chuong 4 - hoc co giam sat - adaboost.pdf
TRANSCRIPT

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Lý Thuyết Nhận DạngPattern Recognition
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 1
Pattern Recognition TS. Nguyễn Đăng Bình
Khoa Công Nghệ Thông Tin, Đại Học Khoa Học HuếURL: http://it.husc.edu.vn/gv/ndbinh/Email: [email protected]

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Nội Dung Bài Giảng
Chương 4Học Có Giám Sát
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 2
Học Có Giám Sát(Supervised Learning)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Nội dung trình bày• Vấn đề học có giám sát (học có mẫu)
� Bài toán� Giới thiệu phương pháp
• Phân lớp tuyến tính� Phân tách tuyến tính (Linear separability)� Thuật toán nhận thức (Perceptron)
• Bộ phân loại Véc tơ hỗ trợ (Support Vector Machine –SVM � Độ rộng của lề (Wide margin)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 3
� Độ rộng của lề (Wide margin)� Hàm giá (Cost function)� Dạng nguyên thủy và đối ngẫu (Primal and dual forms)� Các biến trể (Slack variables)� Hàm tổn thất (Loss functions)
• Nhân (Kernels)• Logistic Regression• Boosting và Học trực tuyến (online learning)• Tối ưu hóa

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Vấn đề học có giám sát
• Bài toán: Quá trình nhận dạng được bắt đầu bởi quá trình học trên cơ sở đã biết sự phân lớp ban đầu hoặc thông tin về sự phân lớp tập các đối tượng của nó.
• Quá trình học nhằm xác định sự phân lớp đúng theo mọi đối tượng của không gian (khi số phần tử của tập để học không thay đổi)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 4
để học không thay đổi)• Ví dụ:
� Bài toán phân lớp tuyến tính: biết dạng phương trình đường biên giới , trong đó w là véc tơ tham số và w0 là giá trị tham số Từ dạng phương trình phân lớp quá trình học nhằm xác định sự hội tụ của các tham số w, w0 với mọi x
� Bài toán nhận dạng theo phương pháp xác suất với phân bố Gauss theo 2 tham số Ak (ma trận hiệp biến) và µk (véc tơ trung bình ) đối với mỗi lớp để tính P(Ck | x)
0w w 0
Tx + =

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Giới thiệu phương pháp
1. Học có mẫu theo tham số
Bài toán: Biết dạng của phương trình phân lớp phụ thuộc vào tham số. Vấn đề học là đi tìm sự hội tụ của tham số với mọi x
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 5
2. Học có mẫu không theo tham số
Bài toán: Biết các mẫu đặc trưng cho các lớp. Vấn đề học là đi tìm dấu hiệu đặc trưng cho mỗi lớp

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phân lớp nhị phân
• Cho tâp dữ liệu huấn luyện , với và , học bộ phân loạisao cho:
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 6

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phân tách tuyến tính
Phân tách tuyến tính
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 7
Không phân tách tuyến tính

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại tuyến tính
• Bộ phân loại tuyến tính có dạng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 8
• Trong không gian 2 chiều phân biệt là một đường thẳng• w bình thường là một mặt phẳng (plane), và b (bias)• w được gọi là véc tơ trọng số (weight vector)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại tuyến tính
• Bộ phân loại tuyến tính có dạng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 9
• Trong không gian 3 chiều phân biệt là một mặt phẳng• Đối với bộ phân loại K-NN nó là cần thiết để “thực hiện”
dữ liệu huấn luyện• Cho một phân loại tuyến tính, dữ liệu huấn luyện được
sử dụng để học w và sau đó dữ liệu huấn luyện loại bỏ đi• Chỉ w là cần thiết để phân loại dữ liệu mới

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Nhắc lại: Bộ phân loại nhận thức (Perceptron)• Cho dữ liệu phân tách tuyến tính xi được gán nhãn
thành 2 loại yi = {-1, +1}, tìm véc tơ trọng số w sao chohàm phân biệt
phân tách thành các loại với i = 1,…,N• Làm thế nào chúng ta có thể tìm thấy siêu phẳng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 10
• Làm thế nào chúng ta có thể tìm thấy siêu phẳngphân tách này ?
• Thuật toán “Perceptron”� Bộ phân loại có dạng
ở đó� Khởi tạo w = 0� Chu trình vòng lặp khi các điểm dữ liệu {xi, yi}
� Nếu xi là phân lớp “nhầm” (misclassified)
� Cho tới khi tất cả dữ liệu là được phân lớp đúng

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Ví dụ trong không gian 2 chiều• Khởi tạo w = 0• Lặp với các điểm dữ liệu {xi, yi}
� Nếu xi là phân lớp “nhầm” (misclassified)
• Cho tới khi tất cả dữ liệu được phân lớp đúng
Trước khi cập nhật Sau khi cập nhật
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 11
• Sau khi hội tụ

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Ví dụ “perceptron”
• Nếu dữ liệu phân tách tuyến tính, thì thuật toán hội tụ
• Hội tụ có thể chậm
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 12
• Đường phân tách gần với dữ liệu huấn luyện
• Chúng tôi muốn có mộtbiên độ lớn hơn (largermargin) cho sự tổng quát

