building workload optimized solutions for business analytics · © 2014 ibm corporationtalk at...
TRANSCRIPT

© 2014 IBM Corporation
Building Workload Optimized Solutions for Business Analytics
René Müller — IBM Research – Almaden
23 March 2014
Talk at FastPath 2014, Monterey, CA
René Müller, IBM Research – Almaden [email protected] GPU Hash Joins with Tim Kaldewey, John McPherson BLU work with Vijayshankar Raman, Ronald Barber, Ippokratis Pandis, Richard Sidle, Guy Lohman IBM Research—Almaden
© 2014 IBM Corporation
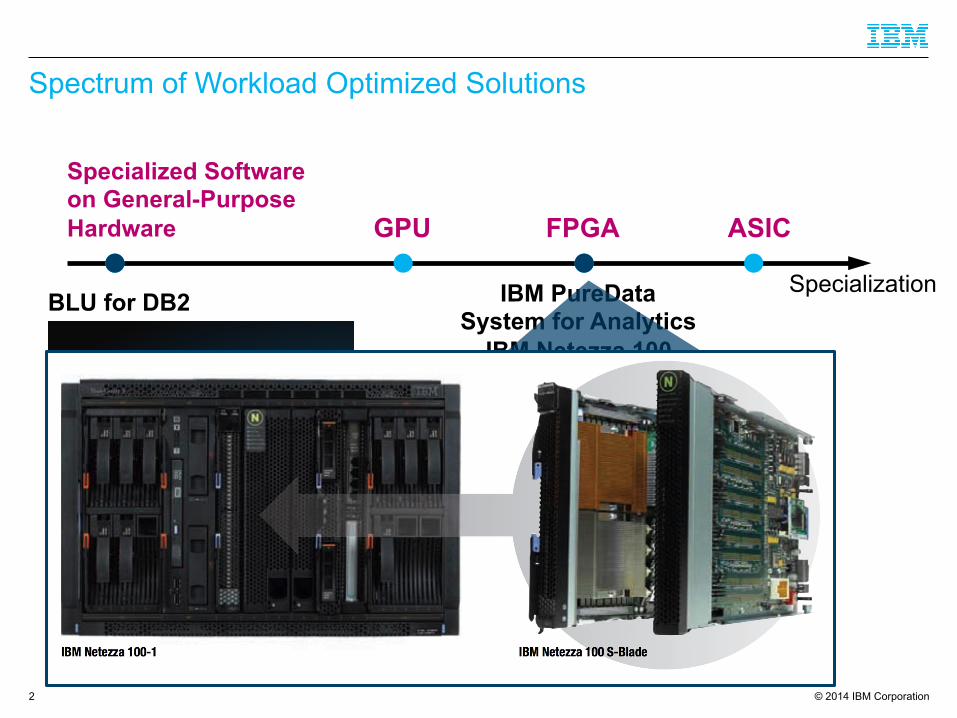
Spectrum of Workload Optimized Solutions
2
ASIC FPGA GPU
Specialized Software on General-Purpose Hardware
Specialization BLU for DB2 IBM PureData
System for Analytics IBM Netezza 100

© 2014 IBM Corporation
Agenda
§ Workload: Business Intelligence, OLAP
§ BLU Acceleration for DB2
§ Study 1: Acceleration of BLU-style Predicate Evaluation SIMD CPU vs. FPGA vs. GPU
§ Study 2: Hash Joins on GPUs
3

© 2014 IBM Corporation
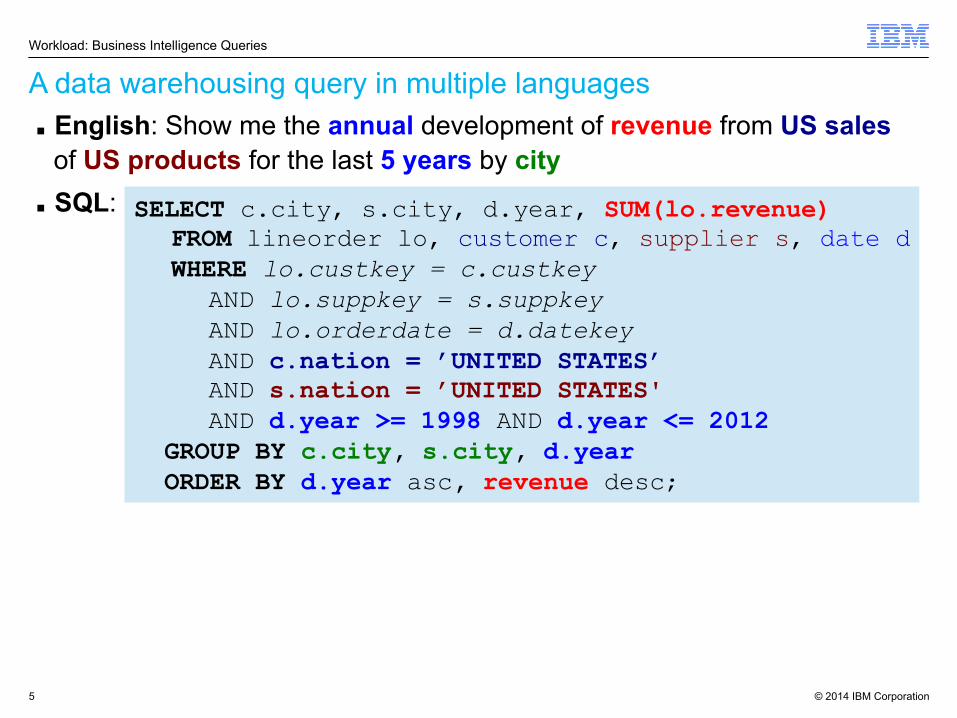
A data warehousing query in multiple languages Workload: Business Intelligence Queries
■ English: Show me the annual development of revenue from US sales of US products for the last 5 years by city
4
© 2014 IBM Corporation
A data warehousing query in multiple languages Workload: Business Intelligence Queries
■ English: Show me the annual development of revenue from US sales of US products for the last 5 years by city
■ SQL: SELECT c.city, s.city, d.year, SUM(lo.revenue) FROM lineorder lo, customer c, supplier s, date d WHERE lo.custkey = c.custkey AND lo.suppkey = s.suppkey AND lo.orderdate = d.datekey AND c.nation = ’UNITED STATES’ AND s.nation = ’UNITED STATES' AND d.year >= 1998 AND d.year <= 2012
GROUP BY c.city, s.city, d.year ORDER BY d.year asc, revenue desc;
5
© 2014 IBM Corporation
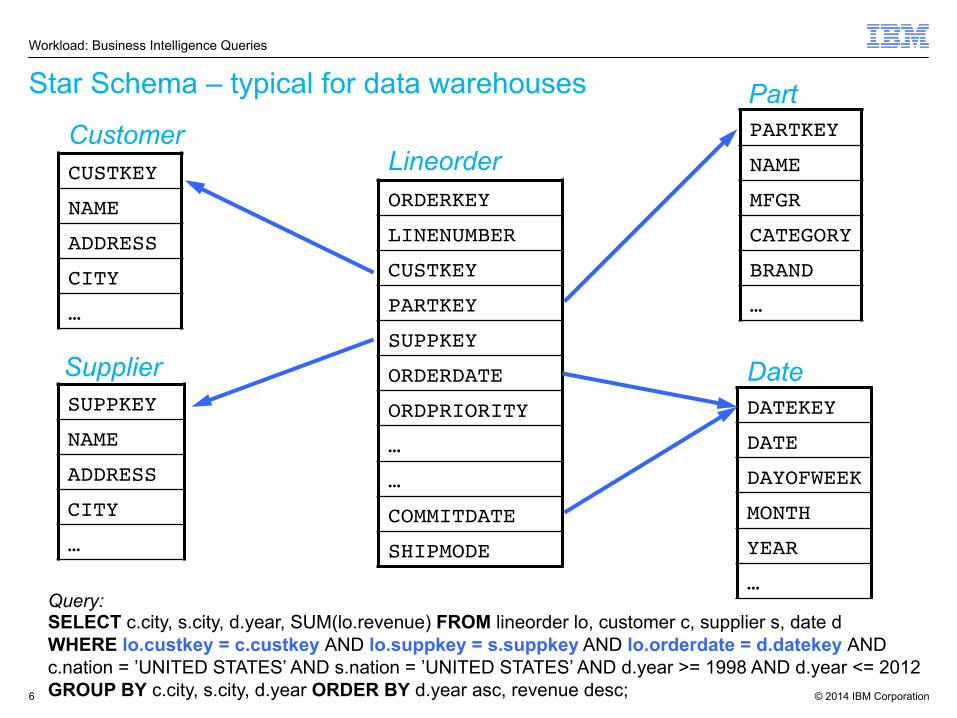
Star Schema – typical for data warehouses
Query: SELECT c.city, s.city, d.year, SUM(lo.revenue) FROM lineorder lo, customer c, supplier s, date d WHERE lo.custkey = c.custkey AND lo.suppkey = s.suppkey AND lo.orderdate = d.datekey AND c.nation = ’UNITED STATES’ AND s.nation = ’UNITED STATES’ AND d.year >= 1998 AND d.year <= 2012 GROUP BY c.city, s.city, d.year ORDER BY d.year asc, revenue desc;
Workload: Business Intelligence Queries
ORDERKEY!
LINENUMBER!
CUSTKEY!
PARTKEY!
SUPPKEY!
ORDERDATE!
ORDPRIORITY!
…!
…!
COMMITDATE!
SHIPMODE!
CUSTKEY!
NAME!
ADDRESS!
CITY!
…!
SUPPKEY!
NAME!
ADDRESS!
CITY!
…!
PARTKEY!
NAME!
MFGR!
CATEGORY!
BRAND!
…!
DATEKEY!
DATE!
DAYOFWEEK!
MONTH!
YEAR!
…!
Customer
Date
Lineorder
Supplier
Part
6

