building largescalepredictionsystemv1
TRANSCRIPT

Building Large Scale Production Ready Prediction System in Python
By Arthi Venkataraman

Agenda
Background
Challenges
Proposed Solution
Software Libraries used
Data Pre-Processing
Natural Language Processing

Agenda
Model Validation and Selection
Making the solution scalable
Results
Conclusions
7
8
10
9

Background

Functions in an Organization

Issues Data – Top level view

Targeted System

To Be Designed System
User types / speaks problem across interfaces
Prediction System
Ticket Logging System
Class of ticket predicted

Challenges

Data related challenges
Unclean DataWrongly Labeled
Data
Un-balanced DataLarge number of
classes
Data related challenges
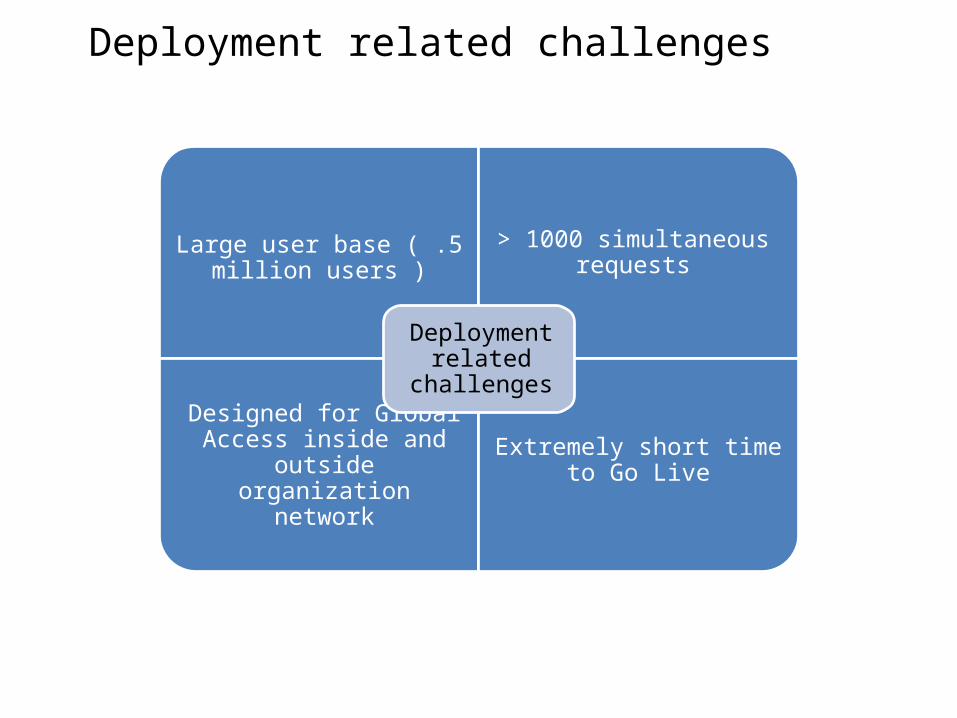
Deployment related challenges
Large user base ( .5 million users )
> 1000 simultaneous requests
Designed for Global Access inside and outside
organization network
Extremely short time to Go Live
Deployment related
challenges

