building efficient hpc clouds with mvapich2 and openstack over
TRANSCRIPT

Building Efficient HPC Clouds with MVAPICH2 and OpenStack over SR-‐IOV Enabled InfiniBand Clusters
Talk at OpenStack Summit (April 2016)
by
Dhabaleswar K. (DK) Panda The Ohio State University
E-‐mail: [email protected]‐state.edu h=p://www.cse.ohio-‐state.edu/~panda
Xiaoyi Lu The Ohio State University
E-‐mail: [email protected]‐state.edu h=p://www.cse.ohio-‐state.edu/~luxi

OpenStack Summit (April ‘16) 2 Network Based CompuTng Laboratory
• Cloud CompuDng focuses on maximizing the effecDveness of the shared resources
• VirtualizaDon is the key technology for resource sharing in the Cloud
• Widely adopted in industry compuDng environment
• IDC Forecasts Worldwide Public IT Cloud Services Spending to Reach Nearly $108 Billion by 2017 (Courtesy: h=p://www.idc.com/getdoc.jsp?containerId=prUS24298013)
Cloud CompuTng and VirtualizaTon
VirtualizaTon Cloud CompuTng

OpenStack Summit (April ‘16) 3 Network Based CompuTng Laboratory
• IDC expects that by 2017, HPC ecosystem revenue will jump to a record $30.2 billion. IDC foresees public clouds, and especially custom public clouds, supporDng an increasing proporDon of the aggregate HPC workload as these cloud faciliDes grow more capable and mature (Courtesy: h=p://www.idc.com/getdoc.jsp?containerId=247846)
• Combining HPC with Cloud is sDll facing challenges because of the performance overhead associated virtualizaDon support – Lower performance of virtualized I/O devices
• HPC Cloud Examples – Amazon EC2 with Enhanced Networking
• Using Single Root I/O VirtualizaDon (SR-‐IOV) • Higher performance (packets per second), lower latency, and lower ji=er
• 10 GigE
– NSF Chameleon Cloud
HPC Cloud -‐ Combining HPC with Cloud

OpenStack Summit (April ‘16) 4 Network Based CompuTng Laboratory
NSF Chameleon Cloud: A Powerful and Flexible Experimental Instrument • Large-‐scale instrument
– TargeDng Big Data, Big Compute, Big Instrument research – ~650 nodes (~14,500 cores), 5 PB disk over two sites, 2 sites connected with 100G network
• Reconfigurable instrument – Bare metal reconfiguraDon, operated as single instrument, graduated approach for ease-‐of-‐use
• Connected instrument – Workload and Trace Archive – Partnerships with producDon clouds: CERN, OSDC, Rackspace, Google, and others – Partnerships with users
• Complementary instrument – ComplemenDng GENI, Grid’5000, and other testbeds
• Sustainable instrument – Industry connecDons
h=p://www.chameleoncloud.org/

OpenStack Summit (April ‘16) 5 Network Based CompuTng Laboratory
• Single Root I/O VirtualizaDon (SR-‐IOV) is providing new opportuniDes to design HPC cloud with very li=le low overhead
Single Root I/O VirtualizaTon (SR-‐IOV)
• Allows a single physical device, or a Physical FuncDon (PF), to present itself as mulDple virtual devices, or Virtual FuncDons (VFs)
• VFs are designed based on the exisDng non-‐virtualized PFs, no need for driver change
• Each VF can be dedicated to a single VM through PCI pass-‐through
• Work with 10/40 GigE and InfiniBand
4. Performance comparisons between IVShmem backed and native mode MPI li-braries, using HPC applications
The evaluation results indicate that IVShmem can improve point to point and collectiveoperations by up to 193% and 91%, respectively. The application execution time can bedecreased by up to 96%, compared to SR-IOV. The results further show that IVShmemjust brings small overheads, compared with native environment.
The rest of the paper is organized as follows. Section 2 provides an overview ofIVShmem, SR-IOV, and InfiniBand. Section 3 describes our prototype design and eval-uation methodology. Section 4 presents the performance analysis results using micro-benchmarks and applications, scalability results, and comparison with native mode. Wediscuss the related work in Section 5, and conclude in Section 6.
2 BackgroundInter-VM Shared Memory (IVShmem) (e.g. Nahanni) [15] provides zero-copy accessto data on shared memory of co-resident VMs on KVM platform. IVShmem is designedand implemented mainly in system calls layer and its interfaces are visible to user spaceapplications as well. As shown in Figure 2(a), IVShmem contains three components:the guest kernel driver, the modified QEMU supporting PCI device, and the POSIXshared memory region on the host OS. The shared memory region is allocated by hostPOSIX operations and mapped to QEMU process address space. The mapped memoryin QEMU can be used by guest applications by being remapped to user space in guestVMs. Evaluation results illustrate that both micro-benchmarks and HPC applicationscan achieve better performance with IVShmem support.
Qemu Userspace
Guest 1
Userspace
kernelPCI Device
mmap region
Qemu Userspace
Guest 2
Userspace
kernel
mmap region
Qemu Userspace
Guest 3
Userspace
kernelPCI Device
mmap region
/dev/shm/<name>
PCI Device
Host
mmap mmap mmap
shared mem fd
eventfds
(a) Inter-VM Shmem Mechanism [15]
Guest 1Guest OS
VF Driver
Guest 2Guest OS
VF Driver
Guest 3Guest OS
VF Driver
Hypervisor PF Driver
I/O MMU
SR-IOV Hardware
Virtual Function
Virtual Function
Virtual Function
Physical Function
PCI Express
(b) SR-IOV Mechanism [22]
Fig. 2. Overview of Inter-VM Shmem and SR-IOV Communication Mechanisms
Single Root I/O Virtualization (SR-IOV) is a PCI Express (PCIe) standard whichspecifies the native I/O virtualization capabilities in PCIe adapters. As shown in Fig-ure 2(b), SR-IOV allows a single physical device, or a Physical Function (PF), to presentitself as multiple virtual devices, or Virtual Functions (VFs). Each virtual device can bededicated to a single VM through the PCI pass-through, which allows each VM to di-rectly access the corresponding VF. Hence, SR-IOV is a hardware-based approach to