© 2014 IBM Corporation
Workload Optimized Systems
§ Optimized for Performance (for us)
§ Primary Performance Metrics – Response time Seconds à minimize – Query throughput Queries/hour à maximize
§ Derived Metrics – Performance/Watt Queries/hour/Watt (Queries/Wh) – Performance/$ Queries/hour/$
§ Cost of Ownership itself usually secondary goal
7
Workload Optimized System. A system whose architecture and design have been designed for a specific and narrow range of applications.
My Definition:
Workload: Business Intelligence Queries

© 2014 IBM Corporation
BLU Acceleration for DB2 Specialized Software on General-Purpose Hardware
8

© 2014 IBM Corporation
What is DB2 with BLU Acceleration?
• Novel Engine for analy/c queries – Columnar storage, single copy of the data – New run-‐/me engine with SIMD processing – Deep mul/-‐core op/miza/ons and cache-‐aware memory management
– “Ac/ve compression” -‐ unique encoding for storage reduc/on and run-‐/me processing without decompression
§ “Revolu/on by Evolu/on” – Built directly into the DB2 kernel – BLU tables can coexist with row tables – Query any combina/on of BLU or row data – Memory-‐op/mized (not “in-‐memory”)
§ Value : Order-‐of-‐magnitude benefits in … – Performance – Storage savings – Simplicity!
§ Available since June 2013 in DB2 v10.5 LUW 2
DB2 with BLU
DB2 Run-time Row-wise Run-time
BLU Run-time
DB2 Bufferpool
Storage
C1 C2 C3 C4 C5 C6 C7 C8C1 C2 C3 C4 C5 C6 C7 C8
BLU Encoded Columnar
Tables C1 C2 C3 C4 C5 C6 C7 C8C1 C2 C3 C4 C5 C6 C7 C8
Traditional Row Tables
DB2 Compiler
BLU Acceleration for DB2

