chembank: a small-molecule screening and cheminformatics
TRANSCRIPT

ChemBank A Small-Molecule Screening and Cheminformatics Resource Database
CitationSeiler Kathleen Petri Gregory A George Mary Pat Happ Nicole E Bodycombe Hyman A Carrinski Stephanie Norton Steve Brudz et al 2008 ChemBank a small-molecule screening and cheminformatics resource database Nucleic Acids Research 36(Supp 1 Database issue) D351-D359
Published Versiondoi101093nargkm843
Permanent linkhttpnrsharvardeduurn-3HULInstRepos4459224
Terms of UseThis article was downloaded from Harvard Universityrsquos DASH repository and is made available under the terms and conditions applicable to Other Posted Material as set forth at httpnrsharvardeduurn-3HULInstReposdashcurrentterms-of-useLAA
Share Your StoryThe Harvard community has made this article openly availablePlease share how this access benefits you Submit a story
Accessibility
Published online 18 October 2007 Nucleic Acids Research 2008 Vol 36 Database issue D351ndashD359doi101093nargkm843
ChemBank a small-molecule screening andcheminformatics resource databaseKathleen Petri Seiler Gregory A George Mary Pat Happ Nicole E Bodycombe
Hyman A Carrinski Stephanie Norton Steve Brudz John P Sullivan
Jeremy Muhlich Martin Serrano Paul Ferraiolo Nicola J Tolliday
Stuart L Schreiber and Paul A Clemons
Chemical Biology Program and Platform Broad Institute of Harvard and MIT 7 Cambridge Center Cambridge MA02142 USA
Received August 17 2007 Revised September 22 2007 Accepted September 25 2007
ABSTRACT
ChemBank (httpchembankbroadharvardedu)is a public web-based informatics environmentdeveloped through a collaboration between theChemical Biology Program and Platform at theBroad Institute of Harvard and MIT This knowledgeenvironment includes freely available data derivedfrom small molecules and small-molecule screensand resources for studying these data ChemBank isunique among small-molecule databases in itsdedication to the storage of raw screening dataits rigorous definition of screening experiments interms of statistical hypothesis testing and itsmetadata-based organization of screening experi-ments into projects involving collections of relatedassays ChemBank stores an increasingly varied setof measurements derived from cells and otherbiological assay systems treated with small mole-cules Analysis tools are available and are continu-ously being developed that allow the relationshipsbetween small molecules cell measurements andcell states to be studied Currently ChemBankstores information on hundreds of thousands ofsmall molecules and hundreds of biomedicallyrelevant assays that have been performed at theBroad Institute by collaborators from the worldwideresearch community The goal of ChemBank is toprovide life scientists unfettered access to biomed-ically relevant data and tools heretofore availableprimarily in the private sector
INTRODUCTION
ChemBank v10 was initiated as a National CancerInstitute (NCI)-sponsored activity within the Initiativefor Chemical Genetics (ICG) originally at HarvardrsquosInstitute of Chemistry and Cell Biology The evolvinginterest of the NCI in sponsoring chemical-geneticresearch has been reported (1) as has the evolution ofICG as a public research effort dedicated to acceleratingthe discovery of cancer-relevant small-molecule probes (2)At present ChemBank v20 (hereafter referred to asChemBank) represents an evolving collaboration betweenthe Chemical Biology Program and Chemical BiologyPlatform at the Broad Institute of Harvard and MITincluding interactions with academic syntheticchemists and biologists interested in high-throughputsmall-molecule screening approachesChemBank houses chemical structures and names
calculated molecular descriptors human-curated biologi-cal information regarding small molecule activities rawexperimental results from high-throughput biologicalassays and extensive metadata describing screeningexperiments While there are many other publicly avail-able small-molecule and drug databases [ChEBI (3)DrugBank (4) PubChem (5) and ZINC (6) amongothers] ChemBank is unique in three important ways(i) its dedication to the storage of raw screening data (ii)its rigorous definition of screening experiments in terms ofstatistical hypothesis testing and (iii) its hierarchicalmetadata-based organization of related assays into screen-ing projects Moreover the ChemBank website is morethan a simple data repository it contains tools forvisualization and analysis of small-molecule results
To whom correspondence should be addressed Email pclemonsbroadharvardeduCorrespondence may also be addressed to Stuart L Schreiber Email stuart_schreiberharvardedu
2007 The Author(s)
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (httpcreativecommonsorglicenses
by-nc20uk) which permits unrestricted non-commercial use distribution and reproduction in any medium provided the original work is properly cited
including raw and normalized high-throughput screening(HTS) data and chemical-genetic profiles Data sets maybe manipulated within ChemBank or downloaded for usewith external analysis tools ChemBank is a powerfulknowledge repository and analysis environment forchemists and biologists alike
RESULTS
ChemBank infrastructure
The ChemBank database consists of 95 tables segmentedinto seven logical groups representing compound informa-tion molecular descriptors assay results assay metadatabiological findings ontological associations and userinformation (Figure 1) Data from over 2500 high-throughput biological assays from 188 screening projectscurrently reside in ChemBank with new assays loadedquarterly ChemBank houses information on 17 millioncompound samples representing more than 12 millionunique small-molecule structures with over 300 calculatedmolecular descriptor values for each molecule Over1000 proteins 500 cell lines and 70 species are associatedwith the assays ChemBank data are stored and searchedusing an Oracle 10g (Oracle Corporation RedwoodShores CA USA) relational database extended with theDayCart Oracle cartridge (Daylight ChemicalInformation Systems Aliso Viejo CA USA) which isused for molecule substructure and similarity searches
Data access and optional registration
Anyone with Internet access can use ChemBank withoutregistering with a username and password using the
lsquoEnter as a Guestrsquo button However registration ishighly encouraged of all users as guest users are notpermitted to export data from ChemBank Registeredusers of ChemBank may download data directlyfrom their search results using the lsquo[export ]rsquo hyperlinkson several ChemBank webpages Downloadableresult files are exported in tab-delimited text formatfor maximum flexibility of use in other applicationsSimple Object Access Protocol (SOAP) web-serviceaccess is provided for much of the data in ChemBankService calls exist to list all projects and assayswithin ChemBank as well as assay plates and wellmeasurements There are also molecule services allowingsimilarity and substructure searches of molecules withinChemBank The Web-service Definition Language(WSDL) files for these services can be found on theChemBank website (httpchembankbroadharvardeduwebServiceshtm)
As a repository of primary data from HTS experimentsChemBank employs a data-embargo strategy to protectnewly generated data for a specified period and accord-ingly ChemBank comprises two separate websites con-taining overlapping datasets Public ChemBank (httpchembankbroadharvardedu) contains small-moleculeassay data that are more than one year old as well asmolecular descriptors and published bioactivity annota-tion for registered small molecules Data-Sharing-Agreement (DSA)-ChemBank contains all of the datacontent of Public ChemBank as well as small-moleculeassay data that are less than one year old Use of the latterdatabase is restricted to scientists who have depositedcompounds or performed screening experiments at theBroad Institute of Harvard and MIT and who have signed
Figure 1 Conceptual summary of ChemBank schema Logical illustration of ChemBank data model in which 95 tables are organized into groupsrepresenting components of the chemical biology research enterprise Each box represents several actual database tables as indicated andpseudocardinality relationships between boxes are meant to convey conceptual relationships rather than the more complex cardinality relationshipsthat relate the actual tables
D352 Nucleic Acids Research 2008 Vol 36 Database issue
a DSA (httpwwwbroadharvardeduchembiosciscreenfacilDataSharingAgreementpdf) The DSA stipu-lates conditions of participation such as shared author-ship intellectual property and expectations for sharingfollow-up data All scientists who have signed theagreement may browse the entire contents of DSA-ChemBank and renew their agreements annually forcontinued access to this resource Registration for thisversion of ChemBank is required and usernames andpasswords are assigned by the ChemBank team uponreceipt of the signed agreement DSA-ChemBank users login using their assigned username and password at adifferent URL (httpchembank-dsabroadharvardedu)
ChemBank queries molecular properties and assayorganization
ChemBank has multiple search interfaces available to theuser to enable both simple and complex queries Users cansearch for small molecules using properties such aspresence of a substructure (Figure 2a) calculated molec-ular descriptors (Figure 2b) or association with a curatedbiological activity (Figure 2c) Results from such searcheslead the user to a lsquoMolecule Displayrsquo view which showsbasic information about the small molecule includingnames structure chemical descriptors biological activityand screening test instances (Figure 2 background)
Users may also search for specific screening assaysby searching by assay or project names by individualscreeners or their home institution by assay type or by thespecies (eg of a cell line) under investigation in aparticular assay Text searches within screening projectdescriptions are also supported Assay search resultwebpages link to both assay and screening projectinformation a project is a grouping of assays under asingle biological motivation Details of an assay orscreening project are displayed on their respectivewebpages including user information and assay metadata(Figure 3)
Simple queries can be combined to generate complexmulti-criterion searches ChemBank has an extensivemulti-criterion search interface which allows searches tobe constructed interactively This interface supportsmodification of prior search criteria or addition of newcriteria and can be used even after initial search resultsare returned Additionally data analysis on a single orcombination of screens housed within ChemBank can beperformed and visualized as detailed in the followingsection More information on conducting ChemBanksearches and webpages can be found in the Help section(httpchembankbroadharvardedudetailshtmtag=Help)
ChemBank standard analysis model and visualizations
ChemBank houses both raw and normalized experimentalresults from many HTS and small-molecule microarray(SMM) (7) projects These datasets are the foundation fora data-analysis model specifically equipped to accumulaterich profiles of small-molecule performance acrossmultiple diverse biological assays One of the primaryrequirements of this approach is a data-analysis strategy
for small-molecule performance that affords normalizedvalues independent of both the screening technologyplatform and the specific biological question underinvestigation ChemBank users are not restricted tothis standard analysis paradigm rather each of theChemBank data-visualization tools affords access tomultiple data types along the analysis process includingraw data background-subtracted data and replicate-handled dataChemBank seeks to provide cross-sectional analysis
and multi-assay performance profiles (8ndash14) Thereforewe supplemented ChemBank raw screening data withnormalized data using an error model with several salientfeatures First it renders the results of multiple parallelassays formally comparable regardless of the originalsignal amplitudes or units of measurement Second itintroduces no assumptions about the strength of signalrequired to call screening positives This condition rulesout the use of arbitrary thresholds such as 2-fold inductionor 50 inhibition (1516) Third it does not rely on globalassumptions about the compound collection particularlythe assumption that most compounds will be inert in anygiven assay (1718)These three conditions suggested the use of only mock-
treatment wells as a basis for well-to-well plate-to-plateand experiment-to-experiment normalization We rea-soned that in any miniaturized assay of small-moleculeperformance we can always define a mock-treatmentcondition that mirrors compound treatment in every wayexcept for the presence of the compound For examplein a typical HTS experiment this condition is representedby the treatment of otherwise identical assay-well contentswith the delivery vehicle usually dimethylsulfoxideWe conceptualize our scoring method in terms of aformal hypothesis test comparing a compound-treatmentwith its associated mock-treatment distribution and thusseek the most reliable estimates of the statistical param-eters associated with this test In an ideal world onewould simply make many measurements of a compoundrsquosperformance in a particular assay system and manymeasurements of the corresponding vehicle mock-treat-ment condition in that assay system In such a case ourprimary score for a compound would be similar to the Zrsquostatistic for evaluating HTS methods during assaydevelopment (1519) Since making a statistically mean-ingful number of measurements of each compoundrsquosperformance is not practical we estimate the parametersof the compound-treatment distribution from the param-eters of the mock-treatment distribution At presentChemBank uses a constant-error assumption for plate-reader assays and a variable error assumption for small-molecule microarrays (see subsequent paragraph)To account for plate-to-plate variation in signal (1516)
