catching the drift: learning broad matches from clickthrough data sonal gupta, mikhail bilenko,...
TRANSCRIPT

Catching the Drift: Learning Broad Matches from Clickthrough Data
Sonal Gupta, Mikhail Bilenko, Matthew Richardson
University of Texas at Austin, Microsoft Research
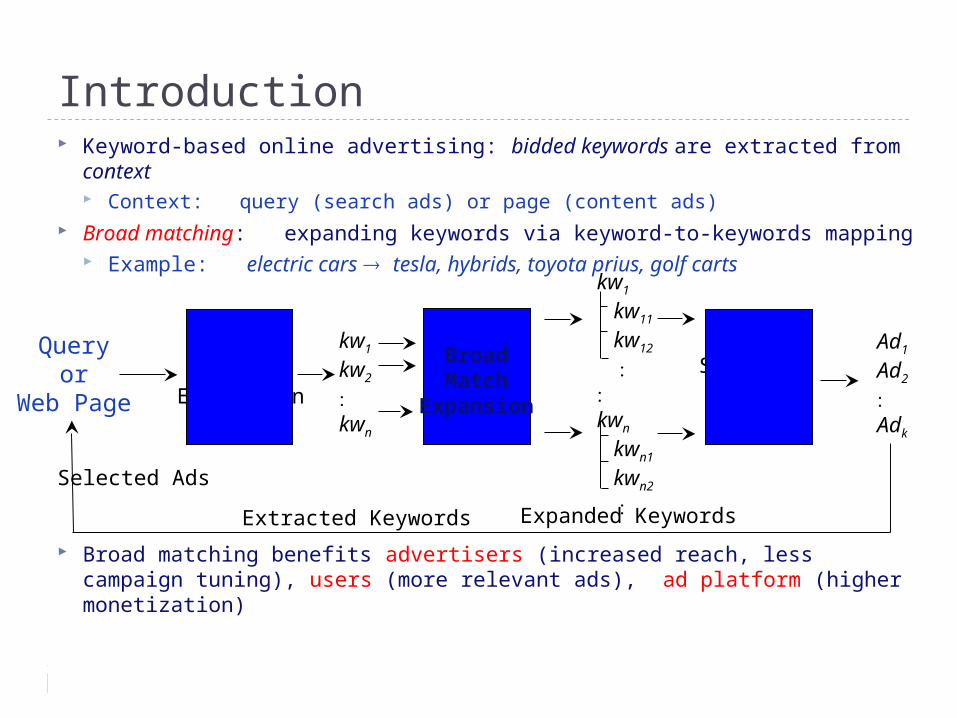
Introduction Keyword-based online advertising: bidded keywords are extracted from
context Context: query (search ads) or page (content ads)
Broad matching: expanding keywords via keyword-to-keywords mapping Example: electric cars tesla, hybrids, toyota prius, golf carts
Broad matching benefits advertisers (increased reach, less campaign tuning), users (more relevant ads), ad platform (higher monetization)
Expanded Keywords
kw1
kw11
kw12
kwn
kwn1
kwn2
BroadMatch
Expansion
AdSelection
andRanking
Ad1
Ad2
Adk
Extracted Keywords
Keyword Extraction
kw1
kw2
kwn
Queryor
Web Page
Selected Ads

Identifying Broad Matches
Good keyword mappings retrieve relevant ads that users click
How to measure what is relevant and likely to be clicked? Human judgments: expensive, hard to scale Past user clicks: provide click data for kw → kw’ when user was
shown ad(kw' ) in context of kw Highly available, less trustworthy
What similarity functions may indicate relevance of kw → kw' ? Syntactic (edit distance, TF-IDF cosine, string kernels, …) Co-occurrence (in documents, query sessions, bid campaigns,
…) Expanded representation (search result snippets, category bags,
…)

Approach
Task: train a learner to estimate p(click | kw → kw' ) for any kw → kw'
Data <kw, ad(kw' ), click> triples from clickthrough logs, where kw →
kw' was suggested by previous broad match mappings
Features Convert each pair to a feature vector capturing similarities etc.
(kw → kw') →
For each triple <kw, ad(kw'), click>, create an instance: (ϕ(kw, kw' ), click)
Learner: max-margin averaged perceptron (strong theory, very efficient)
ϕ1(kw, kw' )
ϕn(kw, kw' )
… where ϕi(kw, kw' ) can be any function of kw, kw' or both

