chris rossbach, jon currey, microsoft research mark silberstein, technion baishakhi ray, emmett...
TRANSCRIPT

PTask: Operating System Abstractions to Manage
GPUs as Compute DevicesChris Rossbach, Jon Currey, Microsoft Research
Mark Silberstein, TechnionBaishakhi Ray, Emmett Witchel, UT Austin
SOSP October 25, 2011

There are lots of GPUs◦ 3 of top 5 supercomputers use GPUs◦ In all new PCs, smart phones, tablets ◦ Great for gaming and HPC/batch◦ Unusable in other application domains
GPU programming challenges◦ GPU+main memory disjoint◦ Treated as I/O device by OS
Motivation
PTask SOSP 2011 2

There are lots of GPUs◦ 3 of top 5 supercomputers use GPUs ◦ In all new PCs, smart phones tablets ◦ Great for gaming and HPC/batch◦Unusable in other application domains
GPU programing challenges◦ GPU+main memory disjoint◦Treated as I/O device by OS
Motivation
These two things are related: We need OS abstractions
PTask SOSP 2011 3

The case for OS support PTask: Dataflow for GPUs Evaluation Related Work Conclusion
Outline
PTask SOSP 2011 4

Traditional OS-Level abstractions
programmer-visible interface
OS-level abstractions
Hardware interface
1:1 correspondence between OS-level and user-level abstractions
PTask SOSP 2011 5

DirectX/CUDA/OpenCL Runtime
Language Integration
Shaders/Kernels
GPGPUAPIs
GPU Abstractions
programmer-visible interface
1 OS-level abstraction!
PTask SOSP 2011 6
1. No kernel-facing API2. No OS resource-management3. Poor composability

CPU-bound processes hurt GPUs
• Image-convolution in CUDA• Windows 7 x64 8GB RAM• Intel Core 2 Quad 2.66GHz• nVidia GeForce GT230
invo
catio
ns p
er s
econ
d
Higher is better
no CPU load high CPU load0
200
400
600
800
1000
1200
GPU benchmark throughput
CPU scheduler and GPU scheduler not integrated!
PTask SOSP 2011 7

GPU-bound processes hurt CPUs
• Windows 7 x64 8GB RAM• Intel Core 2 Quad 2.66GHz• nVidia GeForce GT230
Flatter lines Are better
OS cannot prioritize cursor updates• WDDM + DWM + CUDA == dysfunction
PTask SOSP 2011 8

Composition: Gestural Interface
capture
filterxform
“Hand” events
Raw images
detect
High data rates Data-parallel algorithms
… good fit for GPU
PTask SOSP 2011 9
noisy point cloud
geometric transformation
capture camera images
detect gestures
noise filtering
NOT Kinect: this is a harder problem!

What We’d Like To Do
#> capture | xform | filter | detect &
PTask SOSP 2011 10
Modular design flexibility, reuse
Utilize heterogeneous hardware Data-parallel components GPU Sequential components CPU
Using OS provided tools processes, pipes
CPU CPUGPU GPU

GPUs cannot run OS: different ISA Disjoint memory space, no coherence Host CPU must manage GPU execution
◦ Program inputs explicitly transferred/bound at runtime◦ Device buffers pre-allocated
GPU Execution model
CPUMain memory
GPU memory
GPU
Copy inputs Copy outputs Send commands
User-mode appsmust implement
PTask SOSP 2011 11

OS executive
capture
GPU
Data migrationke
rnel
user
Run!
camdrv GPU driver
HW
PCI-xfer PCI-xfer
xform
copyto
GPU
copyfrom GPU
PCI-xfer PCI-xfer
filter
copyfrom GPU
detect
IRP
HIDdrv
read()
copyto
GPU
write() read() write()read() write() read()
capture xform filter detect
#> capture | xform | filter | detect &
PTask SOSP 2011 12

GPU Analogues for:◦ Process API◦ IPC API◦ Scheduler hints
Abstractions that enable:◦ Fairness/isolation◦ OS use of GPU◦ Composition/data movement optimization
GPUs need better OS abstractions
PTask SOSP 2011 13