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Véc tơ trọng số w tốt nhất là gì?
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 13
• Giải pháp cho khoản cách biên độ lớn nhất: ổn định nhất trong nhiễu và các đầu vào

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Máy véc tơ hỗ trợ (SVM)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 14

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
SVM: Phát thảo sơ lược
• Từ và định nghĩa cùngmột mặt phẳng, chúng ta có quyền tự do lựa chọn chuẩnhóa
• Chọn chuẩn hóa sao cho đối với véc tơhỗ trợ dương (positive) và cho véc tơ hỗ
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 15
hỗ trợ dương (positive) và cho véc tơ hỗtrợ âm (negative) tương ứng.
• Khoản cách lề được cho bởi
• Khoản cách lề (Margin) = khoản cách của các mẫugần nhất từ đường quyết định/siêu phẳng

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
SVM
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 16

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
SVM – Tối ưu• Học SVM có thể được xây dựng như một tối ưu hóa
• Hoặc tương đương
với
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 17
• Đây là một bài toán tối ưu hóa bình phương với ràng buộc tuyến tính và có tối thiểu duy nhất
với

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
SVM – Thuật toán hình học
• Tính bao lồi của các điểm dương (positive), và bao lồi của các điểm âm (negative)
• Đối với mỗi cặp điểm, một trên bao lồi dương và một trên bao lồi âm, tính khoản cách lề.
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 18
• Chọn khoản cách lề lớn nhất

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
SVM
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 19
• Chỉ cần xem xét những điểm trên tập bao lồi(những điểm bên trong không liên quan) để phân tách
• Siêu phẳng xác định bởi các véc tơ hỗ trợ

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phát biểu định lý• Chúng ta có bài toán tối ưu
• Giải pháp tính w luôn luôn có thể được viết như sau:
với
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 20
• Chứng minh: (xem như bài tập)
• Do vậy, bài toán tối ưu hóa tương đương là
với

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Công thức nguyên thủy và đối ngẫu• N là số mẫu huấn luyện, và d là số chiều của véc tơ x• Bài toán nguyên thủy: cho
• Bài toán đối ngẫu: cho
với
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 21
• Độ phức tạp của giải pháp là O(d3) đối với bài toán nguyênthủy, và O(N3) đối với bài toán đối ngẫu
• Nếu N<<d thì sẽ hữu hiệu hơn để giải/tìm α hơn w• Dạng đối ngẫu bao gồm . Chúng ta sẽ trở lại với
điều này là tại sao đây là một ưu điểm khi chúng ta xemxét về Nhân (Kernels)
với

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
• Nguyên thủy dạng của bộ phân loại:
• Đối ngẫu dạng của bộ phân loại:
Công thức nguyên thủy và đối ngẫu
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 22

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Máy véc tơ hỗ trợ (SVM)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 23

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phân tách tuyến tính: w tốt nhất là gì?
• Các mẫu (điểm) có thể đượcphân tách tuyến tính nhưngkhoản cách lề rất hẹp
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 24
• Nhưng có thể có giải pháp chokhoản cách lề lớn là tốt hơn,mặc dù một số ràng buộc là bịvi phạm
• Nói chung cần có sự đánh đổi (cân bằng) giữa khoản cách lề và số lượng các lỗi trên dữ liệu huấn luyện

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Giới thiệu biến bù (slack) cho các mẫu bị phân lớp nhầm
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 25

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Giải pháp lề mềm (soft margin)• Bài toán tối ưu nguyên thủy trở thành
• Với ràng buộc• Mỗi ràng buộc có thể thỏa mãn nếu đủ lớn• C là một tham số điều hòa (regularization)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 26
• C là một tham số điều hòa (regularization) � C nhỏ cho phép ràng buộc có thể bỏ qua -> lề lớn� C lớn mà ràng buộc cứng khó có thể bỏ qua - > lề hẹp� C = ∞ thực thi tất cả các ràng buộc: lề cứng
� Điều này vẫn con là một bài toán tối ưu bậc hai và có một tối thiểuduy nhất. Lưu ý, chỉ có một tham số C.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Ví dụ: bài toán phát hiện người đi bộ
• Mục tiêu: phát hiện (khoanh vùng) vị trí đứng con người trong ảnh
• Phát hiện khuôn mặt sử dụng bộ phân loại với cửa sổ trượt
� Đưa bài toán phát hiện đối
Phương pháp: Bộ phát hiên dựatrên đặc tính HOG
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 27
� Đưa bài toán phát hiện đốitượng về bài toán phân lớpnhị phân
� Trả lời câu hỏi: trong ảnh cóchứa đối tượng hay không?Và nếu có thì nằm ở vị trínào? Chỉ ra vùng xác địnhtọa độ và kích thước của đốitượng đó trong ảnh.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Huấn luyện dữ liệu và các đặc trưng• Dữ liệu mẫu dương (positive): 1208 mẫu dương
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 28
• Dữ liệu mẫu âm: 1218 mẫu âm (khởi tạo)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Đặc tính (features): HOG( Histogram of oriented gradients)
ảnhCác
hướng chính
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 29
Phân chia ảnh thành lưới các vùngđơn vị kích thước 8 x 8 điểm ảnh
Mỗi vùng đơn vị được trích chọn vàbiểu diễn đặc tính bởi HOG
Hướng
Số chiều của véc tơ đặc tính = 16 x 8 (vùng) x 8 (hướng) = 1024

