cascade-structured classifier based on adaptive devices · maior foco para eventos recentes, o que,...
TRANSCRIPT

Abstract— This paper presents a novel approach to decision making based on uncertain data. Typical supervised learning algorithms assume that training data is perfectly accurate, and weight each training instance equally, resulting in a static classifier, whose structure can not be changed once built unless retrained from scratch. In this paper, we address this issue by using adaptive devices that can be incrementally trained, allowing them to aggregate new pieces of information while processing new input entries. We also propose a confidence model to weight each instance according to an estimate of its likelihood.
Keywords— Adaptive technology, cascade-based classification,
classification combination, decision making, hybrid intelligent systems, machine learning.
I. INTRODUÇÃO
OMADA de decisão é um processo cognitivo que resulta na escolha de uma ação a ser tomada como resposta a um
estímulo externo, descrito por um conjunto de atributos [1]. A escolha da melhor ação, então, torna-se uma questão de comparar as alternativas possíveis e escolher aquela que, conjuntamente, tenda a maximizar benefícios e minimizar custos.
Modelos computacionais de tomada de decisão tentam imitar a forma com que humanos tomam suas decisões. Entretanto, ainda que cognitivo, o processo de tomada de decisão nem sempre é perfeitamente racional [2]: fatores emocionais [3], experiências passadas 0, inércia (dificuldade de mudar de opinião), otimismo e até mesmo viés de confirmação (tendência de as pessoas darem peso maior para evidências que aparentem confirmar suas crenças) [5] afetam a forma com que decisões são tomadas, mas são comumente ignorados pelos modelos tradicionais de aprendizagem de máquina. Mesmo a veracidade de uma informação pode ser sensível ao tempo, sendo necessário avaliar se uma informação obtida em um instante anterior permanece válida após certo período de tempo. As pessoas, de forma geral, dão maior foco para eventos recentes, o que, de certa maneira, permite uma rápida adaptação às mudanças comportamentais no processo a ser prognosticado [6]. A estas mudanças ao longo de tempo, dá-se o nome concept drift.
Todavia, modelos computacionais tradicionais possuem uma estrutura imutável, e não permitem que novas informações sejam agregadas, a menos que sejam reconstruídos – ação que, em geral, consome muito tempo, tornando-se um obstáculo para uma atualização contínua e
R. S. Okada, Escola Politécnica, Universidade de São Paulo (USP), São
Paulo, Brasil, [email protected] J. José Neto, Escola Politécnica, Universidade de São Paulo (USP), São
Paulo, Brasil, [email protected]
incremental. Por não se adaptarem a mudanças externas, a taxa de acerto deste tipo de dispositivo se degrada ao longo do tempo, fazendo-se necessário reconstruí-lo para restabelecer seu desempenho.
O objetivo deste trabalho é a criação de uma estrutura reutilizável para sistemas de tomada de decisão capaz de absorver novas informações ao longo de sua execução, fundamentada em um raciocínio baseado em casos e em realimentações. Para esta finalidade, múltiplos dispositivos adaptativos serão utilizados de maneira colaborativa, permitindo que cada um aprenda de forma incremental com base nas soluções dos demais.
II. CONCEITOS
A. Notação:
Empregando a notação frequentemente utilizada em classificadores estatísticos, um estímulo de entrada x é aqui representado por um vetor [x1, x2, ... , xn]
T, onde cada uma das n componentes representa um atributo do estímulo. Este vetor recebe o nome de instância.
Atributos são comumente divididos em dois grupos: • Categórico: atributo é um valor literal dentre um
conjunto finito de valores válidos, representando um nome. Um exemplo é a cor de cabelo, que poderia conter as categorias preto, loiro, ruivo, entre outras.
• Numérico: atributo é um valor numérico, representando uma grandeza que pode ser medida e comparada. Um exemplo seria a temperatura, que pode ser explicitada através de uma escala Kelvin.
A função de um classificador, então, é designar um rótulo a para uma entrada x, escolhendo-o a partir de um conjunto {a1, a2, ... , am} com base em um treinamento realizado previamente através de algum método supervisionado. Instância rotulada, então, designa aquela cujo rótulo é conhecido. Para um problema de tomada de decisão, rótulo pode ser interpretado como a ação a ser tomada frente às circunstâncias atuais – descritas pela instância.
Classificadores mais robustos também fornecem uma estimativa da probabilidade de cada rótulo ser estatisticamente o mais adequado, o que pode ser utilizado para avaliar a solução encontrada [7]. Neste caso, a solução do classificador é representado por um vetor [S1, S2, ... , Sm], onde Si é uma nota atribuído para o i-ésimo rótulo.
Deve-se notar que os nem todos os métodos classificação têm capacidade de tratar ambos os tipos de atributos. Como exemplo, árvores de decisão construídas através do algoritmo ID3 tratam apenas atributos categóricos [8], enquanto SVM (Support-Vector Machines) opera apenas com valores
R. S. Okada and J. J. Neto
Cascade-Structured Classifier Based on Adaptive Devices
T
IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014 1307

numéricos [9]. Métodos mais robustos, como C4.5 0 e K* [11], lidam com ambos nativamente.
B. Tecnologia Adaptativa:
O termo adaptatividade refere-se a dispositivos com a capacidade de alterar sua própria estrutura de acordo com os estímulos de entrada, sem a interferência de agentes externos [12]. Com tal propriedade, o comportamento do dispositivo pode ser modificado em função do histórico de entradas previamente processadas.
Um dispositivo adaptativo típico é composto por algum dispositivo subjacente – e.g., autômatos de estados finitos, gramáticas e tabelas de decisão – e uma camada adaptativa, que contém a lógica necessária para alterar a estrutura do dispositivo [13]. Esta estrutura permite que formalismos consolidados possam ser reutilizados, tornando-os adaptativos ao custo de um pequeno aumento da sua complexidade.
A Fig. 1 ilustra o funcionamento de um dispositivo adaptativo, em que uma função adaptativa é utilizada para modificar o dispositivo subjacente antes que a entrada seja processada. Feito o processamento, outra função adaptativa pode ser utilizada para modificar o dispositivo subjacente de acordo com a saída obtida.
Figura 1. Estrutura de um dispositivo adaptativo.
A definição geral de um dispositivo adaptativo foi
formalizada pela primeira vez por Neto em 2001 na forma de um dispositivo guiado a regra, utilizando uma tabela de decisão como exemplo de reuso de formalismos conhecidos e como torná-los adaptativos [14]. Entretanto, mesmo antes de sua formalização, o conceito de dispositivos com estrutura variável tem sido alvo de estudos em diversos casos individuais sob diversos nomes e formas, tais como autômatos [15], gramáticas e linguagens [16], além da construção de compiladores [17].
O autômato de estados finitos é frequentemente citado como um exemplo de aplicação da adaptatividade e de como seu uso aumenta o poder de representação do dispositivo. No
caso, as funções adaptativas podem introduzir novos estados, além de criar e remover transições – possibilidades que fazem com que este autômato passe a ser Turing-equivalente [18]. Outros casos de uso deste tipo de técnica incluem tomada de decisão [14], navegação robótica [19], processamento de linguagens naturais [20] e aplicações em arte [21]. Ferramentais didáticos também foram desenvolvidos como forma de criar, aplicar e testar técnicas adaptativas, a exemplo do AdapTools [22]. O estudo de processamento de linguagens naturais adaptativas também levou a um desenvolvimento de robôs com comportamento supostamente criativo [23].
C. Tabela de Decisão Adaptativa Estendida:
A Tabela de Decisão Adaptativa Estendida (TDAE) é uma variante da tabela de decisão adaptativa original [14] que insere a funcionalidade de executar funções adaptativas quando a tabela não possui uma regra aplicável para a instância de entrada [24]. Tal comportamento difere da tabela adaptativa descrita por Neto, em que estas funções eram somente chamadas durante a aplicação de uma regra existente. Esta nova funcionalidade é utilizada para criar e incorporar uma nova regra que seja aplicável à instância de entrada, para que ela seja solucionada ao invés de descartada.
A Fig. 2 ilustra seu funcionamento: uma tabela de decisão convencional utiliza uma função adaptativa auxiliar em situações em que a tabela não possui uma regra aplicável. Esta função chama um método multicritério, que, por sua vez, encontra uma solução para a entrada, e a transforma em uma nova regra que é agregada à tabela, permitindo que o problema de entrada seja solucionado. Em sua definição original, o método auxiliar utilizado foi o AHP (Analytic Hierarchy Process) [24].
Figura 2. Estrutura de uma Tabela de Decisão Adaptativa Estendida (TDAE).
Note que a estrutura da TDAE – onde um dispositivo é
utilizado somente se o dispositivo anterior não é capaz de solucionar o problema de entrada [24] – é similar à
Função adaptativa executada antes da execução do dispositivo
Função adaptativa executada após a execução do dispositivo
Camada Adaptativa
Entrada
SaídaDispositivo Subjacente
Instância x
Rótulo a Tabela de Decisão
Função Auxiliar
Método Multicritério
Nova regra (x, a)
Função adaptativa chamada quando a tabela não tem uma regra aplicável para x
Encontra uma regra para a entrada
Função adaptativa para regras existentes
Função adaptativa para regras existentes
1308 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014