© 2014 IBM Corporation
BLU’s Columnar Store Engine
§ Reduce I/O by only reading the columns that are referenced by the query.
§ Traditional row stores read pages with complete rows.
§ Columns are horizontally divided into strides of rows
§ BLU keeps a synopsis (=summary) of min/max values in each stride
SELECT SUM(revenue) FROM lineorder WHERE quantity BETWEEN 1 AND 10
§ Skip strides without matches à further reduces I/O à Skip-sequential access pattern
10
BLU Acceleration for DB2
c1 c2 c3 c4 c5 c6 c7 c1 c2 c3 c4 c5 c6 c7
c1 c2 c3 c4 c5 c6 c7
Stride
Skip strides without matches
© 2014 IBM Corporation
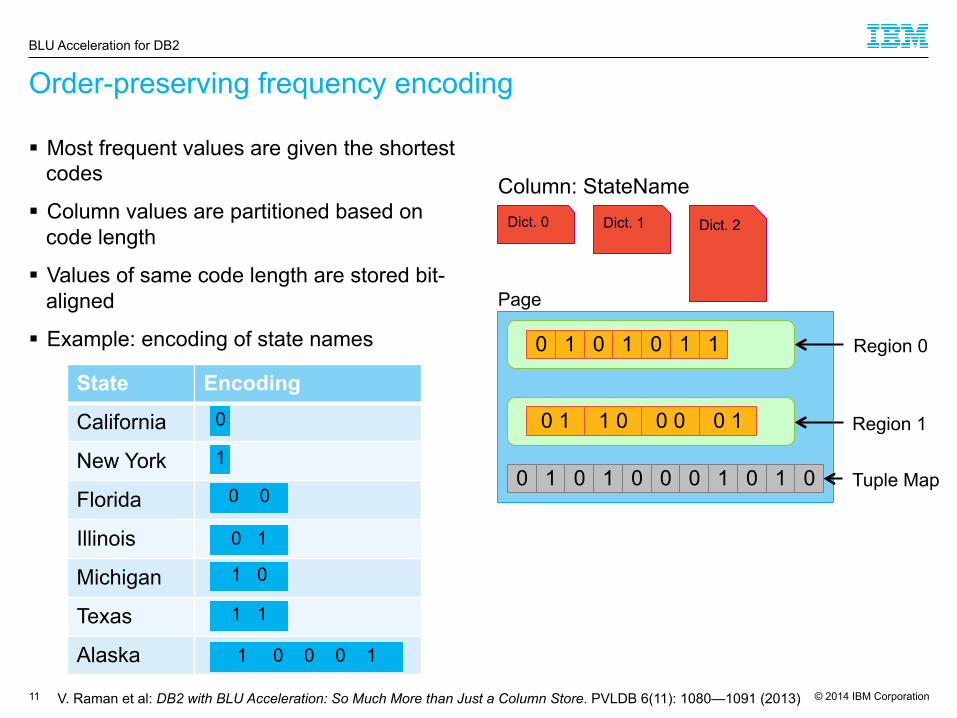
Order-preserving frequency encoding
§ Most frequent values are given the shortest codes
§ Column values are partitioned based on code length
§ Values of same code length are stored bit-aligned
§ Example: encoding of state names
11
BLU Acceleration for DB2
State Encoding
California
New York
Florida
Illinois
Michigan
Texas
Alaska
0
1
0 0
0 1
1 0
1 1
1 0 0 0 1
0 1 0 1 0 1 1
0 1 1 0 0 0 0 1
0 1 0 1 0 0 0 1 0 1 0
Dict. 0 Dict. 1 Dict. 2
Column: StateName
Region 0
Region 1
Tuple Map
Page
V. Raman et al: DB2 with BLU Acceleration: So Much More than Just a Column Store. PVLDB 6(11): 1080—1091 (2013)
© 2014 IBM Corporation
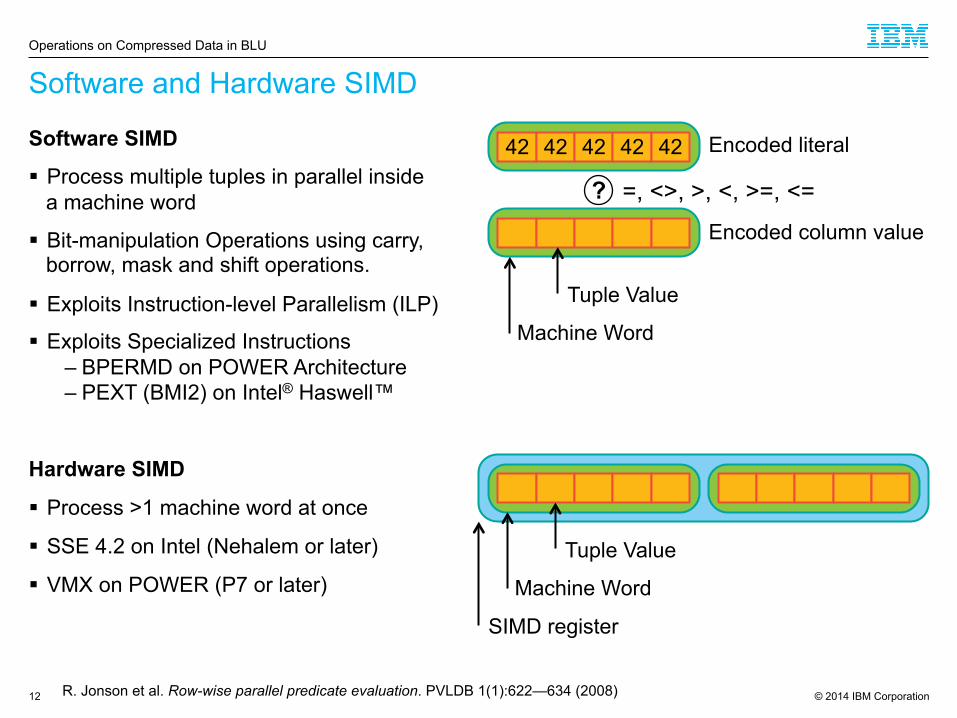
Software and Hardware SIMD
Software SIMD
§ Process multiple tuples in parallel inside a machine word
§ Bit-manipulation Operations using carry, borrow, mask and shift operations.
§ Exploits Instruction-level Parallelism (ILP)
§ Exploits Specialized Instructions – BPERMD on POWER Architecture – PEXT (BMI2) on Intel® Haswell™
Hardware SIMD
§ Process >1 machine word at once
§ SSE 4.2 on Intel (Nehalem or later)
§ VMX on POWER (P7 or later)
12
Operations on Compressed Data in BLU
SIMD register
Machine Word
Tuple Value
Machine Word
Tuple Value
R. Jonson et al. Row-wise parallel predicate evaluation. PVLDB 1(1):622—634 (2008)
42 42 42 42 42
Encoded column value
? =, <>, >, <, >=, <=
Encoded literal
© 2014 IBM Corporation
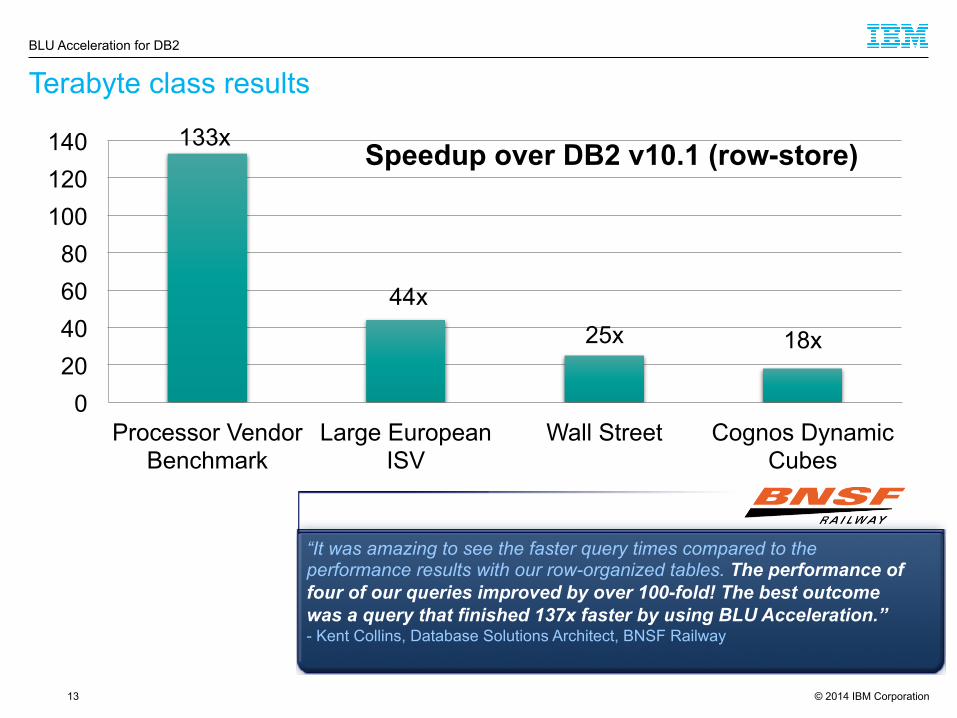
Terabyte class results
13
133x
44x 25x 18x
0 20 40 60 80
100 120 140
Processor Vendor Benchmark
Large European ISV
Wall Street Cognos Dynamic Cubes
Speedup over DB2 v10.1 (row-store)
“It was amazing to see the faster query times compared to the performance results with our row-organized tables. The performance of four of our queries improved by over 100-fold! The best outcome was a query that finished 137x faster by using BLU Acceleration.” - Kent Collins, Database Solutions Architect, BNSF Railway
BLU Acceleration for DB2