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 30

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Các mẫu trung bình
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 31

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Thuật toánHuấn luyện (Học):• Biểu diễn mỗi cửa sổ mẫu bằng một véc tơ đặc tính HOG
với
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 32
• Huấn luyện bộ phân loại bằng thuật toán SVM
Kiểm chứng (testing): sử dụng bộ phân loại đã huấn luyệnđể phát hiện đối tượng từ ảnh mới
• Dùng bộ phân loại trượt cửa sổ để phát hiện đối tượng

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 33
Dalal và Triggs, CVPR 2005

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Mô hình học
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 34
Slide từ Deva Ramanan

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Điều gì làm trọng số âm có nghĩa?
w x > 0(w+ – w- )x > 0
w+ x > w-x
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 35
>Mô hình người đi bộ Mô hình nền

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hàm tổn thất (loss functions)
• Bài toán nguyên thủy: cho
• Ràng buộc có thể được viết gọn hơn như sau
• Điều này tương đương với
với
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 36
• Điều này tương đương với
• ở đó chỉ ra phần dương. Do vậy, bài toán tối ưu hóa tương đương với
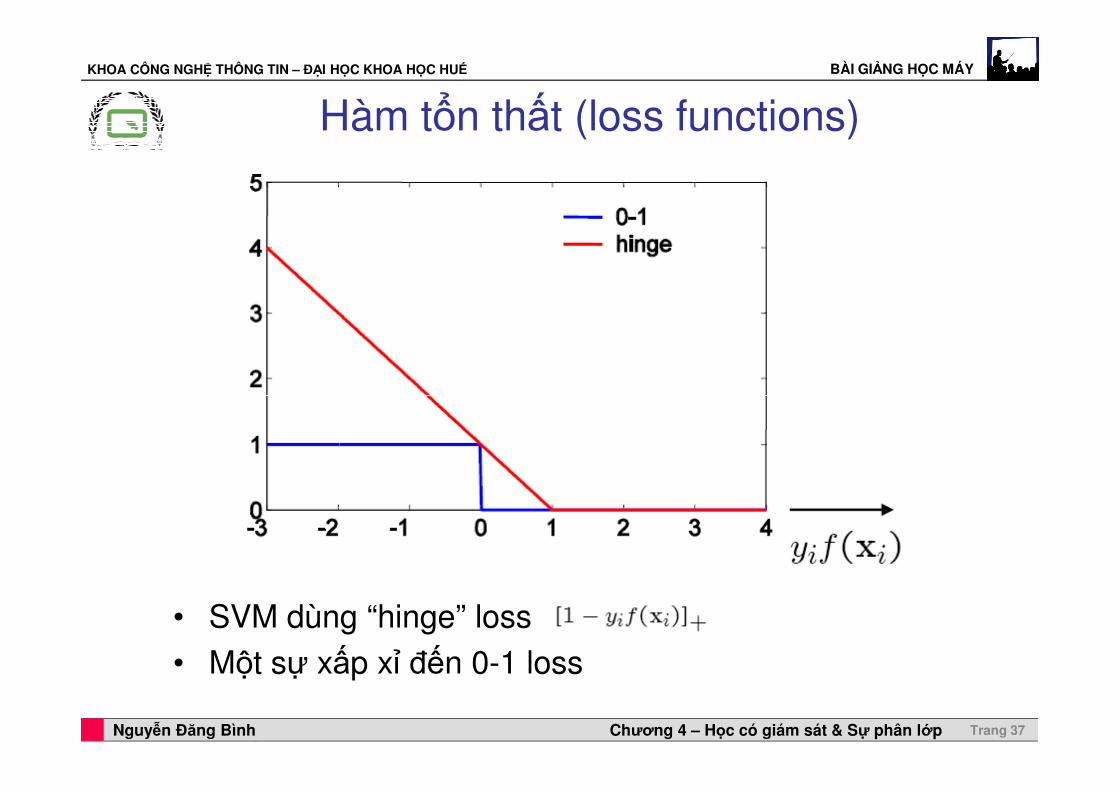
KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hàm tổn thất (loss functions)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 37
• SVM dùng “hinge” loss• Một sự xấp xỉ đến 0-1 loss

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hinge loss vs. 0-1 loss
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 38
Hinge loss là cận trên của 0-1 loss !