the median raw value of mock-treatment signals on agiven assay plate is subtracted from each mock-treatmentvalue on the same plate (Figure 4a) providing a zero-centered distribution of mock-treatment measurementsfor each plate in one experiment In ChemBanka screening experiment is defined as a collection of distinctprobe source plates (eg a multi-microtiter plate library)exposed to the same assay conditions at the same time
Nucleic Acids Research 2008 Vol 36 Database issue D353
Next the population of zero-centered measurements forall mock-treatment wells in the experiment are collectedtogether and values failing Chauvenetrsquos criterion (20) forthis overall distribution are discarded (Figure 4b) toprotect against edge effects and other systematic artifactsknown to present a technical problem for microtiter plateexperiments (2122) The remaining mock-treatment mea-surements are used to normalize each compound-treat-ment well measurement independently first subtracting
the mean of remaining mock-treatment wells on the sameplate to obtain background-subtracted values (Figure 4c)then dividing by the twice the standard deviation of mock-treatment wells in the same experiment to obtaindimensionless Z-scores (Figure 4d) (Note that usingtwice the standard deviation is a consequence of aconstant-error assumption for microplate assaysdescribed in the preceding paragraph a more generalsolution allows the error estimate for positive signals to
Figure 2 ChemBank offers multiple routes to find chemical information Search tools allowing structure drawing (28) for substructure or similaritysearches (a) selection of calculated molecular descriptors (b) and selection of term-based bioactivity annotations (c) each provide avenues to findindividual molecules or sets of molecules in ChemBank The ChemBank lsquoMolecule Displayrsquo webpage (background) provides detailed informationabout each molecule including structure names molecular descriptors biological annotations sample information and screening instances
D354 Nucleic Acids Research 2008 Vol 36 Database issue
depend on signal strength eg the scale factor used forsmall-molecule microarray experiments is very close to[1+ IsignalImock] as determined empirically using controlarrays) Thus each compound well receives an algebrai-cally signed Z-score corresponding to the number ofstandard deviations it fell above or below the mean of awell-defined mock-treatment distribution Finally as mostscreening experiments deposited in ChemBank wereperformed in two technical replicates (A and B) thesereplicates were combined to produce a Composite Z-score(Figure 4e) by scaling the vector [ZAZB] by the cosinecorrelation with a vector corresponding to lsquoperfectreproducibilityrsquo (ie equal Z-scores in both replicates)This overall normalization procedure is similar to thatdescribed in earlier work at the Broad Institute (91223)and forms the basis for many of the ChemBank datavisualizations available to users of the database(Figure 4f)
Currently there are four available screening datavisualizations in ChemBank A simple heatmap visualiza-tion for assay plates corresponds to the microplate layoutin a screening experiment (Figure 5a) For statisticalanalysis of results from multiple assay plates comprisinga single HTS experiment ChemBank offers both histo-gram (Figure 5b) and scatterplot (Figure 4e) viewsFinally multi-assay visualization is possible via thelsquoFeature Visualizationrsquo webpage (Figure 5c) which is
generated by implementation of the standard analysismodel to provide a heatmap representing ChemBanklsquoComposite Z-scorersquo values for a series of assays andcompounds These visualization tools can be used inconjunction with the structure similarity substructurematching and molecular descriptor filtering capabilitiesdescribed previously to perform structurendashactivity rela-tionship analyses (Figure 5d) Taken together these searchand visualization tools represent an implementation ofchemical-genetic profiling and cheminformatic analysiscapabilities within ChemBank
Data curation and annotation
Data curation activities for ChemBank fall into twogeneral categories 1) annotation of information regardingsmall molecules and 2) annotation of informationregarding small-molecule assays Annotations regardingsmall-molecule effects on biological systems are generatedfrom the primary literature Hyperlinks to other databasessuch as Entrez Gene (24) GO (25) MeSH (httpwwwnlmnihgovmeshmeshhomehtml) and PubMed(5) are collected manually during curation activitiesSmall molecules and clinically used drugs often have
multiple names some drugs have dozens of differentbrand and generic names ChemBank names are curatedfrom multiple sources including public databasesthe United States Pharmacopeia (USP) Dictionary
Figure 3 Relationship of ChemBank lsquoView Projectrsquo and lsquoView Assayrsquo webpages Screenshots of representative screening project and assay (inset)webpages Emphasis (red boxes arrow) has been added to highlight key information including project description and motivation (a) individualassays within project (b) detailed description (shared by both webpages) of assay protocol (c) and individual screening plates within assay (d)
Nucleic Acids Research 2008 Vol 36 Database issue D355
the World Health Organization (WHO) InternationalNon-proprietary Name database (httpmednetwhointpublicdefaultaspxc=1f216b1a-c080-46a1-9a39-c33717387926) and chemical vendor websites to providean exhaustive list of names and synonyms for moleculesFor a subset of the bioactive small molecules in
ChemBank activity annotations from the biologicalliterature have been added Bioactivity annotations(see also Figure 2) are divided into four categories(i) Biochemical Interactions which indicate protein molec-ular targets or GO molecular functions (25) affected by thesmall molecule (ii) Therapeutic Indications which specifywhat diseases (ie MeSH terms) a small molecule is usedto treat or manage (iii) Therapeutic Uses terms from aninternally derived vocabulary that indicates what type ofclinical or biological activity a small molecule possessesand (iv) Biological Processes which indicate GO biologi-cal processes affected by the small molecule PubMed IDs(5) corresponding to these citations have been capturedbut are not yet exposed to the user and GO terms(Biochemical Interactions and Biological Processes)describing the effect(s) of the small molecule (eglsquoincreases apoptosisrsquo) are displayed but do not currentlyconnect directly to the GO website (httpamigogeneontologyorg)Annotation surrounding biological assays is collected
as field-based metadata using internal controlledvocabularies and is used to describe screening projects
experiments and assay plates Metadata associated witha screening project express the biological motivationand are displayed on the lsquoView Projectrsquo webpagemetadata associated with the details of a particular assay(instantiated as a screening lsquoexperimentrsquo see above)are displayed on the lsquoView Assayrsquo webpage (see alsoFigure 3)
For many of the most frequently screened smallmolecules in ChemBank annotation of autofluorescenceactivity is available to reduce false positives by providingautomated filtering in addition to detailed informationabout the optical properties of the compoundsAnnotation includes a binary filter of autofluorescencea plot of the range of wavelengths above a signalthreshold a plot of the shape of the spectra and acontour plot showing the autofluorescence over a rangethat includes wavelengths of common filter pairsAdditional details about autofluorescence detection anddata-analysis methods are available on the ChemBankwebsite (httpchembankbroadharvardedudetailshtmtag=HelpautoFluorMethodology)
DISCUSSION
ChemBank is a unique knowledge and analysisenvironment for small molecules and high-throughputsmall-molecule assays It provides calculated molecular
Figure 4 ChemBank standard data-analysis model for high-throughput small-molecule screens All raw small-molecule assay results in ChemBank arefurther processed by comparing each measurement with the collection of mock-treatment well measurements performed in the same screening experimentMedian values from mock-treatment wells on the same plate are used in an initial zero-centering step (a) after which the distribution of mock-treatmentmeasurements for the entire experiment is trimmed to eliminate systematic artifacts (b) Trimmed mock-treatment measurements are used to normalizeassay performance by first subtracting the mean of trimmed mock-treatment measurements on the same plate to give lsquobackground-subtracted valuesrsquo(c) then dividing by twice the standard deviation of trimmed mock-treatment measurements for the entire experiment to give lsquodimensionless Z-scorevaluesrsquo (d) Replicate handling is performed by cosine correlation of the replicate pair (for screens done in duplicate) of lsquodimensionless Z-score valuesrsquo foreach compound with a simple prior model of lsquoperfect reproducibilityrsquo to yield a lsquoComposite Z-score valuersquo (e) that represents the final primary screeningresult The ChemBank web interface provides access to raw and processed data types appropriate for each of its visualization tools (f)
D356 Nucleic Acids Research 2008 Vol 36 Database issue
descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

Published online 18 October 2007 Nucleic Acids Research 2008 Vol 36 Database issue D351ndashD359doi101093nargkm843
ChemBank a small-molecule screening andcheminformatics resource databaseKathleen Petri Seiler Gregory A George Mary Pat Happ Nicole E Bodycombe
Hyman A Carrinski Stephanie Norton Steve Brudz John P Sullivan
Jeremy Muhlich Martin Serrano Paul Ferraiolo Nicola J Tolliday
Stuart L Schreiber and Paul A Clemons
Chemical Biology Program and Platform Broad Institute of Harvard and MIT 7 Cambridge Center Cambridge MA02142 USA
Received August 17 2007 Revised September 22 2007 Accepted September 25 2007
ABSTRACT
ChemBank (httpchembankbroadharvardedu)is a public web-based informatics environmentdeveloped through a collaboration between theChemical Biology Program and Platform at theBroad Institute of Harvard and MIT This knowledgeenvironment includes freely available data derivedfrom small molecules and small-molecule screensand resources for studying these data ChemBank isunique among small-molecule databases in itsdedication to the storage of raw screening dataits rigorous definition of screening experiments interms of statistical hypothesis testing and itsmetadata-based organization of screening experi-ments into projects involving collections of relatedassays ChemBank stores an increasingly varied setof measurements derived from cells and otherbiological assay systems treated with small mole-cules Analysis tools are available and are continu-ously being developed that allow the relationshipsbetween small molecules cell measurements andcell states to be studied Currently ChemBankstores information on hundreds of thousands ofsmall molecules and hundreds of biomedicallyrelevant assays that have been performed at theBroad Institute by collaborators from the worldwideresearch community The goal of ChemBank is toprovide life scientists unfettered access to biomed-ically relevant data and tools heretofore availableprimarily in the private sector
INTRODUCTION
ChemBank v10 was initiated as a National CancerInstitute (NCI)-sponsored activity within the Initiativefor Chemical Genetics (ICG) originally at HarvardrsquosInstitute of Chemistry and Cell Biology The evolvinginterest of the NCI in sponsoring chemical-geneticresearch has been reported (1) as has the evolution ofICG as a public research effort dedicated to acceleratingthe discovery of cancer-relevant small-molecule probes (2)At present ChemBank v20 (hereafter referred to asChemBank) represents an evolving collaboration betweenthe Chemical Biology Program and Chemical BiologyPlatform at the Broad Institute of Harvard and MITincluding interactions with academic syntheticchemists and biologists interested in high-throughputsmall-molecule screening approachesChemBank houses chemical structures and names
calculated molecular descriptors human-curated biologi-cal information regarding small molecule activities rawexperimental results from high-throughput biologicalassays and extensive metadata describing screeningexperiments While there are many other publicly avail-able small-molecule and drug databases [ChEBI (3)DrugBank (4) PubChem (5) and ZINC (6) amongothers] ChemBank is unique in three important ways(i) its dedication to the storage of raw screening data (ii)its rigorous definition of screening experiments in terms ofstatistical hypothesis testing and (iii) its hierarchicalmetadata-based organization of related assays into screen-ing projects Moreover the ChemBank website is morethan a simple data repository it contains tools forvisualization and analysis of small-molecule results
To whom correspondence should be addressed Email pclemonsbroadharvardeduCorrespondence may also be addressed to Stuart L Schreiber Email stuart_schreiberharvardedu
2007 The Author(s)
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (httpcreativecommonsorglicenses
by-nc20uk) which permits unrestricted non-commercial use distribution and reproduction in any medium provided the original work is properly cited
including raw and normalized high-throughput screening(HTS) data and chemical-genetic profiles Data sets maybe manipulated within ChemBank or downloaded for usewith external analysis tools ChemBank is a powerfulknowledge repository and analysis environment forchemists and biologists alike
RESULTS
ChemBank infrastructure