combinação de classificadores em cascata [25]. Nesta arquitetura, os classificadores são ordenados por velocidade – os mais rápidos em primeiro lugar. Para cada instância de entrada, apenas o primeiro classificador é inicialmente executado. Sua solução é avaliada através de algum critério que estima as probabilidades de ela estar incorreta, rejeitando-a caso seja considerada alta demais. Instâncias rejeitadas são repassadas para o classificador seguinte, enquanto soluções aceitas são retornadas. Este processo se repete até que um classificador tenha sua solução aceita, ou até esgotar os classificadores, adotando a solução do último. A Fig. 3 ilustra o funcionamento da cascata.
Figura 3. Classificadores em cascata.
Nesta arquitetura, os classificadores mais rápidos não só
contribuem para a solução final, mas também atuam como reguladores da frequência de uso dos dispositivos mais lentos. Testes indicam que tal regulagem é útil para reduzir significativamente o tempo de resposta de um classificador sem grandes perdas na taxa de acerto [25] – um resultado que pode ser agregado à TDAE.
O maior diferencial da TDAE com relação à cascata é a possibilidade de os dispositivos mais rápidos incorporarem um novo conhecimento de forma incremental a partir das soluções propostas por dispositivos mais capazes em termos de potencial de decisão, permitindo que problemas previamente solucionados por dispositivos mais lentos possam ser solucionados pelos mais rápidos em ocasiões futuras.
D. Evolução dos Sistemas de Apoio à Decisão:
Sistema de apoio à decisão (do inglês decision support system ou DSS) é um artifício computacional utilizado para apoiar um tomador de decisão em sua tarefa de solucionar problemas [26]. Apesar de não haver um modelo único e definitivo, tais sistemas normalmente apresentam uma base de conhecimento, um modelo de decisão e uma interface gráfica [27], e deve ser treinado antes de ser utilizado.
O conceito de sistema de apoio à decisão não é completamente homogêneo: desde sua introdução na década de 1960 como um sistema de apoio à decisão corporativa, seu significado, abrangência e funcionalidade têm sido especializado de acordo com os avanços em múltiplos ramos de pesquisa [28]. Como exemplo, avanços em estudos sociais permitiram uma especialização em decisões orientadas a negócios, enquanto estudos relacionados com banco de dados são bases para o conceito de data warehousing.
A Fig. 4 ilustra alguns dos ramos mais proeminentes desta especialização. Em particular, pesquisas em inteligência artificial permitiram a inclusão de agentes inteligentes, aumentando o potencial de resolução de problemas dos sistemas de apoios à decisão [29]. Em seguida, pesquisas em gerenciamento de conhecimento permitiram uma especialização dos sistemas para identificação de padrões em ramos mais particulares, tais como medicina e finanças.
O treinamento de um sistema normalmente se dá através de um método de aprendizado supervisionado, fornecendo-lhe exemplos de qual é a melhor solução para determinados casos conhecido. O termo eager learning é dado aos métodos de aprendizado que tentam inferir um modelo preditivo durante o treinamento e utilizá-lo para todas as entradas futuras (e.g., árvore de decisão ID3). Por outro lado, o termo lazy learning é atribuído para os métodos cuja inferência ocorre para cada instância, sem manter uma estrutura fixa [30] (e.g., k-Nearest Neighbor). Esta característica permite que a inferência seja local, moldada para o problema corrente, mas faz com que, em geral, sejam mais lentos.
Entretanto, uma vez treinados, sistemas inteligentes tradicionais são imutáveis, e não apresentam mecanismos para aprender de forma contínua e incremental. Sistemas adaptativos e evolucionários têm sido considerados como os próximos passos do desenvolvimento dos sistemas de apoio à decisão [31].
E. Pré-Processamento de Instâncias:
Conforme citado anteriormente, nem todo algoritmo de classificação é capaz de tratar todos os tipos de atributos que uma instância (i.e., categóricos e numéricos). Logo, em determinados casos, pode ser desejável – e até mesmo necessário – converter os atributos de um tipo para outro.
Um caso particular é o classificador de Bayes: em teoria, seria possível tratar tantos os atributos categóricos como os numéricos. Entretanto, o tratamento de atributos numéricos exige que seja conhecida a distribuição de valores do atributo, o que nem sempre é possível. Na prática, atributos numéricos são convertidos para outras categorias em um processo de discretização, eliminando a necessidade de se conhecer a
Classificador 1
Instância x
Classificador 2
Classificador k-1
Classificador k
...
Aceita
Aceita
Aceita
Aceita
Rejeita
Rejeita
Rejeita
Cas
cata
Mai
s rá
pido
s M
ais
lent
os
Tax
a de
ace
rto
men
or
Tax
as d
e ac
erto
mai
or
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1309

distribuição numérica, o que, em geral, resulta em uma melhoria de desempenho [32]. Uma das técnicas mais simples de discretização é o EWD (Equal Width Discretization), que divide o espaço de valores numéricos do atributo em múltiplas faixas de igual largura – cada qual correspondendo a uma categoria [32]. Técnicas mais robustas incluem o RMEP (Recursive Minimal Entropy Partitioning) e uso de clusters [33].
O processo contrário, de transformar um atributo categórico em numérico, pode ser feito substituindo-se os valores nominais por um conjunto de critérios com valores binários
mutuamente exclusivos. Cada componente binária representa uma das categorias do critério nominal a ser convertido [34].
F. Aprendizado Incremental:
O termo aprendizado incremental ou online se refere à capacidade de um sistema de agregar novas informações sem a necessidade de ser treinado novamente, resultando uma atualização contínua, mesmo durante sua execução [35]. Esta propriedade permite que o sistema consiga não só agregar novas informações, mas também descartar informações já ultrapassadas, uma vez que, devido ao concept-drift, soluções
Figura 4. Evolução dos sistemas de apoio à decisão, baseada na linha do tempo sugeria em [28], e expandida com os sistemas evolutivos.
1970 Sistema de Apoio à Decisão Pessoal
Sistemas Computacionais de Informação
Sistemas Transacionais e de Relatórios
Estudos no Ramo Gerencial
Modelos de SimulaçãoTeoria Comportamental de
Decisão
Estudos Sociais
Inteligência Artificial
Sistemas Especialistas
1980 Sistema Inteligente de
Apoio à Decisão Aprendizagem
de Máquina
Sistema de Apoio à Decisão em Grupo
Comportamento em Grupo
1990
Sistema de Informação Executiva
Banco de Dados
OLAP
2000
2010
Sistema de Apoio a Negócios
Teoria de Negócios
Armazém de Dados (Data Warehousing)
Modelagem de Dimensões
Sistema Baseado em Conhecimento
Gerenciamento de Conhecimento
Aprendizagem Online
Técnicas Adaptativas
TDAE
Sistema Evolutivo de Apoio à Decisão
1310 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014

antigas podem não ser mais válidas para problemas futuros [36]. A Fig.5 ilustra a diferença entre o treinamento em batch convencional e o aprendizado incremental.
Figura 5. Relação entre aprendizado incremental e treinamento em batch.
Certos algoritmos, por natureza, são naturalmente incrementais – em especial, classificadores cujo treinamento é feito a partir de um lazy learning. Como os modelos preditivos nesta forma de aprendizagem ocorre somente no instante que uma instância é processada, é garantido que o modelo sempre estará atualizado com as informações mais recentes. Exemplos de algoritmos que fazem uso de lazy learning incluem o classificador de Bayes, k-Nearest Neighbor [37] e K* [11].
Já para métodos do tipo eager learning, a tarefa de agregar a capacidade de aprender de forma incremental torna-se mais complexa, uma vez que tal aprendizagem implica em alterar o modelo preditivo dinamicamente, exigindo que o modelo tenha estrutura variável. Um dos poucos exemplos conhecidos é o ITI (Incremental Tree Inducer) – uma árvore de decisão similar ao C4.5, porém, capaz de manter-se atualizada de forma incremental, se reestruturando a cada nova instância rotulada inserida na árvore [38].
Esta capacidade de aprendizado incremental é utilizada como base para o sistema proposto, utilizando a adaptatividade como meio para inserir e remover informações de um modelo preditivo.
G. Raciocínio Baseado em Casos:
Raciocínio baseado em casos (Case-Based Reasoning, ou então, CBR) é um paradigma de resolução de problemas que, diferentemente das técnicas tradicionais de inteligência artificial, tenta solucionar um novo problema reutilizando soluções de problemas passados que se assemelhavam ao problema corrente [4].
O CBR parte do pressuposto que problemas semelhantes devem, de alguma forma, apresentar soluções semelhantes, e
que, portanto, podem ser reaproveitadas ao invés de tentar inferir uma solução para todo novo problema. Estudos empíricos sugerem que este método é especialmente utilizado na ausência de informações concretas [39][40] e para solucionar problemas de julgamento estético e de senso comum [4].
Tipicamente, o CBR é dividido em quatro etapas [41], conforme ilustra a Fig. 6. Estas etapas são referenciadas por 4R em função das iniciais de seus respectivos nomes:
• Reaver: busca por casos semelhantes ao problema corrente;
• Reusar: adaptação das soluções dos casos encontrados para que se adequem novo problema;
• Revisar: aplicação da solução, e, se possível, revisão da mesma, para eliminar efeitos indesejáveis que possam ocorrer na sua aplicação;
• Reter: caso a nova solução seja avaliada positivamente, ela pode ser agregada ao conhecimento já adquirido, tornando-se uma nova referência para problemas futuros.
Figura 6. Metodologia adotada pelo raciocínio baseado em casos, conforme descrito por Aamodt [41].
Nota-se que as duas últimas etapas conferem um poder
evolutivo para este paradigma de raciocínio. Entretanto, apesar de desejáveis, elas não são indispensáveis para solucionar um novo problema. Certas definições, como a de Leake [42] utiliza apenas as duas primeiras etapas, sob os nomes de Memory Search e Adaptation, respectivamente.
Este raciocínio, contudo, exige uma métrica para estimar a similaridade entre dois casos, o que depende, em grande parte, do problema a ser solucionado. Assim, não há uma métrica formalmente definida que possa ser reutilizada no caso geral. De forma semelhante, a adaptação de um problema depende do domínio do problema, apesar de que, no caso mais simples, seja possível reutilizar uma solução sem nenhuma adaptação.
A revisão de uma solução adotada também apresenta algumas imposições a serem analisadas: nem sempre é possível assegurar-se de que uma solução seja realmente adequada, já que pode haver uma latência até que eventuais efeitos colaterais causados pela solução se manifestem [43],
Modelo Preditivo Inferência
Instância
Instância rotulada
Tomada de Decisão
Treinamento
Aprendizado Incremental
• Reforçar positivamente se estiver correto
• Reforçar negativamente se estiver incorreto
1. Reaver
2. Reusar4. Reter
3. Revisar
Problema
Caso Similar
Solução Solução Revisada
Aprendi-zado
Inserir caso
Buscar casos
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1311

