boost.simd
TRANSCRIPT

Le SIMD en pratique avec Boost.SIMD
Unlocked software performance
Mathias Gaunard, Joel Falcou
NumScale - Université Paris Sud
23 mai 2014

Unlocked software performance
NumScale en quelques mots
La Société■ Start-up implantée sur le campus de l’Université Paris-Sud, sur le plateau de
Saclay■ Expertise en optimisation des logiciels et en calcul parallèle
Solutions■ Proler sous Linux non-intrusif (langages compilés et JIT)■ Bibliothèques C++ pour le calcul optimisé■ Compilateurs (Python, MATLAB)■ Optimisation de logiciels■ Portage et passage à l’échelle
1 of 35

Unlocked software performance
NumScale en quelques mots
■ Permettre aux développeurs d’accéder à la pleine puissance des processeursmodernes
■ Optimisation des calculs en prenant en compte algorithmes, matériel ettechniques de programmation
Algorithme
Analyse numériqueAlgèbre linéaireTraitement du signalTraitement d’imageVisionSimulationStatistiques...
MatérielSIMDMulti-cœursDistribuéGPUSmartphonesEmbarqué, DSPs
Logiciel
C, C++FORTRANMATLABPythonJava, C#
2 of 35

Unlocked software performance
NumScale et le C++
Pourquoi le C++
■ Le C++ a l’accès bas niveau nécessaire pour exploiter au mieux lamémoire, le système, les processeurs et le parallélisme
■ Le C++ a les capacités d’abstraction nécessaires pour pouvoirconstruire des composants portables et ré-utilisables
NumScale s’implique
■ Implication auprès du comité de normalisation ISO■ Participation à la communauté open-source, en particulier via les
bibliothèques Boost
3 of 35

Unlocked software performance
NumScale et le SIMD
■ Parallélisation à l’intérieur même des cœurs, peu utilisé en pratique■ Gains de l’ordre de x2 à x16 cumulable avec le multi-cœurs■ Réduire les temps de calcul sans toucher à l’infrastructure■ Marche particulièrement bien pour tout le calcul numérique type HPC
4 of 35

Les Challenges du SIMD

Unlocked software performance
Un parallélisme toujours plus présent
Le parallélisme évident
■ Architecture Multi-cœurs■ Architecture Many-cœurs■ Systèmes Distribués
Le parallélisme moins évident
■ Pipeline intra-processeurs■ Exécutions super-scalaire et/ou out of order■ les extensions SIMD
6 of 35

Unlocked software performance
Un parallélisme toujours plus présent
Le parallélisme évident
■ Architecture Multi-cœurs■ Architecture Many-cœurs■ Systèmes Distribués
Le parallélisme moins évident
■ Pipeline intra-processeurs■ Exécutions super-scalaire et/ou out of order■ les extensions SIMD
6 of 35
Unlocked software performance
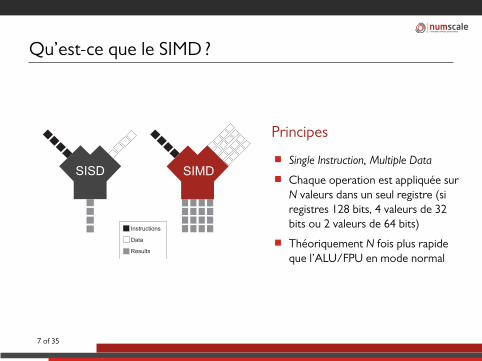
Qu’est-ce que le SIMD ?
Instructions
Data
Results
SISD SIMD
Principes
■ Single Instruction, Multiple Data
■ Chaque operation est appliquée surN valeurs dans un seul registre (siregistres 128 bits, 4 valeurs de 32bits ou 2 valeurs de 64 bits)
■ Théoriquement N fois plus rapideque l’ALU/FPU en mode normal
7 of 35