The ChemBank database consists of 95 tables segmentedinto seven logical groups representing compound informa-tion molecular descriptors assay results assay metadatabiological findings ontological associations and userinformation (Figure 1) Data from over 2500 high-throughput biological assays from 188 screening projectscurrently reside in ChemBank with new assays loadedquarterly ChemBank houses information on 17 millioncompound samples representing more than 12 millionunique small-molecule structures with over 300 calculatedmolecular descriptor values for each molecule Over1000 proteins 500 cell lines and 70 species are associatedwith the assays ChemBank data are stored and searchedusing an Oracle 10g (Oracle Corporation RedwoodShores CA USA) relational database extended with theDayCart Oracle cartridge (Daylight ChemicalInformation Systems Aliso Viejo CA USA) which isused for molecule substructure and similarity searches
Data access and optional registration
Anyone with Internet access can use ChemBank withoutregistering with a username and password using the
lsquoEnter as a Guestrsquo button However registration ishighly encouraged of all users as guest users are notpermitted to export data from ChemBank Registeredusers of ChemBank may download data directlyfrom their search results using the lsquo[export ]rsquo hyperlinkson several ChemBank webpages Downloadableresult files are exported in tab-delimited text formatfor maximum flexibility of use in other applicationsSimple Object Access Protocol (SOAP) web-serviceaccess is provided for much of the data in ChemBankService calls exist to list all projects and assayswithin ChemBank as well as assay plates and wellmeasurements There are also molecule services allowingsimilarity and substructure searches of molecules withinChemBank The Web-service Definition Language(WSDL) files for these services can be found on theChemBank website (httpchembankbroadharvardeduwebServiceshtm)
As a repository of primary data from HTS experimentsChemBank employs a data-embargo strategy to protectnewly generated data for a specified period and accord-ingly ChemBank comprises two separate websites con-taining overlapping datasets Public ChemBank (httpchembankbroadharvardedu) contains small-moleculeassay data that are more than one year old as well asmolecular descriptors and published bioactivity annota-tion for registered small molecules Data-Sharing-Agreement (DSA)-ChemBank contains all of the datacontent of Public ChemBank as well as small-moleculeassay data that are less than one year old Use of the latterdatabase is restricted to scientists who have depositedcompounds or performed screening experiments at theBroad Institute of Harvard and MIT and who have signed
Figure 1 Conceptual summary of ChemBank schema Logical illustration of ChemBank data model in which 95 tables are organized into groupsrepresenting components of the chemical biology research enterprise Each box represents several actual database tables as indicated andpseudocardinality relationships between boxes are meant to convey conceptual relationships rather than the more complex cardinality relationshipsthat relate the actual tables
D352 Nucleic Acids Research 2008 Vol 36 Database issue
a DSA (httpwwwbroadharvardeduchembiosciscreenfacilDataSharingAgreementpdf) The DSA stipu-lates conditions of participation such as shared author-ship intellectual property and expectations for sharingfollow-up data All scientists who have signed theagreement may browse the entire contents of DSA-ChemBank and renew their agreements annually forcontinued access to this resource Registration for thisversion of ChemBank is required and usernames andpasswords are assigned by the ChemBank team uponreceipt of the signed agreement DSA-ChemBank users login using their assigned username and password at adifferent URL (httpchembank-dsabroadharvardedu)
ChemBank queries molecular properties and assayorganization
ChemBank has multiple search interfaces available to theuser to enable both simple and complex queries Users cansearch for small molecules using properties such aspresence of a substructure (Figure 2a) calculated molec-ular descriptors (Figure 2b) or association with a curatedbiological activity (Figure 2c) Results from such searcheslead the user to a lsquoMolecule Displayrsquo view which showsbasic information about the small molecule includingnames structure chemical descriptors biological activityand screening test instances (Figure 2 background)
Users may also search for specific screening assaysby searching by assay or project names by individualscreeners or their home institution by assay type or by thespecies (eg of a cell line) under investigation in aparticular assay Text searches within screening projectdescriptions are also supported Assay search resultwebpages link to both assay and screening projectinformation a project is a grouping of assays under asingle biological motivation Details of an assay orscreening project are displayed on their respectivewebpages including user information and assay metadata(Figure 3)
Simple queries can be combined to generate complexmulti-criterion searches ChemBank has an extensivemulti-criterion search interface which allows searches tobe constructed interactively This interface supportsmodification of prior search criteria or addition of newcriteria and can be used even after initial search resultsare returned Additionally data analysis on a single orcombination of screens housed within ChemBank can beperformed and visualized as detailed in the followingsection More information on conducting ChemBanksearches and webpages can be found in the Help section(httpchembankbroadharvardedudetailshtmtag=Help)
ChemBank standard analysis model and visualizations
ChemBank houses both raw and normalized experimentalresults from many HTS and small-molecule microarray(SMM) (7) projects These datasets are the foundation fora data-analysis model specifically equipped to accumulaterich profiles of small-molecule performance acrossmultiple diverse biological assays One of the primaryrequirements of this approach is a data-analysis strategy
for small-molecule performance that affords normalizedvalues independent of both the screening technologyplatform and the specific biological question underinvestigation ChemBank users are not restricted tothis standard analysis paradigm rather each of theChemBank data-visualization tools affords access tomultiple data types along the analysis process includingraw data background-subtracted data and replicate-handled dataChemBank seeks to provide cross-sectional analysis
and multi-assay performance profiles (8ndash14) Thereforewe supplemented ChemBank raw screening data withnormalized data using an error model with several salientfeatures First it renders the results of multiple parallelassays formally comparable regardless of the originalsignal amplitudes or units of measurement Second itintroduces no assumptions about the strength of signalrequired to call screening positives This condition rulesout the use of arbitrary thresholds such as 2-fold inductionor 50 inhibition (1516) Third it does not rely on globalassumptions about the compound collection particularlythe assumption that most compounds will be inert in anygiven assay (1718)These three conditions suggested the use of only mock-
treatment wells as a basis for well-to-well plate-to-plateand experiment-to-experiment normalization We rea-soned that in any miniaturized assay of small-moleculeperformance we can always define a mock-treatmentcondition that mirrors compound treatment in every wayexcept for the presence of the compound For examplein a typical HTS experiment this condition is representedby the treatment of otherwise identical assay-well contentswith the delivery vehicle usually dimethylsulfoxideWe conceptualize our scoring method in terms of aformal hypothesis test comparing a compound-treatmentwith its associated mock-treatment distribution and thusseek the most reliable estimates of the statistical param-eters associated with this test In an ideal world onewould simply make many measurements of a compoundrsquosperformance in a particular assay system and manymeasurements of the corresponding vehicle mock-treat-ment condition in that assay system In such a case ourprimary score for a compound would be similar to the Zrsquostatistic for evaluating HTS methods during assaydevelopment (1519) Since making a statistically mean-ingful number of measurements of each compoundrsquosperformance is not practical we estimate the parametersof the compound-treatment distribution from the param-eters of the mock-treatment distribution At presentChemBank uses a constant-error assumption for plate-reader assays and a variable error assumption for small-molecule microarrays (see subsequent paragraph)To account for plate-to-plate variation in signal (1516)
the median raw value of mock-treatment signals on agiven assay plate is subtracted from each mock-treatmentvalue on the same plate (Figure 4a) providing a zero-centered distribution of mock-treatment measurementsfor each plate in one experiment In ChemBanka screening experiment is defined as a collection of distinctprobe source plates (eg a multi-microtiter plate library)exposed to the same assay conditions at the same time
Nucleic Acids Research 2008 Vol 36 Database issue D353
Next the population of zero-centered measurements forall mock-treatment wells in the experiment are collectedtogether and values failing Chauvenetrsquos criterion (20) forthis overall distribution are discarded (Figure 4b) toprotect against edge effects and other systematic artifactsknown to present a technical problem for microtiter plateexperiments (2122) The remaining mock-treatment mea-surements are used to normalize each compound-treat-ment well measurement independently first subtracting
the mean of remaining mock-treatment wells on the sameplate to obtain background-subtracted values (Figure 4c)then dividing by the twice the standard deviation of mock-treatment wells in the same experiment to obtaindimensionless Z-scores (Figure 4d) (Note that usingtwice the standard deviation is a consequence of aconstant-error assumption for microplate assaysdescribed in the preceding paragraph a more generalsolution allows the error estimate for positive signals to
Figure 2 ChemBank offers multiple routes to find chemical information Search tools allowing structure drawing (28) for substructure or similaritysearches (a) selection of calculated molecular descriptors (b) and selection of term-based bioactivity annotations (c) each provide avenues to findindividual molecules or sets of molecules in ChemBank The ChemBank lsquoMolecule Displayrsquo webpage (background) provides detailed informationabout each molecule including structure names molecular descriptors biological annotations sample information and screening instances
D354 Nucleic Acids Research 2008 Vol 36 Database issue
depend on signal strength eg the scale factor used forsmall-molecule microarray experiments is very close to[1+ IsignalImock] as determined empirically using controlarrays) Thus each compound well receives an algebrai-cally signed Z-score corresponding to the number ofstandard deviations it fell above or below the mean of awell-defined mock-treatment distribution Finally as mostscreening experiments deposited in ChemBank wereperformed in two technical replicates (A and B) thesereplicates were combined to produce a Composite Z-score(Figure 4e) by scaling the vector [ZAZB] by the cosinecorrelation with a vector corresponding to lsquoperfectreproducibilityrsquo (ie equal Z-scores in both replicates)This overall normalization procedure is similar to thatdescribed in earlier work at the Broad Institute (91223)and forms the basis for many of the ChemBank datavisualizations available to users of the database(Figure 4f)
Currently there are four available screening datavisualizations in ChemBank A simple heatmap visualiza-tion for assay plates corresponds to the microplate layoutin a screening experiment (Figure 5a) For statisticalanalysis of results from multiple assay plates comprisinga single HTS experiment ChemBank offers both histo-gram (Figure 5b) and scatterplot (Figure 4e) viewsFinally multi-assay visualization is possible via thelsquoFeature Visualizationrsquo webpage (Figure 5c) which is
generated by implementation of the standard analysismodel to provide a heatmap representing ChemBanklsquoComposite Z-scorersquo values for a series of assays andcompounds These visualization tools can be used inconjunction with the structure similarity substructurematching and molecular descriptor filtering capabilitiesdescribed previously to perform structurendashactivity rela-tionship analyses (Figure 5d) Taken together these searchand visualization tools represent an implementation ofchemical-genetic profiling and cheminformatic analysiscapabilities within ChemBank
Data curation and annotation
Data curation activities for ChemBank fall into twogeneral categories 1) annotation of information regardingsmall molecules and 2) annotation of informationregarding small-molecule assays Annotations regardingsmall-molecule effects on biological systems are generatedfrom the primary literature Hyperlinks to other databasessuch as Entrez Gene (24) GO (25) MeSH (httpwwwnlmnihgovmeshmeshhomehtml) and PubMed(5) are collected manually during curation activitiesSmall molecules and clinically used drugs often have
multiple names some drugs have dozens of differentbrand and generic names ChemBank names are curatedfrom multiple sources including public databasesthe United States Pharmacopeia (USP) Dictionary
Figure 3 Relationship of ChemBank lsquoView Projectrsquo and lsquoView Assayrsquo webpages Screenshots of representative screening project and assay (inset)webpages Emphasis (red boxes arrow) has been added to highlight key information including project description and motivation (a) individualassays within project (b) detailed description (shared by both webpages) of assay protocol (c) and individual screening plates within assay (d)
Nucleic Acids Research 2008 Vol 36 Database issue D355
the World Health Organization (WHO) InternationalNon-proprietary Name database (httpmednetwhointpublicdefaultaspxc=1f216b1a-c080-46a1-9a39-c33717387926) and chemical vendor websites to providean exhaustive list of names and synonyms for moleculesFor a subset of the bioactive small molecules in