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Nhân (Kernels)• Phân tách tuyến tính
• Các hàm cơ sở
• Nhân cho SVM� Kernel trick
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 39
� Kernel trick� Các yêu cầu� Các hàm cơ sở xuyên tâm (radial basis functions)
• Nhân cho các bộ phân loại khác

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phương pháp Kernel: Một chút về lịch sử
• Minsky and Pappert (1969) chỉ ra hạn chế của perceptrons.
• Mạng nơ ron(từ giữa 1980s) vượt quacác hạn chế bằng cách gắn vào nhaunhiều đơn vị tuyến tính (multilayer
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 40
nhiều đơn vị tuyến tính (multilayerneural networks). Gặp hạn chế của tốcđộ và cực tiểu địa phương.
• Phương pháp Kernels (2000s) nối cáchàm tuyến tính nhưng trong không gianfeature với số chiều cao (highdimensional feature space.)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phương pháp Kernel: ý tưởng chính
• Biến đổi dữ liệu vào không gian nhiều chiều hơn có thể biến dữ liệu thành tách được tuyến tính.
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 41

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Xử lý dữ liệu không phân tách tuyến tính
• Giới thiệu các biến bù (slack)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 42
• Phân loại tuyến tính không thíchhợp
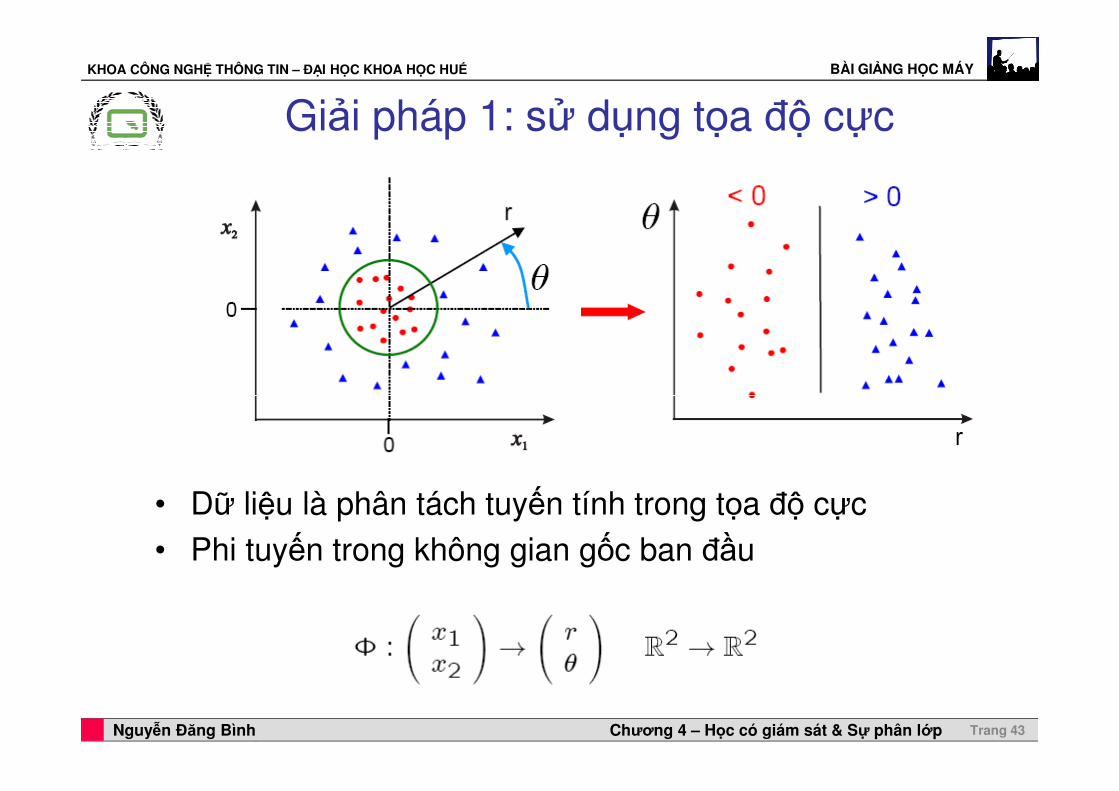
KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Giải pháp 1: sử dụng tọa độ cực
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 43
• Dữ liệu là phân tách tuyến tính trong tọa độ cực• Phi tuyến trong không gian gốc ban đầu

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Giải pháp 2: ánh xạ dữ liệu vào không gian nhiều chiều hơn
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 44
• Dữ liệu tuyến tính trong không gian 3 chiều (3D)• Điều này có nghĩa rằng bài toán có thể được giải quyết bằng một
bộ phân loại tuyến tính

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phương pháp Kernel: Lược đồ biến đổi
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 45

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phương pháp Kernel: nền toán học
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 46

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại SVM trong một không gian đặc trưng biến đổi
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 47
Học bộ phân loại tuyến tính trong w đối với

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại nguyên thủy trong không gian đặc trưng biến đổi
• Bộ phân loại, với :
• Học, cho
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 48
với ràng buộc
- Một ánh xạ đơn từ x vào Φ(x) trong đó dữ liệu được phân tách
- Giải tìm w trong không gian số chiều cao- Độ phức tạp tính toán của giải pháp bây giờ là O(D3)
chứ không phải là O(d3)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại đối ngẫu trong không gian đặc trưng biến đổi
• Bộ phân loại:
• Học:
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 49
với ràng buộc
- Lưu ý rằng Φ(x) chỉ xảy ra trong cặp

