chapter 5 : expression of biological information
TRANSCRIPT

80 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
CHAPTER 5 : EXPRESSION OF BIOLOGICAL INFORMATION
SUBTOPIC 5.1 : DNA and genetic information
LEARNING OUTCOMES:
a) State the concept of Central Dogma.
MAIN IDEAS /
KEY POINT EXPLANATION NOTES
Concept of
Central Dogma
Definition of Central Dogma :
The process by which the instructions in DNA are converted into a
functional product.
It was first proposed in 1956 by Francis Crick (the discoverer of the
structure of DNA)
• In molecular biology, the central dogma explains the flow of
genetic information, from DNA to RNA to make a protein.
• The central dogma states that the pattern of information that
occurs most frequently in our cells is :
o From existing DNA to make new DNA through DNA
replication
o From DNA to make new RNA via transcription
o From RNA to make new proteins through translation
• The central dogma suggests that DNA contains information needed
to make all of our proteins. RNA is a messenger that carries this
information to ribosomes. At ribosomes, the information is
translated from a code into proteins.

81 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS /
KEY POINT EXPLANATION NOTES
• The process by which the DNA instructions are converted into
proteins is called gene expression.
• Gene expression has two key stages - transcription and translation.
• In transcription, information in DNA is converted into small,
portable RNA messages.
• During translation, these RNA messages travel from the cell
nucleus to ribosomes where they are ‘read’ to make specific
protein.
SUBTOPIC 5.2 : DNA replication
LEARNING OUTCOMES:
a) Describe semi-conservative replication of DNA.
b) State the enzymes and proteins involved in DNA replication.
c) Describe the mechanism of DNA replication and the enzymes involved.
MAIN IDEAS /
KEY POINT EXPLANATION NOTES
Semi-
conservative
replication of
DNA
DNA replication is the biological process of producing two identical
DNA molecules from one original DNA molecule.
• Semi-conservative replication model has been demonstrated by
Meselson and Stahl.
• DNA is a double helix molecule
made up of two complementary strands.
• During replication, the two original
DNA strands are separated. Each
strand of the original DNA molecule
then act as a template for the
synthesizing of new complementary
DNA strand. As a result, the new
DNA molecule consist of one original
strand and one new strand. This process
is referred to as semi-conservative
replication of DNA.

82 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS /
KEY POINT EXPLANATION NOTES
Enzymes and
proteins involved
in DNA
replication
Enzymes /
Protein
Function
Helicase
Catalyzed the unwind and separate the
double helix of original DNA strands at
replication forks
Single-strand
binding proteins
Hold the separated original DNA strands
apart and prevent them from re-forming
helix while they act as template
Topoisomerase
Catalyzed in relieving overwinding strain
ahead of replication fork (by breaking,
swiveling and rejoining the strands)
Primase
Catalyzed the synthesis of RNA primer at 5’
end of leading strand and at 5’ end of each
Okazaki fragment of lagging strand
DNA polymerase
III
Catalyzed the synthesizing of new DNA
strand by adding DNA nucleotides to the 3’
end of RNA primer or pre-existing DNA
strand (by specific base pairing rule)
DNA polymerase I
Catalyzed the removal of RNA nucleotides
of primer and replacing them with DNA
nucleotides
DNA ligase
Catalyzed the joining of Okazaki fragments
of lagging strand DNA // Catalyzed the joining
of 3’ end of DNA that replaces primer to the
rest of leading strand DNA.

83 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS /
KEY POINT EXPLANATION NOTES
Mechanism of
DNA replication
DNA Replication : Getting Started
• During S phase of interphase, the replication of DNA begins at
particular sites called origins of replication
• A eukaryotic chromosome may have hundreds or even a few
thousand origins of replication
• Proteins that initiate DNA replication recognize this sequence and
attach to the DNA, separating the two strands and opening up a
replication bubble
• Replication of DNA proceeds in both directions until the entire DNA
molecule is copied.
• Multiple replication bubbles
form and eventually fuse,
thus speeding up the copying
of the very long DNA
molecules.
• At each end of a replication
bubble is a replication fork,
a Y-shaped region where the
parental strands are being
unwound.