Proposed Solution

Predictor NLP Process
Build model
Pre-Processing
Input Text
Training Data
Output Response
Trained Model
High Level Solution Block Diagram
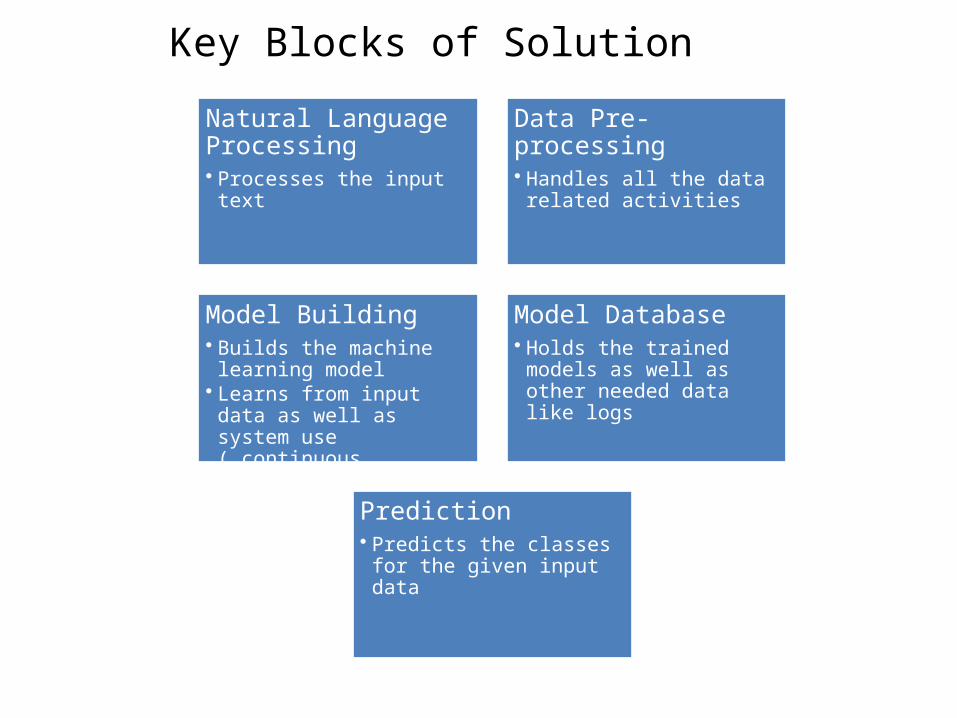
Natural Language Processing • Processes the input text
Data Pre-processing• Handles all the data related
activities
Model Building• Builds the machine learning
model • Learns from input data as well
as system use ( continuous learning)
Model Database• Holds the trained models as
well as other needed data like logs
Prediction• Predicts the classes for the
given input data
Key Blocks of Solution

Software Libraries used

• Scikit learn• Can be insatlled from pypi– https://pypi.python.org/pypi/scikit-learn/0.13.1
Dependencies for sklearn :• Scikit-learn requires:– Python (>= 2.6 or >= 3.3),– NumPy (>= 1.6.1),– SciPy (>= 0.9).
Software Library

Data Pre-processing

• Training data has lot of words which do not add value for the prediction
• Examples include The, is , or, etc…
• Call below function where text is the string from which the stop words needed to be removed
• myStopWordList - This is the list of stop words
def removeStopWord(text) : text = ' '.join([word for word in text.split() if word not in myStopWordList]) return text
Stop word removal

Tried nltk’s Named Entity RecognitionThere were many issues of wrong tagging of entities and in many case not tagging of entitiesWe needed a simple and fool proof way of tagging
For removing names we got a list of possible names from our internal systemsWe followed a similar approach as Stop Word removal for this
Removing names

Natural Language Processing

• Select features according to the k highest scores.
• The output of the TF-IDF vectorizer can be fed to this to reduce the number of feature and only retain the ones with the highest scores
• Y_train is a list of labels which are in same oreder as the X_train data – The first element in Y is the label corresponding to the first sentence in
X_train
• Code snippet for this :• ch2 = SelectKBest(chi2, k='all')
– In this case we have used the chi-squared – We have also opted to select all the features
• X_train = ch2.fit_transform(X_train, y_train)
• Using chi square test ensures only retaining most relevant features where most relevant features are those which have higher correlation with the labels. This test will weed out non-correlated features.
Handling unstructured text – Intelligent Feature reduction

• Xtrain -– Holds the list of input data to be used for training– Each item of list is one sentence in training corpus
• Assuming text has gone through required pre-processing for cleaning we can now - “Convert a collection of raw documents to a matrix of TF-IDF features.”
• Code snippet for this :• vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,• stop_words='english') **• X_train = vectorizer.fit_transform(X_train)
• Note : ** - There are many parameters available for this call. We can discuss about the selected parameters.
Handling unstructured text - Vectorization

