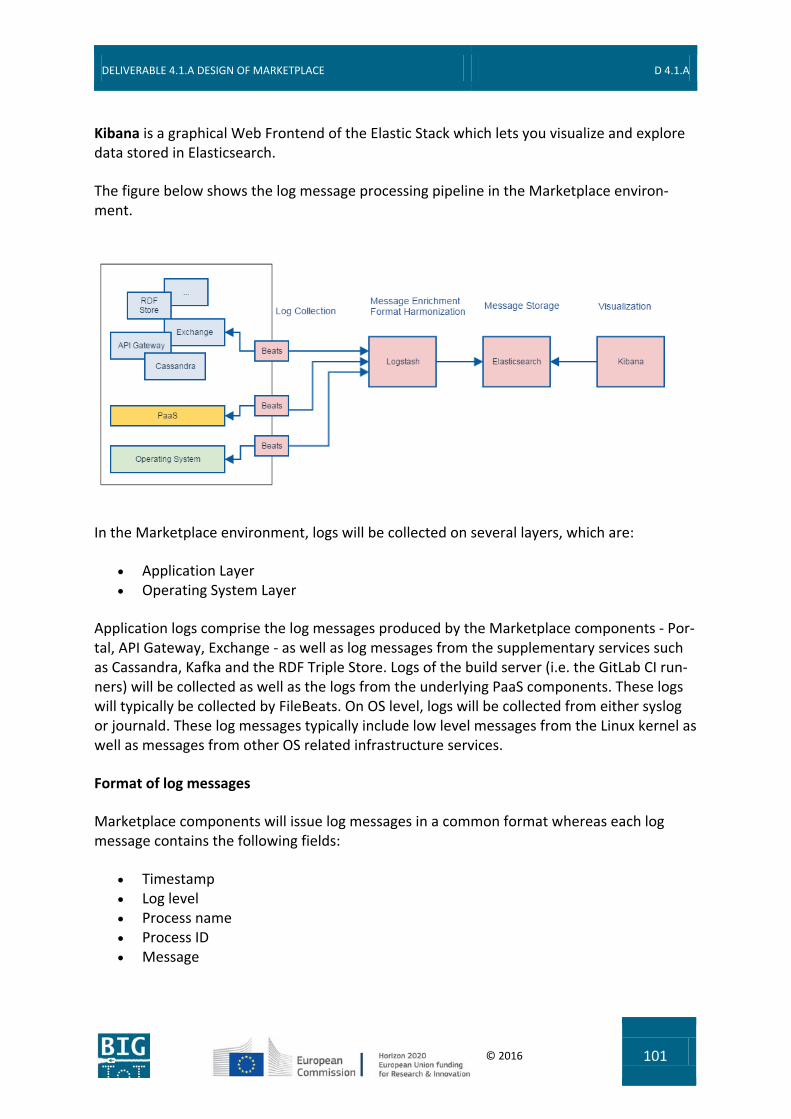
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 101
Kibana is a graphical Web Frontend of the Elastic Stack which lets you visualize and explore data stored in Elasticsearch.
The figure below shows the log message processing pipeline in the Marketplace environ-ment.
In the Marketplace environment, logs will be collected on several layers, which are:
• Application Layer • Operating System Layer
Application logs comprise the log messages produced by the Marketplace components - Por-tal, API Gateway, Exchange - as well as log messages from the supplementary services such as Cassandra, Kafka and the RDF Triple Store. Logs of the build server (i.e. the GitLab CI run-ners) will be collected as well as the logs from the underlying PaaS components. These logs will typically be collected by FileBeats. On OS level, logs will be collected from either syslog or journald. These log messages typically include low level messages from the Linux kernel as well as messages from other OS related infrastructure services.
Format of log messages
Marketplace components will issue log messages in a common format whereas each log message contains the following fields:
• Timestamp • Log level • Process name • Process ID • Message

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 102
Sample log message:
Mon Dec 5 13:08:56 UTC 2016 INFO exchange[36482]: new offering created, id=5fa342eeb name=FreeParkingVienna, ...
Before being stored centrally by Elasticsearch, Logstash enriches the log messages with addi-tional information (e.g. with the originating host name or IP address) and converts them into a format suitable for Elasticsearch.
Note: The final format of the log messages will be defined during the implementation phase
Traceability
Marketplace components involved in related procedures or transactions use common identi-fiers in log messages which can be used to correlate these actions. By using the filtering options in Kibana it is possible to browse through the related log messages in a central place.
9.7 Monitoring and Alerting
Monitoring of distributed systems and applications is a mission-critical process. At its core, monitoring is about metrics and time series. They allow us to gain insights about the system status at any given point in time. They allow us to look into the past and even into the fu-ture. They allow us to detect trends (or anomalies) which in turn can help to employ preventive steps against potentially upcoming failures (by raising alerts).
Monitoring shall be in place starting with the first deployment of the Marketplace. From thereon it will grow with the system, not only uncovering problems but also uncovering im-provement potential at the right places.
There are a couple of open source monitoring products available such as Nagios (from the ancient days...), Icinga, Zabbix and Riemann and Prometheus. The Elastic Stack might also be a candidate for a monitoring solution as it supports the collection of metrics through the utilization of TopBeat and/or MetricBeat. Unfortunately, the monitoring and alerting Add-ons for the Elasticsearch server are not free of charge.
So, for the Marketplace the choice falls to the open source tool Prometheus (https://prometheus.io/).
Rationales:
• Easy to deploy and operate • Scalable architecture • Comprehensive alerting (via E-mail, Pager Duty and others) • Flexible query language • Client libraries for lots of programming languages (Java, Scala, Python, ...)