84 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS /
KEY POINT EXPLANATION NOTES
• Helicases are enzymes that untwist the double helix at the replication
forks and separating the two parental (original) strands, making them
available as template strands.
• After the parental strands separate, single-strand binding proteins
bind to the unpaired DNA strands, keeping them from re-forming
helix.
• The unwinding of the double helix causes tighter twisting and strain
ahead of the replication fork. Topoisomerase is an enzyme that helps
relieve the strain by breaking, swiveling and rejoining DNA strands.
• The enzymes that synthesize DNA cannot initiate the synthesis of a
polynucleotide; they can only add DNA nucleotides to the end of an
already existing strand.
• The initial nucleotide chain that is produced during DNA synthesis
is actually a short chain of RNA called a primer and is synthesized
by the enzyme primase.
• The new DNA strand start from the 3’ end of the RNA primer.
• Enzymes called DNA polymerase III (abbreviated DNA pol III)
catalyze the synthesis of new DNA by adding DNA nucleotides to
the 3’ end of pre-existing RNA primer.
Helicase disrupts
the hydrogen
bonding between
DNA base pairs.

85 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS /
KEY POINT EXPLANATION NOTES
• DNA polymerases can add nucleotides only to the 3’ end of a primer
or growing DNA strand. Thus, a new DNA strand can elongate in
the 5’ to 3’ direction.
• Along one template strand, DNA pol III synthesize a complementary
strand continuously by elongating the new DNA in 5’ to 3’ direction
thus, producing the leading strand. Only one primer is required for
DNA pol III to synthesize the entire leading strand.
• To elongate the other new strand of DNA in 5’ to 3’ direction, DNA
pol III must work along the other template strand in the direction
away from the replication fork. The DNA strand elongating in this
direction is called the lagging strand.
• The lagging strand is synthesized discontinuously, consisting of a
series of Okazaki fragments. Each Okazaki fragment on the lagging
strand must be primed separately.
• Another DNA polymerase, DNA polymerase I (abbreviated DNA
pol I) replaces the RNA nucleotides of the primer with DNA
nucleotides.
• Enzyme DNA ligase catalyze the joining of all Okazaki fragments
into a continuous strand.
DNA ligase catalyze
the formation of
phosphodiester
bond.

86 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS /
KEY POINT EXPLANATION NOTES

87 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
CHAPTER 5 : EXPRESSION OF BIOLOGICAL INFORMATION
SUBTOPIC 5.3 : Protein synthesis (transcription and translation)
LEARNING OUTCOMES:
a) Give an overview of the relationship between DNA and protein synthesis.
b) Explain transcription which involves RNA polymerase to form mRNA.
c) Show the relationship between codon on mRNA with sequence of amino acid using genetic code table.
d) Explain translation of mRNA forming polypeptide chain.
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
Relationship
between DNA
and protein
synthesis.
Genes provide the instructions for making specific proteins. The bridge between DNA and protein
synthesis is the single strand RNA. Getting from DNA to protein requires two stages : transcription
and translation. Transcription is the synthesis of RNA using information in the DNA. The
resulting RNA molecule is messenger RNA (mRNA) because it carries a genetic message from
the DNA to the protein-synthesizing machinery of the cell. (Note that, transcription is the general
term for the synthesis of any kind of RNA on a DNA template). Translation is the synthesis of a
polypeptide using the information in the mRNA. The cell must translate the nucleotide
sequence of an mRNA molecule into the amino acid sequence of a polypeptide. The sites of
translation are ribosomes. In eukaryotic cells, transcription occurs in the nucleus, but the
mRNA must be transported to the cytoplasm for translation.
Definition of protein synthesis :
A process by which amino acids are linearly arranged into proteins through the involvement of
ribosomal RNA, transfer RNA, messenger RNA and various enzymes.