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Phép biến đổi đặc biệt
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 50
Viết k là nhân (kernel)
Thay thế tất cả các lần xuất hiện của bởiở dạng đối ngẫu

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại đối ngẫu với nhân (kernels)• Bộ phân loại:
• Học:
với ràng buộc
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 51
với ràng buộc
Kernel Trick- Bộ phân loại có thể học và áp dụng một cách rõ ràng mà
không cần tính toán Φ(x) - Tất cả những gì cần thiết là - Độ phức tạp vẫn còn O(N3)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Nhân hợp lệ (Valid Kernel)
• Cho một số hàm tùy ý , làm thế nào để chúng ta biết nó tương ứng với tích vô hướng trong một số không gian?
• Mercer kernels: nếu thỏa mãn:� Tính đối xứng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 52
� Tính đối xứng
� Định nghĩa dương, với tất cả , ở đó K là ma trận Gram với các phần tử thì là nhân hợp lệ (valid kernel)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Một số ví dụ về kernel
• Kernel tuyến tính
• Kernel đa thức đối với d bất kỳ� Chứa tất cả các điều kiện đa thức bậc d
• Kernel Gaussian
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 53
• Kernel Gaussian� Không gian đặc trưng có số chiều vô hạn

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại SVM với nhân Gaussian
Trọng số (có thể bằng 0) Véc tơ hỗ trợ
Kích thước tập dữ liệu
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 54
• Hàm xuyên tâm cơ sở (RBF) SVM
Trọng số (có thể bằng 0) Véc tơ hỗ trợ

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
RBF Kernel SVM
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 55
• Dữ liệu không phân tách tuyến tính trong không gian đặc trưng ban đầu

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 56

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 57
• Giảm C, cho độ rộng lề (mềm) lớn hơn

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 58

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 59

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 60
• Giảm sigma, tiến tới bộ phân loại xóm giềng gần nhất

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 61

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Ứng dụng: nhận dạng chữ số viết tay
• Véc tơ đặc trưng: mỗi ảnh là 28x28 điểm ảnh. Sắp xếp lại như là một véc tơ x có 784 chiều
• Huấn luyện: học k=10
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 62
• Huấn luyện: học k=10nhị phân lớp: 1 chống lại phần còn lại.Các bộ phân loại SVM fk(x)
• Phân lớp: Chọn lớn mà ở đó có giá trị dương lớn nhất

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Ví dụ
• Viết tay
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 63
• Phân lớp

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Kết luận về Kernel Trick
• Bộ phân loại co thể học với không gian các đặc trưng số chiều cao, mà không cần phải ánh xạ các điểm vào không gian số chiều cao
• Dữ liệu có thể phân tách tuyến tính trong không gian số chiều cao, nhưng không phân tách trong không gian đặc trưng ban đầu
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 64
đặc trưng ban đầu• Kernels có thể sử dụng cho một SVM bởi vì dạng tích
vô hướng, nhưng cũng có thể được sử dụng ở những nơi khác mà nó không gắn liền với SVM
• Chúng ta sẽ thấy ví dụ khác về Kernels sau này trong lý thuyết hồi quy và học không có giám sát

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Logistic Regression
• Gaussian Naïve Bayes
• Logistic Regression
• Hàm Logistic và hàm Sigmoid
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 65
• Learning & Margin
• Logistic Regression Loss function
• Logistic Regression Learning

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Gaussian Naïve Bayes
Xem xét biến boolean liên tục Giả sử
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 66
giả sử

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Lỗi tối thiểu có thể là gì?• Trường hợp tốt nhất
� Giả sử điều kiện độc lập được thỏa mãn� Chúng ta biết P(Y), P(X|Y) hoàn hảo (ví dụ dữ liệu huấn luyện
vô hạn)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 67

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Logistic Regression
• Logistic regression (LR) thật sự là một phương phápphân lớp
• Ý tưởng� Naïve Bayes cho phép tính toán P(Y|X) bởi học P(Y) và P(X|Y)� Tại sao không học P(Y|X) trực tiếp?
• LR giới thiệu một sự mở rộng của phi tuyến tính qua một
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 68
• LR giới thiệu một sự mở rộng của phi tuyến tính qua một bộ phân loại tuyến tính , bởi sử dụng hàm logistic (hoặc sigmoid)
• Bộ phân loại LR được định nghĩa như sau
ở đó

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
• Xem xét học f: X -> Y hoặc P(Y|X), ở đó� X là một véc tơ các đặc trưng giá trị thực, <X1 …. Xn> � Y là boolean� Giả sử rằng tất cả Xi là điều kiện độc lập cho Y� Mô hình P(Xi | Y = yk) là Gaussian N(µik,σi) (không phải σik)� Mô hình P(Y) là Bernoulli (π)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 69
� Mô hình P(Y) là Bernoulli (π)
Điều đó hàm ý rằng dạng của P(Y|X)?
Tham số

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Dẫn xuất dạng của P(Y|X) cho Xi liên tục
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 70

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hàm ý
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 71
Hàm ý
Hàm ý

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hàm ý
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 72
Hàm ý
Hàm ý
Luậtphân lớptuyến tính

