chapter 2 2images.china-pub.com/ebook60001-65000/64293/ch02.pdf · 2016-03-31 · 第2 章. 词 法...
TRANSCRIPT

第 2 章
词 法 分 析
为了让读者能更直观和更容易地理解本章的内容,我们针对本章内容精心制作了视
频内容,感兴趣的读者可以扫描二维码观看和学习。
2.1 词法分析概要说明
从第 1 章我们了解到,编译时要经过词法分析识别出符号、语法分析生成语法树、语法树生成中间代码、
中间代码生成目标代码这样几个阶段,最终目标代码产生运行时结构。如图 2-1 所示。
本章仍以第 1 章讲解运行时结构时提供的源程序为例,讲解编译的第一阶段——词法分析。词法分析在全
书中的位置如图 2-2 所示。
案例程序的 C 语言表现形式如下所示:
int fun(int a,int b);int m=10;int main(){ int i=4; int j=5; m=fun(i,j); return 0;}int fun(int a,int b){ int c=0; c=a+b; return c;}
这是我们看到的源程序的样子,但它在计算机上存储的形式与我们看到的形式不同,如果以十六进制的数
字形式展现它们,C 语言写的案例程序看上去如图 2-3 所示。
在计算机中,这是一串连续的看起来毫无头绪的数字。词法分析的任务就是要把这一串连续的数字根据 C语言的词法规则切割成 “ int”、“a”、“=”、“10”、“;”——分立的标识符、数字、符号。
词法分析的实现过程是将这一串连续的数字作为字符串逐个读出字符,按照 C 语言的词法规则把连续的字
符切分成独立的符号,并鉴别属性。
Chapter 2

第 2 章 词 法 分 析 29
int fun(int a,int b);int m=10;int main(){
int i=4;int j=5;m = fun(i,j);return 0;
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
10m
m
funfun
mainmain
0x0x
ebpebp
44
ii
55
jj
55
bb
44
aa
0x0x
funfun
ebpebp
0x0x
0
0
c
c
intfun(inta,intb
CONST_INT
sp
movl %eax, 4(%esp) movl 28(%esp), %eaxmovl %eax, (%esp)call funmovl %eax, m
55 89 E5 A1 80 80 04 08 C9 C3 55 89 E5 83 E4 F0 83 EC 20 C7 44 24 1C 04 00 00 00 C7 44 24 18 05 00 00 00 8B 44 24 18 89 44 24 04 8B 44 24 1C 89 04 24 E8 2C 00 00 00 A3 84 80 04 08 E8 BF FF FF FF A3 84 80 04 08 BB 2A 00 00 00
图 2-1 全书讲解内容的总体结构图

30 编译系统透视:图解编译原理
int fun(int a,int b);int m=10;int main(){
int i=4;int j=5;m = fun(i,j);return 0;
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
intfun(inta,intb
CONST_INT
sp
10m
m
funfun
mainmain
0x0x
ebpebp
44
ii
55
jj
55
bb
44
aa
0x0x
funfun
ebpebp
0x0x
0
0
c
c
movl %eax, 4(%esp) movl 28(%esp), %eaxmovl %eax, (%esp)call funmovl %eax, m
55 89 E5 A1 80 80 04 08 C9 C3 55 89 E5 83 E4 F0 83 EC 20 C7 44 24 1C 04 00 00 00 C7 44 24 18 05 00 00 00 8B 44 24 18 89 44 24 04 8B 44 24 1C 89 04 24 E8 2C 00 00 00 A3 84 80 04 08 E8 BF FF FF FF A3 84 80 04 08 BB 2A 00 00 00
图 2-2 词法分析在全书结构中的位置

第 2 章 词 法 分 析 31
69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A 69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E 74 20 6A 3D 35 3B 0A 20 20 20 20 6D 20 3D 20 66 75 6E 28 69 2C 6A 29 3B 0A 20 20 20 20 72 65 74 75 72 6E 20 30 A3 BB 0A 7D 0A 0A 69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E 74 20 62 29 0A 7B 0A 20 20 20 20 69 6E 74 20 63 3D 30 3B 0A 20 20 20 20 63 3D 61 2B 62 3B 0A 20 20 20 20 72 65 74 75 72 6E 20 63 3B 0A 7D 0A
图 2-3 案例程序的十六进制数表现形式
2.2 词法分析过程
词法分析从第一个字符开始遍历,识别出字符“ i”,如图 2-4 所示。
i69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
6969
ii int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
图 2-4 识别出字符“ i”
根据 C 语言的词法规则,以字母或下划线开头的符号是标识符,所以根据“ i”就可以确定当前分析的符
号是一个标识符,但这个标识符的全部内容是什么现在还无法确定,需要继续向后遍历。下面识别出“ n”,如
图 2-5 所示。
i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E69 6E
inin int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
图 2-5 识别出字符“n”
根据词法规则,标识符的后续字符可以是字母、数字或下划线,“n”符合规则,它属于当前这个符号,继

32 编译系统透视:图解编译原理
续遍历。下面识别出“ t”,如图 2-6 所示。
i n t69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
图 2-6 识别出字符“ t”
仍然符合规则。继续遍历,识别出“空格”,如图 2-7 所示。
i n t69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
图 2-7 识别出空格并确定符号“ int”
它不再是字母、数字或下划线,这意味着,当前这个标识符的全部内容是“ int”。下一个字符是空格,如
图 2-8 所示。
i n t69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
图 2-8 继续识别空格

第 2 章 词 法 分 析 33
这个空格为什么要被再次识别呢?这是因为第一次识别的空格是“ int”这个标识符的后续,意味着“ int”
是一个标识符的完整内容。完成“ int”的识别后,词法分析进入对下一个符号的识别,识别的起始位置从上一
个符号的终结位置的下一个字符算起,在此就是空格,于是此时再次识别这个空格。可见,对这个空格的两次
识别,性质是不一样的,分别对应着对前后两个符号的处理。对于其他可以确定前一个标识符终结的分隔符,
也会进行这样的第二次处理。
根据 C 语言规则,空格是间隔符,不是任何符号的起始,于是跳过它,继续向后遍历,陆续识别出“ f”、
“ u”、“ n”、“ (”。当发现“ (”时,不再符合标识符“字母、数字、下划线”的规则,于是可以确定,“ fun”
是一个完整的标识符,如图 2-9 所示。
i n t f u n (69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
66 75 6E66 75 6E
funfun
图 2-9 识别出“ (”后确定符号“ fun”
继续准备识别下面的符号,对下一个字符“ (”也进行了前后两次识别。这与前面我们介绍的对空格的两
次识别是相同的,差异是,根据 C 语言词法规则,“ (”是个符号,不能忽略,如图 2-10 所示。
i n t f u n (69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
66 75 6E66 75 6E
funfun
2828
((
图 2-10 继续识别出“ (”确定符号“ (”
根据前面的方式继续遍历,识别出符号“ int”、“ a”、“ int”、“ b”、“ )”、“ ;”,直到识别出“ \n”,“ \n”
可跳过,如图 2-11 所示。
继续遍历,识别出符号“ int”、“m”,之后遍历到“=”,如图 2-12 所示。
这时候还不能确定当前符号就是“ =”,也有可能是“ ==”的前半部分,根据 C 语言的词法规则,“ =”和
“==”的含义是不一样的,所以还要往后遍历,发现后续字符是“1”,不是“=”,如图 2-13 所示。