The case for OS support PTask: Dataflow for GPUs Evaluation Related Work Conclusion
Outline
PTask SOSP 2011 14

ptask (parallel task) ◦ Has priority for fairness◦ Analogous to a process for GPU execution◦ List of input/output resources (e.g. stdin, stdout…)
ports◦ Can be mapped to ptask input/outputs◦ A data source or sink
channels◦ Similar to pipes, connect arbitrary ports◦ Specialize to eliminate double-buffering
graph◦ DAG: connected ptasks, ports, channels
datablocks◦ Memory-space transparent buffers
PTask OS abstractions: dataflow!
• OS objectsOS RM possible• data: specify where, not how
PTask SOSP 2011 15

PTask Graph: Gestural Interface
PTask SOSP 2011 16
xform
ptask (GPU)
port
channel
clou
d
raw
img filter
f-out
f-incapture
process (CPU)
detect
ptask graph
ptask graph
#> capture | xform | filter | detect &
mapped mem GPU mem GPU mem
Optimized data movement
raw
img
Data arrival triggers computation
datablock

Graphs scheduled dynamically◦ ptasks queue for dispatch when inputs ready
Queue: dynamic priority order◦ ptask priority user-settable◦ ptask prio normalized to OS prio
Transparently support multiple GPUs◦ Schedule ptasks for input locality
PTask Scheduling
PTask SOSP 2011 17

PTask SOSP 2011 18
Main Memory
GPU 0 Memory
GPU 1 Memory
…Datablock
space V M
RW
datamain 1 1 1 1gpu0 0 1 1 0gpu1 1 1 1 0
Logical buffer ◦ backed by multiple physical buffers◦ buffers created/updated lazily◦ mem-mapping used to share across process boundaries
Track buffer validity per memory space◦ writes invalidate other views
Flags for access control/data placement
Location Transparency: Datablocks
Datablockspac
e V MRW
datamain 0 0 0 0gpu 0 0 0 0
Main Memory
GPU Memory
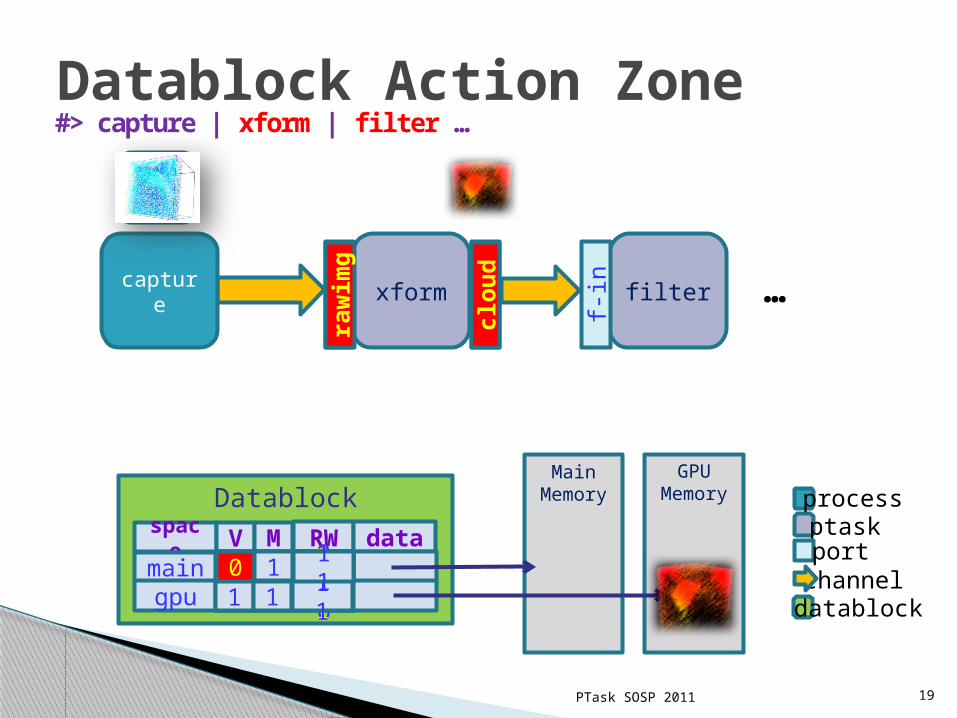
Datablock Action Zone
PTask SOSP 2011 19
xform
clou
d
raw
img filterf-incapture
#> capture | xform | filter …
ptaskport
channel
process
datablock1 1 1 11 1 1 11 1 1 11 1 1 10 1 1 1
raw
img
clo
ud
…