© 2014 IBM Corporation
BLU with Specialized Hardware FPGA vs. GPU vs. BLU on Multicore SIMD CPU
14
© 2014 IBM Corporation
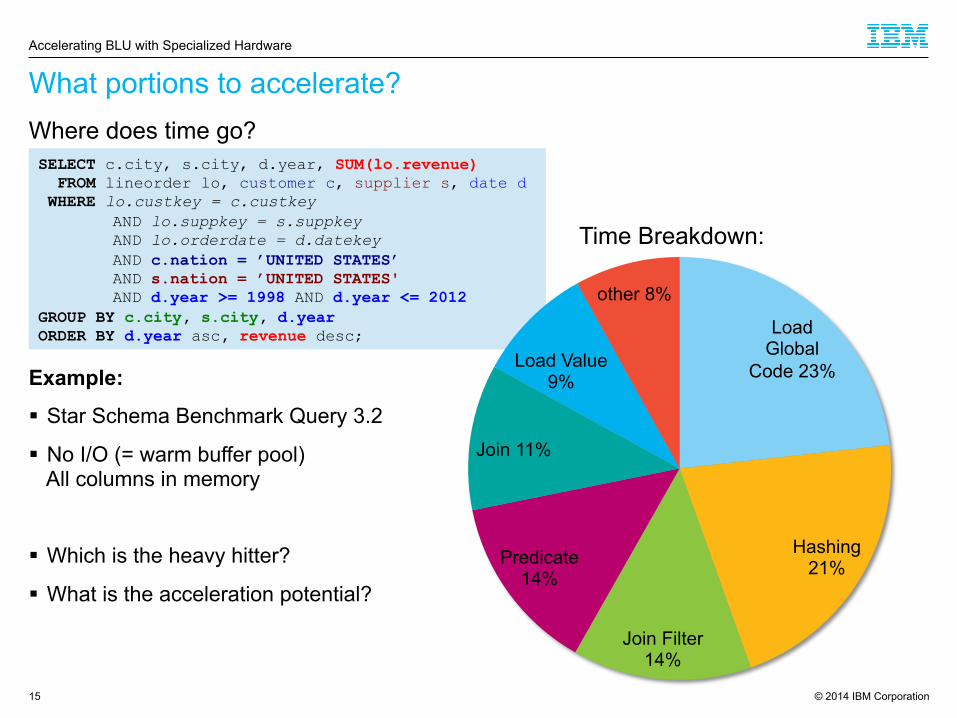
What portions to accelerate?
15
Accelerating BLU with Specialized Hardware
SELECT c.city, s.city, d.year, SUM(lo.revenue) FROM lineorder lo, customer c, supplier s, date d WHERE lo.custkey = c.custkey
AND lo.suppkey = s.suppkey AND lo.orderdate = d.datekey AND c.nation = ’UNITED STATES’ AND s.nation = ’UNITED STATES' AND d.year >= 1998 AND d.year <= 2012
GROUP BY c.city, s.city, d.year ORDER BY d.year asc, revenue desc;
Where does time go?
Load Global
Code 23%
Hashing 21%
Join Filter 14%
Predicate 14%
Join 11%
Load Value 9%
other 8%
Example:
§ Star Schema Benchmark Query 3.2
§ No I/O (= warm buffer pool) All columns in memory
§ Which is the heavy hitter?
§ What is the acceleration potential?
Time Breakdown:
© 2014 IBM Corporation
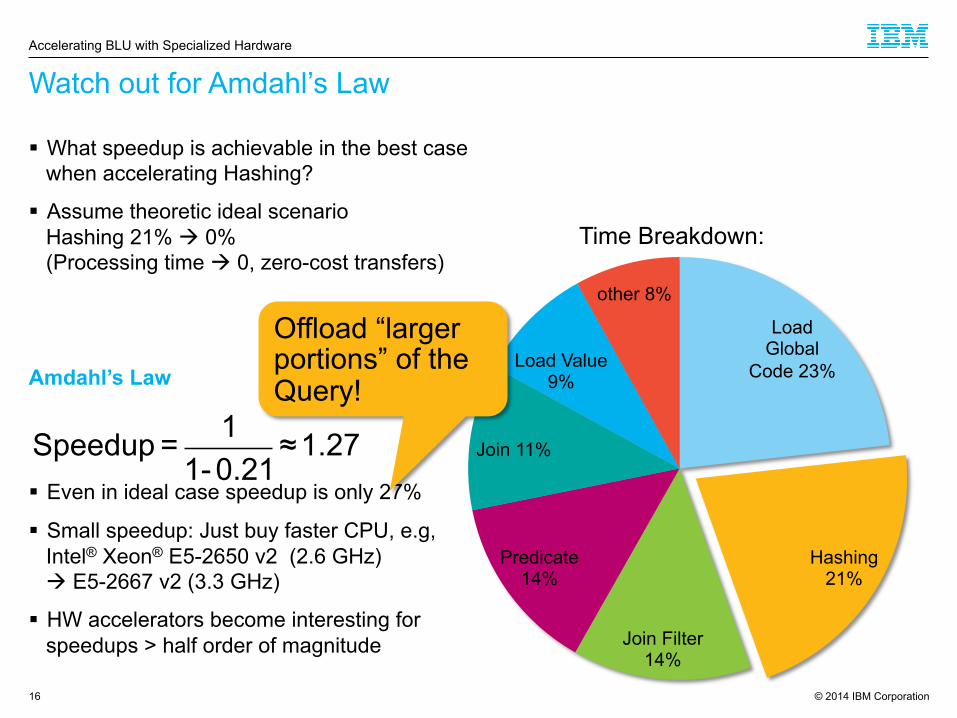
Watch out for Amdahl’s Law
16
Accelerating BLU with Specialized Hardware
Load Global
Code 23%
Hashing 21%
Join Filter 14%
Predicate 14%
Join 11%
Load Value 9%
other 8%
§ What speedup is achievable in the best case when accelerating Hashing?
§ Assume theoretic ideal scenario Hashing 21% à 0% (Processing time à 0, zero-cost transfers)
Amdahl’s Law
§ Even in ideal case speedup is only 27%
§ Small speedup: Just buy faster CPU, e.g, Intel® Xeon® E5-2650 v2 (2.6 GHz) à E5-2667 v2 (3.3 GHz)
§ HW accelerators become interesting for speedups > half order of magnitude
Time Breakdown:
Speedup= 11-0.21
≈1.27
Offload “larger portions” of the Query!

© 2014 IBM Corporation
BLU-like Predicate Evaluation Can FPGAs or GPUs do better than HW/SW SIMD code?
(a) What is the inherent algorithmic complexity?
(b) What is the end-to-end performance including data transfers?
17

© 2014 IBM Corporation
CPU Multi-Threaded on 4 Socket Systems: Intel X7560 vs P7
18
BLU Predicate Evaluation on CPUs
0
20
40
60
80
100
120
140
1 2 3 4 5 6 7 8 9 10 11 13 17 33
Agg
rega
te B
andw
idth
[GiB
/s]
Tuplet Width [bits]
scalar
SSE
64 threads
0
20
40
60
80
100
120
140
1 2 3 4 5 6 7 8 9 10 11 13 17 33
Agg
rega
te B
andw
idth
[GiB
/s]
Tuplet Width [bits]
scalar
VMX
VMX+bpermd
128 threads
IBM x Series x3850 (Intel®, 32 cores) IBM p750 (P7, 32 cores)
*) constant data size, vary tuplet width

© 2014 IBM Corporation
(Equality) Predicate Core on FPGA
19
Predicate Evaluator bitvector
out_valid
predicate
input_word
tuplet_width
Word with N tuplets Bit-vector N bits per input word
BLU Predicate Evaluation on FPGAs
Instantiate comparators for all tuplet widths

© 2014 IBM Corporation
Test setup on chip for area and performance w/o data transfers
20
LFSR
LFSR
LFSR
Parity Sum +
log2(N)
N 1 N
N
tuplet_width bank
predicate
bitvector
enable
Predicate Core
BLU Predicate Evaluation on FPGAs