34 编译系统透视:图解编译原理
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n 74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
66 75 6E66 75 6E
funfun
2828
((
69 6E 7469 6E 74
6161
intint
aa
2C2C
,,
69 6E 7469 6E 74
6262
intint
bb
2929
))
3B3B
;;
图 2-11 识别出“ \n”之前不断确定符号
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m =74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
69 6E 7469 6E 74
6262
intint
bb
2929
))
3B3B
;;
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
图 2-12 刚识别到“=”还不能确定符号全部内容
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 174 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
图 2-13 刚识别到“1”确定符号“=”
现在可以确定,当前符号是“=”,它是个运算符,在确定的符号“=”后继续遍历,还是刚才的字符“1”,
如图 2-14 所示。

第 2 章 词 法 分 析 35
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 174 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
3131
11
图 2-14 识别到“1”后确定符号“=”
根据词法规则,以数字开头的符号是数字,说明当前符号是数字,继续遍历,识别到“0”,如图 2-15 所示。
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 1 074 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
31 3031 30
1010
图 2-15 识别到“0”
继续遍历到“;”,如图 2-16 所示。
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 1 0 ;74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
31 3031 30
1010
图 2-16 识别到“ ;”后确定符号“10”
“ ;”不属于数字,说明前面的数字已经完结,“10”就是当前数字符号的全部。从“10”后继续遍历,也
就是“;”,如图 2-17 所示。

36 编译系统透视:图解编译原理
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 1 0 ;74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
31 3031 30
1010
3B3B
;;
图 2-17 确定符号“ ;”
最后识别到换行符“ \n”,如图 2-18 所示。
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 1 0 ; \n74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
int fun(int a,int b);
int m=10;
int main(){
int i=4;int j=5;m = fun(i,j);return 0
}
int fun(int a,int b){
int c=0;c=a+b;return c;
}
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
31 3031 30
1010
3B3B
;;
图 2-18 识别到“ \n”
跳过换行符,继续按照前面的方式对后续的字符串进行遍历,切分出符号并提取信息。这就是词法分析的
大致过程。
2.3 状态转换图
2.3.1 状态转换图总体介绍词法分析的过程是根据 C 语言的词法规则进行的,为了指导词法分析器的程序设计,需要形式化地表达 C
语言的词法规则。下面我们用状态转换图的形式来展现这个案例程序能用到的词法规则,如图 2-19 所示。
图 2-19 是一个完整的转换图,我们来看词法分析的每个步骤在转换图上对应的状态。
首先是起始状态,即我们前面所介绍的计算机准备识别下一个符号的状态,如图 2-20 所示。
我们以标识符符号的识别为例,只要识别到字母、数字或下划线,就进入标识符识别状态,情景如图 2-21 所示。
之后,只要遇到字母、数字或下划线,就仍然在这个状态中进行识别,情景如图 2-22 所示。
直到条件不再符合,就进入终态,表示此标识符已经识别完毕,情景如图 2-23 所示。
然后从起始状态开始准备识别下一个符号,情景如图 2-24 所示。
下一个字符可能是数字、分隔符或运算符。如果是数字,情景如图 2-25 所示。
如果是分隔符,情景如图 2-26 所示。
如果是运算符,情景如图 2-27 所示。

第 2 章 词 法 分 析 37
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
图 2-19 前面介绍内容所涉及的状态转换图 图 2-20 状态转换图处于起始状态

38 编译系统透视:图解编译原理
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
图 2-21 识别到字母或下划线的状态 图 2-22 不断识别到字母、数字或下划线的状态

第 2 章 词 法 分 析 39
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
图 2-23 进入终态并确定符号为标识符 图 2-24 重新回到起始状态

40 编译系统透视:图解编译原理
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
图 2-25 识别到数字的状态 图 2-26 识别到“ ,”的状态

第 2 章 词 法 分 析 41
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
图 2-27 识别到“=”的状态

42 编译系统透视:图解编译原理
2.3.2 依托状态转换图展现词法分析过程下面我们把前面的词法分析过程映射到状态转换图中。符号“ int”的识别如图 2-28 ~图 2-32 所示。
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
图 2-28 进入起始状态准备识别符号

第 2 章 词 法 分 析 43
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
6969
ii
图 2-29 进入识别到字母的状态

44 编译系统透视:图解编译原理
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E69 6E
inin
图 2-30 继续处于识别字母的状态

第 2 章 词 法 分 析 45
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint
图 2-31 继续处于识别字母的状态

46 编译系统透视:图解编译原理
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t 69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint
图 2-32 识别到空格并进入终态

第 2 章 词 法 分 析 47
继续往后遍历,识别到“ (”后,符号“ fun”被识别出来,如图 2-33 和图 2-34 所示。
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n (69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint
66 75 6E66 75 6E
funfun
图 2-33 识别到“ (”后进入终态