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Giải thích theo xác suất
• Nghĩa rằng σ(f (x)) là xác suất hậu nghiệm mà y = 1, tức là P(y = 1 | x) = σ(f (x))
• Do đó, nếu σ(f (x))> 0,5 thì lớp y = 1 được chọn
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 73

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hàm logistic hoặc hàm sigmoid
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 74
• Khi z đi từ −∞ đến ∞, σ(z) đi từ 0 đến 1, hàm “squashing”.• Hình dạng của “sigmoid” (ví dụ hình dạng giống “S:)• σ(0) = 0.5, và nếu thì

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Trực giác: tai sao dùng sigmod?
• Ở đây, chọn nhị phân lớp để biểu diễn bởichứ không phải là
Tối thiểu bình phương là phù hợp
phù hợp với y
phù hợp với y
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 75
phù hợp với y
•Thích hợp của wx+b chi phốicác điểm ở xa hơn
• Gây ra phân lớp sai
• Thay vì LR sigmod hồi quivới lớp dữ liệu

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Tương tự trong 2 chiều
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 76

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Học (learning)
• Trong hồi qui logistic phù hợp với hàm sigmod số liệu {xi, yi} bằng cách giảm thiểu các lỗi phân loại
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 77

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Tính chất của lề (biên)
• Một hàm sigmod thiên về lề lớn hơn so với bộ phân loại hàm bước
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 78
• Mặc dù vậy, cần phải kiểm soát độ dốc (gradient). Làm thế nào?

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Ước tính khả năng (likelihood) lớn nhất
• Giả sử
• Viết lại gọn hơn
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 79
• Sau đó khả năng xảy ra (giả sử dữ liệu độc lập) là
• Và log likelihood âm là

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hàm tổn thất hồi qui Logistic(Logistic Regression Loss function)
• Sử dụng ký kiệu sau đó cho
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 80
• Vì vậy trong cả hai trường hợp
• Giả sử độc lập, khả năng (likelihood) là
• Và log likelihood âm là
• Đó là định nghĩa hàm tổn thất (loss function)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Học hồi qui Logistic (Logistic Regression Learning)
• Học được hình thành như là bài toán tối tưu
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 81
• Đối với các điểm phân lớp đúng là âm (negative),và là gần tới 0
• Đối với các điểm phân lớp sai là dương (positive),và có thể lớn
• Do đó việc tối ưu hóa các tham số gây bất lợi dẫn đến phân lớp sai (phân nhầm lớp).
• Các qui chuẩn (regularization) để ngăn chặn “over-fitting” và duy trì lề (biên)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
So sánh hàm chi phí của SVM và LR
• SVM
• Logistic regression
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 82
• Lưu ý:� Cả hai xấp xỉ 0-1 loss� Hành vi tiệm cận tương tự� Sự khác biệt chính là độ trơn
của LR và khác 0 ngoài lề SVM� SVM cho giải pháp thưa (sparse)
đối với αi

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
AdaBoost• AdaBoost (Adaptive Boosting) là một thuật toán để xây
dựng bộ phân loại mạnh dựa trên sự kết hợp tuyến tính các bộ phân loại yếu hn(x). Nó cung cấp phương pháp lựa chọn bộ phân loại yếu và thiết lập các trọng số
Bộ phân loại mạnh Bộ phân loại yếu
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 83
Y. Freund and R. Schapire. A decision-theoretic generalization of on-line learning and an application toboosting. Journal of Computer and System Sciences, 1997.
Cập nhật trọng số từ mẫu huấn luyện (Boosting)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
AdaBoost [Freund, Schapire 97]
Đầu vào
- Tập dữ liệu mẫu đã gán nhãn
- Phân bổ trọng số đối với các mẫu
Không gian đặc tính
Đầu ra
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 84
for n=1 to N // N là số lượng bộ phân loại yếu
- huấn luyện bộ phân loại yếu sử dụng mẫu và phân bố trọng số
- tính toán lỗi
- tính toán trọng số bộ phân loại
- cập nhật các trọng số mẫu
end
Thuật toán

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Tai sao nó hoạt động?• Thuật toán AdaBoot thực hiện tối ưu hóa tham lam của
hàm tổn thất (loss function)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 85

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Từ Boosting ngoại tuyến (offline) đến trực tuyến (online)
[Oza, Russel 01]Đầu vào Đầu vào
- tập mẫu huấn luyện đã gán nhãn
- trọng số phân bô trên các mẫu
- MỘT mẫu huấn luyện được gán nhãn
- bộ phân loại mạnh được cập nhật
- khởi tạo trọng số quan trọng
Ngoại tuyến (Off-line) Trực tuyến (On-line)
Đầu ra Đầu ra
[Freund, Schapire 97]
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 86
For n=1 to N
- huấn luyện bộ phân loại yếu sử dụng các mẫu và phân bố trọng số
- tính toán lỗi
- tính toán độ tin cậy
- cập nhật trọng số
End
For n=1 to N
- cập nhật bộ phân loại yếu sử dụng các mẫu và trọng số quan trọng
- cập nhật ước tính lỗi
- cập nhật độ tin cậy
- cập nhật trọng số
End
Thuật toán Thuật toán