ou até mesmo pela falta de realimentação do usuário. Assim, o aprendizado incremental, diferentemente de um treinamento, deve lidar com informações com diferentes níveis de certeza – aspecto discutido na seção seguinte.
H. Tratamento de Incertezas e Confiança:
Em geral, processos computacionais de tomada de decisão partem do pressuposto que as informações utilizadas como base do conhecimento são corretas, dispensando assim uma validação de sua veracidade. Apesar de ser uma boa premissa na fase de treinamento, ela se torna um problema para informações obtidas através de fontes pouco confiáveis.
Seres humanos são capazes de efetuar tal julgamento, e assim, diminuir o impacto que informações pouco confiáveis exercem sobre o processo de tomada de decisão. Segundo Parsloe [44], dentre os fatores que podem afetar tal confiança, destacam-se:
• Repetição: uma afirmação repetida múltiplas vezes torna-se mais facilmente aceita como verdadeira – comportamento este conhecido como viés de repetição;
• Realimentação: opiniões (favoráveis e contrárias) de agentes externos podem interferir na crença acerca de uma informação;
• Opinião própria: cada indivíduo pode apresentar uma opinião formada sobre um fato, seja por convicção, desconhecimento de outros fatos ou observações empíricas.
Em especial, a crença de que uma informação é verdadeira ou falsa é fortemente influenciada por realimentações externas: opiniões que reforçam a ideia original aumenta a confiança, enquanto realimentações negativas alertam sobre a possibilidade de um erro [44].
Estudos passados sugerem que o nível de confiança pode ser estimado em função das realimentações positivas e negativas recebidas. Einhorn sugere que a confiança C de uma determinada informação seja uma função baseado na soma F de realimentações [45]:
( )FfC = (1)
−−++ += NNF ββ (2)
0,,1 ≥=+ −+−+ ββββ (3)
onde N+ e N– são as somas das realimentações positivas e negativas, respectivamente, enquanto β+ e β– são valores relativos de reforço que ponderam a influência de cada tipo de realimentação. Realimentações negativas são representadas por valores negativos, logo, N– ≤ 0.
Note que a função f(F) não foi originalmente definida de maneira formal. Qualitativamente, espera-se um valor próximo de zero para F~0, e sature em 1 quando |F| ∞. O significado de C depende do sinal de F:
• Caso F > 0, o valor C informa a confiança de que a informação realimentada está correta;
• Caso contrário, se F < 0, o valor C informa a confiança de que a informação realimentada está incorreta.
Note que tanto o viés de repetição como o treinamento podem ser considerados uma forma de realimentação, mas com pesos menores na contribuição em N+ e N– para diferenciá-las das realimentações de origens mais confiáveis
(e.g., dados de treinamento). Um exemplo de uso das realimentações como forma de
refinar a confiança é o CBIR (content-based image retrieval) [46], um exemplo de sistema de busca de imagens que utiliza o feedback dos usuários para definir a confiança de que uma imagem está relacionado com o termo de busca.
Nota-se que a confiança e a veracidade de uma solução, apesar de serem utilizadas em conjunto, não necessariamente são correlacionadas. Nada impede que o tomador de decisão, baseado em evidências incorretas, confie que sua solução seja correta, ainda que seja inverídica [47].
III. SISTEMA ADAPTATIVO DE TOMADA DE DECISÃO
A. Visão Geral:
Utilizando o método de combinação de classificadores em cascata e a TDAE como base conceitual, propõe-se um novo modelo preditivo em que múltiplos classificadores são dispostos em uma fila, ordenados de forma que o custo computacional cresça de forma monotônica – i.e., classificadores mais rápidos figuram em primeiro lugar. Em outras palavras, C1 ≤ C2 ≤ ... ≤ Ck, onde Ci é o custo computacional associado ao i-ésimo classificador. A taxa de acerto, por outro lado, não necessariamente cresce de forma monotônica, apesar de que métodos mais robustos costumam ser mais lentos e mais precisos.
A Fig. 7 ilustra a estrutura do sistema proposto, utilizando uma cascata de classificadores como modelo preditivo. Assim como na cascata convencional, apenas o primeiro classificador é inicialmente executado para solucionar um problema. Caso passe por um critério de aceitação, sua solução é retornada, caso contrário, o problema é repassado ao classificador seguinte. Este processo é repetido até que alguma solução seja aceita, ou até esgotar os classificadores.
As soluções podem ser realimentadas, para avaliar se era realmente adequada, permitindo que o sistema corrija seu comportamento e memorize quais informações são realmente corretas. No caso, cada par instância-rótulo possui um contador de realimentações, permitindo estimar um nível de confiança, que pode ser utilizado pelos classificadores como uma fonte de informação adicional para ponderar quais são as instâncias mais confiáveis. Tais realimentações podem ser geradas pelo próprio sistema – através de um bloco de avaliação de decisão – ou então, fornecidas pelo usuário.
A partir destas realimentações, funções adaptativas são utilizadas para informar os classificadores que o nível de confiança de um par instância-rótulo mudou, e que pode ser necessário alterar o modelo preditivo para considerar estas mudanças – como exemplo, a TDAE criava novas regras ao ser informada de uma nova solução proposta pelo AHP.
A manutenção do sistema também pode ser feita através do mecanismo de realimentações, utilizando módulos autônomos para analisar o efeito do tempo sobre as instâncias atualmente conhecidas, para tratar desvios de conceito e diminuir o nível de confiança de instâncias mais antigas. Outro bloco poderia verificar a possibilidade da existência de novos rótulos para problemas semelhantes que fiquem sem solução. Este trabalho, contudo, não entra em detalhes sobre estes módulos,
1312 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014
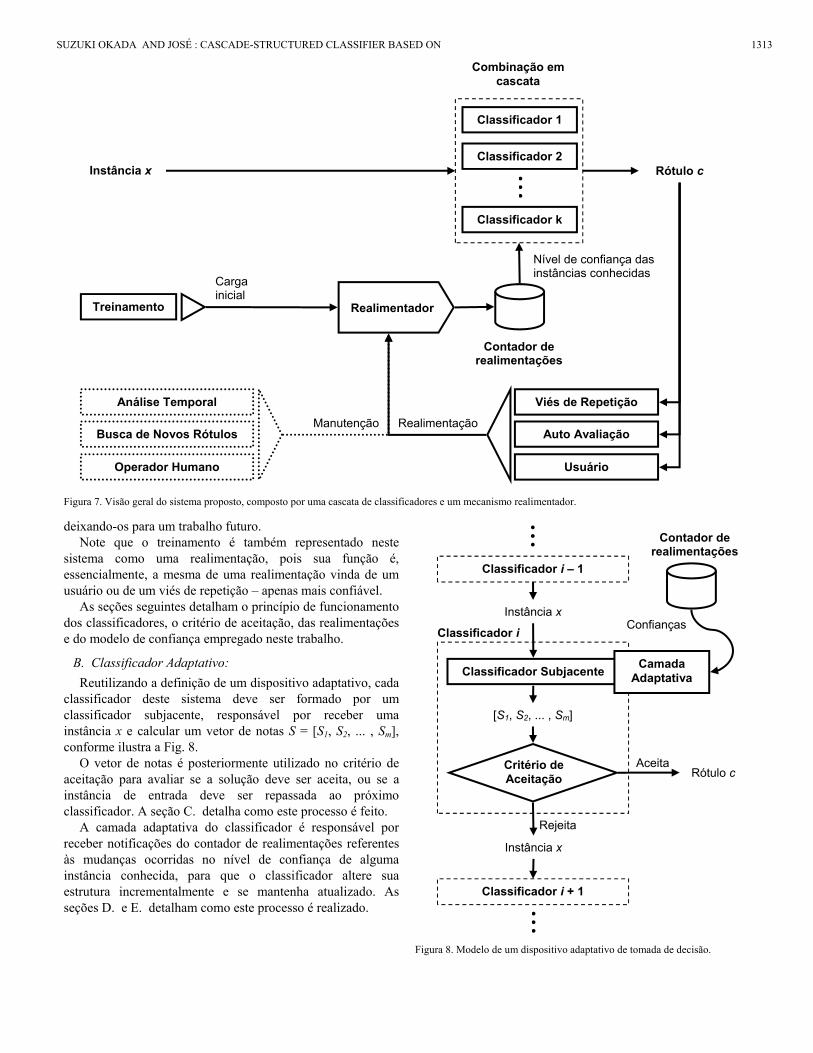
deixando-os para um trabalho futuro. Note que o treinamento é também representado neste
sistema como uma realimentação, pois sua função é, essencialmente, a mesma de uma realimentação vinda de um usuário ou de um viés de repetição – apenas mais confiável.
As seções seguintes detalham o princípio de funcionamento dos classificadores, o critério de aceitação, das realimentações e do modelo de confiança empregado neste trabalho.
B. Classificador Adaptativo:
Reutilizando a definição de um dispositivo adaptativo, cada classificador deste sistema deve ser formado por um classificador subjacente, responsável por receber uma instância x e calcular um vetor de notas S = [S1, S2, ... , Sm], conforme ilustra a Fig. 8.
O vetor de notas é posteriormente utilizado no critério de aceitação para avaliar se a solução deve ser aceita, ou se a instância de entrada deve ser repassada ao próximo classificador. A seção C. detalha como este processo é feito.
A camada adaptativa do classificador é responsável por receber notificações do contador de realimentações referentes às mudanças ocorridas no nível de confiança de alguma instância conhecida, para que o classificador altere sua estrutura incrementalmente e se mantenha atualizado. As seções D. e E. detalham como este processo é realizado.
Figura 8. Modelo de um dispositivo adaptativo de tomada de decisão.
Classificador Subjacente
Classificador i – 1
Classificador i
Instância x
[S1, S2, ... , Sm]
Critério de Aceitação
Instância x
Classificador i + 1
Rótulo c Aceita
Rejeita
...
Camada Adaptativa
Contador de realimentações
Confianças
...
Classificador 1
Instância x Classificador 2
Classificador k
... Rótulo c
Contador de realimentações
Realimentador
Combinação em cascata
Viés de Repetição
Auto Avaliação
Usuário
Treinamento
Realimentação
Carga inicial
Nível de confiança das instâncias conhecidas
Análise Temporal
Busca de Novos Rótulos
Operador Humano
Manutenção
Figura 7. Visão geral do sistema proposto, composto por uma cascata de classificadores e um mecanismo realimentador.
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1313