OpenStack Summit (April ‘16) 6 Network Based CompuTng Laboratory
• High-‐Performance CompuDng (HPC) has adopted advanced interconnects and protocols
– InfiniBand
– 10/40 Gigabit Ethernet/iWARP
– RDMA over Converged Enhanced Ethernet (RoCE)
• Very Good Performance
– Low latency (few micro seconds)
– High Bandwidth (100 Gb/s with EDR InfiniBand)
– Low CPU overhead (5-‐10%)
• OpenFabrics somware stack with IB, iWARP and RoCE interfaces are driving HPC systems
• How to Build HPC Cloud with SR-‐IOV and InfiniBand for delivering opDmal performance?
Building HPC Cloud with SR-‐IOV and InfiniBand

OpenStack Summit (April ‘16) 7 Network Based CompuTng Laboratory
Overview of the MVAPICH2 Project • High Performance open-‐source MPI Library for InfiniBand, 10-‐40Gig/iWARP, and RDMA over Converged Enhanced Ethernet (RoCE)
– MVAPICH (MPI-‐1), MVAPICH2 (MPI-‐2.2 and MPI-‐3.0), Available since 2002
– MVAPICH2-‐X (MPI + PGAS), Available since 2011
– Support for GPGPUs (MVAPICH2-‐GDR) and MIC (MVAPICH2-‐MIC), Available since 2014
– Support for VirtualizaDon (MVAPICH2-‐Virt), Available since 2015
– Support for Energy-‐Awareness (MVAPICH2-‐EA), Available since 2015
– Used by more than 2,550 organizaTons in 79 countries
– More than 365,000 (> 0.36 million) downloads from the OSU site directly
– Empowering many TOP500 clusters (Nov ‘15 ranking) • 10th ranked 519,640-‐core cluster (Stampede) at TACC
• 13th ranked 185,344-‐core cluster (Pleiades) at NASA
• 25th ranked 76,032-‐core cluster (Tsubame 2.5) at Tokyo InsDtute of Technology and many others
– Available with somware stacks of many vendors and Linux Distros (RedHat and SuSE)
– h=p://mvapich.cse.ohio-‐state.edu
• Empowering Top500 systems for over a decade – System-‐X from Virginia Tech (3rd in Nov 2003, 2,200 processors, 12.25 TFlops) -‐>
– Stampede at TACC (10th in Nov’15, 519,640 cores, 5.168 Plops)

OpenStack Summit (April ‘16) 8 Network Based CompuTng Laboratory
MVAPICH2 Architecture
High Performance Parallel Programming Models
Message Passing Interface (MPI)
PGAS (UPC, OpenSHMEM, CAF, UPC++)
Hybrid -‐-‐-‐ MPI + X (MPI + PGAS + OpenMP/Cilk)
High Performance and Scalable CommunicaTon RunTme Diverse APIs and Mechanisms
Point-‐to-‐point
PrimiTves
CollecTves Algorithms
Energy-‐ Awareness
Remote Memory Access
I/O and File Systems
Fault Tolerance
VirtualizaTon AcTve Messages
Job Startup IntrospecTon & Analysis
Support for Modern Networking Technology (InfiniBand, iWARP, RoCE, OmniPath)
Support for Modern MulT-‐/Many-‐core Architectures (Intel-‐Xeon, OpenPower, Xeon-‐Phi (MIC, KNL*), NVIDIA GPGPU)
Transport Protocols Modern Features
RC XRC UD DC UMR ODP* SR-‐IOV
MulT Rail
Transport Mechanisms Shared Memory CMA IVSHMEM
Modern Features
MCDRAM* NVLink* CAPI*
* Upcoming