© 2014 IBM Corporation
Setup on Test Chip
21
...
1-bit reduction tree
chip pin
slower output (read) clock
Now, instantiate as many as possible...
BLU Predicate Evaluation on FPGAs

© 2014 IBM Corporation
Implementation on Xilinx Virtex-7 485T
22
#cores/chip
max. clock *)
chip utilization
estimated power
agg. throughput
1 388 MHz 0.3% 0.3 W 1.5 GiB/s 16 264 MHz 5% 0.6 W 16 GiB/s 64 250 MHz 23% 1.9 W 60 GiB/s 100 250 MHz 30% 2.7 W 93 GiB/s 256 113 MHz 67% 6.6 W 108 GiB/s
GTX Transceiver cap ~65 GiB/s on ingest.
→ Throughput is independent of tuplet width, by design.
BLU Predicate Evaluation on FPGAs
*) Given by max. delay on longest signal path in post-P&R timing analysis

© 2014 IBM Corporation
GPU-based Implementation Data Parallelism in CUDA
23
© 2014 IBM Corporation
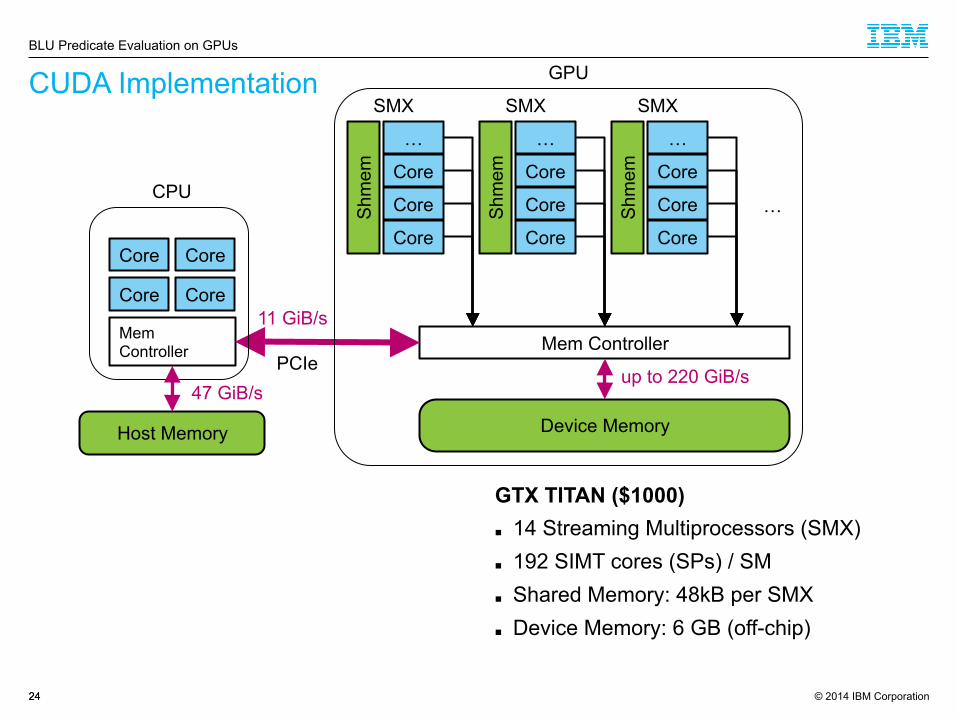
CUDA Implementation
24 24
GTX TITAN ($1000) ■ 14 Streaming Multiprocessors (SMX) ■ 192 SIMT cores (SPs) / SM ■ Shared Memory: 48kB per SMX ■ Device Memory: 6 GB (off-chip)
BLU Predicate Evaluation on GPUs
Core Core
Core Core
Mem Controller
…
Core
Core
Core Shm
em
Mem Controller
SMX
…
Core
Core
Core Shm
em
SMX
…
Core
Core
Core Shm
em
SMX
…
Device Memory Host Memory
11 GiB/s
CPU
GPU
PCIe up to 220 GiB/s
47 GiB/s
© 2014 IBM Corporation
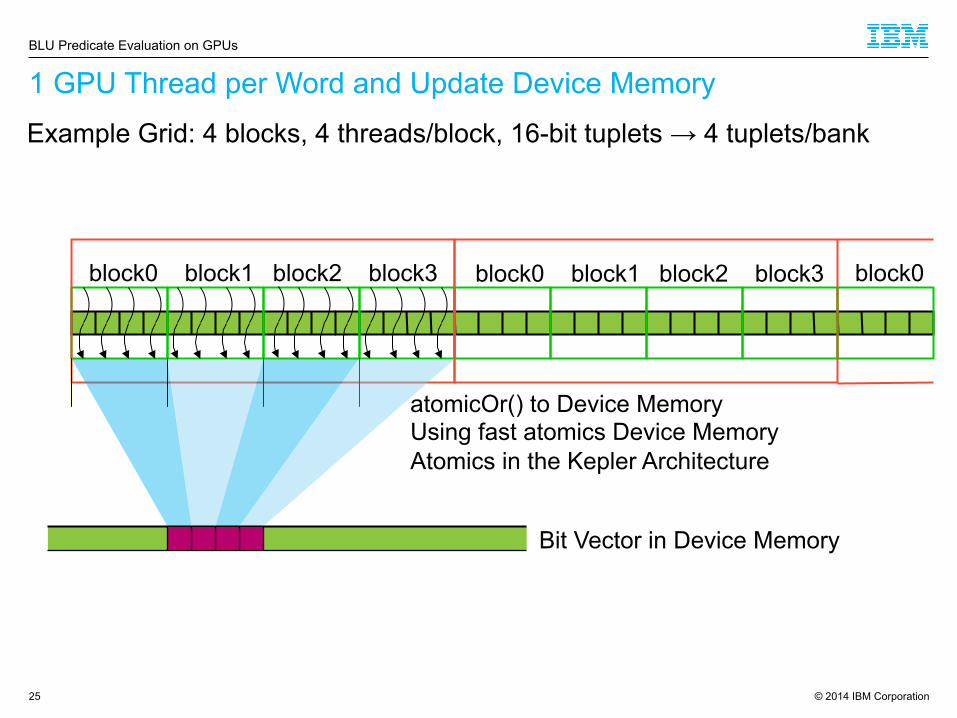
1 GPU Thread per Word and Update Device Memory
25
BLU Predicate Evaluation on GPUs