48 编译系统透视:图解编译原理
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n (69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint
66 75 6E66 75 6E
funfun
图 2-34 回到起始状态准备继续识别
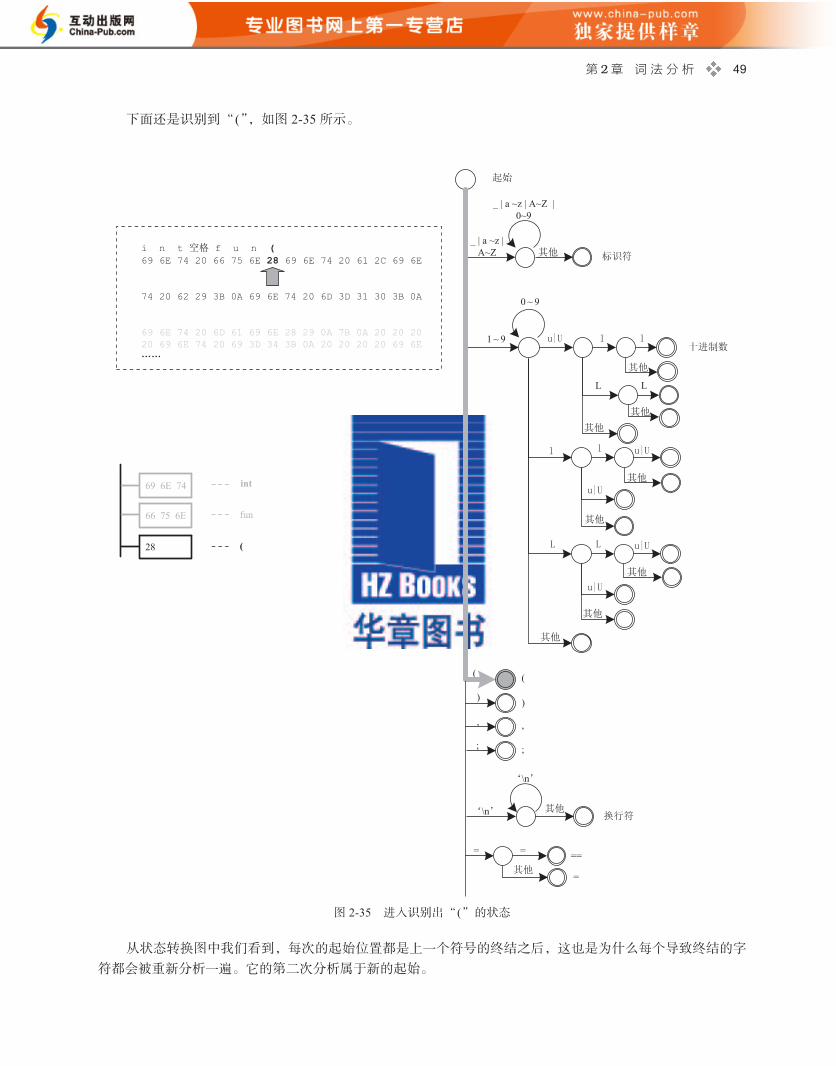
第 2 章 词 法 分 析 49
下面还是识别到“ (”,如图 2-35 所示。
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n (69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
intint
66 75 6E66 75 6E
funfun
2828
((
图 2-35 进入识别出“ (”的状态
从状态转换图中我们看到,每次的起始位置都是上一个符号的终结之后,这也是为什么每个导致终结的字
符都会被重新分析一遍。它的第二次分析属于新的起始。

50 编译系统透视:图解编译原理
识别其他标识符在状态图上的情景与“ int”、“ fun”、“ (”类似,下面我们看一下“=”和数字“10”的识
别情景。
先看“ =”的识别,识别到字符“ =”后无法判断是“ =”还是“ ==”,还得继续向后遍历,如图 2-36 和
图 2-37 所示。
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m =74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
6262
intint
bb
2929
))
3B3B
;;
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
图 2-36 进入识别出“=”的状态

第 2 章 词 法 分 析 51
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 174 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
6262
intint
bb
2929
))
3B3B
;;
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
图 2-37 识别出符号“=”并进入终态

52 编译系统透视:图解编译原理
识别到“1”后,可以确定就是“=”了。再看“10”的识别,如图 2-38 至图 2-40 所示。
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 174 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
3131
11
图 2-38 进入识别到数字的状态

第 2 章 词 法 分 析 53
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 1 074 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
31 3031 30
1010
图 2-39 不断处于识别到数字的状态

54 编译系统透视:图解编译原理
识别到“;”,最终确定了“10”这个符号,如图 2-40 所示。
1 ~ 9
0 ~ 9
L L
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
,,
((
))
;;
\n
\n
= ===
=
i n t f u n ( i n t a , i n69 6E 74 20 66 75 6E 28 69 6E 74 20 61 2C 69 6E
t b ) ; \n i n t m = 1 0 ;74 20 62 29 3B 0A 69 6E 74 20 6D 3D 31 30 3B 0A
69 6E 74 20 6D 61 69 6E 28 29 0A 7B 0A 20 20 20 20 69 6E 74 20 69 3D 34 3B 0A 20 20 20 20 69 6E
69 6E 7469 6E 74
6D6D
intint
mm
3D3D
==
31 3031 30
1010
图 2-40 识别出符号“10”并进入终态
其余状态转换图和我们介绍过的状态转换图的构成是一样的,使用时,都是从起始状态开始,遇到不同的
字符后进入不同的识别状态,最后识别出符号并进入终态。

第 2 章 词 法 分 析 55
2.4 GCC 实现词法分析的源代码
2.4.1 词法分析源代码总览状态转换图体现出来的规则最终要落实在 GCC 源代码中。我们先来总览 GCC 源代码中词法分析的部分程
序调用架构图,如图 2-41 所示。
状态转换图的指导思想主要体现在架构图中 _cpp_lex_direct 函数和 cpp_classify_number 函数部分,其中 _cpp_lex_direct 函数完成了所有符号的识别,从初始状态到终态都是
在这里完成的;数字的识别相对比较复杂,_cpp_lex_direct函数在识别到数字后,先将其存下来,然后在 cpp_classify_number 函数中详细甄别数字的具体类型和属性。除了这两个
函数外,其他的部分,有些用来做预处理(我们会在第 8 章
详细介绍预处理),另外一些则偏重于工程处理,比如符号识
别出来后存储在哪里等。下面我们着重看这两个核心函数的
处理过程。
_cpp_lex_direct 函数对源代码进行遍历分析,我们先来
总体了解此函数。
进入起始状态的代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… fresh_line: // 跳转到下一行继续分析字符串 …… buffer = pfile->buffer; // 字符串都存储在 buffer 中,这里是准备获取字符 …… skipped_white: // 跳过空白继续分析字符 …… c = *buffer->cur++; // cur 指向的是当前正在分析的字符,cur 指向下一个字符 ……}
之后开始分析符号。
2.4.2 结合 GCC 源代码讲解词法分析过程
1. 分析空白分隔符空白分隔符不属于 C 语言中符号的实际内容,遇到它后,会直接将其当作空白字符跳过,即跳转到
skipped_white 这个点,回到初始状态,情景如图 2-42 所示。
' ' | '\t' | '\f ' | '\v' | '\0'
' ' | '\t' | '\f ' | '\v' | '\0'
图 2-42 空白分隔符的状态转换图
代码如下所示:
// 代码路径:libcpp/lex.c:
c_lex_one_token
c_lex_with_flags
cpp_get_token_with_location
cpp_classify_number
cpp_get_token_1
_cpp_lex_token
_cpp_lex_direct
图 2-41 词法分析函数调用图