C. Critério de Aceitação:
Um dos desafios da combinação em cascata é a definição de um critério para identificar soluções errôneas e rejeitá-las. Intuitivamente, quanto maior a nota, menor é a possibilidade de um erro ocorrer, indicando que uma função limiar pode ser um possível critério. Chow sugere uma regra em que a solução de uma instância x deve ser rejeitada se [48]:
( ) txaP imi
<=
|max,...2,1
(4)
onde t ∈ [0...1] é o limiar de aceitação, e P(ai | x) é a probabilidade posteriori de ai ser o rótulo verdadeiro de x. Supondo que a premissa acima seja verdadeira, aumentar o limiar aumenta a rejeição dos erros, mas também aumenta a quantidade de falsos positivos – instâncias corretamente classificadas, mas que foram rejeitadas. Assim, o limiar é o fator que regula o uso dos classificadores seguintes, e, portanto, regula o compromisso entre taxa de acerto e tempo de resposta.
D. Realimentação:
Para fins deste projeto, realimentação é uma avaliação de um par instância-rótulo (x, a), informando se esta é uma solução verdadeira ou falsa. Uma realimentação é representada por uma tupla (x, a, v, β, cr), onde:
• x: instância analisada; • a: rótulo analisado; • v: valor-verdade que indica se a é uma solução adequada
para x – realimentações positivas recebem v = 1, enquanto realimentações negativas recebem v = 0;
• β: valor relativo de reforço, conforme descrito pelas equações (2) e (3);
• cr: credibilidade do gerador desta realimentação, devendo ser um valor positivo.
O valor da credibilidade de uma realimentação é feita de forma a ponderar a influência relativa de cada fonte de realimentação. Valores maiores devem ser atribuídos às fontes mais confiáveis:
• Realimentações de treinamento – criadas para dar a carga inicial ao sistema – devem apresentar um alto valor para cr, já que por hipótese, devem estar corretos.
• Partindo do pressuposto que humanos – em particular, especialistas – são menos propensos a cometer erros do que métodos computacionais, realimentações vindas diretamente do usuário, informando se a solução era a esperada – também devem apresentar um valor para cr relativamente maior do que outras fontes;
• Por outro lado, avaliações através de métodos computacionais, por serem mais sujeitas a erros, devem apresentar cr menor – representado pela Auto Avaliação da Fig. 7;
• Por último, realimentações que representam o viés de repetição devem apresentar baixo valor para cr – no caso, foi escolhida uma constante crrepetition pré-definida.
O peso w que uma realimentação terá frente às demais é emtão formado pela junção entre o valor relativo de reforço e a credibilidade:
crw ⋅= β (5)
A partir de um conjunto destas realimentações, deve-se estabelecer uma forma de estimar o valor-verdade final para um par (x, a) e um nível de confiança que informe a crença de que tal valor-verdade está correto, conforme sugerido por Einhorn [45]. Para tanto, utiliza-se uma soma ponderada por w, conforme descrito a seguir.
E. Valor-Verdade e Intervalo de Confiança:
Em princípio, o cálculo do valor-verdade de um par (x, a) poderia ser feito através de média ponderada dos valores-verdade de todas as n realimentações recebidas que avaliavam este par:
=⋅== ==
n
kk
n
kkk wWwvV
W
Vv
11
, , (6)
onde V representa o número de vezes em que a foi considerada uma solução correta para x dentre as W vezes que ela foi aplicada. Estes são os contadores a serem armazenados pelo sistema. Nota-se que o valor-verdade médio pode ser facilmente atualizado à medida que novas realimentações forem sendo recebidas.
O nível de confiança deste valor-verdade, então, pode ser determinado através do intervalo de confiança: quanto menor o intervalo, mais preciso deve ser o valor-verdade. Para tanto, são definidos dois limites, vlow e, vupp, tal que a probabilidade de a verdadeira média μ (i.e., o valor-verdade verdadeiro) estar neste intervalo seja 1-α. Logo:
( ) αμ −=≤≤ 1upplow vvP (7) onde α representa o nível de significância do intervalo de confiança. Valores típicos para α incluem 10%, 5% e 1%.
Estatisticamente, a estimativa do intervalo de confiança de qualquer parâmetro de uma população depende fortemente da sua distribuição numérica. Como o valor-verdade das realimentações é binário – verdadeiro (1) ou falso (0) – tem-se uma distribuição de Bernoulli, cujo intervalo de confiança em torno da média, quando aproximado por uma distribuição normal, é:
( )W
vvzv
−± −1
2/1 α (8)
tal que z1-α/2 é o (100×(1-α/2))-ésimo percentil de uma distribuição normal, enquanto α é a porcentagem de amostras que devem ficar fora deste intervalo.
Em teoria, o percentil pode ser calculado através da inversa da função distribuição acumulada da distribuição normal – comumente referenciada como probit function. Contudo, na prática, não há uma forma fechada para esta função, devendo ser estimada por aproximações [49].
Entretanto, estudos estatísticos demonstram que este intervalo de confiança pode não representar a verdadeira média, especialmente quando o número de amostras é muito baixo, ou então, se a média verdadeira é muito próxima, mas não 0 ou 1 [50]. Como exemplo, ao lançar uma moeda não viciada três vezes, a possibilidade de serem obtidas três caras é factível (12,5%). No entanto, para esta amostra, a estimativa da massa de probabilidade da moeda dar cara seria 1 ± 0, muito distante do valor real.
Para contornar este problema, utilizam-se outras formas de
1314 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014

cálculo para estimar tanto a média como o intervalo de confiança de um parâmetro binário. Uma delas é o método de Agresti-Coull, que artificialmente insere uma quantidade igual de amostras de valor 0 ou 1. Tal ação move a média para um valor mais próximo de 0,5 e alarga o intervalo de confiança, especialmente quando a quantidade de amostras é pequena. Estes efeitos se dispersam à medida que mais amostras são utilizadas, convergindo para a média convencional.
Utilizando este novo método, a nova estimativa da média do valor-verdade e seu intervalo de confiança são calculados através das seguintes equações:
( )22/1
ˆα−+= zWW (9)
W
zVv
ˆ2/
ˆ2
2/1 α−+= (10)
( )W
vvzvcv
ˆˆ1ˆ
ˆˆ 2/12/1
−±=± −− αα (11)
A equação (9) mostra que o número de amostras artificialmente inseridas é (z1-α/2)
2, enquanto a equação (10) mostra que metade delas são verdadeiras.
A Fig. 9 ilustra um exemplo em que é estimada a média de uma variável que segue uma distribuição de Bernoulli com p = 80% e α = 5% conforme o tamanho da amostra aumenta. Enquanto a média convencional é pouco representativa quando a amostra é pequena, a média de Agresti-Coull sempre se manteve mais próxima da média real.
Figura 9: Gráfico comparativo de uma média convencional (linha marcada com +) com a média de Agresti-Coull (linha contínua).
Nota: o método de Agresti-Coull é funcional até mesmo se
o tamanho da amostra for zero, i.e., W = 0. No caso, tanto a média como o intervalo assumem valor 0,5.
A cada realimentação recebida, os contadores W e V do par (x, a) avaliado devem ser atualizados, bem como seu respectivo valor-verdade e intervalo de confiança. Estas mudanças devem ser informadas aos classificadores através de suas camadas adaptativas, para que se mantenham atualizados.
F. Armazenamento dos Contadores:
Idealmente, o armazenamento dos contadores deve ser feito através de uma estrutura de acesso eficiente, permitindo uma busca de instâncias de forma otimizada (e.g., buscar os vizinhos mais próximos de uma instância em particular). Além disso, é desejável que a estrutura seja dinâmica, permitindo que novas instâncias possam ser inseridas e removidas, para agregar novos conhecimentos e remover as ultrapassadas. A
Fig. 10 ilustra um exemplo de como armazenar estes contadores com o R*-Tree, onde cada folha armazena uma instância x e os contadores para cada par (x, a).
Figura 10: Exemplo de uma base utilizando uma R*-Tree.
A otimização da busca, no entanto, depende fortemente dos
atributos envolvidos. Como exemplo, o R*-Tree [51] lida apenas com atributos numéricos, enquanto Locally Sensitive Hashing (LSH) é mais flexível, permitindo utilizar atributos categóricos. Para fins deste projeto, uma busca linear foi utilizada para simplificação, tornando a busca independente dos atributos. Em aplicações práticas, utiliza-se uma busca que melhor se adéque às características do problema.
Por fim, nota-se que atributos numéricos podem, a princípio, assumir teoricamente uma infinidade de valores. Para evitar um crescimento infinito da estrutura de armazenamento de instâncias, pode-se discretizar os valores numéricos em categorias, para limitar seu tamanho.
G. Treinamento:
Tradicionalmente, o treinamento de uma cascata de classificadores se dá repassando as instâncias de treinamento para cada classificador individualmente, sem a necessidade de verificar o nível de incerteza envolvida em cada uma delas.
No sistema aqui proposto, o treinamento se dá através do mecanismo de realimentações: para cada instância (x, a) de treinamento, é gerada uma tupla (x, a, v=1, β=β+, cr=cr0), onde cr0 é a credibilidade do treinamento. Para as demais combinações (x, a) que não fazem parte do treinamento, utiliza-se (x, a, v=0, β=β-, cr=cr0).
Nota: se cr0 = ∞, o valor-verdade calculado através da equação (10) torna-se 1 para a alternativa treinada e 0 para as demais, com intervalo de confiança 0. Logo, tal valor de credibilidade impede que o valor-verdade desta instância seja alterado em realimentações futuras.
Raiz
Nós
R*-Tree
Folhas
... ... ... ... ...
Instância x (x1, x2, ... , xn)
Alternativa: 1
Alternativa 1 W = 4 | V = 3
Alternativa 2 W = 6 | V = 2
Alternativa m W = 7 | V = 3 ...
Dados armazenados em cada folha
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1315

IV. CLASSIFICADORES
Neste projeto, foram analisados três dispositivos adaptativos, reutilizando métodos desenvolvidos previamente, e que, por natureza, apresentam potencial para adaptatividade: TDAE, k-Nearest Neighbor e classificador de Bayes. Cada um deles será descrito a seguir.
A. TDAE:
Como foi mencionado previamente, a TDAE é uma das bases conceituais deste projeto e é, por construção, um dispositivo adaptativo já disponível para uso. Todavia, algumas considerações devem ser efetuadas:
• A TDAE original aceita somente atributos binários [24] – ao contrário do sistema proposto, que utiliza atributos numéricos e categóricos;
• Por utilizar apenas atributos binários, um mecanismo de redução de regras era utilizado para unir regras similares em regras mais abrangentes (i.e., regras que não avaliem todos os atributos) [24];
• Regras conflitantes também não são aceitas na TDAE. Para fins deste projeto, a TDAE utilizada é uma variante
com a possibilidade de utilizar atributos categóricos. Valores numéricos são obrigatoriamente discretizados, para evitar um crescimento infinito da tabela. Assim, o mecanismo de redução de regras não é utilizado, por ser especificamente projetado para atributos binários [24]. Isso faz com que toda regra seja obrigatoriamente completa.
Como não devem ser aceitas regras conflitantes, uma instância x de entrada deve ter, no máximo, uma única regra aplicável, cuja saída é o rótulo de maior valor-verdade. Assim, a saída deve ser um vetor [S1, S2, ... , Sm] com Si = 1 para o rótulo indicado pela regra, e zero para as demais. Se nenhuma regra aplicável é encontrada, retorna um vetor zero – isso faz com que o critério de aceitação rejeite a solução, forçando a execução do próximo classificador, assim como a TDAE originalmente fazia.
Para cada mudança nos contadores armazenados pelo sistema, a TDAE deve ser informada através de sua camada adaptativa, para que altere suas regras adequadamente:
• Se a instância avaliada já tem uma regra equivalente na tabela, a TDAE deve verificar se o rótulo de maior valor-verdade mudou. Em caso afirmativo, deve alterar a saída da regra;
• Se a instância é nova, uma nova regra deve ser gerada. Por fim, vale notar que a tabela de decisão adaptativa,
originalmente, também permitia executar funções adaptativas ao executar uma regra. Esta funcionalidade não será utilizada neste projeto, apesar de estar prevista na formulação.
B. k-Nearest Neighbor:
Historicamente, o k-Nearest Neighbor (k-NN) representa um dos mais populares algoritmos de aprendizado baseado em instâncias, devido à sua simplicidade de uso e boa taxa de acertos quando bem calibrado [52], tornando-o útil como comparativo entre o desempenho de sistemas de tomada de decisão.
Seu princípio de funcionamento é relativamente simples: o
rótulo a ser designado a uma instância de entrada é escolhido consultando-se as k instâncias mais próximas e escolhendo o rótulo que aparece com maior frequência – uma votação.
O bom funcionamento do k-NN depende, essencialmente, de três fatores:
• Um conjunto de instâncias rotuladas a ser utilizado como treinamentos;
• Uma métrica para computar a distância entre duas instâncias;
• O valor de k, ou seja, o número de vizinhos a serem consultado.
Em sua definição original, a classificação de uma instância x é expressa por [53]:
( ) =∈
==k
ii
aaaaaxy
m 1}...{)(argmax
1
δ (12)
sendo que δ(exp) é a função indicadora, retornando 1 se a condição expressa por exp for verdadeira, e zero, caso contrário. Logo, o retorno da função acima será o rótulo ai com maior frequência entre os vizinhos mais próximos.
No entanto, esta definição considera apenas a frequência com que os rótulos aparecem, sem levar em conta o grau de semelhança entre duas instâncias. Supostamente, quanto maior a semelhança entre duas instâncias, maior a probabilidade de apresentarem rótulos idênticos. Uma extensão popular ao k-NN consiste na inserção de uma função de ponderação pela distância:
( ) ),()(argmax1}...{ 1
i
k
ii
aaaxxwaaxy
m
⋅== =∈
δ (13)
onde w(x, xi) é uma função que pondera a influência de xi pela sua distância até a instância x a ser classificada – pesos maiores são atribuídos para distâncias menores. Dentre as funções conhecidas, destacam-se o método de Shepard [54] e a função de similaridade [53], dados pelas equações (14) e (15) respectivamente:
pShepard yxdyxw
),(
1),( = (14)
max
),(1),(
d
yxdyxw desimilarida −= (15)
Nestas equações, d(a, b) é uma função que calcula a distância entre as instâncias x e y. Já dmax é um fator de normalização que garante que as distâncias estejam no intervalo [0...1]. Já P é um fator de escala – normalmente 1 ou 2.
Para o cálculo desta distância, deve-se considerar que as instâncias podem ser formadas por atributos tanto numéricos como categóricos. Uma possibilidade é utilizar uma função de distância heterogênea:
( )=
Δ=n
iii yxyxd
1
2,),( (16)
Nesta função, Δ(xi, yi) representa a diferença entre as instâncias a e b no i-ésimo atributo, retornando um valor no intervalo [0...1]. Sua definição depende do tipo de atributo avaliado:
1316 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014