Revised technology stack
• 1-1 correspondence between programmer and OS abstractions• GPU APIs can be built on top of new OS abstractions
datablock
port
port
PTask SOSP 2011 20

The case for OS support PTask: Dataflow for GPUs Evaluation Related Work Conclusion
Outline
PTask SOSP 2011 21

Windows 7◦ Full PTask API implementation◦ Stacked UMDF/KMDF driver
Kernel component: mem-mapping, signaling User component: wraps DirectX, CUDA, OpenCL
◦ syscalls DeviceIoControl() calls Linux 2.6.33.2
◦ Changed OS scheduling to manage GPU GPU accounting added to task_struct
Implementation
PTask SOSP 2011 22

Windows 7, Core2-Quad, GTX580 (EVGA) Implementations
◦ pipes: capture | xform | filter | detect◦ modular: capture+xform+filter+detect, 1process◦ handcode: data movement optimized, 1process◦ ptask: ptask graph
Configurations◦ real-time: driven by cameras◦ unconstrained: driven by in-memory playback
Gestural Interface evaluation
PTask SOSP 2011 23

runtime user sys0
0.5
1
1.5
2
2.5
3
3.5
handcodemodularpipesptask
rela
tive t
o h
an
dco
de
Gestural Interface Performance
• Windows 7 x64 8GB RAM• Intel Core 2 Quad 2.66GHz• GTX580 (EVGA)
lower is better compared to pipes
• ~2.7x less CPU usage• 16x higher throughput• ~45% less memory usage
compared to hand-code• 11.6% higher throughput• lower CPU util: no driver
program
PTask SOSP 2011 24

Performance Isolation
2 4 6 80
200
400
600
800
1000
1200
1400
1600
fifopriority
PTask priority
PTask
in
voca
tion
s/se
con
d
• Windows 7 x64 8GB RAM• Intel Core 2 Quad 2.66GHz• GTX580 (EVGA)
Higher is better
• FIFO – queue invocations in arrival order• ptask – aged priority queue w OS priority • graphs: 6x6 matrix multiply• priority same for every PTask node
PTask provides throughput proportional to priority
PTask SOSP 2011 25
ptask

Multi-GPU Scheduling
PTask SOSP 2011 26
dept
h-1
dept
h-2
dept
h-4
dept
h-6
00.20.40.60.8
11.21.41.61.8
prioritydata-aware
Sp
eed
up
over
1 G
PU
• Windows 7 x64 8GB RAM• Intel Core 2 Quad 2.66GHz• 2 x GTX580 (EVGA)
Higher is better
• Data-aware == priority + locality• Graph depth > 1 req. for any benefit
Data-aware provides best throughput, preserves priority
• Synthetic graphs: Varying depths

GPU/CPU
cuda-1Linux
cuda-2Linux
cuda-1PTask
cuda-2 Ptask
Read 1.17x
-10.3x -30.8x 1.16x 1.16x
Write 1.28x
-4.6x -10.3x 1.21x 1.20x
Linux+EncFS Throughput
PTask SOSP 2011 27
R/W bnc
EncFS FUSE libc
Linux 2.6.33
SSD1
cuda-1 cuda-2
SSD2 GPU
user-prgs
user-libs
OS
HW
PTask
…
• EncFS: nice -20• cuda-*: nice +19• AES: XTS chaining• SATA SSD, RAID• seq. R/W 200 MB
Simple GPU usage accounting• Restores performance

The case for OS support PTask: Dataflow for GPUs Evaluation Related Work Conclusion
Outline
PTask SOSP 2011 28

OS support for heterogeneous platforms:◦ Helios [Nightingale 09], BarrelFish [Baumann 09] ,Offcodes
[Weinsberg 08]
GPU Scheduling◦ TimeGraph [Kato 11], Pegasus [Gupta 11]
Graph-based programming models◦ Synthesis [Masselin 89]
◦ Monsoon/Id [Arvind]
◦ Dryad [Isard 07]
◦ StreamIt [Thies 02]
◦ DirectShow ◦ TCP Offload [Currid 04]
Tasking◦ Tessellation, Apple GCD, …
Related Work
PTask SOSP 2011 29

OS abstractions for GPUs are critical◦ Enable fairness & priority◦ OS can use the GPU
Dataflow: a good fit abstraction◦ system manages data movement◦ performance benefits significant
Conclusions
Thank you. Questions?
PTask SOSP 2011 30