56 编译系统透视:图解编译原理
cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的字符,准备分析 { case ' ': case '\t': case '\f': case '\v': case '\0': // 这几个字符就是空白分隔符 result->flags |= PREV_WHITE; // 设置空白分隔符标志 skip_whitespace (pfile, c); // 发现空白字符后一直往后遍历,直到找到 // 非空白分隔符为止 goto skipped_white; // 回到初始状态,准备继续分析下一个字符 ……}
2. 分析换行符换行符也不属于实际的符号内容,从代码中可以看到,没有对这个字符做什么符号属性标记,遇到它后跳
转到 fresh_line 这个点,回到初始状态,情景如图 2-43 所示。
\n
\n
图 2-43 换行符的状态转换图
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的字符 { …… case '\n': // 遇到换行符 …… goto fresh_line; // 跳转到这个点,回到初始状态,准备继续 // 分析下一个字符 ……}
3. 确定符号为数字根据 C 语言规则,如果符号的第一个字符是 0 到 9 中的任意一个,该符号就是数字,如果第一个字符是
“ .”,就要看紧跟着的字符,如果仍是 0 到 9 中的任意一个,也表示该符号是数字,是浮点型数字。至于具体
的情景,我们在介绍完 _cpp_lex_direct 函数后会详细介绍,代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的字符“{” …… case '0': case '1': case '2': case '3': case '4': // 遇到这几个字符就确定当前符号是数字 case '5': case '6': case '7': case '8': case '9': { …… result->type = CPP_NUMBER; // 将当前符号属性设置为数字

第 2 章 词 法 分 析 57
lex_number (pfile, &result->val.str, &nst); // 此函数将数字的全部内容先以字符串的形式 // 存储起来,以待分析 …… break; } …… case '.': // 识别到“.” …… if (ISDIGIT (*buffer->cur)) // 检测后面跟随的是不是 0 到 9 中的字符 { …… result->type = CPP_NUMBER; // 将符号属性设置为数字 lex_number (pfile, &result->val.str, &nst); // 此函数将数字的全部内容先以字符串的形式 // 存储起来,以待分析 …… } else if (*buffer->cur == '.' && buffer->cur[1] == '.') // 再前瞻两个字符,如果都是“.” buffer->cur += 2, result->type = CPP_ELLIPSIS; // 将符号属性设置为缺省符 ……}
4. 确定符号为字符或字符串具体的情景我们在介绍完 _cpp_lex_direct 函数后会详细介绍,这里先总体看一下。如果符号的第一个字符
如果是“ L”、“ u”、“ U”或“ R”,可能是标识符,也可能是字符串,程序中先分析它是不是字符串,代码如
下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的字符 { …… case 'L': // 识别到“L”、“u”、“U”或“R”,先分析 // 是不是字符或字符串 case 'u': case 'U': case 'R': /* 'L', 'u', 'U', 'u8' or 'R' may introduce wide characters, wide strings or raw strings. */ if (c == 'L' || CPP_OPTION (pfile, rliterals) || (c != 'R' && CPP_OPTION (pfile, uliterals)))
{ if ((*buffer->cur == '\'' && c != 'R') // cur指向的是符号第二个字符,cur[1]和cur[2] || *buffer->cur == '"' // 分别是第三个和第四个字符,这里以前瞻的 || (*buffer->cur == 'R' // 方式来判断符号是不是字符或字符串 && c != 'R' && buffer->cur[1] == '"' && CPP_OPTION (pfile, rliterals)) || (*buffer->cur == '8' && c == 'u' && (buffer->cur[1] == '"' || (buffer->cur[1] == 'R' && buffer->cur[2] == '"' && CPP_OPTION (pfile, rliterals))))) { lex_string (pfile, result, buffer->cur - 1); // 如果是字符或字符串,进入这个函数,具体分析 // 它们的内容 break;

58 编译系统透视:图解编译原理
} } /* Fall through. */
case '_': // 执行到这里,说明不是字符串,而是标识符,则处理标识符 case 'a': case 'b': case 'c': case 'd': case 'e': case 'f': case 'g': case 'h': case 'i': case 'j': case 'k': case 'l': case 'm': case 'n': case 'o': case 'p': case 'q': case 'r':……}
符号的第一个字符如果是“ \'”或“ "”,就可以确定符号是字符或字符串,进入 lex_string 函数来分析字
符串内容。代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的 ASCII 码,准备分析 { …… case '\'': // 识别到“\'”或“"”,确定当前符号是字符串 case '"': lex_string (pfile, result, buffer->cur - 1); // 确定是字符串后,进入此函数,具体分析字符串的内容 break; ……}
5. 确定符号为标识符下面我们来看标识符的识别,至于具体的情景,我们在介绍完 _cpp_lex_direct 函数后会详细介绍,先总体
看一下。对于前面介绍的识别字符串,在识别到“L”、“u”、“U”或“R”时,如果当前符号不是字符串,那
就是标识符,标识符的第一个字符是字母或下划线,这几个字符属于字母。我们来看完整的标识符识别条件,
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的 ASCII 码,准备分析 { …… case 'L': // 识别到“L”、“u”、“U”或“R”,先分析是不是字符串 case 'u': case 'U': case 'R': /* 'L', 'u', 'U', 'u8' or 'R' may introduce wide characters, wide strings or raw strings. */ if (c == 'L' || CPP_OPTION (pfile, rliterals) // 如果不是字符或字符串,则是标识符 || (c != 'R' && CPP_OPTION (pfile, uliterals)))
{ if ((*buffer->cur == '\'' && c != 'R') || *buffer->cur == '"' || (*buffer->cur == 'R' && c != 'R' && buffer->cur[1] == '"' && CPP_OPTION (pfile, rliterals)) || (*buffer->cur == '8'

