capitulo 18 modelo de correciÓn de … · 2015-11-20 · teóricamente, un estado de equilibrio...
TRANSCRIPT

CCAAPPIITTUULLOO 1188 MMOODDEELLOO DDEE CCOORRRREECCIIÓÓNN DDEE EERRRROORREESS YY CCOOIINNTTEEGGRRAACCIIÓÓNN
1188..11.. IINNTTRROODDUUCCCCIIÓÓNN
Durante la mayor parte de los capítulos de este libro, en especial hasta antes del análisis de series
de tiempo, la estimación econométrica descansaba sobre modelos estructurales. Se trataba de
encontrar relaciones entre un conjunto de variables, todas ellas estacionarias, y corregir problemas
tales como la heterocedasticidad, la autocorrelación, multicolinealidad, etc. A partir del Capítulo
15, se inicia el análisis univariado de las series. A partir de entonces los modelos emplean rezagos
de la variable explicada y rezagos de los errores. Básicamente, este tipo de análisis tiene como
finalidad la predicción. Sin embargo, a pesar de los buenos resultados y del amplio uso de estos
modelos, es evidente que existen relaciones estructurales entre las series económicas, a pesar que la
mayoría de éstas no sean estacionarias. En este sentido, el objetivo de este capítulo es determinar
una técnica que busque modelar las relaciones entre las series no estacionarias y que a su vez no se
generen regresiones espúreas.
1188..22.. EEQQUUIILLIIBBRRIIOO DDEE LLAARRGGOO PPLLAAZZOO EENNTTRREE SSEERRIIEESS DDEE TTIIEEMMPPOO
Un primer concepto que será necesario considerar para entender las relaciones entre las series no
estacionarias, es el concepto de “equilibrio”. Teóricamente, un estado de equilibrio está definido
como aquel en donde no existe una tendencia inherente de cambio. Sin embargo, existen diversas
clases de equilibrios: estáticos y dinámicos; estable e inestable; o de corto y de largo plazo. A pesar
de su diversidad, cada relación de equilibrio entre n variables de un sistema puede expresarse como
0),...,,( 21 =nxxxf . En lo que respecta al análisis de series de tiempo, la frase “equilibrio de
largo plazo” suele utilizarse para denotar una relación estable entre las series; la misma que no es
evidente en intervalos cortos de tiempo. Esto se da debido a que el conjunto de series se encuentra
constantemente expuesto a diversos shocks. A pesar de esto, el concepto de equilibrio de largo

Econometría Moderna
872
plazo todavía es útil. Esto se debe a que el presente es producto del pasado distante y una relación
de largo plazo siempre se mantendrá “en promedio” a lo largo del tiempo.
El siguiente ejemplo nos puede ayudar a identificar mejor el concepto de equilibrio de largo plazo:
Un análisis de mercado a determinado que la mayoría de los limeños acostumbran tomar un
“lonche” en las tardes, el cual incluye por lo general una tasa de leche con café o de leche con
chocolate. Por este motivo, el café y el cocoa son considerados como productos sustitutos. El
primero es traído de Chanchamayo; el segundo, de Cuzco. Tanto el precio promedio como el
volumen consumido promedio de cada producto está determinado por las preferencias de los
limeños. Sin embargo, el precio corriente de ambos productos está influenciado por diversos
shocks exógenos. Por ejemplo, cuando lluvias torrenciales dañan la vía de comunicación entre
Cuzco y la capital, el precio de la cocoa se incrementa debido a la reducción de la oferta de cacao.
Ante esta situación, los limeños dejan de consumir leche con chocolate y consumen leche con café.
Lo cual, a su vez, hace que por un lado aumente el precio del café; mientras que por el otro,
disminuya en cierta medida el precio del chocolate, al reducirse el exceso de demanda. La misma
mecánica se presenta si el valle de Chanchamayo sufre algún percance climatológico que afecte los
cultivos de café.
De esta manera, a pesar de los diferentes shocks que a través del tiempo se han registrado, en
promedio, en la mayor parte de tiempo, los precios de ambos mantienen una relación cercana de
3/2.
Si se analiza con detenimiento la mecánica descrita anteriormente, se observa que, un shock sobre
uno de estos productos ha afectado al sistema en general, debido a la relación estable entre el
consumo de los dos productos.
1.02
1.04
1.06
1.08
1.10
1.12
1.14
1.16
92 93 94 95 96 97 98
Café Cocoa
Figura 18.1 Series de tiempo del precio real del café y de la cocoa.
Esta característica del comportamiento conjunto de las series puede observarse en la Figura 18.1.
En ella están representadas las series de los precios del café y de la cocoa. Si bien cada una de las
series es I(1), el comportamiento de una influye sobre la trayectoria de la otra. Como se puede
observar en esta figura, la relación existente entre estas variables no se mantiene constante durante
todos los meses. De vez en cuando vemos que el precio de la cocoa inclusive llega a superar el

Capítulo 18: Modelo de Corrección de Errores y Cointegración
873
precio del café; sin embargo este comportamiento no se presenta a lo largo de la muestra y la
relación se mantiene.
Formalmente, se dice que existe una relación de equilibrio entre el precio del café y el de la cocoa,
la cual puede ser representada como 0),( 21 =xxf 1, si la serie ),( 21 ttt xxf≡ε , que representa la
desviación corriente del equilibrio, es un proceso estacionario de media cero2. Esto significa que
esta serie fluctuará alrededor de su media de manera estable. En caso que no sea estacionaria, el
sistema estaría en libertad de moverse sin considerar relación alguna. El inconveniente que suele
presentarse al querer determinar las características de un sistema es lo dificultoso que puede ser
distinguir, en muestras pequeñas, una desviación no estacionaria de una que esté relacionada con la
noción del equilibrio.
Hasta este punto, el lector ya habrá deducido la importancia que tiene la serie de desviaciones, εt,
en nuestro análisis. Esta serie, de tratarse de una relación de equilibrio, no debería presentar algún
tipo de comportamiento sistemático en el tiempo. En el largo plazo no existe una tendencia
sistemática a que este error disminuya debido a que este representa shocks que constantemente
están ocurriendo y afectando a las variables económicas. Sólo podrá caer hacia el cero si los shocks
cesan.
Con relación al caso de las series de los precios del café y de la cocoa, se hace necesario el análisis
de las desviaciones de la regresión entre ambas para estar seguros de la existencia de alguna
relación. Con este fin se han elaborado los siguientes gráficos:
(a) (b)
1.02
1.04
1.06
1.08
1.10
1.12
1.04 1.06 1.08 1.10 1.12 1.14 1.16
Pcaf e
Pcocoa
-0.04
-0.02
0.00
0.02
0.04
92 93 94 95 96 97 98
Residuos
1 En nuestro ejemplo, x1 y x2 representarían al precio del café y de la cocoa respectivamente. Por consiguiente, la función
del equilibrio estaría especificada de la siguiente manera: f(x) = 2x1-3x2. 2 El lector deberá de distinguir que cuando se está haciendo referencia de relaciones de largo plazo entre variables, estas
no llevan el subíndice del tiempo ya que nos estamos refiriendo a una especificación que se presenta a lo largo de la
muestra. Un ejemplo de esto lo obtenemos de la relación de largo plazo f(x) = 2x1-3x2. En cambio, cuando estamos
considerando relaciones de corto plazo, las variables sí llevan tal subíndice ya que es necesario determinar a qué parte de
la muestra nos estamos haciendo referencia. Tenemos como ejemplo de esto al término de error actual )x,x(f t2t1t ≡ε .

Econometría Moderna
874
Figura 18.2 En la parte (a) se ha graficado los pares ordenados de las series de precio del café y de la cocoa. En la parte (b) tenemos los residuos resultantes de la regresión entre ambas variables.
En primer lugar analizaremos la relación lineal que existe entre estas dos variables. Para esto
utilizaremos la parte (a) de la Figura (18.2). Cada punto en el gráfico corresponde a un par
ordenado precio café-cocoa y todos los puntos se sitúan alrededor de la línea de regresión. A veces
esta línea recibe la denominación de “línea de atracción”. Si bien en algunos meses los precios del
café y de la cocoa se separan de ella, en el transcurrir de los años los precios se han situado
alrededor de esta línea.. En la parte (b) se grafican los residuos obtenidos de realizar una estimación
lineal entre estas variables. Este gráfico nos indica tentativamente que la relación entre ambas
variables no es espúrea3.
Ahora introduciremos el precio de la leche en el ejemplo anteriormente tratado. ¿Existirá alguna
relación entre el precio de la leche y el precio del café? Se pueden dar mil y un argumentos que
respalden o refuten la existencia de algún tipo de relación. Sin embargo, nosotros nos remitiremos a
las pruebas objetivas. Estas están graficadas a continuación:
(a)
0.96
1.00
1.04
1.08
1.12
1.16
92 93 94 95 96 97 98
Leche Café
(b) (c)
3 Como veremos más adelante, el empleo del test de Dickey-Fuller en la serie de errores de una regresión en la mayoría
de los casos no es apropiado a menos que se cumplan ciertas condiciones.
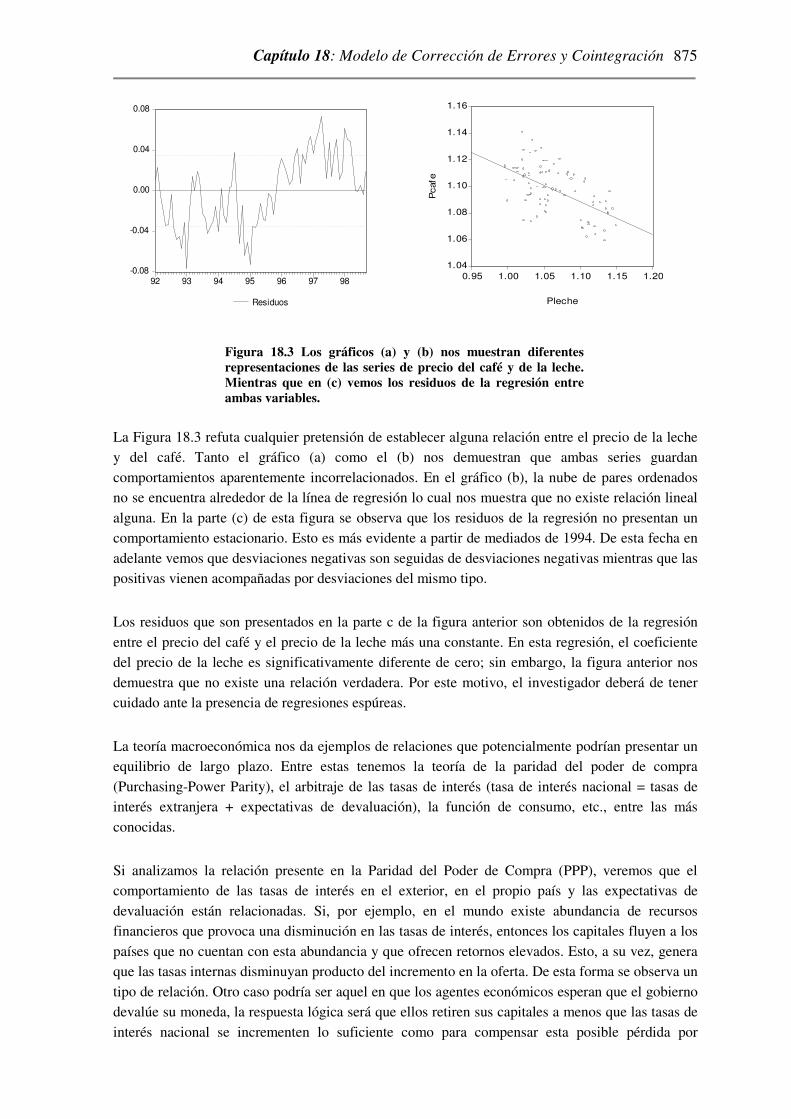
Capítulo 18: Modelo de Corrección de Errores y Cointegración
875
-0.08
-0.04
0.00
0.04
0.08
92 93 94 95 96 97 98
Residuos
1.04
1.06
1.08
1.10
1.12
1.14
1.16
0.95 1.00 1.05 1.10 1.15 1.20
Pleche
Pcafe
Figura 18.3 Los gráficos (a) y (b) nos muestran diferentes representaciones de las series de precio del café y de la leche. Mientras que en (c) vemos los residuos de la regresión entre ambas variables.
La Figura 18.3 refuta cualquier pretensión de establecer alguna relación entre el precio de la leche
y del café. Tanto el gráfico (a) como el (b) nos demuestran que ambas series guardan
comportamientos aparentemente incorrelacionados. En el gráfico (b), la nube de pares ordenados
no se encuentra alrededor de la línea de regresión lo cual nos muestra que no existe relación lineal
alguna. En la parte (c) de esta figura se observa que los residuos de la regresión no presentan un
comportamiento estacionario. Esto es más evidente a partir de mediados de 1994. De esta fecha en
adelante vemos que desviaciones negativas son seguidas de desviaciones negativas mientras que las
positivas vienen acompañadas por desviaciones del mismo tipo.
Los residuos que son presentados en la parte c de la figura anterior son obtenidos de la regresión
entre el precio del café y el precio de la leche más una constante. En esta regresión, el coeficiente
del precio de la leche es significativamente diferente de cero; sin embargo, la figura anterior nos
demuestra que no existe una relación verdadera. Por este motivo, el investigador deberá de tener
cuidado ante la presencia de regresiones espúreas.
La teoría macroeconómica nos da ejemplos de relaciones que potencialmente podrían presentar un
equilibrio de largo plazo. Entre estas tenemos la teoría de la paridad del poder de compra
(Purchasing-Power Parity), el arbitraje de las tasas de interés (tasa de interés nacional = tasas de
interés extranjera + expectativas de devaluación), la función de consumo, etc., entre las más
conocidas.
Si analizamos la relación presente en la Paridad del Poder de Compra (PPP), veremos que el
comportamiento de las tasas de interés en el exterior, en el propio país y las expectativas de
devaluación están relacionadas. Si, por ejemplo, en el mundo existe abundancia de recursos
financieros que provoca una disminución en las tasas de interés, entonces los capitales fluyen a los
países que no cuentan con esta abundancia y que ofrecen retornos elevados. Esto, a su vez, genera
que las tasas internas disminuyan producto del incremento en la oferta. De esta forma se observa un
tipo de relación. Otro caso podría ser aquel en que los agentes económicos esperan que el gobierno
devalúe su moneda, la respuesta lógica será que ellos retiren sus capitales a menos que las tasas de
interés nacional se incrementen lo suficiente como para compensar esta posible pérdida por