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 103
• Integrations for Docker, JMX and others
Visualization is done with Grafana (http://grafana.org/) which is a great tool for querying and visualizing time series and metrics data. It has integrated Prometheus support and pro-vides a flexible, fancy Web-GUI that is easy to customize.
Prometheus consists of several entities, the most obvious are:
• Prometheus Server - collects metrics from configured targets at given intervals, eval-uates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true.
• Metrics exporters - Libraries and servers which help in exporting existing metrics from third-party systems as Prometheus metrics. One exporter that is frequently used for exporting OS metrics is the Node Exporter.
• Alert Manager - handles alerts sent by the Prometheus server. It takes care of de-duplicating, grouping, and routing them to the correct receiver via E-mail, PagerDuty, HipChat or WebHooks (and some more). It also takes care of silencing and inhibition of alerts. The Alert Manager has its own Web-GUI.
The following figure shows the monitoring infrastructure as used in the Marketplace envi-ronment:
Exporters and client libraries typically expose a /metrics endpoint that the Prometheus serv-er pulls in configurable intervals. The Prometheus server then stores the metrics in its time series database. Grafana uses the PromQL (Prometheus Query Language) interface to re-trieve metrics which are then displayed in Grafana's dashboards.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 104
Alerting
Alerting in Prometheus is a 2-step process. Alert rules and conditions are basically config-ured in Prometheus itself, while the handling and types of propagation of alerts is configured in the Alert Manager. An alert configuration may look like this:
ALERT InstanceDown IF up == 0 FOR 5m LABELS { severity = "critical" } ANNOTATIONS { summary = "Instance {{ $labels.instance }} down", description = "{{ $labels.instance }} has been down for more than 5 minutes, intervention required" }
This alert configuration says:
"If the value of the metric "up" has been "0" for the last 5 minutes then raise an alert to-wards the Alert Manager with the name "InstanceDown". The alert shall have a label "severity=critical" and 2 annotations with additional details of the alert.
The Prometheus Alert Manager decides how to deal with an alert based on its configuration. An example configuration may look like this:
global: # The smarthost and SMTP sender used for mail notifications. smtp_smarthost: 'smtp.big-iot.eu:25' smtp_from: '[email protected]' smtp_auth_username: 'alertmanager' smtp_auth_password: 'password' # The root route on which each incoming alert enters. route: # The labels by which incoming alerts are grouped together. For example, # multiple alerts coming in for instance=NNN and alertname=LatencyHigh would # be batched into a single group. group_by: ['alertname', 'instance'] # When a new group of alerts is created by an incoming alert, wait at # least 'group_wait' to send the initial notification. # This way ensures that you get multiple alerts for the same group that start # firing shortly after another are batched together on the first notification. group_wait: 30s # When the first notification was sent, wait 'group_interval' to send a batch # of new alerts that started firing for that group. group_interval: 5m # If an alert has successfully been sent, wait 'repeat_interval' to resend them. repeat_interval: 3h # A default receiver receiver: siteadmin-mails # All the above attributes are inherited by all child routes and can be overwritten.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 105
# The child route trees. routes: - match: severity: critical receiver: siteadmin-pager # Inhibition rules allow to mute a set of alerts given that another alert is firing. # We use this to mute any warning-level notifications if the same alert is already critical. inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' # Apply inhibition if the alertname is the same. equal: ['alertname', 'instance'] # Alert receivers configuration receivers: - name: 'siteadmin-mails' email_configs: - to: '[email protected]' - name: 'siteadmin-pager' pagerduty_configs: - service_key: <siteadmin-key>
Basically, this Alert Manager configuration would cause all alarms with severity = "critical" to be sent to the siteadmin via PagerDuty. Any other alarm will be sent to [email protected] via E-mail.
9.8 Local Development Environment
This chapter describes a virtual machine based environment used throughout the BIG IoT Marketplace development. The goal is to provide the developer with a consistent, easily re-producible local runtime environment that reflects the final deployment environment to a certain degree, thus enabling the developer to run and test the software locally close to pro-duction conditions.
The diagram below outlines the local environment setup.
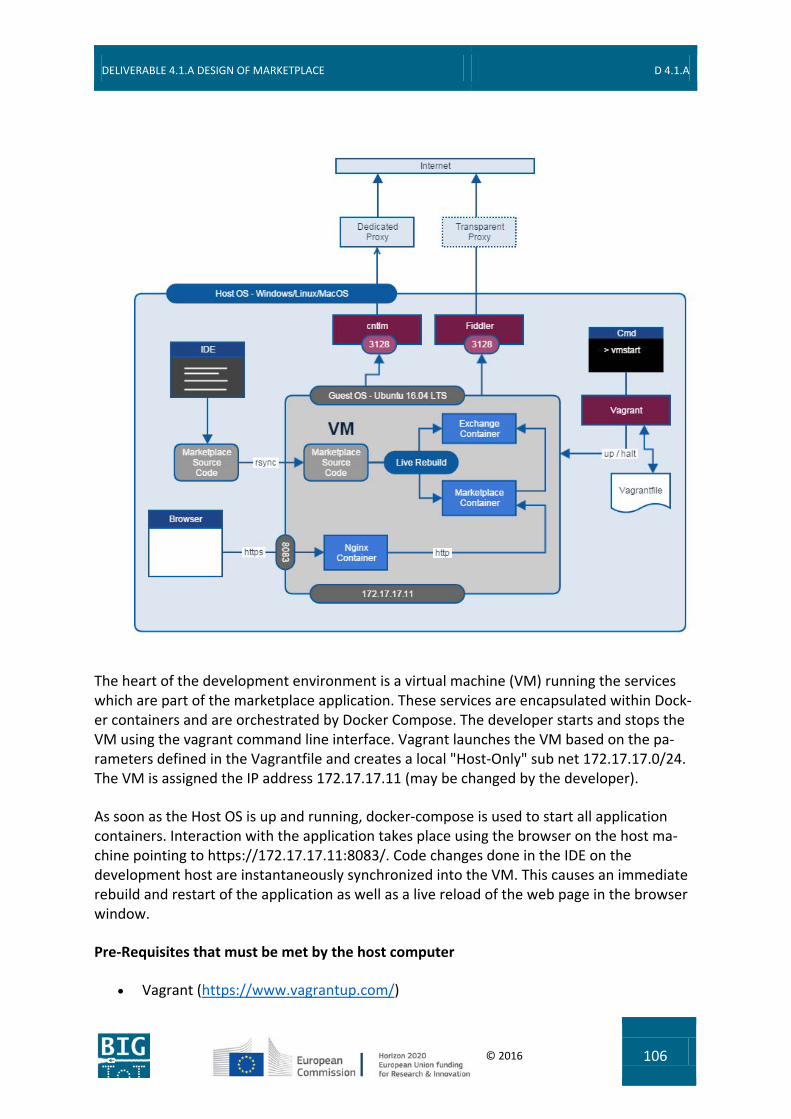
DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 106
The heart of the development environment is a virtual machine (VM) running the services which are part of the marketplace application. These services are encapsulated within Dock-er containers and are orchestrated by Docker Compose. The developer starts and stops the VM using the vagrant command line interface. Vagrant launches the VM based on the pa-rameters defined in the Vagrantfile and creates a local "Host-Only" sub net 172.17.17.0/24. The VM is assigned the IP address 172.17.17.11 (may be changed by the developer).
As soon as the Host OS is up and running, docker-compose is used to start all application containers. Interaction with the application takes place using the browser on the host ma-chine pointing to https://172.17.17.11:8083/. Code changes done in the IDE on the development host are instantaneously synchronized into the VM. This causes an immediate rebuild and restart of the application as well as a live reload of the web page in the browser window.
Pre-Requisites that must be met by the host computer
• Vagrant (https://www.vagrantup.com/)