第 2 章 词 法 分 析 59
&& c == 'u' && (buffer->cur[1] == '"' || (buffer->cur[1] == 'R' && buffer->cur[2] == '"' && CPP_OPTION (pfile, rliterals))))) { lex_string (pfile, result, buffer->cur - 1); // 如果是字符或字符串,进入这个函数,具体分析它们的内容 break; } } /* Fall through. */
case '_': // 字母或下划线开头的符号都是标识符 case 'a': case 'b': case 'c': case 'd': case 'e': case 'f': case 'g': case 'h': case 'i': case 'j': case 'k': case 'l': case 'm': case 'n': case 'o': case 'p': case 'q': case 'r': case 's': case 't': case 'v': case 'w': case 'x': case 'y': case 'z': case 'A': case 'B': case 'C': case 'D': case 'E': case 'F': case 'G': case 'H': case 'I': case 'J': case 'K': case 'M': case 'N': case 'O': case 'P': case 'Q': case 'S': case 'T': case 'V': case 'W': case 'X': case 'Y': case 'Z': result->type = CPP_NAME; // 设置符号属性为标识符 { …… result->val.node.node = lex_identifier (pfile, buffer->cur - 1, false, &nst); // 确定符号为标识符后,进入此函数,继续识别标识符的内容 …… } /* Convert named operators to their proper types. */ …… break; ……}
6. 分析运算符和分隔符下面我们来看各种运算符和分隔符。
先看符号“ /”,它后面紧跟不同的字符来构成不同的运算符。“ /*”和“ //”都是注释的意思,“ /*”和
“*/”组合时可以注释掉它们之间的内容;“//”用来注释掉当前行的内容;“ /=”是指对运算符左边和右边的操
作数做除法,然后将数值赋给左边操作数;不是以上情况才能确定“ /”就是除号,情景如图 2-44 所示。
/
'\n'
*
图 2-44 “注释”、“ /=”和“ /”的状态转换图

60 编译系统透视:图解编译原理
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的 ASCII 码,准备分析 { …… case '/': // 识别到“/” …… c = *buffer->cur; // 获取“/”后面的字符,准备继续往后识别,看是不是除号
if (c == '*') // 识别到后面是“*”,确定是注释一些内容 { if (_cpp_skip_block_comment (pfile)) // 进入该函数,一直遍历后续的 ASCII码,看能不能找到 // “*/”,确定注释掉哪部分内容,这些内容就不参与词法分析了 …… } else if (c == '/' && (CPP_OPTION (pfile, cplusplus_comments) || cpp_in_system_header (pfile))) // 识别到“/”,确定是要注释掉当前行中的内容 { …… if (skip_line_comment (pfile) && CPP_OPTION (pfile, warn_comments)) // 一直遍历 ASCII 码,找到“\n”,确定一行结束, // 此行的内容不再参与词法分析 …… } else if (c == '=') // 识别到“=”,确定是“/=”运算符 { buffer->cur++; // cur 指向“=”后面的字符,准备识别后面的符号 result->type = CPP_DIV_EQ; // 设置当前符号属性为“/=” break; } else { result->type = CPP_DIV; // 后面跟的字符不是以上三种情况,说明当前符号就是 // 除号,设置属性 break; } ……}
下面来看“ <”。如果此时正在进行预处理,“ <”可以用来引用某个头
文件,它就不是小于号,否则,还要看它后面跟着什么字符,如果后续是
“ =”,则构成“ <=”运算符,即小于等于;如果后续仍然是“ <”,就还要
往后看,如果后续仍然是“ =”,就是“ <<=”,即左移并赋值,如果后续没
有“ =”,就是“ <<”,即左移;这些情况都排除掉,才可以确定“ <”就是
小于号,情景如图 2-45 所示。
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的 ASCII 码,准备分析 { …… case '<': // 识别到“<”
< =<=
<
<
<<=
<<
=
图 2-45 “<=”、“<<=”、“<<”、
“<”的状态转换图

第 2 章 词 法 分 析 61
if (pfile->state.angled_headers) // 此时正处于预处理阶段,要确定头文件了 { lex_string (pfile, result, buffer->cur - 1); // 分析头文件的字符串信息 if (result->type != CPP_LESS) break; }
result->type = CPP_LESS; // 默认运算符是小于号,后面如果没有改变,就是它了 if (*buffer->cur == '=') // 识别到下一个字符号是“=” buffer->cur++, result->type = CPP_LESS_EQ; // 设置当前符号是小于等于号 else if (*buffer->cur == '<') // 识别到下一个字符是“<” { buffer->cur++; // 继续往后看 IF_NEXT_IS ('=', CPP_LSHIFT_EQ, CPP_LSHIFT); // 分析出究竟是“<<=”还是“<<” } …… break; ……}
大于号的分析识别过程与小于号类似,如果后续是“=”,则构
成“>=”运算符,即大于等于;如果仍然跟着“>”,就还要往后看,
若后续是“=”,就是“>>=”,即右移并赋值,如果后续没有“=”,
就是“ >>”,即右移;这些情况都排除掉,才可以确定“ >”就是
大于号,情景如图 2-46 所示。
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的 ASCII 码,准备分析 { …… case '>': // 识别到“>” result->type = CPP_GREATER; // 将属性默认设置为大于号,后面没有变动,就是它 if (*buffer->cur == '=') // 识别到后面跟着的字符是“=” buffer->cur++, result->type = CPP_GREATER_EQ; // 设置符号属性为大于等于 else if (*buffer->cur == '>') // 识别到后面跟着的字符是“>” { buffer->cur++; // 还得往后看 IF_NEXT_IS ('=', CPP_RSHIFT_EQ, CPP_RSHIFT); // 分析出究竟是“>>=”还是“>>” } break; ……}
下面来看“ %”,情况比较简单,识别到“ %”后,往后再看
一个字符,如果是“=”,就是“%=”,即求余并赋值,否则就是求
余,情景如图 2-47 所示。
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c 中保存着当前正要分析的 ASCII 码,准备分析 {
>
>
=
> =
>=
>>=
>>
图 2-46 “>=”、“>>=”、“>>”、“>”
的状态转换图
%%=
=
%
图 2-47 “%=”、“%”的状态转换图

62 编译系统透视:图解编译原理
…… case '%': // 识别到“%” result->type = CPP_MOD; // 默认就是求余运算符,后面没有改变,就是它 if (*buffer->cur == '=') // 继续往后识别到“=” buffer->cur++, result->type = CPP_MOD_EQ; // 确定此运算符是“%=” …… break; ……}
下面来看“ .”。如果后面跟着的第二个和第三个字符都是“ .”,说明当前符号是“ ...”,即缺省符,表示
变参,情景如图 2-48 所示。
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *_cpp_lex_direct (cpp_reader *pfile){ …… switch (c) // c中保存着当前正要分析的ASCII码,准备分析 { …… case '.': // 识别到“.” …… if (ISDIGIT (*buffer->cur)) // 检测后面跟随的是不是 0 到 9 中的字符 { …… result->type = CPP_NUMBER; // 将符号属性设置为数字 lex_number (pfile, &result->val.str, &nst); // 此函数将数字的全部内容先以字符串的形式 // 存储起来,以待分析 …… } else if (*buffer->cur == '.' && buffer->cur[1] == '.') // 再往后识别两个字符,如果都是“.” buffer->cur += 2, result->type = CPP_ELLIPSIS; // 将符号属性设置为缺省符 ……}
其他运算符的识别过程大体类似,情景如图 2-49 和图 2-50 所示。
+ =+=
+++
+
-
---
=-=
-
> ->*
->
*
&&&
&
&==
&=
|||
|
|==
|
:::
:
:
图 2-49 各种运算符和分隔符的状态转换图一
. .
*.*
.
图 2-48 “…”、“ .*”的状态转换图