Econometría Moderna
876
devaluación. Todos estos mecanismos operan de tal forma, que la relación entre estas tres variables
se mantiene. Esta relación puede ser representada como f (tnacional, textranjera, exp.devaluación).
1188..33.. EELL CCOONNCCEEPPTTOO DDEE LLAA CCOOIINNTTEEGGRRAACCIIÓÓNN
En la sección anterior se explicó el concepto de equilibrio de largo plazo; sin embargo, no se
precisó la estructura paramétrica del mismo, limitándose la representación a una del tipo
0),...,,( 21 =nxxxf . En esta sección se buscará precisar la forma en que esta relación se presenta.
Cabe destacar que una relación de equilibrio se alcanza automáticamente cuando las series
empleadas son estacionarias ya que cualquier combinación lineal de las mismas siempre resultará
en otra serie estacionaria. En este sentido, para cualquier par de series estacionarias { }tx1 y { }tx2 ,
sin guardar algún tipo de relación económica, una diferencia de la forma { }tt xx 21 β− puede ser
estacionaria para cualquier valor que adopte β. De esta manera, exista o no exista algún valor β que
describa alguna relación económica, cualquier valor β puede hacer que la combinación entre estas
variables cumpla con la condición de equilibrio, es decir, que la serie resultante sea estacionaria, al
igual que la serie de desviaciones.
Sin embargo, el equilibrio que nos interesa es aquel generado por series no estacionarias. Tal como
se planteó en la introducción, este capítulo apunta al desarrollo de una técnica de estimación que
recoja este tipo de relaciones, con el fin de evitar la pérdida de información que se produce de
diferenciar las series.
En lo que se refiere a la relación entre el precio del café y de la cocoa, ésta es una relación de
equilibrio entre variables no estacionarias, tal como se puede ver en Figura 18.1. Ahora la pregunta
que queda en el aire es la siguiente: ¿cualquier relación entre variables no estacionarias representa
un equilibrio de largo plazo?. Como los lectores se imaginan, la respuesta es no. Este punto ha sido
tratado parcialmente en el capítulo 16 cuando nos referíamos a las denominadas “regresiones
espúreas”. Sin embargo, el ejemplo visto en la sección anterior claramente nos señala que puede
existir una función especial en la que las dos series de variables no estacionales realmente lleguen a
formar una relación de largo plazo. Esta relación, para el ejemplo del precio del café y de la cocoa,
puede ser denotada así:
o bien 0)
2
3()(
0)32()(
21
21
=−=
=−=
xxxf
xxxf
donde el vector de coeficientes, ),( 21 βββ = , puede adoptar diferentes valores tales como
)2/3,1( ó )3,2( −=−= ββ , respectivamente4. Sin embargo, siempre se mantiene una misma
relación entre ambos elementos:
3
2
2
1 −=β
β
4 Es importante destacar que estamos empleando el mismo vector de coeficientes sólo que uno ha sido normalizado con
respecto al primer coeficiente.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
877
Cualquier otra combinación que no respete esta relación no nos proporcionaría como resultado una
relación de equilibrio.
Generalizando, si la verdadera relación que existe entre dos series es 21 xx β= , la serie obtenida de
la diferencia 21ˆxx β− no será estacionaria si ββ ˆ≠ . Estos errores se alejarán de tener una media
igual a cero por una proporción constante de )ˆ( ββ − del crecimiento de x2t. Sólo el verdadero
valor de β puede hacer que esta desviación del equilibrio sea estacionaria.
De esta manera, se puede definir el concepto de cointegración. Este implica la existencia de algún
tipo de relación estable entre series inestables (series no estacionarias, integradas de orden d>0). El
análisis univariado de cada una de ellas nos indicaría que su patrón de comportamiento es aleatorio.
Sin embargo, un análisis múltiple de series probablemente determinará la existencia de algún tipo
de relación entre estas variables. Una vez determinada la existencia de cointegración, se buscará
estimar los parámetros que definen esta relación.
La definición teórica más frecuentemente empleada es aquella formulada por Engle y Granger
(1987), en donde definen el concepto de cointegración de la siguiente manera5:
Un conjunto de variables xt son denominadas “cointegradas de orden (d,b)”, y denotadas como
),( bdCIxt ∼ , si:
i. xt es integrada de orden d, I(d),
ii. existe un vector, diferente de cero, tal que una relación lineal
)...( 2211 ntnttt xxxx ββββ +++=′ es integrada de orden I(d-b), 0>≥ bd .
donde el vector β es denominado vector de cointegración.
Esta definición puede ser aplicada al caso del precio del café y de la cocoa de la sección anterior.
Cada una de estas series eran no estacionarias, es decir, I(1). Sin embargo, se puede determinar que
existía una combinación lineal sobre éstas series que nos proporcionaba una serie estacionaria de
desviaciones, I(0). Por consiguiente, los precios del café y de la cocoa son series cointegradas de
orden CI(1,1). El orden de integración de cada serie está determinado por d (las series son I(d=1));
mientras que la reducción del orden de integración de la combinación lineal es 1:
),( PcocoaPcaféfet = , es I(b=1-1).
Es importante destacar la serie resultante de la cointegración entre variables no necesariamente
debe ser I(0). Sin embargo, la noción de equilibrio de largo plazo, desarrollada en la sección
anterior, y la definición restrictiva de cointegración de Engle y Granger6 señalarían que la
5 Esta versión adaptada ha sido tomada y traducida de: Banerjee, Anindya, “Co-integration, error-correction, and the
econometric analysis of non-stationary data”, Oxford University Press, 1993, pag 145. 6 La definición de cointegración dada por Engle y Granger (1987) requiere que la serie de desviaciones de la relación de
largo plazo, { }t2t1 xx β− , sea estacionaria. Es decir, tanto la media incondicional como la varianza deberá de ser
constante.

Econometría Moderna
878
combinación deberían ser I(0). Sin embargo, cualquier set de variables que sean CI(d,b), donde
b>0, contiene cierta información acerca de la conducta de largo plazo de las series involucradas7.
En lo que respecta a la forma en que se estima el set de coeficientes (vector de cointegración), el
estimador MCO sigue presentando sus buenas propiedades a pesar de que sea empleado sobre
series no estacionarias. Sin embargo, esto únicamente se cumple cuando el conjunto de variables
presenta alguna relación de equilibrio.
La estimación MCO de un vector de cointegración es denominada como “superconsistente”. Esto
se debe a que nuestro estimador se aproxima asintóticamente a su verdadero valor de forma más
rápida el estimador MCO tradicional. En este último caso, la tasa a la que β converge a su
verdadero valor es de T/1 . Cuando las variables cointegran, la tasa es de 1/T. Esto significa que
mientras que los estimadores MCO convergen como NT ∼− )ˆ( ββ ; los estimadores de una
regresión de cointegración lo hacen así: NT ∼− )ˆ( ββ .
Una explicación intuitiva de la superconsistencia del estimador MCO está basada en el carácter
único del estimador β de cointegración. Si este estimador adopta un valor diferente al de la
verdadera relación, entonces la serie de errores será no estacionaria por lo que presentará una
varianza que crece con el tiempo. Sin embargo, como el algoritmo de optimización detrás del MCO
busca la minimización de estos errores al cuadrado, es muy probable que se escoja la verdadera
relación ya que ésta es la única que presenta la menor varianza, que además es constante.
Antes de continuar desarrollando esta sección, el lector debe tener bien en claro que para que exista
una relación de cointegración todas las variables empleadas deben de ser integradas del mismo
orden. Además, el avance de las técnicas econométricas tan sólo nos permite determinar si existe
alguna(s) relación(es) lineal(es). Quizás con el desarrollo de los métodos de estimación se pueda
estimar relaciones no lineales.
A continuación veremos dos conceptos importantes relacionados con la noción de cointegración:
Rango de cointegración
Para analizar el concepto de rango de cointegración, o mejor dicho, el rango de la matriz de
cointegración, se utiliza la relación estimada entre el precio del café y el precio de la cocoa.
Anteriormente se había definido esta relación como:
o bien 0
2
3
032
21
21
=−
=−
xx
xx
De esta forma, el vector de cointegración adoptaría los valores de { }3,2 − o bien { }23,1 − . Sin
embargo, ambas representaciones corresponden a un único vector de cointegración. Si estos dos
vectores son agrupados en un matriz:
7 Bajo este concepto más amplio de cointegración podemos incluir a las series de residuos de orden mayor a cero que
potencialmente pueden producirse si existe variables cointegradas de orden (d,b), con d>1 y d>0.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
879
−
−=
−
−
231
231
231
32 λλ xx
en donde vemos que solo existe un vector independiente. El rango de esta matriz es 1.
El concepto de rango de una matriz de cointegración adquiere más importancia cuando se está
analizando más de dos variables ya que puede existir más de un vector de cointegración
independiente.
Para esto ejemplificar esta idea se utiliza la relación existente entre los saldos reales en la economía
y los componentes de la demanda por dinero. Asumiendo que cada variable es I(1), la relación de
cointegración que podríamos encontrar estaría representada de la siguiente forma:
tttt rypm 4321 αααα +=+
donde las variables involucradas conforman el siguiente vector [ ]ttttt rypmx , , ,=′ y el vector de
cointegración está determinado de la siguiente manera:
[ ]4321 - - ααααα =
Por lo general este vector se normaliza. Si lo hacemos en función del coeficiente de mt,
obtendremos el siguiente vector:
[ ]321 1 ββββ =
donde 1
21
α
αβ = ,
1
3
2α
αβ −= y
1
43
α
αβ −= .
Ahora que se está empleando más de dos variables puede ser que se presenten más un vector de
cointegración. Técnicamente, si existen n variables pueden existir n-1 vectores de cointegración. Si
en nuestro ejemplo asumimos que existe otra relación de cointegración entre estas variables,
entonces el vector de cointegración estaría especificado de la siguiente forma:
=
001
1
2
321
γ
ββββ
Esta segunda relación de cointegración tan sólo involucra a las variables mt y rt. ¿Podría existir otra
relación lineal que involucre a las cuatro variables y que sea diferente a la ya presentada?. La
respuesta es sí. Estas relaciones están representadas a partir de la tercera fila de la siguiente matríz:

Econometría Moderna
880
=
321
3222122
3121111
2
321
001
1
βλβλβλλ
βλβλβλλ
βλβλβλλ
γ
βββ
β
nnnn
MMMM
Si bien es cierto que podemos incorporar infinitas relaciones que involucren a las cuatro variables y
cuyos coeficientes sean diferentes de cero, todas ellas son dependientes entre sí. Entonces, si
replanteamos la pregunta anterior a: ¿podría existir otra relación linealmente independiente que
involucre a las cuatro variables?, la respuesta sería negativa.
Como resultado tenemos que existen tan sólo dos relaciones lineales independientes. El número de
relaciones independientes se haya a través del rango de la matriz de cointegración. Este concepto
va a ser de mucha importancia cuando desarrollemos la metodología de Johansen para hallar
relaciones de cointegración.
Tendencias comunes
Un segundo concepto a tener en cuenta al hablar de cointegración, es que ésta se produce a nivel de
las tendencias de las series, tal como lo demuestran Stock y Watson8.
Se debe considerar que toda la serie de tiempo está conformada por un componente tendencial, un
componente estacional o cíclico y un componente estacionario. Si nos olvidamos por el momento
de la existencia del segundo componente, podremos afirmar que las series bajo el análisis de
cointegración están caracterizadas por la presencia de un componente estacionario y un
componente no estacionario (es decir, una tendencia estocástica)9. A continuación se probará que la
relación de cointegración se da a este nivel.
En primer lugar, se determina la conformación de las siguientes variables:
rtrtt
ytytt
mtmtt
r
Y
M
εµ
εµ
εµ
+=
+=
+=
en donde Mt, Yt y rt representan las series de demanda por dinero, el producto y la tasa de interés,
respectivamente. El componente tendencial (µt) está representado por una serie camino aleatorio
(random walk), mientras que el componente (εt) es una serie estacionaria.
8 Stock J. y M. Watson, “Variable Trends in Economic Time Series”, en Journal of Economic Perspectives, vol 2, No. 3,
summer 1998, pp. 147-74. y “Testing for Common Trends”, en Journal of American Statistical Association vol. 83, dic.
1998, pp. 1097-1107. 9 Un componente no estacionario puede estar constituido por una tendencia determinística. Sin embargo, la eliminación
de este tipo de tendencia a través de una primera diferencia no involucra pérdida de información como en el caso de una
tendencia estocástica. En este sentido, el análisis de cointegración se da sobre series no estacionarias de tendencias
estocástica.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
881
En el caso que se llegase a determinar la existencia de un vector de cointegración β entre las tres
variables, entonces la combinación lineal que utiliza como coeficientes a cada elemento del vector
β debería darnos como resultado una serie estacionaria:
tttt rYM εβββ =++ 321 (18.1)
Ahora, si reemplazamos los elementos que conforman cada variable obtendremos:
)()(
)()()(
321321
321
rtytmtrtytmt
rtrtytytmtmt
εβεβεβµβµβµβ
εµβεµβεµβ
+++++
+++++ (18.2)
Como la expresión (18.1) nos indica la presencia de una relación CI(1,1), la combinación lineal de
sus componentes, usando el mismo vector, también debería de darnos una serie estacionaria.
Luego, de la ecuación (18.2) sabemos que el segundo componente del lado derecho de esta
ecuación es estacionario por lo que necesariamente el primer componente debe ser, en promedio,
igual a cero.
0321 =++ rtytmt µβµβµβ
Dado que cualquier combinación lineal entre los elementos εit resulta en una serie estacionaria, la
verdadera relación de equilibrio debe de darse entre las tendencias de las series para que
cointegren. Si bien cada una de estas tendencias es estocástica ( tjtjt ηµµ += −1 ), por lo que no
mantiene ningún patrón establecido, los comovimientos entre estas variables van a estar
relacionados mutuamente para que puedan cumplir con esta relación.
1188..44.. EELL MMOODDEELLOO DDEE CCOORRRREECCIIÓÓNN DDEE EERRRROORREESS ((MMCCEE))
En la sección 18.2 se definió cuál era el significado de un equilibrio, en especial cuando este hacía
referencia al largo plazo. En la sección anterior vimos que si esta relación de equilibrio se mantiene
entre series no estacionarias entonces nos estábamos refiriéndonos a un conjunto de series que
cointegran. En esta sección se demostrará que el concepto de cointegración también tiene
implicancias en el corto plazo. Estas son recogidas en el denominado modelo de corrección de
errores (MCE).
En primer lugar, se va a explicar mediante un ejemplo cual es el comportamiento, en el corto plazo,
de un conjunto de series que cointegran. Luego, se especificará la estructura de un MCE, el cual es
parecido a un sistema de ecuaciones. De esta manera se analizarán sus características. Además se
incorporará al análisis el concepto de raíces características ya que éstas juegan un rol importante
dentro de una de las metodologías de estimación del vector de cointegración.
Finalmente, luego de haber revisado las dos formas de analizar un MCE, intuitivamente y a través
de sistemas de ecuaciones, se demostrará que la existencia de un MCE para variables I(1) requiere
de la existencia de un vector de cointegración entre estas variables y viceversa.