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 107
o Vagrant plugin vagrant-proxyconf o Vagrant plugin vagrant-vbguest
• VirtualBox (https://www.virtualbox.org/) • Git (https://git-scm.com/) • rsync (usually part of the Git package) • cntlm (http://cntlm.sourceforge.net/) - listening on localhost:3128
o if the host computer is in a Windows environment and behind a dedicated proxy
• Fiddler (http://www.telerik.com/fiddler) - listening on localhost:3128 o if the host computer is behind a transparent proxy or has direct internet ac-
cess
The detailed instructions on how to interact with the development VM are beyond the scope of this document and will be available in a README file in the source repository of the pro-ject.
9.8.1 Docker Compose
Docker Compose is used for orchestrating and running the Marketplace containers in the development VM. An excerpt of the docker-compose.yml file used for the Marketplace de-velopment is shown below.
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" volumes: - zookeeper-conf:/opt/zookeeper-3.4.6/conf - zookeeper-data:/opt/zookeeper-3.4.6/data restart: always kafka: image: wurstmeister/kafka ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: kafka KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "exchangequery:1:1,exchangecommand:1:1" volumes: - kafka:/kafka - /var/run/docker.sock:/var/run/docker.sock restart: always depends_on: - zookeeper exchange: build: context: /prj/exchange/docker ports: - "8080:8080"