ChemBank activity annotations from the biologicalliterature have been added Bioactivity annotations(see also Figure 2) are divided into four categories(i) Biochemical Interactions which indicate protein molec-ular targets or GO molecular functions (25) affected by thesmall molecule (ii) Therapeutic Indications which specifywhat diseases (ie MeSH terms) a small molecule is usedto treat or manage (iii) Therapeutic Uses terms from aninternally derived vocabulary that indicates what type ofclinical or biological activity a small molecule possessesand (iv) Biological Processes which indicate GO biologi-cal processes affected by the small molecule PubMed IDs(5) corresponding to these citations have been capturedbut are not yet exposed to the user and GO terms(Biochemical Interactions and Biological Processes)describing the effect(s) of the small molecule (eglsquoincreases apoptosisrsquo) are displayed but do not currentlyconnect directly to the GO website (httpamigogeneontologyorg)Annotation surrounding biological assays is collected
as field-based metadata using internal controlledvocabularies and is used to describe screening projects
experiments and assay plates Metadata associated witha screening project express the biological motivationand are displayed on the lsquoView Projectrsquo webpagemetadata associated with the details of a particular assay(instantiated as a screening lsquoexperimentrsquo see above)are displayed on the lsquoView Assayrsquo webpage (see alsoFigure 3)
For many of the most frequently screened smallmolecules in ChemBank annotation of autofluorescenceactivity is available to reduce false positives by providingautomated filtering in addition to detailed informationabout the optical properties of the compoundsAnnotation includes a binary filter of autofluorescencea plot of the range of wavelengths above a signalthreshold a plot of the shape of the spectra and acontour plot showing the autofluorescence over a rangethat includes wavelengths of common filter pairsAdditional details about autofluorescence detection anddata-analysis methods are available on the ChemBankwebsite (httpchembankbroadharvardedudetailshtmtag=HelpautoFluorMethodology)
DISCUSSION
ChemBank is a unique knowledge and analysisenvironment for small molecules and high-throughputsmall-molecule assays It provides calculated molecular
Figure 4 ChemBank standard data-analysis model for high-throughput small-molecule screens All raw small-molecule assay results in ChemBank arefurther processed by comparing each measurement with the collection of mock-treatment well measurements performed in the same screening experimentMedian values from mock-treatment wells on the same plate are used in an initial zero-centering step (a) after which the distribution of mock-treatmentmeasurements for the entire experiment is trimmed to eliminate systematic artifacts (b) Trimmed mock-treatment measurements are used to normalizeassay performance by first subtracting the mean of trimmed mock-treatment measurements on the same plate to give lsquobackground-subtracted valuesrsquo(c) then dividing by twice the standard deviation of trimmed mock-treatment measurements for the entire experiment to give lsquodimensionless Z-scorevaluesrsquo (d) Replicate handling is performed by cosine correlation of the replicate pair (for screens done in duplicate) of lsquodimensionless Z-score valuesrsquo foreach compound with a simple prior model of lsquoperfect reproducibilityrsquo to yield a lsquoComposite Z-score valuersquo (e) that represents the final primary screeningresult The ChemBank web interface provides access to raw and processed data types appropriate for each of its visualization tools (f)
D356 Nucleic Acids Research 2008 Vol 36 Database issue
descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

including raw and normalized high-throughput screening(HTS) data and chemical-genetic profiles Data sets maybe manipulated within ChemBank or downloaded for usewith external analysis tools ChemBank is a powerfulknowledge repository and analysis environment forchemists and biologists alike
RESULTS
ChemBank infrastructure
The ChemBank database consists of 95 tables segmentedinto seven logical groups representing compound informa-tion molecular descriptors assay results assay metadatabiological findings ontological associations and userinformation (Figure 1) Data from over 2500 high-throughput biological assays from 188 screening projectscurrently reside in ChemBank with new assays loadedquarterly ChemBank houses information on 17 millioncompound samples representing more than 12 millionunique small-molecule structures with over 300 calculatedmolecular descriptor values for each molecule Over1000 proteins 500 cell lines and 70 species are associatedwith the assays ChemBank data are stored and searchedusing an Oracle 10g (Oracle Corporation RedwoodShores CA USA) relational database extended with theDayCart Oracle cartridge (Daylight ChemicalInformation Systems Aliso Viejo CA USA) which isused for molecule substructure and similarity searches
Data access and optional registration
Anyone with Internet access can use ChemBank withoutregistering with a username and password using the
lsquoEnter as a Guestrsquo button However registration ishighly encouraged of all users as guest users are notpermitted to export data from ChemBank Registeredusers of ChemBank may download data directlyfrom their search results using the lsquo[export ]rsquo hyperlinkson several ChemBank webpages Downloadableresult files are exported in tab-delimited text formatfor maximum flexibility of use in other applicationsSimple Object Access Protocol (SOAP) web-serviceaccess is provided for much of the data in ChemBankService calls exist to list all projects and assayswithin ChemBank as well as assay plates and wellmeasurements There are also molecule services allowingsimilarity and substructure searches of molecules withinChemBank The Web-service Definition Language(WSDL) files for these services can be found on theChemBank website (httpchembankbroadharvardeduwebServiceshtm)
As a repository of primary data from HTS experimentsChemBank employs a data-embargo strategy to protectnewly generated data for a specified period and accord-ingly ChemBank comprises two separate websites con-taining overlapping datasets Public ChemBank (httpchembankbroadharvardedu) contains small-moleculeassay data that are more than one year old as well asmolecular descriptors and published bioactivity annota-tion for registered small molecules Data-Sharing-Agreement (DSA)-ChemBank contains all of the datacontent of Public ChemBank as well as small-moleculeassay data that are less than one year old Use of the latterdatabase is restricted to scientists who have depositedcompounds or performed screening experiments at theBroad Institute of Harvard and MIT and who have signed
Figure 1 Conceptual summary of ChemBank schema Logical illustration of ChemBank data model in which 95 tables are organized into groupsrepresenting components of the chemical biology research enterprise Each box represents several actual database tables as indicated andpseudocardinality relationships between boxes are meant to convey conceptual relationships rather than the more complex cardinality relationshipsthat relate the actual tables
D352 Nucleic Acids Research 2008 Vol 36 Database issue
a DSA (httpwwwbroadharvardeduchembiosciscreenfacilDataSharingAgreementpdf) The DSA stipu-lates conditions of participation such as shared author-ship intellectual property and expectations for sharingfollow-up data All scientists who have signed theagreement may browse the entire contents of DSA-ChemBank and renew their agreements annually forcontinued access to this resource Registration for thisversion of ChemBank is required and usernames andpasswords are assigned by the ChemBank team uponreceipt of the signed agreement DSA-ChemBank users login using their assigned username and password at adifferent URL (httpchembank-dsabroadharvardedu)
ChemBank queries molecular properties and assayorganization
ChemBank has multiple search interfaces available to theuser to enable both simple and complex queries Users cansearch for small molecules using properties such aspresence of a substructure (Figure 2a) calculated molec-ular descriptors (Figure 2b) or association with a curatedbiological activity (Figure 2c) Results from such searcheslead the user to a lsquoMolecule Displayrsquo view which showsbasic information about the small molecule includingnames structure chemical descriptors biological activityand screening test instances (Figure 2 background)
Users may also search for specific screening assaysby searching by assay or project names by individualscreeners or their home institution by assay type or by thespecies (eg of a cell line) under investigation in aparticular assay Text searches within screening projectdescriptions are also supported Assay search resultwebpages link to both assay and screening projectinformation a project is a grouping of assays under asingle biological motivation Details of an assay orscreening project are displayed on their respectivewebpages including user information and assay metadata(Figure 3)
Simple queries can be combined to generate complexmulti-criterion searches ChemBank has an extensivemulti-criterion search interface which allows searches tobe constructed interactively This interface supportsmodification of prior search criteria or addition of newcriteria and can be used even after initial search resultsare returned Additionally data analysis on a single orcombination of screens housed within ChemBank can beperformed and visualized as detailed in the followingsection More information on conducting ChemBanksearches and webpages can be found in the Help section(httpchembankbroadharvardedudetailshtmtag=Help)
ChemBank standard analysis model and visualizations
ChemBank houses both raw and normalized experimentalresults from many HTS and small-molecule microarray(SMM) (7) projects These datasets are the foundation fora data-analysis model specifically equipped to accumulaterich profiles of small-molecule performance acrossmultiple diverse biological assays One of the primaryrequirements of this approach is a data-analysis strategy
for small-molecule performance that affords normalizedvalues independent of both the screening technologyplatform and the specific biological question underinvestigation ChemBank users are not restricted tothis standard analysis paradigm rather each of theChemBank data-visualization tools affords access tomultiple data types along the analysis process includingraw data background-subtracted data and replicate-handled dataChemBank seeks to provide cross-sectional analysis
and multi-assay performance profiles (8ndash14) Thereforewe supplemented ChemBank raw screening data withnormalized data using an error model with several salientfeatures First it renders the results of multiple parallelassays formally comparable regardless of the originalsignal amplitudes or units of measurement Second itintroduces no assumptions about the strength of signalrequired to call screening positives This condition rulesout the use of arbitrary thresholds such as 2-fold inductionor 50 inhibition (1516) Third it does not rely on globalassumptions about the compound collection particularlythe assumption that most compounds will be inert in anygiven assay (1718)These three conditions suggested the use of only mock-
treatment wells as a basis for well-to-well plate-to-plateand experiment-to-experiment normalization We rea-soned that in any miniaturized assay of small-moleculeperformance we can always define a mock-treatmentcondition that mirrors compound treatment in every wayexcept for the presence of the compound For examplein a typical HTS experiment this condition is representedby the treatment of otherwise identical assay-well contentswith the delivery vehicle usually dimethylsulfoxideWe conceptualize our scoring method in terms of aformal hypothesis test comparing a compound-treatmentwith its associated mock-treatment distribution and thusseek the most reliable estimates of the statistical param-eters associated with this test In an ideal world onewould simply make many measurements of a compoundrsquosperformance in a particular assay system and manymeasurements of the corresponding vehicle mock-treat-ment condition in that assay system In such a case ourprimary score for a compound would be similar to the Zrsquostatistic for evaluating HTS methods during assaydevelopment (1519) Since making a statistically mean-ingful number of measurements of each compoundrsquosperformance is not practical we estimate the parametersof the compound-treatment distribution from the param-eters of the mock-treatment distribution At presentChemBank uses a constant-error assumption for plate-reader assays and a variable error assumption for small-molecule microarrays (see subsequent paragraph)To account for plate-to-plate variation in signal (1516)
the median raw value of mock-treatment signals on agiven assay plate is subtracted from each mock-treatmentvalue on the same plate (Figure 4a) providing a zero-centered distribution of mock-treatment measurementsfor each plate in one experiment In ChemBanka screening experiment is defined as a collection of distinctprobe source plates (eg a multi-microtiter plate library)exposed to the same assay conditions at the same time
Nucleic Acids Research 2008 Vol 36 Database issue D353
Next the population of zero-centered measurements forall mock-treatment wells in the experiment are collectedtogether and values failing Chauvenetrsquos criterion (20) forthis overall distribution are discarded (Figure 4b) toprotect against edge effects and other systematic artifactsknown to present a technical problem for microtiter plateexperiments (2122) The remaining mock-treatment mea-surements are used to normalize each compound-treat-ment well measurement independently first subtracting