88 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
Transcription
which
involves RNA
polymerase to
form mRNA.
• An enzyme called RNA polymerase unwinds the two strands of DNA
apart and joins together RNA nucleotides complementary to the DNA
template strand, thus elongating the RNA polynucleotide.
• Like the DNA polymerases, RNA polymerases can assemble a
polynucleotide only in its 5’ to 3’ direction, adding the RNA
nucleotides at 3’ end.
• Unlike DNA polymerases, however, RNA polymerases are able to
initiate the synthesis of RNA polynucleotide (they do not need any
pre-existing primer).
• Bacteria have one type of RNA polymerase that synthesizes mRNA
and other types of RNA such as ribosomal RNA (rRNA).
• Eukaryotes have at least three types of RNA polymerase in their
nuclei, the one used for pre-mRNA synthesis is called RNA
polymerase II.
• The three stages of transcription are initiation, elongation and
termination.
Initiation of Transcription
• Specific sequences of nucleotides along the DNA mark where
transcription of a gene begins and ends. The DNA sequence where
RNA polymerase attaches and initiates transcription is known as the
promoter.
• The promoter sequence in DNA is said to be upstream.
• The parts of DNA downstream from the promoter that is transcribed
into RNA is called a transcription unit.
• The promoter of a gene includes within it the transcription start point
– the nucleotide where RNA polymerase actually begins synthesis of
the mRNA.
• In bacteria, the RNA polymerase itself specifically recognizes and
binds to the promoter.
The direction of
transcription is
referred as
downstream and the
other direction as
upstream.

89 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
• In eukaryotes, transcription factors (a collection of proteins) mediate
the binding the binding of RNA polymerase and the initiation of
transcription.
• Eukaryotic promoter commonly includes a TATA box (upstream from
the transcriptional start point).
• Several transcription factors (one recognizing the TATA box), bind to
the DNA. Additional transcription factors bind to the DNA along with
RNA polymerase II, forming the transcription initiation complex.
• RNA polymerase II then unwinds the DNA double helix and RNA
synthesis begins at the start point on the template strand.
Elongation of the RNA strand
• As RNA polymerase moves along the DNA, it unwinds the double
helix, exposing the DNA nucleotides for pairing with RNA
nucleotides.
• The enzyme adds RNA nucleotides to the 3’ end of the growing RNA
strand.
• The new RNA strand peels away from its DNA template and the DNA
double helix re-forms.

90 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
Termination of Transcription
• Bacteria and eukaryotes differ in the way they terminate
transcription.
• In bacteria, transcription proceeds through a terminator sequence
in the DNA. The transcribed terminator functions as the
terminator signal, causing the RNA polymerase to detach from the
DNA and release the RNA transcript (which requires no further
modification before translation).
• In eukaryotes, RNA polymerase II transcribes a sequence on the
DNA called the polyadenylation signal sequence, which specifies
a polyadenylation signal in the pre-mRNA.
• Once the polyadenylation signal sequence appears, it is immediately
bound by certain proteins in the nucleus. Then, these proteins cut the
RNA transcript free from the RNA polymerase II, releasing the pre-
mRNA.
• The pre-mRNA then undergoes RNA processing (RNA splicing)