Unlocked software performance
1001 Saveurs de SIMD
Extensions x86■ MMX 64 bits oat, double■ SSE 128 bits oat■ SSE2 128 bits int8, int16, int32, int64,
double■ SSE3, SSSE3■ SSE4a (AMD)■ SSE4.1, SSE4.2■ AVX 256 bits oat, double■ AVX2 256 bits int8, int16, int32, int64■ FMA3■ FMA4, XOP (AMD)■ MIC 512 bits oat, double, int32, int64
Extensions PowerPC■ AltiVec 128 bits int8, int16, int32,
int64, oat■ Cell SPU et VSX, 128 bits int8,
int16, int32, int64, oat, double■ QPX 512 bits double
Extensions ARM■ VFP 64 bits oat, double■ NEON 64 bits et 128 bits oat,
int8, int16, int32, int64
8 of 35

Unlocked software performance
Le SIMD en mode manuel, int32 * int32 -> int32
// NEONreturn vmul_s32(a0, a1) ; // 64-bitreturn vmulq_s32(a0 , a1) ; // 128-bit
9 of 35

Unlocked software performance
Le SIMD en mode manuel, int32 * int32 -> int32
// SSE4.1return _mm_mullo_epi32(a0 , a1) ;
9 of 35
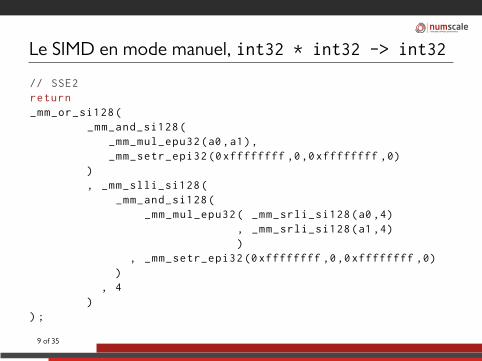
Unlocked software performance
Le SIMD en mode manuel, int32 * int32 -> int32
// SSE2return_mm_or_si128(
_mm_and_si128(_mm_mul_epu32(a0 ,a1),_mm_setr_epi32 (0xffffffff ,0,0xffffffff ,0)
), _mm_slli_si128(
_mm_and_si128(_mm_mul_epu32( _mm_srli_si128(a0 ,4)
, _mm_srli_si128(a1 ,4))
, _mm_setr_epi32 (0xffffffff ,0,0xffffffff ,0))
, 4)
) ;
9 of 35

Unlocked software performance
Le SIMD en mode manuel, int32 * int32 -> int32
// Altivec// reinterpret as u16short0 = (__vector unsigned short)a0 ;short1 = (__vector unsigned short)a1 ;
// shifting constantshift = vec_splat_u32 (-16) ;sf = vec_rl(a1, shift_) ;
// Compute high part of the producthigh = vec_msum( short0 , (__vector unsigned short)sf
, vec_splat_u32 (0)) ;
// Complete by adding low part of the 16 bits productreturn vec_add( vec_sl(high , shift_)
, vec_mulo(short0 , short1)) ;
9 of 35

Unlocked software performance
Et les compilateurs alors ?
Limitations de l’auto-vectorisation■ L’auto-vectorisation ne se déclenche que si :
□ la mémoire est bien agencée□ le code est intrinséquement vectorisable
■ Les fonctions compilées à l’extérieur ne sont pas vectorisées■ Le compilateur peut manquer d’informations pour effectuer la vectorisation
Conclusion■ Le SIMD explicite permet de garantir la vectorisation■ Challenge : Maintenir un code SIMD sur de multiples plate-formes
10 of 35

Unlocked software performance
Notre approche
Une abstraction de haut-niveau■ Utilisation d’un Domain-Specic Embedded Language (DSEL)■ Abstraction des registres SIMD comme un bloc de données■ Applications d’optimisations au niveau des expressions
Integration au langage
■ Permettre l’écriture de code générique
■ Intégration au sein de la STL
■ Reposer sur des concepts issus du C++ moderne
11 of 35