the mean of remaining mock-treatment wells on the sameplate to obtain background-subtracted values (Figure 4c)then dividing by the twice the standard deviation of mock-treatment wells in the same experiment to obtaindimensionless Z-scores (Figure 4d) (Note that usingtwice the standard deviation is a consequence of aconstant-error assumption for microplate assaysdescribed in the preceding paragraph a more generalsolution allows the error estimate for positive signals to
Figure 2 ChemBank offers multiple routes to find chemical information Search tools allowing structure drawing (28) for substructure or similaritysearches (a) selection of calculated molecular descriptors (b) and selection of term-based bioactivity annotations (c) each provide avenues to findindividual molecules or sets of molecules in ChemBank The ChemBank lsquoMolecule Displayrsquo webpage (background) provides detailed informationabout each molecule including structure names molecular descriptors biological annotations sample information and screening instances
D354 Nucleic Acids Research 2008 Vol 36 Database issue
depend on signal strength eg the scale factor used forsmall-molecule microarray experiments is very close to[1+ IsignalImock] as determined empirically using controlarrays) Thus each compound well receives an algebrai-cally signed Z-score corresponding to the number ofstandard deviations it fell above or below the mean of awell-defined mock-treatment distribution Finally as mostscreening experiments deposited in ChemBank wereperformed in two technical replicates (A and B) thesereplicates were combined to produce a Composite Z-score(Figure 4e) by scaling the vector [ZAZB] by the cosinecorrelation with a vector corresponding to lsquoperfectreproducibilityrsquo (ie equal Z-scores in both replicates)This overall normalization procedure is similar to thatdescribed in earlier work at the Broad Institute (91223)and forms the basis for many of the ChemBank datavisualizations available to users of the database(Figure 4f)
Currently there are four available screening datavisualizations in ChemBank A simple heatmap visualiza-tion for assay plates corresponds to the microplate layoutin a screening experiment (Figure 5a) For statisticalanalysis of results from multiple assay plates comprisinga single HTS experiment ChemBank offers both histo-gram (Figure 5b) and scatterplot (Figure 4e) viewsFinally multi-assay visualization is possible via thelsquoFeature Visualizationrsquo webpage (Figure 5c) which is
generated by implementation of the standard analysismodel to provide a heatmap representing ChemBanklsquoComposite Z-scorersquo values for a series of assays andcompounds These visualization tools can be used inconjunction with the structure similarity substructurematching and molecular descriptor filtering capabilitiesdescribed previously to perform structurendashactivity rela-tionship analyses (Figure 5d) Taken together these searchand visualization tools represent an implementation ofchemical-genetic profiling and cheminformatic analysiscapabilities within ChemBank
Data curation and annotation
Data curation activities for ChemBank fall into twogeneral categories 1) annotation of information regardingsmall molecules and 2) annotation of informationregarding small-molecule assays Annotations regardingsmall-molecule effects on biological systems are generatedfrom the primary literature Hyperlinks to other databasessuch as Entrez Gene (24) GO (25) MeSH (httpwwwnlmnihgovmeshmeshhomehtml) and PubMed(5) are collected manually during curation activitiesSmall molecules and clinically used drugs often have
multiple names some drugs have dozens of differentbrand and generic names ChemBank names are curatedfrom multiple sources including public databasesthe United States Pharmacopeia (USP) Dictionary
Figure 3 Relationship of ChemBank lsquoView Projectrsquo and lsquoView Assayrsquo webpages Screenshots of representative screening project and assay (inset)webpages Emphasis (red boxes arrow) has been added to highlight key information including project description and motivation (a) individualassays within project (b) detailed description (shared by both webpages) of assay protocol (c) and individual screening plates within assay (d)
Nucleic Acids Research 2008 Vol 36 Database issue D355
the World Health Organization (WHO) InternationalNon-proprietary Name database (httpmednetwhointpublicdefaultaspxc=1f216b1a-c080-46a1-9a39-c33717387926) and chemical vendor websites to providean exhaustive list of names and synonyms for moleculesFor a subset of the bioactive small molecules in
ChemBank activity annotations from the biologicalliterature have been added Bioactivity annotations(see also Figure 2) are divided into four categories(i) Biochemical Interactions which indicate protein molec-ular targets or GO molecular functions (25) affected by thesmall molecule (ii) Therapeutic Indications which specifywhat diseases (ie MeSH terms) a small molecule is usedto treat or manage (iii) Therapeutic Uses terms from aninternally derived vocabulary that indicates what type ofclinical or biological activity a small molecule possessesand (iv) Biological Processes which indicate GO biologi-cal processes affected by the small molecule PubMed IDs(5) corresponding to these citations have been capturedbut are not yet exposed to the user and GO terms(Biochemical Interactions and Biological Processes)describing the effect(s) of the small molecule (eglsquoincreases apoptosisrsquo) are displayed but do not currentlyconnect directly to the GO website (httpamigogeneontologyorg)Annotation surrounding biological assays is collected
as field-based metadata using internal controlledvocabularies and is used to describe screening projects
experiments and assay plates Metadata associated witha screening project express the biological motivationand are displayed on the lsquoView Projectrsquo webpagemetadata associated with the details of a particular assay(instantiated as a screening lsquoexperimentrsquo see above)are displayed on the lsquoView Assayrsquo webpage (see alsoFigure 3)
For many of the most frequently screened smallmolecules in ChemBank annotation of autofluorescenceactivity is available to reduce false positives by providingautomated filtering in addition to detailed informationabout the optical properties of the compoundsAnnotation includes a binary filter of autofluorescencea plot of the range of wavelengths above a signalthreshold a plot of the shape of the spectra and acontour plot showing the autofluorescence over a rangethat includes wavelengths of common filter pairsAdditional details about autofluorescence detection anddata-analysis methods are available on the ChemBankwebsite (httpchembankbroadharvardedudetailshtmtag=HelpautoFluorMethodology)
DISCUSSION
ChemBank is a unique knowledge and analysisenvironment for small molecules and high-throughputsmall-molecule assays It provides calculated molecular
Figure 4 ChemBank standard data-analysis model for high-throughput small-molecule screens All raw small-molecule assay results in ChemBank arefurther processed by comparing each measurement with the collection of mock-treatment well measurements performed in the same screening experimentMedian values from mock-treatment wells on the same plate are used in an initial zero-centering step (a) after which the distribution of mock-treatmentmeasurements for the entire experiment is trimmed to eliminate systematic artifacts (b) Trimmed mock-treatment measurements are used to normalizeassay performance by first subtracting the mean of trimmed mock-treatment measurements on the same plate to give lsquobackground-subtracted valuesrsquo(c) then dividing by twice the standard deviation of trimmed mock-treatment measurements for the entire experiment to give lsquodimensionless Z-scorevaluesrsquo (d) Replicate handling is performed by cosine correlation of the replicate pair (for screens done in duplicate) of lsquodimensionless Z-score valuesrsquo foreach compound with a simple prior model of lsquoperfect reproducibilityrsquo to yield a lsquoComposite Z-score valuersquo (e) that represents the final primary screeningresult The ChemBank web interface provides access to raw and processed data types appropriate for each of its visualization tools (f)
D356 Nucleic Acids Research 2008 Vol 36 Database issue
descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

a DSA (httpwwwbroadharvardeduchembiosciscreenfacilDataSharingAgreementpdf) The DSA stipu-lates conditions of participation such as shared author-ship intellectual property and expectations for sharingfollow-up data All scientists who have signed theagreement may browse the entire contents of DSA-ChemBank and renew their agreements annually forcontinued access to this resource Registration for thisversion of ChemBank is required and usernames andpasswords are assigned by the ChemBank team uponreceipt of the signed agreement DSA-ChemBank users login using their assigned username and password at adifferent URL (httpchembank-dsabroadharvardedu)
ChemBank queries molecular properties and assayorganization
ChemBank has multiple search interfaces available to theuser to enable both simple and complex queries Users cansearch for small molecules using properties such aspresence of a substructure (Figure 2a) calculated molec-ular descriptors (Figure 2b) or association with a curatedbiological activity (Figure 2c) Results from such searcheslead the user to a lsquoMolecule Displayrsquo view which showsbasic information about the small molecule includingnames structure chemical descriptors biological activityand screening test instances (Figure 2 background)
Users may also search for specific screening assaysby searching by assay or project names by individualscreeners or their home institution by assay type or by thespecies (eg of a cell line) under investigation in aparticular assay Text searches within screening projectdescriptions are also supported Assay search resultwebpages link to both assay and screening projectinformation a project is a grouping of assays under asingle biological motivation Details of an assay orscreening project are displayed on their respectivewebpages including user information and assay metadata(Figure 3)
Simple queries can be combined to generate complexmulti-criterion searches ChemBank has an extensivemulti-criterion search interface which allows searches tobe constructed interactively This interface supportsmodification of prior search criteria or addition of newcriteria and can be used even after initial search resultsare returned Additionally data analysis on a single orcombination of screens housed within ChemBank can beperformed and visualized as detailed in the followingsection More information on conducting ChemBanksearches and webpages can be found in the Help section(httpchembankbroadharvardedudetailshtmtag=Help)
ChemBank standard analysis model and visualizations
ChemBank houses both raw and normalized experimentalresults from many HTS and small-molecule microarray(SMM) (7) projects These datasets are the foundation fora data-analysis model specifically equipped to accumulaterich profiles of small-molecule performance acrossmultiple diverse biological assays One of the primaryrequirements of this approach is a data-analysis strategy
for small-molecule performance that affords normalizedvalues independent of both the screening technologyplatform and the specific biological question underinvestigation ChemBank users are not restricted tothis standard analysis paradigm rather each of theChemBank data-visualization tools affords access tomultiple data types along the analysis process includingraw data background-subtracted data and replicate-handled dataChemBank seeks to provide cross-sectional analysis
and multi-assay performance profiles (8ndash14) Thereforewe supplemented ChemBank raw screening data withnormalized data using an error model with several salientfeatures First it renders the results of multiple parallelassays formally comparable regardless of the originalsignal amplitudes or units of measurement Second itintroduces no assumptions about the strength of signalrequired to call screening positives This condition rulesout the use of arbitrary thresholds such as 2-fold inductionor 50 inhibition (1516) Third it does not rely on globalassumptions about the compound collection particularlythe assumption that most compounds will be inert in anygiven assay (1718)These three conditions suggested the use of only mock-
treatment wells as a basis for well-to-well plate-to-plateand experiment-to-experiment normalization We rea-soned that in any miniaturized assay of small-moleculeperformance we can always define a mock-treatmentcondition that mirrors compound treatment in every wayexcept for the presence of the compound For examplein a typical HTS experiment this condition is representedby the treatment of otherwise identical assay-well contentswith the delivery vehicle usually dimethylsulfoxideWe conceptualize our scoring method in terms of aformal hypothesis test comparing a compound-treatmentwith its associated mock-treatment distribution and thusseek the most reliable estimates of the statistical param-eters associated with this test In an ideal world onewould simply make many measurements of a compoundrsquosperformance in a particular assay system and manymeasurements of the corresponding vehicle mock-treat-ment condition in that assay system In such a case ourprimary score for a compound would be similar to the Zrsquostatistic for evaluating HTS methods during assaydevelopment (1519) Since making a statistically mean-ingful number of measurements of each compoundrsquosperformance is not practical we estimate the parametersof the compound-treatment distribution from the param-eters of the mock-treatment distribution At presentChemBank uses a constant-error assumption for plate-reader assays and a variable error assumption for small-molecule microarrays (see subsequent paragraph)To account for plate-to-plate variation in signal (1516)