第 2 章 词 法 分 析 63
**=
=
*
===
=
=
!!=
=
!
^^=
=
^
###
#
#
??
~~
,,
((
))
[[
]]
{{
}}
;
;
图 2-50 各种运算符和分隔符的状态转换图二
代码如下所示:
// 代码路径:libcpp/lex.c:cpp_token *
_cpp_lex_direct (cpp_reader *pfile)
{
……
switch (c) // c中保存着当前正要分析的ASCII码,准备分析
{
……
case '+': // 识别出字符“+”
result->type = CPP_PLUS; // 默认符号属性是加法运算符
if (*buffer->cur == '+') // 继续往后识别,又识别到了字符“+”
buffer->cur++, result->type = CPP_PLUS_PLUS; // 将符号属性设置为“++”
else if (*buffer->cur == '=') // 继续往后识别,又识别到了字符“=”
buffer->cur++, result->type = CPP_PLUS_EQ; // 将符号属性设置为“+=”
break;
case '-': // 识别出字符“-”
result->type = CPP_MINUS; // 默认符号属性是减法运算符
if (*buffer->cur == '>') // 继续往后识别,识别到了字符“>”

64 编译系统透视:图解编译原理
{
……
result->type = CPP_DEREF; // 确认是“->”运算符,即指向运算符
……
}
else if (*buffer->cur == '-') // 继续往后识别,识别到了字符“-”
buffer->cur++, result->type = CPP_MINUS_MINUS; // 确认是“--”运算符
else if (*buffer->cur == '=') // 继续往后识别,识别到了字符“=”
buffer->cur++, result->type = CPP_MINUS_EQ; // 确认是“-=”运算符
break;
case '&': // 识别出字符“&”
result->type = CPP_AND; // 确定运算符属性是“&”,即按位与
if (*buffer->cur == '&') // 继续识别到字符“&”,
buffer->cur++, result->type = CPP_AND_AND; // 确定运算符为“&&”
else if (*buffer->cur == '=') // 继续识别到字符“=”
buffer->cur++, result->type = CPP_AND_EQ; // 确定运算符为“&=”
break;
case '|': // 识别出字符“|”
result->type = CPP_OR; // 确定运算符属性是“|”,即按位或
if (*buffer->cur == '|') // 继续识别到字符“|”
buffer->cur++, result->type = CPP_OR_OR; // 确定运算符为“||”
else if (*buffer->cur == '=') // 继续识别到字符“=”
buffer->cur++, result->type = CPP_OR_EQ; // 确定运算符为“|=”
break;
case ':': // 识别出字符“:”
result->type = CPP_COLON; // 确定运算符为“:”
……
break;
case '*': IF_NEXT_IS ('=', CPP_MULT_EQ, CPP_MULT); break; // 确定运算符为“*=”或“*”
case '=': IF_NEXT_IS ('=', CPP_EQ_EQ, CPP_EQ); break; // 确定运算符为“==”或“=”
case '!': IF_NEXT_IS ('=', CPP_NOT_EQ, CPP_NOT); break; // 确定运算符为“!=”或“!”
case '^': IF_NEXT_IS ('=', CPP_XOR_EQ, CPP_XOR); break; // 确定运算符为“^=”或“^”
case '#': IF_NEXT_IS ('#', CPP_PASTE, CPP_HASH); result->val.token_no = 0; break;
// 确定运算符为“##”或“#”
case '?': result->type = CPP_QUERY; break; // 确定运算符为“?”
case '~': result->type = CPP_COMPL; break; // 确定运算符为“~”
case ',': result->type = CPP_COMMA; break; // 确定运算符为“,”
case '(': result->type = CPP_OPEN_PAREN; break; // 确定运算符为“(”
case ')': result->type = CPP_CLOSE_PAREN; break; // 确定运算符为“)”
case '[': result->type = CPP_OPEN_SQUARE; break; // 确定运算符为“[”
case ']': result->type = CPP_CLOSE_SQUARE; break; // 确定运算符为“]”
case '{': result->type = CPP_OPEN_BRACE; break; // 确定运算符为“{”
case '}': result->type = CPP_CLOSE_BRACE; break; // 确定运算符为“}”
case ';': result->type = CPP_SEMICOLON; break; // 确定运算符为“;”
……
}
在 _cpp_lex_direct 函数中,每一次 switch...case... 都对应着一次状态转换图上的“起始状态”至“终态”,
即识别一个符号。不难发现,各个运算符的识别过程比较简单,一两步或两三步就到终态了,而标识符、数字
以及字符串的识别过程相对烦琐一些,我们在代码分析中只做了大体介绍。在确定了符号属性后,后续的内容
分别在 lex_identifier、lex_number 和 lex_string 函数中实现,最终达到终态。接下来,我们分别详细讲解这 3个函数的实现过程。

