cassandra summit 2015 - a change of seasons
TRANSCRIPT

A CHANGE OF SEASONSA big move to Apache Cassandra
Eiti Kimura, IT Coordinator @Movile Brazil

Eiti Kimura

Spreading the word...

Leader in Latin America
Mobile phones, Smartphones and Tablets
Movile is the company behind the apps that make your life easier.


We think mobile...Movile develops apps across all platforms for smartphones and tablets to not only make life easier, but also more fun.
The company recorded an annual average growth of 80% in the last 7 years

use cases3
THAT Constitute
THE BIG move toApache Cassandra

- Move I -
The Subscription and Billing System a.k.a SBS

Subscription and Billing Platform
- it is a service API- responsible to manage user’s subscriptions- responsible to charge users in carriers- an engine to renew subscriptions
“can not” stop under any circumstanceit has to be very performatic
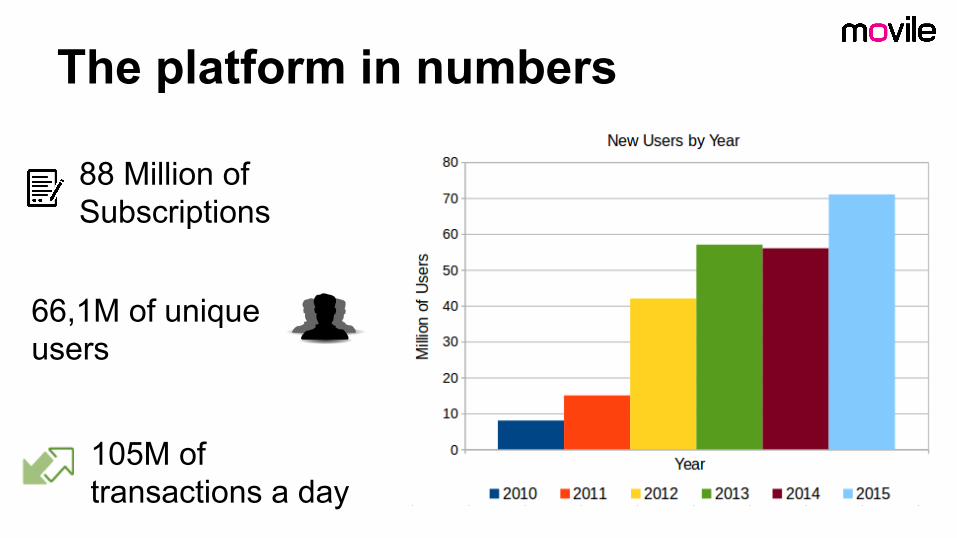
The platform in numbers
88 Million of Subscriptions
66,1M of unique users
105M of transactions a day

Platform Evolution timeline
2008
Pure relational database times
2009
Apache Cassandra adoption (v0.6)
2011
The data model was entirely remodeled4 nodes
Cluster upgrade from version 1.0 to 1.2
2013
Cluster upgrade from version 0.7 to 1.0
Expanded from 4 to 6 nodes
2014
New data index using time series
2015
THE BIG MOVEmigrating complex queries from relational database

Initial architecture revisited
API
DB
API APIAPI API
Engine
Engine Engine
Classical solution using a regular RDBMS

Architecture disadvantages
- single point of failure- slow response times- platform gone down often- hard and expensive to scale- if you scale your platform and forget to scale
database and other related resources you’ll fail
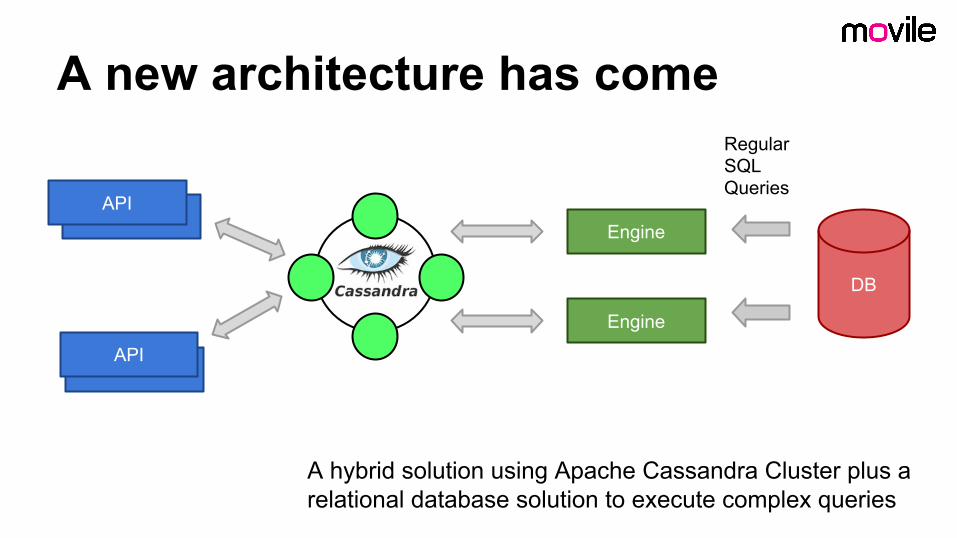
A new architecture has come
APIAPI
Engine
Engine
DB
A hybrid solution using Apache Cassandra Cluster plus a relational database solution to execute complex queries
Regular SQLQueries
APIAPI