−−
=Δdosdesconheci ou 1
categóricofor atributo se),(
numéricofor atributo seminmax
),(
ba
yxOM
yx
yx ii
ii
ii
ii
(17)
Para atributos numéricos, a distância é apenas uma diferença entre os dois atributos, normalizada para que seja um valor entre 0 e 1 – no caso, maxi e mini representam a máxima e mínima distância encontrada nas instâncias conhecidas.
Para atributos categóricos, esta diferença torna-se menos clara. A forma mais simples e intuitiva é utilizar a Overlap Metric (OM), que retorna 0 se a categoria for a mesma, e 1, caso contrário [55]:
==
contrário caso0
se1),( ii
ii
yxyxOM (18)
Outra opção, esta mais completa, é o Value Difference Metric (VDM), que considera as probabilidades de um rótulo aparecer um conjunto com um determinado valor de atributo [55]:
qm
jijijii yaPxaPyxVDM
=
−=1
)|()|(),( (19)
onde q é uma constante (1 ou 2), enquanto P(aj | xi) é a probabilidade de aj ser o rótulo de qualquer instância que tenha o valor xi no i-ésimo atributo. Assim:
( ) ( )( )i
jiij xN
axNxaP
,| = (20)
tal que N(xi) é a frequência com que o i-ésimo atributo apresenta o valor xi dentre as instâncias de treinamento, enquanto N(xi, aj) é a frequência com que uma instância de treinamento apresenta o valor xi e o rótulo aj ao mesmo tempo.
Por fim, vale notar que este projeto faz uso de valores-verdade – logo, as instâncias de treinamento não apresentam um rótulo fixo, mas sim, um valor-verdade para cada rótulo, além de um intervalo de confiança. Assim, a equação ponderada do k-NN é alterada para:
( ) ( ) ),(,),(argmax1}...{ 1
ii
k
ii
aaaxxwaxcaxvxy
m
⋅⋅= =∈
(21)
onde a função indicadora é substituída por v(xi, a), que calcula o valor-verdade de (xi, a) utilizando a equação (10). Já c(xi, a) calcula um nível de confiança conforme a seguir:
( ) 2/121, α−⋅−= caxc i (22)
Nota-se que o modelo preditivo do k-NN não mantém nenhuma estrutura além das instâncias de treinamento – assim, para fins do presente projeto, a camada adaptativa do k-NN não realiza ação alguma, já que toda a estrutura necessária para executá-lo está presente nos contadores armazenados.
C. Classificador de Bayes:
O classificador de Bayes é um método de classificação que estima a classe de uma instância x através de técnicas probabilísticas. Assumindo que cada atributo contribui de forma independente, pode-se estimar a classe de qualquer instância se forem conhecidas todas as probabilidades P(xi | c) de um valor xi qualquer aparecer quando uma instância é
rotulada com a classe c [56]. Assim:
( ) ( ) ( ) ( )∏=
=m
ii cxPcP
xZxcP
1
|1
| (23)
onde P(c) é a probabilidade a priori de uma instância x qualquer ter c como rótulo verdadeiro, podendo ser estimada calculando a porcentagem das instâncias de treinamento que tem c como rótulo. Já a estimativa de P(xi | c) depende do tipo de atributo:
• Em atributos categóricos, calcula-se a porcentagem de instâncias que apresentem o valor xi, dentre aquelas que têm c como rótulo.
• No caso de o atributo ser numérico, o cálculo dependerá da distribuição que caracteriza o atributo. Como exemplo, em uma distribuição normal, utiliza-se:
( ) ( )
−=2
2
2 2exp
2
1|
ic
ici
ic
i
xcxP
σμ
πσ (24)
onde µic é a média e σic é o desvio padrão dos valores no i-ésimo atributo para as instâncias de treinamento que tenham c como rótulo. Na prática, é mais comum discretizar atributos numéricos, tornando-os independentes da distribuição, conforme mencionado anteriormente.
A função Z(x) representa a evidência, normalizando as probabilidades para o intervalo [0...1], a garantindo que a soma de cada P(c | x) seja igual a 1:
( ) ( ) ( ) ∏= =
=n
j
m
ijij cxPcPxZ
1 1
| (25)
Como Z é um valor comum a todas as probabilidades, chega-se à seguinte conclusão:
( ) ( ) ( )∏=
∝m
ii cxPcPxcP
1
|| (26)
Supondo que a alternativa de uma instância seja aquela cuja probabilidade calculada seja a maior, temos:
( ) ( ) ( )∏=∈
=m
ii
ccccxPcPxy
n 1),...(|argmax
1
(27)
Neste trabalho, as probabilidades são calculadas com base nos valores-verdade de cada instância previamente analisada – i.e., com contadores não nulos. Supondo que seja s a quantidade de instâncias com contadores não nulos, temos:
( ) ( )total
v
S
cScP = (28)
( ) ( )( )cS
cxScxP
v
iui
,| = (29)
onde:
( ) ( )=
=s
iiv cxvcS
1
, (30)
( ) ( ) ( )=
=⋅=s
iijijiu xxcxvcxS
1
,, δ (31)
( )= =
=n
j
s
ijitotal cxvS
1 1
, (32)
Apesar de ser possível calcular estes somatórios sob demanda, uma melhoria de desempenho é possível se forem armazenados em memória, fazendo com que o cálculo das probabilidades sejam feitas em uma única operação de divisão.
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1317