第 2 章 词 法 分 析 65
2.4.3 标识符、数字、字符和字符串的详细分析过程
1. 标识符的详细分析过程先来看 lex_identifier 函数,即标识符的识别过程,情景如图 2-51 所示。
_ | a ~z | A~Z
_ | a ~z | A~Z | 0~9
图 2-51 标识符的状态转换图
代码如下所示:
// 代码路径:libcpp/lex.c: static cpp_hashnode * lex_identifier (cpp_reader *pfile, const uchar *base, bool starts_ucn, struct normalize_state *nst) { …… cur = pfile->buffer->cur; // cur 指向的是下一个字符 if (! starts_ucn) while (ISIDNUM (*cur)) // 一直检测,若下一个字符不是字母、数字或下划线,则跳出循环 { hash = HT_HASHSTEP (hash, *cur); cur++; // 符合字母、数字或下划线条件,cur 就继续指向下一个字符 } pfile->buffer->cur = cur; // 跳出循环后,进入终态 ……}
// 代码路径:include/safe-ctype.h: …… _sch_isidnum = _sch_isidst|_sch_isdigit, /* A-Za-z0-9_ */ …… #define ISIDNUM(c) _sch_test(c, _sch_isidnum) // 字母、数字或下划线的判断条件展开形式 ……}
2. 数字的详细分析过程下面我们来看数字的识别过程。后续的数字识别过程在状态转换图的基础上做了调整,大体分为两步:第
一步是,只要识别出是数字,就把后续内容当作字符串存起来,不管是什么;第二步是,根据字符串中的内容,
分析它的具体属性,状态转换图的思想主要体现在第二步。
我们先来看第一步,通过调用 lex_number 函数来实现。代码如下所示:
// 代码路径:libcpp/lex.c: static void lex_number (cpp_reader *pfile, cpp_string *number, struct normalize_state *nst) { …… cur = pfile->buffer->cur;
/* N.B. ISIDNUM does not include $. */ while (ISIDNUM (*cur) || *cur == '.' || VALID_SIGN (*cur, cur[-1])) // 只要符合数字规则,就继续循环 { cur++; // cur不断地指向后面的ASCII码,直到遇到空格,跳出循环 NORMALIZE_STATE_UPDATE_IDNUM (nst);

66 编译系统透视:图解编译原理
}
pfile->buffer->cur = cur; // 跳出循环后,buffer->cur 指向空格 } …… number->len = cur - base; // 计算出数字有多长 dest = _cpp_unaligned_alloc (pfile, number->len + 1); // 为存储数字开辟空间 memcpy (dest, base, number->len); // 把数字的内容记录下来 dest[number->len] = '\0'; // 最后加上“\0”,表明是以字符串的形式记录下 number->text = dest;}
// 代码路径:include/safe-ctype.h: …… _sch_isidnum = _sch_isidst|_sch_isdigit, /* A-Za-z0-9_ */ …… #define ISIDNUM(c) _sch_test(c, _sch_isidnum) // 字母、数字或下划线的判断条件展开形式 ……}
// 代码路径:libcpp/internal.h: …… /* Test if a sign is valid within a preprocessing number. */ #define VALID_SIGN(c, prevc) \ (((c) == '+' || (c) == '-') && \ ((prevc) == 'e' || (prevc) == 'E' \ || (((prevc) == 'p' || (prevc) == 'P') \ && CPP_OPTION (pfile, extended_numbers))))
#define CPP_OPTION(PFILE, OPTION) ((PFILE)->opts.OPTION) // 科学计数法的识别条件 ……
我们再来看第二步。前面介绍了词法分析的函数调用顺序。
第二步等 cpp_get_token_with_location 函数返回后,在 c_lex_with_flags 函数中进行。代码如下所示:
// 代码路径:gcc/c-family/c-lex.c: enum cpp_ttype c_lex_with_flags (tree *value, location_t *loc, unsigned char *cpp_flags, int lex_flags) { …… tok = cpp_get_token_with_location (parse_in, loc); type = tok->type; retry_after_at: switch (type) { …… unsigned int flags = cpp_classify_number (parse_in, tok, &suffix, *loc); // 此函数将确定数据的具体属性 …… } ……}
数字的属性包括三种:类型属性(整型、浮点型等)、进制属性(十进制、八进制、十六进制等)和后缀信
息(如短类型、宽类型等辅助类型信息),下面我们来介绍 cpp_classify_number 函数。情景如图 2-52 至图 2-56所示。

第 2 章 词 法 分 析 67
1 ~ 9
0 ~ 9
L L
0
0 ~ 7
L L
图 2-52 十进制数的状态转换图 图 2-53 八进制数的状态转换图
L L
~ ~
~ ~0 ~ 9
0 ~ 9
图 2-54 十六进制数的状态转换图
0 ~ 9 0 ~ 9 0 ~ 9
0 ~ 9 0 ~ 9
0 ~ 90 ~ 9
0 ~ 9
0 ~ 9 0 ~ 9
0 ~ 9
0 ~ 9图 2-55 十进制数浮点数的状态转换图

68 编译系统透视:图解编译原理
0 ~ 9 0 ~ 9 0 ~ 9
0 ~ 9 0 ~ 9
0 ~ 90 ~ 9
0 ~ 9
0 ~ 9 0 ~ 9
0 ~ 9
0 ~ 9
图 2-55 (续)
0 ~ 9
0 ~ 9
0 ~ 9
0 ~ 9
0 ~ 9
0 ~ 9
~ ~0 ~ 9 ~ ~0 ~ 9
~ ~0 ~ 9
~ ~0 ~ 9
~ ~0 ~ 9
~ ~0 ~ 9
图 2-56 十六进制数浮点数的状态转换图
cpp_classify_number 函数的代码如下所示:
// 代码路径:libcpp/expr.c: unsigned int

第 2 章 词 法 分 析 69
cpp_classify_number (cpp_reader *pfile, const cpp_token *token, const char **ud_suffix, source_location virtual_location) { const uchar *str = token->val.str.text; // 获取字符串的内容(前面 lex_number 函数中已经保存了内容) const uchar *limit; unsigned int max_digit, result, radix; enum {NOT_FLOAT = 0, AFTER_POINT, AFTER_EXPON} float_flag; // 关于浮点数的三种标志:NOT_FLOAT 为非浮点标志, // AFTER_POINT 为已经识别到浮点的标志, // AFTER_EXPON 为科学计数法标志(exponent:指数) bool seen_digit; …… if (token->val.str.len == 1) // 如果字符串的长度为 1 return CPP_N_INTEGER | CPP_N_SMALL | CPP_N_DECIMAL; // 那就不用再分析了,这个数据就是个十进制的短整型 limit = str + token->val.str.len; // 通过起始字符和字符串长度值,获取字符串末尾字符 float_flag = NOT_FLOAT; // 先默认将要分析的数字是非浮点数 max_digit = 0; // 默认识别到的最大数字是 0 radix = 10; // 先默认将要分析的数字是十进制数 seen_digit = false;
// 先确定数字是个几进制的数 if (*str == '0') // 识别到第一个字符是“0” { radix = 8; // 就肯定不是十进制数了,先默认是八进制数,往后看看再说 str++; // 准备往后遍历
/* Require at least one hex digit to classify it as hex. */ if ((*str == 'x' || *str == 'X') // 如果第二个字符是“x”或“X”,同时第三个字符 // 是“.”或 0 ~ 9、A ~ F、a ~ f && (str[1] == '.' || ISXDIGIT (str[1]))) { radix = 16; // 说明是十六进制数 str++; } else if ((*str == 'b' || *str == 'B') && (str[1] == '0' || str[1] == '1')) { // 如果第二个字符是“b”或“B”,同时第三个字符 // 是“0”或“1” radix = 2; // 说明是二进制数 str++; } } // 到这里就确定了数据是几进制数
// 循环中判断数字是非浮点数还是浮点数,以及有没有使用科学计数法 for (;;) { unsigned int c = *str++;
if (ISDIGIT (c) || (ISXDIGIT (c) && radix == 16)) // 识别到 0 ~ 9 或者十六进制下的 0 ~ 9、A ~ F、a ~ f { seen_digit = true; // 确定当前识别到的字符是数字 c = hex_value (c); if (c > max_digit) // 不断更改识别到的最大数字 max_digit = c; } else if (c == '.') // 识别到浮点了 {