the median raw value of mock-treatment signals on agiven assay plate is subtracted from each mock-treatmentvalue on the same plate (Figure 4a) providing a zero-centered distribution of mock-treatment measurementsfor each plate in one experiment In ChemBanka screening experiment is defined as a collection of distinctprobe source plates (eg a multi-microtiter plate library)exposed to the same assay conditions at the same time
Nucleic Acids Research 2008 Vol 36 Database issue D353
Next the population of zero-centered measurements forall mock-treatment wells in the experiment are collectedtogether and values failing Chauvenetrsquos criterion (20) forthis overall distribution are discarded (Figure 4b) toprotect against edge effects and other systematic artifactsknown to present a technical problem for microtiter plateexperiments (2122) The remaining mock-treatment mea-surements are used to normalize each compound-treat-ment well measurement independently first subtracting
the mean of remaining mock-treatment wells on the sameplate to obtain background-subtracted values (Figure 4c)then dividing by the twice the standard deviation of mock-treatment wells in the same experiment to obtaindimensionless Z-scores (Figure 4d) (Note that usingtwice the standard deviation is a consequence of aconstant-error assumption for microplate assaysdescribed in the preceding paragraph a more generalsolution allows the error estimate for positive signals to
Figure 2 ChemBank offers multiple routes to find chemical information Search tools allowing structure drawing (28) for substructure or similaritysearches (a) selection of calculated molecular descriptors (b) and selection of term-based bioactivity annotations (c) each provide avenues to findindividual molecules or sets of molecules in ChemBank The ChemBank lsquoMolecule Displayrsquo webpage (background) provides detailed informationabout each molecule including structure names molecular descriptors biological annotations sample information and screening instances
D354 Nucleic Acids Research 2008 Vol 36 Database issue
depend on signal strength eg the scale factor used forsmall-molecule microarray experiments is very close to[1+ IsignalImock] as determined empirically using controlarrays) Thus each compound well receives an algebrai-cally signed Z-score corresponding to the number ofstandard deviations it fell above or below the mean of awell-defined mock-treatment distribution Finally as mostscreening experiments deposited in ChemBank wereperformed in two technical replicates (A and B) thesereplicates were combined to produce a Composite Z-score(Figure 4e) by scaling the vector [ZAZB] by the cosinecorrelation with a vector corresponding to lsquoperfectreproducibilityrsquo (ie equal Z-scores in both replicates)This overall normalization procedure is similar to thatdescribed in earlier work at the Broad Institute (91223)and forms the basis for many of the ChemBank datavisualizations available to users of the database(Figure 4f)
Currently there are four available screening datavisualizations in ChemBank A simple heatmap visualiza-tion for assay plates corresponds to the microplate layoutin a screening experiment (Figure 5a) For statisticalanalysis of results from multiple assay plates comprisinga single HTS experiment ChemBank offers both histo-gram (Figure 5b) and scatterplot (Figure 4e) viewsFinally multi-assay visualization is possible via thelsquoFeature Visualizationrsquo webpage (Figure 5c) which is
generated by implementation of the standard analysismodel to provide a heatmap representing ChemBanklsquoComposite Z-scorersquo values for a series of assays andcompounds These visualization tools can be used inconjunction with the structure similarity substructurematching and molecular descriptor filtering capabilitiesdescribed previously to perform structurendashactivity rela-tionship analyses (Figure 5d) Taken together these searchand visualization tools represent an implementation ofchemical-genetic profiling and cheminformatic analysiscapabilities within ChemBank
Data curation and annotation
Data curation activities for ChemBank fall into twogeneral categories 1) annotation of information regardingsmall molecules and 2) annotation of informationregarding small-molecule assays Annotations regardingsmall-molecule effects on biological systems are generatedfrom the primary literature Hyperlinks to other databasessuch as Entrez Gene (24) GO (25) MeSH (httpwwwnlmnihgovmeshmeshhomehtml) and PubMed(5) are collected manually during curation activitiesSmall molecules and clinically used drugs often have
multiple names some drugs have dozens of differentbrand and generic names ChemBank names are curatedfrom multiple sources including public databasesthe United States Pharmacopeia (USP) Dictionary
Figure 3 Relationship of ChemBank lsquoView Projectrsquo and lsquoView Assayrsquo webpages Screenshots of representative screening project and assay (inset)webpages Emphasis (red boxes arrow) has been added to highlight key information including project description and motivation (a) individualassays within project (b) detailed description (shared by both webpages) of assay protocol (c) and individual screening plates within assay (d)
Nucleic Acids Research 2008 Vol 36 Database issue D355
the World Health Organization (WHO) InternationalNon-proprietary Name database (httpmednetwhointpublicdefaultaspxc=1f216b1a-c080-46a1-9a39-c33717387926) and chemical vendor websites to providean exhaustive list of names and synonyms for moleculesFor a subset of the bioactive small molecules in
ChemBank activity annotations from the biologicalliterature have been added Bioactivity annotations(see also Figure 2) are divided into four categories(i) Biochemical Interactions which indicate protein molec-ular targets or GO molecular functions (25) affected by thesmall molecule (ii) Therapeutic Indications which specifywhat diseases (ie MeSH terms) a small molecule is usedto treat or manage (iii) Therapeutic Uses terms from aninternally derived vocabulary that indicates what type ofclinical or biological activity a small molecule possessesand (iv) Biological Processes which indicate GO biologi-cal processes affected by the small molecule PubMed IDs(5) corresponding to these citations have been capturedbut are not yet exposed to the user and GO terms(Biochemical Interactions and Biological Processes)describing the effect(s) of the small molecule (eglsquoincreases apoptosisrsquo) are displayed but do not currentlyconnect directly to the GO website (httpamigogeneontologyorg)Annotation surrounding biological assays is collected
as field-based metadata using internal controlledvocabularies and is used to describe screening projects
experiments and assay plates Metadata associated witha screening project express the biological motivationand are displayed on the lsquoView Projectrsquo webpagemetadata associated with the details of a particular assay(instantiated as a screening lsquoexperimentrsquo see above)are displayed on the lsquoView Assayrsquo webpage (see alsoFigure 3)
For many of the most frequently screened smallmolecules in ChemBank annotation of autofluorescenceactivity is available to reduce false positives by providingautomated filtering in addition to detailed informationabout the optical properties of the compoundsAnnotation includes a binary filter of autofluorescencea plot of the range of wavelengths above a signalthreshold a plot of the shape of the spectra and acontour plot showing the autofluorescence over a rangethat includes wavelengths of common filter pairsAdditional details about autofluorescence detection anddata-analysis methods are available on the ChemBankwebsite (httpchembankbroadharvardedudetailshtmtag=HelpautoFluorMethodology)
DISCUSSION
ChemBank is a unique knowledge and analysisenvironment for small molecules and high-throughputsmall-molecule assays It provides calculated molecular
Figure 4 ChemBank standard data-analysis model for high-throughput small-molecule screens All raw small-molecule assay results in ChemBank arefurther processed by comparing each measurement with the collection of mock-treatment well measurements performed in the same screening experimentMedian values from mock-treatment wells on the same plate are used in an initial zero-centering step (a) after which the distribution of mock-treatmentmeasurements for the entire experiment is trimmed to eliminate systematic artifacts (b) Trimmed mock-treatment measurements are used to normalizeassay performance by first subtracting the mean of trimmed mock-treatment measurements on the same plate to give lsquobackground-subtracted valuesrsquo(c) then dividing by twice the standard deviation of trimmed mock-treatment measurements for the entire experiment to give lsquodimensionless Z-scorevaluesrsquo (d) Replicate handling is performed by cosine correlation of the replicate pair (for screens done in duplicate) of lsquodimensionless Z-score valuesrsquo foreach compound with a simple prior model of lsquoperfect reproducibilityrsquo to yield a lsquoComposite Z-score valuersquo (e) that represents the final primary screeningresult The ChemBank web interface provides access to raw and processed data types appropriate for each of its visualization tools (f)
D356 Nucleic Acids Research 2008 Vol 36 Database issue
descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

Next the population of zero-centered measurements forall mock-treatment wells in the experiment are collectedtogether and values failing Chauvenetrsquos criterion (20) forthis overall distribution are discarded (Figure 4b) toprotect against edge effects and other systematic artifactsknown to present a technical problem for microtiter plateexperiments (2122) The remaining mock-treatment mea-surements are used to normalize each compound-treat-ment well measurement independently first subtracting
the mean of remaining mock-treatment wells on the sameplate to obtain background-subtracted values (Figure 4c)then dividing by the twice the standard deviation of mock-treatment wells in the same experiment to obtaindimensionless Z-scores (Figure 4d) (Note that usingtwice the standard deviation is a consequence of aconstant-error assumption for microplate assaysdescribed in the preceding paragraph a more generalsolution allows the error estimate for positive signals to
Figure 2 ChemBank offers multiple routes to find chemical information Search tools allowing structure drawing (28) for substructure or similaritysearches (a) selection of calculated molecular descriptors (b) and selection of term-based bioactivity annotations (c) each provide avenues to findindividual molecules or sets of molecules in ChemBank The ChemBank lsquoMolecule Displayrsquo webpage (background) provides detailed informationabout each molecule including structure names molecular descriptors biological annotations sample information and screening instances
D354 Nucleic Acids Research 2008 Vol 36 Database issue
depend on signal strength eg the scale factor used forsmall-molecule microarray experiments is very close to[1+ IsignalImock] as determined empirically using controlarrays) Thus each compound well receives an algebrai-cally signed Z-score corresponding to the number ofstandard deviations it fell above or below the mean of awell-defined mock-treatment distribution Finally as mostscreening experiments deposited in ChemBank wereperformed in two technical replicates (A and B) thesereplicates were combined to produce a Composite Z-score(Figure 4e) by scaling the vector [ZAZB] by the cosinecorrelation with a vector corresponding to lsquoperfectreproducibilityrsquo (ie equal Z-scores in both replicates)This overall normalization procedure is similar to thatdescribed in earlier work at the Broad Institute (91223)and forms the basis for many of the ChemBank datavisualizations available to users of the database(Figure 4f)
Currently there are four available screening datavisualizations in ChemBank A simple heatmap visualiza-tion for assay plates corresponds to the microplate layoutin a screening experiment (Figure 5a) For statisticalanalysis of results from multiple assay plates comprisinga single HTS experiment ChemBank offers both histo-gram (Figure 5b) and scatterplot (Figure 4e) viewsFinally multi-assay visualization is possible via thelsquoFeature Visualizationrsquo webpage (Figure 5c) which is
generated by implementation of the standard analysismodel to provide a heatmap representing ChemBanklsquoComposite Z-scorersquo values for a series of assays andcompounds These visualization tools can be used inconjunction with the structure similarity substructurematching and molecular descriptor filtering capabilitiesdescribed previously to perform structurendashactivity rela-tionship analyses (Figure 5d) Taken together these searchand visualization tools represent an implementation ofchemical-genetic profiling and cheminformatic analysiscapabilities within ChemBank
Data curation and annotation
Data curation activities for ChemBank fall into twogeneral categories 1) annotation of information regardingsmall molecules and 2) annotation of informationregarding small-molecule assays Annotations regardingsmall-molecule effects on biological systems are generatedfrom the primary literature Hyperlinks to other databasessuch as Entrez Gene (24) GO (25) MeSH (httpwwwnlmnihgovmeshmeshhomehtml) and PubMed(5) are collected manually during curation activitiesSmall molecules and clinically used drugs often have
multiple names some drugs have dozens of differentbrand and generic names ChemBank names are curatedfrom multiple sources including public databasesthe United States Pharmacopeia (USP) Dictionary
Figure 3 Relationship of ChemBank lsquoView Projectrsquo and lsquoView Assayrsquo webpages Screenshots of representative screening project and assay (inset)webpages Emphasis (red boxes arrow) has been added to highlight key information including project description and motivation (a) individualassays within project (b) detailed description (shared by both webpages) of assay protocol (c) and individual screening plates within assay (d)