O valor de cada um dos somatórios deve ser atualizado através da camada adaptativa, sempre que o valor-verdade de alguma instância for alterado. A atualização de qualquer um destes somatórios pode ser feita através da seguinte propriedade:
1||1 ++ +−= tititt ssSS (33) onde St é um somatório em um instante t, enquanto si | t é o valor do i-ésimo elemento da somatória em um instante t. Se este valor, em um instante t+1, for alterado, basta substituir o valor anterior e somar o novo. Assim, se o valor-verdade de um par (xb, cb) for alterado:
( ) ( ) ( )bbtbvtbv cxdifcScS ,1 +=+ (34)
( ) ( ) ( ) ( )ibibbtbiutbiu xxcxdifcxScxS =⋅+=+ δ,,, 1 (35)
( )bbttotalttotal cxdifSS ,1 +=+ (36) onde dif(xb, cb) é a diferença entre o novo valor-verdade e o anterior para o par (xb, cb) especificado.
V. RESULTADOS
A. Análise Preliminar:
Antes de testar o sistema proposto, o k-NN e o classificador de Bayes foram avaliados individualmente nos quesitos taxa de acerto e tempo de resposta, para verificar se a premissa de que classificadores mais lentos são possivelmente mais precisos é válida para este caso.
O teste foi feito sobre 15 datasets publicamente disponíveis pela UCI [57] utilizando um processo de Monte Carlo para a medição destes parâmetros. Foram feitas 100 iterações por dataset, resultando em um erro padrão igual a 1/10 do desvio padrão. Em cada iteração, as instâncias de treinamentos e de validação foram divididas de forma aleatória em uma fração 70:30.
Para o k-NN, o melhor valor de k para cada dataset foi escolhido utilizando o método 10-fold de validação cruzada. A função de ponderação utilizada foi a de Shepard, com P = 2, com VDM como métrica para atributos categóricos. Atributos numéricos foram discretizados utilizado o EWD com 10 divisões de mesmo tamanho.
A Tabela I mostra os datasets empregados nestes testes, e suas respectivas características no que se refere ao número de instâncias, atributos e rótulos. Já a Tabela II mostra a taxa de acerto dos classificadores previamente mencionados, confirmando a premissa: o classificador mais lento – no caso, o k-NN – apresenta melhor taxa de acerto em 12 dos 15 datasets testados.
Nota: como os conjuntos de treinamento e de testes são disjuntos, a TDAE não foi incluída nesta análise, pois ela lida apenas com instâncias previamente treinadas, sendo assim, pouco adequada para este caso em particular.
B. Compromisso de Taxa de Acerto e Tempo de Resposta:
Como foi previamente mencionado, a utilização de classificadores em cascata permite regular o compromisso entre taxa de acerto e tempo de resposta coma ajuda um limiar que regula o acesso aos dispositivos mais lentos. Esta característica do sistema é testada através de uma cascata com o classificador de Bayes em primeiro lugar, seguido pelo k-NN, utilizando os parâmetros citados anteriormente.
TABELA I. CARACTERÍSTICAS DOS DATASETS.
DATASET INSTÂNCIAS ATRIBUTOS RÓTULOS NUM CAT. BLOOD 748 4 0 2 CAR 1728 0 6 4 CARDIO. CLASS 2126 21 0 10 CARDIO. NSP 2126 21 0 3 CONTRACEPTIVE 1473 2 7 3 CREDIT 690 6 9 2 GERMAN 1000 7 13 2 HAYES 132 3 0 3 ILPD 583 9 1 2 IRIS 150 4 0 3 PIMA 768 8 0 2 TEACHING 151 1 4 3 TIC-TAC-TOE 958 0 9 2 VERTEBRAL 310 6 0 3 YEAST 958 8 0 10
TABELA II. TAXA DE ACERTOS INDIVIDUAIS.
DATASET NB K-NN MELHOR K BLOOD 75,89% 77,00% 18 CAR 85,01% 95,62% 8 CARDIO. CLASS 70.69% 75,20% 6 CARDIO. NSP 84.58% 91,28% 6 CONTRACEPTIVE 50,36% 51,29% 36 CREDIT 84,83% 85,62% 20 GERMAN 75.15% 74,08% 43 HAYES 72,11% 65,68% 5 ILPD 67,81% 72,24% 72 IRIS 94,52% 95,84% 24 PIMA 75,65% 74,31% 14 TEACHING 50,41% 56,93% 7 TIC-TAC-TOE 70,58% 89,90% 2 VERTEBRAL 73,73% 77,30% 26 YEAST 57,16% 59,97% 16
Para tanto, para evitar que as realimentações
influenciassem o resultado, crrepetition = 0, enquanto cr0 = ∞, fazendo com que o valor-verdade das instâncias de treinamento sejam fixas em 1 para o rótulo verdadeiro, e zero para as demais.
Em cada dataset, foram calculados a taxa de acerto e o tempo de resposta do sistema utilizando limiares entre 0 e 1 em passos de 0,05 – e.g., [0.00, 0.05, 0.10, ... , 1.00]. De forma similar à análise preliminar, foi utilizado um processo de Monte Carlo com 100 iterações, com uma proporção treinamento-teste de 70:30.
O gráfico da Fig. 11 ilustra uma forma de visualizar o desempenho do sistema, colocando tanto a taxa de acerto como o tempo de resposta em função do limiar escolhido. Já a Fig. 12 mostra a mesma informação omitindo o limiar, colocando a taxa de acerto em função do tempo de resposta.
1318 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014
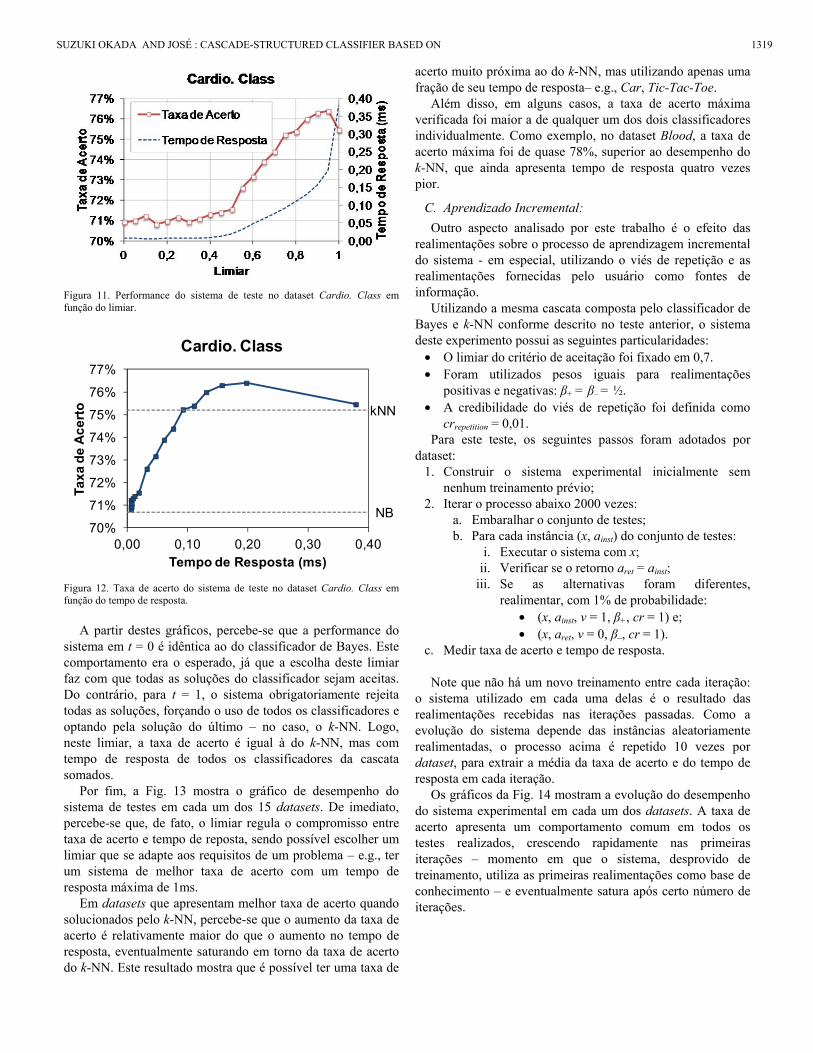
Figura 11. Performance do sistema de teste no dataset Cardio. Class em função do limiar.
Figura 12. Taxa de acerto do sistema de teste no dataset Cardio. Class em função do tempo de resposta.
A partir destes gráficos, percebe-se que a performance do
sistema em t = 0 é idêntica ao do classificador de Bayes. Este comportamento era o esperado, já que a escolha deste limiar faz com que todas as soluções do classificador sejam aceitas. Do contrário, para t = 1, o sistema obrigatoriamente rejeita todas as soluções, forçando o uso de todos os classificadores e optando pela solução do último – no caso, o k-NN. Logo, neste limiar, a taxa de acerto é igual à do k-NN, mas com tempo de resposta de todos os classificadores da cascata somados.
Por fim, a Fig. 13 mostra o gráfico de desempenho do sistema de testes em cada um dos 15 datasets. De imediato, percebe-se que, de fato, o limiar regula o compromisso entre taxa de acerto e tempo de reposta, sendo possível escolher um limiar que se adapte aos requisitos de um problema – e.g., ter um sistema de melhor taxa de acerto com um tempo de resposta máxima de 1ms.
Em datasets que apresentam melhor taxa de acerto quando solucionados pelo k-NN, percebe-se que o aumento da taxa de acerto é relativamente maior do que o aumento no tempo de resposta, eventualmente saturando em torno da taxa de acerto do k-NN. Este resultado mostra que é possível ter uma taxa de
acerto muito próxima ao do k-NN, mas utilizando apenas uma fração de seu tempo de resposta– e.g., Car, Tic-Tac-Toe.
Além disso, em alguns casos, a taxa de acerto máxima verificada foi maior a de qualquer um dos dois classificadores individualmente. Como exemplo, no dataset Blood, a taxa de acerto máxima foi de quase 78%, superior ao desempenho do k-NN, que ainda apresenta tempo de resposta quatro vezes pior.
C. Aprendizado Incremental:
Outro aspecto analisado por este trabalho é o efeito das realimentações sobre o processo de aprendizagem incremental do sistema - em especial, utilizando o viés de repetição e as realimentações fornecidas pelo usuário como fontes de informação.
Utilizando a mesma cascata composta pelo classificador de Bayes e k-NN conforme descrito no teste anterior, o sistema deste experimento possui as seguintes particularidades:
• O limiar do critério de aceitação foi fixado em 0,7. • Foram utilizados pesos iguais para realimentações
positivas e negativas: β+ = β– = ½. • A credibilidade do viés de repetição foi definida como
crrepetition = 0,01. Para este teste, os seguintes passos foram adotados por
dataset: 1. Construir o sistema experimental inicialmente sem
nenhum treinamento prévio; 2. Iterar o processo abaixo 2000 vezes:
a. Embaralhar o conjunto de testes; b. Para cada instância (x, ainst) do conjunto de testes:
i. Executar o sistema com x; ii. Verificar se o retorno aret = ainst;
iii. Se as alternativas foram diferentes, realimentar, com 1% de probabilidade:
• (x, ainst, v = 1, β+, cr = 1) e; • (x, aret, v = 0, β–, cr = 1).
c. Medir taxa de acerto e tempo de resposta.
Note que não há um novo treinamento entre cada iteração: o sistema utilizado em cada uma delas é o resultado das realimentações recebidas nas iterações passadas. Como a evolução do sistema depende das instâncias aleatoriamente realimentadas, o processo acima é repetido 10 vezes por dataset, para extrair a média da taxa de acerto e do tempo de resposta em cada iteração.
Os gráficos da Fig. 14 mostram a evolução do desempenho do sistema experimental em cada um dos datasets. A taxa de acerto apresenta um comportamento comum em todos os testes realizados, crescendo rapidamente nas primeiras iterações – momento em que o sistema, desprovido de treinamento, utiliza as primeiras realimentações como base de conhecimento – e eventualmente satura após certo número de iterações.
NB
kNN
70%
71%
72%
73%
74%
75%
76%
77%
0,00 0,10 0,20 0,30 0,40
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Cardio. Class
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1319