OpenStack Summit (April ‘16) 9 Network Based CompuTng Laboratory
0
50000
100000
150000
200000
250000
300000
350000 Sep-‐04
Jan-‐05
May-‐05
Sep-‐05
Jan-‐06
May-‐06
Sep-‐06
Jan-‐07
May-‐07
Sep-‐07
Jan-‐08
May-‐08
Sep-‐08
Jan-‐09
May-‐09
Sep-‐09
Jan-‐10
May-‐10
Sep-‐10
Jan-‐11
May-‐11
Sep-‐11
Jan-‐12
May-‐12
Sep-‐12
Jan-‐13
May-‐13
Sep-‐13
Jan-‐14
May-‐14
Sep-‐14
Jan-‐15
May-‐15
Sep-‐15
Jan-‐16
Num
ber o
f Dow
nloa
ds
Timeline
MV 0.9.4
MV2
0.9.0
MV2
0.9.8
MV2
1.0
MV 1.0
MV2
1.0.3
MV 1.1
MV2
1.4
MV2
1.5
MV2
1.6
MV2
1.7
MV2
1.8
MV2
1.9 MV2
2.1
MV2
-‐GDR
2.0b
MV2
-‐MIC 2.0
MV2
-‐Virt 2.1rc2
MV2
-‐GDR
2.2b
MV2
-‐X 2.2rc1
MV2
2.2rc1
MVAPICH/MVAPICH2 Release Timeline and Downloads

OpenStack Summit (April ‘16) 10 Network Based CompuTng Laboratory
MVAPICH2 Sokware Family Requirements MVAPICH2 Library to use
MPI with IB, iWARP and RoCE MVAPICH2
Advanced MPI, OSU INAM, PGAS and MPI+PGAS with IB and RoCE MVAPICH2-‐X
MPI with IB & GPU MVAPICH2-‐GDR
MPI with IB & MIC MVAPICH2-‐MIC
HPC Cloud with MPI & IB MVAPICH2-‐Virt
Energy-‐aware MPI with IB, iWARP and RoCE MVAPICH2-‐EA

OpenStack Summit (April ‘16) 11 Network Based CompuTng Laboratory
• RDMA for Apache Spark
• RDMA for Apache Hadoop 2.x (RDMA-‐Hadoop-‐2.x) – Plugins for Apache, Hortonworks (HDP) and Cloudera (CDH) Hadoop distribuDons
• RDMA for Apache Hadoop 1.x (RDMA-‐Hadoop)
• RDMA for Memcached (RDMA-‐Memcached)
• OSU HiBD-‐Benchmarks (OHB) – HDFS and Memcached Micro-‐benchmarks
• hmp://hibd.cse.ohio-‐state.edu
• Users Base: 165 organizaDons from 22 countries
• More than 16,200 downloads from the project site
• RDMA for Apache HBase and Impala (upcoming)
The High-‐Performance Big Data (HiBD) Project
Available for InfiniBand and RoCE

OpenStack Summit (April ‘16) 12 Network Based CompuTng Laboratory
• MVAPICH2-‐Virt with SR-‐IOV and IVSHMEM – Standalone, OpenStack
• MVAPICH2-‐Virt on SLURM – SLURM alone, SLURM + OpenStack
• MVAPICH2 with Containers
• Appliances (HPC & Big Data) on Chameleon Cloud
Approaches to Build HPC Clouds

OpenStack Summit (April ‘16) 13 Network Based CompuTng Laboratory
• Major Features and Enhancements
– Based on MVAPICH2 2.1
– Support for efficient MPI communicaDon over SR-‐IOV enabled InfiniBand networks
– High-‐performance and locality-‐aware MPI communicaDon with IVSHMEM
– Support for auto-‐detecDon of IVSHMEM device in virtual machines
– AutomaDc communicaDon channel selecDon among SR-‐IOV, IVSHMEM, and CMA/LiMIC2
– Support for integraDon with OpenStack
– Support for easy configuraDon through runDme parameters
– Tested with • Mellanox InfiniBand adapters (ConnectX-‐3 (56Gbps))
• OpenStack Juno
MVAPICH2-‐Virt 2.1