Nucleic Acids Research 2008 Vol 36 Database issue D355
the World Health Organization (WHO) InternationalNon-proprietary Name database (httpmednetwhointpublicdefaultaspxc=1f216b1a-c080-46a1-9a39-c33717387926) and chemical vendor websites to providean exhaustive list of names and synonyms for moleculesFor a subset of the bioactive small molecules in
ChemBank activity annotations from the biologicalliterature have been added Bioactivity annotations(see also Figure 2) are divided into four categories(i) Biochemical Interactions which indicate protein molec-ular targets or GO molecular functions (25) affected by thesmall molecule (ii) Therapeutic Indications which specifywhat diseases (ie MeSH terms) a small molecule is usedto treat or manage (iii) Therapeutic Uses terms from aninternally derived vocabulary that indicates what type ofclinical or biological activity a small molecule possessesand (iv) Biological Processes which indicate GO biologi-cal processes affected by the small molecule PubMed IDs(5) corresponding to these citations have been capturedbut are not yet exposed to the user and GO terms(Biochemical Interactions and Biological Processes)describing the effect(s) of the small molecule (eglsquoincreases apoptosisrsquo) are displayed but do not currentlyconnect directly to the GO website (httpamigogeneontologyorg)Annotation surrounding biological assays is collected
as field-based metadata using internal controlledvocabularies and is used to describe screening projects
experiments and assay plates Metadata associated witha screening project express the biological motivationand are displayed on the lsquoView Projectrsquo webpagemetadata associated with the details of a particular assay(instantiated as a screening lsquoexperimentrsquo see above)are displayed on the lsquoView Assayrsquo webpage (see alsoFigure 3)
For many of the most frequently screened smallmolecules in ChemBank annotation of autofluorescenceactivity is available to reduce false positives by providingautomated filtering in addition to detailed informationabout the optical properties of the compoundsAnnotation includes a binary filter of autofluorescencea plot of the range of wavelengths above a signalthreshold a plot of the shape of the spectra and acontour plot showing the autofluorescence over a rangethat includes wavelengths of common filter pairsAdditional details about autofluorescence detection anddata-analysis methods are available on the ChemBankwebsite (httpchembankbroadharvardedudetailshtmtag=HelpautoFluorMethodology)
DISCUSSION
ChemBank is a unique knowledge and analysisenvironment for small molecules and high-throughputsmall-molecule assays It provides calculated molecular
Figure 4 ChemBank standard data-analysis model for high-throughput small-molecule screens All raw small-molecule assay results in ChemBank arefurther processed by comparing each measurement with the collection of mock-treatment well measurements performed in the same screening experimentMedian values from mock-treatment wells on the same plate are used in an initial zero-centering step (a) after which the distribution of mock-treatmentmeasurements for the entire experiment is trimmed to eliminate systematic artifacts (b) Trimmed mock-treatment measurements are used to normalizeassay performance by first subtracting the mean of trimmed mock-treatment measurements on the same plate to give lsquobackground-subtracted valuesrsquo(c) then dividing by twice the standard deviation of trimmed mock-treatment measurements for the entire experiment to give lsquodimensionless Z-scorevaluesrsquo (d) Replicate handling is performed by cosine correlation of the replicate pair (for screens done in duplicate) of lsquodimensionless Z-score valuesrsquo foreach compound with a simple prior model of lsquoperfect reproducibilityrsquo to yield a lsquoComposite Z-score valuersquo (e) that represents the final primary screeningresult The ChemBank web interface provides access to raw and processed data types appropriate for each of its visualization tools (f)
D356 Nucleic Acids Research 2008 Vol 36 Database issue
descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

depend on signal strength eg the scale factor used forsmall-molecule microarray experiments is very close to[1+ IsignalImock] as determined empirically using controlarrays) Thus each compound well receives an algebrai-cally signed Z-score corresponding to the number ofstandard deviations it fell above or below the mean of awell-defined mock-treatment distribution Finally as mostscreening experiments deposited in ChemBank wereperformed in two technical replicates (A and B) thesereplicates were combined to produce a Composite Z-score(Figure 4e) by scaling the vector [ZAZB] by the cosinecorrelation with a vector corresponding to lsquoperfectreproducibilityrsquo (ie equal Z-scores in both replicates)This overall normalization procedure is similar to thatdescribed in earlier work at the Broad Institute (91223)and forms the basis for many of the ChemBank datavisualizations available to users of the database(Figure 4f)
Currently there are four available screening datavisualizations in ChemBank A simple heatmap visualiza-tion for assay plates corresponds to the microplate layoutin a screening experiment (Figure 5a) For statisticalanalysis of results from multiple assay plates comprisinga single HTS experiment ChemBank offers both histo-gram (Figure 5b) and scatterplot (Figure 4e) viewsFinally multi-assay visualization is possible via thelsquoFeature Visualizationrsquo webpage (Figure 5c) which is
generated by implementation of the standard analysismodel to provide a heatmap representing ChemBanklsquoComposite Z-scorersquo values for a series of assays andcompounds These visualization tools can be used inconjunction with the structure similarity substructurematching and molecular descriptor filtering capabilitiesdescribed previously to perform structurendashactivity rela-tionship analyses (Figure 5d) Taken together these searchand visualization tools represent an implementation ofchemical-genetic profiling and cheminformatic analysiscapabilities within ChemBank
Data curation and annotation
Data curation activities for ChemBank fall into twogeneral categories 1) annotation of information regardingsmall molecules and 2) annotation of informationregarding small-molecule assays Annotations regardingsmall-molecule effects on biological systems are generatedfrom the primary literature Hyperlinks to other databasessuch as Entrez Gene (24) GO (25) MeSH (httpwwwnlmnihgovmeshmeshhomehtml) and PubMed(5) are collected manually during curation activitiesSmall molecules and clinically used drugs often have
multiple names some drugs have dozens of differentbrand and generic names ChemBank names are curatedfrom multiple sources including public databasesthe United States Pharmacopeia (USP) Dictionary
Figure 3 Relationship of ChemBank lsquoView Projectrsquo and lsquoView Assayrsquo webpages Screenshots of representative screening project and assay (inset)webpages Emphasis (red boxes arrow) has been added to highlight key information including project description and motivation (a) individualassays within project (b) detailed description (shared by both webpages) of assay protocol (c) and individual screening plates within assay (d)
Nucleic Acids Research 2008 Vol 36 Database issue D355
the World Health Organization (WHO) InternationalNon-proprietary Name database (httpmednetwhointpublicdefaultaspxc=1f216b1a-c080-46a1-9a39-c33717387926) and chemical vendor websites to providean exhaustive list of names and synonyms for moleculesFor a subset of the bioactive small molecules in
ChemBank activity annotations from the biologicalliterature have been added Bioactivity annotations(see also Figure 2) are divided into four categories(i) Biochemical Interactions which indicate protein molec-ular targets or GO molecular functions (25) affected by thesmall molecule (ii) Therapeutic Indications which specifywhat diseases (ie MeSH terms) a small molecule is usedto treat or manage (iii) Therapeutic Uses terms from aninternally derived vocabulary that indicates what type ofclinical or biological activity a small molecule possessesand (iv) Biological Processes which indicate GO biologi-cal processes affected by the small molecule PubMed IDs(5) corresponding to these citations have been capturedbut are not yet exposed to the user and GO terms(Biochemical Interactions and Biological Processes)describing the effect(s) of the small molecule (eglsquoincreases apoptosisrsquo) are displayed but do not currentlyconnect directly to the GO website (httpamigogeneontologyorg)Annotation surrounding biological assays is collected
as field-based metadata using internal controlledvocabularies and is used to describe screening projects
experiments and assay plates Metadata associated witha screening project express the biological motivationand are displayed on the lsquoView Projectrsquo webpagemetadata associated with the details of a particular assay(instantiated as a screening lsquoexperimentrsquo see above)are displayed on the lsquoView Assayrsquo webpage (see alsoFigure 3)
For many of the most frequently screened smallmolecules in ChemBank annotation of autofluorescenceactivity is available to reduce false positives by providingautomated filtering in addition to detailed informationabout the optical properties of the compoundsAnnotation includes a binary filter of autofluorescencea plot of the range of wavelengths above a signalthreshold a plot of the shape of the spectra and acontour plot showing the autofluorescence over a rangethat includes wavelengths of common filter pairsAdditional details about autofluorescence detection anddata-analysis methods are available on the ChemBankwebsite (httpchembankbroadharvardedudetailshtmtag=HelpautoFluorMethodology)
DISCUSSION
ChemBank is a unique knowledge and analysisenvironment for small molecules and high-throughputsmall-molecule assays It provides calculated molecular
Figure 4 ChemBank standard data-analysis model for high-throughput small-molecule screens All raw small-molecule assay results in ChemBank arefurther processed by comparing each measurement with the collection of mock-treatment well measurements performed in the same screening experimentMedian values from mock-treatment wells on the same plate are used in an initial zero-centering step (a) after which the distribution of mock-treatmentmeasurements for the entire experiment is trimmed to eliminate systematic artifacts (b) Trimmed mock-treatment measurements are used to normalizeassay performance by first subtracting the mean of trimmed mock-treatment measurements on the same plate to give lsquobackground-subtracted valuesrsquo(c) then dividing by twice the standard deviation of trimmed mock-treatment measurements for the entire experiment to give lsquodimensionless Z-scorevaluesrsquo (d) Replicate handling is performed by cosine correlation of the replicate pair (for screens done in duplicate) of lsquodimensionless Z-score valuesrsquo foreach compound with a simple prior model of lsquoperfect reproducibilityrsquo to yield a lsquoComposite Z-score valuersquo (e) that represents the final primary screeningresult The ChemBank web interface provides access to raw and processed data types appropriate for each of its visualization tools (f)
D356 Nucleic Acids Research 2008 Vol 36 Database issue
descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359
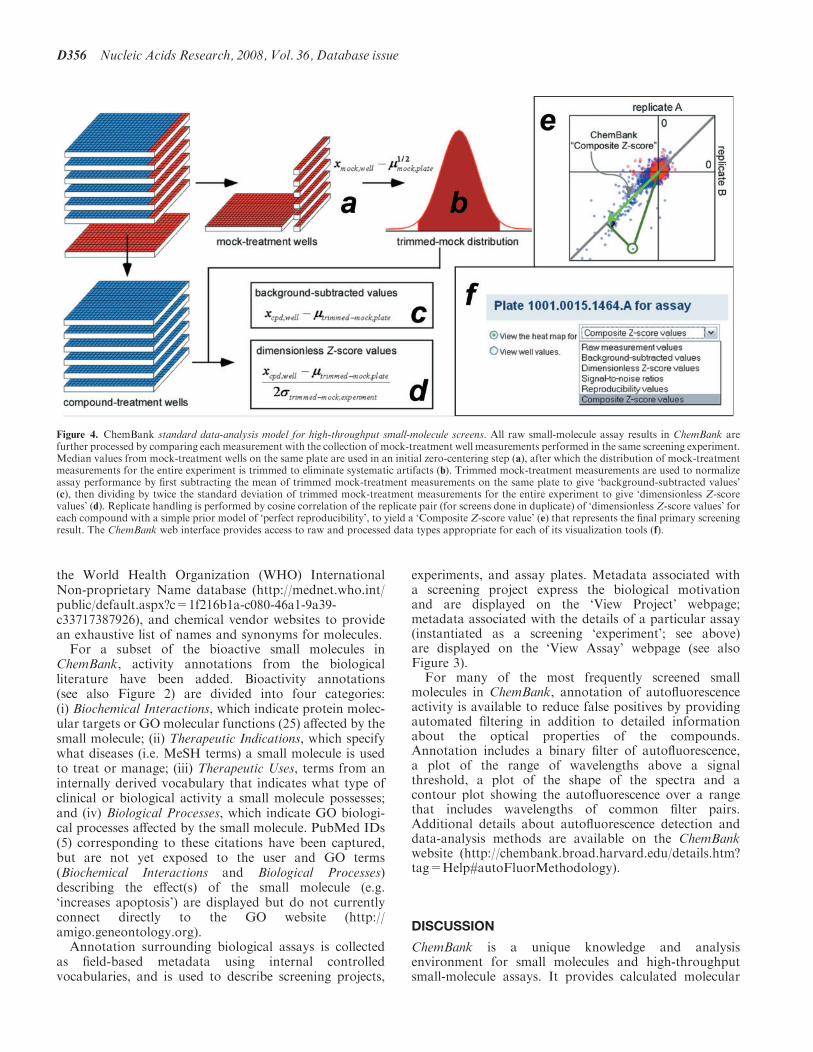
the World Health Organization (WHO) InternationalNon-proprietary Name database (httpmednetwhointpublicdefaultaspxc=1f216b1a-c080-46a1-9a39-c33717387926) and chemical vendor websites to providean exhaustive list of names and synonyms for moleculesFor a subset of the bioactive small molecules in
ChemBank activity annotations from the biologicalliterature have been added Bioactivity annotations(see also Figure 2) are divided into four categories(i) Biochemical Interactions which indicate protein molec-ular targets or GO molecular functions (25) affected by thesmall molecule (ii) Therapeutic Indications which specifywhat diseases (ie MeSH terms) a small molecule is usedto treat or manage (iii) Therapeutic Uses terms from aninternally derived vocabulary that indicates what type ofclinical or biological activity a small molecule possessesand (iv) Biological Processes which indicate GO biologi-cal processes affected by the small molecule PubMed IDs(5) corresponding to these citations have been capturedbut are not yet exposed to the user and GO terms(Biochemical Interactions and Biological Processes)describing the effect(s) of the small molecule (eglsquoincreases apoptosisrsquo) are displayed but do not currentlyconnect directly to the GO website (httpamigogeneontologyorg)Annotation surrounding biological assays is collected
as field-based metadata using internal controlledvocabularies and is used to describe screening projects
experiments and assay plates Metadata associated witha screening project express the biological motivationand are displayed on the lsquoView Projectrsquo webpagemetadata associated with the details of a particular assay(instantiated as a screening lsquoexperimentrsquo see above)are displayed on the lsquoView Assayrsquo webpage (see alsoFigure 3)
For many of the most frequently screened smallmolecules in ChemBank annotation of autofluorescenceactivity is available to reduce false positives by providingautomated filtering in addition to detailed informationabout the optical properties of the compoundsAnnotation includes a binary filter of autofluorescencea plot of the range of wavelengths above a signalthreshold a plot of the shape of the spectra and acontour plot showing the autofluorescence over a rangethat includes wavelengths of common filter pairsAdditional details about autofluorescence detection anddata-analysis methods are available on the ChemBankwebsite (httpchembankbroadharvardedudetailshtmtag=HelpautoFluorMethodology)
DISCUSSION