block0 block1 block2 block3 block0 block1 block2 block3 block0
atomicOr() to Device Memory Using fast atomics Device Memory Atomics in the Kepler Architecture
Bit Vector in Device Memory
Example Grid: 4 blocks, 4 threads/block, 16-bit tuplets → 4 tuplets/bank
© 2014 IBM Corporation
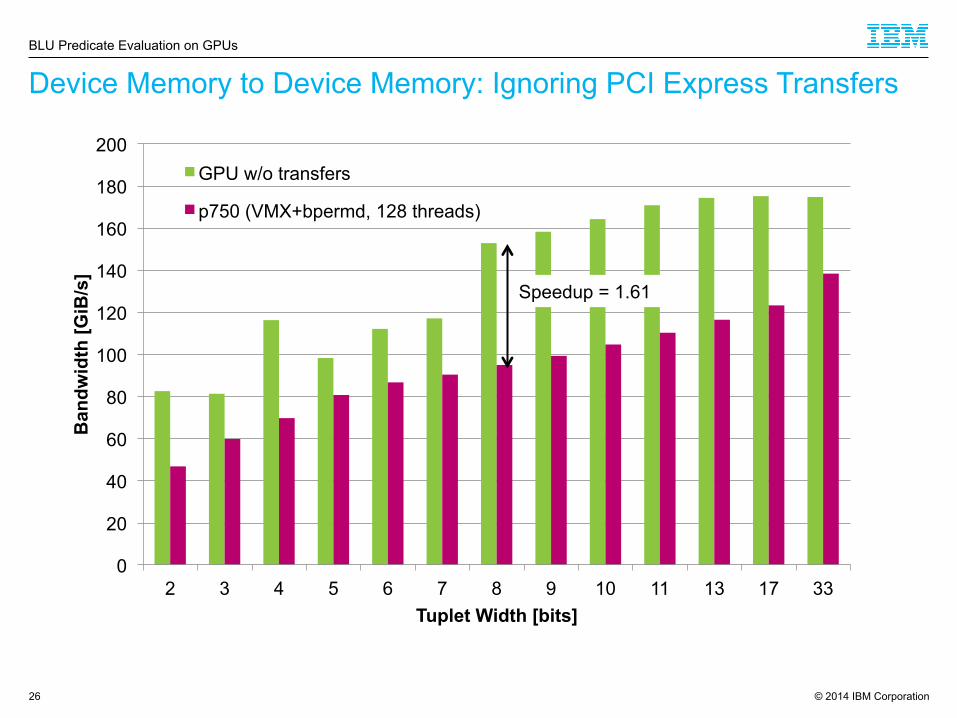
Device Memory to Device Memory: Ignoring PCI Express Transfers
26
BLU Predicate Evaluation on GPUs
0
20
40
60
80
100
120
140
160
180
200
2 3 4 5 6 7 8 9 10 11 13 17 33
Ban
dwid
th [G
iB/s
]
Tuplet Width [bits]
GPU w/o transfers
p750 (VMX+bpermd, 128 threads)
Speedup = 1.61
© 2014 IBM Corporation
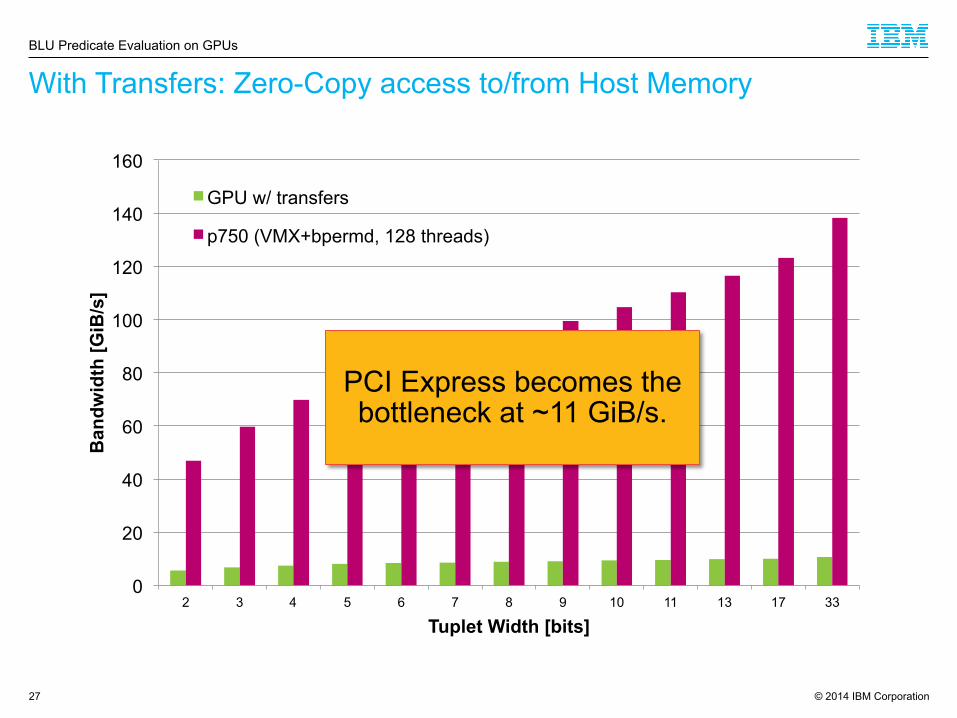
With Transfers: Zero-Copy access to/from Host Memory
27
BLU Predicate Evaluation on GPUs
0
20
40
60
80
100
120
140
160
2 3 4 5 6 7 8 9 10 11 13 17 33
Ban
dwid
th [G
iB/s
]
Tuplet Width [bits]
GPU w/ transfers
p750 (VMX+bpermd, 128 threads)
PCI Express becomes the bottleneck at ~11 GiB/s.
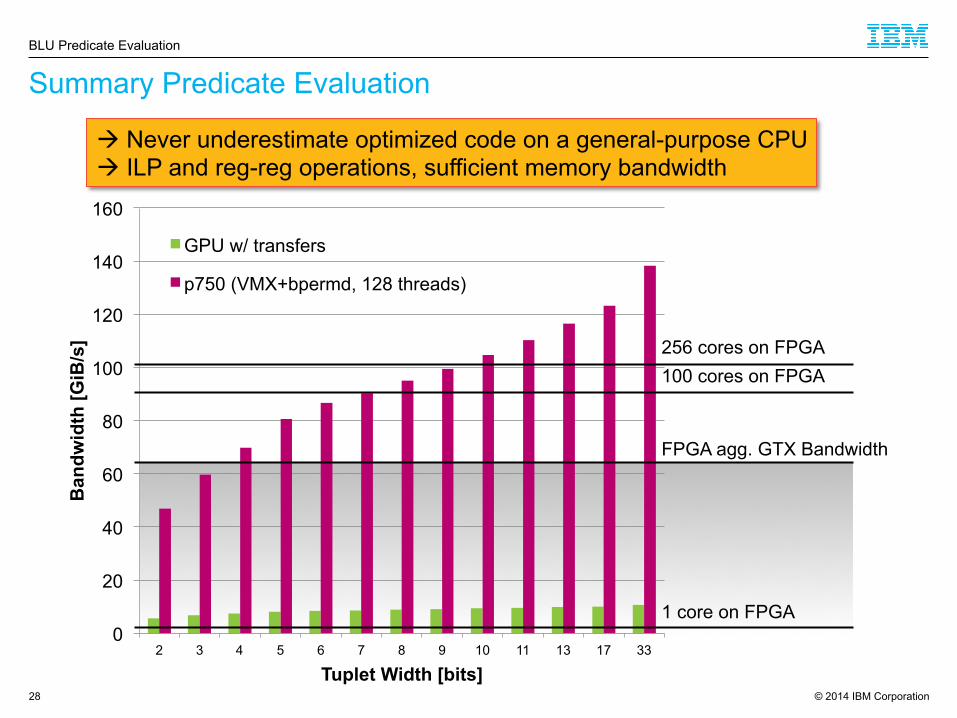
© 2014 IBM Corporation
Summary Predicate Evaluation
28
BLU Predicate Evaluation
0
20
40
60
80
100
120
140
160
2 3 4 5 6 7 8 9 10 11 13 17 33
Ban
dwid
th [G
iB/s
]
Tuplet Width [bits]
GPU w/ transfers
p750 (VMX+bpermd, 128 threads)
FPGA agg. GTX Bandwidth
1 core on FPGA
256 cores on FPGA 100 cores on FPGA
à Never underestimate optimized code on a general-purpose CPU à ILP and reg-reg operations, sufficient memory bandwidth