OpenStack Summit (April ‘16) 14 Network Based CompuTng Laboratory
• Redesign MVAPICH2 to make it virtual machine aware – SR-‐IOV shows near to naDve
performance for inter-‐node point to point communicaDon
– IVSHMEM offers shared memory based data access across co-‐resident VMs
– Locality Detector: maintains the locality informaDon of co-‐resident virtual machines
– CommunicaDon Coordinator: selects the communicaDon channel (SR-‐IOV, IVSHMEM) adapDvely
Overview of MVAPICH2-‐Virt with SR-‐IOV and IVSHMEM
Host Environment
Guest 1
Hypervisor PF Driver
Infiniband Adapter
Physical Function
user space
kernel space
MPI proc
PCI Device
VF Driver
Guest 2user space
kernel space
MPI proc
PCI Device
VF Driver
Virtual Function
Virtual Function
/dev/shm/
IV-SHM
IV-Shmem Channel
SR-IOV Channel
J. Zhang, X. Lu, J. Jose, R. Shi, D. K. Panda. Can Inter-‐VM Shmem Benefit MPI ApplicaDons on SR-‐IOV based Virtualized InfiniBand Clusters? Euro-‐Par, 2014
J. Zhang, X. Lu, J. Jose, R. Shi, M. Li, D. K. Panda. High Performance MPI Library over SR-‐IOV Enabled InfiniBand Clusters. HiPC, 2014
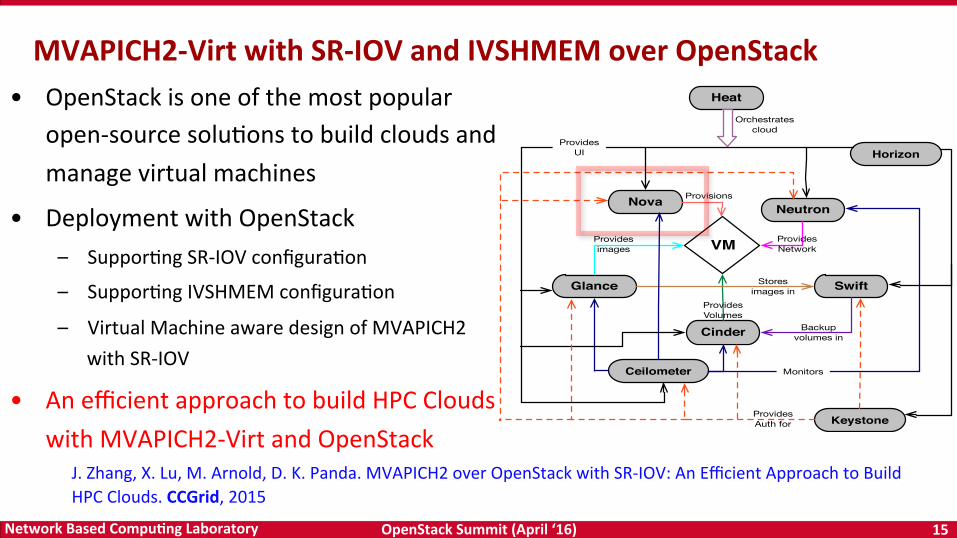
OpenStack Summit (April ‘16) 15 Network Based CompuTng Laboratory
Nova
Glance
Neutron
Swift
Keystone
Cinder
Heat
Ceilometer
Horizon
VM
Backup volumes in
Stores images in
Provides images
Provides Network
Provisions
Provides Volumes
Monitors
Provides UI
Provides Auth for
Orchestrates cloud
• OpenStack is one of the most popular open-‐source soluDons to build clouds and manage virtual machines
• Deployment with OpenStack – SupporDng SR-‐IOV configuraDon
– SupporDng IVSHMEM configuraDon
– Virtual Machine aware design of MVAPICH2 with SR-‐IOV
• An efficient approach to build HPC Clouds with MVAPICH2-‐Virt and OpenStack
MVAPICH2-‐Virt with SR-‐IOV and IVSHMEM over OpenStack
J. Zhang, X. Lu, M. Arnold, D. K. Panda. MVAPICH2 over OpenStack with SR-‐IOV: An Efficient Approach to Build HPC Clouds. CCGrid, 2015

OpenStack Summit (April ‘16) 16 Network Based CompuTng Laboratory
Performance EvaluaTon Cluster Nowlab Cloud Amazon EC2
Instance 4 Core/VM 8 Core/VM 4 Core/VM 8 Core/VM
Plaworm RHEL 6.5 Qemu+KVM HVM SLURM 14.11.8
Amazon Linux (EL6) Xen HVM C3.xlarge [1] Instance
Amazon Linux (EL6) Xen HVM C3.2xlarge [1] Instance
CPU SandyBridge Intel(R) Xeon E5-‐2670 (2.6GHz)
IvyBridge Intel(R) Xeon E5-‐2680v2 (2.8GHz)
RAM 6 GB 12 GB 7.5 GB 15 GB
Interconnect FDR (56Gbps) InfiniBand Mellanox ConnectX-‐3 with SR-‐IOV [2]
10 GigE with Intel ixgbevf SR-‐IOV driver [2]
[1] Amazon EC2 C3 instances: compute-‐opDmized instances, providing customers with the highest performing processors, good for HPC workloads
[2] Nowlab Cloud is using InfiniBand FDR (56Gbps), while Amazon EC2 C3 instances are using 10 GigE. Both have SR-‐IOV

OpenStack Summit (April ‘16) 17 Network Based CompuTng Laboratory
• Point-‐to-‐point – Two-‐sided and One-‐sided – Latency and Bandwidth – Intra-‐node and Inter-‐node [1]
• ApplicaDons – NAS and Graph500
Experiments Carried Out
[1] Amazon EC2 does not support users to explicitly allocate VMs in one physical node so far. We allocate mulDple VMs in one logical group and compare the point-‐to-‐point performance for each pair of VMs. We see the VMs who have the lowest latency as located within one physical node (Intra-‐node), otherwise Inter-‐node.