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 108
- "5005:5005" volumes: - /prj:/prj - sbt:/root/.sbt - ivy2:/root/.ivy2 restart: always marketplace: build: context: /prj/marketplace/devops/localdev/docker depends_on: - exchange ports: - "8082:8082" - "5006:5006" volumes: - /prj:/prj - sbt:/root/.sbt - ivy2:/root/.ivy2 restart: always environment: EXCHANGE_HOST: exchange EXCHANGE_PORT: 8080 nginx-front: image: nginx:alpine ports: - "8083:8083" volumes: - /data/nginx/conf.d:/etc/nginx/conf.d - /data/nginx/includes:/etc/nginx/includes - /data/nginx/upstreams:/etc/nginx/upstreams - /data/nginx/ssl:/etc/nginx/ssl restart: always depends_on: - marketplace # more services below this line ....
A docker-compose.yml file is a kind of a blueprint for a multi-container application. In the snippet above 5 services are defined
• zookeeper • kafka • exchange • marketplace • nginx-front
The services have different docker-related attributes, like the Docker image name, mounted volumes, port mappings and dependencies between them, for instance the marketplace service depends on the exchange service. Docker Compose takes care that the containers are started in the right order corresponding to their dependencies. While the Docker images for kafka, zookeeper and nginx are fetched from Docker Hub, the Docker images for market-place and exchange are build directly in the development machine.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 109
9.8.2 Vagrant
Vagrant is a tool that simplifies the workflow and reduces the workload necessary to run and operate virtual machines (VMs) on your computer, especially on - but not limited to - devel-opment environments. Vagrant is available on all major operating systems and works with virtualization technologies such as VirtualBox, VMware, Hyper-V, and others.
One of the key features of Vagrant is that it facilitates procedures to distribute and share virtual environments. A virtual environment is described in terms of a so called Vagrantfile which is a plain text file containing the specifications of one or several Virtual Machines, Networks, provisioning scripts, etc. The Vagrantfile is stored in the project's Git repository. This means that every developer working on the project uses the same Vagrantfile and thus uses the same Virtual development environment. Another important aspect of storing the environment definition in a text file (and put it under version control) is that, the environ-ment is reproducible and thus can be re-created from scratch any time you like.
For the development of the BIG IoT Marketplace a single-node environment is used, de-scribed by the Vagrantfile shown below:
Vagrantfile $numVM = 1 $numCPU = 2 # number of (virtual) CPUs the VM gets $memSize = 4096 # RAM in MB that shall be allocated for the VM $proxy = "http://10.0.2.2:3128" Vagrant.configure(2) do |config| # This box has all dev dependencies incorporated, download size 2.3G though. # But starts quickly once downloaded. config.vm.box = "https://bigiotdev.blob.core.windows.net/vagrantboxes/marketplace-dev.box" if Vagrant.has_plugin?("vagrant-proxyconf") config.proxy.http = $proxy config.proxy.https = $proxy config.proxy.no_proxy = "localhost,127.0.0.1,172.17.17.0/24" end if Vagrant.has_plugin?("vagrant-vbguest") config.vbguest.auto_update = false config.vbguest.no_install = true config.vbguest.no_remote = true end # spin up my VMs (1..$numVM).each do |i| config.vm.define "bigiot#{i}" do |node| node.vm.network "private_network", ip: "172.17.17.#{10+i}" node.vm.provider "virtualbox" do |vb| vb.name = "bigiot#{i}" vb.memory = $memSize vb.cpus = $numCPU end end end config.vm.synced_folder "..", "/prj", type: "rsync", rsync__verbose: true, rsync__exclude: [ ".sbt", ".ivy2", "marketpla-ce/.idea/", "marketplace/target/", "marketplace/project/target/", "marketplace/.git/", "marketplace/ui/node_modules/",

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 110
"marketplace/ui/public/", "exchange/target/", "exchange/project/target/", "exchange/project/project/target/", "exchan-ge/.idea/", "exchange/.git/", "Vagrantfile"], rsync_args: ["--verbose", "--archive", "-z", "--copy-links"] end
Note that the final version of the Vagrantfile might differ in one or the other detail.
Some of the parameters worth mentioning are:
$numCPU = 2 # number of (virtual) CPUs the VM gets $memSize = 4096 # RAM in MB that shall be allocated for the VM ... config.vm.box = "https://bigiotdev.blob.core.windows.net/vagrantboxes/marketplace-dev.box" ...
$numCPU - defines the number of virtual CPUs which are assigned to the VM, typically half of the number of CPU cores available on the host machine
$memSize - defines the RAM size in MB that is assigned to the VM, should not be less than 4096
config.vm.box - defines the so called "Vagrant Box" which is essentially a hard disk image including the operating system and a bunch of pre-installed development tools
A note on Proxy servers
Dedicated Proxies (=non transparent) in corporate networks that rely on NTLM authentica-tion pose a problem when required to be used from within a Linux machine. This drawback can be overcome by using the authentication proxy utility called "CNTLM" that runs on the Windows host OS and performs the NTLM authentication. The Linux machine has to be con-figured to use CNTLM as its proxy server at http://10.0.2.2:3128. This address refers to the IP address of the host as seen from the VM and is configured in the Vagrantfile.
Now, what if the development environment runs in a network without dedicated proxy or if you just wanted to quickly change the network, e.g mobile hot spot? One option would be to tear down the VM, change the Vagrantfile and restart the VM again. Although this works, there's a much prettier solution - in a network without deditacted proxy, use Fiddler instead of CNTLM. Switching between Fiddler and CNTLM is much faster than a whole boot cycle of the development VM.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 111
10 Conclusions and Future Works
This first iteration of D4.1 summarizes the work done for designing and implementing the Marketplace demonstrator in M10 (October 2016) and gives an outlook what still has to be done for the first release of the Marketplace implementation (T4.4), scheduled for M16 (April 2017).
The focus of the Marketplace demonstrator was on an initial version of the Marketplace API to allow a first implementation of the Provider and Consumer Libs communicating with the Marketplace and an initial version of the Marketplace Portal to enable the necessary man-agement of all involved entities and verify the communication between the Portal and the Marketplace Backend.
The first release of the Marketplace implementation will build upon the results achieved so far and has the main goal to deploy a first running version of the Marketplace in the cloud to support the development of the Pilots and enable the integration of external parties for the open call.
Both Pilots and participants of the open call will give feedback and report additional re-quirements that have to be incorporated into future releases of the Marketplace to support maturing that central piece of the BIG IoT ecosystem.
When more and more clients will make use of the deployed Marketplace, the stability, avail-ability and scaling of the involved services will become more important and will need to be addressed. Monitoring and logging will become crucial and have to prove their helpfulness in recognizing and fixing bugs and instabilities. So the deployment and operations of the Mar-ketplace will be one major topic for the second iteration.
Another important topic will be the usability and implementation of missing features of the Portal to make the Marketplace more attractive for external parties.
Last but not least the Marketplace Backend has to evolve into a reliable and scalable set of services based on the concepts described in this document. Missing services like Charging have to be developed to help making the BIG IoT ecosystem useful for Platform and Service Operators that want to monetize their assets.
Future releases of this document will include description of the work done on all those men-tioned topics.