91 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
Eukaryotic cells modify RNA after transcription
• Enzymes in the eukaryotic nucleus modify pre-mRNA before it is
carried to the cytoplasm
• This is because the pre-mRNA have long noncoding regions that are
not translated. Most of these noncoding sequences are interspersed
between coding segments of the pre-mRNA.
• The noncoding regions are called introns and the coding regions
are exons. (The terms intron and exon are used for both RNA
sequences and DNA sequences)
• During RNA splicing, certain sections of the pre-mRNA are cut out
and the remaining parts sliced together. These modifications
produce an mRNA molecule ready for translation.
• In RNA splicing, the introns are cut out from the pre-mRNA
molecule and the exons joined together, forming an mRNA
• The removal of introns is accomplished by spliceosome (large
complex made of proteins and small RNAs). Spliceosome binds to
intron. The intron is then released (and rapidly degraded) and the
spliceosome joins together the exons
Relationship
between
codon on
mRNA with
sequence of
amino acid
using genetic
code table
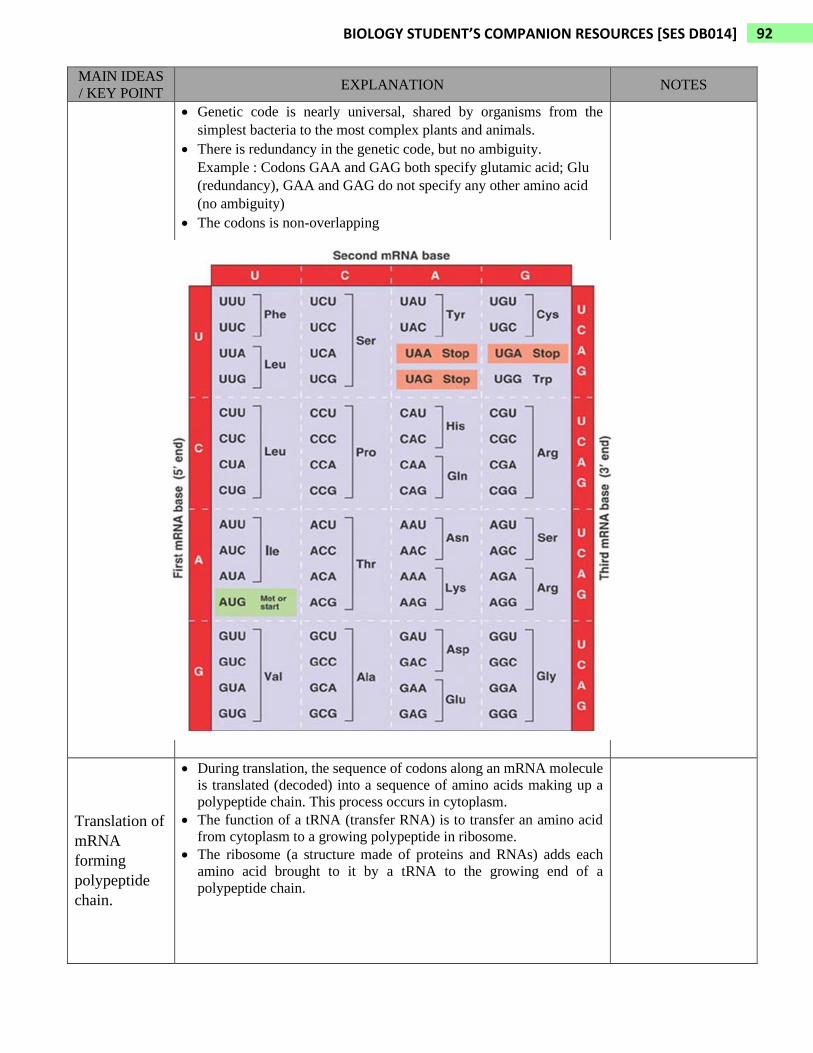
• The mRNA nucleotide triplets are called codons
• Codons are written in the 5’ to 3’ direction.
• There are 64 codons in genetic code table.
• 61 codons code for amino acids.
• The three codons that do not code for amino acids are the stop