OpenStack Summit (April ‘16) 18 Network Based CompuTng Laboratory
• EC2 C3.2xlarge instances
• Compared to SR-‐IOV-‐Def, up to 84% and 158% performance improvement on Lat & BW
• Compared to NaDve, 3%-‐7% overhead for Lat, 3%-‐8% overhead for BW
• Compared to EC2, up to 160X and 28X performance speedup on Lat & BW
Intra-‐node Inter-‐VM pt2pt Latency Intra-‐node Inter-‐VM pt2pt Bandwidth
Point-‐to-‐Point Performance – Latency & Bandwidth (Intra-‐node)
0.1
1
10
100
1000
10000
100000
1 4 16 64 256 1K 4K 16K 64K 256K 1M 4M
Latency (us)
Message Size (bytes)
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve
MV2-‐EC2
0
2000
4000
6000
8000
10000
12000
1 4 16 64 256 1K 4K 16K 64K 256K 1M 4M
Band
width (M
B/s)
Message Size (bytes)
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve
MV2-‐EC2
160X 28X 3%
3% 7%
8%

OpenStack Summit (April ‘16) 19 Network Based CompuTng Laboratory
Point-‐to-‐Point Performance – Latency & Bandwidth (Inter-‐node)
• EC2 C3.2xlarge instances
• Similar performance with SR-‐IOV-‐Def
• Compared to NaDve, 2%-‐8% overhead on Lat & BW for 8KB+ messages
• Compared to EC2, up to 30X and 16X performance speedup on Lat & BW
1
10
100
1000
10000
100000
1 4 16 64 256 1K 4K 16K 64K 256K 1M 4M
Latency (us)
Message Size (bytes)
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve
MV2-‐EC2
0
1000
2000
3000
4000
5000
6000
7000
1 4 16 64 256 1K 4K 16K 64K 256K 1M 4M
Band
width (M
B/s)
Message Size (bytes)
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve
MV2-‐EC2
Inter-‐node Inter-‐VM pt2pt Latency Inter-‐node Inter-‐VM pt2pt Bandwidth
30X 16X

OpenStack Summit (April ‘16) 20 Network Based CompuTng Laboratory
0
50
100
150
200
250
300
350
400
450
20,10 20,16 20,20 22,10 22,16 22,20
ExecuT
on Tim
e (us)
Problem Size (Scale, Edgefactor)
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve
4%
9%
0
5
10
15
20
25
30
35
FT-‐64-‐C EP-‐64-‐C LU-‐64-‐C BT-‐64-‐C
ExecuT
on Tim
e (s)
NAS Class C
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve
1%
9%
• Compared to NaDve, 1-‐9% overhead for NAS
• Compared to NaDve, 4-‐9% overhead for Graph500
ApplicaTon-‐Level Performance (8 VM * 8 Core/VM)
NAS Graph500

OpenStack Summit (April ‘16) 21 Network Based CompuTng Laboratory
0
50
100
150
200
250
300
350
400
milc leslie3d pop2 GAPgeofem zeusmp2 lu
ExecuT
on Tim
e (s)
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve
1% 9.5%
0
1000
2000
3000
4000
5000
6000
22,20 24,10 24,16 24,20 26,10 26,16
ExecuT
on Tim
e (m
s)
Problem Size (Scale, Edgefactor)
MV2-‐SR-‐IOV-‐Def
MV2-‐SR-‐IOV-‐Opt
MV2-‐NaDve 2%
• 32 VMs, 6 Core/VM
• Compared to NaDve, 2-‐5% overhead for Graph500 with 128 Procs
• Compared to NaDve, 1-‐9.5% overhead for SPEC MPI2007 with 128 Procs
ApplicaTon-‐Level Performance on Chameleon
SPEC MPI2007 Graph500
5%

OpenStack Summit (April ‘16) 22 Network Based CompuTng Laboratory
• MVAPICH2-‐Virt with SR-‐IOV and IVSHMEM – Standalone, OpenStack
• MVAPICH2-‐Virt on SLURM – SLURM alone, SLURM + OpenStack
• MVAPICH2 with Containers
• Appliances (HPC & Big Data) on Chameleon Cloud
Approaches to Build HPC Clouds

OpenStack Summit (April ‘16) 23 Network Based CompuTng Laboratory
• SLURM is one of the most popular open-‐source soluDons to manage huge amounts of machines in HPC clusters.
• How to build a SLURM-‐based HPC Cloud with near naDve performance for MPI applicaDons over SR-‐IOV enabled InfiniBand HPC clusters?
• What are the requirements on SLURM to support SR-‐IOV and IVSHMEM provided in HPC Clouds?
• How much performance benefit can be achieved on MPI primiDve operaDons and applicaDons in “MVAPICH2-‐Virt on SLURM”-‐based HPC clouds?
Can HPC Clouds be built with MVAPICH2-‐Virt on SLURM?