ChemBank is a unique knowledge and analysisenvironment for small molecules and high-throughputsmall-molecule assays It provides calculated molecular
Figure 4 ChemBank standard data-analysis model for high-throughput small-molecule screens All raw small-molecule assay results in ChemBank arefurther processed by comparing each measurement with the collection of mock-treatment well measurements performed in the same screening experimentMedian values from mock-treatment wells on the same plate are used in an initial zero-centering step (a) after which the distribution of mock-treatmentmeasurements for the entire experiment is trimmed to eliminate systematic artifacts (b) Trimmed mock-treatment measurements are used to normalizeassay performance by first subtracting the mean of trimmed mock-treatment measurements on the same plate to give lsquobackground-subtracted valuesrsquo(c) then dividing by twice the standard deviation of trimmed mock-treatment measurements for the entire experiment to give lsquodimensionless Z-scorevaluesrsquo (d) Replicate handling is performed by cosine correlation of the replicate pair (for screens done in duplicate) of lsquodimensionless Z-score valuesrsquo foreach compound with a simple prior model of lsquoperfect reproducibilityrsquo to yield a lsquoComposite Z-score valuersquo (e) that represents the final primary screeningresult The ChemBank web interface provides access to raw and processed data types appropriate for each of its visualization tools (f)
D356 Nucleic Acids Research 2008 Vol 36 Database issue
descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

descriptors experimental assay measurements andliterature-based annotation for small molecules allowingintegration of both new and established information in asingle public resource Other public small-moleculedatabases exist and the following examples are meant tobe illustrative not comprehensive BindingDB (26) curatessmall-molecule binding affinities for protein targets fromthe literature KEGG LIGAND (27) and its associatedentry points seek to catalog and integrate chemicalstructures biochemical reactions and biological informa-tion into a single database ZINC (6) is a database of three-dimensional compound structures intended for virtualscreening applications These products and the manyother examples available serve to illustrate that eachproject has a different focus and each is designedaccordingly
PubChem (5) is a public database created by the NIHthat is most similar in aims and data content toChemBank but several important differences existbetween ChemBank and PubChem (Table 1) Bothdatabases house small-molecule structures and screeningdata but ChemBank data are generated and annotatedinternally PubChem is a deposition database and relieson submission of data and structures from outsidesources Importantly ChemBank houses raw screeningdata including assay plate position information andapplies a standard data-analysis procedure to all datasetsPubChem does not require raw data or plate positioninformation from submitters and as such interpretationsof outcomes may be limited to those interpretationssupplied by the submitting organization ChemBankuses controlled vocabularies to capture metadata
Figure 5 Illustration of ChemBank visualizations and linking activities with chemical information Screening data including raw measurements inChemBank are addressable by exact plate and well position in assay plates (a) and statistical data representing outcomes (b) can be reviewed at thelevel of raw or normalized data A multi-assay analysis capability takes advantage of the standard analysis procedure (Figure 4) to display theperformance of such similar compounds in multiple assays to which each has been exposed (c) Each of these capabilities can be combined withstructure and annotation-based search capabilities to provide cheminformatic analysis of molecules scoring as lsquohitsrsquo in biological assays (d)
Nucleic Acids Research 2008 Vol 36 Database issue D357
and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

and especially provides for hierarchical organization ofassays into projects PubChem captures data and proto-cols in free text and organizes data by submission ratherthan grouping assays by common biological motivationThe primary strengths of PubChem are its very usefullinks to other Entrez databases and its capability toleverage the powerful Entrez search engine Howeveralthough both databases house general small-moleculeinformation and bioassay data we believe that storage ofplate locations and raw screening data field-basedmetadata and the standard experiment definition inChemBank afford some distinct advantages overPubChem In particular we believe that ChemBankwill be especially effective in revealing unrecognizedsmall-molecule performance relationships because of itssupport of statistically rigorous cross-sectional analysesthat harness the collective power of all experiments inthe database (ie analyses of data derived from manydifferent types of screens and small molecules)By committing itself to storing raw screening data
defining screening experiments in a rigorous mannerand organizing screening experiments hierarchically usingmetadata ChemBank provides a unique opportunity tothe scientific community even beyond computationalscientists ChemBank provides access to large volumesof data annotating chemical entities with measuredoutcomes and the commitment to storage of raw dataensures that these measurements are available for data-mining activities In this sense ChemBank is an importantsocial experiment in science in that it permits an analysisof whether the interpretation of screening data by theinvestigators performing small-molecule screens indeed
reveal all the value in their performance Alternativelycross-sectional analysis of results deposited by multipleindependent investigators may reveal outcomes notapparent to participants in any individual screeningproject To that end ChemBank allows customization ofoptions for viewing chemical-genetic profiles for theresulting molecules using any associated assay data andas such allows users to exploit this assembled informationto support discovery and experimentation in chemicalbiology research The open standardized data-sharingenvironment of ChemBank is geared toward rapiddiscovery of novel therapeutic candidates and a deepunderstanding of biological systems
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the support ofthe National Cancer Institutersquos Initiative for ChemicalGenetics (N01-CO-12400) the NIH Road MaprsquosExploratory Center for Cheminformatics Research(P20-HG003895) and the NIGMS Center forChemical Methodologies and Library Development(P50-GM069721 including supplemental funds) Wefurther acknowledge the Broad Institutersquos ITSystemsgroup for infrastructural support and numerous contractworkers who have helped to augment ChemBankrsquoscontents Natalia Balabi Jose A Fernandez Cynthia ASaraceni-Richards Karen Rose Laura Selfors NurgeesSulthan-Banu Brian Weiner and Angela Zuniga-MeyerFinally we are indebted to the following investigators forearly modeling efforts helpful discussions andcommunity participation during ChemBank development
Table 1 Content and feature comparison between ChemBank v20 and PubChem
Database contentfeature ChemBank v20 PubChem
Chemical structure gt12 million unique gt10 million unique
Moleculenamessynonyms
IUPAC and manually curatednamessynonyms
IUPAC and depositor-supplied synonyms
Molecular descriptors 36 searchable plus gt300 displayedcalculated properties anddescriptors per molecule
18 calculated chemical properties atom typesand stereochemistry flags per molecule
Literature annotations Manually curated connectedto controlled vocabularies
Extensive linking to Entrez databases
Metadata describingscreens
Extensive field-based metadatacollected (some displayed)standardized terms connectedto controlled vocabularies
Depositor-supplied comments primarilyfree-text no standard controlled vocabulariesfor assay components
Biological assay data Raw data required with platelocations (except legacyChemBank v1data sets)standard data-analysis model
15 of assays display raw data no standardizedanalysis performed beyond submitter interpretations
Screening assay analysisand visualization tools
Plate-map histogram scatterplotand multi-assay heat-mapvisualizations
Structure-activity relationship analysesclustering visualizations
Public data submission Required for Broad Institutescreening center limitedexternal submissions
Required for Molecular Libraries Screening Centersothers may submit voluntarily
D358 Nucleic Acids Research 2008 Vol 36 Database issue
Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359

Elton Dean David DeCaprio Jay Duffner Scott EliasofJoshua Forman Annaliese Franz Julie GorensteinStephen Haggarty Eugenia Harris Angela KoehlerAndrew Lach Justin Lamb Julia Lamenzo RalphMazitschek John McGrath Olivia McPherson JaredShaw Stanley Shaw Lynn Verplank and BridgetWagner Funding to pay the Open Access publicationcharges for this article was provided by Initiative forChemical Genetics (NO1-CO-12400)
Conflict of interest statement We report that MSprovided consultancy services the subject(s) of whichwere unrelated to the ChemBank project to DaylightChemical Information Systems while participating inChemBank development
REFERENCES
1 StrausbergRL and SchreiberSL (2003) From knowing tocontrolling a path from genomics to drugs using small moleculeprobes Science 300 294ndash295
2 TollidayN ClemonsPA FerraioloP KoehlerAN LewisTALiX SchreiberSL GerhardDS and EliasofS (2006) Smallmolecules big players the National Cancer Institutersquos Initiative forChemical Genetics Cancer Res 66 8935ndash8942
3 BrooksbankC CameronG and ThorntonJ (2005) The EuropeanBioinformatics Institutersquos data resources towards systems biologyNucleic Acids Res 33 D46ndashD53
4 WishartDS KnoxC GuoAC ShrivastavaS HassanaliMStothardP ChangZ and WoolseyJ (2006) DrugBank acomprehensive resource for in silico drug discovery and explorationNucleic Acids Res 34 D668ndashD672
5 WheelerDL BarrettT BensonDA BryantSH CaneseKChetverninV ChurchDM DiCuccioM EdgarR et al (2007)Database resources of the National Center for BiotechnologyInformation Nucleic Acids Res 35 D5ndashD12
6 IrwinJJ and ShoichetBK (2005) ZINC - a free database ofcommercially available compounds for virtual screeningJ Chem Inf Model 45 177ndash182
7 DuffnerJL ClemonsPA and KoehlerAN (2007) A pipelinefor ligand discovery using small-molecule microarrays Curr OpinChem Biol 11 74ndash82
8 FliriAF LogingWT ThadeioPF and VolkmannRA (2005)Biological spectra analysis linking biological activity profiles tomolecular structure Proc Natl Acad Sci USA 102 261ndash266
9 FranzAK DreyfussPD and SchreiberSL (2007) Synthesis andcellular profiling of diverse organosilicon small moleculesJ Am Chem Soc 129 1020ndash1021
10 HaggartySJ ClemonsPA and SchreiberSL (2003) Chemicalgenomic profiling of biological networks using graph theory andcombinations of small molecule perturbations J Am Chem Soc125 10543ndash10545
11 KauvarLM HigginsDL VillarHO SportsmanJREngqvist-GoldsteinA BukarR BauerKE DilleyH and
RockeDM (1995) Predicting ligand binding to proteins byaffinity fingerprinting Chem Biol 2 107ndash118
12 KimYK AraiMA AraiT LamenzoJO DeanEF IIIPattersonN ClemonsPA and SchreiberSL (2004) Relationshipof stereochemical and skeletal diversity of small moleculesto cellular measurement space J Am Chem Soc 12614740ndash14745
13 MelnickJS JanesJ KimS ChangJY SipesDGGundersonD JarnesL MatzenJT GarciaME et al (2006)An efficient rapid system for profiling the cellular activities ofmolecular libraries Proc Natl Acad Sci USA 103 3153ndash3158
14 ZaharevitzDW HolbeckSL BowermanC and SvetlikPA(2002) COMPARE a web accessible tool for investigatingmechanisms of cell growth inhibition J Mol Graph Model 20297ndash303
15 BrideauC GunterB PikounisB and LiawA (2003) Improvedstatistical methods for hit selection in high-throughput screeningJ Biomol Screen 8 634ndash647
16 GunterB BrideauC PikounisB and LiawA (2003)Statistical and graphical methods for quality controldetermination of high-throughput screening data J Biomol Screen8 624ndash633
17 ZhangJH ChungTD and OldenburgKR (2000) Confirmationof primary active substances from high throughput screening ofchemical and biological populations a statistical approach andpractical considerations J Comb Chem 2 258ndash265
18 ZhangJH WuX and SillsMA (2005) Probing the primaryscreening efficiency by multiple replicate testing a quantitativeanalysis of hit confirmation and false screening results of abiochemical assay J Biomol Screen 10 695ndash704
19 ZhangJH ChungTD and OldenburgKR (1999) A simplestatistical parameter for use in evaluation and validation ofhigh throughput screening assays J Biomol Screen 4 67ndash73
20 BevingtonPR and RobinsonDK (1991) Data reduction and erroranalysis for the physical sciences 2nd edn McGraw-Hill Boston MA
21 KelleyBP LunnMR RootDE FlahertySP MartinoAMand StockwellBR (2004) A flexible data analysis tool for chemicalgenetic screens Chem Biol 11 1495ndash1503
22 RootDE KelleyBP and StockwellBR (2003) Detecting spatialpatterns in biological array experiments J Biomol Screen 8393ndash398
23 KellyKA ClemonsPA YuAM and WeisslederR (2006)High-throughput identification of phage-derived imaging agentsMol Imaging 5 24ndash30
24 MaglottD OstellJ PruittKD and TatusovaT (2007) Entrezgene gene-centered information at NCBI Nucleic Acids Res 35D26ndashD31
25 Gene OntologyC (2006) The Gene Ontology (GO) project in 2006Nucleic Acids Res 34 D322ndashD326
26 LiuT LinY WenX JorissenRN and GilsonMK (2007)BindingDB a web-accessible database of experimentally determinedprotein-ligand binding affinities Nucleic Acids Res 35 D198ndashD201
27 KanehisaM GotoS HattoriM Aoki-KinoshitaKF ItohMKawashimaS KatayamaT ArakiM and HirakawaM (2006)From genomics to chemical genomics new developments in KEGGNucleic Acids Res 34 D354ndashD357
28 ErtlP and JacobO (1997) WWW-based chemical informationsystem J Mol Struct Theochem 419 113
Nucleic Acids Research 2008 Vol 36 Database issue D359