Building and Predicting using classifier

– Given labelled data set has to be split between train and test sets
– Train sets will be used for training classifier– Test sets will be used for testing classifier– Split can be decided based on available labelled data– We went with 70 : 30 where 70% of the labelled data
was used for training
Selecting training data for the classifier

• Sklearn has a huge repository of algorithms • However not all of them are relevant
• Criteria for selecting– Is a supervised machine learning algorithm
– Handles text classification
– Can handle the size of data• Many algorithms satisfied 1 and 2 above however when
used for training they never completed the cycle
Selecting the classifier

• Sklearn has a standardized interface for training of a classifier
• The difference between two classifier are the parameters available for training
• Code Snippet for classifier training:– clf = XXXX(param1=val1, param2=val2….)– clf.fit(X_train, y_train_text)
– Where XXXX above refers to the relevant classifier
• It is advisable to create the code in a way where new classifiers can easily be prototyped to be tested
Training the classifier

• Once classifier has been trained it can be used for predicting
• X_test – Holds the list of held out set to be used for testing
• Code flow for same :x_test = vectorizer.transform(X_test)
x_test = ch2.transform(X_test)
pred = clf.predict(x_test)
• X_test will be passed through the same pipeline which is the vectorizer and k-best trainsform which was previously fitted with the training data
• Pred - Holds the list of predicted labels
Predicting using the classifier

Model Validation and Selection

• Once we have got the prediction we need to evaluate if classifier is good enough
• For this we have to see if the precision , recall and f-score are good enough
• We can use the following code snippet to check this score metrics.f1_score(y_test, pred) print("f1-score: %0.3f" % score)
This is a score between 0 and 1.The higher the score means it is better For example - f1-score: 0.801 The threshold which we set for accepting this is based on our understanding of the domain
Model validation

• To get a more detailed understanding of how our classifier is performing we can use
• print(metrics.classification_report(y_test, pred,target_names=categories))
• The above will give an a classwise break up of Precision, Recall , F-score and Support ( Number of cases available for that case)
• It will also give these scores for the classifier as a whole• Sample Report
• precision recall f1-score support• Class1 0.99 0.97 0.98 4558• Class2 0.56 0.74 0.63 53• avg / total 0.81 0.81 0.80 19022• From the above report we can see that classifier as a whole is at 80% F-
score. Class 1 is at very good accuracy. Class2 is performing poorly.• Hence if there is a need to improve accuracy a dedicated effort can be
done to improve Class2’s score.
Model validation (contd )

• Based on benchmarking of different algorithms the best performing algorithm can be selected
• Parameters for selection will vary from domain to domain
• Key Parameters which could considered :– F- Score– Precision– Re-call– Model building Time– Prediction Time – Amount of Training data
Algorithm selection

• Selecting the final model is an iterative process
• Tuning will be done based on– Algorithm Selected– Algorithm Parameters– Training Data– Training / Testing Data Ratios
• Once a satisfactory performance has been reached the model will be built and can be used
Train / Re-Train loop

Making the solution scalable

High Level Deployment Diagram

• Sizing the number of instances– Benchmark maximum capacity for the instance - X– Benchmark maximum needed simultaneous request
– Y– Calculate Number of instances
• (Y / ( X – .4 X) ) + 2– Use at only 60% of capacity– Factor for 2 additional instances
– Size requests from within and outside organizations– Size requests based on region– Separate region level farms– Separate farms for users from within and outside the
company
Building a scalable solution

Results

• ~ 50 % reduction in Reassignment index
• Significant savings in efforts due this ( > 100 person months saved ) within just 3 months of release
• First version of our solution released to production in under 2 months
Our results

Our conclusions

Python • Has excellent libraries for handling machine learning
problems
• Python can be used in Live Production environments
• We are able to achieve the needed scalability and performance required using python
• The language itself is easy to learn and we can write maintainable code
Conclusions

Thank You