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
• Các đặc tính– Sóng con “Haar-like”– Biểu đồ định hướng– Nhị phân cục bộ (LBP)
• Tính toán nhanh sử dụng các
Boosting cho lựa chọn đặc trưng
• Mỗi đặc tính tương ứng với một bộ phân loại yếu
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 87
• Tính toán nhanh sử dụng cáccấu trúc dữ liệu hữu hiệu– Ảnh tích hợp -integral images– Các biểu đồ đặc tính tích hợp
F. Porikli. Integral histogram: A fast way to extract histograms in cnartesian
spaces. CVPR 2005.K. Tieu and P. Viola. Booting Image
Retrival, CVPR 2000

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Bộ phân loại
Kết hợp của các đặc tính đơn giảnsử dụng Boosting để lựa chọn đặc tính/đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 88
P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features. CVPR 2001.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
• Giới thiệu Bộ chọn “Selector”� Lựa chọn một đặc trưng từ cơ sở
dữ liệu đặc trưng cục bộ
Boosting ngoại tuyến cho lựa chọn đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 89
Boosting được thực hiện trênbộ chọn (Selectors) chứkhông phải trên bộ phân loạiyếu (weak classifiers) trựctiếp.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Boosting ngoại tuyến cho lựa chọn đặc trưngset of
training samples
inital weight
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 90
weight distribution
straightforward with all training
samples
KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
h1,1
set of training samples
h1,2
inital weight
hSelector1
Boosting ngoại tuyến cho lựa chọn đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 91
h1,M
weight distribution
calculate weight
straightforward with all training
samples
.
.
.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
h1,1
set of training samples
h1,2
update weight
distribution inital
weight
hSelector1
Boosting ngoại tuyến cho lựa chọn đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 92
h1,M
for training samples
weight distribution
calculate weight
straightforward with all training
samples
.
.
.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
h1,1
set of training samples
h1,2
h2,1
h2,2
update weight
distribution
update weight
distribution inital
weight
hSelector1 hSelector2
.
.
Boosting ngoại tuyến cho lựa chọn đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 93
h1,M h2,M
h2,m
for training samples
for training samples
weight distribution
calculate weight
calculate weight
straightforward with all training
samples
.
.
.
.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
h1,1
set of training samples
h1,2
h2,1
h2,2
hT,1
hT,2
hT,mupdate weight
distribution
update weight
distribution ..
inital weight
hSelector1 hSelector2hSelectorT
.
.
Boosting ngoại tuyến cho lựa chọn đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 94
h1,M h2,M
h2,m
hT,M
for training samples
for training samples
.weight
distribution
calculate weight
calculate weight
calculate weight
straightforward with all training
samples
.
.
.
....

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
h1,1
set of training samples
h1,2
h2,1
h2,2
hT,1
hT,2
hT,mupdate weight
distribution
update weight
distribution ..
inital weight
hSelector1 hSelector2hSelectorT
.
.
NOW GO ON-LINE …
Boosting ngoại tuyến cho lựa chọn đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 95
h1,M h2,M
h2,m
hT,M
for training samples
for training samples
.weight
distribution
calculate weight
calculate weight
calculate weight
final strong classifier hStrong
straightforward with all training
samples
.
.
.
....
NOW GO ON-LINE …

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Boosting trực tuyến cho lựa chọn đặc trưng
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 96

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 97

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Mô hình học Boosting trực tuyến với sự giám sát của con người
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 98

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 99

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Tối Ưu Hóa (Optimization)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 100

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Chúng ta đã thấy nhiều hàm chi phí
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 101
• Đó là những giải pháp duy nhất ?• Liệu những giải pháp phụ thuộc vào điểm khởi đầu của một thuật toán
tối ưu hóa lặp đi lặp lại (chẳng hạn như “gradient descent”)• Nếu hàm giá trị (cost function) là hàm lồi (convex) thì điểm tối ưu cục
bộ là tối ưu toàn cục (cung cấp tối ưu hóa trên một tập lồi, mà nó là một trong trường hợp)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Hàm lồi (Convex functions)
• D là miền Rn
• Một hàm lồi là một trong những thỏa mãn đối với bất kỳ x0 và x1 trong D
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 102
• Đường nối (x0, f(x0)) và(x1, f(x1)) nằm trên hàmđồ thị

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Ví dụ về hàm lồi (convex)
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 103
• Tổng không âm của một hàm lồi là lồi(A non-negative sum of convex functions is convex)

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 104

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Thuật toán giảm độ nghiêng (Gradient descent or steepest descent)
• Cách đơn giản nhất để hiểu gradient descent là từ vị trí hiện tại, ta đi theo chiều giảm của đạo hàm bậc nhất cho đến khi không thể giảm được nữa. Khi đó ta đã ở một điểm tối ưu cục bộ.
• Để tối thiểu hóa hàm chi phí C(w) dùng vòng lặp cập nhật
ở đó là tốc độ học
• Trong trường hợp chúng tôi, hàm tổn thất là tổng trên toàn dữ liệuhuấn luyến. Chẳng hạn đối với LR
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 105
huấn luyến. Chẳng hạn đối với LR
• Điều này có nghĩa rằng một cập nhật lặp đi lặp lại bao gồm đi qua cácdữ liệu huấn luyện với một bản cập nhật cho mỗi điểm
• Ưu điểm là cho một lượng lớn dữ liệu, điều này có thể được thựchiện từng điểm một.