The benefits of new solution
- performance problems: solved- availability problems: solved- single point of failure: partially solved- significantly increased read and write
throughput
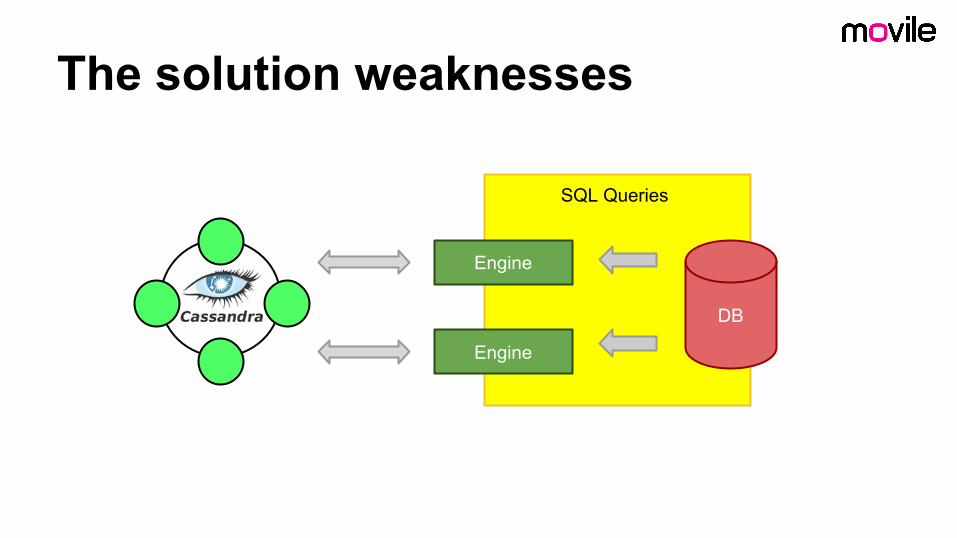
The solution weaknesses
Engine
Engine
DB
SQL Queries


- querying relational database consumes time- has side effects, it locks data being updated
and inserted- concurrency causes performance
degradation- it does not scale well- we still need to use relational database to
execute complex queries
The problems

The complex query..
- query subscription table- selects expired subscriptions- the subscriptions must be grouped by user- must be ordered by priority, criteria, type of
user plan

Sort data
Aggregation
Filter Criterias
Projection
SQLServer’s querySELECT s.phone, MIN(s.last_renew_attempt) AS min_last_renew_attempt
FROM subscription AS s WITH(nolock)
JOIN configuration AS c WITH(nolock)
ON s.configuration_id = c.configuration_id
WHERE s.enabled = 1
AND s.timeout_date < GETDATE()
AND s.related_id IS NULL
AND c.carrier_id = ?
AND ( c.enabled = 1 AND
( c.renewable = 1 OR c.use_balance_parameter = 1 ) )
GROUP BY s.phone
ORDER BY charge_priority DESC, max(user_plan) DESC,
min_last_renew_attempt

The solution- Extract data from Apache Cassandra instead
of use relational database- There is no single point of failure- Performance improved, but more work
querying and filtering dataMain concern: distributed sort data by multiple criterias and data aggregation
- Apache Spark!?

- Databricks to use Apache Spark to sort 100 TB of data on 206 machines in 23 minutes
https://databricks.com/blog/2014/10/10/spark-petabyte-sort.html

Divide-And-Conquer
Preparing for the new solution
Subscription Subscription Index
● configuration_id○ phone-number
Using a new table as index applying data denormalization!
● each subscription becomes a column (time series)

Proof of Concept with Apache Spark
Data Extractor
Processor

Preparing Resources Processor
Java Code Snippet
JavaSparkContext sc = new JavaSparkContext("local[*]", "Simple App",
SPARK_HOME, "spark-simple-1.0.jar");
// Get file from resources folder
ClassLoader classLoader = SparkFileJob.class.getClassLoader();
File file = new File(classLoader.getResource("dataset-10MM.json").getFile());
SQLContext sqlContext = new SQLContext(sc);
DataFrame df = sqlContext.read().json(file.getPath());
df.registerTempTable("subscription");

Preparing and Executing QuerySELECT phone, MAX(charge_priority) as max_priority,
FROM subscription
WHERE enabled = 1
AND timeout_date < System.currentTimeMillis()
AND related_id IS NULL
AND carrier_id in (1, 4, 2, 5)
GROUP BY phone
ORDER BY max_priority DESC, max_plan DESC
sqlContext.sql(query)
.javaRDD()
.foreach(row -> process(row));
Spark SQL Query
Java code snippet

- We have Datastax Spark-Cassandra-Connector!- It allow to expose Cassandra tables as Spark RDDs- use Apache Spark coupled to Cassandra
https://github.com/datastax/spark-cassandra-connector
https://github.com/eiti-kimura-movile/spark-cassandra