OpenStack Summit (April ‘16) 24 Network Based CompuTng Laboratory
Com
pute
Nod
es
MPI MPI
MPI
MPI
MPI
MPI
MPI MPI
MPI MPI
VM VM
VM VM
VM
VM
VM VM
Exclusive Allocations Sequential Jobs
Exclusive Allocations Concurrent Jobs
Shared-host Allocations Concurrent Jobs
Typical Usage Scenarios

OpenStack Summit (April ‘16) 25 Network Based CompuTng Laboratory
• Requirement of managing and isolaDng virtualized resources of SR-‐IOV and IVSHMEM
• Such kind of management and isolaDon is hard to be achieved by MPI library alone, but much easier with SLURM
• Efficient running MPI applicaDons on HPC Clouds needs SLURM to support managing SR-‐IOV and IVSHMEM – Can criDcal HPC resources be efficiently shared among users by extending SLURM with
support for SR-‐IOV and IVSHMEM based virtualizaDon?
– Can SR-‐IOV and IVSHMEM enabled SLURM and MPI library provide bare-‐metal performance for end applicaDons on HPC Clouds?
Need for SupporTng SR-‐IOV and IVSHMEM in SLURM

OpenStack Summit (April ‘16) 26 Network Based CompuTng Laboratory
Submit Job SLURMctld
VM Configuration File
physical node
SLURMd
SLURMd
VM Launching
libvirtd
VM1
VF IVSHMEM
VM2
VF IVSHMEM
physical node
SLURMd
physical node
SLURMd
sbatch File
MPI MPI
physical resource request
physical node list
launch VMs
Lustre
image load
image snapshot
Image Pool
1. SR-IOV virtual function 2. IVSHMEM device 3. Network setting 4. Image management 5. Launching VMs and
check availability 6. Mount global storage,
etc.
….
Workflow of Running MPI Jobs with MVAPICH2-‐Virt on SLURM

OpenStack Summit (April ‘16) 27 Network Based CompuTng Laboratory
load SPANK
reclaim VMs
register job step reply
register job step req
Slurmctld Slurmd Slurmd
release hosts
run job step req
run job step reply
mpirun_vm
MPI Job across VMs
VM Config Reader
load SPANK VM Launcher
load SPANK VM Reclaimer
• VM ConfiguraDon Reader – Register all VM configuraDon opDons, set in the job control environment so that they are visible to all allocated nodes.
• VM Launcher – Setup VMs on each allocated nodes. -‐ File based lock to detect occupied VF and exclusively allocate free VF
-‐ Assign a unique ID to each IVSHMEM and dynamically a=ach to each VM
• VM Reclaimer – Tear down VMs and reclaim resources
SLURM SPANK Plugin based Design
MPI MPI
vm hoswile

OpenStack Summit (April ‘16) 28 Network Based CompuTng Laboratory
• CoordinaDon – With global informaDon, SLURM plugin can manage SR-‐IOV and IVSHMEM resources easily
for concurrent jobs and mulDple users
• Performance – Faster coordinaDon, SR-‐IOV and IVSHMEM aware resource scheduling, etc.
• Scalability – Taking advantage of the scalable architecture of SLURM
• Fault Tolerance
• Permission
• Security
Benefits of Plugin-‐based Designs for SLURM
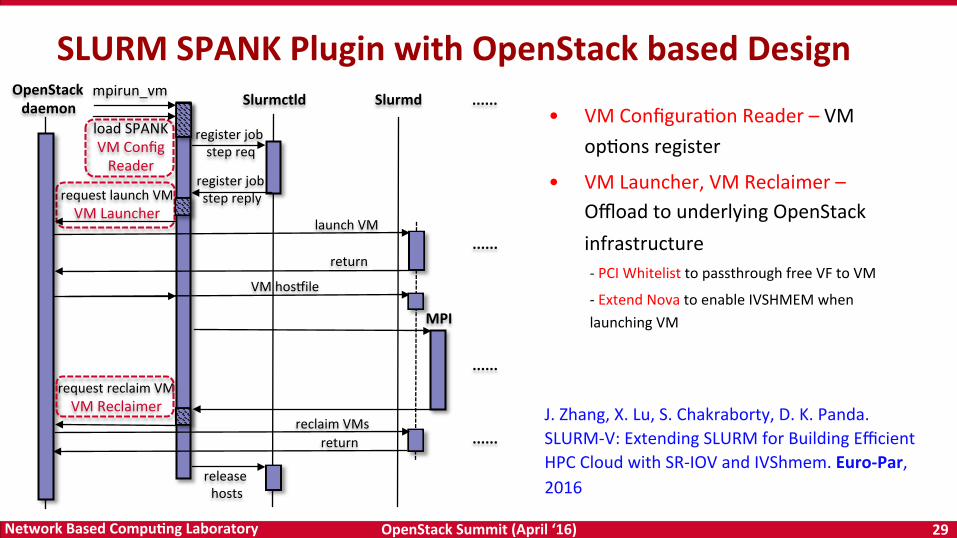
OpenStack Summit (April ‘16) 29 Network Based CompuTng Laboratory
• VM ConfiguraDon Reader – VM opDons register
• VM Launcher, VM Reclaimer – Offload to underlying OpenStack infrastructure -‐ PCI Whitelist to passthrough free VF to VM
-‐ Extend Nova to enable IVSHMEM when launching VM
SLURM SPANK Plugin with OpenStack based Design
J. Zhang, X. Lu, S. Chakraborty, D. K. Panda. SLURM-‐V: Extending SLURM for Building Efficient HPC Cloud with SR-‐IOV and IVShmem. Euro-‐Par, 2016
reclaim VMs
register job step reply
register job step req
Slurmctld Slurmd
release hosts
launch VM
mpirun_vm
load SPANK VM Config Reader
MPI
VM hoswile
OpenStack daemon
request launch VM VM Launcher
return
request reclaim VM VM Reclaimer
return
......
......
......
......