Boost.SIMD
†Boost.SIMD est une bibliothèque candidate à l’inclusion dans Boost

Unlocked software performance
L’abstraction pack
La notion simd::pack<T,N>
pack<T, N> registre SIMD contenant N élements de type Tpack<T> idem avec le N optimal pour l’architecture courante
Se comporte comme une valeur de type T mais en effectuant les opérations sur les Nvaleurs de son contenu en une seul fois.
Contraintes■ T est soit un type fondamental soit un tuple Fusion
■ logical<T> permet de gérer les valeurs booléennes.■ N doit être une puissance de 2.
13 of 35

Unlocked software performance
Opérations sur les pack
Opérateurs du langage
■ Tous les opérateurs classiques sont applicables : pack<T> ⊕ pack<T> , pack<T> ⊕ T ,T ⊕ pack<T>
■ Pas de conversion ni de promotion entière :uint8_t(255) + uint8_t(1) = uint8_t(0)
Comparaisons
■ ==, !=, <, <=,> et >= effectue des comparaisons vectorielles.
■ compare_equal, compare_less, etc. retournent le résultat booléen de lacomparaison lexicographique de leurs paramètres.
Autres propriétés
■ Modélise à la fois une RandomAccessFusionSequence et RandomAccessRange
■ p[i] retourne un proxy pour l’accès aux éléments du registre14 of 35

Unlocked software performance
Gestion des chargements
Chargement
■ Mode aligné (aligned_load/store) et non-aligné (load/store)
■ Gestion des chargements statiquement désalignés
■ Gestion des chargements/stockages conditionnels et/ou dispersés
Exemples
15 of 35

Unlocked software performance
Gestion des chargements
Chargement
■ Mode aligné (aligned_load/store) et non-aligné (load/store)
■ Gestion des chargements statiquement désalignés
■ Gestion des chargements/stockages conditionnels et/ou dispersés
Exemplesaligned_load< pack<T, N> >(p, i) charge un pack depuis l’adresse alignée p + i.
0D 0E 0F 10 11 12 13 14 15 16 17 18
aligned_load<pack<float>>(0x10,0)
Main Memory
... ...
10 11 12 13
15 of 35

Unlocked software performance
Gestion des chargements
Chargement
■ Mode aligné (aligned_load/store) et non-aligné (load/store)
■ Gestion des chargements statiquement désalignés
■ Gestion des chargements/stockages conditionnels et/ou dispersés
Exemplesaligned_load< pack<T, N>, Offset>(p, i) charge un pack depuis l’adresse alignéep + i + Offset.
0D 0E 0F 10 11 12 13 14 15 16 17 18
aligned_load<pack<float>,2>(0x10,2)
Main Memory
... ...
12 13 14 15
15 of 35

Unlocked software performance
Réordonnancement de registre
Principe et Intérêt
■ Les éléments d’un registre SIMD sont permutables par le hardware■ Remplace des chargements mémoires dans certains algorithmes■ Encapsulé par boost::simd::shuffle
Exemples :// a = [ 1 2 3 4 ]pack <float > a = enumerate < pack <float > >(1) ;
// b = [ 10 11 12 13 ]pack <float > b = enumerate < pack <float > >(10) ;
// res = [4 12 0 10]pack <float > res = shuffle <3,6,-1,4>(a,b) ;
16 of 35

Unlocked software performance
Réordonnancement de registre
Principe et Intérêt
■ Les éléments d’un registre SIMD sont permutables par le hardware■ Remplace des chargements mémoires dans certains algorithmes■ Encapsulé par boost::simd::shuffle
Exemples :struct reverse_{
template <class I, class C>struct apply : mpl : :int_ <C : :value - I : :value - 1> {} ;
} ;
// res = [n n-1 ... 2 1]pack <float > res = shuffle <reverse_ >(a) ;
16 of 35