Econometría Moderna
882
3.1.1 Intuición y dinámica del MCE
Un equilibrio estable tiene por propiedad que una desviación del mismo es cada vez más
improbable cuando la magnitud de la misma es más grande. Por consiguiente, se puede concluir
que la discrepancia entre la relación actual y el equilibrio de largo plazo de un conjunto de series
está determinada dentro de ciertos límites. Para ilustrar intuitivamente este punto tomaremos como
ejemplo la relación que existe entre la tasa de interés nacional y la extranjera.
En general, una economía abierta al flujo de capitales presenta una tasa de interés igual a la suma
de la tasa extranjera y del factor riesgo del país. Dado que existe movilidad de capitales, cualquier
variación de alguna de estas tasas repercutirá sobre la otra. En un principio asumiremos que el
factor riesgo del país se mantiene constante a lo largo del análisis, por lo que se espera que la
relación entre ambas tasas sea estable. Sin embargo, si en algún periodo determinado la diferencia
entre la tasa interna y la extranjera es mayor a la determinada por el factor riesgo, los inversionistas
distribuirán sus fondos hacia este país, una vez que perciban este exceso de brecha .
Como consecuencia, la conducta de los inversionistas hará que la relación tasa interna/externa se
mantenga ya que en el siguiente periodo la tasa de interés interna se habrá reducido por el flujo de
capital que este país habrá recibido).
Además, si el país es lo suficientemente importante económicamente hablando, es probable que la
tasa de interés extranjera también ayude a mantener esta relación, corrigiéndose al alza debido a la
disminución del stock de capital del resto del mundo.
Esta misma dinámica se observará si por alguna razón disminuye la brecha entre ambas tasas y el
factor de riesgo se mantiene constante. Es decir, el inversionista, en el periodo “t”, ve que se ha
hecho menos atractivo invertir en esta economía, por lo que retirará sus capitales. Esta acción
provoca, en el periodo “t+1”, un incremento en la tasa interna, al reducirse la oferta de fondos;
mientras que la tasa extranjera se reducirá al recibir este influjo. Por consiguiente, la relación entre
ambas tasas volverá a su equilibrio (de largo plazo10
).
4.2
4.3
4.4
4.5
4.6
4.7
4.8
20 40 60 80 100 120 140
I LIBOR
10 Hasta esta parte del ejemplo estamos asumiendo que el factor riesgo se mantiene constante a lo largo del tiempo.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
883
Figura 18.4 Tenemos la trayectoria de las series de la tasa de interés interna y de la tasa Libor. Ambas son I(1) y mantienen una relación de equilibrio a lo largo de la muestra.
En la Figura 18.4 podemos observar que existe una relación de equilibrio de largo plazo entre estas
dos series. Sin embargo, sabemos que el comportamiento corriente (de corto plazo) de ambas
guarda una estrecha relación con este nivel de equilibrio. Podemos imaginarnos a los inversionistas
que día a día están observando y determinando, según sus decisiones de inversión, el
comportamiento de estas series. De esta forma, ellos buscan aprovechar cualquier “discrepancia”
entre esta relación de largo plazo (relación estática).
Por consiguiente, existe una dinámica de corto plazo que integra el equilibrio de largo plazo. La
modelación de la misma recibe el nombre de Modelo de Corrección de Errores (MCE).
Históricamente, la econometría tradicional ha empleado modelos que buscan establecer alguna
relación de corto plazo. Un cambio fundamental se produjo con la introducción del concepto de
cointegración y de los modelos de corrección de errores (MCE). Estos últimos incorporan dentro de
su modelación dinámica desequilibrios pasados de la relación estática.
Uno de los requisitos para llevar a cabo el análisis univariado era contar con series estacionarias.
Para esto, era necesario aplicar primeras diferencias en el caso que las series no fueran I(0). Sin
embargo, el inconveniente con llevar a cabo este procedimiento radica en la pérdida de información
potencialmente valiosa con respecto de las interelaciones de largo plazo. Siendo precisamente este
tipo de relación la materia de estudio y debate en la macroeconomía.
3.1.2 Representación del MCE
Párrafos arriba vimos que existía una relación de equilibrio entre la tasa de interés interna (it)y la
tasa del exterior (libort). Esta relación puede ser representada como un sistema de ecuaciones. Para
llevar a cabo esto, se tiene que definir la relación de largo plazo que siguen estas variables:
libori βθ += . Ahora bien, el comportamiento corriente de estas variables será formulado de la
siguiente manera:
tttt liborilibor 1111 ) ( εβθρ +−−=∆ −− (18.3)
tttt liborii 2112 ) ( εβθρ +−−−=∆ −− (18.4)
en donde θ es una constante, ε1t y ε2t son errores ruido blanco que pueden estar correlacionados y
los coeficientes ρ1, ρ2 y β son positivos. Estos dos primeros también son conocidos como
coeficientes de ajuste (speed of ajustment parameters). La magnitud de los mismos nos indica cual
de las dos variables responde con mayor celeridad ante un desequilibrio.11
11 En realidad, la magnitud de ambos coeficientes también está influenciada por el tamaño de las variables que se está
empleando, por lo que la única aseveración que se puede formular con certeza es cuando uno de estos coeficientes es
igual a cero. En ese caso, la variable que está siendo explicada no responde a las discrepancias y es la otra la que
mantiene la relación de equilibrio.

Econometría Moderna
884
Como se observa en estas ecuaciones, las posibles fuentes de cambio de las variables libort e it son
los shocks aleatorios o bien la discrepancia pasada con respecto a la relación de equilibrio:
{ }111 −−− −−= ttt liboriZ βθ . Esta discrepancia influirá en el valor que ambas series deberán de
tomar en el periodo t para que el sistema se aproxime a su equilibrio de largo plazo.
Este sistema de ecuaciones representa la dinámica existente detrás de la explicación del
comportamiento de las tasas de interés hecho párrafos arriba. Si existe una discrepancia positiva en
la relación de equilibrio, )0 ( 11 >−− −− tt libori βθ , el ajuste se efectuará de distintas formas. En el
caso en que tanto el coeficiente ρ1 como ρ2 sean significativamente diferentes de cero, el ajuste se
llevará a cabo por ambas tasas. Por un lado la variable libort se incrementará; mientras que por
otro, la variable it disminuirá. De esta forma, el comportamiento conjunto de ambas variables
reduce la discrepancia producida en el periodo anterior12
.
En el caso que la variable it sea la tasa de interés interna de una economía pequeña, entonces es
imposible que alguna variación de ésta provoque efecto alguno sobre la tasa de interés extranjera
(internacional). En cambio, la variación de esta última sí provoca grandes efectos en esta economía.
En este caso, si se plantea un MCE es muy probable que el coeficiente de ajuste de la ecuación de
tlibor∆ no sea significativamente diferente de cero (es decir, es nulo). Por lo que todo el ajuste de
corto plazo se produce en la ecuación de ti∆ . Es importante recalcar que basta que por lo menos
uno de estos coeficientes sean diferente de cero para que exista un MCE.
Las ecuaciones (18.3) y (18.4) pueden incluir rezagos de la primera diferencia de las variables:
t
p
i
it
p
i
ittt iialiboriazlibor 1
1
12
1
1111 )()( ερ +∆+∆+=∆ ∑∑=
−
=
−− (18.5)
t
p
i
it
p
i
ittt iialiboriazi 2
1
22
1
2112 )()( ερ +∆+∆+=∆ ∑∑=
−
=
−− (18.6)
La inclusión de estos rezagos responde a la necesidad de lograr una modelación dinámica que nos
proporcione residuos ruidos blancos. La presencia de los mismos determinará la forma en que se
realiza el ajuste hacia el equilibrio. Este será más o menos gradual en función del número de
rezagos que aparezcan en el modelo de corrección de errores13
.
Si se analizan los componentes de las ecuaciones (18.5) y (18.6), se concluirá que es necesaria la
existencia de una relación de cointegración para que el sistema sea estacionario. En este sentido, se
conoce que las primeras diferencias de las variables { }tlibor y { }ti son estacionarias ya que estas
series en niveles son I(1). Además, por definición, los errores ruido blanco son estacionarios. De
esta manera, la consistencia del modelo descansa en que exista un vector de cointegración entre
estas variables, de la siguiente forma: (1, -θ, -β)
12 En la siguiente sección se discutirá en detalle los valores que pueden adoptar estos coeficientes. 13 Se puede obtener el número adecuados de residuos para el sistema (el orden del sistema) aplicando un test chi-
cuadrado basado en la similitud que tiene este modelo con el de la modelación VAR (Vectores Autorregresivos). Otra
alternativa es ir incrementado el orden del sistema y a la vez ir analizando los errores obtenidos. La primera alternativa
será explicada más adelante.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
885
MCE y las raíces características
En la sección 15.3 se indicó que toda serie de tiempo podía ser analizada como una ecuación en
diferencias. La solución de esta ecuación nos permite calcular el valor de las raíces características,
las cuales indican el comportamiento de estas series. Siguiendo esta misma filosofía y para
demostrar la relación que existe entre la cointegración y el MCE, se especificará el siguiente
sistema de ecuaciones, donde tanto x1 como x2 son I(1):
tttt xaxax 1121211111 ε++= −− (18.7)
tttt xaxax 2122211212 ε++= −− (18.8)
El cálculo de las raíces características para cada serie indicará su comportamiento, y hasta señalará
si estas series cointegran o no.
Un primer paso para determinar cual es el comportamiento de cada una de las variables, consiste en
reescribir estas dos ecuaciones empleando el operador de rezagos:
ttt LxaxLa 1212111 )1( ε=−−
ttt xLaLxa 2222121 )1( ε=−+−
Despejando una variable y reemplazándola en la otra ecuación se obtiene:
2
21122211
212122
1)1)(1(
)1(
LaaLaLa
LaLax tt
t−−−
+−=
εε (18.9)
2
21122211
211121
2)1)(1(
)1(
LaaLaLa
LaLax tt
t−−−
−+=
εε (18.10)
Tal como ya se vio la sección 15.3, la ecuación característica de cada serie se obtiene del
denominador de estas expresiones14
. Además, debido a que ambas son iguales, esto nos indica que
ambas series tienen la misma ecuación característica:
0)()( 211222112211
2 =−++− aaaaaa λλ (18.11)
Esta última expresión nos indica que cada una de las variables tiene dos raíces (iguales para las
dos), de tal forma que de acuerdo con los valores que tomen se caracterizará el comportamiento del
sistema:
♦ Si ambas raíces características (λ1,λ2) caen dentro del círculo unitario, entonces estas
variables son estacionarias (obviamente dejan de ser CI(1,1)).
14 Estas expresiones pueden estar definidas como las vistas en el capítulo 15:
[ ] ),()1)(1( 212,1
2
21122211 ttt fxLaaLaLa εε=−−−
de tal forma que la raíz característica se obtiene reemplazando L=1/λ en el corchete e igualándolo a cero.

Econometría Moderna
886
♦ Si ambas raíces caen fuera del círculo unitario, entonces la solución de cada variable es
explosiva. De igual manera, si ambas raíces son iguales a uno, la primera diferencia de las
mismas no nos dará una variable estacionaria sino I(1). Por consiguiente, estas variables no
pueden ser CI(1,1).
♦ En el caso de que a12 y a21 sean iguales a cero, esto significaría que no existe relación
alguna entre estas dos variables. Si además ambas raíces son iguales a uno, lo único que
obtendríamos es que cada una de ellas presentan raíz unitaria pero sin ninguna relación
entre sí.
♦ Finalmente, si una de estas raíces es igual a uno y la otra es menor a 1 en valor absoluto,
entonces estas variables serán CI(1,1). Cada una de ellas tendrá la misma tendencia
estocástica y su primera diferencia será estacionaria.
3.1.3 Teorema de Representación de Granger
El ejemplo de las tasas de interés nacional y extranjera nos indica claramente que existe una
relación entre la estimación de largo plazo (cointegración) y la de corto plazo (MCE). Los valores
que toman ambas variables día a día no pueden estar divorciado de su relación de largo plazo y
viceversa. Esta relación recibe el nombre del Teorema de Representación de Granger.
Este teorema afirma que si tanto x1 como x2 son series I(1), y si la relación de largo plazo entre
ambas es estable: ttt xxz 21 β−= , entonces se puede afirmar que estas variables son generadas por
un modelo de corrección de errores.
� La existencia variables CI(1,1) implica la existencia de un MCE entre estas.
Para demostrar esto emplearemos las raíces características de las variables incluidas en las
ecuaciones (18.7) y (18.8):
0)()( 211222112211
2 =−++− aaaaaa λλ
Como ya indicamos anteriormente, para que estas variables sean CI(1,1) es necesario que una raíz
característica sea igual a uno mientras que la otra sea menor a uno en valor absoluto. Si
desarrollamos esta ecuaciones sabremos que la mayor raíz característica (la cual debe ser igual a
uno) debe ser:
142(*2
1)(*
2
121122211
2
22
2
112211 =+−+++ aaaaaaaa
luego de algunas simplificaciones podemos obtener el siguiente resultado:
)1/(1 22211211 aaaa −−= (18.12)
Luego, la segunda condición sobre las raíces características es la siguiente:
142(*2
1)(*
2
121122211
2
22
2
112211 <+−+−+ aaaaaaaa