Next Steps
- upgrade cluster version to >= 2.1- cluster read improvements in 50% from thrift
to CQL, native protocol v3- implement the final solution Cassandra +
Spark

- Move II -
The Kiwi Migration

The Kiwi Platform- it is a common backend smartphone
platform- provides user and device management- user event and media tracker- analytics- push notifications
High Performance Availability Required

Kiwi: The beginning
API
Consumer
Consumer
API
DynamoDB
Queue SQS
Queue SQS
PostgreSQL

Push notifications

low reading throughput
The push notification crusade
PostgreSQL
Push Publisher
Push Publisher
Push Publisher
Apple notificationservice
Google notificationservice

The problems (dejavú?)
- single point of failure with PostgreSQL- high costs paying for 2 storage services- DynamoDB does not have good read
throughput for linear readings- RDS PostreSQL tuning limit reached- low throughput sending notifications

Slowness means frustration

The solution in numbers
- data storage cost- Amazon DynamoDB: U$ 4,575.00 / mo- PostgreSQL (RDS): U$ 6,250.00 / mo
- read throughput measured- Amazon DynamoDB: 1,4k /s (linear, sequential reads)- PostgreSQL (RDS): 10k /s
U$ 10,825.00 / mo

Push Publisher
Push Publisher
Push Publisher
Apple notificationservice
Google notificationservice
Remodeled solution, Cassandra Way

Datamodel changes
- Amazon DynamoDB- object serialized with Avro- a few columns
- Apache Cassandra - exploded object- more than 80 columns without serialization

Conclusion
AWS DynamoDB + Postgres = U$ 10,825.00/moRead Throughput = ~ 12k/s
Apache Cassandra (8 nodes c3.2xlarge) = U$ 2,580.00/mo
Read Throughput = ~ 200k/s
Before Migration
After Migration
savings of 300%!!!

- Move III -
Distributing Resources

What a kind of resources?
The black listed phone numbers
The ported phone numbers database
Text file resources

Messaging platform
- resources checked before send messages- identify the user carrier- resources loaded up in the memory (RAM)- servers off-cloud (hard to upgrade)
Problem: larger resource files for the same amount of memory

4GB - 6GB RAM
Loading everything, RAM story
Message Publisher
Black list Portability
- low JVM responses (GC)- server memory limit
reached- files continue to grow- more than 20 instances in
different servers loading the same resources

How about a distributed solution?
- the resource files are the same in all of the servers
- RAM memory does not scale well - It is an expensive solution
So..- Why not distribute resources around a ring?
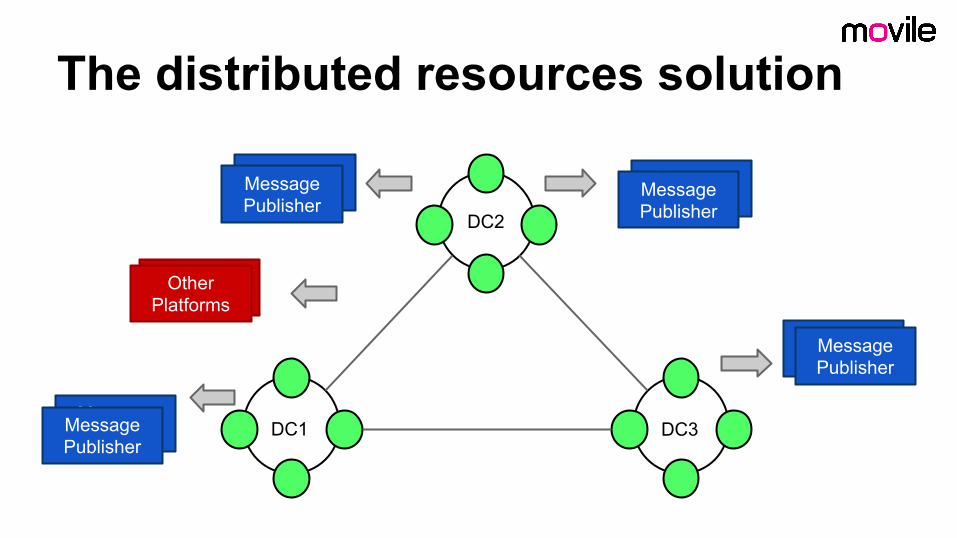
The distributed resources solution
DC1
DC2
DC3
MessagePublisher
MessagePublisher
MessagePublisherMessage
Publisher
MessagePublisherMessage
PublisherMessagePublisherMessage
Publisher
MessagePublisherOther
Platforms

- common information are shared across a Cassandra cluster
- the massive hardware upgrade: solved- the data are available for other platforms- it is highly scalable- easy to accommodate more data
Checking the results


Wrapping up the Moves
- always upgrade to newest versions- high throughput and availability makes a
difference- costs really, really matter!- the horizontal scalability is great! if your
volume of data grow, increase the number of nodes

eitikimura eiti-kimura-movile [email protected]