Unlocked software performance
Intégration avec la STL
■ Algorithmes :□ boost::simd::transform□ boost::simd::fold□ Foncteur polymorphe pour support scalaire/SIMD
■ Iterateurs :□ Encapsule des stratégies de parcours SIMD :□ boost::simd::(aligned_)(input/output_)iterator□ boost::simd::direct_output_iterator□ boost::simd::shifted_iterator
■ Allocateur :□ Fournit de la mémoire correctement alignée□ Possibilité d’adapter un allocateur existant
17 of 35

Unlocked software performance
Intégration avec la STL
■ Algorithmes :□ boost::simd::transform□ boost::simd::fold□ Foncteur polymorphe pour support scalaire/SIMD
■ Iterateurs :□ Encapsule des stratégies de parcours SIMD :□ boost::simd::(aligned_)(input/output_)iterator□ boost::simd::direct_output_iterator□ boost::simd::shifted_iterator
■ Allocateur :□ Fournit de la mémoire correctement alignée□ Possibilité d’adapter un allocateur existant
17 of 35

Unlocked software performance
Intégration avec la STL
■ Algorithmes :□ boost::simd::transform□ boost::simd::fold□ Foncteur polymorphe pour support scalaire/SIMD
■ Iterateurs :□ Encapsule des stratégies de parcours SIMD :□ boost::simd::(aligned_)(input/output_)iterator□ boost::simd::direct_output_iterator□ boost::simd::shifted_iterator
■ Allocateur :□ Fournit de la mémoire correctement alignée□ Possibilité d’adapter un allocateur existant
17 of 35

Unlocked software performance
Intégration avec la STL
std : :vector <float , simd : :allocator <float > > v(N) ;
simd : :transform( v.begin(), v.end(), []( auto const& p)
{return p * 2.f ;
}) ;
18 of 35

Unlocked software performance
Intégration avec la STL
std : :vector <float , simd : :allocator <float > > i(N), o(N) ;
std : :transform( simd : :shifted_iterator <3>(in.begin()), simd : :shifted_iterator <3>(in.end()), simd : :aligned_output_begin(o.begin()), average ()) ;
struct average{
template <class T>typename T : :value_type operator ()(T const& t) const{
typename T : :value_type d(1./3) ;return (t[0]+t[1]+t[2])*d ;
}} ;
18 of 35

Unlocked software performance
Optimisations architecturales
Problématique
■ La plupart des extensions SIMD proposent des opérateurs fusionnés type fma.■ Ces optimisations doivent rester transparentes■ Via une implantation à base d’Expression Templates, B.SIMD auto-optimise
ces motifs.
Exemple :
■ a * b + c s’évalue comme fma(a, b, c)
■ a + b * c s’évalue comme fma(b, c, a)
■ !(a < b) s’évalue comme is_nle(a, b)
19 of 35

Unlocked software performance
Architectures Supportées
Version Open Source
■ Intel SSE2-4, AVX■ PowerPC VMX
Version Propriétaire
■ ARM Neon■ Intel AVX2, XOP, FMA3, FMA4■ Intel MIC
20 of 35

Unlocked software performance
Autres fonctions ...
Arithmetic
■ arithmetique saturée
■ multiplication longue
■ conversion oat/int
■ round, oor, ceil, trunc
■ sqrt, cbrt
■ hypot
■ average
■ random
■ min/max
■ division et reste arrondi
Bitwise
■ select
■ andnot, ornot
■ popcnt
■ ffs
■ ror, rol
■ rshr, rshl
■ twopower
IEEE
■ ilogb, frexp
■ ldexp
■ next/prev
■ ulpdist
Predicates
■ comparaison à zero
■ négation decomparaison
■ is_unord, is_nan,is_invalid
■ is_odd, is_even
■ majority
21 of 35

Unlocked software performance
Réduction et Opérations intra-registre
Reduction■ any, all■ nbtrue■ minimum/maximum,
posmin/posmax■ sum■ product, dot product
SWAR
■ group/split
■ reduction splattée
■ cumsum
■ sort
22 of 35

Parlons performances !