Capítulo 18: Modelo de Corrección de Errores y Cointegración
887
lo que implica:
122 −>a (18.13)
y
1)( 2222112 <+ aaa (18.14)
De esta manera, las ecuaciones (18.12), (18.13) y (18.14) representan restricciones sobre los
coeficientes del sistema conformado por las ecuaciones (18.7) y (18.8) para asegurar que estas
variables son CI(1,1). Este sistema puede ser reespecificado de la siguiente forma:
+
−
−=
∆
∆
−
−
t
t
t
t
t
t
x
x
aa
aa
x
x
2
1
12
11
2221
1211
2
1
1
1
ε
ε (18.15)
Si reemplazamos la restricción (18.12) en el sistema, obtendremos:
[ ] tttt xaxaaax 11212112221121 )1/( ε++−−=∆ −− (18.16)
tttt xaxax 2122211212 )1( ε+−−=∆ −− (18.17)
Finalmente, si tanto a12 como a21 son diferentes de cero, entonces podremos normalizar el vector de
cointegración con respecto a ambas variables. De esta forma obtenemos el siguiente modelo de
corrección de errores:
tttt
tttt
xxx
xxx
2121122
1121111
)(
)(
εβα
εβα
+−=∆
+−=∆
−−
−−
donde: )1/( 2221121 aaa −−=α
212 a=α
2122 /)1( aa−=β
Si analizamos los valores que pueden tomar estos parámetros, veremos que las restricciones (18.12-
18.14) que nos aseguraban que las variables fuesen CI(1,1), también nos aseguran de que β≠0 y
que por lo menos alguno de los coeficientes de ajuste (α1, α2) sea diferente de cero.
De esta manera, queda comprobado que las condiciones para que exista una grupo de variables
CI(1,1) traen consigo la existencia de un modelo de corrección de errores entre esas variables.
� La existencia de un MCE entre un grupo de variables I(1) implica que éstas sean a su
vez CI(1,1).
Esta afirmación ya ha sido probada anteriormente. Sin embargo, en esta oportunidad se
generalizará la especificación de un MCE para un vector )x,...,x,x('X ntt2t1t = de variables I(1):

Econometría Moderna
888
tptptttt XXXXX επππππ +∆++∆+∆++=∆ −−−− ...221110 (18.18)
donde: π0 = un vector (n x 1) de intercepto con elementos πi0
π = es una matriz donde al menos uno de sus elementos (πjk) debe ser diferente
de cero
πi = matriz (nxn) cuyos elementos son πjk(i)
εt = un vector (nx1) de elementos εit
Como ya se señaló anteriormente, este sistema debe estar conformado solamente de variables
endógenas e I(1). De esa forma, sus primeras diferencias nos reportan variables estacionarias.
Además, si el número de rezagos es el adecuado15
, los términos εit son “ruidos blancos”. Por
consiguiente, la consistencia del MCE se centra en los elementos del vector πXt-1.
Si realmente existe un MCE, entonces cada elemento de este vector debe contener una expresión
que sea estacionaria. De esta manera, los elementos de la matriz π determinan las relaciones de
cointegración. De esta manera, se debe cumplir con:
ttX επ =−1 (18.19)
o bien:
=
−
−
−
nt
t
t
nt
t
t
nnn
n
n
x
x
x
ε
ε
ε
ππ
πππ
πππ
MM
L
MMM
L
2
1
1
12
11
1
22221
11211
Este vector contiene las discrepancias con la relación de largo plazo, las cuales se asumen que en
promedio son cero.
De esta manera hemos comprobado que la existencia de un MCE implica que exista(n) relación(es)
de cointegración entre las variables.
3.1.4 Rango y valores propios de la matriz de cointegración
Como ya hemos visto, si existe una representación a través de un MCE de un conjunto de series
I(1), esto requiere que exista alguna relación de cointegración entre estas variables y viceversa.
Ahora que hemos generalizado nuestro análisis a un vector de n variables, el número de vectores de
cointegración puede ser mayor que uno. Como ya se indicó en la sección anterior, para determinar
el número de vectores de cointegración existentes entre un conjunto de variables es necesario
analizar el rango de la matriz π de la expresión (18.19).
15 Para tratar este tipo de problemas existe una metodología denominada VAR (Vector Autoregression). En este libro no
existe un capítulo que la trate extensamente; sin embargo, debido a que su uso “indirecto” es indispensable, el lector
tendrá nociones acerca de su aplicación práctica. En caso que el lector desee una mayor rigurosidad entonces puede
consultar diversos libros de texto de econometría de series de tiempo.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
889
ttX επ =−1
El lector recordará que el rango de una matriz está determinado por el número de valores propios
diferentes de cero (denominados también como raíces características). Por cada valor propio
diferente de cero, existe un vector independiente que conforma esta matriz. Precisamente, nuestro
interés se centra en determinar estos vectores independientes ya que cada uno representa un vector
de cointegración. El máximo número de valores propios que puede tener una matriz nxn es n. De
esta manera puede darse las siguientes situaciones:
• El número de valores propios diferentes de cero de π es cero.
• El número de valores propios diferentes de cero de π es n.
• El número de valores propios diferentes de cero de π es r (0<r<n).
Para el primero de estos casos, el rango de π es cero, es decir, todos sus elementos son iguales a
cero. Entonces no existe ningún vector de cointegración entre estas variables.
=
−
−
−
0
0
0
00
000
000
1
12
11
MM
L
MMM
L
nt
t
t
x
x
x
De esta manera la expresión (18.18) representará un sistema de ecuaciones constituido
integramente por variables endógenas16
.
Para el segundo de los casos, donde todos los valores propios de π son diferentes de cero, se cuenta
con un rango completo (si tenemos n variables, el rango de la matriz es n), por lo que cada una de
estas series es estacionaria. Los n valores propios caen dentro del círculo unitario. El determinante
de esta matriz es diferente de cero. Si todas las series son estacionarias, cualquier combinación de
estas produce otra serie estacionaria. Por consiguiente no existe ningún vector de cointegración.
0...
0...
0...
332211
2323222121
1313212111
=++++
=++++
=++++
ntnntntntn
ntnttt
ntnttt
XXXX
XXXX
XXXX
ππππ
ππππ
ππππ
M
En el último de los casos, donde se cuenta con r valores propios diferentes de cero aunque en
cantidad menor a n, la matriz π es de rango n. De esta manera se puede afirmar que existen r
vectores de cointegración. Como ya sabemos, debe existir por lo menos un valor propio igual a
cero, pero no todos. En este caso, existen n-r valores propios iguales a cero. El resto caen dentro
del círculo unitario por lo está garantizada la estabilidad del sistema.
16 Esta forma de especificación se puede estimar a través de la metodología VAR.

Econometría Moderna
890
En el caso que exista un solo vector de cointegración, la expresión 1−txπ puede ser representada
como:
ntntntttn
tntnttt
tntnttt
XXXX
XXXX
XXXX
εβββα
εβββα
εβββα
=++++
=++++
=++++
)...(
)...(
)...(
13132121
2131321212
1131321211
M
Como vemos, el vector de cointegración está determinado por ),...,,,1( 11312 nβββ . Los
coeficientes de ajuste está formados como: 1ii πα = mientras que los betas se comportan de la
siguiente manera:i
i
α
πβ 2
12 = , y esto se puede generalizar para todos los betas del vector:
i
ij
j
i
i
i
i
α
πβ
α
πβ
α
πβ === 1
4
14
3
13 ,...,, . Todos estos betas llevan el subíndice “1j” debido a que hacen
referencia a un mismo vector de cointegración.
En el caso que exista más de un vector de cointegración, su representación estaría dada de la
siguiente manera17
:
ntntnttnntnttn
tntnttntntt
tntnttntntt
XXXXXX
XXXXXX
XXXXXX
εββαββα
εββαββα
εββαββα
=+++++++
+
=+++++++
=+++++++
)...( )...(
)...( )...(
)...( )...(
222212121211
222221221212121
122221121212111
MM (18.20)
Como se puede concluir, las características que presente la matriz π es de gran ayuda ya que nos
indica el número de vectores de cointegración detrás de estas variables.
Ahora bien, nuestros lectores se estarán preguntando cómo realizar la estimación del MCE. Si bien
es cierto que el parámetro β que caracteriza la verdadera relación entre las variables x1 y x2 no es
conocido de antemano, esta pequeña contrariedad no impide que el mecanismo de corrección de
errores (MCE) nos sirva. Su cálculo puede ser realizado de forma separada a través de una
estimación previa (para calcular la discrepancia rezagada de la relación de largo plazo) o bien
realizado dentro del mismo esquema de corrección de errores. Estas dos formas de calcular el
vector de cointegración determinan las dos técnicas más difundidas para estimar una relación de
cointegración: metodología Engle-Granger y el test de Johansen, respectivamente.
1188..55.. MMEETTOODDOOLLOOGGÍÍAA DDEE EENNGGLLEE YY GGRRAANNGGEERR
Como ya se mencionó líneas arriba, existen dos metodologías para estimar el vector de
cointegración. La primera de ellas elabora esta estimación en “dos etapas”: primero calcula a través
de MCO los posibles coeficientes del vector de cointegración (de la relación estática); y en un
17 En la sección 18.6 se explicará cómo es que se obtiene esta expresión.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
891
segundo paso, se estima el MCE para determinar si estos coeficientes calculados realmente
constituyen los de una relación de equilibrio de largo plazo a través del análisis dinámico de este
modelo. La segunda metodología fue desarrollada por Johansen18
y calcula el MCE al mismo
tiempo que determina los coeficientes del vector de cointegración. Para esto emplea la técnica de
máxima verosimilitud. En esta técnica se emplean los conceptos de rango y de valores propios de la
matriz π.
A continuación desarrollaremos la primera de estas técnicas, la cual fue desarrollada por Engle y
Granger (E&G)19
.
3.1.5 Revisión general del metodología E&G
Como primer paso para analizar el desempeño de la metodología E&G, se especifica un modelo
simple conformado por dos series: x1t y x2t. Estas han sido generadas conjuntamente a partir de las
series de errores aleatorios ε1t y ε2t, los cuales pueden estar correlacionados. El modelo generador
es el siguiente:
tttt uxx 11-1t1t121 uu , εθ +==+ (18.20)
1 ,uu , 21-2t2t221 <+==+ ρερβ tttt uxx (18.21)
Si reespecificamos este sistema de ecuaciones en su forma reducida, entonces se comprueba que
ambas series (x1t, x2t) están en función de u1t y u2t. Por consiguiente, ambas serán I(1). Sin embargo,
se puede deducir otra característica de estas series a partir de la ecuación (18.21). En esta ecuación
se observa que existe una combinación lineal de estas series que resulta ser estacionaria. Por
consiguiente, se concluye que ambas series son CI(1,1).
La metodología de Engle y Granger es bastante sencilla en su modus operandi aunque conlleva a
algunas complicaciones al momento de su aplicación. De forma resumida, esta metodología busca
estimar, como primer paso, el vector de cointegración (β); y luego de reemplazar estos errores en el
MCE, se analiza la presencia de las características propias de un conjunto de variables que en su
comportamiento dinámico (corto plazo) mantienen una relación de largo plazo.
En este sentido, la forma en que se comporta el término de error aleatorio u2t desempeña un rol
importante. Por consiguiente, como primer paso se estimará el valor de ρ. Para esto se empleará el
test de Dickey-Fuller. Sin embargo, en esta situación el rechazo de la hipótesis nula, que
usualmente implicaba la ausencia de una raíz unitaria, ahora implica presencia de cointegración
entre las variables.
Sin embargo, al momento de aplicar este test se debe tomar en cuenta que se lo está aplicando a una
series de residuos de una regresión, por lo que el análisis de los resultados diferirá de su aplicación
tradicional. De esta forma el investigador puede encontrar en dos escenarios:
a. ββββ es conocido
18 Johansen, Soren, “Statistical Analysis of Cointegration Vectors”, Journal of Economic Dynamics and Control, vol 12,
Junio-Septiembre 1988, pp. 231-254. 19 Engle, R.F y C. W. J. Granger, “Co-integrated and Error Correction: Representation, Estimation and Testing”,
Econometrica, vol 55, 1987, pp. 251-276.