5
Example: Creating an Instance Historical broad match clickthrough data: kw kw' ad(kw' ) click event
digital slr canon rebel Canon Rebel Kit for $499 clickseattle baseball mariners tickets Mariners season tickets no click
Feature functions
Instances[0.78 0.001 0.9], 1[0.05 0.02 0.2], 0
Original kw Broad match kw'
ϕ1 ϕ2 ϕ3
digital slr canon rebel 0.78 0.001 0.9
seattle baseball
mariners tickets 0.05 0.02 0.2

Experiments
Data 2 months of previous broad match ads from Microsoft Content Ads
logs 1 month for training, 1 month for testing
68 features (syntactic, co-occurrence based, etc.); greedy feature selection
Metrics LogLoss:
LogLoss Lift: difference between obtained LogLoss and an oracle that has access to empirical p(click | kw → kw' ) in test set.
CTR and revenue results in live test with users
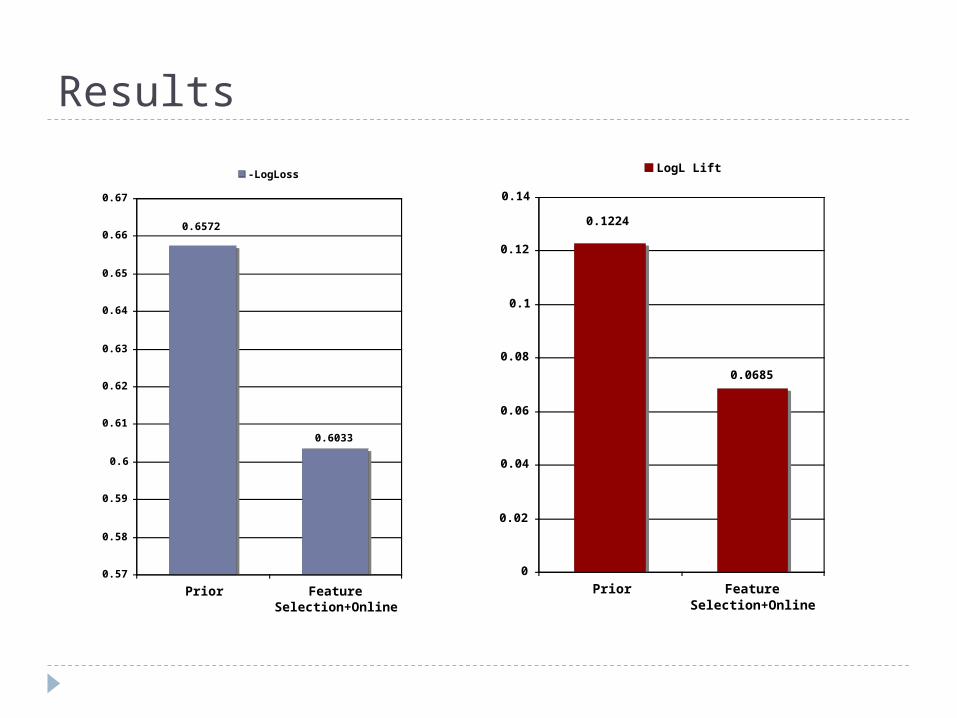
Results
0.6033
0.6572
0.57
0.58
0.59
0.6
0.61
0.62
0.63
0.64
0.65
0.66
0.67
Prior FeatureSelection+Online
-LogLoss
0.0685
0.1224
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
Prior FeatureSelection+Online
LogL Lift
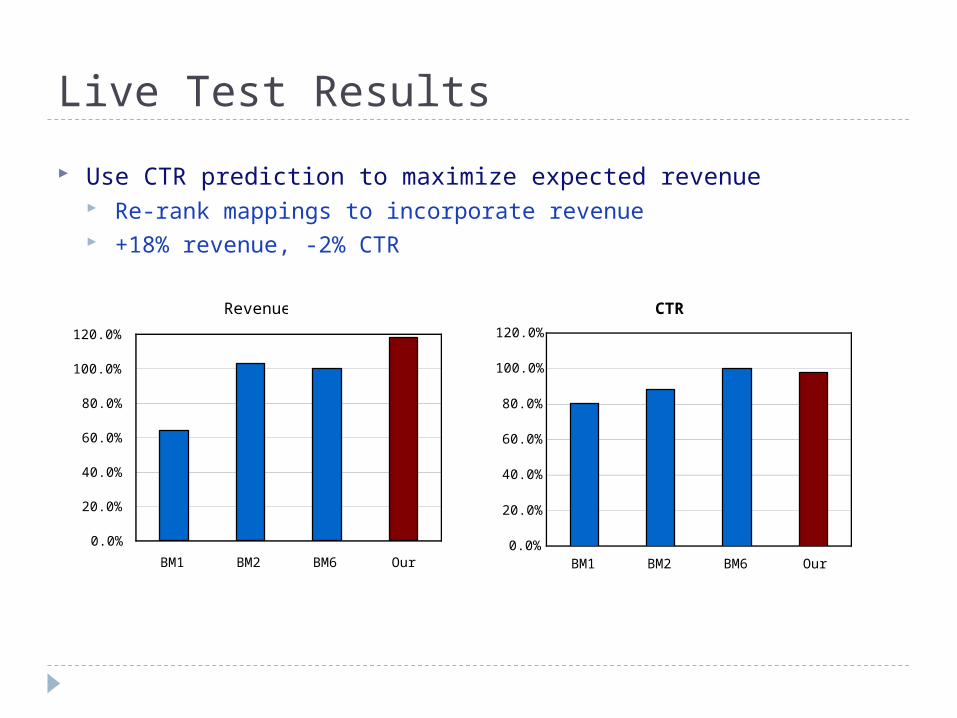
Live Test Results
Use CTR prediction to maximize expected revenue Re-rank mappings to incorporate revenue +18% revenue, -2% CTR
Revenue
0.0%
20.0%
40.0%
60.0%
80.0%
100.0%
120.0%
BM1 BM2 BM6 Our
CTR
0.0%
20.0%
40.0%
60.0%
80.0%
100.0%
120.0%
BM1 BM2 BM6 Our