© 2014 IBM Corporation
Hash Joins on GPUs Taking advantage of fast device memory
29

© 2014 IBM Corporation
vs.
Hash Joins Hash Joins on GPUs
■ Primary data access patterns: – Scan the input table(s) for HT creation and probe – Compare and swap when inserting data into HT – Random read when probing the HT
■ Data (memory) access on
GPU (GTX580)
CPU (i7-2600)
Peak memory bandwidth [spec] 1) 179 GB/s 21 GB/s
Peak memory bandwidth [measured] 2) 153 GB/s 18 GB/s
Random access [measured] 2) 6.6 GB/s 0.8 GB/s
Compare and swap [measured] 3) 4.6 GB/s 0.4 GB/s Build HT Probe
Upper bound for:
30
(1) Nvidia: 192.4 × 106 B/s ≈ 179.2 GB/s (2) 64-bit accesses over 1 GB of device memory (3) 64-bit compare-and-swap to random locations over 1 GB device memory
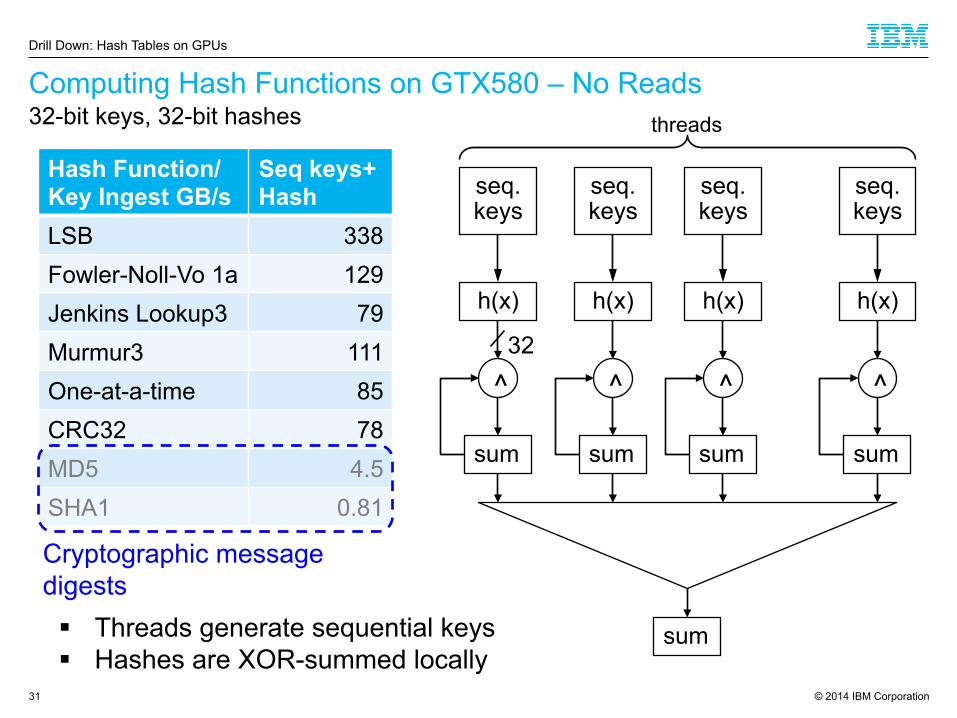
© 2014 IBM Corporation
Computing Hash Functions on GTX580 – No Reads
31
Hash Function/ Key Ingest GB/s
Seq keys+ Hash
LSB 338 Fowler-Noll-Vo 1a 129 Jenkins Lookup3 79 Murmur3 111 One-at-a-time 85 CRC32 78 MD5 4.5 SHA1 0.81
^
seq. keys
h(x)
sum
^
seq. keys
h(x)
sum
^
seq. keys
h(x)
sum
^
seq. keys
h(x)
sum
32
sum
threads
§ Threads generate sequential keys § Hashes are XOR-summed locally
Cryptographic message digests
32-bit keys, 32-bit hashes
Drill Down: Hash Tables on GPUs
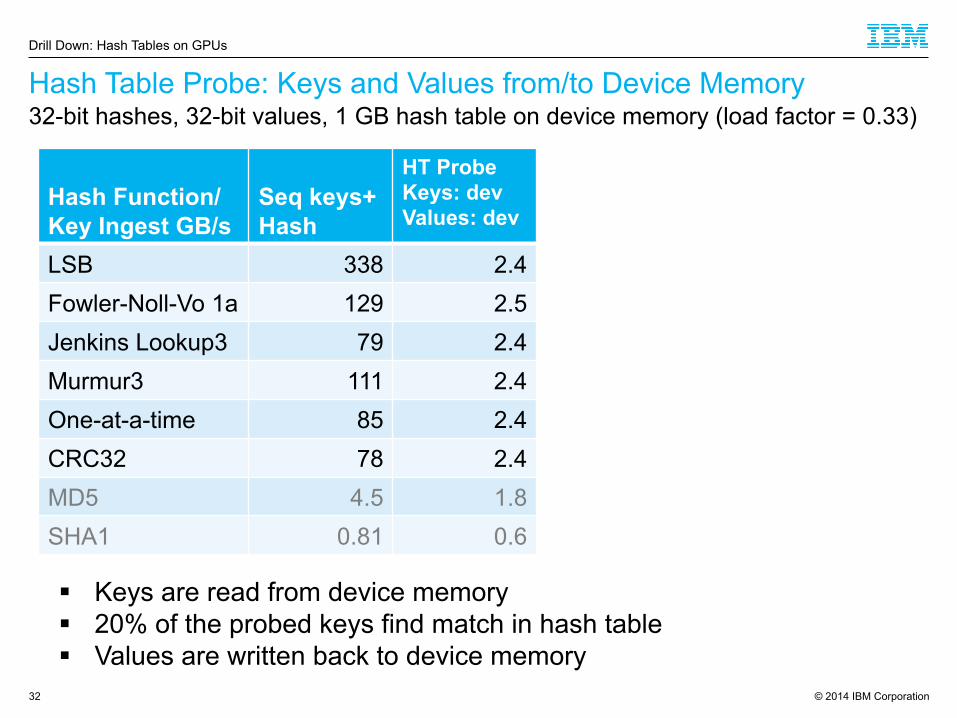
© 2014 IBM Corporation
Hash Table Probe: Keys and Values from/to Device Memory
32
Hash Function/ Key Ingest GB/s
Seq keys+ Hash
HT Probe Keys: dev Values: dev
LSB 338 2.4 Fowler-Noll-Vo 1a 129 2.5 Jenkins Lookup3 79 2.4 Murmur3 111 2.4 One-at-a-time 85 2.4 CRC32 78 2.4 MD5 4.5 1.8 SHA1 0.81 0.6
§ Keys are read from device memory § 20% of the probed keys find match in hash table § Values are written back to device memory
32-bit hashes, 32-bit values, 1 GB hash table on device memory (load factor = 0.33)
Drill Down: Hash Tables on GPUs
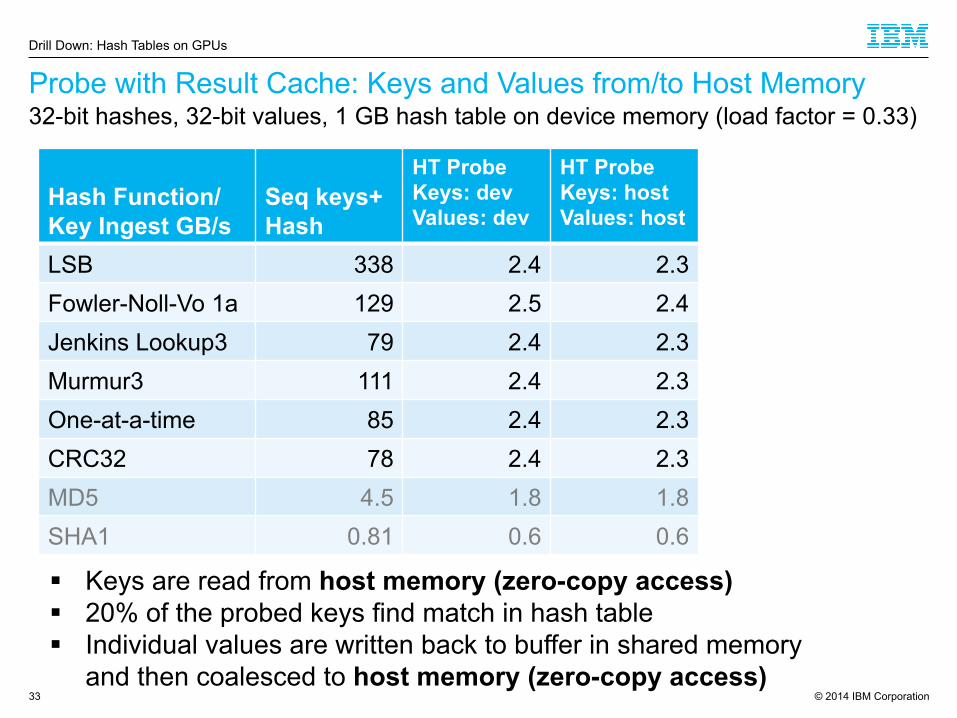
© 2014 IBM Corporation
Probe with Result Cache: Keys and Values from/to Host Memory
33
Hash Function/ Key Ingest GB/s
Seq keys+ Hash
HT Probe Keys: dev Values: dev
HT Probe Keys: host Values: host
LSB 338 2.4 2.3 Fowler-Noll-Vo 1a 129 2.5 2.4 Jenkins Lookup3 79 2.4 2.3 Murmur3 111 2.4 2.3 One-at-a-time 85 2.4 2.3 CRC32 78 2.4 2.3 MD5 4.5 1.8 1.8 SHA1 0.81 0.6 0.6