Econometría Moderna
892
Si asumimos que el investigador determina a priori el vector de cointegración (β), entonces en este
caso, se puede emplear los test de Dickey-Fuller y Dickey-Fuller Aumentado ya que la serie u2t es
“construida” y no estimada. Si bien es cierto que esta distribución no es estándar, los valores
críticos de ésta han sido calculados a través de simulaciones por Dickey(1976). De esta forma, si se
rechaza la hipótesis nula, entonces el vector β podría ser el vector de cointegración.
Para estar completamente seguros de que el vector estimado representa un vector de cointegración,
se necesita examinar las características del MCE. En él se reemplaza la serie “construida” de u2t,
rezagada en un periodo. Para determinar la existencia o no del vector de cointegración, este sistema
deberá de cumplir con las características mencionadas en la sección anterior.
Sin embargo, esta forma de análisis no es frecuentemente utilizada debido a que ésta implica la
comprobación sistemática de diferentes valores del vector de cointegración (β) hasta dar con el
verdadero. Generalmente, los trabajos de investigación buscan estimarlos y no dar con el
iterativamente sin ningún algoritmo preestablecido.
b. ββββ es estimado
En el caso que β no sea conocido, este deberá de ser estimado a partir de los datos.
La estimación de parámetro (β) cuando el verdadero valor de ρ es menor de uno es fácil de realizar
debido a que el MCO ofrece una excelente estimación a pesar de que cada una de estas variables
(x1t , x2t) sean I(1). Esta regresión lleva por nombre “regresión de cointegración”.
Por las características de estas series se conoce que todas sus combinaciones excepto la definida en
la ecuación (18.21) tendrán una varianza infinita y, por lo tanto, producirán una suma del cuadrado
de los errores bastante elevada. Por otro lado, el verdadero valor β generará una serie de errores
I(0), de varianza finita. De esta manera, con el empleo de este valor se contará con una suma de
errores cuadráticos marcadamente menor. Debido a esto, los parámetros estimados por MCO son
superconsistentes20
, es decir, convergen a su verdadero valor con mayor celeridad que cualquier
otro estimador. Esto se produce debido a que la correlación existente entre x2t y u2t, causada por la
omisión de la dinámica en la relación, es de menor orden que la varianza de x2t. Para comprobarlo,
se determinará la expresión de la estimación de β de la ecuación (18.21):
1
1
2
2
1
21ˆ
−
==
= ∑∑
T
t
t
T
t
tt xxxβ
1
1
2
2
1
22
−
==
+= ∑∑
T
t
t
T
t
tt xuxβ (18.22)
Se conoce que el estimador de β es sesgado ya que el error u2t incorpora la relación dinámica que
existe entre estas variables. Sin embargo, debido a que x2t es I(1) y u2t es I(0), el segundo
componente del lado derecho de la expresión anterior va a converger a cero rápidamente. La
20 El teorema de la superconsistencia fue planteado por Stock. J. H, “Asymptotic Properties of Least-Squares Estimators
of Co-integrating Vectors”, Econometrica, vol 55, pp. 1035-56.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
893
convergencia se produce a una tasa de T, mientras que estimadores tradicionales convergen a tasa
T1/2
. Es por esto que reciben el nombre de estimadores superconsistentes21
.
Esta característica es empleada por Engle y Granger como base de su estimador de “dos etapas”
(two-step estimator). Debido a que el estimador de β obtenido en la regresión estática converge con
una mayor “velocidad” que el resto de estimadores, éste puede ser incorporado en el modelo de
corrección de errores y figurar como el verdadero valor del parámetro ya que el resto de parámetros
tardarán mucho más tiempo en converger a su verdadero valor. De esta manera, cuando estos
últimos converjan, ya estarán incorporando en su cálculo no al valor estimado y sesgado de β sino
al verdadero valor.
De esta manera, estos autores formulan el siguiente teorema22
:
La estimación de los parámetros del modelo de corrección de errores, en el cual se haya
calculado el término de corrección empleando el β estimado de la regresión estática entre las
variables, y sólo en el caso que exista un único vector de cointegración, tendrá la misma
distribución límite que la de los parámetros calculados por máxima-verosimilitud conociendo
el verdadero valor de β. Los errores mínimo cuadráticos de esta segunda etapa proveen de
estimadores consistentes de las verdaderas desviaciones estándar de los errores.
Con relación a las pruebas de raíz unitaria sobre los errores de la ecuación (18.21), éstas ya no
podrán ser hechas empleando los valores críticos tradicionales ya que ahora la serie { }t2u es un
residuo estimado de una regresión, por lo que cuenta con una distribución límite diferente. La
explicación intuitiva de esto se encuentra en el hecho que el estimador MCO busca un conjunto de
parámetros que genere una serie de errores que cuente con la varianza mínima, entonces los valores
críticos del DF tradicional estarán sesgados a afirmar que que no existe raíz unitaria. Más adelante
veremos cuáles son los test alternativos con los que cuenta el investigador.
Existen otras formas alternativas para calcular el valor de β; sin embargo éstas no presentan
estimadores consistentes. Se puede colocar como ejemplo el empleo de primeras diferencias de las
variables (x1t , x2t), en vez de la forma en niveles como son empleadas en la ecuación (18.21) y al el
uso de métodos de corrección de correlaciones seriales como el Cochrane-Orcutt en la regresión de
cointegración.
Algunos inconvenientes
A través del empleo de simulaciones de Monte Carlo, Barnerjee ha demostrado que la
superconsistencia de los estimadores MCO no se presentan en muestras pequeñas. De esta manera,
la incorporación de los residuos de la regresión de cointegración en el MCE puede afectar a la
21 Demostración analítica: se conoce que { }t2u es I(0) si existe cointegración y además que { }t2x es I(1), tal manera que:
)(1
2
2
1TOxT p
T
t
t ∼
∑
=
− “Converge en probabilidad a T” y )1(1
22
1
p
T
t
tt OuxT ∼
∑
=
− “converge en probabilidad a cero”
por lo que: )1()ˆ(
1
1
2
2
2
1
22
1
p
T
t
t
T
t
tt OxTuxTT ∼
=−
−
=
−
=
− ∑∑ββ , lo cual implica que )()ˆ( 1−∼− TOpββ
De modo que la convergencia del estimador a su verdadero valor se da a un ratio T. Como se revisó en el Capítulo 10,
Teoría Asintótica, el ratio al que normalmente se da la convergencia es T1/2. Por este motivo, este estimador se denomina
“superconsistente”. 22 Traducción propia. Engle, R.F y C. W. J. Granger, op. cit., pp. 262

Econometría Moderna
894
estimación del resto de parámetros y hasta negar la presencia de un vector de cointegración aun
cuando realmente éste sí existiese realmente.
Además de esto, cuando se cuenta con un modelo que presenta más de dos variables en la relación
de cointegración se pueden presentar dos tipos de problemas:
El primero de ellos se relaciona con la determinación de la variable dependiente. Si primero se
coloca a x1 como la variable dependiente de x2 y x3, la relación estimada puede diferir con aquella
que se obtiene de colocar como variable dependiente a x2. Lo mismo se repite si colocamos a x3.
Asintóticamente estos estimadores son iguales (previa normalización); sin embargo, en la práctica
empleamos muestras que generalmente no son lo suficientemente grandes.
Banerjee, demuestra con simulaciones de Monte Carlo que el sesgo de las muestras chicas está
inversamente relacionada con el R-cuadrado, por lo que sugiere que la normalización se haga en
función al mayor R-cuadrado. En general, la regresión de cointegración que presente un R-
cuadrado bajo debe ser tomada con precaución.
El segundo problema relacionado con esta metodología se encuentra en la serie de residuos que se
puede encontrar cuando se estima una relación bivariada frente a la alternativa de una multivariada.
Existe la posibilidad de obtener resultados no necesariamente verdaderos si, por ejemplo,
queremos comprobar si existe alguna relación entre las variables x1 y x2, cuando en realidad la
verdadera relación involucra una tercera variables, x3: tt xxx 33221 ββ += . En este caso, si se
estima el siguiente modelo:
tt uxx += 221 β
la serie { }tu presenta raíz unitaria al incluir en ella a la serie { }tx3 por lo que nuestro
procedimiento nos indicaría que no existe relación alguna entre estas variables, lo cual es falso. De
esta manera, los resultados de esta metodología depende de la buena especificación del modelo.
Además debido a que nuestro modelo puede presentar más de dos variables puede darse el caso que
entre un mismo grupo de variables se presente dos relaciones de cointegración. Esto implica que
puede existir más de una desequilibrio que afecte la dinámica de las variables que son modeladas
en el MCE. La metodología de Engle y Granger no contempla este caso.
3.1.6 Aplicación de la metodología de E&G
Ahora continuación se determinará cuáles son los pasos a seguir para aplicar esta metodología.
Estos pasos se relacionan con la teoría antes expuesta y consideran en cuenta las dolencias que
posee esta metodología para así realizar una buena estimación. Para mejorar su comprensión, este
procedimiento será aplicado paralelamente a un conjunto de series simuladas. Finalmente, se
aplicará esta metodología a series económicas reales.
� Primer paso: determinación el orden de integración
El objetivo de la metodología E&G es determinar la existencia de un equilibrio de largo plazo
dentro de un conjunto de series no estacionarias. Si nos basamos en la definición restringida de
cointegración de Engle y Granger, este conjunto de variables deben ser I(1). Teóricamente, la

Capítulo 18: Modelo de Corrección de Errores y Cointegración
895
ecuación de regresión puede incluir variables de diferente orden (I(0) y I(2)). La inclusión de
variables I(0) no serían de gran utilidad ya que lo que estamos buscando determinar es una relación
de largo plazo entre estas series, lo que equivale a determinar alguna relación entre las tendencias
de las mismas. Una serie I(0) no presenta un tendencia estocástica, por lo que su aporte al momento
de determinar el vector de cointegración no sería significativo.
Con respecto a la inclusión de series I(2), esto puede realizarse de dos formas: o bien las diferencio
una vez para así incorporar a la regresión de cointegración variables I(1) o bien primero busco
determinar la existencia de una relación de cointegración entre estas variables I(2) e incorporo los
residuos I(1) de esta regresión junto con el resto de series I(1) de la primera regresión.
En la práctica diaria es raro encontrar variables que sean I(2) por lo que generalmente esta
metodología se aplica a series I(1)23
.
De esta manera, el primer paso consiste en determinar el orden de integración de las series. Para
esto se aplican los procedimientos vistos en el capítulo 16.
En el siguiente cuadro se especifica la conformación de las series { }tttt z, y , w, x , que serán
empleadas a lo largo de la aplicación de esta metodología. Las tres primeras mantienen entre ellas
una relación de equilibrio de largo plazo (cointegran); mientras que la última se comporta como un
camino aleatorio independiente.
Cuadro 18.1
{ }tx { }tw { }ty { }tz
Tendencia µxt= µxt-1 +εxt µwt= µwt-1 +εwt µyt= 2µxt +µwt µzt= µzt-1 +εzt
comp..
Estacionario δxt=0.5δxt-1 + ηxt δwt=0.5δwt-1 + ηwt δyt=0.5δyt-1 + ηyt δzt=0.5δzt-1 + ηzt
Serie z xt = µxt + δxt wt = µwt + δwt + 0.5δxt yt = µyt + δyt+0.5δxt+0.5δwt zt = µzt + δzt
Las series { }ztytwtxtztwtxt ηηηηεεε ,,,,,, son secuencias de números aleatorios. Estas series nos
ayudan a “construir” el componente tendencial y el componente estacionario de las series
{ }tttt zywx ,,, . El valor inicial de cada serie de componentes es cero; mientras que el resto de
valores depende de cómo se haya definido su PGD (proceso generador de datos). Cada serie cuenta
con 150 observaciones.
Como era de esperarse, el resultado que se obtuvo de aplicar el test de Dickey-Fuller reconoció la
presencia de una raíz unitaria en cada una de estas series.
� Segundo paso: estimación de la regresión de cointegración
Este segundo paso consiste en estimar la regresión de cointegración. Una vez que se comprueba
que todas las variables son del mismo orden, I(1), se procede a aplicar el procedimiento MCO
sobre estas variables. Como ya se mencionó anteriormente, los estimadores obtenidos son
23 Se pueden encontrar como ejemplos de series I(2) a las series de stock de inventarios ya que éstas resultan de la
agregación de las series de producción y ventas, las cuales son I(1).

Econometría Moderna
896
“superconsistentes”. Sin embargo, esta característica se puede ver afectada por el número de
observaciones de la muestra y por el grado de dependencia de cada serie.
Para determinar los efectos de estos dos factores sobre los estimadores MCO se realizará una
simulación de Monte Carlo. Este experimiento consiste en generar las series { } y , w, x ttt
siguiendo la ley de formación del cuadro anterior y estimar la siguiente regresión:
twtxt WXY ββ +=
Lo que se va a calcular es la magnitud en que se desvían los estimadores MCO de los verdaderos
valores de los parámetros (βx =2, βw = 1), cuando se altera tanto el número de observaciones como
el coeficiente (AR(1)) del componente estacionario de cada serie. Estos son los resultados:
Cuadro 18.2
Modelo Correcto
βx
%desv.
βw
%desv.
Número 50 0.12143 0.21447
De 100 0.07704 0.12947
Obs. 150 0.05751 0.09709
0.50 0.07704 0.12947
AR(1) 0.70 0.10503 0.18254
(obs=10
0) 0.95 0.27160 0.46222
Este cuadro recoge el promedio que se obtuvo luego de 1000 estimaciones para cada tipo de
modelo. Queda como ejercicio al lector ver cómo se alteran estos parámetros si especificamos el
componente estacionario no sólo como un AR(1) sino como un AR(p).
Esta simulación nos indica que el sesgo asintótico tiende a decrecer a medida que se incrementa el
número de observaciones. Con series que cuenten con 50 observaciones, el sesgo alcanza el 12% y
21% del verdadero valor de los coeficientes βx y βw, respectivamente. Este sesgo va disminuyendo
a medida que se incremente el tamaño muestral.
También se determina que el sesgo se incrementa cuando el grado de independencia de las series,
determinado por el coeficiente de AR(1), se incrementa. Para el caso de un AR(1) con ρ=0.5, el
sesgo es de 7.7% y 12.9% de los coeficientes de las series xt y wt, respectivamente. El mismo que
se incrementó a 27% y 42% cuando ρ alcanzó el valor de 0.95.
El investigador deberá tener en cuenta que los coeficientes estimados en esta regresión no
presentan distribuciones “t” asíntóticas si en el modelo no se han incluido todas las variables que
realmente conforman la relación de largo plazo. Si hubiese omisión de una de estas variables
obtendríamos como resultado una regresión espúrea, la cual es identificada aplicando el test de DF
a los residuos. En el caso que exista una variable redundante, su coeficiente debería de ser no
significativo en la regresión de cointegración.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
897
Empleando el modelo de generación del Cuadro 18.1, en la simulación de Monte Carlo se busca
determinar cómo nuestro modelo, que incorpora una variable redundante, se comporta ante
variaciones del número de observaciones y el grado de dependencia entre las observaciones de cada
serie (siempre considerando sólo series AR(1)). Se realizaron 1000 replicaciones para cada uno de
estos casos. Como en el cuadro anterior, la columna de los β(x,w) recoge el promedio de la
desviación de los estimadores con respecto a su verdadero valor y en la columna de las t(x,w,z) se
encuentra el porcentaje en que los respectivos coeficientes resultaron ser significativamente
diferentes de cero.
Cuadro 18.3
Modelo con variable redundante
βx
%desv.
βw
%desv.
t (x)
%sign.
t (w)
%sign.
t (z)
%sign.
50 0.15695 0.25847 100.0 95.4 39.3
Número 75 0.12707 0.19533 100.0 99.5 42.1
De 100 0.10195 0.16067 100.0 99.9 44.9
Obs. 125 0.09037 0.14474 100.0 100 47.8
150 0.07763 0.13537 100.0 100 47.4
0.50 0.10195 0.16067 100.0 99.9 44.9
AR(1) 0.70 0.13774 0.21766 100.0 99.4 53.2
(obs=100) 0.95 0.30078 0.46455 98.6 88.4 72.3
De los resultados que se encuentran resumidos en este cuadro se observa que la presencia de la
variable redundante (Zt) en el modelo de regresión resultó ser significativa en un 39.3% de las
veces cuando contamos con 50 observaciones. Cada vez que se incrementa el número de
observaciones, el porcentaje de veces que esta variable redundante no es especificada como tal
aumenta llegando inclusive a un 47.4% cuando se emplea en la estimación 150 observaciones por
serie.
Este mismo fenómeno se presenta cuando se incrementa el grado de dependencia de las series. Si el
componente estacionario de las series se comporta como un AR(1) con una raíz característica de
0.50, el porcentaje de veces que la variable redundante sale significativa es de 44.9%. Si la raíz
característica se incrementa a 0.95, este porcentaje se incrementa a 72.3%.24
A parte del problema de variables redundantes u omitidas, otro problema que el investigador
deberá de tener en cuenta es la normalización, es decir, qué variable coloca a la izquierda de la
regresión de cointegración. Teóricamente, la disposición de las variables no debe influir sobre el
resultado final. Sin embargo, se ha visto que los coeficientes obtenidos de las distintas formas de
calcular la regresión no guardan la misma relación. Incluso podría darse el caso que si se coloca
una determinada variable como dependiente, la regresión de cointegración nos indique que sí existe
una relación de equilibrio; mientras que si se coloca otra variable como dependiente, el resultado
sería distinto.
En nuestro modelo simulado obtenemos las siguientes estimaciones:
24 También se observa que la serie wt resulta ser menos significativa cuando la raíz característica se incrementa. Vemos
que las alteraciones de las condiciones provocan mayores efectos sobre las variables que presentan una menor
participación en la relación de equilibrio (recordemos que µyt = 2µxt + µwt).