(termination) codons, marking the end of translation.
The three stop codons : UAA, UAG, UGA
• Codon AUG codes for amino acid methionine (Met) and also function
as start (initiation) codon, marking the beginning of translation.
92 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
• Genetic code is nearly universal, shared by organisms from the
simplest bacteria to the most complex plants and animals.
• There is redundancy in the genetic code, but no ambiguity.
Example : Codons GAA and GAG both specify glutamic acid; Glu
(redundancy), GAA and GAG do not specify any other amino acid
(no ambiguity)
• The codons is non-overlapping
Translation of
mRNA
forming
polypeptide
chain.
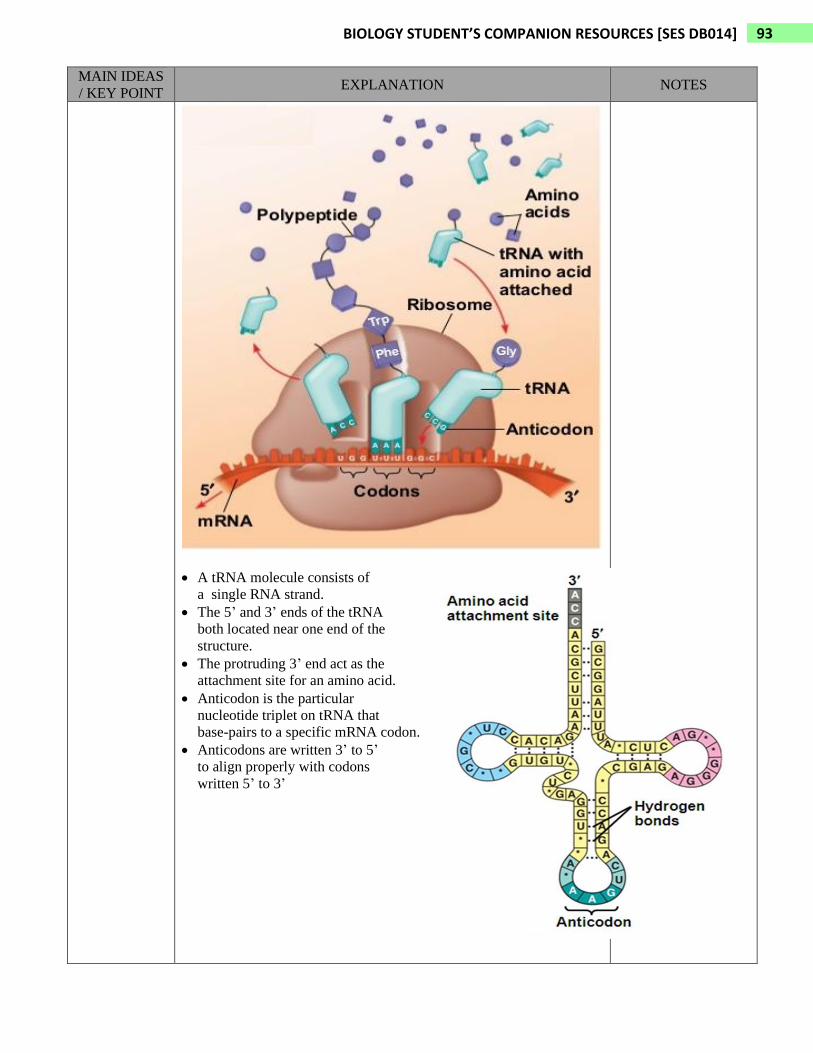
• During translation, the sequence of codons along an mRNA molecule
is translated (decoded) into a sequence of amino acids making up a
polypeptide chain. This process occurs in cytoplasm.
• The function of a tRNA (transfer RNA) is to transfer an amino acid
from cytoplasm to a growing polypeptide in ribosome.
• The ribosome (a structure made of proteins and RNAs) adds each
amino acid brought to it by a tRNA to the growing end of a
polypeptide chain.
93 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
• A tRNA molecule consists of
a single RNA strand.
• The 5’ and 3’ ends of the tRNA
both located near one end of the
structure.
• The protruding 3’ end act as the