§ Keys are read from host memory (zero-copy access) § 20% of the probed keys find match in hash table § Individual values are written back to buffer in shared memory
and then coalesced to host memory (zero-copy access)
32-bit hashes, 32-bit values, 1 GB hash table on device memory (load factor = 0.33)
Drill Down: Hash Tables on GPUs
© 2014 IBM Corporation
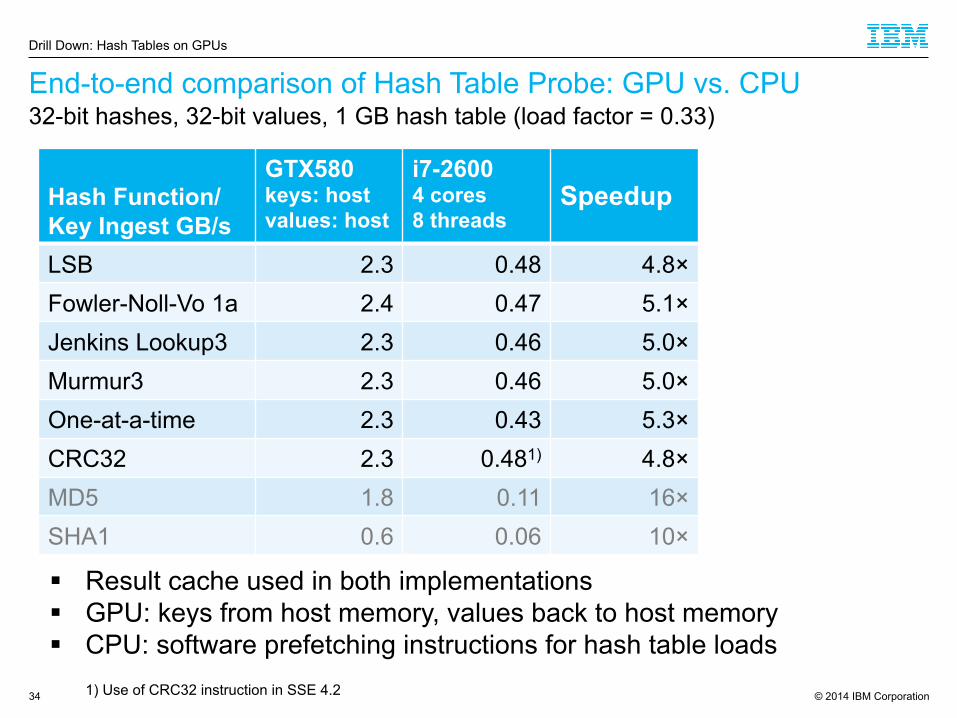
End-to-end comparison of Hash Table Probe: GPU vs. CPU
34
Hash Function/ Key Ingest GB/s
GTX580 keys: host values: host
i7-2600 4 cores 8 threads
Speedup
LSB 2.3 0.48 4.8× Fowler-Noll-Vo 1a 2.4 0.47 5.1× Jenkins Lookup3 2.3 0.46 5.0× Murmur3 2.3 0.46 5.0× One-at-a-time 2.3 0.43 5.3× CRC32 2.3 0.481) 4.8× MD5 1.8 0.11 16× SHA1 0.6 0.06 10×
§ Result cache used in both implementations § GPU: keys from host memory, values back to host memory § CPU: software prefetching instructions for hash table loads
1) Use of CRC32 instruction in SSE 4.2
32-bit hashes, 32-bit values, 1 GB hash table (load factor = 0.33)
Drill Down: Hash Tables on GPUs

© 2014 IBM Corporation
Processing hundreds of Gigabytes in seconds
35
…
…
…Create hash table
Probe hash table
From Hash Tables to Relational Joins
§ Combining GPUs fast storage.
§ How about reading the input tables on the fly from flash?
§ Storage solution delivering data at GPU join speed (>5.7 GB/s): – 3x 900 GB IBM Texas Memory Systems RamSan-70 SSDs – IBM Global Parallel File System (GPFS)
DEMO: At IBM Information on Demand 2012 and SIGMOD 2013

© 2014 IBM Corporation
Summary and Lessons Learned
§ Accelerators are not necessarily faster than well-tuned CPU code
§ Don’t underestimate the compute power and the aggregate memory bandwidth of general-purpose multi-socket systems.
§ Don’t forget Amdahl’s Law, it will bite you.
§ Offload larger portions: Hashing only à Offload complete hash table
§ Take advantage of platform-specific advantages: – FPGA: customized data paths, pipeline parallelism – GPU: fast device memory, latency hiding through large SMT degree – CPU: OO architecture, SIMD and caches are extremely fast if used correctly
36