Econometría Moderna
898
(0.035491) (0.080965)
y *0.824234 x *1.557668- w
(0.023838) (0.004107)
w*0.458607 -y *0.502403 x
(0.040993) (0.016112)
w*0.952004x *1.970943y
+=
=
+=
(18.23)
Sabemos que las variables y, x, w guardan la siguiente relación: 1, -2, -1, respectivamente. Vemos
que aún si normalizamos de diferentes maneras, esta misma relación se mantiene.
Una última recomendación: a menos que sea precisada la ausencia del término de intercepto, es
recomendable que este término sea incluido en el modelo. En las regresiones (18.23) no hemos
incluido intercepto ya que estas series fueron generadas sin este elemento.
� Tercer paso: verificación si los errores estimados son I(0)
Una vez que se ha determinado qué variables deben ser incluidas en el modelo y luego de haber
estimado la regresión de cointegración se debe verificar si estos errores se comportan como I(0). En
caso que esto no se presente, el modelo estaría representando una relación espúrea. Por otro lado, si
los errores efectivamente se comportan como I(0), entonces nuestro modelo estimado recoge una
relación de equilibrio de largo plazo, a pesar de que las series no sean estacionarias.
De esta manera, para realizar la verificación del orden de estos errores debemos utilizar el test de
Dickey-Fuller. Sin embargo, como ya se ha indicado anteriormente, la aplicación de los valores
críticos tradicionales generarían resultados sesgados hacia la negación de la presencia de una raíz
unitaria.
Para determinar la existencia de un sesgo al aplicar el test de Dickey-Fuller, se estimará el siguiente
modelo:
ttt uwx += β
Si nos fijamos en la forma en que se generaron estas series vemos que cada una es I(1) e
independiente de la otra serie. Podría darse el caso que aparentemente el coeficiente β sea
significativamente distinto de cero, pero esto correspondería a una relación espúrea. Sin embargo,
en todos los casos la serie de residuos debe ser I(1).
Se efectuó una simulación de Monte Carlo (1000 replicaciones) y se detectó que en un 37.5% de
las veces el test de Dickey-Fuller, con sus valores tradicionales, nos indicaban que esta serie no
presentaba raíz unitaria.
Debido a la presencia de este sesgo en los valores críticos de Dickey-Fuller, es necesario el empleo
de valores críticos más estrictos. En este sentido Engle y Granger25
calcularon un conjunto de
25 Engle R.F y C. W. J. Granger, op. cit., pp. 269.
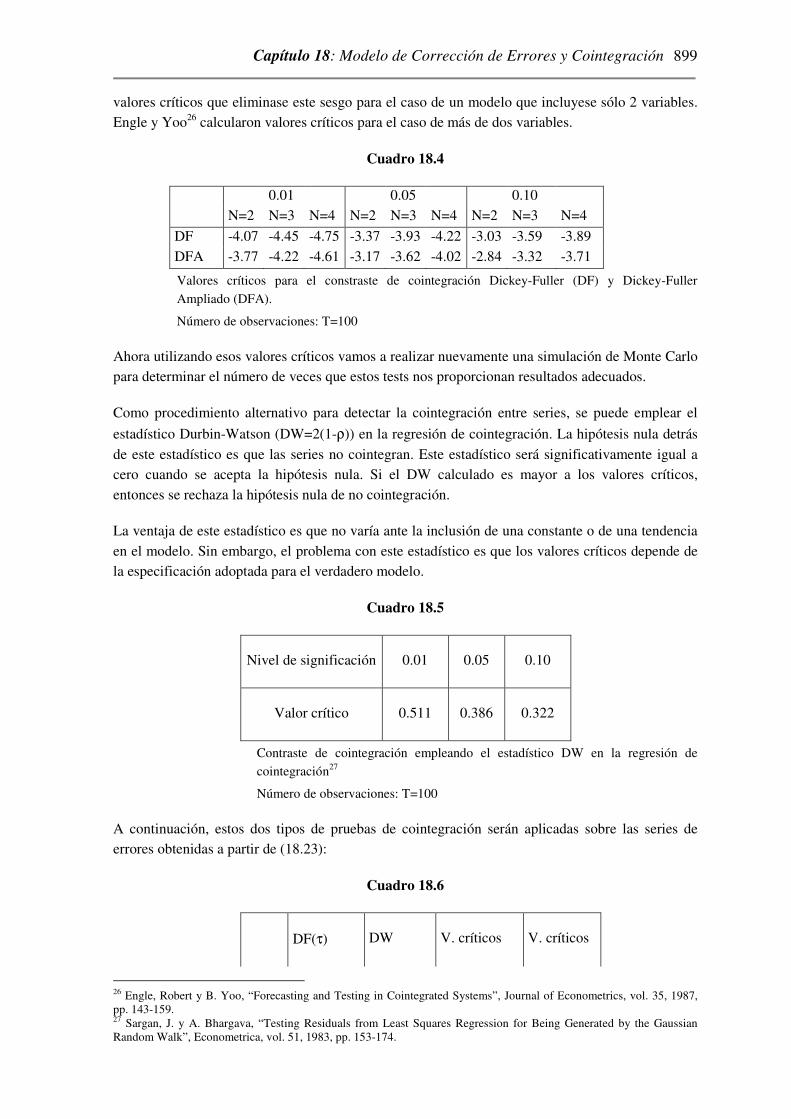
Capítulo 18: Modelo de Corrección de Errores y Cointegración
899
valores críticos que eliminase este sesgo para el caso de un modelo que incluyese sólo 2 variables.
Engle y Yoo26
calcularon valores críticos para el caso de más de dos variables.
Cuadro 18.4
0.01 0.05 0.10
N=2 N=3 N=4 N=2 N=3 N=4 N=2 N=3 N=4
DF -4.07 -4.45 -4.75 -3.37 -3.93 -4.22 -3.03 -3.59 -3.89
DFA -3.77 -4.22 -4.61 -3.17 -3.62 -4.02 -2.84 -3.32 -3.71
Valores críticos para el constraste de cointegración Dickey-Fuller (DF) y Dickey-Fuller
Ampliado (DFA).
Número de observaciones: T=100
Ahora utilizando esos valores críticos vamos a realizar nuevamente una simulación de Monte Carlo
para determinar el número de veces que estos tests nos proporcionan resultados adecuados.
Como procedimiento alternativo para detectar la cointegración entre series, se puede emplear el
estadístico Durbin-Watson (DW=2(1-ρ)) en la regresión de cointegración. La hipótesis nula detrás
de este estadístico es que las series no cointegran. Este estadístico será significativamente igual a
cero cuando se acepta la hipótesis nula. Si el DW calculado es mayor a los valores críticos,
entonces se rechaza la hipótesis nula de no cointegración.
La ventaja de este estadístico es que no varía ante la inclusión de una constante o de una tendencia
en el modelo. Sin embargo, el problema con este estadístico es que los valores críticos depende de
la especificación adoptada para el verdadero modelo.
Cuadro 18.5
Nivel de significación 0.01 0.05 0.10
Valor crítico 0.511 0.386 0.322
Contraste de cointegración empleando el estadístico DW en la regresión de
cointegración27
Número de observaciones: T=100
A continuación, estos dos tipos de pruebas de cointegración serán aplicadas sobre las series de
errores obtenidas a partir de (18.23):
Cuadro 18.6
DF(τ) DW V. críticos V. críticos
26 Engle, Robert y B. Yoo, “Forecasting and Testing in Cointegrated Systems”, Journal of Econometrics, vol. 35, 1987,
pp. 143-159. 27 Sargan, J. y A. Bhargava, “Testing Residuals from Least Squares Regression for Being Generated by the Gaussian
Random Walk”, Econometrica, vol. 51, 1983, pp. 153-174.

Econometría Moderna
900
Signif
.
(0.05) (0.05) Engle&Yoo DW
yte∆ -5.699821 1.019884 -3.93 0.386
xte∆ -5.775792 1.001976 -3.93 0.386
wte∆ -4.982286 0.908438 -3.93 0.386
El test de DF no presentó rezagos significativos
El DW calculado es tomado a partir de las ecuaciones 18.23
Los resultados del Cuadro 18.6 nos indican que las distintas series de residuos son I(0) por lo sí
existe una relación de cointegración entre estas series.
� Cuarto paso: estimación del MCE y determinación de sus características
Se ha visto que según el teorema de representación de Granger todo conjunto de series que
cointegración puede ser representada como un MCE. El cuarto paso en esta metodología consiste
en construir este sistema de ecuaciones y determinar si este presenta coeficientes de ajuste
coherentes28
. Teóricamente, el MCE para nuestro conjunto de series estaría especificado de la
siguiente manera:
yt
p
i
itw
p
i
itx
p
i
itytwtxtyt wiaxiayiawxyy εββρ +∆+∆+∆+−−=∆ ∑∑∑=
−
=
−
=
−−−−
1
1
1
1
1
1111 )()()()(
xt
p
i
itw
p
i
itx
p
i
itytwtxtxt wiaxiayiawxyx εββρ +∆+∆+∆+−−=∆ ∑∑∑=
−
=
−
=
−−−−
1
2
1
2
1
2111 )()()()(
wt
p
i
itw
p
i
itx
p
i
itytwtxtwt wiaxiayiawxyw εββρ +∆+∆+∆+−−=∆ ∑∑∑=
−
=
−
=
−−−−
1
3
1
3
1
3111 )()()()(
(18.24)
Debido a la presencia de estimaciones no lineales, este sistema no puede ser estimado utilizando
MCO. Ante este dificultad, se puede llevar a cabo el reemplazo del factor de corrección por la serie
de residuos de la regresión estática. De esta manera, nuestro sistema se reduce a:
yt
p
i
itw
p
i
itx
p
i
itytyt wiaxiayiaey ερ +∆+∆+∆+=∆ ∑∑∑=
−
=
−
=
−−
1
1
1
1
1
11 )()()()ˆ(
28 Este cuarto paso puede considerarse como un tercer contraste de cointegración. Teóricamente no debería existir
ninguna contradicción severa.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
901
xt
p
i
itw
p
i
itx
p
i
itytxt wiaxiayiaex ερ +∆+∆+∆+=∆ ∑∑∑=
−
=
−
=
−−
1
2
1
2
1
21 )()()()ˆ(
wt
p
i
itw
p
i
itx
p
i
itytwt wiaxiayiaew ερ +∆+∆+∆+=∆ ∑∑∑=
−
=
−
=
−−
1
3
1
3
1
31 )()()()ˆ(
Por este motivo la metodología de Engle y Granger es conocida como una estimación en dos
etapas. En una primera etapa se determina la serie de residuos; y en la segunda, esta serie es
incluida como un elemento explicativo en el MCE.
El número de rezagos (p) de cada ecuación son los necesarios para contar con términos (εt) que
sean ruidos blancos. El máximo número de rezagos de cada variable por serie es T1/3
.
Con respecto a los valores esperados de los coeficientes de ajuste, estos dependen de qué serie de
residuos se esté empleando en la estimación.. En el caso de emplear la serie
twtxtyt wxye ββ −−= , se espera que .0 ,0 ,0 >>< wxy ρρρ Luego de estimar cada
ecuación se obtiene:
(0.076543) (0.086151) (0.059304)
*633112.0*274665.1ˆ*3361.0 1 ytttytt wxey ε+∆+∆+−=∆ − (18.25)
(0.033025) (0.031809) (0.035476)
*230934.0*470655.0ˆ*218056.0 1 xtttytt wyex ε+∆−∆+=∆ − (18.26)
(0.114320) (0.060931) (0.054456)
*497889.0*503980.0ˆ*256339.0 1 wtttytt wxew ε+∆−∆+=∆ − (18.27)
El valor que adopte cada coeficiente de ajuste debe buscar mantener la relación de equilibrio. Por
lo general, se esperaría que si el error es calculado como twtxtyt wxye ββ −−= o bien como
ttyt yye ˆ−= , el coeficiente de ajuste de la ecuación de ∆yt sea negativo y el resto de coeficientes
sean positivos.
De esta forma, si la estimación de yt está por debajo del verdadero valor, en la dinámica de corto
plazo se esperaría que ∆yt sea menor que cero y que ∆xt y ∆wt sean positivos, para reestablecer el
equilibrio. Sin embargo, como nuestro lector se habrá dado cuenta, existen otras formas de
reestrablecer el equilibrio. Por ejemplo, ante un 0>yte , la serie yt puede presentar un 0yt >ρ ; sin
embargo, xtρ y wtρ deberán de ser positivos y de mayor magnitud para reestablecer la relación de
equilibrio. En el caso que 0<ytρ , tanto xtρ como wtρ pueden serlo, aunque en menor
proporción, y así poder volver al equilibrio. Sin embargo, sería incoherente que 0>ytρ , mientras
que xtρ y wtρ sean negativos ya que el sistema no volverá a estar en equilibrio.