NB
kNN
84%
86%
88%
90%
92%
94%
96%
98%
0,00 0,10 0,20 0,30 0,40
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Car
NB
kNN
70%
71%
72%
73%
74%
75%
76%
77%
0,00 0,10 0,20 0,30 0,40
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Cardio. Class
NB
kNN
83%84%85%86%87%88%89%90%91%92%
0,00 0,10 0,20 0,30 0,40
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Cardio. NSP
NB
kNN
50%
51%
52%
53%
0,00 0,10 0,20 0,30 0,40
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Contraceptive
NB
kNN
84%
85%
86%
87%
0,00 0,10 0,20 0,30
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Credit
NB
kNN
73%
74%
75%
76%
0,00 0,20 0,40 0,60
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
German
NB
kNN65%
66%
67%
68%
69%
70%
71%
72%
73%
0,00 0,01 0,01 0,02 0,02
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Hayes
NB
kNN
67%
68%
69%
70%
71%
72%
73%
0,00 0,10 0,20 0,30
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
ILPD
NB
kNN
94%
95%
96%
0,00 0,01 0,02 0,03
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Iris
NB
kNN
49%50%51%52%53%54%55%56%57%58%59%
0,00 0,01 0,02 0,03 0,04
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Teaching
NB
kNN
65%
70%
75%
80%
85%
90%
95%
0,00 0,05 0,10 0,15 0,20
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Tic-Tac-Toe
NB
kNN
73%
74%
75%
76%
77%
78%
0,00 0,02 0,04 0,06 0,08
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Vertebral
NB
kNN
57%
57%
58%
58%
59%
59%
60%
60%
61%
0,00 0,05 0,10 0,15 0,20
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Yeast
Figura 13. Compromisso entre taxa de acerto e tempo de resposta com um sistema composto pelo classificador de Bayes e k-NN.
NB
kNN74%
75%
76%
77%
0,00 0,05 0,10 0,15
Ta
xa
de
Ac
ert
o
Tempo de Resposta (ms)
Pima
1320 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014
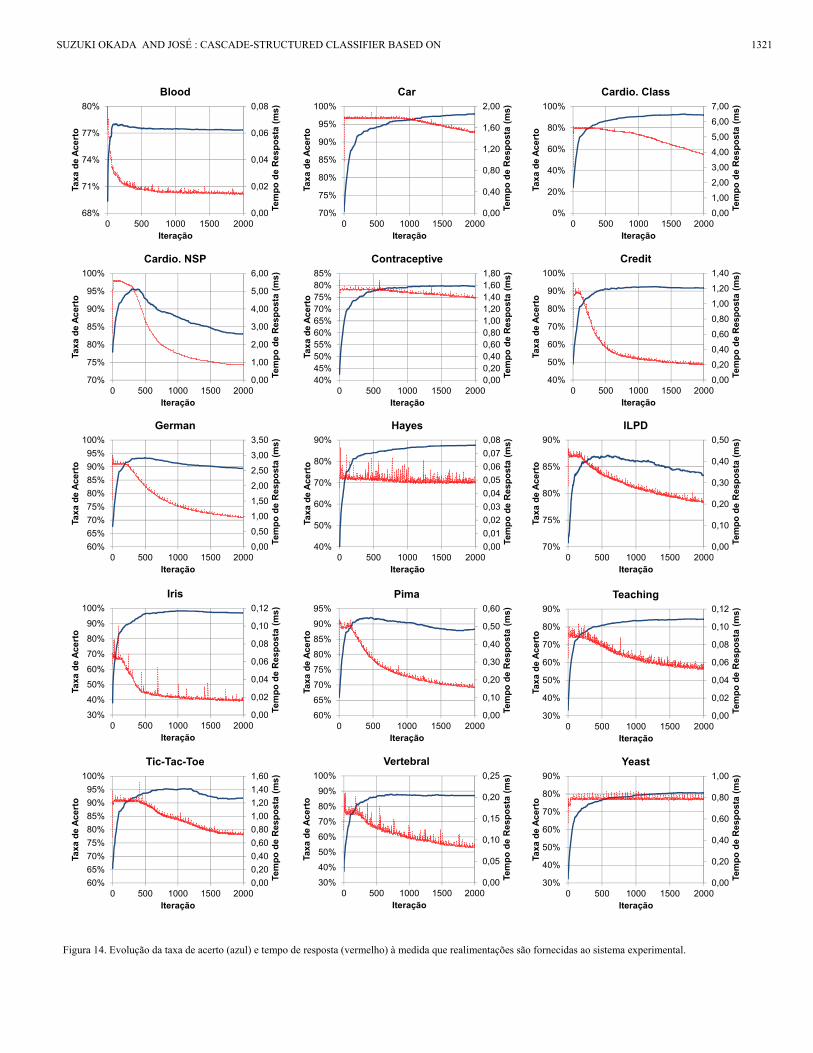
Figura 14. Evolução da taxa de acerto (azul) e tempo de resposta (vermelho) à medida que realimentações são fornecidas ao sistema experimental.
0,00
0,02
0,04
0,06
0,08
68%
71%
74%
77%
80%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Blood
0,00
0,40
0,80
1,20
1,60
2,00
70%
75%
80%
85%
90%
95%
100%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Car
0,00
1,00
2,00
3,00
4,00
5,00
6,00
7,00
0%
20%
40%
60%
80%
100%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Cardio. Class
0,00
1,00
2,00
3,00
4,00
5,00
6,00
70%
75%
80%
85%
90%
95%
100%
0 500 1000 1500 2000
Tem
po
de
Res
po
sta
(ms
)
Taxa
de
Ac
erto
Iteração
Cardio. NSP
0,000,200,400,600,801,001,201,401,601,80
40%45%50%55%60%65%70%75%80%85%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Contraceptive
0,00
0,20
0,40
0,60
0,80
1,00
1,20
1,40
40%
50%
60%
70%
80%
90%
100%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Credit
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
60%
65%
70%
75%
80%
85%
90%
95%
100%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
German
0,00
0,01
0,02
0,03
0,04
0,05
0,06
0,07
0,08
40%
50%
60%
70%
80%
90%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Hayes
0,00
0,10
0,20
0,30
0,40
0,50
70%
75%
80%
85%
90%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
ILPD
0,00
0,02
0,04
0,06
0,08
0,10
0,12
30%
40%
50%
60%
70%
80%
90%
100%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Iris
0,00
0,10
0,20
0,30
0,40
0,50
0,60
60%
65%
70%
75%
80%
85%
90%
95%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Pima
0,00
0,02
0,04
0,06
0,08
0,10
0,12
30%
40%
50%
60%
70%
80%
90%
0 500 1000 1500 2000Te
mp
o d
e R
esp
ost
a (
ms
)
Taxa
de
Ace
rto
Iteração
Teaching
0,00
0,20
0,40
0,60
0,80
1,00
1,20
1,40
1,60
60%
65%
70%
75%
80%
85%
90%
95%
100%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Tic-Tac-Toe
0,00
0,05
0,10
0,15
0,20
0,25
30%
40%
50%
60%
70%
80%
90%
100%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Vertebral
0,00
0,20
0,40
0,60
0,80
1,00
30%
40%
50%
60%
70%
80%
90%
0 500 1000 1500 2000
Tem
po
de
Re
spo
sta
(m
s)
Taxa
de
Ace
rto
Iteração
Yeast
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1321

Em geral, este crescimento da taxa de acerto é acompanhada por uma queda no tempo de resposta, evidenciando um crescimento da aceitação das soluções do classificador de Bayes, e portanto, um menor uso do k-NN. Portanto, o mecanismo de realimentação proposto permite que o sistema agregue novas informações incrementalmente, melhorando seu desempenho ao longo de sua execução.
Entretanto, em determinados casos, pode-se observar que a aceitação maior das soluções do classificador de Bayes causou uma queda na taxa de acertos após o nível de saturação (e.g., Cardio. Class). Tal comportamento indica que informações em excesso podem ser prejudiciais, já que faz com que a confiança do classificador de Bayes aumente além do desejável, diminuindo o desempenho global. Logo, faz-se necessário criar mecanismos para evitar este comportamento indesejável, regulando melhor a relação entre taxa de acerto e tempo de resposta.
VI. CONCLUSÃO
A. Contribuições:
Neste trabalho, foi apresentado um sistema de tomada de decisão que, através de técnicas adaptativas, permite que um conjunto de classificadores utilize um método de aprendizagem incremental para evoluir de acordo com o histórico de entradas processadas, resultando em uma melhora de desempenho ao longo do tempo. O uso de técnicas adaptativas permite que formalismos consolidados possam ser reutilizados para incorporar novas informações incrementalmente.
De forma complementar, um modelo de confiança foi proposto para tratar os diferentes níveis de certeza de uma informação, permitindo que os classificadores atribuam pesos maiores para informações consolidadas há mais tempo. A confiança de uma solução cresce à medida que ela é utilizada através do viés de repetição, ou então, através de realimentações do usuário.
Por fim, o uso da arquitetura em cascata permite que o compromisso entre taxa de acerto e tempo de resposta de um sistema possa ser ajustado de acordo com as necessidades e requisitos do problema a ser solucionado. Para esta finalidade, o uso de um limiar como critério de aceitação mostra-se promissor, desde que seja verdadeira a premissa de que classificadores mais lentos tem maior potencial para solucionar problemas difíceis. Além disso, a disposição em cascata, em conjunto com as técnicas adaptativas empregadas, permite que classificadores mais rápidos aprendam com as soluções dos mais robustos, permitindo uma melhoria no tempo de resposta ao longo do tempo.
B. Trabalho Futuro:
Um aspecto que apresenta um potencial para estudos futuros é a possibilidade de se utilizar outras formas de utilizar múltiplos classificadores de forma colaborativa além da cascata. Estudos anteriores mostram que as soluções de múltiplos dispositivos podem ser mescladas para criar uma solução conjunta, levando a uma melhoria na taxa de acerto [58], o que poderia ser utilizado em conjunto com a cascata
proposta. Outro aspecto a ser explorado é o tratamento da validade
temporal de uma informação – o concept drift. Para esta finalidade, um dispositivo deve apresentar também a capacidade de não só adquirir novas informações de forma incremental, mas também de esquecer aquelas cuja validade expirou. Também pode ser desejável um mecanismo para avaliar o desempenho do sistema, verificando a possibilidade de haver novas alternativas – antes desconhecidas – que possam ser atribuídas para problemas que ficaram sem solução.
Por fim, outros algoritmos podem ser avaliados, para criar sistemas com cascatas mais longas, e avaliar como ela se comporta – e.g., árvore de decisão incremental [38] e K* [11]. O uso de cascatas mais longas também implica que o critério de aceitação possa ser diferente para cada classificador – e.g., limiares diferentes, dependendo do classificador.
REFERÊNCIAS [1] R. Crozier and R. Ranyard, “Decision Making: Cognitive Models and
Explanations”, in Cognitive Process Models and Explanations of Decision Making, Decision Making: Cognitive Models and Explanations, Saffron Walden: Routledge, 1997, pp. 5-20.
[2] D. E. Bell, H. Raiffa and A. Tversky, “Decision Making: Descriptive, Normative, and Prescriptive Interactions”, in Descriptive, Normative, and Prescriptive Interactions in Decision Making, Cambridge: Cambridge University Press, 1988, pp. 9-30.
[3] B. D. Dunn, T. Dalgleish and A. D. Lawrence, “The Somatic Marker Hypothesis: A Critical Evaluation”, Neuroscience and Biobehavioral Reviews, vol. 30, pp. 239–271, 2006.
[4] J. L. Kolodner, “Improving Human Decision Making Through Case-Based Decision Aiding”, AI Mag, vol. 12, no. 2, pp. 52-68, 1991.
[5] S. Plous, “The Psychology of Judgment and Decision Making”, McGraw-Hill, 1993.
[6] L. I. Kuncheva, “Using Control Charts for Detecting Concept Change in Streaming Data”, Bangor University, UK, 2009.
[7] L. Xu, A. Krzyzak, and C. Suen, “Methods of combining multiple classifiers and their applications to handwriting recognition,” Systems, Man and Cybernetics, IEEE Transactions on, vol. 22, no. 3, pp. 418–435, 1992.
[8] J. R. Quinlan, “Induction of Decision Trees”, Machine Learning, vol. 1, no. 1, pp. 81-106, Mar. 1986.
[9] C. Cortes and V. Vapnik, “Support-Vector Networks”, Machine Learning, vol. 20, no. 3, pp. 273-297, 1995.
[10] J. R. Quinlan, “Improved Use of Continuous Attributes in C4.5”, Journal of Artificial Intelligence Research, vol. 4, pp. 77-90, Mar. 1996.
[11] J. G, Cleary and L. E. Trigg, “K*: An Instance-based Learner Using an Entropic Distance Measure”, in Proceedings of the 12th International Conference on Machine Learning, 1995, pp. 108-114.
[12] J. J. Neto, “Um Levantamento da Evolução da Adaptatividade e da Tecnologia Adaptativa”, Revista IEEE América Latina, vol. 5, no. 7, pp. 496-505, Nov. 2007.
[13] H. Pistori, “Tecnologia Adaptativa em Engenharia de Computação: Estado da Arte e Aplicações”, Ph.D. dissertation, Escola Politécnica, Universidade de São Paulo, São Paulo, Brazil, 2003.
[14] J. J. Neto, “Adaptive Rule-Driven Devices - General Formulation and Case Study”, in CIAA ’01: Revised Papers from the 6th International Conference on Implementation and Application of Automata, 2001, pp. 234-250.
[15] G. A. Agasandjan, “Automata with a Variable Structure”, Doklady Akademii Nauk SSSR, vol. 174, pp. 529-530, 1967.
[16] H. Christiansen, “Recognition of Generative Languages”, Programs as Data Objects, pp. 63-81, 1985.
[17] J. J. Neto, “Contribuições à Metodologia de Construção de Compiladores”, Ph.D. dissertation, Escola Politécnica, Universidade de São Paulo, São Paulo, Brazil, 1993.
1322 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014