OpenStack Summit (April ‘16) 30 Network Based CompuTng Laboratory
Benefits of SLURM Plugin-‐based Designs with OpenStack
• Easy Management – Directly use underlying OpenStack infrastructure to manage authenDcaDon, image,
networking, etc.
• Component OpDmizaDon – Directly inherit opDmizaDons on different components of OpenStack
• Scalability – Taking advantage of the scalable architecture of both OpenStack and SLURM
• Performance

OpenStack Summit (April ‘16) 31 Network Based CompuTng Laboratory
Comparison on Total VM Startup Time
• Task -‐ implement and explicitly insert three components in job batch file
• SPANK -‐ SPANK Plugin based design
• SPANK-‐OpenStack – offload tasks to underlying OpenStack infrastructure
24.6 23.769
20.1
0
5
10
15
20
25
30
Task SPANK SPANK-‐OpenStack
VM Startup
Tim
e (s)
VM Startup Scheme
Total VM Startup Time

OpenStack Summit (April ‘16) 32 Network Based CompuTng Laboratory
• 32 VMs across 8 nodes, 6 Core/VM
• EASJ -‐ Compared to NaDve, less than 4% overhead with 128 Procs
• SACJ, EACJ – Also minor overhead, when running NAS as concurrent job with 64 Procs
ApplicaTon-‐Level Performance on Chameleon (Graph500)
Exclusive Allocations Sequential Jobs
0
500
1000
1500
2000
2500
3000
24,16 24,20 26,10
BFS ExecuT
on Tim
e (m
s)
Problem Size (Scale, Edgefactor)
VM
NaDve
0
50
100
150
200
250
22,10 22,16 22,20 BF
S ExecuT
on Tim
e (m
s)
Problem Size (Scale, Edgefactor)
VM NaDve
0
50
100
150
200
250
22 10 22 16 22 20
BFS ExecuT
on Tim
e (m
s)
Problem Size (Scale, Edgefactor)
VM
NaDve
Shared-host Allocations Concurrent Jobs
Exclusive Allocations Concurrent Jobs
4%

OpenStack Summit (April ‘16) 33 Network Based CompuTng Laboratory
• MVAPICH2-‐Virt with SR-‐IOV and IVSHMEM – Standalone, OpenStack
• MVAPICH2-‐Virt on SLURM – SLURM alone, SLURM + OpenStack
• MVAPICH2 with Containers
• Appliances (HPC & Big Data) on Chameleon Cloud
Approaches to Build HPC Clouds

OpenStack Summit (April ‘16) 34 Network Based CompuTng Laboratory
• Container-‐based technologies (such as Docker) provide lightweight virtualizaDon soluDons
• What are the performance bo=lenecks when running MPI applicaDons on mulDple containers per host in HPC cloud?
• Can we propose a new design to overcome the bo=leneck on such container-‐based HPC cloud?
• Can opDmized design deliver near-‐naDve performance for different container deployment scenarios?
• Locality-‐aware based design to enable CMA and Shared memory channels for MPI communicaDon across co-‐resident containers
Containers-‐based Design: Issues, Challenges, and Approaches

OpenStack Summit (April ‘16) 35 Network Based CompuTng Laboratory
0
2
4
6
8
10
12
14
16
18
1 2 4 8 16 32 64 128 256 512 1k 2k 4k 8k 16k 32k 64k
Latency (us)
Message Size (Bytes)
Container-‐Def
Container-‐Opt
NaDve
0
2000
4000
6000
8000
10000
12000
14000
16000
1 2 4 8 16 32 64 128 256 512 1k 2k 4k 8k 16k 32k 64k
Band
width (M
Bps)
Message Size (Bytes)
Container-‐Def
Container-‐Opt
NaDve
• Intra-‐Node Inter-‐Container
• Compared to Container-‐Def, up to 81% and 191% improvement on Latency and BW
• Compared to NaDve, minor overhead on Latency and BW
Containers Support: MVAPICH2 Intra-‐node Inter-‐Container Point-‐to-‐Point Performance on Chameleon
81%
191%