Econometría Moderna
902
En el caso en que no se hubiese encontrado los signos esperados, el investigador podrá cambiar la
serie de errores empleada por otra serie (calculada a parir de una variable dependiente distinta).
Tal como lo demuestran las ecuaciones (18.25-18.27), la estimación del MCE con las series
generadas no presentó ningún rezago de la diferencia de las series significativo. Los que sí
resultaron ser significativos fueron los coeficientes de ajuste. En el caso que uno o dos de ellos
fuesen no significativos todavía sigue existiendo el MCE. En el caso que no tuviésemos algún
coeficiente de corrección distinto de cero, entonces no existe el MCE por lo que las variables no
cointegran.
Problemas subyacentes a esta metodología
Esta estimación del vector de cointegración empleando una metodología de dos etapas está sujeta a
varias críticas. Las más importantes son:
a. Los valores que se puedan estimar del vector de cointegración están sujetos a la variable que se
coloque como dependiente. Es decir, si primero colocamos a yt como la variable dependiente de xt
y wt, la relación estimada puede diferir con aquella que se obtiene de colocar como variable
dependiente a xt. Lo mismo se repite si colocamos a wt. Asintóticamente estos estimadores son
iguales (previa normalización). Sin embargo, en la práctica empleamos muestras que generalmente
no son lo suficientemente grandes.
Se recomienda emplear el criterio de causalidad para determinar cual de todas las series es la más
endógena o exógena.
b. Los resultados obtenidos de aplicar esta metodología dependen de la buena especificación del
modelo. La omisión de variables podría generar conclusiones erróneas con respecto a las relaciones
entre variables.
Si, por ejemplo, se busca comprobar la existencia de alguna relación entre las variables x1 y x2,
cuando en realidad la verdadera relación involucra una tercera variables, x3, se estimaría el
siguiente modelo:
tt uxx += 221 β
la serie { }tu presentará raíz unitaria ya que está incluyendo en ella a la serie { }tx3 . Por lo tanto se
concluiría la no existencia de alguna relación entre estas variables, lo cual es falso.
c. Finalmente, la metodología de Engle y Granger tan sólo considera la presencia de una sola
relación de cointegración. En el caso que se cuente con n variables (n>2), entonces pueden existir
hasta n-1 relaciones de equilibrio. Si el número de relaciones de cointegración es mayor que 1,
entonces los resultados que obtendremos al emplear esta metodología están alterados.
Por este motivo se recomienda el uso de la metodología de Engle y Granger sólo cuando se busque
comprobar alguna relación bivariada. En el caso de querer determinar las relaciones entre tres o
más variables se recomienda el empleo del test de Johansen. Este puede detectar la existencia de
más de una relación de equilibrio.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
903
1188..66.. TTEESSTT DDEE JJOOHHAANNSSEENN
En la sección anterior se desarrolló una primera metodología para el cálculo y análisis de relaciones
de cointegración. La metodología de Engle y Granger representa un método de fácil entendimiento
y aplicación. En éste se emplea al estimador MCO, el cual presenta características asintóticas que
favorecen la estimación de estos parámetros. Sin embargo, al final de esta sección se determinó que
esta metodología presentaba ciertas dolencias debido a que el set de supuestos que existen detrás de
ella no siempre se cumplen (en especial el denominado sesgo asintótico).
Otra característica de la metodología de E&G es que la misma no involucra una estimación directa
(no es un test “directo”) de la cointegración, sino todo lo contrario. En buena parte del
procedimiento está presente la aplicación del test de Dickey-Fuller. Es decir, necesitamos recurrir a
los residuos para determinar si nuestro procedimiento es adecuado o no.
Precisamente, este carácter de “dos etapas” (two step) de esta metodología es uno de sus punto más
criticados. Como primer punto, es un tanto difícil establecer empíricamente el orden de integración
de cada serie, pero por sobre todo, el orden de integración de la combinación lineal entre las
variables es aún más complicado. Por este motivo se tiene que trabajar con distintos set de valores
críticos que dependen de la especificación del modelo y del tipo de contraste empleado.
Felizmente, Johansen29
y Stock y Watson30
desarrollaron un test alternativo que emplea un proceso
de máxima verosimilitud. Esta forma de estimación cuenta con la ventaja de realizar el cálculo del
vector de cointegración dentro de un modelo dinámico (MCE). Además, este test contempla la
posibilidad de contar con más de un vector de cointegración.
A diferencia de la metodología E&G, que analiza los residuos de las regresiones, el test de
Johansen concentra su análisis sobre el rango y las raíces características del sistema de ecuaciones.
De esta manera se elimina procedimientos un tanto subjetivos (como la ordenación de las variables
o bien el empleo de diversos valores críticos).
Una última ventaja a tomar en cuenta es la fácil implementación de diferentes test sobre los
parámetros estimados, tanto de los coeficientes de la regresión de cointegración como de los
coeficientes de ajuste.
3.1.7 Estimación de los vectores de cointegración
Para que el lector tenga una idea lo que implica calcular simultáneamente tanto el vector de
cointegración como el MCE, se reescribirá el sistema (18.24):
yt
p
i
itw
p
i
itx
p
i
itytwtxtyt wiaxiayiawxyy εββρ +∆+∆+∆+−−=∆ ∑∑∑=
−
=
−
=
−−−−
1
1
1
1
1
1111 )()()()(
29 Johansen, Soren, “Statistical Analysis of Cointegration Vectors”, Journal of Economic Dynamics and Control, vol. 12,
Junio-Septiembre 1988, pp. 231-254. 30 Stock, James y Mark Watson, “Testing for Common Trends”, Journal of the American Statistical Association, vol. 83,
Diciembre 1988, pp. 1097- 1107.

Econometría Moderna
904
xt
p
i
itw
p
i
itx
p
i
itytwtxtxt wiaxiayiawxyx εββρ +∆+∆+∆+−−=∆ ∑∑∑=
−
=
−
=
−−−−
1
2
1
2
1
2111 )()()()(
wt
p
i
itw
p
i
itx
p
i
itytwtxtwt wiaxiayiawxyw εββρ +∆+∆+∆+−−=∆ ∑∑∑=
−
=
−
=
−−−−
1
3
1
3
1
3111 )()()()(
Según la metodología de E&G, lo primero que se necesita calcular son los residuos de la regresión
111 −−− += twtxt wxy ββ . Luego estos serán reemplazados en todas estas ecuaciones para proceder
con su estimación.
El procedimiento de estimación propuesto por Johansen es distinto. La implementación de este test
no estima ecuación por ecuación. Este realiza la estimación de manera conjunta de todo el sistema,
logrando calcular los coeficientes de tando la relación de cointegración (βx y βw) como del resto de
coeficientes del sistema (ayi, axi, awi). Por este motivo, el estimador MCO no puede ser empleado en
este contexto, siendo necesario la aplicación de un procedimiento de máxima verosimilitud.
¿Cómo se realiza esta estimación?
Para realizar la estimación del sistema completo, primero éste debe ser especificado de una forma
conveniente. Esta forma es bastante parecida a la empleada en el test de Dickey-Fuller. Sin
embargo, en este caso se emplea un vector de variables. Primero se define la siguiente relación:
ttt XAX ε+= −11 (18.28)
donde: Xt = vector de n variables
A1 = matriz de nxn
εt = vector de errores aleatorios (nx1)
Esta representación se parece a un AR(1) con la diferencia que no se está analizando una sola serie
sino un vector de series. Por este motivo, esta denominación es conocida como un vector de
autocorrelación (VAR)31
.
Ahora se procede a restar a cada lado de la ecuación el vector Xt-1. De esta manera se va
construyendo el MCE:
ttt
ttttt
XX
XXAXX
επ
ε
+=∆
+−=−
−
−−−
1
1111
(18.29)
de esta manera se obtiene la matriz π (nxn) definida de como: π = A1 - I. De esta matriz nos interesa
conocer dos cosas: sus valores propios diferentes de cero y la estimación de cada uno de los
vectores linealmente independientes.
31 La singularidad de una estimación VAR consiste en que considera como variables explicativas a todos los rezagos de
las variables explicadas. De esta manera se elimina los problemas causalidad o exogeneidad. En series macroeconómicas
no es fácil encontrar variables puramente exógenas ya que la mayoría de ellas están relacionadas de alguna manera; por
lo que una variable no puede ser afectada sin que ésta tarde o temprano afecte al desempeño de otra serie.

Capítulo 18: Modelo de Corrección de Errores y Cointegración
905
Determinación de los valores propios
Para determinar los valores propios (o raíces características) de la matriz π se debe recordar que
toda matriz puede ser expresada en términos de estos:
tt XX λπ =
luego:
0)( =− tXIλπ
de esta manera, y para que no exista una solución trivial (es decir, que las variables del vector sean
iguales a cero), se debe de cumplir con:
0 =− Iλπ
De esta expresión se puede calcular el valor de los valores propios. Como ya se trató en la sección
18.4, la presencia de un valor propio (o raíz característica) diferente de cero indica la existencia de
una relación linealmente independiente dentro del vector π.
Dada la siguiente especificación de un MCE:
+
−−=
∆
∆
−
−
t
t
t
t
t
t
x
x
x
x
2
1
12
11
2
1
80.080.1
40.090.0
ε
ε (18.30)
Si se busca determinar las raíces características de la matriz π, entonces:
0 80.080.1
40.090.0 =
−−−
−
λ
λ
de donde se obtiene las siguientes raíces características: λ1=0.10 y λ2 = 0.
De esta manera se determina que una relación en la matriz π no es linealmente independiente. El
número de raíces iguales a cero está dado por n - r, donde r es el número de relaciones de
cointegración. Por consiguiente, este MCE cuenta con 2-1=1 vector de cointegración.
Sin embargo, no se pretende que este modelo se limite a la especificación de la ecuación (18.29).
Al igual que en la metodología de E&G, el MCE debe contener con la suficiente cantidad de
rezagos de tal forma que los errores de cada ecuación del sistema se comporte como un ruido
blanco.
Ahora, se generaliza la ecuación (18.29) para el caso de una relación de autocorrelación de orden p:
tptpttt XAXAXAX ε++++= −−− ...2211
Si se sustrae Xt-1 de ambos lados de esta ecuación, se obtendrá:

Econometría Moderna
906
tptpttt XAXAXIAX ε++++−=∆ −−− ...)( 2211
Como nuestro objetivo es contar con valores rezagados de las diferencias del vector Xt, entonces
primero se resta y suma al lado derecho de la última expresión el monto de (A1-I) Xt-2, de tal forma
que se obtenga:
tptpttt XAXIAAXIAX ε+++−++∆−=∆ −−− ...)()( 21211
Si se continúa con esta operación, finalmente se obtiene:
tptit
p
i
it XXX εππ ++∆=∆ −−
−
=
∑1
1
(18.31)
donde:
)AI(i
1jji ∑
=
−−=π ; )(1
∑=
−−=p
i
iAIπ
Por lo que el rango de π indicará el número de vectores de cointegración independientes. Si el
rango de π = 0, esto significa que esta matriz está compuesta por ceros. De esta forma, lo que se
obtendría sería un VAR en primeras diferencias. En el caso que el rango de esta matriz fuese igual
a n (es decir, que todas sus raíces características se encuentren entre 0 y1), esto significaría que las
series son estacionarias por lo que cualquier combinación de éstas será estacionaria. Si se cuenta
con r raíces características distintas de cero (0 < r < n), esto equivale a decir que existen r
relaciones linealmente independiente en nuestra matriz π.
Una pregunta que se puede estar planteando el lector es la forma de determinar el número de
rezagos dentro del sistema. Por regla se ha determinado que el número máximo de rezagos es de
T1/3
(donde T es igual al número de observaciones). Al iniciar el análisis se puede emplear los T1/3
rezagos, y luego ir desechando los rezagos que no sean significativos para lograr un modelo más
parsimonioso.
La estimación de los vectores de cointegración
En este punto del proceso de estimación ya se conocen los valores de la matriz π, estimados a partir
del desarrollo del sistema autoregresivo. Además, de la determinación del número de valores
propios diferentes de cero se conoce el número de vectores de cointegración involucrados en el
MCE. Finalmente, se debe considerar que el valor esperado de π X t-1 es cero.
Con esta información, y aplicando un algoritmo de máxima verosimilitud32
, el test de Johansen
busca determinar los valores de los elementos de la matriz α y β de la siguiente relación:
βαπ ′= (18.32)
32 Johansen, Soren, op. cit., pp. 234

Capítulo 18: Modelo de Corrección de Errores y Cointegración
907
donde α y β son matrices de nxr. La primera matriz corresponde a los coeficientes de ajuste,
mientras que la segunda guarda los coeficientes de las relaciones de cointegración. De esta manera,
en el caso que existiese un solo vector de cointegración entre tres variables, la estimación del
vector de cointegración y de los coeficientes de ajuste sería de la siguiente forma:
[ ] [ ]111
1
1
1
−−−
−
−
−
++
⇒=
twtxty
w
x
y
t
t
t
t
wxy
w
x
y
wxy
w
x
y
βββ
α
α
α
εβββ
α
α
α
t
twtxtyw
twtxtyx
twtxtyy
wxy
wxy
wxy
ε
βββα
βββα
βββα
=
++
++
++
⇒
−−−
−−−
−−−
)(
)(
)(
111
111
111
Para el caso de detectarse 2 vectores de cointegración, la especificación de la matriz π sería la
siguiente:
=
−
−
−
−
1
1
1
222
111
21
21
21
1
t
t
t
wxy
wxy
ww
xx
yy
t
w
x
y
Xβββ
βββ
αα
αα
αα
π
si se opera y factoriza adecuadamente, se obtiene:
+++++
+++++
+++++
=
−−−−−−
−−−−−−
−−−−−−
−
)()(
)()(
)()(
12121221111111
12121221111111
12121221111111
twtxtywtwtxtyw
twtxtyxtwtxtyx
twtxtyytwtxtyy
pt
wxywxy
wxywxy
wxywxy
X
βββαβββα
βββαβββα
βββαβββα
π
en esta matriz se observa claramente la existencia de dos vectores de cointegración, cada uno de los
cuales está multiplicado por su coeficiente de ajuste.
Incorporación de tendencia e intercepto al modelo
El modelo representado en la ecuación (18.31), el cual incluye p rezagos del vector en diferencias,
puede generalizarse aún más si se incluyese un intercepto y una tendencia tanto en el MCE como
en el vector de cointegración.
De esta manera se puede contar con diferentes tipos de modelos.
Modelo #1: 1−′
tzβα
Este tipo de modelo no incorpora intercepto ni pendiente tanto en el vector de cointegración como
dentro del modelo de corrección de errores. Este puede presentar la siguiente estructura:
ε
ε+
−
−=
∆
∆
−
−
yt
xt
1t
1t
t
t
y
x
3.03.0
3.03.0
y
x (18.33)