[18] R. L. A. Rocha and J. J. Neto, “Autômato Adaptativo, Limites e Complexidade em Comparação com Máquina de Turing”, in Proceedings of the second Congress of Logic Applied to Technology - LAPTEC 2000, 2000, pp. 33-48.
[19] A. R. Hirakawa, A. M. Saraiva and C. E. Cugnasca, “Autômatos Adaptativos Aplicados em Automação e Robótica”, Revista IEEE América Latina, vol. 5, no. 7, pp. 539-543, 2007.
[20] C. E. D. Menezes and J. J. Neto, “Um Método Híbrido para a Construção de Etiquetadores Morfológicos, Aplicado à Líıngua Portuguesa, Baseado em Autômatos Adaptativos”, in Anais da Conferencia Iberoamericana em Sistemas, Cibernética e Informática, 2002, pp. 19-21.
[21] B. A. Basseto and J. J. Neto, “A Stochastic Musical Composer Based on Adaptative Algorithms”, in Proceedings of the 6th Brazilian Symposium on Computer Music - SBC&M99, 1999, pp. 105-113.
[22] J. Jesus, D. G. Santos, A. A. C. Junior and H. Pistori, “Adaptools 2.0: Aspectos de Implementação e Utilização”, Revista IEEE América Latina, vol. 5, no. 7, pp. 527-532, 2007.
[23] D. A. Alfenas, M. R. Pereira-Barreto, “Adaptatividade em Robôs Sociáveis: uma Proposta de um Gerador de Diálogos”, in 6o Workshop de Tecnologia Adaptativa, 2012.
[24] A. H. Tchemra, “Tabela de Decisão Adaptativa na Tomada de Decisão Multicritério”, Ph.D. dissertation, Escola Politécnica, Universidade de São Paulo, São Paulo, Brazil, 2009.
[25] K. Chellapilla, M. Shilman, and P. Simard, “Combining multiple classi-fiers for faster optical character recognition,” in Proceedings of the 7th international conference on Document Analysis Systems, ser. DAS’06. Berlin, Heidelberg: Springer-Verlag, 2006, pp. 358–367.
[26] H. G. Sol, C. A. T. Takkenberg and P. F. V. Robbé, “Expert Systems and Artificial Intelligence in Decision Support Systems”, in Proceedings of the Second Mini Euroconference, 1985, pp. 17-20.
[27] R. H. Sprague and E. D. Carlson, Building Effective Decision Support Systems, Englewood Cliffs: Prentice Hall Professional Technical Reference, 1982, pp. 30-32.
[28] D. Arnott and G. Pervan, “A Critical Analysis of Decision Support Systems Research”, Journal of Information Technology, vol. 20, no. 2, pp. 67-87, 2005.
[29] T. Bui and J. Lee, “An Agent-Based Framework for Building Decision Support Systems”, Decision Support Systems, vol. 25, no. 3, pp. 225-237, Apr. 2003.
[30] I. Hendrickx and A. Bosch, “Hybrid Algorithms with Instant-Based Classification”, in Machine learning - ECML 2005, 2005, pp 158-169.
[31] D. Arnott, “Decision Support Systems Evolution: Framework, Case Study and Research Agenda”, European Journal of Information Systems, vol. 13, no. 4, pp. 247-259, Dec. 2004.
[32] Y. Yang and G. I. Webb, “A Comparative Study of Discretization Methods for Naive-Bayes Classifiers”, in Proceedings of PKAW 2002: The 2002 Pacific Rim Knowledge Acquisition Workshop, 2002, pp. 159-173.
[33] J. Dougherty, R. Kohavi and M Sahami, “Supervised and Unsupervised Discretization of Continuous Features”, in Machine Learning: Proceedings of the Twelfth International Conference, 1995, pp. 194-202.
[34] I. H. Witten and E. Frank, Data mining: Practical Machine Learning Tools and Techniques, San Francisco: Morgan Kaufmann, 2005, pp. 393-399.
[35] D. A. Ross, J. Lim, R. S. Lin and M. H. Yang, “Incremental Learning for Robust Visual Tracking”, International Journal of Computer Vision, vol. 77, no. 1, pp. 125-141, May 2008.
[36] A. Tsymbal, M. Pechenizkiy, P. Cunningham and S. Puuronen, “Dynamic Integration of Classifiers for Handling Concept Drift”, Information Fusion, vol. 9, no. 1, pp. 56-68, Jan. 2008.
[37] D. W. Aha and D. Kibler, “Instance-based Learning Algorithms”, in Machine Learning, 1999, pp. 37-66.
[38] P. E. Utgoff, N. C. Berkman and J. A. Clouse, “Decision Tree Induction Based on Efficient Tree Restructuring”, Machine Learning, vol. 29, no. 1, pp. 5-44, Oct. 1997.
[39] J. R. Anderson, “The Architecture of Cognition”, Havard University Press, 1983.
[40] D. Gentner, “Structure mapping - a theoretical framework for analogy”, Cognitive Science, vol. 7, pp. 155-170, 1983.
[41] A. Aamodt and E. Plaza, “Case-based Reasoning: Foundational Issues, Methodological Variations, and System Approaches”, AI Communications, vol. 7, no. 1, pp. 39-59, 1994.
[42] D. B. Leake, A. Kinley and D. Wilson, “Learning to Improve Case Adaptation by Introspective Reasoning and CBR”, in Proceedings of the First International Conference on Case-Based Reasoning, pp. 229-240, 1995.
[43] B. E. Bakken, “Learning and Transfer of Understanding in Dynamic Decision Environments”, Ph.D. dissertation, Sloan School of Management, Massachusetts Institute of Technology, Cambridge, USA, 1993.
[44] E. Parsloe and M. J. Wray. Coaching and Mentoring: Practical Methods to Improve Learning. London: Kogan Page Publishers, 2000, pp. 33-40.
[45] H. J. Einhorn and R. M. Hogarth, “Confidence in Judgment: Persistence of the Illusion of Validity”, Psychological Review, vol. 85, no. 5, pp. 395-416, Sep. 1978.
[46] D. Ding, Q. Li and J. Yang, “Multimedia Data Integration and Navigation Through Mediaview: Implementation, Evolution and Utilization”, in Lecture Notes in Computer Science, vol. 2973, pp. 263-271, 2004.
[47] J. I. Westbrook, A. S. Gosling and E. W. Coiera, “The Impact of an Online Evidence System on Confidence in Decision Making in a Controlled Setting”, Medical Decision Making, vol. 25, no. 2, pp. 178-185, 2005.
[48] C. Chow, “On optimum recognition error and reject tradeoff”, Information Theory, IEEE Transaction on, vol. 16, no. 1, pp. 41-46, 1970.
[49] P. J. Acklam. “An algorithm for computing the inverse normal cumulative distribution function”. Internet: home.online.no/~pjacklam/notes/invnorm/, Feb. 27, 2009 [Apr 5, 2011].
[50] L. D. Brown, T. T. Cai and A. Dasgupta, “Interval Estimation for a Binomial Proportion”, Statistical Science, vol. 16, no. 2, pp. 101-133, 2001.
[51] N. Beckmann, H. P. Kriegel, R. Schneider and B. Seeger, “The R*-Tree: an Efficient and Robust Access Method for Points and Rectangles”, in International Conference on Management of Data, 1990, pp. 322-331.
[52] R. Caruana and A. Niculescu-Mizil, “An Empirical Comparison of Supervised Learning Algorithms”, in Proceedings of the 23rd International Conference on Machine Learning, 2006, pp. 161-168.
[53] W. Liu and S. Chawla, “Class Confidence Weighted kNN Algorithms for Imbalanced Data Sets”, in Proceedings of the 15th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining, 2011, pp. 345-356.
[54] D. Shepard, “A Two-Dimensional Interpolation Function for Irregularly-Spaced Data”, in Proceedings of the 1968 ACM National Conference, 1968, pp. 517-524.
[55] C. Li and H. Li, “A Survey of Distance Metrics for Nominal Attributes”, Journal of Software, vol. 5, no. 11, pp. 1262-1269, 2010.
[56] S. Akaho, “Conditionally Independent Component Extraction for Naive Bayes Inference”, in Proceedings of the International Conference on Artificial Neural Networks, Springer-Verlag, 2001, pp. 535-540.
[57] A. Frank and A. Asuncion, “UCI Machine Learning Repository”. Internet: http://archive.ics.uci.edu/ml, Sep. 13, 2011 [Sep. 29, 2011].
[58] S. Tulyakov, S. Jaeger, V. Govindaraju and D. Doermann, “Review of Classifier Combination Methods”, in Machine Learning in Document Analysis and Recognition, ser. Studies in Computational Intelligence, S. Marinai and H. Fujisawa, Eds. Springer Berlin Heidelberg, 2008, vol. 90, pp. 361–386.
Rodrigo Suzuki Okada é graduado em Engenharia Elétrica pela Escola Politécnica da Universidade de São Paulo (USP), Brasil, em 2008. Entre os anos de 2007 a 2008, participou de pesquisas relacionadas à simulação de eventos estocásticos através do Laboratório de Arquitetura e Redes de Computadores (LARC). Desde 2010 é aluno de Mestrado em Engenharia Elétrica, na área de técnicas adaptativa através do Laboratório de Linguagens e Técnicas
Adaptativas (LTA) da Universidade de São Paulo (USP). Suas pesquisas se concentram nas técnicas adaptativas voltadas para o aprendizado de máquina, cognição e reconhecimento de padrões.
SUZUKI OKADA AND JOSÉ : CASCADE-STRUCTURED CLASSIFIER BASED ON 1323

João José Neto é graduado em Engenharia de Eletricidade (1971), mestre em Engenharia Elétrica (1975), doutor em Engenharia Elétrica (1980) e livre-docente (1993) pela Escola Politécnica da Universidade de São Paulo. Atualmente, é professor associado da Escola Politécnica da Universidade de São Paulo e coordena o LTA – Laboratório de Linguagens e Técnicas Adaptativas do PCS – Departamento de Engenharia de Computação e Sistemas
Digitais da EPUSP. Tem experiência na área de Ciência da Computação, com ênfase nos Fundamentos da Engenharia da Computação, atuando principalmente nos seguintes temas: dispositivos adaptativos, tecnologia adaptativa, autômatos adaptativos, e em suas aplicações à Engenharia de Computação, particularmente em sistemas de tomada de decisão adaptativa, análise e processamento de linguagens naturais, construção de compiladores, robótica, ensino assistido por computador, modelagem de sistemas inteligentes, processos de aprendizagem automática e inferências baseadas em tecnologia adaptativa.
1324 IEEE LATIN AMERICA TRANSACTIONS, VOL. 12, NO. 7, OCTOBER 2014