cache coherence for gpu architectures inderpreet singh 1, arrvindh shriraman 2, wilson fung 1, mike...
TRANSCRIPT

Cache Coherence for GPU Architectures
Inderpreet Singh1, Arrvindh Shriraman2, Wilson Fung1, Mike O’Connor3, Tor Aamodt1
Image source: www.forces.gc.ca
1 University of British Columbia2 Simon Fraser University
3 AMD Research

Inderpreet Singh Cache Coherence for GPU Architectures 2
What is a GPU?
GPU
CPUspawn
doneCPU
CPU
GPU
spawn
time
GPU Core
L1D ▪▪▪
Interconnect
▪▪▪
L2 Bank
GPU Core
L1D
Workgroups
Wavefronts

Inderpreet Singh Cache Coherence for GPU Architectures 3
Evolution of GPUs
• Graphics pipeline
• Compute (OpenCL, CUDA)• e.g. Matrix Multiplication
VertexShader
PixelShaderOpenGL/
DirectX

Inderpreet Singh Cache Coherence for GPU Architectures 4
Evolution of GPUs
• Future: coherent memory space• Efficient critical sections• Load balancing
Stencil computation
Workgroups
lock shared structure…computation…
unlock

Inderpreet Singh Cache Coherence for GPU Architectures 5
C4
L1D
A B
C3
L1D
A B
C2
L1D
A B
GPU Coherence Challenges
• Challenge 1: Coherence traffic
Do not requirecoherence
No coherence MESI
GPU-VI
0.5
1.0
1.5
2.2
Inte
rco
nn
ect
traf
fic
1.3 Recalls
C1
L1D
A B
Load C
gets C
rcl A rcl A rcl A
rcl A
ack
ack ackack
Load CLoad DLoad ELoad F…
Load GLoad HLoad ILoad J…
Load KLoad LLoad MLoad N…
Load OLoad PLoad QLoad R…
A B
L2/Directory

Inderpreet Singh Cache Coherence for GPU Architectures 6
L2 / Directory
MSHR
GPU Coherence Challenges
• Challenge 2: Tracking in-flight requests• Significant % of L2
SShared
MModified
S_M

Inderpreet Singh Cache Coherence for GPU Architectures 7
GPU Coherence Challenges
• Challenge 3: Complexity
Non-coherent L1
Non-coherent L2
MESI L1 States
MESI L2 States
States
Events

Inderpreet Singh Cache Coherence for GPU Architectures 8
GPU Coherence Challenges
All three challenges result from introducing coherence messages on a GPU
1. Traffic: transferring2. Storage: tracking3. Complexity: managing
GPU cache coherence without coherence messages?
• YES – using global time

Inderpreet Singh Cache Coherence for GPU Architectures 9
Core 1
L1D ▪▪▪
Temporal Coherence (TC)
• Global time
Interconnect
▪▪▪
L2 Bank
A=00
A=00
Global Timestamp
< Global Time NO L1
COPIES
Core 2
L1D
Local Timestamp
> Global Time VALID

Inderpreet Singh Cache Coherence for GPU Architectures 10
T=0T=11T=15
Core 1
L1D
Interconnect
L2 Bank
Core 2
L1D
Temporal Coherence (TC)
▪▪▪A=00
Load A
T=10
A=010 A=010
A=010
Sto
re A
=1
A=1
A=010No coherence messages

Inderpreet Singh Cache Coherence for GPU Architectures 11
Temporal Coherence (TC)
What lifetime values should be requested on loads?
• Use a predictor to predict lifetime values
What about stores to unexpired blocks?
• Stall them at the L2?

Inderpreet Singh Cache Coherence for GPU Architectures 12
TC Stalling Issues
Stall?
Problem #1: Sensitive to mispredictions
Problem #2: Impedes other accesses
Problem #3: Hurts existing GPU applications
Solution: TC-Weak

Inderpreet Singh Cache Coherence for GPU Architectures 13
L2 Bank
47
T=1T=31
TC-Weak
• Stores return Global Write Completion Time (GWCT)
GPU Core 2
L1D
Interconnect
GWCT Table W0: W1:
data=OLD30
30 data=OLD
flag=NULL
GPU Core 1
L1DGWCT Table
W0: W1:
1 data=NEW2 FENCE3 flag=SET
Store
data=NEWS
tore
flag=SET
1 data=NEW2 FENCE3 flag=SET
30
1 data=NEW2 FENCE3 flag=SET
1 data=NEW2 FENCE3 flag=SET
data=NEW
flag=SET
data=OLD30
T=0
47
No stalling at L2

Inderpreet Singh Cache Coherence for GPU Architectures 14
TC-Weak
Stalling TC-Weak
Misprediction sensitivity
Doesn’t impedes other accesses
Good for existing GPU applications

Inderpreet Singh Cache Coherence for GPU Architectures 15
Methodology
• GPGPU-Sim v3.1.2 for GPU core model• GEMS Ruby v2.1.1 for memory system• All protocols written in SLICC• Model a generic NVIDIA Fermi-based GPU (see paper for details)• Applications:
• 6 do not require coherence
• 6 require coherence• Barnes Hut• Cloth Physics• Versatile Place and Route• Max-Flow Min-Cut• 3D Wave Equation Solver• Octree Partitioning
Locks
Stencil communication
Load balancing