attachment site for an amino acid.
• Anticodon is the particular
nucleotide triplet on tRNA that
base-pairs to a specific mRNA codon.
• Anticodons are written 3’ to 5’
to align properly with codons
written 5’ to 3’
94 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
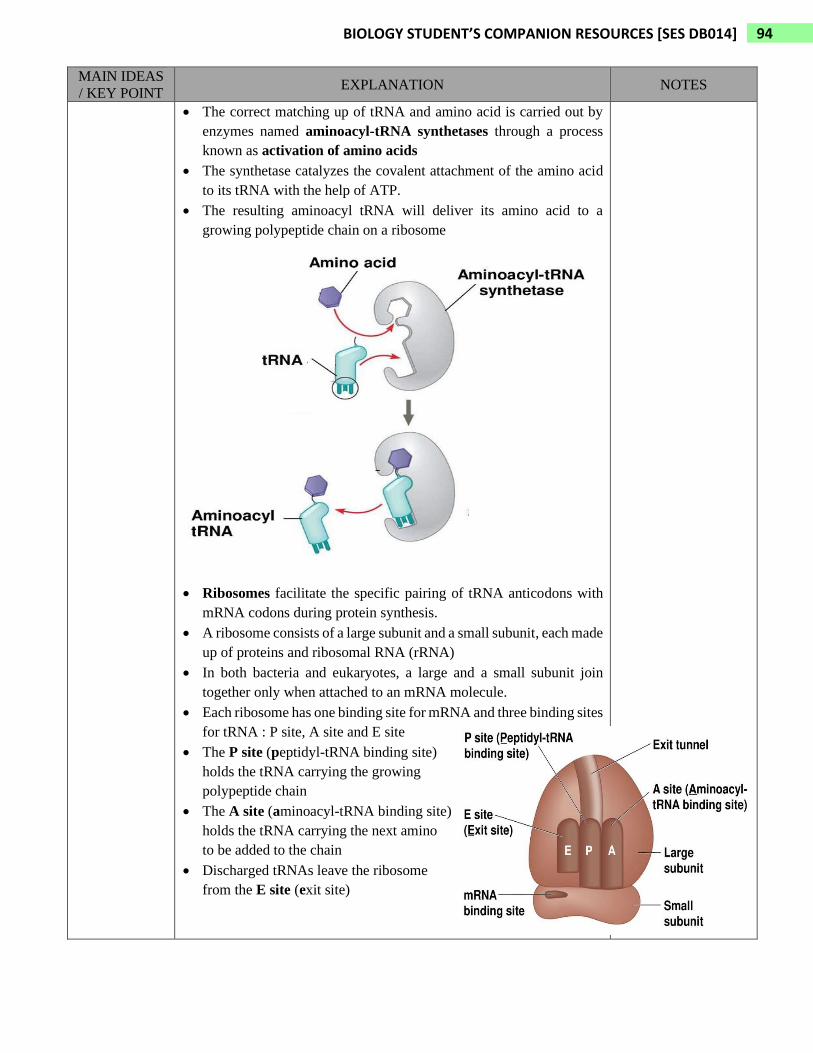
• The correct matching up of tRNA and amino acid is carried out by
enzymes named aminoacyl-tRNA synthetases through a process
known as activation of amino acids
• The synthetase catalyzes the covalent attachment of the amino acid
to its tRNA with the help of ATP.
• The resulting aminoacyl tRNA will deliver its amino acid to a
growing polypeptide chain on a ribosome
• Ribosomes facilitate the specific pairing of tRNA anticodons with
mRNA codons during protein synthesis.
• A ribosome consists of a large subunit and a small subunit, each made
up of proteins and ribosomal RNA (rRNA)
• In both bacteria and eukaryotes, a large and a small subunit join
together only when attached to an mRNA molecule.
• Each ribosome has one binding site for mRNA and three binding sites
for tRNA : P site, A site and E site
• The P site (peptidyl-tRNA binding site)
holds the tRNA carrying the growing
polypeptide chain
• The A site (aminoacyl-tRNA binding site)
holds the tRNA carrying the next amino
to be added to the chain
• Discharged tRNAs leave the ribosome
from the E site (exit site)