Online Learning with Amnesia Advertisers, campaigns, bidded keywords and delivery
contexts change very rapidly: high concept drift
Recent data is more informative Goal: utilize older data while capturing changes in
distributions Averaged Perceptron doesn’t capture drift
Solution: Amnesiac Averaged Perceptron Exponential weight decay when averaging hypotheseswavg
t = α (wt + (1−α)wt−1 + (1−α)2wt−2 + ...)
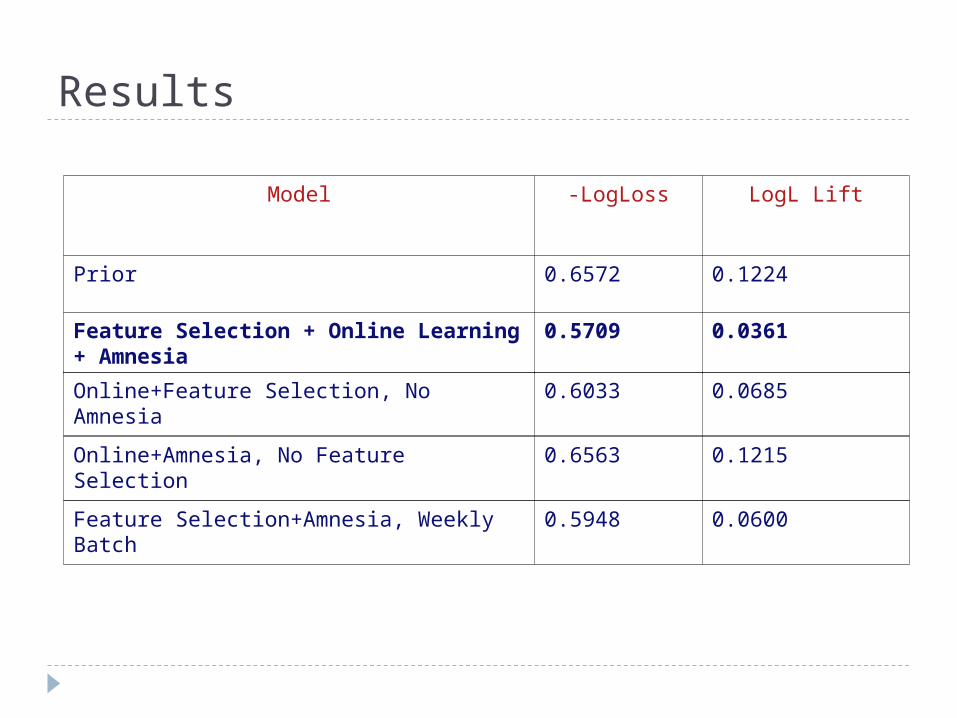
Results
Model -LogLoss LogL Lift
Prior 0.6572 0.1224
Feature Selection + Online Learning + Amnesia
0.5709 0.0361
Online+Feature Selection, No Amnesia 0.6033 0.0685
Online+Amnesia, No Feature Selection 0.6563 0.1215
Feature Selection+Amnesia, Weekly Batch
0.5948 0.0600