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Gradient Descent
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 106

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Thuật toán giảm độ nghiêng cho LR
• Tối thiểu hóa sử dụng “gradient descent” cho luật cập nhật [xem như bài tập]
ở đó • Lưu ý:
� Điều này tương tự nhưng không giống hệt nhau với luật cập nhật
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 107
� Điều này tương tự nhưng không giống hệt nhau với luật cập nhật của “perceptron”
� Có một giải phapr duy nhất cho w� Trong thực tế phương pháp Newton hiệu quả hơn được sử dụng
để tối thiểu hóa LR� Có thể bài toán với w trở thành vô hạn cho dữ liệu phân tách
tuyến tính

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Giảm độ nghiêng cho SVM
• Đầu tiên, bài toán tối ưu hóa được viết lại như là trung bình
• Với λ = 2/(NC) lên đến tỉ lệ chung của bài toán và
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 108
• Với λ = 2/(NC) lên đến tỉ lệ chung của bài toán và
• Bởi vì “hinge loss” không khả vi, một tiểu dốc (sub-gradient) được tính
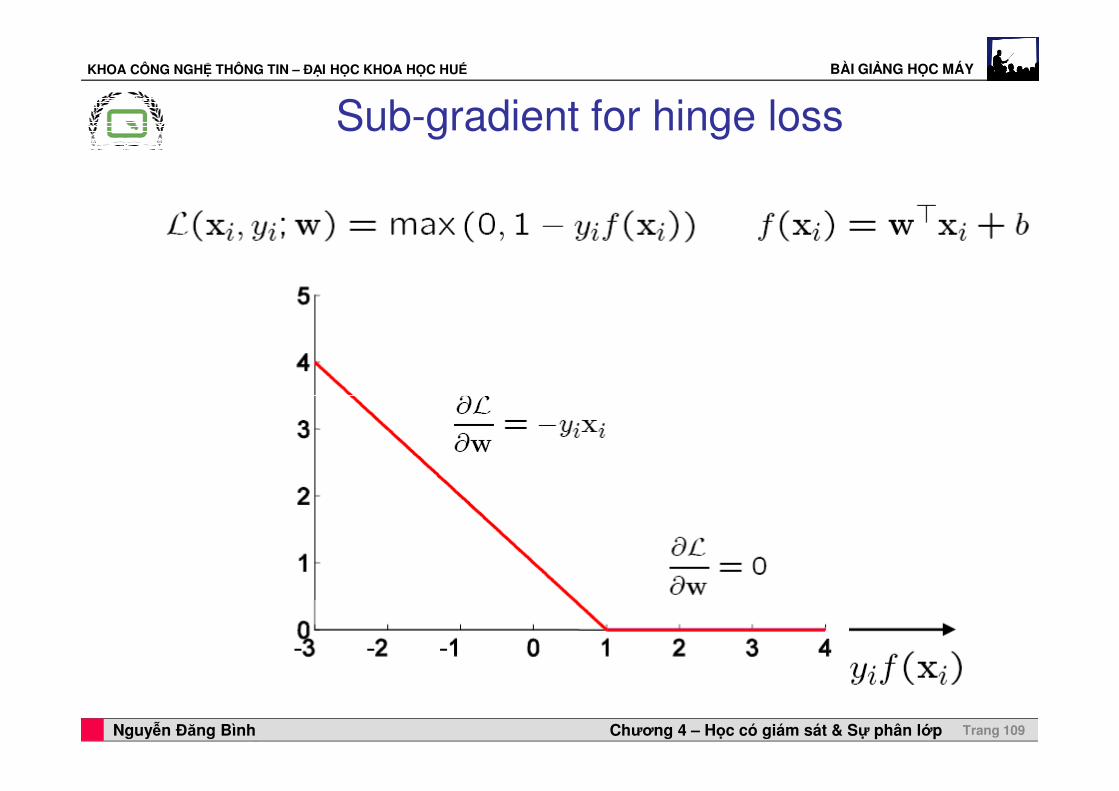
KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Sub-gradient for hinge loss
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 109

KHOA CÔNG NGHỆ THÔNG TIN – ĐẠI HỌC KHOA HỌC HUẾ BÀI GIẢNG HỌC MÁY
Thuật toán giảm tiểu độ nghiêng cho SVM
• Cập nhật lặp đi lặp lại là:
Professor Horst Cerjak, 19.12.2005Nguyễn Đăng Bình Chương 4 – Học có giám sát & Sự phân lớp Trang 110
ở đó là tốc độ học• Sau đó, mỗi lần lặp t bao gồm chu trình qua dữ liệu
huấn luyện với các cập nhật:
• Trong thuật toán Pegasos tỉ lệ học được thiết lập ηt = 1/λt