Econometría Moderna
908
En este sistema se está considerando un coeficiente de ajuste de –1. El movimiento de las series se
caracteriza por mantener tan solo una tendencia estocástica propia de las series random walk.
Modelo # 1 Modelo # 2
(A) (B)
-8
-4
0
4
8
12
20 40 60 80 100 120 140
X Y
-6
-4
-2
0
2
4
6
8
10
20 40 60 80 100 120 140
X Y
Figura 18.5
Modelo #2: )( 01 ρβα +′−tz
Ahora en este modelo vamos a incorporar la presencia de una constante en el vector de
cointegración. La presencia de la misma responde a la modelación de largo plazo, mas no a alguna
característica sobre el comportamiento dinámico. Es decir, esto no va a provocar la presencia de
algún tipo de tendencia determinística. Ambas series continúan siendo random walk.
Estas series, graficadas en la Figura 18.5 (b), fueron construidas considerando los siguientes
valores:
+
−−
−=
∆
∆−
−
yt
xt
t
t
t
ty
x
y
x
ε
ε
14.03.03.0
4.03.03.01
1
(18.34)
El lector deberá de notar que la incorporación de la constante dentro del vector de cointegración
debió de guardar relación con el coeficiente de ajuste(-1). En el caso que se hubiese incorporado
una constante de 0.4 en la primera fila y una de 0.4 en la segunda fila, lo que estaríamos
provocando sería la inclusión de una constante a cada ecuación del sistema y no al vector.
Modelo # 3: 0101 )( γαρβα ++′−tz
Para entender mejor lo expuesto en el párrafo anterior, se procede a desarrollar el sistema matricial
(18.34):
ytttt
xtttt
yxy
yxx
εα
ε
++−=∆
++−=∆
−−
−−
)4.03.03.0(
)4.03.03.0(
11
11
En este sistema se determina la incorporación de la constante –0.4 en la segunda ecuación fue la
acertada para incorporar una constante en el vector de cointegración debido a que el valor del
coeficiente de ajuste es α=-1. De esta manera se presenta el mismo vector de cointegración para

Capítulo 18: Modelo de Corrección de Errores y Cointegración
909
ambas ecuaciones. ¿Qué hubiese pasado si en vez de colocar –0.4 hubiese incorporado al sistema
0.8?.
La respuesta se encuentra en el gráfico (a) de la siguiente figura:
Modelo # 3 Modelo # 4
(A) (B)
-4
0
4
8
12
16
20 40 60 80 100 120 140
X Y
0
10
20
30
40
50
60
20 40 60 80 100 120 140
X Y
Figura 18.6
Como este valor no guarda relación alguna con el coeficiente de ajuste, no pudo ser incorporado al
vector de cointegración por lo que ambas constantes son ahora constantes del sistema:
ytttt
xtttt
yxy
yxx
εα
ε
++−=∆
++−=∆
−−
−−
8.0)3.03.0(
4.0)3.03.0(
11
11
La presencia de estas constantes en el sistema han incorporado una tendencia determinística a cada
una de las series. Ahora ambas se comportan como series random walk with drift. Es necesario
precisar que debido a que ambas series cointegran, por más variado sean estos “drift”, ambas
siempre se moverán juntas alrededor de la tendencia generada por el mayor “drift”.
Generalmente se incorpora una constante al MCE si se observa las series bajo análisis presentan
cierta tendencia determinística.
Modelo #4: )( 101 tzt ρρβα ++′−
La incorporación de una tendencia dentro del vector de cointegración no incorpora ningún tipo de
tendencia determinística al modelo, tal como lo demuestra la parte (b) de la Figura 18.6. Si también
se incorpora una tendencia al MCE, lo que se estaría determinando es una tendencia cuadrática a
las series, tal como lo demuestra la siguiente figura.
Modelo #5

Econometría Moderna
910
-20
0
20
40
60
80
20 40 60 80 100 120 140
X Y
Figura 18.7
3.1.8 Test de Cointegración
El número de vectores de cointegración está determinado por el número de valores propios
mayores a cero. Bajo esta consideración se plantean un par de test LR (máxima verosimilitud) que
buscan determinar cuántos vectores de cointegración existen. Para esto, ambos test calculan los
valores propios y luego los ordenan de mayor a menor.
El primero de ellos calcula el siguiente estadístico:
∑+=
−−=n
ri
ir TQ1
)1log( λ
donde r representa el número de vectores de cointegración: r = 0, 1, ..., k-1. Además, los λi están
ordenados de forma descendente. Este estadístico Qr es denominado “trace statistic” y cuenta por
hipótesis nula que el número de vectores de cointegración es menor o igual a r, frente a una
hipótesis alternativa que enuncia la existencia de n vectores de cointegración, es decir, que
considera la matriz π como una matriz de rango completo.
La intuición detrás de este test es sencilla: si queremos probar que no existe ningún vector de
cointegración, es decir, que las raíces características son cercanamente iguales a cero, la sumatoria
del log(1-λi) difícilmente alcanzará un valor muy alto ya que log(1) es cero.
Si el valor calculado de Q0 es menor al valor crítico, entonces no puedo rechazar la hipótesis nula
de no existencia de algún vector de cointegración (es decir, no hay ningún vector de cointegración).
En el caso que sea mayor al valor crítico, se rechazaría la hipótesis, es decir, por lo menos existe un
vector de cointegración. El siguiente paso es probar Q1. La lógica es la misma. Si Q1 es menor a un
determinado valor crítico, no se rechaza la hipótesis nula de existencia de un solo vector de
cointegración. En el caso contrario, acepto que existen más de un vector de cointegración, y así
sucesivamente.
Johansen también propone un test LR alternativo conocido como el test de la “máxima raíz
característica” (maximun eigenvalue statistic). Este es calculado de la siguiente forma:
)1log( 1max +−−= rTQ λ

Capítulo 18: Modelo de Corrección de Errores y Cointegración
911
En este caso, la hipótesis nula es la existencia de r vectores de cointegración frente a la hipótesis
alternativa de r + 1.
Pongamos como ejemplo la estimación de una relación de largo plazo entre las series de la tasa de
interés, tipo de cambio y emisión primaria. Los valores de los estadístico Qtrace y el Qmax son los
siguientes:
Tabla 18.1
Qtrace Qmax
-TΣln(1-λi) -Tln(1-λr+1)
n - r = 3 39.895 21.910 r = 0
n - r = 2 17.985 10.683 r = 1
n - r = 1 7.302 7.302 r = 2
Los valores críticos se encuentran en la Tabla B al final del libro. Debido a que se incluyó una
constante en el vector de cointegración, los valores adecuados son lo que se encuentran al final de
esta tabla.
En la primera fila de la Tabla 18.1, lo que se está probando es la presencia o no de un vector de
cointegración (r). La hipótesis nula es que r=0, es decir, que no exista vector alguno. Sin embargo,
vemos que el valor Qtrace calculado sobrepasa a los valores críticos (32.093 y 35.068 al 90 y 95% de
confianza, respectivamente), por lo que se rechaza esta hipótesis.
De esta manera se conoce que por lo menos existe un vector de cointegración, por lo que vamos a
verificar la existencia de otro más. Para esto se continúa con la siguiente fila de la tabla, en donde
la hipótesis es que r<=2 y el estadístico estimado es igual a 17.985. Si nuevamente se compara con
los valores críticos (17.957 y 20.168 para el 90 y 95% de confianza), se observa que ahora existe
cierta duda con respecto a la existencia de un segundo vector de cointegración: al 90% sí existiría;
mientras que a un 95% de confianza, no.
Ante esta duda se recurre al estadístico Qmax. Este estadístico, para n - r = 3, alcanza un valor
21.910. Con este valor se rechaza la hipótesis nula de que el número de vectores es cero (r = 0) ya
que los valores críticos de tabla son de 19.796 y 21.894 al 90 y 95%, respectivamente. Cuando
probamos la hipótesis nula r = 1 contra la alternativa (r = 2), el valor que se obtiene es de 10.683,
mientras que los valores tabulares son de 13.781 y 15.752. De esta manera no se puede rechazar la
presencia de un solo vector de cointegración.
3.1.9 Pasos para la aplicación del test de Johansen
A continuación se indican cuáles son los pasos básicos que se deben tomar en cuenta para aplicar el
test de Johansen y cómo interpretar sus resultados. En esta parte utilizan los mismos datos
generados y empleados en la sección anterior con el fin de comparar los resultados.
Como recordará, el modelo generador de estas series contemplaba la siguiente relación:
ttt WXY += 2 , mientras que Zt no es más que una serie random walk independiente de las demás.
� Determinación del número de rezagos

Econometría Moderna
912
La determinación del número de rezagos tiene bastante importancia ya que la incorporación de un
número inadecuado de los mismos puede generar diferentes resultados. Por este motivo se recurre
al test LR de determinación del número óptimo de rezagos del sistema. El estadístico calculado es
el siguiente:
[ ] 2 lnln )( qXriiCT ∼+−− ∑∑
donde: T = número de observaciones
c = número de parámetros en el sistema no restringido
iΣln = el logaritmo natural del determinante de la matriz de covarianzas del sistema
restringido
ri+Σln = el logaritmo natural del determinante de la matriz de covarianzas del sistema
sin restringir
Ho: el número óptimo de rezagos del sistema es i
Ha: el número óptimo de rezagos del sistema es i+r
Donde i + r = t1/3
(t es el número de observaciones las series). Si, por ejemplo, t1/3
=5, la primera
prueba buscaría determinar si se puede eliminar el quinto rezago, por lo que la hipótesis nula sería
Ho: i=4 (número de rezagos del sistema restringido). En el caso que se acepte, entonces se prueba
con la hipótesis Ho: i=3. Si en este caso se rechaza la Ho, entonces se concluye que el número de
rezagos óptimo es 4. Sino se rechazase, se continuaría disminuyendo los rezagos hasta que se
rechace la hipótesis nula.
Se tiene que considerar que q representa el número total de restricciones en el sistema (2.grq = ),
donde g es el número de variables del sistema.
El resultado de aplicar este test sobre el conjunto de series generadas, nos indicó que este sistema,
que incluye las variables xt, wt, yt y zt, no incluye ningún rezago de ellas mismas. Recordemos que
esta misma situación sucedió cuando determinábamos el número de rezagos en la metodología
E&G. Esto se debe a la forma en que han sido generados los datos.
� Estimación de las raíces características
Una vez que se ha determinado el número de rezagos a incorporar en el MCE, el siguiente paso
será calcular las raíces características. Para esto se puede aplicar diversos paquetes econométricos.
Los resultados que a continuación se mostrarán corresponden a los obtenidos al aplicar el test de
Johansen del Econometrics Views 3.0.

Este test ofrece como opciones la incorporación de una constante y una tendencia en el vector de
cointegración y en el sistema. Si se observa que la data tiene algún tipo de tendencia determinística,
entonces es recomendable que se incorpore la constante a todo el sistema.
A continuación se presenta la estimación del estadístico Qtrace junto con los valores críticos:
Test assumption: No deterministic trend in the data
Series: W X Y Z
Lags interval: No lags
Likelihood 5 Percent 1 Percent Hypothesized
Eigenvalue Ratio Critical Value Critical Value No. of CE(s)
0.282911 71.86245 53.12 60.16 None **
0.074399 22.31163 34.91 41.07 At most 1
0.052588 10.79211 19.96 24.60 At most 2
0.018241 2.742974 9.24 12.97 At most 3
*(**) denotes rejection of the hypothesis at 5%(1%) significance level
L.R. test indicates 1 cointegrating equation(s) at 5% significance level
Los valores de las raíces características se encuentran en la primera columna y en orden
descendente. En la siguiente columna se calcula el estadístico Qtrace. Si se compara el primer
estadístico LR con los valores críticos correspondientes, se observa que existe 1 vector de
cointegración tal como lo indica el Eviews.
� Determinación de los coeficientes del vector de cointegración y los coeficientes de ajuste
Una vez que ya se determina el número de vectores de la matriz π se procede a normalizar y
calcular los coeficientes de este vector. La normalización puede ser tomada de cualquier
coeficiente.
Los resultados que presentamos a continuación nos indican de alguna manera si existe alguna
variable redundante. Para esto se puede emplear los estadísticos t que parecen debajo de los
parámetros estimados. Si bien es cierto que este estadístico no es exacto, puede proporcionar una
idea de la significancia de los coeficientes. Si el ratio entre el coeficiente y la desviación estándar
es menor que dos en valor absoluto o está muy cercano a este valor, entonces se puede concluir que
esta variable no es significativa. Si se calcula el t-estadístico de cada uno de los coeficientes
obtiene: τx = 74.75 ; τw = 14.99 ; τz = 1.97. De esta manera resulta claro que el aporte de la variable
zt a la relación de equilibrio no es significativo.
Normalized Cointegrating Coefficients: 1 Cointegrating Equation(s)
Y X W Z
1.000000 1.981692 1.037160 0.134975
(0.02651) (0.06918) (0.06829)
Log likelihood 1091.881
Estos resultados son bastante parecidos a los obtenidos en la aplicación de la metodología de Engle
y Granger.

Econometría Moderna
872
Una ventaja que tiene el test de Johansen del Eviews es que normaliza las ecuaciones como si
existiese no sólo uno sino todos los posibles vectores de cointegración (n-1), permitiendo al
investigador tener la certeza de entre qué variables existe esta relación de cointegración.
En lo referido a los coeficientes de ajuste, estos se calculan a partir del vector de cointegración
calculado en la parte anterior. Es importante que el investigador tenga sumo cuidado al determinar
el número de rezagos apropiados así como eliminar del modelo todas las variables reduntantes.
Si se estima el MCE del modelo anterior, sin eliminar la serie Zt, entonces este sería el resultado
obtenido:
VAR Model - Substituted Coefficients:
D(Y) = 0.03291033621*( Y(-1) - 1.981692456*X(-1) - 1.037159503*W(-1) + 0.1349753188*Z(-1) )
D(X) = 0.1939057704*( Y(-1) - 1.981692456*X(-1) - 1.037159503*W(-1) + 0.1349753188*Z(-1) )
D(W) = 0.1945428908*( Y(-1) - 1.981692456*X(-1) - 1.037159503*W(-1) + 0.1349753188*Z(-1) )
D(Z) = 0.008081624393*( Y(-1) - 1.981692456*X(-1) - 1.037159503*W(-1) + 0.1349753188*Z(-1) )
Vemos que por defecto, este paquete econométrico coloca como variable normalizada a la primera
en ser digitada. Este orden será de ayuda al momento de determinar el signo del coeficiente de
ajuste. Teóricamente, el coeficiente de la regresión de D(Y) debe ser negativo o bien tener una
menor magnitud que los coeficientes de ajuste de la regresión D(X) y D(W), como en el presente
caso. Se observa que el coeficiente de ajuste de la regresión D(Z) no guarda relación ya que ésta es
la variable redundante.