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 112
11 Appendix
11.1 Marketplace GraphQL Schema
The following listing shows the complete GraphQL schema of the Marketplace. This is a snapshot as of December 2016. The schema is subject of change according to the needs of our development and it will eventually be split up into several schemas for each of the sepa-rate services within the Marketplace Backend that will be merged into one combined Marketplace API.
You can always get an up to date schema on the reative URL "/schema" on the running Mar-ketplace (e.g. http://localhost:8080/schema). The format of this schema is described in detail on http://graphql.org/docs/typesystem.
The listing starts with the root entry "schema" that defines what the defined types for que-ries and mutations are, and then gives an alphabetically ordered list of all types used in the Marketplace API.
Please note, that comments start with ##.
The current naming convention is as follows (motivated by the naming convention of the GraphQL JavaScript library Relay.js. This might change in the future):
• Input types (from client to server) end with Input, e.g. ConsumerInput • The domain entity has no ending, e.g. Consumer • The return types of mutations end with Payload, e.g. ConsumerPayload. It typically
wraps some domain entity, e.g. Consumer, together with a client id
Marketplace GraphQL Schema schema { query:ExchangeQueries mutation: ExchangeMutations } ## Type of AccessInterface enum AccessInterfaceType { EXTERNAL BIGIOT_LIB } ## Postal Address type Address { city: String! } ## Postal Address input AddressInput { city: String! }

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 113
## Offering Consumer (Application or Service) type Consumer { id: String! name: String! queries: [OfferingQuery!]! organization: Organization } ## New Offering Consumer to be created input ConsumerInput { organizationId: String! name: String! localId: String clientMutationId: String } ## Mutated Consumer type ConsumerPayload { consumer: Consumer clientMutationId: String } ## List of Consumers type Consumers { consumers: [Consumer!]! } ## Currency enum Currency { EUR } ## Data flowing into or out of Offering type Data { name: String! rdfType: RdfType! } ## Data flowing into or out of Offering input DataInput { name: String! rdfUri: String! } ## Endpoint to access Offering type Endpoint { endpointType: NamedEndpointType! uri: String! accessInterfaceType: NamedAccessInterfaceType! } ## Endpoint to access Offering input EndpointInput { endpointType: String! uri: String! accessInterfaceType: String } ## Type of Endpoint enum EndpointType {

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 114
WEBSOCKET HTTP_POST HTTP_GET } ## Exchange is a place where Providers can register Offerings and Consumer can query and subscribe those Offerings type Exchange { organizations: [Organization!]! } ## BIG IoT Exchange mutations type ExchangeMutations { ## Create new Organization createOrganization(input: OrganizationInput!): OrganizationPayload! ## Create new User createUser(input: UserInput!): UserPayload! ## Create new Provider createProvider(input: ProviderInput!): ProviderPayload! ## Create new Offering createOffering(input: OfferingInput!): OfferingPayload! ## Create multiple new Offerings createOfferings(input: OfferingsInput!): OfferingsPayload! ## Activate Offering activateOffering(input: IdInput!): OfferingPayload! ## Deactivate Offering deactivateOffering(input: IdInput!): OfferingPayload! ## Create new Consumer createConsumer(input: ConsumerInput!): ConsumerPayload! ## Create new OfferingQuery createOfferingQuery(input: OfferingQueryInput!): OfferingQueryPayload! ## Create new Subscription createSubscriptions(input: SubscriptionInput!): OfferingQueryPayload! ## Delete Subscription deleteSubscriptions(input: SubscriptionInput!): OfferingQueryPayload! } ## BIG IoT Exchange queries type ExchangeQueries { ## List of all supported Currencies allCurrencies: NamedCurrencies! ## List of all supported PricingModels allPricingModels: NamedPricingModels! ## List of all supported LicenseTypes allLicenseTypes: NamedLicenseTypes! ## List of all supported EndpointTypes allEndpointTypes: NamedEndpointTypes! ## List of all supported AccessInterfaceTypes

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 115
allAccessInterfaceTypes: NamedAccessInterfaceTypes! ## List of all Offering types allOfferingTypes: OfferingType! ## Find OfferingType by rdfUri findOfferingType(rdfUri: String!): OfferingType! ## List of all Data types allDataTypes: RdfTypes! ## Exchange root node exchange: Exchange! ## List all Organizations allOrganizations: Organizations! ## Find Organization by id findOrganization(id: String!): Organization ## Find Provider by id findProvider(id: String!): Provider ## List all my Providers myProviders(offeringTypeUri: String): Providers! ## List all Offerings allOfferings(offeringTypeUri: String): Offerings! ## List all my Offerings myOfferings(offeringTypeUri: String): Offerings! ## List all Offerings registered by given Provider findOfferingsForProvider(providerId: String!): Offerings! ## Find Offering by id findOffering(id: String!): Offering ## Find Offerings matching the OfferingQuery with given id findMatchingOfferings(queryId: String!): Offerings! ## Find Consumer by id findConsumer(id: String!): Consumer ## List all my Consumers myConsumers: Consumers! ## Find OfferingQuery by id findOfferingQuery(id: String!): OfferingQuery } input IdInput { id: String! clientMutationId: String } ## License for accessing an Offering type License { licenseType: NamedLicenseType! }