Contributions and Conclusions learning broad matches from implicit feedback
Combining arbitrary similarity measures/features
Using clickthrough logs as implicit feedback
Amnesiac Averaged Perceptron Exponentially weighted averaging: distant examples “fade
out” Online learning adapts to market dynamics
Thank You!

13
Features and Feature Selection Co-occurrence feature examples:
User search sessions: keywords searched within 10 mins Advertiser campaigns: keywords co-bidded by the same advertiser
Past clickthrough rates of original and broad matched keywords Various syntactic similarities Various existing broad matching lists and so on…
Feature Selection: A total of 68 features Greedy feature selection

Additional Information Estimation of expected value of click over all the ads shown
for a broad match mapping E(p(click(ad(kw))|q))
Query Expansion vs. Broad Matching Our broad matching algorithm can be extended for query
expansion But, broad matching is for a fixed set of bidded keywords
Forgetron vs. Amesiac Averaged Perceptron Forgetron maintains a set of budget support vectors: stores
examples explicitly and does not take into account all the data
AAP: weighted average over all the examples, no need to store examples explicitly
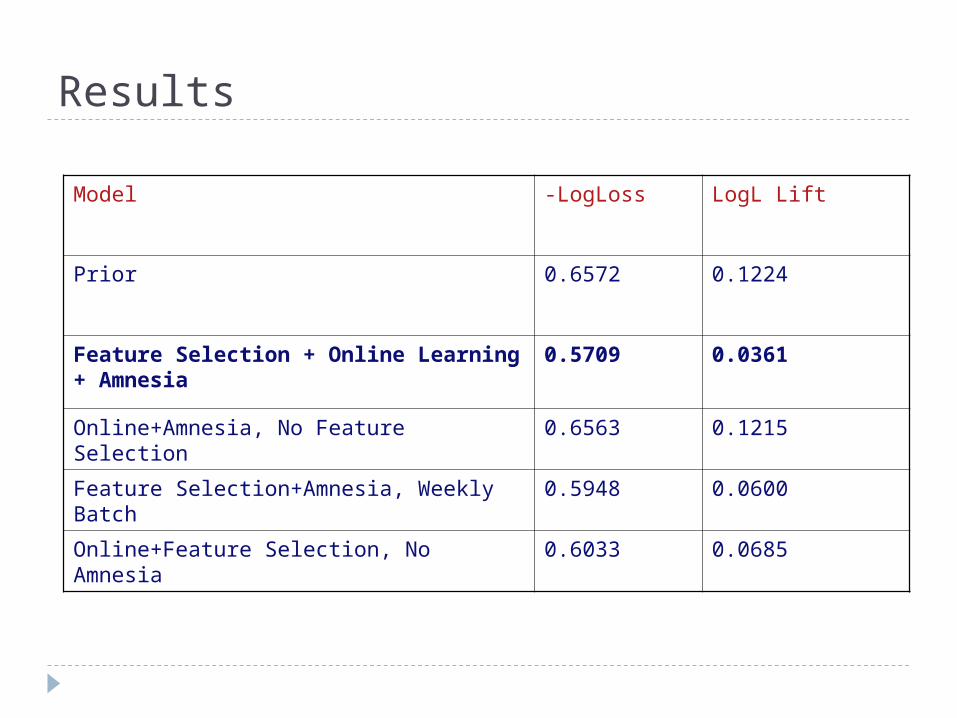
Results
Model -LogLoss LogL Lift
Prior 0.6572 0.1224
Feature Selection + Online Learning + Amnesia
0.5709 0.0361
Online+Amnesia, No Feature Selection 0.6563 0.1215
Feature Selection+Amnesia, Weekly Batch
0.5948 0.0600
Online+Feature Selection, No Amnesia 0.6033 0.0685

16
Amnesiac Averaged Perceptron