95 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
• Ribosome holds the tRNA and mRNA
in close proximity and positions the
new amino acid so that it can be
added to the carboxyl end of the
growing polypeptide.
• It then catalyzes the formation of
peptide bond.
• When the polypeptide is complete,
it is released through the exit tunnel
in the ribosome’s large subunit.
• Translation can be divided into three
stages : initiation, elongation
and termination.
Initiation of Translation
• In bacteria and eukaryotes, the
start codon (AUG) signals the
start of translation
• In the first step of translation,
a small ribosomal subunit binds
to both the mRNA and a specific
initiator tRNA, which carries the
amino acid methionine.
• The initiator tRNA hydrogen-bonds
to the AUG start codon.
• This followed by the attachment
of a large ribosomal subunit,
forming the translation initiation
complex.
• At the end of the initiation process,
the initiator tRNA sits in the P site
of the ribosome, and the vacant
A site is ready for the next
aminoacyl tRNA.
• Polypeptide is always synthesized
in one direction, from the initial
methionine at the amino end
(N-terminus) toward the final
amino acid at the carboxyl end
(C-terminus)

96 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
Elongation of the Polypeptide Chain
• Amino acids are added one by one to the previous amino acids at the
carboxyl end (C-terminus) of the growing chain.
• Each addition involves three steps : codon recognition, peptide bond
formation and translocation.
• The mRNA move through the ribosome in one direction only,
starting from the 5’ end. This is equivalent to the ribosome moving
5’ → 3’ on the mRNA.
• The ribosome and the mRNA move relative to each other
unidirectionally, codon by codon
• During codon recognition :
Anticodon of an incoming
aminoacyl tRNA base pairs
with the complementary
mRNA codon in A site.
• During peptide bond formation :
An rRNA molecule of the large
ribosomal subunit catalyzes the
formation of a peptide bond
between the two amino acids
(between amino end / amino group
of the new amino acid in the A site
and the carboxyl end / carboxyl
group of the growing polypeptide
in P site)
97 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]
MAIN IDEAS
/ KEY POINT EXPLANATION NOTES
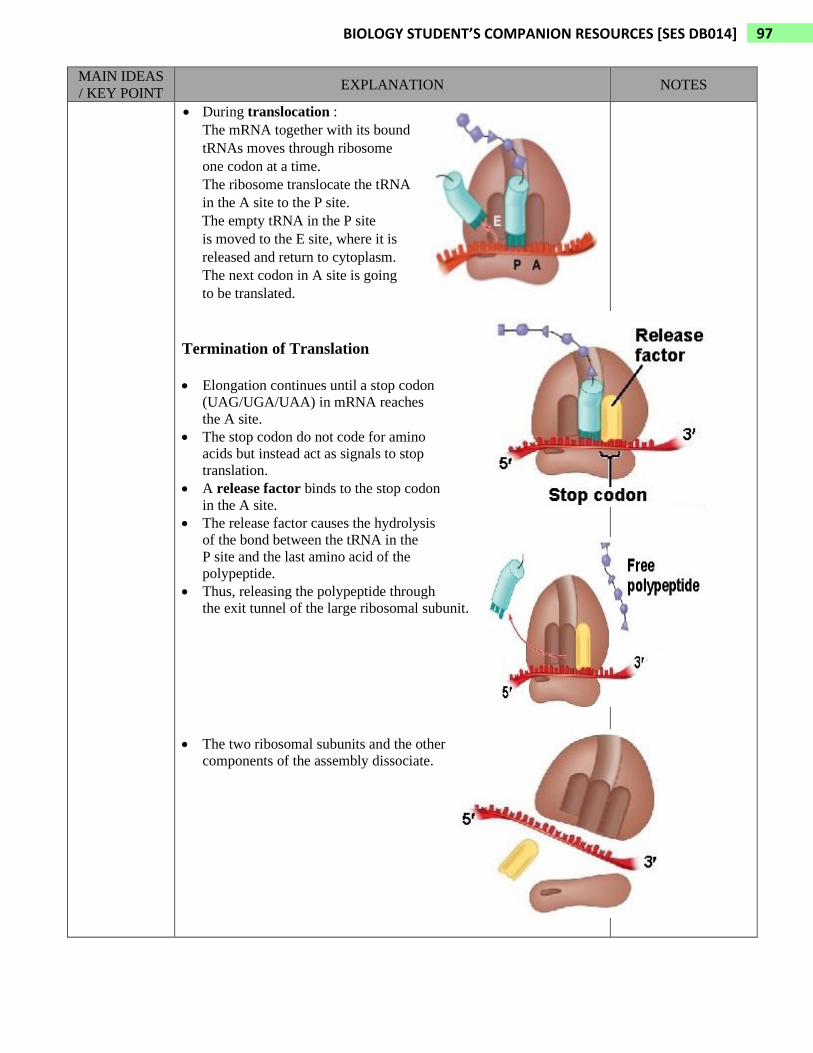
• During translocation :
The mRNA together with its bound
tRNAs moves through ribosome
one codon at a time.
The ribosome translocate the tRNA
in the A site to the P site.
The empty tRNA in the P site
is moved to the E site, where it is
released and return to cytoplasm.
The next codon in A site is going
to be translated.
Termination of Translation
• Elongation continues until a stop codon
(UAG/UGA/UAA) in mRNA reaches
the A site.
• The stop codon do not code for amino
acids but instead act as signals to stop
translation.
• A release factor binds to the stop codon
in the A site.
• The release factor causes the hydrolysis
of the bond between the tRNA in the
P site and the last amino acid of the
polypeptide.
• Thus, releasing the polypeptide through
the exit tunnel of the large ribosomal subunit.
• The two ribosomal subunits and the other
components of the assembly dissociate.

1 BIOLOGY STUDENT’S COMPANION RESOURCES [SES DB014]