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 116
## Type of License enum LicenseType { NON_COMMERCIAL_DATA_LICENSE OPEN_DATA_LICENSE CREATIVE_COMMONS } ## Monetary amount with NamedCurrency type Money { amount: BigDecimal! currency: NamedCurrency! } ## Monetary amount with Currency input MoneyInput { amount: BigDecimal! currency: String! } ## AccessInterfaceType with displayable name type NamedAccessInterfaceType { name: String! accessInterfaceType: AccessInterfaceType! } ## List of NamedAccessInterfaceTypes type NamedAccessInterfaceTypes { accessInterfaceTypes: [NamedAccessInterfaceType!]! } ## List of NamedCurrencies type NamedCurrencies { currencies: [NamedCurrency!]! } ## Currency with displayable name type NamedCurrency { name: String! currency: Currency! } ## EndpointType with displayable name type NamedEndpointType { name: String! endpointType: EndpointType! } ## List of NamedEndpointTypes type NamedEndpointTypes { endpointTypes: [NamedEndpointType!]! } ## LicenseType with displayable name type NamedLicenseType { name: String! licenseType: LicenseType! } ## List of NamedLicenseTypes type NamedLicenseTypes { licenseTypes: [NamedLicenseType!]!

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 117
} ## PricingModel with displayable name type NamedPricingModel { name: String! pricingModel: PricingModel! hasMoney: Boolean! } ## List of NamedPricingModels type NamedPricingModels { pricingModel: [NamedPricingModel!]! } ## An Offering is registered on the Exchange by an Offering Provider to be consumed by an Offering Consumer type Offering { id: String! name: String! active: Boolean! rdfType: RdfType! rdfContext: RdfContext endpoints: [Endpoint!]! outputData: [Data!]! inputData: [Data!]! extent: Address license: License! price: Price! provider: Provider } ## New Offering to be created input OfferingInput { providerId: String! name: String! localId: String rdfUri: String! rdfContext: RdfContextInput endpoints: [EndpointInput!] = [] outputData: [DataInput!] = [] inputData: [DataInput!] = [] extent: AddressInput licenseType: String! price: PriceInput! active: Boolean = false clientMutationId: String } ## Mutated Offering type OfferingPayload { offering: Offering clientMutationId: String } ## Offering Query to find and subscribe matching Offerings type OfferingQuery { id: String! name: String! rdfContext: RdfContext rdfType: RdfType outputData: [Data!]! inputData: [Data!]!

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 118
extent: Address license: License price: Price subscriptions: [Subscription!]! matchingOfferings: [Offering!]! consumer: Consumer } ## New OfferingQuery to be created input OfferingQueryInput { consumerId: String! name: String! localId: String rdfContext: RdfContextInput rdfUri: String outputData: [DataInput!] = [] inputData: [DataInput!] = [] extent: AddressInput licenseType: String price: PriceInput clientMutationId: String } ## Mutated OfferingQuery type OfferingQueryPayload { offeringQuery: OfferingQuery clientMutationId: String } ## Categorization of Offerings type OfferingType { rdfType: RdfType! inputTypes: [RdfType!]! outputTypes: [RdfType!]! subTypes: [OfferingType!]! } ## List of Offerings type Offerings { offerings: [Offering!]! } ## Multiple new Offerings to be created input OfferingsInput { offerings: [OfferingInput!]! clientMutationId: String } ## Mutated Offerings type OfferingsPayload { offerings: [Offering!]! clientMutationId: String } ## Organization of Offering Provider / Consumer type Organization { id: String! name: String! rdfContext: RdfContext license: License price: Price

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 119
users: [User!]! providers: [Provider!]! consumers: [Consumer!]! } ## New Organization to be created input OrganizationInput { name: String! localId: String rdfContext: RdfContextInput licenseType: String price: PriceInput clientMutationId: String } ## Mutated Organization type OrganizationPayload { organisation: Organization clientMutationId: String } ## List of Organizations type Organizations { organisations: [Organization!]! } ## Prefix to enable shortcuts for semantic links type Prefix { prefix: String! uri: String! } ## Prefix to enable shortcuts for semantic links input PrefixInput { prefix: String! uri: String! } ## Price for accessing an Offering type Price { pricingModel: NamedPricingModel! money: Money } ## Price for accessing an Offering input PriceInput { pricingModel: String! money: MoneyInput } ## Model for Pricing enum PricingModel { PER_BYTE PER_ACCESS PER_MONTH FREE } ## Offering Provider (Platform or Service) type Provider { id: String!