Inderpreet Singh Cache Coherence for GPU Architectures 16
0.00
0.25
0.50
0.75
1.00
1.25
1.502.3
Interconnect Traffic
• Reduces traffic by 53% over MESI and 23% over GPU-VI for intra-workgroup applications
• Lower traffic than 16x-sized 32-way directory
Inte
rco
nn
ect
Traf
fic
NO-COH
MESI GPU-VI TC-Weak
Do not require coherence

Inderpreet Singh Cache Coherence for GPU Architectures 17
Performance
• TC-Weak with simple predictor performs 85% better than disabling L1 caches
• Performs 28% better than TC with stalling
• Larger directory sizes do not improve performance
MESI GPU-VI TC-Weak
0.0
0.5
1.0
1.5
2.0
Require coherence
NO-L1
Sp
eed
up

Inderpreet Singh Cache Coherence for GPU Architectures 18
Complexity
Non-Coherent L1
Non-Coherent L2
MESI L1 States
MESI L2 StatesTC-Weak L1
TC-Weak L2

Inderpreet Singh Cache Coherence for GPU Architectures 19
Summary
• First work to characterize GPU coherence challenges
• Save traffic and energy by using global time
• Reduce protocol complexity
• 85% performance improvement over no coherence
Questions?

Inderpreet Singh Cache Coherence for GPU Architectures 20
Backup Slides

Inderpreet Singh Cache Coherence for GPU Architectures 21
Lifetime Predictor
• One prediction value per L2 bank
• Events local to L2 bank update prediction value
L2 Bank
T = 0
Prediction Value
Load A
A10
Events Prediction
1. Expired load: ↑
2. Unexpired store: ↓
3. Unexpired eviction: ↓prediction++
T = 20
Store A
A30prediction--

Inderpreet Singh Cache Coherence for GPU Architectures 22
TC-Strong vs TC-Weak
Fixed lifetime for all applications
0.6
0.8
1.0
1.2
1.4
All applications
Sp
eed
up
0.6
0.8
1.0
1.2
All applications
Sp
eed
up
TCSUO TCS TCSOO
TCW TCW w/ predictor
Best lifetime for each application
Inderpreet Singh Cache Coherence for GPU Architectures 23
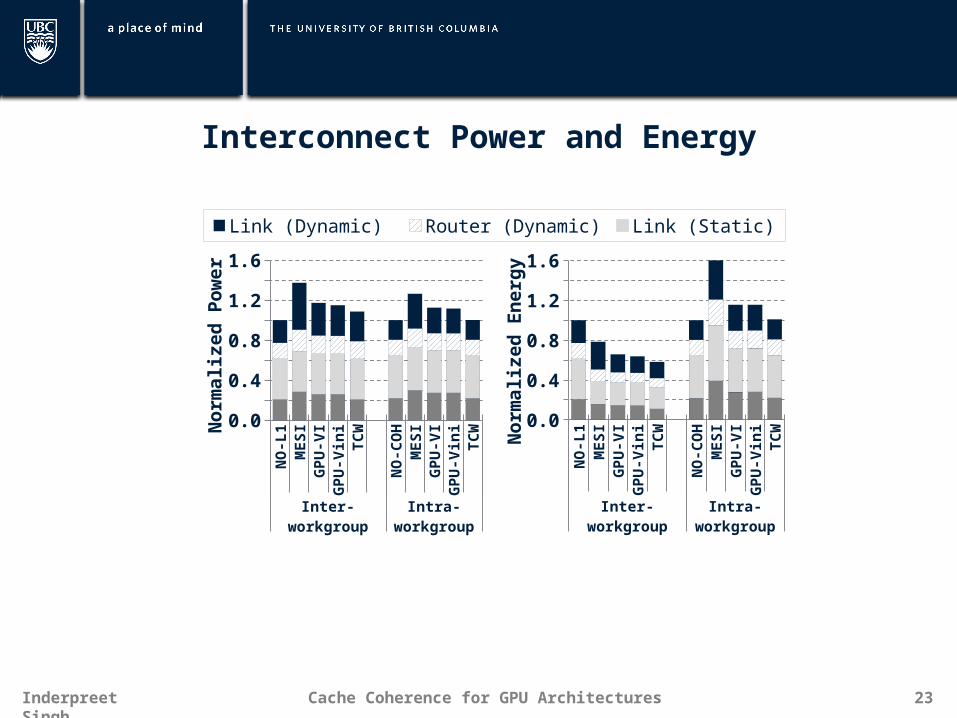
Interconnect Power and Energy
NO
-L1
ME
SI
GP
U-V
IG
PU
-Vin
iT
CW
NO
-CO
HM
ES
IG
PU
-VI
GP
U-V
ini
TC
W
Inter-workgroup
Intra-workgroup
0.0
0.4
0.8
1.2
1.6
Link (Dynamic) Router (Dynamic) Link (Static) Router (Static)
No
rma
lize
d E
ne
rgy
NO
-L1
ME
SI
GP
U-V
IG
PU
-Vin
iT
CW
NO
-CO
HM
ES
IG
PU
-VI
GP
U-V
ini
TC
W
Inter-workgroup
Intra-workgroup
0.0
0.4
0.8
1.2
1.6
No
rma
lize
d P
ow
er