Unlocked software performance
Fonctions de base
Fonctions trigonométriques simple précisionArchitecture : Core i7 SandyBridge, AVX en cycles/valeurs
Fonction Intervalle std Scalaire SIMDexp [−10, 10] 46 38 7log [−10,−10] 42 37 5asin [−1, 1] 40 35 13cos [−20π, 20π] 66 47 6
fast_cos [−π/4, π/4] 32 9 1.3
24 of 35

Unlocked software performance
Générateur de fractale
■ Génére une image fractale via l’évalutaion d’un fonction complexe■ Application compute-bound■ Challenge : Quantité de travail dépendante du pixel
25 of 35

Unlocked software performance
Générateur de fractale
template <class T> typename meta : :as_integer <T> : :typejulia(T const& a, T const& b){
typename meta : :as_integer <T> : :type iter ;std : :size_t i = 0 ;T x, y ;
do {T x2 = x * x ;T y2 = y * y ;T xy = s_t(2) * x * y ;x = x2 - y2 + a ;y = xy + b ;iter = selinc(x2 + y2 < T(4), iter) ;
} while(any(mask) && i++ < 256) ;
return iter ;}
26 of 35

Unlocked software performance
Générateur de fractale
.....256 x 256
.512 x 512
.1024 x 1024
.2048 x 2048
..0 .
200
.
400
.
600
.
800
.....
x2.9
3
.
x2.9
9
.
x3.0
2
.
x3.0
3
.
x6.6
4
.
x6.9
4
.x6
.09
.
x6.1
6
.
x6.5
2
.
x6.8
1
.x5
.97
.
x6.0
5
.
Size
.
cpe
.
. ..scalar SSE2
. ..simd SSE2
. ..simd AVX
. ..simd AVX2
27 of 35

Unlocked software performance
Détection de Mouvements
■ Algorithme Sigma-Delta par Manzanera et al.■ Approche mono-modale basé sur l’extraction du fond■ Modélise la variation d’intensité par une gaussienne en chaque pixel■ Challenge : Intensité arithmétique très faible
28 of 35

Unlocked software performance
Détection de Mouvements
template <typename T>T sigma_delta(T& bkg , T const& frm , T& var){
bkg = selinc(bkg < frm , seldec(bkg > fr, bkg)) ;
T dif = dist(bkg , frm) ;T mul = muls(dif ,3) ;
var = if_else( dif != T(0), selinc(var < mul , seldec(var > mul , var)), var) ;
return if_zero_else_one( dif < var ) ;}
29 of 35

Unlocked software performance
Détection de Mouvements
.....480 x 640 @5
.600 x 800 @5
.1024 x 1280 @5
.1080 x 1920 @5
.2160 x 3840 @5
..0 .
1
.
2
.
3
.
·104
......
x3.8
0
.
x6.6
3
.
x3.6
4
.x5
.63
. x3.5
0
.
x6.6
9
.
x6.5
3
.
x5.7
5
.x5
.74
. x5.7
1
.
x26.
26
.
x26.
96
.
x19.
05
.
x17.
19
. x10.
81
.
Size
.
FPS
.
. ..scalar SSE2
. ..simd SSE2
. ..simd AVX
. ..simd AVX2
30 of 35

Unlocked software performance
Solveur de Système Tridiagonal Creux
■ Résout Ax = b avec A sparse■ Application : mécanique des
uides■ Challenge : vectoriser malgré
l’aspect sparse■ Solution : Mélanges arbitraires
pour recompactication
31 of 35

Unlocked software performance
Solveur de système Tridiagonal creux
32 of 35

Conclusion

Unlocked software performance
Conclusion
Boost.SIMD
■ C++ permet d’allier abstraction et performance■ Une accélération garantie sur un large panel d’architectures■ Retrouvez nous sur https://github.com/MetaScale/nt2■ Tests, commentaires et retours bienvenus
À venir
■ Intégration de la version Open Source dans Boost■ Support pour nouvelles architectures : QPX, C6x, etc...
34 of 35

Merci de votre attention !