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 120
name: String! rdfContext: RdfContext license: License price: Price offerings: [Offering!]! organization: Organization } ## New Offering Provider to be created input ProviderInput { organizationId: String! name: String! localId: String rdfContext: RdfContextInput licenseType: String price: PriceInput clientMutationId: String } ## Mutated Provider type ProviderPayload { provider: Provider clientMutationId: String } ## List of Providers type Providers { providers: [Provider!]! } ## RDF context and prefixes type RdfContext { context: String prefixes: [Prefix!]! } ## RDF context and prefixes input RdfContextInput { context: String prefixes: [PrefixInput!] = [] } ## Categorization of Offerings type RdfType { uri: String! name: String! } type RdfTypes { rdfTypes: [RdfType!]! } ## Result of subscribing to an Offering type Subscription { id: String! offering: Offering! query: OfferingQuery } ## Multiple new Subscriptions to be created input SubscriptionInput {

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 121
queryId: String! offeringIds: [String!]! clientMutationId: String } ## User (belonging to Organization) that can log into Marketplace type User { id: String! name: String! organization: Organization } ## New User for Organization to be created input UserInput { organizationId: String! id: String! name: String! password: String! clientMutationId: String } ## Mutated User type UserPayload { user: User clientMutationId: String } schema { query: ExchangeQueries mutation: ExchangeMutations } ## Type of AccessInterface enum AccessInterfaceType { EXTERNAL BIGIOT_LIB } ## Postal Address type Address { city: String! } ## Postal Address input AddressInput { city: String! } ## Offering Consumer (Application or Service) type Consumer { id: String! name: String! queries: [OfferingQuery!]! organization: Organization } ## New Offering Consumer to be created input ConsumerInput { organizationId: String! name: String! localId: String clientMutationId: String

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 122
} ## Mutated Consumer type ConsumerPayload { consumer: Consumer clientMutationId: String } ## List of Consumers type Consumers { consumers: [Consumer!]! } ## Currency enum Currency { EUR } ## Data flowing into or out of Offering type Data { name: String! rdfType: RdfType! } ## Data flowing into or out of Offering input DataInput { name: String! rdfUri: String! } ## Endpoint to access Offering type Endpoint { endpointType: NamedEndpointType! uri: String! accessInterfaceType: NamedAccessInterfaceType! } ## Endpoint to access Offering input EndpointInput { endpointType: String! uri: String! accessInterfaceType: String } ## Type of Endpoint enum EndpointType { WEBSOCKET HTTP_POST HTTP_GET } ## Exchange is a place where Providers can register Offerings and Consumer can query and subscribe those Offerings type Exchange { organizations: [Organization!]! } ## BIG IoT Exchange mutations type ExchangeMutations { ## Create new Organization createOrganization(input: OrganizationInput!): OrganizationPayload!

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 123
## Create new User createUser(input: UserInput!): UserPayload! ## Create new Provider createProvider(input: ProviderInput!): ProviderPayload! ## Create new Offering createOffering(input: OfferingInput!): OfferingPayload! ## Create multiple new Offerings createOfferings(input: OfferingsInput!): OfferingsPayload! ## Activate Offering activateOffering(input: IdInput!): OfferingPayload! ## Deactivate Offering deactivateOffering(input: IdInput!): OfferingPayload! ## Create new Consumer createConsumer(input: ConsumerInput!): ConsumerPayload! ## Create new OfferingQuery createOfferingQuery(input: OfferingQueryInput!): OfferingQueryPayload! ## Create new Subscription createSubscriptions(input: SubscriptionInput!): OfferingQueryPayload! ## Delete Subscription deleteSubscriptions(input: SubscriptionInput!): OfferingQueryPayload! } ## BIG IoT Exchange queries type ExchangeQueries { ## List of all supported Currencies allCurrencies: NamedCurrencies! ## List of all supported PricingModels allPricingModels: NamedPricingModels! ## List of all supported LicenseTypes allLicenseTypes: NamedLicenseTypes! ## List of all supported EndpointTypes allEndpointTypes: NamedEndpointTypes! ## List of all supported AccessInterfaceTypes allAccessInterfaceTypes: NamedAccessInterfaceTypes! ## List of all Offering types allOfferingTypes: OfferingType! ## Find OfferingType by rdfUri findOfferingType(rdfUri: String!): OfferingType! ## List of all Data types allDataTypes: RdfTypes! ## Exchange root node exchange: Exchange! ## List all Organizations

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 124
allOrganizations: Organizations! ## Find Organization by id findOrganization(id: String!): Organization ## Find Provider by id findProvider(id: String!): Provider ## List all my Providers myProviders(offeringTypeUri: String): Providers! ## List all Offerings allOfferings(offeringTypeUri: String): Offerings! ## List all my Offerings myOfferings(offeringTypeUri: String): Offerings! ## List all Offerings registered by given Provider findOfferingsForProvider(providerId: String!): Offerings! ## Find Offering by id findOffering(id: String!): Offering ## Find Offerings matching the OfferingQuery with given id findMatchingOfferings(queryId: String!): Offerings! ## Find Consumer by id findConsumer(id: String!): Consumer ## List all my Consumers myConsumers: Consumers! ## Find OfferingQuery by id findOfferingQuery(id: String!): OfferingQuery } input IdInput { id: String! clientMutationId: String } ## License for accessing an Offering type License { licenseType: NamedLicenseType! } ## Type of License enum LicenseType { NON_COMMERCIAL_DATA_LICENSE OPEN_DATA_LICENSE CREATIVE_COMMONS } ## Monetary amount with NamedCurrency type Money { amount: BigDecimal! currency: NamedCurrency! } ## Monetary amount with Currency input MoneyInput {