70 编译系统透视:图解编译原理
if (float_flag == NOT_FLOAT) // 如果此时还默认数字是非浮点数 float_flag = AFTER_POINT; // 就要改设为浮点数了,而且确定此时已经遍历过了浮点 …… } else if ((radix <= 10 && (c == 'e' || c == 'E')) || (radix == 16 && (c == 'p' || c == 'P'))) // 识别到了科学计数法标志 { float_flag = AFTER_EXPON; // 设置科学计数法标志 break; // 终止对科学计数法部分数据的进一步识别,跳出循环 } else { /* Start of suffix. */ str--; break; // 如果执行到这里,整个数字的数值内容就算识别完了, // 要么是非浮点数,要么是浮点数,但不会有科学计数法, // 识别完后,准备识别后缀信息 } } if (radix != 16 && float_flag == NOT_FLOAT) // 确定数字不是十六进制数,而且是非浮点数 { result = interpret_float_suffix (pfile, str, limit - str); // 设置后缀信息 …… else result = 0; // 后缀信息设置为 0,这个 result 最终将用来存储 // 数字的全部属性信息 } if (float_flag != NOT_FLOAT && radix == 8) // 如果数字是浮点型或包含科学计数法,同时还是个八进制数 radix = 10; // 设置为十进制数 …… if (float_flag != NOT_FLOAT) // 数字是浮点型或包含科学计数法 { …… if (float_flag == AFTER_EXPON) // 如果用了科学计数法,前面跳出了循环,这里继续遍历 { if (*str == '+' || *str == '-') // 判断指数是“+”还是“-” str++;
…… do str++; while (ISDIGIT (*str)); // 只要是 0 ~ 9,就说明符合指数规则,继续遍历 } result = interpret_float_suffix (pfile, str, limit - str); // 设置后缀信息 …… result |= CPP_N_FLOATING; // 确定此数字为浮点数,设置标志位 } else // 数字是非浮点数 { result = interpret_int_suffix (pfile, str, limit - str); // 设置后缀信息 …… result |= CPP_N_INTEGER; // 确定此数字为非浮点数,设置标志位 } …… // 到这里为止,后缀类型信息都已经确定了,下面最后再把几进制这一信息加上,数字就算分析完了

第 2 章 词 法 分 析 71
if (radix == 10) result |= CPP_N_DECIMAL; // 确定数字为十进制数,设置信息 else if (radix == 16) result |= CPP_N_HEX; // 确定数字为十六进制数,设置信息 else if (radix == 2) result |= CPP_N_BINARY; // 确定数字为二进制数,设置信息 else result |= CPP_N_OCTAL; // 确定数字为八进制数,设置信息
return result; // 数字分析完毕,返回结果 ……}
3. 字符或字符串的详细分析过程先来看 lex_string 函数,即字符或字符串的识别过程,情景如图 2-57 和图 2-58 所示。
~ ~0 ~ 9
0 ~ 7 0 ~ 7 0 ~ 7
~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9
~ ~0 ~ 9~ ~0 ~ 9~ ~0 ~ 9~ ~0 ~ 9
~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9
L|U
backslash\ newline
\
’ " ? \a b f n r t v
x
u
U
backslash\ newline
\
u
8
图 2-57 字符常量的状态转换图一

72 编译系统透视:图解编译原理
backslash\ newline
\
’ " ? \a b f n r t v
x
u
U
L | U
u8
~ ~0 ~ 9
~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9
~ ~0 ~ 9~ ~0 ~ 9~ ~0 ~ 9
~ ~0 ~ 9
~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9 ~ ~0 ~ 9
0 ~ 7 0 ~ 7 0 ~ 7
图 2-58 字符常量的状态转换图二
代码如下所示:
// 代码路径:libcpp/lex.c:static voidlex_string (cpp_reader *pfile, cpp_token *token, const uchar *base){ …… cur = base; terminator = *cur++; // 获取到字符或字符串的第一个字符,cur 指向第二个字符 if (terminator == 'L' || terminator == 'U') // 先看看字符或字符串前面有没有修饰符,“L”、“U”、“u”、“8” // 都是修饰符 terminator = *cur++; else if (terminator == 'u') { terminator = *cur++; if (terminator == '8') terminator = *cur++; } …… // 开始识别字符或字符串的实质内容了 if (terminator == '"') // 识别到“"”,说明是字符串 type = (*base == 'L' ? CPP_WSTRING : // 根据修饰符有无或种类来设置字符串的类型 *base == 'U' ? CPP_STRING32 : *base == 'u' ? (base[1] == '8' ? CPP_UTF8STRING : CPP_STRING16) : CPP_STRING); else if (terminator == '\'') // 识别到“\'”,说明是字符

第 2 章 词 法 分 析 73
type = (*base == 'L' ? CPP_WCHAR : // 根据修饰符有无或种类来设置字符的类型 *base == 'U' ? CPP_CHAR32 : *base == 'u' ? CPP_CHAR16 : CPP_CHAR); else terminator = '>', type = CPP_HEADER_NAME; // 还有一种情况,此时正在识别某个头文件的名字,设置类型 for (;;) // 继续向后遍历字符或字符串的内容 { cppchar_t c = *cur++; // 根据字符串或字符的词法规定, “"”或“\”成对出现 …… else if (c == terminator) // 找到另一个“"”或“\”,说明内容识别完毕了
break; else if (c == '\n') // 遇到“\n”,就要准备处理头文件的名字了 { cur--; // cur 指针往前退一个字符
if (terminator == '>') // 退了一个正好是“>”,说明头文件的名字识别完毕 { token->type = CPP_LESS; return; } …… } …… }……
}