OpenStack Summit (April ‘16) 36 Network Based CompuTng Laboratory
0
500
1000
1500
2000
2500
3000
3500
4000
1 2 4 8 16 32 64 128 256 512 1k 2k 4k
Latency (us)
Message Size (Bytes)
Container-‐Def
Container-‐Opt
NaDve
0
10
20
30
40
50
60
70
80
4 8 16 32 64 128 256 512 1k 2k 4k
Latency (us)
Message Size (Bytes)
Container-‐Def
Container-‐Opt
NaDve
• 64 Containers across 16 nodes, pinning 4 Cores per Container
• Compared to Container-‐Def, up to 64% and 86% improvement on Allreduce and Allgather
• Compared to NaDve, minor overhead on Allreduce and Allgather
Containers Support: MVAPICH2 CollecTve Performance on Chameleon
64%
86%
Allreduce Allgather

OpenStack Summit (April ‘16) 37 Network Based CompuTng Laboratory
0
500
1000
1500
2000
2500
3000
3500
4000
22, 16 22, 20 24, 16 24, 20 26, 16 26, 20
ExecuT
on Tim
e (m
s)
Problem Size (Scale, Edgefactor)
Container-‐Def
Container-‐Opt
NaDve
0
10
20
30
40
50
60
70
80
90
100
MG.D FT.D EP.D LU.D CG.D
ExecuT
on Tim
e (s)
Container-‐Def
Container-‐Opt
NaDve
• 64 Containers across 16 nodes, pining 4 Cores per Container
• Compared to Container-‐Def, up to 11% and 16% of execuDon Dme reducDon for NAS and Graph 500
• Compared to NaDve, less than 9 % and 4% overhead for NAS and Graph 500
• OpTmized Container support will be available with the upcoming release of MVAPICH2-‐Virt
Containers Support: ApplicaTon-‐Level Performance on Chameleon
Graph 500 NAS
11%
16%

OpenStack Summit (April ‘16) 38 Network Based CompuTng Laboratory
• MVAPICH2-‐Virt with SR-‐IOV and IVSHMEM – Standalone, OpenStack
• MVAPICH2-‐Virt on SLURM – SLURM alone, SLURM + OpenStack
• MVAPICH2 with Containers
• Appliances (HPC & Big Data) on Chameleon Cloud
Approaches to Build HPC Clouds

OpenStack Summit (April ‘16) 39 Network Based CompuTng Laboratory
Available Appliances on Chameleon Cloud*
Appliance DescripTon
CentOS 7 KVM SR-‐IOV Chameleon bare-‐metal image customized with the KVM hypervisor and a recompiled kernel to enable SR-‐IOV over InfiniBand. h=ps://www.chameleoncloud.org/appliances/3/
CentOS 7 SR-‐IOV MVAPICH2-‐Virt
The CentOS 7 SR-‐IOV MVAPICH2-‐Virt appliance is built from the CentOS 7 KVM SR-‐IOV appliance and addiDonally contains MVAPICH2-‐Virt library. h=ps://www.chameleoncloud.org/appliances/9/
CentOS 7 SR-‐IOV RDMA-‐Hadoop
The CentOS 7 SR-‐IOV RDMA-‐Hadoop appliance is built from the CentOS 7 appliance and addiDonally contains RDMA-‐Hadoop library with SR-‐IOV. h=ps://www.chameleoncloud.org/appliances/17/
[*] Only include appliances contributed by OSU NowLab
• Through these available appliances, users and researchers can easily deploy HPC clouds to perform experiments and run jobs with – High-‐Performance SR-‐IOV + InfiniBand
– High-‐Performance MVAPICH2 Library with VirtualizaDon Support
– High-‐Performance Hadoop with RDMA-‐based Enhancements Support

OpenStack Summit (April ‘16) 40 Network Based CompuTng Laboratory
• MVAPICH2-‐Virt with SR-‐IOV and IVSHMEM is an efficient approach to build HPC Clouds – Standalone
– OpenStack
• Building HPC Clouds with MVAPICH2-‐Virt on SLURM is possible – SLURM alone
– SLURM + OpenStack
• Containers-‐based design for MPAPICH2-‐Virt
• Very li=le overhead with virtualizaDon, near naDve performance at applicaDon level
• Much be=er performance than Amazon EC2
• MVAPICH2-‐Virt 2.1 is available for building HPC Clouds – SR-‐IOV, IVSHMEM, OpenStack
• Appliances for MVAPICH2-‐Virt and RDMA-‐Hadoop are available for building HPC Clouds
• Future releases for supporDng running MPI jobs in VMs/Containers with SLURM
• SR-‐IOV/container support and appliances for other MVAPICH2 libraries (MVAPICH2-‐X, MVAPICH2-‐GDR, ...) and RDMA-‐Spark/Memcached
Conclusions

OpenStack Summit (April ‘16) 41 Network Based CompuTng Laboratory
Thank You!
The High-‐Performance Big Data Project h=p://hibd.cse.ohio-‐state.edu/
Network-‐Based CompuDng Laboratory h=p://nowlab.cse.ohio-‐state.edu/
The MVAPICH2/MVAPICH2-‐X Project h=p://mvapich.cse.ohio-‐state.edu/
[email protected]‐state.edu, [email protected]‐state.edu