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 125
amount: BigDecimal! currency: String! } ## AccessInterfaceType with displayable name type NamedAccessInterfaceType { name: String! accessInterfaceType: AccessInterfaceType! } ## List of NamedAccessInterfaceTypes type NamedAccessInterfaceTypes { accessInterfaceTypes: [NamedAccessInterfaceType!]! } ## List of NamedCurrencies type NamedCurrencies { currencies: [NamedCurrency!]! } ## Currency with displayable name type NamedCurrency { name: String! currency: Currency! } ## EndpointType with displayable name type NamedEndpointType { name: String! endpointType: EndpointType! } ## List of NamedEndpointTypes type NamedEndpointTypes { endpointTypes: [NamedEndpointType!]! } ## LicenseType with displayable name type NamedLicenseType { name: String! licenseType: LicenseType! } ## List of NamedLicenseTypes type NamedLicenseTypes { licenseTypes: [NamedLicenseType!]! } ## PricingModel with displayable name type NamedPricingModel { name: String! pricingModel: PricingModel! hasMoney: Boolean! } ## List of NamedPricingModels type NamedPricingModels { pricingModel: [NamedPricingModel!]! } ## An Offering is registered on the Exchange by an Offering Provider to be consumed by an Offering Consumer

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 126
type Offering { id: String! name: String! active: Boolean! rdfType: RdfType! rdfContext: RdfContext endpoints: [Endpoint!]! outputData: [Data!]! inputData: [Data!]! extent: Address license: License! price: Price! provider: Provider } ## New Offering to be created input OfferingInput { providerId: String! name: String! localId: String rdfUri: String! rdfContext: RdfContextInput endpoints: [EndpointInput!] = [] outputData: [DataInput!] = [] inputData: [DataInput!] = [] extent: AddressInput licenseType: String! price: PriceInput! active: Boolean = false clientMutationId: String } ## Mutated Offering type OfferingPayload { offering: Offering clientMutationId: String } ## Offering Query to find and subscribe matching Offerings type OfferingQuery { id: String! name: String! rdfContext: RdfContext rdfType: RdfType outputData: [Data!]! inputData: [Data!]! extent: Address license: License price: Price subscriptions: [Subscription!]! matchingOfferings: [Offering!]! consumer: Consumer } ## New OfferingQuery to be created input OfferingQueryInput { consumerId: String! name: String! localId: String rdfContext: RdfContextInput rdfUri: String

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 127
outputData: [DataInput!] = [] inputData: [DataInput!] = [] extent: AddressInput licenseType: String price: PriceInput clientMutationId: String } ## Mutated OfferingQuery type OfferingQueryPayload { offeringQuery: OfferingQuery clientMutationId: String } ## Categorization of Offerings type OfferingType { rdfType: RdfType! inputTypes: [RdfType!]! outputTypes: [RdfType!]! subTypes: [OfferingType!]! } ## List of Offerings type Offerings { offerings: [Offering!]! } ## Multiple new Offerings to be created input OfferingsInput { offerings: [OfferingInput!]! clientMutationId: String } ## Mutated Offerings type OfferingsPayload { offerings: [Offering!]! clientMutationId: String } ## Organization of Offering Provider / Consumer type Organization { id: String! name: String! rdfContext: RdfContext license: License price: Price users: [User!]! providers: [Provider!]! consumers: [Consumer!]! } ## New Organization to be created input OrganizationInput { name: String! localId: String rdfContext: RdfContextInput licenseType: String price: PriceInput clientMutationId: String }

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 128
## Mutated Organization type OrganizationPayload { organisation: Organization clientMutationId: String } ## List of Organizations type Organizations { organisations: [Organization!]! } ## Prefix to enable shortcuts for semantic links type Prefix { prefix: String! uri: String! } ## Prefix to enable shortcuts for semantic links input PrefixInput { prefix: String! uri: String! } ## Price for accessing an Offering type Price { pricingModel: NamedPricingModel! money: Money } ## Price for accessing an Offering input PriceInput { pricingModel: String! money: MoneyInput } ## Model for Pricing enum PricingModel { PER_BYTE PER_ACCESS PER_MONTH FREE } ## Offering Provider (Platform or Service) type Provider { id: String! name: String! rdfContext: RdfContext license: License price: Price offerings: [Offering!]! organization: Organization } ## New Offering Provider to be created input ProviderInput { organizationId: String! name: String! localId: String rdfContext: RdfContextInput licenseType: String

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 129
price: PriceInput clientMutationId: String } ## Mutated Provider type ProviderPayload { provider: Provider clientMutationId: String } ## List of Providers type Providers { providers: [Provider!]! } ## RDF context and prefixes type RdfContext { context: String prefixes: [Prefix!]! } ## RDF context and prefixes input RdfContextInput { context: String prefixes: [PrefixInput!] = [] } ## Categorization of Offerings type RdfType { uri: String! name: String! } type RdfTypes { rdfTypes: [RdfType!]! } ## Result of subscribing to an Offering type Subscription { id: String! offering: Offering! query: OfferingQuery } ## Multiple new Subscriptions to be created input SubscriptionInput { queryId: String! offeringIds: [String!]! clientMutationId: String } ## User (belonging to Organization) that can log into Marketplace type User { id: String! name: String! organization: Organization } ## New User for Organization to be created input UserInput { organizationId: String!

DELIVERABLE 4.1.A DESIGN OF MARKETPLACE D 4.1.A
© 2016 130
id: String! name: String! password: String! clientMutationId: String } ## Mutated User type UserPayload { user: User clientMutationId: String }